Библиотеки доступа
В мире приложений баз данных сложилось несколько устоявшихся подходов к работе с базами данных. Для InterBase можно выделить около пяти таких подходов: это работа с базой данных через BDE (Borland Database Engine, см. глоссарий), использование ODBC, применение OLE DB (ADO), работа через dbExpress и библиотеки прямого доступа.
Долгое время использование BDE для доступа к базам данных InterBase было фактически монопольной технологией. BDE представляет обобщенный механизм работы сразу со многими SQL-серверами, в том числе и с InterBase. Технология BDE поддерживалась в основном в продуктах компании Borland: Delphi, C++ Builder и др. Преимущество BDE, состоящее в универсальности подхода к работе с различными SQL-серверами, что значительно облегчает перенос приложений с одного сервера на другой, является также и его недостатком. Прежде всего это невозможность воспользоваться уникальными особенностями каждого SQL-сервера. Реализованная в BDE модель управления транзакциями, основной целью которой было облегчить перенос приложений с Paradox, не отвечала требованиям современных клиент-серверных приложений. Таким образом, в целом BDE не может рассматриваться как эффективная библиотека доступа именно к InterBase, хотя, как уже было сказано, в определенных условиях данный механизм может оказаться удобным. Тем не менее в этой книге мы не будем рассматривать работу с InterBase через BDE, тем более что этот вопрос освещается практически в любой книге о разработке приложений баз данных при помощи Borland Delphi.
ODBC (Open Database Connectivity) является одним из наиболее распространенных стандартов, которые обеспечивают доступ к базам данных. В огличие от BDE, ODBC позволяет разрабатывать приложения баз данных InterBase практически в любых средах программирования, а не только в продуктах компании Borland. В настоящее время существует несколько ODBC-драйверов, поддерживающих все функции семейства InterBase 6.x и эффективно реализующих работу с базами данных. Работа с одним из наиболее распространенных ODBC- драйверов - Gemini - коротко описана в данной книге.
Несмотря на существование ODBC, корпорация Microsoft в настоящее время продвигает новый ключевой механизм доступа - технологию OLE DB. Разумеется, существуют продукты, поддерживающие эту технологию для InterBase. В данной книге мы рассмотрим, в частности, IBProvider - мощную OLE DB-библиотеку для работы с InterBase. Разработчики приложений на Visual C++, Visual Basic, ASP и других популярных систем могут создавать с помощью IBProvider эффективные приложения, использующие все преимущества как технологии OLE DB, так и СУБД InterBase. В числе уникальных возможностей IBProvider хочется отметить возможность прозрачной интеграции данных баз данных InterBase с базами данных MS SQL Server.
Технология dbExpress, появившаяся в последних версиях продуктов компании Borland (Delphi, C++Builder и Kylix), позволяет проектировать приложения, переносимые между различными SQL-серверами, и в то же время в полной мере использовав уникальные особенности каждого из серверов. Тем не менее на сегодняшний день существует не так много приложений, использующих эту новую технологию, поскольку разработчики все еще предпочитают устоявшиеся методы работы с базами данных InterBase. Мы не станем рассматривать использование dbExpress, хотя возможно, что этот вопрос будет включен в следующие издания этой книги.
И наконец, мы можем сказать несколько слов о библиотеках прямого доступа - наиболее эффективном способе работы с базами данных InterBase. Используя такие библиотеки, можно добиться минимального количества "прослоек" между непосредственно кодом клиентского приложения и вызовами InterBase API. Это позволяет получить в приложениях максимальную производительность; полную поддержку всех возможностей InterBase, а также минимальный объем конечного продукта - для работы приложений на базе библиотек прямого доступа требуется лишь минимальная установка клиента InterBase (см. главу "Установка InterBase - взгляд изнутри" (ч. 4)).
В нашей книге подробно рассмотрено применение наиболее прогрессивной, по мнению авторов, библиотеки доступа - Devrace™ FIBPlus™, которая поддерживает все версии InterBase, начиная с 4.x, а также все клоны InterBase: Firebird и Yaffil.
Несомненно, нельзя забывать про использование баз данных в приложениях, ориентированных на Интернет. Прежде всего это работа с базами данных в Java, а также в CGl-приложениях. Этим вопросам в книге посвящены две главы, рассматривающие простые примеры работы с базами данных InterBase.
Для популярных языков Perl, Python и РНР также существуют свои собственные библиотеки доступа к базам данных InterBase, с помощью которых можно легко построить динамический сайт с поддержкой базы данных. Эги библиотеки перечислены ниже в таблице 1.6, содержащей общий список всех библиотек доступа к InterBase.
Завершая этот обзор, необходимо добавить, что большинство библиотек доступа поддерживают возможность разработки кросс-платформенных клиентских приложений, которые можно легко переносить с Windows на Linux или другие ОС.
Быстрый старт
Установка InterBase
Что ставить?
Установка InterBase на платформе Windows
Подготовка к установке
Установка
Установка InterBase на платформе Linux/Unix
Установка инструментария для администрирования InterBase
Заключение
Создаем базу данных
Строка соединения
Диалект базы данных
Размер страницы
Кодировка (CharSet)
Имя пользователя и пароль
Что получилось
Типы данных
О типах данных
Синтаксис определения типов данных
Целочисленные типы
Вещественные типы данных
Типы данных с фиксированной точкой
Типы для хранения даты и времени
Типы данных для хранения текста
Тип данных BLOB
Массивы
Заключение
Таблицы. Первичные ключи и генераторы
Первичные ключи в таблицах
Генераторы - лучшие друзья первичных ключей
Заключение
Индексы
Для чего нужны индексы?
Как устроены индексы
Применение индексов
Ускорение выполнения запросов с помощью индексов
Обеспечение ссылочной целостности с помощью индексов
Оптимизация производительности индексов
Ограничения базы данных
Виды ограничений в базе данных
Пример типичного ограничения
Создание ограничений
Первичный и уникальный ключи
Внешние ключи
Использование NULL в полях внешнего ключа
Расширенные возможности поддержки ссылочной целостности с помощью внешнего ключа
Ограничение CHECK
Удаление ограничений
Представления
Синтаксис DDL для работы с представлениями
Примеры представлений
Модифицируемые представления
Заключение
Хранимые процедуры
Пример простой хранимой процедуры
Разделители в хранимых процедурах
Вызов хранимой процедуры
Циклы и операторы ветвления
Рекурсивные хранимые процедуры
Заключение
Расширенные возможности языка хранимых процедур InterBase
Обработка исключений и ошибок
Исключения
Обработка ошибок SQL и InterBase
Работа с массивами в хранимых процедурах
Заключение
Триггеры
Пример триггера
Контекстные переменные
Управление состоянием триггера
Ошибки и исключения в триггерах
События InterBase
Заключение
User Defined Functions
Механизм подключения функций
Создание собственных функций
Заключение
Русификация InterBase
Русификация базы данных InterBase
Наборы символов
Хранение символьных данных без использования наборов символов
Вносим ясность
Русификация клиентских приложений InterBase
Собственные наборы символов и способы сортировки
Транзакции. Параметры транзакций
Концепция транзакций
Что такое транзакции?
Изолированность транзакций
Механизм транзакций в InterBase
Многоверсионная архитектура InterBase
Реализация многоверсионности. Страницы учета транзакций
Сборка мусора
Взаимодействие транзакций
Уровни изоляции транзакций
Параметры транзакций
Виды параметров транзакции
Режим доступа
Режим блокировки
Взаимоблокировка
Установка уровней изоляции
Рекомендации по использованию параметров транзакций
За пределами транзакций
Двухфазное подтверждение транзакций
Заключение
Обзор библиотек доступа к InterBase
Основа библиотек доступа к InterBase
Библиотеки доступа
Список библиотек доступа к InterBase
Целочисленные типы
К целочисленным типам относятся SMALLINT и INTEGER. Надо сказать, что SMALLINT представляет собой урезанную версию INTEGER и имеет длину 2 байта, в отличие от 4 байт, выделяемых для хранения INTEGER. Обычно экономить на дисковом пространстве не следует, и поэтому общей рекомендацией будет использовать для хранения целых значений тип INTEGER.
Область применения целочисленных типов очевидна: они нужны для полей, содержащих только целые числа - для хранения счетчиков, количества и т.д. Обычно тип INTEGER имеют также поля, содержащие первичные ключи.
Что получилось
В данном примере мы создаем базу данных InterBase с именем 'my.gdb' в каталоге 'C:\Database' на локальном компьютере. Размер страницы создаваемой базы данных равен 16384 байтам, в качестве кодировки по умолчанию выбрана WIN1251- набор символов, включающих кириллицу. Выберем для базы SQLDialect 3.
BlazeTop предоставляет очень удобный интерфейс для создания базы данных, однако надо сказать, что создание базы данных "вручную" не намного сложнее. Для этого достаточно создать два файла. Первый из них - это файл с командами SQL (его называют файлом скрипта), который создаст базу данных, второй - командный файл WINDOWS, который передаст этот SQL-файл на выполнение утилите isql.exe. Эта утилита выполнит выполнит скрипт создания базы данных. Вот содержимое этих двух файлов для нашего случая: файл скрипта crebas.sql:
SET SQL DIALECT 3; SET NAMES WIN1251;
CREATE DATABASE 'Localhost:С:\Database\my.gdb1
USER 'SYSDBA' PASSWORD 'masterkey'
PAGE_SIZE 16384
DEFAULT CHARACTER SET WIN1251;
командный файл runscr.bat:
"C:\IBServer\Bin\isql.exe" -i "C:\temp\crebas.sql"
Естественно, в командном файле должны быть прописаны реальные пути к isql.exe (это интерпретатор команд SQL, входящий в комплект InterBase) и к нашему файлу скрипта crebas.sql.
Результат выполнения runscr.bat будет точно таким же, как и использование BlazeTop для создания базы данных.
Нажмем "Create" для создания базы данных InterBase.
Что ставить?
Прежде чем устанавливать InterBase, надо решить, какой из его клонов (версий) мы выберем для работы. Прежде всего надо сказать, какую версию однозначно НЕ РЕКОМЕНДУЕТСЯ использовать. Это бета-версия InterBase 6.0.хх, одна из самых первых версий, выпущенных после объявления InterBase 6 бесплатным. Версия InterBase 6.x послужила основой для выпуска трех клонов - Firebird, InterBase 6.5 и Yaffil.
Клон Firebird появился вскоре после опубликования исходных кодов InterBase 6.x. Он является абсолютно бесплатным продуктом в открытых кодах (open source). В его создании принимало участие множество бывших сотрудников InterBase Software Corporation. Версия Firebird 1.0 отлично подойдет для освоения материала этой книги и начала работы с InterBase.
Компания Borland в конце 2001 года выпустила версию InterBase 6.5. Ее также можно установить и использовать для изучения материала этой книги. Для этих целей можно воспользоваться триал-версией с ограничением времени использования в 90 дней. Эту версию InterBase 6.5 можно скачать с сайта компании Borland.
Помимо Firebird и InterBase, существует еще и российская ветка InterBase 6.x - Yaffil, который отпочковался от Firebird в 2001 году. Yaffil существует пока только для платформы Windows, и часть его кода оптимизирована именно для этой ОС. Подробнее о новых свойствах Yaffil можно узнать в приложении «Yaffil - российский клон InterBase 6.x». Yaffil также можно использовать для изучения материала этой книги.
Следует отметить, что все клоны InterBase 6.x совместимы между собой и базу данных с одного сервера можно легко перевести под другой с помощью процесса backup/restore (см. главу «Миграция» (ч. 4)). Поэтому ничего страшного не произойдет, если вы пожелаете сменить одну версию (и даже клон) InterBase 6.x на другую.
Многих разработчиков пугает значительное разнообразие версий и потомков InterBase 6 и вызывает чувство неуверенности - много разных СУБД, которые непонятно чем отличаются. На самом деле это совершенно нормальная ситуация, типичная для проекта Open Source и свидетельствующая о том, что InterBase 6 активно развивается. Аналогичная ситуация сложилась и в Linux- сообществе, где количество возможных сочетаний ядро + дистрибутив давно перевалило за сотню.
Немного «пообщавшись» с InterBase (с любым его клоном), вы легко сможете выбрать, что же больше подходит для конкретной задачи.
Вопрос - где находятся дистрибутивы различных клонов InterBase? Различные варианты дистрибутивов представлены на сайте поддержки данной книги www.InterBase-world.corn, а также на сайте http://www.ibase.ru. Там же обычно можно получить ссылку на самый «свежий» дистрибутив всех клонов InterBase, а также массу другой полезной информации по использованию InterBase и разработке приложений баз данных.
Непосредственно из первоисточника дистрибутивы и исходные коды InterBase можно взять на сайте http://sourceforge.net/projects/InterBase, а дистрибутивы Firebird - на сайте http://sourceforge.net/projects/Firebird. В общем, хорошая поисковая машина вам поможет в получении практически любого дистрибутива.
На компакт-диске с Delphi Client/Server и Enterprise Edition всех версий (3.x, 4.x, 5.x и 6.x) также содержится InterBase, обычно версии 5.х/6.х. Его также можно использовать для работы с материалом этой книги, за исключением некоторых моментов, которые описывают функциональность, присущую только некоторым версиям клонов InterBase.
Определившись с версией InterBase, следует выбрать, под какой ОС мы будем работать. Для нашего случая предположим, что работа будет происходить на ОС Windows (версии старше 95 или NT 4.0). Если вы поклонник другой ОС, не расстраивайтесь: существуют дистрибутивы для Linux/Unix, FreeBSD, Solaris, и даже Mac OS X Darwin. Здесь мы рассмотрим процесс установки для платформ Windows и Linux, предполагая, что именно одна из этих ОС установлена на вашем рабочем компьютере.
Если в будущем потребуется «переехать» на другую ОС, нет проблем: это несложная процедура, которую мы рассмотрим в главе «Миграция».
Что такое транзакции?
В этой книге практически в каждой главе упоминаются транзакции. Понятие транзакции пронизывает всю теорию и практику работы с базами данных. Транзакции всегда, транзакции везде - вот лозунг разработчиков СУБД.
Понятие транзакции само по себе чрезвычайно простое и очевидное.
Транзакция - это логический блок, объединяющий одну или более операций в базе данных и позволяющий подтвердить или отменить результаты работы всех операций в блоке
Возможность отмены - только одно из свойств. Определение обычно дается очень обтекаемое, транзакция - последовательность операций с базой данных, логически выполняемая как единое целое. Транзакция обладает свойствами атомарности, согласованности, изоляции и долговременности (по-английски ACID - Atomicity, Consistency, Isolation, Durability).
Давайте рассмотрим более подробно это определение. Операции, о которых идет речь в определении - это INSERT/UPDATE/DELETE и, конечно, SELECT. Если транзакция объединяет какие-то операции в единый блок, то говорят, что эти действия выполняются в контексте данной транзакции.
Вторая часть определения гласит: - "Позволяющий подтвердить или отменить результаты работы всех операций в блоке". Это очень важная часть, содержащая в себе суть идеи транзакций. Эту часть определения мы проиллюстрируем нижеследующим классическим примером транзакции
Представьте себе перевод денег с одного счета в банке на другой Когда клиент инициирует перевод денег, то начинается транзакция. Деньги снимаются со счета-источника и переводятся на счет-приемник. Когда приходит подтверждение, что деньги переведены, транзакция завершается, т. е. именно в этот момент происходит "узаконивание" перевода денег. Если же хотя бы один этап перевода не состоялся, то транзакция откатывается и все проведенные в ее рамках изменения отменяются. Только после подтверждения транзакции пришедшие на счет деньги станут "реальными" (а ушедшие со счета - реально исчезнут).
Понятие транзакции как логического блока операций, которым можно оперировать как единым целым при подтверждении/отмене результатов, очень популярно среди программистов-разработчиков баз данных. Оно позволяет объяснить большинство феноменов, которые происходят в приложениях баз данных и в то же время достаточно простое для интуитивного понимания.
В сущности, это определение абсолютно верно для всех случаев жизни, но в то же время оно не подчеркивает некоторых важных особенностей транзакций, которые могут проявиться в самый неподходящий момент и удивить даже опытного разработчика. Чтобы разобраться в сущности транзакций в InterBase, нам придется пойти дальше этого простого определения и углубиться в тонкости.
Прежде всего давайте внесем важное уточнение в определение транзакции:
Транзакция - это механизм, позволяющий объединять различные действия в логические блоки и обеспечить возможность принимать решения об успешности действий всего блока операций в целом
Обратите внимание на смещение акцента в определении: "транзакция - это механизм..."! Именно от представления о транзакции как о механизме, выполняющем определенные функции, мы и будем отталкиваться в дальнейших рассуждениях.
Давайте разберемся в некоторых фактах, которые необходимо знать для того, чтобы двигаться дальше в понимании транзакций.
Механизм транзакций обязательно используется для ВСЕХ операций в базе данных (о некоторых особых случаях будет рассказано ниже). Возможно, некоторые разработчики, пользующиеся высокоуровневыми инструментами разработки приложений баз данных, могут заявить, что они никогда не применяли транзакции и не видят в них нужды. Но это всего лишь означает, что всю работу по управлению транзакциями брал на себя инструмент разработки (и вряд ли он управлял ими достаточно эффективно!).
Сочетание слов "логический блок" напоминает нам, что транзакции изначально задумывались и реализовывались как механизм управления бизнес- логикой в базах данных. Это означает, что объединением некоторой последовательности операций в транзакцию управляет клиентское приложение базы данных (а в конечном итоге - пользователь).
Подтверждение или отмена результатов операций, объединенных одной транзакцией, не означает, что все эти операции выполнились успешно (или закончились ошибкой). Подтверждение транзакции - это решение о том, что следует оставить в базе данных результаты работы всех операций, входящих в транзакцию, вне зависимости от того, как они закончились. Если клиентское приложение (фактически человек-пользователь) решило подтвердить результаты транзакции, то при этом подтвердятся результаты всех успешных действий (а у неуспешных действий просто не будет результатов, поэтому произойдет лишь формальное подтверждение). Если клиентское приложение решило откатить транзакцию, то все результаты всех действий и успешные, и неуспешные, будут аннулированы.
Хочется отметить, что начинающие пользователи часто ставят знак равенства между подтверждением транзакции и успешностью проведенных в ее рамках действий. На самом деле здесь нет четкой связи - решение о подтверждении транзакции принимается на основании логики клиентского приложения (проще говоря, зависит от произвола пользователя). Да, обычно если все операции в транзакции прошли успешно, то транзакция подтверждается и все полученные результаты "узакониваются", но такое поведение не является обязательным. Ведь ничто не должно мешать пользователю отменить результаты успешных операций, исходя из каких-то своих высших соображений.
Пора разобраться в понятиях подтверждения ("узаконивания") и отмены (отката) транзакций. Следующий раздел внесет ясность в этот вопрос.
Циклы и операторы ветвления
Помимо команды FOR SELECT... DO, организующей цикл по записям какой-либо выборки, существует другой вид цикла - WHILE...DO, который позволяет организовать цикл на основе проверки любых условий. Вот пример ХП, использующей цикл WHILE.. DO. Эта процедура возвращает квадраты целых чисел от 0 до 99:
CREATE PROCEDJRE QUAD
RETURNS (QUADRAT INTEGER)
AS
DECLARE VARIABLE I INTEGER;
BEGIN
I = 1;
WHILE (i<100) DO
BEGIN
QUADRAT= I*I;
I=I+1;
SUSPEND;
END
END
В результате выполнения запроса SELECT • FROM QUAD мы получим таблицу, содержащую один столбец QUADRAT, в котором будут квадраты целых чисел от 1 до 99
Помимо перебора результатов SQL-выборки и классического цикла, в языке хранимых процедур используется оператор IF...THEN..ELSE, позволяющий организовать ветвление в зависимости от выполнения каких-либо \словий Его синтаксис похож на большинство операторов ветвления в языках программирования высокого уровня, вроде Паскаля и Си.
Давайте рассмотрим более сложный пример хранимой процедуры, которая делает следующее.
Вычисляет среднюю цену в таблице Table_example (см. глава "Таблицы Первичные ключи и генераторы")
Далее для каждой записи в таблице делает след>ющ)ю проверку, если существующая цена (PRICE) больше средней цены, то устанавливает цену, равную величине средней цены, плюс задаваемый фиксированный процент
Если существующая цена меньше или равна средней цене, то устанавливает цену, равную прежней цене, плюс половина разницы между прежней и средней ценой.
Возвращает все измененные строки в таблице.
Для начала определим имя ХП, а также входные и выходные параметры Все это прописывается в заголовке хранимой процедуры
CREATE PROCEDURE IncreasePrices (
Percent2lncrease DOUBLE PRECISION)
RETURNS (ID INTEGER, NAME VARCHAR(SO), new_price DOUBLE
PRECISION) AS
Процедура будет называться IncreasePrices, у нее один входной параметр Peiceni21nciease, имеющий тип DOUBLE PRECISION, и 3 выходных параметра - ID, NAME и new_pnce. Обратите внимание, что первые два выходных параметра имеют такие же имена, как и поля в таблице Table_example, с которой мы собираемся работать Это допускается правилами языка хранимых процедур.
Теперь мы должны объявить локальную переменную, которая будет использоваться для хранения среднего значения Эго объявление будет выглядеть следующим образом:
DECLARE VARIABLE avg_price DOUBLE PRECISION;
Теперь перейдем к телу хранимой процедуры Откроем тело ХП ключевым словом BEGIN.
Сначала нам необходимо выполнить первый шаг нашего алгоритма - вычислить среднюю цену. Для этого мы воспользуемся запросом следующего вида:
SELECT AVG(Price_l)
FROM Table_Example
INTO :avg_price,-
Этот запрос использует агрегатную функцию AVG, которая возвращает среднее значение поля PRICE_1 среди отобранных строк запроса - в нашем случае среднее значение PRICE_1 по всей таблице Table_example. Возвращаемое запросом значение помещается в переменную avg_price. Обратите внимание, что переменная avg_pnce предваряется двоеточием -для того, чтобы отличить ее от полей, используемых в запросе.
Особенностью данного запроса является то, что он всегда возвращает строго одну-единственную запись. Такие запросы называются singleton-запросами И только такие выборки можно использовать в хранимых процедурах. Если запрос возвращает более одной строки, то его необходимо оформить в виде конструкции FOR SELECT...DO, которая организует цикл для обработки каждой возвращаемой строки
Итак, мы получили среднее значение цены. Теперь необходимо пройтись по всей таблице, сравнить значение цены в каждой записи со средней ценой и предпринять соответствующие действия
С начала opганизуем перебор каждой записи из таблицы Table_example
FOR
SELECT ID, NAME, PRICE_1
FROM Table_Example
INTO :ID, :NAME, :new_price
DO
BEGIN
/*_здесь оОрсшатыьаем каждую запись*/
END
При выполнении этой конструкции из таблицы Table_example построчно будут выниматься данные и значения полей в каждой строке будут присвоены переменным ID, NAME и new_pnce. Вы, конечно, помните, что эти переменные объявлены как выходные параметры, но беспокоиться, что выбранные данные будут возвращены как результаты, не стоит: тот факт, что выходным параметрам что-либо присвоено, не означает, что вызывающий ХП клиент немедленно получит эти значения! Передача параметров осуществляется только при исполнении команды SUSPEND, а до этого мы можем использовать выходные параметры в качестве обычных переменных - в нашем примере мы именно так и делаем с параметром new_price.
Итак, внутри тела цикла BEGIN.. . END мы можем обработать значения каждой строки. Как вы помните, нам необходимо выяснить, как существующая цена соотносится со средней, и предпринять соответствующие действия. Эту процедуру сравнения мы реализуем с помощью оператора IF:
IF (new_price > avg_price) THEN /*если существующая цена больше средней цены*/
BEGIN
/*то установим новую цену, равную величине средней цены, плюс фиксированный процент */
new_price = (avg_price + avg_price*(Percent2Increase/100));
UPDATE Table_example
SET PRICE_1 = :new_price
WHERE ID = :ID;
END
ELSE
BEGIN
/* Если существующая цена меньше или равна средней цене, то установим цену, равную прежней цене, плюс половина разницы между прежней и средней ценой */
new_price = (new_pnce + ( (avg_pnce new_price)/2) ) ;
UPDATE Table_example
SET PRICE_1 = :new_price
WHERE ID = .ID;
END
Как видите, получилось достаточно большая конструкция IF, в которой трудно было бы разобраться, если бы не комментарии, заключенные в символы /**/.
Для того чтобы изменить цену в соответствии с вычисленной разницей, мы воспользуемся оператором UPDATE, который позволяет модифицировать существующие записи - одну или несколько. Для того чтобы однозначно указать, в какой записи нужно изменять цену, мы используем в условии WHERE поле первичного ключа, сравнивая его со значением переменной, в которой хранится значение ID для текущей записи: ID=:ID. Обратите внимание, что переменная ID предваряется двоеточием.
После выполнения конструкции IF...THEN...ELSE в переменных ID, NAME и new_price находятся данные, которые мы должны возвратить клиент\, вызвавшему процедуру. Для этого после IF необходимо вставить команду SUSPEND, которая перешлет данные туда, откуда вызвали ХП На время пересылки действие процедуры будет приостановлено, а когда от ХП потребуется новая запись, то она будет вновь продолжена, - и так будет продолжаться до тех пор, пока FOR SELECT...DO не переберет все записи своего запроса.
Надо отметить, что помимо команды SUSPEND, которая только приостанавливает действие хранимой процедуры, существует команда EXIT, которая прекращает хранимую процедуру после передачи строки. Однако командой EXIT пользуются достаточно редко, поскольку она нужна в основном для того, чтобы прервать цикл при достижении какого-либо условия
При этом в случае, когда процедура вызывалась оператором SELECT и завершена по EXIT, последняя извлеченная строка не будет возвращена. То есть, если вам нужно прервать процедуру и все-таки >получить эту строку, надо воспользоваться последовательностью
SUSPEND;
EXIT;
Основное назначение EXIT - получение singleton-наборов данных, возвращаемых параметров путем вызова через EXECUTE PROCEDURE. В этом случае устанавливаются значения выходных параметров, но из них не формируется набор данных SQL, и выполнение процедуры завершается.
Давайте запишем текст нашей хранимой процедуры полностью, чтобы иметь возможность охватить ее логику одним взглядом:
CREATE PROCEDURE IncreasePrices (
Percent2Increase DOUBLE PRECISION)
RETURNS (ID INTEGER, NAME VARCHAR(80),
new_price DOUBLE PRECISION) AS
DECLARE VARIABLE avg_price DOUBLE PRECISION;
BEGIN
SELECT AVG(Price_l)
FROM Table_Example
INTO :avg_price;
FOR
SELECT ID, NAME, PRICE_1
FROM Table_Example
INTO :ID, :NAME, :new_price
DO
BEGIN
/*здесь обрабатываем каждую запись*/
IF (new_pnce > avg_price) THEN /*если существующая цена больше средней цены*/
BEGIN
/*установим новую цену, равную величине средней цены, плюс фиксированный процент */
new_price = (avg_price + avg_price*(Percent2lncrease/100));
UPDATE Table_example
SET PRICE_1 = :new_price
WHERE ID = :ID;
END
ELSE
BEGIN
/* Если существующая цена меньше или равна средней цене, то устанавливает цену, равную прежней цене, плюс половина разницы между прежней и средней ценой */
new_price = (new_price + ((avg_price - new_price)/2));
UPDATE Table_example
SET PRICE_1 = :new_price
WHERE ID = :ID;
END
SUSPEND;
END
END
Данный пример хранимой процедуры иллюстрирует применение основных конструкций языка хранимых процедур и триггеров. Далее мы рассмотрим способы применения хранимых процедур для решения некоторых часто возникающих задач.
Диалект базы данных
Вернемся к окну создания базы данных, изображенному на рисунке 1.3. Выбор диалекта базы данных очень важен. Свойство может принимать только два возможных значения: 1 или 3. Какое же выбрать?
Диалект 1 и Диалект 3 отличаются друг от друга следующими принципиальными вещами:
Диалект 3 позволяет использовать расширенный набор типов данных, таких, как типы для работы с большими целыми числами, типы для работы с датой и временем - DATE и ТГМЕ.
Диалект 3 различает регистр идентификаторов, если >идентификатор заключен в двойные кавычки Table 1 и TABLE1 в обоих диалектах будут равнозначны, а вот "Tablel" и "TABLE!" (TABLE1) - сервер будет интерпретировать как разные идентификаторы.
Диалект 3 не поддерживает неявное приведение типов данных (как это было в Диалекте 1). Это означает, что в Диалекте 1 выражение '25'+5 будет корректным и в результате мы получим 30. В Диалекте 3 это выражение вызовет ошибку несоответствия типов.
Помимо этого, есть еще ряд отличий. Например, Borland Database Engine (BDE) вплоть до версии 5.2 плохо работает с 3-м диалектом - возникают проблемы с поддержкой новых типов данных.
Выбор SQLDialect, в котором будет создаваться база данных, важен также по той причине, что переход между разными диалектами - занятие достаточно нетривиальное и трудоемкое, которого по возможности следует избегать. Иными словами, если есть возможность, то лучше сразу выбрать верный диалект.
В общем случае надо руководствоваться следующими правилами:
выбираем Диалект 3, если мы будем проектировать базу данных для приложения, которое будет использовать только современные библиотеки прямого доступа к InterBase, которые полностью поддерживают Диалект 3;
выбираем Диалект 1, если нам важна совместимость с более ранними библиотеками доступа к InterBase, такими, как BDE.
Может возникнуть вопрос, почему диалекты бывают 1 и 3, а где же 2? Диалект 2 действительно существует, но используется в качестве промежуточного этапа при миграции с Диалекта 1 на Диалект 3.
Для чего нужны индексы?
Единственное, чему способствуют индексы, - это ускорению поиска записи по ее индексированному полю (индексированное - значит входящее в индекс).
Итак, основная функция индексов - обеспечивать быстрый поиск записи в таблице. Любое использование индексов сводится именно к этому.
Как реализована эта функция поиска? На входе функции мы имеем значение индексированного поля (или нескольких полей). В результате поиска мы должны получить всю запись, в которой индексированное поле имеет заданное значение. Сначала в индексе (точнее, в упорядоченном массиве значений индексированного поля) ищется нужное значение, затем берется адрес страницы данных, на которой лежит искомая запись, сервер перемещается на эту страницу и читает найденную запись. Выглядит довольно громоздко, однако поиск с помощью индекса происходит во много раз быстрее, чем при последовательном переборе всех значений из таблицы.
Если продолжить аналогию индекса с библиотечным каталогом, то поиск записи с помощью индекса очень похож на поиск книги с помощью карточки. Сюит нам найти книгу в относительно небольшом по объему каталоге (по сравнению со всем библиотечным хранилищем), как сразу получаем информацию о точном местонахождении книги и можем направиться прямиком туда. Поиск же без использования индекса можно сравнить с последовательным перебором всех книг в библиотеке!
Перебор всех записей в таблице называется прямым или естественным (NATURAL). Надо сказать, что, несмотря на мощности современных компьютеров, при достаточно большом количестве записей в таблице естественный перебор можег быть очень долгим процессом.
Двухфазное подтверждение транзакций
В завершение этой главы хочется рассказать о механизме двухфазного подтверждения транзакций. Дело в том, что InterBase предлагает уникальную возможность организовывать распределенные транзакции между разными базами данных и даже разными серверами (пожалуйста, не путайте двухфазное подтверждение транзакций с гетерогенными запросами, которые невозможно выполнять в InterBase).
Суть двухфазного подтверждения состоит в том, что в клиентском приложении можно запустить транзакцию сразу на двух серверах. Фактически проще всего это сделать, привязав один компонент транзакции сразу к двум компонентам базы данных.
Такая транзакция запустится сразу на двух серверах. Чтобы синхронизировать процесс завершения этой транзакции, вводится особое состояние, называемое Prepared. Это состояние означает, что транзакция завершилась на одном сервере и готова перейти в состояние Committed, как только транзакции на остальных серверах также перейдут в состояние Prepared. Если же транзакция хотя бы на одном из участвующих в процессе серверов завершится Rollback, то все транзакции из состояния Prepared тоже откатятся.
Теперь ясно, отчего могут возникнуть лимбо-транзакции, о которых упоминалось выше. Если между серверами разорвется соединение в тот момент, когда одна транзакция перешла в состояние Prepared и готова подтвердиться, то сервер не сможет решить, подтвердить или удалить изменения, сделанные этой транзакцией.
Не следует использовать двухфазное подтверждение транзакций на серверах, соединенных медленными каналами связи (модемами, например).
Генераторы - лучшие друзья первичных ключей
Надо сказать несколько слов о реализации первичного ключа. Так как он предназначен для обеспечения уникальности, то никакие две записи в одной таблице не могут иметь одинаковых значений этого ключа. То есть, чтобы удовлетворить этому условию, при занесении новой записи в таблицу InterBase должен просмотреть все записи в таблице и выяснить, нет ли уже таких значений в таблице. Для быстрого поиска в InterBase существует механизм индексов - специальных объектов InterBase, которые позволяют очень быстро найти запись в таблице. Поэтому при создании и удалении первичного ключа создается или удаляется индекс на то поле (или поля), которое входит в первичный ключ.
Как уже было сказано, первичный ключ может содержать несколько полей. При этом будет отслеживаться уникальность сочетания значений этих полей. Например, если мы определим ключ на поля ID и NAME, то сервер будет следить за тем, чтобы во всей таблице не было одинаковых сочетаний этих полей. То есть сочетания полей ID и NAME вроде 1 и "Иванов", 2 и "Иванов" будут корректными, поскольку они отличаются значениями поля ID.
Таким образом, первичный ключ может включать несколько полей любых типов. Однако на практике самым распространенным видом ключа является счетчик - целочисленное поле, которое содержит увеличивающиеся значения.
Почему так? Это является отражением давнего спора между естественными и суррогатными ключами. Концепция естественных ключей утверждает, что в качестве ключа надо стараться использовать значения, реально существующие в предметной области, которую отражает база данных. Например, если мы разрабатываем систему учета людей для паспортного стола, то согласно этой концепции необходимо в качестве первичного ключа взять сочетание номера и серии паспорта. Действительно, каждый человек должен иметь свое уникальное сочетание номера и серии паспорта. Однако как быть с тем, что человек может поменять паспорт в течение жизни (в связи с достижением определенного возраста, при заключении брака и т. д.)? В этом случае нам б>дет необходимо сменить номер и серию паспорта, поставленные в соответствие конкретному человеку, т. е. фактически, сменить наш первичный ключ. Эго нежелательно с точки зрения разработки приложений баз данных: при разветвленной системе связей между таблицами (этому посвящена следующая глава) может понадобиться слишком много усилий разработчика для отслеживания этой ситуации.
Поэтому в большинстве случаев используется суррогатный ключ. Суррогатный - значит искусственный, т. е. не существующий в предметной области, которую описывает наша база данных, а созданный искусственно - для удобства разработки приложений базы данных.
Как уже было сказано, обычно первичным ключом является счетчик. Некоторые СУБД, такие, как Paradox и MS SQL, имеют специальный тип - счетчик (auto increment). При добавлении в таблицу новой записи значение поля с этим типом автоматически увеличивается на величину приращения - обычно на единицы. В InterBase нет поля типа счетчик, однако есть возможность реализовать подобное поведение. Для создания поля, которое бы заполнялось автоматически при добавлении записи в таблицу, используется совокупность средств: первым из них является генератор.
Что такое генератор! Говоря по-простому, 1енератор - это именованный счетчик. Внутри базы данных мы можем создать счегчик, дать ему уникальное имя в пределах этой базы и управлять значениями этого счетчика. Это и будет генератор. Чтобы это пояснить - вот пример предложений DDL:
CREATE GENERATOR gl;
SET GENERATOR gl TO 2445;
В этом примере в первой строчке в базе данных создается генератор с именем gl, а во второй - этому генератору присваивается значение 2445. Теперь возникает вопрос, как нам использовать полученный генератор. Чтобы получать и изменять значения генераторов, существует встроенная в InterBase функция GEN_ID. Эта функция принимает в качестве параметров имя генератора и величину приращения, которую нужно применить к данному генератору, а возвращает целочисленное значение, соответствующее значению генератора, полученному в результате прибавления к нему приращения. Вот пример вызова функции GEN_ID в тригере или хранимой процедуре:
Current_value = GEN_ID (gl, 1)
Чтобы получить значение генератора в клиентском приложении, можно воспользоваться таким запросом:
SELECT GEN_ID(gl, 1)FROM
RDB$ DATABASE
Так как в таблице RDB$ Database всегда содержится только одна запись, то мы получим в результате данного запроса значение генератора gl.
Здесь current_value - переменная (как использовать переменные в InterBase - см. в следующих главах), gl - генератор, 1 -приращение. В этом примере в переменную current_value попадет значение генератора gl после прибавления к нему приращения 1, т. е. следующее значение генератора!
Обратите внимание, что приращение может быть не равно единице! Более того, оно может быть даже отрицательным:
Current_value = GEN_ID (gl, -23)
В результате выполнения этой функции текущее значение генератора gl уменьшиться на 23. Как видите, диапазон возможных применений генераторов довольно широк - его можно использовать не только для получения значений первичных ключей, но и для отслеживания глобальных изменений в базе данных.
Люди, знакомые с базами данных, могут задать вопрос: "А что будет, если одновременно несколько клиентов попробуют внести данные в одну и ту же таблицу и одновременно "дернут" генераторы? Получат ли они одно или разные значения генератора?" Однозначно, что они получат РАЗНЫЕ значения генератора. Какой бы "одновременной" ни была попытка получить значение генератора, каждый обратившийся получит свое уникальное значение. Это гарантируется самой "конструкцией" генераторов: они работают на самом низком уровне сервера и никакие процессы записи и вставки не влияют на них - часто говорят, что генераторы работают "вне контекста транзакций". Что такое транзакции, вы можете узнать в главе "Транзакции. Параметры транзакций" (ч. 1), а как устроены генераторы - в главе "Структура базы данных InterBase" (ч. 4).
Ну хорошо, в лице генераторов мы имеем надежный механизм для формирования уникальных первичных ключей. Однако как же нам воспользоваться этим механизмом? Как поместить получаемое от генератора значение в поле первичного ключа?
Для этого есть два способа - вставка первичного ключа на стороне клиента и на стороне сервера. Чтобы освоить первый способ, следует обратиться к главе "Использование основных компонентов FIBPlus", а чтобы понять второй - к главе "Триггеры" (ч. 1). Здесь мы лишь кратко скажем, в чем заключается суть обоих способов.
В случае формирования первичного ключа на клиенте происходит следующее. Когда сформирована запись, которая будет вставлена в базу данных, выполняется вызов функции GEN_ID(<имя генератора>,1) и полученное значение подставляется в сформированную запись. Происходит вставка в таблицу, при этом мы получаем гарантированно уникальный первичный ключ.
Второй способ - формирование первичного ключа на стороне сервера - вообще исключает всякую заботу на стороне клиента о том, каково будет значение первичного ключа. В этом случае при вставке записи срабатывает триггер - специальный объект базы данных, который может осуществлять какие-либо действия при вставке/удалении/изменении записей в таблицах. И в этом триггере происходит вызов функции GEN_ID, получение нужного значения генератора и вставка его в таблицу.
Достоинством второго способа является то, что при разработке клиентского приложения совершенно не надо заботиться о формировании первичного ключа, достаточно лишь раз написать нужный триггер. Но его недостатком является то, что мы не можем получить в приложении значение сформированного ключа сразу после вставки! При использовании первого способа мы, хотя и сами должны каждый раз при вставке первичного ключа заботиться о его формировании, можем получить его значение. Какой способ лучше - однозначно сказать нельзя, все зависит от конкретной задачи, но возможные варианты разрешения вопросов работы с первичным ключом будут еще не раз затронуты далее в этой книге.
Хранение символьных данных без использования наборов символов
Считать данные таблицы, в которой символьные поля имеют разные наборы символа с помощью одного SQL-запроса также не получится, если мы укажем один из трех наборов данных, то InterBase попытается привести все данные к этому набору, а это может у него не получиться - и тогда возникнет ошибка "Cannot transliterate characters between character sets".
Однако существует еще один, недокументированный способ хранить в базе данных символы из различных наборов. Этот способ заключается в том, чтобы вообще не указывать набор символов, тогда по умолчанию будет применять character set NONE, использование которого дает понять InterBase, что символьные данные должны храниться так, как они есть, без всяких интерпретаций. При этом всю ответственность за интерпретацию данных берет на себя разработчик клиентского приложения. Таким образом, отказавшись от использования наборов символов, мы получаем возможность читать и хранить любые символьные данные.
Казалось бы, надо всегда пользоваться CHARACTER SET NONE и избегать различных проблем, однако, отказываясь от наборов символов, мы отказываемся и от полезных свойств, которые они с собой несут. Прежде всего, использование CHARACTER SET, а, точнее, их COLLATION ORDERS (способов упорядочения) позволяет корректно сортировать русские символы и приводить их к верхнему регистру.
Дело в том, что по умолчанию русские буквы сортируются в двоичном порядке, т. е. в соответствии с порядком расположения кодов символов. При этом строчные буквы располагаются после прописных, а буква "Ы" вообще располагается отдельно. Чтобы заставить их сортироваться правильно, надо указать способ упорядочения, т. е. COLLATION ORDER.
Хранимые процедуры
Предметом этой главы является один из наиболее мощных инструментов, предлагаемых разработчикам приложений баз данных InterBase для реализации бизнес-логики Хранимые процедуры (англ, stoied proceduies) позволяют реализовать значительную часть логики приложения на уровне базы данных и таким образом повысить производительность всего приложения, централизовать обработку данных и уменьшить количество кода, необходимого для выполнения поставленных задач Практически любое достаточно сложное приложение баз данных не обходится без использования хранимых процедур.
Помимо этих широко известных преимуществ использования хранимых процедур, общих для большинства реляционных СУБД, хранимые процедуры InterBase могут играть роль практически полноценных наборов данных, что позволяет использовать возвращаемые ими результаты в обычных SQL-запросах.
Часто начинающие разработчики представляют себе хранимые процедуры просто как набор специфических SQL-запросов, которые что-то делают внутри базы данных, причем бытует мнение, что работать с хранимыми процедурами намного сложнее, чем реализовать ту же функциональность в клиентском приложении, на языке высокого уровня
Так что же такое хранимые процедуры в InterBase?
Хранимая процедура (ХП) - это часть метаданных базы данных, представляющая собой откомпилированную во внутреннее представление InterBase подпрограмму, написанную на специальном языке, компилятор которого встроен в ядро сервера InteiBase
Хранимую процедуру можно вызывать из клиентских приложений, из триггеров и других хранимых процедур. Хранимая процедура выполняется внутри серверного процесса и может манипулировать данными в базе данных, а также возвращать вызвавшему ее клиенту (т е триггеру, ХП, приложению) результаты своего выполнения
Основой мощных возможностей, заложенных в ХП, является процедурный язык программирования, имеющий в своем составе как модифицированные предложения обычного SQL, такие, как INSERT, UPDATE и SELECT, так и средства организации ветвлений и циклов (IF, WHILE), а также средства обработки ошибок и исключительных ситуаций Язык хранимых процедур позволяет реализовать сложные алгоритмы работы с данными, а благодаря ориентированности на работу с реляционными данными ХП получаются значительно компактнее аналогичных процедур на традиционных языках.
Надо отметить, что и для триггеров используется этот же язык программирования, за исключением ряда особенностей и ограничений. Отличия подмножества языка, используемого в триггерах, от языка ХП подробно рассмотрены в главе "Триггеры" (ч 1).
Имя пользователя и пароль
Для создания базы необходимо указать имя пользователя и его пароль. Этот пользователь будет владельцем создаваемой базы данных (OWNER). Это дает ему право полностью управлять базой данных - создавать и удалять различные объекты базы данных, выполнять запросы на выборку и изменение данных - в общем, быть ее полным хозяином.
Обычно для создания базы применяют права встроенного пользователя InterBase - SYSDBA. Этот пользователь реализует функции системного администратора базы данных. По умолчанию SYSDBA может изменять все объекты базы данных, вне зависимости от того, кем они созданы - самим SYSDBA или другим пользователем.
Конечно, очень удобно иметь полный набор прав "в одном флаконе", когда разрабатываешь базу данных, но во время промышленной эксплуатации часто требуется разделить права между различными группами пользователей. Вот тогда применяются пользователи (USERS) и роли (ROLES) для того, чтобы на уровне базы данных разграничить доступ к информации, хранящейся в базе данных. Подробнее о безопасности в InterBase см. главу "Безопасность в IlnterBase: Пользователи, роли и права" (ч. 4).
Рекомендованный пользователь для создания базы данных - SYSDBA. Это позволяет на этапе начального проектирования базы не беспокоиться о распределении прав - этим можно будет заняться несколько позже. Пароль для SYSDBA по умолчанию - 'masterkey'. Конечно, этот пароль лучше сменить, особенно на серверах, находящихся в промышленной эксплуатации.
Индексы
Концепция, положенная в основу индексов, проста и наглядна и является одной из важнейших основ проектирования баз данных. На основе индексов базируются многие основополагающие объекты базы данных, к тому же правильное использование индексов является ключом к улучшению производительности приложений баз данных.
Что же представляет собой индекс? Индекс - это упорядоченный указатель на записи в таблице. Указатель означает, что индекс содержит значения одного или нескольких полей в таблице и адреса страниц данных, на которых располагаются эти значения (про страницы данных см. главу "Структура базы данных InterBase") (ч 4). Другими словами, индекс состоит из пар значений "значение поля" - "физическое расположение этого поля". Таким образом, по значению поля (или полей), входящего в индекс, при помощи индекса можно быстро найти то место в таблице, где располагается запись, содержащая это значение.
Упорядоченный - означает, что значения полей, хранящихся в индексе, упорядочены.
Очень часто индекс сравнивают с библиотечным каталогом, в котором все книги записаны на карточки и упорядочены каким-то образом: по алфавиту или по темам, а в каждой карточке написано, где именно в хранилище располагается данная книга.
Исключения
Первой из рассматриваемых особенностей языка хранимых процедур (ХП) и триггеров InterBase является возможность использовать "исктючения"
Исключения InterBase во многом похожи на исключения других языков высокого уровня, однако имеют свои особенности Фактически исключение InterBase - это сообщение об ошибке, которое имеет собственное, задаваемое программистом имя и текст сообщения об ошибке. Создается исключение следующим образом:
СРЕАТЕ EXCEPTION <имя_исключения> <текст_исключения>;
Например, мы можем создать исключение такого вида:
CREATE EXCEPTION test_except 'Test exception';
Исключение легко удалить или изменить - удаление совершается командой DROP EXCEPTION <имя_удаляемого_исключения>, а изменение - ALTER EXCEPTION <имя_исключения> <текст_исключения>
Чтобы использовать исключение в хранимой процедуре или триггере, необходимо воспользоваться командой следующего вида:
EXCEPTION <имя_исключения>;
Давайте рассмотрим применение исключений на простом примере хранимой процедуры, выполняющей деление одного числа на другое и возвращающей результат Нам необходимо отследить случай деления на нуль и возбудить исключение, если делитель равен нулю.
Для нашего примера создадим следующее исключение:
CREATE EXCEPTION zero_divide 'Cannot divide by zero!';
Создадим хранимую процедуру, использующую это исключение:
CREATE PROCEDURE SP_DIVIDE (
DELIMOE DOUBLE PRECISION,
DELITEL DOUBLE PRECISION)
RETURNS (
RESULT DOUBLE PRECISION)
AS
BEGIN
if (Delitel<0.0000001) then
BEGIN
EXCEPTION zero_divide;
Result=0;
END
ELSE
BEGIN
Result=Delimoe/Delitel;
END
SUSPEND;
END
Как видите, текст ХП тривиален - на входе получаем Delitel и Delimoe, затем сравниваем Delitel с 0.0000001, т. е. фактически с нулем, в пределах выбранной погрешности в одну десятимиллионную (так как вещественные числа невозможно непосредственно сравнивать из-за погрешностей в дробной части). Если Delitel близок к нулю в пределах выбранной погрешности, то мы возбуждаем исключение zero_divide. Что же происходит в случае возникновения исключения? Если мы попробуем вызвать исключение, выполняя процедуру SP_divide с нулевым делителем в isql. то получим следующее
SQL> select * from sp_divide(300,0);
RESULT
==========
Statement failed, SQLCODE = -836
exception 1
-Cannot divide by zero!
Если мы вызовем эту ХП с нулевым делителем в каком-либо другом приложении, то скорее всего получим сообщение об ошибке следующего вида:
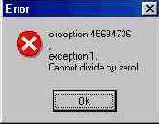
Рис 1.4. Сообщение о возникновении исключения
Другими словами, сообщение об ошибке - это результат обработки нашего исключения сервером InterBase. Когда InterBase обнаруживает возникшее в ХП или триггере исключение он прерывает работу этой хранимой процедуры и откатывает все изменения, сделанные в текущем блоке BEGIN END, причем если ХП является процедурой-выборкой, то отменяются действия лишь до последнего оператора SUSPEND.
Это значит, что если в процедуре-выборке есть цикл, в котором производятся какие-то действия, и в теле цикла есть SUSPEND, то при возбуждении исключения О1меня1ся все дейс1вия, выполненные в этом цикле до последнего оператора SUSPEND.
Надо сказать, что в исключениях было бы мало пользы, если бы у разработчика СУБД не было возможности обработать их на уровне базы данных. Чтобы разработчик смог обработать возникшее исключение, применяется следующая конструкция языка XП и триггеров:
WHEN EXCEPTION <имя_исключения> DO
BEGIN
/*обработка исключения*/
END
Использование этой конструкции помогает избежать возвращения стандартной ошибки с текстом исключения и произвести собственные действия по обработке исключения.
Когда возбуждается исключение, происходит следующее: выполнение хранимой процедуры (или триггера) прерывается. InterBase начинает искать конструкцию WHEN EXCEPTION...DO для обработки возникшего исключения в текущем блоке BEGIN...END. Если не находит, то поднимается на уровень выше (выше в том смысле, если имеются вложенные блоки BEGIN...END или когда одна ХП вызвана из другой) и ищет обработчик исключения там и т. д., пока либо не найдет подходящий обработчик исключения, либо не закончится вложенность уровней хранимой процедуры. Если обработчик исключения так и не был найден, то возвращается стандартное сообщение об ошибке, включающее текст исключения. Если обработчик найден, то выполняются действия в его блоке BEGIN...END и управление передается на первый оператор, следующий за END обработчика.
Давайте рассмотрим пример обработки исключения, возбуждаемого в нашей процедуре SP_DIVIDE. Предположим, что мы имеем некоторую внешнюю процедуру SP_divide_all, вызывающую SPJDFVIDE для того, чтобы поделить два числа. Конечно, пример сильно утрирован, но он позволяет пояснить способ и смысл использования исключений.
Итак, вот текст нашей хранимой процедуры:
CREATE PROCEDURE sp_test_except(Delltel DOUBLE PRECISION)
RETURNS (rslt DOUBLE PRECISION, status VARCHAR(SO))
AS
BEGIN
Status='Everything is Ok';
SELECT result FROM sp_divide(12,:Delitel) INTO :rslt;
SUSPEND;
WHEN EXCEPTION Zero_divide DO
BEGIN
Status='zero value found!';
rslt=-l;
SUSPEND;
END
END
Эта процедура вызывает процедуру SP_DIVIDE. Если параметр Delitel не равен нулю, то процедура SP_DIVIDE выполняется без проблем и в возвращаемое значение rslt помещается частное от деления, а статусная переменная status принимает значение 'Everything is Ok'. В случае, если возникла исключительная ситуация деления на нуль, то результирующая переменная rslt будет равна -1, а в переменной status будет содержаться сообщение об ошибке - 'zero value found!'. Разумеется, в обработчике исключения можно произвести и более сложную обработку, например записать некорректные данные в особую таблицу или попытаться изменить данные для выполнения операции и вновь попробовать ее выполнить и т. д.
Использование NULL в полях внешнего ключа
В полях, на основе которых создается внешний ключ, допускается применение NULL-полей. Эта возможность добавлена для разрешения взаимных ссылок. Например, еспи есть две таблицы, ссылающиеся друг на друга с помощью внешних ключей Ьсли не разрешить пустую ссылку (т. е. на NULL) в этих внешних ключах, то в связанные таблицы невозможно будет добавить ни одной записи: чтобы добавить запись в первую таблицу, надо будет иметь запись во второй таблице, и наоборот.
Использование NULL в качестве пустой ссылки позволяет организовать взаимные ссылки двух перекрестно ссылающихся таблиц, а также хранить иерархические структуры в реляционных таблицах - при этом корневые узлы ссылаются на "п\стые" записи (т. е. просто содержат NULL).
Изолированность транзакций
Давайте углубимся в рассмотрение того, зачем нужны транзакции в базе данных. Пример с переводом денег дает верную подсказку, представляя транзакцию как некоторый черный ящик, в котором производятся действия над содержимым базы данных. В этот ящик нельзя заглянуть до того, как транзакция завершится подтверждением или откатом. Если бы сумели все-таки заглянуть "внутрь" транзакции, в контексте которой осуществляется перевод денег, то увидели бы печальную картину, что-то вроде того, что: деньги уже ушли с одного счета, но на другой не пришли, или, наоборот, пришли, но "размножились" и существуют сразу на обоих счетах. Другими словами, "внутри" транзакции база данных в какие-то моменты находится в неправильном с точки зрения бизнес-логики состоянии Такое неправильное состояние называется "нецелостным", а правильное соответственно - "целостным".
Целостное состояние базы данных - состояние, в котором база данных содержит корректную информацию, соответствующую правилам бизнес-логики, применяющимся в данном принижении
Отсюда следует еще одно определение транзакции:
Транзакция - механизм, позволяющий переводить базу данных из одного целостного состояния в другое
Обратите внимание на слово "позволяющий": оно подчеркивает потенциальность возможностей механизма транзакций по обеспечению целостности базы данных.
Во время выполнения транзакции результаты операций, выполняющихся в ее контексте, невидимы для остальных пользователей, вплоть до момента подтверждения. Учитывая то, что все действия выполняются в контексте транзакций, то можно утверждать следующее: результаты операций, выполняющихся в контексте одной транзакции, невидимы для операций, осуществляющихся в контексте других транзакций.
Конечно, это только в идеальном случае, когда транзакции полностью изолированы. В реальности добиться такого трудно из-за сокращения числа одновременно выполняемых транзакций, работающих с общими данными. Поэтому для каждой транзакции предусматривается уровень изоляции, выбираемый как компромисс между снижением производительности и допустимым нарушением изолированности
Давайте поясним эти мысли с помощью такого примера.
Предположим, у нас есть документ, разные части которого хранятся в нескольких таблицах - таблице заголовка и нескольких таблицах-подробностях. Очевидно, что документ должен существовать только как целостная сущность, у которой заполнены параметры заголовка и корректно определены данные в таблицах-подробностях. Также очевидно, что процесс составления документа может быть достаточно длительным - сначала пользователь введет заголовок, затем заполнит содержание и т. д. В то же время, другие пользователи должны увидеть документ в целостном виде, т. е. не может быть документа без заголовка или с некорректными данными.
В данном примере транзакция начинается в момент начала создания/редактирования документа и заканчивается после окончания этого редактирования, т. е. тогда, когда пользователь, редактирующий документ, сочтет, что документ находится в целостном состоянии.
Следует четко понимать отличия двух понятий - изолированности, когда одна транзакция не видит изменения, совершаемые в контексте другой (причем это настраивается уровнями изоляции), и целостности, когда состояние всей базы (а не с точки зрения какой-то отдельной транзакции) после завершения транзакции всегда должно соответствовать всем ограничениям предметной области (правилам бизнес-логики). В течение выполнения транзакции в принципе возможны нарушения целостности.
В результате все остальные пользователи в базе данных видят документ только в целостном состоянии, соответствующем правилам бизнес-логики для данной задачи.
Таким образом, можно сформулировать наиболее общее определение механизма транзакций:
Транзакция - это механизм, позволяющий объединять различные действия в логические блоки и обеспечить возможность принимать решения об успешности действий всего блока операций в целом. Логические блоки операций осуществляют перевод базы данных из одного целостного состояния, соответствующего бизнес-правилам задачи, в другое целостное состояние. Механизм транзакций служит для обеспечения изоляции изменений, совершаемых операциями в контексте одной транзакции, от операций в других транзакциях.
Можно считать, что это определение достаточно точно отражает понятие транзакции. Это определение применимо для всех реляционных СУБД. Однако предметом рассмотрения данной книги является InterBase, поэтому в следующих разделах мы будем рассматривать конкретные особенности механизма транзакций именно в InterBase.
Как устроены индексы
Индекс не является частью таблицы - это отдельный объект, связанный с таблицей и другими объектами базы данных. Это очень важный момент реализации СУБД, который позволяет отделить хранение информации от ее представления.
InterBase, как и всякая другая реляционная база данных, хранит записи в таблицах в неупорядоченном виде, т. е. совершенно не заботится о том, как физически располагаются записи в таблице. Неупорядоченность хранения означает, что две записи, добавляемые в таблицу одна за другой, совсем не обязательно окажутся "рядом". Более того, данные, извлекаемые из таблицы, также не имеют какого-либо порядка, кроме того, который явно должен быть указан пользователем, составляющим запрос на выборку.
Однако без упорядочения хранящихся данных обойтись невозможно: конечные пользователи приложений хотят видеть свои данные в определенном порядке - например, фамилии людей по алфавиту. Задачу представления данных в упорядоченном виде решают индексы. Значения полей, входящих в индекс упорядочены и представлены в особом виде, оптимизированном для поиска нужных значений (а именно это и нужно для построения упорядоченных последовательностей). Отделение хранения данных от их представления дает дополнительные преимущества по сравнению с непосредственной сортировкой - исходную таблицу может потребоваться отсортировать по-разному. Тогда на помощь приходят индексы - их может быть до 64 на каждую таблицу!
Если говорить о реализации индексов на физическом уровне, то они представляют двоичное дерево, узлы которого представляют собой пары "значение поля в индексе" - "расположение данных в таблице". Поиск нужной записи в индексе идет с помощью механизма хеш-поиска - одною из самых быстрых алгоритмов поиска.
Кодировка (CharSet)
Кодировка также очень важна для базы данных. Кодировка определяет, символы какого национального алфавита будут использоваться в базе данных по умолчанию. Если вы предполагаете работать только с русским и английским языком, то лучше всего выставить кодировку WIN1251. Если же необходимо хранить информацию в базе на разных языках, то можно оставить значение кодировки как NONE, а уже в настройках драйверов для библиотеки доступа определять необходимые опции для поддержки того или иного языка.
Как уже сказано, определение кодировки при создании базы данных задает набор используемых символов только по умолчанию. >Во время создания таблиц, представлений и других объектов базы данных можно устанавливать другой набор символов, указав его явным образом.
Для большинства приложений баз данных вполне достаточно указать кодировку WIN 1251 для всей базы данных по умолчанию.
Контекстные переменные
Как уже говорилось выше, триггер похож на цензора, бесцеремонно досматривающего все. что относится к интересующему его предмету Интерес нашего триггера-"цензора" описан сочетанием ключевых слов BEFORE INSERT - это значит, что все операции вставки (INSERT) вызовут срабатывание триггера. Причем он сработает ДО (BEFORE) того, как вставка физически осуществлена. То есть в момент срабатывания триггера данные, присланные кем-либо на вставку, еще не занесены в таблицу. Они находятся в некотором промежуточном буфере. И у триггера есть возможность обращаться к этому буферу, чтобы проверить и/или изменить значения данных-кандидатов на вставку. Эта возможность реализована с помощью контекстной переменной NEW. Можно рассматривать эту переменную как структуру (что-то подобное struct в Си или record в Pascal), элементы которой представляют собой значения, присланные для осуществления операции (INSERT в нашем примере). То есть внутри триггера мы можем обратиться ко всем полям еще не вставленной записи, используя для этого обращение: New.ID, New.NAME и New PRICE_1.
Мы можем узнать значение каждого поля вставляемой записи, сравнить его или изменить. Это собственно и делается в этом кусочке кода:
IF (NEW.ID IS NULL) THEN
NEW.ID = GEN_ID(GEN_TABLE_EXAMPLE_ID, 1) ;
Сначала в операторе IF...THEN проверяем идентификатор ID на наличие какого-либо значения, ведь он может быть сгенерирован на клиенте. Если значением NEW.ID является NULL, то вызываем функцию GEN_ID, которая увеличивает значение генератора GEN_TABLE_EXAMPLE_ID на единицу и затем возвращает полученное число, которое присваивается полю NEW.ID Таким образом, мы "налету" изменили значения во вставляемой записи!
Кроме контекстной переменной NEW, существует ее зеркальный аналог - переменная OLD. В отличие от NEW, OLD содержит старые значения записи, которые удаляются или изменяются. Например, мы можем использовать переменную OLD для получения значений записей, которые удаляются из таблицы:
CREATE TRIGGER Table_example_adO FOR Table_example
ACTIVE AFTER DELETE POSITION 0
AS
BEGIN
IF (OLD.id>1000) THEN
BEGIN
/*..do something..*/
OLD.ID=10;
END
END
Здесь мы создаем триггер, который срабатывает ПОСЛЕ УДАЛЕНИЯ (AFTER DELETE) Как видите, мы можем получить доступ к уже удаленным данным Конечно, присвоение OLD.1D=10; не имеет никакого смысла - присвоенное значение пропадет на выходе из триггера. Однако этот пример показывает, что мы можем перехватить удаляемые значения и записать, например, в некую таблицу, где хранится история всех изменений.
Использование контекстных переменных часто вызывает множество вопросов Дело в том. что в различных видах триггеров NEW и OLD используются по- разному, а в некоторых их вообще невозможно использовать. Если мы рассмотрим триггер в нашем примере, то он вызывается ДО ВСТАВКИ. О каких значениях OLD может идти речь? Ведь вставляется совершенно новая запись! И действительно, контекстная переменная OLD не может быть использована в триггерах BEFORE/AFTER INSERT. А переменная NEW не может быть использована в BEFORE/AFTER DELETE. Обе этих переменные одновременно могут быть использованы в триггерах BEFORE/AFTER UPDATE, причем изменять что-либо можно, только используя переменную NEW (действительно, что можно изменять в удаляющихся значениях, доступных через OLD?), и только в триггерах BEFORE INSERT/UPDATE.
Довольно сложные правила использования, не так ли? Давайте попробуем формализовать их в виде простых правил, которые сведены в таблицу 1.3. В ней мы опишем, как можно применять контекстные переменные в различных триггерах Эту таблицу удобно использовать в качестве подсказки при разработке триггеров.
В этой таблице для каждой контекстной переменной заведено по два столбца - "Читать" и Изменять", отражающих возможные действия с этими переменными В столбце 6 строчек - по числу типов триггеров. Например, если на пересечении типа триггера и возможного действия с контекстной переменной NEW стоит Y, это значит, что в данном типе триггер можно читать или одновременно читать и менять данные Если стоит N/A. то в этом триггере нельзя осуществить это действие с данной контекстной переменной.
Табл 1.3. Использование контекстных переменных NEW и OLD в триггерах
|
Тип триггера |
Контекстныепеременные |
|||
|
NEW |
OLD |
|||
|
Читать |
Изменять |
Читать |
Изменять |
|
|
BEFORE INSERT |
Y |
Y |
N/A |
N/A |
|
AFTER INSERT |
Y |
N/A |
N/A |
N/A |
|
BEFORE UPDATE |
Y |
Y |
Y |
N/A |
|
AFTER UPDATE |
Y |
N/A |
Y |
N/A |
|
BEFORE DELETE |
N/A |
N/A |
Y |
N/A |
|
AFTER DELETE |
N/A |
N/A |
Y |
N/A |
Массивы
СУБД InterBase была одной из первых, в которой появились массивы. Поддержка массивов в базе данных является расширением традиционной реляционной модели. Наличие массивов позволяет упростить работу со множествами данных одного типа.
Массив - это совокупность значений одного типа, имеющая общее имя и позволяющая обратиться к любому элементу массива по его номеру. Массивы в InterBase могут быть одномерными и многомерными.
Для того чтобы создать в таблице поле типа массив чисел INTEGER, необходимо написать что-то вроде следующего:
CREATE TABLE test(
myOneDimArray INTEGER[12],
myTwoDimArray INTEGER[5,4],
myThreeDimArray INTEGER[2,10,8]);
При этом создадутся 3 поля типа массив: поле myOneDimArray, содержащее одномерный массив длиной 12 чисел, myTwoDimArray, содержащее двумерный массив (матрицу) 5x4 чисел Integer, и поле myThreeDimArray - трехмерный массив 2x10x8. Надо отметить, что при таком определении элементы массива нумеруются начиная с единицы, т. е. первый элемент имеет номер 1, второй - номер 2 и т. д. Если кто-то хочет указать границы массива самостоятельно, например с 0 до 5, то он должен задать определение поля так:
myArray INTEGER[0:5]
Массивы реализованы на базе полей типа BLOB, поэтому не следует опасаться, что многомерный массив "загрязнит" вашу таблицу невероятным количеством данных: InterBase аккуратно разместит данные массива на отдельных страницах, чтобы оптимизировать операции ввода-вывода в этих полях.
Как использовать массивы? Они предоставляют удобный механизм для хранения однотипных объектов. Однако в 80 % случаев вместо массивов разработчики предпочитают держать множественные данные в подчиненных (detail) таблицах, поэтому массивы не так часто используются в клиентских приложениях СУБД InterBase. Этому немало способствует то, что поставляемые в комплекте с Delphi и C++Builder библиотеки доступа, такие, как BDE и ГВХ, не имеют возможности работать с массивами. В документации по InterBase упоминается о возможности работать с массивами с помощью препроцессора gpre, однако это не самый удобный способ для разработчика Delphi/C-H-Builder. К счастью, в библиотеке FIBPlus имеется поддержка полей-массивов в InterBase, о чем подробно рассказано в главе "Специальные возможности FIBPlus". Клиентская библиотека IBProvider, позволяющая создавать клиентские приложения для InterBase с помощью средств разработки компании Microsoft, также поддерживает работу с массивами (см. главу "Разработка клиентских приложений СУБД InterBase с использованием технологии Microsoft OLE DB" (ч. 3)).
Механизм подключения функций
Специально для расширения функциональности SQL InterBase предлагает механизм функций, определяемых пользователем (user defined functions). Вы можете создать динамическую библиотеку (Dynamic Link Library) при помощи любой системы разработки, которая позволяет создавать выполнимые файлы данного формата. В частности, можно использовать Borland Delphi, Borland C++ Builder, Microsoft Visual C++ и т. д. Далее, необходимо поместить полученную DLL в каталог, из которого InterBase сможет вызывать библиотеку, и декларировать нужные функции из DLL в своей базе данных при помощи команды DECLARE EXTERNAL FUNCTION. После этого вы сможете вызывать указанные функции, как если бы они были встроенными функциями InterBase.
InterBase до версии 6.0 требовал, чтобы DLL находилась в любом из каталогов, указанных в системной переменной PATH InterBase 6 и выше (включая клоны Firebird и Yaffil) требует, чтобы DLL была помещена в специальный каталог UDF, находящийся в общем каталоге установки InterBase
Механизм транзакций в InterBase
Надо сказать, что реализация транзакций в InterBase отличается от реализации транзакции в большинстве других СУБД. Это связано с особой архитектурой баз данных InterBase, именуемой Multi Generation Architecture (MGA) - многоверсионной архитектурой.
Чтобы разобраться в реализации транзакций в InterBase, придется совершить экскурс в многоверсионную архитектуру баз данных, а также затронуть аспекты низкоуровневой реализации ядра InterBase. Возможно, в процессе чтения этого раздела необходимо будет обратиться к главе "Структура базы данных InterBase".
Итак, приступим. Давайте сначала разберем сущность многоверсионной архитектуры.
Многоверсионная архитектура InterBase
InterBase - это первая в мире СУБД, в которой реализована многоверсионная архитектура. Именно многоверсионная архитектура позволяет организовать взаимодействие пользователей таким образом, что читающие пользователи не блокируют пишущих, а также дает возможность очень быстро восстанавливаться после сбоев в базе данных и отказаться от ведения протокола транзакций (transaction log), а также предоставляет массу других преимуществ.
Сущность многоверсионной архитектуры достаточно проста. Основная идея состоит в том, что все изменения, проводимые над конкретными записями (а к этому сводятся любые операции над информацией в базе данных), производятся не над самой записью, а над ее версией. Версия записи - это копия записи, которая создается при попытке ее изменить.
Можно также сказать, что для каждой записи возможно существование нескольких ее версий, при этом каждая транзакция видит только одну их этих версий.
Пусть у нас есть некоторое начальное состояние базы данных, в котором имеется таблица с одной записью. Для простоты предположим, что сначала нет подключенных к базе данных пользователей и соответственно нет никаких изменений в данных. Когда к базе данных подключится пользователь и запустит транзакцию, в рамках которой он начнет производить какие-нибудь изменения над этой записью, то специально для этого пользователя (точнее, для транзакции, в контексте которой производятся операции) запись, содержащаяся в таблице, будет скопирована - появится версия записи. Эта версия целиком принадлежит транзакции, и все операции в рамках этой транзакции будут производить изменения над версией записи, а не над исходным оригиналом.
Далее, транзакция может либо подтвердиться, либо отмениться. При подтверждении транзакции произойдет следующее: InterBase попытается пометить предыдущую (исходную) версию записи как удаленную и сделать текущую (измененную в рамках этой завершающейся транзакции) версию основной. Если только один пользователь менял запись, то именно так все и произойдет - измененная версия записи станет основной и именно ее увидят все остальные операции в транзакциях, которые запустятся позже подтверждения.
Предположим теперь, что после запуска описанной в примере транзакции (назовем ее № 1), но до подтверждения ее результатов запустится транзакция № 2, в которой пользователь желает прочитать изменяющуюся запись. Так как неподтвержденные в № 1 изменения нельзя увидеть (в том числе и в транзакции № 2) по крайней мере до подтверждения этой транзакции, то транзакция № 2 увидит предыдущую версию записи!
Как видите, идея версионности гениально проста - дать каждой выполняющейся транзакции по своей собственной версии записей и пусть они наслаждаются одновременной работой с данными - читающие пользователи не мешают пишущему пользователю.
Но обратите внимание, что пишущий пользователь всегда может быть только один! Негоже давать изменять запись сразу двоим пользователям. Если попытаться редактировать одну и ту же запись одновременно в разных транзакциях, то, в зависимости от параметров транзакции, возникнет конфликт обновления записей - в той или иной форме. См. ниже раздел "Конфликты в транзакциях".
Итак, основной постулат многоверсионной архитектуры изложен. Конечно, в случае одновременной работы множества пользователей могут возникать сложные комбинации версий, и это может привести к странным на первый взгляд конфликтам.
Чтобы сформировать четкую и ясную картину того, как работает многоверсионность данных и транзакции в InterBase, придется углубиться в их реализацию на уровне базы данных InterBase.
Модифицируемые представления
Выше мы упомянули о том, чт. е. возможность создавать изменяемые представления данных. Это действительно так - существует возможность не только читать данные из представления, но и изменять их!
Есть два способа сделать представление модифицируемым. Первый способ применим, когда представление создается на основе единственной 1аблицы (или другого модифицируемого представления), причем все столбцы данной таблицы должны позволять наличие NULL. При этом запрос, на котором основано представление, не может содержать подзапросов, агрегатных функций. UDF, хранимых процедур, предложений DISTINCT и HAVING. Если выполняются все эти условия, то представление автоматически становится модифицируемым, т. е. для него можно выполнять запросы DELETE, INSERT и UPDATE, которые будут изменять данные в таблице-источнике.
Список условий довольно внушительный и сильно ограничивает применение таких модифицируемых представлений, поэтому они ИСПОЛЬЗУЮТСЯ относительно редко.
Чтобы сделать модифицируемым представление, которое нарушает любое из вышеперечисленных условий, применяется механизм триггеров. Подробнее о том. что такое триггер, рассказывается в главе "Триггеры" (ч 1). а сейчас мы лишь рассмотрим общие принципы организации изменения данных во VIEW.
Для реализации обновляемого представления с помощью триггеров необходимо сделать следующее.
Создать 3 триггера для данного представления на события: BEFORE DELETE, BEFORE UPDATE и BEFORE INSERT. В этих триггерах описать, что должно происходить с данными при удалении, изменении и вставке.
Затем следует использовать данное представление в запросах на модификацию - DELETE, INSERT или UPDATE. Когда InterBase примет этот запрос, то проверит, существуют ли для данного представления соответствующие триггеры, т. е. BEFORE DELETE/INSERT/UPDATE. Если триггер для выполняемого действия существует, то InterBase вызовет его для модификации реальных данных в таблицах, лежащих в основе представления (хотя это могут быть и другие данные - каких-либо ограничений на текст этих триггеров нет), а затем перечитает строку (или строки), над которой производилась модификация
Таким образом, есть возможность реализовать сложные цепочки обновлений данных в представлениях.
В описании синтаксиса создания представления упоминалась опция WITH CHECK OPTION. Если при создании модифицируемого представления будет указана эта опция, то каждая строка данных, вставляемая или изменяемая в этом представлении, будет проверена на условие "попадания" в представление. Это можно объяснить так: если новая запись, вставляемая пользователем или получившаяся в результате обновления существующей записи, не удовлетворяет условиям запроса, который является поставщиком данных для VIEW, то вставка этой записи будет отменена и возникнет ошибка.
Наборы символов
Чтобы указать InterBase, как интерпретировать и хранить помещаемую в базу данных символьную информацию, необходимо указать набор символов (.character set), который будет использоваться для представления этих символов в нужном виде (см. выше главу "Типы данных" для информации о хранении символьных данных). Чтобы пользоваться набором символов, необходимо указать его как атрибут объектов в базе данных, а также указать его для использования в клиентском приложении.
Если вы уверены в том, каким набором символов будете пользоваться в вашей базе данных, то можете установить единый набор символов по умолчанию для всей базы данных. Для этого в команде создания базы данных следует указать набор символов по умолчанию с помощью опции DEFAULT CHARACTER SET. Для того чтобы работать с русскими буквами, следует указывать набор символов WIN1251. Можно также использовать набор UNICODE_FSS, который поддерживает любые символы UNICODE в представлении UTF-8. Однако большинство производителей библиотек доступа не полностью поддерживают этот набор символов, поэтому лучше использовать проверенный WIN1251.
Чтобы указать набор символов по умолчанию для всех объектов базы данных, надо применить команду наподобие этой:
CREATE DATABASE 'C:\Database\rusbase.gdb' USER 'SYSDBA' PASWORD
'masterkey' DEFAULT CHARACTER SET WIN1251;
Указание набора символов по умолчанию не означает, что все таблицы и поля в базе данных должны иметь тот же самый тип. Они будут использовать этот набор символов, если явно не указать какой-нибудь другой. Мы всегда можем переопределить набор символов. Например, мы можем создать таблицу, в которой 3 поля имеют разные наборы символов:
CREATE TABLE langTable(
NAME_RUS VARCHAR(255) CHARACTER SET WIN1251,
NAME_ENG VARCHAR(255) CHARACTER SET WIN1250,
NAME_UNI VARCHAR(255) CHARACTER SET UNICODE_FSS);
Однако, создав такую таблицу, не думайте, что вы сможете с помощью одного SQL-запроса заносить данные на разных языках в эту таблицу. Дело в том,
что при подключении к базе данных приложение также должно указывать набор символов (см. ниже), при помощи которого оно будет интерпретировать получаемые данные. Поэтому, чтобы записать в каждое поле символы из разных наборов данных, он должен трижды подключиться к базе данных с указанием разных наборов символов либо использовать набор UNICODE_FSS, если клиентская библиотека это позволяет.
О типах данных
Типы данных - это базовые элементы любого языка программирования или любого сервера СУБД, и InterBase не исключение. Когда мы говорим, что в базе данных хранится какая-то информация, то должны всегда четко осознавать, что эта информация не может быть свалена в одну большую кучу; наоборот, данные должны быть рассортированы и разложены по "полочкам". Типы данных определяют, что можно положить на соответствующую "полочку", а что нельзя. Под "полочками" понимаются прежде всего поля таблиц в базе данных (см. главу "Таблицы. Первичные ключи и генераторы" (ч. 1)), а также переменные внутри триггеров, хранимых процедур и т. д.
Каждый тип данных имеет набор операций, которые можно выполнять над значениями этого типа, поэтому необходимо правильно выбрать тип данных при проектировании базы данных, что поможет избежать многих проблем при разработке клиентских программ.
В InterBase существует 12 типов данных, которые способны удовлетворить практически любые потребности разработчика в хранении данных. Эти типы условно подразделяются на 6 следующих групп:
для хранения целых чисел - INTEGER и SMALLINT;
для хранения вещественных чисел - FLOAT и DOUBLE PRECISION;
для чисел с фиксированной точностью - NUMERIC и DECIMAL;
для хранения даты, времени и даты/времени - DATE, TIME и TIMESTAMP;
для хранения символов - CHARACTER (сокращенно CHAR) и VARYING CHARACTER (VARCHAR);
Для хранения динамически расширяемых данных - BLOB.
Также возможно определять массивы значений элементарных типов, т.е. всех перечисленных типов, кроме BLOB.
Большинство типов данных InterBase соответствуют типам, определенным в стандарте SQL92, однако, помимо этого, есть и собственные "изюминки" - массивы элементарных типов данных и BLOB.
Массивы в InterBase могут содержать множество данных одного типа в одном поле, например можно определить массив значений типа INTEGER. Причем массивы могут иметь несколько размерностей!
Тип данных BLOB - это динамически расширяемый тип данных, название которого часто расшифровывается как Binary Large OBject - "большие двоичные объекты". Надо сказать, что BLOB - это изобретение разработчиков InterBase, которое позже распространилось и прижилось во всех современных SQL-серверах.
Обеспечение ссылочной целостности с помощью индексов
В определении индекса имеется еще одна опция - UNIQUE. Если ее указать, то индекс позволит заносить в таблицу только уникальные значения. Фактически это служит основой для реализации уникальных ключей (UNIQUffi KEY). Уникальные ключи широко используются в базах данных. То есть РК - это уникальный ключ-индекс, но не всякий UK - это РК. Выше речь шла только о РК. Первичный ключ (Primary key) - самый распространенный вид уникального ключа. При создании первичного ключа на таблицу автоматически создается уникальный индекс, который получает имя, составленное из RDBSPRIMARYNNN, где NNN - последовательный уникальный в пределах базы данных номер. Таким образом, с помощью уникального индекса реализуются два из важнейших ограничений ссылочной целостности - уникальный ключ и первичный ключ. Очевидно, что понятие уникальности несовместимо с понятием неопределенного значения, т. е. другими словами, в полях, содержащихся в уникальных индексах, не должно быть значений типа NULL. Перед созданием уникального индекса на поле следует придать ему статус NOT NULL. Если индекс создается для уже существующих данных, то при создании будет проверено, не содержит ли индексированное поле повторяющихся значений. И если содержит, то в создании индекса будет отказано.
Помимо ограничений уникального и первичного ключа, механизм индексов лежит в основе реализации еще одного ограничения ссылочной целостности - внешнего ключа. Ограничение внешнего ключа накладывается на одно или несколько полей какой-либо таблицы и препятствует внесению в эти поля таких значений, которые не входят в первичный ключ другой, родительской таблицы. Для реализации внешнего ключа, т. е. для осуществления проверки того, существует ли значение в родительской таблице, автоматически создается особый индекс. Он имеет наименование RDB$FOREIGNNN, где NNN - последовательный у никальный в пределах базы данных номер.
Почему именно механизм индексов используется для реализации ограничений ссылочной целостности? Дело в том, что индексы в InterBase находятся в особом, привилегированном положении - говорят, что они выполняются вне контекста транзакций. Это очень важное свойство. О транзакциях мы поговорим позже, в посвященной им главе, а пока лишь скажем, что нахождение индексов вне транзакций означает, что все пользователи, одновременно работающие с данными в одной и той же таблице, вынуждены соблюдать ограничения ссылочной целостности.
Обработка ошибок SQL и InterBase
Разобравшись с обработкой исключений, определяемых пользователем, можем перейти к обработке ошибок InterBase. Ошибка - это фактически то же самое исключение, только возбуждаемое InterBase. Принцип обработки ошибок тот же самый что и исключений: если возникает какая-то ошибка, то сервер ищет ее обработчик, последовательно просматривая все уровни вложенности (если они есть) хранимой процедуры, начиная с того уровня, на котором возникла ошибка.
Если обработчик найден, то выполняется код внутри его, а затем управление передается на первый оператор за обработчиком исключений.
Конструкция, с помощью которой производится обработка ошибок, такая же, как и для обработки исключений, только вместо EXCEPTION стоит либо GDSCODE, либо SQLCODE:
WHEN GDSCODE SQLCODE <код_ошибки> DO
BEGIN
/*обрабатываем ошибку*/
END
В зависимости от того, стоит ли в конструкции обработки ошибок GDSCODE или SQLCODE, обрабатываются различные ошибки. Если стоит SQLCODE, то обрабатываются ошибки SQL, а если GDSCODE - то ошибки InterBase. Примером ошибки SQL является ошибка с SQLCODE=-802 "Arithmetic exception, numeric overflow, or string truncation" или SQLCODE=-817 "Attempted update during read-only transaction" Список ошибок SQL и соответствующих им значений SQLCODE приведен в таблице "SQLCODE codes and messages'. Примером ошибки InterBase является ошибка isc_bad_dbkey 335544322L "invalid database key".
Таким образом, внутри хранимой процедуры можно "перехватить" практически любую ошибку и корректно на нее отреагировать. Можно перечислять обработчики ошибок один за другим, чтобы определить реакцию на разные ошибки.
А что делать, если нужно прореагировать на любую ошибку? Не прописывать же обработчики всех сотен возможных ошибок? Конечно же, нет. Для того чтобы написать безусловный обработчик, реагирующий на любую ошибку - SQL, InterBase или исключение, следует воспользоваться конструкцией WHEN DO с ключевым словом ANY:
WHEN ANY DO
BEGIN
/*действия при любой нестандартной операции ошибке
или исключении */
END
С помощью использования описанных механизмов можно предусмотреть развитые механизмы обработки ошибок, которые сделают приложения баз данных значительно более устойчивыми.
Обзор библиотек доступа к InterBase
В данной главе мы рассмотрим существующие библиотеки доступа к InterBase и коротко охарактеризуем их свойства. Под "библиотекой доступа" будем понимать набор средств разработки, позволяющий разработчикам приложений баз данных InterBase создавать свои программы.
Ограничение CHECK
Одним из наиболее полезных ограничений в базе данных является ограничение проверки. Идея его очень проста - проверять вставляемое в таблицу значение на какое-либо условие и, в зависимости от выполнения условия, вставлять или не вставлять данные.
Синтаксис его достаточно прост:
<tconstraint> = [CONSTRAINT constraint] CHECK (
<search_condition>)}
Здесь constraint - имя ограничения; <search_condition> - условие поиска, в котором в качестве параметра может участвовать вставляемое/изменяемое значение. Если условие поиска выполняется, то вставка/изменение этого значения разрешаются, если нет - возникает ошибка.
Самый простой пример проверки:
create table checktst(
ID integer CHECK(ID>0));
Эта проверка устанавливает, больше ли нуля вставляемое/изменяемое значение поля ID, и в зависимости от результата позволяет вставить/изменить новое значение или возбудить исключение (см. главу "Расширенные возможности языка хранимых процедур InterBase" (ч. 1)).
Возможны и более сложные варианты проверок. Полный синтаксис условия поиска <search_condition> следующий:
<search_condition> = {<val> <operator>
{ <val> | (<select_one>)}
|<val> [NOT] BETWEEN <val> AND <val>
| <val> [NOT] LIKE <val> [ESCAPE <val>]
| <val> [NOT] IN ( <val> [ , <val> ...] | <select_list>)
| <val> IS [NOT] NULL
| <val> {[NOT] {= | < | >} | >= | <=}
{ALL | SOME | ANY} (<select_list>)
|EXISTS ( <select_expr>)
| SINGULAR ( <select_expr>)
| <val> [NOT] CONTAINING <val>
|<val> [NOT] STARTING [WITH] <val>
| (<search_condition>)
| NOT <search_condition>
| <search_condition> OR <search_condition>
| <search_condition> AND <search_condition>}
Таким образом, CHECK предоставляет большой набор опций для проверки вставляемых/изменяемых значений. Необходимо помнить о следующих ограничениях в использовании СНЕК:
Данные в CHECK берутся только из текущей записи. Не следует брать данные для выражения в CHECK из других записей этой же таблицы - они могут быть изменены другими пользователями.
Поле может иметь только одно ограничение CHECK.
Если для описания поля использовался домен, который имеет доменное ограничение CHECK, то его нельзя переопределить на уровне конкретного поля в таблице.
Надо сказать, что CHECK реализованы при помощи системных триггеров, поэтому следует быть осторожным в использовании очень больших условий, которые могут сильно замедлить процессы вставки и обновления записей.
Ограничения базы данных
Эта глава посвящена ограничениям базы данных InterBase. Ограничения базы данных, - это правила, которые определяют взаимосвязи между таблицами и могут проверять и изменять данные в базе данных Реализованы эти правила в виде особых объектов базы данных.
Главное преимущество использования ограничений состоит в возможности реализовать проверку данных, а значит, и часть бизнес-логики приложения на уровне базы данных, т. е. централизовать и упростить ее, а значит, сделать разработку приложений баз данных проще и надежнее.
Часто начинающие разработчики пренебрегают использованием ограничений базы данных, считая, что они стесняют возможность творчества. Однако на самом деле такое мнение происходит от недостаточного знания теории и практики проектирования баз данных.
В то же время наиболее опытные разработчики позволяют себе отказаться от использования некоторых видов ограничений, за счет чего их приложения выигрывают в быстродействии. Опыт высококвалифицированных разработчиков позволяет им очень хорошо понимать работу сервера и точно предсказывать его поведение в сложных случаях, поэтому начинающим программистам InterBase лучше не апеллировать к подобным действиям опытных коллег.
В рамках данной книги мы не рассматриваем проектирование баз данных, поэтому для получения дополнительной информации по этому вопросу следует обратиться к списку литературы в конце книги. Здесь же мы лишь проведем обзор всех видов ограничений в базе данных InterBase и рассмотрим примеры их применения.
Оптимизация производительности индексов
В названии этого раздела можно обнаружить некоторый парадокс - индексы, как говорилось выше, служат для того, чтобы ускорить выполнение запросов, и оказывается, что их самих надо тоже оптимизировать! Но что делать (такова жизнь) - кто-то должен заботиться и об индексах.
Что же случается с индексами? Почему они "теряют форму"? Нам придется еще раз сказать о том, что индексы реализованы в виде двоичного дерева И когда в таблицу добавляется (изменяется, удаляется - выберите по вкусу) новая запись, в дерево добавляется новая веточка. Причем веточки добавляются не в середину дерева, а на концах других веточек. Постепенно дерево становится все более "раскидистым" (также говорят - несбалансированным), а поиск по нему - все менее эффективным. Поправить положение может перестройка дерева или (в некоторых случаях) пересчет статистики. Периодически требуется пересоздавать индекс, чтобы восстанавливать его производительность. Пересоздание индекса происходит в следующих случаях:
При перестройке индекса с помощью команды ALTER INDEX.
При удалении и повторном создании индекса командами DROP INDEX и CREATE INDEX.
При резервном копировании и восстановлении из резервной копии с использованием инструмента gbak.
Также можно использовать пересчет статистики. Но надо понимать, что это действие не изменяет состояние индекса, а просто сообщает оптимизатору точные данные о его состоянии, что позволяет правильно использовать этот индекс. Другими словами, пересчет статистики - это не "лечение" индекса, а только точная диагностика его состояния.
Рассмотрим подробнее все эти способы оптимизации индексов.
Использование команды ALTER INDEX имеет следующий формат:
ALTER INDEX name {ACTIVE | INACTIVE};
Здесь name - имя индекса, a ACTIVE и INACTIVE - два состояния индекса, в которые его можно перевести при помощи команды ALTER INDEX. Параметр ACTIVE означает, что индекс активен и может применяться во всех запросах и процедурах. Установка индекса в INACTIVE (неактивен) приводит к отключению его использования. Для перестройки дерева надо последовательно выполнить две команды:
ALTER INDEX name INACTIVE;
ALTER INDEX name ACTIVE;
При этом индекс будет перестроен. Использование ALTER INDEX имеет ряд ограничений: с его помощью нельзя перестроить индексы, используемые в первичных, уникальных и внешних ключах; нельзя перестроить индекс, если он используется в данный момент каким-либо запросом; а также для изменения индекса необходимо иметь права администратора (SYSDBA) или быть создателем данного индекса.
Пересоздание индекса с помощью команд DROP INDEX и CREATE INDEX приводит к полному удалению индекса из базы данных, а затем к его созданию с чистого листа. Синтаксис команды DROP INDEX очевиден:
DROP INDEX имя_индекса;
После удаления необходимо создать индекс с тем же именем и параметрами с помощью команды CREATE INDEX, синтаксис которой мы уже рассматривали.
У способа перестройки индекса путем его полного пересоздания есть ограничения, аналогичные ограничениям на использование ALTER INDEX.
Третий способ перестройки индекса основан на свойстве резервных копий баз данных InterBase, которые создаются с помощью утилиты gbak. Дело в том, что при резервном копировании данные, входящие в индекс, не сохраняются в резервной копии, а хранится только определение индекса. При восстановлении из резервной копии индекс создается заново. Подробнее о резервном копировании см. главу "Резервное копирование и восстановление из резервной копии" (ч. 4).
Четвертый способ улучшить производительность индекса - это собрать статистику по индексам с помощью команды SET STATISTICS Статистика таблицы - это величина в пределах от 0 до 1, значение которой зависит от числа различных (неодинаковых) записей в таблице. Оптимизатор InterBase использует статистику для определения эффективности применения того или иного индекса в запросе Когда число записей в таблице может сильно изменяться (например, при большом количестве вставок или удалений), то пересчет статистики может значительно улучшить производительность.
Команда пересчета статистики следующая:
SET STATISTICS INDEX name;
Здесь name - имя индекса, для которого пересчитывается статистика.
Пересчет статистики не перестраивает индекс и потому свободен от большинства ограничений, накладываемых на описанные выше способы улучшения производительности, за исключением того, что пересчитывать статистику может либо создатель индекса, либо системный администратор (пользователь с именем SYSDBA). Правильная статистика дает оптимизатору возможность принять верное решение об использовании или неиспользовании какого-либо индекса.
Мы рассмотрели несколько способов улучшить производительность индексов. С помощью команд ALTER INDEX и DROP/CREATE INDEX можно перестраивать любые индексы, за исключением системных, создаваемых автоматически индексов, служащих для поддержания ссылочной целостности. Чтобы перестроить эти индексы, необходимо воспользоваться командами изменения и создания таблиц - ALTER TABLE и CREATE TABLE, так как эти индексы являются неотъемлемой частью табличных ключей.
Ошибки и исключения в триггерах
Если база достаточно сложная (лучше сказать, достаточно реальная), то вам никак не избежать появления ошибок. Более того, ошибки типа "конфликт с другими пользователями" являются повседневным и нормальным явлением в многопользовательской среде. Как InterBase обрабатывает ошибки в триггерах? Ведь ситуация может быть достаточно нетривиальная - например, вставка записи в главную таблицу запускает хранимую процедуру, которая вставляет записи в подчиненные таблицы, причем при вставке в подчиненные таблицы срабатывают триггеры на вставку, которые получают новые значения генераторов и подставляют их в нужные поля. Можно представить не один подобный уровень вложенности. Что произойдет, когда где-то в "дальних" ветках этого дерева событий возникнет ошибка?
При возникновении ошибок на любом этапе - в триггере, в вызываемых им ХП или в неявно активизируемых других триггерах - InterBase сообщит об ошибке и откатит изменения в таблицах, проведенные в рамках инициировавшего эту цепочку оператора. Оператор - это предложение INSERT/UPDATE/DELETE или SELECT, а также EXECUTE PROCEDURE.
Таких операторов может быть в транзакции несколько. Отменяется все действия только в рамках оператора, вызвавшего ошибку. Клиентское приложение может отследить возникновение ошибки и подтвердить транзакцию. Другими словами, ошибка в триггере не обязательно требует отката транзакции. Клиентское приложение может обработать ошибку, полученную при выполнении оператора и, например, выполнить вместо этих изменений какие-то другие, если такова логика предметной области, или изменить логику выполнения дальнейших изменений в этой транзакции и подтвердить реально выполненные в транзакции изменения
Теперь, когда мы знаем, что делает InterBase при возникновении ошибки в триггере, неплохо бы понять, что можем сделать мы, чтобы обработать ошибочную ситуацию. Если мы будем верить в то, что все наши триггеры и ХП не имеют ошибок и конфликтов между действиями пользователей быть не может, то можем вообще не обрабатывать ошибки на уровне базы данных. Если же ошибка возникнет, InterBase пошлет нашему клиентскому приложению сообщение об ошибке, которое мы вольны обработать или нет, - в любом случае InterBase уже выполнил свою миссию - откатил ошибочное действие в триггере. Однако есть и другой путь.
Мы можем воспользоваться обработкой ошибочных ситуаций непосредственно в теле триггера (или хранимой процедуры) с помощью конструкции WHEN...DO. Использование этой конструкции аналогично применению ее в хранимых процедурах, и подробнее об использовании WHEN...DO см. главу "Расширенные возможности языка хранимых процедур InterBase" (ч. 1).
Точно так же как и в хранимых процедурах, в триггерах можно возбуждать собственные исключения. Так как триггер фактически представляет собой разновидность исполнимой хранимой процедуры, то возбуждение в нем исключения прервет работу триггера и приведет к отмене всех действий, совершенных в триггере, - явных и неявных.
Основа библиотек доступа к InterBase
Какова бы ни была библиотека доступа, для какой бы среды разработки она ни предназначалась, в любом случае основой является InterBase API. InterBase API предоставляет базовый набор функций низкого уровня для работы с базами данных. Таким образом, любая библиотека доступа представляет собой "обертку" (wrapper) над функциями API. Библиотеки доступа организовывают функции API в соответствии с идеологией сречы разработки дня которой предназначена библиотека.
Тем не менее нужно сказать, что, имея общую основу, все библиотеки доступа зачастую принципиально отличаются друг от друга. Любой опытный программист, попробовавший разрабатывать приложения с использованием различных библиотек, сможет рассказать о множестве отличий.
Параметры транзакций
В первом разделе этой главы была сделана попытка рассмотреть механизм работы транзакций в СУБД InterBase в целом. Теперь необходимо рассмотреть практические аспекты применяющие транзакций в InterBase.
Программисты, использующие такие современные библиотеки для доступа к базам данных InterBase, как FIBPlus, IBProvider, IBX и IBObjects (см. главу "Обзор библиотек доступа к InterBase"), имеют возможность гибко управлять параметрами транзакций для получения наилучших результатов. Поэтому имеет смысл рассматривать параметры транзакций именно в интерпретации для этих библиотек.
Настройка параметров транзакции осуществляется с помощью перечисления набора констант, определяющих поведение транзакции, например, уровень изоляции. Эти константы пришли из InterBase API и имеют следующий вид: isc_tpb_read, isc_tpb_write, isc_tpb_ read_committed и т. д.
Обычно префикс isc_tpb_ опускается и константы для определения параметров транзакции пишутся без него.
Давайте рассмотрим значение и синтаксис применения каждой константы.
Первичные ключи в таблицах
Конечно, мы можем создать таблицу, не содержащую никаких ключей. Это никто нам не запрещает. Но, как уже говорилось, создание работоспособной базы данных невозможно без следования правилам нормализации. Наличие ключей - важнейший элемент нормализации. Поэтому, хоть мы и не ставим целью на рассмотрение теории и нормализации баз данных, нам придется ввести определение ключей и рассмотреть их роль в InterBase.
Будем двигаться постепенно и начнем с самого распространенного типа ключей - с первичного ключа.
Итак, что же такое первичный ключ! Это одно или более полей в таблице, однозначно идентифицирующих записи в пределах этой таблицы. Звучит сложно, однако на самом деле все очень просто. Представьте себе обыкновенную таблицу, например бухгалтерскую ведомость. Что является самым первым столбцом? Правильно, порядковый номер - 1, 2, 3... Этот номер указывает на уникальную строку в пределах таблицы, и достаточно знать этот номер, чтобы найти в этой таблице строку. В данном примере это и будет первичный ключ.
Абсолютное большинство таблиц в реляционной базе данных обязательно имеют первичный ключ (часто пишут РК - сокращение от Primary key). Общей рекомендацией при создании таблиц является создавать первичный ключ. Создать первичный ключ можно как при создании таблицы, так и позже. Допустим, мы >же к моменту создания таблицы решили, что первичным ключом у нас будет поле ID Тогда добавить первичный ключ можно следующим образом:
CREATE TABLE Table_example (
ID INTEGER NOT NULL,
NAME VARCHAR(80),
PRICE_1 DOUBLE PRECISION,
CONSTRAINT pkTable PRIMARY KEY (ID));
Итак, что необходимо сделать, чтобы создать первичный ключ на таблицу table_example. Внимательно рассмотрим, что изменилось в определении таблицы? Во-первых, колонка ID получила дополнительное определение NOT NULL. Это важно - первичный ключ должен быть уникальным и не допускать неопределенных значений. A NULL, как вы знаете, это неопределенное значение. Таким образом, все поля, входящие в первичный ключ, должны иметь ограничение NOT NULL.
Чтобы завершить создание первичного ключа, в конце таблицы дописывается предложение вида CONSTRAINT <имя_ключа> <тип_ключа> (<поля_входя- щие_ в_ключ>). Полный синтаксис ограничений рассмотрен в главе "Ограничения базы данных" ч. 1, и для нашего примера первичного ключа будет иметь вид:
CONSTRAINT pkTable PRIMARY KEY (ID)
Здесь - pkTable - имя первичного ключа, a ID - столбцы, входящие в него.
Такой способ определять первичные ключи для таблиц удобен при массовом создании таблиц (например, при построении прототипа базы данных на основе скриптов, получаемых с помощью различных CASE-средств). Но что делать, если нам нужно добавить/удалить первичный ключ в таблицу, когда она уже существует и наполнена данными? Для этого следует воспользоваться еще одним расширением команды - ALTER TABLE. Пример добавления первичного ключа в нашу таблицу:
ALTER TABLE TABLE_EXAMPLE ADD CONSTRAINT FF PRIMARY KEY (ID);
При этом в таблицу Table_example добавится точно такой же первичный ключ, как и в предыдущем примере, когда он создавался вместе с таблицей. Чтобы удалить первичный ключ, необходимо ввести следующую команду:
ALTER TABLE Table_example DROP CONSTRAINT pkTable;
При этом ключ с именем pkTable будет удален из базы данных.
Первичный и уникальный ключи
Первичные ключи являются одним из основных видов ограничений в базе данных. Они применяются для однозначной идентификации записей в таблице. Допустим, мы храним в базе данных список людей. Вполне вероятно, что могут появиться два (или больше) человека с одинаковыми фамилией, именем и отчеством Как же гарантированно отличить одного человека от другого (конечно. речь идет о том, чтобы отличить одного человека от другого на основании информации, хранящейся в базе данных)?
В данном случае "человек" представлен одной записью в таблице, поэтому можно задаться более общим вопросом — как отличить одну запись в (любой) таблице от другой записи в этой же таблице. Для этого используются ограничения - первичные кпочи. Первичный ключ представляет собой одно или несколько полей в таблице, сочетание которых уникально для каждой записи. Для одной таблицы не существует повторяющихся значений первичного ключа.
Уникальные кчочи несут аналогичную нагрузку - они также служат для однозначной идентификации записей в таблице. Отличие первичных ключей от уникальных состоит в том, что первичный ключ может быть в таблице только один, а уникатьных ключей - несколько. Надо отметить, что и первичный и уникальный ключ могут быть использованы в качестве ссылочной основы для внешних ключей (см. далее).
Синтаксис создания первичного и уникального ключа на основе единственного поля следующий:
<pkukconstraint> = [CONSTRAINT constraint] {PRIMARY KEY |
UNIQUE}
Примеры первичных и уникальных ключей:
CREATE TABLE pkuk(
pk NUMERIC(15,0) NOT NULL PRIMARY KEY, /*первичный ключ*/
ukl VARCHAR(SO) NOT NULL UNIQUE,/*уникальный ключ */
uk2 INTEGER NOT NULL UNIQUE /* еще уникальный ключ */);
Синтаксис создания первичного и уникального ключей на основе нескольких полей:
<pkuktconstraint> = [CONSTRAINT constraint] {PRIMARY KEY |
UNIQUE) ( col [, col ...] )
Такой синтаксис позволяет создавать ключи на основе комбинации полей. Вот примеры создания первичных и уникальных ключей из нескольких полей:
CREATE TABLE pkuk2(
Number1 INTEGER NOT NULL,
Namel VARCHAR(SO) NOT NULL,
Kol INTEGER NOT NULL,
Stoim NUMERIC(15,4) NOT NULL,
CONSTRAINT pkt PRIMARY KEY (Numberl, Namel), /*первичный ключ pkt на
основе двух полей*/
CONSTRAINT uktl UNIQUE (kol, Stoim) ); /* уникальный ключ uktl на основе
двух полей*/
Обратите внимание, что все поля, входящие в состав первичного и уникального ключей, должны быть объявлены как NOT NULL, так как эти ключи не могут
иметь неопределенного значения.
Помимо создания ограничения первичных и уникальных ключей в момент создания таблицы имеется возможность добавлять ограничения в уже существующую таблицу. Для этого используется предложение DDL: ALTER TABLE. Синтаксис добавтения ограничений первичного или уникального ключа в существующую таблицу аналогичен описанному выше:
ALTER TABLE tablename
ADD [CONSTRAINT constraint] {PRIMARY KEY | UNIQUE) ( col [, col ...] )
Давайте рассмотрим пример создания первичного и уникального ключа с помощью ALTER TABLE. Сначала создаем таблицу:
CREATE TABLE pkalter(
ID1 INTEGER NOT NULL,
ID2 INTEGER NOT NULL,
UID VARCHAR(24));
Затем добавляем ключи. Сначала первичный:
ALTER TABLE pkalter
ADD CONSTRAINT pkall PRIMARY KEY (idl, id2);
Затем уникальный ключ:
ALTER TABLE pkalter
ADD CONSTRAINT ukal UNIQUE (uid) ;
Важно отметить, что добавление (а также удаление) ограничений первичных и уникальных ключей к таблице может производить только владелец этой таблицы или системный администратор SYSDBA (подробнее о владельцах и пользователе SYSDBA см. главу "Безопасность в InterBase: пользователи, роли и права") (ч. 4).
Подготовка к установке
Инсталлятор (программа, которая занимается установкой продукта) любого клона InterBase занимает всего около 5,5 Мбайт. Для запуска установки просто запустите файл установки (он может называться xxWin32SetupXX.exe, где хх определяют различные версии клонов InterBase).
Давайте рассмотрим установку клона InterBase 6.x - Firebird 1.0. Установка других клонов ничем кардинально от Firebird не отличается.
Если на компьютере, куда устанавливается InterBase, уже установлена любая версия InterBase, то ее сначала необходимо обязательно остановить. Для этого следует воспользоваться либо «Панелью управления» Windows, апплетом «Службы», если установка идет на Windows NT72000/XP, либо иконкой InterBase- сервера на панели задач Windows, если устанавливаем на Windows 95/98/Ме.
Внимание! Остановка уже существующей версии InterBase при установке новой обязательна. Рекомендуется вообще удалить предыдущую версию, чтобы не сталкиваться с конфликтами обновления файлов. Желательно удалить файлы gds32.dll из всех папок данного компьютера, указанных в переменной пути поиска Path (проще всего это сделать так: поискать на локальных дисках gds32.dll и удалить их отовсюду, кроме папок с дистрибутивами).
Представления
Те, кто знаком с языком SQL, не нуждаются в подробных объяснениях эиио предмета, но для сохранения порядка изложения приведем все же краткое определение представлений.
Представление (VIEW) - это виртуальная таблица, созданная на основе запроса к обычным ыб шцам Представление реализовано как запрос, хранящийся на сервере и выполняющийся всякий раз. когда происходит обращение к представлению.
Давайте рассмотрим различные варианты использования представлений. Представления дают возможность создать уровни организации данных, позволяющие отделить реализацию хранения данных от их вида. Например, можно создать представление, которое выбирает данные из несколько таблиц. Если клиенты будут использовать это представление, а не напрямую обращаться к лежащим в его основе таблицам, то у разработчика базы данных появляется возможность менять запрос, лежащий в основе представления, изменять его (с целью оптимизации, например), а клиент ничего не будет замечать - для него это будет все то же представление.
Помимо того что они изолируют реализацию хранения данных от пользователя, представления позволяют организовать данные в более удобном и простом виде. Проблема "упрощения" организации данных возникает, когда число таблиц в базе данных становится достаточно большим, а взаимосвязи между ними - сложными. Представление позволяет исключить (или, наоборот, добавить) часть данных, не нужных конкретному клиенту базы данных (или - необходимых).
Также представления позволяют более просто организовать безопасность в базе данных InterBase. Определенные пользователи могут иметь права только на чтение/изменение данных в представлении, но не иметь никаких прав (и даже никакого понятия) о таблицах, лежащих в основе представления! Подробнее о вопросах безопасности в InterBase см. главу "Безопасность в InterBase: пользователи, роли и права" (ч. 4).
Применение индексов
Теперь, когда ясно, что можно требовать от индексов, настало время разобраться с тем, какую роль они играют в базе данных. Индексы используются в трех основных случаях:
Ускорение выполнения запросов. Индексы создаются для полей, которые используются в условиях поиска SQL-запросов.
Обеспечение уникальности значений в полях; Ограничение первичного ключа (о которых рассказывалось в главе "Таблицы. Первичные ключи") требует, чтобы во всей таблице не нашлось двух одинаковых значений полей, входящих в первичный ключ. Чтобы выполнить это условие, необходимо при каждой вставке новой записи производить поиск такого же значения, которые будет вставлено. Для поиска записи используется особая разновидность индекса - уникальный индекс (см. ниже).
Обеспечение ссылочной целостности. Ограничения внешних ключей Foreign key (которые рассмотрены в главе "Ограничения базы данных") используются для проверки того, чтобы вставляемые в таблицу значения обязательно существовали в другой таблице. При создании внешнего ключа автоматически создается индекс, который применяется как для ускорения запросов, использующих соединение таблиц, так и для проверки условий внешнего ключа.
Вот вкратце и все возможные применения индексов. Теперь мы рассмотрим особенности каждого случая более подробно и ответим на ряд часто возникающих вопросов, связанных с применением индексов.
Пример простой хранимой процедуры
Настало время создать первую хранимую процедуру и на ее примере изучить процесс создания хранимых процедур. Но для начала следует сказать несколько слов о том, как работать с хранимыми процедурами Дело в том, что своей славой малопонятного и неудобного инструмента ХП обязаны чрезвычайно бедным стандартным средствам разработки и отладки хранимых процедур. В документации по InterBase рекомендуется создавать процедуры с помощью файлов SQL-скриптов, содержащих текст ХП, которые подаются на вход интерпретатору isql, и таким образом производить создание и модификацию ХП Если в этом SQL-скрипте на этапе компиляции текста процедуры в BLR (о BLR см главу "Структура базы данных InterBase" (ч. 4)) возникнет ошибка, то isql выведет сообщение о том, на какой строке файла SQL-скрипта возникла эта ошибка. Исправляйте ошибку и повторяйте все сначала. Про отладку в современном понимании этого слова, т. е. о трассировке выполнения, с возможностью посмотреть промежуточные значения переменных, речь вообще не идет. Очевидно, что такой подход не способствует росту привлекательности хранимых процедур в глазах разработчика
Однако помимо стандартного минималистского подхода к разработке ХП <_\ществ\ют также инструменты сторонних разработчиков, которые делают работу с хранимыми процедурами весьма удобной Большинство универсальных продуктов для работы с InterBase, перечисленных в приложении "Инструменты администратора и разработчика InterBase", предоставляют удобный инструментарий для работы с ХП. Мы рекомендуем обязательно воспользоваться одним из этих инструментов для работы с хранимыми процедурами и изложение материала будем вести в предположении, что у вас имеется удобный GUI-инструмент, избавляющий от написания традиционных SQL-скриптов
Синтаксис хранимых процедур описывается следующим образом:
CREATE PROCEDURE name
[ ( param datatype [, param datatype ...] ) ]
[RETURNS ( param datatype [, param datatype ...])]
AS
<procedure_body>;
< procedure_body> = [<vanable_declaration_list>]
< block>
< vanable_declaration_list> =
DECLARE VARIABLE var datatype;
[DECLARE VARIABLE var datatype; ...]
<block> =
BEGIN
< compound_statement>
[< compound_statement> ...]
END
< compound_statement> = (<block> statement;}
Выглядит довольно объемно и может быть даже громоздко, но на самом деле все очень просто Для того чтобы постепенно освоить синтаксис, давайте будем рассматривать постепенно усложняющиеся примеры.
Итак, вот пример очень простой хранимой процедуры, которая принимает на входе два числа, складывает их и возвращает полученный результат:
CREATE PROCEDURE SP_Add(first_arg DOUBLE PRECISION,
second_arg DOUBLE PRECISION)
RETURNS (Result DOUBLE PRECISION)
AS
BEGIN
Result=first_arg+second_arg;
SUSPEND;
END
Как видите, все просто: после команды CREATE PROCEDURE указывается имя вновь создаваемой процедуры (которое должно быть уникальным в пределах базы данных) - в данном случае SP_Add, затем в скобках через запятую перечисляются входные параметры ХП - first_arg и second_arg - с указанием их типов.
Список входных параметров является необязательной частью оператора CREATE PROCEDURE - бывают случаи, когда все данные для своей работы процедура получает посредством запросов к таблицам внутри тела процедуры.
В хранимых процедурах используются любые скалярные типы данных InteiBase He предусмотрено применение массивов и типов, определяемых пользователем, - доменов
Далее идет ключевое слово RETURNS, после которого в скобках перечисляются возвращаемые параметры с указанием их типов — в данном случае только один - Result.
Если процедура не должна возвращать параметры, то слово RETURNS и список возвращаемых параметров отсутствуют.
После RETURNSQ указано ключевое слово AS. До ключевого слова AS идет заголовок, а после него - течо процедуры.
Тело хранимой процедуры представляет собой перечень описаний ее внутренних (локальных) переменных (если они есть, подробнее рассмотрим ниже), разделяемый точкой с запятой (;), и блок операторов, заключенный в операторные скобки BEGIN END. В данном случае тело ХП очень простое - мы просю складываем два входных аргумента и присваиваем их результат выходному, а затем вызываем команду SUSPEND. Чуть позже мы разъясним суть действия этой команды, а пока лишь отметим, что она нужна для передачи возвращаемых параметров туда, откуда была вызвана хранимая процедура.
Пример типичного ограничения
Фактически ограничения на основе одного поля являются частным сл\чаем ограничений на основе нескольких полей.
Пример создания ограничения первичного ключа с использованием этих двух различных подходов приведен ниже. Давайте создадим таблицу, содержащую только одно поле и наложим на нее ограничение первичного ключа.
Первичный ключ с использованием синтаксиса ограничения на основе одного поля.
CREATE TABLE testl(
ID_PK INTEGER CONSTRAINT pktest NOT NULL PRIMARY KEY) ;
В этом примере создается первичный ключ с именем pktest на поле ID_PK. Получаем весьма компактное описание в одну строчку.
Для той же самой цели можно воспользоваться синтаксисом ограничений на основе нескольких полей:
CREATE TABLE test2(
ID_PK INTEGER NOT NULL,
CONSTRAINT pktst PRIMARY KEY (ID_PK));
Пример триггера
Давайте рассмотрим простой пример триггера, который срабатывает ДО ВСТАВКИ в таблицу и заполняет поле первичного ключа. Мы воспользуемся в качестве основы для триггера таблицей из примера в главе "Таблицы. Первичные ключи и генераторы" этой части:
CREATE TABLE Table_example (
ID INTEGER NOT NULL,
NAME VARCHAR(80),
PRICE_1 DOUBLE PRECISION,
CONSTRAINT pkTable PRIMARY KEY (ID));
Здесь поле ID является первичным ключом и значения этого поля должны быть уникальными в пределах таблицы. Чтобы обеспечить выполнение этого требования, создадим генератор и триггер, который будет получать значение генератора и подставлять его в таблицу. Таким образом, в поле ID всегда будет уникальные значения, так как значение генератора будет увеличиваться каждый раз при обращении к триггеру. Итак, создаем генератор:
CREATE GENERATOR GEN_TABLE_EXAMPLE_ID;
И устанавливаем его начальное значение в единицу:
SET GENERATOR GEN_TABLE_EXAMPLE_ID TO 1;
Теперь необходимо создать триггер. Надо сказать, что триггер, как и хранимая процедура, может содержать в своем теле несколько операторов, разделенных точкой с запятой. Поэтому если вы не используете один из инструментов, рекомендованных в приложении "Инструменты администратора и разработчика InterBase", а работаете с isql, то вам необходимо воспользоваться командой смены разделителя команд SET TERM, как это было описано в главе "Хранимые процедуры". Мы же будем приводить тексты триггеров без обрамления командами смены разделителя.
Итак, рассмотрим текст нашего триггера:
CREATE TRIGGER Table_example_bi FOR Table_example
ACTIVE BEFORE INSERT POSITION 0
AS
BEGIN
IF (NEW.ID IS NULL) THEN
NEW. ID GEN_ID(GEN_TABLE_EXAMPLE_ID, 1);
END
Как видите, триггер очень напоминает хранимую процедуру (фактически, как )же было сказано, это и есть особая разновидность ХП), но есть и несколько отличий Давайте подробно разберем "строение" триггера.
Описание команды создания триггера начинается с ключевых слов CREATE TRIGGER, после которых следует имя триггера - Table_example_bi. Потом следует ключевое слово FOR, после которого указано имя таблицы, для которой создается триггер, - Table_example.
На второй строке команды приводится описание сущности триггера - ключевое слово ACTIVE указывает, что триггер является "активным". Триггер также может быть переведен в состояние INACTIVE. Это означает, что он будет храниться в базе данных, но он не будет срабатывать. Сочетание ключевых слов BEFORE INSERT определяет, что триггер срабатывает ДО ВСТАВКИ; а ключевое слово POSITION и число 0 указывают очередность (позицию) создаваемого триггера среди триггеров того же типа для данной таблицы. Позиция триггера нужна потому, что в InterBase возможно создать более 32000 триггеров каждого вида (например, BEFORE INSERT или AFTER UPDATE), и серверу нужно указать, в каком порядке эти триггеры будут выполняться. Триггеры с меньшей позицией выполняются первыми. Если имеется несколько триггеров с одинаковой позицией, то они будут выполняться в алфавитном порядке.
Все рассмотренное выше до ключевого слова AS образует заголовок триггера. После AS следует тело триггера. Собственно в теле и осуществляется вставка значения в поле первичного ключа. Но сначала с помощью уже знакомого вам оператора IF.. .THEN проверяется, не было ли заполнено это поле на клиенте. Выражение проверки возвращающей булеву TRUE (истина) или FALSE (ложь), выгядит так:
NEW. ID IS NULL
"Интересно, что такое NEW?" - спросите вы. Это одна из особенностей, присущая только триггерам, - контекстная переменная. Давайте взглянем, как она действует
Примеры представлений
Вот пример простого представления:
CREATE VIEW MyView AS
SELECT NAME, PRICE_1
FROM Table_example;
В этом примере мы создаем представление на основе запроса к таблице Table_example, которую мы рассматривали в главе "Таблицы. Первичные ключи и генераторы". В данном случае представление будет состоять из двух полей - NAME и PRICE_1, которые будут выбираться из таблицы Table_example без всяких условий, т. е. число записей в представлении MyView будет равно числу записей в Table_example.
Однако представления не всегда являются такими простыми. Они могут основываться на данных из нескольких таблиц и даже на основе других представлений. Также представления могут содержать данные, получаемые на основе различных выражений - в том числе на основе агрегатных функций.
Чтобы подробнее рассмотреть использование этого применения представлений, давайте создадим две таблицы, связанные отношением один-ко-многим (часто такое отношение называют мастер-деталью или master-detail). Вот DDL-скрипт для создания этих таблиц:
/* Table: WISEMEN */
CREATE TABLE WISEMEN (
ID_WISEMAN INTEGER NOT NULL,
WISEMAN_NAME VARCHAR(80));
/* Primary keys definition */
ALTER TABLE WISEMEN ADD CONSTRAINT PK_WISEMEN PRIMARY KEY
(ID_WISEMAN);
/* Table: WISEBOOK */
CREATE TABLE WISEBOOK (
ID_BOOK INTEGER NOT NULL,
ID_WISEMAN INTEGER,
BOOK VARCHAR (80) ) ;
/* Primary keys definition */
ALTER TABLE WISEBOOK ADD CONSTRAINT PK_WISEBOOK PRIMARY KEY
(ID_BOOK);
/* Foreign keys definition */
ALTER TABLE WISEBOOK ADD CONSTRAINT FK_WISEBOOK FOREIGN KEY
(ID_WISEMAN) REFERENCES WISEMEN (ID_WISEMAN);
Итак, мы создали две таблицы - WISEMEN и WISEBOOK, которые связали между собой отношением master-detail с помощью ограничения внешнего ключа - FOREIGN KEY. Предположим, что эти таблицы будут хранить информацию о великих китайских мудрецах и их произведениях. Теперь мы можем создать несколько представлений на основе этих таблиц. Например, создадим представление, которое показывает, сколько произведений есть у каждого мудреца:
CREATE VIEW WiseBookCount (WISEMAN,
HOW_WISEBOOKS) AS SELECT M.WISEMAN_NAME, COUNT(B.BOOK)
FROM WISEMEN M, WISEBOOK В
WHERE (M.ID_WISEMAN = В.ID_WISEMAN)
GROUP BY M.WISEMAN_NAME
Обратите внимание, что при использовании любых вычисляемых выражений вроде агрегатных функций COUNTQ, SUMQ, МАХ() и т. д., необходимо использовать явное именование полей представления, т. е. давать имена всем полям, возвращаемым запросом. Как видно из этого примера, эти имена не обязательно должны совпадать с именами полей запроса, но их количество должно совпадать с количеством полей, возвращаемых запросом. Установление того, какое поле, возвращаемое запросом, соответствует какому полю представления, осуществляется по порядковому номеру — первое поле запроса отобразится в первое поле представления, второе - во второе и т. д.
А если мы захотим узнать, какой же из мудрецов написал больше всего книг? И попытаемся добавить в запрос, лежащий в основе представления, выражение для сортировки - ORDER BY. Однако эта попытка будет неудачной: использование сортировки ORDER BY в представлениях не допускается и при попытке создать представление с запросом, содержащим ORDER BY, возникнет ошибка. Если мы желаем отсортировать результаты, возвращаемые представлением, то придется это сделать на стороне клиента:
SELECT * FROM WiseBookCount ORDER BY HOW_WISEBOOKS
Выполнение этого SQL-запроса приведет к желаемому результату.
Помимо ограничения на использование выражения ORDER BY в представлениях, шк/ке нсмьзя использовать в качес!ве источника данных набор данных, получаемых в результате выполнения хранимых процедур (см. чуть ниже главу "Хранимые процедуры").
Пожалуй, стоит привести еще один пример, иллюстрирующий применение представлений. Предположим, нам необходимо вывести список мудрецов, чье имя начинается с буквы "К". В этом случае нам поможет представление с условиями:
CREATE VIEW WiseMen2
(WISEMAN) AS
SELECT M.WISEMAN_NAME
FROM WISEMEN M
WHERE M.WISEMAN_NAME LIKE 'K%'
Таким образом, легко создавать представления, которые исполняют роль постоянно обновляемых поставщиков данных, отбирая их из базы данных по определенным условиям.
Работа с массивами в хранимых процедурах
Массивы, как было сказано в главе "Типы данных", позволяют хранить в одном поле набор данных какого-нибудь одного элементарного типа. Однако "простым" SQL-запросом данные не извлечь и не изменить. Необходим особый пеиход для раосмы с массивами InteiBase в клиешских приложениях - см paздел "Поддержка array-полей в FIBPIus" в главе (ч 2) и "Разработка клиентских приложений СУБД InterBase с использованием технологии Microsoft OLE DB" (ч. 3). К тому же не все библиотеки доступа поддерживают работу с массивами.
Хранимые процедуры позволяют легко просматривать данные из массивов. Они используют простой и очевидный синтаксис для обращения к элементам массива. Например, пусть у нас будет таблица, содержащая поле типа массив целых чисел:
CREATE TABLE table_array(
ID_table INTEGER,
Arrayl INTEGER[3,2]);
Теперь можно продемонстрировать, как можно просмотреть данные из этого массива. Для этого внутри хранимой процедуры применяется конструкция вида
SELECT Arrayl[:i, :j] FROM table_array INTO :ElemValue;
Давайте оформим механизм доступа к массиву в виде следующей хранимой процедуры:
CREATE PROCEDURE SelectFromArr(ID_row INTEGER,
x INTEGER, у INTEGER, vl integer)
Returns (ElemValue INTEGER)
AS
BEGIN
SELECT arrayl[:x,:y]
FROM table_array
WHERE id_cable=:ID_row
INTO :ElemValue;
SUSPEND;
END
Как видите, текст ХП очевиден - просто извлекаем нужные значения из элемента массива с заданными индексами х и у в строке таблицы table_array с идентификатором ID_table=ID_row. К сожалению, такой синтаксис доступа к элементам массива доступен только внутри хранимых процедур и только для чтения. Для заполнения массива придется воспользоваться программой, применяющей либо InterBase API, либо библиотеки доступа, поддерживающие работу с массивами InterBase - FIBPIus для Delphi/C-H-Builder/Kylix или IBProvider для продуктов Microsoft.
Расширенные возможности языка хранимых процедур InterBase
Эта глава посвящена тем возможностям языка хранимых процед>р InteiBase, которые позволяют эффективно реализовывать бизнес-логику на уровне базы данных и разрабатывать устойчивые и высокопроизводительные приложения баз данных
Расширенные возможности поддержки ссылочной целостности с помощью внешнего ключа
Обычно вполне достаточно декларативного варианта ограничения внешнего ключа, при котором сервер только следит за тем, чтобы в таблицу с внешним ключом нельзя было вставить некорректные значения или - при попытке сделать это возникает ошибка. Но InterBase позволяет выполнять ряд автоматических действий при изменении/удалении внешнего ключа. Для этого служит следующий набор опций внешнего ключа:
[ON DELETE {NO ACTION|CASCADE|SET DEFAULT|SET NULL}]
[ON UPDATE {NO ACTIONjCASCADEjSET DEFAULT]SET NULL}]
Эти опции позволяют определить различные действия при изменении или удалении значения внешнего ключа.
Например, мы можем указать, что при удалении первичного ключа в таблице-мастере необходимо удалять все записи с таким же внешним ключом в подчиненной таблице. Для этого следует так определить внешний ключ:
ALTER TABLE INVENTORY
ADD CONSTRAINT fkautodel
FOREIGN KEY (FK_TITLE) REFERENCES TITLE(ID_TITLE)
ON DELETE CASCADE
Фактически для реализации этих действий создается системный триггер, который и выполняет определенные действия. В табл. 1.2 приведено описание происходящих действий при различных опциях (обратите внимание, что опции NO ACTION|CASCADE|SET DEFAULT|SET NULL не могут использоваться совместно в одном предложении ON XXX).
Табл 1.2.
|
Событие |
Действие | ||||||||
|
NO ACTION |
CASCADE |
SET DEFAULT |
SET NULL | ||||||
|
ON DELETE |
При удалении внешнего ключа ничего не делать - используется по умолчанию |
При удалении удалить все связанные записи из подчиненной таблицы |
При изменении установить поле внешнего ключа в значение по умолчанию |
При изменении установить поле внешнего ключа в NULL | |||||
|
ON UPDATE |
При изменении ничего не делать - используется по умолчанию |
При изменении записи изменить во всех связанных записях в подчиненных таблицах |
При удалении установить поле внешнего ключа в значение по умолчанию |
При удалении установить поле внешнего ключа в NULL | |||||
Если мы ничего не указываем или указываем NO ACTION, то необходимо позаботиться об изменении внешнего ключа (в случае изменения первичного) самостоятельно, а при удалении первичного ключа предварительно удалить записи из подчиненной таблицы.
Осторожно надо обращаться с опцией CASCADE: неосторожное ее использование может привести к удалению большого количества связанных записей.
Разделители в хранимых процедурах
Обратите внимание, что оператор внутри процедуры заканчивается точкой с запятой (;). Как известно, точка с запятой является стандартным разделителем команд в SQL - она является сигналом интерпретатору SQL, что текст команды введен полностью и надо начинать его обрабатывать. Не получится ли так, что, обнаружив точку с запятой в середине ХП, интерпретатор SQL сочтет, что команда введена полностью и попытается выполнить часть хранимой процедуры? Это предположение не лишено смысла. Действительно, если создать файл, в который записать вышеприведенный пример, добавить команду соединения с базы данных и попытаться выполнить этот SQL-скрипт с помощью интерпретатора isql, то будет возвращена ошибка, связанная с неожиданным, по мнению интерпретатора, окончанием команды создания хранимой процедуры. Если создавать хранимые процедуры с помощью файлов SQL-скриптов, без использования специализированных инструментов разработчика InterBase, то необходимо перед каждой командой создания ХП (то же относи 1ся и к триггерам) менять разделитель команд скрипта на другой символ, отличный от точки с запятой, а после текста ХП восстанавливать его обратно. Команда isql, изменяющая разделитель предложений SQL, выглядит так:
SET TERM <new_term><old_term>
Для типичного случая создания хранимой процедуры это выглядит так:
SET TERM ^;
CREATE PROCEDURE some_procedure
... . .
END
^
SET TERM ;^
Размер страницы
Выбор размера страницы очень важен для обеспечения эффективной работы сервера InterBase с базой данных. Файл базы данных разбивается на страницы фиксированного размера, и все обращения к диску, которые выполняет InterBase, считывают и записывают информацию постранично. Выбирать следует размер страницы не менее 4096 байт, а лучше еще больше. Почему так? Дело в том, что если установить малый размер страницы, то записи большой длины (например, представьте себе 10 строковых полей в таблице, заполненных строками размером в 255 символов) будут занимать несколько страниц, и для чтения единственной записи InterBase будет вынужден осуществить несколько обращений к диску! Очевидно, что это не лучшим образом скажется на быстродействии.
Изменить размер страницы можно будет и позже, в процессе восстановления базы данных из резервной копии, но лучше все делать сразу и правильно, не так ли?
Рекомендации по выбору размера страницы следующие:
Для дисковых накопителей с файловой системой NTFS выбираем размер страницы, равный 4096 байтам. Перед этим следует убедиться, что размер кластера у NTFS-диска установлен в 4096 байт (если не знаете, что такое кластер, спросите у вашего системного администратора).
Для дисков с FAT32 (думаю, что FAT16 редко используется в наш век дешевых гигабайтов) устанавливаем размер страницы 8192 или 16384 байта (хотя стоит заметить, что размер страницы 16384 байта есть далеко не во всех клонах InterBase).
Реализация многоверсионности. Страницы учета транзакций
Каждая транзакция в InterBase имеет свой уникальный идентификатор - transaction ID или TID (фактически это номер транзакции с момента создания базы данных или последнего restore). Каждая транзакция, запускаясь, получает свой номер, который последовательно увеличивается - т. е. более старые транзакции имеют меньшие номера, чем новые.
Для учета транзакций используются страницы учета транзакций (Transaction Inventory Page, TIP). Когда в InterBase начинается транзакция, то на странице учета транзакций появляется отметка о том, что транзакция с определенным идентификатором ТГО# находится в состоянии выполнения (т. е. она является активной - active).
Всего имеется 4 возможных состояния транзакции: активная (active), подтвержденная (Commited), отмененная (Rolled back) и лимбо (limbo). Статус активной имеют выполняющиеся в данный момент транзакции.
Подтвержденные транзакции - обычно те транзакции, что завершились командой Commit. Отмененные транзакции - это обычно те транзакции, которые завершились командой Rollback.
Транзакции Лимбо - это транзакции с неопределенным статусом, которые возникают при использовании механизма двухфазного подтверждения транзакций, который применяется при проведении транзакций сразу в нескольких базах данных.
Когда операция в контексте транзакции с идентификатором ТID# изменяет какие-либо записи, то для этого изменения создаются версии записей. И каждая версия помечается идентификатором ТID# - на физическом уровне это выглядит как номер транзакции в заголовке версии записи.
Если транзакция с номером ТID# подтверждается, т. е. переходит в состояние Commited (а процесс подтверждения часто называют commit), то на странице учета транзакций производится отметка об этом. При этом никаких действий над измененными записями не происходит!
Но как же следующие транзакции узнают о том, какая версия записи является актуальной - та ли, которая была изменена транзакцией ТID#, или исходная, помеченная другой транзакцией. Вот здесь заключается один фокус - читающая транзакция считывает все версии измененной записи, берет номера транзакций из заголовков записей и та запись считается актуальной, чей номер больше.
При чтении версий записей происходит дополнительная проверка и на подтвержденность транзакции, которая создала версию. Для этого в момент чтения версий не просто сравниваются номера транзакций, чтобы определить актуальную запись, но еще и проверяется на странице учета транзакций, а в каком состоянии находится транзакция с определенным TID.
Если транзакция, создавшая версию записи, откачена (т. е. находится в состоянии Rollbacked), то такая версия является мусором (garbage) и ее необходимо удалить.
Если же транзакция, создавшая версию записи, подтверждена (находится в состоянии Committed), то такую запись можно считать полноценной претенденткой на самую актуальную запись.
"Почему претенденткой?" - может спросить уважаемый читатель. А потому что может быть две и больше версий записей, которые созданы подтвержденными на текущий момент транзакциями. И поэтому читающая запись выберет среди этих версий записей в качестве актуальной ту версию, в которой ТID# больше.
Рекомендации по использованию параметров транзакций
Как использовать транзакции - с этим вопросом часто сталкиваются начинающие разработчики. Конечно, для каждой конкретной задачи нужно решать вопрос индивидуально. Обычно все запросы к базе данных подразделяются на группы - запросы на чтение самого "свежего" состояния базы данных, запросы на текущие изменения, запросы на чтение справочных таблиц, запросы на чтение данных для построения отчета и т. д. Для каждой группы запросов обычно устанавливается своя транзакция (или группа транзакций) с набором параметров, нужных для выполнения задачи.
Рассмотрим типичное приложение базы данных, с помощью которого пользователь желает читать и изменять данные. В приложении имеется сетка (dbGrid в Delphi/C++Builder), в которой пользователь просматривает текущее содержание какой-то таблицы. Сетка содержит lookup-поля, которые заполняются значениями из справочников. Когда пользователь находит запись, которую нужно изменить (или просто желает добавить запись в таблицу), то он нажимает кнопку добавления/редактирования и в появившемся диалоге заполняет/изменяет поля записи и затем сохраняет/отменяет редактирование.
Как же настроить транзакции для такого приложения?
Для запроса SELECT. ., который читает данные в сетку, следует использовать транзакцию с доступом "только для чтения" с уровнем изоляции READ COMMITED, чтобы получить самые "свежие" данные из таблицы, как только они будут обновлены/добавлены (не надо забывать о том, что наше приложение многопользовательское и одновременно могут работать несколько приложений). Примерный набор параметров такой:
read
read_committed
rec_version
nowait
При этом обеспечивается чтение всех подтвержденных другими транзакциями записей, причем без конфликтов с параллельно работающими пишущими и читающими транзакциями.
Такую транзакцию можно длительное время держать открытой - сервер не нагружается версиями записей.
Для запроса на изменение/добавление данных можно использовать транзакцию с уровнем изоляции concurrency. Запрос на обновление в этом случае должен быть очень коротким: пользователь заполняет необходимые поля, запускается транзакция, делается попытка выполнить запрос, и затем, если не возник н> конфликта на запись с другой транзакцией, подтверждение нашей транзакции или откат, если был конфликт (на уровне клиентского приложения конфлнмы проявляются в виде исключений, которые удобно отлавливать с помощью коп струкций try.. .except или try.. .catch)
Параметры такой транзакции будут следующими:
write
concurrency
nowait
Такой набор параметров позволит нам сразу (nowait) выявить то, что запись редактируется/изменяется другим пользователем (возникнет ошибка), а также предотвратить попытки других пользователей начать изменение записей, трансформированных нашей транзакцией (у претендента возникнет ошибка "update conflict"). Надо отметить, что перед редактированием нужно перечитать запись, потому что она могла быть изменена, а в кеше сетки может все еще находиться старая версия
Для запросов, которые применяются для построения отчетов, однозначно нужно использовать транзакцию с режимом доступа "только для чтения" и с уровнем изоляции concurrency:
read
concurrency
nowait
Такая транзакция будет возвращать строго те данные, что существовали на момент ее запуска, - это очень важная особенность для отчетов, которые строятся за несколько проходов по базе данных.
Для запросов на чтение справочных данных можно использовать транзакцию, аналогичную запросу SELECT для выборки данных в сетку.
Рекурсивные хранимые процедуры
Хранимые процедуры InterBase могут быть рекурсивными. Это означает, что из хранимой процедуры можно вызвать саму себя. Допускается до 1000 уровней вложенности хранимых процедур, однако надо помнить о том, что свободные ресурсы на сервере могут закончиться раньше, чем будет достигнута максимальная вложенность ХП.
Одно из распространенных применений хранимых процедур - это обработка древовидных структур, хранящихся в базе данных. Деревья часто используются в задачах состава изделия, складских, кадровых и в других распространенных приложениях.
Давайте рассмотрим пример хранимой процедуры, которая выбирает все товары определенного типа, начиная с определенного уровня вложенности.
Пусть у нас есть следующая постановка задачи: имеем справочник товаров с иерархической структурой такого вида:
-Товары
- Бытовая техника
- Холодильники
- Трехкамерные
- Двухкамерные
- Однокамерные
- Стиральные машины
- Вертикальные
- Фронтальные
- Классические
- Узкие
- Компьютерная техника
....
Эта структура справочника категорий товаров может иметь ветки различной глубины. а также нарастать со временем. Наша задача - обеспечить выборку всех конечных элементов из справочника с "разворачивание полного имени", начиная с любого узла. Например, если мы выбираем узел "Стиральные машины", то нам надо получить следующие категории:
Стиральные машины - Вертикальные
Стиральные машины - Фронтальные Классические
Стиральные машины - Фронтальные Узкие
Определим структуру таблиц для хранения информации справочника товаров. Используем упрощенную схему для организации дерева в одной таблице:
CREATE TABLE GoodsTree
(ID_GOOD INTEGER NOT NULL,
ID_PARENT_GOOD INTEGER,
GOOD_NAME VARCHAR(80),
constraint pkGooci primary key (ID_GOOD) );
Создаем одну таблицу GoodsTree, в которой всего 3 поля: ID_GOOD - умн кальный идентификатор категории, ID_PARENT_GOOD - идентификатор кшс гории-родителя для данной категории и GOOD_NAME - наименование катсш- рии. Чтобы обеспечить целостность данных в этой таблице, наложим на эту таблиц} ограничение внешнего ключа:
ALTER TABLE GoodsTree
ADD CONSTRAINT FK_goodstree
FOREIGN KEY (ID_PARENT_GOOD)
REFERENCES GOODSTPEE (ID__GOOD)
Таблица ссылается сама на себя и данный внешний ключ следит за тем. чтобы в таблице не было ссылок на несуществующих родителей, а также препятствует попыткам удалить категории товаров, у которых есть потомки.
Давайте занесем в нашу таблицу следующие данные:
|
ID_GOOD 1 2 3 4 5 6 7 8 9 10 11 12 |
ID_PARENT_GOOD 0 1 1 2 2 4 4 4 5 5 10 10 |
GOOD_NAME GOODS Бытовая техника Компьютеры и комплектующие Холодильники Стиральные машины Трехкамерные Двухкамерные Однокамерные Вертикальные Фронтальные Узкие Классические |
В хранимых процедурах, обрабатывающих древообразные структуры, сложилась своя терминология. Каждый элемент дерева называются узлом; а отношения между ссылающимися друг на друга узлами называется отношениями родитель-потомок. Узлы, находящиеся на самом конце дерева и не имеющие потомков, называются "листьями".
У кашей хранимой процедуры входным параметром будет идентификатор категории, начиная с которого мы должны будем начать развертку. Хранимая процедура будет иметь следующий вид:
CREATE PROCEDURE GETFULLNAME (ID_GOOD2SHOW INTEGER)
RETURNS (FULL_GOODS_NAME VARCHAR(1000),
ID_CHILD_GOOD INTEGER)
AS
DECLARE VARIABLE CURR_CHILD_NAME VARCHAR(80);
BEGIN
/*0рганизуем внешний цикл FOR SELECT по непосредственным потомкам товара с ID_GOOD=ID_GOOD2SHOW */
FOR SELECT gtl.id_good, gtl.good_name
FROM GoodsTree gtl
WHERE gtl.id_parent_good=:ID_good2show
INTO:ID_CHILD_GOOD, :full_goods_name
DO
BEGIN
/"Проверка с помощью функции EXISTS, которая возвращает TRUE, если запрос в скобках вернет хотя бы одну строку. Если у найденного узла с ID_PARENT_GOOD = ID_CHILD_GOOD нет потомков, то он является "листом" дерева и попадает в результаты */
IF (NOT EXISTS(
SELECT * FROM GoodsTree
WHERE GoodsTree.id_parent_good=:id_child_good))
THEN
BEGIN
/* Передаем "лист" дерева в результаты */
SUSPEND;
END
ELSE
/* Для узлов, у которых есть потомки*/
BEGIN
/*сохраняем имя узла-родителя во временной переменной */
CURR_CHILD_NAME=full_goods_name;
/* рекурсивно запускаем эту процедуру */
FOR
SELECT ID_CHILD_GOOD, full_goods_name
FROM GETFULLNAME (:ID_CHILD_GOOD)
INTO:ID_CHILD_GOOD, :full_goods_name
DO BEGIN
/*добавляем лмя узла-родителя к найденном., имени потомка с помощью операции конкатенации строк || */
full_goods_name=CURR_CHILD_NAME| ' ' | f ull_goods_name,-
SUSPEND; /* возвращаем полное имя товара*/
END
END
END
END
Если мы выполним данную процедуру с входным параметром ID_GOOD2SHOW= 1, то получим следующее:
|
FULL_GOODS__NAME Бытовая техника Холодильники Трехкамерные Бытовая техника Холодильники Двухкамерные Бытовая техника Холодильники Однокамерные Бытовая техника Стиральные машины Вертикальные Бытовая техника Стиральные машины Фронтальные Узкие Бытовая техника Стиральные машины Фронтальные Классические Компьютеры и комплектующие |
ID_CHILD_GOOD 6 7 8 9 11 12 3 |
Режим блокировки
Режим блокировки определяет, как будут разрешаться конфликты. Если возникает конфликт, то у транзакции, обнаружившей конфликт, есть два выхода - либо немедленно возбудить исключение, либо подождать некоторое время, после чего опять попытаться разрешить конфликт.
Соответственно есть два варианта режима блокировки - wait и nowait. По умолчанию используется режим wait.
Конфликты, о которых идет речь, возникают как в случае чтения записей, так и в случае записи. На конфликты при чтении записей, помимо wait/nowait, влияют также установки уровня изоляции, и поэтому мы их рассмотрим в разделе про уровни изоляции. А вот на объяснение влияния режима блокировки на конфликты при записи уровень изоляции не влияет, поэтому мы сейчас рассмотрим его.
Рассмотрим случай, когда транзакция А вставляет запись, но еще не подтвердила ее. Затем в рамках другой транзакции, Б, делается попытка вставить запись с тем же самым первичным ключом, уже вставлена в транзакции А. Вот здесь и начинаются отличия между режимами блокировки:
если транзакция Б запущена в режиме wait, то она будет ожидать завершения транзакции А, и если А завершится подтверждением (commit), то вставленная в Б запись будет признана неактуальной и возникнет ошибка Deadlock, а если она откатится (rollback), то изменения в транзакции Б будут приняты и она сможет подтвердить их (т. е. сделать commit);
если транзакция Б запущена в nowait, то немедленно возникнет ошибка 'lock conflict on no wait transaction'.
Рассмотрим другой случай: транзакция А изменила запись, но еще не подтвердила ее изменения. Транзакция Б пытается удалить или изменять эту же самую запись. Опять влияет режим блокировки:
если Б в режиме wait, то она будет ждать пока А не подтвердится или не отменится; если А подтвердится, то в Б возникнет ошибка 'Deadlock - update conflict with concurrent update', - потому как А подтвердила свои изменения, изменения в Б признаются неактуальными; если же транзакция А откатится, Б получит возможность подтвердиться;
если Б в режиме nowait, то немедленно возникнет ошибка 'lock conflict on no wait transaction'.
Возможно, неясна практическая ценность описаний режима блокировки. Однако чуть ниже это поможет понять суть рекомендованных наборов параметров для транзакций в типичных приложениях баз данных.
Вы, вероятно, заметили, что в сообщении об ошибке конфликта блокировки фигурирует слово "deadlock", однако это слово выбрано не совсем удачно. В переводе с английского оно означает "мертвая блокировка", или "взаимоблокировка". В нашем случае, несмотря на грозное сообщение, никаких взаимоблокировок не возникает.
Что же такое взаимоблокировка на самом деле и когда она может возникнуть?
Режим доступа
Режим доступа определяет, какие операции могут осуществляться в контексте транзакции. По умолчанию (т. е. если ничего не указывать) ставится режим чтения-записи, т. е. могут осуществляться любые операции. Часто задают вопрос, имеет ли смысл запускать транзакции в режиме только для чтения, если не предполагается операций по изменению данных. Ответ: да, имеет. Особенно в последних клонах InterBase 6.x - InterBase 6.5, Yaffil и Firebird. Транзакции с режимом доступа только для чтения меньше нагружают сервер, так как не создают лишних версий записей.
Для установки режима чтения-записи используется сочетание констант read write. Обычно константы записывают в столбик одну под другой, вот так: read write
Русификация InterBase
Borland InterBase 6.x и его клоны Firebird и Yaffil - продукты, ориентированные на международного потребителя и позволяющие работать со множеством разных языков, в том числе и русским. Однако по умолчанию InterBase будет ориентироваться на работу с английским языком, поэтому для того, чтобы хранить в базе данных кириллицу и иметь возможность извлекать ее в читабельном виде, необходимо произвести ряд действий по "русификации" базы данных и включению поддержки кириллицы в клиентских приложениях.
Русификация клиентских приложений InterBase
Разобравшись с русификацией баз данных InterBase и с тем, как обеспечить хранение и интерпретацию символов на уровне базы данных, необходимо рассмотреть вопрос о том, как сделать так, чтобы клиентские приложения могли корректно читать и записывать символьные данные.
Принцип здесь очень простой: при подключении к базе данных в клиентских приложениях необходимо указать точно такой же набор символов, как и в самой базе данных. В этом случае передаваемые данные будут интерпретироваться правильно и появляться у пользователя на экране в виде корректных символов, а не бессмысленных значков.
Способ указания того, какой набор символов использовать, различен для каждой библиотеки доступа. Для библиотек FEBPlus и ЕВХ для подключения к базе данных с набором символов, например, WIN125I, нужно указать в параметрах подключения lc_type=WIN1251.
Для работы с базами данных, использующими WIN1251, через Borland Database Engine необходимо указать в параметрах псевдонима LANGDRJVER=PDOX ANSI Cyrr.
Для работы с базой данных через JDBC необходимо указать в настройках драйвера строку charset=cp!251 (подробнее см. в главе "Разработка клиента InterBase на Java" (ч. 3)).
Сборка мусора
Как видите, при использовании многоверсионной архитектуры постоянно накапливаются устаревшие версии, называемые "мусором". Эти версии не являются актуальными и подлежат удалению. Процесс удаления ненужных версий записей называется сборкой "мусора"..
Главное, что следует отметить в сборке "мусора" - это то, что она является кооперативной. Как вы поняли из предыдущего описания, транзакции, изменяющие данные, не "убирают за собой": когда происходит завершение, то на странице учета транзакций просто ставится отметка о том, что транзакция с определенным TID подтверждена (committed). При этом не происходит удаления старых версий записей.
Сборка мусора происходит, когда какая-либо транзакция пожелает прочитать данную запись. Эта транзакция считывает все существующие версии этой записи, выясняет по таблице TIP, что версии устарели и удаляет их.
Синтаксис DDL для работы с представлениями
Для создания и удаления представлений существуют команды, определенные DDL (Data Definition Language - подмножество SQL, см. глоссарий), которые мы сейчас рассмотрим.
Чтобы создать представление в InterBase, необходимо использовать предложение следующего синтаксиса:
CREATE VIEVJ viewname [ (view_column [, view_column...] ) ]
AS <SELECT> [WITH CHECK OPTION];
Здесь viewname - имя представления, которое должно быть уникальным в пределах базы данных, далее идет группа не всегда обязательных наименований полей, входящих в представление: [(view_column [, view_column...])]. Обязательно необходимо определить предложение <SELECT>, которое выбирает данные, включаемые в представление. Необязательный параметр WITH CHECK OPTION мы обсудим ниже - в разделе "Модифицируемые представления".
Чтобы изменить какое-либо представление, придется его пересоздать, т. е. удалить и создать заново. При удалении представления необходимо также удалить все зависимые от него объекты - триггеры, хранимые процедуры и другие представления. В этом заключается одно из главных неудобств работы с представлениями - необходимость пересоздавать дерево использующих представление объектов (существуют утилиты, которые позволяют сделать это более "безболезненно", например IBAlterView, см. приложение "Инструменты администратора и разработчика InterBase"). Чтобы удалить представление, необходимо воспользоваться следующей командой DDL:
DROP VIEW viewname;
Синтаксис определения типов данных
Типы данных используются для описания полей в таблицах, переменных в триггерах и хранимых процедурах. Ниже представлен общий синтаксис определения всех возможных в InterBase типов данных.
< datatype> =
(SMALLINT | INTEGER | FLOAT | DOUBLE PRECISION}[ <array_dim>] {DATE | TIME | TIMESTAMP} [ <array_dim>]
{DECIMAL | NUMERIC) [( precision [, scale])] [ <array_dim>] {CHAR | CHARACTER | CHARACTER VARYING | VARCHAR) [( int)]
[ <array_dim>] [CHARACTER SET charname]
| {NCHAR NATIONAL CHARACTER | NATIONAL CHAR)
[VARYING] [( int)] [ <array_dim>]
| BLOB [SUB_TYPE { int | subtype_name}] [SEGMENT SIZE int]
[CHARACTER SET charname]
| BLOB [(seglen [, subtype])]
Подробно свойства типов данных, такие, как размер, точность и диапазон возможных значений, описаны в табл. 4.1 в [1], поэтому повторяться здесь не будем. Далее кратко рассмотрим основные особенности типов данных и сосредоточимся на их возможном применении.
Собственные наборы символов и способы сортировки
Сами кодировки хранятся в файле gdsintl.dll, который находится в каталоге %INTERBASE%\Intl. Вы можете самостоятельно разрабатывать и подключать свои собственные наборы символов и COLATION ORDERS в InterBase и во все его клоны. Для их разработки существует специальный инструментарий, ссылки на который вы можете найти на сайте www InterBase-world.com.
События InterBase
Одной из мощных возможностей InterBase, часто используемых в триггерах, являются события (events). События представляют собой строковые сообщения, которые могут быть посланы из триггера или хранимой процедуры. Получат эти события те клиенты InterBase, которые зарегистрированы как заинтересованные в данных событиях. Таким образом, можно оповещать клиента о каких-то изменения внутри базы данных.
События не являются постоянным объектом базы данных - они нигде в базе данных не хранятся, не создаются и не модифицируются, а порождаются "на лету". Чтобы послать какое-то событие, необходимо воспользоваться следующей конструкцией:
POST_EVENT 'текст_сообщения';
Надо сказать, что 'текст_сообщения' может браться из переменной и, таким образом, можно порождать события динамически, например так:
...
If (<какое-то булево выражение>) then
BEGIN
Event_text ='IT IS TRUE!';
END
ELSE
BEGIN
Event_text ='IT IS FALSE!';
END
FALSE_EVENT :Event_text;
Однако если ни одно клиентское приложение, соединенное с базой данных, в которой порождаются какие-то события, не является зарегистрированным на получение этих событий, то все они "уйдут в эфир" и фактически пропадут.
Для регистрации (подписки) на получение нужных событий используют специальные функции InterBase API, которые реализованы, например, в библиотеке FIBPlus - в компоненте SuperlBAlerter.
Как только приложение регистрируется для получения какого-либо события, запись об этом заносится в таблицу блокировок InterBase, которая является единой для всех пользователей сервера InterBase, и сервер начинает просматривать все порождаемые события на предмет появления зарегистрированных данным клиентом. Если такое событие появляется, то клиентское приложение получает соответствующий сигнал, на который может отреагировать каким-либо образом.
События в триггерах являются удобным механизмом для организации протокола изменений в определенных таблицах.
Создаем базу данных
Итак, нам необходимо создать новую базу данных. Это проще всего сделать при помощи какой-либо программы администрирования (например, BlazeTop: http-//www.blazetop.com). Запустите BlazeTop, затем выберите в меню "Файл\Новый\Сервер". На экране появится диалог регистрации сервера InterBase. Он изображен на рис. 1.2.
Рис 1.2. Диалог регистрации сервера InterBase
Укажите тип подключения к серверу. Он может быть двух типов: локальным или удаленным. Имя сервера - это название компьютера в сети, на котором установлен InterBase. Укажите также сетевой протокол, который используется для подключения к серверу. По умолчанию это TCP/IP, а значит, в качестве названия сервера вы можете указывать прямой IP-адрес компьютера с установленным InterBase. Имя для подключения к серверу - это имя администратора базы данных. Для InterBase это всегда SYSDBA, это имя нельзя изменять. Однако настоятельно рекомендуется изменить пароль для SYSDBA. По умолчанию это 'masterkey'. После регистрации сервера мы можем создавать базу данных. Выберите в меню "Файл\Новый\База данных". Появится диалог регистрации/создания базы данных (рис. 1.3).
Создание ограничений
Давайте рассмотрим создание ограничений подробнее. Первой в описании общего синтаксиса ограничений идет опция [CONSTRAINT constraint]. Как видите, эта опция взята в квадратные скобки и, значит, необязательна.
С помощью этой опции можно задавать имя создаваемому ограничению и в случае использования синтаксиса ограничений на основе одного поля, и в случае ограничений на основе нескольких полей.
Если не указать имя для ограничения, InterBase автоматически сгенерирует его. Но лучше все же явно назначить имя создаваемому ограничению, чтобы улучшить читабельность схемы базы данных, а также упростить управление ограничениями в дальнейшем.
Назначив имя ограничению, необходимо определить его тип. Рассмотрим различные типы ограничений в том порядке, как они указаны в описании общего синтаксиса ограничений.
Создание собственных функций
Мы не будем подробно останавливаться на всех особенностях создания пользовательских функций, поскольку данный механизм достаточно прост, однако продемонстрируем написание и подключение одной функции на примере. В качестве средства разработки мы будем использовать Borland Delphi. Для примера также будет применяться стандартная база данных EMPLOYEE.GDB.
В нашем примере мы создадим функцию, которая будет преобразовывать строку к верхнему регистру. Подобная функция может оказаться полезной, если вы не задали опцию COLLATE для ваших строковых полей. Кроме того, работа со строковыми параметрами, как правило, вызывает наибольшее количество вопросов при создании пользовательских функций. Разумеется, мы исходим из предположения, что вы знакомы с принципом создания DLL при помощи Delphi.
library TestUDF;
uses SysUtils;
function malloc(Size: Integer): Pointer; cdecl; external
'msvcrt.dll';
function StrUpperCase(sz: PChar): PChar; cdecl; export;
var Tmp: string;
begin
Tmp := AnsiUpperCase(sz);
Result := malloc(length(Tmp) + 1);
StrPCopy(Result, Tmp);
end;
exports
StrUpperCase;
begin
end.
Динамическая библиотека экспортирует только одну функцию: StrUpperCase. Для передачи строковых параметров, равно как и результата функции, используется тип Pchar, т е. динамическая строка, ограниченная символами #0. Смысл кода нашей функции очевиден: мы приводим строку sz у верхнему регистру, используя стандартную функцию AnsiUpperCase. Данная функция корректно работает с русскими буквами, если в системе установлена русская кодовая страница. После этого выделяем память для результирующей переменной, используя malloc - стандартную функцию Windows. Остается только скопировать значение временной переменной Tmp в переменную Result. Скомпилируйте библиотеку и поместите полученный файл TestUDF.dll в нужный каталог. Если вы используете InterBase 6.x или его клоны, то это каталог \Udf, который находится в каталоге установки сервера. Необходимо зарегистрировать функцию в базе данных. Для регистрации необходимо выполнить команду DECLARE EXTERNAL FUNCTION, которая имеет следующий синтаксис:
DECLARE EXTERNAL FUNCTION name [datatype | CSTRING (int)
[, datatype | CSTRING (int) ...] ]
RETURNS (datatype [BY VALUE] | CSTRING (int)} [FREE_IT]
ENTRY_POINT 'entryname'
MODULE_NAME ' modulename';
Параметр name - это имя пользовательской функции внутри базы данных. Он не обязательно должен совпадать с реальным названием функции в DLL.
Параметр datatype определяет тип параметров. На параметры накладываются следующие ограничения:
все параметры передаются по ссылке;
выходной параметр (значение функции) может возвращаться по значению;
параметры не могут быть массивами.
Если вы хотите применять строковые параметры, то вы должны использовать тип CSTRING В скобках необходимо указать максимальную длину строки. Если строка является результатом функции, она всегда передается по ссылке, а не по значению.
Параметр FREE_IT указывает InterBase, что после выполнения функции необходимо автоматически освободить память, выделенную для параметров. Очевидно, данная опция нужна только в том случае, если наша библиотека сама мм делила память под какие-либо параметры функции.
В параметре entryname необходимо указывать название функции в DLL, ко торую мы собственно и хотим декларировать как пользовательскую функцию.
В параметре modulename необходимо указать название файла DLL, в котором находится декларируемая функция пользователя.
Стоит заметить, что параметры entryname и modulename регистрочувствительные.
Таким образом, чтобы добавить нашу функцию в базу данных, нам необходимо выполнить следующую команду:
DECLARE EXTERNAL FUNCTION USTRUPPERCASE
cstring(254)
RETURNS cstnng(254) FREE_IT
ENTRY_POINT 'StrUpperCase' MODULE_NAME 'TestUDF.dll'
После этого мы сможем использовать новую функцию USTRUPPERCASE в любом SQL-запросе. Например, мы можем проверить, как работает функция на следующем запросе:
SELECT USTRUPPERCASE(DEPARTMENT) FROM DEPARTMENT
Запрос вернет названия отделов из таблицы DEPARTMENT:
Рис 1.5. Результат использования UDF USTRUPPERCASE
Список библиотек доступа к InterBase
Широкое распространение InterBase и его клонов по всему миру и использование в самых различных ипостасях привело к тому, что было создано множество библиотек доступа к InterBase/Firebird, ориентированных на самые различные среды программирования. Ниже, в таблице 1.6, приведен список наиболее популярных продуктов:
Табл 1.6.
|
Библиотека |
Краткое описание |
Где взять | |||
|
Free IB Components (FIBC) |
Четыре компонента, написанные в 1998 г. Грегори Детцем. Идеи, заложенные в FIBC, послужили основой для создания библиотек FIBPlus и IBX |
ftp.ibphoenix.com /download | |||
|
FIBPlus |
Библиотека прямого доступа, оформленная в виде компонентов, применяется в Delphi 3-6, C++ Builder 3-6, Kylix. Поддерживает интеграцию со стандартными data-aware-компонентами. Основана на коде Free IB Components |
www.fibplus.net | |||
|
IBObjects |
Набор компонентов для прямого доступа, включающий также визуальные компоненты для работы с базой данных |
www.ibobjects.com | |||
|
InterBase Express (IBX) |
Набор компонентов для работы с базами данных InterBase, позволяющий использовать data-aware- компоненты для представления данных. Продукт основан на коде FreelBComponents и входит в стандартную поставку Borland Delphi/C++ Builder Enterprise Edition |
codecentral.borland.com/ codecentral/ccweb.exe/ author?authorid=102 | |||
|
Zeos Database Objects |
Набор компонентов для работы с различными серверами баз данных, в том числе и InterBase. Позволяет использовать стандартные data- aware-компоненты для представления данных, а также содержит свои собственные визуальные компоненты |
www.zeoslib.org | |||
|
SQLAPI++ |
Библиотека классов для C++, позволяющая работать со многими SQL- серверами, в том числе и InterBase |
www.sqlapi.com | |||
|
Open Source Firebird and InterBase ODBC Driver |
ODBC-драйвер для InterBase/Firebird. Существует в виде открытых кодов. Также поддерживает возможность организации "моста" ODBC-JDBC |
www.ibphoenix.com /ibp_60_odbc.html | |||
|
Gemini InterBase ODBC Driver |
ODBC-драйвер, поддерживает все версии InterBase, начиная с 4.x, а также предоставляет поддержку всех возможностей InterBase 6.5 и Firebird 1.0 |
www.ibdatabase.com | |||
|
IBProvider |
OLE DB-провайдер для доступа к базам данных InterBase. Полностью поддерживает все свойства InterBase б.х/Firebird 1.0 |
WWW. lbprovider.com | |||
|
SIBProvider |
OLE DB-провайдер для доступа к базам данных InterBase |
www.sibprovider.com | |||
|
IBPerl |
Объектно-ориентированная библиотека для PerlS для работы с базами данных InterBase |
www.karwin.com/ibperl | |||
|
DBD .InterBase |
DBI-драйвер для InterBase |
dbi-lnterBase.sourceforge.net | |||
|
PHPLib for InterBase |
Библиотека доступа к InterBase для языка РНР |
www.intelicom.si | |||
|
ADODB - InterBase PHP4 Database Wrapper |
Библиотека доступа к InterBase для языка РНР |
php.weblogs.com/adodb | |||
|
Zope Driver for InterBase |
Библиотека доступа к InterBase для языка Python |
www.zope.org/Members /mcdonc/RS/lnterBaseStorage | |||
|
InterClient |
JDBC-драйвер для доступа к базам данных InterBase из Java |
Включен в стандартную поставку Borland InterBase |
Самый полный и "свежий" список библиотек доступа всегда можно найти на сайте поддержки данной книги www.InterBase-world.com, а также на сайте www.ibase.ru
Строка соединения
В свойстве ServerName укажите имя сервера из списка зарегистрированных (очевидно, что вы можете иметь несколько серверов на разных компьютерах). DatabaseName - это локальный путь к файлу базы данных на сервере. Если вы хотите зарегистрировать новую базу данных в BlazeTop, вы также можете присвоить базе какой-либо псевдоним при помощи свойства AliasName. Для собственно создания базы данных это не является необходимым. Укажите также дополнительные свойства: PageSize (размер страницы базы данных), CharSet (кодировка или кодовая страница по умолчанию для строковых полей), SQLDialect (только для InterBase 6.x и Firebird). Вы можете также создать базу данных от имени любого пользователя, зарегистрированного на сервере.
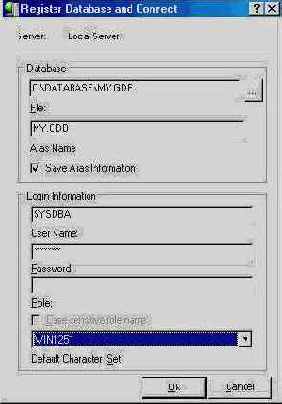
Рис 1.3. Диалог создания базы данных
По умолчанию это, конечно, SYSDBA. Теперь BlazeTop сам создаст необходимый DDL-код для создания базы данных с теми свойствами, которые вы указали. Сначала он сформирует полный путь к базе данных, который называется строкой соединения (connection string).
Вы уже знаете, что создать базу данных при помощи BlazeTop можно как на локальном компьютере, так и на удаленном. Если сервер InterBase находится над машиной под управлением какой-либо версии Windows (именно этот случай мы рассматривали в главе "Установка InterBase" в качестве типичного), а в качестве сетевого протокола установлен TCP/IP, то формат строки соединения, в котором указывается путь к вновь создаваемой базе и имя файла этой базы данных, будет следующий:
<имя_компьютера>:<Путь на компьютере\имя_базы_данных.gdt»
Несколько важных замечаний:
1 Формат строки соединения для других сетевых протоколов здесь не рассматривается - для получения информации о том, как сконфигурировать InterBase для работы по другим протоколам, обратитесь к разделу документации Operation Guide - Network configuration
2 В данном примере рассматривается сл>чай, когда InterBase-сервер (и база данных соответственно) находится на компьютере под >правлением ОС Windows В этом случае путь к базе данных начинается с б>квы диска и каталоги разделяются обратной косой чертой. В случае, если InterBase-сервер и база данных расположены на машине под управлением *шх, то <п\ть на компьютере> будет начинаться с прямой косой черты и выглядеть примерно так:
/opt/database/firstbase.gdb.
Например, если мы создаем базу данных с именем firstbase.gdb у себя на компьютере в каталоге C:\Temp, то строка соединения будет выглядеть следующим образом:
localhost:С:\temp\firstbase.gdb
Здесь localhost - имя компьютера, на котором создается база, C:\Temp - путь к вновь создаваемой базе данных, firstbase.gdb - имя базы данных. Localhost - это имя, зарезервированное для текущего (т.е. локального, Вашего, того, на котором запускаете программу) компьютера. Если понадобится создать базу данных на удаленном компьютере, например, server_nt, где-нибудь в каталоге CAdatabase, то путь будет, соответственно:
server_nt:C:\database\firstbase.gdb
Если на компьютере server_nt не будет каталога C:\Database, то вы получите ошибку. Также ошибка создания возникнет, если на server_nt не запущен (или вообще не установлен) InterBase - т. е. просто некому будет обработать запрос на создание базы данных. Момент создания и подключения к базе данных обычно вызывает массу проблем у новичков — они не сразу понимают, как правильно составить строку соединения. Запомните, что надо указывать путь к базе данных на том компьютере, где она находится (или будет находиться, если мы создаем базу).
Помните, что имена netbios sharename, присваиваемые каталогам, отданным в совместное использование, никакого отношения к <пути_на_компьютере> не имеют Также нет необходимости (и очень нежелательно с точки зрения безопасности) предоставлять разрешения на дост> п к файлам баз данных пользователям
Таблицы. Первичные ключи и генераторы
InterBase - это реляционная СУБД. Помимо всего прочего это означает, что все данные в InterBase хранятся в виде таблиц. Таблица, как ее понимают с точки зрения SQL, очень похожа на обычную таблицу, которую можно нарисовать от руки на листе бумаги или создать в программе вроде Microsoft Excel. У таблиц в InterBase имеются столбцы и строки, в которых размещаются данные. Таблица обязательно имеет имя, уникальное в пределах одной базы данных. Таблицы являются основным хранилищем информации в базе данных, и поэтому необходимо ответственно относиться к созданию таблиц.
Существуют правила, описывающие, как создавать таблицы в реляционной базе данных, отражающие данные реального мира и в то же время позволяющие организовать эффективное хранение информации с базе данных. Процесс применения этих правил для проектирования "правильной" базы данных называется нормализаг/ией. Мы не зря взяли слово "правильной" в кавычки, потому что "нормализованная база данных" и "оптимизированная база данных" не являются синонимами. Необходимо не просто слепо следовать правилам нормализации, но и всегда делать поправку на условия конкретной задачи.
Нормализация таблиц в базе данных хорошо и подробно рассмотрена в книге [14J, и потому мы не будем пытаться объять необъятное и вернемся к нашей конкретной области - к таблицам InterBase. Рассмотрим синтаксис предложения DDL (DDL - это Data Definition Language, подробнее см. в глоссарии), которое позволяет создавать таблицы:
CREATE TABLE table [EXTERNAL [FILE] "<filespec>"]
( <col_def> [, <col_def> | <tconstraint> ...]);
Здесь table - имя создаваемой таблицы, <col_def> - описание столбцов (иногда мы будем говорить - полей) создаваемой таблицы. Опция table [EXTERNAL [FILE] "<filespec>"] означает, что будет создана так называемая внешняя таблица, которая хранится не в общем файле базы данных, а в отдельном файле с именем <filespec>.
Как видите, все просто - определяем имя таблицы и столбцы, которые в нее входят. Теперь надо подробнее рассмотреть, как определить столбцы. Синтаксис создания столбца описывается следующим предложением DDL:
<col_def> = col { datatype COMPUTED [BY] (< expr>) | domain}
[DEFAULT { literal NULL | USER}]
[NOT NULL] [ <col_constraint>]
[COLLATE collation]
Довольно большое определение, однако лишь небольшая часть приведенных в определении столбца предложений является обязательной. Каждый столбец в таблице должен иметь имя, уникальное в пределах таблицы, а также либо тип данных, определяемый предложением datatype, либо выражение <ехрг> для вычисления значения столбца (для вычисляемых столбцов), либо домен (см. ниже), определяемый domain. Типы данных были рассмотрены в главе "Типы данных", поэтому вы легко можете понять, как формируется SQL-выражение для создания таблицы.
Давайте подключимся к нашей базе данных FIRSTBASE.gdb, созданной ранее в главе "Создаем базу данных", и попробуем поработать с таблицами на практике. Для создания, удаления и модифицирования таблиц подойдет как любой из административных инструментов InterBase - из тех, что перечислены в приложении "Инструменты администратора и разработчика InterBase", так и стандартная утилита isql.exe из комплекта поставки любого клона InterBase.
Вот пример простой таблицы, названной TABLE_EXAMPLE и содержащей 3 поля различных типов:
CREATE TABLE Table_example (
ID INTEGER,
NAME VARCHAR(80),
PRICE_1 DOUBLE PRECISION);
Эта таблица иллюстрирует наиболее часто встречающийся в процессе разработки базы данных случай.
Однако возможны и другие способы определения полей. Например, мы можем задать тип поля, используя домены. Домен - это тип, определяемый пользователем для удобства применения определенных сочетаний параметров типов. Например, можно определить домен D_ID для задания полей идентификаторов. Определив домен, можно воспользоваться им для задания типа поля:
CREATE DOMAIN D_ID AS INTEGER;
CREATE TABLE Table_example (
ID D_ID,
NAME VARCHAR(80) ,
PRICE_1 DOUBLE PRECISION);
При этом поле ID будет иметь тип, определяемый доменом D_ID. Таким образом, определив в домене тип поля, необходимые проверки и ограничения, мы можем многократно применять этот домен для создания полей одинакового назначения, например денежных, без утомительного и таящего в себе опасность ошибиться переписывания определений типов переменных.
Третий способ задать столбец в таблице - это определить его как вычисляемый (COMPUTED BY) и задать условие, согласно которому будет вычисляться его значение. Например, мы можем пожелать иметь в нашей таблице столбец, вычисляющий 10% от значения поля PRICE_1. Для этого мы можем ввести следующую команду:
CREATE TABLE Table_example ( '
ID INTEGER,
NAME VARCHAR(80),
PRICE_1 DOUBLE PRECISION,
PRICE_10 COMPUTED BY (PRICE_1*0.1)) ;
Но не думайте, что теперь, как только мы вставим данные в поле PRICE_1, в поле PRICE_10 окажется десятая часть от значения этого поля. Нет, процесс тут более сложен. На самом деле мы получим искомую десятую часть только при обращении к полю PRICE_10, например при выполнении запроса SELECT
к этой таблице. То есть в вычисляемом поле не хранятся какие-либо данные, а при каждой выборке производится вычисление выражения, связанного с полем, и результат выдается в ответ на запрос.
Итак, мы рассмотрели 3 основных способа задания полей в таблице. Теперь давайте подробнее рассмотрим опции, которые можно задать при создании столбца.
Опция [DEFAULT {literal | NULL | USER}] - позволяет задать значение столбца по умолчанию. Это очень удобная возможность для автоматического заполнения данных. Существует 3 возможности задавать значения по умолчанию. Первая обозначена как literal и позволяет задавать значения по умолчанию в виде текстовых констант, чисел или даты. Например, мы можем сформировать следующие выражения для создания столбца с текстовыми значениями по умолчанию:
NAME VARCHAR(SO) DEFAULT 'Василий Станиславович1
При этом все заносимые в таблицу поля будут принимать значения по умолчанию, т. е. если не было определено другого значения для поля NAME, то там появится строка 'Василий Станиславович'.
Вторая возможность задавать значения по умолчанию это указать DEFAULT NULL в определении столбца. При этом во вновь создаваемых записях значение этого столбца будет NULL, если, конечно, не было явно задано иное значение. Пример:
PRICE_1 DOUBLE PRECISION DEFAULT NULL
И третий способ задать значение по умолчанию - это указать DEFAULT USER в определении столбца. При этом во вновь создаваемых записях в это поле будет заноситься имя текущего пользователя, т. е. пользователя, который установил соединение с InterBase и выполнил эту вставку (подробнее о пользователях см. главу "Безопасность в InterBase: пользователи, роли и права" (ч. 4)).
Для некоторых полей совершенно необходимо, чтобы поле имело какое-то непустое значение. Например, поле, которое по условиям задачи не может быть пустым. Чтобы на уровне базы данных задать ограничение о том, что поле должно иметь какое-то определенное значение, нужно внести следующее добавление в описание столбца:
NAME VARCHAR(SO) NOT NULL
При этом создастся поле, в котором нельзя хранить неопределенные (NULL) значения. Обычно ограничение NOT NULL сочетается с опцией DEFAULT, которая гарантированно присваивает какое-либо корректное значение этому полю.
Но часто ограничения NOT NULL бывает недостаточно. Например, в случае хранения в базе данных каких-либо цен совершенно очевидно, что они не могут принимать отрицательные значения (хотя было бы здорово, чтобы нам приплачивали при покупке какого-нибудь товара). Чтобы заставить сервер проверять заносимые в базу данных значения цен на условие положительности, следует так определить столбец:
PRICE_1 DOUBLE PRECISION CHECK (PRICE_1>0)
При этом заносимые в столбец PRICE_1 значения будут проверяться на условие положительности. Надо отметить, что различные непротиворечивые опции могут сочетаться, например можно задать непустое значение и проверку на положительность:
PRICE_1 DOUBLE PRECISION NOT NULL CHECK (PRICE_1>0)
Некоторые опции при создании столбцов сочетаться не могут, например нельзя задать значение по умолчанию NULL и одновременно ограничение на непустое значение.
Надо отметить, что проверки могут выполнять множество полезных функций по управлению данными в базе данных. Подробнее их использование мы рассмотрим в главе "Ограничения базы данных".
Итак, мы рассмотрели способы создания таблиц и полей с различными опциями.
Однако бывают случаи, когда необходимо изменить уже существующую таблицу. Конечно, мы можем пересоздать таблицу целиком. Для этого следует выполнить команду удаления таблицы и вновь создать ее, например так:
DROP TABLE Table_example;
CREATE TABLE Table_example(ID NUMERIC(15,2);
Но такой способ изменения таблиц имеет значительные недостатки. При удалении таблицы с помощью команды DROP все данные, которые существовали в таблице, уничтожаются и, чтобы их не потерять, приходится копировать их во временные таблицы. Это весьма хлопотно. Поэтому для легкого изменения структуры таблиц существует команда ALTER TABLE, которая позволяет добавлять новые поля, удалять существующие, а также добавлять/удалять ограничения ссылочной целостности.
Например, мы желаем добавить в таблицу еще один столбец, предназначенный для хранения данных об отчестве человека:
ALTER TABLE Table_example ADD Patronimic VARCHAR(SO);
После выполнения этой команды в нашей таблице Table_example появится новый столбец с именем Patronimic и типом VARCHAR(SO). А если мы пожелаем удалить из таблицы столбец с именем NAME, то следует выполнить
ALTER TABLE Table_example DROP Name;
Полный синтаксис предложения ALTER TABLE можно узнать в [1]. Это очень полезная команда, и мы будем часто ею пользоваться.
А что делать, спросите вы, если надо изменить сам столбец? Например, мы решили, что для хранения имен лучше использовать поле HUMAN_NAME, а не просто NAME. В этом случае мы можем применить команду ALTER TABLE <table> ALTER COLUMN, которая позволяет изменять наименование столбца.
Это новая команда, поддерживаемая только в InterBase 6.x и его клонах. В InterBase более ранних версий для изменения имени и любых параметров столбца пришлось бы создавать временное поле, удалять существующий столбец, создавать новый - с нужным именем и параметрами - и затем копировать данные из временного поля в новый столбец. А в 6-м InterBase это можно сделать одной командой, например такой:
ALTER TABLE Table_example
ALTER COLUMN NAME TO HUMAN_NAME;
Если же мы решили изменить тип поля, например увеличить число символов, хранимых в поле, то придется изменять домен этого поля, используя предложение ALTER DOMAIN (см. выше главу "Типы данных").
Итак, мы рассмотрели создание и модификацию таблиц в InterBase. Теперь придется немного углубиться в теорию баз данных. InterBase, как уже было сказано, является реляционной базой данных. Помимо всего прочего это означает, что каждая запись в таблице должна иметь некоторый признак, по которому одну запись можно отличить от другой. Для этой цели служит специальный механизм уникальных ключей.
Тип данных BLOB
Тип данных BLOB предназначен для хранения большого количества данных переменного размера. Тип BLOB позволяет хранить данные, которые не могут быть помещены в поля других типов, - например, картинки, музыкальные файлы, видеофрагменты и т. д.
Чтобы определить самое простое поле типа BLOB в таблице, не нужно ничего сверх того, что обычно требуется для определения поля любого элементарного типа:
CREATE TABLE testBLOB(
myBlobField BLOB);
В результате будет создано поле myBlobField, в котором можно хранить данные большого размера. Но несмотря на то что поля BLOB по способу определения никак не отличаются от других, реализация их внутри базы данных значительно отличается. He-BLOB-поля расположены на странице данных (см. главу "Структура базы данных InterBase" (ч. 4)) рядом друг с другом, а в случае BLOB на странице данных хранится только идентификатор BLOB, а сам BLOB располагается на специальной странице. Именно такая организация данных позволяет хранить данные нефиксированного размера.
У типа BLOB имеется возможность определять набор нескольких подтипов и специальных процедур, называемых фильтрами (BLOB filters), для работы с этими подтипами. Существует несколько предопределенных подтипов BLOB, которые встроены в InterBase. Все эти подтипы имеют неотрицательные номера, например subtype 0 - это данные неопределенного типа, subtype 1 - текст, subtype 2 - BLR (Binary Language Representation, см. глоссарий и главу "Структура базы данных InterBase") и т. д. Пользователь также может определять свои подтипы BLOB, которые могут иметь отрицательные значения. Каждому типу может быть поставлен в соответствие фильтр, который преобразует поле этого подтипа в другой подтип.
Надо отметить, что использование BLOB-полей обычно служит альтернативой хранению внешних относительно базы данных файлов. Что касается фильтров BLOB, то они используются достаточно редко по причине своей ориентации на узкий класс задач.
Типы данных
Несмотря на то, что типы данных подробно описаны в документации (см. [1, гл. 4]), необходимо рассмотреть ряд понятий, которые будут часто использоваться в последующих главах книги. Помимо изложения сведений общего характера будут рассмотрены также примеры использования типов данных в базах данных InterBase и изложены рекомендации по их использованию и преобразованию. Также подробно рассмотрим отличия в типах данных, существующие 1-м и 3-м диалектах базы данных InterBase.
Типы данных для хранения текста
В InterBase существует два типа, предназначенных для хранения текстовой информации - CHAR и VARCHAR. Полные их названия, - CHARACTER и CHARACTER VARYING, однако нет никакой причины пользоваться длинными именами - даже команда Show tables в утилите isql выдает краткие наименования типов.
Чтобы определить поле или переменную символьного типа, необходимо в скобках после имени типа либо указать число символов, которое будет использоваться в определяемом объекте, либо опустить число символов - при этом будет создано поле с длиной 1 символ.
CREATE TABLE testCHARLen(
Fieldl CHAR(255),
Field2 CHAR);
В результате создания этой таблицы поле Fieldl будет иметь длину 255 символов, a Field2 - 1 символ.
Типы CHAR и VARCHAR во многом схожи - оба могут содержать до 32768 символов, однако есть и отличия. Хотя хранятся эти два типа в базе данных одинаково, но работает с ними InterBase по-разному. Это можно продемонстрировать следующим примером:
SQL> create table testCHAR ( cl char(10), c2 varchar(10));
SQL> insert into testCHAR(cl,c2) values('Test','Test');
SQL> SELECT '{' |cl||')', '('||c2 |')' from testCHAR;
В результате получим следующий результат:
(Test ) (Test)
Как видите, после значения Test', выбранного из поля cl, оказались пробелы. Это означает, что при выборке данных из поля типа CHAR возвращаемое значение дополняется пробелами до полной длины поля. Сложно предположить, для чего необходимо подобное поведение, которое приводит к значительному увеличению сетевого трафика (загрузки сети).
В любом случае рекомендованным к использованию символьным типом является VARCHAR.
Одной из важнейших характеристик символьного типа является его набор символов - CHARACTER SET. Набор символов определяется для всей базы данных и используется по умолчанию для всех символьных полей, если не переопределяется явно при создании поля.
Чтобы создать символьное поле с явным указанием набора символов, необходимо в описании столбца (в предложениях CREATE TABLE или ALTER TABLE) добавить описание набора символов. Для поддержки русского языка обычно используется набор символов WEN1251 (подробнее об использовании русского языка в InterBase см. главу "Русификация InterBase" (ч. 1)). Вот пример таблицы, содержащей символьное поле с явно описанным набором символов WIN1251:
CREATE TABLE TestCHARSET(
Fieldl VARCHAR(255),
Field2 VARCHAR(255) CHARACTER SET winl251);
Здесь Fieldl - поле без явного указания набора символов, поэтому для него будет использоваться тот набор символов, который был указан при создании базы данных. Для поля Field2 явно определено, что в нем будут храниться символы в кодировке WIN 1251.
Помимо указания набора символов, для символьных полей возможно также указывать порядок сортировки (COLLATION ORDER), который определяет, как будут сортироваться символы этого набора данных. Для русского языка существуют два варианта сортировки - WIN1251 и PXW_CYRL. Подробнее об использовании COLLATION ORDER рассказано в главе "Русификация InterBase".
Полный список наборов символов и применяемых для них COLLATION ORDER можно найти в документации [1, гл. 13].
Внимание! В документации на InterBase 6 сказано, что символьных типов 4: помимо указанных выше типов данных существуют еще NCHAR и NCHAR VARYING, однако ниже в той же документации объясняется, что последние два типа являются теми же типами CHAR и VARCHAR, только используют по умолчанию набор символов ISO8859_1. To есть фактически использование псевдотипа NCHAR равносильно применению CHAR DEFAULT CHARACTER SET ISO8859_1. Аналогично и для NCHAR VARYING, только там вместо CHAR используется VARCHAR. Очевидно, что применение этих псевдотипов ориентировано на пользователей в Западной Европе и США, для поддержки языков в которых и создан набор символов ISO8859_1.
Типы данных с фиксированной точкой
К этим типам данных относятся NUMERIC и DECIMAL. Часто звучит вопрос, чем NUMERIC отличается от DECIMAL. Оба этих типа имеют одинаковую разрядность - от 1 до 18 знаков, одинаковую точность - от нуля до разрядности.
Напомним, что разрядность - это общее число цифр в числе, а точность - число знаков после запятой
Самое забавное, что. несмотря на то что в документации написано, что эти типы отличаются максимальной разрядностью, на самом деле реализованы они практически одинаково и разницы между ними никакой нет! Вы легко можете это проверить, запустив утилиту isql и произведя нижеследующую очередность действий.
Создаем таблицу следующего вида:
SQL> CREATE TABLE test (
CON> Num_field NUMERIC(15,2),
CON> Dec_field DECIMAL(15,2));
Затем даем команду показать структуру таблицы:
SQL> show tables test;
И наблюдаем такую картину:
NUM_FIELD NUMERIC(15, 2) Nullable
DEC_FIELD NUMERIC(15, 2) Nullable
Как видите. InterBase сообщает о том. что оба данных столбцы имеют тип NUMERIC!
Причины такого поведения лежат в реализации типов данных с фиксированной точкой. Дело в том, что InterBase имеет всего 3 механизма хранения любого целочисленного выражения, и все типы, как бы они ни назывались, приводятся к этим вариантам реализации.
Вот таблица из [1], которая иллюстрирует, как хранятся различные целочисленные типы (табл. 1.1). Как видите, хранение данных в 3-м диалекте отличается для чисел с большой разрядностью:
Табл 1.1. Хранение чисел с фиксированной точкой
|
Разрядность |
Диалект 1 |
Диалект З | |||||||
|
От 1 до 4 |
SMALLINT для NUMERIC INTEGER для DECIMAL |
SMALLINT | |||||||
|
От 5 до 9 |
INTEGER |
INTEGER | |||||||
|
От 10 до 18 |
DOUBLE PRECISION |
INT64 | |||||||
Итак, теперь мы точно можем сказать, чем отличаются типы NUMERIC и DECIMAL: в случае определения поля (переменной) с малой разрядностью (до четырех) первый хранится в виде 2 байтового целого числа SMALLINT, а второй - в виде 4 байтового INTEGER.
Таким образом, в случае разрядности, большей четырех, типы DECIMAL и NUMERIC окажутся абсолютно эквивалентными!
Обратите внимание на отличие реализации типов с большой разрядностью в 1-м и 3-м диалектах. В 1-м диалекте число с фиксированной точкой превращалось из целого в вещественное, к которому применялись механизмы округления! В 3-м диалекте эта странность была ликвидирована - большие целые числа хранятся действительно как целые - с использованием механизма INT64, который может хранить 64-битовые числа в диапазоне +/- 2Л32. Поэтому рекомендуется хранить данные о денежных средствах в базах данных, созданных с использованием 3-го диалекта, - только при использовании механизма INT64 можно гарантировать сохранность малых денежных остатков.
Типы для хранения даты и времени
Типы для хранения даты и времени изменились в версии InterBase 6.x и его клонах по сравнению с 4.x и 5.x. Чтобы не путаться в исторических хитросплетениях с этими типами, рассмотрим ситуацию именно в 6-й версии InterBase, а затем на основе этого кратко упомянем о том, что было раньше, - это делается для тех пользователей, кто все еще работает на ранних версиях InterBase
Итак, в InterBase 6.x существует 3 типа для хранения даты и времени - это DATE, TIME и ТГМЕ8ТАМР.
Тип DATE хранит даты с точностью до дня. Диапазон возможных значений - от 1 января 100 года н. э. до 29 февраля 32768 года.
Тип TIME хранит данные о времени с точностью до десятитысячной доли секунды. Диапазон возможных значений - от 00:00 AM до 23:59.9999 РМ.
Тип TIMESTAMP представляет собой комбинацию типов DATE и TIME.
Как работать с датами? Если речь идет о работе на уровне сервера в хранимых процедурах или триггерах, то все достаточно просто - мы всегда можем объявить переменную нужного нам типа и присваивать ей значения из таблиц и наоборот. Однако необходимо передавать данные из базы данных в приложение и обратно. В этом случае есть два подхода - либо использовать библиотеки, которые применяют оригинальный формат дат InterBase для доступа к объектам этих типов и преобразуют этот формат в привычные внутриязыковые типы даты/времени (примером такой библиотеки является FIBPlus), либо использовать механизм преобразования дат в строки, встроенный в InterBase.
Что делать, если нужно вырезать из полной даты только год или месяц? Для этого используется группа функций EXTRACT (доступная во всех клонах InterBase 6.x), которая позволяет выделить из даты только нужную часть. Используются эти функции следующим образом:
EXTRACT (MONTH FROM DATE_FIELD)
EXTRACT (YEAR FROM DATE_FIELD)
Полный список параметров в функции EXTRACT таков: YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, WEEKDAY, YEARDAY. Их назначение очевидно следует из их названия, поэтому не будем приводить здесь расшифровки.
Триггеры
Триггеры - одно из замечательнейших изобретений разработчиков баз данных. Триггеры позволяют придать "активность" данным, хранящимся в базе данных, централизовать их обработку и упростить логику клиентских приложений.
Что же такое триггер?
Триггер в InterBase - это особый вид хранимой процедуры, которая выполняется автоматически при вставке, удалении или модификации записи таблицы или представления (view). Триггеры могут "срабатывать" непосредственно до или сразу же после указанного события.
Может быть, это звучит достаточно сложно, однако, как это бывает во многих случаях, сама идея, лежащая в основе триггеров, очень проста.
Как вы знаете. SQL дает возможность нам вставлять, удалять и модифицировать данные в таблицах базы данных при помощи соответствующих команд - INSERT, DELETE и UPDATE. Согласитесь, что было бы неплохо иметь возможность перехватить передаваемую команду и что-нибудь сделать с данными, которые добавляются, удаляются или изменяются. Например, записать эти данные в специальную табличку, а заодно записать, кто и когда произвел операцию над данной таблицей. Или сразу же проверить вставляемые данные на какое- нибудь хитрое условие, которое невозможно реализовать с помощью опции CHECK (см. выше главу "Ограничения базы данных"), и в зависимости от результатов проверки принять проводимые изменения или отвергнуть их; изменить эти данные на основании какого-либо запроса или изменить данные в других связанных таблицах.
Вот для того, чтобы выполнять какие-либо действия, связанные с изменением данных в базе данных, и существуют триггеры.
Фактически триггер представляет собой набор команд процедурного языка InterBase, который исполняется при выполнении операций TNSERT/DELETE/UPDATE В отличие от хранимых процедур, триггер никогда ничего не возвращает (да и некому возвращать. ведь триггер явно не вызывается) По той же причине он не имеет также входных параметров, но вместо них имеет контекстные переменные NEW и OLD. Эти переменные позволяют получить доступ к полям таблицы, к которой присоединен триггер (мы расскажем об этом чуть позже).
Триггеру предназначена роль виртуального цензора, который просматривает "письма" и который волен сделать все, что угодно, - пропустить их неизменными, подправить их, просигнализировать об ошибках или даже "доложить об этом" кому следует.
Триггер всегда привязан к какой-то определенной таблице или представлению и может "перехватывать" данные только этой таблицы. Давайте рассмотрим классификацию триггеров и назначение каждого вида. Как уже было сказано, существует 3 основных SQL-операции, применимые к данным, - INSERT/DELETE/UPDATE. Соответственно первое разделение триггеров - по обслуживаемым операциям. Каждый конкретный триггер привязан к какой-либо операции, т. е. триггер срабатывает, когда в "его" таблице происходит данная операция.
В клоне Yaffil 1 0 реализована поддержка универсальных триггеров, срабатывающих при любой операции.
Также срабатывание триггера может происходить "до" и "после" операции. Таким образом, мы получаем 6 возможных видов триггеров на таблицу - до и после каждой из трех возможных SQL-операций.
Удаление ограничений
Часто приходится удапять различные ограничения по самым разным причинам. Чтобы удалить ограничение, необходимо воспользоваться предложением ALTER TABLE следующего вида:
ALTER TABLE cablename
DROP CONSTRAINT constraintname
где constraintname - имя ограничения, которое следует удалять. Если при создании ограничения было задано какое-то имя, то следует им воспользоваться, а если нет, то надо открыть какое-либо средство администрирования InterBase, поискать все связанные с ним ограничения и выяснить, какое системное имя сгенерировал InterBase для искомого ограничения.
Надо отметить, что удалять ограничения может только владелец таблицы или системный администратор SYSDBA.
Управление состоянием триггера
По умолчанию триггер создается активным, т. е. он будет срабатывать при осуществлении соответствующей операции. Состоянием триггера управляет ключевое слово ACTIVE в заголовке Если же триггер сделать неактивным, то он не будет исполняться при возникновении операции. Это бывает полезным при осуществлении каких-либо внеплановых операций надданными, например массовой заливке данных или ручном исправлении данных. Чтобы отключить триггер, необходимо выполнить команду DDL:
ALTER TRIGGER <tngger_name> INACTIVE;
Обратите внимание, что это команда относится к Data Definition'Language, и ее нельзя вызвать из хранимых процедур или других триггеров. Вообще говоря, существует способ управлять состоянием триггеров с помощью модификации системных таблиц. Конечно, модификация системных таблиц является недокументированным способом работы с триггерами и рекомендовать ее мы не будем, но для иллюстрации возможностей работы с системными таблицами InterBase приведем пример. Для того чтобы установить состояние триггера в INACTIVE, достаточно выполнить следующую команду:
UPDATE rdb$triggers trg
SET erg id£>$t.rigger_inactive = l
WHERE trg.rdb$trigger_name='TABLE_EXAMPLE_AD0'
Эта команда аналогична по действию вышеприведенной команде DDL, но ее можно вызывать в других триггерах и процедурах.
Тут следует лишить вас некоторых надежд, которые могли зародиться, когда вы увидели, что метаданные триггеров можно с легкостью изменять с помощью обычного SQL-запроса. Часто такую возможность принимают за хороший способ управлять цепочками триггеров, т е. в одном триггере или хранимой процедуре включать или выключать нужные триггеры и таким образом управлять обработкой данных, включая или выключая нужные триггеры Однако изменять состояние триггеров "налету" не удастся.
Дело в том, что триггеры работают в рамках той же транзакции, что и вызвавшее их изменение. Поэтому если один триггер изменит состояние другого в зависимости от каких-либо условий, то механизм "активных таблиц", который занимается запуском триггеров (хоть мы и говорим, что триггер запускается неявно, но "кто-то внутри сервера" должен их все-таки запускать!), не увидит эти изменения, так как они еще не подтверждены! Таким образом, в рамках одной транзакции нельзя управлять состоянием триггеров.
Если сделать подтверждение транзакции, в которой выполнился первый триггер, который выключил (или включил) второй триггер, а затем запустить снова транзакцию, то мы увидим изменения в состоянии второго триггера. Но какой смысл это делать, ведь суть идеи состояла в том, чтобы включать триггеры на лету, не теряя значения в буфере контекстных переменных NEW или OLD.
В общем, это был пример того, что не следует делать в триггерах. Другим примером того, чего не следует делать в триггерах, является изменение данных в той же таблице, к которой привязан триггер, не через контекстные переменные, а с помощью обычных SQL-команд INSERT/UPDATE/DELETE. Например некий триггер на вставку вызывает хранимую процедуру, внутри которой происходит вставка записи в ту же таблицу. Вставка опять вызовет срабатывание нашего триггера, и возникнет зацикливание. Следует очень внимательно относиться к использованию триггеров, так как зацикливание в ряде случаев может привести к аварийному завершению сервера InterBase.
Уровни изоляции транзакций
Как уже было сказано выше, транзакции обеспечивают изолирование проводящихся в их контексте изменений, так что эти изменения невидимы пользователям вплоть до подтверждения транзакции. Но вот вопрос: а должна ли транзакция видеть те изменения, которые были подтверждены другими транзакциями уже после ее запуска? Вот пример.
Допустим, у нас есть таблица с данными, к которой обращаются два пользователя одновременно - один из них изменяет данные, а второй читает. Возникает вопрос, должен ли (или может ли) пользователь, читающий таблицу, видеть изменения, производимые другим пользователем.
Должен или нет - это определяется уровнем изоляции.
Уровень изолированности транзакции определяет, какие изменения, сделанные в других транзакциях, будут видны в данной транзакции.
Каждая транзакция имеет свой уровень изоляции, который устанавливается при ее запуске и остается неизменным в течение всей ее жизни.
Транзакции в InterBase могут иметь 3 основных возможных уровня изоляции: READ COMMITTED, SNAPSHOT и SNAPSHOT TABLE STABILITY. Каждый из этих трех уровней изоляции определяет правила видимости тех действий, которые выполняются другими транзакциями. Давайте рассмотрим уровни изоляции более подробно.
READ COMMITTED. Буквально переводится как "читать подтвержденные данные", однако это не совсем (точнее, не всегда) так. Уровень изоляции READ COMMITTED используется, когда мы желаем видеть все подтвержденные результаты параллельно выполняющихся (т. е. в рамках других транзакций) действий. Этот уровень изоляции гарантирует, что мы НЕ сможем прочитать неподтвержденные данные, измененные в других транзакциях, и делает ВОЗМОЖНЫМ прочитать подтвержденные данные.
SNAPSHOT. Этот уровень изоляции используется для создания "моментального" снимка базы данных. Все операции чтения данных, выполняемые в рамках транзакции с уровнем изоляции SNAPSHOT, будут видеть только состояние базы данных на момент начала запуска транзакции. Все изменения, сделанные в параллельных подтвержденных (и разумеется, неподтвержденных) транзакциях, не видны в этой транзакции. В то же время SNAPSHOT не блокирует данные, которые он не изменяет.
SNAPSHOT TABLE STABILITY. Это уровень изоляции также создает "моментальный" снимок базы данных, но одновременно блокирует на запись данные, задействованные в операциях, выполняемые данной транзакцией. Это означает, что если транзакция SNAPSHOT TABLE STABILITY изменила данные в какой-нибудь таблице, то после этого данные в этой таблице уже не могут быть изменены в других параллельных транзакциях. Кроме того, транзакции с уровнем изоляции SNAPSHOT TABLE STABILITY не могут получить доступ к таблице, если данные в них уже изменяются в контексте других транзакций.
User Defined Functions
Зачастую от программистов, использующих другие серверы баз данных, можно услышать мнение, что SQL InterBase не отличается большим разнообразием встроенных функций. Формально такая точка зрения имеет основания, однако разработчики InterBase сознательно пошли на это ограничение. Как уже неоднократно было сказано, InterBase отличается скромными системными требованиями и занимает мало места на жестком диске. Небольшой совокупный размер файлов продиктован, в частности, тем, что InterBase не перегружен разнообразными дополнительными и, в общем-то, редко используемыми функциями Зато InterBase включает возможность расширить стандартный набор функций любыми дополнениями, которые нужны в конкретной базе данных. Таким образом, разработчик может реализовать для своих приложений даже такие функции, которые никогда не входят в поставку серверов баз данных.
Ускорение выполнения запросов с помощью индексов
Выше описано, что применение индексов может значительно ускорить выполнение запросов. Это действительно так для большинства случаев, но есть и определенные оговорки. Сначала ответим на вопрос, часто возникающий у тех, кто познакомился с индексами. Раз индексы ускоряют выборку из базы данных, почему бы не проиндексировать все поля в таблице? Есть два момента, препятствующих всеобщей индексации, - это дисковое пространство и издержки при модификации данных в таблице. Каждый создаваемый индекс имеет объем, равный объему данных в индексированном поле, плюс объем данных о расположении записей. Если создать индексы на каждое поле в таблице, то их суммарный объем будет больше, чем объем данных в таблице! Поэтому создание большого количества индексов приводит к большому расходу дискового пространства.
Второй момент более важен - это издержки при модификации данных в таблице. В реляционной СУБД, как вы знаете, записи в таблицах неупорядочены и потому добавление/удаление записей происходят без значительных затрат ресурсов сервера. Даже если удаляется запись из середины базы данных, то не происходит перемещения объемов данных для того, чтобы закрыть "дыру", - это попросту не нужно: сервер просто пометит освободившееся место и при случае запишет туда что-нибудь. Что касается добавления, то оно почти всегда происходит в конец таблицы. Однако хотя основные данные в таблице и не "дергаются" сервером при модификации, но данные, хранящиеся в индексах, переупорядочиваются каждый раз при добавлении/удалении записей! То есть серверу при добавлении записи в середину таблицы, например, приходится перестраивать индекс! Конечно, реализация индекса некоторым образом рассчитана на частые перестройки, но эти действия все же занимают время и ресурсы процессора и при слишком большом количестве индексов в таблице модификация данных в ней может быть в десятки раз медленнее, чем у такой же таблицы без индексов!
Это две основные причины, которые препятствуют всеобщей индексации. Помимо них есть и еще несколько замечаний, ограничивающих применение индекса. Первое - это правило 20 %. Оно гласит, что если запрос на выборку возвращает более 20 % записей из таблицы, то использование индекса может замедлить выборку данных! Конечно, ситуация зависит от конкретного запроса и условий, наложенных на выборку, но нужно помнить, что 20 % записей являются порогом, когда эффективность использования индексов ставится под вопрос. Второе замечание формулируется не так очевидно. Оно связано с работой оптимизатора InterBase.
Оптимизатор - это совокупность механизмов, которые разрабатывают таи выполнения запроса. Когда пользователь передает InterBase какой-либо SQL-запрос, он указывает, ЧТО должен вернуть сервер в результате выполнения запроса, но не определяет, КАК сервер должен выполнять запрос. Оптимизатор на основе переданного запроса строит план его выполнения, т. е. откуда и в каком порядке будут браться данные для выполнения запроса, какие индексы будут при этом использоваться. Когда сервер анализирует условия на выборку (это в основном части выражения WHERE, ORDER BY и т. д.), то для каждого поля, входящего в условие, сервер пытается использовать индекс. К сожалению, алгоритм создания плана несовершенен и оптимизатор часто использует индексы, которые не слишком эффективны для конкретного запроса, из-за чего может существенно замедлиться время выполнения. Поэтому создание лишних индексов может привести к созданию неоптимальных планов.
Надо отметить, что в клоне Yaffil эта проблема разрешена за счет использования современных алгоритмов построения пчанов.
Третьим случаем, когда индекс не нужен, являются поля с ограниченным набором значений - например, поле, которое хранит информацию о поле человека и содержит только два возможных значения - "м" и "ж"; нет никакого смысла индексировать это поле.
Итак, основные ограничения на создание индексов мы рассмотрели. Теперь следует рассмотреть вопрос, когда следует использовать индексы, чтобы добиться улучшения производительности. Существует 3 основных случая, когда необходимо проиндексировать поле:
Когда это поле используется в условиях поиска в запросах.
Когда соединения таблиц (JOIN) используют это поле.
Когда это поле используется в предложениях сортировки ORDER BY.
Если поле применяется указанным выше образом, то создание индекса на него может привести к улучшению производительности запроса.
Давайте рассмотрим синтаксис создания индексов. Вот полный формат команды DDL, который позволяет создавать индексы:
CREATE [UNIQUE] [ASC[ENDING] | DESC[ENDING]]
INDEX index ON table (col [, col ...]);
Минимальным выражением, создающим индекс, является следующее:
CREATE INDEX my_index ON Table_example(ID)
В этом примере создается индекс с именем my_index для таблицы Table_example, причем индексированным полем является поле ID. Индекс является возрастающим, т. е. значения в нем упорядочены по возрастанию, а также неуникальным, т. е. значит, что поле ID может иметь несколько одинаковых значений. Это, конечно же, самый простой пример индекса - самый распространенный.
Как видно из описания синтаксиса, индекс может содержать не одно, а несколько полей. Такой индекс используется при часто выполняющихся запросах, которые содержат в условиях поиска или сортировки сочетание индексированных полей. Например, если у нас есть таблица, содержащая поля Фамилия, Имя, Отчество, то при запросе, использующем сортировку по ФИО, будет применен 1акой индекс. Вообще говоря, необязательно вводить условия на все 3 поля, применяемые в индексе, чтобы использовать его преимущества. Если мы желаем сортировать результат запроса, то индекс будет использован в случае, если первое поле в условии сортировки совпадает с первым полем в индексе, например наш индекс будет задействован в случае сортировки по Фамилии и Имени.
В документации для оптимизации выполнения запроса, содержащего в предложении WHERE соединение полей с условием OR рекомендуется, использовать не составной индекс, а несколько одинарных индексов на все поля, входящие в условие OR.
К вопросу о порядке сортировки индекса: как видно, он может быть либо возрастающим (ASQENDING]), либо убывающим (DESCENDING]). Зачем нужны разные порядки сортировки? Очевидно, для разных сортировок! Если мы желаем сортировать людей по фамилии в возрастающем порядке, то создаем возрастающий индекс (ASC), а если в убывающем (от Я до А) - то убывающий! А если хотим и то и другое, то необходимо создавать оба индекса.
Установка
После запуска инсталлятора появится оповещение о том, что ставится именно та версия, которая нам нужна, - в данном случае Firebird 1.0. Нажмите Next для перехода к следующему шагу установки. На экране появится текст InterBase Public License. Выберите I agree и перейдите к следующему шагу. Появится окно, в котором предлагается выбрать путь для установки Firebird. Это важная опция. Обычно по умолчанию инсталлятор предлагает путь C:\Program FilesMnterBase. Однако часто имеет смысл переопределить этот путь во что-то вроде C:\IBServer.
Выбрав путь для установки, нажмите Next для перехода к следующему шагу установки. При этом на экране появится окно, изображенное на рис. 1.1. (вполне возможно, что дизайн его может отличаться для различных версий InterBase, но смысл остается тем же). На этом шаге мы выберем компоненты, необходимые для работы. Этот выбор достаточно прост - выберите все компоненты, находящиеся в списке. Как видите, они займут весьма скромное место на диске - всего около 16 Мбайт.
Если же на компьютере, куда устанавливается InterBase, существует недостаток дискового пространства, то можете ограничиться только опциями Server for Windows, Client for Windows и Command Line Tools. Абсолютно минимальная установка InterBase описана в главе «Установка InterBase - взгляд изнутри» (ч. 4).
Нажмите Next для перехода к следующему шагу.
Внимание! В этот момент инсталлятор может выдать сообщение «InterBase is running on this machine...» и прекратить установку. Это означает, что на компьютере уже установлен и запущен InterBase (возможно, он был установлен вместе с Delphi). В этом случае надо удалить предыдущую версию InterBase, согласно рекомендациям раздела «Подготовка к установке». После чего можно продолжить установку.
Если же после выбора компонентов не возникло никаких проблем и началось копирование файлов, то все в порядке, просто дождитесь завершения копирования, затем нажмите Finish.
Вот и все - установка InterBase закончилась. Обратите внимание, что для ее завершения не понадобилась перезагрузка компьютера - сервер уже запустился. Если вы используете ОС Windows 95/98/Ме, то работающий InterBase отобразится на панели задач в виде значка среди системных иконок, если NT 4/2000 - то сервер запустится как служба (service) и на экране никак его функционирование не отразится - наблюдать за его статусом и управлять работой можно лишь через апплет «Панели управления» «InterBase Manager» или через аплет «Службы» («Services»).
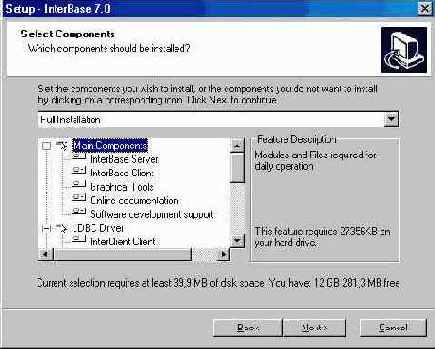
Рис 1.1. Выбор компонентов при установке Firebird
Установка инструментария для админист рирования InterBase
С InterBase всегда поставляются средства администрирования командной строки. Это очень мощные средства, которые мы будем постоянно применять для работы с примерами в этой книге. Однако пользователи привыкли использовать инструменты с графическим интерфейсом пользователя.
Вместе с InterBase поставляется один инструмент администрирования - IBConsole. К сожалению, этот инструмент недостаточно надежен и удобен, чтобы пользоваться им для администрирования InterBase и тем более для разработки баз данных.
К счастью, существует множество отличных инструментов от сторонних разработчиков (т. е. не работающих в компании Borland), которые удовлетворяют самым изысканным потребностям администратора и разработчика InterBase.
Среди самых известных и популярных можно перечислить InterBase Expert, IBManagen, IBWorkbench и IBAdmin. Часть из этих продуктов являются свободно распространяемым (freeware), т. е. они полностью бесплатные, другая часть - условно бесплатные (shareware), т. е. имеется возможность использования ознакомительной версии. Со списком различных полезных инструментов и их краткими характеристиками можно ознакомиться в приложении "Инструменты администратора и разработчика InterBase".
Выберите инстр\мент по своему вкусу. Ряд этих продуктов разрабатывается российскими программистами, которые, понимая экономическую ситуацию в РФ и ближнем зарубежье, позволяют коллегам из бывшего СССР пользоваться своими инструментами бесплатно! Поэтому обязательно воспользуйтесь предоставленной возможностью и обзаведитесь удобным инструментом для работы с InterBase.
Все примеры в книге рассчитаны и на использование стандартного инструмента isql или других утилит командной строки, если это не оговорено особо. Но зачем делать что-то неудобным способом, когда есть прекрасная возможность избежать рутинной работы и потратить время на творчество?
Установка InterBase
Перед тем как начать разрабатывать приложения баз данных с помощью InterBase, необходимо позаботиться о его установке. Обычно InterBase устанавливают как на сервер, так и на рабочую станцию программиста, разрабатывающего приложение. Разработчику InterBase нужен для внутренних экспериментов и отладки рабочих версий базы данных и программ, a InterBase на сервере используется для тестирования программы пользователями или совместной разработки в случае, если над проектом работает команда. Благодаря своей легковесности и нетребовательности к ресурсам InterBase можно спокойно устанавливать прямо на рабочие станции разработчиков, не беспокоясь о снижении быстродействия. Когда InterBase не обслуживает подключений к базам данных, находясь в ожидании запросов, то занимает памяти меньше, чем такие популярные программы, как ICQ или WinAmp.
Установка InterBase на платформе Linux/Unix
Установка InterBase под Linix немного сложнее, чем на Windows, если вы не являетесь знатоком этой ОС. Для Linux InterBase (а также Firebird) существуют два варианта архитектуры сервера - SuperServer и Classic. Про их различия, а также про достоинства и недостатки поговорим позже, в главе "Classic и SuperServer", а пока будем считать, что речь идет о сервере с архитектурой SuperServer.
Инсталляционный пакет под Linux бывает двух видов - в формате rpm (для некоторых дистрибутивов Linux типа RedHat) и tar.gz (более универсальный пакет). Что это такое, можно узнать в любом приличном руководстве по Linux/Unix. Скачайте инсталляционный пакет того или иного вида (например, с сайта www.lnterBase-world.com) и можно приступать к установке.
Для того чтобы произвести установку, необходимо выполнить следующие условия:
Необходимо войти в систему как пользователь root.
Для варианта Firebird SuperServer необходимо добавить в файл /etc/hosts.equiv строку вида localhost 127.0.0.1. Если такого файла нет, то его необходимо создать.
Если необходимо получать доступ к установленному серверу с удаленных машин, то надо прописать имена и ГР-адреса этих машин в файле hosts.equiv или позаботиться о разрешении имен с помощью DNS.
Для установки из rpm пакета необходимо выполнить следующую команду:
$rpm -Uvh InterBase.x.x.x.rpm
где InterBase.x.x.x.rpm является именем скачанного инсталляционного пакета.
Для установки с использованием пакета в формате tar.gz необходимо выполнить следующее:
$tar -xzf InterBase.x.x.x.tar.gz
$cd install
$./install.sh
Выполнение этих команд приводит к одному и тому же результату - на Linux-машине будет установлен InterBase (Firebird для нашего примера). Вариант с архитектурой SuperServer будет функционировать в виде демона, a Classic - в виде сервиса (см. главу "Classic и SuperServer" (ч. 4)).
Надо заметить, что приведенный порядок установки годится практически для любой версии InterBase 6.х/Firebird 1.0. Правда, для различных дистрибутивов Linux могут существовать свои особенности и хитрости при установке, так что лучше посмотреть рекомендации по установке для вашей версии ОС Linux/Unix.
Во время процесса установки останавливается
Во время процесса установки останавливается любая предыдущая версия InterBase/Firebird, если она существует, конечно. Затем эта предыдущая версия архивируется (для целей резервного копирования, чтобы не потерять ценную информацию из-за ошибки или забывчивости).
Установка основного программного обеспечения производится в каталог /opt/InterBase, а библиотек и заголовков - в каталоги /usr/InterBase и /usr/include соответственно. В процессе установки изменяется пароль SYSDBA, причем каждый вид установочного пакета делает это по-разному: rpm создает случайный пароль и помещает его в файл /opt/InterBase/SYSDBA.password, a tar.gz запрашивает пароль в процессе установки.
Интересный вопрос - как запускается InterBase/Firebird под Linux? Вариант с архитектурой Classic запускается через inetd, как только поступает входящий запрос на соединение на порт, к которому привязан InterBase/Firebird (для InterBase 4.x, 5.x - только 3050, для Firebird - по умолчанию 3050, однако можно изменить это значение), inetd запускает новый экземпляр сервера и передает ему управление. Если нет соединений, то ничего и не запущено.
Вариант InterBase с архитектурой SuperServer прописывает стартовый скрипт в /etc/re.d/init.d/Firebird и запускается в виде демона.
Для проверки инсталляции под Linux необходимо сначала проверить локальное соединение:
$cd /opt/InterBase/bin
$isql -user sysdba -password <password>
>connect /opt/InterBase/examples/employee.gdb;
>select * from sales;
>quit;
Затем необходимо протестировать удаленное подключение:
$cd /opt/InterBase/bin
$isql -user sysdba -password <password>
>connect <hostname>:/opt/InterBase/examples/employee.gdb;
>select * from sales;
>quit;
Если выполняются запросы к Sales, то все в порядке - InterBase/Firebird работает.
Установка уровней изоляции
Итак, как было упомянуто выше, уровень изоляции транзакции определяет, какие изменения, сделанные в других транзакциях, может видеть данная транзакция.
Как было сказано в разделе "Уровни изоляции", в InterBase есть 3 основных уровня изоляции. Теоретически существует также четвертый уровень изоляции, так называемое DIRTY READ - "грязное чтение". Транзакции с уровнем изоляции DIRTY READ могут читать неподтвержденные данные в других транзакциях. В InterBase пользователю нельзя запускать транзакции с таким уровнем изоляции, хотя теоретически многоверсионная архитектура могла бы обеспечить такой уровень изоляции.
Давайте перейдем к реально существующим в InterBase уровням изоляции. Сначала рассмотрим уровень Read Committed, задающийся константой read_committed. Транзакция, запущенная с таким уровнем изоляции, может читать изменения, произведенные из параллельно выполняющихся транзакций.
Этот уровень изоляции часто используется для получения самого "свежего" состояния базы данных.
Как видно из таблицы 1.4, существуют две разновидности этого уровня изоляции: read_committed rec_version и read_committed no_rec_version. По умолчанию используется вариант с параметром rec_version. Это означает, что при чтении какой-либо записи просто считывается последняя подтвержденная версия , записи.
Вариант с no_rec_version более сложен для объяснения. Вообще говоря, суть использования уровня read_committed с опцией no_rec_version сводится к тому, "что транзакция будет не только пытаться считать самую последнюю подтвержденную версию записи, но и требовать, чтобы не было более свежей неподтвержденной версии.
При чтении записи в такой транзакции производится проверка, не существует ли у этой записи неподтвержденной версии. Если существует, то происходит следующее (в зависимости оттого, какой режим блокировки выбран):
Если wait, то наша транзакция ждет, пока не завершится транзакция, в которой создана неподтвержденная запись. И если она подтвердилась или отменилась, то считывается последняя подтвержденная версия.
Если блокировка nowait, то немедленно возникает ошибка "Deadlock".
Очевидно, что уровень изоляции read_committed no_rec_version может привести к множеству конфликтов, и использовать его следует с большой осторожностью.
Уровень изоляции SNAPSHOT задается параметром concurrency. Можно сказать, что SNAPSHOT - самый "родной" режим InterBase, при котором преимущества версионности проявляются наиболее полно. При его использовании транзакция делает "снимок" маски транзакций в базе данных на момент запуска, и поэтому, пока она длится, видит те же самые данные, которые существовали на момент ее запуска. Никакие изменения, которые делаются параллельно выполняющимися транзакциями, ей не видны. Ей видны только свои изменения. При попытке в этой транзакции изменить данные, измененные другими транзакциями уже после ее запуска (имеются в виду как уже подтвержденные, так и еще неподтвержденные данные), возникает конфликт.
Пока выполняется транзакция с уровнем изоляции concurrency, удерживаются все версии записей на момент ее запуска, так как конкурирующие транзакции видят, что SNAPSHOT активен и не имеют права собрать версии записей, так как они могут (гипотетически) понадобится нашему SNAPSHOT.
Обычно SNAPSHOT применяется либо для длительных по времени запросов (отчетов), либо для организации блокирования записей, чтобы предотвратить их одновременное редактирование/удаление другими транзакциями.
Уровень изоляции SNAPSHOT TABLE STABILITY задается параметром consistency. Этот уровень изоляции аналогичен уровню SNAPSHOT, но дополнительно блокирует таблицу на запись. Суть идеи проста - если транзакция с уровнем изоляции consistency проводит изменения на какой-либо таблице, то транзакции с уровнями изоляции read_committed и concurrency могут только читать эту таблицу, а транзакции с таким же уровнем изоляции (т. е. consistency) не смогут даже читать.
Очевидно, что использование этого уровня изоляции позволяет организовать последовательные (сериализуемые) обновления таблицы. Обычно такой уровень изоляции используется только для коротких обновляющих транзакций. Транзакция запускается, проводит очень короткое по времени изменение и сразу завершается Другие транзакции в зависимости от режима блокировки wait или nowait либо ждут своей очереди, либо возбуждают исключение.
Вещественные типы данных
К вещественным типам (их еще называют типами чисел с плавающей точкой) относятся FLOAT и DOUBLE PRECISION. Сразу следует предостеречь читателя от использования типа FLOAT - его точность недостаточна для хранения большинства дробных значений. Особенно не рекомендуется хранить в нем денежные величины - в переменных типа FLOAT очень быстро нарастают ошибки округления, что может сильно удивить бухгалтера при подведении итогов.
Если в базе данных предполагается хранить числа с плавающей точкой (например, в бухгалтерских системах или в системах для научных расчетов), то лучшим выбором будет тип DOUBLE PRECISION.
Надо отметить, что в 3-м диалекте InterBase для хранения денежных величин существует механизм хранения типов с фиксированной точкой длиной 64 бита. Использование этих типов обеспечивает наилучшую точность.
Виды ограничений в базе данных
Существуют следующие виды ограничений в базе данных InterBase:
первичный ключ - PRIMARY KEY;
уникальный ключ - UNIQUE KEY;
внешний ключ - FOREIGN KEY
- может включать автоматические триггеры ON UPDATE и ON DELETE;
проверки - CHECK.
В предыдущих главах уже упоминались некоторые из этих ограничений, что было необходимо для логичного изложения материала, но теперь мы рассмотрим их синтаксис, применение и реализацию более обстоятельно.
Ограничения базы данных бывают двух типов - на основе одного поля и на основе нескольких полей таблицы. Синтаксис обоих видов ограничений приведен ниже.
<col_constraint> = [CONSTRAINT constraint] <constraint_def>
[ <col_constramt> . . . ]
<constraint_def> = {UNIQUE | PRIMARY KEY
| CHECK ( <search_condition>)
| REFERENCES other_table [( other_col [, other_col ...])]
[ON DELETE (NO ACTION|CASCADE|SET DEFAULT|SET NULL}]
[ON UPDATE (NO ACTION CASCADEjSET DEFAULTjSET NULL}]
}
Для ограничений на основе нескольких полей синтаксис следующий:
<tconstraint> = [CONSTRAINT constraint] <tconstraint_def>
[< tconstraint> ...]
<tconstraint_def> = {{PRIMARY KEY | UNIQUE} ( col [, col ...] )
FOREIGN KEY ( col [, col ...] ) REFERENCES other_table [ ( other_col [ , other_col ...] ) ]
[ON DELETE (NO ACTION|CASCADE SET DEFAULT|SET NULL}] [ON UPDATE {NO ACTION|CASCADE|SET DEFAULT|SET NULL}]
| CHECK ( <search_condition>)}
Разница в синтаксисе между ограничениями на основе одного поля и на основе нескольких очевидна - в последних молено указать несколько полей, которые входя i в ограничение. В сд\чае ограничения на основе одного поля все описанные опции относятся только к текущему полю.
Конечно, у этих двух типов ограничений отличается способ их применения: ограничения на основе одного поля просто дописываются к определению нужного поля, а ограничения на основе нескольких полей указываются через запятую в общем определении таблицы. Подробные примеры приведены в следующих разделах этой главы.
Виды параметров транзакции
Все параметры транзакции можно подразделить на группы, каждая из которых отвечает за определенный момент в поведении транзакций. Эти группы приведены в таблице 1.4:
Табл 1.4. Параметры транзакций
|
Группы параметров |
Константа |
Краткое описание константы | |||
|
Режим доступа |
Read |
Разрешает только операции чтения | |||
|
write |
Разрешает операции записи | ||||
|
Режим блокировки |
Wait |
Устанавливает режим отсроченного разрешения конфликтов. См. ниже раздел "Режим блокировки" | |||
|
nowait |
При возникновении конфликта немедленно возникает ошибка | ||||
|
Уровень |
read_committed rec_version |
Возможность читать подтвержденные данные других транзакций. Дополнительный параметр rec_version позволяет читать записи, имеющие неподтвержденные версии | |||
|
read_committed no_rec_version |
Возможность читать подтвержденные данные других транзакций. Дополнительный параметр no_rec_version не позволяет читать записи, имеющие неподтвержденные версии | ||||
|
concurrency |
При запуске транзакции создается мгновенный "снимок" состояния базы данных (точнее, копируется "маска транзакций" на этот момент), поэтому изменения, сделанные в других транзакциях, не видны в этой транзакции | ||||
|
consistency |
Аналогичен уровню concurrency, но помимо этого блокирует таблицу на запись. См. ниже |
Обилие параметров впечатляет, ведь их сочетания должны покрывать все возможные нужды разработчиков приложений баз данных. Однако обычно используется лишь небольшой набор параметров для определения необходимых видов транзакций. Давайте подробно рассмотрим каждую группу параметров транзакций.
Внешние ключи
Следующим ограничением, которое часто используется в базах данных InterBase, является ограничение внешнего ключа. Это очень мощное средство для поддержания ссылочной целостности в базе данных, которое позволяет не только контролировать наличие правильных ссылок в базе данных, но и автоматически управлять этими ссылками!
Смысл создания внешнего ключа следующий: если две таблицы служат для хранения взаимосвязанной информации, то необходимо гарантировать, чтобы эта взаимосвязь была всегда корректной. Пример — документ "накладная", содержащий общий заголовок (дата, номер накладной и т. д.) и множество подробных записей (наименование товара, количество и т. д.).
Для хранения такого документа в базе данных создается две таблицы - одна для хранения заголовков накладных, а вторая - для хранения содержимого накладной - записей о товарах и их количестве. Такие таблицы называются главной и подчиненной или таблицей-мастером и деталь-таблицей.
Согласно здравому смыслу невозможно существование содержимого накладной без наличия ее заголовка. Другими словами, мы не можем вставлять записи о товарах, не создав заголовок накладной, а также не можем удалять запись заголовка, если существуют записи о товарах.
Для реализации такого поведения таблица заголовка соединяется с таблицей подробностей с помощью ограничения внешнего ключа.
Давайте рассмотрим смысл наложения ограничений внешнего ключа на примере таблиц, содержащих информацию о накладных.
Для этого создадим две таблицы для хранения накладной - таблицу TITLE для хранения заголовка и таблицу INVENTORY для хранения информации о товарах, входящих в накладную.
CREATE TABLE TITLE(
IDJTITLE INTEGER NOT NULL Primary Key,
DateNakl DATE,
NumNakl INTEGER,
NoteNakl VARCHAR(255));
Обратите внимание на то, что мы сразу определили первичный ключ в таблице заголовка на основе поля ID_TITLE. Остальные поля таблицы TITLE содержат тривиальную информацию о заголовке накладной - дату, номер, примечание.
Теперь определим таблицу для хранения информации о товарах, входящих в накладную:
CREATE TABLE INVENTORY(
ID_INVENTORY INTEGER NOT NULL PRIMARY KEY,
FK_TITLE INTEGER NOT NULL,
ProductName VARCHAR (255),
Kolvo DOUBLE PRECISION,
Positio INTEGER);
Давайте рассмотрим, какие поля входят в таблицу INVENTORY. Во-первых, это ID_INVENTORY - первичный ключ этой таблицы. Затем идет целочисленное поле FK_TITLE, которое служит для ссылки на идентификатор заголовка
ID_TITLE в таблице заголовков накладных. Далее идут поля ProductName, Kolvo и Positio. описывающие наименование товара, его количество и позицию в накладной.
Для нашего примера важнее всего поле FK_TITLE. Если мы захотим вывести информацию о товарах определенной накладной, то нам следует воспользоваться следу ющиУ1 запросом, в котором параметр mas_ID_TITLE определяет идентификатор заголовка:
SELECT *
FROM INVENTORY II
WHERE II.FK_TITLE=?mas_ID_TITLE
В сущности, в описываемой ситуации ничто не мешает заполнить таблицу INVENTORY записями, ссылающимися на несуществующие записи в таблице TITEE. Также ничего не препятствует удалению заголовка уже существующей накладной, в результате чего записи о товарах могут стать "бесхозными".
Сервер не будет препятствовать всем этим вставкам и удалениям. Таким образом, контроль за целостностью данных в базе данных полностью возлагается на клиентское приложение. А ведь с одной базой данных могут работать несколько приложений, разрабатываемых, быть может, разными программистами, что может привести к различной интерпретации данных и к ошибкам.
Поэтому необходимо явно наложить ограничение на то, что в таблиц} INVENTORY могут помещаться лишь такие записи о товарах, которые имеют корректною ССЫЛКУ на заголовок накладной. Собственно это и есть ограничение внешнего ключа, которое позволяет вставлять в поля, входящие в ограничения, только те значения, которые есть в другой таблице.
Такое ограничение можно организовать с помощью внешнего ключа. Для данного примера необходимо наложить ограничения внешнего ключа на поле FK_TITLE и связать его с первичным ключом ID_TITLE в TITEE. Добавить внешний ключ в уже существующую таблицу можно следующей командой:
ALTER TABLE INVENTORY
ADD CONSTRAINT fktitlel FOREIGN KEY(FK_TITLE) REFERENCES
TITLE(ID_TITLE)
Часто при добавлении внешнего ключа возникает ошибка object is in use (объект используется) Дело в ю, что для создания внешнею ключа, необходимо открьпь базу данных в монопольном режиме - чтобы оиювременно не бьпо других пользователей Также нетьзя производить никаких обращений к модифицируемой таблице-это может вызвать object is in use
Здесь INVENTORY - имя таблицы, на которую накладывается ограничение внешнего ключа; fktitlel - имя внешнего ключа; FK_TITLE - поля, составляющие внешний ключ; TITLE — имя таблицы, предоставляющей значения (ссылочную ОСНОВУ) для внешнего ключа; ID_TITLE — поля первичного или уникального ключа в таблице TITLE которые являются ссылочной основой для внешнего ключа.
Полный синтаксис ограничения внешнего ключа (с возможностью создавать ограничения на основании нескольких полей) приведен ниже:
<tconstraint> = [CONSTRAINT constraint] FOREIGN KEY ( col [,
col } ) REFERENCES other_table [ ( other__col [ , other_col ...] } ]
[ON DELETE {NO ACTION CASCADE|SET DEFAULT|SET NULL}]
[ON UPDATE (NO ACTION|CASCADE|SET DEFAULT SET NULL}]
Как видите, определения содержат большой набор опций. Для начала давайте рассмотрим базовое определение внешнего ключа, которое наиболее часто используется в реальных базах данных, а затем разберем возможные опции.
Чаще всего употребляются декларативная форма ограничения внешнего ключа, когда указывается набор полей (col [, col ...]), которые будут составлять ограничение; таблица other_table, которая содержит в полях [( other_col [, other_col ...]) список возможных значений для внешнего ключа.
Пример такого определения при создании таблицы:
CREATE TABLE Inventory2(
...
FK_TABLE INTEGER NOT NULL CONSTRAINT fkinv REFERENCES
TITLE(ID_TITLE)
...) ;
Обратите внимание, что в этом определении опущены ключевые слова FOREIGN KEY, а также подразумевается, что в качестве внешнего ключа будет использоваться единственное поле - FK_TITLE.
А в следующем примере приведена более полная форма создания внешнего ключа одновременно с таблицей:
CREATE TABLE Inventory2(
...
FK_TABLE INTEGER NOT NULL,
CONSTRAINT fkinv FOREIGN KEY (FKJTABLE) REFERENCES
TITLE(IDJTITLE)
...) ;
Вносим ясность
У начинающих разработчиков часто возникает путаница в голове от многочисленных опций, определяющих поведение InterBase с русскими буквами. Вероятно, дочитав до этого места, вы уже достаточно запутались во множестве взаимнопересекающихся определений. Чтобы внести ясность в эти понятия, давайте еще раз их прокомментируем.
Основа всего - символьные типы InterBase, которые позволяют хранить в каждом поле до 32767 байт. Однако байты в общем случае не равнозначны символам, потому что в различных системах кодировки для представления одного символа могут использоваться 1, 2 или даже 3 байта. Таким образом, когда мы определяем поле типа CHAR или VARCHAR, то мы задаем количество символов, которые там могут поместиться, а количество байтов определяется умножением заданной длины на максимальный размер символа для данного набора символов Для набора символов WIN1251 любой символ занимает 1 байт, поэтому размер поля в байтах будет равен объявленной длине. А вот при использовании кодировки UNICODE_FSS максимальный размер символа составляет 3 байта; таким образом, реальная длина поля будет равна утроенному объявленному размеру. Вы не сможете создать поле с кодировкой UNICODE_FSS с длиной более чем 32767 div 3 = 10921 символ. В то же время реальный размер символа может быть меньше максимального, использовавшегося InterBase для расчета размера поля, т. е. вы сможете записать в такое поле больше символов, чем его объявленная длина!
Наборы символов (CHARACTER SET) - это фактически таблицы перекодировки физического представления (где один символ занимает 2 или 3 байта) в желаемое (т. е. такое, каким эти символы хотят видеть соответствующие клиентские приложения).
В InterBase существует множество наборов символов, полный список которых можно найти в документации по InterBase. Каждый набор символов использует для хранения тех или иных символов разное количество байт. Проще говоря, это таблица, где каждому символу поставлен в соответствие 1- или 2- или 3-байтовый код.
Когда мы создаем символьное поле и указываем набор символов явно или с помощью установок по умолчанию, то в этом случае мы неявно задаем, сколько символов поместится в это поле. Например, набор символов UNICODE_FSS использует 2 байта для кодирования русских букв. Следовательно, мы можем поместить в поле, объявленное как VARCHAR(255) CHARACTER SET UNICODE_FSS, количество русских символов, равное 255 * 3 div 2, т. е. 382.
Далее, каждый набор символов ( CHARACTER SET) имеет свой порядок сортировки по умолчанию. Очень часто этот порядок сортировки не отражает принятую в языке сортировку конкретных символов. Например, русский набор символов WIN1251 неправильно сортирует символы русского алфавита, т. е. сортирует их в порядке следования двоичных кодов символов.
Как же изменить сортировку символов по умолчанию внутри набора символов? Для этого применяются порядки (или способы) сортировки наборов символов - так называемые COLLATION ORDERS. Дополнительно с каждым COLLATION ORDER связаны таблицы преобразования в нижний и верхний регистр. Для каждого набора символов существуют свои определенные порядки сортировки Например, для самого распространенного русского набора символов WIN1251 существуют два способа сортировки: WIN1251, который задается по умолчанию, и опциональная сортировка PWX_CYRL. В порядке сортировки PXW_CYRL одни и те же прописные и строчные буквы имеют одинаковый вес, т. е. этот порядок сортировки не зависит от регистра символов (case insensitive). Русские буквы будут располагаться в следующем порядке: аАбБвВ...яЯ.
Как устроены способы сортировки? В COLLATION ORDERS строится дополнительная таблица пересортировки, определяющая порядок (условный вес) символов при сортировке. И в этой таблице для представления порядка символа может использоваться несколько байтов (2 или 3, например). В частности, в COLLATION ORDER WIN1251 используется 1 байт для представления символа и его порядка, а в опциональной PWX_CYRL - целых 3 байта!
Размер представления веса символа в таблице порядка сортировки имеет значение при использовании индексов по полям символьных типов данных. Дело в то, что в индексе хранятся не исходные символьные строки, а ключи, полученные из строки на основе таблицы сортировки. Размер ключа может быть больше размера исходной строки: так, для порядка сортировки PXW_CYRL размер ключа может быть больше максимум в 3 раза, чем исходная строка. InterBase использует максимальный коэффициент для ограничения размера индекса по символьным полям. Таким образом, при максимальном размере индекса 254 байта вы не сможете создать индекс по полю с длиной более 254 div 3 = 84 символа Поэтому использование COLLATION ORDER может оказаться вещью, требующей достаточно многих ресурсов. Тем не менее весь вопрос в том, как ее применять Параметр COLLATE можно использовать и по требованию, прямо в тексте запроса, не указывая его в самом определении поля Когда мы указываем в запросе использовать для сортировки или приведения к верхнему регистру какой-либо способ сортировки, то InterBase сам достраивает данные из этого поля с учетом указанного способа
Использовать конкретный COLLATE в запросе очень легко, правда, в этом случае не может быть использован индекс:
SELECT *
FROM table1
ORDER BY SYMBOLIC_FIELD1 COLLATE PXW_CYRL
Другой пример - для встроенной функции UPPER.
SELECT UPPER(fieldl COLLATE PXW_CYRL) From tablel
Этот способ является наиболее гибким: хранить можно лишь сами символы, а специальный порядок сортировки применять, только когда это требуется.
Вызов хранимой процедуры
Но вернемся к нашей хранимой процедуре. Теперь, когда она создана, ее надо как-то вызвать, передать ей параметры и получить возвращаемые результаты. Это сделать очень просто - достаточно написать SQL-запрос следующего вида:
SELECT *
FROM Sp_add(181.35, 23.09)
Этот запрос вернет нам одну строку, содержащую всего одно поле Result, в котором будет находиться сумма чисел 181.35 и 23.09 т. е. 204.44.
Таким образом, нашу процедуру можно использовать в обычных SQL- запросах, выполняющихся как в клиентских программах, так и в других ХП или триггерах. Такое использование нашей процедуры стало возможным из-за применения команды SUSPEND в конце хранимой процедуры.
Дело в том, что в InterBase (и во всех его клонах) существуют два типа хранимых процедур: процедуры-выборки (selectable procedures) и исполняемые процедуры (executable procedures). Отличие в работе этих двух видов ХП заключается в том, что процедуры-выборки обычно возвращают множество наборов выходных параметров, сгруппированных построчно, которые имеют вид набора данных, а исполняемые процедуры мог)т либо вообще не возвращать параметры, либо возвращать только один набор выходных параметров, перечисленных в Returns, где одну строку параметров. Процедуры-выборки вызываются в запросах SELECT, а исполняемые процедуры - с помощью команды EXECUTE PROCEDURE.
Оба вида хранимых процедур имеют одинаковый синтаксис создания и формально ничем не отличаются, поэтому любая исполнимая процедура может быть вызвана в SELECT-запросе и любая процедура-выборка - с помощью EXECUTE PROCEDURE. Вопрос в том, как поведут себя ХП при разных типах вызова. Другими словами, разница заключается в проектировании процедуры для определенного типа вызова. То есть процедура-выборка специально создается для вызова из запроса SELECT, а исполняемая процедура - для вызова с использованием EXECUTE PROCEDURE. Давайте рассмотрим, в чем же заключаются отличия при проектировании этих двух видов ХП.
Для того чтобы понять, как работает процедура-выборка, придется немного углубиться в теорию. Давайте представим себе обычный SQL-запрос вида SELECT ID, NAME FROM Table_example. В результате его выполнения мы получаем на выходе таблицу, состоящую из двух столбцов (ID и NAME) и некоторого количества строк (равного количеству строк в таблице Table_example). Возвращаемая в результате этого запроса таблица называется также набором данных SQL Задумаемся же, как формируется набор данных во время выполнения этого запроса Сервер, получив запрос, определяет, к каким таблицам он относится, затем выясняет, какое подмножество записей из этих таблиц необходимо включить в результат запроса. Далее сервер считывает каждую запись, удовлетворяющую результатам запроса, выбирает из нее нужные поля (в нашем случае это ID и NAME) и отсылает их клиенту. Затем процесс повторяется снова - и так для каждой отобранной записи.
Все это отступление нужно для того, чтобы уважаемый читатель понял, что все наборы данных SQL формируются построчно, в том числе и в хранимых процедурах! И основное отличие процедур-выборок от исполняемых процедур в том, что первые спроектированы для возвращения множества строк, а вторые - только для одной. Поэтому они и применяются по-разному: процедура-выборка вызывается при помощи команды SELECT, которая "требует" от процедуры отдать все записи, которая она может вернуть. Исполняемая процедура вызывается с помощью EXECUTE PROCEDURE, которая "вынимает" из ХП только одну строку, а остальные (даже если они есть!) игнорирует.
Давайте рассмотрим пример процедуры-выборки, чтобы было понятнее. Для > прощения создадим хранимую процедуру, которая работает точно так же, как запрос SELECT ID, NAME FROM Table_Example, т е она просто делает выборку полей ID и NAME из всей таблицы. Вот этот пример:
CREATE PROCEDURE Simple_Select_SP
RETURNS (
procID INTEGER,
procNAME VARCHAR(80))
AS
BEGIN
FOR
SELECT ID, NAME FROM table_example
INTO :procID, :procNAME
DO
BEGIN
SUSPEND;
END
END
Давайте разберем действия этой процедуры, названной Simple_Select_SP. Как видите, она не имеет входных параметров и имеет два выходных параметра - ID и NAME. Самое интересное, конечно, заключено в теле процедуры. Здесь использована конструкция FOR SELECT:
FOR
SELECT ID, NAME FROM table_example
INTO :procID, :procNAME
DO
BEGIN
/*что-то делаем с переменными procID и procName*/
END
Этот кусочек кода означает следующее: для каждой строки, выбранной из таблицы Table_example, поместить выбранные значения в переменные procID и procName, а затем произвести какие-то действия с этими переменными.
Вы можете сделать удивленное лицо и спросить: "Переменные? Какие еще переменные9" Это нечто вроде сюрприза этой главы - то, что в хранимых процедурах мы можем использовать переменные. В языке ХП можно объявлять как собственные локальные переменные внутри процедуры, так и использовать входные и выходные параметры в качестве переменных.
Для того чтобы объявить локальную переменную в хранимой процедуре, необходимо поместить ее описание после ключевого слова AS и до первого слова BEGIN Описание локальной переменной выглядит так:
DECLARE VARIABLE <vanable_name> <variable_type>;
Например, чтобы объявить целочисленную локальную переменную Mylnt, нужно вставить между AS и BEGIN следующее описание
DECLARE VARIABLE Mylnt INTEGER;
Переменные в нашем примере начинаются с двоеточия. Это сделано потому, что обращение к ним идет внутри SQL-команды FOR SELECT, поэтому для различения полей в таблицах, которые используются в SELECT, и переменных необходимо предварять последние двоеточием. Ведь переменные могут иметь точно такое же название, как и поля в таблицах!
Но двоеточие перед именем переменной необходимо использовать только внутри SQL-запросов. Вне текстов обращение к переменной делается без двоеточия, например:
procName='Some name';
Но вернемся к телу нашей процедуры. Предложение FOR SELECT возвращает данные не в виде таблицы - набора данных, а по одной строчке. Каждое возвращаемое поле должно быть помещено в свою переменную: ID => procID, NAME => procName. В части DO эти переменные посылаются клиенту, вызвавшем) процед>р>, с помощью команды SUSPEND
Таким образом, команда FOR SELECT... DO организует цикл по записям, выбираемым в части SELECT этой команды. В теле цикла, образуемого частью DO, выполняется передача очередной сформированной записи клиенту с помощью команды SUSPEND.
Итак, процедура-выборка предназначена для возвращения одной или более строк, для чего внутри тела ХП организуется цикл, заполняющий результирующие параметры-переменные. И в конце тела этого цикла обязательно стоит команда SUSPEND, которая вернет очередную строку данных клиенту.
Взаимоблокировка
Взаимоблокировка - классическая проблема при синхронизации доступа к ресурсу, при котором принципиально невозможна дальнейшая работа конкурирующих транзакций. Для иллюстрации рассмотрим две транзакции Т1 и Т2
и два ресурса - А и В; в контексте разговора о базах данных ресурсами могут быть, например, записи в некоторой таблице. Допустим, выполняется такая последовательность действий:
Транзакция Т1 блокирует ресурс А, после чего благополучно работает с ним.
Транзакция Т2 блокирует ресурс В, после чего также с ним работает.
Транзакция Т1 желает поработать с ресурсом В, для чего она пытается установить на него блокировку. Так как в это время ресурс В уже занят транзакцией В, транзакция Т1 входит в состояние ожидания.
Транзакция Т2 желает поработать с ресурсом А, пытается выполнить его блокирование и также переходит в состояние ожидания.
В результате мы имеем печальную ситуацию: транзакции не имеют никакого шанса продолжить свое выполнение из-за того, что намертво блокируют друг друга. Любой сервер баз данных должен быть способен выходить из этой ситуации по возможности достойно, и InterBase не исключение. Проблема решается выбором одной из транзакций в качестве жертвы и ее откате, при этом другая транзакция получает возможность выполниться до конца.
Алгоритм распознавания ситуации взаимоблокировки в InterBase не запускается сразу при возникновении конфликта, что сделано из соображений производительности. Вместо этого выдерживается определенный интервал времени, задаваемый параметром DEADLOCK_TIMEOUT в конфигурационном файле InterBase ibconfig, только после этого и производится сканирование таблицы блокировок на предмет взаимного блокирования.
В реальной практике программирования баз данных взаимоблокировки возникают крайне редко, поэтому не стоит считать, что вам так повезло, увидев слово "deadlock" в сообщении об ошибке. Скорее всего это всего лишь конфликт обновления.
Теперь давайте рассмотрим параметры, которые влияют на уровни изоляции.
Взаимодействие транзакций
Интересен процесс определения, является ли текущая версия мусором или, возможно, она еще нужна какой-то транзакции.
Для описания этого процесса придется ввести несколько важных понятий. Прежде всего, надо отметить, что все определения строятся относительно какой- либо транзакции, которую называют текущей, - обычно это та транзакция, поведение которой необходимо исследовать и которой надо принять решение, что является мусором, а что нет.
Итак, определения:
Заинтересованная транзакция - это транзакция, конкурирующая с текущей.
Старейшая заинтересованная транзакция (oldest interesting transaction) - это старейшая транзакция, конкурирующая с текущей транзакцией.
Каждая транзакция (и текущая тоже, разумеется) имеет "маску транзакций", которая представляет собой снимок страницы учета транзакций, начиная от старейшей заинтересованной транзакции до текущей.
Старейшая активная транзакция (oldest active transaction, OAT) - это транзакция, которая была активной в тот момент, когда запускалась самая старая из активных транзакций в момент запуска текущей.
Именно старейшая активная транзакция и занимается сборкой мусора, так как все остальные транзакции и их изменения "моложе" ее.
Обратите внимание на два момента: во-первых, старейшая активная транзакция - это не постоянно существующая транзакция, а всего лишь обязанность, которую получают транзакции; во-вторых, старейшая транзакция убирает только мусор от завершившихся транзакций, которые еще старше ее! Другими словами, следует рассматривать процесс сборки мусора динамически - как постоянную передачу обязанностей по сборке мусора от одной транзакции к другой.
Разумеется, здесь приведено лишь краткое изложение вопросов, связанных с многоверсионной архитектурой InterBase и ее особенностями. На сайтах www.InterBase-world.com и www.ibase.ru читатель сможет ознакомиться с множеством статей по данной проблеме.
За пределами транзакций
Мы рассмотрели общие вопросы, связанные с транзакциями, а также особенности их практического применения в базе данных. В самом начале главы было сказано, что все действия в InterBase выполняются в контексте транзакций.
Однако существуют объекты, про которые говорят, что они находятся вне контекста транзакций Это генераторы и внешние таблицы.
Генератор, как было описано в главе "Таблицы. Первичные ключи и генераторы", является счетчиком, хранящим некоторое целочисленное значение Однако по своей реализации генератор является объектом совершенно уникальным В отличие от остальных данных в базе данных значения генераторов хранятся на самом низком физическом уровне - на особых страницах генераторов. Это позволяет одновременно всем транзакциям одновременно видеть значения генераторов в любой момент времени. Это очень ценная возможность, которая позволяет организовать бесконфликтные конкурентные вставки в параллельно выполняющихся транзакциях.
Внешние таблицы представляют собой файлы, находящиеся за пределами основного файла базы данных. Над внешними таблицами позволены только one-
рации вставки и выборки (INSERT/SELECT). Отсутствие обновлений во внешних таблицах позволяет отказаться от хранения версий записей в этих таблицах, поэтому там всегда находятся актуальные данные, что позволяет отказаться от применения механизма транзакций для работы с данными в этих таблицах.
когда на вашем рабочем компьютере
Теперь, когда на вашем рабочем компьютере установлен сервер и клиент какого-либо клона InterBase и мы обзавелись удобным инструментом для его администрирования, можно приступить к разработке базы данных на InterBase.
Надо отметить, что невозможно рассказать о типах данных, не забегая вперед, — настолько они проникают во все ключевые области, связанные с разработкой приложений баз данных. Поэтому в процессе чтения этой книги стоит использовать данную главу как справочник, к которому можно обращаться всякий раз, когда надо освежить в памяти основы InterBase.
Итак, в этой главе мы рассмотрели, как создавать и модифицировать таблицы в InterBase, а также как обращаться с первичными ключами. Таким образом, мы рассмотрели главные объекты в InterBase, которые можно условно назвать статическими, поскольку они только хранят информацию и не осуществляют ее преобразования. Далее мы поведем разговор о методах контроля за информацией и о преобразовании информации внутри базы данных.
Несмотря на кажущуюся простоту создания и использования представлений, они дают большие возможности для улучшения организации данных в базе данных и позволяют создавать иерархию организации данных.
Одни разработчики приложений базы данных очень активно используют представления в своей работе, другие избегают их применения, мотивируя это сложностью модификации представлений и стремлением сохранить схему своей базы данных максимально простой и эффективной. Как вы будете применять представления в своей работе - решать вам. Главное - помнить о существовании такого мощного инструмента, как представление, и уметь им пользоваться.
На этом закончим рассмотрение основных возможностей языка хранимых процедур. Очевидно, что полностью освоить разработку хранимых процедур при чтении одной главы невозможно, однако здесь мы постарались представить и объяснить основные концепции, связанные с хранимыми процедурами. Описанные конструкции и приемы проектирования ХП могут быть применены в большинстве приложений баз данных
Часть важных вопросов, связанных с разработкой хранимых процедур, будет раскрыта в следующей главе - "Расширенные возможности языка хранимых процедур InterBase", которая посвящена обработке исключений, разрешению ошибочных ситуаций в хранимых процедурах и работе с массивами.
В этой главе был рассмотрен ряд дополнительных возможностей языка хранимых процедур (и триггеров) СУБД InterBase. Использование описанных конструкций языка позволит разрабатывать более развитые и надежные хранимые процедуры, а значит, более быстрые и надежные приложения баз данных.
Триггеры являются мощным средством для реализации бизнес-логики на стороне сервера Размещение операций обработки данных в триггерах позволяет упростить и централизовать бизнес-логику приложений, но одновременно несет в себе определенные трудности, связанные с отладкой приложений СУБД на уже работающих базах.
В любом случае при разработке достаточно сложных приложений для СУБД InterBase использование триггеров является одной из возможностей сделать работу создателя СУБД проще и приятнее.
Мы рассмотрели на примере, как можно расширять набор доступных SQL-функций при помощи механизма User Defined Functions. Имея этот простой, но очень мощный механизм, вы сможете сделать обработку бизнес-правил в ваших базах данных гораздо более эффективно и удобно. В сущности, механизм пользовательских функций InterBase имеет только одно серьезное ограничение - он не позволяет обрабатывать NULL-параметры. В остальном функциональность пользовательских "расширений" SQL зависит только от ваших потребностей.
Широкий выбор UDF-библиотек, а также более подробную информацию об их использовании и разработке всегда можно найти на сайтах www.InterBaseworld.com и www.ibase.ru.
Транзакции - один из наиболее сложных для понимания и объяснения вопросов в разработке приложений баз данных, независимо от того, о каком сервере баз данных идет речь. Поэтому изучение их применения является необходимой задачей для каждого разработчика приложений баз данных, если он хочет достигнуть вершин мастерства в своей профессии. Материал данной главы дает необходимые минимальные сведения о транзакциях и пищу для размышлений, однако для полного понимания транзакций следует обратиться к специальным статьям, посвященным различным аспектам этого вопроса. Эти статьи всегда можно найти на сайтах www.InterBase-world.com и www.ibase.ru.
