А.ЗЦЕЛОСТНОСТЬ РЕЛЯЦИОННЫХ ДАННЫХ
Одно важное следствие из определений, приведенных в предыдущем разделе, заключается в том, что каждое отношение имеет первичный ключ. Поскольку отношение — это множество, а множества по определению не содержат совпадающих элементов, никакие два кортежа отношения в произвольный заданный момент времени не могут быть дубликатами друг друга. Пусть R — отношение с атрибутами A1, A2, ..., An. Говорят, что множество атрибутов К= (Ai, Aj, ..., Ak)
отношения R является возможным ключом R тогда и только тогда, когда удовлетворяются два следующих независимых от времени условия:
1. Уникальность:
В произвольный заданный момент времени никакие два различных кортежа R не имеют одного и того же значения для Ai, Aj, ..., Ak.
2. Минимальность:
Ни один из атрибутов Ai, Aj, ..., Ak не может быть исключен из К без нарушения условия уникальности.
Каждое отношение обладает по крайней мере одним возможным ключом, поскольку по меньшей мере комбинация всех его атрибутов удовлетворяет условию уникальности. Один произвольным образом выбранный возможный ключ для данного отношения принимается за его первичный ключ. Остальные возможные ключи, если они имеются, называются альтернативными
ключами.
Пример.
Предположим, что как фамилии поставщиков, так и их номера являются уникальными — никакие два поставщика не имеют одного и того же номера или одной и той же фамилии. Тогда отношение S имеет два возможных ключа — НОМЕР_ПОСТАВЩИКА и ФАМИЛИЯ. Выберем НОМЕР_ПОСТАВЩИКА в качестве первичного ключа. Тогда ФАМИЛИЯ будет альтернативным ключом. Отметим, однако, что система DB2 не располагает какими-либо знаниями ни о первичном, ни об альтернативных ключах как таковых, хотя добиться уникальности можно с помощью предложения CREATE UNIQUE INDEX (см. раздел 3.3).
Продолжая обсуждение данного примера, рассмотрим атрибут НОМЕР_ПОСТАВЩИКА отношения SP. Ясно, что появление заданного значения этого атрибута, скажем, S1, в базе данных должно допускаться, только если это же значение входит как значение первичного ключа НОМЕР_ПОСТАВЩИКА в отношение S. В противном случае нельзя считать, что база данных находится в целостном состоянии. Такой атрибут, как SР.НОМЕР_ПОСТАВЩИКА, называется внешним
ключом. В общем случае внешний ключ — это атрибут или комбинация атрибутов одного отношения R2, значение которого обязательно должно совпадать со значением первичного ключа некоторого другого отношения R1, причем не требуется, чтобы R1 и R2 были различны. Заметим, что внешний ключ и соответствующий ему первичный ключ должны быть определены на одних и тех же доменах.
Теперь мы можем сформулировать два правила целостности для реляционной модели.
Примечание. Эти правила являются общими в том смысле, что от любой базы данных, которая согласуется с этой моделью, требуется удовлетворение этих правил. Однако для любой конкретной базы данных будет иметься множество дополнительных специфических правил, которые относятся к ней одной. Например, для базы данных поставщиков и деталей может иметься специфическое правило, требующее, чтобы объемы поставок находились, к примеру, в диапазоне от 1 до 9999. Но такие специфические правила выходят за рамки самой по себе реляционной модели.
1. Целостность по сущностям.
Не допускается, чтобы какой-либо атрибут, участвующий в первичном ключе базового отношения, принимал неопределенные значения.
2. Целостность по ссылкам.
Если базовое отношение R2 включает некоторый внешний ключ FK, соответствующий первичному ключу РК какого-либо базового отношения R1, то каждое значение FK в R2 должно либо а) быть равным значению РК в некотором кортеже R1, либо б) должно быть полностью неопределенным, т. е. каждое значение атрибута, участвующее в этом значении FK, должно быть неопределенным. При этом R1 и R2 не обязательно различны.
Базовое отношение соответствует тому, что мы назвали в тексте этой книги базовой таблицей: это — независимое именованное отношение (дальнейшее обсуждение см. в главе 3). Мотивировка правила целостности по сущностям заключается в следующем:
1. Базовые отношения соответствуют сущностям в реальном мире. Например, базовое отношение S соответствует множеству поставщиков в реальном мире.
2. Сущности в реальном мире по определению отличимы, т. е. они имеют некоторого рода уникальную идентификацию.
3. В реляционной модели функцию уникальной идентификации выполняют первичные ключи.
4. Таким образом, ситуация, когда первичный ключ принимает неопределенное значение, была бы, по существу, противоречивой — это, в действительности, говорило бы о том, что имеется некоторая сущность, которая не обладает индивидуальностью, и, следовательно, не существует. Отсюда название «целостность по сущностям».
Относительно второго правила («целостность по ссылкам») ясно, что для заданного значения внешнего ключа должно иметься соответствующее значение первичного ключа в некотором кортеже отношения, на которое производится ссылка, если это значение внешнего ключа не является неопределенным. Иногда, однако, необходимо допустить, чтобы внешний ключ принимал неопределенные значения. Предположим, например, что в данной компании может иметь место ситуация, когда некоторый служащий в настоящее время не назначен вообще ни в какой отдел. Для такого служащего атрибут — номер отдела, являющийся внешним ключом, должен был бы иметь неопределенное значение в кортеже, представляющем этого служащего в рассматриваемой базе данных.
Мы должны будем еще поговорить о первичных и внешних ключах в Приложении В.
АМАНИПУЛИРОВАНИЕ РЕЛЯЦИОННЫМИ ДАННЫМИ
Манипулятивная часть реляционной модели состоит из множества операций, получивших в совокупности название реляционной алгебры, и реляционной операции присваивания, которая присваивает значение некоторого произвольного выражения этой алгебры другому отношению. Обсудим сначала реляционную алгебру.
Каждая операция реляционной алгебры использует одно или два отношения в качестве ее операндов и продуцирует в результате некоторое новое отношение. Первоначально Кодд определил восемь таких операций, две группы по четыре операции в каждой: 1) традиционные теоретико-множественные операции объединения, пересечения, разности и декартова произведения, которые были несколько модифицированы с тем, чтобы принять во внимание тот факт, что их операнды являются отношениями, а не произвольными множествами и 2) специальные реляционные операции селекции, проекции, соединения и деления. Эти восемь операций символически показаны на рис. А.2. Ниже дается краткое определение каждой из них. Для простоты в этих определениях предполагается, что в отношениях принимается упорядочение атрибутов слева направо — не потому, что это необходимо сделать, а для того, чтобы упростить обсуждение.
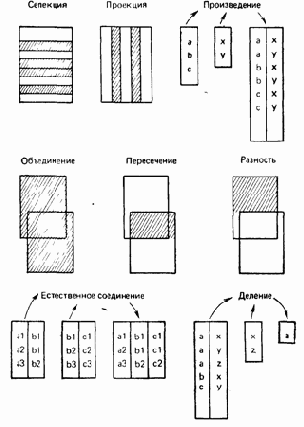
Риc. A.2.
Реляционная алгебра
Традиционные теоретико-множественные операции
В каждой из традиционных теоретико-множественных операций используются два операнда. Для всех операций, кроме декартова произведения, эти два операнда должны быть совместимыми по объединению, т. е. они должны быть одной и той же степени, например п, и i-e их атрибуты (i = 1, 2, ...,. п) должны быть связаны с одним и тем же доменом. Они не должны, однако, иметь одинаковое имя.
— Объединение
Объединением двух (совместимых по объединению) отношений А и В называется множество всех кортежей t, принадлежащих либо А, либо В, либо им обоим.
Пример в языке SQL:
SELECT НОМЕР_ПОСТАВЩИКА FROM S
UNION
SELECT НОМЕР_ПОСТАВЩИКА FROM SP;
— Пересечение
Пересечением двух (совместимых по объединению) отношений А и В называется множество всех кортежей t, каждый из которых принадлежит как А, так и В.
Пример в языке SQL;
SELECT НОМЕР_ПОСТАВЩИКА FROM S
WHERE EXISTS
(SELECT НОМЕР_ПОСТАВЩИКА FROM SP
WHERE SP.HOMEP_ПОСТАВЩИКА =
S.НОМЕР_ПОСТАВЩИКА);
— Разность
Разностью между двумя (совместимыми по объединению) отношениями А и В называется множество всех кортежей t, каждый из которых принадлежит А и не принадлежит В.
Пример в языке SQL:
SELECT НОМЕР_ПОСТАВЩИКА FROM S
WHERE NOT EXISTS
(SELECT НОМЕР_ПОСТАВЩИКА FROM SP
WHERE SP.HOMEP_ПОСТАВЩИКА =
S. НОМЕР_ПОСТАВЩИКА);
— Декартово произведение
Декартовым произведением двух отношений А и В называется множество всех кортежей t,
таких, что t является конкатенацией некоторого кортежа а,
принадлежащего А, и какого-либо кортежа t, принадлежащего В.
Пример в языке SQL:
SELECT S.*, SP.*
FROM S, SP;
Специальные реляционные операции
— Селекция
Пусть theta представляет собой любой допустимый оператор сравнения скаляров, например =, ¬ =,
>, >= и т. д. Theta-ceлекцией отношения А по атрибутам Х и Y называется множество всех кортежей t
из А, таких, что истинен предикат «t. X theta t. Y». Атрибуты Х и Y должны быть определены на одном и том же домене, и для этого домена оператор theta должен иметь смысл. Вместо атрибута Y может быть специфицирована константа. Таким образом, оператор theta-селекции позволяет получать «горизонтальное» подмножество заданного отношения, т. е. подмножество таких кортежей заданного отношения, для которых удовлетворяется специфицированный предикат.
Примечание. «Theta-селекцию» часто для краткости называют просто «селекцией». Но нужно отметить, что «селекция» — это не то же самое, что оператор SELECT языка SQL.
Пример в языке SQL:
SELECT *
FROM S
WHERE ГОРОД ¬= 'Лондон';
—— Проекция
Операция проекции позволяет получать «вертикальное» подмножество заданного отношения, т. е. такое подмножество, которое получается выбором специфицированных атрибутов с последующим исключением, если это необходимо, избыточных дубликатов кортежей, состоящих из значений выбранных атрибутов.
Пример в языке SQL: .
SELECT DISTINCT ЦВЕТ, ГОРОД
FROM P;
— Соединение
Пусть theta
имеет тот же смысл, что и в случае селекции. Тогда theta-соединением отношения А по атрибуту Х с отношением В по атрибуту Y называется множество всех кортежей t, таких, что t является конкатенацией какого-либо кортежа а, принадлежащего А, и какого-либо кортежа Ь,
принадлежащего В, и предикат «а. Х theta b. Y» принимает значение «истина». При этом атрибуты А.Х и B.Y должны быть определены на одном и том же домене, и оператор theta должен иметь смысл для этого домена.
Пример в языке SQL:
SELECT S.*, P.*
FROM S, P
WHERE S. ГОРОД > Р. ГОРОД;
Если оператор theta — равенство, то соединение называется эквисоединением. Из этого определения следует, что результат эквисоединения должен включать два идентичных атрибута. Если один из этих двух атрибутов исключается, что можно осуществить с помощью проекции, результат называется естественным соединением. Под неуточненным термином «соединение» обычно понимается естественное соединение.
— Деление
В ее простейшей форме, и только она здесь рассматривается, операция деления делит отношение степени два (делимое) на отношение степени один (делитель) и продуцирует результирующее отношение степени один (частное). Пусть делимое А имеет атрибуты Х и Y, а делитель В — атрибут Y. Атрибуты A.Y и B.Y должны быть определены на одном и том же домене. Результатом деления А на В является отношение С с единственным атрибутом X, таким, что каждое значение х этого атрибута С.Х появляется как значение А.Х и пара значений (х,у)
входит в А для всех значений у, входящих в В.
Пример в языке SQL:
SELECT DISTINCT НОМЕР_ПОСТАВЩИКА FROM SP, SP1
WHERE NOT EXISTS
(SELECT НОМЕР_ДЕТАЛИ FROM P
WHERE NOT EXISTS
(SELECT * FROM SP, SP2
WHERE SP2. НОМЕР_ПОСТАВЩИКА =
SP1 .НОМЕР_ПОСТАВЩИКА
AND SP2. НОМЕР_ДЕТАЛИ = Р.НОМЕР_ДЕТАЛИ));
Здесь для простоты предполагается, что: а) отношение SP имеет только два атрибута, а именно НОМЕР_ПОСТАВЩИКА и НОМЕР_ДЕТАЛИ (атрибут КОЛИЧЕСТВО игнорируется) и б) отношение Р имеет только один атрибут — НОМЕР_ДЕТАЛИ (игнорируются атрибуты НАЗВАНИЕ, ЦВЕТ, ВЕС, ГОРОД). Первое из этих двух отношений делится на второе; в результате получается отношение с одним атрибутом НОМЕР_ПОСТАВЩИКА, в котором перечисляются номера поставщиков для тех поставщиков, которые поставляют все детали.
Целесообразно упомянуть, что из восьми рассмотренных операций только пять являются примитивами, а именно: селекция, проекция, декартово произведение, объединение и разность. Другие три операции могут быть определены через первые пять. Например, естественное соединение может быть выражено как проекция селекции декартова произведения. Однако эти три другие операции, особенно соединение, оказываются настолько полезными на практике, что хорошо было бы поддерживать их непосредственно, несмотря на то, что они не являются примитивами.
Обратимся теперь к реляционной операции присваивания. Цель этой операции заключается просто в том, чтобы дать возможность сохранять значение какого-либо алгебраического выражения, например соединения, в некотором более или менее постоянном месте. Ее можно смоделировать в языке SQL с помощью операций INSERT. . .SELECT. Предположим, например, что отношение XYZ имеет два атрибута, НОМЕР_ПОСТАВЩИКА и НОМЕР-ДЕТАЛИ. Предположим также, что в настоящее время это отношение пусто (не содержит никаких кортежей). Тогда предложение SQL:
INSERT INTO XYZ (НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ)
SELECT S. НОМЕР_ПОСТАВЩИКА, Р. НОМЕР_ДЕТАЛИ
FROM S, P
WHERE S. ГОРОД = Р. ГОРОД;
присваивает результат входящего в него предложения SELECT, а именно проекцию соединения, отношению XYZ.
В качестве заключения на рис. А.3 приводится сводка основных компонентов реляционной модели.
Структура данных
домены (значения)
n-арные отношения (атрибуты, кортежи)
ключи (возможные, первичные, альтернативные, внешние)
Целостность данных
1. значения первичных ключей не должны быть неопределенными
2. значения внешних ключей должны соответствовать значениям первичных ключей
(или быть неопределенными)
Манипулирование данными
реляционная алгебра
объединение, пересечение, разность, декартово произведение
селекция, проекция, соединение, деление
реляционное присваивание
Рис. А.3. Реляционная модель
АРЕЛЯЦИОННАЯ СТРУКТУРА ДАННЫХ
Наименьшей единицей данных в реляционной модели является отдельное значение данных. Такие значения рассматриваются как атомарные, т. е. они неразложимы, когда дело касается данной модели. Доменом называется множество таких значений одного и того же типа. Например, домен номеров поставщиков — это множество допустимых номеров поставщиков, домен объемов поставки — множество всех целых, больших нуля и меньших, например 10000. Таким образом, домены представляют собой пулы, значений, из которых берутся фактические значения, появляющиеся в атрибутах (столбцах). Смысл доменов заключается в следующем. Если значения двух атрибутов берутся из одного и того же .домена, то, вероятно, имеют смысл сравнения, вовлекающие эти два атрибута, а следовательно, и соединения, объединения и т. д., поскольку они сравнимы друг с другом. Если, наоборот, значения двух атрибутов берутся из различных доменов, то сравнения и т. д., вовлекающие эти два атрибута, вероятно, лишены смысла. Например, следующий запрос в языке SQL:
SELECT S.*, SP.*
FROM S, SP
WHERE S. НОМЕР_ПОСТАВЩИКА = SP.HOMEP_ПОСТАВЩИКА;
по-видимому, имеет смысл в отличие от запроса:
SELECT S.*, SP.*
FROM S, SP
WHERE S.COCТОЯHИE = SP.КОЛИЧЕСТВО;
В системе DB2, однако, понятие домена как таковое не используется. Оба приведенных предложения SELECT представляют собой допустимые запросы в DB2.
Отметим, что домены по природе своей являются в большой степени концептуальными. Они могут явным образом храниться или не храниться в базе данных как фактические множества значений. Но они должны специфицироваться как часть определения базы данных (в системе, которая вообще поддерживает эту концепцию; однако большинство систем в настоящее время не выполняет такой функции), и определение каждого атрибута должно далее включать ссылку на соответствующий домен. Заданный атрибут может иметь то же самое имя, что и у соответствующего домена, или какое-либо иное имя. Он должен, очевидно, иметь другое имя, если в противном случае возникала бы какая-либо двусмысленность. Такая ситуация имела бы место, в частности, если два атрибута одного и того же отношения основывались бы на одном и том же домене (см. ниже определение отношения и обратите внимание на фразу «не обязательно, чтобы все они были различны»).
Теперь мы в состоянии определить термин «отношение». Отношение на доменах D1, D2, ..., Dn ( не обязательно, чтобы все они были различны) состоит из заголовка
и тела. Заголовок состоит из такого фиксированного множества атрибутов Al, A2, .... An, что существует взаимно однозначное соответствие между этими атрибутами Ai и определяющими их доменами Di (i== I, 2,.. .,n). Тело состоит из меняющегося во времени множества кортежей, где каждый кортеж состоит в свою очередь из множества пар атрибут—значение (Ai:Vi), (i= I, 2,..., n), по одной такой паре для каждого атрибута Ai в заголовке. Для любой заданной пары атрибут—значение (Ai:Vi). Vi является значением из единственного домена Di, который связан с атрибутом Ai.
Рассмотрим для примера, как соответствует этому определению отношение поставщиков S (рис. 1.3). Определяющими доменами являются домен номеров поставщиков, скажем, Dl, домен фамилий поставщиков D2, домен значений состояния поставщиков D3 и домен названий городов D4. Заголовок S состоит из атрибутов НОМЕР_ПОСТАВЩИКА (определяющий домен D1), ФАМИЛИЯ (домен D2), СОСТОЯНИЕ (домен D3) и ГОРОД (домен D4). Тело S состоит из множества кортежей: пять кортежей показаны на рис. 1.3, но это множество изменяется во времени, когда осуществляются обновления данного отношения. Каждый кортеж представляет собой множество, состоящее из четырех пар атрибут—значение, по одной такой паре для каждого из четырех атрибутов в заголовке. Например, кортеж для поставщика S1 состоит из следующих пар:
(НОМЕР_ПОСТАВЩИКА : 'S1')
(ФАМИЛИЯ : 'Смит')
(СОСТОЯНИЕ : 20)
(ГОРОД : 'Лондон')
(хотя в неформальном контексте обычно можно опустить имена атрибутов). И конечно, значение каждого атрибута действительно взято из соответствующего определяющего домена. Значение 'S1', например, взято из домена номеров поставщиков D1. Таким образом, S в действительности является отношением, согласно данному определению.
Для строгости заметим, что когда мы изображаем отношение, например S, в виде таблицы, как это было сделано на рис. 1.3, мы просто используем удобный метод для представления отношения на бумаге. Таблица и отношение в действительности — это не одно и то же, хотя в большей части данной книги предполагалось, что это так. Например, ясно, что строки таблицы упорядочены (от верхней к нижней), а кортежи отношения —нет: отношение — это математическое множество, а множества в математике не обладают каким-либо упорядочением. Подобным же образом упорядочены также столбцы таблицы (слева направо), а атрибуты отношения — нет.
Обратите внимание, что от определяющих доменов отношения не требуется, чтобы все они были различны. Уже было приведено много примеров, в которых определяющие домены не были различными. Так, результирующее отношение в примере 4.3.1 (глава 4) включает два атрибута, которые определены на домене названий городов.
Значение n — число атрибутов в отношении или, что то же самое, число определяющих доменов — называется степенью отношения. Отношение степени один называется унарным,
отношение степени два — бинарным,
отношение степени три — тернарным
.... а отношение степени п — п-арным.
В базе данных поставщиков и деталей отношения S, Р и SP имеют степени 4, 5 и 3 соответственно. Число кортежей в отношении называется кардинальным числом этого отношения. Кардинальные числа отношений S, Р и sp, представленных на рис. 1.5, равны соответственно 5, 6 и 12. Кардинальное число отношения изменяется во времени в отличие от его степени[27].
АРЕЛЯЦИОННЫЕ СИСТЕМЫ
Теперь, наконец, имеется возможность точно определить, что мы понимаем под реляционной системой управления базами данных (реляционной СУБД или, для краткости, реляционной системой). Дело в том, что в настоящее время никакая система не поддерживает реляционную модель во всей ее полноте — несколько систем приблизилось к этому, но большинство из них «спотыкается» на ограничениях целостности, если не где-либо еще. С другой стороны, было бы неразумно утверждать, что некоторая система — не реляционная, если она не поддерживает эту модель вплоть до последней детали. Но дело в том, что не все аспекты реляционной модели в равной степени важны. Конечно, некоторые из них критичны, а другие могут рассматриваться только как возможности, которые было бы «приятно иметь». Поэтому будем называть систему реляционной, если она поддерживает, по крайней мере:
— реляционные базы данных, т. е. базы данных, которые могут восприниматься пользователем как таблицы, и только как таблицы;
— операции селекции, проекции и соединения реляционной алгебры, не требуя при этом, чтобы каким-либо образом были предопределены физические пути доступа для поддержки этих операций[28].
Для строгости заметим, что для квалификации системы как реляционной не требуется, чтобы она обязательно поддерживала операции селекции, проекции и соединения в явном
виде. Здесь речь идет лишь о функциональных возможностях этих операций. Например, система DB2 обеспечивает функциональные возможности всех этих трех операций и многое сверх того средствами ее собственного оператора SELECT. Более важно отметить, что в соответствии с нашим определением система, которая поддерживает реляционные базы данных, но не поддерживает эти три операции, не квалифицируется как реляционная. Подобным же образом система, которая, например, позволяет пользователю осуществлять селекцию кортежей в соответствии со значениями некоторого атрибута X, только если этот атрибут индексирован, также не относится к числу реляционных, поскольку здесь требуется предварительно определить физические пути доступа.
Мы мотивируем наше определение следующим образом:
1. Хотя селекция, проекция и соединение не образуют полной алгебры, они представляют собой чрезвычайно полезное ее подмножество. Можно насчитать сравнительно немного практических задач, которые решаются с помощью полной алгебры, но неразрешимы с помощью только селекции, проекции и соединения.
2. Система, которая поддерживает реляционную структуру данных, но не поддерживает реляционных операций, не обеспечивает продуктивности настоящих реляционных систем.
3. Хорошая реализация реляционных операций требует, чтобы система осуществляла некоторую оптимизацию. Система, которая бы только в точности исполняла запрашиваемые пользователем операции более или менее примитивным образом, почти наверняка имела бы неприемлемую производительность. Таким образом, создание системы, которая бы эффективным образом реализовала потенциал реляционной модели, — это весьма нетривиальная задача.
В соответствии с нашим определением DB2 — реляционная система, хотя она и не поддерживает некоторых аспектов реляционной модели. То же самое можно сказать и о SQL/DS. Однако в настоящее время имеется ряд коммерческих систем, которые рекламируются как «реляционные», но вместе с тем не удовлетворяют сформулированным выше критериям. Мы предполагаем, что эти критерии полезны как средство, позволяющее четко разграничить подлинно реляционные и «реляционно-подобные» системы. «Реляционно-подобные» системы в действительности не реализуют преимущества реляционной модели. Таким образом, целесообразно проводить такое различие, поскольку оно гарантирует, что этикетка «реляционная» не будет вводить в заблуждение.
AВВЕДЕНИЕ
DB2 — это реляционная СУБД (для краткости «реляционная система»). Задача данного приложения состоит в том, чтобы точно пояснить, что означает это утверждение. По существу, реляционная система — это такая система, которая строится в соответствии с реляционной моделью
данных или по крайней мере в соответствии с основными принципами этой модели, а реляционная модель — это способ видения данных, т. е. предписание, определяющее, каким образом следует представлять данные и как манипулировать этим представлением. Точнее говоря, реляционная модель имеет дело с тремя аспектами данных: со структурой
данных, с целостностью данных и с манипулированием данными. Рассмотрим поочередно каждый из них соответственно в разделах А.2, А.З и А.4, а затем обсудим вопрос о том, что в точности представляет собой реляционная система (раздел А.5).
Примечание. В этом приложении используется по большей части формальная реляционная терминология. Для удобства читателя на рис. A.1 повторяются из главы 1 основные реляционные термины и их неформальные эквиваленты.
Формальные реляционные термины
Неформальные эквиваленты
Отношение
кортеж
атрибут
таблица
запись, строка
поле, столбец
Рис. A.1. Некоторые термины
БАЗОВЫЕ ТАБЛИЦЫ
Базовая таблица — (важный) специальный случай более общего понятия «таблица». Поэтому давайте начнем с того, что несколько уточним это более общее понятие.
БАЗЫ ДАННЫХ
База данных в системе
DB2 представляет собой совокупность логически связанных объектов — хранимых таблиц, некоторым образом связанных друг с другом, вместе с относящимися к ним индексами и с множеством пространств, содержащих эти таблицы и индексы. Таким образом, база данных состоит из множества табличных пространств, каждое из которых содержит одну или несколько хранимых таблиц, а также множества индексных пространств, содержащих в точности по одному индексу. Как указывалось ранее, данная хранимая таблица и все связанные с нею индексы должны полностью содержаться в одной базе данных.
База данных представляет собой «старт-стопное устройство» в том смысле, что оператор может с консоли сделать данную базу данных доступной или недоступной для обработки с помощью соответствующих команд START и STOP. Следует отметить поэтому, что объекты группируются в одной и той же базе данных, главным образом, по причинам операционального характера. Пользователи (в нашем понимании этого термина) вообще не обязаны иметь дело с базами данных, и могут просто сосредоточиться на данных,
т. е. на таблицах — базовых таблицах и представлениях. Таблицы могут пересылаться из одной базы данных в другую, не оказывая какого-либо влияния на пользователей. И наконец, как уже указывалось в конце предыдущего раздела, база данных не является даже отдельным «физическим» объектом. В частности, она обычно не является отдельным диском или отдельным множеством дисков, а состоит, скорее, из частей многих дисков, другие части которых могут быть выделены для иных баз данных.
БИБЛИОГРАФИЯ
Ниже приводится краткий список литературы для дальнейшего чтения.
1. IBM Database 2 General Information. IBM Form No. GC26-4073.
2. IBM Database 2 Introduction to SQL IBM Form No. GC26-4082.
В этих двух руководствах даются обзоры программного продукта DB2 и используемого в DB2 диалекта языка SQL
соответственно. В них имеются также ссылки на ряд других руководств фирмы IBM по системе DB2.
3. Query Management Facility: General Information. IBM Form No. GC26-4071.
4. Data Extract: General Information. IBM Form No. GC26-4070.
В этих двух руководствах содержатся обзоры соответственно QMF и DXT и, подобно двум указанным выше руководствам по системе DB2, в них имеется также много ссылок на другую относящуюся к делу документацию фирмы IBM.
5. SQL/Data System for VSE: A Relational Data System for Application Development. IBM Form No. G320-6590. Вводное руководство по SQL/DS.
6. M. М. Astrahan et al. «System R: Relational Approach to Database Management.» ACM Transactions on Database Systems 1, No. 2 (June 1976).
Статья, в которой впервые описана общая архитектура System R — прототипа-предшественника DB2 (и SQL/DS).
7. М. W. Blasgen et al. «System R: An Architectural Overview». IBM System Journal, 20, No. 1 (February 1981).
Описывается архитектура System R в том виде, какой она стало ко времени полного завершения реализации системы.
8. D. D. Chamberlin et al. «A History and Evaluation of System R». Communications of the ACM, 24, No. 10 (October 1981). Обсуждаются уроки, извлеченные из разработки прототипной
System R.
9. D. D. Chamberlin, A. M. Gilbert, and R. A. Yost. «A History of System R and SQL/Data System». Proceedings of the Seventh International Conference on Very Large Data Bases (September 1981). Obtainable from ACM IEEE and INRIA. Приведено описание основных различий между
System R и SQL/DS.
10. E. F. Codd. «A Relational Model of Data for Large Shared Data Banks». Communications of the ACM, 13, No. 6 (June 1970). Reprinted in Communications of the ACM, 26, No. 1 (January 1983). В этой статье были впервые (не считая некоторых внутренних документов фирмы IBM) предложены идеи реляционной модели.
11. E. F. Codd. « Extending the Relational Database Model to Capture More Meaning». ACM Transactions on Database Systems, 4, No. 4 (December 1979). Предлагается расширенная версия реляционной модели, названная
RM/T. Схема классификации сущностей, описанная в Приложении В, основана на некоторых идеях из этой статьи.
12. E. F Codd. «Relational Database: A Practical Foundation for Productivity». Communication of the ACM, 25, No. 2 (February 1982). Сштья, подготовленная Коддом по случаю получения им Тьюринговской премии в 1981 году. Определение «реляционной системы» в Приложении А этой киши заимствовано из данной статьи.
13. W. Kent. «A Simple Guide to Five Normal Forms in Relational Database Theory». Communications of the ACM, 26, No. 2 (February 1983). Неформальное описание первой, второй, . . ., пятой нормальной формы (см. Приложение В этой книги).
14. С ,1. Date. <A Practical Approach to Database Design». IBM Technical Report TR 03.220 (December 1982). Методология проектирования, представленная в Приложении В, в большой пенсии основана на этом отчете. (См. также статью Кодда по RM/T [III.)
15. Г. ,1. Date. «An Introduction to Database Systems. Volume I (Third Edition), Addison-Wesley (1981).
(Есть русский перевод второго издания: Введение в системы баз данных. — М : Наука, 1981).
Volume II (First Edition), Addison-Wesley (1983).
Эти две книги обеспечивают основу для исчерпывающего изучения большинства пспркюв технологии баз данных. Они содержат, в частности, подробный учебный курс по реляционному подходу.
БЛАГОДАРНОСТИ
Во-первых, мне доставляет удовольствие поблагодарить Тэда Кодда за дружбу и поддержку, оказываемую им не только во время написания этой книги, но и во всей моей профессиональной деятельности на протяжении последних нескольких лет. Подобно многим другим людям, работающим в этой области, своими успехами и материальным благополучием я обязан той работе, которую первоначально выполнил Тэд в конце шестидесятых — начале семидесятых годов, и я счастлив возможностью публично признать здесь этот долг. Эта книга, несомненно, должна быть посвящена ему.
Во-вторых, хотелось бы поблагодарить моих друзей и коллег — Джнана Даша, Уолта Розберри, Фила Шоу и особенно Шарона Вейнберга — за их помощь и поддержку в ходе всего второго проекта, а также за их конструктивную критику начальных вариантов рукописи.
В-третьих, хотелось бы выразить благодарность моим бывшим коллегам по проекту DB2 и группе разработчиков за их терпение при разбирательстве моих многочисленных технических вопросов. Есть еще довольно много людей, достойных того, чтобы их всех здесь назвать, но мне особенно хотелось бы упомянуть моих сотрудников из отдела технического планирования DB2: Сэнди Эвеленда, Пола Хиггинботема, Роджера Рейнша, Дэна Вордмена и Джорджа Загелоу. Наконец, мне очень приятно высказать благодарность за ту тяжелую работу, которая проведена в издательстве Addison-Wesley и других местах многими людьми, непосредственно участвующими в издании этой книги. Я надеюсь, что результат воздаст должное их усилиям.
К. Д. Дейт
Саратога, Калифорния Сентябрь 1983 г.
БУДУЩИЕ РАЗРАБОТКИ
Реляционные системы, например DB2, в значительно большей степени, чем нереляционные, подчеркнули различия между внешним и внутренним или, что равносильно, между логическим и физическим уровнями системы. На логическом уровне делается акцент на применяемость: система представляет простую структуру данных и простые операции для манипулирования этой структурой, и эта простота приводит к высокой производительности пользовательского труда, как было показано в разделе 16.2. На физическом же уровне делается акцент на свободу: разделение двух уровней означает, что на данной установке системы предоставляется свобода для осуществления нетривиальных изменений на физическом уровне таким образом, чтобы это не оказывало влияния на логический уровень, конечно, не считая производительности.
Возвращаясь теперь, в частности, к DB2, можно предположить, что в ближайшем будущем мы явимся свидетелями важных достижений, связанных с обоими уровнями. На физическом уровне должны быть, вероятно, обеспечены новые виды механизмов доступа (хеширование, цепочки указателей и т. д.) в качестве альтернативы существующему механизму индексирования. Для того чтобы учитывать эти новые структуры, должен быть также усовершенствован оптимизатор. Такие новые механизмы не должны быть, конечно, видимыми на логическом уровне. На логическом уровне должны быть, вероятно, реализованы расширения языка SQL, обеспечивающие непосредственную поддержку таких функций, как внешнее соединение. Можно ожидать также, что получит развитие поддержка целостности данных, особенно целостности по ссылкам (см. Приложения А и В).
В течение долгосрочного периода можно ожидать появления других далеко идущих разработок. Для того чтобы получить некоторое понятие о том, что они могут собой представлять, можно посмотреть, какие работы проводятся в настоящее время в некоторых университетских лабораториях и научно-исследовательских учреждениях. Фактически имеется большое число таких работ, и все они основаны на реляционной модели. К их числу относятся:
— системы распределенных баз данных
— совместно используемые машины баз данных
— семантическое моделирование
— включение новых видов данных (например, текстов, изображений)
— экспертные системы
— новые виды интерфейсов, в том числе естественный язык
— системы баз данных для инженерного дела и научных исследований и др. Некоторые из перечисленных выше разработок являются, конечно, значительно менее «долговременными», чем другие. Например, машины баз данных коммерчески доступны уже сегодня. То же можно сказать о системах, использующих естественный язык. Но дело в том, что по всем этим направлениям исследования продолжаются, и все они основаны на реляционном подходе. Кроме того, тот факт, что они строятся на реляционной основе, важен сам по себе. Многие из этих исследований едва ли были бы осуществимы на основе любого другого подхода. Таким образом, к приведенному в разделе 16.2 списку преимуществ реляционного подхода можно было бы добавить еще и расширяемость. Пользователи существующих реляционных систем находятся в лучшем положении (чем если бы они были пользователями системы некоторого иного вида) благодаря тому, что они смогут использовать достоинства новых технологий, когда они появятся.
По вопросу о распределенных системах интересно, в частности, отметить что научно-исследовательская лаборатория фирмы IBM в Сан-Хосе проводила в течение некоторого времени работу по созданию системы-прототипа под названием R* (произносится «Р-стар»). Система R* является распределенной версией более раннего прототипа, который назывался System R. В свою очередь, как уже указывалось в предисловии к этой книге, System R послужила базой для разработки программных продуктов DB2 и SQL/DS. Не исключается, таким образом, вероятность того, что технология системы R* когда-либо будет использована в распределенных версиях SQL/DS и DB2.
Тот факт, что все эти исследования основаны на реляционной модели, свидетельствует о всеобщем признании этой модели в академическом мире[26]. Совсем недавно реляционные идеи стали общепризнанными также и в коммерческих кругах. В поддержку этого утверждения можно указать на большое число объявленных в этой области новых программных продуктов, фактически почти каждый объявленный в последнее время программный продукт в области баз данных является либо «новенькой с иголочки» реляционной системой (такой, как DB2), либо «реляционным» расширением одной из более старых систем. (Здесь слово «реляционным» заключено в кавычки, поскольку всегда никоим образом неясно, что эти расширения на самом деле являются реляционными. См. обсуждение этого вопроса в Приложении А.) По заниженным оценкам в настоящее время на рынке имеется более сорока реляционных систем, в том числе большое их число для микроЭВМ, и нет сомнения, что это число, вероятно, значительно выросло за время, пока эта книга вышла из печати. И объявление системы DB2 фирмой IBM может в действительности лишь усилить влияние реляционной технологии в коммерческих кругах. Что касается управления базами данных, становится все более ясно — реляционные системы являются технологией будущего.
BВВЕДЕНИЕ
Проектирование баз данных — это крупный вопрос. Невозможно по-настоящему воздать ему должное в приложении, состоящем всего из нескольких страниц. Можно рассчитывать лишь на то, чтобы представить здесь общий подход, который был бы полезен в проектировании реляционных баз данных вообще и баз данных системы DB2 в частности. Многие конкретные вопросы останутся при этом без ответа. Мы надеемся, однако, что этот общий подход будет полезен как некоторая схема, в рамках которой пользователи могут пытаться самостоятельно отвечать на эти более конкретные вопросы.
Предполагается, что читателю хорошо знакомы и удобны такие термины, как «сущность», «связь» и «свойство». Эти термины можно неформально определить следующим образом:
— Сущность
представляет собой любой отличимый объект,
где объект, о котором идет речь, может быть настолько конкретным или абстрактным, насколько нам это нравится. Примерами сущностей могут служить люди, места, самолеты, рейсы, джаз, красный цвет и т. д. Конечно, в контексте базы данных сущности, которыми мы главным образом интересуемся,— это такие объекты, информацию о которых мы хотим хранить в базе данных.
— Связью
называется ассоциирование двух или более сущностей Примерами связей являются зачисления служащих в отделы (связь многие-к-одной) и поставка деталей поставщиками (связь многие-ко-многим).
—- Свойство —
это однозначный факт о некоторой сущности.
Примерами свойств являются зарплата служащих, вес деталей, объем поставок и т. п.
В следующем разделе будет приведена схема классификации сущностей, которая образует основу нашей методологии проектирования. После этого рассматриваются та важная роль, которую играют в проектировании баз данных первичные и внешние ключи, последовательность основных шагов, входящих в процедуру проектирования, предложения относительно способа формальной записи проектных решений, некоторые «рецепты», касающиеся отображения этих решений в формальные конструкции системы DB2. Обсуждаются также основные идеи нормализации, приводится краткий список разнообразных советов и рекомендаций.
Отметим в заключение еще один момент. Читатель, должно быть, уже понял, что термин «проектирование баз данных» используется здесь в смысле логического
проектирования. Этот факт вовсе не означает, что мы считаем физическое проектирование не настолько важным. Дело в том, что оно представляет собой самостоятельную задачу, которой можно и нужно заниматься отдельно после того, как выполнено логическое проектирование. Такая возможность строгого разделения указанным образом двух видов деятельности, связанных с логическим и физическим проектированием, является в действительности одним из основных достижений реляционной технологии.
ЧТО ТАКОЕ ТРАНЗАКЦИЯ
Транзакция в том смысле, в котором мы используем этот термин,— это логическая единица работы. Рассмотрим следующий пример (обобщенный вариант примера 6.2.4 из главы 6, представленный в форме встроенного SQL): заменить номер 'Sx' поставщика на 'Sy', где Sx и Sy — параметры. Для простоты опустим ряд проверок достоверности данных, которые обычно включаются в реальную программу. Кроме того, опустим все объявления.
TRANEX: PROC OPTIONS (MAIN); /* пример транзакции */
EXEC SQL WHENEVER SQLERROR GO TO UNDO;
GET LIST (SX, SY);
EXEC SQL UPDATE S
SET НОМЕР_ПОСТАВЩИКА = :SY
WHERE НОМЕР_ПОСТАВЩИКА = :SX;
EXEC SQL UPDATE SP
SET НОМЕР_ПОСТАВЩИКА == :SY
WHERE НОМЕР_ПОСТАВЩИКА = :SX;
EXEC SQL COMMIT;
GO TO FINISH;
UNDO: EXEC SQL ROLLBACK;
FINISH: RETURN;
END TRANEX;
Смысл данного примера заключается в том, что выражение «Заменить номер поставщика Sx на Sy», воспринимаемое конечным пользователем, вероятно, как единственная атомарная операция, требует на самом деле двух операций UPDATE над базой данных. Более того, между этими двумя операциями может даже нарушаться непротиворечивость базы данных. Например, в ней могут временно содержаться некоторые записи поставок, для которых не имеется соответствующих записей поставщиков. Заметим, что это наблюдение остается в силе, если изменить порядок исполнения двух операций UPDATE в приведенном примере. Таким образом, транзакция или логическая единица работы — не обязательно только одна операция языка SQL. В общем случае это, скорее, последовательность
нескольких таких операций, которая преобразует некоторое непротиворечивое состояние базы данных в другое непротиворечивое состояние, но не гарантирует сохранения непротиворечивости во все промежуточные моменты времени.
Ясно теперь, что в данном примере не следует допускать таких случаев, когда одна из двух операций
UPDATE исполняется, а другая — нет, поскольку при этом база данных осталась бы в состоянии, когда нарушена ее непротиворечивость. В идеальном случае нам хотелось бы, конечно, иметь твердые гарантии того, что обе операции UPDATE будут выполнены. К сожалению, обеспечить какие-либо гарантии такого рода невозможно. Всегда есть некоторый шанс, что могут возникнуть ошибки, и, более того, ошибки могут возникнуть в наихудший возможный момент. Например, аварийный отказ системы может иметь место между двумя операциями UPDATE, или сама программа может аварийно завершиться между этими двумя операциями, например в связи с ошибкой переполнения (в рассматриваемом случае такая ошибка невозможна). Однако система, которая поддерживает обработку транзакций, действительно является лучшей с точки зрения обеспечения таких гарантий. В частности, она гарантирует, что если в транзакции осуществлялись некоторые обновления и затем по какой-либо причине имела место ошибка до того, как транзакция достигла ее нормального завершения, то эти обновления будут аннулированы. Таким образом, транзакция либо полностью исполняется, либо полностью аннулируется, как будто бы она никогда не исполнялась вообще. При этом последовательность операций, не являющаяся по существу атомарной, может быть представлена таким образом, чтобы она выглядела (с точки зрения конечного пользователя) как если бы она в действительности была атомарной.
Администратор транзакций — это системный компонент, который обеспечивает такую атомарность или подобие атомарности, а операции COMMIT (фиксировать) и ROLLBACK (откат) полностью определяют способ его функционирования. Операция COMMIT сигнализирует об успешном завершении транзакции. Она сообщает администратору транзакций, что логическая единица работы была успешно завершена, что база данных снова находится (или должна находиться) в непротиворечивом состоянии, и все произведенные этой единицей работы обновления могут быть теперь «зафиксированы», т. е. приняты за свершившиеся. Напротив, команда ROLLBACK сигнализирует о неудачном завершении транзакции. Она сообщает администратору транзакций, что что-то испортилось, что непротиворечивое состояние базы данных, возможно, нарушено и что для всех произведенных до сих пор данной логической единицей работы обновлений следует сделать «откат», т. е. аннулировать их. Под «обновлением» здесь понимаются, конечно, операции INSERT и DELETE, а также сами по себе операции UPDATE.
В приведенном примере команда COMMIT издается, следовательно, в том случае, если успешно проведены обе операции UPDATE, в результате чего изменения будут фиксироваться в базе данных и принимаются за свершившиеся. Если, однако, что-нибудь испортится, т. е. для какой-либо из операций UPDATE возвращаемое значение SQLCODE будет отрицательным, то вместо этого издается ROLLBACK с тем, чтобы аннулировать сделанные до сих пор изменения. В приведенном примере операции COMMIT и ROLLBACK издаются явным образом. Однако, как указывалось в конце главы 10, для любой исполняемой в обстановке системы DB2 программы при ее нормальном завершении будет автоматически издаваться COMMIT. В противном случае для нее автоматически будет издаваться ROLLBACK, независимо от причины аварийного завершения программы. Если, в частности, программа аварийно завершается в связи со сбоем системы, ROLLBACK издается от имени этой программы при рестарте системы. Следовательно, в приведенном примере можно было бы опустить явно специфицированное предложение COMMIT, но не следует опускать явного предложения ROLLBACK.
Примечание. Читатель может заинтересоваться, каким образом возможно аннулировать обновление. Ответ заключается, конечно, в том, что система ведет журнал, в который записываются подробности всех операций обновления, в частности значения до и после обновления. (Фактически в журнал помещается регистрационная запись для каждой заданной операции обновления прежде, чем это обновление будет осуществлено над базой данных. Этот вопрос обсуждается в следующем разделе.) Поэтому, если возникает необходимость в том, чтобы аннулировать некоторое конкретное обновление, система может использовать соответствующую регистрационную запись для восстановления предыдущего значения обновленного элемента.
Отметим в заключение еще один момент. Как уже было указано в главе 1, предложения манипулирования данными языка SQL относятся к уровню множеств, и обычно операция осуществляется одновременно над множеством записей. Что же тогда произойдет, если возникнет какая-либо ошибка во время исполнения такого предложения? Возможно ли, например, чтобы вторая операция UPDATE в приведенном примере обновила бы некоторые из ее целевых записей в таблице SP, а затем неудачно завершилась, не осуществив обновления остальных записей этой таблицы? Ответ отрицателен, это невозможно. Система DB2 гарантирует, что все предложения языка SQL в отдельности являются атомарными, по крайней мере, в отношении их влияния на базу данных. Если во время исполнения такого предложения все же имела место ошибка, то база данных останется полностью неизменной.
CВВЕДЕНИЕ
В данном разделе приводится представленная в виде нормальных форм Бэкуса (Язык нормальных форм Бэкуса — формальный метаязык, используемый для описания синтаксиса различных языков программирования, языков описания данных и других искусственных языков. Впервые был предложен Д. Бэкусом для описания синтаксиса алгоритмического языка АЛГОЛ-60.— Примеч. пер.) грамматика четырех операций манипулирования данными языка SQL (SELECT, UPDATE, DELETE и INSERT), описанных в этой книге. В этой грамматике используется следующее удобное сокращение:
— Если «xyz» — какая-либо синтаксическая категория, то «список-xyz» — это синтаксическая категория, которая представляет собой список, состоящий из одной или более «xyz». При этом каждая пара смежных «xyz» в списке разделяется последовательностью литер, включающей запятую, а также, возможно, предшествующие ей и следующие за ней один или более пробелов.
Категории «идентификатор», «константа» и «целое» являются по отношению к этой грамматике терминальными.
Примечание. Не описанные в тексте этой книги аспекты четырех рассматриваемых предложений, например операторы сравнения >ANY, =ALL и др., игнорируются. Кроме того, в интересах ясности и краткости предлагаемая грамматика не отражает точно диалекта языка SQL, поддерживаемого системой DB2, и является в некоторой степени нестрогой в том смысле, что она допускает генерацию определенных конструкций, которые оказываются недопустимыми в DB2. Она позволяет, например, использовать в качестве аргумента такой функции, как AVG, ссылку на другую функцию, скажем, SUM, что не допускается в DB2.
DB РЕЛЯЦИОННАЯ СИСТЕМА
Базы данных системы DB2 являются реляционными. Реляционная база данных это такая база данных, которая воспринимается ее пользователями как совокупность таблиц (и ничего иного, кроме таблиц). Пример такой базы данных (поставщики и детали) показан на рис. 1.3.
Нетрудно видеть, что эта база данных состоит из трех таблиц, а именно: S, Р и SP.
— Таблица S представляет поставщиков. Каждый поставщик имеет номер, уникальный для этого поставщика, фамилию— не обязательно уникальную, значение рейтинга или состояния и местонахождение (город). Для целей примера предположим, что каждый поставщик находится в точности в одном городе.
— В таблице Р представлены детали (точнее, виды деталей). Каждый вид деталей имеет уникальный номер детали, название, цвет, вес и место (город), где хранятся детали этого вида. Вновь для целей примера предположим, что каждый вид деталей имеет в точности один цвет и хранится на складе только одного города.
— Таблица SP представляет поставки деталей. Она служит для того, чтобы в некотором смысле связать между собой две другие таблицы. Например, первая строка этой таблицы на рис. 1.3 связывает определенного поставщика из таблицы S (а именно, поставщика S1) с определенной деталью из таблицы Р (а именно, с деталью P1). Иными словами, она представляет поставку деталей вида Р1 поставщиком по фамилии S1 и объем поставки, равный 300 деталям. Таким образом, для каждой поставки имеется номер поставщика, номер детали, и количество деталей. Для целей примера снова предположим, что может существовать не более одной поставки в любой заданный момент времени для заданного поставщика и заданной детали. Итак, комбинация значений НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ является уникальной для заданной поставки относительно множества поставок, представленных в текущий момент времени в таблице.
S
НОМЕР_ПОСТАВЩИКА
ФАМИЛИЯ
СОСТОЯНИЕ
ГОРОД
S1
S2
S3
S4
S5
Смит
Джонс
Блейк
Кларк
Адамс
20
10
30
20
30
Лондон
Париж
Париж
Лондон
Атенс
НОМЕР_ДЕТАЛИ
НАЗВАНИЕ
ЦВЕТ
ВЕС
ГОРОД
Р1
Р2
РЗ
Р4
Р5
Р6
гайка
болт
винт
винт
кулачок
блюм
красный
зеленый
голубой
красный
голубой
красный
12
17
17
14
12
19
Лондон
Париж
Рим
Лондон
Париж
Лондон
НОМЕР_ПОСТАВЩИКА
НОМЕР_ДЕТАЛИ
КОЛИЧЕСТВО
S1
S1
S1
S1
S1
S1
S2
S2
S3
S4
S4
S4
Р1
Р2
РЗ
Р4
Р5
Р6
Р1
Р2
Р2
Р2
Р4
Р5
300
200
400
200
100
100
300
400
200
200
300
400
Рис. 1.3. База данных поставщиков и деталей (пример)
Конечно, этот пример чрезвычайно прост. Он значительно проще любого реального примера, с которым, вероятно, можно встретиться на практике. Тем не менее, он достаточен для того, чтобы проиллюстрировать большинство вопросов, которые нам необходимо рассмотреть в этой книге. Поэтому мы будем использовать этот пример как основу для большинства (но не всех) примеров, приводимых в последующих главах, и следует потратить немного времени, чтобы хорошо с ним здесь разобраться.
Примечание. Нет ничего плохого в использовании более описательных имен (таких, как ПОСТАВЩИКИ, ДЕТАЛИ и ПОСТАВКИ) вместо весьма кратких— S, Р и SP. В действительности, на практике вообще нужно рекомендовать описательные имена (Именно так мы поступили при переводе, заменив имена столбцов таблиц этого и других примеров, представленные в виде аббревиатур английских названий, на более понятные русскому читателю содержательные имена.— Примеч. Пер.). Но конкретно в случае базы данных поставщиков и деталей эти три таблицы упоминаются в тексте настолько часто, что представляются более желательными очень краткие имена. Часто повторяемые длинные имена стали бы надоедливыми.
Два возникающих в связи с этим примером вопроса заслуживают, чтобы сказать о них здесь явно.
— Заметим, во-первых, что все значения данных являются атомарными, т. е. в каждой таблице в каждой позиции на пересечении строки и столбца всегда имеется в точности одно значение данных и никогда не бывает множества значений. Таким образом, например, в таблице SP (если для простоты рассматривать только два первых ее столбца) имеем:
НОМЕР_ПОСТАВЩИКА
НОМЕР_ДЕТАЛИ
.
S2
S2
.
S4
S4
S4
.
.
Р1
Р2
.
Р2
Р4
Р5
.
Вместо:
НОМЕР_ПОСТАВЩИКА
НОМЕР_ДЕТАЛИ
.
S2
.
S4
.
.
.
{PI. P2)
.
(Р2, Р4, Р5}
.
.
Столбец НОМЕР_ДЕТАЛИ во втором варианте этой таблицы представляет то, что иногда называется «повторяющейся группой». Повторяющаяся группа — это столбец, который содержит множество значений данных (в различных строках могут быть различные количества значений) вместо ровно одного значения в каждой строке. Реляционные базы данных не допускают повторяющихся групп. Второй вариант приведенной выше таблицы нельзя было бы использовать в реляционной системе.
— Во-вторых, отметим, что полное информационное содержание базы данных представляется в виде явных значений данных. Такой метод представления (в виде явных значений в позициях столбцов и строк таблиц) является единственным методом, имеющимся в распоряжении в реляционной базе данных. В частности, не существует каких-либо «связей» или указателей, соединяющих одну таблицу с другой. Так, имеется связь между строкой S1 таблицы S и строкой Р1 таблицы Р (поставщик S1 поставляет деталь Р1). Но эта связь представляется не с помощью указателей, а благодаря существованию в таблице SP строки, в которой значение номера поставщика равно S1, а значение номера детали равно Р1. Напротив, в системах нереляционного типа (например, в IMS) такая информация обычно представляется с помощью некоторого рода физической связи или указателя, который является явным образом видимым для пользователя.
Читатель может здесь заинтересоваться, почему такая база данных, как приведенная на рис. 1.3, называется «реляционной», Ответ простой: «отношение» — «relation» — просто математический термин для обозначения таблицы (точнее, таблицы определенного специфического вида—подробно об этом идет речь в главе 3). Таким образом, можно, например, сказать, что база данных, приведенная на рис. 1.3, состоит из трех отношений. Фактически в значительной мере можно считать термины «отношение» и «таблица» синонимами. Реляционные системы берут свое начало в математической теории отношений. Это не означает, конечно, что необходимо быть математиком для того, чтобы использовать реляционную систему. Но это означает, что существует значительное количество теоретических результатов, которые можно применять для решения практических проблем использования баз данных, например проблемы проектирования баз данных.
Если правильно то, что отношение— это только таблица, то почему не называть его просто таблицей и не довольствоваться этим? Ответ заключается в том, что мы очень часто это делаем (и обычно так и будем делать в этой книге). Однако стоит затратить немного времени для того, чтобы понять, почему сначала был введен термин «отношение». Кратко объяснение состоит в следующем. Реляционные системы базируются на так называемой реляционной модели данных. Реляционная модель в свою очередь является абстрактной теорией данных, которая основана, в частности, на упомянутой выше математической теории. Основы реляционной модели были первоначально сформулированы доктором Э. Ф. Коддом из фирмы IBM. В конце 1968 года Кодд, математик по образованию, впервые ясно понял, что можно использовать математику для придания надежной основы и строгости области управления базами данных, которая до настоящего времени была слишком несовершенной в указанных аспектах. Идеи Кодда были впервые широко опубликованы в ставшей теперь классической работе [10]. С тех пор эти идеи (к настоящему времени принятые почти повсюду) оказали весьма широкое влияние на технологию баз данных почти во всех ее аспектах, а в действительности также и на другие области, например на область искусственного интеллекта и обработку текстов на естественных языках.
Далее, реляционная модель, первоначально предложенная Коддом, требовала очень осмотрительного использования определенных терминов, например самого термина «отношение», которые не были хорошо известными в то время в сфере обработки данных, хотя эти концепции в некоторых случаях существовали. Неприятность, однако, заключалась в том, что были очень нечеткими многие более известные термины. Им недоставало точности, необходимой для формальной теории такого рода, какая была предложена Коддом. Рассмотрим, например, термин «запись». В различных ситуациях этот термин может означать экземпляр записи, либо тип записей, запись в стиле Кобола (которая допускает повторяющиеся группы) или плоскую запись (которая их не допускает), логическую запись или физическую запись, хранимую запись или виртуальную запись и т. д. Поэтому в формальной реляционной модели вообще не используется термин «запись». Вместо этого в ней используется термин «кортеж» (сокращение для «кортеж длины п»), которому было дано точное определение, когда Кодд впервые ввел его. Мы не приводим здесь это определение. Для наших целей достаточно сказать, что термин «кортеж» приблизительно соответствует понятию экземпляра плоской записи (точно так же, как термин «отношение» приблизительно соответствует понятию таблицы). Если Вы желаете изучить какие-либо более формальные публикации по реляционным системам баз данных, следует, конечно, познакомиться и с формальной терминологией. Но в этой книге мы не пытаемся быть очень формальными и будем по большей части придерживаться таких терминов, как «запись», которые являются достаточно хорошо знакомыми. На рис. 1.4 приведены термины, которые мы будем использовать наиболее часто (таблица, запись, строка, поле, столбец). Для справки в каждом случае дается также соответствующий формальный термин. Заметим, что термины «запись» и «строка»
Неформальные эквиваленты
отношение
кортеж
атрибут
таблица
запись, строка
поле, столбец
Рис. 1.4. Некоторые термины
мы используем как равнозначные. Аналогично используются термины «поле» и «столбец». Заметим также, что мы, следовательно, принимаем по определению, что «запись» означает «экземпляр записи», а «поле» означает «тип поля».
DB2 можно использовать на любой
DB2 можно использовать на любой вычислительной системе, поддерживаемой операционной системой MVS Version 1 Release 3 (MVS/370) или MVS Version 2 Release 1.1 (MVS/XA). Для вычислительной системы 3033 рекомендуется использовать при этом аппаратные средства перекрестного расширения памяти. В DB2 память, прямого доступа используется для:
– наборов данных базы данных (по выбору пользователя может использоваться подсистема массовой памяти — MSS)
– наборов данных каталога наборов данных активных журналов
– наборов данных архивных журналов (по выбору пользователя может использоваться магнитная лента или MSS)
– наборов данных для копий содержимого базы данных (можно использовать по выбору магнитную ленту или MSS)
– рабочих наборов данных утилит (можно использовать по выбору магнитную ленту или MSS)
– набора данных самозагрузки.
Примечание. Набор данных самозагрузки используется при рестартах системы.
Виртуальная память: Минимальная потребность в общей области памяти (CSA) в обстановке MVS/370, примерно равна 512 K байт. Практическая минимальная потребность в приватной виртуальной памяти составляет примерно 4,5—5 мегабайт. В обстановке MVS/XA большинство требуемых для DB2 областей размещается в расширенной общей области памяти. Большинство программных модулей, управляющих блоков и буферов DB2 размещается в расширенной приватной области.
Для поддержки системы необходимы следующие средства программного обеспечения:
1. MVS/SP-JES2 или -JES3, Version 1 Release 3 или Version 2 Release 1.1 (либо последующие выпуски)
2. MVS/370 Data Facility Product Release 1 или MVS/XA Data Facility Product Release 1.1
3. MVS TSO Command Package Release 1.1 или MVS TSO Extensions (TSO/E) Release 1
4. OS/VS Sort/Merge Release 5
5. Interactive System Productivity Facility (ISPF и ISPF/Program Development Facility (ISPF/PDF
или PDF) по выбору пользователя, необязательны для работы
DB2I.
6. System Maintenance Program (SMP) Version 1 Release 4
Следующие средства используются по выбору пользователя:
1. Query Management Facility (QMF) Release 1
2. Data Extract (DXT) Release 1
3. Information Management System/Virtual Storage (IMS/VS) Version 1 Release 3
4. Customer Information Control System/OS/Virtual Storage (CICS/OS/VS) Version 1 Release 6
5. Resource Access Control Facility (RACF) Release 5
6. OS/VS COBOL Compiler and Library Release 2.3
7. TSO Assembler Prompter Release 1
8. TSO COBOL Prompter Release 1
9. OS PL/I Optimizing Compiler Release 4
10. VS FORTRAN Release 1.1
11. OS Assembler H Release 5
12. Assembler H Version 2 Release I
DТРЕБОВАНИЯ DXT
Для работы с DB2 системе DXT требуется:
1. DB2
2. ISPF/PDF Release 1.1
3. OS/VS DB/DC Data Dictionary Release 4 (по выбору пользователя)
DТРЕБОВАНИЯ QMF
Для работы с DB2 системе QMF требуется:
1. DB2
2. ISPF Release 1.1
3. Graphical Data Display Manager, Release 2
ЕДИНИЧНОЕ SELECT
Выдать состояние и город для поставщика, номер которого задается переменной включающего языка ЗАДАННЫИ_НОМЕР.
ЕХЕС SQL SELECT СОСТОЯНИЕ, ГОРОД
INTO :РАНГ, :ГОРОД
FROM S
WHERE НОМЕР_ПОСТАВЩИКА = :ЗАДАННЫЙ_НОМЕР;
Термин «единичное
SELECT» используется здесь для обозначения предложения SELECT, которое продуцирует таблицу, содержащую не более одной строки. В данном примере, если существует в точности одна запись в таблице S, удовлетворяющая условию WHERE, то значения СОСТОЯНИЕ и ГОРОД из этой записи будут присвоены, как требовалось в запросе, переменным включающего языка РАНГ и ГОРОД, a SQLCODE будет установлено в нуль. Если же никакая запись в S не удовлетворяет условию WHERE, поле SQLCODE примет значение +100. Если, наконец, существует более одной такой записи, возникает ошибка, и значение SQLCODE будет отрицательным. В последних двух случаях значения переменных включающего языка РАНГ и ГОРОД останутся неизменными.
В связи с приведенным примером возникает другой вопрос. Что произойдет, если предложение SELECT в действительности выберет в точности одну запись, но значение поля СОСТОЯНИЕ (или поля ГОРОД) в ней окажется неопределенным? Как показано выше, в таком случае будет иметь место ошибка, и полю SQLCODE будет присвоено некоторое отрицательное значение. Если существует шанс, что выбираемое значение поля может быть неопределенным, пользователь должен предусмотреть индикаторную переменную для этого поля во фразе INTO, а также обычную целевую переменную, как показано в следующем примере:
ЕХЕС SQL SELECT СОСТОЯНИЕ, ГОРОД
INTO :РАНГ: ИНД_РАНГА, :ГОРОД: ИНД_ГОРОДА
FROM S
WHERE НОМЕР_ПОСТАВЩИКА = :ЗАДАННЫЙ_НОМЕР;
IF ИНД_РАНГА < 0 THEN / » значение поля состояние было неопределенным */. . .;
IF ИНД_ГОРОДА < 0 THEN / * значение поля ГОРОД было неопределенным */. . .;
Если поле, выборка которого осуществляется, имеет неопределенное значение, и была специфицирована индикаторная переменная, то этой индикаторной переменной будет присвоено соответствующее отрицательное значение, а обычная целевая переменная останется неизменной. Индикаторная переменная специфицируется, как показано в приведенном примере, т. е. она следует за соответствующей обычной целевой переменной и отделяется от этой целевой переменной двоеточием. Индикаторные переменные следует объявлять как 15-битовые двоичные целые со знаком.
Примечание.
Индикаторные переменные не могут использоваться во фразе WHERE. Например, следующий фрагмент программы некорректен:
ИНД_РАНГА = -1;
ЕХЕС SQL SELECT ГОРОД
INTO :ГОРОД
FROM S
WHERE СОСТОЯНИЕ = :РАНГ : ИНД_РАНГА;
Правильный способ выборки городов при неопределенном значении поля СОСТОЯНИЕ иллюстрируется ниже:
ЕХЕС SQL SELECT ГОРОД
INTO :ГОРОД
FROM S
WHERE СОСТОЯНИЕ IS NULL;
ФУНКЦИЯ В КОРРЕЛИРОВАННОМ ПОДЗАПРОСЕ
Выдать номер поставщика, состояние и город для всех поставщиков, у которых состояние больше или равно среднему для их конкретного города.
SELECT НОМЕР—ПОСТАВЩИКА, СОСТОЯНИЕ, ГОРОД
FROM S SX
WHERE СОСТОЯНИЕ > =
(SELECT AVQ (СОСТОЯНИЕ)
FROM S SY
WHERE SY. ГОРОД = SX. ГОРОД);
Результат:
НОМЕР_ПОСТАВЩИКА
СОСТОЯНИЕ
ГОРОД
S1
20
Лондон
S3
30
Париж
S4
20
Лондон
S5
30
Атенс
Включить в результат среднее состояние для каждого города невозможно. (Почему?)
ФУНКЦИЯ В ПОДЗАПРОСЕ
Выдать номера поставщиков со значением поля СОСТОЯНИЕ меньшим, чем текущее максимальное состояние в таблице S.
SELECT НОМЕР—ПОСТАВЩИКА
FROM S
WHERE СОСТОЯНИЕ <
(SELECT MAX (СОСТОЯНИЕ)
FROM S);
Результат:
НОМЕР_ ПОСТАВЩИКА
S1
S2
S4
ФУНКЦИЯ ВО ФРАЗЕ SELECT
Выдать общее количество поставщиков.
SELECT COUNT (*)
FROM SP
Результат:
5
ФУНКЦИЯ ВО ФРАЗЕ SELECT С ПРЕДИКАТОМ
Выдать количество поставок для детали Р2.
SELECT COUNT (*)
FROM SP
WHERE НОМЕР_ДЕТАЛИ = 'Р2';
Результат:
4
Выдать общее количество поставляемых деталей Р2.
SELECT SUM (КОЛИЧЕСТВО)
FROM SP
WHERE НОМЕР_ДЕТАЛИ = 'Р2';
Результат:
1000
ФУНКЦИЯ ВО ФРАЗЕ SELECT СО СПЕЦИФИКАЦИЕЙ DISTINCT
Выдать общее количество поставщиков, поставляющих в настоящее время детали:
SELECT COUNT (DISTINCT НОМЕР—ПОСТАВЩИКА)
FROM SP;
Результат:
4
ГЕНЕРАЦИЯ ОТЧЕТОВ
Отчет в QMF — это выводимые на экран дисплея или печатаемые результаты выполнения запроса. Каждый отчет форматируется в соответствии с множеством спецификаций, называемым формой. Когда пользователь специфицирует запрос, ему предоставляется факультативная возможность явного задания соответствующей формы. Если он не задает такой явной спецификации, QMF автоматически создает «системную» форму по умолчанию, и вывод результатов выполнения запроса будет осуществляться в соответствии с этой формой. Впоследствии пользователь может пересмотреть эту форму и снова запросить вывод результатов на экран в соответствии с пересмотренной формой. Этот цикл может повторяться необходимое количество раз до тех пор, пока пользователь не будет удовлетворен. Таким образом, типичный интерактивный сеанс работы с QMF мог бы проходить следующим образом (рис. 15.1):
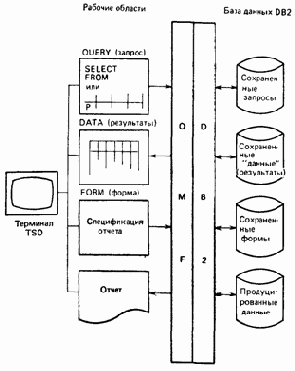
Риc. 15.1. Использование QMF
1. Используя функции полноэкранного редактора QMF, пользователь с помощью SQL либо Query-By-Example формулирует запрос QMF. Этот запрос сохраняется во временной рабочей области, называемой QUERY (запрос).
2. Используя, вероятно, программируемую функциональную клавишу, пользователь выдает команду RUN QUERY (исполнить запрос) с тем, чтобы выполнить запрос из области QUERY. Peзультаты его выполнения сохраняются в другой временной рабочей области, называемой DATA (данные).
3. QMF создает «системную» форму по умолчанию для данных из области DATA и выводит эти данные в соответствии с построенной таким образом формой. Эта форма сохраняется в еще одной временной рабочей области—FORM (форма).
4. После рассмотрения полученного на предыдущем шаге отчета пользователь выдает команду DISPLAY FORM (показать форму), вероятно, снова с помощью программируемой функциональной клавиши, чтобы вывести на экран текущее содержимое области FORM.
5. Снова используя функции полноэкранного редактирования, пользователь пересматривает текущее содержимое области FORM.
6. Для формирования пересмотренного отчета, соответствующего переработанной форме, пользователь издает команду DISPLAY REPORT (показать отчет). Заметим, что при этом нет необходимости заново исполнять первоначальный запрос. Результаты этого запроса сохранены в области DATA, и при исполнении команды DISPLAY REPORT текущее содержимое FORM используется для форматизации и вывода на экран текущего содержимого DATA.
7. Шаги 4 — 6 повторяются необходимое количество раз до тех пор, пока пользователь не будет удовлетворен окончательным результатом.
8. При желании пользователь выдает команду PRINT REPORT—опять-таки, вероятно, с помощью программируемой функциональной клавиши — для получения печатной копии окончательного результата.
Рассмотрим теперь пример, показывающий, каким образом эта последовательность событий могла бы выглядеть на практике. Предположим, что первоначальный запрос имеет следующий вид:
SELECT S.ГОРОД, S.СОСТОЯНИЕ, SP.НОМЕР_ПОСТАВЩИКА,
SP.НОМЕР_ДЕТАЛИ, SP.КОЛИЧЕСТВО FROM S, SP
WHERE S.HOMEP_ПОСТАВЩИКА == SP. НОМЕР_ПОСТАВЩИКА
ORDER BY S.ГОРОД, SP.НОМЕР_ПОСТАВЩИКА,
SP.НОМЕР_ДЕТАЛИ
** * END * * *
В QMF запросы завершаются строкой * * * END * * * (КОНЕЦ), а не точкой с запятой. Пользователь не должен, однако, печатать этот признак конца, так как он является стандартным для функции показа запроса QMF. Указанный запрос исполняется QMF, и результат запоминается в области DATA. Далее создается системная форма для этого запроса, которую мы рассмотрим позднее, и полученная форма запоминается в области FORM. Наконец, QMF форматирует и выводит на экран содержимое области DATA в соответствии с формой, хранимой в FORM. Полученный и результате отчет показан на рис. 15.2.
СОСТОЯНИЕ
НОМЕР_
ПОСТАВЩИКА
НОМЕР_
ДЕТАЛИ
КОЛИЧЕСТВО
Лондон
Лондон
Лондон
Лондон
Лондон
Лондон
Лондон
Лондон
Лондон
Париж
Париж
Париж
*** END***
20
20
20
20
20
20
20
20
20
10
10
30
S1
S1
S1
S1
S1
S1
S4
S4
S4
S2
S2
S3
P1
P2
P3
P4
P5
P6
P2
P4
P5
P1
P2
P2
300
200
400
200
100
100
200
300
400
300
400
200
Рис. 15.2.Отчет, содержащий результаты исполнения запроса
Автоматически сгенерированная системная форма для этого отчета, хранимая в области FORM, показана на рис. 15.3. Эта форма интерпретируется следующим образом:
1. Результат исполнения запроса, хранимый в области DATA, содержит 5 столбцов. Эти столбцы должны появиться в отчете с заголовками соответственно ГОРОД, СОСТОЯНИЕ, НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ и КОЛИЧЕСТВО.
2. Ширина этих столбцов составляет соответственно 15, 9, 10, 6 и. 11 символов, и между столбцами должны быть промежутки
Описания столбцов: Ширина страницы теперь — 61
ЗАГОЛОВОК СТОЛБЦА
ИСПОЛЬЗОВАНИЕ
ОТСТУП
ШИРИНА
РЕДАКТИРОВАНИЕ
1
2
3
4
5
ГОРОД
СОСТОЯНИЕ
НОМЕР_
ПОСТАВЩИКА
НОМЕР_ ДЕТАЛИ
КОЛИЧЕСТВО
2
2
2
2
2
15
9
10
6
11
С
L
С
С
L
***
END ***
Текст при прерывании ТРЕБУЕТСЯ ЛИ ПОДАВЛЕНИЕ ДУБЛИКАТОВ?
управления: = = = >ДА
1= = => 4= = =>
2= = => 5= = =>
3= = => 6= = =>
ЗАГОЛОВОК СТРАНИЦЫ = = = >
КОНЦОВКА СТРАНИЦЫ = = = >
Рис. 15.3. Автоматически сгенерированная форма отчета
в две позиции—в
каждом случае параметр ОТСТУП составляет 2 позиции.
3. Общая ширина данного отчета—61 символ.
4. Заголовки ГОРОД, НОМЕР_ПОСТАВЩИКА и НОМЕР_ДЕТАЛИ должны быть показаны «как они есть», т. е. как простые нередактируемые строки символов (параметр РЕДАКТИРОВАНИЕ равен С), а СОСТОЯНИЕ и КОЛИЧЕСТВО—как десятичные целые (параметр РЕДАКТИРОВАНИЕ равен L).
5. Никаких прерываний управления не специфицировано (см. ниже), и поэтому не специфицирован также никакой текст, показываемый при прерывании управления. Спецификация значения «ДА» для параметра ПОДАВЛЕНИЕ ДУБЛИКАТОВ не оказывает никакого влияния при отсутствии прерываний управления.
6. Не специфицированы также никакой заголовок страницы или концовка страницы.
Предположим теперь, что эта форма выводится на экран по команде DISPLAY и редактируется следующим образом (рис. 15.4):
1 Заголовки столбцов ГОРОД, СОСТОЯНИЕ, НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ и КОЛИЧЕСТВО заменяются на ГОРОД_ПОСТАВЩИКА, СОСТОЯНИЕ, ПОСТАВЩИК, ДЕТАЛЬ и КОЛИЧЕСТВО соответственно. Для первого из них, как и для двух других в предыдущем варианте, специфицируется символ разрыва, указывающий, что два слова в заголовке должны находиться в отдельных строках отчета (слово ГОРОД должно быть над словом ПОСТАВЩИКА и должно быть отцентрировано). Для столбца СОСТОЯНИЕ не специфицируется никакого нового заголовка, поскольку предполагается, что значения СОСТОЯНИЕ не будут представлены в отчете (см. ниже п. 4).
Ширина страницы теперь —56
НОМЕР
ЗАГОЛОВОК СТОЛБЦА
ИСПОЛЬЗОВАНИЕ
ОТСТУП
ШИРИНА
РЕДАКТИРОВАНИЕ
1
ГОРОД_ПОСТАВЩИКА
ПРЕРЫВАНИЕ!
3
10
2
СОСТОЯНИЕ
ОПУСТИТЬ
3
9
3
ПОСТАВЩИК
3
9
4
ДЕТАЛЬ
3
6
5
КОЛИЧЕСТВО
СУММИРОВАТЬ
3
10
* * *END * * *
ТЕKCT ПРИ ПРЕРЫВАНИИ ТРЕБУЕТСЯ ЛИ ПОДАВЛЕНИЕ ДУБЛИКАТОВ УПРАВЛЕНИЯ- = = =>ДА
1 = = = > * * * Итого для 4 = = = >
ГОРОДА &1
2= = => 5 = = =>
3 = = => б = = =>
ЗАГОЛОВОК СТРАНИЦЫ = = => ПОСТАВКИ ПО ПОСТАВЩИКАМ ГОРОДАМ
КОНЦОВКА СТРАНИЦЫ = = = > ПОДРОБНЫЙ ОТЧЕТ
Рис. 15.4. Отредактированная форма отчета
2. Ширина столбцов ГОРОД_ПОСТАВЩИКА, ПОСТАВЩИК, ДЕТААЛЬ и КОЛИЧЕСТВО изменяется соответственно на 10, 9, 6 и 10. Значение ОТСТУП в каждом случае изменяется с 2 на 3.
3. В качестве значения параметра ИСПОЛЬЗОВАНИЕ для столбца ГОРОД_ПОСТАВЩИКА принимается ПРЕРЫВАНИЕ1.
Примечание. Смысл этой спецификации в том, что для первоначального запроса ГОРОД является, вероятно, старшим полем упорядочения. ПРЕРЫВАНИЕ1 означает, что каждый раз, когда изменяется значение в столбце ГОРОД_ПОСТАВЩИКА, должно иметь место «прерывание управления». Цель спецификации прерываний управления состоит в том, чтобы дать возможность QMF вычислять и выводить на экран частичные итоги или другие промежуточные результаты при генерации отчета (см. ниже п. 5).
4. Для столбца СОСТОЯНИЕ параметр ИСПОЛЬЗОВАНИЕ принимает значение ОПУСТИТЬ. В результате никакие значения столбца СОСТОЯНИЕ не войдут в отчет.
5. В качестве значения параметра ИСПОЛЬЗОВАНИЕ для столбца КОЛИЧЕСТВО принимается СУММИРОВАТЬ. Оно указывает, что по значениям КОЛИЧЕСТВО должны формироваться итоговые суммы для каждого прерывания управления, т. е. для каждого города, а также и для отчета в целом, т. е. для всех городов. Аналогичным образом можно запросить вывод средних значений, подсчет числа записей и т. д.
ПОСТАВКИ ПО ПОСТАВЩИКАМ ГОРОДАМ
ПОСТАВЩИК
ДЕТАЛЬ
КОЛИЧЕСТВО
Лондон
S1
Р1
300
S1
Р2
200
S1
РЗ
400
S1
Р4
200
S1
Р5
100
S1
Р6
100
S4
Р2
200
S4
Р4
300
S4
Р5
400
* * * итого для города Лондон
2200
Париж
S2
Р1
300
S2
Р2
400
S3
Р2
200
* * * итого для города Париж
900
3100
83/06/29 10 : 46
ПОДРОБНЫЙ ОТЧЕТ
СТРАНИЦА 1
Рис. 15.5. Окончательный вариант отчета
6. Текст, который выводится при прерывании управления, для прерывания управления 1, единственного прерывания управления в данном примере, специфицируется следующим образом:
* * * ИТОГО ДЛЯ ГОРОДА & 1
Спецификация «& 1» обозначает текущее значение в столбце номер 1 отчета, а именно в столбце ГОРОД_ПОСТАВЩИКА. Таким образом, это — переменная,
которая позволяет QMF выводить на экран различные строки текста каждый раз, когда фактически имеет место прерывание управления. Результат этой спецификации можно видеть в приведенном окончательном варианте отчета (рис. 15.5).
7. Для параметра ПОДАВЛЕНИЕ ДУБЛИКАТОВ оставляется значение «ДА». Результат такой спецификации заключается в том, что подавляется вывод на экран идентичных значений и столбцах, для которых специфицировано прерывание управления (см. снова окончательный отчет— рис. 15.5). 8. Наконец, задается заголовок страницы:
ПОСТАВКИ ПО ПОСТАВЩИКАМ ГОРОДАМ
и концовка страницы:
ПОДРОБНЫЙ ОТЧЕТ
Сформирована, таким образом, пересмотренная форма (см. рис. 15.4). Теперь выданный по команде DISPLAY REPORT отчет представлен на рис. 15.5. Заметим, что дата, время и номера страниц включаются в этот отчет автоматически.
Приведенный выше пример дает некоторое представление о том, как легко получать с помощью QMF отчеты, имеющие привычный вид или сформированные с учетом конкретных потребностей. Он, однако, не позволяет проиллюстрировать полный диапазон возможностей генерации отчетов в QMF. Перечислим кратко некоторые дополнительные возможности:
— Предусмотрены возможности пролистывания—UP (назад), DOWN (вперед), LEFT (влево) и RIGHT (вправо) —для просмотра отчетов, а также других объектов, например форм, которые оказываются слишком большими для того, чтобы целиком поместить их на одном экране.
— Вдобавок к показанным в примере кодам редактирования С и L предусмотрены дополнительные коды, которые позволяют, например, вставлять в числовые результаты символы редактирования (например, знак доллара, десятичную точку), а также выводить на экран значения с плавающей точкой, используя их обозначения, принятые в научной литературе.
— Заголовки и концовки страниц, аналогично текстам, которые выводятся при прерываниях управления, могут включать ссылки на переменные вида «&n», что обозначает текущее значение в столбце номер n.
— Можно специфицировать несколько уровней (до 6) прерываний управления с различными итоговыми функциями и различными текстами, выводимыми на каждом уровне. Можно было бы, например, расширить рассмотренный пример и специфицировать прерывание управления по поставщикам (уровень 2) внутри городов (уровень 1). Для этого следовало бы специфицировать значение ПРЕРЫВАНИЕ2 параметра ИСПОЛЬЗОВАНИЕ для столбца ПОСТАВЩИК. В результате мы могли бы, например, получать частичные итоги по количеству поставляемых деталей по каждому поставщику, а также по каждому городу. Вывод идентичных номеров поставщиков можно было бы также подавить, предполагая, что для параметра ПОДАВЛЕНИЕ ДУБЛИКАТОВ специфицировано все еще значение «ДА».
Примечание. Когда специфицируются прерывания управления, в первоначальном запросе должна быть задана соответствующая спецификация упорядочения. В противном случае этот отчет не будет иметь смысла. В запросе, связанном с рассмотренным примером, вероятно, должна была указываться фраза ORDER BY, специфицирующая ГОРОД как старшее поле упорядочения, а НОМЕР_ПОСТАВЩИКА—как младшее поле упорядочения.
— Отчеты могут состоять только из сводной информации, т. е. только из итогов или средних, а также из сводной и подробной информации, как в приведенном примере. И опять-таки для того, чтобы отчет имел смысл, исходный запрос должен включать соответствующую спецификацию упорядочения. Сводные отчеты могут быть получены как в формате «поперек страницы», так и в более удобном формате «вдоль страницы». Мы могли бы, в частности, пересмотреть наш пример таким образом, чтобы генерировался отчет, в котором города были бы представлены вдоль страницы, а поставщики — поперек. Для каждого города имелась бы тогда строка, содержащая общее количество деталей для поставщика S1, поставщика S2, . . ., а также общее их количество для всех поставщиков в этом городе.
— Для того чтобы сохранять под выбранными пользователем именами специфицированное содержимое областей DATA, QUERY или FORM, предусмотрена команда SAVE (сохранить). В команде RUN (выполнить) можно специфицировать для выполнения указанный сохраненный запрос, а для форматирования результатов — указанную сохраненную форму. Аналогично в команде DISPLAY (показать) можно специфицировать для вывода на экран в соответствии с формой, хранимой в настоящее время в области FORM, указанной сохраненной таблицы. Указанная таблица либо может быть создана по команде SAVE DATA, либо может являться любой таблицей из базы данных. Сохраненный запрос может включать параметры. В таком случае, когда этот запрос будет вызываться для выполнения, QMF запросит у пользователя фактические значения для замены этих параметров.
Следует, наконец, упомянуть процедуры. Процедура — это последовательность команд QMF (RUN, DISPLAY, SAVE и т. д.), которая сама хранится под некоторым специфицированным именем. Она выполняется с помощью некоторого варианта команды RUN.
ГРУППЫ ПАМЯТИ
Группа памяти—это именованная совокупность томов с прямым доступом, причем все они относятся к устройствам одного и того же типа. С каждым простым табличным пространством, простым индексным пространством, сегментом сегментированного табличного пространства и сегментом сегментированного индексного пространства связана некоторая группа памяти[24]. Когда для пространства или сегмента требуется память, она берется из специфицированной группы памяти. Таким образом, группы памяти предоставляют установке системы возможности для разделения и сближения данных. Они могут, например, обеспечить хранение двух таблиц на различных томах. В то же время они дают возможность возложить на систему управление большей частью детальных аспектов размещения наборов данных, экстентов и т. д.
Пространства и сегменты в каждой группе памяти поддерживаются с использованием наборов данных
VSAM с последовательным входом. При этом одному пространству или сегменту, вообще говоря, соответствует множество наборов данных. Система DB2 использует VSAM также для управления пространствами с прямым доступом и для каталогизации наборов данных. Управление пространством внутри страниц, т. е. оперирование управляющими интервалами VSAM, осуществляется системой DB2, а не средствами VSAM, и индексирование VSAM вообще не используется. Таким образом, как уже упоминалось в главе 9, наборы данных системы DB2 не являются обычными наборами данных VSAM. Их внутренний формат не совпадает с форматом, предусмотренным для VSAM, и обращаться к этим наборам данных с использованием обычного VSAM невозможно. По тем же причинам невозможно обращаться к существующим наборам данных VSAM, используя возможности DB2, например язык SQL.
ХРАНИМЫЕ ТАБЛИЦЫ
Хранимая таблица — это хранимое представление базовой таблицы. Она состоит из множества хранимых записей, по одной для каждой строки данных в рассматриваемой базовой таблице. Каждая хранимая запись будет полностью содержаться на одной странице. Однако каждая хранимая таблица может размещаться на множестве страниц, и в простом табличном пространстве одна страница может содержать хранимые записи из многих хранимых таблиц.
Хранимая запись не идентична соответствующей записи базовой таблицы. Она состоит из строки байтов, включающей:
– префикс, содержащий управляющую информацию, например внутреннее системное имя для хранимой таблицы, частью которой является данная хранимая запись, за которым следует
– до N хранимых полей, где N — число столбцов в данной базовой таблице. Хранимых полей будет меньше, чем N, если хранимая запись имеет переменную длину, т. е. если в ней есть какие-либо поля переменной длины, и одно или несколько полей в правой части записи имеют неопределенные значения. Поля, имеющие неопределенные значения, в конце записи переменной длины физически не хранятся.
Каждое хранимое поле в свою очередь состоит из:
– префикса длины (если поле имеет переменную длину), который задает фактическую длину данных, в том числе префикса индикатора неопределенного значения, если он имеется (см. ниже);
– префикса индикатора неопределенного значения (если неопределенные значения допускаются), указывающего, должно ли значение в той части поля, которая отведена для данных: а) приниматься за действительное значение данных; б) игнорироваться, т. е. интерпретироваться как неопределенное значение;
– фактического значения данных в кодированном формате. Хранимые данные кодируются таким образом, что команда «сравнение логическое» (CLC) системы IBM/370 всегда будет давать подходящий ответ, когда она выполняется над двумя значениями данных одного и того же типа в SQL. Например, значения типа INTEGER хранятся вместе с их знаковым битом н обратном коде. Таким образом, все хранимые поля данных рассматриваются программой управления хранимыми данными просто как последовательности байтов. Любая интерпретация такой последовательности, например, как значения типа INTEGER, осуществляется указанным выше интерфейсом управления данными. Достоинство такого подхода заключается в том, что можно вводить новые типы данных, не оказывая какого-либо влияния на компоненты нижнего уровня системы. В качестве упражнения предлагаем читателю попытаться разработать подходящие способы кодирования для других типов данных SQL.
Все хранимые поля выравниваются по границе байта. Между полями не оставляется никаких промежутков. Данные переменной длины занимают ровно столько байтов, сколько это необходимо для хранения фактического их значения.
Примечание. Выше описано стандартное представление хранимых записей. Однако для любой заданной таблицы установка системы располагает факультативной возможностью предоставления «процедуры редактирования», которой будет передаваться управление каждый раз, когда осуществляется запоминание или выборка записи. При «запоминании» эта процедура редактирования может преобразовывать стандартное представление в какой-либо другой требуемый формат, и запись будет храниться именно в этом формате. При «выборке» процедура редактирования должна, конечно, выполнять обратное преобразование. Таким образом, конкретная установка системы может, например, решать, хранить ли данные в сжатом или в кодированном формате. Более того, такое решение она может принимать исходя из свойств каждой конкретной таблицы.
Для внутренней адресации записей используются идентификаторы записей (ID или RID ( Аббревиатура словосочетания «Record Identifier».—Примеч. пер. )). Например, все указатели в индексах представляют собой RID. Все RID являются уникальными в базе данных, содержащей соответствующие записи. На рис. 13.2 показано, каким образом реализованы RID. Для хранимой записи R RID состоит из двух частей: из номера Р страницы, содержащей R, и из байта смещения от конца страницы Р, указывающего участок, который в свою очередь содержит байт смещения записи R от начала страницы Р. Такой метод представляет собой хороший компромисс между быстрым доступом при прямой адресации и гибкостью косвенной адресации. Можно проводить реорганизацию записей в рамках содержащей их страницы, например ликвидировать промежуток при удалении записи или подготавливать пространство для вставки записи, не создавая необходимости изменения RID. Должны изменяться только локальные смещения, хранимые в конце данной страницы. И тем не менее доступ к записи при заданном ее RID является быстрым. Он требует доступа только к одной странице.
ИДЕНТИФИКАЦИЯ ПОЛЬЗОВАТЕЛЕЙ
Пользователи известны системе DB2 по их «идентификаторам санкционирования доступа» (для краткости, ИД санкционирования). ИД санкционирования — это то, что называлось в предшествующих главах «известным системе именем» пользователя. Если Вы — законный пользователь системы, некоторое ответственное лицо в Вашей организации, вероятно, администратор системы (см. ниже раздел 9.4), назначит для Вашего конкретного использования некоторый ИД санкционирования. На Вас возлагается обязанность идентифицировать себя с помощью этого ИД при предъявлении пароля системе. Заметим, что Вы при этом не предъявляете пароль непосредственно самой системе DB2. Пароль предъявляется соответствующей подсистеме MVS (IMS, CICS или TSO—вспомните из главы 1, что каждая прикладная задача DB2 должна исполняться под управлением в точности одной из этих трех подсистем). Эта подсистема передаст затем Ваш ИД системе DB2, когда будет передавать ей управление. Таким образом, проверка достоверности или подтверждение подлинности Вашего ИД осуществляется каждый раз соответствующей подсистемой, а не DB2. Если о каком-либо пользовательском запросе системе DB2 сообщается, что он исходит от пользователя, скажем, xyz, она предполагает, что это действительно так.
Рассмотрение подробностей процедуры предъявления пароля (а следовательно, информации о том, как в точности специфицируется ИД санкционирования) для каждого из возможных вариантов операционной обстановки выходит за рамки данной книги.
ИНДЕКСНЫЕ ПРОСТРАНСТВА
Индексное пространство играет такую же роль для индексов, как табличное пространство для таблиц. Однако в связи с тем, что соответствие между индексами и индексными пространствами всегда является взаимно однозначным (в отличие от соответствия между таблицами и табличными пространствами), нет никаких предложений определения данных для самих по себе индексных пространств. Вместо этого в предложениях определения соответствующих индексов специфицируются необходимые параметры индексных пространств. Так, например, нет предложения CREATE INDEXSPACE (создать индексное пространство), а индексное пространство создается автоматически при создании соответствующего индекса путем спецификации предложения CREATE INDEX (создать индекс). Указанное предложение может включать такие параметры, как имя связанной с этим индексом группы памяти и т. п.
Страницы в индексном пространстве всегда имеют размер 4К байт. Однако единица для целей блокирования может быть меньше, чем одна страница (это другое отличие от табличного пространства). Она может, например, составлять четверть страницы (1024 байта).
Подобно табличным пространствам индексные пространства могут реорганизовываться и восстанавливаться независимо. Индексное пространство, которое содержит требуемый индекс кластеризации для сегментированного табличного пространства, само предполагается сегментированным. Во всех других случаях индексное пространство рассматривается как простое (несегментированное). Сегмент сегментированного индексного пространства может быть реорганизован независимо. Отдельные сегменты могут быть связаны с различными группами памяти.
ИНДЕКСЫ
Подобно базовым таблицам индексы создаются и уничтожаются путем использования предложений определения данных языка SQL. Однако CREATE INDEX и DROP INDEX (а также alter INDEX и некоторые предложения управления данными) вообще являются единственными предложениями в языке SQL, в которых имеются ссылки на индексы. Другие предложения, в частности предложения манипулирования данными, такие, как SELECT, намеренно не включают каких-либо таких ссылок. Решение о том, использовать или не использовать какой-либо индекс при обработке некоторого конкретного запроса в языке SQL, принимается не пользователем, а системой DB2 (фактически оптимизатором — составной частью генератора планов прикладных задач), как указывалось в главе 2.
Предложение CREATE INDEX имеет следующий общий формат:
CREATE [UNIQUE] INDEX имя—индекса
ON имя—базовой—таблицы (имя—столбца [упорядочение]
[имя—столбца [упорядочение]] . . .)
[другие—параметры] ;
Факультативные «другие — параметры» имеют отношение к проблемам физического хранения, как и в случае предложения CREATE TABLE. Каждая спецификация «упорядочение» представляет собой либо ASC (возрастание), либо DESC (убывание). Если не специфицировано ни ASC, ни DESC, то по умолчанию предполагается ASC. Последовательность указания имен столбцов в предложении CREATE INDEX соответствует обычным образом упорядочению от старшего к младшему. Например, предложение
CREATE INDEX X ON В (Р, Q DESC, R)
создает индекс с именем Х над базовой таблицей В, в котором статьи упорядочиваются по возрастанию значений R в рамках убывающих значений Q в рамках возрастающих значений Р. Столбцы Р, Q и R не обязательно должны быть смежными. Не обязательно также, чтобы все они имели один и тот же тип данных. Наконец, не обязательно, чтобы все они были фиксированной длины.
После того как индекс создан, он автоматически поддерживается (программой управления хранимыми данными) с тем, чтобы отражать все обновления базовой таблицы, до тех пор, пока этот индекс не будет уничтожен.
Факультативный параметр
UNIQUE (уникальный) в предложении CREATE INDEX специфицирует, что никаким двум записям к индексируемой базовой таблице не позволяется принимать одно и то же значение для индексируемого поля (или комбинации полей) в одно и то же время. В случае базы данных поставщиков и деталей, например, мы специфицировали бы, вероятно, следующие индексы с параметром UNIQUE:
CREATE UNIQUE INDEX XS ON S (НОМЕР_ПОСТАВЩИКА);
CREATE UNIQUE INDEX XP ON P (НОМЕР_ДЕТАЛИ);
CREATE UNIQUE INDEX XSP ON SP (НОМЕР_ПОСТАВЩИКА,
НОМЕР_ДЕТАЛИ);
Индексы, подобно базовым таблицам, могут создаваться и уничтожаться в любое время. В приведенном примере, однако, нам хотелось бы, вероятно, создать индексы XS, XP и XSP в то же время, когда создаются сами базовые таблицы S, Р и SP. Если же эти базовые таблицы будут непустыми в то время, когда издается предложение CREATE INDEX, ограничения уникальности могут уже оказаться нарушенными. Попытка создания индекса с параметром UNIQUE над таблицей, которая в настоящее время не удовлетворяет ограничению уникальности, будет завершаться неудачно.
Примечание. Два неопределенных значения считаются равными друг другу для целей индексирования с параметром UNIQUE. Смысл этого довольно загадочного замечания состоит в том, что неопределенные значения не всегда рассматриваются как эквивалентные друг другу во всех контекстах. Обсуждение этого вопроса содержится в главе 4.
Над одной и той же базовой таблицей может быть построено любое число индексов. Например, другой индекс для таблицы S:
CREATE INDEX XSC ON S (ГОРОД);
В этом случае не было специфицировано UNIQUE, поскольку множество поставщиков может находиться в одном и том же городе.
Предложение уничтожения индекса имеет вид:
DROP INDEX имя—индекса;
в результате индекс уничтожается, т. е. его описание удаляется из каталога. Если какой-либо существующий план прикладной задачи зависит от этого уничтоженного индекса, то (как указывалось в главе 2) этот план будет помечен как недействительный супервизором стадии исполнения. Когда этот план будет в дальнейшем вызываться для исполнения, супервизор стадии исполнения автоматически вызовет генератор планов прикладных задач с тем, чтобы сгенерировать заменяющий его план, который поддерживал бы первоначальные предложения SQL, не используя исчезнувший теперь индекс. Этот процесс полностью скрыт от пользователя.
Поскольку уже говорилось о том, что система DB2 осуществляет автоматическую перегенерацию планов прикладных задач, если уничтожается существующий индекс, читатель может пожелать узнать, будет ли также выполняться автоматическая перегенерация, если создается какой-нибудь новый индекс. Ответ отрицателен, этого не делается. Причина такого положения вещей заключается в отсутствии в этом случае какой-либо гарантии относительно того, что перегенерация на самом деле будет полезной. Автоматическая перегенерация могла бы означать просто много не необходимой работы, т. к. существующие планы прикладных задач могут быть уже основанными на оптимальной стратегии. Иная ситуация с предложением DROP. Некоторый план просто не будет работать, если он предусматривает использование несуществующего индекса. И в этом случае перегенерация является необходимой. Следовательно, если создается новый индекс и имеется некоторый план, который, как Вы подозреваете, целесообразно заменить, то запрос на явную перегенерацию этого плана на Вашей ответственности. Явная перегенерация обсуждается в главе 14.
ИСЧЕРПЫВАЮЩИЙ ПРИМЕР
Эту главу мы завершим надуманным, но исчерпывающим примером (рис. 10.3), позволяющим проиллюстрировать ряд дополнительных моментов. Рассматриваемая программа получает четыре значения входных данных: номер детали (ЗАДАННАЯ_ДЕТАЛЬ), название города (ЗАДАННЫЙ_ГОРОД), прирост состояния (ЗАДАННЫЙ_ПРИРОСТ) и уровень состояния (ЗАДАННЫЙ_УРОВЕНЬ). Программа просматривает всех поставщиков детали, идентифицируемой значением ЗАДАННАЯ_ДЕТАЛЬ. Для каждого такого поставщика состояние увеличивается на заданный прирост, если он находится в городе ЗАДАННЫЙ_ГОРОД. В противном случае, если состояние поставщика меньше значения ЗАДАННЫЙ_УРОВЕНЬ, поставщик удаляется вместе со всеми его поставками. Во всех случаях информация о поставщике выводится на печать с указанием, каким образом программа поступила с этим конкретным поставщиком.
SQLEX: PROC OPTIONS (MAIN);
DCL ЗАДАННАЯ_ДЕТАЛЬ CHAR 16);
DCL ЗАДАННЫЙ_ГОРОД CHAR (16);
DCL ЗАДАННЫЙ_ПРИРОСТ FIXED BINARY (15);
DCL ЗАДАННЫЙ_УРОВЕНЬ FIXED BINARY (16);
DCL HOMEP_ ПОСТАВЩИКА CHAR (5);
DCL ФАМИЛИЯ CHAR (20);
DCL СОСТОЯНИЕ FIXED BINABY(15);
DCL ГОРОД CHAR 115);
DCL ДИСПОЗИЦИЯ CHAR (7);
DCL ДРУГИЕ_ПОСТАВЩИКИ ВIТ(1);
EXEC SQL INCLUDE SQLCA;
EXEC SQL DECLARE S TABLE
(НОМЕР_ПОСТАВЩИКА CHAR (5) NOT NULL,
ФАМИЛИЯ CHAR (20),
СОСТОЯНИЕ SMALLINT,
ГОРОД CHAR (20));
EXEC SQL DECLARE SP TABLE
(НОМЕР_ПОСТАВЩИКА CHAR (5) NOT NULL.
НОМЕР_ДЕТАЛИ CHAR (6) NOT NULL,
КОЛИЧЕСТВО INTEGER);
EXEC SQL DECLARE Z CURSOR FOR
SELECT HOMEP_ПОСТАВЩИКА, ФАМИЛИЯ, СОСТОЯНИЕ,
ГОРОД
FROM S
WHERE EXISTS
(SELECT
FROM SP
WHERE SP. НОМЕР_ПОСТАВЩИКА=
S.HOMEP_ПОСТАВЩИКА
AND SP. НОМЕР_ДЕТАЛИ =
:ЗАДАННЫЙ_НОМЕР)
FOR update OF СОСТОЯНИЕ ;
EXEC SQL WHENEVER NOT FOUND CONTINUE;
EXEC SQL WHENEVER SQLERROR CONTINUE;
ЕХEС SQL whenever SQLWARNING CONTINUE;
ON CONDITION (DBEXCEPTION)
BEGIN:
PUT SKIP LIST (SQLCA);
EXEC SQL ROLLBACK;
GO TO QUIT;
END;
GET LIST (ЗАДАННАЯ_ДЕТАЛЬ, ЗАДАННЫЙ_ГОРОД, ЗАДАННЫЙ_ПРИРОСТ,
ЗАДАННЫЙ_УРОВЕНЬ);
EXEC SQL OPEN Z;
IF SQLCODE Ø= 0
THEN SIGNAL CONDITION (DBEXCEPTION)
ДРУГИЕ_ПОСТАВЩИКИ =‘1’ B;
DO WHILE (ДРУГИЕ_ПОСТАВЩИКИ);
EXEC SQL FETCH Z INTO
:НОМЕР_ПОСТАВЩИКА,
:ФАМИЛИЯ,
:СОСТОЯНИЕ,
:ГОРОД;
SELECT; /*SELECT языка ПЛ/1, а не SQL*/
WHEN (SQLCODE Ø= 100)
ДРУГИЕ_ПОСТАВЩИКИ = '0'B
WHEN (SQLCODE =100 & SOLCODE Ø= 0)
SIGNAL CONDITION (DBEXCEPTION);
WHEN- (SQLCODE =0)
DO;
ДИСПОЗИЦИЯ = ‘bbbbbbb ';
IF ГОРОД = ЗАДАННЫЙ_ ГОРОД
THEN
DO;
EXEC SQL UPDATE S
SET СОСТОЯНИЕ = СОСТОЯНИЕ
+ : ЗАДАННЫЙ_ПРИРОСТ
WHERE CURRENT OF Z ;
IF SQLCODE Ø=0
THEN SIGNAL CONDITION (DBEXCEPTION);
ДИСПОЗИЦИЯ = 'ОБНОВЛЕН ' ;
END;
ELSE
IF СОСТОЯНИЕ < ЗАДАННЫЙ_УРОВЕНЬ
THEN
DO;
EXEC SQL DELETE
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА =
: НОМЕР_ПОСТАВЩИКА;
IF SQLCODE Ø= 0 & SQLCODE Ø= 100
THEN SIGNAL CONDITION (DBEXCEPTION);
EXEC SQL DELETE
FROM S
WHERE CURRENT OF Z;
IF SQLCODE Ø= 0
THEN SIGNAL CONDITION (DBEXCEPTION);
ДИСПОЗИЦИЯ= ‘УДАЛЕН';
END;
PUT SKIP LIST (НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, СОСТОЯНИЕ, ГОРОД,
ДИСПОЗИЦИЯ);
END; /*WHEN (SQLCODE=0) ...* /
END; /*SELECT языка ПЛ/1 */
END; /*DO WHILE* /
EXEC SQL CLOSE Z;
EXEC SOL COMMIT;
QUIT: RETURN;
END; /*SQLEX */
Рис. 10.3. Исчерпывающий пример
Возникают следующие проблемы.
1. Во-первых, всюду игнорируется возможность того, что некоторое поле, выборка которого производится, может иметь неопределенное значение. Такое упрощение введено исключительно с целью сокращения размеров примера.
2. Далее обратите внимание на два предложения DECLARE для таблиц S и SP. Эти объявления, очевидно, представляют собой не что иное, как небольшие текстуальные вариации соответствующих предложений CREATE TABLE языка SQL. Для построения таких деклараций в интересах пользователей предусматривается специальная служебная программа — генератор деклараций (DCLGEN).
Примечание.
Название DCLGEN обычно произносится «деклеген» с мягким «г».
По существу, DCLGEN использует информацию из каталога системы DB2 для построения одной или обеих следующих синтаксических конструкций:
— предложения DECLARE для данной таблицы
— соответствующей декларации в языках ПЛ/1 или Кобол для структуры того же вида, что и таблица, которая будет использоваться в качестве мишени для выборки и/или источника для обновления.
Результаты работы программы DCLGEN сохраняются в форме раздела библиотечного набора данных, имя которого специфицировано пользователем. Он может быть в дальнейшем включен в программу, записанную на включающем языке, с помощью следующего предложения:
ЕХЕС SQL INCLUDE раздел;
где «раздел» — это имя рассматриваемого раздела.
Предыдущее обсуждение показывает, что DCLGEN подобно каталогу выполняет некоторые функции, которые в более старых системах по традиции считались функциями отдельного программного продукта — словаря.
3. Как уже указывалось в разделе 10.2, каждое предложение языка SQL в принципе должно сопровождаться проверкой возвращаемого значения SQLCODE. Для того чтобы упростить этот процесс, предусмотрено предложение WHENEVER (всякий раз, когда). Это предложение имеет следующий синтаксис:
ЕХЕС SQL WHENEVER условие действие;
где «условие» может быть одним из следующих:
NOT FOUND (не найдено)
SQLWARNING (SQL-предупреждение)
SQLERROR (SQL-ошибка),
а «действие»—это либо предложение CONTINUE (продолжать), либо предложение GO TO (перейти к). Предложение WHENEVER не является исполняемым предложением. Оно представляет собой, скорее, директиву для прекомпилятора. Предложение «WHENEVER условие GO TO метка» заставляет прекомпилятор вставлять после каждого встречающегося ему исполняемого предложения языка SQL предложение вида «IF условие GO TO метка». В свою очередь предложение «WHENEVER условие CONTINUE» заставляет прекомпилятор не вставлять какие-либо такие предложения в связи с тем, что программист вставит их вручную. Указанные выше три «условия» определяются следующим образом:
NOT FOUND означает, что SQLCODE = 100
SQLWARNING означает, что SQLCODE > 0 и SQLCODE Ø= 100
SQLERROR означает, что SQLCODE < О
Каждое предложение
WHENEVER, которое встречается прекомпилятору при последовательном просмотре им текста программы (для конкретного условия), отменяет действие предыдущего найденного им такого предложения (для этого условия). Предполагается, что в начале текста программы для каждого из трех возможных условий имеется неявное предложение WHENEVER, специфицирующее в каждом случае CONTINUE.
В приведенном примере программы в учебных целях явным образом делаются все проверки на исключительную ситуацию. Если какая-либо исключительная ситуация имеет место, управление передается процедуре, которая печатает диагностическую информацию (в данном примере, область связи SQL), издает команду ROLLBACK (см. п. 4 ниже), а затем передает управление заключительному RETURN.
4. Когда программа некоторым образом обновляет базу данных, такое обновление следует рассматривать первоначально лишь как предварительное — предварительное в том смысле, что если что-либо в дальнейшем выполнится с ошибкой, это обновление может быть аннулировано самой программой или системой. Если, например, в программе встречается неожиданная ошибка, скажем, переполнение, и она аварийно завершается, то система от имени программы автоматически аннулирует все такие предварительные обновления. Обновления остаются предварительными до тех пор, пока не произойдет одно из двух: а) исполнится предложение COMMIT (фиксировать), которое все предварительные обновления сделает окончательными («зафиксированными»), или б) исполнится предложение ROLLBACK (откат), которое аннулирует все предварительные обновления. После того как обновление зафиксировано, гарантируется, что оно никогда не будет аннулировано (это определение понятия «зафиксированное обновление»).
В рассматриваемом примере программа издает COMMIT, когда она приходит к своему нормальному завершению, и издает ROLLBACK, если встречается какая-либо исключительная ситуация при исполнении предложений SQL. На самом деле, такая явная спецификация предложения COMMIT не является необходимой. Система автоматически будет издавать COMMIT от имени программы для любой программы, которая достигает нормального завершения. Она также автоматически будет издавать ROLLBACK от имени программы для любой программы, которая не достигает нормального завершения. В данном примере, однако, обязательна явная спецификация предложения ROLLBACK, поскольку программа спроектирована таким образом, чтобы осуществлять нормальное ее завершение даже в случае, если имеют место исключительные ситуации SQL.
Примечание.
Вопросы обновления рассматривались выше в предположении обстановки TSO, поскольку предложения COMMIT и ROLLBACK допустимы только в этом случае. Эффект выполнения этих предложений в обстановке IMS и CICS достигается соответствующими обращениями (с помощью CALL) к IMS и CICS. Значительно более глубокое и полное обсуждение вопроса о «зафиксированных обновлениях» и связанного с этим понятия обработки транзакций приводится в следующей главе.
ИСПОЛЬЗОВАНИЕ ФРАЗЫ GROUP BY
В примере 5.4.4 показано, как можно вычислить общий объем поставок для некоторой конкретной детали. Предположим, что теперь требуется вычислить общий объем поставок для каждой детали, т. е. для каждой поставляемой детали выдать номер этой детали и общий объем поставок.
SELECT НОМЕР—ДЕТАЛИ, SUM (КОЛИЧЕСТВО)
FROM SP
GROUP BY НОМЕР—ДЕТАЛИ;
Результат:
НОМЕР_ДЕТАЛИ
Р1
600
Р2
1000
РЗ
400
Р4
500
Р5
500
Р6
100
Пояснение. С концептуальной точки зрения, оператор GROUP BY (группировать по) перекомпоновывает таблицу, представленную фразой FROM, в разделы или группы
таким образом, чтобы в каждой группе все строки имели одно и то же значение поля, указанного во фразе GROUP BY. Это, конечно, не означает, что таблица физически перекомпоновывается в базе данных. В рассматриваемом примере строки таблицы SP группируются таким образом, что в одной группе содержатся все строки для детали Р1, в другой—все строки для детали Р2 и т. д. Далее, к каждой группе перекомпонованной таблицы, а не к каждой строке исходной таблицы применяется фраза SELECT. Каждое выражение во фразе SELECT должно принимать единственное значение для группы, т. е. оно может быть либо самим полем, указанным во фразе GROUP BY, либо арифметическим выражением, включающим это поле, либо константой, либо такой функцией, как SUM, которая оперирует всеми значениями данного поля в группе и сводит эти значения к единственному значению.
Строки таблицы можно группировать по любой комбинации ее полей. В разделе 5.6 приведен пример, иллюстрирующий группирование более чем по одному полю. Заметим, что фраза GROUP BY не предполагает ORDER BY (упорядочить по). Чтобы гарантировать упорядочение результата этого примера по номерам деталей, следует специфицировать фразу ORDER BY НОМЕР-ДЕТАЛИ после фразы GROUP BY. Если поле, по значениям которого осуществляется группирование, содержит какие-либо неопределенные значения, то каждое из них порождает отдельную группу.
ИСПОЛЬЗОВАНИЕ ФРАЗЫ WHERE с GROUP BY
Выдать для каждой поставляемой детали ее номер и общий объем поставок, за исключением поставок поставщика S1:
SELECT НОМЕР_ДЕТАЛИ, SUM (КОЛИЧЕСТВО)
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА Ø= 'S1'
GROUP BY НОМЕР_ДЕТАЛИ;
Результат:
НОМЕР_ДЕТАЛИ
Р1
300
Р2
800
Р4
300
Р5
400
Строки, не удовлетворяющие фразе WHERE, исключаются до того, как будет осуществляться какое-либо группирование.
ИСПОЛЬЗОВАНИЕ HAVING
Выдать номера деталей для всех деталей, поставляемых более чем одним поставщиком (тот же пример, что и в 5.2.5).
SELECT НОМЕР_ДЕТАЛИ
FROM SP
GROUP BY НОМЕР_ДЕТАЛИ
HAVING COUNT (*)>1;
Результат:
НОМЕР_ДЕТАЛИ
P1
Р2
Р4
Р5
Фраза HAVING играет такую же роль для групп, что и фраза WHERE для строк. (Конечно, если специфицирована фраза HAVING, то должна быть специфицирована и фраза GROUP BY.) Иными словами, HAVING используется для того, чтобы исключать группы, точно так же, как WHERE используется для исключения строк. Выражение во фразе HAVING должно принимать единственное значение для группы.
В примере 5.2.5 уже было показано, что этот запрос может быть сформулирован без GROUP BY (и без HAVING) с использованием коррелированного подзапроса. Однако пример 5.2.5 в действительности основан на несколько ином восприятии логики, связанной с определением ответа на этот вопрос. Можно также сформулировать запрос, используя по существу ту же логику, что и в варианте GROUP BY/HAVING, но без явного использования фраз GROUP BY и HAVING вообще:
SELECТ DISTINCT НОМЕР_ДЕТАЛИ
FROM SP SPX
WHERE 1 <
(SELECT COUNT (*)
FROM SP SPY
WHERE SPY.НОМЕР_ДЕТАЛИ = SPX.HOMEP_ДЕТАЛИ);
Следующий вариант, в котором вместо SPX используется таблица Р, является, вероятно, более ясным:
SELECT НОМЕР_ДЕТАЛИ
FROM Р
WHERE 1 <
(SELECT COUNT (НОМЕР_ПОСТАВЩИКА)
FROM SP
WHERE НОМЕР_ДЕТАЛИ = P. НОМЕР_ДЕТАЛИ);
Еще одна формулировка связана с использованием EXISTS:
SELECT НОМЕР_ДЕТАЛИ
FROM P
WHERE EXISTS
(SELECT *
FROM SP SPX
WHERE SPX. НОМЕР_ДЕТАЛИ = Р. НОМЕР_ДЕТАЛИ
AND EXISTS
(SELECT *
FROM SP SPY
WHERE SPY. НОМЕР_ДЕТАЛИ = Р. НОМЕР_ДЕТАЛИ
AND SPY. НОМЕР_ПОСТАВЩИК Ø= SPX. НОМЕР_
ПОСТАВЩИКА);
Все эти альтернативные варианты являются в некотором отношении более предпочтительными по сравнению с вариантом GROUP BY/HAVING в связи с тем, что они по крайней мере логически более понятны и, в частности, не требуют этих дополнительных языковых конструкций. Из первоначальной формулировки задачи на естественном языке — «Выдать номера деталей для всех деталей, поставляемых более чем одним поставщиком» — без сомнения, не ясно, что группирование само по себе—это то, что необходимо для ответа на данный вопрос, и в нем, действительно, нет необходимости. Не является также непосредственно очевидным, что необходимо условие HAVING, а не условие WHERE. Вариант GROUP-BY/HAVING более похож на процедурное предписание для решения задачи, чем просто на ясную логическую формулировку ее существа. С другой стороны, нельзя опровергнуть тот факт, что вариант GROUP-BY/HAVING наиболее лаконичен. Далее, в свою очередь имеются некоторые задачи такого же общего характера, для которых GROUP BY и HAVING просто неадекватны, в силу чего следует использовать один из альтернативных подходов. Пример такой задачи представлен в упражнении 5.24.
Наконец, конструкции
GROUP BY свойственно серьезное ограничение — она работает только на одном уровне. Невозможно разбить каждую из этих групп на группы более низкого уровня и т. д., а затем применить некоторую стандартную функцию, например SUM или AVG на каждом уровне группирования[16].
ИСПОЛЬЗОВАНИЕ INSERT..SELECT ДЛЯ ПОСТРОЕНИЯ ВНЕШНЕГО СОЕДИНЕНИЯ
Для каждого поставщика получить его номер, фамилию, состояние и город вместе с номерами всех поставляемых им деталей, Если данный поставщик не поставляет вообще никаких деталей, то выдать информацию для этого поставщика, оставляя в результате пробелы вместо номера детали.
CREATE TABLE ВНЕШ_СОЕДИНЕНИЕ
(НОМЕР_ПОСТАВЩИКА CHAR (5),
ФАМИЛИЯ CHAR (20),
СОСТОЯНИЕ SMALLINT,
ГОРОД CHAR (15)),
НОМЕР_ДЕТАЛИ CHAR (6);
INSERT
INTO ВНЕШ_СОЕДИНЕНИЕ
SELECT S.*, SP.HOMEP_ДЕТАЛИ
FROM S, SP
WHERE S. НОМЕР_ПОСТАВЩИКА=SP. НОМЕР_ПОСТАВЩИКА;
INSERT
INTO ВНЕШ_СОЕДИНЕНИЕ
SELECT S.*, 'bb'
FROM S
WHERE NOT EXISTS
(SELECT *
FROM SP
WHERE SP. НОМЕР_ПОСТАВЩИКА=
S. НОМЕР_ПОСТАВЩИКА);
Теперь таблица BHEШ_СОЕДИНЕНИЕ выглядит так:
ВНЕШ_СОЕДИНЕНИЕ
НОМЕР_
ПОСТАВЩИКА
ФАМИЛИЯ
СОСТОЯНИЕ
ГОРОД
НОМЕР_
ДЕТАЛИ
S1
S1
S1
S1
S1
S1
S2
S2
S3
S4
S4
S4
S5
Смит
Смит
Смит
Смит
Смит
Смит
Джонс
Джонс
Блейк
Кларк
Кларк
Кларк
Адамc
20
20
20
20
20
20
10
10
30
20
20
20
30
Лондон
Лондон
Лондон
Лондон
Лондон
Лондон
Париж
Париж
Париж
Лондон
Лондон
Лондон
Атенс
Р1
Р2
РЗ
Р4
Р5
Р6
Р1
Р2
Р2
Р2
Р4
Р5
bb
Здесь 'bb' используется для представления строки пробелов. Пояснение. Первые двенадцать строк приведенного результата, как легко видеть, соответствуют первому из двух INSERT.. .SELECT и представляют собой обычное естественное соединение таблиц S и SP по номерам поставщиков, за исключением того, что не включен столбец КОЛИЧЕСТВО. Последняя строка результата соответствует второму INSERT.. .SELECT и сохраняет информацию для поставщика S5, который не поставляет никаких деталей. Полный результат представляет собой внешнее соединение таблиц S и SP по номерам поставщиков, в котором опущен столбец КОЛИЧЕСТВО. В противоположность этому обычное соединение называется иногда внутренним
соединением.
Заметим, что нужны два отдельных INSERT.. .SELECT, поскольку подзапрос не может содержать UNION.
ЯЗЫК QUERY-BY-EXAMPLE
Как указывалось в разделе 15.1, QMF обеспечивает интерфейс Query-By-Example, а также интерфейс SQL. Query-By-Example (QBE) — реляционный язык запросов, который в некотором отношении более «дружествен для пользователей», чем SQL, по крайней мере для пользователей, не имеющих профессиональной подготовки в области обработки данных. Несомненно, справедливо, что SQL—более «дружествен для пользователей», чем более старые языки, например DL/1. Однако в нем все еще предполагается определенный опыт программирования. По существу, он является все-таки языком программирования в традиционном смысле, хотя и языком очень высокого уровня. Напротив, QBE—это язык, в котором все операции формулируются просто путем занесения данных в пустые таблицы на экране—по существу, путем заполнения форм. Такой стиль «заполнения бланков» является весьма легким для изучения и понимания и часто оказывается более привлекательным, чем стиль SQL, для пользователей с незначительной подготовкой или вообще не имеющих подготовки в области обработки данных.
С помощью интерфейса
QBE для QMF пользователь может запрашивать операции, аналогичные операциям манипулирования данными SQL - SELECT, UPDATE, DELETE и INSERT. Однако все другие операции определения данных и управления данными, например CREATE и GRANT, могут запрашиваться только через интерфейс SQL. В QBE доступны операции Р., U., D. и I., соответствующие операциям SQL - SELECT, UPDATE, DELETE и INSERT.
Примечание. «Р.» обозначает «print» (печатать), однако эта команда фактически не вызывает какой-либо печати. Для этой цели предназначена команда PRINT в QMF, как указывалось и разделе 15.2.
Основная идея, лежащая в основе QBE, очень проста и иллюстрируется следующим примером. Рассмотрим запрос «Выдать номера поставщиков, находящихся в Париже и имеющих состояние больше 20» (пример 4.2.5 из главы 4). Этот запрос может быть представлен в QBE следующим образом:
S
НОМЕР_ПОСТАВЩИКА
ФАМИЛИЯ
СОСТОЯНИЕ
ГОРОД
Р.
>20
Париж
Пояснение.
Сначала, выдавая команду DRAW S (нарисоватьS), пользователь заставляет QMF вывести на экран пустую таблицу S, т. е. таблицу, в которой показаны только ее имя и имена столбцов без каких-либо значений данных. Затем пользователь конструирует запрос, печатая элементы трех позиций в теле этой таблицы. А именно, он печатает «Р.» в позиции НОМЕР_ПОСТАВЩИКА, чтобы указать цель запроса, в данном случае значения, которые должны быть «напечатаны» или показаны на экране. Помимо этого, он задает «>20» и «Париж» в позициях СОСТОЯНИЕ и ГОРОД, чтобы указать условия, которым должны удовлетворять эти целевые значения.
Можно специфицировать также «Р.» относительно полной строки, например, следующим образом:
НОМЕР_ПОСТАВЩИКА
ФАМИЛИЯ
СОСТОЯНИЕ
ГОРОД
Р.
>20
Париж
что эквивалентно спецификации «Р.» в позиции каждого столбца таблицы:
НОМЕР_ПОСТАВЩИКА
ФАМИЛИЯ
СОСТОЯНИЕ
ГОРОД
Р.
Р.
Р.>20
Р. Париж
Отметим, между прочим, что значения, являющиеся строками символов, например Париж, могут специфицироваться без заключения их в кавычки. Однако не будет ошибки, если такое значение заключается в кавычки, а иногда, например если в строке содержатся пробелы, кавычки необходимы.
В остальной части этой главы с помощью ряда дальнейших примеров иллюстрируются некоторые важные особенности интерфейса QBE. Для удобства там, где это уместно, даются ссылки на варианты этих примеров в SQL из глав 4, 5 и 6. Мы не будем, однако, настолько же вдаваться в подробности, насколько это делали в случае SQL. Прежде чем перейти к рассмотрению примеров, сделаем еще два предварительных замечания:
— В QMF имеется команда, которая дает пользователю возможность специфицировать, будут ли запросы формулироваться в SQL или в QBE. Возможно динамическое переключение этих интерфейсов в одном сеансе QMF.
— Для формирования пустых таблиц на экране путем добавления или удаления столбцов и строк, а также расширения и сужения столбцов пользователь имеет в распоряжении команды редактирования. Таким образом, таблицы могут редактироваться для того, чтобы удовлетворить требованиям любой операции, которую пытается формулировать пользователь. В частности, могут быть исключены столбцы, которые не требуются для выполнения специфицированной в запросе операции. Например, в первом из приведенных выше примеров запросов столбец ФАМИЛИЯ мог быть исключен:
S
НОМЕР_ПОСТАВЩИКА
СОСТОЯНИЕ
ГОРОД
Р.
>20
Париж
В дальнейшем мы не будем беспокоиться относительно обсуждения таких подробностей.
ЯЗЫК SQL
На рис. 1.3 представлено состояние базы данных поставщиков и деталей в некоторый конкретный момент времени. Это — фотография базы данных. В противоположность этому на рис. 1.5 показана структура
этой базы данных. Она показывает, как эта база данных определена или описана[5].
CREATE TABLE S
(НОМЕР_ПОСТАВЩИКА
CHAR (5),
ФАМИЛИЯ
CHAR (20),
СОСТОЯНИЕ
SMALLINT.
ГОРОД
CHAR (15));
CREATE TABLE P
(НОМЕР_ДЕТАЛИ
CHAR (5),
НАЗВАНИЕ
CHAR (20),
ЦВЕТ
CHAR (7),
ВЕС
SMALLINT,
ГОРОД
CHAR (15));
CREATE TABLE SP
(НОМЕР_ПОСТАВЩИКА
CHAR (5)
НОМЕР_ДЕТАЛИ
CHAR (6)
КОЛИЧЕСТВО
INTEGER);
Рис. 1.5. База данных поставщиков и деталей (определение данных)
Нетрудно видеть, что определение базы данных в рассматриваемом примере включает по одному предложению CREATE TABLE (СОЗДАТЬ ТАБЛИЦУ) для каждой из трех составляющих ее таблиц. CREATE TABLE представляет собой пример предложения определения данных языка SQL. Каждое предложение CREATE TABLE специфицирует имя таблицы, которая должна быть создана, имена ее столбцов и типы данных для этих столбцов (а также, возможно, некоторую дополнительную информацию, не иллюстрируемую данным примером).
В данный момент детальное описание предложения CREATE TABLE не является нашей задачей. Оно будет приведено позже, в главе 3. Однако с самого начала необходимо подчеркнуть, что CREATE TABLE — выполняемое предложение. (Фактически, как мы увидим позднее, каждое предложение SQL является выполняемым.) Если три представленные на рис. 1.5 предложения CREATE TABLE будут введены с терминала в точности так, как они показаны, система в действительности тотчас же построит эти три таблицы. Конечно, сначала эти таблицы будут пустыми. Каждая из них будет содержать только строку заголовков столбцов, но не будет еще содержать никаких строк с данными. Мы можем, однако, немедленно приступить к вставке таких строк данных, возможно, с помощью предложения INSERT языка SQL, которое будет обсуждаться в главе 6. Буквально за несколько минут работы мы можем получить в свое распоряжение, вероятно, небольшую, но тем не менее полезную и пригодную к использованию базу данных и можем начать делать с нею некоторые полезные вещи. Таким образом, этот простой пример сразу же показывает одно из достоинств реляционных систем вообще и системы DB2 в частности — они являются очень легкими для использования. Конечно, легкость «вступления в контакт» это лишь один аспект легкости использования вообще. В результате пользователь может работать очень продуктивно. Позже мы увидим много других достоинств.
Примечание. Хотя это в действительности и не имеет никакого отношения к теме данного параграфа (к языку SQL), целесообразно, между прочим, упомянуть, что DB2 разрабатывалась, в частности, с целью создания легко устанавливаемой системы. Это означает, что не только легко в любое время «установить» или создать новую базу данных, но прежде всего легко установить также и полную систему. Иными словами, процесс построения необходимых библиотечных наборов данных DB2, специфицирующих требуемые параметры системы, определяющих некоторые характеристики системы по умолчанию и т. п. намеренно сделан настолько простым, насколько это возможно. Для верификации корректности функционирования установки системы предоставляются контрольные примеры программ. Полная процедура установки системы обычно занимает от одного до двух рабочих дней.
Теперь вернемся к примеру. После создания трех наших таблиц и загрузки в них некоторых записей можно начать делать с ними полезную работу, используя предложения манипулирования данными языка SQL. Одна из вещей, которую мы можем делать,— это поиск данных, специфицируемый в языке SQL с помощью предложения SELECT. Пример поиска данных приведен на рис. 1.6.
SELECT ГОРОД Результат: ГОРОД
FROM S Лондон
WHERE НОМЕР-ПОСТАВЩИКА == 'S4';
а) Интерактивный (DB2I)
ЕХЕС SQL SELECT ГОРОД Результат: ХГОРОД
INTO :X ГОРОД Лондон
FROM S
WHERE НОМЕР_ПОСТАВЩИКА =='S4';
б) Встроенный в ПЛ/1 (может использоваться также КОБОЛ, ФОРТРАН или Ассемблер).
Рис. 1.6. Пример поиска данных в базе данных
Довольно важная особенность реализации языка SQL в системе DB2 (и, между прочим, в SQL/DS) заключается в том, что один и тот же язык предоставляется через два различных интерфейса, а именно через интерактивный интерфейс (DB2I в случае системы DB2) и через интерфейс прикладного программирования. На рис. 1.6,а показан пример использования интерактивного интерфейса DB2I. Пользователь вводит с терминала предложение SELECT, а система DB2 отвечает через ее компонент DB2I, показывая непосредственно на терминале результат «Лондон». На рис 1.6,б показано фактически то же самое предложение SELECT, встроенное в прикладную программу (в примере—в программу на языке ПЛ/1). В этом втором случае указанное предложение будет исполняться, когда будет исполняться программа, а результат «Лондон» будет возвращаться не на терминал, а программной переменной ХГОРОД (благодаря фразе INTO в предложении SELECT; переменная ХГОРОД представляет собой как раз область ввода в программе). Таким образом, SQL представляет собой и интерактивный язык запросов и язык программирования в обстановке базы данных. Это замечание относится ко всему языку SQL, т. е. любое предложение SQL, которое может быть введено с терминала, может быть альтернативно встроено в программу. Отметим, в частности, что приведенное замечание относится даже к таким предложениям, как CREATE TABLE. Вы можете создавать таблицы из прикладной программы, если это имеет смысл н вашей прикладной задаче и если Вы обладаете полномочиями на выполнение таких операций. Предложения языка SQL могут быть встроены в программы, записанные на любом из следующих языков: ПЛ/1, КОБОЛ, ФОРТРАН и язык ассемблера IBM/370. (Помимо этого фирма IBM объявила о своем намерении поддерживать в будущем БЭИСИК и АПЛ).
Примечание. На рис. 1.6, б префикс EXEC SQL необходим для того, чтобы отличить данное предложение SQL от предложений языка ПЛ/1, которые его окружают. Кроме того, чтобы обозначить область ввода, необходима, как мы видим, фраза INTO; указанная в этой фразе переменная должна иметь в качестве префикса двоеточие с тем, чтобы отличать ее от имени столбца в SQL. Конечно, не совсем точно, что предложение SELECT является одним и тем же для обоих интерфейсов. Но это вполне справедливо, если отвлечься от незначительных различий в деталях.
Теперь мы в состоянии понять, как выглядит система DB2 для пользователя. Под «пользователем» мы понимаем здесь либо конечного пользователя, работающего в интерактивном режиме терминала, либо прикладного программиста, пишущего программы на ПЛ/1, КОБОЛе, ФОРТРАНе или на языке ассемблера. (Заметим, между прочим, что мы будем использовать термин «пользователь» всюду в этой книге в каком-либо одном или в обоих этих смыслах). Как уже разъяснялось, каждый такой пользователь будет использовать SQL для того, чтобы оперировать таблицами (см. рис. 1.7).
Рис. 1.7. База данных системы DB2 в восприятии отдельного пользователя
Первое соображение, касающееся рис. 1.7, состоит в том, что обычно множество пользователей обоих видов будет оперировать одними и теми же данными в одно и то же время. Система DB2 будет автоматически использовать необходимые средства управления (см. главу 11) с тем, чтобы обеспечить защиту всех этих пользователей друг от друга, т. е. гарантировать, что обновления, осуществляемые одним пользователем, не могут привести к некорректному результату операций, выполняемых другим пользователем.
Отметим далее, что на рисунке также представлены таблицы двух видов, а именно: базовые таблицы, и представления. Базовая таблица это «реальная» таблица, т. е. таблица, которая существует физически в том смысле, что в одном или более наборах данных VSAM существуют физически хранимые записи и, возможно, физические индексы, которые непосредственно представляют эту таблицу в памяти. В противоположность этому представление является «виртуальной таблицей», т. е. таблицей, которая непосредственно не существует в физической памяти, но для пользователя выглядит так, как будто она существует. Представления можно считать различными способами видения «реальных» таблиц. Тривиальный пример: данный пользователь мог бы располагать представлением базовой таблицы поставщиков, в котором видимы только те поставщики, которые находятся в Лондоне. Представления определяются на основе одной или более базовых таблиц. Способ их определения рассматривается в главе 8.
Примечание.
Сказанное в предыдущем абзаце не следует интерпретировать таким образом, что базовая таблица физически хранится как таблица, т. е. как множество физически смежных хранимых записей, каждая из которых представляет собой просто непосредственную копию какой-либо строки базовой таблицы. Существуют многочисленные различия между базовой таблицей и ее представлением в среде хранения. Некоторые из них будут позднее обсуждаться. Дело в том, что пользователи всегда могут считать базовые таблицы «физически существующими», не касаясь того, каким образом эти таблицы на самом деле реализованы в памяти. Фактически проблема реляционных баз данных в полном ее объеме заключается в том, чтобы дать пользователям возможность иметь дело с данными в форме таблиц самих по себе, а не в виде представлений таких таблиц в среде хранения. Как уже говорилось в разделе 1.4, реляционная база данных—это база данных, которая воспринимается ее пользователями как
совокупность таблиц. Это совсем не база данных, в которой данные физически хранятся, как таблицы.
Представления, как и базовые таблицы, могут быть созданы в любое время. То же самое справедливо и для индексов. Уже указывалось, что предложение CREATE TABLE служит для создания «реальных» или базовых таблиц. Имеется аналогичное предложение CREATE VIEW (создать представление) для создания представлений или «виртуальных» таблиц и аналогичное предложение CREATE INDEX (создать индекс) для создания индексов. Подобным же образом базовые таблицы (а также представления и индексы) могут быть «уничтожены» (иначе говоря, разрушены) в любое время с использованием предложений DROP TABLE (уничтожить таблицу), DROP VIEW (уничтожить представление) или DROP INDEX (уничтожить индекс). Относительно индексов заметим для строгости, что хотя пользователь (т. е. некоторый пользователь, вероятно, администратор базы данных— см. главу 9) ответствен за их создание и уничтожение, он не является ответственным за их сохранность, когда эти индексы должны использоваться. Индексы никогда не упоминаются в предложениях манипулирования данными языка SQL, например в SELECT. Решение о том, использовать ли или не использовать какой-либо конкретный индекс при обработке, например, определенного предложения SELECT, принимается системой, а не пользователем. Этот вопрос более подробно обсуждается в главе 2.
Пользовательский интерфейс системы DB2 — это язык SQL. Мы уже указывали, что:
а) SQL может использоваться как в интерактивной, так и во встроенной обстановке и
б) он обеспечивает не только функции определения данных, но и функции манипулирования данными (как будет видно далее, он фактически обеспечивает также некоторые функции «управления данными»).
Выше мы уже касались главных функций определения данных:
CREATE TABLE
CREATE VIEW
CREATE INDEX
DROP TABLE
DROP VIEW
DROP INDEX
Главными функциями манипулирования данными являются (на самом деле, если на время игнорировать некоторые функции, относящиеся только к встроенному SQL, то это полный перечень таких функций):
SELECT (выбрать)
UPDATE (обновить)
DELETE (удалить)
INSERT (вставить)
Приведенные ниже примеры (рис. 1.8) предложений SELECT и UPDATE иллюстрируют важный момент, заключающийся в том, что предложения манипулирования данными языка SQL обычно оперируют одновременно полным множеством записей, а не просто одной записью. Если принять данные из примера на рис. 1.3, то предложение SELECT, приведенное на рис. 1.8 а, возвращает множество, Состоящее из четырех значений, а не из одного. В то же время, предложение UPDATE (рис. 1.8,б) изменяет две записи, а не одну. Другими словами, SQL является языком уровня множеств.
а) SELECT НОМЕР_ПОСТАВЩИКА Результат: НОМЕР_ПОСТАВЩИКА
FROM SP S1
WHERE НОМЕР_ДЕТАЛИ = 'Р2' S2
S3
S4
б) UPDATE S Результат: удвоенное состояние для
поставщиков S1 и S4
SET СОСТОЯНИЕ == 2*СОСТОЯНИЕ
WHERE ГОРОД = 'Лондон';
Рис. 1.8. Примеры манипулирования данными для языка SQL
Языки уровня множеств, такие, как SQL иногда характеризуются как «непроцедурные» на том основании, что пользователи специфицируют что, а не как (т. е. они указывают, какие данные необходимо иметь, не специфицируя процедуру для их получения). Иными словами, процесс «навигации» в физической базе данных с целью определения местонахождения требуемых данных выполняется автоматически системой, а не вручную пользователем. Однако «непроцедурный» в действительности не очень хороший термин, поскольку как процедурность, так и непроцедурность не являются абсолютными. Лучший способ выразить это — сказать, что некоторый язык А является более либо менее процедурным, чем некоторый другой язык В. Возможно, более хорошим способом выражения этого обстоятельства является утверждение о том, что некоторый язык, например SQL, находится на более высоком уровне абстракции, чем такой язык, как КОБОЛ (или DL/1). Иными словами, системе приходится в связи с языком типа SQL иметь дело с большим числом деталей, чем для языка типа КОБОЛ (или, например, DL/1). По существу, это такое повышение уровня абстракции, которое является причиной возросшей производительности, обеспечиваемой реляционными системами, такими, как DB2.
КАК ОБОЙТИСЬ БЕЗ DB
Как указывалось во введении (см. раздел 14.1), не обязательно использовать DB2I. Имеется возможность вызывать приложение DB2 в интерактивном режиме, не используя DB2I. Для этого выдается команда TSO «DSN» (вызывающая DB2), за которой должна следовать команда:
RUN PROGRAM (имя—программы) PLAN (имя—плана)
Можно также вызвать приложение DB2 в пакетном режиме с помощью предложений JCL, которые: а) специфицируют в качестве программы, подлежащей исполнению, терминальную мониторную программу TSO (TMP) и б) передают команды DSN и RUN на вход этой мониторной программе.
КАК СИСТЕМА DBРЕШАЕТ ЭТИ ТРИ ПРОБЛЕМЫ ПАРАЛЛЕЛЬНЫХ ПРОЦЕССОВ
Как уже упоминалось в начале предыдущего раздела, механизм управления параллельными процессами системы DB2, подобно предназначенным для этого механизмам большинства других доступных в настоящее время систем, основан на технике, называемой блокированием.
Главная идея блокирования проста: если транзакции нужны гарантии, что некоторый объект, в котором она заинтересована—обычно запись базы данных, не будет изменен каким-либо непредсказуемым образом в течение требуемого промежутка времени, она устанавливает блокировку этого объекта. Результат блокировки заключается в том, чтобы изолировать этот объект от других транзакций и, в частности, предотвратить его изменение средствами этих транзакций. Для первой транзакции, таким образом, имеется возможность выполнять предусмотренную в ней обработку, располагая определенными знаниями о том, что объект в запросе будет оставаться в стабильном состоянии до тех пор, пока данная транзакция этого пожелает.
Перейдем теперь к более детальному рассмотрению принципа действия блокирования конкретно для системы DB2. Начнем с некоторых упрощающих предположений.
1. Предполагается, что единственным видом объектов, подверженных действию механизма блокирования, является запись базы данных, т. е. строка базовой таблицы. Вопрос о блокировании объектов других видов отложим до раздела 11.6.
2. Будут обсуждаться только два вида блокировок, а именно — монопольные блокировки (тип X) и совместные блокировки (тип S) (Названия типов блокировок Х и S происходят от английских слов Shared (совместный) и exclusive (монопольный).—Примеч. пер.). В некоторых системах существуют другие типы блокировок. Фактически сама система DB2 внутренне поддерживает некоторые дополнительные их типы, но для пользователей в DB2 представляют интерес только блокировки типов Х и S.
3. Здесь рассматриваются только операции уровня записей (FETCH, UPDATE CURRENT и т. д.). Операции уровня множеств для целей блокирования могут рассматриваться как краткое обозначение соответствующих последовательностей операций уровня записей.
Теперь приступим к детальному рассмотрению вопроса.
1. Прежде всего если транзакция А устанавливает монопольную блокировку ( тип X) записи R, то запрос из транзакции В на любого типа блокировку записи R приведет к тому, что В перейдет в состояние ожидания. Транзакция В будет находиться в этом состоянии до тех пор, пока не будет снята блокировка, установленная транзакцией А.
2. Далее, если транзакция А устанавливает совместную блокировку (тип S) записи R, то: а) запрос из транзакции В на блокировку типа Х записи R заставит В перейти в состояние ожидания, и В будет находиться в этом состоянии до тех пор, пока не будет снята блокировка, установленная транзакцией А; б) запрос из транзакции В на блокировку типа S записи R будет удовлетворен, т. е. теперь транзакция В будет также удерживать блокировку типа S записи R.
Сказанное можно удобно резюмировать с помощью матрицы совместимости (рис. 11.5). Эта матрица интерпретируется следующим образом. Рассмотрим некоторую запись R. Предположим, что в настоящее время А удерживает блокировку R, тип которой указывается элементами в заголовках столбцов (тире обозначает отсутствие блокировки). Пусть теперь некоторая другая транзакция В издает запрос на блокировку R, тип которой указывается в левом столбце таблицы. Здесь для полноты снова включен случай «отсутствие блокировки». Тогда значение «N» на пересечении соответствующих столбца и строки матрицы указывает на конфликт—запрос транзакции В не может быть удовлетворен, и В переходит в состояние ожидания. Значение «Y» указывает совместимость — запрос В удовлетворяется. Очевидно, что приведенная матрица симметрична.
S
—
Х
S
—
N
N
Y
N
Y
Y
Y
Y
Y
Рис. 11.5. Матрица совместимости типов блокировки
Продолжим наше рассмотрение.
3. Запросы транзакций на блокировку записей всегда являются неявными. Когда транзакция успешно осуществляет выборку записи (операция FETCH), она автоматически устанавливает блокировку типа S этой записи. Когда транзакция успешно обновляет запись, она автоматически устанавливает блокировку типа Х этой записи. Если же она уже удерживала блокировку типа Х для этой записи, как это будет происходить в случае последовательности операций FETCH . . . UPDATE, то операция UPDATE «повышает» блокировку типа S до уровня X.
4. Блокировки типа Х удерживаются до следующей точки синхронизации. Блокировки типа S обычно также удерживаются до этого момента времени (см. однако обсуждение вопроса об уровне изоляции в разделе 11.6).
Теперь мы имеем возможность уяснить, каким образом в системе DB2 решаются три проблемы, описанные в предыдущем разделе. Снова будем рассматривать их поочередно.
Проблема утраченного обновления
Рис. 11.6 представляет собой модифицированный вариант рис. 11.1, показывающий, что произошло бы при параллельном" исполнении приведенных на рисунке транзакций под управлением механизма блокирования, предусмотренного в системе DB2.
Время
Транзакция В
—
—
—
—
FETCH R
t1
—
(установить блокировку
—
типа S для R)
—
—
t2
FETCH R
—
(установить блокировку
—
типа S для R)
—
—
UPDATE R
t3
—
(запрос блокировки
—
типа Х для R)
—
ждать
t4
UPDATE R
ждать
(запрос блокировки
ждать
типа Х для R)
ждать
ждать
ждать
ждать
ждать
ждать
Рис. 11.6. Не утрачиваются никакие обновления, но в момент t4 возникает тупиковая ситуация
Легко видеть, что запрос транзакции А в момент t3 на операцию UPDATЕ не принимается, поскольку это неявный запрос на блокировку типа Х для записи R, и такой запрос противоречит блокировке типа S, уже установленной транзакцией В. Поэтому А переходит в состояние ожидания. По аналогичным причинам транзакция В переходит в состояние ожидания в момент t4. Теперь обе транзакции не могут быть продолжены. Поэтому не возникает вопрос о том, что какое-либо обновление может быть утрачено. Таким образом, в системе DB2 проблема утраченного обновления решается путем сведения ее к другой проблеме, но это, по крайней мере, действительно решает первоначальную проблему! Эта новая проблема называется проблемой тупиковых ситуаций. Решение этой проблемы в системе DB2 обсуждается в разделе 11.7.
Проблема зависимости от незафиксированных обновлений
Рис. 11.7 и 11. 8 являются модифицированными вариантами рис. 11.2 и 11.3 соответственно, показывающими, что произошло бы при параллельном исполнении представленных на этих рисунках транзакций под управлением механизма блокирования, используемого в системе DB2. Нетрудно видеть, что операция транзакции А, запрашиваемая в момент t2 (FETCH—на рис. 11.7 и UPDATE—на рис. 11.8), в обоих случаях не выполняется, поскольку это неявный запрос на блокировку R, а такой запрос вступает в конфликт с уже установленной транзакцией В блокировкой типа X. Поэтому А переходит в состояние ожидания. Она остается в этом состоянии до тех пор, пока В не достигнет точки синхронизации, выполняя операцию COMMIT или ROLLBACK. При этом установленная транзакцией В блокировка снимается, и А получает возможность продолжать исполнение. В этот момент А «видит» зафиксированное значение — либо значение, предшествующее исполнению В, если В завершается операцией ROLLBACK, либо значение, соответствующее успешному завершению В, в противном случае. В любом случае А больше не зависит от незафиксированных обновлений.
Время
Транзакция В
—
—
—
—
—
t1
UPDATE R
—
(запрос блокировки
—
типа Х для R)
FETCH R
t2
—
(запрос блокировки
—
типа S для R)
—
ждать
—
t3
точка синхронизации
ждать
(снять блокировку типа
Х для R)
ждать
—
повторно: FETCH R
t4
(установить блокировку
типа S для R) — Рис. 11.7. Предотвращается ситуация, когда транзакция А «увидела» бы в момент t2 незафиксированное изменение
—
(установить блокировку
—
типа S для СЧЕТА 3):
—
—
—
t4
UPDATE СЧЕТ 3
—
(установить блокировку
—
типа Х для СЧЕТА З):
—
30®20
—
—
t5
FETCH СЧЕТ 1 (40) (
—
запрос блокировки)
—
типа S для СЧЕТА 1
—
ждать
—
t6
UPDATE СЧЕТ 1
—
(установить блокировку
—
типа Х для СЧЕТА 1)
FETCH СЧЕТ 3 (20):
t7
ждать
(запрос блокировки
ждать
S для СЧЕТА З):
ждать
Ждать
ждать
Ждать
Рис. 11.9. Исключается анализ на противоречивость, но в момент t6 возникает тупиковая ситуация
Рис. 11.9—это модифицированный вариант рис. 11.4, показывающий, что произошло бы при параллельном исполнении представленных на этом рисунке транзакций под управлением механизма блокирования, который используется в системе DB2. Нетрудно видеть, что запрос транзакции В на операцию UPDATE и момент t6 не принимается, поскольку он является неявным запросом на блокировку типа Х для СЧЕТА 1, а такой запрос вступает в конфликт с блокировкой типа S, уже установленной транзакцией А. Поэтому В переходит в состояние ожидания. Подобным же образом в момент t7 не принимается также запрос транзакции А на выполнение операции FETCH, так как он является неявным запросом на установление блокировки типа S для СЧЕТА 3, а такой запрос вступает в конфликт с блокировкой типа X, уже установленной транзакцией В. По этой причине А также переходит в состояние ожидания. Итак, снова первоначальная проблема (в данном случае, проблема анализа на противоречивость) решается в системе DB2 путем форсирования возникновения тупиковой ситуации. Как уже говорилось, проблема тупиковых ситуаций обсуждается в разделе 11.7.
КОМАНДЫ ОПЕРАТОРА
Это меню позволяет пользователю вводить команды с консоли оператора, например START DATABASE, STOP DATABASE и т. п.
КОРРЕЛИРОВАННЫЙ ПОДЗАПРОС
Выдать фамилии поставщиков, которые поставляют деталь P2. Этот пример уже рассматривался в п. 5.2.1. Однако для иллюстрации проблемы, рассматриваемой в данном разделе, приведем иное решение этой задачи.
SELECT ФАМИЛИЯ
FROM S
WHERE 'P2' IN
(SELECT НОМЕР_ДЕТАЛИ
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА =
S. НОМЕР_ПОСТАВЩИКА);
Пояснение. В последней строке приведенного запроса неуточненная ссылка на НОМЕР-ПОСТАВЩИКА уточняется неявным образом именем таблицы SP. Другая ссылка явно уточняется именем таблицы S. Этот пример отличается от предыдущих тем, что внутренний подзапрос не может быть обработан раз навсегда прежде, чем будет обрабатываться внешний запрос, поскольку этот внутренний подзапрос зависит от переменной, а именно от S.HOMEP_ПОСТАВЩИКА, значение которой изменяется
по мере того, как система проверяет различные строки таблицы S. Следовательно, с концептуальной точки зрения обработка осуществляется следующим образом.
а) Система проверяет первую строку таблицы S. Предположим, что это строка поставщика «S1». Тогда переменная S.НОМЕР_ПОСТАВЩИКА в данный момент имеет значение 'S1', и система обрабатывает внутренний запрос
(SELECT НОМЕР_ДЕТАЛИ
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА ='S1'),
получая в результате множество ('Р1, 'P2', 'РЗ', 'Р4', 'Р5', 'Р6'). Теперь она может завершить обработку для S1. Выборка значения ФАМИЛИЯ для S1, а именно Смит, будет произведена тогда и только тогда, когда 'Р2' принадлежит этому множеству, что, очевидно, справедливо.
б) Далее система будет повторять обработку такого рода для следующего поставщика и т. д. до тех пор, пока не будут рассмотрены все строки таблицы S.
Такой подзапрос, как в этом примере, называется коррелированным. Коррелированный подзапрос — это такой подзапрос, результат которого зависит от некоторой переменной. Эта переменная принимает свое значение в некотором внешнем запросе. Обработка такого подзапроса, следовательно, должна повторяться для каждого значения переменной в запросе, а не выполняться раз навсегда. Далее будет приведен другой пример коррелированного подзапроса (см. п. 5.2.5). Несколько других примеров приведено в разделах 5.3 и 5.4.
Для того чтобы сделать более ясной связь коррелированных подзапросов с внешними запросами, некоторые пользователи любят вводить псевдонимы (если требуется освежить в памяти вопрос относительно псевдонимов, см. пример 4.3.6 из главы 4). Например:
SELECT SX.ФАМИЛИЯ
FROM S SX
WHERE 'P2' IN
(SELECT НОМЕР_ДЕТАЛИ
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА=
SX.НОМЕР_ПОСТАВЩИКА);
В этом примере псевдонимом является имя SX, введенное во фразе FROM как альтернативное имя таблицы S и используемое далее в качестве явного уточнителя во фразе WHERE подзапроса, а также во фразе SELECT внешнего запроса. Действие приведенного выше полного предложения можно теперь описать более понятно и более точно следующим образом:
— SX — это переменная, областью определения которой является множество записей таблицы S, т. е. переменная, представляющая в любой заданный момент времени некоторую запись таблицы S.
— Поочередно для каждого возможного значения SX выполнить следующее:
+ вычислить подзапрос и получить множество номеров деталей, например Р;
+ добавить к результирующему множеству значение SX.ФАМИЛИЯ, если и только если P2 принадлежит множеству Р.
В предыдущем варианте этого запроса символ «S» в действительности выполнял две различные функции. Он обозначал, конечно, саму базовую таблицу, а также переменную, которая определена на множестве записей этой базовой таблицы. Как уже указывалось, многие считают более ясным использование двух различных символов для того, чтобы различать эти две различные функции.
Введение псевдонима никогда не является ошибкой, а иногда оно необходимо (см. ниже пример 5.2.5).
ЛОГИЧЕСКАЯ НЕЗАВИСИМОСТЬ ДАННЫХ
Мы еще не объяснили на самом деле, для чего нужны представления. Одна из задач, которую они позволяют решать — обеспечение того, что принято называть логической независимостью данных. Понятие физической независимости данных было введено в главе 2. Говорят, что система, подобная DB2, обеспечивает физическую независимость данных, поскольку пользователи и программы пользователей не зависят от физической структуры хранимой базы данных. Система обеспечивает логическую независимость данных, если пользователи и программы пользователей независимы также от логической структуры базы данных. Имеется два аспекта такой независимости — рост и реструктуризация.
Рост
Когда база данных растет в связи с включением новых видов информации, должно также соответственно расти ее определение.
Примечание. Вопрос о росте базы данных обсуждается здесь только для полноты. Он важен, но не имеет какого-либо отношения к самим по себе представлениям. Существуют два возможных типа роста, которые могут иметь место:
1. Расширение существующей базовой таблицы для включения в нее нового поля в соответствии с добавлением новой информации относительно некоторого существующего типа объектов, например добавление поля СКИДКА к базовой таблице поставщиков.
2. Включение новой базовой таблицы в соответствии с добавлением нового типа объектов, например при добавлении информации об изделиях в базу данных поставщиков и деталей.
Ни один из этих двух видов изменений не должен вообще оказывать какого-либо влияния на существующих пользователей, если только они не использовали предложения «SELECT *» или INSERT, в которых опущены списки имен полей. Как уже указывалось ранее в этой книге, смысл этих предложений может изменяться, если для них потребуется повторно произвести связывание, а рассматриваемая таблица была изменена (операция ALTER) в данном промежутке времени.
Реструктуризация
Иногда может стать необходимой реструктуризация базы данных. Хотя при этом общее информационное содержание остается тем же самым, размещение информации в этой базе данных изменяется, т. е. некоторым образом изменяется размещение полей в таблицах. Прежде чем продолжить обсуждение, отметим, что такая реструктуризация вообще нежелательна. Однако иногда она неизбежна. Например, может оказаться необходимым «вертикально» расщепить таблицу так, чтобы часто требующиеся столбцы могли храниться на более быстром устройстве, а реже требующиеся столбцы—на более медленном устройстве. Рассмотрим этот случай более подробно. Предположим для примера, что необходимо по некоторой причине — точная причина не является здесь важной — заменить базовую таблицу S следующими двумя базовыми таблицами:
SX (НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, ГОРОД)
SY (НОМЕР-ПОСТАВЩИКА, СОСТОЯНИЕ)
Примечание. Эта операция замены, между прочим, не совсем тривиальна. Один из способов ее осуществления состоит в следующей последовательности операций языка SQL:
CREATE TABLE SX
(НОМЕР_ПОСТАВЩИКА CHAR (5) NOT NULL,
ФАМИЛИЯ CHAR (20),
ГОРОД CHAR (15));
CREATE TABLE SY
(НОМЕР_ПОСТАВЩИКА CHAR (5) NOT NULL,
СОСТОЯНИЕ SMALLINT);
CREATE UNIQUE
CREATE UNIQUE INDEX XSX ON SX (НОМЕР_ПОСТАВЩИКА);
CREATE UNIQUE I NDEX XSY ON SY (НОМЕР_ПОСТАВЩИКА);
INSERT INTO SX (НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, ГОРОД)
SELECT НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, ГОРОД
FROM S;
INSERT INTO SY (НОМЕР_ПОСТАВЩИКА, СОСТОЯНИЕ)
SELECT НОМЕР_ПОСТАВЩИКА, СОСТОЯНИЕ
FROM S;
DROP TABLE S;
Важный факт, который обнаруживается в данном примере, заключается в том, что старая таблица S представляет собой соединение двух новых таблиц SX и SY по номерам поставщиков. В таблице S, например, была строка
('S1', 'Смит', 20, 'Лондон'). В таблице SX мы имеем теперь строку ('S1', 'Смит', 'Лондон'), а в SY—строку ('S1', 20). Соединение их дает, как и ранее, строку ('S1', 'Смит', 20, 'Лондон'). Поэтому создадим представление, которое является в точности этим соединением, и назовем его S:
CREATE VIEW S (НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, СОСТОЯНИЕ,
ГОРОД)
AS SELECT SX.НОМЕР_ПОСТАВЩИКА, SX.ФAMИЛИЯ,
SY СОСТОЯНИЕ, SX ГОРОД
FROM SX,SY
WHERE SX НОМЕР_ПОСТАВЩИКА =
SY.HOMEP_ПОСТАВЩИКА;
Каждая программа, которая ранее обращалась к базовой таблице S, теперь будет вместо этого обращаться к представлению S. Операции SELECT будут продолжать работать в точности как и ранее, хотя они потребуют дополнительного анализа во время процесса связывания и дополнительных накладных расходов на стадии исполнения. Однако операции обновления больше не будут работать, поскольку система DB2, как уже пояснялось в разделе 8.4, не будет допускать обновлений представления, определяемого как соединение. Иными словами, выполняющий операции обновления пользователь не обладает иммунитетом к этому типу изменений. Он должен вручную внести некоторые изменения, касающиеся предложений обновления, а затем произвести их прекомпиляцию и повторное связывание.
Таким образом показано, что система DB2 не
обеспечивает полной защиты от изменений в логической структуре базы данных. И в этом в первую очередь причина того, что проведение таких изменений вряд ли является хорошей идеей. Но дела могут быть не настолько плохими, как кажется, даже если требуются ручные изменения. Во-первых, легко обнаружить, какие программы должны быть изменены в связи с любыми такими изменениями. Эта информация может быть получена из каталога. Во-вторых, легко найти такие предложения, которые необходимо изменить в этой программе. Все они совершенно отдельны от всего другого и начинаются с префикса EXEC SQL. В-третьих, SQL — язык очень высокого уровня. Поэтому число подлежащих изменениям предложений обычно невелико, и смысл этих предложений можно легко уяснить. В результате необходимые изменения делаются, как правило, легко. Это не похоже на предложения обновления в языках сравнительно низкого уровня, таких, как PL/1 или КОБОЛ, где смысл данного предложения в большой степени зависит от динамической логики управления—от программы к предложению в запросе. Поэтому, хотя и справедливо, что должны быть сделаны некоторые поправки вручную, требуемый объем работ на практике не будет настолько большим.
Вернемся на минутку к примеру с таблицами SX и SY. Фактически представление S, определенное как соединение SX и SY, это хороший пример представления — соединения, которое теоретически обновляемо. Если предположить, что всегда существует взаимно однозначное соответствие между SX и SY таким образом, что любой поставщик, указанный в SX, должен быть указан также в SY, и наоборот, то воздействие на представление S всех возможных операций обновления понятным образом определяется в терминах SX и SY. (Упражнение. Согласны ли Вы с этим утверждением?) Таким образом, данный пример иллюстрирует, не только почему способность обновлять представления — соединения была бы полезной системной возможностью, но и случай, где такое обновление, по-видимому, является осуществимым.
МЕНЮ BIND/REBIND/FREE
Это меню позволяет пользователю выдавать команды BIND, REBIND и FREE.
1. Команда BIND создает план прикладной задачи из одного или более модулей запросов к базе данных (DBRM—см. главу 2, разделы 2.1 и 2.2). Наряду с другими могут быть специфицированы следующие параметры:
– Должен ли новый план заменить существующий.
– Уровень изоляции (RR и CS) для нового плана.
– Следует ли проверять правильность плана на стадии связывания или на стадии исполнения. Проверка правильности представляет собой процесс, позволяющий убедиться в том, что ссылки на таблицы, столбцы и т. п. являются синтаксически корректными и что пользователь, который выдает команду BIND, обладает полномочиями на исполнение данных операций SQL в связываемых модулях запросов к базе данных. Обычно проверка правильности осуществляется на стадии связывания. В некоторых случаях такая проверка может, однако, оказаться невозможной на стадии связывания. Например, план может содержать ссылки на таблицу, которая еще не существует (может быть, сам этот план создает указанную таблицу), или он может включать такие операции, на выполнение которых пользователь еще не имеет необходимых полномочий. В таких случаях следует запрашивать проверку правильности плана на стадии исполнения. Заметим, однако, что проверка правильности на стадии исполнения является сравнительно дорогой, поскольку она должна осуществляться для данного предложения каждый раз, когда оно исполняется.
2. Команда REBIND заново осуществляет связывание существующего плана. Она отличается от варианта команды BIND с заменой имеющегося плана тем, что исходными данными для нее является некоторый план, а не множество модулей запросов к базе данных. Команду REBIND обычно используют после существенного изменения физической структуры базы данных, например если были созданы какие-либо новые индексы. В результате становится целесообразной переоценка стратегии доступа для плана, указанного в запросе.
3. Команда FREE уничтожает специфицированный существующий план.
МЕНЮ DCLGEN
Меню DCLGEN позволяет пользователю вызывать программу генератора деклараций. Как уже отмечалось в главе 10, DCLGEN — это программа, которая создает предложения EXEC SQL DECLARE TABLE и декларации соответствующих структур в Коболе или ПЛ/1 из описаний таблиц в каталоге. Результаты DCLGEN сохраняются как раздел библиотечного набора данных, из которого они могут быть внесены в прикладную программу с помощью предложения EXEC SQL INCLUDE.
МЕНЮ ПОДГОТОВКИ ПРОГРАММ
Меню подготовки программ позволяет пользователю выполнять любую (или все) из указанных ниже функций:
— прекомпиляция
— компиляция или ассемблирование
— обращение к редактору связей
— обращение к генератору планов прикладных задач
— исполнение программы.
Все необходимые параметры для прекомпилятора, генератора планов и т. д. могут быть заданы с помощью меню. Заметим, что сама исходная программа должна уже к этому времени быть создана с помощью соответствующего текстового редактора, например редактора ISPF.
МЕНЮ RUN
Меню RUN, по существу, является как раз частью «исполнения» из множества всех меню, связанных с подготовкой программ. Оно позволяет пользователю исполнить предварительно подготовленную прикладную программу при условии, что эта программа, как уже упоминалось выше, является приложением TSO, а не IMS или CICS.
МЕНЮ SPUFI
SPUFI обозначает «процессор языка SQL, использующий входные данные из файла» (SQL Processor Using File Input). Как указывалось в разделе 14.1, SPUFI поддерживает интерактивное исполнение предложений SQL с терминала TSO. Основная идея заключается в том, что можно создать файл, содержащий одно или более предложений SQL, используя редактор ISPF, и затем исполнить этот файл предложений с помощью SPUFI, а далее снова использовать редактор ISPF для просмотра результатов исполнения этих предложений, которые будут записаны в другой файл. Отметим, следовательно, что SPUFI—это инструмент профессионала в области обработки данных, а не конечного пользователя. Соответствующим средством для конечного пользователя является QMF (см. главу 15). SPUFI предназначен, главным образом, для прикладных программистов, которые хотят проверить SQL-части их программ, или для администраторов, которые хотят исполнить предложения определения данных SQL, хотя QMF фактически может также использоваться для выполнения обеих этих функций.
Наряду с прочим меню SPUFI позволяет пользователю, а в некоторых случаях требует от него специфицировать:
— Файл, содержащий предложение (или предложения) SQL; этот файл должен уже существовать, хотя он может в настоящее время быть пустым.
— Указание, должен ли этот файл редактироваться с помощью редактора ISPF, прежде чем он будет готов к исполнению (обычно — ДА).
— Файл для получения результатов исполнения предложения (предложений) SQL; этот файл не обязательно должен уже существовать—если он не существует, SPUFI создаст его.
— Уровень изоляции — RR или CS (см. главу 11).
— Требуется ли «автоматическая фиксация» (обычно—ДА). Положительный ответ означает, что SPUFI будет автоматически выдавать команду COMMIT после исполнения входного файла, если не возникнут никакие ошибки, или команду ROLLBACK— в противном случае. Отрицательный ответ означает, что сам входной файл включает предложения COMMIT или, если это не так, то у пользователя после исполнения в интерактивном режиме будет запрашиваться, какую из команд—COMMIT или ROLLBACK—следует выдать.
Если входной файл содержит множество предложений SQL, SPUFI прекратит исполнение этих предложений, как только он встретит в одном из них ошибку. Выходной файл будет содержать последовательность результатов каждого из предложений, в том числе возвращаемые значения SQLCODE, с последующим резюме всего исполнения. Оно включает, в частности, указание, какая из команд—COMMIT или ROLLBACK—была выполнена. На рис. 14.4 показан пример выходного файла SPUFI.
ПРОСМОТР _ _ КДДЕЙТ. РЕЗУЛЬТАТ _ _ _ _ _ _ КОЛОНКИ 001 072
ВВОД КОМАНД = = = > ПРОСМОТР => СТРАНИЦАМИ
––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | –
SELECT * 00010000
FROM P 00020000
WHERE ВЕС
IN (12, 16, 17) 00030000
ORDER BY НОМЕР_ДЕТАЛИ; 00040000
––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | –
НOMEР_ДЕТАЛИ НАЗВАНИЕ ЦВЕТ ВЕС ГОРОД
P1 гайка красный 12 Лондон
P2 болт зеленый 17 Париж
P3 винт голубой 17 Рим
P5 кулачок голубой 12 Париж
––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | –
DSNEG10I ЧИСЛО ПОКАЗАННЫХ СТРОК 4.
DSNE616I ИСПОЛНЕНИЕ ПРЕДЛОЖЕНИЯ БЫЛО УСПЕШНЫМ,
SQLCODE 100.
––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | –
DSNE617I ВЫПОЛНЕНА КОМАНДА COMMIT, SQLCODE 0.
Рис. 14.4. Пример выходного файла SPUFI
МНОГОАСПЕКТНЫЙ ПРИМЕР
Выдать номер детали, вес в граммах, цвет и максимальный объем поставки для всех красных и голубых деталей, таких, что общий объем их поставки больше, чем 350, исключая при этом из общего объема все такие поставки, для которых количество меньше или равно 200 деталей. Результат упорядочить по убыванию номеров деталей в рамках возрастающих значений этого максимального объема поставки.
SELECT Р. НОМЕР_ДЕТАЛИ, 'вес в граммах = ', Р. ВЕС*454, Р. ЦВЕТ *
'максимальный объем поставки = ',
MAX (SP. КОЛИЧЕСТВО)
FROM P, SP
WHERE Р. НОМЕР_ДЕТАЛИ = SP. НОМЕР_ДЕТАЛИ
AND P. ЦВЕТ IN ('Красный', 'Голубой')
AND SP. КОЛИЧЕСТВО > 200
GROUP BY Р. НОМЕР_ДЕТАЛИ, Р. ВЕС, Р. ЦВЕТ
HAVING SUM (КОЛИЧЕСТВО) > 350
ORDER BY 6, P. НОМЕР_ДЕТАЛИ DESC;
Результат:
НОМЕР_ДЕТАЛИ
ЦВЕТ
Р1
Р5
РЗ
вес в граммах=
вес в граммах=
вес в граммах=
5448
5448
7718
Красный
Голубой
Голубой
максимальный объем поставки=
максимальный объем поставки=
максимальный объем поставки=
300
400
400
Пояснение. Фразы предложения SELECT применяются в таком порядке, в котором они записаны, за исключением самой фразы SELECT, которая применяется между фразами HAVING и ORDER BY, если они имеются. В данном примере, следовательно, можно представить себе, что результат строится следующим образом.
1. FROM. В результате обработки фразы FROM создается новая таблица, которая является декартовым произведением таблиц Р и SP.
2. WHERE. Из результата шага 1 исключаются все строки, не удовлетворяющие фразе WHERE. В данном примере исключаются строки, не удовлетворяющие предикату:
Р.НОМЕР-ДЕТАЛИ
=SP.HOMEP_ДETAЛИ AND Р.ЦВЕТ IN ('Красный', 'Голубой') AND SP.KOAH4ECTBO>200.
3. GROUP BY. Результат шага 2 группируется по значениям поля (полей), указанного во фразе GROUP BY. В нашем примере это поля Р.НОМЕР-ДЕТАЛИ, Р.ВЕС и Р.ЦВЕТ. Замечание. Теоретически в качестве поля группирования было бы достаточно использовать только Р.НОМЕР-ДЕТАЛИ, так как Р.ВЕС и Р.ЦВЕТ однозначно определяются номером детали. Однако система DB2 не осведомлена об этом последнем факте, и если Р.ВЕС и Р.ЦВЕТ будут опущены во фразе GROUP BY, возникнет условие ошибки, поскольку они включены
во фразу SELECT. Основная проблема состоит здесь в том, что система DB2 не поддерживает первичных ключей. См. Приложение А.
4. HAVING. Группы, не удовлетворяющие условию SUM (КОЛИЧЕСТВО) > 350, исключаются из результата, полученного на шаге 3.
5. SELECT. Каждая группа, полученная на шаге, 4, следующим образом генерирует единственную строку для результата. Во-первых, из группы выделяются номер детали, вес, цвет и максимальный объем поставки. Во-вторых, вес преобразуется в граммы. В-третьих, в соответствующие места полученной строки вставляются две строковые константы 'вес в граммах=' и 'максимальный объем поставки='.
6. ORDER BY. Результат шага 5 упорядочивается в соответствии со спецификацией фразы ORDER BY для получения окончательного результата.
Конечно, приведенный выше запрос весьма сложен, но представим себе, какую он выполняет работу. Обычная программа, например, в языке КОБОЛ, которая выполняет ту же самую работу, вполне могла бы составить девять страниц по сравнению только с девятью строками, приведенными выше. При этом работа, необходимая для того, чтобы эта программа стала действующей, значительно больше, чем это необходимо для формулировки приведенного варианта запроса на языке SQL. Большинство запросов на практике будет, конечно, во всяком случае значительно проще по сравнению с ним.
ОБЪЕДИНЕНИЕ
Объединением двух множеств называется множество всех элементов, принадлежащих какому-либо одному или обоим исходным множествам. Поскольку отношение—это множество (множество строк), можно построить объединение двух отношений. Результатом будет множество, состоящее из всех строк, входящих в какое-либо одно или в оба первоначальных отношения. Если, однако, этот результат сам по себе должен быть другим отношением, а не просто разнородной смесью строк, то два исходных отношения должны быть совместимыми по объединению. Нестрого говоря, строки в обоих отношениях должны быть одной и той же «формы». Что касается SQL, то две, таблицы совместимы по объединению (и к ним может быть применен оператор UNION) тогда и только тогда, когда:
а) они имеют одинаковое число столбцов, например, m;
б) для всех i (i= 1,2,..., m) i-й столбец первой таблицы и i-й столбец второй таблицы имеют в точности одинаковый тип данных;
— если тип данных—DECIMAL (p, q), то р должно быть;
одинаковым для обоих столбцов и q должно быть одинаковым для обоих столбцов;
— если тип данных—•
CHAR (n), то n должно быть. одинаковым для обоих столбцов;
— если тип данных—VARCHAR;(n), то n должно быть одинаковым для обоих столбцов;
— если NOT NULL специфицировано для какого-либо из этих столбцов, то такая же спецификаций должна быть для другого столбца.
ОБНОВЛЕНИЕ ЕДИНСТВЕННОЙ ЗАПИСИ
Изменить цвет детали Р2 на желтый, увеличить ее вес на 5 и установить значение города «неизвестен» (NULL).
UPDATE P
SET ЦВЕТ = 'Желтый',
ВЕС = ВЕС + 5,
ГОРОД = NULL
WHERE НОМЕР_ДЕТАЛИ =
'Р2';
Для каждой записи, которая должна быть обновлена (т. е. для каждой записи, которая удовлетворяет предикату WHERE, или для всех записей, если фраза WHERE опущена), ссылки во фразе SET на поля этой записи обозначают значения этих полей перед тем, как будет выполнено какое-либо присваивание в этой фразе SET.
