Помещение локальных переменных на стек
Команда iload - загрузить
целое из локальной переменной. Операндом является смещение переменной в области локальных переменных. Указываемое значение копируется на верхушку стека операций. Имеются аналогичные команды для помещения плавающих, двойных целых, двойных плавающих и т.д.
Команда istore - сохранить целое в локальной переменной. Операндом операции является смещение переменной в области локальных переменных. Значение с верхушки стека операций копируется в указываемую область
локальных переменных. Имеются аналогичные команды для помещения плавающих, двойных целых, двойных плавающих и т.д.
Построение детерминированного конечного автомата по недетерминированному
Рассмотрим алгоритм построения по недетерминированному конечному автомату детерминированного конечного автомата, допускающего тот же язык.
Алгоритм 3.2. Построение детерминированного конечного автомата по недетерминированному.
Вход. НКА M = (Q, T, D, q0, F).
Выход. ДКА M' = (Q', T, D', q0', F'), такой что L(M) = L(M').
Метод. Каждое состояние результирующего ДКА - это некоторое множество состояний исходного НКА.
В алгоритме будут использоваться следующие функции:
e-closure(R) (R


move(R, a) (R

Вначале Q' и D' пусты. Выполнить шаги 1-4:
Определить q0' = e-closure({q0}).
Добавить q0' в Q' как непомеченное состояние.
Выполнить следующую процедуру:
while (в Q' есть непомеченное состояние R){
пометить R;
for (каждого входного символа a

S = e-closure(move(R, a));
if (S


if (S

добавить S в Q' как непомеченное состояние;
определить D'(R, a) = S;
}
}
}
Определить F' = {S|S


Пример 3.6. Результат применения алгоритма 3.2 приведен на рис. 3.10.

|
Приведем теперь алгоритм построения по регулярному выражению детерминированного конечного автомата, допускающего тот же язык[10].
Пусть дано регулярное выражение r в алфавите T. К регулярному выражению r добавим маркер конца: (r)#. Такое регулярное выражение будем называть пополненным. В процессе своей работы алгоритм будет использовать пополненное регулярное выражение.
Алгоритм будет
оперировать с синтаксическим деревом для пополненного регулярного выражения (r)# , каждый лист которого помечен символом a

(конкатенация), | (объединение), * (итерация).
Каждому листу дерева (кроме e-листьев) припишем уникальный номер, называемый позицией, и будем использовать его, с одной стороны, для ссылки на лист в дереве, и, с другой стороны, для ссылки на символ, соответствующий этому листу. Заметим, что если некоторый символ
используется в регулярном выражении несколько раз, он имеет несколько позиций.
Теперь, обходя дерево T снизу-вверх слева-направо, вычислим четыре функции: nullable, firstpos, lastpos и followpos. Функции nullable, firstpos и lastpos определены на узлах дерева, а followpos - на множестве позиций. Значением всех функций, кроме nullable, является множество позиций. Функция followpos вычисляется через три остальные функции.
Функция firstpos(n) для каждого узла n синтаксического дерева регулярного выражения дает множество позиций, которые соответствуют
первым символам в подцепочках, генерируемых подвыражением с вершиной в n. Аналогично, lastpos(n) дает множество позиций, которым соответствуют последние символы в подцепочках, генерируемых подвыражениями с вершиной n. Для узла n, поддеревья которого (т.е. деревья, у которых узел n является корнем) могут породить пустое слово, определим nullable(n) = true, а для остальных узлов nullable(n) = false.
Таблица для вычисления функций nullable, firstpos и lastpos приведена на рис. 3.11.

|
Пример 3.7.
Рассмотрим теперь алгоритм построения ДКА с минимальным числом состояний, эквивалентного данному ДКА [10].
Пусть M = (Q, T, D, q0, F) - ДКА. Будем называть M всюду определенным, если D(q, a)

Лемма. Пусть M = (Q, T, D, q0, F) - ДКА, не являющийся всюду определенным. Существует всюду определенный ДКА M', такой что L(M) = L(M'). Доказательство. Рассмотрим автомат M' = (Q

состояние, а функция D' определяется следующим образом:
Для всех q
Q и a

Для всех q
Q и a
Для всех a
T определить D'(q', a) = q'.
Легко показать, что автомат M' допускает тот же язык, что и M. __
Приведенный ниже алгоритм получает на входе всюду определенный автомат. Если автомат не является всюду определенным, его можно сделать таковым на основании только что приведенной леммы.
Алгоритм 3.4. Построение ДКА с минимальным числом состояний.
Вход. Всюду определенный ДКА M = (Q, T, D, q0, F).
Выход. ДКА M' = (Q', T, D', q0', F'), такой что L(M) = L(M') и M' содержит наименьшее возможное число состояний.
Метод. Выполнить шаги 1-5:
Построить начальное разбиение

Применить к
for (каждой группы G в
разбить G на подгруппы
так, чтобы
состояния s и t из G оказались
в одной подгруппе тогда и только тогда,
когда для каждого входного символа a
состояния s и t имеют переходы по a
в состояния из одной и той же группы в
заменить G в
полученных подгрупп;
}
Если
Пусть
Q' = {G1, ..., Gn};
q0' = G, где группа G
F' = {G|G

D'(p', a) = q', если D(p, a) = q, где p
Таким образом, каждая группа в
Синтаксическое дерево для пополненного регулярного выражения (a|b)*abb# с результатом вычисления функций firstpos и lastpos приведено на рис. 3.12. Слева от каждого узла расположено значение firstpos, справа от узла - значение lastpos. Заметим, что эти функции могут быть вычислены за один обход дерева.

|

|
d.
Функция followpos может быть вычислена также за один обход дерева снизу-вверх по следующим двум правилам.
1. Пусть n - внутренний узел с операцией .
(конкатенация), u и v - его потомки. Тогда для каждой позиции i, входящей в lastpos(u), добавляем к множеству значений followpos(i) множество firstpos(v).
2. Пусть n - внутренний узел с операцией *
(итерация), u - его потомок. Тогда для каждой позиции i, входящей в lastpos(u), добавляем к множеству значений followpos(i) множество firstpos(u).
Пример 3.8. Результат вычисления
функции followpos для регулярного выражения из предыдущего примера приведен на рис. 3.13.
Алгоритм 3.3. Прямое построение ДКА по регулярному выражению.
Вход. Регулярное выражение r в алфавите T.
Выход. ДКА M = (Q, T, D, q0, F), такой что L(M) = L(r).
Метод. Состояния ДКА соответствуют множествам позиций.
Вначале Q и D пусты. Выполнить шаги 1-6:
Построить синтаксическое дерево для пополненного регулярного выражения (r)#.
Обходя синтаксическое дерево, вычислить значения функций nullable, firstpos, lastpos и followpos.
Определить q0 = firstpos(root), где root - корень синтаксического дерева.
Добавить q0 в Q как непомеченное состояние.
Выполнить следующую процедуру:
while (в Q есть непомеченное состояние R){
пометить R;
for (каждого входного символа a
в R имеется позиция, которой соответствует a){
пусть символ a в R соответствует позициям
p1, ..., pn, и пусть S =

1<i<nfollowpos(pi);
if (S

if (S

добавить S в Q как непомеченное состояние;
определить D(R, a) = S;
}
}
}
Определить F как множество всех состояний из Q, содержащих позиции, связанные с символом #.
Пример 3.9. Результат применения алгоритма 3.3 для регулярного выражения (a|b)*abb приведен на рис. 3.14.

|
Если группа содержит начальное состояние автомата M, эта группа становится начальным состоянием автомата M'. Если группа содержит заключительное состояние M, она становится заключительным состоянием M'. Отметим, что каждая группа
Если M' имеет «мертвое» состояние, т.е. состояние, которое не является допускающим и из которого нет путей в допускающие, удалить его
и связанные с ним переходы из M'. Удалить из M' также все состояния, недостижимые из начального.
Пример 3.10. Результат применения алгоритма 3.4 приведен на рис. 3.15.

|
Построение недетерминированного конечного автомата по регулярному выражению
Рассмотрим алгоритм построения по регулярному выражению недетерминированного конечного автомата, допускающего тот же язык.
Алгоритм 3.1. Построение недетерминированного конечного автомата по регулярному выражению.
Вход. Регулярное выражение r в алфавите T.
Выход. НКА M, такой что L(M) = L(r).
Метод. Автомат для выражения строится композицией из автоматов, соответствующих подвыражениям. На каждом шаге построения строящийся автомат
имеет в точности одно заключительное состояние, в начальное состояние нет переходов из других состояний и нет переходов из заключительного состояния в другие.
Для выражения e строится автомат

|

|
Для выражения s|t автомат M(s|t) строится как показано на рис. 3.7. Здесь i - новое начальное состояние и f - новое заключительное состояние. Заметим, что имеет место переход по e из i в начальные состояния M(s) и M(t) и переход по e из заключительных состояний M(s) и M(t) в f. Начальное и заключительное состояния автоматов M(s) и M(t) не являются таковыми для автомата M(s|t).

|

|
Начальное состояние M(s) становится начальным для нового автомата, а
заключительное состояние M(t) становится заключительным для нового автомата. Начальное состояние M(t) и заключительное состояние M(s) сливаются, т.е. все переходы из начального состояния M(t) становятся переходами из заключительного состояния M(s). В новом автомате это объединенное состояние не является ни начальным, ни заключительным.
Для выражения s* автомат M(s*) строится следующим образом:

|
Здесь i - новое начальное состояние, а f - новое заключительное состояние.
Представление языков
Процедура - это конечная последовательность
инструкций, которые могут быть механически выполнены. Примером может служить машинная программа. Процедура, которая всегда заканчивается, называется алгоритмом.
Один из способов представления языка - дать алгоритм, определяющий, принадлежит ли цепочка языку. Более общий способ состоит в том, чтобы дать процедуру, которая останавливается с ответом «да» для цепочек, принадлежащих языку, и либо останавливается с ответом «нет», либо вообще не останавливается для цепочек, не принадлежащих языку. Говорят,
что такая процедура или алгоритм распознает язык.
Такой метод представляет язык с точки зрения распознавания. Язык можно также представить методом порождения. А именно, можно дать процедуру, которая систематически порождает в определенном порядке цепочки языка.
Если мы можем распознать цепочки языка над алфавитом V либо с помощью процедуры, либо с помощью алгоритма, то мы можем и генерировать язык, поскольку мы можем систематически генерировать все цепочки из V *, проверять
каждую цепочку на принадлежность языку и выдавать список только цепочек языка. Но если процедура не всегда заканчивается при проверке цепочки, мы не сдвинемся дальше первой цепочки, на которой процедура не заканчивается. Эту проблему можно обойти, организовав проверку таким образом, чтобы процедура никогда не продолжала проверять одну цепочку бесконечно. Для этого введем следующую конструкцию.
Предположим, что V имеет p символов. Мы можем рассматривать цепочки из V * как числа,
представленные в базисе p, плюс пустая цепочка e. Можно занумеровать цепочки в порядке возрастания длины и в «числовом» порядке для цепочек одинаковой длины. Такая нумерация для цепочек языка {a, b, c}*
приведена на рис. 2.1, а.
Пусть P - процедура для проверки принадлежности цепочки языку L. Предположим, что P может быть представлена дискретными шагами, так что имеет смысл говорить об i-ом шаге процедуры для любой данной цепочки.
Прежде чем дать процедуру перечисления цепочек языка L, дадим
процедуру нумерации пар положительных чисел.
Все упорядоченные пары положительных чисел (x, y) можно отобразить на множество положительных чисел следующей формулой:

Пары целых положительных чисел можно упорядочить в соответствии со значением z (рис. 2.1, б).

|
видеть, что эта процедура перечисляет все цепочки L.
Если мы имеем процедуру генерации цепочек языка, то мы всегда можем построить процедуру распознавания предложений языка, но не всегда алгоритм. Для определения того, принадлежит ли x языку L, просто нумеруем предложения L и сравниваем x с каждым предложением. Если сгенерировано x, процедура останавливается, распознав, что x принадлежит L. Конечно, если x не принадлежит L, процедура никогда не закончится.
Язык, предложения которого
могут быть сгенерированы процедурой, называется рекурсивно перечислимым. Язык рекурсивно перечислим, если имеется процедура, распознающая предложения языка. Говорят, что язык рекурсивен, если существует алгоритм для распознавания языка. Класс рекурсивных языков является собственным подмножеством класса рекурсивно перечислимых языков. Мало того, существуют языки, не являющиеся даже рекурсивно перечислимыми.
Представление в виде ориентированного графа
Простейшей формой промежуточного представления является синтаксическое дерево программы. Ту же самую информацию о входной программе, но в более компактной форме дает ориентированный ациклический граф (ОАГ), в котором в одну вершину объединены вершины синтаксического дерева, представляющие общие подвыражения. Синтаксическое дерево и ОАГ для оператора присваивания
a := b *-c + b *-c
приведены на рис.8.1.
На рис. 8.2 приведены два представления в памяти
синтаксического дерева на рис. 8.1, а. Каждая вершина кодируется записью с полем для операции и полями для указателей на потомков. На рис. 8.2, б, вершины размещены в массиве записей и индекс (или вход) вершины служит указателем на нее.


|
Преобразования КС-грамматик
Рассмотрим ряд преобразований, позволяющих «улучшить» вид контекстно-свободной грамматики, без изменения порождаемого ею языка.
Назовем символ X
грамматики. Иными словами, символ X является недостижимым, если в G не существует вывода S



Алгоритм 4.1. Устранение недостижимых символов.
Вход. КС-грамматика G = (N, T, P, S).
Выход. КС-грамматика G' = (N', T', P', S) без недостижимых символов, такая, что L(G') = L(G).
Метод. Выполнить шаги 1-4:
Положить V 0 = {S} и i = 1.
Положить V i = {X | в P есть A

Если V i

Положить N' = V i
Назовем символ X
Алгоритм 4.2. Устранение бесполезных символов.
Вход. КС-грамматика G = (N, T, P, S).
Выход. КС-грамматика G' = (N', T', P', S) без бесполезных символов, такая, что L(G') = L(G).
Метод. Выполнить шаги 1-5:
Положить N0 =
Положить Ni = {A|A
Если Ni

Положить G1 = ((N
Применив к G1 алгоритм 4.1, получить G' = (N', T', P', S).
КС-грамматика без бесполезных символов называется приведенной. Легко видеть, что для любой КС-грамматики существует эквивалентная приведенная. В дальнейшем будем предполагать, что все рассматривамые
грамматики - приведенные.
Преобразователи с магазинной памятью
Рассмотрим важный класс абстрактных устройств, называемых преобразователями с магазинной памятью. Эти преобразователи получаются из автоматов с магазинной памятью, если к ним добавить выход и позволить на каждом шаге выдавать выходную цепочку.
Преобразователем с магазинной памятью (МП-преобразователем) называется восьмерка P = (Q, T,

того, что
в множество конечных подмножеств множества Q Ч
Определим конфигурацию преобразователя P как четверку (q, x, u, y), где q
Если множество D(q, a, Z) содержит элемент (r, u, z), то будем писать (q, ax, Zw, y)

Цепочку y назовем
выходом для x, если (q0, x, Z0, e)


Будем говорить, что МП-преобразователь P является детерминированным (ДМП-преобразователем), если выполняются следующие условия:
для всех q
если D(q, e, Z)

то D(q, a, Z) =
Пример5.1. Рассмотрим перевод


Этот перевод может быть реализован ДМП-преобразователем P = ({q0, qf}, {a, b, $}, {Z, a, b}, {a, b}, D, q0, Z, {qf}) c функцией переходов:
D(q0, X, Z) = {(q0, XZ, e)}, X
D(q0, $, Z) = {(qf, Z, e)},
D(q0, X, X) = {(q0, XX, e)}, X
D(q0, X, Y ) = {(q0, e, ab)}, X

Программирование лексического анализа
Как уже отмечалось ранее, лексический анализатор (ЛА) может быть оформлен как подпрограмма. При обращении к ЛА,
вырабатываются как минимум два результата: тип выбранной лексемы и ее значение (если оно есть).
Если ЛА сам формирует таблицы объектов, он выдает тип лексемы и указатель на соответствующий вход в таблице объектов. Если же ЛА не работает с таблицами объектов, он выдает тип лексемы, а ее значение передается, например, через некоторую глобальную переменную. Помимо значения лексемы, эта глобальная переменная может содержать некоторую дополнительную информацию: номер текущей строки, номер
символа в строке и т.д. Эта информация может использоваться в различных целях, например, для диагностики.
В основе ЛА лежит диаграмма переходов соответствующего конечного автомата. Отдельная проблема здесь - анализ ключевых слов. Как правило, ключевые слова - это выделенные идентификаторы. Поэтому возможны два основных способа распознавания ключевых слов: либо очередная лексема сначала диагностируется на совпадение с каким-либо ключевым словом и в случае неуспеха делается
попытка выделить лексему из какого-либо класса, либо, наоборот, после выборки лексемы идентификатора происходит обращение к таблице ключевых слов на предмет сравнения. Подробнее о механизмах поиска в таблицах будет сказано ниже (гл. 7), здесь отметим только, что поиск ключевых слов может вестись либо в основной таблице имен и в этом случае в нее до начала работы ЛА загружаются ключевые слова, либо в отдельной таблице. При первом способе все ключевые
слова непосредственно встраиваются в конечный автомат лексического анализатора, во втором конечный автомат содержит только разбор идентификаторов.
В некоторых языках (например, ПЛ/1 или Фортран) ключевые слова могут использоваться в качестве обычных идентификаторов. В этом случае работа ЛА не может идти независимо от работы синтаксического анализатора. В Фортране возможны, например, следующие строки:
| DO 10 I=1,25 |
| DO 10 I=1.25 |
В первом случае строка - это заголовок цикла DO, во втором - оператор присваивания. Поэтому, прежде чем можно будет выделить лексему, лексический анализатор должен заглянуть довольно далеко.
Еще сложнее дело в ПЛ/1. Здесь возможны такие операторы:
|
IF ELSE THEN ELSE = THEN; ELSE THEN = ELSE; |
|
DECLARE (A1, A2, ... , AN) |
Рассмотрим несколько подробнее вопросы программирования ЛА. Основная операция лексического анализатора, на которую уходит большая часть времени его работы - это взятие очередного символа и проверка на
принадлежность его некоторому диапазону. Например, основной цикл при выборке числа в простейшем случае может выглядеть следующим образом:
|
while (Insym='0') { ... } |
|
map['a']=LETTER; ........ map['z']=LETTER; map['0']=DIGIT; ........ map['9']=DIGIT; map[' ']=BLANK; ........ |
|
while (map[Insym]==DIGIT) { ... } |
Для этого строится конечный автомат, описывающий множество ключевых слов. На рис. 3.17 приведен фрагмент такого автомата. Рассмотрим пример программирования этого конечного автомата на языке Си, приведенный в [14]:
 |
Поскольку ЛА анализирует каждый символ входного потока, его скорость существенно зависит от скорости выборки очередного символа входного потока. В свою очередь, эта скорость во многом определяется схемой буферизации. Рассмотрим
возможные эффективные схемы буферизации.
Будем использовать буфер, состоящий из двух одинаковых частей длины N (рис. 3.18, а), где N - размер блока обмена (например, 1024, 2048 и т.д.).
 |
выделена лексема, и устанавливается на ее конец. После обработки лексемы оба указателя устанавливаются на символ, следующий за лексемой. Если указатель продвижение переходит середину буфера, правая половина заполняется новыми N символами. Если указатель продвижение переходит правую границу буфера, левая половина заполняется N символами и указатель продвижение устанавливается на начало буфера.
При каждом продвижении указателя необходимо проверять, не достигли ли мы границы одной из
половин буфера. Для всех символов, кроме лежащих в конце половин буфера, требуются две проверки. Число проверок можно свести к одной, если в конце каждой половины поместить дополнительный «сторожевой» символ, в качестве которого логично взять eof (рис. 3.18, б).
В этом случае почти для всех символов делается единственная проверка на совпадение с eof и только в случае совпадения нужно дополнительно проверить, достигли ли мы середины или правого конца.
Промежуточное представление программы
В процессе трансляции компилятор часто используют промежуточное представление (ПП) исходной программы, предназначенное прежде всего для удобства генерации кода и/или проведения различных оптимизаций. Сама форма ПП зависит от целей его использования.
Наиболее часто используемыми формами ПП является ориентированный граф (в частности, абстрактное синтаксическое дерево, в том числе атрибутированное), трехадресный код (в виде троек или четверок), префиксная и постфиксная запись.
Реализация блочной структуры
С точки зрения структуры программы блоки (и/или процедуры) образуют дерево. Каждой вершине дерева этого представления, соответствующей блоку, можно сопоставить свою таблицу символов (и, возможно, одну общую таблицу идентификаторов). Работу с таблицами блоков можно организовать в магазинном
режиме: при входе в блок создавать таблицу символов, при выходе - уничтожать. При этом сами таблицы должны быть связаны в упорядоченный список, чтобы можно было просматривать их в порядке вложенности. Если таблицы организованы с помощью функций расстановки, это означает, что для каждой таблицы должна быть создана своя таблица расстановки.
Регулярные множества и их представления
В разделе 3.3.3 приведен алгоритм построения детерминированного конечного автомата по регулярному выражению. Рассмотрим теперь как по описанию конечного автомата построить регулярное множество, совпадающее с языком, допускаемым конечным автоматом.
Теорема3.1. Язык, допускаемый детерминированным конечным автоматом, является регулярным множеством.
Доказательство. Пусть L - язык допускаемый детерминированным
конечным автоматом M = ({q1, ..., qn}, T, D, q1, F). Введем De - расширенную функцию переходов автомата M: De(q, w) = p, где w
Обозначим Rijk множество всех слов x таких, что De(qi, x) = qj и если De(qi, y) = qs
для любой цепочки y - префикса x, отличного от x и e, то s

Иными словами, Rijk есть множество всех слов, которые переводят конечный автомат из состояния qi
в состояние qj, не проходя ни через какое состояние qs
для s > k. Однако, i и j могут быть больше k.
Rijk может быть определено рекурсивно следующим образом:
Rij0 = {a|a
Rijk = Rijk-1
Rikk-1(Rkkk-1)*Rkjk-1, где 1
Таким образом, определение Rijk означает, что для входной цепочки w, переводящей M из qi в qj без перехода через состояния с номерами, большими k, справедливо ровно одно из следующих двух утверждений:
Цепочка w принадлежит Rijk-1, т.е. при анализе цепочки w автомат никогда не достигает состояний с номерами, большими или равными k.
Цепочка w может быть представлена в виде w = w1w2w3, где w1
M сначала в qk), w2

|
Тогда L =
qj

Таким образом, для всякого регулярного множества имеется конечный автомат, допускающий в точности это регулярное множество, и наоборот - язык, допускаемый конечным автоматом есть регулярное множество.
Рассмотрим теперь соотношение между языками, порождаемыми праволинейными грамматиками и допускаемыми конечными автоматами.
Праволинейная грамматика G = (N, T, P, S) называется регулярной,
если
каждое ее правило, кроме S
в том случае, когда S
Лемма. Пусть G - праволинейная грамматика. Существует регулярная грамматика G' такая, что L(G) = L(G').
Доказательство. Предоставляется читателю в качестве упражнения. __
Теорема 3.2. Пусть G = (N, T, P, S) - праволинейная грамматика. Тогда существует конечный автомат M = (Q, T, D, q0, F) для которого L(M) = L(G).
Доказательство. На основании приведенной выше леммы, без ограничения общности можно считать, что G - регулярная грамматика.
Построим недетерминированный конечный автомат M следующим образом:
состояниями M будут нетерминалы G плюс новое состояние R, не принадлежащее N. Так что Q = N
{R};
в качестве начального состояния M примем S, т.е. q0 = S;
если P содержит правило S
e, то F = {S, R}, иначе F = {R}. Напомним, что S не встречается в правых частях правил, если S
состояние R
того, D(A, a) содержит все B такие, что A
T.
M, читая вход w, моделирует вывод w в грамматике G. Покажем, что L(M) = L(G). Пусть w = a1a2...an


Аналогично, если w = a1a2...an
D(S, a1) содержит A1, D(A1, a2) содержит A2, и т.д. Поэтому

- вывод в G и x
Теорема 3.3. Для каждого конечного автомата M = (Q, T, D, q0, F) существует праволинейная грамматика G = (N, T, P, S) такая, что L(G) = L(M).
Доказательство. Без потери общности можно считать, что автомат M - детерминированный. Определим грамматику G следующим образом:
нетерминалами грамматики
G будут состояния автомата M. Так что N = Q;
в качестве начального символа грамматики G примем q0, т.е. S = q0;
A
A
S
Доказательство того, что S
Регулярные множества и выражения
Введем понятие регулярного множества, играющего важную роль в теории формальных языков.
Регулярное множество в алфавите T определяется рекурсивно следующим образом:
{e} - регулярное множество в алфавите T (e - пустая цепочка);
{a} - регулярное множество в алфавите
T для каждого a
если P и Q - регулярные множества в алфавите T, то регулярными являются и множества
P
PQ (конкатенация, т.е. множество {pq|p
P* (итерация: P* =
n=0

ничто другое не является регулярным множеством в алфавите T.
Итак, множество в алфавите T регулярно тогда и только тогда, когда оно либо
можно получить из этих множеств применением конечного числа операций объединения, конкатенации и итерации.
Приведенное выше определение регулярного множества позволяет ввести следующую удобную форму его записи, называемую регулярным выражением.
Регулярное выражение в алфавите T и обозначаемое им регулярное множество в алфавите T определяются рекурсивно следующим образом:
e - регулярное выражение, обозначающее
множество {e};
a - регулярное выражение, обозначающее множество {a};
если p и q - регулярные выражения, обозначающие регулярные множества P и Q соответственно, то
(p|q) - регулярное выражение, обозначающее регулярное множество P
(pq) - регулярное выражение, обозначающее регулярное множество PQ,
(p*) - регулярное выражение, обозначающее регулярное множество P*;
ничто другое не является регулярным
выражением в алфавите T.
Мы будем опускать лишние скобки в регулярных выражениях, договорившись о том, что операция итерации имеет наивысший приоритет, затем идет операции конкатенации, наконец, операция объединения имеет наименьший приоритет.
Кроме того, мы будем пользоваться записью p+ для обозначения pp*. Таким образом, запись (a|((ba)(a*))) эквивалентна a|ba+.
Наконец, мы будем использовать запись L(r) для регулярного множества, обозначаемого регулярным выражением
r.
Пример 3.1. Несколько примеров регулярных выражений и обозначаемых ими регулярных множеств:
a(e|a)|b - обозначает множество {a, b, aa};
a(a|b)* - обозначает множество всевозможных цепочек, состоящих из a и b, начинающихся с a;
(a|b)*(a|b)(a|b)* - обозначает множество всех непустых цепочек, состоящих из a и b, т.е. множество {a, b}+;
((0|1)(0|1)(0|1))* - обозначает множество всех цепочек, состоящих из нулей и единиц, длины которых делятся на 3.
Ясно, что для каждого регулярного множества можно найти регулярное выражение, обозначающее это
множество, и наоборот. Более того, для каждого регулярного множества существует бесконечно много обозначающих его регулярных выражений.
Будем говорить, что регулярные выражения равны или эквивалентны (=), если они обозначают одно и то же регулярное множество.
Существует ряд алгебраических законов, позволяющих осуществлять эквивалентное преобразование регулярных выражений.
Лемма. Пусть p, q и r - регулярные выражения. Тогда справедливы следующие соотношения:
| (1) | p|q = q|p; | (7) | pe = ep = p; | |||
| (2) | | (8) | |
|||
| (3) | p|(q|r) = (p|q)|r; | (9) | p* = p|p*; | |||
| (4) | p(qr) = (pq)r; | (10) | (p*)* = p*; | |||
| (5) | p(q|r) = pq|pr; | (11) | p|p = p; | |||
| (6) | (p|q)r = pr|qr; | (12) | p| |
|||
В дальнейшем будем рассматривать только регулярные выражения, не содержащие в своей записи
При практическом описании лексических структур бывает полезно сопоставлять регулярным выражениям некоторые имена, и ссылаться на них по этим именам. Для
определения таких имен мы будем использовать запись вида
| d1 = r1 | |
| d2 = r2 | |
| ... | |
| dn = rn | |
Пример 3.2. Использование имен для регулярных выражений.
Регулярное выражение для множества идентификаторов.
| Letter = a|b|c|...|x|y|z | |
| Digit = 0|1|...|9 | |
| Identifier = Letter(Letter|Digit)* | |
| Digit = 0|1|...|9 | |
| Integer = Digit+ | |
| Fraction = .Integer|e | |
| Exponent = (E(+|-|e)Integer)|e | |
| Number = Integer Fraction Exponent | |
Рекурсивный спуск
Выше был рассмотрен таблично-управляемый вариант предсказывающего анализа, когда магазин явно использовался в процессе работы анализатора. Можно предложить другой вариант предсказывающего анализа, в котором каждому
нетерминалу сопоставляется процедура (вообще говоря, рекурсивная), и магазин образуется неявно при вызовах таких процедур. Процедуры рекурсивного спуска могут быть записаны, как показано ниже.
В процедуре A для случая, когда имеется правило A
этого не делается, так что анализ ошибки откладывается на процедуру, вызвавшую A.
void A(){ // A
if (InSym
if (parse(ui))
result("A
else error();
else
//Вариант 1:
if (имеется правило A
такое, что ui
//Вариант 1.1
if (InSym
result("A
else error();
//Конец варианта 1.1
//Вариант 1.2:
result("A
//Конец варианта 1.2
//Конец варианта 1
//Вариант 2:
if (нет правила A
error();
//Конец варианта 2
}
boolean parse(u){ // из u не выводится e!
v = u;
while (v

if (X - терминал a)
if (InSym

return(false);
else InSym = getInsym();
else // X - нетерминал B
B();
v = z;
}
return(true);
}
Синтаксически управляемый перевод
Другим формализмом, используемым
для определения переводов, является схема синтаксически управляемого перевода. Фактически, такая схема представляет собой КС-грамматику, в которой к каждому правилу добавлен элемент перевода. Всякий раз, когда правило участвует в выводе входной цепочки, с помощью элемента перевода вычисляется часть выходной цепочки, соответствующая части входной цепочки, порожденной этим правилом.
Синтаксический анализ для T-грамматик
Обычно код генерируется из некоторого промежуточного языка с довольно жесткой структурой. В частности, для каждой операции известна ее размерность, то есть число операндов, большее или равное 0. Операции задаются терминальными символами, и наоборот - будем считать все терминальные символы знаками операций. Назовем
грамматики, удовлетворяющие этим ограничениям, T-грамматиками. Правая часть каждой продукции в Т-грамматике есть правильное префиксное выражение, которое может быть задано следующим определением:
Операция размерности 0 является правильным префиксным выражением;
Нетерминал является правильным префиксным выражением;
Префиксное выражение, начинающееся со знака операции размерности n > 0, является правильным, если после знака операции следует
n правильных префиксных выражений;
Ничто другое не является правильным префиксным выражением.
Образцы, соответствующие машинным командам, задаются правилами грамматики (вообще говоря, неоднозначной). Генератор кода анализирует входное префиксное выражение и строит одновременно все возможные деревья разбора. После окончания разбора выбирается дерево с наименьшей стоимостью. Затем по этому единственному оптимальному дереву генерируется
код.
Для T-грамматик все цепочки, выводимые из любого нетерминала A, являются префиксными выражениями с фиксированной арностью операций. Длины всех выражений из входной цепочки a1...an можно предварительно вычислить (под длиной выражения имеется ввиду длина подстроки, начинающейся с символа кода операции и заканчивающейся последним символом, входящим в выражение для этой операции). Поэтому можно проверить, сопоставимо ли некоторое правило с подцепочкой ai...ak входной цепочки a1...an,
проходя слева-направо по ai...ak. В процессе прохода по цепочке предварительно вычисленные длины префиксных выражений используются для того, чтобы перейти от одного терминала к следующему терминалу, пропуская подцепочки, соответствующие нетерминалам правой части правила.
Цепные правила не зависят от операций, следовательно, их необходимо проверять отдельно.
Применение одного цепного правила может зависеть от применения другого цепного правила. Следовательно, применение
цепных правил необходимо проверять до тех пор, пока нельзя применить ни одно из цепных правил. Мы предполагаем, что в грамматике нет циклов в применении цепных правил. Построение всех вариантов анализа для T-грамматики дано ниже в алгоритме 9.1. Тип Titem в алгоритме 9.1 ниже служит для описания ситуаций (т.е. правил вывода и позиции внутри правила). Тип Tterminal - это тип терминального символа грамматики, тип Tproduction - тип для правила вывода.
Алгоритм 9.1
|
Tterminal a[n]; setofTproduction r[n]; int l[n]; // l[i] - длина a[i]-выражения Titem h; // используется при поиске правил, // сопоставимых с текущей подцепочкой // Предварительные вычисления Для каждой позиции i вычислить длину a[i]-выражения l[i]; // Распознавание входной цепочки for (int i=n-1;i>=0;i-){ for (каждого правила A -> a[i] y из P){ j=i+1; if (l[i]>1) // Первый терминал a[i] уже успешно сопоставлен {h=[A->a[i].y]; do // найти a[i]y, сопоставимое с a[i]..a[i+l[i]-1] {Пусть h==[A->u.Xv]; if (X in T) if (X==a[j]) j=j+1; else break; else // X in N if (имеется X->w in r[j]) j=j+l[j]; else break; h=[A->uX.v]; //перейти к следующему символу } while (j!=i+l[i]); } // l[i]>1 if (j==i+l[i]) r[i]=r[i] + { (A->a[i]y) } } // for по правилам A -> a[i] y // Сопоставить цепные правила while (существует правило C->A из P такое, что имеется некоторый элемент (A->w) в r[i] и нет элемента (C->A) в r[i]) r[i]=r[i] + { (C->A) }; } // for по i Проверить, принадлежит ли (S->w) множеству r[0]; |
Множества r[i] имеют размер O(|P|). Можно показать, что алгоритм
имеет временную и емкостную сложность O(n).
Рассмотрим вновь пример рис. 9.15. В префиксной записи приведенный фрагмент программы записывается следующим образом:
|
= + a x + @ + + b y @ + i z 5 |

|
PARSE. После обхода поддерева данной вершины в ней применяется процедура MATCHED, которая пытается найти все образцы, сопоставимые поддереву данной вершины. Для этого каждое правило-образец разбивается на компоненты в соответствии с встречающимися в нем операциями. Дерево обходится справа налево только для того, чтобы иметь соответствие с порядком вычисления в алгоритме 9.1. Очевидно, что можно обходить дерево вывода и слева направо.
Структура данных, представляющая
вершину дерева, имеет следующую форму:
|
struct Tnode { Tterminal op; Tnode * son[MaxArity]; setofTproduction RULEs; }; |
Алгоритм 9.2
|
Tnode * root; bool MATCHED(Tnode * n, Titem h) { bool matching; пусть h==[A->u.Xvy], v== v_1 v_2 ... v_m, m=Arity(X); if (X in T)// сопоставление правила if (m==0) // if l[i]==1 if (X==n->op) //if X==a[j] return(true); else return(false); else // if l[i]>1 if (X==n->op) //if X==a[j] {matching=true; for (i=1;i matching=matching && //while (j==i+l[i]) MATCHED(n->son[i-1],[A->uXv'.v_i v"y]); return(matching); //h=[A->uX.v] } else return(false); else // X in N поиск подвывода if (в n^.RULEs имеется правило с левой частью X) return(true); else return(false); } void PARSE(Tnode * n) { for (i=Arity(n->op);i>=1;i-) // for (i=n; i>=1;i-) PARSE(n->son[i-1]); n->RULEs=EMPTY; for (каждого правила A->bu из P такого, что b==n->op) if (MATCHED(n,[A->.bu])) //if (j==i+l[i]) n->RULEs=n->RULEs+{(A->bu)}; // Сопоставление цепных правил while (существует правило C->A из P такое, что некоторый элемент (A->w) в n->RULEs и нет элемента (C->A) в n->RULEs) n->RULEs=n->RULEs+{(C->A)}; } Основная программа // Предварительные вычисления Построить дерево выражения для входной цепочки z; root = указатель дерева выражения; // Распознать входную цепочку PARSE(root); Проверить, входит ли во множество root->RULEs правило с левой частью S; |
Система СУПЕР
Программа на входном языке СУПЕР («метапрограмма») состоит из следующих разделов:
- Заголовок;
- Раздел констант;
- Раздел типов;
- Алфавит;
- Раздел файлов;
- Раздел библиотеки;
- Атрибутная схема.
Заголовок определяет имя атрибутной грамматики, первые три буквы имени задают расширение имени входного
файла для реализуемого транслятора.
Раздел констант содержит описание констант, раздел типов - описание типов.
Алфавит содержит перечисление нетерминальных символов и классов лексем, а также атрибутов (и их типов), сопоставленных этим символам. Классы лексем являются терминальными символами с точки зрения синтаксического анализа, но могут иметь атрибуты, вычисляемые в процессе лексического анализа. Определение класса лексем состоит в задании
имени класса, имен атрибутов для этого класса и типов этих атрибутов.
В разделе определения нетерминальных символов содержится перечисление этих символов с указанием приписанных им атрибутов и их типов. Аксиома грамматики указывается первым символом в списке нетерминалов.
Раздел библиотеки содержит заголовки процедур и функций, используемых в формулах атрибутной грамматики.
Раздел файлов содержит описание файловых переменных, используемых в формулах атрибутной грамматики.
Файловые переменные можно рассматривать как атрибуты аксиомы.
Атрибутная схема состоит из списка синтаксических правил и сопоставленных им семантических правил. Для описания синтаксиса языка используется расширенная форма Бэкуса-Наура. Терминальные символы в правой части заключаются в кавычки, классы лексем и нетерминалы задаются их именами. Для задания в правой части необязательных символов используются скобки [ ], для задания повторяющихся конструкций используются скобки
( ). В этом случае может быть указан разделитель символов (после /). Например,
| A ::= B [ C ] ( D ) ( E / ',' ) |
Первым правилом в атрибутной схеме должно быть правило для аксиомы.
Каждому синтаксическому правилу могут быть сопоставлены семантические действия. Каждое такое действие - это оператор, который может использовать атрибуты как символов данного правила (локальные атрибуты), так и символов, могущих быть предками (динамически) символа левой части данного правила
в дереве разбора (глобальные атрибуты). Для ссылки на локальные атрибуты символы данного правила (как терминальные, так и нетерминальные) нумеруются от 0 (для символа левой части). При ссылке на глобальные атрибуты надо иметь в виду, что атрибуты имеют области видимости на дереве разбора. Областью видимости атрибута вершины, помеченной N, является все поддерево N, за исключением его поддеревьев, также помеченных N.
Исполнение операторов
семантической части правила привязывается к обходу дерева разбора сверху вниз слева направо. Для этого каждый оператор может быть помечен меткой, состоящей из номера ветви правила, к выполнению которой должен быть привязан оператор, и, возможно, одного из суффиксов A, B, E, M.
Суффикс A задает выполнение оператора перед каждым вхождением синтаксической конструкции, заключенной в скобки повторений ( ). Суффикс B задает выполнение оператора после
каждого вхождения синтаксической конструкции, заключенной в скобки повторений ( ). Суффикс M задает выполнение оператора между вхождениями синтаксической конструкции, заключенной в скобки повторений ( ). Суффикс E задает выполнение оператора в том случае, когда конструкция, заключенная в скобки [ ], отсутствует.
Пример использование меток атрибутных формул:
|
D ::= 'd' => $0.y:=$0.x+1. A ::= B (C) [D] => $2.x:=1; 2M: $2.x:=$2.x+1; $3.x:=$2.x; 3E: $3.y:=$3.x; 3: writeln($3.y). |
Система Yacc
В основу системы Yacc положен синтаксический анализатор типа LALR(1), генерируемый по входной (мета) программе. Эта программа
состоит из трех частей:
| %{ Си-текст %} %token Список имен лексем %% Список правил трансляции %% Служебные Си-подпрограммы |
Си-текст (который вместе с окружающими скобками %{ и %} может отсутствовать) обычно содержит Си-объявления (включая #include и #define), используемые в тексте ниже. Этот Си-текст может содержать и объявления (или предобъявления) функций.
Список имен лексем содержит имена, которые преобразуются Yacc-препроцессором в объявления констант (#define). Как правило, эти имена используются
как имена классов лексем и служат для определения интерфейса с лексическим анализатором.
Каждое правило трансляции имеет вид
| Левая_часть : альтернатива_1 {семантические_действия_1} | альтернатива_2 {семантические_действия_2} |... | альтернатива_n {семантические_действия_n} ; |
Каждое семантическое действие - это последовательность операторов Си. При этом каждому нетерминалу может быть сопоставлен один синтезируемый атрибут. На атрибут нетерминала левой части ссылка осуществляется посредством значка $$, на атрибуты символов правой части - посредством значков $1, $2 , ..., $n, причем номер соответствует порядку элементов правой части, включая
семантические действия. Каждое семантическое действие может вырабатывать значение в результате выполнения присваивания $$=Выражение. Исполнение текого оператора в последнем семантическом действии определяет значение атрибута символа левой части.
В некоторых случаях допускается использование грамматик, имеющих конфликты. При этом синтаксический анализатор разрешает конфликты следующим образом:
- конфликты типа свертка/ свертка разрешаются выбором правила, предшествующего во входной
метапрограмме;
- конфликты типа сдвиг/свертка разрешаются предпочтением сдвига. Поскольку этих правил не всегда достаточно для правильного определения анализатора, допускается определение старшинства и ассоциативности терминалов.
Например, объявление
|
%left '+' '-' |
|
%right '^' |
|
%nonassoc ' |
старшинства s или если старшинство одинаково, а правило левоассоциативно. В противном случае делается сдвиг.
Обычно за старшинство правила принимается старшинство самого правого терминала правила. В тех случаях, когда самый правый терминал не дает нужного приоритета, этот приоритет можно назначить следующим объявлением:
|
%prec терминал |
Yacc не сообщает о конфликтах, разрешаемых с помощью ассоциативности и приоритетов. Восстановление после ошибок управляется пользователем с помощью введения в грамматику «правил ошибки» вида
A
Здесь error - ключевое слово Yacc. Когда встречается синтаксическая ошибка, анализатор трактует состояние, набор ситуаций
для которого содержит правило для error, некоторым специальным образом: символы из стека выталкиваются до тех пор, пока на верхушке стека не будет обнаружено состояние, для которого набор ситуаций содержит ситуацию вида [A
Если w пусто, делается свертка. После этого анализатор пропускает входные символы, пока не найдет такой, с которым
можно продолжить нормальный разбор.
Если w не пусто, просматривается входная строка и делается попытка свернуть w. Если w состоит только из терминалов, эта строка ищется во входном потоке.
Системы автоматизации построения трансляторов
Системы автоматизации построения трансляторов (САПТ) предназначены для автоматизации процесса разработки трансляторов. Очевидно, что для того, чтобы описать транслятор, необходимо иметь формализм для описания. Этот формализм затем реализуется в виде входного языка САПТ. Как правило, формализмы основаны на атрибутных грамматиках. Ниже описаны две САПТ, получившие распространение: СУПЕР[3] и Yacc. В основу первой
системы положены LL(1)-грамматики и L-атрибутные вычислители, в основу второй - LALR(1)-грамматики и S-атрибутные вычислители.
Сопоставление образцов
Техника генерации кода, рассмотренная выше, основывалась на однозначном соответствии структуры промежуточного представления и описывающей это представление грамматики. Недостатком такого «жесткого» подхода является то, что как правило одну и ту же программу на промежуточном языке можно
реализовать многими различными способами в системе команд машины. Эти разные реализации могут иметь различную длину, время выполнения и другие характеристики. Для генерации более качественного кода может быть применен подход, изложенный в настоящей главе.
Этот подход основан на понятии «сопоставления образцов»: командам машины сопоставляются некоторые «образцы», вхождения которых ищутся в промежуточном представлении программы, и делается
попытка «покрыть» промежуточную программу такими образцами. Если это удается, то по образцам восстанавливается программа уже в кодах. Каждое такое покрытие соответствует некоторой программе, реализующей одно и то же промежуточное представление.

|
На рис. 9.15 показано промежуточное дерево для оператора a = b[i] + 5, где a, b, i - локальные переменные, хранимые со смещениями x, y, z соответственно в областях данных с одноименными адресами.
Элемент массива b занимает память в одну машинную единицу. 0-местная операция const возвращает значение атрибута соответствующей вершины промежуточного дерева, указанного на рисунке в скобках после оператора. Одноместная операция @ означает косвенную адресацию и возвращает содержимое регистра
или ячейки памяти, имеющей адрес, задаваемый аргументом операции.

|
На рис. 9.16 показан пример сопоставления образцов машинным командам. Приведены два варианта задания образца: в виде дерева и в виде правила контекстно-свободной грамматики. Для каждого образца указана машинная команда, реализующая этот образец, и стоимость этой команды.
В каждом дереве-образце корень или лист может быть помечен терминальным и/или нетерминальным символом.
Внутренние вершины помечены терминальными символами
- знаками операций. При наложении образца на дерево выражения, во-первых, терминальный символ образца должен соответствовать терминальному символу дерева, и, во-вторых, образцы должны «склеиваться» по типу нетерминального символа, т.е. тип корня образца должен совпадать с типом вершины, в которую образец подставляется корнем. Допускается использование «цепных» образцов, т.е. образцов, корню которых не соответствует терминальный символ, и имеющих единственный элемент
в правой части. Цепные правила служат для приведения вершин к одному типу. Например, в рассматриваемой системе команд одни и те же регистры используются как для целей адресации, так и для вычислений. Если бы в системе команд для этих целей использовались разные группы регистров, то в грамматике команд могли бы использоваться разные нетерминалы, а для пересылки из адресного регистра в регистр данных могла бы использоваться соответствующая команда и образец.
Нетерминалы Reg на образцах могут быть помечены индексом (i или j), что (неформально) соответствует номеру регистра и служит лишь для пояснения смысла использования регистров. Отметим, что при генерации кода рассматриваемым методом не осуществляется распределение регистров. Это является отдельной задачей.
Стоимость может определяться различными способами, например числом обращений к памяти при выборке и исполнении команды. Здесь мы не рассматриваем этого вопроса. На рис. 9.17
приведен пример покрытия промежуточного дерева рис. 9.15 образцами рис. 9.16. В рамки заключены фрагменты дерева, сопоставленные образцу правила, номер которого указывается в левом верхнем углу рамки. В квадратных скобках указаны результирующие вершины.

|
|
MOVE b,Rb ADD #y,Rb MOVE i,Ri ADD z(Ri),Rb MOVE (Rb),Rb ADD #5,Rb MOVE a,Ra MOVE Rb,x(Ra) |
Основная идея подхода заключается в том, что каждая команда машины описывается в виде такого образца. Различные покрытия дерева промежуточного представления соответствуют различным последовательностям машинных команд. Задача выбора команд состоит в том, чтобы выбрать наилучший способ реализации того или иного
действия или последовательности действий, т. е. выбрать в некотором смысле оптимальное покрытие.
Для выбора оптимального покрытия было предложено несколько интересных алгоритмов, в частности использующих динамическое программирование [11, 13]. Мы здесь рассмотрим алгоритм [12], комбинирующий возможности синтаксического анализа и динамического программирования. В основу этого алгоритма положен синтаксический анализ неоднозначных грамматик (модифицированный алгоритм Кока, Янгера и Касами [15, 16]), эффективный в реальных приложениях. Этот же
метод может быть применен и тогда, когда в качестве промежуточного представления используется дерево.
Сравнение методов реализации таблиц
Рассмотрим преимущества
и недостатки рассмотренных методов реализации таблиц с точки зрения техники использования памяти.
Использование динамической памяти, как правило, довольно дорогая операция, поскольку механизмы поддержания работы с динамической памятью могут быть достаточно сложны. Необходимо поддерживать списки свободной и занятой памяти, выбирать наиболее подходящий кусок памяти при запросе, включать освободившийся кусок в список свободной памяти и, возможно, склеивать
куски свободной памяти в списке.
С другой стороны, использование массива требует отведения заранее довольно большой памяти, а это означает, что значительная память вообще не будет использоваться. Кроме того, часто приходится заполнять не все элементы массива (например, в таблице идентификаторов или в тех случаях, когда в массиве фактически хранятся записи переменной длины, например, если в таблице символов записи для различных
объектов имеют различный состав полей). Обращение к элементам массива может означать использование операции умножения при вычислении индексов, что может замедлить исполнение.
Наилучшим, по-видимому, является механизм доступа по указателям и использование факта магазинной организации памяти в компиляторе. Для этого процедура выделения памяти выдает необходимый кусок из подряд идущей памяти, а при выходе из процедуры вся память, связанная с этой
процедурой, освобождается простой перестановкой указателя свободной памяти в состояние перед началом обработки процедуры. В чистом виде это не всегда, однако, возможно. Например, локальный модуль в Модуле-2 может экспортировать некоторые объекты наружу. При этом схему реализации приходится «подгонять» под механизм распределения памяти. В данном случае, например, необходимо экспортированные объекты вынести в среду охватывающего блока и свернуть блок
локального модуля.
Структура компилятора
Обобщенная структура компилятора и основные фазы компиляции показаны на рис. 1.1.

|
На фазе лексического анализа входная программа, представляющая собой поток литер, разбивается на лексемы - слова в соответствии с определениями языка. Основными формализмами, лежащим в основе реализации лексических анализаторов, являются конечные автоматы и регулярные выражения. Лексический анализатор может работать в двух основных режимах: либо как подпрограмма, вызываемая синтаксическим анализатором для получения очередной лексемы, либо как полный проход,
результатом которого является файл лексем.
В процессе выделения лексем лексический анализатор может как самостоятельно строить таблицы объектов (идентификаторов, строк, чисел и т.д.), так и выдавать значения для каждой лексемы при очередном к нему обращении. В этом случае таблицы объектов строятся в последующих фазах (например, в процессе синтаксического анализа).
На этапе лексического анализа обнаруживаются некоторые (простейшие) ошибки (недопустимые символы, неправильная запись чисел, идентификаторов
и др.).
Основная задача синтаксического анализа - разбор структуры программы. Как правило, под структурой понимается дерево, соответствующее разбору в контекстно-свободной грамматике языка. В настоящее время чаще всего используется либо LL(1)-анализ (и его вариант - рекурсивный спуск), либо LR(1)-анализ и его варианты (LR(0), SLR(1), LALR(1) и другие). Рекурсивный спуск чаще используется при ручном программировании синтаксического анализатора, LR(1) - при использовании систем автоматического построения синтаксических анализаторов.
Результатом синтаксического
анализа является синтаксическое дерево со ссылками на таблицы объектов. В процессе синтаксического анализа также обнаруживаются ошибки, связанные со структурой программы.
На этапе контекстного анализа выявляются зависимости между частями программы, которые не могут быть описаны контекстно-свободным синтаксисом. Это в основном связи «описание-использование», в частности, анализ типов объектов, анализ областей видимости, соответствие параметров, метки и другие.
В процессе контекстного анализа
таблицы объектов пополняются информацией об описаниях (свойствах) объектов.
Основным формализмом, использующимся при контекстном анализе, является аппарат атрибутных грамматик. Результатом контекстного анализа является атрибутированное дерево программы. Информация об объектах может быть как рассредоточена в самом дереве, так и сосредоточена в отдельных таблицах объектов. В процессе контекстного анализа также могут быть обнаружены ошибки, связанные с неправильным использованием объектов.
Затем программа может быть переведена во внутреннее представление. Это делается для целей оптимизации и/или удобства генерации кода. Еще одной целью преобразования программы во внутреннее представление является желание иметь переносимый компилятор. Тогда только последняя фаза (генерация кода) является машинно-зависимой. В качестве внутреннего представления может использоваться префиксная или постфиксная запись, ориентированный граф, тройки, четверки и другие.
Фаз оптимизации может быть
несколько. Оптимизации обычно делят на машинно-зависимые и машинно-независимые, локальные и глобальные. Часть машинно-зависимой оптимизации выполняется на фазе генерации кода. Глобальная оптимизация пытается принять во внимание структуру всей программы, локальная - только небольших ее фрагментов. Глобальная оптимизация основывается на глобальном потоковом анализе, который выполняется на графе программы и представляет по существу преобразование этого графа. При этом могут учитываться такие свойства
программы, как межпроцедурный анализ, межмодульный анализ, анализ областей жизни переменных и т.д.
Наконец, генерация кода - последняя фаза трансляции. Результатом ее является либо ассемблерный модуль, либо объектный (или загрузочный) модуль. В процессе генерации кода могут выполняться некоторые локальные оптимизации, такие как распределение регистров, выбор длинных или коротких переходов, учет стоимости команд при выборе конкретной последовательности
команд. Для генерации кода разработаны различные методы, такие как таблицы решений, сопоставление образцов, включающее динамическое программирование, различные синтаксические методы.
Конечно, те или иные фазы транслятора могут либо отсутствовать совсем, либо объединяться. В простейшем случае однопроходного транслятора нет явной фазы генерации промежуточного представления и оптимизации, остальные фазы объединены в одну, причем нет и явно построенного синтаксического дерева.
Таблицы идентификаторов
Как уже было сказано, информацию об объекте обычно можно разделить на две части: имя (идентификатор) и описание. Если длина идентификатора ограничена (или имя идентифицируется по ограниченному числу первых символов идентификатора), то таблица символов может быть организована в виде простого массива строк фиксированной длины, как это изображено на рис.7.1. Некоторые входы могут быть заняты,
некоторые - свободны.

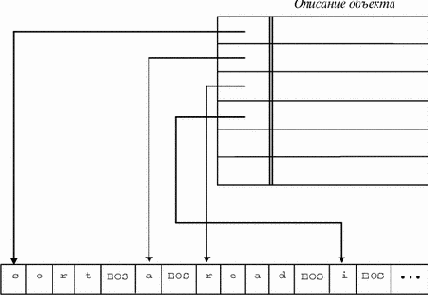
|
Ясно, что, во-первых, размер массива должен быть не меньше числа идентификаторов, которые могут реально появиться в программе (в противном случае возникает переполнение таблицы); во-вторых, как правило, потенциальное число различных идентификаторов существенно больше размера таблицы.
Заметим, что в большинстве языков программирования символьное представление идентификатора может иметь произвольную длину. Кроме того, различные объекты в
одной или в разных областях видимости могут иметь одинаковые имена, и нет большого смысла занимать память для повторного хранения идентификатора. Таким образом, удобно имя объекта и его описание хранить по отдельности.
В этом случае идентификаторы хранятся в отдельной таблице - таблице идентификаторов. В таблице символов же хранится указатель на соответствующий вход в таблицу идентификаторов. Таблицу идентификаторов можно организовать, например, в виде сплошного
массива. Идентификатор в массиве заканчивается каким-либо специальным символом EOS (рис. 7.2). Второй возможный вариант - в качестве первого символа идентификатора в массив заносится его длина.
Таблицы на деревьях
Рассмотрим еще один способ организации таблиц символов с использованием двоичных деревьев.
Ориентированное дерево называется двоичным, если у него в каждую вершину, кроме одной (корня), входит одна дуга, и из каждой вершины
выходит не более двух дуг. Ветвью дерева называется поддерево, состоящее из некоторой дуги данного дерева, ее начальной и конечной вершин, а также всех вершин и дуг, лежащих на всех путях, выходящих из конечной вершины этой дуги. Высотой дерева называется максимальная длина пути в этом дереве от корня до листа.
Пусть на множестве идентификаторов задан некоторый линейный (например, лексикографический) порядок

отношение. Таким образом, для произвольной пары идентификаторов id1 и id2 либо id1
совпадает с id2.

|
Каждой вершине двоичного дерева, представляющего таблицу символов, сопоставим идентификатор. При этом, если вершина (которой сопоставлен id) имеет левого потомка (которому сопоставлен idL), то idL
Поиск в такой таблице может быть описан следующей функцией:
| struct TreeElement * SearchTree(String Id, struct TreeElement * TP) {int comp; if (TP==NULL) return NULL; comp=IdComp(Id,TP->IdentP); if (compLeft)); if (comp>0) return(SearchTree(Id,TP->Right)); return TP; } |
где структура для для элемента дерева имеет вид
| struct TreeElement {String IdentP; struct TreeElement * Left, * Right; }; |
Занесение в таблицу осуществляется функцией
| struct TreeElement * InsertTree(String Id, struct TreeElement * TP) {int comp=IdComp(Id,TP->IdentP); if (compLeft, &(TP->Left))); if (comp>0) return(Fill(Id,TP->Right, &(TP->Right))); return(TP); } |
Как показано в работе [8], среднее время поиска в таблице размера n, организованной в виде двоичного дерева, при равной вероятности появления каждого объекта равно (2 ln 2) log 2n + O(1). Однако, на практике случай
равной вероятности появления объектов встречается довольно редко. Поэтому в дереве появляются более длинные и более короткие ветви, и среднее время поиска увеличивается.

|
Чтобы уменьшить среднее время поиска в двоичном дереве, можно в процессе построения дерева следить за тем, чтобы оно все время оставалось сбалансированным. А именно, назовем дерево сбалансированным, если ни для какой вершины высота выходящей из нее правой ветви не отличается от высоты левой более чем на 1. Для того, чтобы достичь сбалансированности, в процессе добавления новых вершин дерево можно слегка
перестраивать следующим образом [1].
Определим для каждой вершины дерева характеристику, равную разности высот выходящих из нее правой и левой ветвей. В сбалансированном дереве характеристика вершины может быть равной -1, 0 и 1, для листьев она равна 0.


|
Пусть мы определили место новой вершины в дереве. Ее характеристика равна 0. Назовем путь, ведущий от корня к новой вершине, выделенным. При добавлении новой вершины могут измениться характеристики только тех вершин, которые лежат на выделенном пути. Рассмотрим заключительный отрезок выделенного пути, такой, что до добавления вершины характеристики всех вершин на нем были равны 0. Если верхним концом этого отрезка
является сам корень, то дерево перестраивать не надо, достаточно лишь изменить характеристики вершин на этом пути на 1 или -1, в зависимости от того, влево или вправо пристроена новая вершина.
Пусть верхний конец заключительного отрезка - не корень. Рассмотрим вершину A - «родителя» верхнего конца заключительного отрезка. Перед добавлением новой вершины характеристика A была равна ±1. Если A имела характеристику 1 (-1) и новая вершина добавляется в левую (правую) ветвь, то
характеристика вершины A становится равной 0, а высота поддерева с корнем в A не меняется. Так что и в этом случае дерево перестраивать не надо.
Пусть теперь характеристика A до перестраивания была равна -1 и новая вершина добавлена к левой ветви A (аналогично - для случая 1 и добавления к правой ветви). Рассмотрим вершину B - левого потомка A. Возможны следующие варианты.
Если характеристика B после добавления новой вершины в D стала равна -1, то дерево
имеет структуру, изображенную на рис. 7.6, а. Перестроив дерево так, как это изображено на рис. 7.6, б, мы добьемся сбалансированности (в скобках указаны характеристики вершин, где это существенно, и соотношения высот после добавления).
Если характеристика вершины B после добавления новой вершины в E стала равна 1, то надо отдельно рассмотреть случаи, когда характеристика вершины E, следующей за B на выделенном пути, стала равна -1, 1 и 0 (в последнем случае вершина E - новая). Вид
дерева до и после перестройки для этих случаев показан соответственно на рис. 7.7, 7.8 и 7.9.
Таблицы расстановки
Одним из эффективных способов организации таблицы символов является таблица расстановки (или хеш-таблица). Поиск в такой таблице может быть организован методом повторной расстановки. Суть его заключается в следующем.
Таблица символов
представляет собой массив фиксированного размера N. Идентификаторы могут храниться как в самой таблице символов, так и в отдельной таблице идентификаторов.
Определим некоторую функцию h1
(первичную функцию расстановки), определенную на множестве идентификаторов и принимающую значения от 0 до N - 1 (т.е. 0
Пусть мы хотим найти в таблице идентификатор
id. Если элемент таблицы с номером h1(id) не заполнен, то это означает, что идентификатора в таблице нет. Если же занят, то это еще не означает, что идентификатор id в таблицу занесен, поскольку (вообще говоря) много идентификаторов могут иметь одно и то же значение функции расстановки. Для того чтобы определить, нашли ли мы нужный идентификатор, сравниваем id с элементом таблицы h1(id). Если они равны - идентификатор найден, если нет - надо продолжать поиск
дальше.
Для этого вычисляется вторичная функция расстановки h2(h) (значением которой опять таки является некоторый адрес в таблице символов). Возможны четыре варианта:
- элемент таблицы не заполнен (т.е. идентификатора в таблице нет),
- идентификатор элемента таблицы совпадает с искомым (т.е. идентификатор найден),
- адрес элемента совпадает с уже просмотренным (т.е. таблица вся просмотрена и идентификатора нет)
- предыдущие варианты не выполняются, так что необходимо продолжать
поиск.
Для продолжения поиска применяется следующая функция расстановки h3(h2), h4(h3) и т.д. Как правило, hi = h2 для i
является целое в диапазоне [0, N - 1] и она может быть быть устроена по-разному. Приведем три варианта.
1) h2(i) = (i + 1) mod N.
Берется следующий (циклически) элемент массива.
Этот вариант плох тем, что занятые элементы «группируются», образуют последовательные занятые участки и в пределах этого участка поиск становится по-существу
линейным.
2) h2(i) = (i + k) mod N, где k и N взаимно просты.
По-существу это предыдущий вариант, но элементы накапливаются не в последовательных элементах, а «разносятся».
3) h2(i) = (a * i + c) mod N - «псевдослучайная последовательность».
Здесь c и N должны быть взаимно просты, b = a - 1 кратно p для любого простого p, являщегося делителем N, b кратно 4, если N кратно 4 [5].
Поиск в таблице расстановки можно описать следующей функцией:
|
void Search(String Id,boolean * Yes,int * Point) {int H0=h1(Id), H=H0; while (1) {if (Empty(H)==NULL) {*Yes=false; *Point=H; return; } else if (IdComp(H,Id)==0) {*Yes=true; *Point=H; return; } else H=h2(H); if (H==H0) {*Yes=false; *Point=NULL; return; } } } |
Функция IdComp(H,Id) сравнивает элемент таблицы на входе H с идентификатором и вырабатывает 0, если они равны. Функция Empty(H) вырабатывает NULL, если вход H пуст. Функция Search присваивает параметрам Yes и Pointer соответственно следующие значения :
true, P - если нашли требуемый идентификатор, где P - указатель на соответствующий этому идентификатору вход в таблице,
false, NULL - если искомый идентификатор не найден, причем в таблице нет свободного места, и
false, P - если искомый идентификатор не найден, но в таблице есть свободный вход P.
Занесение элемента в таблицу можно осуществить следующей функцией:
|
int Insert(String Id) {boolean Yes; int Point=-1; Search(Id,&Yes,&Point); if (!Yes && (Point!=NULL)) InsertId(Point,Id); return(Point); } |
Здесь функция InsertId(Point,Id) заносит идентификатор Id для входа Point таблицы.
Таблицы расстановки со списками
Только что описанная схема страдает одним недостатком - возможностью переполнения таблицы. Рассмотрим ее модификацию, когда все элементы, имеющие одинаковое значения (первичной) функции расстановки, связываются в список
(при этом отпадает необходимость использования функций hi для i
Вначале таблица расстановки пуста (все элементы имеют значение NULL). При поиске идентификатора Id вычисляется функция расстановки h(Id) и просматривается соответствующий линейный список. Поиск в таблице может быть описан следующей функцией:
| struct Element {String IdentP; struct Element * Next; }; struct Element * T[N]; |


|
Занесение элемента в таблицу можно осуществить следующей функцией:
| struct Element * Insert(String Id) {struct Element * P,H; P=Search(Id); if (P!=NULL) return(P); else {H=H(Id); P=alloc(sizeof(struct Element)); P->Next=T[H]; T[H]=P; P->IdentP=Include(Id); } return(P); } |
Процедура Include заносит идентификатор в таблицу идентификаторов. Алгоритм иллюстрируется рис. 7.4.
Типы грамматик и их свойства
Рассмотрим классификацию грамматик (предложенную Н.Хомским), основанную на виде их правил.
Определение. Пусть дана грамматика G = (N, T, P, S). Тогда
если правила грамматики не удовлетворяют никаким ограничениям, то ее называют грамматикой типа 0, или грамматикой без ограничений.
если
каждое правило грамматики, кроме S
в том случае, когда S
S не встречается в правых частях правил,
то грамматику называют грамматикой типа 1, или неукорачивающей.
если каждое правило грамматики имеет вид A
если каждое правило грамматики имеет вид либо A
Легко видеть, что грамматика в примере 2.5 - неукорачивающая, в примере 2.6 - контекстно-свободная, в примере 2.7 - праволинейная.
Язык, порождаемый
грамматикой типа i, называют языком типа i. Язык типа 0 называют также языком без ограничений, язык типа 1 - контекстно-зависимым (КЗ), язык типа 2 - контекстно-свободным (КС), язык типа 3 - праволинейным.
Теорема 2.1. Каждый контекстно-свободный язык может быть порожден неукорачивающей контекстно-свободной грамматикой.
Доказательство. Пусть L - контекстно-свободный язык. Тогда существует контекстно-свободная грамматика G = (N, T, P, S), порождающая L.
Построим новую грамматику G' = (N', T, P', S') следующим образом:
1. Если в P есть правило вида A
цепочки

где Xi - это либо Bi, либо e.
2. Если S
Порождает ли грамматика пустую цепочку можноо установить следующим простым алгоритмом:
Шаг 1. Строим множество N_0 = N | N
Шаг 2. Строим множество N_i = N | N
Шаг 3. Если N_i = N_i-1, перейти к шагу 4, иначе шаг 2.
Шаг 4. Если S
Легко видеть, что G' - неукорачивающая грамматика. Можно показать по индукции, что L(G') = L(G). __
Пусть Ki - класс всех языков типа i. Доказано, что справедливо следующее (строгое) включение: K3

Заметим, что если язык порождается некоторой грамматикой, это не означает, что он не может быть порожден грамматикой с более сильными ограничениями на правила. Приводимый ниже пример иллюстрирует этот факт.
Пример 2.8. Рассмотрим грамматику G = ({S, A, B}, {0, 1}, {S

является контекстно-свободной. Легко показать, что L(G) = {0n1m|n, m > 0}. Однако, в примере 2.7 приведена праволинейная грамматика, порождающая тот же язык.
Покажем что существует алгоритм, позволяющий для произвольного КЗ-языка L в алфавите T, и произвольной цепочки w
определить, принадлежит ли w языку L.
Теорема 2.2. Каждый контекстно-зависимый язык является рекурсивным языком.
Доказательство. Пусть L - контекстно-зависимый язык. Тогда существует некоторая неукорачивающая грамматика G = (N, T, P, S), порождающая L.
Пусть w
образом. Так что будем предполагать, что n > 0.
Определим множество Tm
как множество строк u
длины не более n таких, что вывод S
Легко показать, что Tm можно получить из Tm-1
просматривая, какие строки с длиной, меньшей или равной n можно вывести из строк из Tm-1
применением одного правила, т.е.
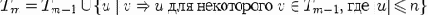
Если S
m. Если из S не выводится u или |u| > n, то u не принадлежит Tm ни для какого m.
Очевидно, что Tm

Покажем, что существует такое m, что Tm = Tm-1. Поскольку для каждого i

n равно k + k2 + ... + kn
Трансляция арифметических выражений
Одной из важнейших задач при генерации кода является распределение регистров. Рассмотрим хорошо известную технику распределения регистров при трансляции арифметических выражений,
называемую алгоритмом Сети-Ульмана. (Замечание: в целях большей наглядности, в данном параграфе мы немного отступаем от семантики арифметических команд MC68020 и предполагаем, что команда
Op Arg1, Arg2
выполняет действие Arg2:=Arg1 Op Arg2.)
Пусть система команд машины имеет неограниченное число универсальных регистров, в которых выполняются арифметические команды. Рассмотрим, как можно сгенерировать код, используя для данного арифметического выражения минимальное число регистров.

|
Пусть имеется синтаксическое дерево выражения. Предположим сначала, что распределение регистров осуществляется по простейшей схеме сверху-вниз слева-направо, как изображено на рис. 9.5. Тогда к моменту генерации кода для поддерева LR занято n регистров. Пусть поддерево L требует nl
регистров, а поддерево R - nr регистров. Если nl = nr, то при вычислении L будет использовано nl регистров и под результат будет занят (n + 1)-й регистр. Еще nr(= nl) регистров будет использовано
при вычислении R. Таким образом, общее число использованных регистров будет равно n + nl + 1.
Если nl > nr, то при вычислении L будет использовано nl регистров. При вычислении R будет использовано nr < nl регистров, и всего будет использовано не более чем n+nl регистров. Если nl < nr, то после вычисления L под результат будет занят один регистр (предположим, (n + 1)-й) и nr
регистров будет использовано для вычисления R. Всего будет использовано n+nr+1 регистров.
Видно,
что для деревьев, совпадающих с точностью до порядка потомков каждой вершины, минимальное число регистров при распределении их слева-направо достигается на дереве, у которого в каждой вершине слева расположено более «сложное» поддерево, требующее большего числа регистров. Таким образом, если дерево таково, что в каждой внутренней вершине правое поддерево требует меньшего числа регистров, чем левое, то, обходя дерево слева направо,
можно оптимально распределить регистры. Без перестройки дерева это означает, что если в некоторой вершине дерева справа расположено более сложное поддерево, то сначала сгенерируем код для него, а затем уже для левого поддерева.
Алгоритм работает следующим образом. Сначала осуществляется разметка синтаксического дерева по следующим правилам.
Правила разметки:
1) если вершина - правый лист или дерево состоит из единственной вершины, помечаем
эту вершину числом 1, если вершина - левый лист, помечаем ее 0 (рис. 9.6).

|
или l2 либо число l1 + 1, если l1 = l2 (рис. 9.7).

|
1) Корню назначается первый регистр.
2) Если метка левого потомка меньше метки правого, то левому потомку назначается регистр на единицу больший, чем предку, а правому - с тем же номером (сначала вычисляется правое
поддерево и его результат помещается в регистр R), так что регистры занимаются последовательно. Если же метка левого потомка больше или равна метке правого потомка, то наоборот, правому потомку назначается регистр на единицу больший, чем предку, а левому - с тем же номером (сначала вычисляется левое поддерево и его результат помещается в регистр R - рис. 9.7).
После этого формируется код по следующим правилам:
1) если вершина
- правый лист с меткой 1, то ей соответствует код
|
MOVE X, R |

|
|
Код правого поддерева Op X, R |
где R - регистр, назначенный этой вершине, X - адрес переменной, связанной с вершиной, а Op - операция, примененная в вершине (рис. 9.8, а);
3) если непосредственные потомки вершины не листья и метка правой вершины больше метки левой, то вершине соответствует код
|
Код правого поддерева Код левого поддерева Op R+1, R |

|
|
Код левого поддерева Код правого поддерева Op R, R+1 MOVE R+1, R |
Рассмотрим атрибутную схему, реализующую эти правила генерации кода (для большей наглядности входная грамматика соответствует обычной инфиксной записи, а не Лидер-представлению). В этой
схеме генерация кода происходит не непосредственно в процессе обхода дерева, как раньше, а из-за необходимости переставлять поддеревья код строится в виде текста с помощью операции конкатенации. Практически, конечно, это нецелесообразно: разумнее управлять обходом дерева непосредственно, однако для простоты мы будем пользоваться конкатенацией.
|
RULE Expr ::= IntExpr SEMANTICS Reg=1; Code=Code; Left=true. RULE IntExpr ::= IntExpr Op IntExpr SEMANTICS Left=true; Left=false; Label=(Label==Label) ? Label+1 : Max(Label,Label); Reg=(Label ) ? Reg+1 : Reg; Reg=(Label ) ? Reg : Reg+1; Code=(Label==0) ? Code + Code + Code + "," + Reg : (Label ) ? Code + Code + Code + (Reg+1) + "," + Reg : Code + Code + Code + Reg + "," + (Reg+1) + "MOVE" + (Reg+1) + "," + Reg. RULE IntExpr ::= Ident SEMANTICS Label=(Left) ? 0 : 1; Code=(!Left) ? "MOVE" + Reg + "," + Val : Val. RULE IntExpr ::= '(' IntExpr ')' SEMANTICS Label=Label; Reg=Reg; Code=Code. RULE Op ::= '+' SEMANTICS Code="ADD". RULE Op ::= '-' SEMANTICS Code="SUB". RULE Op ::= '*' SEMANTICS Code="MUL". RULE Op ::= '/' SEMANTICS Code="DIV". |

|
|
MOVE B, R1 MUL A, R1 MOVE E, R2 ADD D, R2 MUL C, R2 ADD R1, R2 MOVE R2, R1 |
Пусть мы произвели разметку дерева разбора так же, как и в предыдущем алгоритме. Назначение
регистров будем производить следующим образом.
Левому потомку всегда назначается регистр, равный его метке, а правому - его метке, если она не равна метке его левого брата, и метке + 1, если метки равны. Поскольку более сложное поддерево всегда вычисляется раньше более простого, его регистр результата имеет больший номер, чем любой регистр, используемый при вычислении более простого поддерева, что гарантирует
правильность использования регистров.
Приведенные соображения реализуются следующей атрибутной схемой:
|
RULE Expr ::= IntExpr SEMANTICS Code=Code; Left=true. RULE IntExpr ::= IntExpr Op IntExpr SEMANTICS Left=true; Left=false; Label=(Label==Label) ? Label+1 : Max(Label,Label); Code=(Label > Label) ? (Label==0) ? Code + Code + Code + "," + Label : Code + Code + Code + Label + "," + Label : (Label ) ? Code + Code + Code + Label + "," + Label + "MOVE" + Label + "," + Label : // метки равны Code + "MOVE" + Label + "," + Label+1 + Code + Code + Label + "," + Label+1. RULE IntExpr ::= Ident SEMANTICS Label=(Left) ? 0 : 1; Code=(Left) ? Val : "MOVE" + Val + "R1". RULE IntExpr ::= '(' IntExpr ')' SEMANTICS Label=Label; Code=Code. RULE Op ::= '+' SEMANTICS Code="ADD". RULE Op ::= '-' SEMANTICS Code="SUB". RULE Op ::= '*' SEMANTICS Code="MUL". RULE Op ::= '/' SEMANTICS Code="DIV". |
Команды пересылки требуются для согласования номеров регистров, в которых осуществляется выполнение операции, с регистрами, в которых должен быть выдан результат. Это имеет смысл, когда эти регистры разные. Получиться это может из-за того, что по приведенной
схеме результат выполнения операции всегда находится в регистре с номером метки, а метки левого и правого поддеревьев могут совпадать.
Для выражения A*B+C*(D+E) будет сгенерирован следующий код:
|
MOVE E, R1 ADD D, R1 MUL C, R1 MOVE R1, R2 MOVE B, R1 MUL A, R1 ADD R1, R2 |
Трансляция целых выражений
Трансляция выражений различных типов управляется синтаксически благодаря наличию указателя типа перед каждой операцией. Мы рассмотрим некоторые наиболее характерные проблемы генерации кода для
выражений.
Система команд МС68020 обладает двумя особенностями, сказывающимися на генерации кода для арифметических выражений (то же можно сказать и о генерации кода для выражений типа «множества»):
1) один из операндов выражения (правый) должен при выполнении операции находиться на регистре, поэтому если оба операнда не на регистрах, то перед выполнением операции один из них надо загрузить на регистр;
2) система команд довольно «симметрична», т.е. нет специальных требований
к регистрам при выполнении операций (таких, например, как пары регистров или требования четности и т.д.).
Поэтому выбор команд при генерации арифметических выражений определяется довольно простыми таблицами решений. Например, для целочисленного сложения такая таблица приведена на рис.9.4.

|
Здесь имеется в виду, что R - операнд на регистре, V - переменная или константа. Такая таблица решений должна также учитывать коммутативность операций.
| RULE IntExpr ::= 'PLUS' IntExpr IntExpr SEMANTICS if (Address.AddrMode!=D) && (Address.AddrMode!=D) {Address.AddrMode=D; Address.Addreg=GetFree(RegSet); Emit2(MOVE,Address,Address); Emit2(ADD,Address,Address); } else if (Address.AddrMode==D) {Emit2(ADD,Address,Address); Address:=Address); } else {Emit2(ADD,Address,Address); Address:=Address); }. |
Трансляция логических выражений
Логические выражения, включающие
логическое умножение, логическое сложение и отрицание, можно вычислять как непосредственно, используя таблицы истинности, так и с помощью условных выражений, основанных на следующих простых правилах:
| AAND B | эквивалентно | if A then B else False, | |
| A OR B | эквивалентно | if A then True else B. | |
Если в качестве компонент выражений могут входить функции с побочным эффектом, то, вообще говоря, результат вычисления может зависеть от способа вычисления. В некоторых языках программирования
не оговаривается, каким способом должны вычисляться логические выражения (например, в Паскале), в некоторых требуется, чтобы вычисления производились тем или иным способом (например, в Модуле-2 требуется, чтобы выражения вычислялись по приведенным формулам), в некоторых языках есть возможность явно задать способ вычисления (Си, Ада). Вычисление логических выражений непосредственно по таблицам истинности аналогично вычислению арифметических выражений, поэтому мы не будем их рассматривать отдельно. Рассмотрим
подробнее способ вычисления с помощью приведенных выше формул (будем называть его «вычислением с условными переходами»). Иногда такой способ рассматривают как оптимизацию вычисления логических выражений.
Рассмотрим следующую атрибутную грамматику со входным языком логических выражений:
| RULE Expr ::= BoolExpr SEMANTICS FalseLab=False; TrueLab=True; Code=Code. |
Здесь предполагается, что все вершины дерева
занумерованы и номер вершины дает атрибут NodeLab. Метки вершин передаются, как это изображено на рис. 9.11.

|
|
F OR ( F AND T AND T ) OR T |
|
1:7: GOTO 2 2:8:4:9: GOTO 3 5:10: GOTO 6 6: GOTO True 3: GOTO True True: ... False: ... |

|
значение выражения, если в результате ее выполнения (от первой строки) мы придем к строке, содержащей GOTO True или GOTO False.
Утверждение 9.1. В результате интерпретации поддерева с некоторыми значениями атрибутов FalseLab и TrueLab в его корне выполняется команда GOTO TrueLab, если значение выражения истинно, и команда GOTO FalseLab, если значение выражения ложно.
Доказательство. Применим индукцию по высоте дерева. Для деревьев высоты 1, соответствующих правилам
BoolExpr ::= F и BoolExpr ::= T,
справедливость утверждения следует из
соответствующих атрибутных правил. Пусть дерево имеет высоту n > 1. Зависимость атрибутов для дизъюнкции и конъюнкции приведена на рис. 9.13.

|
(= FalseLab). Если же значение левого поддерева истинно, то его вычисление завершается командой перехода GOTO TrueLab (= NodeLab). Если значение правого поддерева ложно, то вычисление всего дерева завершается командой GOTO FalseLab (= FalseLab). Если же оно истинно, вычисление
всего дерева завершается командой перехода GOTO TrueLab (= TrueLab). Аналогично - для дизъюнкции._
Утверждение 9.2. Для любого логического выражения, состоящего из констант, программа, полученная в результате обхода дерева этого выражения, завершается со значением логического выражения в обычной интерпретации, т.е. осуществляется переход на True для значения, равного true, и переход на метку False для значения false.
Доказательство. Это утверждение является частным случаем предыдущего.
Его справедливость следует из того, что метки корня дерева равны соответственно TrueLab = True и FalseLab = False. _
Добавим теперь новое правило в предыдущую грамматику:
|
RULE BoolExpr ::= Ident SEMANTICS Code=NodeLab + ":" + "if (" + Val + "==T) GOTO" + TrueLab + "else GOTO" + FalseLab. |
|
1:7: if (A==T) GOTO True else GOTO 2 2:8:4:9: if (B==T) GOTO 5 else GOTO 3 5:10: if (C==T) GOTO 6 else GOTO 3 6: if (D==T) GOTO True else GOTO 3 3: if (E==T) GOTO True else GOTO False True: ... False: ... |
При каждом конкретном наборе данных эта программа превращается в программу вычисления логического значения.
Утверждение 9.3. В каждой строке программы, сформированной предыдущей атрибутной схемой, одна из меток внутри условного оператора совпадает с меткой следующей строки.
Доказательство. Действительно, по правилам наследования атрибутов TrueLab и FalseLab, в правилах
для дизъюнкции и конъюнкции либо атрибут FalseLab, либо атрибут TrueLab принимает значение метки следующего поддерева. Кроме того, как значение FalseLab, так и значение TrueLab, передаются в правое поддерево от предка. Таким образом, самый правый потомок всегда имеет одну из меток TrueLab или FalseLab, равную метке правого брата соответствующего поддерева. Учитывая порядок генерации команд, получаем справедливость утверждения._
Дополним теперь
атрибутную грамматику следующим образом:
|
RULE Expr ::= BoolExpr SEMANTICS FalseLab=False; TrueLab=True; Sign=false; Code=Code. RULE BoolExpr ::= BoolExpr 'AND' BoolExpr SEMANTICS FalseLab=FalseLab; TrueLab=NodeLab; FalseLab=FalseLab; TrueLab=TrueLab; Sign=false; Sign=Sign; Code=NodeLab + ":" + Code + Code. RULE BoolExpr ::= BoolExpr 'OR' BoolExpr SEMANTICS FalseLab=NodeLab; TrueLab=TrueLab; FalseLab=FalseLab; TrueLab=TrueLab; Sign=true; Sign=Sign; Code=NodeLab + ":" + Code + Code. RULE BoolExpr ::= 'NOT' BoolExpr SEMANTICS FalseLab=TrueLab; TrueLab=FalseLab; Sign=! Sign; Code=Code. RULE BoolExpr ::= '(' BoolExpr ')' SEMANTICS FalseLab=FalseLab; TrueLab=TrueLab; Sign=Sign; Code=NodeLab + ":" + Code. RULE BoolExpr ::= F SEMANTICS Code=NodeLab + ":" + "GOTO" + FalseLab. RULE BoolExpr ::= T SEMANTICS Code=NodeLab + ":" + "GOTO" + TrueLab. RULE BoolExpr ::= Ident SEMANTICS Code=NodeLab + ":" + "if (" + Val + "==T) GOTO" + TrueLab + "else GOTO" + FalseLab. |
Правила наследования атрибута Sign приведены на рис. 9.14.
|
Утверждение 9.4. В каждой терминальной вершине, метка ближайшего правого для нее поддерева равна значению атрибута FalseLab этой вершины, тогда и только тогда, когда значение атрибута Sign этой вершины равно true, и наоборот, метка ближайшего правого для нее
поддерева равна значению атрибута TrueLab этой вершины, тогда и только тогда, когда значение атрибута Sign равно false.
Доказательство. Действительно, если ближайшей общей вершиной является AND, то в левого потомка передается NodeLab правого потомка в качестве TrueLab и одновременно Sign правого потомка равен true. Если же ближайшей общей вершиной является OR, то в левого потомка передается NodeLab правого потомка в качестве FalseLab и одновременно Sign правого потомка равен false. Во все же правые
потомки значения TrueLab, FalseLab и Sign передаются из предка (за исключением правила для NOT, в котором TrueLab и FalseLab меняются местами, но одновременно на противоположный меняется и Sign). _
Эти два утверждения (3 и 4) позволяют заменить последнее правило атрибутной грамматики следующим образом:
|
RULE BoolExpr ::= Ident SEMANTICS Code=NodeLab + ":" + (Sign ? "if (" + Val + "==T) GOTO" + TrueLab : "if (" + Val + "==F) GOTO" + FalseLab). |
|
RULE BoolExpr ::= Ident SEMANTICS Code=NodeLab + ":" + "TST" + Val + (Sign ? "BNE" + TrueLab : "BEQ" + FalseLab). |
Таким образом, для выражения A OR ( B AND C AND D ) OR E получим следующий код на командах перехода:
|
1:7: TST A BNE True 2:8:4:9: TST B BEQ 3 5:10: TST C BEQ 3 6: TST D BNE True 3: TST E BEQ False True: ... False: ... |
Трансляция переменных
Переменные отражают все многообразие механизмов доступа в языке. Переменная имеет синтезированный атрибут ADDRESS - это запись, описывающая адрес в команде МС68020. Этот атрибут сопоставляется всем нетерминалам, представляющим
значения. В системе команд МС68020 много способов адресации, и они отражены в структуре значения атрибута ADDRESS, имеющего следующий тип:
| enum Register {D0,D1,D2,D3,D4,D5,D6,D7,A0,A1,A2,A3,A4,A5,A6,SP,NO}; |
Значение регистра NO означает, что соответствующий регистр в адресации не используется.
Доступ к переменным осуществляется в зависимости от их уровня: глобальные переменные адресуются с помощью абсолютной адресации; переменные в процедуре текущего уровня адресуются через регистр базы А6.
Если стек организован
с помощью статической цепочки, то переменные предыдущего статического уровня адресуются через регистр статической цепочки А5; переменные остальных уровней адресуются «пробеганием» по статической цепочке с использованием вспомогательного регистра. Адрес переменной формируется при обработке структуры переменной слева направо и передается сначала сверху вниз как наследуемый атрибут нетерминала VarTail, а затем передается снизу-вверх как глобальный атрибут нетерминала Variable. Таким
образом, правило для обращения к переменной имеет вид (первое вхождение Number в правую часть - это уровень переменной, второе - ее Лидер-номер):
| RULE Variable ::= VarMode Number Number VarTail SEMANTICS int Temp; struct AddrType AddrTmp1, AddrTmp2; 3: if (Val==0) // Глобальная переменная {Address.AddrMode=Abs; Address.AddrDisp=0; } else // Локальная переменная {Address.AddrMode=Index; if (Val==Level) // Переменная текущего уровня Address.AddrReg=A6; else if (Val==Level-1) // Переменная предыдущего уровня Address.AddrReg=A5; else {Address.Addreg=GetFree(RegSet); AddrTmp1.AddrMode=Indirect; AddrTmp1.AddrReg=A5; Emit2(MOVEA,AddrTmp1,Address.AddrReg); AddrTmp1.AddrReg=Address.AddrReg; AddrTmp2.AddrMode=A; AddrTmp2.AddrReg=Address.AddrReg; for (Temp=Level-Val;Temp>=2;Temp-) Emit2(MOVEA,AddrTmp1,AddrTmp2); } if (Val==Level) Address.AddrDisp=Table[Val]; else Address.AddrDisp=Table[Val]+Table[LevelTab[Val]]; }. |
Функция GetFree выбирает очередной свободный регистр (либо регистр данных, либо адресный
регистр) и отмечает его как использованный в атрибуте RegSet нетерминала Block. Процедура Emit2 генерирует двухадресную команду. Первый параметр этой процедуры - код команды, второй и третий параметры имеют тип AddrType и служат операндами команды. Смещение переменной текущего уровня отсчитывается от базы (А6), а других уровней - от указателя статической цепочки, поэтому оно определяется как алгебраическая сумма размера локальных параметров и величины смещения переменной. Таблица
LevelTab - это таблица уровней процедур, содержащая указатели на последовательно вложенные процедуры.
Если стек организован с помощью дисплея, то трансляция для доступа к переменным может быть осуществлена следующим образом:
|
RULE Variable ::= VarMode Number Number VarTail SEMANTICS int Temp; 3: if (Val==0) // Глобальная переменная {Address.AddrMode=Abs; Address.AddrDisp=0; } else // Локальная переменная {Address.AddrMode=Index; if (Val=Level) // Переменная текущего уровня {Address.AddrReg=A6; Address.AddrDisp=Table[Val]; } else {Address.AddrMode=IndPost; Address.AddrReg=NO; Address.IndexReg=NO; Address.AddrDisp=Display[Val]; Address.IndexDisp=Table[Val]; } }. |
|
RULE VarTail ::= 'FIL' Number VarTail SEMANTICS if (Address.AddrMode==Abs) {Address.AddrMode=Abs; Address.AddrDisp=Address.AddrDisp+Table[Val]; } else {Address=Address; if (Address.AddrMode==Index) Address.AddrDisp=Address.AddrDisp+Table[Val]; else Address.IndexDisp=Address.IndexDisp+Table[Val]; }. |
Трехадресный код
Трехадресный код - это последовательность операторов вида x := y op z, где x, y и z - имена, константы или сгенерированные компилятором временные объекты. Здесь op - двуместная операция, например операция плавающей или фиксированной арифметики, логическая или побитовая. В правую часть может входить только один знак операции.
Составные выражения должны быть разбиты на подвыражения, при этом могут появиться
временные имена (переменные). Смысл термина «трехадресный код» в том, что каждый оператор обычно имеет три адреса: два для операндов и один для результата. Трехадресный код - это линеаризованное представление синтаксического дерева или ОАГ, в котором временные имена соответствуют внутренним вершинам дерева или графа. Например, выражение x+y*z может быть протранслировано в последовательность операторов
| t1 := y * z t2 := x + t1 |
В виде трехадресного кода представляются не только двуместные операции, входящие в выражения. В таком же виде представляются операторы управления программы и одноместные операции. В этом случае некоторые из компонент трехадресного кода могут не использоваться. Например, условный оператор
| if A > B then S1 else S2 |
может быть представлен следующим кодом:
| t := A - B JGT t, S2 ... |
Здесь JGT - двуместная операция условного перехода, не вырабатывающая результата.
Разбиение арифметических выражений и операторов управления делает трехадресный код удобным при генерации машинного кода и оптимизации. Использование имен промежуточных значений, вычисляемых в программе, позволяет легко переупорядочивать трехадресный код.

|
Представления синтаксического дерева и графа рис. 8.1 в виде трехадресного кода дано на рис. 8.3, а, и 8.3, б, соответственно.
Трехадресный код - это абстрактная форма промежуточного кода. В реализации трехадресный код может быть представлен записями с полями для операции и операндов. Рассмотрим три способа реализации трехадресного кода: четверки, тройки и косвенные тройки.
Четверка - это запись с четырьмя полями, которые будем называть op, arg1, arg2 и result. Поле op содержит код операции. В
операторах с унарными операциями типа x := -y или x := y поле arg2 не используется. В некоторых операциях (типа «передать параметр») могут не использоваться ни arg2, ни result. Условные и безусловные переходы помещают в result метку перехода. На рис. 8.4, а, приведены четверки для оператора присваивания a := b *-c + b *-c. Они получены из трехадресного кода на рис. 8.3, а.

|
Чтобы избежать внесения новых имен в таблицу символов, на временное значение можно ссылаться, используя позицию вычисляющего его оператора. В этом случае трехадресные операторы могут быть представлены записями только с тремя полями: op, arg1
и arg2, как это показано на рис. 8.3, б. Поля arg1 и arg2 - это либо указатели на таблицу символов (для имен, определенных программистом, или констант), либо указатели на тройки (для временных значений). Такой способ представления трехадресного кода называют тройками. Тройки соответствуют представлению синтаксического дерева или ОАГ с помощью массива вершин.
Числа в скобках - это указатели на тройки, а имена - это указатели на таблицу символов. На практике информация,
необходимая для интерпретации различного типа входов в поля arg1 и arg2, кодируется в поле op или дополнительных полях. Тройки рис. 8.4, б, соответствуют четверкам рис. 8.4, а.
Для представления тройками трехместной операции типа x[i] := y требуется два входа, как это показано на рис. 8.5, а, представление x := y[i] двумя операциями показано на рис. 8.5, б.
Трехадресный код может быть представлен не списком троек, а списком указателей на них. Такая реализация обычно называется косвенными тройками.
Например, тройки рис. 8.4, б, могут быть реализованы так, как это изображено на рис. 8.6.

|

|
Более существенно преимущество четверок проявляется в оптимизирующих компиляторах, когда может возникнуть необходимость перемещать операторы. Если перемещается
оператор, вычисляющий x, не требуется изменений в операторе, использующем x. В записи же тройками перемещение оператора, определяющего временное значение, требует изменения всех ссылок на этот оператор в массивах arg1 и arg2. Из-за этого тройки трудно использовать в оптимизирующих компиляторах.
В случае применения косвенных троек оператор может быть перемещен переупорядочиванием списка операторов. При этом не надо менять указатели на op, arg1 и arg2. Этим косвенные тройки похожи на четверки. Кроме того,
эти два способа требуют примерно одинаковой памяти. Как и в случае простых троек, при использовании косвенных троек выделение памяти для временных значений может быть отложено на этап генерации кода. По сравнению с четверками при использование косвенных троек можно сэкономить память, если одно и то же временное значение используется более одного раза. Например, на рис. 8.6 можно объединить строки (14) и (16), после чего можно объединить строки (15) и
(17).
Удаление левой рекурсии
Основная трудность при использовании предсказывающего анализа - это нахождение такой грамматики для входного языка, по которой можно построить таблицу анализа с однозначно определенными входами. Иногда с помощью некоторых простых преобразований грамматику, не являющуюся LL(1), можно привести к эквивалентной LL(1)-грамматике. Среди этих преобразований наиболее эффективными являются левая факторизация и удаление левой
рекурсии. Здесь необходимо сделать два замечания. Во-первых, не всякая грамматика после этих преобразований становится LL(1), и, во-вторых, после таких преобразований получающаяся грамматика может стать менее понимаемой.
Непосредственную левую рекурсию, т.е. рекурсию вида A

где никакая из строк
этот набор правил на


где A' - новый нетерминал. Из нетерминала A можно вывести те же цепочки, что и раньше, но теперь нет левой рекурсии. С помощью этой процедуры удаляются все непосредственные левые рекурсии, но не удаляется левая рекурсия, включающая два или более шага.
Приведенный ниже алгоритм 4.7 позволяет удалить все левые рекурсии из грамматики.
Алгоритм 4.7. Удаление левой рекурсии.
Вход. КС-грамматика G без e-правил (правил вида A
Выход. КС-грамматика G' без левой рекурсии, эквивалентная G.
Метод. Выполнить шаги 1 и 2.
Упорядочить нетерминалы грамматики G в произвольном порядке.
Выполнить следующую процедуру:
for (i=1;i for (j=1;j пусть Aj
- все текущие правила для Aj;
заменить
все правила вида Ai
на правила Ai
}
удалить правила вида Ai
удалить непосредственную левую рекурсию в правилах для Ai;
}
После (i - 1)-й итерации внешнего цикла на шаге 2 для любого правила вида Ak
для Ai-правил, m становится больше i.
Алгоритм 4.7 применим, если грамматика не имеет e-правил (правил вида A
Уровень промежуточного представления
Как видно из приведенных примеров, промежуточное представление программы может в различной степени быть близким либо к исходной программе, либо к машине. Например, промежуточное представление
может содержать адреса переменных, и тогда оно уже не может быть перенесено на другую машину. С другой стороны, промежуточное представление может содержать раздел описаний программы, и тогда информацию об адресах можно извлечь из обработки описаний. В то же время ясно, что первое более эффективно, чем второе. Операторы управления в промежуточном представлении могут быть представлены в исходном виде (в виде операторов языка if, for, while и т.д.), а могут содержаться в виде переходов.
В первом случае некоторая информация может быть извлечена из самой структуры (например, для оператора for - информация о переменной цикла, которую, может быть, разумно хранить на регистре, для оператора case - информация о таблице меток и т.д.). Во втором случае представление проще и унифицированней.
Некоторые формы промежуточного представления удобны для различного рода оптимизаций, некоторые - нет (например, косвенные тройки, в отличие от префиксной записи, позволяют
эффективное перемещение кода).
Варианты LR-анализаторов
Часто построенные таблицы для LR(1)-анализатора оказываются довольно
большими. Поэтому при практической реализации используются различные методы их сжатия. С другой стороны, часто оказывается, что при построении для языка синтаксического анализатора типа «сдвиг-свертка» достаточно более простых методов. Некоторые из этих методов базируются на основе LR(1)-анализаторов.
Одним из способов такого упрощения является LR(0)-анализ - частный случая LR-анализа, когда ни при построении таблиц, ни при анализе не учитывается аванцепочка.
Еще одним вариантом LR-анализа являются так называемые SLR(1)-анализаторы (Simple LR(1)). Они строятся следующим образом. Пусть C = {I0, I1, ..., In} - набор множеств допустимых LR(0)-ситуаций. Состояния анализатора соответствуют Ii. Функции действий и переходов анализатора определяются следующим образом.
Если [A
Если [A

Если [S'
Если goto(Ii, A) = Ij, где A
Остальные входы для функций Action и Goto определим как error.
Начальное состояние соответствует множеству ситуаций, содержащему ситуацию [S'
Распространенным вариантом LR(1)-анализа является также LALR(1)-анализ. Он основан на объединении (слиянии) некоторых таблиц. Назовем ядром множества LR(1)-ситуаций множество их первых компонент (т.е. во множестве ситуаций не учитываются аванцепочки). Объединим все множества ситуаций с
одинаковыми ядрами, а в качестве аванцепочек возьмем объединение аванцепочек. Функции Action и Goto строятся очевидным образом. Если функция Action таким образом построенного анализатора не имеет конфликтов, то он называется LALR(1)-анализатором (LookAhead LR(1)).
Виртуальная машина Java
Программы на языке Java транслируются в специальное промежуточное представление, которое
затем интерпретируется так называемой «виртуальной машиной Java». Виртуальная машина Java представляет собой стековую машину: она не имеет памяти прямого доступа, все операции выполняются над операндами, расположенными на верхушке стека. Чтобы, например, выполнить операцию с участием константы или переменной, их предварительно необходимо загрузить на верхушку стека. Код операции - всегда один байт. Если операция имеет операнды, они располагаются в следующих байтах.
К элементарным типам данных, с которыми работает машина, относятся short, integer, long, float, double (все знаковые).
Восстановление после синтаксических ошибок
В приведенных программах рекурсивного спуска использовалась процедура реакции на синтаксические ошибки error(). В простейшем случае эта процедура выдает диагностику
и завершает работу анализатора. Но можно попытаться некоторым разумным образом продолжить работу. Для разбора сверху вниз можно предложить следующий простой алгоритм.
Если в момент обнаружения ошибки на верхушке магазина оказался нетерминальный символ A и для него нет правила, соответствующего входному символу, то сканируем вход до тех пор, пока не встретим символ либо из FIRST(A), либо из FOLLOW(A). В первом случае разворачиваем A по соответствующему правилу, во втором - удаляем A из магазина.
Если на
верхушке магазина терминальный символ, то можно удалить все терминальные символы с верхушки магазина вплоть до первого (сверху) нетерминального символа и продолжать так, как это было описано выше.
Одним из простейших методов восстановления
после ошибки при LR(1)-анализе является следующий. При синтаксической ошибке просматриваем магазин от верхушки, пока не найдем состояние s с переходом на выделенный нетерминал A. Затем сканируются входные символы, пока не будет найден такой, который допустим после A. В этом случае на верхушку магазина помещается состояние Goto[s, A] и разбор продолжается. Для нетерминала A может иметься несколько таких вариантов. Обычно A - это нетерминал,
представляющий одну из основных конструкций языка, например оператор.
При более детальной проработке реакции на ошибки можно в каждой пустой клетке анализатора поставить обращение к своей подпрограмме. Такая подпрограмма может вставлять или удалять входные символы или символы магазина, менять порядок входных символов.
Выбор дерева вывода наименьшей стоимости
T-грамматики, описывающие системы команд, обычно
являются неоднозначными. Чтобы сгенерировать код для некоторой входной цепочки, необходимо выбрать одно из возможных деревьев вывода. Это дерево должно представлять желаемое качество кода, например размер кода и/или время выполнения.
Для выбора дерева из множества всех построенных деревьев вывода можно использовать атрибуты стоимости, атрибутные формулы, вычисляющие их значения, и критерии стоимости, которые оставляют для каждого нетерминала
единственное применимое правило. Атрибуты стоимости сопоставляются всем нетерминалам, атрибутные формулы - всем правилам T-грамматики.
Предположим, что для вершины n обнаружено применимое правило

где zi
Вначале атрибуты стоимости инициализируются неопределенным значением UndefinedValue. Предположим, что значения атрибутов стоимости для всех потомков n1, ..., nk вершины n вычислены. Если правилу p сопоставлена формула

стоимости. Отсутствие примененных правил обозначается через Undefined, значение которого полагается большим любого определенного значения.
Добавим в алгоритм 9.2 реализацию атрибутов стоимости, формул их вычисления и критериев отбора. Из алгоритма можно исключить поиск подвыводов, соответствующих правилам, для которых значение атрибута стоимости не определено. Структура данных, представляющая вершину дерева, принимает следующий вид:
| struct Tnode { Tterminal op; Tnode * son[MaxArity]; struct * { unsigned CostAttr; Tproduction Production; } nonterm [Tnonterminal]; OperatorAttributes ... |
Тело процедуры PARSE принимает вид
void PARSE(Tnode *n)
|
{for (i=Arity(n->op);i>=1;i-) PARSE(n->son[i]); for (каждого A из N) {n->nonterm[A].CostAttr=UndefinedValue; n->nonterm[A].production=Undefined; } for (каждого правила A->bu из P такого, что b==n->op) if (MATCHED(n,[A->.bu])) {ВычислитьАтрибутыСтоимостиДля(A,n,(A->bu)); ПроверитьКритерийДля(A,n->nonterm[A].CostAttr); if ((A->bu) лучше, чем ранее обработанное правило для A) {Модифицировать(n->nonterm[A].CostAttr); n->nonterm[A].production=(A->bu); } } // Сопоставить цепные правила while (существует правило C->A из P, которое лучше, чем ранее обработанное правило для A) {ВычислитьАтрибутыСтоимостиДля(C,n,(C->A)); ПроверитьКритерийДля(C,n->nonterm[C].CostAttr); if ((C->A) лучше) {Модифицировать(n->nonterm[C].CostAttr); n->nonterm[C].production=(C->A); } } } |
наименьшей стоимости, вычисляются значения атрибутов, сопоставленных вершинам дерева вывода, и генерируются соответствующие машинные команды. Вычисление значений атрибутов, генерация кода осуществляются в процессе обхода выбранного дерева вывода сверху вниз, слева направо. Обход выбранного дерева вывода выполняется процедурой вычислителя атрибутов, на вход которой поступают корень дерева выражения и аксиома грамматики. Процедура использует правило A
связанное с указанной вершиной n, и заданный нетерминал A, чтобы определить соответствующие им вершины n1, ..., nk
и нетерминалы X1, ..., Xk. Затем вычислитель рекурсивно обходит каждую вершину ni, имея на входе нетерминал Xi.
Выделение общих подвыражений
Выделение общих подвыражений относится к области оптимизации программ. В общем случае трудно (или даже невозможно) провести границу между оптимизацией и «качественной трансляцией». Оптимизация - это и есть качественная трансляция. Обычно термин «оптимизация» употребляют, когда для повышения качества программы используют ее глубокие преобразования такие, например, как перевод в графовую форму для изучения нетривиальных свойств программы.
В этом смысле выделение общих подвыражений - одна из простейших оптимизаций. Для ее осуществления требуется некоторое преобразование программы, а именно построение ориентированного ациклического графа, о котором говорилось в главе, посвященной промежуточным представлениям.
Линейный участок - это последовательность операторов, в которую управление входит в начале и выходит в конце без остановки и перехода изнутри.
Рассмотрим дерево линейного участка, в котором вершинами служат операции, а
потомками - операнды. Будем говорить, что две вершины образуют общее подвыражение, если поддеревья для них совпадают, т.е. имеют одинаковую структуру и, соответственно, одинаковые операции во внутренних вершинах и одинаковые операнды в листьях. Выделение общих подвыражений позволяет генерировать для них код один раз, хотя может привести и к некоторым трудностям, о чем вкратце будет сказано ниже.
Выделение общих подвыражений проводится на линейном участке и
основывается на двух положениях.
1. Поскольку на линейном участке переменной может быть несколько присваиваний, то при выделении общих подвыражений необходимо различать вхождения переменных до и после присваивания. Для этого каждая переменная снабжается счетчиком. Вначале счетчики всех переменных устанавливаются равными 0. При каждом присваивании переменной ее счетчик увеличивается на 1.
2. Выделение общих подвыражений осуществляется при обходе дерева выражения снизу вверх
слева направо. При достижении очередной вершины (пусть операция, примененная в этой вершине, есть бинарная op; в случае унарной операции рассуждения те же) просматриваем общие подвыражения, связанные с op.
Если имеется выражение, связанное с op и такое, что его левый операнд есть общее подвыражение с левым операндом нового выражения, а правый операнд - общее подвыражение с правым операндом нового выражения, то объявляем новое выражение
общим с найденным и в новом выражении запоминаем указатель на найденное общее выражение. Базисом построения служит переменная: если операндами обоих выражений являются одинаковые переменные с одинаковыми счетчиками, то они являются общими подвыражениями. Если выражение не выделено как общее, оно заносится в список операций, связанных с op.
Рассмотрим теперь реализацию алгоритма выделения общих подвыражений. Поддерживаются следующие глобальные
переменные:
Table - таблица переменных; для каждой переменной хранится ее счетчик (Count) и указатель на вершину дерева выражений, в которой переменная встретилась в последний раз в правой части (Last);
OpTable - таблица списков (типа LisType) общих подвыражений, связанных с каждой операцией. Каждый элемент списка хранит указатель на вершину дерева (поле Addr) и продолжение списка (поле List).
С каждой вершиной дерева выражения связана запись типа NodeType, со следующими полями:
Left - левый
потомок вершины,
Right - правый потомок вершины,
Comm - указатель на предыдущее общее подвыражение,
Flag - признак, является ли поддерево общим подвыражением,
Varbl - признак, является ли вершина переменной,
VarCount - счетчик переменной.
Выделение общих подвыражений и построение дерева осуществляются приведенными ниже правилами. Атрибут Entry нетерминала Variable дает указатель на переменную в таблице Table. Атрибут Val символа Op дает код операции. Атрибут Node символов IntExpr и Assignment дает указатель на запись типа NodeType соответствующего
нетерминала.
|
RULE Assignment ::= Variable IntExpr SEMANTICS Table[Entry].Count=Table[Entry].Count+1. // Увеличить счетчик присваиваний переменной RULE IntExpr ::= Variable SEMANTICS if ((Table[Entry].Last!=NULL) // Переменная уже была использована && (Table[Entry].Last->VarCount == Table[Entry].Count )) // С тех пор переменной не было присваивания {Node->Flag=true; // Переменная - общее подвыражение Node->Comm= Table[Entry].Last; // Указатель на общее подвыражение } else Node->Flag=false; Table[Entry].Last=Node; // Указатель на последнее использование переменной Node->VarCount= Table[Entry].Count; // Номер использования переменной Node->Varbl=true. // Выражение - переменная RULE IntExpr ::= Op IntExpr IntExpr SEMANTICS LisType * L; //Тип списков операции if ((Node->Flag) && (Node->Flag)) // И справа, и слева - общие подвыражения {L=OpTable[Val]; // Начало списка общих подвыражений для операции while (L!=NULL) if ((Node==L->Left) && (Node==L->Right)) // Левое и правое поддеревья совпадают break; else L=L->List;// Следующий элемент списка } else L=NULL; //Не общее подвыражение Node->Varbl=false; // Не переменная Node->Comm=L; //Указатель на предыдущее общее подвыражение или NULL if (L!=NULL) {Node->Flag=true; //Общее подвыражение Node->Left=Node; // Указатель на левое поддерево Node->Right=Node; // Указатель на правое поддерево } else {Node->Flag=false; // Данное выражение не может рассматриваться как общее // Если общего подвыражения с данным не было, // включить данное в список для операции L=alloc(sizeof(struct LisType)); L->Addr=Node; L->List=OpTable[Val]; OpTable[Val]=L; }. |
Рассмотрим теперь некоторые простые правила распределения регистров при наличии общих подвыражений. Если число регистров ограничено, можно выбрать один из следующих двух вариантов.
1. При обнаружении
общего подвыражения с подвыражением в уже просмотренной части дерева (и, значит, с уже распределенными регистрами) проверяем, расположено ли его значение на регистре. Если да, и если регистр после этого не менялся, заменяем вычисление поддерева на значение в регистре. Если регистр менялся, то вычисляем подвыражение заново.
2. Вводим еще один проход. На первом проходе распределяем регистры. Если в некоторой вершине обнаруживается, что ее поддерево общее с уже
вычисленным ранее, но значение регистра потеряно, то в такой вершине на втором проходе необходимо сгенерировать команду сброса регистра в рабочую память. Выигрыш в коде будет, если стоимость команды сброса регистра + доступ к памяти в повторном использовании этой памяти не превосходит стоимости заменяемого поддерева. Поскольку стоимость команды MOVE известна, можно сравнить стоимости и принять оптимальное решение: пометить предыдущую вершину для
сброса либо вычислять поддерево полностью.
Вызов метода
Команда invokevirtual.
При трансляции объектно-ориентированных языков программирования из-за возможности перекрытия виртуальных методов, вообще говоря, нельзя статически протранслировать вызов метода объекта. Это связано с тем, что если метод перекрыт в производном классе, и вызывается метод
объекта-переменной, то статически неизвестно, объект какого класса (базового или производного) хранится в переменной. Поэтому с каждым объектом связывается таблица всех его виртуальных методов: для каждого метода там помещается указатель на его реализацию в соответствии с принадлежностью самого объекта классу в иерархии классов.
В языке Java различные классы могут реализовывать один и тот же интерфейс. Если объявлена переменная или параметр типа
интерфейс, то динамически нельзя определить объект какого класса присвоен переменной:
| interface I; class C1 implements I; class C2 implements I; I O; C1 O1; C2 O2; ... O=O1; ... O=O2; ... |
В этой точке программы, вообще говоря, нельзя сказать, какого типа значение хранится в переменной O. Кроме того, при работе программы на языке Java имеется возможность использования методов из других пакетов. Для реализации этого механизма в Java-машине используется динамическое связывание.
Предполагается,
что стек операндов содержит handle объекта или массива и некоторое количество аргументов. Операнд операции используется для конструирования индекса в области констант текущего класса. Элемент по этому индексу в области констант содержит полную сигнатуру метода. Сигнатура метода описывает типы параметров и возвращаемого значения. Из handle объекта извлекается указатель на таблицу методов объекта. Просматривается сигнатура метода в таблице методов. Результатом
этого просмотра является индекс в таблицу методов именованного класса, для которого найден указатель на блок метода. Блок метода указывает тип метода (native, synchronized и т.д.) и число аргументов, ожидаемых на стеке операндов.
Если метод помечен как synchronized, запускается монитор, связанный с handle. Базис массива локальных переменных для нового стек-фрейма устанавливается так, что он указывает на handle на стеке. Определяется общее число локальных переменных, используемых методом,
и после того, как отведено необходимое место для локальных переменных, окружение исполнения нового фрейма помещается на стек. База стека операндов для этого вызова метода устанавливается на первое слово после окружения исполнения. Затем исполнение продолжается с первой инструкции вызванного метода.
Занесение в среду и поиск объектов
Рассмотрим схему реализации простой блочной структуры, аналогичной процедурам в Паскале или блокам в Си. Каждый блок может иметь свой набор описаний. Программа состоит из основного именованного блока, в котором имеются описания и операторы. Описания состоят из описаний типов и объявлений переменных. В качестве типа может использоваться целочисленный тип и тип
массива. Два типа T1 и T2 считаются эквивалентными, если имеется описание T1=T2 (или T2=T1). Операторами служат операторы присваивания вида Переменная1=Переменная2 и блоки. Переменная - это либо просто идентификатор, либо выборка из массива. Оператор присваивания считается правильным, если типы переменных левой и правой части эквивалентны. Примером правильной программы может служить
| program Example begin type T1=array 100 of array 200 of integer; T2=T1; var V1:T1; V2:T2; begin V1=V2; V2[1]=V1[2]; begin type T3=array 300 of T1; var V3:T3; V3[50]=V1; end end end. |
Рассматриваемое подмножество языка может быть порождено следующей грамматикой (запись в расширенной БНФ):
| Prog ::= 'program' Ident Block '.' Block ::= 'begin' [( Declaration )] [ (Statement) ] 'end' Declaration ::= 'type' ( Type_Decl ) Type_Decl ::= Ident '=' Type_Defin Type_Defin ::= 'ARRAY' Index 'OF' Type_Defin Type_Defin ::= Type_Use Type_Use ::= Ident Declaration ::= 'var' ( Var_Decl ) Var_Decl ::= Ident_List ':' Type_Use ';' Ident_List ::= ( Ident / ',' ) Statement ::= Block ';' Statement ::= Variable '=' Variable ';' Variable ::= Ident Access Access ::= '[' Expression ']' Access Access ::= |
Для реализации некоторых атрибутов ( в частности среды, списка идентификаторов и т.д.) в качестве типов данных мы будем использовать различные множества. Множество может быть упорядоченным или неупорядоченным, ключевым или простым. Элементом ключевого множества
может быть запись, одним из полей которой является ключ:
SETOF T - простое неупорядоченное множество объектов типа T;
KEY K SETOF T - ключевое неупорядоченное множество объектов типа T с ключом типа K;
LISTOF T - простое упорядоченное множество объектов типа T;
KEY K LISTOF T - ключевое упорядоченное множество объектов типа T с ключом типа K;
Над объектами типа множества определены следующие операции:
Init(S) - создать и проинициализировать переменную S;
Include(V,S) - включить объект V в множество S; если множество упорядоченное, то включение осуществляется в качестве последнего элемента;
Find(K,S) - выдать указатель на объект с ключом K во множестве S и NIL, если объект с таким ключом не найден.
Имеется специальный оператор цикла, пробегающий элементы множества:
|
for (V in S) Оператор; |
Среда представляет собой ключевое множество с ключом - именем объекта. Идентификаторы имеют тип TName. Обозначение
в позиции типа - это указатель на вершину типа Нетерминал. Обозначение
в выражении - это взятие значения указателя на ближайшую
вершину вверх по дереву разбора, помеченную соответствующим нетерминалом.
Для реализации среды каждый нетерминал Block имеет атрибут Env. Для обеспечения возможности просматривать компоненты среды в соответствии с вложенностью блоков каждый нетерминал Block имеет атрибут Pred - указатель на охватывающий блок. Кроме того, среда блока корня дерева (нетерминал Prog) содержит все предопределенные описания (рис. 6.2). Это заполнение реализуется процедурой PreDefine.
Атрибут Pred блока корневой компоненты
имеет значение NULL.

|
|
// Описание атрибутов ALPHABET Prog:: KEY TName SETOF TElement Env. // Корневая компонента, содержащая предопределенные описания. Block:: KEY TName SETOF TElement Env; Pred. Ident_List:: SETOF TName Ident_Set. // Ident_Set - список идентификаторов Type_Defin, Type_Use, Access, Expression:: TType ElementType. // ElementType - указатель на описание типа Declaration, Var_Decl, Type_Decl::. Ident:: TName Val. Index:: int Val. // Описание синтаксисических и семантических правил RULE Prog ::= 'program' Ident Block '.' SEMANTICS 0:{Init(Env); PreDefine(Env); Pred=NULL }. RULE Block ::= 'begin' [( Declaration )] [ (Statement) ] 'end' SEMANTICS 0: if (!=NULL){ Init(Env); Pred= }. RULE Declaration ::= 'type' ( Type_Decl ). RULE Type_Decl ::= Ident '=' Type_Defin SEMANTICS TElement V; if (Find(Val,Env)!=NULL) Error("Identifier declared twice"); // Идентификатор уже объявлен в блоке // В любом случае заносится новое описание V.Name=Val; V.Object=TypeObject; V.Type=ElementType; Include(V,Env). RULE Type_Defin ::= 'ARRAY' Index 'OF' Type_Defin SEMANTICS ElementType=ArrayType(ElementType,Val). RULE Type_Defin ::= Type_Use SEMANTICS ElementType=ElementType. RULE Type_Use ::= Ident SEMANTICS TElement * PV; PV=FindObject(Val,,TypeObject,); If (PV!=NULL) ElementType=PV->Type. // В этом правиле анализируется использующая позиция // идентификатора типа. RULE Declaration ::= 'var' ( Var_Decl ). RULE Var_Decl ::= Ident_List ':' Type_Use ';' SEMANTICS TElement V; TName N; for (N in Ident_Set){ // Цикл по (неупорядоченному) списку идентификаторов if (Find(N,Env)!=NULL) Error("Identifier declared twice"); // Идентификатор уже объявлен в блоке // В любом случае заносится новое описание V.Name=N; V.Object=VarObject; V.Type=ElementType; Include(V,Env) }. // N - рабочая переменная для элементов списка. Для каждого // идентификатора из множества идентификаторов Ident_Set // сформировать объект-переменную в текущей компоненте среды // с соответствующими характеристиками. RULE Ident_List ::= ( Ident /',' ) SEMANTICS 0:Init(Ident_Set); 1A:Include(Val,Ident_Set). RULE Statement ::= Block ';'. RULE Statement ::= Variable '=' Variable ';' SEMANTICS if (ElementType!=NULL) && (ElementType!=NULL) && (ElementType!=ElementType) Error("Incompatible Expression Types"). RULE Variable ::= Ident Access SEMANTICS TElement * PV; PV=FindObject(Val,,VarObject,); if (PV==NULL){ Error("Identifier used is not declared"); ElementType=NULL ; } else ElementType=PV->Type. RULE Access ::= '[' Expression ']' Access SEMANTICS ElementType=ArrayElementType(ElementType, ElementType). RULE Access ::= SEMANTICS ElementType=ElementType. |
Поиск в среде осуществляется следующей функцией:
|
TElement * FindObject(TName Ident, BlockPointer, TObject Object, Prog) { TElement * ElementPointer; // Получить указатель на ближайший охватывающий блок do{ ElementPointer=Find(Ident, BlockPointer->Env); BlockPointer=BlockPointer->Pred; } while (ElementPointer==NULL)&&(BlockPointer!=NULL); // Искать до момента, когда либо найдем нужный идентификатор, // либо дойдем до корневой компоненты if (ElementPointer==NULL)&&(BlockPointer==NULL) // Дошли до корневой компоненты и еще не нашли идентификатора // Найти объект среди предопределенных ElementPointer=Find(Ident, Prog->Env); if (ElementPointer!=NULL) // Нашли объект с данным идентификатором // либо в очередном блоке, либо среди предопределенных if (ElementPointer->Object!=Object){ // Проверить, имеет ли найденный объект // нужную категорию Error("Object of specified category is not found"); ElementPointer=NULL; } else // Объект не найден Error("Object is not found"); return ElementPointer; } |
переходим к охватывающему блоку. Если дошли до корневой компоненты, пытаемся найти объект среди предопределенных объектов. Если объект нашли, надо убедиться, что он имеет нужную категорию.
Функция ArrayElementType(TType EntryType, TType ExprType) осуществляет проверку допустимости применения операции взятия индекса к переменной и возвращает тип элемента массива.
Функция ArrayType(TType EntryType, int Val) возвращает описание типа - массива с типом элемента EntryType и диапазоном индекса Val.
