Флэш-память, гибриды и применимость жестких дисков
Говоря о современных жестких дисках, нельзя не коснуться вопроса о конкуренции магнитных носителей и флэш-памяти (которая уже сегодня наблюдается в ряде продуктовых сегментов, например, среди MP3-плееров). Производители жестких дисков всячески открещиваются от конкуренции, говоря, скорее, о сосуществовании и даже об интеграции обеих технологий в так называемых гибридных винчестерах. Подобные устройства используют магнитную технологию для хранения больших массивов информации, а флэш-память применяется для наиболее часто используемых данных (в частности, модулей операционной системы). По всей видимости, через несколько лет «чистых» жестких дисков практически не останется — их место займут «гибридные» накопители. Было бы наивно полагать, что в ближайшем будущем удельная стоимость флэш-памяти приблизится к показателям магнитных носителей. Вместе с тем возникает вопрос — а требуются ли конечным пользователям те объемы информации, которые способны хранить будущие винчестеры? Конечно, количество и качество цифрового контента растет, но ведь растут и скорости доступа в Интернет. Сейчас нетрудно представить ситуацию, когда весь контент будет расположен в централизованных интернет-хранилищах, а конечные пользователи станут пользоваться им оттуда, даже не скачивая. И далеко не факт, что этим пользователям понадобится винчестер, ведь с функциями загрузки системы и редактирования личных данных вполне справится более производительная и экономичная флэш-память. Такое положение вещей можно наблюдать уже сегодня в так называемых домовых сетях.
Добавим, что подобные тезисы можно услышать и от руководителей ведущих IT-компаний. Например, во время своего визита в Москву руководитель Microsoft Билл Гейтс (Bill Gates) рассказывал о перспективах создания дешевого универсального устройства, предназначенного, прежде всего, для активной работы в Сети. Похожий проект есть и у компании AMD — Personal Internet Communicator. Такие устройства вряд ли будут обладать большим объемом дисковой памяти просто потому, что они в ней совершенно не нуждаются. Впрочем, даже если IT-отрасль пойдет по этому пути развития, винчестеры все равно останутся — они будут присутствовать хотя бы в тех самых централизованных хранилищах контента. Здесь у жестких дисков пока нет разумной альтернативы: флэш-память не обеспечивает должного объема, а лента, соответственно — скорости.
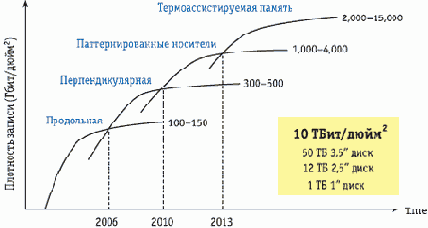
График.Радикальные технологические изменения ближайших 10 лет
Индустрия жестких дисков: дальше — больше
Данил Анисимов, Евгений Патий
"Экспресс Электроника"
За последние полгода мировая индустрия жестких дисков отметила сразу две знаменательные даты. В сентябре 2006-го исполнилось ровно 50 лет со дня выхода в свет дисковой системы IBM RAMAC (Random Access Method of Accounting and Control), а буквально месяц назад компания Hitachi Global Storage Technologies объявила о выпуске первого винчестера форм-фактора 3,5 дюйма объемом 1 Тбайт.
Создание IBM RAMAC, первой коммерческой системы с произвольным доступом к данным, считается официальным рождением жесткого диска. За время, прошедшее с этого момента, индустрия сделала гигантский шаг вперед. Судите сами: объем накопителей увеличился примерно в 200 тыс. раз, их удельная стоимость — в 25 млн, а поверхностная плотность записи — в 75 млн раз (см. таблицу).
| Год выпуска | 1956 | 1991 | 2007 |
| Объем | 5 Мбайт | 40 Мбайт | 1 Тбайт |
| Количество пластин | 50 | 3 | 5 |
| Диаметр пластины | 24 дюйма | 3,5 дюйма | 3,5 дюйма |
| Плотность записи | 2 кбит/дюйм2 | 10 Мбит/дюйм2 | 150 Гбит/дюйм2 |
| Скорость вращения | 1200 об/мин | 3500 об/мин | 7200 об/мин |
| Среднее время доступа | 1 с | 30 мс | 4,17 мс |
| Максимальная скорость интерфейса | 9 кбайт/с | 800 кбайт/с | 300 Мбайт/с |
| Удельная стоимость | $10 000/Мбайт | $6/Мбайт | $0,4/Гбайт |
Таблица. Сравнение основных параметров винчестеров
Созданная 50 лет назад система IBM RAMAC напоминала два больших холодильника. Она состояла из 50-ти покрытых оксидом железа 24-дюймовых пластин, способных хранить 5 Мбайт информации. Для сравнения: текстовый файл с четырьмя томами романа Льва Толстого «Война и мир» занимает на современных дисках 2,5 Мбайт данных, то есть система IBM RAMAC была способна вместить два таких файла. По тем временам это был весьма существенный показатель, достаточный для решения большинства задач. Поэтому абсолютный объем жестких дисков на первых порах увеличивался не сильно, разработчики пытались повысить показатель плотности записи, уменьшая габариты устройств и их стоимость.
Любопытно, что компьютеры на основе дисковой системы IBM RAMAC не продавались, а сдавались в аренду. Причем, несмотря на относительно высокую стоимость арендной платы, компания IBM сумела найти более сотни заказчиков.

Система IBM RAMAC состояла из 50-ти покрытых оксидом железа 24-дюймовых пластин, способных хранить 5 Мбайт информации
Далее индустрия жестких дисков развивалась по экстенсивному пути: производители просто уменьшали размер битовых ячеек. Совершенствовались остальные компоненты накопителей — материал покрытия пластин, считывающая головка и электроника, однако сама технология записи принципиально не менялась. Такая ситуация не могла продолжаться вечно, поскольку при очень маленьких размерах ячеек вступали в силу квантовые эффекты, нехарактерные для классической физики. Понимание того, что для дальнейшего увеличения плотности необходимы новые технологии, пришло к разработчикам в XXI веке.
Любая магнитная запись базируется на ферромагнитных свойствах некоторых веществ, способных сохранять намагниченное состояние в условиях отсутствия магнитного поля. В случаях, когда это состояние не сохраняется (или вероятность сохранения недостаточно высока), запись информации невозможна. Если же размер магнитного домена очень мал, возможно возникновение суперпарамагнитного эффекта, то есть несохранения намагниченного состояния в результате случайных движений частиц. Если вещество намагничено, его частицы имеют определенный магнитный порядок, устойчивость которого напрямую зависит от размеров домена. В то же время частицы вещества находятся в непрерывном движении, причем энергия этого движения пропорциональна температуре тела. Поэтому, если размер домена мал и энергия магнитного взаимодействия сравнима с температурной энергией, магнитный порядок может нарушиться в результате температурных флуктуаций. Последний тезис означает, что размер домена имеет определенный физический предел, дальнейшее уменьшение не имеет смысла.
От чего же зависит этот предел? Прежде всего от температуры носителя — чем она меньше, тем меньше суперпарамагнитный эффект.
Несмотря на теоретическую обоснованность, уменьшить температуру винчестеров на практике так же сложно, как и представить себе домашний компьютер с системой охлаждения, скажем, на жидком азоте. Поэтому методы, основанные на простом понижении температуры, вряд ли получат широкое распространение. Суперпарамагнитный предел существенно зависит и от свойств используемого вещества. Одной из характеристик магнетиков является константа магнитной анизотропии — величина, показывающая, какую (коэрцитивную) силу надо приложить к веществу для изменения его намагниченности. Чем больше эта сила, тем стабильнее ведет себя вещество и тем меньше его суперпарамагнитный предел. Однако применение веществ с высокой коэрцитивностью приводит к усложнению процесса записи, поскольку для этого надо приложить большую силу. Далее мы увидим, что один из «методов будущего» (а именно — термоассистирующая запись) базируется на изменении температуры тела и применении веществ с высокой коэрцитивностью. При использовании традиционной параллельной записи суперпарамагнитный эффект наступает при достижении плотности записи 100–150 Гбит/дюйм2, что соответствует емкости 500–750 Гбайт в случае 3,5-дюймовых жестких дисков. В прошлом году широкое распространение получила перпендикулярная запись, позволяющая несколько отодвинуть предел плотности. Поэтому, прежде чем рассказывать о будущих технологиях, остановимся на различии параллельной записи и перпендикулярной.
Параллельная и перпендикулярная запись
Главное отличие между данными технологиями заключается в направлении намагниченности доменов — в случае параллельной записи оно параллельно плоскости диска, а в случае перпендикулярной, соответственно, перпендикулярно (см. схему). Однако если мы посмотрим на конкретный домен в отдельности, то никакой разницы не увидим, поскольку суперпарамагнитный предел не зависит от направления намагниченности. Причина более высокой плотности перпендикулярной записи объясняется не какими-то внутренними характеристиками одного домена, а силами взаимодействия между соседними ячейками.
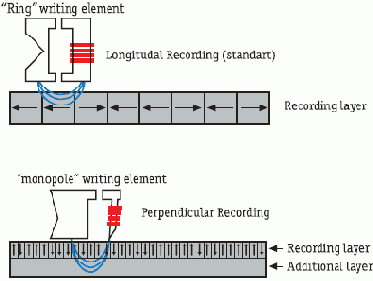
Схема. Параллельная и перпендикулярная запись
Из школьного курса физики известно, что постоянные магниты, расположенные одинаковыми полюсами друг к другу, отталкиваются, а разными, наоборот, притягиваются. Как следствие, при использовании технологии последовательной записи возникают силы магнитного взаимодействия соседних доменов, влияющие на магнитные поля каждой из этих частиц. Другими словами, магнитная энергия каждого домена может уменьшиться, и тогда вероятность влияния термофлуктуаций на магнитный порядок данного домена увеличится. При использовании перпендикулярного расположения доменов их влияние друг на друга существенно уменьшается. Возникает естественный вопрос — почему же, несмотря на кажущуюся простоту и широкую известность метода, коммерческие реализации перпендикулярной записи появились спустя 50 лет после создания первого жесткого диска?
Ответ на него можно разделить на две основные части. Во-первых, традиционная параллельная технология успешно развивалась и до недавнего времени не сталкивалась с жесткими физическими ограничениями. Во-вторых, техническая реализация перпендикулярной записи была сопряжена с рядом сложностей, обусловленных принципиально другим способом расположения магнитных доменов. Действительно, перпендикулярная запись требует наличия специальной дополнительной подложки под слоем записи, а также принципиально других, «двусторонних», головок, способных генерировать более сильное магнитное поле. Вполне возможно, перпендикулярная запись могла появиться и раньше, только производители не хотели осложнять себе жизнь и постепенно совершенствовали параллельную технологию, пока она не приблизилась к физическому пределу.
По оценкам экспертов, современная технология перпендикулярной записи имеет физический предел плотности в 500 Гбит/дюйм2. Предполагается, что он будет достигнут в 2010 году. Таким образом, использование данного типа записи позволит довести емкость 3,5-дюймовых винчестеров до нескольких терабайт, а дальнейшее увеличение объема пока не представляется возможным. Сегодня видны два основных вектора развития индустрии жестких дисков — структурированная и термоассистирующая запись. Рассмотрим их подробнее.
Структурированные носители
Концептуальная идея структурированных носителей крайне проста, однако перспективы ее практической реализации до сих пор не понятны. Как видно из рис. 1, в современных накопителях каждый магнитный домен состоит из нескольких десятков (70–100) мелких структурных элементов («зерен»), каждое из которых теоретически способно выполнять функции домена и содержать в себе 1 бит информации.
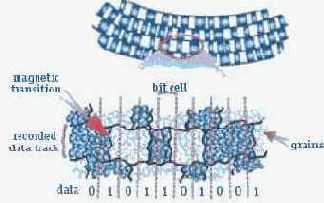
Рисунок 1.Традиционная запись
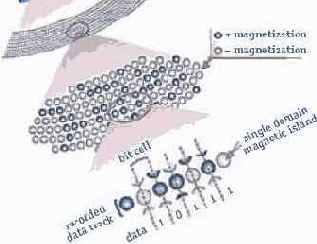
Рисунок 2. Структурированная запись
В результате появляется возможность уменьшить суперпарамагнитный предел: увеличить размеры отдельного «зерна» и хранить единицу информации в меньшем количестве «зерен». Основная сложность внедрения структурированных технологий заключается в производстве требуемых носителей. Если плотность записи составляет 100 Гбит/дюйм2 (современные носители), то линейный размер одного «острова» (множества «зерен», хранящих 1 бит) должен равняться 86 нм, а для перехода к терабитным плотностям требуются «островки» длиной в 27 нм (квадрат линейного размера ячейки обратно пропорционален плотности — то есть при росте плотности вчетверо размер ячейки уменьшается вдвое). Таким образом, для того чтобы изготовить структурированные диски, требуется технология, способная наносить на поверхность носителя отпечатки столь малой длины. Значение 27 нм находится на пределе возможности оптической литографии — метода, применяющегося сегодня для изготовления микросхем и продуктов на их основе (например процессоров). Поэтому производители жестких дисков планируют применять другие литографические методы или использовать самоорганизующиеся материалы (примером подобного материала может послужить железо-платиновый сплав — FePt). Добавим, что материал носителя — не единственная проблема структурированной технологии, инженерам также придется разработать механизмы синхронизации магнитных импульсов головки и «островов», а также создать специальные навигационные метки для головки. В настоящее время разработки, связанные со структурированными носителями, ведут как минимум две лидирующие компании-производителя — Hitachi Global Storage Technologies (HGST) и Seagate. Причем первая из них возлагает на данный метод большие надежды. Согласно информации HGST, появление коммерческих структурированных носителей должно произойти в 2010 году, а предел их теоретической плотности может достигнуть отметки несколько терабит на квадратный дюйм. Если же разработчикам удастся придумать материалы с однозернистыми «островами», то возможны и вовсе фантастические результаты — с плотностью до нескольких десятков и даже сотен терабит.
Термоассистируемая магнитная запись (Heat-Assisted Magnetic Recording, HAMR)
Как мы уже отмечали выше, термоассистируемая запись сочетает два способа обхода суперпарамагнитного эффекта — с помощью изменения температуры и использования веществ с высокой коэрцитивностью. Подобные вещества стабильны, они имеют низкий суперпарамагнитный предел, однако для изменения их магнитного состояния (записи) требуется значительная коэрцитивная сила, которая не может создаваться современными головками. В технологии HAMR она и не создается — во время записи носитель нагревается, его коэрцитивность падает и требуемая сила становится гораздо меньше. После того как запись завершена, носитель остывает и остается в стабильном состоянии на долгое время (рис. 3).
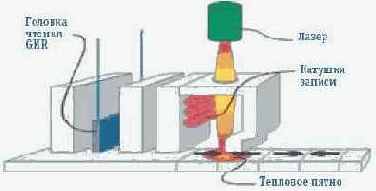
Рисунок 3. Лазер для нагрева носителя, интегрированный в головку записи
Планируется, что нагрев малой части носителя будет происходить с помощью теплового лазера, интегрированного в записывающую головку. Тут же возникает масса проблем — во-первых, непонятно, как «запихнуть» лазер в головку, во-вторых, как обеспечить нагрев именно той области, которая необходима, в-третьих, как ее охладить. Кроме того, требуется учитывать макроскопическое нагревание винчестера. Как известно, эта проблема актуальна даже в современных жестких дисках. Наконец, важно придумать материал носителя с заданными свойствами, а именно: с высокой коэрцитивностью при комнатной температуре и низкой при температуре записи.
Разработки HAMR-технологий ведутся довольно давно (с конца прошлого века), однако эксперты до сих пор расходятся в оценках максимальной плотности записи и сроках массового применения подобных винчестеров. Так, компания HGST называет предел в 15 Тбит/дюйм2, а Seagate предполагает, что HAMR-носители могут достигнуть плотности 50 Тбит/дюйм2. По всей видимости, широкого распространения данной технологии можно ожидать в 2010– 2013 годах. Несмотря на то, что структурированная и термоассистируемая записи абсолютно различны, теоретически эти методы не противоречат друг другу. Другими словами, в будущем возможно появление накопителей, сочетающих оба подхода. Однако необходимо понимать, что одной из главных сложностей разработки и структурированных, и термоассистируемых носителей является дисковый материал, то есть разработать доступное вещество, удовлетворяющее требованиям обеих технологий, будет крайне сложно.
мапа развития технологий, согласно точке
Как видно из роад- мапа развития технологий, согласно точке зрения HGST (см. график), в ближайшие несколько лет в индустрии жестких дисков ожидаются более существенные технологические изменения, чем за весь пятидесятилетний период ее существования. Сейчас трудно сказать, насколько точными окажутся прогнозы вендоров, однако совершенно ясно другое — технологические изменения неизбежно приведут к изменениям рыночной ситуации. Тем интереснее нам будет за ней наблюдать.
При написании статьи использовались
материалы Hitachi Global Storage Technologies
Устройство жесткого диска
Артём Рубцов, R.LAB
Уточнение связи между русскоязычной и англоязычной терминологией выполнено Леонидом Воржевым.
Цель этой статьи — описать устройство современного жёсткого диска, рассказать о его главных компонентах, показать, как они выглядят и называются. Кроме того, мы покажем связь между русскоязычной и англоязычной терминологиями, описывающими компоненты жестких дисков.
Для наглядности, разберём 3.5-дюймовый SATA диск. Это будет совершенно новый терабайтник Seagate ST31000333AS. Осмотрим нашего подопытного кролика.

Зелёный текстолит с медными дорожками, разъемами питания и SATA называется платой электроники или платой управления (Printed Circuit Board, PCB). Она служит для управления работой жесткого диска. Чёрный алюминиевый корпус и его содержимое называется гермоблоком (Head and Disk Assembly, HDA), специалисты также называют его «банкой». Сам корпус без содержимого также называют гермоблоком (base).
Теперь снимем печатную плату и изучим размещённые на ней компоненты.

Первым в глаза бросается большой чип, расположенный посередине – микроконтроллер, или процессор (Micro Controller Unit, MCU). На современных жёстких дисках микроконтроллер состоит из двух частей – собственно центрального процессора (Central Processor Unit, CPU), который производит все вычисления, и канала чтения/записи (read/write channel) — особого устройства, преобразующего поступающий с головок аналоговый сигнал в цифровые данные во время операции чтения и кодирующий цифровые данные в аналоговый сигнал при записи. Процессор имеет порты ввода-вывода (IO ports) для управления остальными компонентами, расположенными на печатной плате, и передачи данных через SATA-интерфейс.
Чип памяти (memory chip) представляет собой обычную DDR SDRAM память. Объем памяти определяет размер кэша жёсткого диска. На этой печатной плате установлена память Samsung DDR объемом 32 Мб, что в теории даёт диску кэш в 32 Мб (и именно такой объём приводится в технических характеристиках жёсткого диска), но это не совсем верно.
Дело в том, что память логически разделена на буферную память (кэш) и память прошивки. Процессору требуется некоторый объём памяти для загрузки модулей прошивки. Насколько нам известно, только Hitachi/IBM указывают действительный объём кэша в описании технических характеристик; относительно остальных дисков, об объёме кэша остаётся только гадать.
Следующий чип – контроллер управления двигателем и блоком головок, или «крутилка» (Voice Coil Motor controller, VCM controller). Кроме того, этот чип управляет вторичными источниками питания, расположенными на плате, от которых питается процессор и микросхема предусилителя-коммутатора (preamplifier, preamp), расположенная в гермоблоке. Это главный потребитель энергии на печатной плате. Он управляет вращением шпинделя и движением головок. Ядро VCM-контроллера может работать даже при температуре в 100° C.
Часть прошивки диска хранится во флэш-памяти. При подаче питания на диск микроконтроллер загружает содержимое флэш-чипа в память и приступает к исполнению кода. Без корректно загруженного кода диск даже не пожелает раскручиваться. Если на плате отстутствует флэш-чип, значит, он встроен в микроконтроллер.
Датчик вибрации (shock sensor) реагирует на опасную для диска тряску и посылает сигнал об этом контроллеру VCM. Контроллер VCM немедленно паркует головки и может остановить вращение диска. Теоретически, такой механизм должен защищать диск от дополнительных повреждений, но на практике он не работает, так что не роняйте диски. На некоторых дисках датчик вибрации обладает повышенной чувствительностью, реагируя на малейшую вибрацию. Полученные с датчика данные позволяют контроллеру VCM корректировать движение головок. На таких дисках установлено как минимум два датчика вибрации.
На плате имеется ещё одно защитное устройство — ограничитель переходного напряжения (Transient Voltage Suppression, TVS). Он защищает плату от скачков напряжения. При скачке напряжения TVS перегорает, создавая короткое замыкание на землю. На этой плате установлено два TVS, на 5 и 12 вольт.
Теперь рассмотрим гермоблок.

Под платой находятся контакты мотора и головок. Кроме того, на корпусе диска имеется маленькое, почти незаметное отверстие (breath hole). Оно служит для выравнивания давления. Многие считают, что внутри жёсткого диска находится ваккум. На самом деле это не так. Это отверстие позволяет диску выровнять давление внутри и снаружи гермозоны. С внутренней стороны это отверстие прикрыто фильтром (breath filter), который задерживает частицы пыли и влаги.
Теперь заглянем внутрь гермозоны. Снимем крышку диска.

Сама крышка не представляет собой ничего интересного. Это просто кусок металла с резиновой прокладкой для защиты от пыли. Наконец, рассмотрим начинку гермозоны.

Драгоценная информация хранится на металлических дисках, называемых также блинами или пластинами (platters). На фотографии вы видите верхний блин. Пластины изготавливаются из полированного алюминия или стекла и покрываются несколькими слоями различного состава, в том числе ферромагнитным веществом, на котором, собственно, и хранятся данные. Между блинами, а также над верхним из них, мы видим специальные пластины, называемыми разделителями или сепараторами (dampers or separators). Они нужны для выравнивания потоков воздуха и снижения акустических шумов. Как правило, их изготавливают из алюминия или пластика. Алюминиевые разделители успешнее справляются с охлаждением воздуха внутри гермозоны.
Вид блинов и сепараторов сбоку.

Головки чтения-записи (heads), устанавливаются на концах кронштейнов блока магнитных головок, или БМГ (Head Stack Assembly, HSA). Парковочная зона — это область, в которой должны находиться головки исправного диска, если шпиндель остановлен. У этого диска, парковочная зона расположена ближе к шпинделю, что видно на фотографии.

На некоторых накопителях парковка производится на специальных пластиковых парковочных площадках, расположенных за пределами пластин.
Жёсткий диск — механизм точного позиционирования, и для его нормальной работы требуется очень чистый воздух.
В процессе использования внутри жёсткого диска могут образовываться микроскопические частицы металла и смазки. Для немедленной очистки воздуха внутри диска имеется циркуляционный фильтр (recirculation filter). Это высокотехнологичное устройство, которое постоянно собирает и задерживает мельчайшие частицы. Фильтр находится на пути потоков воздуха, создаваемых вращением пластин.

Теперь снимем верхний магнит и посмотрим, что скрывается под ним.

В жёстких дисках используются очень мощные неодимовые магниты. Эти магниты настолько мощны, что могут поднимать вес в 1300 раз больший их собственного. Так что не стоит класть палец между магнитом и металлом или другим магнитом — удар получится очень чувствительным. На этой фотографии изображены ограничители БМГ. Их задача — ограничить движение головок, оставляя их на поверхности пластин. Ограничители БМГ разных моделей устроены по-разному, но их всегда два, они используются на всех современных жестких дисках. На нашем накопителе второй ограничитель расположен на нижнем магните.
Вот что можно там увидеть.

Ещё мы видим здесь катушку (voice coil), которая является частью блока магнитных головок. Катушка и магниты образуют привод БМГ (Voice Coil Motor, VCM). Привод и блок магнитных головок образуют позиционер (actuator) — устройство, которое перемещает головки. Чёрная пластиковая деталь сложной формы называется фиксатором (actuator latch). Это защитный механизм, освобождающий БМГ после того, как шпиндельный двигатель наберёт определённое число оборотов. Происходит это за счёт давления воздушного потока. Фиксатор защищает головки от нежелательных движений в парковочном положении.
Теперь снимем блок магнитных головок.

Точность и плавность движения БМГ поддерживается прецизионным подшипником. Самая крупная деталь БМГ, изготовленная из алюминиевого сплава, обычно называется кронштейном или коромыслом (arm). На конце коромысла находятся головки на пружинной подвеске (Heads Gimbal Assembly, HGA).
Обычно сами головки и коромысла поставляют разные производители. Гибкий кабель (Flexible Printed Circuit, FPC) идёт к контактной площадке, стыкующейся с платой управления.
Рассмотрим составляющие БМГ подробнее.
Катушка, соединенная с кабелем.

Подшипник.

На следующей фотографии изображены контакты БМГ.

Прокладка (gasket) обеспечивает герметичность соединения. Таким образом, воздух может попасть внутрь блока с дисками и головками только через отверстие для выравнивания давления. У этого диска контакты покрыты тонким слоем золота для улучшения проводимости.
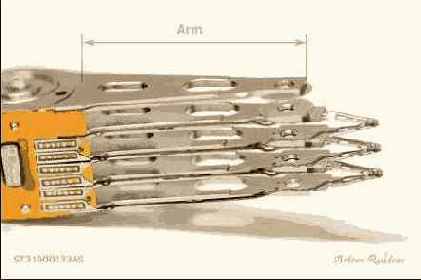
Это классическая конструкция коромысла.

Маленькие чёрные детали на концах пружинных подвесов называют слайдерами (sliders). Многие источники указывают, что слайдеры и головки — это одно и то же. На самом же деле слайдер помогает считывать и писать информацию, поднимая головку над поверхностью блинов. На современных жёстких дисках головки двигаются на расстоянии 5–10 нанометров от поверхности блинов. Для сравнения: человеческий волос имеет диаметр около 25000 нанометров. Если под слайдер попадёт какая-нибудь частица, это может привести к перегреву головок из-за трения и выходу их из строя, именно поэтому так важна чистота воздуха внутри гермозоны. Сами считывающие и записывающие элементы находятся на конце слайдера. Они так малы, что разглядеть их можно только в хороший микроскоп.

Как видите, поверхность слайдера не плоская, на ней имеются аэродинамические канавки. Они помогают стабилизировать высоту полёта слайдера. Воздух под слайдером образует воздушную подушку (Air Bearing Surface, ABS). Воздушная подушка поддерживает почти параллельный поверхности блина полёт слайдера.
Вот ещё одно изображение слайдера.

Здесь хорошо видны контакты головок.
Это ещё одна важная часть БМГ, которая пока не обсуждалась. Она называется предусилителем (preamplifier, preamp). Предусилитель — это чип, управляющий головками и усиливающий поступающий к ним или от них сигнал.

Предусилитель располагают прямо в БМГ по очень простой причине — сигнал, идущий с головок, очень слаб. На современных дисках он имеет частоту около 1 ГГц. Если вынести предусилитель за пределы гермозоны, такой слабый сигнал сильно затухнет по пути к плате управления.
От предусилителя к головкам (справа) ведёт больше дорожек, чем к гермозоне (слева). Дело в том, что жёсткий диск не может одновременно работать более чем с одной головкой (парой пишущих и считывающих элементов). Жёсткий диск посылает сигналы на предусилитель, и он выбирает головку, к которой в данный момент обращается жёсткий диск. У этого жёсткого диска к каждой головке ведёт шесть дорожек. Зачем так много? Одна дорожка — земля, ещё две — для элементов чтения и записи. Следующие две дорожки — для управления мини-приводами, особыми пьезоэлектрическими или магнитными устройствами, способными двигать или поворачивать слайдер. Это помогает точнее задать положение головок над треком. Последняя дорожка ведёт к нагревателю. Нагреватель служит для регулирования высоты полёта головок. Нагреватель передаёт тепло подвесу, соединяющему слайдер и коромысло. Подвес изготавливается из двух сплавов, имеющих разные характеристики теплового расширения. При нагреве подвес изгибается к поверхности блина, уменьшая, таким образом, высоту полёта головки. При охлаждении подвес выпрямляется.
Хватит о головках, давайте разбирать диск дальше. Снимем верхний сепаратор.
Вот как он выглядит.

На следующей фотографии вы видите гермозону со снятыми верхним разделителем и блоком головок.

Стал виден нижний магнит.
Теперь прижимное кольцо (platters clamp).

Это кольцо удерживает блок пластин вместе, не давая им двигаться друг относительно друга.
Блины нанизаны на шпиндель (spindle hub).

Теперь, когда блины ничто не удерживает, снимем верхний блин. Вот что находится под ним.

Теперь понятно, за счёт чего создается пространство для головок — между блинами находятся разделительные кольца (spacer rings).На фотографии виден второй блин и второй сепаратор.
Разделительное кольцо — высокоточная деталь, изготовленная из немагнитного сплава или полимеров. Снимем его.

Вытащим из диска все остальное, чтобы осмотреть дно гермоблока.

Так выглядит отверстие для выравнивания давления. Оно располагается прямо под воздушным фильтром. Рассмотрим фильтр внимательнее.
Так как поступающий снаружи воздух обязательно содержит пыль, фильтр имеет несколько слоёв. Он гораздо толще циркуляционного фильтра. Иногда он содержит частицы силикагеля для борьбы с влажностью воздуха.
Голографическая запись
Евгений Патий
"Экспресс Электроника"
Сегодня наблюдается бурный рост рынка носителей информации, предназначенных для корпоративных пользователей. Это неудивительно, поскольку увеличиваются объемы обрабатываемых данных, которые необходимо каким-то образом хранить.
Особый сегмент рынка составляют средства для резервного хранения информации. Наибольшее распространение получили такие решения для резервирования данных, как жесткие диски и ленточные носители.
Первый метод выбирают компании с ограниченным бюджетом на IT, второй — предприятия, ставящие во главу угла надежность и безопасность. Однако совершенно очевидно, что существующие подходы уже не могут справиться с нарастающими объемами информации и обеспечить быстрое оперативное резервирование, сделать «слепок во времени».
Сегодня необходим качественный прорыв в технологиях хранения. И если с объемом ситуация разрешима — в конце концов можно увеличить число жестких дисков или ленточных кассет для резервирования, то скорость уже давно стала узким местом всего процесса резервирования. Реалии требуют универсального накопителя, сопоставимого или превосходящего по объемам жесткий диск и ленточный картридж, но выполняющего процедуры записи и считывания с гораздо большей скоростью. Решить проблему могут устройства на основе голографических технологий.
Еще пять лет назад начались работы в этой области: в 2000 году на рынке технологий хранения данных возникла новая компания InPhase Technologies, приступившая к созданию устройств записи данных принципиально нового типа. Новый разработчик появился не на пустом месте — о создании этого небольшого предприятия объявила корпорация Lucent Technologies.
InPhase занялась созданием голографических систем хранения на основе технологии, разработанной в бюро Bell Labs. В отличие от существующих методов записи информации на поверхность диска, новая технология позволяет использовать всю толщину материала, то есть запись ведется не по поверхности, а по объему. Помимо многократного увеличения плотности записи, данная разработка предоставляет возможность повысить скорость считывания информации — за один «машинный отсчет» с носителя можно скачать до 1 млн бит информации.
К сегодняшнему дню появились готовые решения, разработанные InPhase в сотрудничестве с Maxell, в частности оптические носители, использующие голографический метод. По заявлению разработчиков, с применением данной технологии на пятидюймовый оптический диск можно записать 1,6 Тбайт информации при пропускной способности до 120 Мбайт/с. В сочетании с невысокой ценой хранения за 1 Гбайт и обеспечением успешного чтения данных более чем через 50 лет после записи эта технология выглядит весьма перспективной. Но все же интересно, откуда появилась цифра «50», если с начала работ до появления коммерческих изделий не прошло и шести лет?
Технология голографической записи позволяет реализовывать разнообразные приложения, например, использовать носители разнообразных форм-факторов (помимо дисков, это могут быть, скажем, карты и другие типы накопителей) или лазеры с различной длиной волны (красные, зеленые и голубые). Первое поколение голографических носителей появилось в сентябре 2006 года. InPhase Technologies и Hitachi Maxell Conduct (партнер и инвестор InPhase Technologies) провели испытания действующей технологии совместно с компанией Turner Entertainment Networks, одним из ведущих игроков на рынке телевещания. Новая голографическая система хранения данных получила название Tapestry. Ее демонстрация оказалась довольно простой, но наглядной. На диск Tapestry специалисты записали рекламный ролик, который впоследствии переписывался на сервер и в заданное время воспроизводился в трансляционной сети Turner Entertainment Networks. Как отметил вице-президент Turner Entertainment Networks Рон Тарасов (Ron Tarasov), «демонстрация проводилась для того, чтобы показать возможности голографических систем хранения данных с точки зрения трансляции телевизионного контента. Голографические носители — идеальный способ хранения видеороликов в высоком разрешении, так как огромная емкость голографических дисков позволяет нам хранить телепрограммы в виде файлов, а скорость передачи данных подразумевает очень быстрое чтение и запись с диска и на диск».
Специалисты подсчитали, что один диск Tapestry способен хранить до 26 часов видеоматериала высокого разрешения в качестве, приемлемом для телевещания, — подразумевается диск емкостью 300 Гбайт, записанный с потоком 160 Мбайт/с.
Отгрузки дисков Tapestry емкостью 300 Гбайт начнутся в конце текущего года, а нынешний уровень развития технологий голографической записи допускает емкость до 1,6 Тбайт при потоке до 960 Мбайт/с. Разработчики обещают, что в массовом сегменте это произойдет к 2010 году. Одним из последних шагов InPhase Technologies на пути коммерциализации голографической технологии стало заключение соглашения с австрийской компанией DaTARIUS, которая занимается разработкой и производством тестового оборудования для оптических дисков. Голографические тестовые системы используются в производственном процессе для того, чтобы убедиться, соответствует ли качество оптического носителя определенным требованиям. Что ж, технология действительно интересная и перспективная, а значит, имеет смысл рассмотреть ее во всех подробностях.
Как известно, современные методы записи основаны на последовательных принципах: в каждый момент времени на поверхность плоского носителя может быть записан только один бит информации (мы не рассматриваем случаи с множеством головок записи, при которых имеет место «квазипараллельный» процесс). В то же время голографический метод выглядит как действительно параллельный: единственная вспышка лазера формирует пространственную запись миллионов битов информации. Различие существенно: один бит на поверхности носителя или же миллионы битов в пространстве, ограниченном структурой носителя.
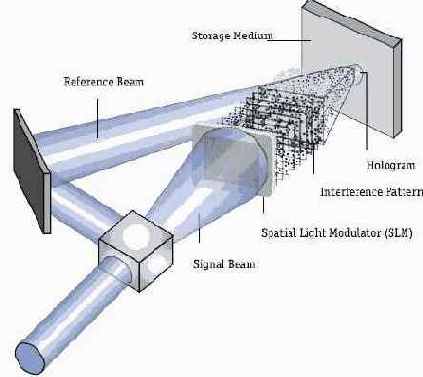
Схема 1. Принцип голографической записи
В общих чертах принцип голографической записи InPhase Technologies выглядит достаточно просто (схема 1). Световой поток разделяется на два луча: сигнальный и референсный; сигнальный луч обеспечивает запись данных, референсный остается неизменным. Цифровые данные формируют «образ» сигнального луча при помощи специального устройства — пространственного светового модулятора (Spatial Light Modulator, SLM), который преобразует последовательность нулей и единиц, составляющих страницу данных, в массив черных и белых точек.
Грубо говоря, создается подобие решетки, в которой просветы соответствуют очередной порции цифровых данных, а сквозь эту решетку просвечивает сигнальный луч, имеющий на выходе точную копию текущего состояния решетки в SLM. Разумеется, чем больше разрешающая способность пространственного светового модулятора, тем большую порцию данных может запечатлеть сигнальный луч в текущий момент времени, но на сегодня эта способность исчисляется миллионами битов.
После преобразования в SLM уже несущий определенную информационную нагрузку сигнальный луч проецируется на физический носитель. В точку проекции направляется и референсный луч, пересекаясь в ней с сигнальным. В этот момент происходит химическая реакция и, как следствие, запись информации на носитель, причем там, где в SLM была непрозрачная точка. Отпечатка на носителе не остается, иначе соответствующая точка «выжигается». Если изменять длину волны референсного луча, угол его наклона или пространственное положение носителя, в один момент времени можно записать множество разных голограмм. Процесс записи данных на поверхности и в глубине носителя назвали мультиплексированием.
Кстати, есть несколько способов выполнения мультиплексирования, например при помощи варьирования угла наклона референсного луча. К сожалению, неизвестно, какова степень мультиплексирования и как, например, «толщина» одной записанной голограммы соотносится с толщиной носителя, ведь, если предположить, что один молекулярный или атомарный слой соответствует одной голограмме, это могло бы стать настоящей революцией на рынке хранения данных.
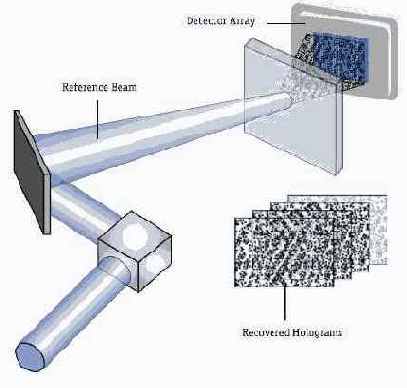
Схема 2. Считывание записанных данных
Считывание записанных голограмм обеспечивается одним референсным лучом, который создает отражение записанной голограммы и проецирует его на особый чувствительный элемент (схема 2). Этот же элемент преобразует попадающую на него «решетку» в последовательность битов, а чтение голограмм на различной глубине носителя обеспечивается тем же способом, который применялся и при записи, — изменением угла наклона референсного луча и т.
д.
Естественно, для воплощения идеи голографической записи потребовалось разработать особый тип носителя, который бы сочетал большую светочувствительность, прочность, дешевизну производства и стабильность. Немаловажны и линейные размеры носителя, поэтому специалисты InPhase Technologies решили, что оптимальным вариантом будет использование фотополимерных дисков, заключенных в особые картриджи, — примерно как в свое время DVD-RAM. Диаметр голографического диска ненамного превышает диаметр современных CD- и DVD-дисков и составляет 130 мм. Необходимо подчеркнуть, что сам диск полностью находится в «темном» картридже и попадание света на поверхность фотополимера вызовет химическую реакцию, способную разрушить записанные данные.
На сегодня имеются лишь устройства одноразовой записи, но InPhase Technologies уверяет, что в 2008 году появятся и перезаписываемые носители. Компания-разработчик Tapestry уделила огромное внимание безопасности информации, благо кое-какие аспекты присутствовали изначально, в силу самой природы процессов голографической записи-чтения.
Во-первых, при голографической записи невозможно получить прямой доступ к носителю, в отличие от жестких дисков и CD, — данные находятся в глубине носителя, что уже намного усложняет попытки несанкционированного доступа.
Кроме того, InPhase Technologies озаботилась логическими методами обеспечения безопасности. Каждый накопитель Tapestry снабжен особой микросхемой, в которую занесена информация о размещении данных на диске. При чтении привод в первую очередь обращается к этой информации, а если, например, ее зашифровать с учетом определенных условий, считать данные окажется невозможно (без необходимых сведений для доступа). То же происходит и в случае повреждения информации в микросхеме — в бытовых условиях диск станет нечитаемым, хотя путем определенных усилий информацию все-таки можно спасти.
Помимо этого, имеется и более примитивный метод — нанесение особых меток, которые также необходимо считать и распознать.
На более глубоком уровне защиты расположены уникальные метки с определенными координатами. Для того чтобы взломать этот вид защиты, требуется красный лазер, недоступный в массовых приводах Tapestry, — иначе, без знания координат «секретных» меток, данные считать невозможно.
Весьма эффективна защита, основанная на изменении длины волны лазера (в диапазоне 403–407 нм). Привод, в котором используется лазер с «несоответствующей» длиной волны, диск прочитать не сможет. Более того, возможны даже такие меры, как привязка диска к микропрограмме конкретного привода, — также при помощи особых встроенных средств защиты.
Голографическая технология InPhase Technologies выглядит достаточно впечатляюще, особенно если «примерить» все возможности Tapestry на потребности корпоративного рынка: высокая емкость, высокая скорость записи-чтения информации, средства защиты от несанкционированного доступа.
Остается надеяться, что конечные продукты попадут в приемлемую ценовую категорию и будут востребованы на рынке СХД.
По материалам InPhase Technologies
С:Предприятие файловая БД

Внешний Serial ATA RAID-контроллер совсем незначительно опережает Matrix Storage в файловом варианте — и довольно ощутимо (на 16%) в варианте SQL. Хотя с оптимальным значением strip size Matrix RAID-0 работает быстрее (см. основную статью).
Таким образом, внешний Serial ATA RAID-контроллер более предпочтителен для серверов или ПК, на которых есть выделенные RAID-массивы под конкретные задачи. Но если у вас только два HDD — однозначно лучше использовать Matrix Storage. И надежность получите, и практически ту же производительность.
Что такое stripe
stripe — непрерывная последовательность дисковых блоков. stripe может быть размером с один дисковый блок, но может состоять и из тысяч.
Устройства RAID разделяют содержащие их разделы дисков на страйпы; различные уровни RAID различаются в способе организации страйпов и в том, как размещаются на них данные. Взаимодействие между размером stripe, типичными размерами файлов в системе и их положением на диске — все это определяет общую производительность подсистемы RAID.
В RAID-0 компоненты разделов делятся на страйпы и затем чередуются. В результате получаем один большой виртуальный раздел. Такой подход не предполагает избыточности и снижает общую надежность: отказ одного диска уничтожит весь раздел.
Эффективность встроенных RAID
Сергей Антончук, "Комиздат"
Статья посвящена вопросу производительности дисковой подсистемы при использовании технологии Matrix Storage.
Напомним, что технология Matrix Storage реализована в новых южных мостах ICH6R и ключевой ее возможностью (если не говорить о реализации стандартных RAID-0 и RAID-1) является реализация такой схемы работы, при которой на двух дисках создается два массива уровней RAID-0 и RAID-1 (matrix RAID-0 и matrix RAID-1).
Тестирование серьезной технологии, конечно же, требует серьезного инструмента. Поэтому данное исследование проводилось в деловом приложении, использующем трехуровневую архитектуру. А точнее — в "1С:Предприятие 8.0".
"1С:Предприятие" работало в трехуровневой архитектуре "клиент — сервер приложения — SQL-сервер" на одном ПК. При этом основную нагрузку на дисковую подсистему ПК давал SQL-сервер.
Тестирование именно в этой архитектуре было выбрано потому, что производительность RAID-0 вообще и Matrix RAID-0 в частности серьезно зависит от параметра strip size.
Очевидно, что быстродействие системы в целом наибольшим будет тогда, когда данные от приложения или к нему будут поступать от дисковой подсистемы порциями, равными размеру strip size.
Но в компьютере всегда работает множество приложений с разной спецификой, поэтому размер strip size для RAID-0 в системах общего назначения — это всегда значение компромиссное. Однако если у нас есть приложение, которое должно работать быстро — пусть даже в ущерб всем остальным, то RAID-0 можно подстроить именно под него.
Вообще, такую настройку легче всего (и наиболее правильно) делать для SQL-серверов. Легче — потому что кратность данных, с которой SQL сервер взаимодействует с дисковой подсистемой, всегда известна. Это размер страницы (page size).
Для MS SQL сервера размер страницы составляет 8 Кб. Индексы записываются восьмистраничными блоками по 64 Кб.
Для Matrix RAID-0 значение strip size по умолчанию составляет 128 Кб. Так что, если планируется работа ПК, в основном, в качестве SQL-сервера (как в нашем случае), необходимость оптимизации налицо.
Вот этим и займемся.
Чтобы все было по-настоящему, на двух SATA- дисках Maxtor MaXLine III 250 Гб были построены два раздела: Matrix RAID-1 — для системы и бэкапов; Matrix RAID-0 — для свопа, временных файлов и рабочей SQL-базы.
Matrix RAID-0 сначала создавался по умолчанию, затем размер strip size задавался в 64 Кб, 32 Кб, 16 Кб и 8 Кб.
Вот что получилось в результате замеров производительности серверного трехуровневого варианта работы "1С:Предприятие 8.0" для одного клиента:
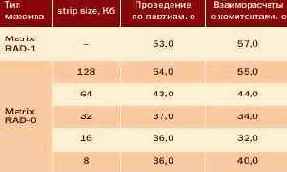
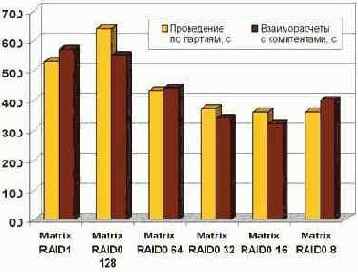
Полученные результаты достаточно красноречивы. При неудачном для данного случая значении strip size, которое составляет 128 Кб и было создано по умолчанию, сервер работает даже медленнее, чем в случае размещения СУБД на Matrix RAID-1. Зато в случае с "правильным" значением strip size в 8 Кб имеем 31% роста производительности в "проведении по партиям" по сравнению с Matrix RAID-1.
Вообще, все варианты со значением strip size от 64 Кб до 8 Кб показали прирост скорости, а наиболее оптимальным оказался вариант 16 Кб. Хотя для систем общего назначения, в которых SQL-сервер является одним из главных приложений, более предпочтительным может оказаться вариант 32 Кб.
Дело в том, что уменьшение значения strip size замедляет работу дисковой подсистемы в том случае, когда обмен данными идет очень большими блоками. Например, если вы занимаетесь видеомонтажом, то при выборе strip size лучше руководствоваться правилом "чем больше, тем лучше".
Matrix storage против внешнего Serial ATA RAID-контроллера
Мы намеренно не делали сравнение внешнего и внутреннего RAID-контроллеров основной темой статьи. Дело в том, что эти контроллеры довольно сильно отличаются по функциональности — как ни странно это звучит на первый взгляд.
Технология Matrix Storage очень гибкая. Мало того что она позволяет создавать на двух HDD разделы RAID разных типов — она еще дает возможность достаточно просто использовать различные размеры strip size. Для внешних Serial ATA RAID-контроллеров, как правило, существуют определенные ограничения: например, не для всех strip size раздел может быть загрузочным.

Зато внешние Serial ATA RAID-контроллеры обычно имеют средства для миграции, позволяющие "зазеркалить" существующий HDD или, что сложнее, преобразовать его (естественно, добавив еще один HDD) в RAID-0.
Недостатком Matrix Storage также можно признать довольно большую (до 12%) загрузку ЦПУ.
В нашем случае в качестве "оппонента" ICH6R был выбран Adaptec 1210SA. Неплохой контроллер с очень хорошим софтом, работающим почти под всеми ОС и поставляемый в исходниках.
Но в случае с Adaptec 1210SA загрузочным для Windows может быть только раздел RAID-0 со strip size 64 Кб. И именно с этим показателем и проводились измерения с HDD Maxtor MaXLine III. Результаты ниже.
P. S.
Хотя наш интерес в этом тестировании был искренним и чисто познавательным, подсказки о том, какой именно режим будет оптимальным, все же были. Хотя их поиском мы занялись позже. При создании раздела RAID-0 внизу экрана высвечивается такая информация:
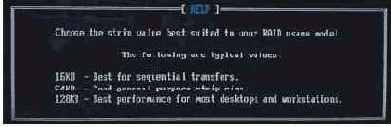
Что называется, читайте инструкцию, она рулез. Кроме того, запрос в Google "strip size производительность" уже на первом экране среди прочего мусора выдает следующую ссылку:
в руководствах по Tuning Oracle говорят о striping factor.
По их руководствам stripe size =striping factor*Block size(Cylinder).
А типичный striping factor — 32 блока.
Следовательно, если принять Block size= 512|1024 bytes (зависит от модели и производителя): stripe size =32 *512|1024 =16|32 Kb.
Попадание 100%. Именно эти размеры и оказались оптимальными. Oracle и MSSQL — это, конечно, разные СУБД, но физика процесса одинакова везде.
Почему нужно возиться с SQL
Почему мы выбрали для тестирования SQL вариант работы "1С:Предприятия 8.0"? Ведь система может работать, например, и в файл-серверном варианте. Дело в том, что "1С:Предприятие" версии 8 с выделенным SQL-сервером работает гораздо быстрее, чем в файловом варианте. При уже упоминавшемся первом обзоре LGA775 (К+П № Х, стр. ХХ) время выполнения "проведения по партиям" и запроса в отчете "взаиморасчеты с комитентами" составили 1095 с и 119 с соответственно. Это в файловом варианте. Сравните с показателями 36 с и 32 с — наилучшими в SQL-системе. Ради тридцатикратного прироста производительности можно и повозиться.
Влияние замены HDD на производительность
Помимо "образцового" Maxtor MaXLine III 250 Гб, который обычно используется в наших тестированиях, у нас была возможность опробовать пару винчестеров ST3160827AS (160 Гб, 7200 оборотов в минуту, среднее время доступа 8,5 мс; интерфейс Serial ATA, буфер 8 Мб).
Мы обратили внимание на эти HDD, так как они тоже поддерживают NCQ (native command queuing). У "образцового" Maxtor MaXLine III 250 Гб другой объем несколько большее время доступа (9,3 мс — это хуже) и больший кэш (16 Мб, это лучше). Подбором strip size здесь мы уже не занимались, хотя и сделали два измерения для 64 и 32 Кб. Результаты ниже.
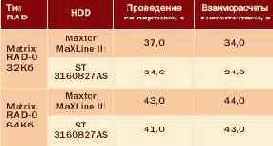
HDD от Seagate чуть опережает Maxtor. Можно сделать вывод, что время доступа при работе с деловыми приложениями имеет большее значение, чем больший кэш.
<
<
/p>
 |
|
This Web server launched on February 24, 1997 Copyright © 1997-2000 CIT, © 2001-2009 CIT Forum |
| Внимание! Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских прав. Подробнее... |
|
Узнать точную стоимость дизельного генератора, а также другую полезную информацию Вы сможете, связавшись с менеджером нашей фирмы! |
