ОБНОВЛЕНИЕ КАТАЛОГА
Выше было показано, каким образом можно запрашивать сведения из каталога с помощью предложения
SELECT языка SQL. Однако нельзя обновлять каталог, используя предложения SQL UPDATE, DELETE и INSERT, и система DB2 будет отвергать любые попытки сделать это. Причина, конечно, заключается в том, что потенциально было бы очень опасно допустить такие операции: можно было бы слишком легко умышленно или неумышленно разрушить информацию в каталоге, так что DB2 не смогла бы больше правильно функционировать. Предположим, например, что было бы допустимо предложение:
DELETE
FROM SYSIBM. SYSCOLUMNS
WHERE TBNAME = 'S'
AND NAME = 'НОМЕР_ПОСТАВЩИКА';
Результатом его было бы удаление строки ('НОМЕР_ПОСТАВЩИКА','S','CHAR',. ..) из таблицы SYSCOLUMNS. Что касается системы, DB2, то столбец НОМЕР_ПОСТАВЩИКА в таблице S теперь больше бы не существовал, т. е. DB2 не располагала бы больше какими-либо знаниями об этом столбце. Поэтому попытки доступа к данным на основе значений в этом столбце, например:
SELECT ГОРОД
FROM S
WHERE НОМЕР_ПОСТАВЩИКА = 'S4';
были бы безуспешными. В таких случаях система будет выдавать некоторое сообщение об ошибке, например «неопределенный столбец». К более тяжелым последствиям, а возможно, и к потере работоспособности системы, могли бы привести при этом попытки обновления записей поставщиков. Например, вставка новой записи могла бы привести к тому, что номер поставщика будет приниматься за его фамилию, фамилия поставщика — за состояние и т. д.
По причинам такого рода операции UPDATE, DELETE и INSERT для таблиц в каталоге, как уже указывалось, не допускаются. Такие обновления осуществляются с помощью предложений определения данных (CREATE TABLE, CREATE INDEX и т. д.). Например, предложение CREATE TABLE для таблицы S приводит: а) к созданию записи для S в таблице SYSTABLES и б) к созданию в таблице SYSCOLUMNS множества из четырех записей, по одной для каждого из четырех столбцов таблицы S. Оно вызывает также и ряд других действий, которые, однако, не имеют отношения к нашему обсуждению здесь. Следовательно, предложение CREATE является в некотором смысле аналогом INSERT для каталога. Таким же образом, предложение DROP — аналог DELETE, a ALTER — аналог UPDATE.
Кстати, каталог, конечно, включает также и записи для самих таблиц каталога. Однако эти записи не создаются с помощью явных операций CREATE TABLE. Они создаются автоматически самой системой DB2, как часть процедуры установки системы. Они фактически «зашиты» в систему.
Хотя, как мы только что видели, обычные предложения обновления данных SQL не могут использоваться для обновления каталога, имеется одно предложение SQL, а именно, COMMENT, которое реализует некоторого рода функцию обновления каталога. Каждая из таблиц каталога SYSTABLES и SYSCOLUMNS включает столбец, не показанный на рис. 7.1, называемый REMARKS (комментарии), который может в каждой конкретной строке рассматриваемой таблицы содержать текстовую строку, описывающую объект, идентифицируемый остальной частью этой строки. Предложение COMMENT позволяет вводить такие описания в столбец REMARKS в эти две таблицы. В следующих примерах иллюстрируются два основных формата этого предложения. Первый пример:
COMMENT ON TABLES IS
'Каждая строка представляет одного поставщика';
Специфицированная в этом примере текстовая строка запоминается в поле REMARKS таблицы SYSTABLES в строке для таблицы S, замещая значение, ранее запомненное в этой позиции. Заметим, что таблица, указываемая фразой «TABLE имя-таблицы» в предложении COMMENT, может быть либо базовой таблицей, либо представлением. Другой пример:
COMMENT ON COLUMN Р.ГОРОД IS
'Местоположение (единственного) склада, где хранится эта деталь’;
Специфицированная строка запоминается в поле REMARKS таблицы SYSCOLUMNS в строке для столбца Р.ГОРОД, замещая значение, ранее запомненное в этой позиции. Вообще говоря, специфицированный столбец может быть столбцом либо базовой таблицы, либо представления.
Выборка комментариев может осуществляться с помощью обычного предложения SELECT языка SQL.
ОБНОВЛЕНИЕ МНОЖЕСТВА ЗАПИСЕЙ
Удвоить состояние всех поставщиков, находящихся в Лондоне.
UPDATE S
SET СОСТОЯНИЕ = 2*СОСТОЯНИЕ
WHERE ГОРОД = 'Лондон';
Установить нулевой объем поставок для всех поставщиков, находящихся в Лондоне (пример 6.2.3):
SP
НОМЕР_
ПОСТАВЩИКА
КОЛИЧЕСТВО
S
НОМЕР_
ПОСТАВЩИКА
ГОРОД
_SX
U.O.
_SX
Лондон
ОБНОВЛЕНИЕ НЕСКОЛЬКИХ ТАБЛИЦ
Изменить номер поставщика S2 на S9.
UPDATE S
SET НОМЕР_ПОСТАВЩИКА = 'S9'
WHERE НОМЕР_ПОСТАВЩИКА = 'S2';
UPDATE SP
SET НОМЕР_ПОСТАВЩИКА = 'S9'
WHERE НОМЕР_ПОСТАВЩИКА = 'S2';
Невозможно обновить более одной таблицы в единственном запросе. Иными словами, в предложении UPDATE должна специфицироваться в точности одна таблица. Поэтому в данном примере мы сталкиваемся со следующей проблемой целостности (точнее, с проблемой целостности по ссылкам): база данных становится противоречивой после выполнения первого предложения UPDATE — она включает теперь некоторые поставки, для которых не имеется соответствующей записи о поставщике, и остается в таком состоянии до тех пор, пока не будет выполнено второе предложение UPDATE. Изменение порядка предложений UPDATE, конечно, не решает эту проблему. Поэтому важно обеспечить выполнение обоих
этих предложений, а не только одного. Этот вопрос о поддержании целостности в условиях, когда требуется множество обновлений, детально обсуждается в главе 11. Кроме того, проблема целостности по ссылкам, в частности, подробно описана в Приложении А, а использованный в системе DB2 подход к ее решению представлен в Приложении В.
ОБНОВЛЕНИЕ ОДНОЙ ЗАПИСИ
Изменить цвет детали Р2 на желтый, увеличить ее вес на 5, а для города установить неопределенное значение (пример 6.2.1):
Р
НОМЕР_ДЕТАЛИ
НАЗВАНИЕ
ЦВЕТ
ВЕС
ВЕС
ГОРОД
Р2
U. желтый
_WT
U._WT+5
U.NULL
ОБНОВЛЕНИЕ С ПОДЗАПРОСОМ
Установить объем поставок равным нулю для всех поставщиков из Лондона.
UPDATE SP
SET КОЛИЧЕСТВО = О
WHERE 'Лондон' =
(SELECT ГОРОД FROM S
WHERE S. НОМЕР_ПОСТАВЩИКА =
SP. НОМЕР_ПОСТАВЩИКА);
ОБРАБОТКА ПРЕДЛОЖЕНИИ, ОТЛИЧНЫХ ОТ SELECT
Два основных предложения динамического SQL — PREPARE (подготовить) и EXECUTE (выполнить). Их использование проиллюстрируем следующим (правильным, но нереалистичным) примером на языке ПЛ/1:
DCL ИСХОДНЫЙ_SQL CHAR(256) VARYING;
EXEC SQL DECLARE ОБЪЕКТНЫЙ_SQL STATEMENT;
ИСХОДНЫЙ_SQL = 'DELETE FROM SP WHERE
КОЛИЧЕСТВО < 100';
EXEC SQL PREPARE ОБЪЕКТНЫЙ_SQL FROM : ИСХОДНЫЙ-SQL;
EXEC SQL EXECUTE ОБЪЕКТНЫЙ_SQL;
Пояснение. Здесь ИСХОДНЫЙ-SQL это переменная ПЛ/1 типа строки символов переменной длины, в которой программа построит некоторое предложение SQL в исходном формате, т. е. представление его в виде строки символов. Напротив, ОБЪЕКТНЫЙ_SQL это переменная SQL, а не ПЛ/1, которая будет содержать для предложения SQL, заданного в исходном формате в строке ИСХОДНЫИ_SQL, его запись в объектном формате, т. е. представление этого предложения в машинном коде. Имена ИСХОДНЫЙ_SQL и ОБЪЕКТНЫИ_SQL выбраны произвольно. Оператор присваивания «ИСХОДНЫЙ_SQL =...;» присваивает переменной ИСХОДНЫЙ_SQL запись в исходном формате предложения DELETE языка SQL. (Как уже отмечалось в разделе 12.1, на практике процесс построения такого исходного предложения является, вероятно, несколько более сложным, требует ввода нескольких команд с терминала и их анализа.) Далее предложение PREPARE осуществляет прекомпиляцию и связывание этого исходного предложения и на этой основе продуцирует некоторый вариант программы в коде машины, который она запоминает как значение переменной ОБЪЕКТНЫЙ_SQL. Наконец, предложение EXECUTE исполняет этот вариант программы и, таким образом, приводит (в данном примере) к фактическому исполнению операции DELETE. Информация обратной связи, порождаемая этой операцией, будет, как обычно, возвращаться в область связи SQLCA.
Отметим, между прочим, что поскольку имя предложения ОБЪЕКТНЫЙ_SQL обозначает переменную SQL, а не ПЛ/1, оно не
имеет префикса — двоеточия в предложениях PREPARE и EXECUTE.
Предложение PREPARE
Предложение PREPARE имеет следующий синтаксис:
EXEC SQL PREPARE имя — предложения FROM строковое — выражение;
Здесь «строковое — выражение» это выражение включающего языка, которое определяет представление некоторого предложения SQL в форме строки символов, а «имя—предложения»—имя переменной SQL, которая будет использоваться для того, чтобы содержать подготовленный операцией PREPARE, т. е. прекомпилированный и связанный вариант этого предложения языка SQL. Предложение, которое обрабатывается с помощью PREPARE, должно быть только одним из следующих:
UPDATE (включая форму CURRENT)
DELETE (включая форму CURRENT)
INSERT
SELECT
CREATE
DROP
ALTER
COMMENT
GRANT
REVOKE
COMMIT
ROLLBACK
LOCK
Исходный формат обрабатываемого PREPARE предложения не должен включать ни фразы EXEC SQL, ни признака конца предложения.
Предложение EXECUTE
Предложение EXECUTE имеет следующий синтаксис:
ЕХЕС SQL EXECUTE имя — предложения [USING аргументы];
Исполняется предложение
SQL, сформированное с помощью PREPARE в переменной SQL, которая идентифицируется «именем—предложения». Фраза USING поясняется в следующем параграфе «Аргументы и параметры».
Аргументы и параметры
Предложения SQL, которые должны обрабатываться с помощью PREPARE, не могут включать каких-либо обращений к переменным включающего языка. Они могут, однако, содержать параметры, обозначаемые в исходном формате предложения вопросительными знаками. Параметры могут использоваться всюду, где допускаются переменные включающего языка.
Например:
ИСХОДНЫЙ_SQL = 'DELETE
FROM SP
WHERE КОЛИЧЕСТВО > ?
AND КОЛИЧЕСТВО < ?';
ЕХЕС SQL PREPARE ОБЪЕКТНЫЙ _ SQL FROM :ИСХОДНЫЙ_SQL;
Аргументы для замещения параметров специфицируются с помощью фразы USING предложения EXECUTE, обеспечивающего исполнение сформированного предложения. Например:
ЕХЕС SQL EXECUTE ОБЪЕКТНЫЙ_SQL USING
: НИЖНЕЕ_ЗНАЧЕНИЕ, : ВЕРХНЕЕ_ЗНАЧЕНИЕ;
Фактически исполняемое в данном примере предложение эквивалентно обычному предложению встроенного
SQL:
ЕХЕС SQL DELETE FROM SP WHERE
КОЛИЧЕСТВО > : НИЖНЕЕ_ЗНАЧЕНИЕ
AND КОЛИЧЕСТВО < :ВЕРХНЕЕ_ЗНАЧЕНИЕ;
В общем случае фраза
USING предложения EXECUTE имеет формат:
USING аргумент [, аргумент] . . .
где каждый «аргумент» в свою очередь имеет формат:
: переменная — включающего — языка [: переменная — включающего — языка]
точно такой же, как и у ссылки на целевую переменную во фразе INTO. Необязательная вторая переменная включающего языка представляет собой индикаторную переменную неопределенного значения. При этом n-й аргумент в списке аргументов соответствует n-му параметру, т. е. n-му вопросительному знаку, в исходном формате обрабатываемого PREPARE предложения,
ОБРАБОТКА ПРЕДЛОЖЕНИЙ SELECT
Как указывалось ранее, описанная в общих чертах в разделе 12.2 процедура пригодна для динамической подготовки и исполнения всех предложений SQL (точнее, всех предложений SQL, которые могут правильно обрабатываться с помощью PREPARE), за исключением SELECT. Причина такого отличия SELECT состоит в том, что оно возвращает программе данные, в то время как другие предложения возвращают только информацию обратной связи в область связи SQLCA.
Использующей SELECT программе необходимо кое-что знать о значениях тех данных, выборка которых должна производиться, поскольку в ней должно быть специфицировано множество принимающих эти значения целевых переменных. Необходимо знать но крайней мере сколько будет значений в каждой строке результата, а также каковы типы данных и длины этих значений. Если данное предложение SELECT генерируется динамически, программе обычно невозможно заранее «знать» эту информацию. Поэтому она должна получать эту информацию динамически, используя другое предложение динамического SQL, называемое DESCRIBE (описать). Реализуемая такой программой процедура в общих чертах может быть охарактеризована следующим образом.
1. Она формирует и обрабатывает с помощью PREPARE предложение SELECT без фразы INTO. (Обрабатываемое с помощью PREPARE предложение SELECT не должно включать фразу INTO.)
2. Используя DESCRIBE, она запрашивает систему о результатах, которых можно ожидать при исполнении данного предложения SELECT. Описание этих результатов возвращается в область, называемую областью дескрипторов SQL (SQLDA).
3. Далее, в соответствии с только что полученной с помощью DESCRIBE информацией распределяется память для множества целевых переменных, предназначенных для получения результатов. Адреса этих целевых переменных также помещаются в SQLDA.
4. Наконец, с помощью курсора последовательно по одной запрашиваются строки результата. Для этого используются предложения OPEN, FETCH и CLOSE. Если это требуется, в программе можно также использовать для этих строк предложения UPDATE CURRENT (обновить текущую) и DELETE CURRENT (удалить текущую). Эти предложения однако должны, вероятно, реализовываться с помощью PREPARE и EXECUTE.
Для того чтобы описанные идеи стали несколько более конкретными, приведем простой пример, показывающий, как могла бы выглядеть в общих чертах такая программа. Этот пример написан на языке ПЛ/1. Отметим, что он должен быть написан либо на ПЛ/1, либо на языке Ассемблера, поскольку должна иметься возможность динамического распределения памяти. Поэтому интерактивное приложение, осуществляющее выборку данных, должно быть написано на одном из двух указанных языков. Вместе с тем интерактивное приложение, использующее лишь средства, описанные в разделе 12.2, может быть также написано, если это требуется, на Коболе или Фортране. Перейдем теперь к примеру.
DCL ИСХОДНЫЙ_SQL CHAR(256) VARYING;
EXEC SQL DECLARE ОБЪЕКТНЫЙ_SQL STATEMENT;
EXEC SQL DECLARE X CURSOR FOR ОБЪЕКТНЫЙ_SQL;
EXEC SQL INCLUDE SQLDA;
/* Пусть максимальное число ожидаемых значений, подлежащих выборке, равно N */
SQLSIZE = N;
ALLOCATE SQLDA;
ИСХОДНЫЙ_SQL = 'SELECT * FROM SP WHERE
КОЛИЧЕСТВО > 100';
EXEC SQL PREPARE ОБЪЕКТНЫЙ_SQL FROM :ИСХОДНЫЙ_SQL;
EXEC SQL DESCRIBE ОБЪЕКТНЫЙ_SQL INTO SQLDA;
/* Теперь наряду с прочей информацией SQLDA содержит следующее: */
/* — в SQLN — фактическое число подлежащих выборке значений */
/* — в SQLVAR(i) — тип данных и длину i-го значения. */
/* Используя возвращаемую DESCRIBE информацию, программа может */
/* теперь распределить память для каждого значения, выборка */
/* которого должна быть осуществлена, и поместить адрес i-й */
/* выделенной области в
SQLVAR(i). Тогда: */
EXEC SQL OPEN X;
DO WHILE (еще — поступают— записи);
EXEC SQL FETCH X
USING DESCRIPTOR SQLDA;
. . . .
END;
EXEC SQL CLOSE X;
Пояснение. Здесь ИСХОДНЫИ_SQL и ОБЪЕКТНЫЙ_SQL имеют в основном такой же смысл, как и ранее: ИСХОДНЫЙ_SQL будет содержать предложение SQL в исходном формате (в данном примере, конечно, предложение SELECT), а ОБЪЕКТНЫЙ_SQL — это же предложение в соответствующем объектном формате. X — курсор для этого SELECT. Обратите внимание, что он описывается предложением DECLARE CURSOR нового формата:
EXEC SQL DECLARE имя — курсора CURSOR FOR имя — предложения;
Объявление области дескрипторов SQL включается в программу с помощью предложения:
EXEC SQL INCLUDE SQLDA;
Это предложение генерирует объявление структуры SQLDA в языке ПЛ/1, а также объявление числовой переменной SQLSIZE. Программа должна установить SQLSIZE, равное N, где N — верхняя граница числа значений, которые должны быть выбраны в каждой строке предложением SELECT, выделить память для SQLDA. Объем выделяемой памяти будет функцией значения SQLSIZE.
Далее, в строке ИСХОДНЫЙ_SQL формируется требуемое предложение SELECT в исходном формате, которое затем обрабатывается с помощью PREPARE. В результате будет получен в ОБЪЕКТНЫИ_SQL соответствующий его объектный формат. После этого программа выдает команду DESCRIBE в связи с переменной ОБЪЕКТНЫИ_SQL с тем, чтобы получить описание значений, ожидаемых в каждой строке результата исполнения этого предложения SELECT. Такое описание состоит из двух частей:
а) фактическое число значений, подлежащих выборке, указывается в поле SQLN структуры SQLDA;
б) тип данных и длина каждого такого значения указываются в массиве SQLVAR структуры SQLDA.
Используя это описание, программа может теперь распределить помять для каждого из этих значений. Далее она помещает адреса выделенных областей памяти в SQLDA, а точнее — в массив SQLVAR.
Наконец, для выборки фактических данных программа использует предложения OPEN, FETCH и CLOSE в связи с курсором X. Следует обратить внимание, что при этом используется новый формат предложения FETCH. Вместо фразы INTO оно включает фразу USING DESCRIPTOR, а структура, указанная в этой фразе (обычно SQLDA), в свою очередь идентифицирует целевые переменные для подлежащих выборке значений.
С помощью PREPARE можно также обрабатывать предложения SELECT, которые содержат параметры, указываемые вопросительным знаком. Например:
ИСХОДНЫЙ_SQL = 'SELECT *
FROM SP
WHERE КОЛИЧЕСТВО > ?
AND КОЛИЧЕСТВО < ?';
ЕXEC SQL PREPARE ОБЪЕКТНЫЙ_SQL FROM :ИСХОДНЫЙ_SQL;
Аргументы специфицируются в соответствующем предложении OPEN. Например:
ЕXEC SQL OPEN X USING НИЖНЕЕ_ЗНАЧЕНИЕ, :ВЕРХНЕЕ_ЗНАЧЕНИЕ;
К SELECT не применяется предложение EXECUTE. Если выполняемое предложение—SELECT, функция EXECUTE выполняется предложением OPEN.
ОБСУЖДЕНИЕ
Возможность исполнения предложений определения данных в любое время делает систему DB2 очень гибкой. В более старых (нереляционных) системах добавление нового типа объекта, например нового типа записей, нового индекса или нового поля, представляет собой операцию, выполнить которую не так легко. Оно требует обычно приведения всей системы в состояние остановки, разгрузки базы данных, изменения и перекомпиляции определения базы данных и, наконец, перезагрузки базы данных к соответствии с этим измененным определением. В такой системе весьма желательно выполнить процесс определения данных раз и навсегда, прежде чем начать их загрузку и использование. Это означает, что: а) для того чтобы система была установлена и стала действующей, могут потребоваться в буквальном смысле месяцы или даже годы работы высококвалифицированных специалистов и б) после того как система стала функционировать, может быть трудно и дорого, а может быть и невозможно, исправить ранние ошибки проектирования.
Напротив, в DB2 можно создать и загрузить совсем немного базовых таблиц, а затем немедленно начать использовать эти данные. Позднее постепенно могут добавляться новые базовые таблицы и новые поля, не оказывая какого-либо влияния на существующих пользователей базы данных. Можно также проводить эксперименты с результатами использования или отказа от каких-либо конкретных индексов, опять-таки совсем не оказывая влияния на существующих пользователей, не считая, конечно, производительности. Более того, как будет показано в главе 8, при определенных условиях можно даже произвести реструктуризацию базы данных, например перенести некоторое поле из одной таблицы в другую, и все же не затронуть логики существующих программ. Короче говоря, нет необходимости в осуществлении полного процесса проектирования базы данных, прежде чем с помощью системы можно будет сделать какую-либо полезную работу. Нет также и необходимости в том, чтобы получать все прямо с первого раза. Система DB2 снисходительна.
Предостережение.
Не следует полагать, однако, что снисходительность системы означает отсутствие необходимости проектирования базы данных. Конечно, проектирование базы данных все же необходимо. Однако:
— не обязательно выполнять его полностью единовременно;
— не требуется, чтобы оно было совершенным с первого раза;
— можно взяться за логическое и физическое проектирование раздельно;
— если изменяются потребности, то проект может быть также изменен сравнительно безболезненно;
— в системе, подобной DB2, становятся осуществимыми многие новые приложения, типичным образцом которых являются небольшие прикладные задачи, требующие, например, базу данных сотрудников или отделов. Подобные приложения просто никогда не рассматривались в обстановке более старых (нереляционных) систем, поскольку эти системы были слишком сложны для того, чтобы такие приложения имели смысл с экономической точки зрения.
ОГРАНИЧЕННАЯ ВЫБОРКА
Выдать номера поставщиков, которые находятся в Париже и имеют состояние большее, чем 20:
SELECT НОМЕР_ПОСТАВЩИКА
FROM S
WHERE ГОРОД ='Париж
AND СОСТОЯНИЕ > 20;
Результат:
НОМЕР_ПОСТАВЩИКА
S3
Условие, или предикат,
следующий за ключевым словом WHERE, может включать операторы сравнения =, -ù = (неравно), >,ù >, > =,
<, ù
< и <=, булевские операторы AND (и), OR (или) и NOT (нет), а скобки указывают требуемый порядок вычислений. В таком предикате числа сравниваются алгебраически — отрицательные числа считаются меньшими, чем положительные, независимо от их абсолютной величины. Строки литер сравниваются в соответствии с их представлением в коде EBCDIC. Если нужно сравнить две строки литер, имеющих разные длины, более короткая строка концептуально дополняется справа пробелами для того, чтобы обе строки имели одинаковую длину перед тем, как будет осуществляться их сравнение.
ОПЕРАЦИИ, НЕ ТРЕБУЮЩИЕ ИСПОЛЬЗОВАНИЯ КУРСОРОВ
Следующие предложения манипулирования данными не требуют использования курсоров:
— «единичное SELECT»
— UPDATE, за исключением формы CURRENT (см. раздел 10.4)
— DELETE, опять-таки за исключением формы CURRENT (см. раздел 10.4)
— INSERT.
Приведем поочередно примеры каждого из этих предложений.
ОПЕРАЦИИ ОБНОВЛЕНИЯ
В главе 6 уже указывалось, что не все представления являются обновляемыми.
Теперь мы в состоянии высказать более сильное утверждение. Рассмотрим сначала два представления ХОРОШИЕ_ПОСТАВЩИКИ и ПАРЫ_ГОРОДОВ, определенные ранее в этой главе. Для удобства повторим здесь их определения:
CREATE VIEW
ХОРОШИЕ_
ПОСТАВЩИКИ
CREATE VIEW
ПАРЫ_ГОРОДОВ (ГОРОД_ПОСТАВЩИКА,
ГОРОД_ДЕТАЛИ)
AS SELECT
НОМЕР_ПОСТАВЩИКА, СОСТОЯНИЕ, ГОРОД
AS SELECT
ГОРОД_ПОСТАВЩИКА, ГОРОД_ДЕТАЛИ
FROM
S
FROM
S, SP, Р
WHERE
СОСТОЯНИЕ >15;
WHERE
S НОМЕР_ПОСТАВЩИКА=SP. НОМЕР_ПОСТАВЩИКА
AND
SP. НОМЕР_ДЕТАЛИ = Р. НОМЕР_ДЕТАЛИ);
Из этих двух представлений ХОРОШИЕ_ПОСТАВЩИКИ обновляемо, а ПАРЫ_ГОРОДОВ нет. Поучительно рассмотреть, почему это так. В случае представления ХОРОШИЕ_ПОСТАВЩИКИ можно:
а) вставить (операция
INSERT) новую строку в представление, например строку ('S6', 40, 'Рим'), фактически вставляя соответствующую строку ('S6', NULL, 40, 'Рим') в лежащую в основе базовую таблицу;
б) удалить (операция
DELETE) существующую строку из представления, например строку ('S1', 20, 'Лондон'), фактически удаляя соответствующую строку ('S1', 'Смит', 20, 'Лондон') из лежащей в основе базовой таблицы;
в) обновить (операция
UPDATE) какое-либо поле в существующей строке представления, например изменить город (Лондон) для поставщика S1 на Рим, фактически осуществляя то же самое изменение в соответствующем поле лежащей в основе базовой таблицы.
Будем называть такое представление, как ХОРОШИЕ_ПОСТАВЩИКИ, которое продуцируется из единственной базовой таблицы путем простого исключения некоторых строк и некоторых столбцов этой базовой таблицы, представлением-подмножеством строк и столбцов.
Такие представления по своей природе обновляемы, как показывает обсуждение предшествующего примера.
Рассмотрим теперь представление ПАРЫ_ГОРОДОВ, которое, конечно, не является представлением-подмножеством строк и столбцов. Как было показано ранее, одна из строк этого представления —('Лондон', 'Лондон'). Предположим, что некоторый пользователь имел бы возможность заменить эту строку, например, на ('Рим', 'Осло'). Что означало бы такое обновление? По-видимому, некоторый поставщик — но мы не знаем, какой именно, поскольку мы отбросили эту информацию при конструировании представления — переместился из Лондона в Рим. Подобным же образом местом хранения некоторой детали — но мы не знаем, какой именно, поскольку мы опять-таки исключили эту информацию, когда конструировалось представление,— был Лондон, а стал город Осло. Поскольку неизвестно, какой поставщик и какая деталь затрагиваются, нет способа, позволяющего спуститься к лежащим в основе базовым таблицам и сделать там соответствующие изменения. Иными словами, первоначальное UPDATE является внутренне неподдерживаемой операцией. Можно привести аналогичные аргументы для того, чтобы показать, что INSERT и DELETE — также внутренне неподдерживаемые операции над этим представлением.
Мы видели, таким образом, что некоторые представления по своей природе обновляемы, в то время как другие таковыми не являются. Обратите здесь внимание на слова «по своей природе». Дело заключается не просто в том, что некоторая система не способна поддерживать определенные обновления, в то время как другие системы могут это делать. Никакая система не может непротиворечивым образом поддерживать без дополнительной помощи обновления для такого представления, как ПАРЫ_ГОРОДОВ. «Без дополнительной помощи» означает здесь «без помощи какого-либо человека — пользователя». Вследствие этого факта можно классифицировать представления в соответствии с приведенной на рис. 8.2 диаграммой Венна.
На основе этой диаграммы заметим для строгости, что все представления-подмножества строк и столбцов (например, ХОРОШИЕ_ПОСТАВЩИКИ) теоретически обновляемы, но что не все теоретически обновляемые представления — это представления-подмножества строк и столбцов. Иными словами, существуют некоторые представления, которые теоретически обновляемы, но не являются представлениями-подмножествами строк и столбцов.
Хотя нам известно, что такие представления существуют, трудность заключается в том, что точно неизвестно, какие они. Для точного установления характеристик таких представлений требуется провести исследования. Поэтому для целей этой книги важным моментом является следующее:
В системе DB2 могут обновляться только представления-подмножества строк и столбцов.
На самом деле, это утверждение несколько упрощает ситуацию. Позднее мы уточним его. Между прочим, DB2 — не единственная в этом отношении система. Насколько известно автору, в настоящее время никакая реляционная система не поддерживает операций обновления над представлениями, не являющимися подмножествами строк и столбцов.
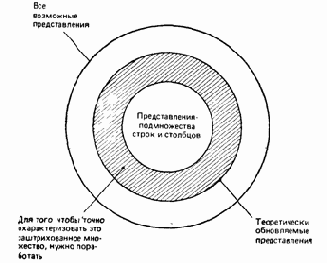
Рис. 8.2. Классификация представлений
Тот факт, что не все представления обновляемы, часто выражается так: «нельзя обновить соединение». Однако это утверждение не только не дает точной характеристики ситуации, но и не отражает в действительности существа проблемы. Существуют некоторые представления, которые не являются соединениями, но не обновляемы. Кроме того, существуют некоторые представления, которые являются соединениями, но (теоретически) обновляемы, хотя они и не обновляемы в системе DB2. Но, без сомнения, соединение представляет собой «интересный случай» в том смысле, что было бы очень удобно иметь возможность обновлять представление, в определении которого используется соединение. Из предыдущего обсуждения должно быть ясно, что такие представления действительно могут быть обновляемыми в какой-либо будущей системе. Но здесь мы имеем дело лишь с тем, что в настоящее время допускается в системе DB2. Постараемся теперь уяснить, что это такое.
В системе DB2 представление, допускающее обновление, должно быть производным от единственной базовой таблицы. Более того:
а) Если поле данного представления продуцируется из арифметического выражения или константы, то над этим полем не допускаются операции INSERT и UPDATE. Однако операции DELETE допускаются.
б) Если какое-либо поле представления продуцируется из стандартной функции, то данное представление необновляемо.
в) Если в определении представления используется фраза GROUP BY, то данное представление необновляемо.
г) Если в определении представления используется спецификация DISTINCT, то данное представление необновляемо.
д) Если определение представления включает вложенный подзапрос и во фразе FROM подзапроса указывается базовая таблица, над которой определяется данное представление, то это представление необновляемо.
е) Если во фразе FROM в определении представления указано несколько таблиц, то это представление необновляемо. Кроме того, конечно, если данное представление определено над необновляемым представлением, то оно само также необновляемо.
Убедимся в разумности этих ограничений. Рассмотрим поочередно каждый из случаев а)—е). Для каждого из них будет приведен пример представления, иллюстрирующий соответствующее ограничение.
Случай а). Поле представления, продуцируемое с помощью арифметического выражения или константы.
CREATE VIEW ВЕС_В_ГРАММАХ (НОМЕР_ДЕТАЛИ, ВЕС)
AS SELECT НОМЕР_ДЕТАЛИ, ВЕС * 454
FROM P;
Если предположить, что таблица Р имеет вид, показанный на рис. 1.3 (глава 1), то через это представление видимо следующее множество строк:
НОМЕР_ДЕТАЛИ
ВЕС
Р1
Р2
РЗ
Р4
Р5
Р6
5448
7718
7718
6356
5448
8626
Должно быть ясно, что ВЕС_В_ГРАММАХ не может поддерживать операции INSERT, а также операции UPDATE над полем ВЕС. Каждая из этих операций потребовала бы, чтобы система была способна преобразовывать вес в граммах обратно в фунты без каких-либо инструкций относительно того, как выполнять такое преобразование. С другой стороны, операции DELETE могут быть поддержаны, например, таким образом, что удаление строки для детали Р1 из данного представления может осуществляться путем удаления строки для детали Р1 из лежащей в основе базовой таблицы. Могут быть поддержаны также операции UPDATE над полем НОМЕР_ДЕТАЛИ. Такие операции требуют просто соответствующих операций UPDATE над полем НОМЕР_ДЕТАЛИ этой базовой таблицы. Аналогичные соображения относятся к представлению, включающему поле, которое продуцируется из константы, а не из арифметического выражения.
Случай б). Поле представления, продуцируемое с помощью стандартной функции.
CREATE VIEW TQ (ОБЩЕЕ_КОЛИЧЕСТВО)
AS SELECT SUM (КОЛИЧЕСТВО)
FROM SP;
В нашем случае имеем:
ОБЩЕЕ_КОЛИЧЕСТВО
3100
Вероятно, очевидно, что никакие операции UPDATE, INSERT, DELETE не имеют какого-либо смысла для этого представления.
Случай в).
Представление, в определении которого используется фраза GROUP BY.
CREATE VIEW P Q (НОМЕР_ДЕТАЛИ, ОБЩЕЕ_КОЛИЧЕСТВО)
AS SELECT НОМЕР_ДЕТАЛИ, SUM (КОЛИЧЕСТВО)
FROM SP
GROUP BY НОМЕР_ДЕТАЛИ;
В данном случае имеем:
НОМЕР_ДЕТАЛИ
ОБЩЕЕ_КОЛИЧЕСТВО
Р1
Р2
РЗ
Р4
Р5
Р6
600
1000
400
500
500
100
Очевидно, что представление PQ не может поддерживать ни операций INSERT, ни операций UPDATE над полем ОБЩЕЕ_КОЛИЧЕСТВО. Операции DELETE и UPDATE над полем НОМЕР_ДЕТАЛИ можно было бы определить как удаление или обновление соответствующих строк в таблице SP. Например, операцию
DELETE
FROM PQ
WHERE НОМЕР_ДЕТАЛИ = 'Р1’;
можно было бы определить как переводимую в
DELETE
FROM SP
WHERE НОМЕР_ДЕТАЛИ = 'Р1’;
но такие операции можно было бы во всяком случае в равной степени хорошо выразить и в терминах таблицы SP. По меньшей мере, можно утверждать, что запрашивающий такие операции пользователь должен, вероятно, интересоваться, какие точно реальные записи затрагиваются этими операциями.
Случай г).
Представление, определенное со спецификацией DISTINCT:
CREATE VIEW CC
AS SELECT DISTINCT ЦВЕТ, ГОРОД
FROM P;
Имеем в этом случае (в скобках указаны соответствующие номера деталей):
ЦВЕТ
ГОРОД
Красный
Зеленый
Голубой
Голубой
Лондон
Париж
Рим
Париж
(Р1, P4, P6)
(Р2)
(РЗ)
(Р5)
И снова должно быть ясно, что представление CC не может поддерживать операций INSERT. Такие операции над лежащей в основе таблицей Р требуют, чтобы пользователь специфицировал значение поля НОМЕР_ДЕТАЛИ, поскольку для него специфицировано NOT NULL. Как и в случае в), операции DELETE и UPDATE теоретически могут быть здесь определены (как удаления или обновления всех соответствующих строк в таблице Р), но замечания относительно этой возможности, высказанные для случая в), справедливы здесь, возможно, даже в большей степени.
Рассмотрим другой пример для случая г):
CREATE VIEW PC
AS SELECT DISTINCT НОМЕР_ДЕТАЛИ, ЦВЕТ
FROM P;
Имеем:
НОМЕР_ДЕТАЛИ
ЦВЕТ
P1
Р2
РЗ
P4
Р5
P6
Красный
Зеленый
Голубой
Красный
Голубой
Красный
Это — пример представления, которое, очевидно, является теоретически обновляемым. Ясно, что все возможные операции INSERT, DELETE и UPDATE над этим представлением вполне определены. Фактически это представление является на самом деле представлением-подмножеством строк и столбцов. Однако система DB2 не осведомлена об этом факте. Другими словами, система DB2 не осведомлена о том, что спецификация DISTINCT является здесь фактически излишней. Вместо этого она просто предполагает, что присутствие DISTINCT означает возможность продуцирования любой заданной строки представления из множества строк базовой таблицы, как в предыдущем примере, и по этой причине не считает данное представление обновляемым.
Случай д).
Представление, в котором используется подзапрос над той же самой таблицей:
CREATE VIEW ПОСТАВЩИК_НИЖЕ_СРЕДНЕГО
AS SELECT НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, СОСТОЯНИЕ,
ГОРОД
FROM S
WHERE СОСТОЯНИЕ <
(SELECT AVG (СОСТОЯНИЕ)
FROM S);
Операции UPDATE и DELETE над представлением ПОСТАВЩИК_НИЖЕ_СРЕДНЕГО незаконны, поскольку они нарушали бы ограничения, налагаемые на такие операции, указанные в разделе 6.5. Как и операции INSERT, они могли бы в принципе поддерживаться, но давали бы непредсказуемый результат.
Случай е).
Представление, определенное на множестве таблиц.
CREATE VIEW ПАРЫ_ГОРОДОВ (ГОРОД_ПОСТАВЩИКА,
ГОРОД_ДЕТАЛИ);
AS SELECT S. ГОРОД, P. ГОРОД
FROM S. SP, P
WHERE S. НОМЕР_ПОСТАВЩИКА = SP.HOMEP_ПОСТАВЩИКА
AND SP.HOMEP_ДЕТАЛИ = Р.НОМЕР_ДЕТАЛИ;
Это представление необновляемо по тем причинам, которые уже были достаточно подробно обсуждены. Рассмотрим, однако, следующий пример:
CREATE VIEW ПОСТАВЩИКИ_Р2
AS SELECT DISTINCT S. *
FROM S, SP
WHERE S. НОМЕР_ПОСТАВЩИКА =
SP. НОМЕР_ПОСТАВЩИКА
AND SP НОМЕР_ДЕТАЛИ = 'P2';
Это представление также необновляемо в системе DB2, даже несмотря на то, что оно является фактически представлением-подмножеством строк и столбцов. Здесь снова DB2 не имеет возможности распознать этот факт. В этом примере интересно отметить, что может быть определено семантически эквивалентное обновляемое представление, а именно:
CREATE VIEW ПОСТАВЩИКИ_Р2
AS SELECT S. *
FROM S
WHERE НОМЕР_ПОСТАВЩИКА IN'
(SELECT НОМЕР_ПОСТАВЩИКА
FROM SP
WHERE НОМЕР_ДЕТАЛИ = 'P2');
В этом определении не нарушается правило «несколько таблиц во фразе FROM» (см. выше правило е).
Вернемся, наконец, снова к представлению ХОРОШИЕ_ПОСТАВЩИКИ с тем, чтобы обсудить ряд оставшихся вопросов. Напомним определение этого представления:
CREATE VIEW ХОРОШИЕ_ПОСТАВЩИКИ
AS SELECT НОМЕР_ПОСТАВЩИКА, СОСТОЯНИЕ, ГОРОД
FROM S
WHERE СОСТОЯНИЕ > 15;
Это представление является представлением-подмножеством строк и столбцов и, следовательно, обновляемо. Но нужно отметить следующее:
а) Успешно выполненная операция INSERT для представления ХОРОШИЕ_ПОСТАВЩИКИ должна будет сгенерировать неопределенное значение для опущенного поля ФАМИЛИЯ, как уже указывалось в начале этого раздела. Конечно, для поля ФАМИЛИЯ не должен был специфицироваться вариант NOT NULL (При создании таблицы S.— Примеч. пер.), если требуется выполнять операцию INSERT.
б) При значениях данных, приведенных на рис. 1.3, поставщик S2 не будет видимым через представление ХОРОШИЕ_ПОСТАВЩИКИ. Но это не означает, что пользователь может вставить (операция INSERT) в это представление запись с номером поставщика S2 или обновить (операция UPDATE) какую-либо другую запись таким образом, чтобы значение ее номера поставщика стало равным S2. Такая операция должна быть отвергнута точно так же, как если бы она осуществлялась непосредственно над таблицей S.
в) Рассмотрим, наконец, следующий пример с использованием операции UPDATE:
UPDATE ХОРОШИЕ_ПОСТАВЩИКИ
SET СОСТОЯНИЕ = О
WHERE НОМЕР_ПОСТАВЩИКА ='S1';
Должна ли быть принята эта операция UPDATE? Если да, то результатом ее выполнения будет удаление поставщика S1 из данного представления, поскольку запись этого поставщика не будет больше удовлетворять предикату, определяющему представление. Подобным же образом операция INSERT:
INSERT
INTO ХОРОШИЕ_ПОСТАВЩИКИ (НОМЕР_ПОСТАВЩИКА,
СОСТОЯНИЕ, ГОРОД)
VALUE ('S8', 7, 'Стокгольм');
если она будет принята, создаст запись нового поставщика, но эта запись немедленно исчезнет из представления. Для того чтобы иметь дело с такими ситуациями, предназначена спецификация CHECK, упоминаемая в разделе 8.2. Если в определении представления включается фраза
WITH CHECK OPTION,
то все операции INSERT и UPDATE над этим представлением будут подвергаться проверке, чтобы обеспечить действительное удовлетворение предиката, определяющего представление, вновь вставляемой или обновленной записью. Если предикат не удовлетворяется, данная операция будет отвергнута.
Вариант CHECK может быть специфицирован только если данное представление обновляемо и его определение не включает вложенных подзапросов. Если данное представление таково, что обновления (операция UPDATE) допустимы только над определенными полями, а вставка (операция INSERT) не допускается вообще, то вариант CHECK относится только к этим операциям UPDATE.
ОПЕРАЦИИ, ТРЕБУЮЩИЕ ИСПОЛЬЗОВАНИЯ КУРСОРОВ
Вернемся теперь к случаю предложения SELECT, которое продуцирует целое множество записей, а не только одну запись. Как уже было объяснено в разделе 10.2, здесь необходим механизм, обеспечивающий последовательный доступ к записям в этом множестве. Такой механизм обеспечивают курсоры. В общих чертах процесс доступа иллюстрируется в примере, приведенном на рис. 10.2, в котором предусматривается выборка деталей (полей НОМЕР_ДЕТАЛИ, НАЗВАНИЕ и СОСТОЯНИЕ) для всех поставщиков, находящихся в городе, заданном переменной включающего языка Y.
ЕХЕС SQL DECLARE X CURSOR FOR / * определить курсор X * /
SELECT НОМЕР_ПОСТАВЩИКА, НАЗВАНИЕ,
СОСТОЯНИЕ
FROM S
WHERE ГОРОД = >У;
ЕХЕС SQL OPEN X; / * исполнить запрос * /
DO WHILE (пока еще есть записи);
ЕХЕС SQL FETCH X INTO :НОМЕР_
ПОСТАВЩИКА, :НАЗВАНИЕ, :СОСТОЯНИЕ;
/ * выбрать следующего поставщика * /
END;
ЕХЕС SQL CLOSE X; / * дезактивировать курсор Х * /
Рис. 10.2. Выборка множества записей
Пояснение.
Предложение DECLARE X CURSOR... определяет курсор, названный X, и ассоциированный с ним запрос, специфицированный с помощью предложения SELECT, которое образует часть этого предложения DECLARE. Указанное предложение SELECT не исполняется в данный момент, так как DECLARE CURSOR это чисто декларативное предложение. Оно исполняется, когда открывается курсор в процедурной части программы. Предложение FETCH ... INTO ... (выбрать ... в ...) используется для выборки записей результирующего множества и присваивает найденные значения переменным включающего языка в соответствии со спецификациями фразы INTO в этом предложении. Для простоты в приведенном примере переменным включающего языка даны те же самые имена, что и соответствующим полям базы данных. Заметим, что предложение SELECT в объявлении курсора не содержит фразы INTO. Поскольку в результате будет получено множество записей, предложение FETCH будет обычно входить в некоторый цикл (в языке ПЛ/1—DO... END). Этот цикл будет повторяться до тех пор, пока в этом результирующем множестве еще существуют непросмотренные записи. При выходе из цикла курсор Х закрывается (дезактивируется) с помощью соответствующего предложения CLOSE (закрыть).
2.Предложение
ЕХЕС SQL FETCH имя — курсора INTO мишень [, мишень] . . .;
где каждая «мишень» имеет формат
переменная — включающего — языка [:переменная — включающего — языка]
как в единичном SELECT, и где идентифицированный курсор должен быть открыт, продвигает этот курсор к следующей записи в активном множестве, а затем присваивает значения полей из этой записи переменным включающего языка, в соответствии с фразой INTO. Как уже указывалось, предложение FETCH обычно исполняется в программном цикле (см. рис. 102). Если при исполнении FETCH не существует следующей записи, то выборка данных не производится и SQLCODE принимает значение +100.
Отметим, между прочим, что «выбрать следующую» представляет собой единственную
операцию перемещения курсора. Невозможно переместить курсор, например, «вперед на три позиции» или «назад на две позиции» и т. п.
3. Предложение
ЕХЕС SQL CLOSE имя — курсора;
закрывает или дезактивирует специфицированный курсор, который в этот момент должен быть открыт. Теперь этот курсор не имеет соответствующего активного множества. Его можно, однако, теперь снова открыть. В этом случае с ним будет связано другое активное множество, вероятно, не в точности то же самое, что и ранее, особенно если значения переменных включающего языка, упоминаемые в предложении
SELECT, тем временем изменились. Заметим, что изменение значений этих переменных в то время, когда курсор открыт, не оказывает влияния на активное множество.
Два следующих предложения могут включать ссылки на курсоры. Имеются формы CURRENT для предложений UPDATE и DELETE. Если, например, курсор Х в настоящее время позиционирован на конкретную запись в базе данных, то можно обновить (UPDATE) или удалить (DELETE) «текущую X», т. е. запись, на которую позиционирован X. Синтаксис этих предложений таков:
ЕХЕС SQL UPDATE имя — таблицы
SET имя — поля = выражение
[, имя — поля == выражение] . . .
WHERE CURRENT OF имя — курсора;
ЕХЕС SQL DELETE
FROM имя — таблицы
WHERE CURRENT OF имя — курсора;
Пример:
ЕХЕС SQL UPDATE S
SET СОСТОЯНИЕ = СОСТОЯНИЕ + :ПРИРОСТ
WHERE CURRENT OF X;
Использование предложений UPDATE CURRENT и DELETE CURRENT не допускается, если предложение SELECT в объявлении курсора включает UNION или ORDER BY, или если это предложение SELECT определяет необновляемое представление и является частью предложения CREATE VIEW (см. раздел 8.4). Как пояснялось ранее, в случае UPDATE CURRENT предложение DECLARE должно включать фразу FOR UPDATE, идентифицирующую все поля, которые входят как мишени во фразу SET предложения UPDATE CURRENT для этого курсора.
ОПЕРАЦИИ ВЫБОРКИ
В разделе 8.1 уже было показано в общих чертах, каким образом операции выборки данных над представлением преобразуются в эквивалентные операции над лежащей в его основе базовой таблицей (или базовыми таблицами). Обычно этот процесс преобразования совершенно ясен и осуществляется вполне хорошо, без каких-либо неожиданностей для пользователя. Однако иногда такие неожиданности могут иметь место. Так, могут возникнуть проблемы, если пользователь пытается интерпретировать поле представления как обычное поле, а это поле представления продуцируется из чего-либо иного, чем простое поле лежащей в основе базовой таблицы. Например, оно может продуцироваться с помощью стандартной функции. Рассмотрим следующий пример определения представления:
CREATE VIEW PQ (НОМЕР_ДЕТАЛИ, ОБЩЕЕ_КОЛИЧЕСТВО)
AS SELECT НОМЕР_ДЕТАЛИ, SUM (КОЛИЧЕСТВО)
FROM SP
GROUP BY НОМЕР_ДЕТАЛИ;
Это представление — «статистическая сводка» из раздела 8.2, пример 2.
Предпринятый запрос:
SELECT *
FROM PQ
WHERE ОБЩЕЕ_КОЛИЧЕСТВО > 500;
Если применить простой процесс слияния, описанный в разделе 8.1, для того, чтобы скомбинировать этот запрос с определением представления, хранимым в каталоге, мы получим нечто подобное следующему:
SELECT НОМЕР_ДЕТАЛИ, SUM (КОЛИЧЕСТВО)
FROM SP
WHERE SUM (КОЛИЧЕСТВО) > 500
GROUP BY НОМЕР_ДЕТАЛИ;
Такое предложение
SELECT недопустимо. Не разрешается, чтобы в предикате во фразе WHERE использовалась стандартная функция, например SUM. Первоначальный запрос следовало бы на самом деле преобразовать в нечто подобное следующему:
SELECT НОМЕР_ДЕТАЛИ, SUM (КОЛИЧЕСТВО)
FROM SP
GROUP BY НОМЕР_ДЕТАЛИ
HAVING SUM (КОЛИЧЕСТВО) > 500;
Однако система DB2 не умеет выполнять такое преобразование.
Ниже приводится другой пример, в котором рассматриваемое преобразование снова не работает. В этом примере опять используется представление — статистическая сводка PQ. Предпринимаемый запрос:
SELECT AVG (ОБЩЕЕ_КОЛИЧЕСТВО)
FROM PQ;
«Преобразованная» форма:
SELECT AVG (SUM (КОЛИЧЕСТВО))
FROM SP
GROUP BY НОМЕР_ДЕТАЛИ;
И снова это недопустимое предложение. В языке SQL не разрешается использовать вложенные таким образом стандартные функции.
Общий принцип, который нарушается в этих двух примерах, таков: преобразованная форма первоначального запроса всегда должна быть допустимым предложением SELECT языка SQL.
Определение
В реляционной системе таблица состоит из строки заголовков столбцов
и нуля или более строк значений данных
(число строк данных может быть каждый раз разным). Для заданной таблицы:
а) Строка заголовков столбцов специфицирует один или более столбцов, задавая наряду с прочим тип данных для каждого из них;
б) Каждая строка данных содержит в точности одно значение данных для каждого из столбцов, специфицированных в строке заголовков столбцов. Кроме того, все значения в заданном столбце имеют один и тот же тип, а именно: тип данных, специфицированный для этого столбца в строке заголовков столбцов.
В связи с предыдущим определением следует коснуться двух моментов.
1. Отметим, что в этом определении нет никакого упоминания об упорядочении строк.
Строго говоря, строки реляционной таблицы считаются неупорядоченными. (Отношение — это математическое множество—множество строк, а множество в математике не обладает каким-либо упорядочением.) Как мы увидим, можно, однако, задавать некоторый порядок для этих строк, когда осуществляется их выборка в ответ на запрос, но такое упорядочение следует считать не чем иным, как удобством для пользователя. Оно не существенно для понятия таблицы.
2. В отличие от строк столбцы таблицы предполагаются упорядоченными слева направо. (По крайней мере, они считаются упорядоченными таким образом в большинстве систем, в том числе в DB2). В таблице S, например (рис. 1.3), столбец НОМЕР-ПОС-ТАВЩИКА — первый столбец, ФАМИЛИЯ — второй столбец и т. д. Однако на практике существует очень немного ситуаций, когда такое упорядочение слева направо является существенным. Подобных ситуаций можно избегать при некоторой дисциплине, и это рекомендуется делать, как будет показано позднее.
Обратимся теперь, в частности, к базовым таблицам. Базовая таблица — это автономная именованная таблица. Под «автономностью» понимается то, что эта таблица существует сама по себе в отличие от представления, которое существует не само по себе, а является производным от одной или нескольких базовых таблиц. Представление служит просто альтернативным способом рассмотрения этих базовых таблиц. Под «именованной» понимается, что этой таблице с помощью соответствующего предложения CREATE явно задается некоторое имя в отличие от таблицы, которая строится как результат запроса и не имеет сама по себе какого-либо явного имени. Такая таблица существует в течение непродолжительного времени. Примерами такого рода неименованных таблиц служат две таблицы результатов, приведенные на рис. 1.1.
Предложение CREATE TABLE
Теперь мы в состоянии подробно обсудить предложение CREATE TABLE. Это предложение имеет следующий общий формат:
CREATE TABLE имя—базовой—таблицы
(определение—столбца [, определение—столбца] . . . )
[другие—параметры];
Здесь «определение—столбца» в свою очередь имеет формат:
имя—столбца тип—данных
[NOT NULL]
Факультативные «другие — параметры» имеют дело главным образом с проблемами физического хранения и кратко обсуждаются в главе 13. Примечание. В этой книге прямые скобки в синтаксических определениях используются для того, чтобы указать, что конструкции, заключенные в эти скобки, являются необязательными (т. е. могут быть опущены). Многоточие указывает, что непосредственно предшествующая ему синтаксическая единица факультативно может повторяться один или более раз. Конструкции, представленные прописными буквами, должны быть записаны в точности так, как показано. Наконец, конструкции, представленные строчными буквами, должны заменяться конкретными значениями, выбранными пользователем.
Ниже приведен пример предложения CREATE TABLE для таблицы S, теперь уже в полном виде:
CREATE TABLE S
CHAR (5) NOT NULL,
ФАМИЛИЯ
CHAR (20),
СОСТОЯНИЕ
SMALLINT,
ГОРОД
CHAR (15));
Результат этого предложения состоит в том, что создается новая пустая базовая таблица, названная xyz.S, где xyz — имя, под которым известен системе пользователь, издающий предложение CREATE TABLE (см. главу 9). В системный каталог при этом помещается статья, описывающая эту таблицу. Пользователь xyz может обращаться к таблице по ее полному имени xyz.S или по сокращенному имени S. Другие пользователи должны обращаться к ней только по ее полному имени. Данная таблица состоит из четырех столбцов с именами xyz.S.НОМЕР_ПОСТАВЩИКА, xyz.S.ФАМИЛИЯ, хуг.S.СОСТОЯНИЕ и хуг.S.ГОРОД, имеющих указанные в определении типы данных. (Типы данных будут рассматриваться ниже). Пользователь xyz может обращаться к этим столбцам по их полным или по сокращенным именам: S.HOMEP-ПОСТАВЩИКА, S.ФАМИЛИЯ, S.СОСТОЯНИЕ и S.ГОРОД. Другие пользователи должны применять только полные имена столбцов. Заметим, однако, что независимо от того, включается ли в имя часть «xyz», часть «S» может быть опущена, если это не приводит к двусмысленности, но ее включение никогда не является ошибкой. Вообще относительно имен справедливы следующие правила. Имена пользователей, например xyz, являются уникальными во всей системе. Имена таблиц (неуточненные) уникальны для пользователя. Имена столбцов (неуточненные) уникальны для таблицы[9]. Под «таблицей» здесь понимаются как базовые таблицы, так и представления. Таким образом, представление не может иметь такое же имя, как и базовая таблица.
После того как таблица создана, в нее могут быть введены данные с помощью предложения INSERT (вставить) языка SQL, которое обсуждается в главе 6, или утилиты загрузки системы DB2, рассматриваемой в главе 14.
Типы данных
поддерживает следующие типы данных:
INTEGER
— двоичное целое число, занимающее полное машинное слово, 31 бит со знаком
SMALLINT
— двоичное целое число, занимающее полуслово, 15 бит со знаком
DECIMAL (p, q)
— упакованное десятичное число, включающее р цифр и знак (0 < р < 16); предполагается q цифр справа от десятичной точки (q < р; если q = 0, она может быть опущена)
FLOAT
— число n с плавающей точкой, занимающее двойное слово и представленное шестнадцатеричной мантиссой f с точностью до 15 знаков (—1 < f < +1) и двоичным целочисленным порядком е (—65<е < +64) таким образом, что n= = f* (16 * * е); примерный диапазон значений (По абсолютной величине — Примеч. пер.) n — от 5.4Е—79 до 7.2Е + 75; см. также ниже пояснения для констант типа FLOAT
CHAR (n)
— литерная строка фиксированной длины из n литер (О < n < 255)
VARCHAR (n)
— литерная строка переменной длины, не превышающей n литер (0 < n; максимальное значение n зависит от ряда факторов, но в общем случае должно быть меньше, чем «размер страницы» — 4К либо 32K — пространства, содержащего данную таблицу — см. главу 13)[10].
Константы
Хотя это и в некоторой степени отступление от основной темы данной главы, сейчас удобно рассмотреть различные виды констант, которые поддерживаются в DB2:
— записывается как десятичное целое число со знаком или без знака, без десятичной точки;
примеры: 4 —95 +364 О
десятичная
— записывается как десятичное число со знаком или без знака, с десятичной точкой;
примеры: 4,0 —95.7 +364.05 0.007
с плавающей точкой
— записывается как десятичная константа, за которой следует буква Е с последующей целочисленной константой;
примеры: 4ЕЗ —95.7Е46 +364Е—5 0.7Е1 (примечание:
выражение хЕу представляет значение х*(10**у))
строковая
— записывается либо как строка литер, заключенная в одиночные кавычки, либо как строка пар шестнадцатеричных цифр, представляющих рассматриваемые литеры в коде EBCDIC, заключенная в одиночные кавычки, которой предшествует буква X;
примеры: '123 Main St.' 'PIG'
X'F1F2F340D481899540E2A34B'
X'D7C9C7'
(первый и третий примеры представляют одно и то же значение, так же как второй и четвертый)
Неопределенное значение
Вернемся теперь к основной теме данной главы. Система DB2 поддерживает концепцию неопределенного значения данных. Фактически любой столбец может содержать неопределенное значение, если в определении этого столбца в предложении CREATE TABLE явным образом не специфицировано NOT NULL (неопределенное значение не допускается). Неопределенное значение— это специальное значение, которое используется для того, чтобы представлять «неизвестное значение» или «неприменимое значение». Это не то же самое, что пробел или ноль. Например, запись поставки может содержать неопределенное значение поля КОЛИЧЕСТВО (известно, что поставка имела место, но неизвестен объем поставки). Запись поставщика может также содержать неопределенное значение в столбце СОСТОЯНИЕ (может быть, например, что СОСТОЯНИЕ не соотносится по некоторой причине поставщикам в Сан-Хосе).
Вернемся к предложению
CREATE TABLE для базовой таблицы S. Мы специфицировали NOT NULL только для столбца НОМЕР_ПОСТАВЩИКА. Результатом этой спецификации является гарантия того, что запись каждого поставщика в базовой таблице S всегда будет содержать какой-либо реальный (отличный от неопределенного значения) номер поставщика. Напротив любое из значений ФАМИЛИЯ, СОСТОЯНИЕ и ГОРОД или все они могут быть неопределенными в той же самой записи. (Причины нашего требования о том, чтобы номера поставщиков не имели неопределенных значений, станут ясны в Приложениях А и В.)
Столбец, который может принимать неопределенные значения, физически представляется в хранимой базе данных двумя столбцами: самим столбцом данных и скрытым столбцом индикатора с длиной значений в один байт, который хранится как префикс к столбцу фактических данных. Значение X'FF' в столбце индикатора указывает, что соответствующее значение в столбце данных следует игнорировать, т. е. принять его за неопределенное значение. Значение Х'00' в столбце индикатора указывает, что в качестве соответствующего значения столбца данных следует принять его действительное значение.
Более подробно о неопределенных значениях пойдет речь в главах 4, 5, 6 и 10, а также в Приложении В.
Предложение ALTER TABLE
Точно так же, как в любое время можно с помощью предложения CREATE TABLE создать новую базовую таблицу, можно также в любое время изменить существующую базовую таблицу, добавляя к ней справа новый столбец. Для этого используется предложение ALTER TABLE:
ALTER TABLE имя—базовой— таблицы
ADD имя—столбца тип—данных;
Например:
ALTER TABLE S
ADD СКИДКА SMALLINT;
Это предложение добавляет к таблице S столбец СКИДКА. Все существующие записи таблицы S расширяются с четырех значений полей данных до пяти, и во всех случаях новое пятое поле принимает неопределенное значение. Спецификация NOT NULL в предложении ALTER TABLE не допускается. Заметим, между прочим, что только что описанное расширение существующих записей, не означает, что в это время физически обновляются записи в базе данных. Изменяется лишь хранимое в каталоге, описание таблицы. Отдельные записи физически не изменяются до тех пор, пока они в следующий раз не станут целевыми для предложения UPDATE языка SQL (см. главу 6).
Предложение DROP TABLE
Существующую базовую таблицу можно в любое время уничтожить с помощью предложения:
DROP TABLE имя—базовой—таблицы;
Специфицированная базовая таблица удаляется из системы (точнее, из каталога удаляется описание этой таблицы). Автоматически удаляются также все индексы и представления, определенные над этой базовой таблицей.
ОПРЕДЕЛЕНИЕ ПРЕДСТАВЛЕНИЯ
Общий синтаксис предложения CREATE VIEW (создать представление):
CREATE VIEW имя—представления
[(имя—столбца[ , имя—столбца] . . .)]
AS подзапрос
[WITH CHECK OPTION];
Как обычно, подзапрос не может включать ни оператора UNION, ни фразы ORDER BY. Однако при этих ограничениях любая таблица, выборка которой может быть осуществлена с помощью предложения SELECT, может быть, с другой стороны, определена как представление. Ниже приведено несколько примеров.
1. CREATE VIEW КРАСНЫЕ_ДЕТАЛИ (НОМЕР—ДЕТАЛИ,
НАЗВАНИЕ, ВЕС, ГОРОД)
AS SELECT НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ВЕС, ГОРОД
FROM P
WHERE ЦВЕТ = 'Красный';
Действие этого оператора заключается в том, чтобы создать новое представление, названное xyz.КРАСНЫЕ_ДЕТАЛИ, где xyz — известное системе имя пользователя, издавшего предложение CREATE VIEW. Пользователь xyz может называть это представление просто КРАСНЫЕ_ДЕТАЛИ. Другие же пользователи должны называть его xyz.КРАСНЫЕ_ДЕТАЛИ. С другой стороны, они могут, конечно, ввести для него синоним, как указывалось в главе 7. В этом представлении четыре столбца — НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ВЕС и ГОРОД, соответствующих четырем столбцам НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ВЕС и ГОРОД лежащей в основе базовой таблицы Р. Если имена столбцов явно не специфицированы в предложении CREATE VIEW, то представление очевидным образом наследует имена столбцов его источника. В приведенном примере наследуемыми именами были бы НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ВЕС и ГОРОД. Имена столбцов должны быть специфицированы явно для всех столбцов представления, если: а) какой-либо столбец этого представления продуцируется с помощью стандартной функции, арифметического выражения или константы (и не имеет, следовательно, имени, которое он мог бы наследовать) или б) два или более столбцов имели бы в противном случае одно и то же имя. Каждый из этих двух случаев иллюстрируется в следующих двух примерах.
2. CREATE VIEW PQ (НОМЕР_ДЕТАЛИ, ОБЩЕЕ_КОЛИЧЕСТВО)
AS SELECT НОМЕР_ДЕТАЛИ, SUM (КОЛИЧЕСТВО)
FROM SP
GROUP BY НОМЕР_ДЕТАЛИ;
В этом примере нет такого имени, которое могло бы наследоваться для второго столбца, поскольку этот столбец продуцируется с помощью стандартной функции. Поэтому имена столбцов здесь должны быть специфицированы явным образом, как было показано в примере. Обратите внимание, что это представление не является просто подмножеством строк и столбцов лежащей в основе базовой таблицы (в отличие от рассмотренных выше представлений КРАСНЫЕ_ДЕТАЛИ и ХОРОШИЕ_ПОСТАВЩИКИ). Его можно было бы рассматривать как некоторого рода статистическую сводку или сжатие лежащей в основе таблицы.
3. CREATE VIEW ПАРЫ_ГОРОДОВ (ГОРОД_ПОСТАВЩИКА,
ГОРОД_ДЕТАЛИ)
AS SELECT S. ГОРОД, Р. ГОРОД
FROM S, SP, P
WHERE S. НОМЕР_ПОСТАВЩИКА =
SP. НОМЕР_ПОСТАВЩИКА
AND SP.HOMEP_ДЕТАЛИ = Р.НОМЕР_ДЕТАЛИ;
Смысл этого представления в том, что пара имен городов (х,у) будет входить в данное представление, если поставщик с местоположением в городе х поставляет какую-либо деталь, хранимую в городе у. Например, поставщик S1 поставляет деталь Р1. При этом поставщик S1 находится в Лондоне и деталь Р1 хранится тоже в Лондоне. И поэтому пара (Лондон, Лондон) входит в данное представление. Обратите внимание, что в определении этого представления используется соединение и, таким образом, оно является примером представления, продуцируемого из нескольких положенных в основу таблиц. Примечание. Мы могли бы при желании включить в определение этого представления спецификацию DISTINCT. Сравните с примером 4.3.5 в главе 4.
4. CREATE VIEW ЛОНДОНСКИЕ_КРАСНЫЕ_ДЕТАЛИ
AS SELECT НОМЕР_ДЕТАЛИ, ВЕС
FROM КРАСНЫЕ_ДЕТАЛИ
WHERE ГОРОД = 'Лондон';
Поскольку определение представления может быть любым допустимым подзапросом и поскольку подзапрос может осуществлять выборку данных как из представлений, так и из базовых таблиц, вполне возможно определять представление в терминах других представлений, как это сделано в данном примере.
5. CREATE VIEW ХОРОШИЕ_ПОСТАВЩИКИ
AS SELECT НОМЕР_ПОСТАВЩИКА, СОСТОЯНИЕ, ГОРОД
FROM S
WHERE СОСТОЯНИЕ > 15
WITH CHECK OPTION;
Фраза «WITH CHECK OPTION» ( с проверкой) указывает, что для операций UPDATE и INSERT над этим представлением должна осуществляться проверка, которая обеспечивает удовлетворение определяющего представление предиката обновленной или вставляемой строкой (в данном примере СОСТОЯНИЕ>15). Вариант CHECK более подробно описан в разделе 8.4.
Предложение DROP VIEW имеет следующий синтаксис:
DROP VIEW имя — представления;
В результате исполнения этого предложения уничтожается специфицированное представление, т. е. из каталога удаляется его определение. Все представления, определенные с его использованием, также автоматически уничтожаются.
Пример рассматриваемого предложения:
DROP VIEW КРАСНЫЕ_ДЕТАЛИ;
Если уничтожается базовая таблица, то все определенные над нею (или над представлениями этой базовой таблицы и т. д.) представления также автоматически уничтожаются.
Предложения ALTER VIEW (изменить представление) в языке SQL нет. Предложение ALTER TABLE, которое добавляет новый столбец к базовой таблице, не оказывает влияния на любые существующие представления.
ОСНОВНЫЕ КОМПОНЕНТЫ
Внутренняя структура системы DB2 является весьма сложной, как и следует ожидать от системы, соответствующей современному уровню развития и обеспечивающей все функции, которыми обычно обладают современные СУБД (в том числе, например, управление восстановлением, параллельными процессами, санкционированием доступа и т. д.), и многое сверх того. Однако многие из этих функций не представляют непосредственного интереса для пользователя (в нашем понимании этого термина, т. е. конечного пользователя или прикладного программиста), хотя они и имеют решающее значение для общего функционирования системы. С точки зрения пользователя, систему можно фактически рассматривать как состоящую просто из четырех основных компонентов, которые называются следующим образом[6]:
Прекомпилятор (PRECOMPILER)
Генератор планов прикладных задач (BIND)
Супервизор стадии исполнения (RUNTIME SUPERVISOR)
Программа управления хранимыми данными (STORED DATA MANAGER).
Функции этих четырех компонентов в общих чертах заключаются и следующем.
Прекомпилятор
Прекомпилятор является препроцессором для языков прикладного программирования (ПЛ/1, КОБОЛ, ФОРТРАН и язык ассемблера). Его функция состоит в том, чтобы проанализировать исходный модуль на любом из этих языков, удалить из него все найденные предложения SQL, заменяя их предложениями CALL входного языка. На стадии исполнения эти предложения CALL будут передавать управление непосредственно супервизору времени исполнения. Из предложений SQL, которые ему встречаются, Прекомпилятор строит модуль запросов к. базе данных (DHRM), который используется в качестве входных данных для генератора планов прикладных задач, рассматриваемого ниже.
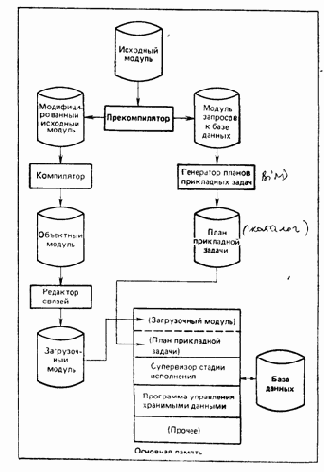
Рис. 2.1. Подготовка и исполнение прикладной задачи системы DB2 (общее представление)
Генератор планов прикладных задач
Функция генератора планов прикладных задач состоит в том, чтобы скомпилировать
один или более DBRM и создать тем самым план прикладной задачи. План прикладной задачи содержит необходимые команды машинного кода, реализующие первоначальные предложения SQL, из которых были построены эти DBRM. Он включает, в частности, команды обращения к программе управления хранимыми данными (см. ниже).
Супервизор стадии исполнения
При исполнении прикладной программы супервизор стадии исполнения постоянно находится в основной памяти. Его функции заключаются в том, чтобы следить за исполнением прикладной программы. Когда прикладной программе потребуется выполнить некоторую операцию, связанную с базой данных (говоря нестрого, когда будет необходимо выполнить какое-либо предложение SQL), управление передается сначала супервизору стадии исполнения, который в свою очередь передает его соответствующей части плана прикладной задачи. План прикладной задачи, наконец, передает управление программе управления хранимыми данными.
Программа управления хранимыми данными
Программу управления хранимыми данными можно рассматривать как весьма утонченный метод доступа. Она выполняет все обычные функции метода доступа, например выборку, поиск, обновление, поддержание индекса и т. д. В общих чертах программа управления хранимыми данными — это компонент, управляющий физическими базами данных. Когда во время исполнения его основной задачи необходимо выполнять более детальные функции, такие, как блокирование, запись в журнал, сортировку и т. п., он вызывает другие компоненты более низкого уровня.
На рис. 2.1 сказанное выше подытоживается в форме логической схемы. В следующем разделе основные шаги этого полного процесса будут рассмотрены более подробно.
ПОДРОБНОЕ ОБСУЖДЕНИЕ ЛОГИКИ УПРАВЛЕНИЯ
Рассмотрим сначала пример программы Р на языке ПЛ/1 (точнее, исходный модуль Р на языке ПЛ/1), которая включает плюс или более предложений SQL. Язык ПЛ/1 здесь взят для определенности. Суммарный процесс остается, по существу, неизменным и для других языков. Прежде чем программа Р может быть скомпилирована компилятором ПЛ/1, она должна быть обработана прекомпилятором (рис. 2.2). Примечание. Если Р содержит также какие-либо предложения CICS (вида ЕХЕС, СICS...;), то она должна быть также обработана препроцессором СICS. Прекомпилятор DB2 и препроцессор CICS могут исполнятся при этом в любом порядке.
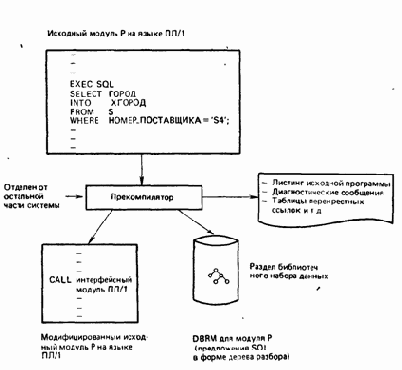
Рис. 2.2. Прекомпиляция
Как указывалось в предыдущем разделе, прекомпилятор DB2 удаляет все найденные им в Р предложения SQL и заменяет[7]
их предложениями CALL языка ПЛ/1. (Эти предложения CALL осуществляют обращения к интерфейсному модулю ПЛ/1—см. ниже.) Предложения SQL он использует при этом для построения модуля запросов к базе данных
(DBRM) программы Р, который хранится вне этой программы как раздел библиотечного набора данных. В DBRM содержится копия первоначальных предложений SQL вместе с внутренней формой этих предложений в виде дерева разбора. Прекомпилятор формирует также листинг исходной программы, содержащий первоначальный исходный текст программы, диагностические сообщения, таблицы перекрестных ссылок и т. д.
Далее, модифицированный исходный модуль на языке ПЛ/1 компилируется и редактируется обычным образом за исключением того, что интерфейсный модуль языка ПЛ/1, который предоставляется системой DB2, должен быть частью входной информации для редактора связей. Условимся называть результат этого шага «загрузочным модулем Р на языке ПЛ/1».
Теперь мы подошли к шагу генератора планов прикладных задач (рис. 2.3).
В действительности, этот компонент является оптимизирующим компилятором. Он преобразует запросы высокого уровня к базе данных (на самом деле, предложения SQL) в оптимизированную машинную программу. Входной информацией для генератора служит множество, состоящее из одного или более DBRM. Таких модулей запросов будет несколько, если первоначальная программа на ПЛ/1 состоит более чем из одной внешней процедуры, т. е. включает несколько исходных модулей. Результат работы генератора, т. е. скомпилированный им код, называется планом прикладной задачи и он хранится в системной базе данных, называемой каталогом[8]
( о каталоге более подробно пойдет речь в главе 7). Таким образом, главные функции генератора типов прикладных задач состоят в следующем.
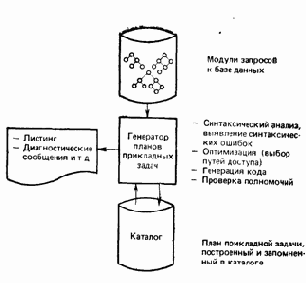
Рис. 2.3. Генератор планов прикладных задач
Выявление синтаксических ошибок
Генератор планов прикладных задач исследует предложения SQL во входных DBRM, осуществляет их синтаксический анализ и выдает сообщения обо всех синтаксических ошибках, которые он обнаружил. Такие проверки необходимы несмотря на то, что подобные проверки уже выполнялись прекомпилятором, поскольку прекомпилятор отделен от остальной части системы DB2. Его исполнение возможно, даже если DB2 недоступна. Он может даже исполняться на другой машине, и его выходные данные автоматически не защищаются. Поэтому нельзя предполагать, что входные данные генератора представляют собой достоверные результаты работы прекомпилятора — пользователь мог построить недопустимый «DBRM» с помощью некоторого другого механизма.
Оптимизация
Важной составной частью генератора планов прикладных задач является оптимизатор.
Функция оптимизатора состоит в том, чтобы выбрать для каждого обрабатываемого им манипулятивного предложения SQL оптимальную стратегию реализации этого предложения. Напомним, что предложения манипулирования данными, например SELECT, специфицируют только то, что хочет получить пользователь, а не как добраться до этих данных. Путь доступа, позволяющий добраться к этим данным, будет выбираться оптимизатором. Таким образом, программы независимы от таких путей доступа (дальнейшее обсуждение этой важной проблемы см. в заключении этого раздела).
Рассмотрим в качестве примера предложение SELECT из исходного модуля Р на языке ПЛ/1, приведенного на рис. 2.2. Даже в этом очень простом случае имеется, по крайней мере, два способа выполнения требуемого поиска: 1) путем физически последовательного просмотра (хранимой версии) таблицы S до тех пор, пока не будет найдена запись для поставщика S4; 2) если имеется индекс по столбцу НОМЕР_ПОСТАВЩИКА этой таблицы, что, вероятно, будет иметь место по причинам, которые подробно обсуждаются в Приложениях А и В, то используя этот индекс и, таким образом, непосредственно приходя к записи S4. Оптимизатору предстоит выбрать, какую из этих двух стратегий принять. Обычно оптимизатор будет делать свой выбор на основе следующих соображений: на какие таблицы ссылается данное предложение SQL (их может быть более одной), насколько велики эти таблицы, какие имеются индексы, каковы селективные их возможности, каким образом данные физически группируются на диске, какова форма фразы WHERE в запросе и т. п. Генератор планов прикладных задач будет далее генерировать машинный код, который тесно связан с
выбранной оптимизатором стратегией, т. е. в большой степени зависит от нее. Если, например, оптимизатор принимает решение использовать индекс X, то в плане прикладной задачи будут иметься команды машинного языка, которые явно обращаются к индексу X.
Генерация кода
Это процесс фактического построения плана прикладной задачи.
Проверка полномочий
Генератор планов прикладных задач осуществляет также проверку полномочий. Иными словами, он проверяет, позволяется ли лицу, выполняющему генерацию (т. е. пользователю, вызывающему генератор — см. главу 14), производить требуемые в DBRM операции, которые должны быть включены в план прикладной задачи. Вопросы санкционирования доступа будут подробно рассматриваться в главе 9.
Мы подошли, наконец, к процессу исполнения. Поскольку первоначальная программа теперь в действительности разбита на две части (загрузочный модуль и план прикладной задачи), эти две чисти должны быть на стадии исполнения каким-либо образом снова собраны вместе. Рассмотрим, как она работает (см. рис. 2.4).
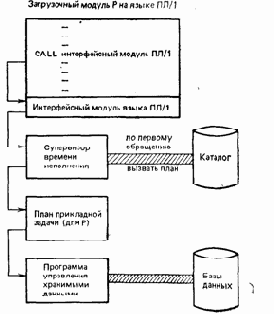
Рис. 2.4. Процесс исполнения
Сначала в основную память загрузится загрузочный модуль Р на языке ПЛ/1 и он обычным образом начиняет исполняться. В конце концов, он достигает первого обращения к интерфейсному модулю языка ПЛ/1. Этот модуль получает управление и в свою очередь передает управление супервизору стадии исполнения. Далее, супервизор стадии исполнения производит поиск плана прикладной задачи в системном каталоге, загружает его в основную память и передает ему управление. План прикладной задачи в свою очередь вызывает программу управления хранимыми данными, которая выполняет необходимые операции над фактически хранимыми данными и возвращает результаты в подходящем виде программе на языке ПЛ/1.
До сих пор в нашем обсуждении умалчивался один чрезвычайно важный момент, который мы теперь поясним. Прежде всего, как уже говорилось, DB2—это компилирующая система.
В отличии от нее большинство других систем управления базами данных и, без сомнения, все системы нереляционного типа, насколько известно автору, являются, по существу, интерпретирующими.
Далее, компиляция, несомненно, имеет преимущества с точки зрения производительности. Она почти всегда будет давать лучшие характеристики времени исполнения, чем интерпретация. Однако она страдает следующим важным недостатком: возможно, что решения, принятые в процессе компиляции «компилятором» (фактически генератором планов прикладных задач), более не имеют силы на стадии исполнения. Эту проблему иллюстрирует следующий простой пример.
1. Предположим, что программа Р компилируется в понедельник, и генератор планов прикладных задач принимает решение использовать в стратегии для Р индекс, например, индекс X. Тогда план прикладной задачи для Р будет включать, как говорилось ранее, явные обращения к X.
2. В четверг некоторый обладающий полномочиями пользователь издает предложение DROP INDEX X;
3. В пятницу некоторый пользователь пытается исполнить программу Р. Что при этом происходит?
При этом происходит следующее. Когда уничтожается индекс, DB2 исследует все планы прикладных задач в каталоге с тем, чтобы установить, какие из них зависят от этого индекса, если они вообще зависят от индексов. Каждый из таких планов, который он обнаружил, помечается как «недействительный». Когда супервизор стадии исполнения осуществляет выборку такого плана для исполнения, он обнаруживает маркер «недействительный» и поэтому вызывает генератор планов прикладных задач для продуцирования нового плана, т. е. для того, чтобы выбрать какую-либо иную стратегию доступа, а затем перекомпилировать первоначальные предложения SQL, которые были сохранены в каталоге, в соответствии с этой новой стратегией. Если перекомпиляция была успешной, старый план заменяется в каталоге новым, и супервизор стадии исполнения продолжает работу уже с новым планом. Таким образом, весь процесс перегенерации (или «автоматического связывания», как его называют) является «прозрачным для пользователя». Единственный эффект, который может наблюдаться,— это незначительная задержка исполнения первого предложения SQL в программе.
Заметим, что та перекомпиляция, о которой здесь говорилось, это перекомпиляция SQL, а не ПЛ/1. Перекомпилируется не программа на языке ПЛ/1, которая стала недействительной вследствие уничтожения индекса, а лишь план прикладной задачи.
Теперь можно видеть, каким образом становится возможной независимость программ от физических путей доступа, или более определенно, каким образом возможно создавать и уничтожать такие пути доступа без необходимости в то же время изменять программы. Как указывалось ранее, предложения манипулирования данными языка SQL, например SELECT и UPDATE, никогда не включают какого-либо явного упоминания о таких путях доступа. Вместо этого в них просто указывается, в каких данных заинтересован пользователь. Выбор пути, позволяющего добраться до этих данных, а также замена его другим путем, если старый путь более не существует,— это обязанности системы, а в действительности—генератора планов прикладных задач. Будем говорить, что система типа DB2 обеспечивает высокую степень физической независимости данных: пользователь и пользовательские программы не зависят от физической структуры хранимой базы данных. Достоинство такой системы—весьма значительное достоинство—состоит в том, что можно делать изменения в физической базе данных, например по соображениям производительности, не имея необходимости делать какие-либо соответствующие изменения в прикладных программах. В системе, не обладающей такой независимостью, прикладные программисты вынуждены уделять довольно значительную часть времени—доля 50 процентов является весьма типичной—для внесения в существующие программы изменений, которые становятся необходимыми просто вследствие изменений в физической базе данных. Напротив, в системе типа DB2 эти программисты могут сосредоточиться исключительно на производстве новых прикладных задач.
Ещё один момент, касающийся предыдущего вопроса. Наш пример был связан с уничтоженным индексом и это, вероятно, наиболее частый случай на практике. Однако аналогичная последовательность событий имеет место при удалении любого объекта, а не только индекса, а также когда отменяются полномочия пользователя (см. главу 9). Поэтому, например, уничтожение какой-либо таблицы приведет к тому, что все планы, которые обращаются к этой таблице, будут помечены как недействительные. Конечно, автоматическая перегенерация будет работать лишь в том случае, если ко времени, когда ее следует выполнять, была создана другая таблица с тем же именем, что и у старой (и, вероятно, не тогда, когда имеются значительные различия между старой и новой таблицами).
В заключение данной главы отметим, что SQL всегда компилируется в DB2 и никогда не интерпретируется, даже если предложения в запросе вводятся через интерактивный интерфейс DB2I или через QMF. Иными словами, если ввести, например, предложение SELECT с терминала, то этот оператор будет компилироваться, и для него сгенерируется план прикладной задачи. Далее этот план будет исполняться. Наконец, после того как исполнение будет завершено, этот план будет удален. Практический опыт показал, что даже в интерактивном случае при компиляции почти всегда достигается лучшая общая производительность, чем при интерпретации. Достоинство компиляции состоит в том, что процесс физического доступа к требуемым данным осуществляется скомпилированной программой, т. е. программой, которая хорошо приспособлена для конкретного запроса, а не универсальной интерпретирующей программой. Недостаток состоит, конечно, в том что имеются затраты, связанные с компиляцией, т. е. с подготовкой этой хорошо приспособленной программы. Но указанное преимущество почти всегда перевешивает этот недостаток, причем иногда поразительным образом. Только в случае чрезвычайно простого запроса затраты на выполнение компиляции могут быть больше, чем потенциальная экономия. В качестве примера мог бы служить следующий простой запрос: «Осуществить выборку записи поставщика для поставщика S1». Здесь запрашивается единственная конкретная запись при заданном значении для поля, которое уникально идентифицирует эту запись. Обратим внимание, что такой запрос в действительности совсем не использует средств уровня множеств языка SQL.
ПОДЗАПРОС С НЕСКОЛЬКИМИ УРОВНЯМИ ВЛОЖЕННОСТИ
Выдать фамилии поставщиков, которые поставляют по крайней мере одну красную деталь.
SELECT ФАМИЛИЯ
FROM S
WHERE НОМЕР_ПОСТАВЩИКА IN
(SELECT НОМЕР_ПОСТАВЩИКА
FROM SP
WHERE НОМЕР_ДЕТАЛИ IN
(SELECT НОМЕР_ДЕТАЛИ
FROM P
WHERE ЦВЕТ = 'Красный'));
Результат:
ФАМИЛИЯ
Смит
Джонс
Кларк
Пояснение.
Результатом самого внутреннего подзапроса является множество ('Р1, 'Р4', 'Р6'). Подзапрос следующего уровня в свою очередь дает в результате множество ('S1', 'S2', 'S4'). Последний, самый внешний SELECT, вычисляет приведенный выше окончательный результат. Вообще допускается любая глубина вложенности подзапросов.
Для того чтобы убедиться в Вашем понимании этого примера, попытайтесь выполнить следующие упражнения:
а) Перепишите данный запрос так, чтобы все уточнения имен были указаны явным образом.
б) Напишите эквивалентную формулировку этого же запроса с использованием соединения.
ПОДЗАПРОС С ОПЕРАТОРОМ СРАВНЕНИЯ, ОТЛИЧНЫМ ОТ IN
Выдать номера поставщиков, находящихся в том же городе, что и поставщик S1.
SELECT НОМЕР_ПОСТАВЩИКА
FROM S
WHERE ГОРОД =
(SELECT ГОРОД
FROM S
WHERE НОМЕР_ПОСТАВЩИКА = 'S1');
Результат:
НОМЕР_ПОСТАВЩИКА
S1
S4
Иногда пользователь может знать, что заданный подзапрос должен возвратить в точности одно значение, как в рассматриваемом примере. В таком случае можно использовать вместо обычного IN более простой оператор сравнения (например, =, > и т. д.). Однако, если подзапрос возвращает более одного значения и не используется оператор IN, будет возникать ошибка. Ошибка не возникнет, если подзапрос не возвратит вообще ни одного значения. При этом сравнение интерпретируется в точности так, как если бы подзапрос возвратил неопределенное значение. Иными словами, если х — переменная, то сравнение
х простой—оператор—сравнения (подзапрос),
где «подзапрос» возвращает пустое множество, имеет значение истинности не истина или ложь, а неизвестно
(см. главу 4, пример 4.2.10).
Нужно отметить, что сравнение в предыдущем примере должно быть записано именно так, как показано — подзапрос должен следовать за оператором сравнения. Иначе говоря, следующая запись запроса некорректна:
SELECT НОМЕР_ПОСТАВЩИКА
FROM S
WHERE (SELECT ГОРОД
FROM S
WHERE НОМЕР_ПОСТАВЩИКА = 'S1') = ГОРОД;
Более того, подзапрос не может включать фраз GROUP BY или HAVING, если он используется с простым оператором сравнения, например с =, > и т. д.
ПОДЗАПРОСЫ
В этом разделе обсуждаются подзапросы или вложенные предложения SELECT. Говоря нестрого, подзапрос представляет собой выражение SELECT-FROM-WHERE, которое вложено в другое такое предложение [13]'. Обычно подзапросы используются для представления множества значений, исследование которых должно осуществляться в каком-либо предикате IN, как иллюстрируется в следующем примере.
Предмет обсуждения этой книги, система
Предмет обсуждения этой книги, система DB2, представляет собой программный продукт фирмы IBM, функционирующий в обстановке операционной системы MVS, а точнее — реляционную систему управления базами данных для MVS. Это означает, что рассматриваемый программный продукт позволяет пользователю (как конечному пользователю, так и прикладному программисту) в такой операционной обстановке запоминать данные в базах данных и осуществлять их выборку, воспринимая при этом базу данных как совокупность отношений или таблиц. DB2 обеспечивает доступ к таким базам данных посредством реляционного языка, называемого SQL («Structured Query Language» — Структуризованный язык запросов).
Вряд ли можно сказать, что название «DB2» вносит какую-либо ясность — оно мало что говорит о природе этого программного продукта. Ненамного лучше и полное его название — «IBM Database 2» («База данных 2 фирмы IBM»). В частности, из него, не ясно, что речь идет о реляционном программном продукте, или что он поддерживает язык SQL, или, наконец, что он функционирует в обстановке MVS. Более того, такое название даже и не совсем корректно, поскольку это вовсе не база данных, а система управления базами данных. Столь неблагоприятное начало не может, однако, затушевать того факта, что DB2 является исключительно важным продуктом. Его объявление в июне 1983 г. было значительным событием: оно окончательно наложило печать одобрения IBM на то, что стало называться реляционным подходом к. управлению базами данных. Этот подход, впервые предложенный в 1969—70-х годах Э. Ф. Коддом из Научно-исследовательской лаборатории фирмы IBM в Сан-Хосе, с тех пор медленно, но уверенно получал признание в самой фирме IBM и вне ее. DB2 занимает в настоящее время ведущее место среди основных программных продуктов IBM. Все они—реляционные, поддерживают язык SQL и функционируют в обстановке одной из главных операционных систем IBM: DB2 — в обстановке MVS, SQL/DS — DOS/VSE и SQL/DS Release 2 — VM/CMS.
Как только что упоминалось, реляционный подход был впервые предложен в 1969—70-х годах. Язык SQL был разработан в 1974 году, а основная реализация — прототип этого языка под названием System R — была создана и исследована IBM в течение приблизительно пятилетнего периода — в 1975—79 годах. Разработанная в рамках этого прототипа технология была далее использована в SQL/DS", первое полностью поддерживаемом реляционном программном продукте IBM, объявленном для DOS/ VSE в 1981 году, а для VM/CMS — в 1983 году. Впоследствии. она была использована и в DB2, объявленной для MVS в 1983 году. Все эти продукты — System R, SQL/DS и DB2 — внешне очень похожи. В частности, во всех трех системах очень похож язык SQL. Поэтому, несмотря на то что данная книга посвящена системе DB2, большинство сказанного в ней относится с небольшими изменениями также к System R и SQL/DS. Однако, начиная с этого места и далее, ссылка на «язык SQL», если не оговаривается иное, должна относиться специально к диалекту этого языка, поддерживаемому DB2.
Основная задача этой книги— дать подробное описание продукта DB2, не лишенное, однако, некоторых критических замечаний: что он собой представляет и чего не представляет, для чего он предназначен и как он может быть использован. Книга ориентирована на специалистов по управлению обработкой данных, по организации работы конечных пользователей, на специалистов в области баз данных, в том числе администраторов баз данных, системных администраторов, проектировщиков баз данных и прикладных программистов, работающих в обстановке баз данных. Она рассчитана также на студентов, специализирующихся в области обработки данных, на преподавателей этих дисциплин, на конечных пользователей и профессиональных специалистов по обработке данных, желающих расширить свои знания в области баз данных путем изучения системы, воплощающей современный уровень развития технологии баз данных. На протяжении всей книги при этом основное внимание уделяется пользователю, где под «пользователем» мы понимаем, главным образом, конечного пользователя либо прикладного программиста. Дается достаточно основательная интерпретация материала, ориентированного на пользователя, например материала, связанного с языком SQL. Наоборот, подробности, представляющие интерес только для системных программистов или операторов, связанные, например, с системными командами, вообще опущены или, в лучшем случае, обсуждаются только в общих чертах. Предполагается, что читатели имеют по крайней мере некоторое представление об общей структуре, концепциях и назначении систем баз данных. Однако от них не требуется, по существу, каких-либо знаний в области реляционных систем.
Книга имеет следующую структуру. В главах 1 и 2 приводится обзор возможностей системы DB2, показывающий, каким образом она соотносится с ее обстановкой и, в общих чертах, как она функционирует. Глава 3 посвящена определению данных, а главы 4—6 — манипулированию данными. В главе 7 обсуждается системный каталог. В главе 8 описываются специальные реляционные возможности, называемые механизмом представлений. В главе 9 обсуждается подсистема безопасности данных DB2, в частности показывается, как представления, о которых идет речь в предыдущей главе, могут использоваться для обеспечения безопасности. Главы 10—12 имеют дело с прикладным программированием. Наряду с другими вопросами в них обсуждается использование языка SQL для написания прикладных программ, довольно подробно освещаются вопросы обработки транзакций, в том числе соображения, касающиеся восстановления целостности данных и параллелизма. В главе 13 рассматриваются структуры хранения данных системы DB2. В главе 14 описывается интерактивный интерфейс DB2I, а в главе 15—периферийный программный продукт QMF (Query Management Facility), позволяющий запрашивать данные из базы данных и генерировать отчеты. Наконец, в главе 16 подытоживаются достоинства системы типа DB2, обсуждаются некоторые соображения о производительности, высказываются предположения о будущем реляционных систем. В книге содержится значительное число проверенных на ЭВМ примеров и в большинстве глав — множество упражнений вместе с ответами к ним.
Предлагаемая монография принадлежит перу известного
Предлагаемая монография принадлежит перу известного специалиста в области баз данных, одного из пионеров технологии реляционных баз данных— К. Дейта.
Эта работа посвящена детальному обсуждению нового программного продукта, созданного крупнейшим в мире производителем средств вычислительной техники и программного обеспечения—американской фирмой International Business Machines Corporation (IBM), в которой автор сотрудничал в течение многих лет. Речь идет о реляционной СУБД DB2, поставляемой фирмой с 1983 года. Появление на рынке программного обеспечения такого крупного программного продукта — весьма значительное событие. В немалой степени это связано и с тем, что он относится к такой сложной и перспективной области, как реляционные базы данных.
Прежде чем предоставить читателю возможность начать знакомство с системой, целесообразно кратко охарактеризовать предысторию ее создания. Это поможет лучше осознать проблемы, связанные с разработкой систем такого класса, объективно оценить научно-технический уровень системы DB2, понять, почему именно фирма IBM смогла создать такой сложный программный продукт.
Подход, основанный на реляционной модели данных, занял важное место в развитии технологии баз данных. Нет необходимости подробно обсуждать здесь его достоинства, как, впрочем, и трудности, связанные с его реализацией и использованием — они достаточно хорошо известны. Системами реляционного типа оснащены сегодня многие серийно выпускаемые модели ЭВМ, от мощных вычислительных комплексов до персональных компьютеров. Реляционный инструментарий предполагается использовать в качестве основного средства управления базами данных и базами знаний в разрабатываемых проектах ЭВМ нового поколения.
Значительный вклад в разработку теории реляционных баз данных и создание СУБД этого класса внесла фирма IBM. Еще в конце 60-х годов в ряде ее научных центров начали активно проводить теоретические исследования и экспериментальные разработки новых нетрадиционных подходов к управлению данными, базирующихся на строгом математическом понятии отношения. Необходимо было при этом решить целый ряд задач — определить целесообразную архитектуру СУБД нового типа, разработать новую модель данных, адекватные ей методы доступа и технологию обработки запросов, создать языковые средства, ориентированные на теоретико-множественный характер структур данных и операций над ними, предложить пути реализации программных систем такого типа, обеспечивающие достаточно высокую их производительность, создать прототипы будущих коммерческих СУБД, обладающих указанными возможностями, и экспериментально оценить их характеристики на ЭВМ.
Разработки, связанные с системами нового типа, получившими название «реляционных», проводились и многими другими группами специалистов. Однако именно результаты, полученные в этой области сотрудниками IBM, оказали определяющее влияние на формирование новой ветви в технологии баз данных.
В этой связи следует назвать прежде всего новаторские работы Э. Кодда, посвященные реляционной модели данных и ее математическим основам: исследования в области реляционной алгебры и реляционного исчисления, разработка алгоритма редукции (интерпретации выражений реляционного исчисления в реляционной алгебре), создание одного из первых реляционных языков, формулировка концепции реляционной полноты языка, разработка основ теории нормализации отношений. До сих пор повсеместно цитируется известная статья Кодда, опубликованная еще в 1970 году в журнале Communications of the ACM. Не здесь ли был впервые введен термин «реляционная модель данных»? Позднее, в 1979 году, Кодд опубликовал фундаментальную работу, в которой систематизируются и обобщаются результаты исследований ряда авторов, направленных на повышение семантического уровня моделей данных. В работе Кодда предлагается ввести в базовую реляционную модель новые механизмы, обеспечивающие более развитые возможности для формулировки ограничений целостности, или, иначе говоря, для выражения семантики предметной области. Тем самым были преодолены значительные трудности, связанные с использованием реляционной модели данных. Расширенная таким образом модель была названа автором RM/T.
Исследования Кодда в области реляционных баз данных получили широкое признание. В 1981 г. он был удостоен весьма престижной Тьюринговской премии, присуждаемой Ассоциацией по вычислительной технике США (ACM) за выдающийся вклад в развитие информатики.
Заслуживает внимания другой весьма интересный комплекс исследований, выполненный М. Сенко и руководимой им группой. Был предложен и конструктивно, вплоть до языковых спецификаций, проработан оригинальный подход к построению СУБД, в котором используется частный случай реляционной модели данных—модель бинарных отношений. Основная цель этого подхода, получившего название Data Independent Access Method (DIAM),—развитие концепций многоуровневой архитектуры СУБД, обеспечивающих высокую степень независимости данных. В публикациях группы Сенко, а впоследствии в большой серии принадлежащих ему лично статей и Докладов детально специфицированы все уровни архитектуры СУБД, реализующей предлагаемый подход. В частности, рассмотрены специальные методы доступа, организация среды хранения и способы представления хранимых данных, сформулированы ключевые идеи модели бинарных отношений и предложен синтаксис пользовательского языка FORAL (для версии DIAM II). Идеи СУБД с многоуровневой архитектурой были высказаны в этих работах за несколько лет до публикации известного отчета ANSI/SPARC (1975 г.), на который обычно ссылаются по этому поводу. В рамках DIAM специально изучались также возможности использования дисплея со световым пером для оперирования графическим представлением схемы базы данных. Эту работу можно рассматривать как одну из ранних попыток создания инструментария автоматизированного проектирования баз данных. К сожалению, подход DIAM не был практически реализован в какой-либо коммерческой системе. Весьма вероятно, что причиной этому явилась скоропостижная кончина М. Сенко.
Особое внимание в исследованиях IBM уделялось разработке языковых средств реляционных систем баз данных. Важное место при этом отводилось изучению психологических аспектов применения таких языков, с тем чтобы минимизировать потенциальную возможность пользовательских ошибок.
Наиболее заметными в этом направлении являются работы Д. Чемберлина, Р. Бойса и их соавторов по созданию реляционного языка, упоминаемого в литературе как SEQUEL или SQL (в процессе эволюции языка было создано несколько его версий). Благодаря большой популярности и тщательности отработки SEQUEL приобрел статус стандарта де-факто. Его описание можно найти в каждой более или менее серьезной монографии или учебном пособии по реляционным базам данных. И не случайно Комитет по разработке стандартов в области баз данных Американского национального института стандартов принял SEQUEL в качестве отправной точки в своей деятельности по созданию стандарта реляционного языка.
Наряду с SEQUEL следует указать здесь и другое направление работ IBM в области реляционных языков, связанное с именем М. Злуфа. Цель заключалась в создании более «дружественного» по сравнению с SEQUEL реляционного интерфейса, которым можно было бы воспользоваться, не обладая специальной профессиональной подготовкой в области баз данных. Исследования Злуфа увенчались созданием получившего широкую известность языка Query-By-Example (QBE). В отличие от SEQUEL, близкого по стилю к языкам программирования, QBE является «графически-ориентированным» языком и предназначен специально для интерактивной работы. Пользователь оперирует на экране дисплея формами таблиц, составляющих базу данных, и продуцируемых из них таблиц. Для спецификации запроса задаются образцы заполнения строк этих таблиц, ограничения, которым удовлетворяют их элементы, и требуемые операции над строками таблиц. В более сложных случаях применяются также другие средства языка. Интерфейс QBE поддерживается в ряде программных продуктов. Об одном из них идет речь в этой книге.
Нужно сказать, наконец, о разработках, направленных на создание собственно программного инструментария для реляционных баз данных, в основу которых были положены рассмотренные теоретические исследования. Понимая все трудности, связанные с созданием эффективной реляционной СУБД на существующем оборудовании, фирма не спешила с созданием коммерческого продукта, предназначенного для массового применения. Чтобы не дискредитировать идею с самого начала, нужна была известная осторожность.
Первым «пробным шаром» фирмы в этой области, вызвавшим большой интерес, явилась экспериментальная реляционная СУБД System R, в которой реализован язык SEQUEL. Работы над системой проводились в 1975—1979 гг. и дали возможность определить рациональные пути реализации систем подобного типа.
Развитие System R осуществлялось в двух направлениях. Одно из них — создание системы управления распределенными базами данных. Результатом этих работ стала система R*, которой посвящены многочисленные публикации. Другое направление — создание на основе System R коммерческой реляционной СУБД. Эта задача была решена к 1981 г., когда фирма начала поставку своего первого коммерческого реляционного продукта — системы SQL/DS. Спустя два года был сделан еще один шаг в этом направлении — IBM начала поставлять новую систему DB2, которой и посвящена предлагаемая монография К. Дейта.
Можно без преувеличения сказать, что система DB2 интегрирует весь арсенал современных достижений в технологии реляционных баз данных. Как видно из сказанного, ее разработке предшествовала многолетняя подготовительная работа — проведение разносторонних научных исследований, создание экспериментальных реализации и прототипов будущих программных продуктов, изучение их характеристик.
При создании системы DB2 особое внимание уделялось проблеме повышения ее производительности. В частности, DB2 реализована с этой целью по принципу компиляции запросов, тогда как в большинстве других существующих систем осуществляется их интерпретация. Связанное с этим решением определенное отступление в отношении независимости данных компенсируется в некоторой степени за счет принятия специальных мер. Тщательно продумана организация среды хранения данных, предусмотрен ряд механизмов, служащих для оптимизации обработки запросов, на самом современном уровне решены вопросы управления параллельным исполнением транзакций.
В качестве пользовательского языка в системе реализована новая версия все того же SEQUEL (называемого здесь SQL). На его основе строится как интерфейс включающего языка для прикладных программ («встроенный SQL»), так и интерактивный интерфейс для пользователя. Особый интерес представляет «динамический SQL»—интерфейс, позволяющий обрабатывать системными средствами запросы (SQL-тексты), задаваемые в прикладной программе как значения переменных типа литерной строки. Это позволяет легко создавать на основе DB2 различные интерактивные прикладные системы, причем отображение пользовательского языка в SQL осуществляется прикладной программой с помощью «динамического SQL».
Для системы DB2 предусмотрены различные варианты операционной обстановки, и пользователь может выбрать для себя наиболее подходящий. Совместно с системой могут использоваться такие полезные программные продукты, как QMF и DXT. QMF — это генератор отчетов, функционирующий по отношению к DB2 как периферийный компонент. Он позволяет специфицировать запросы не только на языке SQL, но и на QBE. В свою очередь, DXT дает возможность обрабатывать с помощью DB2 данные, хранимые в базах данных системы IMS или в наборах данных VSAM.
Совместимость системы DB2 и DXT имеет важное значение для расширения сферы ее потенциального применения. Благодаря этому новой системе открываются двери в те области, которые уже «обжиты» другой СУБД, созданной фирмой IBM,— системой IMS. За два десятилетия, прошедшие с момента начала ее поставки, система IMS получила массовое распространение — сфера ее действия стала весьма широкой. Поэтому забота о совместимости DB2 и DXT не лишена оснований.
На этом можно завершить обзор разработок фирмы IBM в области реляционных баз данных, поскольку читатель уже получил достаточно полное представление о предыстории создания системы DB2, и пора сказать несколько слов о самой книге.
Она представляет собой профессионально написанное руководство по системе DB2. В ней содержатся необходимые сведения об операционной обстановке системы, ее организации и архитектуре, принципах функционирования, порядке взаимодействия с программными продуктами QMF и DXT. Центральное место отводится детальному обсуждению функций языка SQL и особенностей его использования для всех предусмотренных пользовательских интерфейсов. В заключительной главе сжато характеризуются общие возможности системы DB2, рассматривается проблема производительности реляционных систем вообще и применительно к DB2, намечаются перспективы развития функциональных возможностей этой системы.
Читателю будет полезен и материал приложений. Здесь приведены строгие определения основных понятий реляционной модели данных, излагается точка зрения на вопрос о том, какая система имеет право называться «реляционной», рассматриваются важные методологические аспекты логического проектирования баз данных. Приводятся также требования системы DB2 и сопутствующих ей программных продуктов к операционной обстановке и оборудованию ЭВМ. Для справочных целей включена сводка синтаксических спецификаций предложений манипулирования данными языка SQL.
Новая работа К. Дейта не только будет интересна специалистам по программному обеспечению информационных систем, но и с успехом может быть использована как учебное пособие по реляционным СУБД. Для этого в книге при всей ее лаконичности имеется все необходимое — от концепций реляционной модели данных и методологии проектирования реляционных баз данных до систематического рассмотрения архитектуры, пользовательских интерфейсов и технологии функционирования самой современной СУБД такого класса, от теоретического материала до технических спецификаций и проверенных на ЭВМ многочисленных практических упражнений и ответов к ним. Книга хорошо скомпонована, написана четким и ясным языком. Умело подобран иллюстративный материал.
В заключение коротко об авторе. С начала 70-х годов К. Дейт занимается реляционными базами данных и стал одним из ведущих специалистов в этой области. В течение многих лет он тесно сотрудничал с Э. Коддом, которому в знак признательности он посвящает эту книгу. К. Дейт — один из руководителей и непосредственный участник разработки системы DB2. Знание системы «изнутри» помогло объективно показать не только ее достоинства, но и слабые места.
Можно не сомневаться в том, что советский читатель получил полезную и нужную книгу.
М. Когаловский
ПРЕДЛОЖЕНИЕ DELETE
Предложение DELETE имеет следующий общий формат:
DELETE
FROM таблица
[WHERE предикат];
Удаляются все записи в «таблице», которые удовлетворяют «предикату».
Удалить все поставки тех поставщиков, которые находятся в городе, заданном переменной включающего языка ГОРОД.
ЕХЕС SQL DELETE
FROM SP
WHERE :ГОРОД=
(SELECT ГОРОД
FROM S
WHERE S.HOMEP_ПОСТАВЩИКА =
SP.НОМЕР_ПОСТАВЩИКА);
И снова, если никакие записи не удовлетворяют условию WHERE, для поля SQLCODE будет установлено значение +100.
ПРЕДЛОЖЕНИЕ INSERT
Предложение INSERT имеет следующий общий формат:
INSERT
INTO таблица [(поле [,поле] . . .)]
VALUES (константа [,константа] . . .);
ИЛИ:
INSERT
INTO таблица [(поле [,поле] . . .)]
подзапрос;
В первом формате в «таблицу» вставляется строка, имеющая заданные значения для указанных полей, причем 1-я константа в списке констант соответствует i-му полю в списке полей. Во втором формате вычисляется «подзапрос»; копия результата, представляющего собой, вообще говоря, множество строк, вставляется в «таблицу». При этом 1-й столбец этого результата соответствует f-му полю в списке полей. В обоих случаях отсутствие списка полей эквивалентно спецификации списка всех полей в таблице (см. ниже пример 6.4.2).
Вставить в таблицу Р новую деталь. При этом номер детали, название и вес заданы соответственно переменными включающего языка НОМ_ДЕТАЛИ, НАЗВ_ДЕТАЛИ и ВЕС_ДЕТАЛИ, а цвет и город неизвестны.
ЕХЕС SQL INSERT
INTO Р (НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ВЕС)
VALUES (:HOM_ДЕТАЛИ, :НАЗВ_ДЕТАЛИ,
:ВЕС_ДЕТАЛИ);
Опять здесь можно использовать индикаторные переменные. Например, если ЦВЕТ_ДЕТАЛИ и ГОР_ДЕТАЛИ — две следующие переменные включающего языка, ИНД_ЦВЕТА и ИНД_ГОРОДА — соответствующие индикаторные переменные, то последовательность
ИНД_ЦВЕТА = -1;
ИНД_ГОРОДА = -1;
ЕХЕС SQL INSERT
INTO Р (НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ЦВЕТ, ВЕС,
ГОРОД)
VALUES (:HOM_ДЕТАЛИ, :НАЗВ_ДЕТАЛИ,
:ЦВЕТ_ДЕТАЛИ: ИНД_ЦВЕТА,
:ВЕС_ДЕТАЛИ,
:ГОР_ДЕТАЛИ: ИНД_ГОРОДА);
дает тот же результат, что и приведенное выше предложение INSERT.
Для простоты в дальнейшем (в этой и двух следующих главах) будем в большинстве случаев игнорировать индикаторные переменные и возможность неопределенных значений.
ПРЕДЛОЖЕНИЕ UPDATE
Предложение UPDATE имеет следующий общий формат:
UPDATE таблица
SET поле = выражение
[,поле = выражение] . . .
[WHERE предикат];
Все записи в «таблице», которые удовлетворяют «предикату», обновляются в соответствии с присваиваниями «поле = выражение» во фразе SET (установить).
Увеличить состояние всех поставщиков из Лондона на величину, заданную переменной включающего языка ПРИРОСТ:
ЕХЕС SQL UPDATE S
SET СОСТОЯНИЕ = СОСТОЯНИЕ + :ПРИРОСТ
WHERE ГОРОД = 'Лондон';
Если записей, удовлетворяющих условию WHERE, нет, для поля SQLCODE будет установлено значение +100. Справа от знака присваивания во фразе SET может быть использована индикаторная переменная. Например, предложение:
ИНД_РАНГА = -1;
ЕХЕС SQL UPDATE S
SET СОСТОЯНИЕ = :РАНГ :ИНД_РАНГА
WHERE ГОРОД = 'Лондон';
установит состояние всех лондонских поставщиков в неопределенное значение. То же самое можно, конечно, сделать с помощью предложения:
ЕХЕС SQL UPDATE S
SET СОСТОЯНИЕ = NULL
WHERE ГОРОД = 'Лондон';
ПРЕДЛОЖЕНИЯ COMMIT И ROLLBACK
Из предыдущего раздела должно быть ясно, что COMMIT и ROLLBACK в действительности не являются такими же операциями управления базой данных, как SELECT, UPDATE и т. д. Предложения COMMIT и ROLLBACK—это вообще не команды для СУБД. Они представляют собой команды для администратора транзакций, который не является, конечно, частью СУБД. Наоборот, СУБД подчиняется администратору транзакций в том смысле, что СУБД — это только один из нескольких возможных «администраторов ресурсов», которые обеспечивают обслуживание транзакций, выполняемых под управлением этого администратора транзакций. В частности, в случае системы DB2 имеются три таких администратора транзакций — IMS, CICS и TSO, и заданная транзакция DB2 может исполняться под управлением в точности одного из них. Как уже указывалось (в несколько иных терминах) в главе 1:
— транзакция, исполняемая под управлением администратора транзакций IMS, может использовать услуги трех администраторов ресурсов — системы баз данных IMS, системы передачи данных IMS и системы DB2;
— транзакция, исполняемая под управлением администратора транзакций CICS, также может использовать услуги трех администраторов ресурсов — опять-таки системы баз данных IMS, системы передачи данных CICS и системы DB2;
— транзакция, исполняемая под управлением администратора транзакций TSO, может использовать услуги двух администраторов ресурсов — терминальной системы TSO и системы DB2.
Рассмотрим транзакцию, которая обновляет как базу данных системы IMS, так и базу данных системы DB2. Если эта транзакция завершается успешно, то все произведенные ею обновления как данных IMS, так и данных DB2, должны быть зафиксированы. Наоборот, если она завершается неудачно, то для всех
произведенных ею обновлений должен быть осуществлен откат. Не должна допускаться такая возможность, чтобы обновления для IMS были зафиксированы, а для обновлений в DB2 был осуществлен откат, и наоборот. При этом транзакция не была бы больше атомарной (все или ничего). Очевидно, таким образом, что для транзакции не имеет смысла издавать, например, COMMIT для IMS и ROLLBACK для DB2. И если даже в обоих случаях издаются одинаковые команды, в системе может все же возникнуть отказ в промежутке между ними, и результат будет неудовлетворительным. Следовательно, транзакция должна издавать единственную общесистемную команду COMMIT (или ROLLBACK), адресуя се соответствующему администратору транзакций, а этот администратор транзакций в свою очередь гарантирует, что все администраторы ресурсов в унисон будут фиксировать или осуществлять откат обновлений, за которые они ответственны. (Более того, он обеспечивает такую гарантию, даже если возникнет отказ системы в ходе этого процесса, благодаря протоколу, называемому двухфазной фиксацией. Однако подробности об этом протоколе выходят за рамки этой книги (Заинтересованный читатель может найти подробное обсуждение этого вопроса в книге Д. Ульмана «Основы систем баз данных» (М.: Финансы и статистика, 1983).— Примеч. пер.)
Именно поэтому СУБД подчиняется (подчиняются) администратору транзакций. COMMIT и ROLLBACK должны быть глобальными (общесистемными) операциями, и администратор транзакций действует как необходимый центральный пункт управления, который обеспечивает, чтобы это было так.
Из предыдущего также ясно, почему требуются различные функции «фиксации» и «отката» при трех разных вариантах операционной обстановки системы DB2. Поскольку они вообще являются не операциями DB2, а, скорее, операциями администратора транзакций, они должны запрашиваться в том стиле, который предписан для рассматриваемого администратора транзакций. В обстановке TSO они запрашиваются с помощью явных операторов языка SQL — COMMIT и ROLLBACK (подробности приведены ниже). В случае IMS и CICS они запрашиваются с помощью соответствующих обращений к IMS и CICS, подробности о которых можно найти в руководствах фирмы IBM по этим системам. В остальной части данного раздела основное внимание уделено обстановке TSO[20].
Прежде чем перейти к подробному рассмотрению предложений COMMIT и ROLLBACK как таковых, определим сначала важное понятие «точка синхронизации». Точка синхронизации представляет собой граничную точку между двумя последовательными транзакциями. Грубо говоря, она соответствует концу логической единицы работы и таким образом является точкой, в которой база данных находится в непротиворечивом состоянии. Точка синхронизации учреждается при инициации программы, издании COMMIT и ROLLBACK и только в этих случаях. Напомним, однако, что COMMIT и ROLLBACK иногда могут быть неявными.
Предложение COMMIT
Предложение COMMIT языка SQL имеет следующий формат:
COMMIT [WORK];
Это предложение сигнализирует об успешном завершении транзакции и учреждает точку синхронизации. Все обновления, сделанные данной программой со времени предыдущей точки синхронизации, фиксируются. Все открытые курсоры закрываются. Снимаются все блокировки записей. Блокировки, установленные с помощью LOCK TABLE, вероятно, не будут сняты (см. разделы 11.5 и 11.6).
Необязательный операнд
WORK (работа) является чисто вспомогательным и не оказывает какого- либо влияния на выполнение этого предложения.
Предложение ROLLBACK
Предложение ROLLBACK языка SQL имеет следующий формат:
ROLLBACK [WORK];
Это предложение сигнализирует о неудачном завершении транзакции и учреждает точку синхронизации. Все обновления, сделанные программой после учреждения последней точки синхронизации, аннулируются. Все открытые курсоры закрываются. Снимаются все блокировки записей. Однако блокировки, установленные с помощью LOCK TABLE, вероятно, не будут сняты (см. разделы 11.5 и 11.6).
Необязательный операнд
WORK является чисто вспомогательным и не оказывает какого-либо влияния на выполнение этого предложения.
Предыдущие определения порождают ряд вопросов, явно заслуживающих более серьезного обсуждения.
1. Прежде всего отметим, что каждая операция в системе DB2 исполняется в контексте некоторой транзакции. Это касается и операций SQL, которые вводятся в интерактивном режиме через интерфейс DB2I. Точки синхронизации для операций, введенных через интерфейс DB2I, учреждаются способом, который рассматривается в главе 14.
2. Из приведенных определений следует, что транзакции не могут быть вложены одна в другую, поскольку каждое из предложений COMMIT или ROLLBACK завершает одну транзакцию и инициирует другую.
3. Следствием предыдущего пункта является тот факт, что исполнение отдельной программы состоит из последовательности одной или более транзакций (часто, но совсем не обязательно, только одной). Если это только одна транзакция, часто будет возможно кодировать программу вообще без каких-либо явных предложений COMMIT или ROLLBACK.
Наконец, из всего сказанного выше следует, что транзакции являются не только единицами работы, но также и единицами восстановления. Если транзакция успешно выполнит операцию COMMIT, то администратор транзакций должен гарантировать, что сделанные ею обновления будут обязательно отражены в базе данных, даже если в следующий момент будет иметь место отказ системы. Вполне возможно, например, что отказ системы произойдет после того, как будет выполнена операция COMMIT, но прежде, чем обновления будут физически записаны в базу данных,—они могли еще оставаться в буфере в основной памяти, и поэтому утратились бы во время такого отказа системы. Даже если это случится, процедура рестарта системы все же установит эти обновления в базе данных. Она способна восстановить значения, которые должны быть записаны в базу данных благодаря анализу соответствующих записей в журнале. (Из этого следует, в частности, что запись в журнал будет физически осуществляться до того, как может завершиться обработка операции COMMIT. Это правило называется протоколом упреждающей записи в журнал.)
Таким образом, процедура рестарта будет восстанавливать любые единицы работы (транзакции), которые завершились успешно, но для которых не удалось физически записать сделанные ими обновления до того, как произойдет отказ. Следовательно, как утверждалось выше, транзакция с достаточным на то основанием может определяться и как единица восстановления.
ПРЕДЛОЖЕНИЯ GRANT И REVOKE
Рассмотренный в разделе 9.3 механизм представлений концептуально позволяет различными способами подразделить базу данных на подмножества таким образом, чтобы секретные сведения могли быть скрыты от пользователя, не обладающего правом доступа. Однако в нем не предусматривается спецификация тех операций, которые разрешается выполнять над этими подмножествами полномочному пользователю. Эту функцию выполняют предложения GRANT (предоставить) и REVOKE (отменить) языка SQL, которые обсуждаются ниже.
Прежде всего, чтобы вообще быть способным выполнить какую-либо операцию в DB2, пользователь должен обладать соответствующей привилегией (или полномочиями) на выполнение этой операции. В противном случае операция будет отвергнута с выдачей надлежащего сообщения об ошибке или кода исключительного состояния. Например, чтобы успешно выполнить предложение
SELECT *
FROM S;
пользователь должен обладать привилегией на выполнение операции
SELECT над таблицей S. В системе DB2 предусматривается широкий диапазон привилегий. Вообще говоря, каждая привилегия попадает, однако, в один из следующих классов:
а) привилегии на таблицы., связанные с такими операциями, как SELECT, которые выполняются над таблицами — как над базовыми таблицами, так и над представлениями;
б) привилегии на планы, которые имеют отношение к таким вещам, как полномочия на выполнение заданного плана прикладной задачи;
в) привилегии на базу данных, которые касаются таких операций, как создание таблицы в конкретной базе данных;
г) привилегии на использование, которые связаны с использованием определенных объектов среды хранения, а именно: с группами хранения, табличными пространствами и буферными пулами (см. главу 13);
и, наконец,
д) системные
привилегии, имеющие отношение к некоторым общесистемным операциям, таким, как операция создания новой базы данных.
Имеются также некоторые «пакетированные» привилегии, которые фактически служат кратким обозначением для совокупностей других привилегий, не всегда относящихся в точности к одному из указанных выше пяти классов. В частности, привилегия системного администрирования SYSADM является кратким обозначением для совокупности всех других привилегий в системе. Таким образом, пользователь, обладающий привилегией SYSADM, может выполнять любую операцию во всей системе при условии ее корректности. Примером операции, которая не была бы «корректной» в этом смысле, могла бы быть попытка уничтожить одну из таблиц каталога. Этого не может делать даже пользователь, обладающий привилегией SYSADM.
Итак, когда система DB2 впервые устанавливается, некоторая часть процесса установки требует назначения одного особо привилегированного пользователя системным администратором этой установленной системы. Для DB2 системный администратор идентифицируется идентификатором санкционирования доступа, точно так же, конечно, как и все другие пользователи. Этот пользователь, который автоматически получает привилегию SYSADM, становится ответственным за общее управление системой в течение всей продолжительности ее жизни. Например, в обязанности системного администратора входит текущий контроль за функционированием системы, сбор статистики о ее производительности и учетной информации. Но мы обсуждаем здесь лишь вопросы безопасности. Поэтому вернемся к главной теме обсуждения. Сначала имеется, таким образом, один пользователь, который может делать все, в частности, он или она может предоставлять привилегии другим пользователям, и никто иной не может делать вообще все.
Отметим, между прочим, что, хотя системный администратор является, конечно, обладателем привилегии SYSADM, не все обладатели привилегии SYSADM являются системными администраторами. Привилегия SYSADM может быть в дальнейшем предоставлена также другим пользователям, но эта привилегия может быть впоследствии снова отменена. Для системного администратора привилегия SYSADM никогда не может быть отменена[18].
Далее, пользователь, который создает некоторый объект, например базовую таблицу, автоматически получает полные привилегии на этот объект, включая, в частности, привилегию предоставления таких привилегий другому пользователю. Конечно, «полные привилегии» не включают здесь привилегий, которые не имеют смысла. Если, например, пользователь U обладает только привилегией на выполнение операции SELECT над базовой таблицей Т и создает некоторое представление V, которое основано на Т, то U, естественно, не получает привилегии на выполнение операции UPDATE над V. Подобным же образом, если U создает представление С, которое является соединением таблиц А и В, то U не получает привилегии на выполнение операции UPDATE над С, независимо от того, обладал ли он такими привилегиями для таблиц А и В, поскольку система DB2 не допускает каких-либо операций обновления по отношению к представлению, являющемуся соединением.
Предложение GRANT
Предоставление привилегий осуществляется с помощью предложения GRANT (предоставить). Общий формат этого предложения:
GRANT привилегии [ON тип — объектов объекты] ТО пользователи;
где «привилегии» — список, состоящий из одной или более привилегий, разделенных запятыми, либо фраза ALL PRIVILEGES (все привилегии); «пользователи» — это список, включающий один или более идентификаторов санкционирования, разделенных запятыми, либо специальное ключевое слово PUBLIC (общедоступный); «объекты» — это список имен одного или более объектов одного и того же типа, разделенных запятыми; наконец, «тип — объектов» указывает тип этого объекта или этих объектов. Фраза ON не используется, если предоставляемые привилегии являются системными.
Приведем несколько примеров.
Привилегии на таблицы
GRANT SELECT ON TABLE S TO ЧАРЛИ;
GRANT SELECT, UPDATE (СОСТОЯНИЕ, ГОРОД) ON TABLE S
TO ДЖУДИ, ДЖЕК, ДЖОН;
GRANT ALL PRIVILEGES ON TABLE S, P, SP TO УОЛТ, ТЕД;
GRANT SELECT ON TABLE P TO PUBLIC;
GRANT DELETE ON S TO ФИЛ;
Примечание. Если «тип—объектов»—TABLE (таблица), его можно опустить, как показано в последнем примере.
Привилегии на планы:
GRANT EXECUTE ON PLAN ПЛАН1 TO ДЖУДИ;
Привилегии на базу данных:
GRANT CREATETAB ON DATABASE DBX TO ШАРОН;
Пользователю Шарону разрешается создавать таблицы в базе данных DBX. Организация баз данных в системе DB2 обсуждается в главе 13.
Привилегии на использование:
GRANT USE ON TABLESPACE TSE TO КОЛИН;
Пользователю Колину разрешается использовать табличное пространство TSE для хранения любых таблиц, которые он может создавать. Более подробную информацию по этому вопросу также можно найти в главе 13.
Системные привилегии:
GRANT CREATEDBC ТО ЖАК, МАРИАН;
Пользователям Жаку и Мариан разрешается создавать новые базы данных. Если они будут это делать, то автоматически получат привилегию DBCTRL на эти базы данных (см. в конце данного раздела).
Здесь не ставилась задача в полной мере и исчерпывающим образом рассмотреть все множество привилегий, которые признает система DB2. Однако будут полностью рассмотрены привилегии на таблицы, поскольку они, вероятно, представляют наиболее широкий интерес. К таблицам (как к базовым таблицам, так и к представлениям) относятся следующие привилегии:
SELECT
UPDATE (может относиться к конкретным столбцам)
DELETE
INSERT
Две остальные привилегии относятся только к базовым таблицам:
ALTER (привилегия на исполнение предложения ALTER TABLE над данной
таблицей)
INDEX (привилегия на исполнение предложения CREATE INDEX над данной
таблицей)
Для того чтобы создать
таблицу, требуется, как уже говорилось, привилегия CREATETAB для базы данных, к которой относится эта таблица. Для создания представления требуется привилегия SELECT на каждую таблицу, упоминаемую в определении этого представления. Заметим, что привилегия SELECT, в отличие от UPDATE, не может относиться к конкретным столбцам. Причина заключается в том, что эффекта привилегии SELECT, распространяющейся на конкретные столбцы, всегда можно добиться путем предоставления привилегии SELECT, не относящейся к конкретным столбцам, на представление, состоящее как раз из рассматриваемых столбцов.
Предложение REVOKE
Если пользователь U1 предоставляет какую-либо привилегию некоторому другому пользователю U2, то пользователь U1 может впоследствии отменить эту привилегию для пользователя U2. Отмена привилегий осуществляется с помощью предложения REVOKE (отменить), общий формат которого очень похож на формат предложения GRANT:
REVOKE привилегии [ON тип — объектов объекты] FROM пользователи;
Отмена данной привилегии для данного пользователя приводит к тому, что все планы прикладных задач, связывание которых осуществлялось этим пользователем, помечаются как «недействительные» и, следовательно, автоматически приводит при следующем вызове каждого такого плана к повторному связыванию. Этот процесс, по существу, аналогичен тому, что происходит, когда уничтожается такой объект, как индекс. Ниже приводится несколько примеров предложения REVOKE:
REVOKE SELECT ON TABLE S FROM ЧАРЛИ;
REVOKE UPDATE ON TABLE S FROM ДЖОН;
REVOKE CREATETAB ON DATABASE DBX FROM НАНСИ, ДЖЕК;
REVOKE SYSADM FROM СЭМ;
Отмена привилегии
UPDATE не может относиться к конкретным столбцам.
Факультативная возможность GRANT
Если пользователь U1 имеет полномочия на предоставление привилегии Р другому пользователю U2, то пользователь U1 имеет также полномочия на предоставление привилегии Р пользователю U2 «с возможностью GRANT» (путем спецификации фразы WITH GRANT OPTION в предложении GRANT). Передача таким образом возможности GRANT от пользователя U1 пользователю U2 означает, что U2 теперь в свою очередь имеет полномочия на предоставление привилегии Р некоторому третьему пользователю U3. И, следовательно, U2, конечно, также обладает полномочиями на передачу возможности GRANT с таким же успехом пользователю U3 и т. д. Например:
Пользователь U1:
GRANT SELECT ON TABLE S TO U2 WITH GRANT OPTION;
Пользователь U2:
GRANT SELECT ON TABLE S TO U3 WITH GRANT OPTION;
Пользователь U3:
GRANT SELECT ON TABLE S TO U4 WITH GRANT OPTION;
и т. д. Если пользователь U1 издает теперь предложение:
REVOKE SELECT ON TABLE S FROM U2;
то отмена будет распространяться каскадом, т. е. будут автоматически отменены также передачи привилегий пользователем U2 пользователю U3 и пользователем U3 пользователю U4. Заметим, однако, что из этого не следует, что пользователи U2, U3 и U4 более не имеют привилегии SELECT на таблицу S—они могут помимо этого иметь такие привилегии, полученные от некоторого другого пользователя U5. Когда пользователь U1 издает предложение REVOKE, то фактически аннулируются только привилегии, которые предоставлялись этим пользователем. Рассмотрим, например, следующую последовательность событий.
Пользователь U1 в момент времени t1:
GRANT SELECT ON TABLE S TO U2 WITH GRANT OPTION;
Пользователь U5 в момент времени t2:
GRANT SELECT ON TABLE S TO U2 WITH GRANT OPTION;
Пользователь U2 в момент времени t3:
GRANT SELECT ON TABLE S TO U3;
Пользователь U1 в момент времени t4:
REVOKE SELECT ON TABLE S FROM U2;
Пусть при этом t1<t2<t3<t4.
Предложение REVOKE, изданное пользователем U1 в момент времени t4, фактически не лишает пользователя U2 привилегии на таблицу S, поскольку пользователь U2 получил эту привилегию также от U5 в момент времени t2. Поскольку далее предложение GRANT пользователя U2 для пользователя U3 было выполнено в момент времени t3 и t3> t2, то, возможно, что это GRANT было привилегией, которая была получена от пользователя U5, а не от U1. Поэтому пользователь U3 также не утрачивает этой привилегии. И если бы в момент t4 предложение REVOKE издал бы пользователь U5, а не U1, пользователи U2 и U3 также все еще сохранили бы эту привилегию. U2 сохранил бы привилегию, полученную от U1, и GRANT, изданный пользователем U2, мог бы, вероятно, служить для предоставления привилегии, полученной от U1, а не от U5, и пользователь U3 снова не утратил бы привилегию. Предположим, однако, что имела место другая последовательность событий.
Пользователь U1 в момент времени t1:
GRANT SELECT ON TABLE S TO U2 WITH GRANT OPTION;
Пользователь U2 в момент времени t2:
GRANT SELECT ON TABLE S TO U3 WITH GRANT OPTION;
Пользователь U5 в момент времени t 3:
GRANT SELECT ON TABLE S TO U2 WITH GRANT OPTION;
Пользователь U1 в момент времени t4:
REVOKE SELECT ON TABLE S FROM U2;
Тогда REVOKE пользователя U1 в момент времени t4 не будет лишать пользователя U3 привилегии SELECT на таблицу S, поскольку пользователь U2 получил эту привилегию также от U5 в момент t3. Однако, в противоположность предыдущему примеру, U3, утратит привилегию в этот момент времени, поскольку GRANT пользователя U2, возможно, имел дело с привилегией, полученной от пользователя U1.
Возможность GRANT нельзя отменить, не отменяя в то же время привилегии, к которой эта возможность относится.
Пакетированные (административные) привилегии
Для справочных целей завершим этот раздел кратким обзором пяти «пакетированных» привилегий, а именно: SYSADM, DBADM, DBCTRL, DBMAINT, SYSOPR.
— SYSADM
Привилегия SYSADM («системный администратор») позволяет ее обладателю выполнять любую операцию, которую поддерживает система.
— DBADM
Привилегия DBADM («администрирование базой данных»)
— относительно конкретной базы данных позволяет ее обладателю выполнять любую операцию, которую поддерживает система для этой базы данных.
— DBCTRL
Привилегия DBCTRL («управление базой данных») относительно конкретной базы данных позволяет ее обладателю выполнять любую операцию, которую поддерживает система для этой базы данных, за исключением операций доступа к значениям данных в этой базе данных, т. е. такие обслуживающие операции, как «восстановить базу данных», допускаются, а операции манипулирования данными языка SQL—нет.
— DBMAINT
Привилегия DBMAINT («ведение базы данных») относительно конкретной базы данных позволяет ее обладателю выполнять над этой базой данных обслуживающие операции, связанные только с чтением данных, например вспомогательную операцию «копировать содержимое базы данных в среде хранения».
— SYSOPR
Привилегия SYSOPR («системный оператор») позволяет ее обладателю выполнять системные функции оператора консоли, например операции начала и завершения трассировки функционирования системы.
Для конкретной базы данных привилегии категории DBADM включают DBCTRL, а привилегии DBCTRL включают DBMAINT. И конечно же, SYSADM включает привилегии всех других категорий.
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
B
B-дерево, 193
А
Автоматическая навигация, 33
Администратор базы данных, 136, 186
— системный, 136
— транзакций, 163
Алгебра реляционная, 234
Анализ на непротиворечивость, 169
Аргумент (динамический SQL), 182
Ассоциация, 241
Атомарность значений данных, 24
— операций, 164
— транзакций, 163
Атрибут, 26
Б
База данных, 186
— —по умолчанию, 195
— —
пользовательская, 186
— — реляционная, 22
— — системная, 186
Безопасность данных, 132
— представления, 133
Блок условия, 211
Блокирование, 169
Блокировка монопольная, 169
— совместная, 170
В
Вариант CHECK, 118
— GRANT, 138
Восстановление, 166
Г
Генератор деклараций DCLGEN, 155
— планов прикладных задач, 35
Генерация кода, 38
Граф ожидания, 179
Группа памяти, 188
— — по умолчанию, 196
— повторяющаяся, 25
Д
Данные скрытые, 128
Домен, 231
Е
Единица блокирования, 176
— восстановления, 166
Ж
Журнал, 163
З
Зависимость от незафиксированного обновления, 167
— функциональная, 249
Запись хранимая, 190
Значение неопределенное, 45
— — в арифметическом выражении, 55
— — в индексе с параметром UNIQUE, 47
— — в предложении SELECT DISTINCT, 60
— — в предложении UPDATE, 98
— — в сравнениях, 59
— — во встроенном языке, 149
— — во фразе GROUP BY, 86
— — во фразе ORDER BY, 60
— — при проектировании базы данных, 252
И
Идентификатор записи, 191
— санкционирования доступа, 132
Импликация, 81
Имя, 43
— представления, 116
— уточненное, 53
Индекс, 138, 187, 188, 190
— кластеризации, 190
Интерфейс интерактивный, 197
Исключение дубликатов, 54
К
Каталог, 39, 109
Квантор, 77
— общности FORALL, 79
— существования, 77
Классификация связей, 241
— сущностей, 240
Кластеризация внутритабличная, 190
— межтабличная, 190
Ключ альтернативный, 233
— внешний, 234
— возможный, 233
Команда BIND, 201
— DISPLAY FORM, 204
— DISPLAY REPORT, 205
— DRAW COND, 212
— FREE, 201
— PRINT REPORT, 205
— REBIND, 201
— RUN QUERY, 204
— DRAW, 210
Константы, 45
Кортеж, 231
Курсор, 151
—, стабильноcть его, 175
М
Макетирование, 223
Манипулирование данными, 28
Модель данных реляционная, 25
Модуль запросов к базе данных, 34
— языка программирования интерфейсный, 37
Н
Навигация, 31
— автоматическая, 221
— ручная, 221
Независимость данных, 40, 222
— логическая, 222
— физическая, 40
Нормализация, 240, 248
О
Области рабочая QUERY, 204
— дескрипторов SQLDA, 183
— рабочая FORM, 205
— рабочая временная, 204
— связи SQLCA, 183
Обновление данных, 98
— —
незафиксированное, 167
— —утраченное, 167
Обозначение, 241
Обстановка операционная системы DB2, 20
Ограничение санкционирования доступа, 132
Оператор сравнения ALL, 71
— — ANY, 71
Операция декартова произведения, 236
— деления, 237
— присваивания реляционная, 238
— проекции, 236
— разности, 236
— соединения, 237
Отношение, 232
— базовое, 234
Отношения, совместимые по объединению, 235
Отчет, 204
П
Параметр UNIQUE, 47
— динамического SQL, 182, 184
Переменная включающего языка, 146
— индикаторная, 149
— системная USER, 134
План прикладной задачи, 35, 38
Подзапрос, 72
— коррелированный, 74
Подтип сущностей, 251
Поле SQLCODE, 147
Пользователь, 28
Предикат BETWEEN, 57
— IN, 57
— — с подзапросами, 72
— LIKE, 58
Предлжение DELETE CURRENT, 153
— INSERT встроенного языка, 150
— ALTER TABLE, 46
— CLOSE, 151
— COMMENT ON, 112
— COMMIT, 155
— CREATE INDEX, 47
— CREATE SYNONYM, 113
— CREATE TABLE, 43, 46
— CREATE VIEW, 115
— DECLARE CURSOR, 151
— DECLARE TABLE, 146
— DELETE, 99
— DELETE встроенного языка, 150
— DROP INDEX, 48
— DROP SYNONYM, 113
— DROP TABLE, 46
— DROP VIEW, 118
— EXECUTE, 182
— FETCH, 151
— GRANT, 135
—INCLUDE (декларация), 155
— INCLUDE SQLCA, 147
— INCLUDE SQLDA, 183
— INSERT, 100
— LOCK TABLE, 174
— OPEN курсор, 152
— PREPARE, 181
— REVOKE, 135
— ROLLBACK, 156
— SELECT, 53
— SELECT вложенное, 72
— SELECT встроенного языка, 148
— SELECT единичное, 148
— SELECT обработка, 90
— SELECT*, 55
— UPDATE, 98
— UPDATE CURRENT, 153
— UPDATE встроенного языка, 149
— WHENEVER, 155
Представление, условие обновляемости, 121
Представления, 29
Преимущества реляционных систем, 220
Прекомпилятор, 34
Привилегия, 135
— BCTRL, 140
— DBADM, 140
— DBMAINT, 140
— SYSADM, 140
— SYSOPR, 140
— административная, 140
— требуемая пользователю, 140
Приложение интерактивное, 21
— пакетное, 21
Принцип двухрежимный, 145
Проверка полномочий, 38
—правильности плана, 201
Программа управления хранимыми данными, 36
Проектирование базы данных, 240
Производительность системы, 225
Пространство индексное, 186
— табличное, 186
— — по умолчанию, 189
— — простое, 189
— — табличное сегментированное, 190
Протокол упреждающей записи в журнал, 166
Процедура проверки достоверности, 192
— редактирования, 191
Процессор SPUFI, 199
Псевдоним, 66
ПсевдоЯОД, 245
Пул буферный, 196
Путь доступа, 38
Р
Реорганизация, 189
Реструктуризация, 126
С
Свойство, 240
Связь, 240
Сегментирование пространства, 189
Синоним, 113
Система R*, 230
— SQL/DS, 230
— реляционная, 238
Ситуация тупиковая, 176
Словарь данных (каталог), 109
Спецификация DISTINCT, 53
Средство программное DL/1 Extract, 22
— — DXT, 22
— — QMF, 22
Степень отношения, 233
Страница, 186
Супервизор стадии исполнения, 35
Сущность, 240
— ассоциативная, 240
— стержневая, 240
—
характеристическая, 240
Т
Таблица, 42
— базовая, 42
— виртуальная, 30
— каталога, 109
— хранимая, 186
Тип данных, 44
Точка синхронизации, 165
Транзакция, 162
У
Умолчание системное, 188
Управление параллельными процессами, 166
Уровень изоляции, 175
Утилита, 202
Ф
Фиксация автоматическая, 163
— двухфазная, 165
Форма отношения нормальная, 248
— отчета по умолчанию, 204
Фраза FOR UPDATE, 152
— GROUP BY, 85
— HAVING, 86
— NOT NULL, 45
— ORDER BY (определение курсора), 152
— ORDER BY (предложение SELECT), 56
— USING (предложения EXECUTE), 182
— USING (предложение FETCH), 184
Функция стандартная AVG, 83
— — COUNT (*), 83
— — MIN, 83
— — SUM, 83
— — МАХ, 83
Х
Характеристика, 241
Ц
Целостность по ссылкам, 99, 234
— — сущностям, 234
Ч
Число кардинальное отношения, 233
Чтение повторяемое, 175
Э
Эквисоединение, 62
Элемент образца, 212
Я
Язык QBE, 210
— SQL встроенный, 145
— SQL динамический, 180
— SQL интерактивный, 197
— SQL статический, 185
[1]
В этой книге мы будем использовать термин «MVS» для обозначения как стандартной операционной системы MVS (т. е. системного продукта фирмы IBM «Multiple Virtual Systems»), так и расширенной ее версии, называемой MVS/XA («MVS/Extended Architecture»). Каждая ссылка в этом тексте на MVS относится в равной степени к обеим ее версиям.
[2]
В интересах точности следует заметить, что TSO в действительности не является «подсистемой» в том специальном смысле, в котором этот термин используется в MVS Скорее она является неотъемлемой частью самой MVS. Можно приобрести систему MVS без IMS или CICS, но нельзя без TSO. Но эти различия не представляются важными для наших целей, и для простоты мы будем рассматривать в этой книге все три компонента как подсистемы.
[3]
Для читателей, хорошо знающих MVS и/или TSO, заметим, что пакетное приложение TSO есть не что иное, как обычное пакетное приложение MVS, которое исполняется под управлением телемонитора TSO (ТМР). См. раздел 14.9.
[4]
Формат хранимых данных — это, конечно, не единственное, чем отличаются эти две системы. Имеется ряд других отличий, о которых упоминается ниже. Большинство из них связано с тем фактом, что система DB2 специально разработана для обстановки больших систем (MVS). Например, объем данных в базе данных, которые могут запоминаться в интерактивном режиме в системе DB2, ограничивается только объемом памяти, доступной в таком режиме, в то время как система SQL/DS ограничивается единственной базой данных, функционирующей в интерактивном режиме, объемом 64 гигабайта (теоретический максимум; практический максимум несколько меньше). Подобным образом механизм безопасности данных системы DB2 значительно более тщательно разработан, чем в SQL/DS, отражая тог факт, что существует, вероятно, намного больше пользователей и намного больше категорий пользователей для установки DB2, чем для SQL/DS. Детальный разбор всех таких различий не является целью этой книги.
[5]
В этой книге предложения SQL, команды и т. п. для ясности записываются прописными буквами. На практике же обычно более удобно вводить такие предложения и команды строчными буквами. Система DB2 допускает то и другое.
[6]
В фирменных руководствах по системе термины «RUNTIME SUPERVISOR» или «STORED DATA MANAGER» не используются.
[7] Он оставляет также копию каждого такого предложения
SQL в модифицированом исходном модуле в форме комментария.
[8]
Точнее, план хранится в справочнике
DB2, который в действительности является расширением каталога, предназначенным только для использования самой системой. С точки зрения пользователя разница между ними состоит в том, что каталог в отличие от справочника имеет форму, позволяющую делать к нему запросы с помощью обычных предложений SQL (см. главу 7).
[9]
Кроме того, в качестве имен не могут использоваться ключевые слова языка SQL (CREATE, TABLE, SELECT и т. д.). Первая литера любого имени должна быть буквой (А—Z или одной из специальных литер ^, $, @), а остальные литеры — буквами, цифрами (0-9) или знаком подчеркивания. Имена таблиц и столбцов могут содержать максимум 18 литер, а имена пользователей—максимум 8 литер.
[10]
Если n>254, то поле является и «длинным полем», и объектом строгих ограничений. Длинные поля предназначены для того, чтобы иметь дело с данными в свободном формате, такими, как длинные текстовые строки, а не с простыми форматизированными данными, например номер поставщика или объем поставки. По существу, единственной операцией, в которой могут в качестве операндов использоваться такие поля, является операция присваивания базе данных (INSERT или UPDATE) либо из базы данных (SELECT). He допускаются какие-либо операции, которые предполагают сравнение с длинным полем Поэтому, например, длинные поля не могут быть индексированными, на них нельзя ссылаться во фразах WHERE, GROUP BY или ORDER BY и т. п. Две последние фразы рассматриваются в главах 4 и 5.
[11]
В связи с этим фактом можно сказать, что реляционные таблицы образуют замкнутую систему относительно операторов выборки данных языка, подобного SQL. Вообще говоря, замкнутая система—это совокупность (возможно, бесконечная) объектов некоторого типа, например OBJS, и соответствующая совокупность операторов, например OPS, таких, что а) операторы из OPS применяются ни к объектам из OBJS и б) результат применения любого такого оператора к любому такому объекту (любым таким объектам) является другим объектом из OBJS. Практический смысл этого соображения (в частности, для случая отношений) заключается в следующем. Поскольку результатом одной операции SELECT является другое отношение, то, по крайней мере, принципиально возможно применить другую операцию SELECT к этому результату, конечно, предусматривая, чтобы он был где-либо сохранен. Это означает, также, опять-таки принципиально, что операции SELECT могут быть вложенными друг в друга. Такая возможность иллюстрируется в разделах 5.2, 6.4 и 8.1.
[12]
Все они имеют значение истинности «неизвестно».
При наличии неопределенных значений необходимо принять трехзначную логику, значениями истинности в которой являются: истина, ложь и неизвестно.
«Неизвестно» в действительности представляет собой, по сути дела, неопределенное значение истинности. Предложение SELECT осуществляет выборку записей, для которых предикат WHERE имеет значение истина, т. е. не ложь и не неизвестно.
[13] Подзапрос может включать также фразы GROUP BY и HAVING. Однако комбинация ORDER BY и UNION недопустима.
[14] Между прочим, этот пример иллюстрирует важный момент, заключающийся в том, что порядок кванторов существен в выражениях, содержащих кванторы обоих типов Выражение FORALLx(EXISTSy (y>x)) истинно. Однако выражение EXISTSy(FORALLx(yx))—«существует действительное у такое, что для всех действительных х справедливо у больше х», т.е. «существует некоторое число, большее всех других чисел», — которое получается из предыдущего выражения просто перестановкой порядка кванторов, является ложным.
[15] EXISTS (существует) также рассматривается как стандартная функция, но она отличается от функций, обсуждаемых в данном разделе, тем, что она возвращает значение истинности, а не арифметическое или строковое значение, т. е это не числовая функция.
[16] Этого результата («группы внутри групп» и т. д.) можно достигнуть, однако, с помощью QMF. См. главу 15.
[17]
Каталог не является одинаковым в различных реализациях языка SQL, поскольку он по необходимости содержит для конкретной системы много информации, специфичной для этой системы. В частности, каталоги DB2 и SQL/DS различны.
[18]
Не следует, конечно, понимать этот абзац таким образом, что имеется фактически единственное лицо, которое на все время является системным администратором, даже если это лицо, например, покидает компанию. Имеется, скорее, один неизменный идентификатор санкционирования, который рассматривается системой как идентифицирующий системного администратора. Каждый, кто может войти в систему с этим идентификатором (и может выдержать тесты на достоверность), будет считаться системным администратором, пока он или она не выйдет из системы. Эти тесты на достоверность могут и, конечно, должны время от времени изменяться.
[19]
На самом деле, внутренняя структура этих наборов данных VSAM значительно отличается во всяком случае от структуры, которая предполагается для VSAM, поскольку управление всем их пространством осуществляется DB2, а не средствами VSAM (см главу 13). Таким образом, попытка понять их содержимое была бы нетривиальной задачей, даже если бы их можно было обработать с помощью обычных обращений к VSAM.
[20] Мы ограничимся при этом лишь обстановкой прикладного программировании. Предложения COMMIT и ROLLBACK могут быть введены и в интерактивном режиме, но делать это на практике не рекомендуется, как будет ясно позднее в этой главе, поскольку это обычно означает, что блокировки будут установлены на нежелательно долгое время.
[21]
При определенных условиях, которые здесь детально не обсуждаются, эта блокировка будет сниматься в следующей точке синхронизации, а не при завершении программы. В частности, это будет происходить в случае, если предложение LOCK TABLE вводится через DB2I (что само по себе маловероятно).
[22] Сегментированное пространство может иметь несколько групп памяти для каждого сегмента (см. раздел 13.3).
[23] Интересно отметить, что пространство памяти в 64 гигабайта со страни-1|яМ11 по 4К эквивалентно приблизительно 128 токам, т. е. 32 устройствам пря-Мпго доступа IBM 3380.
[24] Установка системы всегда располагает факультативной возможностью вообще не использовать какую-либо группу памяти для заданного пространства или его сегмента. Если это так, то для определения, расширения и удаления наборов данных необходимым образом следует использовать утилиту обслуживания методов доступа VSAM. Подробное обсуждение этих вопросов выходит за рамки данной книги.
[25]
Нельзя отрицать, что сегодня большинство систем, даже систем реляционного типа, тем не менее действительно проявляет весьма зависимое от ситуации и непредсказуемое поведение в некоторых областях. Для примера можно сослаться на обработку обновления представления в системе DB2, при которой действительно обнаруживается в некоторой степени неприятный произвол (см. раздел 8.4). Но такой произвол имеет тенденцию проявиться именно в тех вопросах, где реализация отклонилась от базовой теории. Так, важнейшим компонентом реляционной модели данных является понятие первичного ключа (см. Приложение А). Однако в системе DB2 такие ключи не поддерживаются, и это упущение является непосредственной причиной упоминаемого выше произвола. Конечно, система DB2—не единственный «правонарушитель» в этом отношении; подобная критика относится к большинству других систем, известных в момент написания этой книги, однако DB2 может служить для иллюстрации нежелательных последствий пренебрежения предписаниями модели, положенной в ее основу.
[26]
Дополнительным доказательством такого признания может служить тот факт, что Ассоциация по вычислительной технике (The Association for computing Machinery—ACM) присудила Тьюринговскую премию за 1981 год доктору Кодду, первому архитектору реляционной модели, за его работы, посвященные этой модели. Тьюринговская премия присуждается ежегодно за важнейшие работы в области информатики. По всеобщему признанию, она является наиболее престижной наградой во всей информатике.
[27]
Такая операция, как ALTER TABLE, в языке .SQL может рассматриваться не как изменение степени отношения с n на n+l, а, скорее, как создание нового отношения степени n+1 из отношения степени п.
[28]
' Под «соединением» здесь понимается либо естественное соединение, либо эквисоединение.
[29]
Это предложение включает также комментарий и ключевое слово FIELDS. Ни то ни другое не является частью реального ЯОД системы DB2.
ПРЕДСТАВЛЕНИЯ И БЕЗОПАСНОСТЬ
Чтобы проиллюстрировать использование представлений для целей безопасности, приведем ряд примеров, основанных (по большей части) опять-таки на базе данных поставщиков и деталей.
1. Пользователю разрешен доступ к полным записям поставщиков, но лишь для поставщиков, находящихся в Париже:
CREATE VIEW ПАРИЖСКИЕ_ПОСТАВЩИКИ
AS SELECT НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ,
СОСТОЯНИЕ, ГОРОД
FROM S
WHERE ГОРОД = 'Париж';
Пользователи этого представления видят «горизонтальное подмножество» (или, точнее, подмножество строк, подмножество, зависящее от значений) базовой таблицы S.
2. Пользователю разрешен доступ ко всем записям поставщиков, но не к рейтингам поставщиков (значение поля СОСТОЯНИЕ):
CREATE VIEW СКРЫТОЕ_СОСТОЯНИЕ
AS SELECT НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ,
ГОРОД
FROM S;
Пользователи этого представления видят «вертикальное подмножество» (или, точнее, подмножество столбцов, независимое от значений) подмножество базовой таблицы S.
3. Пользователю разрешен доступ к записям поставщиков только для поставщиков, находящихся в Париже, но не к рейтингам поставщиков:
CREATE VIEW ПАРИЖСКИЕ_БЕЗ_РЕЙТИНГОВ
AS SELECT НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, ГОРОД
FROM S
WHERE ГОРОД = 'Париж';
Пользователи этого представления видят подмножество строк и столбцов базовой таблицы S.
4. Пользователю разрешен доступ к записям каталога, т. е. к строкам таблицы SYSTABLES, только для таблиц, созданных этим пользователем:
CREATE VIEW МОИ_ТАБЛИЦЫ
AS SELECT *
FROM SYSIBM.SYSTABLES
WHERE CREATOR = USER;
Ключевое слово USER (пользователь) обозначает системную переменную, значение которой представляет собой ИД санкционирования. Оно может входить во фразу SELECT, во фразу WHERE, во фразу SET предложения UPDATE, либо как вставляемое значение — в предложение INSERT. Идентификатор санкционирования в запросе — это ИД санкционирования для пользователя, исполняющего фразы SELECT или WHERE (либо предложения UPDATE или INSERT), в которые он входит. В приведенном примере, следовательно, он представляет не ИД пользователя, который создает это представление, а ИД пользователя, который использует это представление. Если, например, пользователь xyz издает предложение:
SELECT *
FROM МОИ_ТАБЛИЦЫ;
то DB2, а фактически генератор планов прикладных задач, по существу, преобразует это предложение в следующее:
SELECT *
FROM SYSIBM.SYSTABLES
WHERE CREATOR = 'xyz';
Аналогично представлению из приведенного выше первого примера, это представление является «горизонтальным подмножеством» лежащей в основе базовой таблицы. Однако в данном примере различные пользователи видят здесь различные подмножества. Фактически эти подмножества не пересекаются ни для каких двух пользователей. Такие подмножества иногда называются контекстно-зависимыми.
5. Пользователю разрешен доступ к средним объемам поставок по поставщикам, но не к каким-либо индивидуальным объемам поставок:
CREATE VIEW AVG (НОМЕР_ПОСТАВЩИКА, СРЕДНИЙ_ОБЪЕМ)
AS SELECT НОМЕР_ПОСТАВЩИКА, AVG (КОЛИЧЕСТВО)
FROM SP
GROUP BY НОМЕР_ПОСТАВЩИКА;
Пользователи этого представления видят статистическую сводку лежащей в основе базовой таблицы S.
Примечание.
Создатель приведенных выше представлений должен иметь по крайней мере привилегию на исполнение предложения SELECT над всеми таблицами, на которые ссылаются определения этих представлений. Привилегии доступа обсуждаются в следующем разделе.
Как показывают приведенные примеры, механизм представлений системы DB2 «задаром» обеспечивает очень важные средства безопасности — «задаром» во всяком случае потому, что механизм представлений включен в систему для иных целей, как указывалось в главе 8. Более того, многие проверки полномочий доступа, даже проверки, зависимые от значений, могут осуществляться на стадии компиляции (во время связывания), а не на стадии исполнения, что обеспечивает существенный выигрыш производительности. Однако подход к безопасности, основанный на представлениях, иногда оказывается несколько тяжеловесным, в частности, если некоторому конкретному пользователю необходимы различные привилегии доступа к различным подмножествам одной и той же таблицы в одно и то же время. Рассмотрим следующий пример. Предположим, что данному пользователю разрешена выборка (операция
SELECT) рейтингов, т. е. значений состояния, для всех поставщиков, а обновлять их (операция UPDATE) разрешается только для поставщиков из Парижа. Тогда потребуется два следующих представления:
VIEW
ВСЕ_РЕЙТИНГИ
CREATE
VIEW
ПАРИЖСКИЕ_
РЕЙТИНГИ
AS
SELECT
НОМЕР_
ПОСТАВЩИКА, СОСТОЯНИЕ
AS
SELECT
НОМЕР_
ПОСТАВЩИКА, СОСТОЯНИЕ
FROM
S;
FROM
S
WHERE
ГОРОД=' ПАРИЖ';
При этом операции
SELECT могут быть адресованы представлению ВСЕ_РЕЙТИНГИ, а операции обновления — только представлению ПАРИЖСКИЕ_РЕЙТИНГИ. В связи с этим программирование становится довольно невразумительным. В этом можно, например, убедиться, рассматривая структуру программы, которая просматривает и печатает рейтинги всех поставщиков, а также обновляет некоторые из них (рейтинги поставщиков из Парижа), когда это требуется.
Другой недостаток связан с тем, что при вставке (операция INSERT) или обновлении (операция UPDATE) записей при помощи представления система DB2 не требует, чтобы новая или обновленная запись удовлетворяла предикату, определяющему это представление. Такое требование можно ввести с помощью спецификации CHECK, но эта возможность, как пояснялось в главе 8, не всегда может быть использована и во всяком случае это факультативная возможность — пользователь не обязан
ее специфицировать. Таким образом, приведенное выше представление ПАРИЖСКИЕ_ПОСТАВЩИКИ, например, может не дать пользователю возможности видеть поставщиков, которые находятся не в Париже, но при отсутствии спецификации CHECK оно не может помешать пользователю создать такого поставщика или переместить какого-либо существующего парижского поставщика в некоторый другой город. Такая операция, конечно, приведет к тому, что новая или обновленная запись немедленно исчезнет из этого представления, но она однако же появится в соответствующей базовой таблице.
ПРЕДВАРИТЕЛЬНЫЕ ЗАМЕЧАНИЯ
Прежде чем мы сможем перейти к рассмотрению предложений встроенного языка SQL самих по себе, необходимо предварительно обсудить некоторые детали. Большинство из них иллюстрируется фрагментом программы, показанным на рис. 10.1. ( Здесь и далее в переводе мы отступаем от синтаксиса языка ПЛ/1, не предусматривающего использование букв русского алфавита в идентификаторах. Это же замечание относится, впрочем, и к языку SQL.— Примеч. пер.)
Рассматривая этот пример, нетрудно установить следующее:
1. Предложениям встроенного SQL всегда предшествует ЕХЕС SQL, так что их можно легко отличить от предложений включающего языка, а завершаются они следующим образом:
в ПЛ/1 — точка с запятой
в Коболе — END ЕХЕС
в Фортране — отсутствие символа продолжения в колонке 6
в языке Ассемблера — отсутствие символа продолжения в колонке 72.
2. Исполняемые
предложения SQL (далее для краткости слово «встроенный» обычно опускается) могут использоваться во всех тех случаях, когда могут использоваться исполняемые предложения включающего языка. Обратим внимание здесь на уточнитель «исполняемые». В отличие от интерактивного SQL встроенный SQL включает некоторые предложения, которые являются чисто декларативными, неисполняемыми. Например, DECLARE TABLE (объявить таблицу) не является исполняемым предложением, так же как и DECLARE CURSOR (объявить курсор),—см. раздел 10.4.
3. Предложения SQL могут содержать обращения к переменным включающего языка. Перед такими обращениями ставится двоеточие с тем, чтобы отличать их от имен полей SQL. Переменные включающего языка могут появляться в предложениях манипулирования данными языка SQL только в следующих местах:
— фраза INTO в предложении SELECT (результирующая величина, которой присваивается значение, выбираемое из базы данных)
DCL ЗАДАННЫЙ_НОМЕР CHAR (5);
DCL РАНГ FIXED BIN (15);
DCL ГОРОД CHAR (15);
DCL АЛЬФА . . . ;
DCL БЕТА . . . ;
ЕХЕС SQL DECLARE S TABLE
(НОМЕР_ПОСТАВЩИКА CHAR (5)
NOT NULL,
ФАМИЛИЯ CHAR (20),
СОСТОЯНИЕ SMALLINT,
ГОРОД CHAR (15));
ЕХЕС SQL INCLUDE SQLCA;
. . . . . . . . . . . . . . . . . . . . . . .
IF АЛЬФА > БЕТА THEN
GETSTC:
ЕХЕС SQL SELECT СОСТОЯНИЕ, ГОРОД
INTO :РАНГ,: ГОРОД
FROM S
WHERE НОМЕР_ПОСТАВЩИКА = : ЗАДАННЫЙ_НОМЕР;
. . . . . . . . . . . . . . . . . . . . . . .
PUT SKIP LIST (РАНГ, ГОРОД);
Рис. 10.1. Фрагмент программы на языке ПЛ/1 с предложениями встроенного SQL
— фраза SELECT (значение, выборку - которого нужно произвести)
— фраза WHERE в предложениях SELECT, UPDATE, DELETE (значение, которое следует сравнивать)
— фраза SET в предложении UPDATE (источник для обновляемого значения)
— фраза VALUES в предложении INSERT (источник для вставляемого значения)
— элемент арифметического выражения во фразах SELECT, WHERE или SET, но не VALUES, где в результате вычисления этого выражения в свою очередь определяется значение, которое подлежит выборке, сравнению или обновлению. Они могут появляться также в некоторых предложениях, относящихся только к встроенному языку (подробности приведены ниже). Они не могут появиться в каких-либо других предложениях SQL.
4. Любые используемые в программе таблицы (базовые таблицы или представления) должны быть объявлены при помощи предложения ЕХЕС SQL DECLARE для того, чтобы сделать программу в большей степени самодокументируемой и дать возможность прекомпилятору выполнять некоторые синтаксические проверки манипулятивных предложений.
5. После того как было выполнено любое предложение SQL, информация обратной связи возвращается программе в область, называемую областью связи SQL (SQLCA — SQL Communication Area). В частности, в поле области SQLCA, называемое SQLCODE, возвращается числовой индикатор состояния. Нулевое значение SQLCODE означает, что данное предложение выполнено успешно. Положительное значение означает, что предложение все же выполнено, но предупреждает, что имела место некоторая исключительная ситуация. Например, значение +100 указывает, что не было найдено никаких данных, удовлетворяющих запросу. Наконец, отрицательное значение указывает, что имела место ошибка, и данное предложение не было успешно выполнено. Поэтому в принципе за каждым предложением SQL в программе должна следовать проверка значения SQLCODE и должно предприниматься соответствующее действие, если это значение оказывается не тем, которое ожидалось. Но этот шаг не показан на рис. 10.1. Как указывается в разделе 10.5, на практике такое явное тестирование значений SQLCODE, возможно, не является необходимым. Область связи SQL включается в программу с помощью предложения
ЕХЕС SQL INCLUDE SQLCA;
6. Как уже упоминалось, предложение SELECT встроенного языка должно содержать фразу INTO, специфицирующую переменные включающего языка, которым должны быть присвоены значения, найденные в базе данных. Переменные во фразе INTO могут быть скалярными переменными (элементами) или структурами. Структура рассматривается просто как краткая запись списка элементов, составляющих эту структуру. Структуры могут использоваться также во фразе VALUES предложения INSERT.
7. Переменные включающего языка должны иметь типы данных, совместимые с типами данных языка SQL тех полей, с которыми они должны сравниваться, значения которых им должны быть присвоены, или которым должны быть присвоены значения этих переменных. Совместимость типов данных определяется следующим образом:
а) литерные данные SQL совместимы с литерными данными включающего языка, независимо от их длины и независимо от того, является ли какая-либо из этих длин переменной;
б) числовые данные SQL совместимы с числовыми данными включающего языка, независимо от основания системы счисления (десятичная или двоичная), способа представления (с фиксированной или плавающей точкой) и точности (число цифр). Система DB2 выполнит все необходимые преобразования. Если при присваивании значения в программе либо в предложении языка SQL имеет место потеря значащих цифр или литер, связанная с тем, что поле, принимающее значение, слишком мало, программе возвращается информация об ошибке.
8. Отметим, что переменные включающего языка и поля базы данных могут иметь одни и те же имена. Переменная включающего языка может быть элементом структуры. Например:
DCL 1 ДАНО,
2 НОМЕР_ПОСТАВЩИКА CHAR(5),
2 . . .;
ЕХEС SQL SELECT . . .
. . . . . . .
WHERE НОМЕР_ПОСТАВЩИКА =
:ДАНО. НОМЕР_ПОСТАВЩИКА;
Заметим, что в предложениях SQL используется уточнение имен в стиле ПЛ/1, а не Кобола (:ДАНО.НОМЕР_ПОСТАВЩИКА, а не НОМЕР_ПОСТАВЩИКА OF ДАНО), даже когда включающим языком фактически является Кобол.
Это все, что касается предварительных замечаний. В остальной части данной главы мы сосредоточим внимание, главным образом, на операциях манипулирования данными SELECT, UPDATE, DELETE и INSERT. Как уже указывалось, к большинству из этих операций можно обратиться довольно простым образом, т. е. лишь с небольшими изменениями в их синтаксисе. Однако предложения SELECT требуют особого рассмотрения. Проблема заключается в том, что исполнение предложения SELECT порождает таблицу—таблицу, которая, в общем случае, содержит множество записей, а такие языки, как Кобол и ПЛ/1, просто не обладают хорошими средствами, позволяющими оперировать одновременно более чем одной записью. По этим причинам необходимо обеспечить своего рода мост между уровнем множеств языка SQL и уровнем записей включающего языка. Такой мост обеспечивают курсоры.
Курсор — это новый вид объекта языка SQL, относящийся только к встроенному SQL, поскольку интерактивный SQL, конечно же, в нем не нуждается. Курсор состоит, по существу, из некоторого рода указателя,
который может использоваться для просмотра множества записей. Поочередно указывая каждую запись в данном множестве, он обеспечивает, таким образом, возможность обращения к этим записям по одной одновременно. Отложим, однако, детальное обсуждение курсоров до раздела 10.4, а сначала рассмотрим (в разделе 10.3) те предложения, для которых они не требуются.
ПРЕИМУЩЕСТВА ПРЕДСТАВЛЕНИЙ
Завершим эту главу краткой сводкой преимуществ представлений.
— Они обеспечивают определенную степень логической независимости данных, несмотря на реструктуризацию базы данных, как было пояснено в предыдущем разделе.
— Они дают возможность различным пользователям по-разному видеть одни и те же данные, возможно, даже в одно и то же время. Это соображение, очевидно, имеет важное значение, когда имеется много различных категорий пользователей и все они взаимодействуют с единой интегрированной базой данных.
— Упрощается пользовательское восприятие. Очевидно, что механизм представлений дает возможность пользователям сосредоточить внимание именно на тех данных, которые представляют для них интерес, и игнорировать остальные данные. Вместе с тем не настолько очевидно, что по крайней мере в отношении поиска данных этот механизм может также значительно упростить пользовательские операции манипулирования данными. В частности, поскольку для пользователя может быть предусмотрено представление, в котором все лежащие в его основе таблицы соединены вместе, необходимость явных операций для перехода от одной таблицы к другой может быть значительно уменьшена. В качестве примера рассмотрим представление ПАРЫ_ГОРОДОВ и сопоставим предложение SELECT, необходимое для нахождения городов, где хранятся поставляемые из Лондона детали, и использующее это представление, с предложением SELECT, требующимся для получения того же результата непосредственно из базовых таблиц. В действительности, сложный процесс выборки был перенесен здесь из сферы манипулирования данными в сферу определения данных. (На самом деле различия между этими двумя сферами в реляционных языках, подобных SQL, далеко не ясны.)
— Для скрытых данных автоматически обеспечивается секретность. «Скрытые данные» обозначает здесь данные, невидимые через некоторое заданное представление. Ясно, что такие данные защищены от доступа через это конкретное представление. Таким образом, принуждение пользователя осуществлять доступ к базе данных через представления является простым, но эффективным механизмом для управления санкционированием доступа. Этот аспект представлений более подробно обсуждается в следующей главе.
ПРЕИМУЩЕСТВА РЕЛЯЦИОННЫХ СИСТЕМ
Если нужно выразить преимущества реляционной системы, такой, как DB2, единственным словом, то это слово — простота, где под «простотой» мы понимаем главным образом простоту для пользователя. Простота в свою очередь трансформируется в применяемость и производительность. Применяемость означает, что даже сравнительно неквалифицированные пользователи могут использовать систему для выполнения полезной работы. Иначе говоря, конечные пользователи часто могут получать от системы полезные результаты, избегая при этом необходимости преодолевать потенциально узкие места, с которыми сталкивается подразделение обработки данных. Производительность означает, что как конечные пользователи, так и профессиональные специалисты в области обработки данных могут более продуктивно выполнять свои каждодневные обязанности. В результате они могут внести значительный вклад в решение известной проблемы невыполненного заказа на разработку приложения (см. ниже параграф «Разработка приложения»). В данном разделе обсуждаются некоторые факторы, способствующие простоте такой системы, как DB2.
Теоретическая основа
Первый фактор заключается в том, что реляционные системы основаны на формальном теоретическом фундаменте — на реляционной модели, подробно обсуждаемой в Приложении А. В результате такие системы ведут себя строго определенным образом, и пользователи, возможно, не осознавая этого факта, руководствуются простой моделью их поведения, которая позволяет с уверенностью предсказывать, что будет делать система в любой заданной ситуации. Нет или не должно быть никаких неожиданностей[25]. Такая предсказуемость означает, что этому пользовательскому интерфейсу легко обучать, его легко изучить, использовать и запомнить.
В частности, отметим, между прочим, что многие критики реляционных систем в прошлом высказывали возражения именно по этому вопросу. Смысл возражений заключался, по-видимому, в том, что лишь теоретики способны понять или нуждаются в понимании чего-либо, что основано на теории. Наша точка зрения совершенно противоположна: системы, не основанные на теории, весьма трудны для понимания. Без преувеличения можно сказать, что «теоретический» вовсе не означает «не практичный». Наоборот, соображения, которые сначала отвергаются как «только теоретические» (!), имеют скверную привычку несколько лет спустя становиться чрезвычайно практичными.
Небольшое число понятий
Реляционная модель выделяется среди других моделей данных благодаря небольшому числу используемых в ней понятий. Как указывалось в главе 6, все данные в реляционной базе данных представляются одним и только одним способом, а именно как значения в столбцах и строках некоторых таблиц, и для каждой из четырех основных функций (выборка, изменение, вставка, удаление) необходим, следовательно, только один оператор. По тем же самым причинам требуется меньше операторов для всех других функций — для определения данных, обеспечения безопасности данных и санкционирования доступа, отображения в среду хранения и т. д.,—чем это необходимо в нереляционных системах. В частности, в случае санкционирования доступа простота и регулярность структуры данных дают возможность определить достаточно утонченный механизм защиты данных. При таком механизме, как отмечалось в главе 9, могут быть легко определены и удобным образом реализованы зависимые и независимые от значений данных, контекстно-зависимые и другие ограничения.
Самостоятельное значение имеет факт, связанный с указанным выше, и заключающийся в том, что в реляционной модели различные понятия четко разделены и не переплетаются сложными взаимосвязями. Напротив, конструкция связи типа владелец— член или отец — сын, встречающаяся во многих нереляционных системах, образует сложную взаимосвязь нескольких существенно различных понятий. Она одновременно является представлением связи вида один-ко-многим, путем доступа или совокупностью путей доступа, механизмом для реализации определенных ограничений целостности и т. д. В результате становится трудно установить, какой цели служит данная связь, и она может использоваться для таких целей, для которых она не была предназначена. Например, программа может воспользоваться некоторым путем доступа, появление которого в действительности является побочным эффектом того способа, который был выбран проектировщиком базы данных для представления определенного ограничения целостности. Если же потребуется изменить это ограничение, то необходимо будет произвести реструктуризацию базы данных. При этом с большой вероятностью потребуется также переписать данную программу, даже если она совершенно не заинтересована в рассматриваемом ограничении целостности как таковом.
Операции над множествами
Реляционные операции манипулирования данными, например SELECT, UPDATE и т. д., в языке SQL являются операциями над множествами. Этот факт означает, что пользователи должны просто специфицировать, что они хотят, а не как получить то, что они хотят. Например, пользователь, которому требуется узнать, какие детали поставляются поставщиком S2, просто выдает на языке SQL запрос:
SELECT НОМЕР_ДЕТАЛИ
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА ='S2';
Система DB2 принимает решение, каким образом осуществить навигацию в физической структуре данных на диске для того, чтобы ответить на этот запрос. По этой причине подобные DB2 системы, как уже упоминалось в главе 1, часто характеризуются как системы с «автоматической навигацией». Напротив, системы, в которых пользователи должны сами осуществлять такую навигацию, характеризуются как системы с «ручной навигацией». Избавляя пользователя от этих забот, система DB2 позволяет ему сосредоточиться на решении настоящей задачи, т. е. в данном случае, на поиске ответа на запрос и использовании этой информации для какой-либо цели, где она необходима, во внешнем мире. В случае конечных пользователей фактически именно благодаря автоматической навигации обеспечивается возможность использования системы. Нетрудно найти такой пример запроса на языке SQL, для которого эквивалентная программа на Коболе занимала бы десять или двадцать страниц, и о написании такой программы для большинства пользователей не могло бы быть и речи, а может быть она и не стоила бы необходимых для этого усилий.
Кроме того, средствами системы для автоматической навигации могут точно так же, как конечные пользователи, воспользоваться прикладные программисты. Поэтому результативность работы прикладных программистов в реляционной системе также может быть более высокой.
Язык, используемый в двух режимах
Один и тот же язык SQL используется в системе DB2 как для программирования, так и для интерактивного доступа к базе данных. Из этого факта непосредственно следует:
1. Все пользователи различных категорий — системные администраторы и администраторы баз данных, прикладные программисты, конечные пользователи с разным уровнем подготовки — по существу, используют один и тот же язык и поэтому способны лучше общаться друг с другом. Пользователю легко также переходить из одной категории в другую — в одном случае выполнять функции администратора по определению данных, а в другом — функции конечного пользователя по спецификации специальных запросов.
2. Прикладные программисты могут отлаживать записанные на SQL части их программ через интерактивный интерфейс (SPUFI или, возможно, QMF). Этот момент несколько подробнее обсуждался в разделе 12.4.
Независимость данных
Независимость данных — это независимость пользователей, и пользовательских программ от некоторых подробностей способа хранения и доступа к данным. Она имеет важное значение по крайней мере по двум причинам:
1. Для прикладных программистов она важна, поскольку без этого изменения в структуре базы данных приводят к соответствующим изменениям в прикладных программах. При отсутствии такой независимости происходит одно из двух: либо становится почти невозможно сделать требуемые изменения в базе данных из-за капиталовложений в существующие программы, либо, что более вероятно, значительная часть усилий по прикладному программированию посвящается исключительно сопровождению, т. е. такой эксплуатационной работе, необходимость в которой была бы исключена, если бы система обеспечивала независимость данных. Оба этих фактора в значительной степени способствуют возникновению проблемы невыполненного заказа на разработку приложения, о которой упоминалось во введении к данному разделу.
2. Она важна и для конечных пользователей, поскольку без этого непосредственный доступ конечного пользователя к базе данных вообще едва ли был бы возможен. При этом независимость данных и очень высокий уровень таких языков, как SQL, дополняют друг друга.
Независимость данных не является неким абсолютом — различные системы обеспечивают ее в различной степени. (Иными словами, существуют системы, которые вообще не обеспечивают независимости данных. Это как раз и означает, что некоторые системы в большей мере зависимы от данных, чем другие.) Кроме того, термин «независимость данных» в действительности охватывает два несколько разных понятия, а именно: понятие физической независимости данных, т. е. независимости физической организации данных в среде хранения, и понятие логической независимости данных, т. е. независимости логической структуры данных как таблиц и полей. Система DB2 достаточно развита в обоих аспектах, хотя, без сомнения, еще есть поле деятельности для ее развития и в той и в другой областях. Так, например, жаль, что логическое понятие принудительной уникальности взаимосвязано с физическим понятием индекса. По существу, DB2 обеспечивает физическую независимость данных благодаря ее возможностям автоматической навигации и автоматического связывания (для того, чтобы вспомнить об автоматическом связывании, см. раздел 2.2). Подобным же образом она обеспечивает логическую независимость данных благодаря ее механизму представлений (более подробно об этом см. раздел 8.5).
Разработка приложений
Системы, подобные DB2, в целом ряде аспектов облегчают процесс разработки приложений.
1. Во-первых, возможности спецификации специализированных запросов и генерации отчетов означают, что вообще может отсутствовать необходимость разработки прикладных программ в традиционном понимании этого термина. Важность этого фактора трудно переоценить. Одна из реляционных систем (здесь нет возможности назвать ее, но это не какая-нибудь малозначащая система) обладает единственной традиционной прикладной программой. Все остальное делается с помощью препроцессорных системных средств обработки запросов и генерации отчетов.
2. Во-вторых, обеспечение высокой степени независимости данных вместе с высоким уровнем операций манипулирования данными означает, что если программу писать все-таки нужно, то писать ее легче, она требует меньше усилий для сопровождения и ее легче изменять, если в этом действительно возникает необходимость, чем это было бы в более старых нереляционных системах.
3. В-третьих, и это в большой степени является следствием указанного в предыдущем пункте, цикл разработки приложения может гораздо в большей мере, чем это обычно делается, вовлекать макетирование: первая версия может быть создана и показана предполагаемым пользователям, которые имеют далее возможность предложить некоторые улучшения для включения в следующую версию и т. д. В результате окончательный вариант приложения будет в точности соответствовать потребностям пользователя. Общий процесс разработки становится значительно менее жестким, чем обычно, и пользователи приложения могут в гораздо большей степени вовлекаться в этот процесс на пользу всем заинтересованным.
Динамическое определение данных
Преимущества динамического определения данных уже подробно обсуждались в главе 3 (см. раздел 3.4), и мы не будем здесь повторять эти аргументы. Однако отметим здесь одно дополнительное обстоятельство. Способность в любое время создавать новые определения, не требуя для этого остановки системы,— в действительности только одна из составных частей более крупной общей задачи, состоящей в том, чтобы вообще исключить необходимость каких-либо запланированных остановок системы. При этом, например, утилиты можно вызывать с работающего в интерактивном режиме терминала, и они могут исполняться параллельно с решением основных задач. Можно, например, делать копию содержимого базы данных несмотря на то, что она одновременно обновляется некоторыми транзакциями. В идеальном случае систему нужно будет стартовать только один раз, когда она впервые устанавливается, и далее она должна будет функционировать «вечно». Мы, однако, не утверждаем, что указанная задача уже решена.
Легкость установки и легкость эксплуатации
Система DB2 разрабатывалась таким образом, чтобы она была, по возможности, легкой для установки и эксплуатации. Достижению этой цели способствует ряд возможностей системы, некоторые из которых были рассмотрены выше в данном разделе. Подробное обсуждение таких возможностей, помимо тех, что уже обсуждались в предыдущих главах, выходит за рамки данной книги. Однако целесообразно явным образом указать одно весьма важное следствие, вытекающее из них, а именно: для того, чтобы предоставить услуги системы DB2 весьма большой группе пользователей (прикладных программистов и конечных пользователей), требуется лишь сравнительно маленькая группа профессиональных специалистов в области обработки данных (администраторов, системных программистов, работающих за консолью операторов). DB2—чрезвычайно экономичная система.
Проектирование баз данных
В реляционной системе проектировать базы данных легче, чем нереляционной, по ряду причин, хотя при этом в сложных ситуациях могут потребоваться некоторые трудные решения. Во-первых, разделение логического и физического уровней означает, что проблемы логического и физического проектирования можно решать по отдельности. Во-вторых, существует ряд надежных принципов, которые могут быть использованы для решения проблемы логического проектирования. В-третьих, возможности динамического определения данных и высокая степень независимости данных опять-таки означают, что нет необходимости одновременно разрабатывать весь проект, и что не настолько критична потребность в получении его прямо с первого раза. Вопрос о проектировании баз данных для системы довольно подробно обсуждается в Приложении В.
Интегрированный каталог
Как уже указывалось в главе 7, каталог в системе DB2 полностью интегрирован с остальными данными в том смысле, что он представлен точно таким же образом (в виде таблиц) и что его содержимое можно запрашивать точно таким же образом (с помощью SQL). Иными словами, нет никаких искусственных и ненужных различий между данными каталога и другими данными или между данными и «данными о данных» (или «метаданными», как их иногда называют). Такая интеграция обеспечивает ряд преимуществ, в том числе:
1. Поиск чего-либо в базе данных и поиск чего-либо в каталоге — это один и тот же процесс. Для того чтобы усмотреть здесь преимущество, рассмотрим аналогичную ситуацию — поиск чего-либо в книге и поиск чего-либо в оглавлении этой книги. Было бы очень досадно, если бы это оглавление оказалось бы где-либо в ином месте, а не в самой этой книге, и в формате, который бы требовал несколько иного способа доступа, например, если бы оглавление было бы на испанском языке и хранилось бы на карточках размером 3 на 5, в то время как сама книга была бы на английском языке. Роль каталога по отношению к базе данных совершенно аналогична роли оглавления по отношению к книге.
2. Значительно упрощается процесс создания универсальных, т. е. управляемых «метаданными», прикладных программ. Допустим, например, что требуется написать программу, которая проверяет, чтобы значение номера поставщика, появляющееся где-либо в базе данных, входило бы также в столбец НОМЕР_ПОСТАВЩИКА таблицы поставщиков S — разумное само по себе требование. Необходимо при этом, чтобы рассматриваемая программа выполняла свои функции без каких-либо предварительных предположений о структуре базы данных, т. е. в программу не должны быть встроены какие-либо знания относительно того, какие существуют таблицы и какие в них столбцы. В более общем виде предположим, что нужно написать программу, которая бы проверяла, что каждое появляющееся где-либо в базе данных значение типа Х появляется также в некотором специфицированном столбце Y некоторой специфицированной таблицы Z, где X, Y и Z — параметры. И снова здесь не принимается каких-либо предварительных предположений о структуре базы данных. В обоих этих примерах решающее значение имеет интегрированный каталог. Примечание. Такие программы были бы очень нужны на практике. См. Приложение В, раздел В.7.
ПРИМЕРЫ ЗАПРОСОВ
Начнем с простого примера — с запроса «Выдать номера и состояния для поставщиков, находящихся в Париже». Этот запрос может быть выражен в SQL следующим образом:
SELECT НОМЕР_ПОСТАВЩИКА, СОСТОЯНИЕ
FROM S
WHERE ГОРОД = 'Париж';
В качестве результата получим:
НОМЕР_ПОСТАВЩИКА
СОСТОЯНИЕ
S2
S3
10
30
Этот пример иллюстрирует самую общую форму предложения SELECT в языке SQL—
"SELECT (выбрать) специфицированные поля
FROM (из) специфицированной таблицы
WHERE (где) некоторое специфицированное условие является истинным"
Заметим, что результатом запроса является другая таблица — таблица, которая некоторым образом получается из заданных в базе данных таблиц. Иными словами, в реляционной системе типа DB2 пользователь всегда действует в рамках простой табличной структуры, и это—весьма привлекательная особенность таких систем [11].
В данном случае было бы вполне возможно сформулировать запрос, используя уточненные имена полей:
SELECT S.HOMEP_ПОСТАВЩИКА, S. СОСТОЯНИЕ
FROM S
WHERE S ГОРОД = 'Париж';
Использование уточненных имен никогда не рассматривается как ошибка, и иногда это существенно, как мы увидим в разделе 4.3. Для справочных целей ниже показана общая форма предложения SELECT, в которой, однако, опущена возможность UNION, обсуждаемая в следующей главе:
SELECT [DISTINCT] элемент(ы)
FROM таблица (или таблицы)
[WHERE предикат]
[GROUP BY поле (или поля) [HAVING предикат] ]
[ORDER BY поле (или поля) ];
Перейдем теперь к иллюстрации основных особенностей этого предложения с помощью весьма продолжительной серии примеров. Примечание. Фразы GROUP BY (группировать по) и HAVING (имея) обсуждаются в главе 5. Со всеми остальными фразами читатель по крайней мере познакомится в этой главе, хотя рассмотрение более сложных их аспектов также отложено до главы 5.
Ряд других программных продуктов фирмы
Ряд других программных продуктов фирмы IBM является более или менее тесно связанным с DB2. Основные из них рассматриваются ниже.
SQL/DS (Structured Query Language/Data System)
Как уже указывалось, SQL/DS — это реляционная СУБД для операционных систем DOS/VSE и VM/CMS. Она принадлежит «семейству» DB2 в том смысле, что в обеих системах используется по существу один и тот же язык SQL. Если говорить точнее, в обеих системах — одни и те же предложения манипулирования данными и большинство предложений определения данных, которые различаются некоторыми незначительными деталями. Однако формат хранимых данных в этих системах не одинаков, но предоставляются утилиты, помогающие осуществлять передачу данных из базы данных SQL/DS в базу данных DB2 и наоборот[4].
Примечание. SQL/DS включает как части базового продукта:
а) интерактивный интерфейс запросов и генератора отчетов, называемый ISQL («Interactive SQL»); и
б) средство «DL/1 Extract» для копирования специфицированных данных из базы данных DL/1-DOS в базу данных SQL/DS, так что к ним можно осуществлять доступ через интерфейс ISQL (DL/1-DOS является по существу урезанной версией системы IMS для операционной системы DOS/VSE. DL/1—язык доступа К базам данных, используемый как в DL/1-DOS, так и в IMS).
В отношении указанных возможностей DB2 в определенной мере отличается от SQL/DS. Базовый продукт DB2 также включает интерактивный интерфейс, в некоторой степени близкий к ISQL, называемый DB2I («DB2 Interactive»). Однако DB2I в действительности предназначен для профессионалов в области обработки данных, например для прикладных программистов, а не для случайных пользователей. Настоящий интерфейс для конечных пользователей DB2 обеспечивается отдельным периферийным продуктом, называемым QMF (см. подробности ниже). Аналогично, функции «DL/1 Extract» реализуются в обстановке DB2 другим отдельным продуктом — DXT (и снова подробности см. ниже).
QMF (Query Management Facility)
QMF (Query Management Facility) — развитое периферийное средство спецификации запросов и генерации отчетов как для DB2 (под TSO), так и для SQL/DS (под DOS/VSE или VM/CMS).
Заметим, Что это отдельный программный продукт. С точки зрения DB2 это фактически не что иное, как интерактивное приложение TSO. QMF позволяет конечным пользователям вводить случайные
запросы либо на языке SQL, либо на языке QBE (Query-By-Example), и продуцировать разнообразные форматизированные отчеты из результатов обработки таких запросов. Он похож, таким образом, на встроенный интерфейс спецификации запросов/генерации отчетов ISQL, предоставляемый SQL/DS в качестве части базового продукта. Однако предоставляемый QMF диапазон возможностей значительно превосходит возможности ISQL. В частности, ISQL не поддерживает языка QBE.
Более подробная информация о QMF приводится в главе 15.
DXT (Data Extract)
DXT (Data Extract) — это универсальная программа копирования данных. Она позволяет скопировать в последовательный файл специфицированное подмножество данных заданной базы данных системы IMS либо набора данных VSAM или SAM. При этом копирование осуществляется в формате, подходящем для загрузки (с помощью соответствующей утилиты загрузки) в базу данных системы DB2 либо SQL/DS. В главе 15 содержится более подробная информация относительно DXT.
ПРОИЗВОДИТЕЛЬНОСТЬ
В последние несколько лет в области обработки данных сложился ряд ошибочных представлений, касающихся реляционных систем, большинство из которых связано с их производительностью. Очень часто можно услышать два таких мнения:
«Все реляционные системы очень хороши для обработки специальных запросов, но они никогда не достигнут уровня производительности, требуемого для производственных систем (или систем обработки транзакций или ...)».
«Для того чтобы реляционные системы были способны достигнуть приемлемой производительности, нужны новые достижения в технологии аппаратного обеспечения, например аппаратная реализация ассоциативной памяти».
Противоположное мнение, которого придерживается и автор, заключается в следующем:
«Нет никакой внутренней причины, благодаря которой производительность реляционной системы должна быть сколько-нибудь ниже — или, в действительности, сколько-нибудь выше (!) — чем у системы какого-либо иного типа».
Обсудим и попытаемся обосновать это мнение.. Отметим прежде всего, что двумя основными характеристиками производительности являются число операций ввода-вывода и продолжительность обработки (объем работы центрального процессора). Рассмотрим каждую из них поочередно.
Продолжительность обработки
DB2 — система компилирующего типа, точно так же, как и SQL/DS. Большинство других систем, реляционных или другого типа, во время написания этой книги являются системами интерпретирующего типа. Однако преимущества компиляции получили широкое признание, и известно, что в направлении подхода, основанного на компиляции, развивается несколько других реляционных систем. Преимущество компиляции заключается именно в том, что она уменьшает продолжительность обработки на стадии исполнения. При этом на стадии исполнения исключаются все перечисленные ниже операции:
— синтаксический анализ первоначального запроса
— обнаружение синтаксических ошибок и выдача сообщений о них
— отображение имен логического уровня в адреса физического уровня
— выбор стратегии доступа
— проверка полномочий доступа
— генерация машинного кода.
Наиболее важной из этих операций является, вероятно, выбор стратегии доступа, или, иными словами, оптимизация. Таким образом, в случае компиляции продолжительность обработки на стадии исполнения значительно короче, чем она была бы в иных случаях. Немаловажно также, что при компиляции машинный код генерируется для конкретного исходного запроса, и поэтому он может оказаться более эффективным, чем более универсальный код, используемый в режиме интерпретации. Более того, система достигает этого преимущества компиляции в производительности, как уже указывалось в главе 2, без какой-либо соответствующей потери гибкости в функционировании: если становится необходимой перекомпиляция, например, в случае, когда уничтожен какой-либо индекс, то система осуществляет ее автоматически («автоматическое связывание»).
Заметим, между прочим, что компиляция в том смысле, как этот термин понимается в системе DB2, т. е. оптимизированная компиляция, не была бы осуществима в системе, ориентированной на обработку записей, поскольку такая система просто неспособна подобным же образом воспринимать намерения пользователя. Понятно поэтому, что реляционная система в конечном счете может обеспечить меньшую продолжительность обработки, чем нереляционная, если, например, нереляционная система всегда должна будет осуществлять синтаксический анализ запросов на стадии исполнения.
Операции ввода-вывода
Число операций ввода-вывода, требуемых для обработки конкретного запроса, является функцией физической
структуры базы данных, а не ее логической структуры. Иными словами, оно не имеет ничего общего с тем, каким образом база данных воспринимается ее пользователями — как реляционная или как некоторая другая структура. Поэтому можно разбить вопрос о том, сколько операций ввода-вывода требуется в реляционной системе, на два составляющих вопроса:
1. Способны ли поддерживаемые данной системой физические структуры обеспечить некоторый требуемый уровень производительности операций ввода-вывода?
2. Если ответ на первый вопрос положителен, то способна ли данная система принимать реляционные запросы высокого уровня, например предложения SELECT, и преобразовывать их в операции над такими физическими структурами, настолько же эффективные, насколько написанная вручную программа, т. е. программа, которая была бы составлена квалифицированным программистом, работающим непосредственно на физическом уровне?
В связи с первым вопросом нужно отметить, что в большинстве реляционных систем в настоящее время поддерживаются индексы, имеющие структуру В-деревьев. В некоторых системах, помимо этого, поддерживается техника хеширования и т. п., однако DB2 не относится к их числу. Фактически мало сомнения в том, что если должна быть выбрана единственная структура, то, очевидно, будут выбраны организованные в виде В-деревьев индексы. Далее, индексы с такой организацией, несомненно, способны обеспечить адекватный многим приложениям уровень производительности. Это утверждение должно быть справедливым, иначе никто не использовал бы VSAM. С другой стороны, справедливо также, что имеются некоторые приложения, для удовлетворения требований которых к производительности следует просто использовать, например, хеширование. Таким образом, ответ на первый вопрос, что касается системы DB2, положителен, если индексы приемлемы для рассматриваемого приложения, и отрицателен — в противном случае. (Конечно, и в этой ситуации ответ может быть все же положительным для некоторых других реляционных систем.)
Рассмотрим теперь второй вопрос (может ли данная система продуцировать программу, которая в такой же мере эффективна, как и программа, составленная вручную?), предполагая, что ответ на первый вопрос положителен. Краткий ответ — «да, может» (во многих, но не во всех случаях). Функция оптимизатора системы DB2 заключается именно в том, чтобы преобразовывать предложения SQL в оптимизированную машинную программу, где «оптимизированная» означает, главным образом, что сгенерированная программа использует лучшую из возможных стратегий для обработки первоначального запроса. Например, если задан запрос из раздела 16.2—«Выдать номера деталей, поставляемых поставщиком S2» — то в сгенерированной программе будет использоваться индекс по номерам поставщиков для таблицы SP, а не последовательный просмотр этой таблицы, конечно, в предположении, что такой индекс существует. Разумеется, не для каждого возможного запроса оптимизатор продуцирует наилучшую возможную программу. Но с другой стороны, этого не делает и большинство программистов. Кроме того, заметим, что здесь говорится о первой версии нового программного продукта. Естественно ожидать, что в процессе эксплуатации будут продолжаться его усовершенствования в области оптимизации. В действительности область оптимизации в базах данных в настоящее время это нечто, аналогичное оптимизации в языках программирования, какой она была примерно пятнадцать лет назад. Многочисленные исследователи занимаются этой проблемой в университетах и других организациях, и плоды этой деятельности, несомненно, найдут свое место в реализованных программных продуктах. Подобные усовершенствования могут быть осуществлены при этом так, чтобы они каким-либо образом не затрагивали форму внешнего интерфейса (это приблизительно и есть то, что представляет собой независимость данных).
На самом деле, понятно, что оптимизатор мог бы продуцировать лучшую программу, чем написанная вручную. Дело заключается в том, что оптимизатору доступна информация, касающаяся, например, физической кластеризации данных, размеров таблиц, избирательности индексов и т. д., которой обычно не обладает программист, разрабатывающий программу вручную. Кроме того, эта информация со временем может изменяться. В такой ситуации может возникать необходимость в повторной оптимизации. Выполнение ее в системе, подобной DB2, имеет тривиальный характер — достаточно просто выполнить операцию REBIND. В системе с ручным программированием это было бы весьма трудно сделать.
В связи с этим отметим еще один заключительный момент, касающийся оптимизации. Имеется другая причина, в связи с которой реляционная система может в некоторых случаях превосходить нереляционную по производительности. Эта причина состоит как раз в том, что система типа DB2 является оптимизирующей. Реляционные операции высокого уровня удается оптимизировать именно благодаря их высокому уровню — они содержат много семантики, и поэтому оптимизатор способен распознать, что же пытается сделать пользователь, и способен среагировать на это оптимальным образом. В противоположность этому в нереляционной системе, в которой пользователь действует на уровне записей, а не на уровне множеств, стратегии доступа выбираются самим пользователем. Если при этом пользователь сделает ошибочный выбор, то имеется мало шансов, что система будет способна оптимизировать такую пользовательскую программу. Предположим, например, что пользователь в действительности пытается вычислить соединение двух таблиц А и В. Существуют две возможные стратегии: а) поочередно для каждой записи из А найти все соответствующие ей записи в В; б) поочередно для каждой записи из В найти все соответствующие ей записи в А. В зависимости от относительных размеров А и В и от характеристик их физической кластеризации одна из этих стратегий может, вероятно, превзойти по производительности другую на несколько порядков величины. И если, как указывалось ранее, пользователь выберет ошибочную стратегию, то в действительности пет никакого способа, позволяющего системе заменить ее на другую, поскольку выбор пользователя выражается в виде последовательности операций низкого уровня, а не единственной операции высокого уровня.
Из всего сказанного можно сделать вывод, что нет абсолютно никакой причины для того, чтобы реляционная система, которая реализована на совершенно обычном оборудовании, использующем совершенно стандартную технику программного обеспечения, не функционировала вполне приемлемым образом. И вовсе не обязательно ждать новых достижений в разработке аппаратных средств, хотя если, например, ассоциативная память большой емкости па чипах когда-либо действительно стала бы коммерческой реальностью, несомненно, ею легче было бы воспользоваться в реляционной системе, чем в нереляционной.
Предостережение.
Для строгости заметим, что все предыдущие рассуждения были очень общими. В частности, не говорилось, что DB2 способна обеспечивать такую же производительность, как и какая-либо уже давно созданная система, например IMS. Пока еще слишком рано даже давать какие-либо оценки производительности системы DB2, хотя можно заключить беспроигрышное пари по поводу того, что любые такие оценки были бы существенно менее привлекательны, чем соответствующие оценки для IMS. Не приходится сомневаться в том, что для заданного приложения, где структуры данных и образцы транзакций заблаговременно хорошо изучены, какая-либо существующая система, например IMS, может быть конфигурирована и настроена в соответствии с требованиями заказчика таким образом, что она будет обеспечивать значительно более внушительную производительность, чем может обеспечить в настоящее время система DB2. С другой стороны:
а) Система, настроенная в соответствии с требованиями заказчика, будет выглядеть не настолько внушительной, когда к ней станут добавляться другие приложения. Реализация приложения 2 в обстановке системы, которая настроена на приложение 1, подобна рубке дерева поперек волокна — мешают делу чуждые намерения.
Заметим, что речь идет здесь не только о производительности, но также и о логическом уровне системы. Имеется в виду, что приложение 2, вероятно, будет также менее удобно писать. Логические структуры данных в нереляционной системе имеют тенденцию подвергаться влиянию одних приложений вопреки другим именно в связи с тем, что они подробно отражают физическую структуру данных. Логические структуры данных в реляционных системах, напротив, более нейтральны. Специфика приложения проявляется не в логической структуре данных, а в манипулятивных операциях, которые по определению являются значительно более гибкими, чем сравнительно статичная структура данных. Эта специфика будет, конечно, проявляться и в физической структуре данных.
б) Одна из причин преимущества нереляционных систем в производительности заключается просто в том, что эти системы эксплуатируются уже в течение десяти —пятнадцати лет и на протяжении этого времени постоянно усовершенствовались и настраивались. Реляционные системы также будут усовершенствоваться в течение следующих нескольких лет. Кроме того, неясно, возможны ли дальнейшие значительные усовершенствования нереляционных систем. В то же время, как указывалось ранее, имеется широкое поле деятельности для таких усовершенствований в реляционном случае.
в) Если даже нереляционная система обеспечивает на стадии исполнения более высокую производительность, ценность такого преимущества должна быть в первую очередь сбалансирована с затратами времени, необходимыми для приведения системы в работоспособное состояние. Капиталовложения на установку будут значительно быстрее окупаться для реляционной системы, поскольку значительно скорее начнут эксплуатироваться приложения. Конечная прибыль на капиталовложения может быть также более высокой при реляционной версии, если срок жизни данного приложения меньше, чем время, необходимое для того, чтобы нереляционная версия «догнала» его, говоря экономическим языком.
Повторяем, однако, что все сказанное выше — это теоретические рассуждения. Дело в том, что в настоящее время совершенно маловероятно, чтобы система типа DB2 была способна достигнуть уровня производительности системы типа IMS. Компромисс, который следует принимать во внимание в настоящее время — это производительность против применяемости или, другими словами, производительность машины против производительности человека. Общеизвестно, что стоимость человеческого труда быстро растет, а стоимость машинного времени также быстро снижается. В результате производительность человеческого труда очень быстро становится во многих приложениях доминирующим фактором, и, в действительности, во многих случаях это уже имеет место. Очевидно, что для таких приложений идеально подходят реляционные системы даже при их существующем уровне производительности. Имеется, однако, также и ряд приложений, для которых представляет пока преобладающий интерес производительность собственно оборудования. Поэтому системы типа IMS должны будут еще играть важную роль на протяжении нескольких лет. И если даже реляционные системы в конечном счете действительно достигнут паритета в отношении производительности, огромные капиталовложения в нереляционные системы являются фактором, обеспечивающим продолжение существования этих систем в обозримом будущем. Несомненно, это одна из причин, по которой фирма IBM рассматривает DB2 как дополнение, а не замену IMS, и в связи с которой эти два продукта разрабатывались таким образом, чтобы они могли работать совместно, как указывалось в предыдущих главах.
ПРОСТАЯ ВЫБОРКА
Выдать номера для всех поставляемых деталей:
SELECT НОМЕР_ДЕТАЛИ
FROM SP;
Имеем результат:
НОМЕР_ДЕТАЛИ
Р1
Р2
РЗ
Р4
Р5
Р6
Р1
Р2
Р2
Р2
Р4
Р5
Обратим внимание на дубликаты номеров деталей в этом результате. Система DB2 не исключает дубликатов из результата предложения SELECT, если пользователь явно не потребует это сделать с помощью ключевого слова DISTINCT (различный, различные), как показано в следующем примере.
ПРОСТАЯ ВЫБОРКА «SELECT*»
Выдать полные характеристики для всех поставщиков:
SELECT *
FROM S;
Результатом служит копия полной таблицы S.
Здесь звезда или звездочка служит кратким обозначением списка всех имен полей в таблице (таблицах), указанной(ых) во фразе FROM (из) в том порядке, в котором эти поля определяются в соответствующем (их) предложении(ях) CREATE TABLE. Таким образом, записанное выше предложение SELECT эквивалентно следующему:
SELECT НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, СОСТОЯНИЕ, ГОРОД
FROM S;
Обозначение в виде звездочки удобно для интерактивных запросов, поскольку оно уменьшает число ударов по клавишам. Однако, оно таит потенциальную опасность при использовании во встроенном SQL (т. е. в предложениях SQL в прикладной программе), поскольку смысл знака «*» может измениться, если для этой программы перегенерируется план прикладной задачи, а в данном промежутке времени к рассматриваемой таблице был добавлен другой столбец. В этой книге «SELECT *» будет использоваться только в таких контекстах, где так делать безопасно (в основном только в интерактивных контекстах), и фактическим пользователям DB2 рекомендуется поступать подобным образом.
Отметим, наконец, что «*» может уточняться именем соответствующей таблицы. Допустима, например, следующая форма
SELECT S.*
FROM S;
ПРОСТОЕ ЭКВИСОЕДИНЕНИЕ
Выдать все комбинации информации о таких поставщиках и деталях, которые размещены в одном и том же городе (иначе говоря, «соразмещены» — безобразный, но удобный термин):
SELECT S.*, Р.*
FROM S, P
WHERE S.ГОРОД = Р.ГОРОД;
Заметим, что здесь ссылки на поля во фразе WHERE должны уточняться именами содержащих их таблиц. В результате получим следующую ниже таблицу 1. (Во избежание двусмысленности в этой таблице два столбца ГОРОД показаны явным образом как S.ГОРОД и Р.ГОРОД.)
Таблица 1
НОМЕР_ПОСТАВЩИКА
ФАМИЛИЯ
СОСТОЯНИЕ
S.ГОРОД
S1
S1
S1
S2
S2
S3
S3
S4
S4
S4
Смит
Смит
Смит
Джонс
Джонс
Блейк
Блейк
Кларк
Кларк
Кларк
20
20
20
10
10
30
30
20
20
20
Лондон
Лондон
Лондон
Париж
Париж
Париж
Париж
Лондон
Лондон
Лондон
Продолжение табл. 1
НОМЕР_ДЕТАЛИ
НАЗВАНИЕ
ЦВЕТ
ВЕС
Р.ГОРОД
Р1
Р4
Р6
Р2
Р5
Р2
Р5
Р1
Р4
Р6
Гайка
Винт
Блюм
Болт
Кулачок
Болт
Кулачок
Гайка
Винт
Блюм
Красный
Красный
Красный
Зеленый
Голубой
Зеленый
Голубой
Красный
Красный
Красный
12
14
19
17
12
17
12
12
14
19
Лондон
Лондон
Лондон
Париж
Париж
Париж
Париж
Лондон
Лондон
Лондон
Пояснение. Из формулировки задачи на естественном языке ясно, что требуемые данные можно получить из двух таблиц — S и Р. Поэтому в формулировке запроса на языке SQL мы прежде всего указываем эти две таблицы во фразе FROM, а затем выражаем во фразе WHERE соединение между ними, т. е. тот факт, что значения ГОРОД должны быть равны. Для того чтобы понять, как это делается, представим себе две строки, по одной из каждой таблицы, например строки, показанные ниже:
НОМЕР_ПОСТАВЩИКА
ФАМИЛИЯ
СОСТОЯНИЕ
S. ГОРОД
равны

Смит
20
Лондон
НОМЕР_ДЕТАЛИ
НАЗВАНИЕ
ЦВЕТ
ВЕС
P. ГОРОД
Р1
Гайка
Красный
12
Лондон
Из этих двух строк можно видеть, что поставщик S1 и деталь Р1 в действительности «соразмещены». Из таких двух строк будет сформирована строка результата:
НОМЕР_ПОСТАВЩИКА
ФАМИЛИЯ
СОСТОЯНИЕ
S. ГОРОД
S1
Смит
20
Лондон
НОМЕР_ДЕТАЛИ
НАЗВАНИЕ
ЦВЕТ
ВЕС
P. ГОРОД
Р1
Гайка
Красный
12
Лондон
поскольку они удовлетворяют предикату во фразе WHERE (S.ГОРОД = Р.ГОРОД). Это имеет место и для всех других пар строк, содержащих соответствующие значения ГОРОД. Обратите внимание на то, что поставщик S5, размещающийся в Атенсе, не попадает в результирующую таблицу, так как нет каких-либо деталей, хранимых в этом городе. Подобным же образом результат не содержит детали РЗ, хранимой в Риме, ввиду того, что нет поставщиков, размещенных в Риме.
Результат данного запроса называется соединением таблиц S и Р по соответствию значений ГОРОД. Термин «соединение» используется также для обозначения операции конструирования такого результата. Условие S.ГОРОД = Р.ГОРОД называется условием соединения или предикатом соединения. В связи с приведенным примером нужно отметить ряд моментов. Одни из них имеют важное значение, другие не настолько существенны.
— Оба поля в предикате соединения должны быть либо числовыми, либо строками литер. Не обязательно, чтобы их типы данных были идентичны. Однако, по соображениям производительности, это было бы, вообще говоря, неплохо.
— Необязательно, чтобы поля в предикате соединения имели одинаковые имена, хотя очень часто это будет именно так.
— Нет необходимости в том, чтобы оператор сравнения в предикате соединения обязательно был равенством, хотя это будет очень часто. В дальнейшем будут приведены примеры такого рода (пример 4.3.2 и последняя часть примера 4.3.6). В случае оператора равенства соединение называют иногда эквисоединением.
— Фраза WHERE в SELECT-соединении может включать, помимо самого предиката соединения, другие условия. Эта возможность иллюстрируется ниже в примере 4.3.3.
— Можно, конечно, предусмотреть в SELECT выборку только специфицированных полей соединения, а не их всех. Эта возможность иллюстрируется ниже в примерах 4.3.4—4.3.6.
— Выражение
SELECT S.*,P.*
FROM S, P
. . . . . . ;
может быть еще более упрощено:
SELECT *
FROM S,P
. . . . . . ;
С другой стороны, оно может быть записано и в расширенном виде:
SELECT НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, СОСТОЯНИЕ, S.город
НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ЦВЕТ, ВЕС, Р. ГОРОД
FROM S, P
. . . . . . ;
В такой формулировке для S.ГОРОД и Р.ГОРОД во фразе SELECT следует указывать их уточненные имена, как показано в примере, поскольку неуточненное имя ГОРОД было бы двусмысленным. Если Вам нужно освежить в памяти вопросы, касающиеся уточненных имен полей, см. введение к разделу 4.2.
— По определению, эквисоединение должно продуцировать результат, содержащий два идентичных столбца. Если исключить один из этих столбцов, то оставшееся называется естественным соединением. Для того, чтобы построить естественное соединение таблиц S и Р по городам в SQL, следовало бы записать:
SELECT НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, СОСТОЯНИЕ, S.ГОРОД,
НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ЦВЕТ, ВЕС
FROM S, P
WHERE S.ГОРОД = Р.ГОРОД;
Естественное соединение является, вероятно, одной из наиболее полезных форм соединения — в такой степени, что мы часто используем неуточненный термин «соединение» специально для обозначения этого случая.
— Можно образовывать соединения также и трех, четырех, ... или любого числа таблиц. В примере 4.3.5, приведенном ниже, показано соединение трех таблиц.
Таблица 2
ФАМИЛИЯ
СОСТОЯНИЕ
S.ГОРОД
S1
S1
S1
S1
S1
S1
S2
.
.
.
S5
Смит
Смит
Смит
Смит
Смит
Смит
Джонс
.
.
.
Адамc
20
20
20
20
20
20
10
.
.
.
30
Лондон
Лондон
Лондон
Лондон
Лондон
Лондон
Париж
.
.
.
Атенс
Продолжение табл. 2
НАЗВАНИЕ
ЦВЕТ
ВЕС
Р.ГОРОД
Р1
Р2
РЗ
Р4
Р5
Р6
Р1
.
.
.
Р6
Гайка
Болт
Винт
Винт
Кулачок
Блюм
Гайка
.
.
Блюм
Красный
Зеленый
Голубой
Красный
Голубой
Красный
Красный
.
.
.
Красный
12
17
17
14
12
19
12
.
.
.
19
Лондон
Париж
Рим
Лондон
Париж
Лондон
Лондон
.
.
.
Лондон
— В табл. 2 рассматривается альтернативный ( и полезный) способ, позволяющий представить себе, каким образом концептуально могут конструироваться соединения. Прежде всего построим декартово произведение таблиц, перечисленных во фразе FROM. Декартово произведение множества, состоящего из n таблиц,— это таблица, содержащая всевозможные строки r, такие, что r является конкатенацией какой-либо строки из первой таблицы, строки из второй таблицы, ... и строки из n-й таблицы. Например, табл. 2 (назовем ее СР) представляет собой декартовым произведением таблиц S и Р (в указанном порядке). Полная таблица СР содержит 5х6=30 строк. Теперь исключим из этого декартова произведения все такие строки, которые не удовлетворяют предикату соединения. То, что останется, является требуемым соединением В рассматриваемом случае мы исключаем из таблицы СР все те строки, в которых S.ГОРОД не равен Р.ГОРОД. В результате получим в точности приведенное выше соединение. Между прочим, вполне возможно, хотя, может быть, и несколько необычным образом, сформулировать в языке SQL запрос, результатом которого будет декартово произведение. Например:
SELECT S S.*, P.*
FROM S, Р;
Результат. Упомянутая выше таблица СР.
ПРОСТОЙ ПОДЗАПРОС
Выдать фамилии поставщиков, которые поставляют деталь Р2.
SELECT ФАМИЛИЯ
FROM S
WHERE НОМЕР_ПОСТАВЩИКА IN
(SELECT НОМЕР_ПОСТАВЩИКА
FROM SP
WHERE НОМЕР_ДЕТАЛИ = 'P2');
Результат:
ФАМИЛИЯ
Смит
Джонс
Блейк
Кларк
Пояснение. При обработке полного запроса система обрабатывает прежде всего вложенный подзапрос. Этот подзапрос возвращает множество номеров поставщиков, которые поставляют деталь P2, а именно множество ('S1', 'S2', 'S3', 'S4'). Поэтому первоначальный запрос эквивалентен следующему простому запросу:
SELECT ФАМИЛИЯ FROM S
WHERE НОМЕР_ПОСТАВЩИКА IN ('S1'.'S2','S3','S4');
и, следовательно, получаем приведенный ранее результат.
Неявное уточнение фамилии в этом примере требует дополнительного обсуждения. Заметим, в частности, что «НОМЕР-ПОСТАВЩИКА» слева от IN неявным образом уточняется именем таблицы S, в то время как «НОМЕР-ПОСТАВЩИКА» в подзапросе неявно уточняется именем таблицы SP. Справедливо следующее общее правило: предполагается, что неуточненное имя поля должно уточняться именем таблицы (или псевдонимом таблицы — см. примеры 5.2.3–5.2.5 ниже), указанным в той фразе FROM, которая является непосредственной частью того же самого запроса или подзапроса. В случае поля НОМЕР-ПОСТАВЩИКА слева от IN этой фразой является «FROM S», а в случае поля НОМЕР-ПОСТАВЩИКА в подзапросе—это фраза «FROM SP». Для большей ясности повторим первоначальный запрос с явно указанными предполагаемыми уточнениями:
SELECT S. ФАМИЛИЯ
FROM S
WHERE S. НОМЕР_ПОСТАВЩИКА IN
(SELECT SP. НОМЕР_ПОСТАВЩИКА
FROM SP
WHERE SP. НОМЕР_ДЕТАЛИ = 'P2');
Неявные уточнения всегда можно отвергнуть путем задания явных уточнений. Это демонстрируется ниже в примерах 5.2.3–5.2.5.
Прежде чем перейти к нашему следующему примеру подзапроса, необходимо отметить еще один важный момент. Первоначальная задача — «Выдать фамилии поставщиков, которые поставляют деталь P2» — может быть эквивалентным образом выражена как запрос с использованием соединения:
SELECT S. ФАМИЛИЯ
FROM S, SP
WHERE S. НОМЕР_ПОСТАВЩИКА = SP. НОМЕР_ПОСТАВЩИКА
AND SP. НОМЕР_ДЕТАЛИ = 'P2';
Пояснение.
Соединение S и SP по номерам поставщиков представляет собой таблицу из 12 строк (по одной строке для каждой строки SP), каждая из которых состоит из соответствующей строки SP, дополненной значениями ФАМИЛИЯ, СОСТОЯНИЕ и ГОРОД для поставщика, указываемого значением НОМЕР-ПОСТАВЩИКА в этой строке. Из этих 12 строк только четыре относятся к детали P2. Окончательный результат получается, таким образом, выделением значения ФАМИЛИЯ из этих четырех строк.
Обе формулировки первоначального запроса, одна из которых использует подзапрос, а другая — соединение, в равной степени корректны. Вопрос о том, какой из этих формулировок отдать предпочтение,— исключительно дело вкуса данного пользователя.
Этим разделом завершается данная вводная
Этим разделом завершается данная вводная глава. В ней был приведен краткий обзор DB2, реляционной системы управления базами данных фирмы IBM для операционной системы MVS. Было пояснено в общих чертах, что такое реляционная система. Рассмотрена реляционная (табличная) структура данных и описаны некоторые из имеющихся в SQL операторов для работы с данными в такой табличной форме. В частности, мы коснулись вопроса о трех категориях предложений SQL (определение данных, манипулирование данными и управление данными) и привели примеры из первых двух категорий. Напоминаем читателю, что:
а) все предложения SQL являются выполняемыми; б) каждое предложение SQL, которое может быть введено с терминала, может быть также встроено в программу на языке ПЛ/1, КОБОЛ, ФОРТРАН или на языке ассемблера; в) предложения манипулирования данными SQL (SELECT, UPDATE и т. д.) оперируют над множествами. Наконец, были рассмотрены также различные варианты операционной обстановки., в которых может исполняться прикладная задача системы DB2, а именно: IMS, CICS и TSO. В следующей главе мы познакомимся с внутренней структурой и с основными компонентами DB2.
С.ЗСКАЛЯРНЫЕ ВЫРАЖЕНИЯ
скалярное — выражение
. : : скалярный—терм [арифметический—оператор скалярное — выражение]
скалярный — терм : : = [+ | –] скалярное — значение
скалярное — значение : : = имя — столбца
| ссылка — на — функцию | константа | USER
| (скалярное — выражение)
ссылка — на — функцию : : = COUNT (*)
| имя — функции (скалярное — выражение)
| имя — функции (DISTINCT имя — столбца)
имя — функции : : = COUNT | SUM|AVG | MAX | MIN
арифметический — оператор : : = + | – |*|/
СИМЕНА
имя — таблицы : : =
имя — базовой — таблицы
| имя — представления | псевдоним ) синоним
имя — базовой — таблицы : : = [имя — пользователя.] идентификатор
имя — пользователя : : = идентификатор
имя — представления : : = [имя — пользователя.] идентификатор
псевдоним : : = идентификатор
синоним : : = идентификатор
имя—столбца : := [имя—таблицы.] идентификатор
СИНОНИМЫ
Удобно завершить эту главу кратким обсуждением вопроса о синонимах, хотя он, в действительности, и не имеет отношения к каталогу как таковому, за исключением того, что синонимы записываются в каталог, как и многие другие объекты. Если говорить кратко, синоним представляет собой альтернативное имя таблицы — базовой таблицы или представления. В частности, можно определить синоним для таблицы, которая была создана каким-либо другим пользователем и для которой Вы должны были бы в противном случае использовать полностью уточненное имя. Например, пользователь АЛЬФА издает предложение:
CREATE TABLE ПРИМЕР. . .;
Пользователь БЕТА может обращаться к этой таблице, указывая АЛЬФА.ПРИМЕР:
SELECT *
FROM АЛЬФА.ПРИМЕР;
С другой стороны, пользователь БЕТА может издать предложение CREATE SYNONYM IJK FOR АЛЬФА.ПРИМЕР;
и может теперь обращаться к этой таблице, указывая просто IJK, например:
SELECT *
FROM IJK,
Имя IJK является совершенно приватным и локальным для пользователя БЕТА. Другой пользователь ГАММА также может иметь приватное и локальное имя IJK, отличное от имени, введенного пользователем БЕТА.
Другой пример:
CREATE SYNONYM ТАБЛИЦЫ FOR SYSIBM.SYSTABLES;
Имеется также предложение DROP SYNONYM (уничтожить синоним). Его синтаксис:
DROP SYNONYM синоним;
Например:
DROP SYNONYM ТАБЛИЦЫ;
СЛУЧАЙ ИСПОЛЬЗОВАНИЯ ОДНОЙ И ТОЙ ЖЕ ТАБЛИЦЫ В ПОДЗАПРОСЕ И ВНЕШНЕМ ЗАПРОСЕ
Выдать номера поставщиков, которые поставляют по крайней мере одну деталь, поставляемую поставщиком S2.
SELECT DISTINCT НОМЕР_ПОСТАВЩИКА
FROM SP
WHERE НОМЕР_ДЕТАЛИ IN
(SELECT НОМЕР_ДЕТАЛИ
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА = 'S2');
Результат:
НОМЕР_ПОСТАВЩИКА
S1
S2
S3
S4
Отметим здесь, что ссылка на SP в подзапросе означает не то же самое, что ссылка на SP во внешнем запросе. В действительности, два имени SP обозначают различные переменные. Чтобы этот факт стал явным, можно использовать псевдонимы:
SELECT DISTINCT SPX. НОМЕР_ПОСТАВЩИКА
FROM SP SPX
WHERE SPX. НОМЕР_ДЕТАЛИ IN
(SELECT SPY. НОМЕР_ДЕТАЛИ
FROM SP SPY
WHERE SPY. НОМЕР_ПОСТАВЩИКА ='S2');
Эквивалентный запрос с использованием соединения имеет вид;
SELECT DISTINCT SPX. НОМЕР_ПОСТАВЩИКА
FROM SP SPX, SP SPY
WHERE SPX. НОМЕР_ДЕТАЛИ = SPY. НОМЕР_ДЕТАЛИ
AND SPY. НОМЕР_ ПОСТАВЩИКА = 'S2';
СЛУЧАЙ, КОГДА В КОРРЕЛИРОВАННОМ И ВНЕШНЕМ ЗАПРОСЕ ИСПОЛЬЗУЕТСЯ ОДНА И ТА ЖЕ ТАБЛИЦА
Выдать номера всех деталей, поставляемых более чем одним поставщиком. (Другое решение этой задачи дается позднее в примере 5.4.9):
SELECT DISTINCT SPX. НОМЕР_ДЕТАЛИ
FROM SP SPX
WHERE SPX. НОМЕР_ДЕТАЛИ IN
(SELECT SPY. НОМЕР_ДЕТАЛИ
FROM SP SPY
WHERE SPY. НОМЕР_ПОСТАВЩИКА
Ø
= SPX. НОМЕР_ПОСТАВЩИКА);
Результат:
НОМЕР_ДЕТАЛИ
P1
P2
P4
P5
Действие этого запроса можно пояснить следующим образом. «Поочередно для каждой строки таблицы SP, скажем SPX, выделить значение НОМЕР_ДЕТАЛИ, если и только если это значение входит в некоторую строку, скажем SPY, таблицы SP, значение столбца НОМЕР_ПОСТАВЩИКА в которой не является его значением в строке SPX». Заметим, что в этой формулировке должен
быть использован по крайней мере один псевдоним — либо SPX, либо SPY, но не они оба, может быть заменен просто на SP.
СОЕДИНЕНИЕ ПО УСЛОВИЮ «БОЛЬШЕ ЧЕМ»
Выдать все комбинации информации о поставщиках и деталях, таких, что город местонахождения поставщика следует за городом, где хранится деталь, в алфавитном порядке:
SELECT S.*, P.*
FROM S.P
WHERE S.ГOPOД > Р.ГОРОД;
Получим в результате следующую таблицу 3.
Таблица 3
НОМЕР_ПОСТАВЩИКА
ФАМИЛИЯ
СОСТОЯНИЕ
S.ГОРОД
S2
S2
S2
S3
S3
S3
Джонс
Джонс
Джонс
Блейк
Блейк
Блейк
10
10
10
30
30
30
Париж
Париж
Париж
Париж
Париж
Париж
Продолжение табл. 3
НОМЕР_ДЕТАЛИ
НАЗВАНИЕ
ЦВЕТ
ВЕС
Р.ГОРОД
P1
Р4
Р6
Р1
Р4
Р6
Гайка
Винт
Блюм
Гайка
Винт
Блюм
Красный Красный Красный Красный Красный Красный
12
14
19
12
14
19
Лондон
Лондон
Лондон
Лондон
Лондон
Лондон
СОЕДИНЕНИЕ С ДОПОЛНИТЕЛЬНЫМ УСЛОВИЕМ
Выдать все комбинации информации о поставщиках и информации о деталях, такие, что рассматриваемые поставщики и детали «соразмещены». Опустить при этом поставщиков с состоянием, равным 20:
SELECT S.*, Р.*
FROM S,P
WHERE S.ГОРОД = Р.ГОРОД
AND S.СОСТОЯНИЕ = 20;
Результат представлен в таблице 4.
Таблица 4
НОМЕР_ПОСТАВЩИКА
ФАМИЛИЯ
СОСТОЯНИЕ
S.ГОРОД
S2
S2
S3
S3
Джонс
Джонс
Блейк
Блейк
10
10
30
30
Париж
Париж
Париж
Париж
Продолжение табл. 4
НОМЕР_ДЕТАЛИ
НАЗВАНИЕ
ЦВЕТ
ВЕС
Р.ГОРОД
P2
Р5
Р2
Р5
Болт
Кулачок
Болт
Кулачок
Зеленый
Голубой
Зеленый
Голубой
17
12
17
12
Париж
Париж
Париж
Париж
СОЕДИНЕНИЕ ТАБЛИЦЫ С НЕЙ САМОЙ
Выдать все пары номеров поставщиков, такие, что образующие их поставщики соразмещены.
SELECT ПЕРВАЯ НОМЕР_ПОСТАВЩИКА,
ВТОРАЯ. НОМЕР_ПОСТАВЩИКА
FROM S ПЕРВАЯ, S ВТОРАЯ
WHERE ПЕРВАЯ.ГОРОД = ВТОРАЯ.ГОРОД;
Нетрудно видеть, что в этом запросе требуется соединение таблицы S с ней самой по соответствию городов. Поэтому таблица S дважды указывается во фразе FROM. Для того чтобы различать эти два ее вхождения, мы вводим в этой фразе два произвольных ее псевдонима, ПЕРВАЯ и ВТОРАЯ, и используем их как явные уточнители во фразах SELECT и WHERE. Получаем результат:
НОМЕР_ПОСТАВЩИКА
НОМЕР_ПОСТАВЩИКА
S1
S1
S2
S2
S3
S3
S4
S4
S5
S1
S4
S2
S3
S2
S3
S1
S4
S5
Мы можем привести в порядок этот результат, расширив следующим образом фразу WHERE:
SELECT ПЕРВАЯ.НОМЕР_ПОСТАВЩИКА.ВТОРАЯ.НОМЕР_ПОСТАВЩИКА
FROM S ПЕРВАЯ, S ВТОРАЯ
WHERE ПЕРВАЯ.ГОРОД = ВТОРАЯ.ГОРОД
AND ПЕРВАЯ.НОМЕР_ПОСТАВЩИКА < ВТОРАЯ. НОМЕР_ПОСТАВЩИКА
Условие ПЕРВАЯ.НОМЕР_ПОСТАВЩИКА < ВТОРАЯ.НОМЕР_ПОСТАВЩИКА дает двоякий эффект: а) оно исключает пары номеров поставщиков вида (х,х); б) оно гарантирует, что не будут появляться одновременно пары (х, у)
и (у, х).
Имеем в результате:
НОМЕР_ПОСТАВЩИКА
НОМЕР_ПОСТАВЩИКА
S1
S2
S4
S3
Это первый пример, в котором мы видели, что использование синонимов необходимо. Однако введение таких синонимов никогда не будет ошибкой, даже если их использование не необходимо, и иногда они могут помочь в том, чтобы данное предложение стало более ясным. Мы иногда будем использовать их в наших примерах в следующей главе.
Выдать все пары номеров поставщиков таких, что входящие к каждую пару поставщики соразмещены (пример 4.3.6);
S
НОМЕР_
ПОСТАВЩИКА
ГОРОД
S
НОМЕР_
ПОСТАВЩИКА
ГОРОД
_SX
_сZ
_SY
_сZ
P.
_SX
_SY
Для того чтобы специфицировать дополнительное условие SX<SY, если это необходимо, может быть использован блок условия. Обсуждение этого вопроса см. в главе 4.
СОЕДИНЕНИЕ ТРЕХ ТАБЛИЦ
Выдать все пары названий городов, таких, что какой-либо поставщик, находящийся в первом из этих городов, поставляет некоторую деталь, хранимую во втором городе. Например, поставщик Sl поставляет деталь Р1. Поставщик Sl находится в Лондоне, а деталь Р1 хранится также в Лондоне. Поэтому пара городов «Лондон, Лондон» — это пара городов, которая содержится в результате.
SELECT DISTINCT S.ГOPOД, Р.ГОРОД
FROM S, SP, P
WHERE S.HOMEP_ПОСТАВЩИКА = SP.HOMEP_ПОСТАВЩИКА
AND SP.HOMEP_ДЕТАЛИ = Р.НОМЕР_ДЕТАЛИ;
Получаем результат:
S.ГOPOД
Р.ГОРОД
Лондон
Лондон
Лондон
Париж
Париж
Лондон
Париж
Рим
Лондон
Париж
В качестве упражнения читателю следует установить, какие конкретно комбинации поставщик — деталь порождают каждую из строк результата в этом примере.
СПРЕДИКАТЫ
предикат
: : = условие
|условие AND предикат
|условие OR предикат
|NOT предикат
условие
: : = условие — сравнения
| условие — between
|условие — like
|условие — in
|условие — exists
условие — сравнения
: : = скалярное — выражение оператор — сравнения скалярное — выражение
|скалярное — выражение оператор — сравнения
(выражение — селекции — для — столбца)
[скалярное—выражение IS [NOT] NULL
оператор – сравнения
: : =+| ¬=| < | ¬ < | <= | > | ¬ > | > =
выражение — селекции — для — столбца
: : = фраза — селекции — для — столбца
фраза — from
[ фраза — where]
[фраза — группирования [фраза — having]]
фраза — селекции — для — столбца
: : = SELECT [DISTINCT] скалярное — выражение
условие — between
: : = имя — столбца [NOT] BETWEEN скалярное — выражение
AND скалярное — выражение условие — like
: : = имя — столбца
[NOT] LIKE скалярное — выражение
условие — in
: : = скалярное выражение [NOT] IN (множество — скаляров)
множество — скаляров
: : = список — константа
| выражение — селекции — для — столбца
условие — exists
: := EXISTS (выражение—селекции)
