Формат даты и времени
ISO-8601 допускает много опций и вариаций в представлении дат и времени. Но основным форматом HTML следует считать следующий:
yyyy-mm-ddthh:mm:sstzd
| Где | yyyy | = четыре цифры года |
| mm | = две цифры месяца (01 - январь) | |
| dd | = две цифры дня месяца (01-31) | |
| hh | = две цифры часа (00-23; am/pm запрещены) | |
| mm | = две цифры минут (00-59) | |
| ss | = две цифры секунд (00-59) | |
| tzd | = идентификатор временной зоны |
В качестве tzd (код временной зоны) можно использовать следующие:
| z | обозначает utc (coordinated universal time) |
| +hh:mm | указывает местное время в часах и минутах опережающее utc. |
| -hh:mm | указывает местное время в часах и минутах отстающее от utc. |
Символ t указывает на начало строки символов времени.
Формат пакета
Один пакет RADIUS вкладывается в одну UDP-дейтограмму [2]. При этом порт назначения равен 1812 (десятичное). При формировании отклика коды портов отправителя и получателя меняются местами. Формат пакета RADIUS показан на рис. .1. Разряды пронумерованы в порядке их передачи.
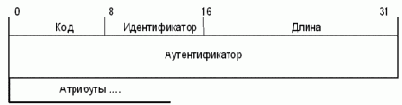
Рис. .1. Формат пакета RADIUS
Поле код содержит один октет и идентифицирует тип пакета RADIUS. Если получен пакет с неверным значением поля код, он молча отбрасывается.
Стандартизованы следующие значения поля код:
| Код | Назначение |
| 1 | Запрос доступа (Access-Request) |
| 2 | Доступ разрешен (Access-Accept) |
| 3 | Доступ не разрешен (Access-Reject) |
| 4 | Accounting-Request |
| 5 | Accounting-Response |
| 11 | Access-Challenge |
| 12 | Сервер состояния (экспериментальный) |
| 13 | Клиент состояния (экспериментальный) |
| 255 | Зарезервировано |
Коды 4 и 5 будут описаны в документе [RFC-2139]. Коды 12 и 13 зарезервированы для возможного использования.
Поле идентификатор имеет один октет, и служит для установления соответствия между запросом и откликом.
Поле длина имеет два октета. Оно определяет длину пакета, включая поля код, идентификатор, длина, аутентификатор и атрибуты. Октеты за пределом, указанным полем длина, рассматриваются как заполнитель и игнорируются получателем. Если пакет короче, чем указано в поле длина, он должен быть молча выкинут. Минимальная длина равна 20, а максимальная - 4096.
Поле аутентификатор имеет 16 октетов. Старший октет пересылается первым. Этот параметр служит для аутентификации отклика от сервера RADIUS, и используется в алгоритме сокрытия пароля.
В пакетах Access-Request, значение поля аутентификатор равно 16-октетному случайному числу, называемому аутентификатор запроса. Его значение должно быть непредсказуемым и уникальным на протяжении жизни секретного пароля, совместно используемого клиентом и RADIUS-сервером.
Значение аутентификатора запроса в пакете Access-Request должно быть также непредсказуемым, чтобы исключить возможные атаки.
Хотя протокол RADIUS не может исключить всех возможных атак, в частности с использованием подключения к линии в реальном масштабе времени, но генерация псевдослучайных аутентификаторов все же обеспечивает относительную безопасность.
NAS и сервер RADIUS используют секретный пароль совместно. Этот секретный пароль и аутентификатор запроса пропускаются через хэширование MD5, чтобы получить 16-октетный дайджест, который объединяется посредством операции XOR с паролем, введенным пользователем, результат помещается в атрибут пароля пользователя пакета Access-Request.
Значение поля аутентификатор в пакетах Access-Accept, Access-Reject, и Access-Challenge называется аутентификатором отклика (Response Authenticator). Оно представляет собой однопроходную хэш-функцию MD5, вычисленную для потока октетов, включающих в себя: пакет RADIUS, начинающийся с поля код, и включающий поля идентификатор, длина, аутентификатор запроса из пакета Access-Request, и атрибуты отклика, за которыми следует общий секретный пароль. То есть ResponseAuth = MD5(Код+ID+длина+RequestAuth+атрибуты+секретный_пароль) где знак + означает присоединение.
Секретный пароль, совместно используемый клиентом и сервером RADIUS, должен быть достаточно большим и непредсказуемым, как хороший пароль. Желательно, чтобы секретный пароль имел, по крайней мере, 16 октетов. Сервер RADIUS должен использовать IP-адрес отправителя UDP-пакета, чтобы решить, какой секретный пароль использовать.
Когда используется переадресующий прокси-сервер, он должен быть способен изменять пакет при проходе в том или ином направлении. Когда прокси переадресует запрос, он может добавить атрибут Proxy-State, а при переадресации отклика, он удаляет атрибут Proxy-State. Так как ответы Access-Accept и Access-Reject аутентифицированы по всему своему содержимому, удаление атрибута Proxy-State сделает сигнатуру пакета некорректной. По этой причине прокси должен вычислить ее заново.
Атрибуты
Многие атрибуты могут быть записаны несколько раз, в этом случае порядок следования атрибутов одного и того же типа должен быть сохранен. Порядок атрибутов различных типов может быть изменен.
В данном документе регламентированы атрибуты для пакетов с полем код, равным 1, 2, 3 и 11.Чтобы определить, какие атрибуты допускаются для пакетов с полем код=4 и 5, смотри [9].
Формы
HTML-форма представляет собой часть документа, содержащая обычный текст, разметку (markup) и специальные элементы управления, называемые controls. controls служат для приема и обработки текста, вводимого пользователем. Форма - это аналог стандартного бланка, заполняемого пользователем. Заполненная форма может быть послана по почте другому пользователю, или передана программе для последующей обработки. Каждый control (графа бланка) должен иметь имя, а его значение определяется его типом. Ниже приведен пример формы, где используются метки и различного типа кнопки:
<form action="http://somesite.com/prog/adduser" method="post">
<p>
<label for="firstname">first name: </label>
<input type="text" id="firstname"><br>
<label for="lastname">last name: </label>
<input type="text" id="lastname"><br>
<label for="email">email: </label>
<input type="text" id="email"><br>
<input type="radio" name="sex" value="male"> male<br>
<input type="radio" name="sex" value="female"> female<br>
<input type="submit" value="send"> <input type="reset">
</p>
</form>
Каждый control имеет исходное и текущее значение, каждое из которых представляет собой символьную строку. Исходное значение может быть определено с помощью соответствующего атрибута.
Кнопки
Разработчики могут создавать три типа кнопок:
submit-кнопки. При активации эти кнопки преадресуют форму адресату. Форма может содержать более одной submit-кнопки.
Кнопки сброса: При активации эти кнопки возвращают все controls в исходное состояние.
Кнопки нажатия. Эти кнопки не имеют какого-либо фиксированного назначения. Каждой такой кнопке может быть поставлен в соответствие, например, скрипт клиента.
Разработчик создает кнопку с помощью элемента button или input.
Следует иметь в виду, что элемент button предоставляет более широкие возможности, чем input.
Переключатели
Переключатели (chekbox; и радио-кнопки) представляют собой двухпозиционные приборы, которые могут находиться в состоянии on/off (вкл/выкл). Пользователь может переводить этот переключатель из одного состояния в другое. Переключатель находится в состоянии "on", когда установлен соответствующий атрибут управляющего элемента.
Несколько переключателей могут относиться к одному и тому же control, позволяя, например, выбрать одно из нескольких значений определенного параметра. Для формирования переключателя используется элемент input.
Радио-кнопки
Радио-кнопки схожи с переключателями. Но здесь при наличии нескольких кнопок, относящихся к одному имени control, перевод одной кнопки в состояние "on" переводит все другие кнопки с тем же именем в состояние "off". Для создания радио-кнопок используется элемент input.
Меню
Меню предоставляет пользователю выбор из нескольких возможностей. Для формирования меню используется элемент select, в сочетании с элементами optgroup и option.
Ввод текста
Разработчик может создать два типа controls, которые позволяют вводить текст. Элемент input создает однострочный control для ввода, а textarea предназначен для многострочного ввода. В обоих случаях введенный текст становится текущим значением control.
Выбор файла
Этот тип control позволяет пользователю выбрать файлы, так что их содержимое будет введено в форму. Для обеспечения выбора файла используется элемент input.
Скрытые элементы управления control
Разработчик может создать control, которые не отображаются на экране, но величины которых заносятся в форму. Для формирования скрытого control используется элемент input.
Объектные control
Разработчик может ввести в форму общие объекты, так что соответствующие величины будут заноситься в форму. Для работы с объектными control используется элемент object.
Элементы, используемые для создания controls, обычно вводятся в элемент FORM, но могут появляться и вне декларации FORM, когда они используются для построения интерфейса пользователя.
25.1. Элемент FORM
| <!element form - - (%block;|script)+ -(form) | -- интерактивная форма --> | |
| <!attlist form %attrs; | -- %coreattrs, %i18n, %events -- | |
| action %uri; #required | -- хандлер форм со стороны сервера -- | |
| method (get|post) get | -- http метод для ввода форм -- | |
| enctype %contenttype; "application/x-www-form-urlencoded" | ||
| onsubmit %script; #implied | -- форма введена -- | |
| onreset %script; #implied | -- форма возвращена в исходное состояние -- | |
| accept-charset %charsets; #implied | -- список поддерживаемых символьных наборов --> | |
Определение атрибутов
action = url
Этот атрибут специфицирует агента, который осуществляет обработку формы. Например, возможным значением атрибута может быть HTTP URI (для передачи формы программе) или mailto URI (для пересылки формы по электронной почте).
method = get|post
Этот атрибут специфицирует http-метод, который будет использоваться для представления данных. Возможные значения: "get" (по умолчанию) и "post". Метод post вводит пары имя/значение в тело формы.
enctype = content-type
Этот атрибут специфицирует тип содержимого (internet media type), используемого при передаче формы серверу (когда метод = "post"). Значение по умолчанию атрибута равно "application/x-www-form-urlencoded". Значение "multipart/form-data" должно использоваться в сочетании с type="file" элемента input.
accept-charset = charset list
Этот атрибут специфицирует список кодировок символов для входных данных, которые должны быть приняты сервером, обрабатывающим эти формы. Значения атрибута представляют собой список значений символьных комбинаций, разделенных пробелами или запятыми. Сервер должен интерпретировать этот список и воспринимать любой односимвольный код. Значение этого атрибута по умолчанию равно "unknown". Агент пользователя может интерпретировать это значение как символьную комбинацию, которая была использована для передачи документа, содержащего этот элемент form.
accept = content-type-list
Этот атрибут специфицирует список типов содержимого (в качестве разделителей используются занятые), которые сможет корректно воспринять и обработать сервер форм.
Элемент form работает как контейнер для controls. Он специфицирует:
Выкладку формы (заданную содержимым элемента).
Программу, которая будет обрабатывать заполненную форму (атрибут action). Принимающая программа должна быть способна разобрать пары имя/значение, для того чтобы использовать их.
Метод, посредством которого данные пользователя будут посланы серверу (атрибут method).
Кодировку символов, которая должна быть воспринята сервером, для того чтобы успешно произвести последующую обработку полученной формы (атрибут accept-charset). Агенты пользователя могут подсказать пользователю значения атрибута accept-charset и/или ограничить возможность ввода неузнаваемых символов.
Ниже приведен пример, который показывает форму, которая должна быть обработана программой "adduser". Форма посылается программе с помощью метода http "post".
<form action="http://somesite.com/prog/adduser" method="post">
...form contents...
</form>
Следующий пример показывает, как послать форму по заданному электронному адресу:
<form action="mailto:kligor.t@gee.whiz.com" method="post">
...содержимое формы...
</form>
25.2. Элемент input
<!entity % inputtype
"(text | password | checkbox | radio | submit | reset |
file | hidden | image | button)" >
<!-- имя атрибута необходимо для всех кроме submit & reset -->
| <!element input - o empty | -- управление формой --> |
| <!attlist input %attrs; | -- %coreattrs, %i18n, %events -- |
| type %inputtype; text | -- what kind of widget is needed -- |
| name cdata #implied | -- представить как часть формы -- |
| value cdata #implied | -- необходимо для радио-кнопок и переключателей -- |
| checked (checked) #implied | -- для радио-кнопок и переключателей -- |
| disabled (disabled) #implied | -- не доступно в данном контексте -- |
| readonly (readonly) #implied | -- для текста и пароля -- |
| size cdata #implied | -- разный для каждого типа полей -- |
| maxlength number #implied | -- макс. число символов для текст. полей -- |
| src %uri; #implied | -- для полей с изображением -- |
| alt cdata #implied | -- краткое описание -- |
| usemap %uri; #implied | -- использование карты изображения клиента -- |
| tabindex number #implied | -- position in tabbing order -- |
| accesskey %character; #implied | -- клавиша доступа -- |
| onfocus %script; #implied | -- элемент выделен -- |
| onblur %script; #implied | -- элемент не выделен -- |
| onselect %script; #implied | -- некоторый текст был выбран -- |
| onchange %script; #implied | -- значение элемента изменилось -- |
| accept %contenttypes; #implied | -- list of mime types for file upload --> |
/p> Определение атрибутов
type = text|password|checkbox|radio|submit|reset|file|hidden|image|button
Этот атрибут специфицирует тип создаваемого control. Значение по умолчанию "text".
name = cdata
Этот атрибут присваивает имя control.
value = cdata
Этот атрибут специфицирует начальное значение control.
size = cdata
Этот атрибут сообщает агенту пользователя исходную ширину control. Ширина задается в пикселях, за исключением случая, когда тип атрибута "text" или "password". В этом варианте ширина измеряется числом символов.
maxlength = number
Когда тип атрибута "text" или "password", этот атрибут специфицирует максимальное число символов, которое предлагается ввести пользователю. Это число может превзойти указанный размер, тогда агент пользователя должен предложить механизм скроллинга.
checked.
Когда тип атрибута "radio" или "checkbox", этот булев атрибут указывает, что кнопка нажата. Агент пользователя должен игнорировать этот атрибут для всех других видов control.
src = url
Когда тип атрибута "image", этот атрибут специфицирует положение изображения, которое будет использовано для украшения кнопки.
Атрибут type элемента input определяет то, какой управляющий элемент создан.
| text | Этот тип создает текстовый бокс на одну строчку. Значение текстового control равно введенному тексту. |
| password | Подобен типу "text", но отображение ввода делается так, что вводимые символы не видны (напр. каждому введенному символу ставится в соответствие *). Значение данного типа control равно введенному тексту. Служит для ввода паролей. |
| checkbox | Представляет собой двух позиционный переключатель (вкл/выкл=on/off). Когда переключатель в положении on, значение checkbox = "active". Состояние переключателя передается только в случае, когда переключатель в состоянии on. |
Нижеследующий фрагмент HTML представляет собой пример простой формы, которая позволяет пользователю ввести свою фамилию имя, электронный адрес и т.д.
<form action="http://somesite.com/prog/adduser" method="post">
<p>
first name: <input type="text" name="firstname"><br>
last name: <input type="text" name="lastname"><br>
email: <input type="text" name="email"><br>
<input type="radio" name="sex" value="male"> male<br>
<input type="radio" name="sex" value="female"> female<br>
<input type="submit" value="send"> <input type="reset">
</p>
</form>
| radio | также является двухпозиционным переключателем. Единственным отличием от checkbox является то, что при наличии нескольких радио-кнопок с идентичным именем в состоянии on может быть всегда только одна. | ||
| submit | формирует кнопку submit. При активации этой кнопки пользователем, форма передается по адресу, указанному атрибутом action элемента form. Форма может содержать несколько таких кнопок. | ||
| image | Создает графический образ кнопки submit. Значение атрибута src специфицирует URL изображения кнопки. Рекомендуется воспользоваться атрибутом alt, чтобы создать альтернативный текст для агентов пользователя, не поддерживающих графику. Если кнопка активизирована, форма передается серверу-адресату. Передаваемые данные содержат значения name.x=x и name.y=y, где "name" - значение атрибута name, х - число пикселей от левого края изображения, а у - число пикселей от верхней кромки изображения. Это позволяет варьировать реакцию сервера от координат места, где была нажата кнопка мышки. | ||
| reset | Создает кнопку сброса. При нажатии этой кнопки пользователем всем controls формы присваиваются исходные значения, заданные атрибутом value. Пара имя/значение кнопки reset вместе с формой не пересылается. | ||
| button | Создает кнопку, которая не имеет заранее определенной функции. Эта функция определяется скриптом клиента, который запускается при нажатии этой кнопки. Например, создадим кнопку, которая вызывает функцию verify: | ||
<input type="button" value="click me" onclick="verify()"> | |||
| hidden | Создает элемент, не видимый при работе агента пользователя. Однако, имя и значение элемента передаются серверу вместе с формой. Эта форма controls используется для запоминания информации в паузах между обменами клиент/сервер. Следующий control типа hidden, тем не менее, должен передавать свое значение вместе с формой. | ||
| <input type="password" style="display:none" | |||
| name="invisible-password" | |||
| value="mypassword"> | |||
| file | Позволяет пользователю присоединить содержимое файла к форме. | ||
/p> Следующий пример представляет собой анкету, предложенную выше, дополненную кнопками submit и reset. Кнопки содержат изображения, для чего использован элемент img.
<form action="http://somesite.com/prog/adduser" method="post">
<p>
first name: <input type="text" name="firstname"><br>
last name: <input type="text" name="lastname"><br>
email: <input type="text" name="email"><br>
<input type="radio" name="sex" value="male"> male<br>
<input type="radio" name="sex" value="female"> female<br>
<button name="submit" value="submit" type="submit">
send<img src="/icons/wow.gif" alt="wow"></button>
<button name="reset" type="reset">
reset<img src="/icons/oops.gif" alt="oops"></button>
</p>
</form>
Внешне данная форма будет выглядеть для пользователя следующим образом:
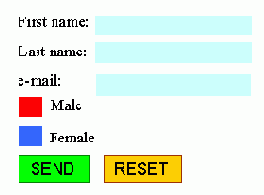
FRED
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
FRED - система поиска информации о пользователях ЭВМ, сходная с WHOIS. Пользователи в архивах Интернет ("белые страницы", OSI X.500) идентифицируются уникальным образом, например:
"@c=RU@o=Institute for Theoretical and Experimental Physics@cn=Director"
Так как в системе WHOIS пользователи идентифицируются короткими ключами, содержащими, например, три символа, система FRED использует в процессе своей работы список цифровых псевдонимов.
Доступ к системе осуществляется, напимер, командой: telnet wp.psi.net. В качестве имени-идентификатора нужно ввести слово FRED. После этого появляется приглашение FRED> и вы можете приступать к работе. Система имеет удобную систему команд, основная из которых whois имеет несколько модификаций:
| whois "semenov" | Поиск записей с таким именем в области по умолчанию. |
| whois surname "semenov" | Поиск записей с данной фамилией. |
| whois fullname "yuri semenov" | Поиск записей с указанным полным именем. |
| whois "semenov" -org itep | Поиск записей с указанным именем во всех организациях, в названии которых присутствует "itep". |
whois "semenov" -area "@c=RU@o=Institute for Theoretical and Experimental Physics команда используется, когда название "area" (место) известно.
| whois semenov@itep | Идентична предшествующей команде; |
| whois semenov@cl.itep.ru | Поиск записей с указанным почтовым адресом. |
| whois -title operator | Поиск записей, относящихся к операторам. |
| whois -org * | Выдача списка всех зарегистрированных организаций (для данной области поиска). |
| whois -org * -geo @c=US | Выдача списка зарегистрированных организаций для домена US. |
Сначала FRED считывает файл fredrc в системном каталоге ISODE (обычно /usr/etc/). Затем FRED читает файл .fredrc в каталоге пользователя. В этих файлах, если они присутствуют, содержатся описания предпочтений пользователя. После этого система выдает приглашение для ввода команд поиска. Команда INTR, выданная на базовом уровне, не вызывает никаких последствий, выдача ее дважды подряд вызовет завершение работы FRED (аналог QUIT).
На других уровнях работы FRED команда INTR прерывает выполнение процедуры. Приведем перечень служебных команд.
| alias имя | При отсутствии аргументов печатает все псевдонимы, описанные в ходе данной сессии, если же аргумент имеется, определяет числовой псевдоним для данного имени. |
| Help команда ... | Выдает справочную информацию о командах. |
| Manual | Распечатывает подробное руководство по применению FRED. |
| Quit | Уход из системы FRED. |
| report subject | Позволяет вам ввести текст сообщения, которое по почте будет передано вашему местному менеджеру справочной системы "белые страницы". |
| set переменная значение | Производит присвоение нужных значений системным переменным FRED. |
| version -fred | Сообщает версию программного обеспечения. |
Список системных переменных FRED представлен в таблице:
| Переменная FRED | Описание |
| debug | Отладка FRED |
| manager | Почтовый адрес местного менеджера "белых страниц". |
| namesearch | Тип имени, используемый при поиске, "fullname", "surname" или "frandly". |
| pager | Программа, используемая для разбивки текста на терминале на страницы |
| query | Подтверждение двух-шаговых операций |
| server | IP-адрес вспомогательного сервера |
| timelimit | Максимальное число секунд, которое может быть потрачено на поиск |
| verbose | Интерактивный режим с полной выдачей диагностической информации |
| ufn | Тип фильтрации при поиске: "none", "approx" или "wild". |
Вообще говоря синтаксис команды whois (FRED) аналогичен тому, что используется в системе WHOIS:
входное_поле тип_записи признак_области_поиска управление_выводом
Эти четыре компоненты могут встречаться в любом порядке и только входное_поле должно присутствовать обязательно. Это поле характеризует то, что вы желаете найти. Поле тип_записи говорит о том, какой вид записи в банке данных вас интересует. Поле признак_области_поиска может содержать ключи: -org (сокращение от "организация"); -unit или -locality, за которыми следует имя. Поле управление_выводом может содержать следующие ключи:
| * | выдача детальной информации со ссылками; |
| ~ | выдача минимальной информации; |
| % | выдача результатов поиска в одну строку и ссылок; |
| | | выдача полной информации. |
FRED имеет некоторые преимущества перед WHOIS и, возможно, вы предпочтете именно эту систему. Введем команду вызова сервера:
telnet nic.switch.ch
Trying 130.59.1.40 ...
Connected to nic.switch.ch.
Escape character is '^]'.
После установления связи сервер выдаст на экран:
SWITCH (Swiss Academic and Research Network)
SunOS UNIX (nic) (ttyp9)
login: dua
SWITCHdirectory main menu (choose desired service)
| [ 1 ] | Query the Directory, select a User Interface |
| [ 2 ] | Information about the User Interfaces |
| [ 3 ] | Terminal/X Window Configuration |
| [ 4 ] | Send Message to Administrator |
| [ 5 ] | Information about the Directory Project |
| [ 6 ] | Acknowledgement |
| [ 0 ] | Leave this Menu (back to previous Menu) |
Выберем пункт 1 (с другими видами сервиса читателям предлагается познакомиться самостоятельно):
SWITCHdirectory User Interfaces
| [ 1 ] | de (simple interface to find persons) |
| [ 2 ] | fred (simple white pages interface ('whois') |
| [ 3 ] | sd (menu oriented, only read functionality) |
| [ 4 ] | Dish (command line, full X.500 functionality) |
| [ 5 ] | Xdi (X window interface) |
| [ 6 ] | Xlu (X window interface) |
| [ 7 ] | XT-DUA (Commercial X window interface) |
[ 0 ] | Leave this Menu (back to previous Menu) |
Выбираем пункт 2 и получаем:
invoking interface "fred", please wait....
fred> whois -org cern
CERN (1) +41 22
767 6111
aka: European Laboratory for Particle Physics
CERN CH-1211 Geneve 23
FAX: +41 22 767 6555
Mailbox information:
X.400: /S=postmaster/O=CERN/PRMD=CERN/ADMD=ARCOM/C=CH/
High Energy Physics research
Business: Research Laboratory Research Lab
Locality: Geneve
Name: CERN, CH (1)
Modified: Wed Aug 31 09:03:59 1994
by: DSAmanager, SWITCHdirectory, SWITCH, CH (2)
20 imprecise matches for '*', select from them [y/n] ? y
После ряда ответов на вопросы (Y/N) получаем:
7 matches found.
| 1. | CERN +41 22 767 6111 |
| 4. | Hochschule St. Gallen +41 71 30 2111 |
| 5. | IDIAP +41 26 22 7664 |
| 6. | Ingenieurschule HTL Biel +41 32 273 111 |
| 7. | Paul Scherrer Institute +41 56 992111 |
| 8. | Schweizerische Hochschulkonferenz +41 31 302 55 33 |
| 10. | SWITCH +41 1 268 1515 |
Теперь посмотрим, что имеется в Германии (код=DE), для этого введем команду: whois -org * -geo @c=DE.
100 matches found. (найдено 100 записей)
| 16. BASF-AG | +49 621-600 | |
| 21. Berufsakademie Stuttgart | +49 711 6673-6965 | |
| 29. Competence Center Informatik | +49-5931-805-0 | |
| 30. Computer-Communication Networks | +49 211 905828 | |
| 40. Deutsche Fernkabel Gesellschaft mbH | +49 30 54686-256 | |
| 41. Deutsche Forschungsgemeinschaft | +49 228/885-2485 | |
| 44. Deutsches Forschungsnetz | +49 30 884299-20 | |
| 51. DKRZ Hamburg | +49 40-41173-0 | |
| 53. ECRC | +49 89 92 69 90 | |
| 54. ERNO Raumfahrttechnik GmbH | +49 421 539 - 0 | |
| 55. EUnet Deutschland GmbH | +49 231 972-00 | |
| 58. European Space Agency | +49 6151-90-0 | |
| 63. Fachhochschule Darmstadt | +49 6151-168876 | |
| 64. Fachhochschule Dortmund | +49 231 9112-0 | |
| 71. Fachhochschule Fulda | +49 661 9640-0 | |
| 83. Fachhochschule Nuernberg | +49/911/58800 | |
| 85. Fachhochschule Rheinland-Pfalz | +41 6131 23920 | |
| 87. Fachhochschule Schweinfurt | (049) 9721 940 5 | |
| 96. Fraunhofer-Gesellschaft | +49 89 1205 x01 | |
| 97. Freie Universitaet Berlin | +49 30 838-1 | |
| 105. GMD | +49 2241 14-0 | |
Список, разумеется, напечатан в сокращенном виде.
fred> q (до свидания FRED!).
Генерация событий по методу даггера
Метод генерации событий даггера был разработан Кумамото [K.Kumamoto et al “Dagger sampling Monte-Carlo for system unavailability evaluation”, IEEE Transaction Reliability, R-29 (1980)122-125] и может рассматриваться как “m-мерное” расширение антитетического способа. Идея, которая является общей для нескольких методик Монте-Карло, заключается в том, чтобы разбросать отдельные неудачи на краях так, что повторные испытания минимизируются. Процедура описана ниже.
Генерация событий по методу даггера (кинжала)
1. Пусть (Ne: eОE) является вектором целых чисел, выбранных пропорционально (действительным) qe.
2. Генерируем вектор события размером К*, так что для каждого ребра е последовательность К* репликаций может быть разделена на Ne субблоков размера К*/Ne.
3. Для каждого ребра е выбираем случайным образом репликацию в каждом из субблоков Ne, для того края, для которого испытание оказалось неудачным. В результате получается совокупность неудач для репликаций К*, для которых частота неудач на каждом из краев пропорциональна среднему значению частоты неудач данного края.
4. Делаем окончательный проход по репликациям К*, вычисляя усредненную долю репликаций, соответствующих работе системы. Это число является несмещенной оценкой R.
Гипертекстный протокол HTTP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Протокол передачи гипертекста HTTP является протоколом прикладного уровня для распределенных мультимедийных информационных систем. Это объектно-ориентированный протокол, пригодный для решения многих задач, таких как создание серверов имен, распределенных объектно-ориентированных управляющих систем и др.. Структура HTTP позволяет создавать системы, независящие от передаваемой информации.
Протокол HTTP использован при построении глобальной информационной системы World-Wide Web (начиная с 1990).
Первые версии, такие как HTTP/0.9, представляли собой простые протоколы для передачи данных через Интернет. Версия HTTP/1.0, описанная в RFC-1945 [6], улучшила протокол, разрешив использование сообщений в формате MIME, содержащих метаинформацию о передаваемых данных, и модификаторы для запросов/откликов. Дальнейшее развитие сетей WWW-серверов потребовало новых усовершенствований, которые вряд ли являются последними.
Реальные информационные системы требуют больших возможностей, чем простой поиск и доставка данных. Для описания характера, наименования и места расположения информационных ресурсов введены: универсальный идентификатор ресурса URI (Uniform Resource Identifier), универсальный указатель ресурса URL и универсальное имя ресурса URN. Формат сообщений сходен с используемыми в электронной почте и описанный в стандарте MIME (Multipurpose Internet Mail Extensions).
HTTP используется также в качестве базового протокола для коммуникации пользовательских агентов с прокси-серверами и другими системами Интернет, в том числе и использующие протоколы SMTP, NNTP, FTP, Gopher и Wais. Последнее обстоятельство способствует интегрированию различных служб Интернет. Ниже описаны базовые понятия и термины протокола HTTP.
Прокси
Промежуточная программа, которая выполняет функции, как сервера, так и клиента. Такая программа предназначена для обслуживания запросов так, как если бы это делал первичный сервер. Запросы обслуживаются внутри или переадресуются другим серверам.
Туннель
Промежуточная программа, которая работает как ретранслятор между двумя объектами. Туннель закрывается, когда обе стороны, соединенные им прерывают сессию. Туннель может быть активирован с помощью HTTP-запроса.
Время пригодности объекта (expiration time)
Время, при котором исходный сервер требует, чтобы объект не посылался более кэшем без перепроверки пригодности.
Эвристическое значение времени жизни (heuristic expiration time)
Время пригодности, присваиваемое объекту в кэше, если это время не задано явно.
Возраст
Возраст отклика - время с момента его посылки или проверки его пригодности исходным сервером.
Время жизни (freshness lifetime)
Продолжительность времени с момента генерации отклика до истечения его пригодности.
Свежий
Отклик считается свежим, если его возраст не превысил времени его пригодности.
Устаревший
Отклик считается устаревшим, когда его возраст превысил время жизни.
Семантическая прозрачность
Кэш по отношению к конкретному отклику функционирует в "семантически прозрачном" режиме, когда его использование не имеет последствий ни для исходного сервера, ни для запрашивающего клиента. Когда кэш семантически прозрачен, клиент получает в точности тот же отклик (за исключением транспортных заголовков), какой он бы получил при непосредственном обращении к исходному серверу.
Валидатор
Протокольный элемент (например, метка объекта или время last-modified), который используется для выяснения того, является ли запись в кэше эквивалентной копией объекта.
Метод
Процедура, выполняемая над ресурсом (get, put, head, post, delete, trace и т.д.).

Рис. 4.5.6.1.1. Взаимодействие клиента, кэша и исходного сервера в протоколе HTTP
Кэш может находиться в ЭВМ клиента или агента пользователя, но может размещаться на соседнем континенте. Число прокси между клиентом и исходным сервером может варьироваться и ограничивается сверху только здравым смыслом.

Рис. 4.5.6.1.2. Структура ресурса и объекта
Протокол HTTP представляет собой протокол запросов-откликов.
Клиент посылает запрос серверу в форме, определяющей метод, URI и версию протокола. В конце запроса следует MIME-подобное сообщение, содержащее модификаторы, информацию о клиенте и, возможно, другие данные. Сервер откликается, посылая статусную строку, которая включает в себя версию протокола, код результата (успех/неудача) и MIME-подобное сообщение, в котором содержатся данные о сервере и метаинформация.
Большинство HTTP-обменов инициируются пользователем и состоят из запросов ресурсов, имеющихся на определенном сервере. В простейшем случае такой запрос может быть реализован путем соединения пользовательского агента (UA) и базового сервера.
Более сложная ситуация возникает, когда присутствует один или более посредников в цепочке обслуживания запроса/отклика. Существует три стандартные формы посредников: прокси, туннель и внешний порт (gateway). Прокси представляет собой агент переадресации, получающий запрос для URI, переписывающий все сообщение или его часть и отправляющий переделанный запрос серверу, указанному URI. Внешний порт (gateway) представляет собой приемник, который работает на уровень выше некоторых других серверов и транслирует, если необходимо, запрос нижележащему протоколу сервера. Туннель действует как соединитель точка-точка и не производит каких-либо видоизменений сообщений. Туннель используется тогда, когда нужно пройти через какую-то систему (например, Firewall) в условиях, когда эта система не понимает (не анализирует) содержимое сообщений.
Запрос -------------------------------------->
UA -----v----- A -----v----- B -----v----- C -----v----- O
<------------------------------------- отклик
Рис. 4.5.6.1.3. UA - агент пользователя
На рисунке показаны три промежуточные ступени (A, B, и C) между агентом пользователя (UA) и базовым сервером (O). Запрос или отклик, двигаясь по этой цепочке, должен пройти четыре различных соединительных сегмента. Это обстоятельство крайне важно, так как некоторые опции HTTP применимы только для ближайших соединений.
Хотя схема линейна, на практике узлы могут участвовать в большом числе других взаимодействий. Например, B может получать запросы от большого числа клиентов помимо A, и переадресовывать запросы к другим серверам кроме C.
Любой участник обмена, который не используется в качестве туннеля, может воспользоваться кэшем для запоминания запросов. Буфер может сократить длину цепочки в том случае, если у одного из участников процесса имеется в буфере отклик для конкретного запроса, что может, кроме прочего, заметно снизить требования к пропускной способности канала. Не все запросы могут записываться в кэш, некоторые из них могут содержать модификаторы работы с кэшем.
В действительности имеется широкое разнообразие архитектур и конфигураций буферных запоминающих устройств и прокси, разрабатываемых в настоящее время или уже доступных через World Wide Web. Эти системы включают иерархии прокси-серверов национального масштаба, задачей которых является сокращение трансокеанского трафика, системы, которые обслуживают широковещательные и мультикастинговые обмены, организации, распространяющие фрагменты информации с CD-ROM, занесенной в кэши и т. д.. HTTP-системы, используются в корпоративных сетях Интранет с большими пропускными способностями и перемежающимися соединениями. Целью HTTP/1.1 является поддержка широкого разнообразия уже существующих систем и расширение возможностей будущих приложений в отношении надежности и адаптируемости.
Коммуникации HTTP обычно реализуются через соединения TCP/IP. Порт по умолчанию имеет номер 80, но и другие номера портов вполне допустимы. Это не исключает использования HTTP поверх любого другого протокола в Интернет, или других сетей. HTTP предполагает надежное соединение; применим любой протокол, который может гарантировать корректную доставку сообщений.
В HTTP/1.0, большинство приложений используют новое соединение для каждого обмена запрос/отклик. В HTTP/1.1, соединение может быть использовано для одного или более обменов запрос/отклик, хотя соединение может быть разорвано по самым разным причинам.
4.5.6.1.1. Соглашения по нотации и общая грамматика
1.1. Расширенные BNF
Все механизмы, специфицированные в данном документе, описаны с использованием обычного текста и расширенных форм Бахуса-Наура BNF (Backus-Naur Form; см. RFC 822). Пользователи должны быть знакомы с этой нотацией для понимания данной спецификации. Расширение BNF включает в себя следующие конструкции:
name = definition
Имя правила не требует помещения в угловые скобки. Некоторые базовые правила записываются прописными буквами, например, SP, LWS, HT, CRLF, DIGIT, ALPHA и пр.
"literal"
Двойные кавычки используются для выделения символьного текста.
rule1 | rule2
Элементы, разделенные вертикальной чертой, ("|") являются альтернативными, например, "yes | no" допускает yes или no (да или нет).
(rule1 rule2)
Элементы, помещенные в круглые скобки, рассматриваются как один элемент. Так, "(elem (foo | bar) elem)" допускают последовательности "elem foo elem" и "elem bar elem".
*rule
Символ "*", предшествующий элементу, указывает на повторение. Полная форма "*element" указывает как минимум на и как максимум повторений элемента. Значения по умолчанию равны 0 и бесконечности, так что "*( элемент)" позволяет любое число, включая ноль; "1*element" требует по меньшей мере один; а "1*2element" допускает один или два.
[rule]
В квадратные скобки заключаются опционные элементы; "[foo bar]" эквивалентно "*1(foo bar)".
N rule
Специальный повтор: "(элемент)" эквивалентно "*(элемент)"; то есть, точно (element). Таким образом, 2DIGIT является 2-значным числом, а 3ALPHA представляет собой строку из трех буквенных символов.
#rule
Конструкция "#" определена подобно "*", для описания списка элементов. Полная форма имеет вид "#element ", отмечая, по меньшей мере и по большей элементов, отделенных друг от друга одной или более запятыми (",") и опционно строчным пробелом (LWS - Linear White Space).
Это делает обычную форму списков очень простой. Запись "( *LWS элемент *( *LWS "," *LWS элемент)) " может быть представлена как "1#element". Всюду, где используется эта конструкция, допускаются нулевые элементы, но они не учитываются при подсчете элементов. То есть, допускается запись "(элемент), (элемент) ", но число элементов при этом считается равным двум. Следовательно, там, где необходим хотя бы один элемент, должен присутствовать, по крайней мере, один ненулевой элемент. Значениями по умолчанию являются 0 и бесконечность, таким образом "#элемент" позволяет любое число, включая нуль; "1#элемент" требует, по меньшей мере один, а "1#2элемент" допускает один или два.
; комментарий
Точка с запятой, смещенная вправо от линейки текста, открывает комментарий, который продолжается до конца строки. Это простой способ включения замечаний в текст спецификаций.
implied *LWS
Грамматика, описанная в данной спецификации, ориентирована на слова. Если не оговорено обратное, строчный пробел (LWS) может быть заключен между любыми двумя соседними словами (лексема или заключенная в кавычки строка), и между смежными лексемами (token) и разделителями (TSpecials) без изменения интерпретации поля. По крайней мере один разграничитель (TSpecials) должен присутствовать между любыми двумя лексемами, так как они иначе будут интерпретироваться как одна.
1.2. Основные правила
Следующие правила используются практически во всей спецификации для описания основных конструкций разбора (парсинга).
| OCTET | = <любая 8-битовая последовательность данных> |
| CHAR | = <любой символ US-ASCII (октеты 0 - 127)> |
| UPALPHA | = <любая прописная буква US-ASCII "A".."Z"> |
| LOALPHA | = < любая строчная буква US-ASCII "a".."z"> |
| ALPHA | = UPALPHA | LOALPHA (строчная или прописная буква) |
| DIGIT | = <любая цифра US-ASCII "0".."9"> |
| CTL | = <любой управляющий символ US-ASCII (октеты 0 - 31) и DEL (127)> |
| CR | = |
| LF | = |
| SP | = |
| HT | = |
| <"> | = |
/p> HTTP/1. 1 определяет последовательность CR LF, как маркер конца для всех протокольных элементов, за исключением тела элемента. Маркер конца строки в пределах тела объекта определен соответствующим типом среды.
| CRLF | = CR LF |
HTTP/1.1 заголовки могут занимать несколько строк, если продолжение строки начинается с пробела или символа горизонтальной табуляции. Все строчные пробелы имеют ту же семантику, что и обычный пробел (SP).
| LWS | = [CRLF] 1*( SP | HT ) |
Правило TEXT используется только для содержимого описательных полей и значений, которые не предполагается передавать интерпретатору сообщений. Слова *TEXT могут содержать символы из символьного набора, не совпадающего с ISO 8859-1 [22], только когда они закодированы согласно правилам RFC-1522 [14].
| TEXT | = <любой OCTET за исключением CTL, но включая LWS> |
В некоторых протокольных элементах используются шестнадцатеричные цифровые символы.
| HEX | = "A" | "B" | "C" | "D" | "E" | "F" | "a" | "b" | "c" | "d" | "e" | "f" | DIGIT |
Многие значения полей заголовков HTTP/1.1 состоят из слов, разделенных LWS или специальными символами. Эти специальные символы должны представлять собой строки, заключенные в кавычки, чтобы использоваться в качестве значения параметра.
| Token | = 1*<любой CHAR за исключением CTLs или tspecials> |
| Tspecials | = "(" | ")" | "<" | ">" | "@" |
| "," | ";" | ":" | "\" | <"> | |
| "/" | "[" | "]" | "?" | "=" | |
| | "{" | "}" | SP | HT |
Комментарии могут быть включены в некоторые поля HTTP заголовков, при этом текст комментария заключается в скобки. Комментарии допустимы только для полей, содержащих "comment", как часть описания поля. В других полях скобки рассматриваются как элемент содержимого поля.
| Комментарий | = "(" *( ctext | комментарий) ")" |
| ctext | = <любой TEXT, исключая "(" и ")"> |
/p> Строка текста воспринимается как одно слово, если она помещена в двойные кавычки.
| quoted-string | = ( <"> *(qdtext) <"> ) |
| qdtext | = <любой TEXT, исключая <">> |
Символ обратная косая черта ("\") может использоваться вместо кавычки внутри закавыченного текста или в структурах комментариев.
| quoted-pair | = "\" CHAR |
4.5.6.1.2. Параметры протокола
2.1. Версия HTTP
HTTP использует схему нумерации "." для отображения версии протокола. Политика присвоения версии протоколу ориентирована на то, чтобы позволить отправителю указать формат сообщения и его емкость. Номер версии не меняется при добавлении компонент сообщения, которые не влияют на характер обмена.
Число увеличивается, когда в протокол внесены изменения, которые не изменили общий алгоритм разбора сообщений, но которые изменили семантику сообщений и добавили новые возможности отправителю. Число увеличивается в случае, когда изменен формат протокольного сообщения.
Версия HTTP-сообщения указывается в поле HTTP-Version в первой строке сообщения.
| HTTP | Version = "HTTP" "/" 1*DIGIT "." 1*DIGIT |
Заметьте, что числа major и minor должны рассматриваться как независимые целые, так что каждое из них может быть увеличено за пределы одной цифры. Таким образом, HTTP/2.4 является более низкой версией, чем HTTP/2.13, которая в свою очередь ниже, чем HTTP/12.3. Начальные нули должны игнорироваться и не пересылаться
Приложения, посылающие запросы или отклики, так как это определено в спецификации, должны включать HTTP-Version "HTTP/1.1". Использование этого номера версии указывает, что посылающее приложение совместимо с этой спецификацией.
Версия HTTP приложения является верхней, совместимость с которой гарантируется. Приложения прокси-серверов и сетевых портов должны проявлять осторожность при переадресации сообщений с протокольной версией, отличной от поддерживаемой ими. Так как версия протокола указывает на возможности отправителя, прокси никогда не должны пересылать сообщения с версией больше, чем их собственная; если получено сообщение более высокой версии, прокси/порт должен либо понизить версию запроса, либо послать отклик об ошибке или переключиться в режим туннеля.
Запросы с версией ниже, чем у прокси/ порта могут быть повышены при переадресации, при этом major часть версии сервера и запроса должны совпадать.
Замечание: Преобразование между версиями может включать модификацию полей заголовка.
2.2. Универсальные идентификаторы ресурсов (URI)
URI известен под многими именами: WWW адрес, универсальный идентификатор документа (Universal Document Identifiers), универсальный идентификатор ресурса (Universal Resource Identifiers), и, наконец, универсальный локатор ресурса URL (Uniform Resource Locators; тождество URI и URL сомнительно, так как URL является частным случаем URI (примечание переводчика)) и универсальное имя ресурса (URN). Что касается HTTP, универсальный идентификатор ресурса представляет собой форматированную строку символов, которая идентифицирует имя, положение или какие-то еще характеристики ресурса.
2.2.1. Общий синтаксис
URI в HTTP может быть представлен в абсолютной или относительной форме по отношению к некоторому известному базовому URI, в зависимости от контекста его использования. Эти две формы отличаются тем, что абсолютный URI всегда начинается с имени схемы, за которым следует двоеточие (например HTTP: или FTP:).
| URI | = ( absoluteURI | relativeURI ) [ "#" фрагмент ] |
| AbsoluteURI | = схема ":" *( uchar | reserved ) |
| RelativeURI | = net_path | abs_path | rel_path |
| net_path | = "//" net_loc [ abs_path ] |
| abs_path | = "/" rel_path |
| rel_path | = [ проход ] [ ";" params ] [ "?" query ] |
| path | = fsegment *( "/" сегмент ) |
| fsegment | = 1*pchar |
| segment | = *pchar |
| params | = param *( ";" param ) |
| param | = *( pchar | "/" ) |
| scheme | = 1*( ALPHA | DIGIT | "+" | "-" | "." ) |
| net_loc | = *( pchar | ";" | "?" ) |
| query | = *( uchar | reserved ) |
| fragment | = *( uchar | reserved ) |
| pchar | = uchar | ":" | "@" | "&" | "=" | "+" |
| uchar | = unreserved | escape |
| unreserved | = ALPHA | DIGIT | safe | extra | national |
| escape | = "%" HEX HEX |
| reserved | = ";" | "/" | "?" | ":" | "@" | "&" | "=" | "+" |
| extra | = "!" | "*" | "'" | "(" | ")" | "," |
| safe | = "$" | "-" | "_" | "." |
| unsafe | = CTL | SP | <"> | "#" | "%" | "<" | ">" |
| national | = <любой OCTET, исключая ALPHA, DIGIT, зарезервированный, extra, safe, и unsafe> |
/p> Более детальную информацию о синтаксисе и семантике URL можно найти в RFC-1738 [4] и RFC-1808 [11]. Приведенные выше BNF включают в себя национальные символы, недопустимые в URL, так как это специфицировано в RFC 1738, так как серверам HTTP не запрещено использование любых наборов символов, допустимых в rel_path частях адресов, HTTP-прокси могут получить запросы URI, не определенные в рамках RFC-1738.
Протокол HTTP не устанавливает каких-либо ограничений на длину URI. Серверы должны быть способны обрабатывать URI любых ресурсов, имеющих любую длину. Сервер должен выдать отклик 414 (Request-URI Too Long - URI запроса слишком длинен), если URI длиннее, чем может обработать сервер (см. раздел 9.4.15).
Замечание: Серверы должны избегать использования URI длиннее 255 байт, так как некоторые старые клиенты или прокси-приложения не могут корректно работать с такими длинами.
2.2.2. HTTP URL
Схема "HTTP" используется для локализации сетевых ресурсов с помощью протокола HTTP. Далее определены синтаксис и семантика HTTP URL, зависящие от схемы.
| http_URL | = "http:" "//" host [ ":" port ] [ abs_path ] |
| host | = <Легальное имя ЭВМ в Интернет или IP-адрес (в точечно-цифровой форме), как это определено в разделе 2.1 RFC 1123> |
| port | = *DIGIT |
Если номер порта не указан, предполагается порт 80. Семантика устроена так, что идентифицированный ресурс размещается на сервере, который ожидает TCP-соединения через порт данной ЭВМ, а Request-URI для ресурса находится в abs_path. Использование IP адресов в URL следует избегать всюду, где это возможно (см. RFC-1900 [24]). Если abs_path в URL отсутствует, он должен считаться равным "/", в случае, если он используется в качестве Request-URI для ресурса (раздел 4.1.2).
2.2.3. Сравнение URI
При сравнении двух URI с целью проверки их идентичности, клиент должен использовать по октетное сравнение с учетом регистра, в котором напечатаны символы. Допускаются следующие исключения:
Номер порта не указан, тогда для данного URI берется значение по умолчанию;
Сравнение имен ЭВМ и схем не должно быть чувствительным к строчным/прописным буквам;
Пустой abs_path эквивалентен abs_path "/".
Символы, отличные от типов "reserved" и "unsafe" устанавливаются равными их эквивалентам в кодировке ""%" HEX HEX".
Например, следующие три URI являются эквивалентными:
http://abc.com:80/~smith/home.html
http://ABC.com/%7Esmith/home.html
http://ABC.com:/%7Esmith/home.html
2.3. Форматы даты/времени
2.3.1. Полная дата
HTTP приложения допускают три различных формата для представления метки времени и даты:
Sun, 06 Nov 1994 08:49:37 GMT ; RFC-822, актуализировано в RFC-1123
Sunday, 06-Nov-94 08:49:37 GMT ; RFC-850, объявлено устаревшим в RFC-1036
Sun Nov 6 08:49:37 1994 ; ANSI C's ASCtime() format
Первый формат предпочтительнее, как стандарт Интернет и представляет собой форму фиксированной длины, определенную RFC-1123. Второй формат используется достаточно широко, но базируется на устаревшем документе RFC-850 [12], формат даты не имеет 4 цифр года. Клиенты и серверы HTTP/1.1, которые анализируют дату, должны уметь работать со всеми тремя форматами (для совместимости с HTTP/1.0), хотя они должны сами генерировать время/дату согласно формату RFC-1123.
Замечание: Получатели значений даты должны быть готовы принять коды, которые посланы не приложениями HTTP, что случается, когда данные поступают через прокси/порты или по почте в SMTP- или NNTP-форматах.
Все марки времени/даты HTTP должны соответствовать времени по Гринвичу (GMT). Это указано в первых двух форматах путем включения строки "GMT" и должно предполагаться во всех прочих случаях.
| HTTP-date | = RFC-1123-date | rRFC-850-date | asctime-date | |
| RFC-1123-date | = wkday "," SP date1 SP time SP "GMT" | |
| RFC-850-date | = weekday "," SP date2 SP time SP "GMT" | |
| asctime-date | = wkday SP date3 SP time SP 4DIGIT | |
| date1 | = 2DIGIT SP month SP 4DIGIT | ; day month year (e.g., 02 Jun 1982) |
| date2 | = 2DIGIT "-" month "-" 2DIGIT | ; day-month-year (e.g., 02-Jun-82) |
| date3 | = month SP ( 2DIGIT | ( SP 1DIGIT )) | ; month day (e.g., Jun 2) |
| time | = 2DIGIT ":" 2DIGIT ":" 2DIGIT | ; 00:00:00 - 23:59:59 |
| wkday | = "Mon" | "Tue" | "Wed" | "Thu" | "Fri" | "Sat" | "Sun" | |
| weekday | = "Monday" | "Tuesday" | "Wednesday" | "Thursday" | "Friday" | "Saturday" | "Sunday" | |
| month | = "Jan" | "Feb" | "Mar" | "Apr" | "May" | "Jun" | "Jul" | "Aug" | "Sep" | "Oct" | "Nov" | "Dec" |
/p> Замечание: HTTP требования для формата метки даты/времени применимы только для использования в рамках реализации самого протокола. Клиенты и сервера не требуют применения этих форматов для пользовательских презентаций, протоколирования запросов и т.д..
2.3.2. Интервалы времени в секундах
Некоторые поля заголовка HTTP допускают спецификацию значения времени в виде целого числа секунд, представленного в десятичной форме и равного времени с момента получения сообщения.
delta-seconds = 1*DIGIT
2.4. Наборы символов
HTTP использует то же определение термина "набор символов", что дано для MIME:
Термин "набор символов", используемый в данном документе, относится к методу, который с помощью одной или более таблиц преобразует последовательность октетов в последовательность символов. Заметьте, что не требуется безусловное обратное преобразование, при этом не все символы могут быть доступны и одному и тому же символу может соответствовать более чем одна последовательность октетов. Это определение имеет целью допустить различные виды кодировок символов, от простых однотабличных, таких как US-ASCII, до сложных - таблично переключаемых методов, используемых, например, в ISO 2022. Однако, определение, связанное с набором символов MIME, должно полностью специфицировать схему соответствия октетов и символов. Использование внешних профайлов для определения схемы шифрования не допустимо.
Замечание. Здесь "набор символов" ближе к понятию "кодирование символов". Однако так как HTTP и MIME используют один и тот же регистр, важно, чтобы терминология также была идентичной.
Наборы символов HTTP идентифицируются лексемами, которые не чувствительны к использованию строчных или прописных букв. Полный набор лексем определен регистром наборов символов IANA [19].
charset = token
Несмотря на то, что HTTP позволяет использовать произвольную лексему в качестве значения charset, любая лексема, значение которой определено в рамках регистра набора символов IANA, должна представлять символьный набор, определенный этим регистром.Приложение должно ограничить использование символьных наборов только теми, которые определены регистром IANA.
Примеры сетевых топологий
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
GOPHER (RFC-1436) представляет собой систему для поиска и доставки документов, хранящихся в распределенных хранилищах-депозитариях. Система разработана в университете штата Миннесота (на гербе этого штата изображен хомяк, по-английски gopher). Программа Gopher предлагает пользователю последовательность меню, из которых он может выбрать интересующую его тему или статью. Объектом поиска может быть текст или двоичный файл (во многих депозитариях даже текстовые файлы хранятся в архивированном, а следовательно, двоичном виде), графический или звуковой образ. Gopher кроме того предлагает шлюзы в другие поисковые системы WWW, Wais, Archie, Whois, а также в сетевые утилиты типа telnet или FTP. Gopher может предложить больше удобств для работы с оглавлением файлов (directory), чем FTP. Для доступа в глобальную сеть Gopher использует модель клиент-сервер. Система Gopher в настоящее время устарела, многие ее серверы интегрированы в сеть WEB. Но gopher явился прототипом современных интерфейсов WWW и именно делает его интересным.
Для реализации доступа пользователь должен работать в рамках протоколов TCP/IP и иметь на своей машине программу-клиент одной из версий gopher. Существуют версии Gopher на IBM/PC (MS-DOS), VMS, UNIX, X-Windows и т.д. Многие версии публично доступны с помощью анонимного FTP в различных депозитариях, например, секция /pub/gopher. При постановке программы-клиента необходимо среди прочего указать адрес сервера-gopher. Для России можно использовать серверы (при равных условиях предпочтительнее серверы, отстоящие на меньшее число шагов; многие серверы gopher в настоящее время уже закрыты):
| internet адрес | login | Страна |
| gopher.chalmers.se (129.16.221.40) | gopher | Швеция |
| gopher.sunet.se (192.36.125.2) | gopher | Швеция |
| gopher.uv.es (147.156.1.12) | gopher | Испания |
| gopher.brad.ac.uk (143.53.2.5) | info | Англия |
| gopher://gopher.bubl.bath.ac.uk/ | Англия | |
| gopher://gopher.uni-bayreuth.de/ | Германия | |
| gopher://gopher.uni-paderborn.de/ | Германия | |
| gopher://gopher.uni-essen.de/ | Германия | |
| gopher://gopher.uni-passau.de/ | Германия | |
| gopher://gopher.ebone.net/ | gopher | Европа |
| gopher://gopher.e-technik.tu-muenchen.de/ | Германия | |
| gopher://gopher.dkrz-hamburg.de/ | Германия | |
| gopher.denet.dk (129.142.6.66) | gopher | Дания |
| gopher.uiuc.edu (128.174.5.61) | gopher | США |
| gopher.virginia.edu (128.143.22.36) | gwis | США |
| consultant.micro.umn.edu (134.84.132.4) | gopher | США |
| gopher://gopher.info.usaid.gov/ | США | |
| gopher.ohiolink.edu (130.108.120.25) | gopher | США |
| info.anu.edu.au (150.203.84.20) | info | Австралия |
| infopath.ucsd.edu (132.239.50.100) | info path | США |
| jake.esu.edu | США | |
| nic.merit.edu | США | |
| scilibx.ucsc.edu (128.114.143.4) | gopher | США |
| trainmat.ncl.ac.uk | Англия | |
| grits.vadosta.peachnet.edu (131.144.8.206) | gopher | США |
| panda.uiowa.edu (128.255.40.201) | США | |
| wsuaix.csc.wsu.edu (134.121.1.40) | wsuinfo | США |
| gopher.msu.edu (35.8.2.61) | gopher | США |
| gopher.unc.edu (152.2.22.81) | gopher | США |
| twosocks.ces.ncsu.edu (152.1.45.21) | gopher | США |
| ecosys.drdr.virginia.edu (128.143.96.10) | gopher | США |
| gopher.ncc.go.jp (160.190.10.1) | gopher | Япония |
При выдаче команды Gopher система свяжет вас с сервером, указанным вами при постановке программы. Можно связаться с любым другим сервером, выдав команду: Gopher <имя_сервера>, где <имя_сервера> имя Gopher-сервера, выбранного вами.
Большинство программ-клиентов позволяют пользователю делать "закладки" (bookmarks), которые содержат информацию о месте хранения объекта и пути доступа к нему. Закладки сохраняются и при выходе из Gopher, что облегчает продолжение поиска или нахождение объекта, найденного ранее. Набор функций программы-клиента зависит от ее конкретной реализации и от программного обеспечения ЭВМ, на которой она работает. Gopher обеспечивает простой и удобный интерфейс (лучше чем в обычном www с использованием меню, но хуже чем в MS internet explorer или netscape), позволяя работать с мышкой и предельно упрощая копирование найденных файлов.
Обычно gopher имеет также автоматическую систему поиска объектов по ключевым словам в более чем 500 меню. Это крайне важно, так как пользователь не может знать все адреса серверов. Система носит имя Veronica (Very Easy Rodent-Oriented Net-wide Indexed Computerized Archives). Ключевое слово может быть набрано строчными или заглавными буквами. Veronica-сервер возвращает результат поиска в виде gopher-меню, где содержатся записи, в текстах которых присутствуют искомые ключевые слова. Доступ к Veronica возможен либо из базового меню или из из рубрики Other gopher servers... Для того чтобы ваш сервер стал известен окружающему миру, он должен быть зарегистрирован в сервере университета Миннесоты (США) или в любом другом уже зарегистрированном сервере.
Объекты в меню обычно снабжаются символами-признаками, которые позволяют судить о типе объекта. Так, например, "<?>" означает полнотекстный индексный поиск, "/" - subdirectory, "<picture>" - указывает, что здесь хранится изображение, отсутствие какого-либо символа означает, что это текстовый файл.
Если вы располагаете рабочей версией gopher, вызов программы можно выполнить командой Gopher или, например, gopher gopher.micro.umn.edu 70.
В последнем случае обращение будет произведено к конкретному серверу, имя которого указано в качестве параметра команды. Число 70 указывает на номер порта (стандартное значение для gopher). Ниже приводится пример меню gopher:
Internet gopher information client v2.0.12 information about gopher
1. about gopher.
2. search gopher news <?>
3. gopher news archive/
4. comp.infosystems.gopher (usenet newsgroup)/
5. gopher software distribution/
6. gopher protocol information/
7. university of minnesota gopher software licensing policy.
8. frequently asked questions about gopher.
9. gopher93/
10. gopher example server/
11. how to get your information into gopher.
--> 12. new stuff in gopher.
13. reporting problems or feedback.
14. big ann arbor gopher conference picture.gif <Picture>
Press ? for Help, q to Quit, u to go up a menu Page: 1/1
Выбор пункта из меню может выть выполнен мышкой, путем печатания номера соответствующей строки и последующего нажатия клавиши <Enter>, или путем движения курсора с помощью клавишей стрелок с последующим нажатием клавиши <Enter>. В приведенном выше примере курсор указывает на пункт меню с номером 12. Если в такой ситуации нажать клавишу <Enter>, обращение произойдет именно сюда. Звуковые и графические файлы имеют формат uuencode.
Существует возможность доступа к GopherMail-серверам, которые пересылают заказчику текст базового меню. GopherMail включат в себя следующие возможности (что-то вроде игры в шахматы по переписке):
Разбиение сообщений, если они слишком велики.
Деление меню на части, если его число строк слишком велико.
Повторное использование связей, записанных в файлах-закладок (bookmarks).
Запрос меню Gopher заданной ЭВМ.
Пометка выбранного пункта меню символом "X" (или Xn, где n - номер строки меню).
Запрос help-файла.
Запрос записей из архива Info-Mac.
Запрос записей Gopher с их аннотациями.
Вы можете задать предельные размеры сообщения и меню, включив в текст сообщения команды, например:
Split=25K
Menu=75
Для работы с Gopher через электронную почту вы можете выбрать ближайший GopherMail-сервер из предлагаемого списка:
| gopher@earn.net | France |
| gopher@ftp.technion.ac.il | Israel |
| gopher@join.ad.jp | Japan |
| gopher@nig.ac.jp | Japan |
| gopher@nips.ac.jp | Japan |
| gopher@solaris.ims.ac.jp | Japan |
| gophermail@ncc.go.jp | Japan |
| gopher@dsv.su.se | USA |
Если вы хотите узнать больше о GOPHER можете подписаться на новости о GOPHER по адресу: gopher-news-request@boombox.micro.umn.edu. Если для вас доступен NEWS-server, то секция GOPHER имеет там имя omp.infosystem.gopher. В сложных случаях за справками можно обратиться к разработчикам GOPHER по адресу:
gopher@boombox.micro.umn.edu. При проблемах с VERONICA можно написать письмо ее разработчикам Steve Foster и Fred Barrie в университет Невады по адресу:
gophadm@futique.scs.unr.edu. Но не злоупотребляйте этим, у них есть и свои заботы.
Горизонтальное и вертикальное выравнивание
<!entity % cellhalign "align (left|center|right|justify|char) #implied
char cdata #implied -- выравнивание по символу, напр. char=":" --
charoff cdata #implied -- смещение выравнивания по символу -- >
<!entity % cellvalign "valign (top|middle|bottom|baseline) #implied" >
Определения атрибутов
align = left|center|right|justify|char
Этот атрибут определяет способ выравнивания текста в ячейке. Возможны следующие значения:
| left: | выравнивание по левому краю (значение атрибута по умолчанию) |
| center: | Выравнивание текста в ячейке по центру (значение по умолчанию для заголовков) |
| right: | выравнивание текста по правому краю ячейки. |
| justify: | выравнивание текста по правой и левой границам. |
| char: | выравнивание текста по некоторому символу. |
valign = top|middle|bottom|baseline
Этот атрибут определяет вертикальное позиционирование текста в ячейке таблицы. Возможны следующие значения:
| top: | текст прижимается к верхней границе ячейки. |
| middle: | текст размещается по центру ячейки (значение по молчанию для заголовков) |
| bottom: | текст прижимается к нижней границе ячейки. |
| baseline: | все ячейки в ряду должны быть выровнены по высоте так, чтобы их первые строки были на одной высоте. Это не касается последующих строк. |
char = cdata
Этот атрибут определяет символ в тексте, который будет выполнять роль оси для выравнивания. Значением по умолчанию является точка для английского языка и запятая - для французского (бывает полезно для колонок цифр с долями целого).
charoff = length
Если этот атрибут присутствует, он определяет смещение текста относительно символа выравнивания (рассматривается первый такой символ). Если в строке такого символа нет, то она должна быть сдвинута горизонтально в конец относительно позиции выравнивания.
Рассмотрим пример таблицы с выравниванием по символу точка.
<table border="border">
<colgroup>
<col><col align="char" char=".">
<thead>
<tr><th>Vegetable <th>Cost per kilo
<tbody>
<tr> <td> lettuce <td>$1
<tr> <td> silver carrots <td>$10.50
<tr> <td>golden turnips <tr>$100.30
</table>
Отформатированная таблица будет выглядеть как:
| vegetable | cost per kilo |
| lettuce | $1 |
| silver carrots | $10.50 |
| golden turnips | $100.30 |
Границы и линии
Следующие атрибуты влияют на рамки таблицы и внутренние линии.
frame = void|above|below|hsides|lhs|rhs|vsides|box|border
Эти атрибуты определяют, какая из сторон рамки, окружающей таблицу, будет видимой.
| void: | Ни одна из сторон. Значение по умолчанию. |
| above: | Только верхняя сторона. |
| below: | Только нижняя сторона. |
| hsides: | Только нижняя и верхняя стороны. |
| vsides: | Только правая и левая стороны. |
| lhs: | Только левая сторона. |
| rhs: | Только правая сторона. |
| box: | Все четыре стороны. |
| border: | Все четыре стороны. |
rules = none|groups|rows|cols|all
Этот атрибут определяет, какие линии появится между ячейками в пределах таблицы. Возможные значения:
| none: | Никаких линий, значение по умолчанию. |
| groups: | Линии имеются только между группами рядов и столбцов. |
| rows: | Линии имеются только между рядами. |
| cols: | Линии имеются только между столбцами. |
| all: | Линии имеются между рядами и столбцами. |
border = cdata
Эти атрибуты определяют ширину рамки вокруг таблицы в пикселях. В приведенном ниже примере таблица имеет рамку в 5 пикселей и присутствует с правой и левой сторон таблицы. Разделительные линии имеются между всеми колонками.
<table border="5" frame=vsides" rules="cols">
<tr> <td>1 <td>2 <td>3
<tr> <td>4 <td>5 <td>6
<tr> <td>7 <td>8 <td>9
</table>
Следующие установки должны выполняться агентом пользователя для совместимости. Установка border="0" подразумевает frame="void" и, если не специфицировано иного, rules="none". Другие установки border подразумевают frame="border" и, если не оговорено иное, rules="all". Значение "border" в стартовой метке элемента table должно интерпретироваться как значение атрибута frame. Это предполагает, что rules="all" и ненулевое значение атрибута border. Так, например:
<frame border="2"> у <frame border="2" frame="border" rules="all">
и
<frame border> <=< frame frame="border" rules="all">
Границы сетевой надежности
Существенно, то, что проблемы надежности, представляющие интерес, являются #P-полными, и, следовательно тот факт, что описанные точные алгоритмы совершенно неэффективны не вызывают удивления. Несмотря на это при оценке сетевой надежности абсолютно необходимо, чтобы работа завершалась за “разумное” время. Конфликтные требования быстрого вычисления при высокой точности приводят к разнообразной коллекции методов установления мер надежности.
Возникают две основные темы: оценка надежности с привлечением моделирования по методу Монте-Карло и оценка границ надежности. В первом случае целью является получение точной оценки меры надежности путем рассмотрения малой доли состояний, выбранных случайно. Это приводит к точечной оценке меры надежности и получению доверительных интервалов этой оценки. Ограничение отличается от этого как по методике, так и по результатам. Современные методики расчета ограничений пытаются найти комбинаторные или алгебраические структуры в проблеме надежности, позволяющие извлечь структурную информацию при рассмотрении малой доли состояний. В отличие от методов Монте-Карло, рассматриваются состояния, выбранные неслучайно. Целью ограничения является формирование абсолютной верхней и нижней границы меры надежности.
Проведение связи между методами Монте-Карло и методиками ограничений, возможно, вводит в заблуждение, так как многие методы Монте-Карло используют ограничения как средство определения размера пространства выборки. Мы сначала рассмотрим случай, когда все ребра работают независимо с одной и той же известной вероятностью. Затем мы рассмотрим вариант, когда ребра работают независимо с произвольными (но все же известными) вероятностями.
Группирование ребер
Пусть G=(V,E) является графом (или диграфом, или мультиграфом). Секция G содержит k графов G1,….,Gk с Gi=(V,Ei), где набор ребер Е поделен на k классов Е1,…,Еk. Группа ребер G из k графов G1,….,Gk получается путем выделения набора ребер Е в k+1 класс Е1,…,Еk, и определения Gi=(V,Ei). Главное, на что здесь следует обратить внимание, достаточно просто:
Лемма 4.1. Если G имеет группу ребер по k графам G1,….,Gk, а Rel является любой сопряженной мерой надежности, то

Неравенство в лемме 4.1 возникает из-за того, что существуют рабочие состояния G, в которых ни один Gi не работает. Сделаем несколько замечаний, чтобы применение леммы 4.1 было эффективным при получении нижней границы надежности. Рассмотрим группу ребер G из G1,….,Gk. Если любой Gi находится в нерабочем состоянии, когерентность (сцепление) гарантирует, что Rel(Gi)=0; в данном случае включение Gi в группу ребер не окажет влияния на ограничение и Gi может быть просто опущено. Таким образом, нам нужно в случае группы ребер заботиться только о работоспособных субграфах.
Нашей целью является получение эффективно вычислимых границ; следовательно, необходимо, чтобы мы вычисляли (или хотя бы устанавливали границы) Rel(Gi) для каждого Gi. Одним из таких решений, предложенных Полесски [V. P. Polesskii, “A lower boundary for the reliability of information networks”, Problems of Information Transmission, 7, (1971), 165-171], является алгоритм группирования ребер G с минипроходами. Надежность минипрохода легко вычисляется. Это дает решение, в котором мы формируем группу ребер G с максимально возможным числом минипроходов, а затем применяем лемму 4.1. Эта базовая стратегия активно использовалась.
Важно заметить, что в то время как вычислимые ограничения требуют, чтобы ребра имели равную вероятность сохранения работоспособности, здесь это предположение не требуется; нужно только вычислить вероятность для минипрохода, как произведение вероятностей работоспособности ребер, составляющих минипроход. Принимая это во внимание, можно модифицировать нашу задачу группирования ребер, потребовав, чтобы в группу входили наиболее надежные проходы, а не максимально возможное число минипроходов.
Ничего не стоит также, чтобы любая группа ребер работоспособных субграфов G1,….,Gk, для которых легко вычислить Rel(Gi), предоставляла возможность эффективного вычисления нижней границы. Это приводит к задачам, таким как группирование ребер для последовательно-параллельных графов, или к частичным k-деревьям при фиксированном k. Этот последний подход, кажется, еще не изучен в литературе, следовательно, мы сосредоточимся на формировании групп ребер с минипроходами.
Используя теорему Таттла и Нэш-Вильямса, Полесски заметил, что граф с n вершинами и с-связанными ребрами имеет, по крайней мере,

Для двухтерминальной надежности минипроходы являются лишь s,t-проходами. Теорема Менгера утверждает, что максимальное число s,t-проходов с разделенными ребрами равно мощности минимального s,t-разреза. Таким образом, используя методики сетевых потоков, можно найти максимум группирования ребер. Проблема нахождения наилучшего группирования ребер, даже если все вероятности работоспособности ребер равны, является сложной из-за того факта, что минипроходы демонстрируют большую вариацию мощности.
Обратимся к k-терминальной надежности, где ситуация не столь удовлетворительна.
Здесь минипутем является субдерево, в котором каждый листик представляет собой терминал, т.е. дерево Штайнера. Оказалось, что никакой эвристики для нахождения “хороших” групп ребер для деревьев Штайнера не найдено.
До этого момента мы рассматривали нижние границы, базируясь на методике группирования ребер в рамках минипроходов. Теперь обратимся к верхним границам. Не удивительно, что лемма 4.1 имеет “дуальный” вид для верхних границ при замене набора проходов на набор разрезов:
Лемма 4.2. Пусть G=(V,E) является графом (или диграфом, или мультиграфом). Пусть Rel является когерентной мерой надежности. Пусть С1,…,Сs является группой ребер G набора разрезов. Тогда

где ре - вероятность работоспособности ребра е.
Лемма 4.2 дает верхнюю границу, так как отказ для любого разреза при группировании ребер вызывает отказ G, но отказ G может случиться, даже когда ни один из наборов разрезов в группе не дает отказа.
Нахождение максимального набора разрезов, разъединяющих ребра, достаточно прямолинейно - просто следует пометить каждый узел его расстоянием от s. Если t получает метку l, формируем набор разрезов Сi, содержащий все ребра между вершинами, помеченными i-1 и вершинами, помеченными i для 1 Ј i Ј l. В результате получается l s,t-разрезов, разъединяющих ребра. Нахождение ”хороших” наборов разрезов для определения верхних границ методом группирования ребер оказывается более сложным, чем для нижних границ. В последнее время Вагнер [D.K.Wagner, “Disjoint (s,t)-cuts in a network”, Networks 20, (1990), 361-372] предложил алгоритм с полиномиальным временем для нахождения набора s,t-разрезов, разъединяющих ребра, с минимальной стоимостью при максимальной мощности.
Обратившись к верхним границам все- и k-терминальной надежности с привлечением группирования ребер миниразрезами, мы сталкиваемся с главной трудностью: даже для всетерминальной надежности нахождение максимальной группировки посредством миниразрезов является NP-трудным. Таким образом, верхняя граница всетерминальной надежности может быть получена путем использования ограничения группирования дуг для достижимости.
Выделяются два потенциальных метода улучшения стратегии группирования ребер. Первый - заключается в рассмотрении более надежных субграфов для группировки; второй - связан c расширением рассматриваемых наборов проходов и разрезов с целью разрешения некоторых пересечений ребер (таким образом, теряя независимость наборов ребер в группировке). Мы рассматриваем второе расширение, которое используется более активно в следующем подразделе. Для первого метода оказалось выполнено мало работы. Используя эффективный точный алгоритм для достижимости в случае бесцикловых ориентированных графов, Раманатхан и Кольбурн [A.Ramanathan, and C.J.Colbourn, “Bounds on all-terminal reliability via arc packing”, Ars Combinatoria 23A, (1987), 91-94] получили улучшения верхних границ достижимости, а также всетерминальных верхних границ надежности. Однако использование группирования ребер с привлечение не минимальных проходов или набора разрезов не развивается, частично из-за нехватки точных алгоритмов для ограниченных классов, частично по причине трудности нахождения подходящей группы ребер.
Группирующие элементы div и span
<!element div - - %block>
| <!attlist div %attrs; | -- %coreattrs, %i18n, %events -- | |
| %align; | -- align, выравнивание текста -- > | |
| <!element span - - (%inline) * |
-- базовый языковый/стилевой контейнер -- > | |
| <!element span %attrs; | -- %coreattrs, %i18n, %events -- > | |
Атрибуты определенные где-то еще
id, class (идентификаторы, действующие в пределах документа)
lang (языковая информация), dir (направление текста/отступ)
title (заголовок элемента)
style (текущая стилевая информация)
align (выравнивание)
onclick, ondblclick, onmousedown, onmouseup, onmouseover, onmousemove, onmouseout, onkeypress, onkeydown, onkeyup (события)
Элементы div и span в сочетании с атрибутами id и class предлагают обобщенный механизм структурирования документа. Таким образом, сформировав примеры и классы и используя для них стилевые листы, программист может придать HTML-документу необходимую структуру и форму.
Предположим нужно сформировать документ на основе базы данных клиента. Так как HTML не имеет элементов, идентифицирующих такие объекты как "клиент", "телефонный номер" и т.д., для решения стоящей задачи воспользуемся элементами div и span.
В приведенном примере каждое имя клиента принадлежит классу client-last-name. Присвоим также уникальные идентификаторы каждому клиенту (client-stepanov, client-ivanov).
<div id="client-stepanov" class="client">
<span class="client-last-name">last name:</span> stepanov,
<span class="client-first-name">first name:</span> stepa
<span class="client-tel">telephone:</span> (095) 123-9442
<span class="client-email">email:</span> s.s@itep.ru">s.s@itep.ru
</div>
<div id="client-ivanov" class="client">
<span class="client-last-name">last name:</span> ivanov,
<span class="client-first-name">first name:</span> vanja
<span class="client-tel">telephone:</span> (095) 123-5442
<span class="client-email">email:</span> s.s@itep.ru">v.i@itep.ru
</div>
Позднее может быть легко добавлена стилевая информация для тонкой настройки представления записей этой базы данных.
span является строчным элементом и его зона ответственности - параграф. span не может быть использован для группирования элементов блочного уровня. div, напротив, предназначен для работы с блочными элементами. div элемент, за которым следует незакрытый p-элемент, завершает параграф. Агент пользователя помещает разрыв строки до и после div-элемента, например строка:
<p>aaaaaa<div>bbbbbb</div><div>ccccc<p>ccccc</div>
обычно развертывается в:
aaaaaa
bbbbbb
ccccc
ccccc
Агент пользователя развернет ее как:
aaaaaabbbbbbccccc
ccccc
5.3. Элементы заголовков h1, h2, h3, h4, h5, h6
<!entity % heading "h1, h2, h3, h4, h5, h6">
<!-- Существует шесть уровней заголовков, начиная с Н1 (наиважнейший), кончая Н6 -- >
<!element (%heading) - - (%inline;)*>
<!attlist (%heading) %attrs; | -- %coreattrs, %i18n, %events -- | |
| %align; | -- align, выравнивание текста -- > | |
Элементы заголовка кратко описывают тему раздела, который они открывают. Содержимое заголовка может использоваться агентом пользователя, например, для автоматического формирования оглавления документа.
Визуальные броузеры отображают заголовки более высокого уровня буквами более крупного кегля. Ниже приведен пример использования div-элемента для установления связи заголовка со следующей за ним секцией документа. Это позволяет определить стиль раздела с помощью стилевых листов.
<div class="section" id="forest-elephants" >
<h1>forest elephants </h1>
В этом разделе обсуждаются менее известные лесные слоны.
… далее следует продолжение текста …
<div class="subsection" id="forest-habitant" >
<h2> habitant </h2>
Лесные слоны живут не на деревьях (:-))
… далее следует рассказ о том, где и как живут лесные слоны …
</div>
</div>
Структура может быть улучшена с помощью стилевой информации, например:
<head>
<style>
div.section { text-align: justify; font-size: 12pt }
div.subsection { text-ident: 2em }
h1 {font-style: italic; color: green }
h2 { color: green }
</style>
</head>
5.4. Элементы address
<!element address - - ((%inline;) | p) *>
| <!attlist address %attrs; | -- %coreattrs, %i18n, %events -- > |
Элемент address служит для введения контактного адреса с автором документа, например:
<address>
newsletter editor<br>
j. r. brown<br>
8723 buena vista, smallville, ct 01234<br>
tel: +1 (123) 456 7890
</address>
6. Спецификация языка содержимого документа. Атрибут lang
lang = language-code
Специфицирует базовый язык, на котором написан документ. Значением этого атрибута является код языка (см. RFC-1766). В пределах кода языка пробелы использоваться не должны. Значение этого кода по умолчанию "unknown". Код языка состоит из базового кода и субкода.
language-code = primary-code *( "-" subcode )
Атрибуты, определенные где-либо еще.
id, class (идентификаторы, действующие в пределах документа)
lang (языковая информация), dir (направление текста/отступ)
onclick, ondblclick, onmousedown, onmouseup, onmouseover, onmousemove, onmouseout, onkeypress, onkeydown, onkeyup (события)
Ниже приведено несколько примеров кодов языка.
"en":english
"en-us":the u.s version of english
| "en-cockney":the cockney version of english | (версия английского - кокни) |
| "i-cherokee":the cherokee language spoken by some native americans | (Чероки - язык, на котором говорят некоторые коренные американцы) |
Две первые буквы базового кода зарезервированы ISO-639.
| fr | французский |
| de | немецкий |
| it | итальянский |
| nl | голландский |
| el | греческий |
| es | испанский |
| pt | португальский |
| ar | арабский |
| he | еврейский |
| ru | русский |
| zh | китайский |
| ja | японский |
| hi | хинди |
| ur | урду |
Любые две буквы субкода воспринимаются как код страны ISO3166.
7. Наследование языковых кодов
Элемент наследует информацию языкового кода согласно следующим приоритетам (сверху вниз):
Атрибут lang устанавливает значение элемента.
Глобальный элемент, имеющий атрибут lang.
http заголовок "content-language", устанавливающий значения языка, например,
content-language: en-us.
Задание языкового атрибута извне.
В ниже приведенном примере базовый язык документа является французским. Один параграф декларирован как испанский, после чего базовый язык восстанавливается. Следующий параграф включает встроенную фразу на японском, после чего следует снова текст на французском.
<html lang="fr">
<body>
… текст интерпретируется как французский …
<p lang="es">… текст интерпретируется как испанский …
<p>… текст интерпретируется снова как французский …
<p> … французский текст интерпретируется с помощью <em lang="ja"> немного японского </em> далее следует снова текст на французском …
</body>
</html>
Группы колонок Элементы colgroup и col
<!element colgroup - o (col*) >
| <!attlist colgroup %attrs; | -- %coreattrs, %i18n, %events -- | |
| span number 1 | -- число колонок в группе по умолчанию -- | |
| width cdata #implied | -- ширина колонки по умолчанию -- | |
| %CEllhalign; | -- горизонтальное выравнивание в ячейках -- | |
| %CEllvalign; | -- вертикальное выравнивание в ячейках -- > | |
Определения атрибутов
span = integer
Атрибут в случае своего присутствия определяет число колонок в группе по умолчанию. Агент пользователя должен игнорировать этот атрибут, если текущая группа содержит один или более элементов col. Значение атрибута по умолчанию равно единице.
width = length
Атрибут определяет значение ширины колонки по умолчанию для текущей группы колонок. Кроме того, для стандартных значений пикселя и процента этот атрибут может иметь специальную форму "0*", которая означает, что ширина каждой колонки в группе должна иметь минимальную ширину для размещения имеющегося текста.
Таблица должна иметь как минимум одну группу колонок. В отсутствии определения группы считается, что таблица имеет одну группу колонок, включающую в себя все колонки таблицы. Атрибут width элемента colgroup определяет ширину по умолчанию каждой из колонок в группе. Формат "0*", требующий минимальной ширины, может быть отменен элементом col.
Таблица в приведенном ниже примере имеет две группы колонок. Первая группа содержит 10 колонок, а вторая - 5 колонок. Значение ширины колонки по умолчанию для каждой из колонок в первой группе равно 50 пикселей. Для второй группы ширина колонки определяется минимально возможным значением.
<table>
<colgroup span="10" width="50">
<colgroup span="5" width="0*">
<thead>
<tr> ….
</thead>
Группы рядов Элементы thead, tfoot и tbody
<!element thead - o (tr+)>
<!element tfoot - o (tr+)>
<!element tbody o o (tr+) >
|
<!attlist (thead|tfoot|tbody)-- секция таблицы -- | ||
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| %CEllhalign; | -- горизонтальное выравнивание в ячейке -- | |
| %CEllvalign; | -- вертикальное выравнивание в ячейке -- > | |
Таблица должна содержать хотя бы одну группу рядов. Каждая группа рядов делится на три секции: заголовок, собственно таблица и подпись под таблицей. Заголовок и подпись являются опционными. Элемент thead определяет заголовок, tfoot - подпись под таблицей, а элемент tbody - тело таблицы. thead, tfoot и tbody, если они присутствуют, должны содержать один или более рядов. Ниже приведен пример использования элементов thead, tfoot и tbody.
<table>
<thead>
| <tr> … информация заголовка … |
</thead>
<tfoot>
| <tr> … информационная подпись под таблицей … |
</tfoot>
<tbody>
|
<tr> … первый ряд блока первых данных … | |
|
<tr> … второй ряд блока первых данных … |
</tbody>
<tbody>
| <tr> … первый ряд блока вторых данных … | |
| <tr> … второй ряд блока вторых данных … | |
| <tr> … третий ряд блока вторых данных … |
</tbody>
</table>
tfoot в рамках определения table должен появляться до tbody, так чтобы агент пользователя мог осуществлять разбор подписи до получения всех данных таблицы.
Группы строк и колонок
Таблицы рассматриваются как соединение опционной надписи и последовательность рядов, которые в свою очередь состоят из последовательности ячеек. Модель еще более дифференцирует заголовок и информационные ячейки и позволяет ячейкам занимать несколько рядов и колонок.
Эта спецификация (модель таблиц cals) позволяет группировать ряды в секции заголовка, тела и основания. Она упрощает представление информации и может использоваться для повторения верхней и нижней секций при разбиении таблиц на несколько страниц, или для обеспечения фиксированного заголовка над панелью со скролированием текста. Это позволяет отображать нижнюю секцию, не дожидаясь пока вся таблица будет обработана.
Имя пользователя
Этот атрибут указывает имя пользователя, который должен быть аутентифицирован. Он используется в пакетах Access-Request. Формат атрибута показан на рис. .3.

Рис. .3. Формат атрибута
Поле тип=1, длина і 3. Поле строка имеет один или более октетов. NAS может ограничить максимальную длину имени пользователя, но рекомендуется, чтобы программа была способна обрабатывать как минимум 63 октета. Применяется несколько форматов имени пользователя:
| монолитный |
Состоит только из буквенно-цифровых символов. Эта простая форма может использоваться для локального управления NAS. |
| простой | Состоит только из печатных символов ASCII. |
| name@fqdn SMTP адрес | Стандартное имя домена (Fully Qualified Domain Name; с или без завершающей точкой) указывает область, где применимо имя. |
| уникальное имя | Имя в формате ASN.1 используется в аутентификационных системах с общедоступным ключом. |
Инициализация объекта Элемент param
| <!element param - empty | -- именованное значение параметра -- > | |
|
<!attlist param name cdata #required | -- имя параметра -- | |
| value cdata #implied | -- значение параметра -- | |
| valuetype (data|ref|object) data | -- способ интерпретации значения -- | |
| type cdata #implied | -- internet media type -- > | |
Определения атрибутов
name = cdata
| Этот атрибут определяет имя параметра исполнения. |
value = cdata
Этот атрибут специфицирует значение параметра исполнения, заданного атрибутом name. Значение этого параметра не имеет какого-либо смысла для HTML, он определяется рассматриваемым объектом.
valuetype=data|ref|object
Этот атрибут специфицирует тип значения, определенного атрибутом value. Возможны значения:
| data: | значение, заданное value, после преобразования любых вложенных символов и цифровых объектов будет непосредственно передано механизму отображения в виде строки. Этот тип используется по умолчанию и может появляться в стартовой метке элемента. |
| ref: | значение, заданное value, является url, который определяет ресурс, где записано значение параметра исполнения. URL должно передаваться механизму отображения в не преобразованном виде. |
| object: | значение, заданное value, является фрагментом URL, который определяет декларацию object в том же самом документе. В этом случае определение object должно идентифицироваться его атрибутом ID. |
type = cdata
Этот атрибут специфицирует internet media type ресурса, определенного атрибутом value, только в случае, когда атрибут valuetype = "ref". Этот атрибут, таким образом, специфицирует для агента пользователя тип значений, которые будут обнаружены в URL, определенном атрибутом value.
Элемент param специфицирует набор значений, которые могут требоваться механизму отображения. В начале декларации object может появиться любое число элементов param. Синтаксис имен и значений предполагается понятным механизму отображения. Имена и значения передаются механизму отображения, как стандартный ввод. Рассмотрим пример. Здесь предполагается, что механизм отображения может воспринять два параметра, которые определяют начальную высоту и ширину (часов).
Задаем эти начальные параметры равными 40х40 пикселей.
<object classid="http://www.miamachina.it/ahalogclock.py">
<param name="height" value="40" valuetype="data">
<param name="width" value="40" valuetype="data">
Этот агент пользователя не может исполнять приложения, написанные на языке python.
</object>
Так как значение по умолчанию valurtype для элемента param равно "data", мы можем заменить вышеприведенную декларацию следующей:
<param name="height" value="40">
<param name="width" value="40">
или
<param name="height" value="40" data>
<param name="width" value="40" data>
В следующем исходные данные исполнения для параметра механизма отображения "init_values" заданы как внешний ресурс (GIF-файл). Значение атрибута valuetype установлено равным "ref", а атрибут value равен URL.
<object classid="html://www.gifstuff.com/gifappli" standby="loading elvis…">
<param name="init_values" value="./images/elvis.gif">
</object>
Здесь установлен также атрибут standby так, что агент пользователя может отобразить сообщение в процессе загрузки механизма отображения. Механизмы отображения локализуются с помощью URL. Первая секция абсолютного URL характеризует протокол, используемый для передачи данных, которые указаны в URL. Для HTML-документов протокол обозначается как HTTP. Но возможны и другие варианты, например, в случае использования механизма отображения java вы можете использовать URL, начинающиеся со слова Java, а для аплетов activex - "clsid". В предлагаемом примере в HTML-документ введен Java-аплет.
<object classid="java:program.start">
</object>
Некоторые схемы отображения требуют дополнительной информации для идентификации их применения и должны сообщить, где можно найти эту информацию.
Инкрементное отображение
Для больших таблиц или для медленных сетевых соединений пользователю важна возможность реализации инкрементного отображения таблицы. Агенты пользователя должны быть способны начать отображение таблицы до того, как будут получены все данные. Ширина окна по умолчанию для большинства агентов пользователя равна 80 символам, а графика для многих HTML страниц сконструирована с учетом этого значения. При специфицировании числа колонок, включая различные механизмы управления шириной колонок, разработчики могут подсказать агенту пользователя как организовать инкрементное отображение таблицы.
Для инкрементного отображения броузер должен знать число колонок и их ширину. Ширина таблицы по умолчанию определяется размером текущего окна (ширина="100%"). Это значение может быть изменено путем установки атрибута width в элементе table. По умолчанию, все колонки имеют равные ширины, но вы можете специфицировать ширины колонок с помощью одного или нескольких элементов col.
Последний пункт - число колонок. Некоторые люди предлагают ждать, пока первый ряд таблицы будет получен, но это может занять много времени, если ячейки содержат много материала. Имеет смысл, особенно для целей инкрементного отображения таблиц, задать разработчикам число колонок в таблице явно (в элементе table).
Разработчикам нужен способ, сообщить агенту пользователя, следует ли использовать инкрементное отображение или изменить размер таблицы с тем, чтобы можно было разместить содержимое ячеек. В режиме двухпроходного определения размеров число колонок определяется при первом проходе. При инкрементном режиме сначала должно быть объявлено число колонок (с помощью элементов col или colgroup).
Использование вычислительных методик на практике
После прочтения предыдущих 6 разделов будет вполне вероятно, что кто-то запутается, решая как применить мириад метрик надежности, алгоритмов, ограничений и т.д. к решению реальных задач. В этом последнем разделе мы предоставляем некоторое руководство по этому вопросу.
Испытания с использованием ограничений
Это является мощным гибридом классических приоритетных испытаний и схем Монте-Карло с управляемыми случайными величинами. Метод может быть в принципе применен к любой задаче надежности, где системная функция Ф ассоциирована с нижней ограничивающей функцией связи ФL и верхней ограничивающей функцией ФU, имеющими следующие свойства
· ФL(х) Ј Ф(х) Ј ФU(х) для каждого вектора состояния х.
·Для k = 0,…,m и любых значений


и

могут быть вычислены в рамках полиномиальной оценки.
Значения








Значения

в пропорции к их вероятности для исходного пространства. Известная вероятность для пространства, где испытания не проводятся, т.е., где ФL(x)=1 или ФL(x)=0, учитывается при оценке надежности R для пространства испытаний Х. Полученный выигрыш находится в прямой пропорции к доле исходной вероятности, которая оставлена для испытаний в Х. Соответствующая схема Монте-Карло представлена ниже.
Метод испытаний, базирующийся на ограничениях
1. Берутся события



2. Вычисляем пропорцию


Простой пример этой схемы использует тот факт, что для любого вектора состояния х, по крайней мере, r элементов должно работать, чтобы работала система и, по крайней мере, g элементов должно отказать, для того чтобы системы вышла из строя, где r равно минимальному числу путей для системы, а g минимальному числу разрезов (обрывов) для системы.
Теперь мы определяем ФU(x) равным 1, когда, по крайней мере, r элементов из х работают, и 0 в противном случае, мы также определяем ФL(x) равным 0, когда, по крайней мере, g элементов х отказало, и 1 в противном случае. Вычисления RL и RU являются задачами определения надежности k-из-m, которые, как известно, имеют эффективные алгоритмы расчета вероятности, а пространство испытаний Х является пространством векторов состояния х, имеющих, по крайней мере r, но не больше чем m-g работающих элементов. Ограничения по числу проходов/разрезов, рассмотренные в 4.2.1, могут использоваться для получения эффективной схемы Монте-Карло, базирующейся на ограничениях. Здесь, если С1,…,Сr являются отдельными разрезами, а Р1,…,Рs - отдельными проходами, тогда


Значения


Изображения Элемент img
| <!element img - o empty | -- введение изображения в текст документа -- > | |
| <!attlist img %attrs; | -- %coreattrs, %i18n, %events -- | |
| src %url #required | -- url вводимого рисунка -- | |
| alt cdata #implied | -- описание для чисто текстовых броузеров -- | |
| align %ialign #implied | -- вертикальное или горизонтальное выравнивание -- | |
| height %pixels #implied | -- предлагаемая высота в пикселях -- | |
| width %pixels #implied | -- предлагаемая ширина в пикселях -- | |
| border %pixels #implied | -- предлагаемая толщина рамки в пикселях -- | |
| hspace %pixels #implied | -- предлагаемая ширина горизонтального поля -- | |
| vspace %pixels #implied | -- предлагаемая ширина вертикального поля -- | |
| usemap %url #implied | -- use client-side image map -- | |
| ismap (ismap) #implied | -- use server-side image map -- | |
Определение атрибутов
src = URL
Этот атрибут специфицирует положение (указатель на) ресурса, содержащего изображение. Общепринятые форматы: GIF, JPG, PNG.
align = bottomiddle|top|left|right
Применение не рекомендуется. Атрибуты определяют положение изображения по отношению к окружающему тексту.
Элемент IMG вводит изображение в текущий документ в точке его описания. Но тем не менее, рекомендуется вводить рисунок в текст с помощью элемента object. Рассмотрим, как семейное фото может быть включено в документ.
<img src="html://www.somecompany.com/people/ian/vocation/family.png"
|
alt="a photo of my family at the lake."> |
Это же может быть сделано с помощью object следующим образом.
<object data=
| type="image/png"> |
Фото моей семьи на озере.
</object>
Атрибут alt специфицирует текст, который будет выведен в случае, когда изображение не может быть отображено по какой-либо причине.
Ячейки таблицы Элементы th и td
<!element (th|td) - o %block>
| <!attlist (th|td) | -- Заголовок или данные ячейки -- | |
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| axis cdata #iplied | -- содержимое ячейки по умолчанию -- | |
| axes cdata #iplied | -- список имен axis -- | |
| nowrap (nowrap) #implied | -- блокирует разрыв слов -- | |
| bgcolor %color #implied | -- цвет фона ячейки -- | |
| rowspan number | -- число рядов, охватываемых ячейкой -- | |
| colspan number | -- число колонок, охватываемых ячейкой -- | |
| %CEllhalign; | -- горизонтальное выравнивание в ячейках -- | |
| %CEllvalign; | -- вертикальное выравнивание в ячейках -- > | |
Определения атрибутов
axis = cdata
Атрибут определяет сокращенное имя заголовка ячейки. Имя ячейки по умолчанию - ее содержимое.
axes = cdata-list
Значение этого атрибута представляет собой список имен axis, разделенных запятыми. Эти имена представляют собой заголовки рядов и колонок, принадлежащих данной ячейке. В отсутствии этого атрибута агент пользователя идентифицирует эти имена сам.
rowspan = integer
Этот атрибут специфицирует число рядов в текущей ячейке. Значение этого атрибута по умолчанию равно 1. Значение нуль означает, что ячейка включает в себя все ряды, начиная с текущего, до конца таблицы.
colspan = integer
Этот атрибут специфицирует число колонок в текущей ячейке. Значение этого атрибута по умолчанию равно 1. Значение нуль означает, что ячейка включает в себя все колонки, начиная с текущей, до конца таблицы.
nowrap
Использование не рекомендуется. В случае присутствия этот булев атрибут указывает агенту пользователя заблокировать автоматический разрыв слов при выкладке их в ячейку. Вместо этого атрибута рекомендуется использовать стилевой лист.
Элемент TH запоминает заголовок, в то время как TD - данные. Это позволяет агенту пользователя обрабатывать заголовки и данные по-разному даже в отсутствии стилевого листа. Ячейки могут быть пустыми (не содержать данных). Ниже приведен пример таблицы с четырьмя колонками, имеющими заголовки.
<table>
<caption>Cups of coffee consumed by each senator</caption>
<tr> <th>name <th>Cups <th> Type of coffee <th> Suger?
<tr> <td>T. Sexton <td>10 <td>espresso <td>no
<tr> <td>J. Dinnen <td>5 <td>decaf <td>yes
… остальная часть таблицы …
</table>
Агент пользователя представит верхнюю часть данной таблицы в виде:
Cups of coffee consumed by each senator
| Name | Cups | Type of coffee | Sugar |
| T. Sexton | 10 | espresso | no |
| J. Dinnen | 5 | decaf | yes |
Для того чтобы сделать таблицу более выразительной, можно ввести атрибут border в элемент table.
<table border="border">
… остальная часть таблицы …
</table>
Тогда агент пользователя отобразит начало данной таблицы следующим образом:
Cups of coffee consumed by each senator
| Name | Cups | Type of coffee | Sugar |
| T. Sexton | 10 | espresso | no |
| J. Dinnen | 5 | decaf | yes |
Ячейки с этикетками
Атрибуты axis и exes предоставляют возможность снабжать ячейки таблицы этикетками (labels). Синтезаторы речи могут использовать эти этикетки для идентификации содержимого и положения каждой ячейки. Программное обеспечение может рассматривать эти этикетки как имена полей базы данных при занесении содержимого таблицы в банк данных. Ниже представлен пример таблицы, где значение атрибута axis представляет собой фамилию сенатора.
<table border="border">
<caption>Caps of coffee consumed by each senator</caption>
<tr> <th>Name <th>Cups <th> Type of coffee <th> suger?
<tr> <td axis="sexton" exes="name">T. Sexton <td>10
<td>espresso <td>no
<tr> <td axis="dinnen" exes="name">J. Dinnen <td>5 <td>decaf <td>yes
</table>
14.11. Ячейки, которые занимают несколько рядов или колонок
Ячейки могут охватывать несколько рядов или колонок. Число рядов или колонок в ячейке определяется атрибутами rowspan и colspan для соответственно TH или TD-элементов. В таблице, которая была описана, ячейка в ряду 4 вторая колонка должна занимать три колонки, включая текущий ряд.
<table border="border">
<caption> Caps of coffee consumed by each senator</caption>
<tr> <th>Name <th>Cups <th> Type of coffee <th> suger?
<tr> <td>T. Sexton <td>10 <td>espresso <td>no
<tr> <td>J. dinnen <td>5 <td>decaf <td>yes
<tr> <td>A. Soria <td colspan="3"<em>not available</em>
</table>
Эта таблица будет развернута визуальным агентом пользователя как:
Caps of coffee consumed by each senator
| Name | Cups | Type of coffee | Suger? |
| T. Sexton | 10 | espresso | no |
| J. Dinnen | 5 | decaf | yes |
| A. Soria | not available | ||
Этот пример иллюстрирует как описания ячеек, которые распространяются более чем на один ряд или колонку, влияет на определение последующих ячеек. Рассмотрим следующее описание таблицы.
<table border="border">
<tr> <td>1 <td rowspan="2">2 <td>3
<tr> <td>4 <td>6
<tr> <td>7 <td>8 <td>9
</table>
Таблица может быть представлена в виде:
| 1 | 2 | 3 |
| 4 | 6 | |
| 7 | 8 | 9 |
Версия HTML 4.0 включает в себя механизмы контроля горизонтального и вертикального выравнивания, стилями границ таблицы и полями ячеек.
Язык HTML
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Язык программирования HTML (Hypertext Markup Language) предназначен для создания гипертекстных документов, формат которых не зависит от ЭВМ или используемой ОС. HTML-документы являются SGML-документами (Standard Generalized Markup Language, [ISO 8879]) с семантикой, пригодной для представления информации от широкого круга доменов. Файлы HTML-документов должны иметь расширение .html или .htm. Данный формат пригоден для представления почтовых сообщений, новостей, меню, опций, гипермедийных документов, результатов запросов к базам данных, графических документов и т.д.
HTML используется во всемирной информационной системе World Wide Web (WWW) с 1990 года (разработчик Tim Berners-Lee).
В настоящее время существует также простой диалект языка SGML - XML (Extensible Markup Language). Смотри http://win.www.citycat.ru/doc/html/xml/wd-xml-lang или www.w3.org/put/www/tr (первоисточник). Предполагается, что этот язык совместим с SGML и HTML (последнее справедливо лишь частично).
Любое приложение SGML состоит из нескольких частей:
SGML-декларация определяет, какие символы и разделители могут быть использованы в приложении.
dtd (document type definition) определяет стандарт на типы документов и задает синтаксис базовых конструкций.
Спецификация семантики, которая может также включать определенные ограничения на синтаксис, не включенные в DTD и т.д. …
SGML - это система описания языков разметки (markup). HTML - пример такого языка. Каждый язык разметки, определенный в SGML, называется приложением SGML. HTML 4.0 является приложением SGML, соответствующим международному стандарту international standard ISO 8879:1986 -- Standard Generalized Markup Language SGML (определено в [ISO8879]).
Приложение SGML характеризуется:
Декларацией SGML. SGML-декларация специфицирует, какие символы и разграничители могут использоваться в приложении.
Описанием типа документа DTD (Document Type Definition). DTD определяет синтаксис конструкций разметки.
DTD может включать в себя дополнительные определения, такие как эталонные символьные объекты (entity).
Спецификацией, которая описывает семантику разметки. Эта спецификация также определяет синтаксические ограничения, которые не могут быть выражены в рамках DTD.
Примерами документов, содержащих данные и разметку. Каждый пример содержит ссылку на DTD, которая используется для его интерпретации.
HTML предоставляет разработчику следующие возможности:
Публиковать в реальном масштабе времени документы с заголовками, текстом, таблицами, рисунками, фотографиями и т.д.
Одним нажатием клавиши мышки извлекать документы через гипертекстные связи.
Конструировать формы (бланки) для осуществления удаленных операций, для заказа продуктов, резервирования билетов или поиска информации.
Включать электронные таблицы (напр. Excel), видеоклипы, звуковые клипы и другие приложения непосредственно в документ.
1. Синтаксис HTML
Символьные объекты (entity) представляют собой цифровые или символьные имена символов, которые могут быть включены в документ HTML. Эти объекты нужны в тех случаях, когда прямой их ввод по каким-либо причинам невозможен. Эти объекты начинаются с символа & и завершаются точкой с запятой (;).
Элементы в SGML представляют собой структуры или описывают требуемое поведение. Элементы начинаются со стартовой метки (TAG), за которой следует содержание, и завершаются конечной меткой. Стартовая метка обычно записывается как <имя_элемента>, а конечная метка, как </имя_элемента>. Некоторые элементы могут не иметь содержания или конечной метки. "Пустые" элементы не имеют конечной метки. Имена элементов обычно записываются прописными буквами, но HTML использование прописных или строчных букв в именах элементов не регламентировано.
Атрибуты. Элементы могут иметь определенные свойства, эти свойства характеризуются атрибутами, которым пользователь может присваивать некоторые значения. Пары атрибут/значение должны быть записаны до появления закрывающей угловой скобки (>) стартовой метки.
Если используется несколько атрибутов/значений, они разделяются пробелами. Порядок их записи не играет роли. По умолчанию SGML требует, чтобы значения были помещены в двойные или одинарные кавычки. Для этих же целей могут использоваться символьные объекты " или " для двойной кавычки и ' для одинарной кавычки. Значения могут содержать помимо латинских букв и цифр символы (-) и (.). Имена атрибутов не чувствительны к тому, прописными или строчными буквами они напечатаны (как правило, их имена записываются в HTML строчными буквами).
Агент пользователя HTML - любой прибор, который интерпретирует HTML документы. К агентам пользователей относятся визуальные броузеры (текстовые и графические), не визуальные броузеры (звуковые и Брейля), поисковые роботы и т.д.. Агент пользователя должен игнорировать любые не узнанные атрибуты.
Пользователь - лицо, взаимодействующее с агентом пользователя, для того чтобы тем или иным способом ознакомиться с документом HTML.
URI. Любой ресурс в WWW - HTML документ, изображение, видео-клип, программа и пр. имеют адрес, который может быть представлен в виде универсального идентификатора ресурса (URI).
Комментарии в HTML имеют следующий синтаксис:
<!-- Комментарий -->
<!-- Если комментарий занимает более одной строки,
то он записывается так -->
dtd-комментарии выделяются двумя черточками (--) в начале и в конце текста.
HTML DTD начинается с серии описаний каких-то объектов (entities). Описание объекта представляет собой макрос, который может быть развернут где-либо в DTD(в HTML не применим). Когда макрос вызывается (по имени), он разворачивается в строку.
Описание объекта (entity) начинается с ключевого слова <!entity %, за которым следует имя объекта и помещенная в кавычки строка, которая разворачивается. Описание завершается символом >. Развертываемая строка может содержать другие имена объектов. Конкретные значения объекта начинаются с символа "%" и завершается опционно символом ";".
Эти объекты будут также развернуты (если требуется рекурсивно). Например:
<!entity %fontstyle "tt | i | b | big | small">
<!entity %inline "#pcdata | %fontstyle; | %phrase; | %formctrl;">
Большая часть HTML DTD состоит из описаний элементов и их атрибутов. Ключевое слово <!element> открывает описание элемента, а символ > - завершает. Между ними размещается имя элемента, две черточки после имени указывают на то, что стартовая и конечная метки являются обязательными. Одна черточка после имени элемента и последующая буква О указывают на то, что конечная метка может отсутствовать. Две буквы О означают допустимость отсутствия как стартовой, так и конечной метки. После имени может следовать содержимое элемента, которое называется моделью содержимого. Элементы без содержимого называются пустыми (empty). Пустые элементы описываются ключевым словом "empty". Например, <!element ccc - o empty>. ccc - имя элемента; - О говорит о допустимости отсутствия конечной метки. В сочетании с моделью empty это означает, что конечная метка должна отсутствовать.
Модель содержимого описывает то, что может содержать элемент. Определения содержимого могут включать:
Имена допустимых и запрещенных элементов.
dtd-объекты.
Текст документа, отмеченный SGML-конструкцией "#pcdata". Текст может содержать цифровые и именные символьные объекты.
Модель содержимого имеет следующий синтаксис.
| (…) | специфицирует группу. |
| А|b | Допускается присутствие А и В в любом порядке. |
| А,В | А должно появиться раньше, чем В. |
| a&b | a и b должны появиться только один раз, но в любом порядке. |
| А? | А может появиться не более одного раза. |
| А* | А может появиться любое число раз, включая 0. |
| А+ | А может появиться один или более раз. |
Ниже приведены примеры HTML DTD:
<!element select - - (option+)>
Элемент select должен содержать один или более элементов option.
<!element dl - - (dt|dd)+>
Элемент dl должен содержать один или более dt или dd элементов в любом порядке.
<!element option - o (#pcdata) *>
Элемент option может содержать только текст и символьные объекты.
2. Описания атрибутов
Описание атрибутов начинается с ключевого слова <!attlist>. Описание атрибута включает в себя:
Имя атрибута.
Тип значения атрибута или набор возможных значений.
Значение атрибута может быть определено тремя способами. Когда значение атрибута по умолчанию задано неявно (ключевое слово "#implied"), оно должно быть задано агентом пользователя или наследуется из определения порождающего элемента. Возможны также ключевые слова "#required" (всегда необходимо) и "#fixed" - присвоено фиксированное значение.
Рассмотрим описание элемента map с опционным атрибутом.
<!attlist map name cdata #implied >, здесь тип допустимого значения задан DATA (тип данных SGML). CDATA - представляет собой текст, который может содержать символьный объекты.
Описания атрибутов могут содержать объекты DTD. Например:
| <!attlist link %attrs; | -- id, class, style, lang, dir, title - |
| bref %url @implied | -- url для подключенного ресурса -- > |
Объект %attrs разворачивается в:
| <!attrlist p | id id #implied -- уникальный идентификатор для данного документа -- | ||
| class cdata #implied | -- список значений классов -- | ||
| style cdata #implied | -- информация о стиле -- | ||
| title cdata #implied | -- рекомендуемые заголовки/расширения -- | ||
| lang name #implied | -- [rfc1766] код идентификатор языка -- | ||
| dir (ltr|rtl) #implied | -- direction for weak/neutral text -- | ||
| align (left|center|right|justified) #implied > | |||
Аналогично DTD определяет объект %URL как расширение в строку cdata.
<!entity % URL "CDATA" -- термин URL означает атрибут, значение которого равно универсальному указателю ресурса URL (uniform resource locator), см. RFC-1808 и RFC-1738 -->
2.1. Булевы атрибуты
Некоторые атрибуты выполняют роль булевых переменных. Их появление в стартовой метке элемента предполагает, что значение атрибута равно "true" (истинно). Их отсутствие означает, что их значение равно "false" (ложно).
В HTML допускается сжатая форма записи булевых атрибутов:
<option selected> вместо
<option selected="selected">.
3. HTML и URL
World Wide Web (WWW) представляет собой всемирную сеть информационных ресурсов. WWW базируется на трех механизмах, которые обеспечивают доступ к этим ресурсам:
Однородная схема имен для описания положения ресурсов в сети WWW(например, URI).
Протоколы доступа к именованным ресурсам через WWW-сеть (напр., HTTP).
Гипертекст, который обеспечивает простую технику поиска и перемещения (навигации) в сетях WWW (например, HTML).
Каждый ресурс, доступный в WWW (HTML-документ, видео-клип, программа или статическое изображение) имеет адрес, который кодируется с помощью универсального идентификатора ресурса universal resource identifier, или uri. URI состоит из трех частей:
Схема имен механизмов доступа к ресурсам [см. RFC-2068; далее в тексте данного документа ссылки на публикации и сервера, представленные в конце выделены квадратными скобками [].].
Имя машины, где размещается ресурс.
Имя самого ресурса в виде прохода к нему (path).
Примером URI может служить адрес, где размещено описание языка HTML v4.0:
http://www.w3.org/tr/rec-html4/
Этот URI можно воспринимать следующим образом: имеется документ, доступный через протокол HTTP (см. [RFC-2068]), этот документ находится на ЭВМ www.w3.org, проход к нему имеет вид /tr/rec-html4/.
Замечание. Большинство читателей знакомо с термином URL (Universal Resource Locator; [RFC-1738]) URL представляет собой подмножество более общей системы имен URI.
Следует помнить, что запись URL чувствительна к тому, строчные или прописные буквы используются при его написании (это не относится только к имени ЭВМ).
Спецификация URL определяет положение документа в сети, но не позицию внутри документа. По этой причине введено понятие URL-фрагмента, который может указывать на определенную часть документа. URL-фрагмент завершается символом #, за которым следует идентификатор указателя (anchor).
Примером такого URL-фрагмента может служить http://store.in.ru/semenov/intro.htm#intr_1, где int_1 - имя метки в тексте документа intro.htm.
Для локальной адресации HTML- документов используется относительные URL, которые не имеют секций протокола и ЭВМ. Относительный URL может содержать компоненты относительного прохода к ресурсу (".." означает положение порождающего URL). Документ RFC-1808 определяет алгоритм работы с относительными URL. Относительный URL может быть частью полного URL. Полный URL можно определить следующим образом:
Если базовый URL завершается символом (/), то он получен путем добавления относительного URL. Например, если базовый URL http://nosite.com/dir1/dir2/, а относительный - gee.html, то полный URL будет выглядеть как http://nosite.com/dir1/dir2/gee.html.
Если базовый URL не завершается /, последнюю секцию базового URL следует рассматривать как ресурс.
Для связи через электронную почту иногда используется специальная разновидность URL - mailto, которая имеет формат:
mailto:e-mail_адрес.
В HTML, URI используются для:
Связи с другим документом или ресурсом (см. элементы и ).
Связи с внешним стилевым списком или скриптом (см. элементы link и ).
Включения изображений объектов или аплетов в страницу (см. элементы , , и input).
Создания карты изображения (см. элементы ).
Предоставления форм (см. ).
Создания рамочных документов (см. элементы и ).
Цитирования внешних ссылок (см. элементы , ).
Ссылок на соглашения по метаданным, описывающим документ (см. элемент ).
Поскольку люди на Земле пока используют различные языки, в которых применяются совершенно не схожие наборы символов, необходимо как-то управлять процессом описания набора символов, используемого в данном документе. Для документов HTML используется универсальный набор символов UCS (Universal Character Set) [ISO10646; cм. также RFC-2070]. Этот набор эквивалентен Unicode 2.0 [unicode]. Агент пользователя может получить, послать или воспроизвести документ в любой кодировке.
Это может быть набор ISO-8859-1 ("latin-1"), ISO-8859-5 (кирилица), shift_jis (японская кодировка) и так далее. Пользователь должен позаботиться, чтобы его документ в конечном итоге был приведен в соответствие с Unicode, тогда у него не будет более проблем с национальным шрифтовым набором.
Для того чтобы облегчить представление полученного документа, можно проанализировать первые несколько байт документа и в процессе пересылки соответствующим образом задать параметр charset поля "content-type". Например:
content-type: text/html; charset= euc-jp
В качестве значения параметра charset может быть выбрано стандартное имя из документа [RFC-2045]. Но, к сожалению, отнюдь не все сервера присылают информацию об используемом символьном наборе даже в случае несовпадения с ISO-8859-1. Другим способом решить проблему является включение в заголовок документа соответствующего meta-элемента. Например:
<meta http-equiv="content-type" content="text/html; charset=euc-jp">
Здесь крайне важно, чтобы агент пользователя был способен правильно интерпретировать элемент meta-декларации. Если других указаний не распознано, считается, что использован набор ISO-8859-1.
Значение типа атрибута "color" служит для описания цвета. Значение этого атрибута может быть шестнадцатеричным числом, перед которым записывается символ #, или одним из 16 имен цветов:
| black="#000000" | white="#ffffff" |
| silver="#c0c0c0 | gray="#808080" |
| green="#008000" | lime="#00ff00" |
| olive="#808000" | maroon="#800000" |
| yellow="#ffff00" | aqua="#00ffff" |
| red="#ff0000" | blue="#0000ff" |
| purple="#800080" | teal="#008080" |
| fuchsia="#ff00ff" | navy="#000080" |
Цвета могут заметно улучшить выразительность и читаемость документов, но следует иметь в виду, что использование стилевых листов более эффективно. Нужно также учитывать, что цвета отображаются на разных рабочих станциях по-разному.
HTML- документ состоит из трех частей, строки с информацией о версии, секции заголовка и собственно содержания документа. В первой строке документа должна быть внесена конструкция doctype, описывающая использованную версию HTML. Например:
<!doctype html public "-//w3c//dtd html 4.0 draft//en">
Последние две буквы этой декларации характеризуют язык HTML dtd, в данном случае английский ("en"). Агент пользователя может игнорировать эту информацию. Слово draft говорит о том, что использована предварительная версия HTML 4.0. В случае работы с окончательной версией html 4.0 это слово должно быть заменено на strict. Часть документа, следующая после описания версии, должна быть оформлена в виде HTML-элемента. Таким образом, HTML-документ имеет следующую структуру:
<!doctype html public -//w3c//dtd html 4.0 draft//en>
<html>
Заголовок, текст документа …
</html>
Рассмотрим возможные варианты HTML-элементов.
<!entity % version "version cdata #fixed '%html.version;'">
<!entity % html.content "head, (fragment|body) ">
<!entity html o o (%html.content)>
<!attlist html %version; %i18n; >
Стартовая и конечная метки являются опционными.
Ниже приведены примеры элементов-заголовков.
<!entity % head.content "title & isindex? & base?">
<!element head o o (%head.content) +(%head.misc)>
<!attlist head %i18n; profile %url #implied - named directory of meta info -- >
Для элемента title стартовая и конечная метки являются обязательными. Элемент head содержит информацию о документе, он не является частью текста и служит в качестве источника ключевых слов для поисковых систем. HTML-документ должен иметь только один элемент title в секции head.
Не следует путать элемент title с атрибутом title, который предоставляет справочную информацию об элементе, для которого установлен. Атрибут title имеет формат: title=cdata. В отличие от элемента title, который характеризует весь документ в целом и может появиться в пределах документа только раз, атрибуту title позволено аннотировать любое число элементов.
Агент пользователя может интерпретировать этот атрибут самым различным способом. Визуальные броузеры могут отобразить его текст в качестве совета, аудио агент может воспроизвести текст, говорящий о ресурсах подключенного сервера. Специфическую роль играет атрибут title при использовании для элемента link.
В HTML 4.0 программист может использовать метаданные в своем документе следующим способом:
Можно описать свойства метаданных во внешнем профайле. Профайл может определить свойства вспомогательной системы поиска (help), такой как "автор", "ключевые слова" и т.д..
Программист может установить значения определенных параметров. Это можно сделать внутри документа с помощью meta-элемента. В этом случае профайл определяет имена свойств, которые могут быть заданы с помощью META-элемента. Установить конкретные значения можно и извне, связав метаданные с элементом link. В этом варианте профайл определяет имена соотношений типов, которые может использовать элемент LINK.
Если профайл определен для элемента Head, тот же профайл будет присутствовать во всех элементах META и LINK в заголовке документа. Ниже приведены примеры записи элементов meta.
| <!element meta - o empty | -- Базовая метаинформация --> |
| <!attlist meta %i18n; | -- lang, dir, для использования со строкой содержимого -- |
| http-equiv name #implied | -- имя заголовка http-отклика -- |
| name name #implied | -- Имя метаинформации -- |
| content cdata #required | -- соответствующая информация -- |
| scheme sdata #implied | -- select form of content --> |
Для META-элемента стартовая метка необходима, а конечная не нужна. Атрибуты, их значения и интерпретация зависят от профайла.
| name=Cdata | Этот атрибут определяет имя свойства. |
| content=Cdata | определяет значение свойства. |
| scheme=Cdata | определяет схему интерпретации значения свойства. |
| HTTP-equiv=cdata | может использоваться вместо атрибута name. http-серверы используют этот атрибут при сборе информации для заголовков откликов. |
Например, <meta name="interpreter" content="yuri semenov">.
Атрибут lang может использоваться с элементом meta для определения языка для значения атрибута content. Этот атрибут позволяет синтезаторам речи корректно выбрать правила произношения. Например:
<meta name="interpreter" lang="ru" content="semenov">.
Некоторые агенты пользователья используют meta для обновления текущей страницы каждые несколько секунд. При этом страница может обновляться полностью. Например:
<meta name="refresh" content="3,http://www.acme.com/intro.html">
Слово content определяет задержку в секундах, за этим числом следует URL, который должен быть загружен по истечении указанного времени. К сожалению не все агенты пользователя поддерживают такую возможность.
Атрибут HTTP-equiv может использоваться вместо атрибута name. HTTP-серверы могут работать с именами свойств, заданными атрибутом HTTP-equiv, что позволяет им формировать заголовок HTTP-отклика согласно требованиям RFC-822. Декларация <meta http-equiv="expires" content="Mon, 17 Aug 1998 16:35:08 GMT"> приведет к формированию следующей строки в HTTP-заголовке: expires: Mon, 17 Aug 1998 16:35:08 GMT. Это позволяет определить время доступности свежей копии документа.
Одним из важных функция элемента meta является описание ключевых слов для поисковых систем. Например:
<meta name="keywords" content="information, retrieval, indexing">
4. Элементы, используемые в тексте документа
<!entity % block "(%blocklevel | %inline)*">
<!entity % color "cdata" - a color using srgb: #rrggbb as hex values -->
| <!entity % bodycolors "bgcolor | %color #implied | |
| text | %color #implied | |
| link | %color #implied | |
| vlink | %color #implied | |
| alink | %color #implied"> |
<!element body o o (%block) -(body) +(ins|del)>
<!attlist body
| %attrs; | -- %coreattrs, %i18n, %events - | |
| background %url #implied | -- раскладка текстуры для фона документа -- | |
| %bodycolors; | -- bgcolor, text, link, vlink, alink - | |
| onload %script #implied | -- документ загружен -- | |
| onunload $script #implied | -- документ удален --> |
Для этого элемента стартовая и конечная метки являются опционными. Здесь применимы следующие атрибуты.
| Background=URL | указывает на место, где лежит изображение мозаичного образа для фона документа. |
| text=color | устанавливает фоновый цвет для текста. |
| Link=color | определяет цвет не посещенных гипертекстных объектов. |
| vlink=color | определяет цвет посещенных гипертекстных объектов. |
| alink=color | определяет цвет выбранного пользователем объекта. |
Помимо перечисленных ряд атрибутов могут задаваться извне:
id, class, (идентификаторы действуют для всего документа) lang (языковая информация), dir (направление текста/отступ), title, style (текущая стилевая информация), bgcolor (цвет фона), onload, onunload, onclick, ondblclick, onmousedown, onmouseup, onmouseover, onmousemove, onmouseout, onkeypress, onkeydown, onkeyup (действительные события).
Презентация документа определяется стилем (использование атрибутов презентации не желательно). Атрибуты презентации могут применяться только для агентов пользователя, не поддерживающих стили. Ниже представлена иллюстрация представления документа, где фон имеет белый цвет, текст черный, гиперсвязи в исходный момент красные, темные при активации и темно бордовые после первого визита.
<html>
<head>
| <title> a study of population dynamics </title> |
</head>
<body bgcolor="white" text="black" link="red" alink="fuschia" vlink="maroon">
… текст документа …
</body>
</html>
То же самое с использованием стилевого листа.
<html>
<head>
| <title> a study of population dynamics </title> |
<style type="text/css">
| body { background: white color: black} | |
| a:link { color: red } | |
| a:visited { color: fuschia } |
</style>
</head>
<body>
| …текст документа … |
</body>
</html>
Использование связанного стилевого листа добавляет гибкости при реализации презентации.
<html>
<head>
| <title> a study of population dynamics </title> |
<link rel="stylesheet" type="text/css" href="smartstyle.css">
</head>
<body>
| …текст документа… |
</body>
</html>
5. Идентификаторы элементов. ID и атрибуты классов.
Определения атрибутов
ID = name
Этот атрибут присваивает имя элементу, которое действительно в пределах данного документа. Значение ID должно быть уникальным для данного документа.
class = cdata-list
Этот атрибут присваивает некоторому элементу значение класса или набора классов. Одно и тоже имя класса может быть присвоено любому числу элементов. Значение класса позволяет определить или уточнить функцию данного элемента или группы элементов.
Эти атрибуты могут использоваться в следующих случаях:
Атрибут id может использоваться в качестве адреса места назначения гипертекстной связи.
Атрибут id может использоваться скриптами для ссылки на какой-то конкретный элемент.
Стилевые листы могут использовать атрибут ID для того, чтобы определить элемент, на который распространяется действие данного стиля.
Атрибут ID может использоваться для идентификации деклараций object.
Стилевые листы могут использовать атрибут class для идентификации списка элементов, на которые распространяется действие данного стиля.
Атрибуты id и class могут использоваться для целей обработки, например, для идентификации полей при извлечении информации с HTML-страниц в базу данных, при трансляции HTML-документов в другие форматы.
Предположим, что пишется документ о языке программирования. Документ включает в себя некоторое число отформатированных примеров. В этом случае для форматирования используется элемент pre. Пусть также задан цвет фона = green для всех случаев, когда элемент pre принадлежит классу "example".
<head>
<style pre.example { background : green } </style>
</head>
<body>
<pre class = "example" id = "example-1">
… текст программы примера …
</pre>
</body>
5.1 Элемент html
<!entity % html.content "head, body">
| <!element html o o (%html.content;) | -- корневой элемент документа --> |
| <!attlist html %i18n; | -- lang, dir -- > |
Определение атрибута
version = cdata [cn]
Применять не рекомендуется. Значение атрибута специфицирует то, какая версия HTML DTD используется в данном документе. Этот атрибут не рекомендован из-за того, что в качестве стандарта принято определение версии в декларации типа документа.
После декларации типа документа оставшаяся часть документа содержит элемент HTML. Таким образом, HTML-документ имеет структуру:
<!doctype html public "-//w3c//dtd html 4.0//en"
"http://www.w3.org/tr/rec-html40/strict.dtd">
<html>
...Заголовок, тело, и т.д. следует здесь...
</html>
Эффективные алгоритмы для ограниченных классов
Нашей первой и наиболее важной целью является получение алгоритмов с полиномиальным временем для вычисления мер надежности, когда это возможно. В виду получаемой сложности мы не можем надеяться в настоящее время получить эффективные методы для сети вообще. Однако мы можем эффективно анализировать ограниченные классы сетей.
В параграфе 3.1 мы получили большую коллекцию редукций, сохраняющих значение надежности, которые, по крайней мере, в своей простейшей форме могут обеспечить полиномиальное время расчета. Например, отбрасывание нерелевантных ребер и стягивание необходимых ребер вмести дает алгоритм для надежности k-терминальных деревьев. Еще лучше результат может быть получен при использовании последовательных и параллельных редукций. Далее может быть вычислена двухтерминальная надежность параллельно последовательных сетей. Когда вместо этого добавляются двухступенчатая и параллельное редукции, в алгоритме все-терминальной надежности для параллельно-последовательных графов непосредственно используются теоремы характеристик параллельно-последовательных графов.
Для k-терминальной надежности параллельно-последовательных графов существует два алгоритма с линейным временем работы. Сатайанарайана и Вуд [A.Satyanarayana and R.K.Wood “A linear time algorithm for computing k-terminal reliability in serial-parallel networks”, SIAM, J. Computing 14 (1985), 818-832] использовали последовательную, параллельную и двухступенчатую редукцию совместно с редукциями двухсвязных сетей, называемых также преобразованиями многогранник-цепочка, чтобы свести последовательно-параллельную терминальную сеть к одновершинному графу.
Когда две субсети сопряжены с s узлами, надежность их объединения может быть полностью определена из значений для каждой субсети. Это может быть фактически выполнено посредством алгоритма динамического программирования, чье время работы линейно по отношению к числу вершин, но экспоненциально относительно числа точек соединения. Метод Уолда и Кольбурна использует тот факт, что последовательно-параллельные графы могут быть рекурсивно разъединены с помощью парных разрезов в вершинах - то есть, последовательно параллельные графы имеют ширину дерева равную двум.
Вычисление Ф для последовательно-параллельных графов может быть выполнено тем же способом, каким это делается для задачи (s,t)-связности с последовательным и параллельным сокращениями, выполненными как это описано выше. Сложность равна O(Rn), где R является сложностью наихудшего варианта выполнения операции свертки или определения min/max в любой момент реализации алгоритма. Таким образом, сложность этих алгоритмов критически зависит от времени выполнения последовательных и параллельных операций. Для трех типов распределений, представленных в начале данного раздела, R является линейным в nq (в конечном случае) или nqr (в двух бесконечных случаях). Обычно считается, что существуют полиномиальные алгоритмы и для графов с ограниченной шириной дерева (смотри раздел 3.2) хотя это специально и не рассматривалось.
6.5. Методы, базирующиеся на состояниях
Нумерационные методы для вычисления надежности систем с большим числом состояний обязательно ограничены кругом проблем с конечным числом состояний для каждой из связей. В частности, пусть каждое ребро ej имеет ассоциированный параметр Xj из ряда значений 1, 2,…,q, с вероятностями pij=Pr[Xj = xj], xj =1,…,q, и пусть функция оценки системы Ф принимает значения из ряда 1,…,К. Тогда две классические, стохастические величины, а именно, cdf для Ф, вычисленная при заданном уровне a О{1,…,К} и среднее значение Ф могут быть записаны как

Ф(x1,…,xn) Ј?

число членов в приведенных двух выражениях может иметь порядок q|E|, и, следовательно, эти проблемы становятся трудноразрешимыми в существенно меньшем масштабе, чем даже в случае расчета надежности для систем с двумя состояниями.
Метод факторизации, предложенный в разделе 3.3, имеет здесь аналогичную (если не более громоздкую) форму. А именно, если для “осевого ребра” e и параметра ребра х определить сеть Ge,x, имеющая дугу е с фиксированным значением х. Тогда теорема факторизации для двух указанных метрик приобретает вид

Методика базируется на простом наблюдении, что в любом нециклическом графе без параллельных ребер всегда может быть осуществлена редукция, по крайней мере, одного узла, скажем путем подключения ребра е, один из концов которого v имеет только е в качестве входного (выходного) ребра.
Расширение алгоритма с линейным временем на деревья любой ширины является непосредственным, за исключением трудности распознавания сетей с заданной шириной дерева.
Получение эффективных алгоритмов путем ограничения ширины дерева рассматривается в литературе для большинства эффективных алгоритмов. Важно заметить, что у планарных графов ширина дерева зависит от числа вершин, несмотря на то, что ширина дерева ограничена O (

Помимо графов с фиксированной шириной, мало что известно по поводу мер надежности неориентированных графов. Гильберт разработал элегантный рекурсивный метод вычисления всетерминальной надежности полных сетей, когда все ребра работоспособны с равной вероятностью. Метод требует линейного времени. Он обобщается естественным образом для k-терминальной надежности, и для полных двучастных систем, а также связанных сетей. Метод существенно зависит от соблюдения условия, что несколько неизоморфных субграфов связаны множественно с некоторым числом вершин. Методу динамического программирования нужно тогда только определить полиномиальное число субсетей.
При обращении к мерам надежности ориентированных графов выделяется один важный алгоритм. Болл и Прован разработали алгоритм с линейным временем для вычисления достижимости в ориентированных нециклических сетях. Алгоритм базируется на соблюдении условия, что такая сеть функционирует (с точки зрения достижимости) тогда и только тогда, когда каждый некорневой узел имеет, по крайней мере, одну из входных дуг в рабочем состоянии.
В последнее время проводятся интенсивные исследования эффективно решаемых классов проблем узловой надежности. Узловая двухтерминальная надежность (без отказов ребер) допускает эффективные алгоритмы для графов перестановок и графов интервалов. Из этого можно получить эффективные алгоритмы для двухтерминальной надежности при отказе ребра, когда сеть имеет линейный граф, который является графом интервалов или перестановок, используя переход от проблем отказов ребер, к проблемам отказов узлов.
Классы, для которых известны точные эффективные алгоритмы, достаточно редки и не относятся к числу наиболее практичных. Несмотря на это, присутствие точных алгоритмов даже для редких классов может использоваться для ускорения точных алгоритмов для более широких классов, которые упрощают сеть некоторым образом; они имеют также использование для вычисления ограничений надежности.
Пусть е1,…, еk являются другими концами по отношению к вершине v. Тогда система Ge,x, заданная выше, является просто GЧe с переменными, ассоциированными с е1,…, еk, модифицированными следующим образом
Кратчайший путь: Lei является смещенным на х, т.е.

Максимальный поток: Сei ограничивается сверху величиной х, т.е.

Работоспособность сети PERT: Tei также смещается на величину х, i=1,…,k.
Распределения этих модифицированных случайных переменных легко вычисляются для распределений конечных состояний, например, путем обработки их как сверток или максимумов, имеющих одну случайную переменную с одним значением. Таким образом, уравнение (2) сводит конкретную проблему сети G к k субпроблем, где k равно числу значений, характеризующих дугу е, для одной и той же сети GЧe, но с разными распределениями для ребер е1,…, еk. Сложность вычисления значения или среднего cdf в этом случае критически зависит от числа таких редукций узлов, которые должны быть произведены, в комбинации с выполнением возможных последовательных и параллельных сокращений, для того чтобы уменьшить сеть до одного ребра. Бейн и др. выдали алгоритм О(n3) для определения минимального числа редукций узлов, которые должны быть выполнены, для того чтобы сократить граф выше описанным образом. Это число, следовательно, в некотором смысле также представляет “сложность” сети с точки зрения проблем пути и потока.
Методики нумерации, предложенные выше, мало используются в решении проблем, сопряженных с бесконечным числом или непрерывным рядом случайных переменных ребер. Когда случайные переменные ребер имеют экспоненциальное распределение, Кулькарни и др. предложили интересные процедуры для решения проблем наикратчайшего пути, максимального потока для плоских сетей и проблем PERT. Мы показываем, что для проблем наикратчайшего пути, максимального потока и PERT имеются аналогичные, хотя более сложные методики решения. Мы рассматриваем команду “бегунов”, которые стартуют в узле отправления s и далее двигаются по ребрам, исходящим из s.
Спустя некоторое время при известном (гамма) распределении, один из бегунов достигает конца своего ребра. В этой точке бегун останавливается, и новые бегуны устремляются вдоль ребер, исходящих из данной вершины. (Бегуны не посылаются бежать по ребрам, откуда прибыл бегун предыдущего этапа). Благодаря экспоненциальному распределению (отсутствие памяти) для времен пробега, следует, что в точке, откуда стартуют бегуны, они начинают новый этап одновременно. Короче говоря, процесс путешествия бегунов по сети является цепью Маркова с непрерывным временем. Состояние этой цепи Маркова соответствует возможному набору вершин, которые бегуны посетили и набору ребер, по которым они движутся в данный момент, а состояния поглощения соответствуют тем, что помечены t в качестве вершины адресата. Среднее время для вероятности поглощения этой цепи Маркова в точности равно длине наикратчайшего пути. Вероятность состояния поглощения может быть вычислена легко путем соответствующего упорядочения состояний цепи Маркова. Хотя время вычисления является линейным по отношению к числу состояний цепи Маркова, это число растет экспоненциально с ростом размера сети. Для сетей порядка 15-20 дуг, этот метод вполне эффективен при нахождении соответствующих решений.
Электронная почта
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Электронная почта - наиболее популярный и быстро развивающийся вид общения. Широко используются протоколы электронной почты UUCP (unix-to-unix copy protocol, RFC-976) и SMTP (simple mail transfer protocol; RFC-821, -822, -1351, -1352). Один из протоколов (RFC-822) определяет формат почтовых сообщений, второй (RFC-821) управляет их пересылкой. Имея механизмы промежуточного хранения почты (spooling) и механизмы повышения надежности доставки, протокол smtp базируется на TCP-протоколе в качестве транспортного и допускает использование различных транспортных сред. Он может доставлять сообщения даже в сети, не поддерживающие протоколы TCP/IP. Протокол SMTP обеспечивает как транспортировку сообщений одному получателю, так и размножение нескольких копий сообщения для передачи по разным адресам. Обычно в любом узле Интернет имеется почтовый сервер (MX), который принимает все сообщения и устанавливает их в очередь. Далее производится раскладка сообщений по почтовым ящикам ЭВМ пользователей. Если какая-то ЭВМ не включена, сервер попытается доставить почту позднее (например, через 30 мин). После заданного числа неудачных попыток или по истечении определенного времени (> 4-5 дней) сообщение может быть утрачено. При этом отправитель должен получить уведомление об этом. Над SMTP располагается почтовая служба конкретных вычислительных систем (например, POP3(RFC-1460), IMAP (RFC-2060), sendmail (UNIX), pine, elm (надстройка над sendmail), mush, mh и т.д.). Схема пересылки электронных почтовых сообщений (RFC-821) показана на рис. 4.5.10.1.
Существует множество реализаций электронной почты. Имеются версии практически для всех ЭВМ, операционных систем и сред.
Адреса электронной почты уникальны и однозначно определяют адресата, обладая иногда даже некоторой избыточностью. Символьные адреса электронной почты вполне соответствуют IP-нотации. Электронный почтовый адрес содержит две части, местную и доменную, например, vanja.ivanov@itep.ru (vanya.ivanov - местная).
Доменная часть обычно совпадает с символьным IP-именем домена.
Если между отправителем и приемником имеется непосредственная связь, адрес имеет вид имя_пользователя@имя_ЭВМ. Когда приемник находится на ЭВМ, которая не поддерживает SMTP и передача происходит через промежуточный почтовый сервер, то адрес может иметь вид, например, ivanov%имя_удаленной_ЭВМ@имя_сервера (благодаря быстрому развитию Интернет в мире и даже в России такая схема используется сейчас крайне редко). Местная часть адреса определяется пользователем и часто совпадет с его именем или фамилией. Электронный адрес несравненно компактнее традиционных почтовых адресов, которые мы пишем на конвертах. Да и сами возможности электронной почты несравненно богаче почты традиционной. По этой причине можно утверждать, что традиционная почта постепенно будет в ближайшем будущем вытеснена ее электронным аналогом. Схема взаимодействия различных объектов электронной почты показана на рис. 4.5.10.1
Рис. 4.5.10.1. Схема пересылки электронных почтовых сообщений
Со временем можно ожидать, что электронные адреса станут универсальными, но это произойдет не скоро. Для этого нужно чтобы транспорт и другие службы научились работать с такими адресами. Электронные (IP) адреса удобнее для ЭВМ, чем традиционные, а принимая во внимание, что применение вычислительной техники повсеместно, вывод напрашивается сам собой. То что удобно для ЭВМ, удобно в конечном итоге для всех.
Любое почтовое сообщение можно разделить на три части: "конверт" (RFC-821), заголовки (RFC-822) и собственно текст. Конверт используется почтовым сервером и содержит две команды (тексты после двоеточия приведены в качестве примера):
MAIL From: <semenov@cl.itep.ru>
RCPT To: <king_penguin@antarctic.edu>
Существует девять полей заголовка, используемые почтовой программой пользователя: Received, From, To, Date, Subject, Message-Id, X-Phone, X-Mailer, Reply-To. Каждое из этих полей содержит имя, за которым после двоеточия следует его значение.
Документ RFC-822 определяет формат и интерпретацию полей заголовка. Заголовки, начинающиеся с X- являются полями, определяемые пользователем.
При вызове почты (командой mail или mailx) на экране будет распечатан служебный текст, который зависит от конкретной реализации mail, но практически непременным атрибутом любой версии будет являться полное число полученных вами почтовых сообщений (если таковые были). Это могут быть и сообщения, оставленные вами там после предшествующего чтения почты. Непрочитанные вами сообщения так или иначе помечаются (например, символом U на левом поле строки-описания сообщения или N для новых). Далее следует аннотация сообщения, по одной строке на сообщение. Аннотация обычно содержит номер сообщения (нумерация всегда начинается с 1), имя и адрес отправителя, дата и время отправки. После этого следуют (в некоторых реализациях) два числа, разделенных косой чертой ("/"). Они характеризуют размер сообщения в строках и полное число символов. В заключение следует, если еще есть место, предмет сообщения (Subject:). Ниже приведен пример текста такого аннотационного сообщения (SUN):
Mail version SMI 4.1-OWV3 Mon Sep 23 07:17:24 PDT 1991 Type ? for help.
"/usr/spool/mail/semenov": 4 messages 4 new
>N 1 mw@isds.Duke.EDU Wed Aug 23 14:15 92/4350
N 2 hochreit@informatik.tu-muenchen.de Wed Aug 23 23:54 71/2767 TR announcement: Long Sho
N 3 Voz@dice.ucl.ac.be Thu Aug 24 07:08 501/21416 ELENA Classification data
N 4 S.Renals@dcs.shef.ac.uk Thu Aug 24 07:08 58/2837 AbbotDemo: Continuous Spe
&
Не ленитесь заполнять поле Subject, иначе при большой почте ваш адресат может пропустить ваше сообщение. Среди наиболее значимых для пользователя полей заголовка можно выделить: адрес и имя отправителя (From:), дата отправки (Date:), адрес получателя (To:), адреса и время прохождения промежуточных узлов, списки лиц (Cc:), кому кроме вас послано это сообщение, предмет сообщения (Subject:), некоторая служебная информация и т.д. Число строк заголовка зависит от программы, реализующей функцию почты и от параметров, определенных пользователем, например, путем задания значений системных переменных.
Практически все пакеты электронной почты имеют возможность переадресовать сообщение другому адресату (Forward); отправить ответ (Replay) пославшему вам сообщение человеку (в этом случае в заголовке появится поле Replay-To); стереть сообщение не читая; в случае смены места работы или длительной командировки установить постоянную переадресацию (на ЭВМ SUN для этого нужно указать адрес нового почтового ящика в файле .forward); записать сообщение в файл (Save имя_файла) или отпечатать его на принтере.
Команда обращение к почтовому серверу обычно имеет вид:
mail местный_адрес@имя_домена, (все что записано после команды mail, является электронным адресом адресата). Например, если вы посылаете сообщение автору, то команда приобретает вид: mail semenov@itep.ru.
Использование промежуточного почтового сервера (mail gateway) несколько усложнит запись электронного адреса (это бывает нужно, например, когда кто-то вне Internet хочет послать сообщение клиенту Internet):
semenov%cl.itep.ru@имя_промежуточного_почтового_сервера
При этом предполагается, что промежуточный почтовый сервер возьмет местную часть адреса, заменит символ "%" на традиционный "@" и перешлет полученное сообщение по данному адресу. Встречаются нотации (хотя сегодня их уже смело можно назвать устаревшими), когда адрес имеет вид:
идентификатор_пользователя%имя_домена
или
идентификатор_пользователя:имя_домена.
При возникновении проблем рекомендуется обращаться к администратору вашей локальной сети.
Если вы любопытны и хотите посмотреть, какие служебные команды выдаются при отправке электронного сообщения, воспользуйтесь командой (в качестве адресата (xxxxxxxx) выберите своего друга, коллегу или знакомого, которому вам нужно что-то сообщить):
mail -v xxxxxxxx@cernvm.cern.ch (обращение к почтовой программе пользователя)
| Subject: Test it. | (пользовательская программа предлагает ввести тему почтового сообщения) |
| Privet... | (текст почтового сообщения) |
| . | (команда отправки сообщения) |
xxxxxxxx@cernvm.cern.ch...
Connecting to dxmint.cern.ch (TCP)...
220 dxmint.cern. ch Sendmail ready at Thu, 6 Jul 1995 07:43:27 +200
>>> HELO itep.ru
250 dxmint.cern.ch Hello itep.ru, pleased to meet you
>>> MAIL From:<xxxxxxx@itep.ru>
250 <xxxxxxx@itep.ru>... Sender ok
>>> RCPT To:<xxxxxxxx@crnvma.cern.ch>
250 <xxxxxxxx@crnvma.cern.ch>... Recipient ok
>>> DATA
354 Enter mail, end with "." on line by itself
>>> . (команда завершения сообщения и его отправки адресату)
250 Ok
>>> QUIT
221 dxmint.cern.ch closing connection
xxxxxxxx@crnvma.cern.ch... Sent (сессия завершена)
Именно модификация команды mail -v обеспечивает вывод сообщений, отпечатанных ниже строки "Privet...". Для посылки почтового сообщения используется только пять команд: HELO, MAIL, RCPT, DATA и QUIT. Строчки, начинающиеся с >>>, являются командами, которые посланы SMTP-клиентом (xxxxxxx@ns.itep.ru). Строки же, которые начинаются с трехзначной цифры, представляют собой коды-отклики SMTP-сервера (в данном случае он имеет имя dxmint.cern.ch), тексты же, следующие после кода-отклика необязательны и могут отсутствовать. Процедура отправки сообщения начинается с того, что клиент выполняет операцию active open для TCP-порта 25. Далее клиент идентифицирует себя командой HELO, выдавая в качестве параметра адрес своего домена. Команда MAIL идентифицирует отправителя, команда RCPT - получателя. Число команд RCPT всегда равно числу получателей. Команда DATA служит для передачи сообщения, а QUIT - для завершения этой процедуры и ликвидации TCP-канала. Посмотрим как выглядит посланное выше сообщение после того, как я его переадресовал себе по адресу semenov@itep.ru:
From xxxxxxxx@crnvma.cern.ch Sat Jul 29 12:15:13 1995
Received: from cearn.cern.ch by ns.itep.ru with SMTP id AA25862
(5.67a8/IDA-1.5 for <SEMENOV@NS.ITEP.RU>); Sat, 29 Jul 1995 12:15:08 +0300
Received: from CERNVM.CERN.CH by CEARN.cern.ch (IBM VM SMTP V2R2)
with BSMTP id 3114; Sat, 29 Jul 95 10:07:15 SET
Received: from CERNVM.cern.ch (NJE origin@CERNVM) by CERNVM.CERN.CH (LMail
1.2a/1.8a) with BSMTP id 4132; Sat, 29 Jul 1995 10:11:12 +0200
Resent-Date: Sat, 29 Jul 95 10:10:30 SET
Resent-From: xxxxxxxx@crnvma.cern.ch
Resent-To: SEMENOV@NS.ITEP.RU
Received: from CERNVM (NJE origin SMTPIBM@CERNVM) by CERNVM.CERN.CH
Lmail V1.2a/1.8a) with BSMTP id 4125; Sat, 29 Jul 1995 10:08:44 +0200
Received: from dxmint.cern.ch by CERNVM.CERN.CH (IBM VM SMTP V2R2) with TCP;
Sat, 29 Jul 95 10:08:43 SET
Received: by ns.itep.ru id AA25665
(5.67a8/IDA-1.5 for xxxxxxxx@cernvm.cern.ch); Sat, 29 Jul 1995 12:12:26 +0300
Date: Sat, 29 Jul 1995 12:12:26 +0300
From: Yuri Semenov <semenov>
Message-Id: <199507290912.AA25665@ns.itep.ru>
To: xxxxxxxx@crnvma.cern.ch
Subject: Test it.
Status: R
--------------------------Original message---------------
Privet...
Текст, выделенный курсивом, представляет собой то, что пришло в CERN. "Накладные расходы" даже здесь значительны, ведь собственно текст состоит из одного слова, следующего после надписи "Original message". Переадресация же увеличивает издержки еще больше.
При описании DNS говорилось о существовании MX-записей, которые являются одной из разновидностей ресурсных рекордов. MX-записи могут использоваться для доставки почтовых сообщений адресатам, не имеющим прямого доступа к Интернет (RFC-974). Еще одним применением MX-записей является предоставление альтернативного получателя почтовых сообщений в случае, когда ЭВМ-получатель вышла из строя. Для выяснение конкретной конфигурации почтовых серверов можно воспользоваться командой host:
host -a -v -t mx cernvm.cern.ch (команда выданная с терминала, ниже следует отклик на эту команду)
Trying domain "itep.ru"
rcode = 3 (Non-existent domain), ancount=0
Trying null domain
rcode = 0 (Success), ancount=3
The following answer is not authoritative:
| cernvm.cern.ch | 30450 | IN | CNAME | crnvma.cern.ch |
| crnvma.cern.ch | 86042 | IN | MX | 20 dxmint.cern.ch |
| crnvma.cern.ch | 86042 | IN | MX | 40 relay.EU.net |
For authoritative answers, see:
| cern.ch | 198821 | IN | NS | dxmon.cern.ch |
| cern.ch | 198821 | IN | NS | ns.eu.net |
| cern.ch | 198821 | IN | NS | sunic.sunet.se |
| cern.ch | 198821 | IN | NS | scsnms.switch.ch |
Additional information:
| dxmint.cern.ch | 31455 | IN | A | 128.141.1.113 |
| relay.EU.net | 8411 | IN | A | 192.16.202.2 |
| dxmon.cern.ch | 371619 | IN | A | 192.65.185.10 |
| ns.eu.net | 38326 | IN | A | 192.16.202.11 |
| sunic.sunet.se | 331044 | IN | A | 192.36.148.18 |
| sunic.sunet.se | 331044 | IN | A | 192.36.125.2 |
| scsnms.switch.ch | 28536 | IN | A | 130.59.10.30 |
| scsnms.switch.ch | 28536 | IN | A | 130.59.1.30 |
..................................
MX-записи с наименьшим предпочтением ( код предпочтения следует сразу за MX) указывают, что сначала следует попытаться переслать сообщение ЭВМ dxmint.cern.ch.
Следующий уровень предпочтения соответствует адресу relay.EU.net. Здесь же вы найдете CNAME-запись (канонические имена DNS). Кроме списка альтернативных почтовых серверов эта команда выдает информацию о списке серверов имен (DNS-серверов). В приведенном примере их четыре, они помечены символами NS и обслуживают домен cern.ch (см. первую колонку). В нижней части полученной таблицы вы можете найти IP-адреса приведенных MX- и NS-серверов (помечены символом A). Пояснения расшифровки содержимого других колонок можно найти выше, в описании DNS-системы (раздел 1.13 ).
При подготовке текста сообщения вы можете сначала воспользоваться традиционным редактором. Текст будет тогда размещен в файле и при отправке вы можете использовать, например, команду send имя_файла (в системе VMS) или командой GET ввести содержимое файла в текст сообщения (с помощью команды ~r имя_файла в UNIX). Чаще текст сообщения печатается в реальном масштабе времени, непосредственно перед отправкой. В этом случае сигналом конца ввода будет Ctrl-D или символ "." (точка) в начале очередной строки (или Ctrl-Z в VAX/VMS). Если по какой-либо причине вы передумали и не хотите отправлять уже набранное сообщение, процедуру можно прервать, нажав Ctrl-C.
При необходимости посылки одного и того же текста нескольким пользователям можно воспользоваться командой:
mail (или mailx) адрес_1 адрес_2 и т.д.
В этом случае сообщение будет послано по всем перечисленным адресам. Формат этой операции заметно варьируется для разных ЭВМ и программных пакетов. Вместо адресов могут использоваться псевдонимы, что несколько облегчает задачу. Для хранения псевдонимов (alias) служит специальный служебный файл. За описанием работы с псевдонимами вынужден отослать вас к описанию почтового пакета, с которым вы работаете.
На последней строке будет напечатан символ &, который указывает, что система ждет ввода команды (просмотр почты). Уход из mail производится по команде q (quit). В ответ на & вы можете ввести следующие команды (набор команд и их синтаксис может варьироваться от ЭВМ к ЭВМ и от реализации к реализации, см. табл. 4.5.10.1).
При работе в Unix в процессе печатания текста сообщения вы можете выдать почтовой программе определенные команды. Такие команды начинаются с символа "~" (тильда). Ниже приведен список таких команд, текст набранный курсивом, означает, что вместо него должны быть впечатаны имена, адреса и т.д. Многоточие показывает, что может быть введено более одного имени, адреса и пр.
Таблица 4.5.10.1. Внутренние команды почтовой программы UNIX
| Субкоманда MAIL | Описание |
| ~? | Отображает весь набор описаний ~-команд |
| ~b адрес... | Добавляет адрес в строку "Blind copy" (слепая копия "Bcc:"). |
| ~c адрес... | Добавляет адрес(а) в строку "Copy" или "Cc:". |
| ~d | Читает содержимое файла dead.letter |
| ~e | Вызывает редактор текста |
| ~f сообщения | Считывает сообщения |
| ~h | Редактирует все строки заголовка. |
| ~m сообщения | Считывает сообщения, сдвигает указатель вправо на одну табуляцию |
| ~p | Отображает (печатает) текущее сообщение |
| ~q | Уход из почты (Quit), эквивалентно двойному Ctrl-C |
| ~r файл | Считывает содержимое указанного файла в текст сообщения |
| ~s subject | Изменяет содержимое строки Subject |
| ~t адрес... | Добавляет адрес в строку "To:". |
| ~v | Вызывает альтернативный редактор (то же, что и ~e). |
| ~w файл | Записывает текущее сообщение в файл |
| ~! команда | Выполняет команду Shell и возвращается к сообщению |
| ~| команда | Пропускает текущее сообщение через фильтр |
/p> Если вы напечатаете ~f (без указания номера сообщения), в текст текущего сообщения будет внесено содержимое сообщения, которое вы читали последним. Стандартной формой использования ~f является, например, ~f 5, где 5 - номер сообщения. ~m делает тоже самое, но каждая строка сдвигается на один tab вправо.
В UNIX многие команды имеют разные функции, если они напечатаны строчными или прописными буквами, смотри, например, команды r и R в таблице 4.5.10.2. Не безразлично в UNIX и применение строчных и прописных символов в именах файлов, что бывает существенно, в частности, при работе с FTP-сервером.
Важной командой является SET, которая позволяет изменять системные переменные. Формат использования:
SET переменная=значение (Например, SET EDITOR=/bin/edMe=/bin/eda).
Уже сегодня можно переслать поздравительную цветную открытку вашим знакомым. Возможна по такой схеме пересылка и звуковых писем, лишь бы у вашего адресата была звуковая карта в ЭВМ. Ведутся работы и над протоколами видео-писем (NETBLT).
Тот факт, что электронная почта является наиболее популярным видом сервиса, делает ее объектом непрерывных доработок и усовершенствований. Так в документах RFC-1425, -1426, -1427 предлагается вариант расширения возможностей SMTP (ESMTP). Эта модификация сохраняет совместимость со старыми версиями. Клиент, желающий воспользоваться расширенными возможностями, посылает команду EHLO вместо HELO. Если сервер поддерживает ESMTP, он выдаст код-отклик 250. Этот вид отклика является многострочным, что позволяет серверу сообщить о видах сервиса, которые он поддерживает. Например:
250-8BITMIME (RFC-1426)
250-EXPN (RFC-821)
250-SIZE (RFC-1427)
250-HELP (RFC-821)
250-XADR
Таблица 4.5.10.2. Команды, выполняемые почтовой программой
| Команда | Описание | |
| Сокращение | Полное имя | |
| ? | - | Отображение списка исполняемых команд |
| ! | - | Выполнение одной команды Shell |
| + | - | Отобразить следующее сообщение |
| RETURN | - | Отобразить следующее сообщение |
| - | - | Отобразить предшествующее сообщение |
| число | - | Отобразить сообщение с номером "число". |
| d | delete | Стереть текущее сообщение |
| dp | - | Стереть текущее сообщение и отобразить следующее |
| e | edit | Вызвать редактор для работы с сообщениями |
| h | headers | Отобразить список заголовков сообщений |
| l | list | Выдать список имен всех доступных команд |
| m | Послать сообщение по указанному адресу или адресам | |
| n | - | Отобразить следующее сообщение и распечатать его |
| p | Отобразить (отпечатать) сообщения | |
| pre | preserve | Сохранить сообщения в системном почтовом ящике |
| q | quit | Завершить работу с почтой |
| r | replay | Ответить отправителю и всем прочим получателям |
| R | Replay | Ответить только отправителю |
| s | save | Сохранить сообщения в указанном файле или в mbox, если имя файла не указано |
| sh | shell | Временно уйти из почты и вернуться в shell |
| t | type | Тоже что и print |
| to | top | Отобразить несколько верхних строчек сообщения |
| u | undelete | Восстановить ранее стертые сообщения |
| v | - | Редактирование сообщения с помощью экранного редактора |
| w | write | Тоже что и s, но без записи заголовка |
| x | exit | Выйти из почты без спасения внесенных изменений |
| z | - | Отобразить следующий набор заголовков |
| z- | - | Отобразить предшествовавший набор заголовков сообщений |
Ключевое слово 8BITMIME говорит о том, что клиент может добавить ключевое слово BODY к команде MAIL FROM и определить тип символов, используемых в сообщении (ASCII или 8-битные). Ключевое слово XADR указывает на то, что любые ключевые слова, начинающиеся с X, относятся к местным модификациям SMTP. Документ RFC-1522 определяет способ, как можно включить не ASCII-символы в заголовок почтового сообщения. Например:
=?набор_символов ?кодировка ?закодированный_текст ?=
набор_символов - спецификация набора символов: us-ascii или ISO-8859-X, где X - одиночная цифра, например ISO-8859-1. Поле кодировка содержит один символ, характеризующий метод кодировки. В настоящее время описаны два метода:
1. Q - набор печатных символов; символы, коды которых имеют неравный нулю 8-ой бит, отображается тремя символами: знаком равенства (=), за которым следует два шестнадцатеричных числа (например =AD). Так пробел будет иметь кодировку =20.
2. B - 64-символьный набор (Base64, латинские буквы, 10 цифр, а также символы + и /). Набор кодов Base64 приведен в таблице:
Таблица 4.5.10.3. Коды Base64
Код символа (6 бит) | ASCII символ | Код символа (6 бит) | ASCII символ | Код символа (6 бит) | ASCII символ | Код символа (6 бит) | ASCII символ |
| 0 | A | 10 | Q | 20 | g | 30 | w |
| 1 | B | 11 | R | 21 | h | 31 | x |
| 2 | C | 12 | S | 22 | i | 32 | y |
| 3 | D | 13 | T | 23 | j | 33 | z |
| 4 | E | 14 | U | 24 | k | 34 | 0 |
| 5 | F | 15 | V | 25 | l | 35 | 1 |
| 6 | G | 16 | W | 26 | m | 36 | 2 |
| 7 | H | 17 | X | 27 | n | 37 | 3 |
| 8 | I | 18 | Y | 28 | o | 38 | 4 |
| 9 | J | 19 | Z | 29 | p | 39 | 5 |
| A | K | 1A | a | 2A | q | 3A | 6 |
| B | L | 1B | b | 2B | r | 3B | 7 |
| C | M | 1C | c | 2C | s | 3C | 8 |
| D | N | 1D | d | 2D | t | 3D | 9 |
| E | O | 1E | e | 2E | u | 3E | + |
| F | P | 1F | f | 2F | v | 3F | / |
Интересным дополнением к традиционной электронной почте является ее расширение MIME (Multipurpose Internet Mail Extensions, RFC-1521). MIME не требует каких-либо переделок в почтовых серверах, это расширение определяет пять новых полей-заголовков (расширение RFC-822):
| MIME-Version: | (версия MIME, сейчас 1.0) |
| Content-Type: | (тип содержимого, см. таблицу на рис. 4.5.10.4) |
| Content-Transfer-Encoding: | (кодирование содержимого) |
| Content-ID: | (идентификатор содержимого) |
| Content-Description: | (описание содержимого) |
Поле заголовка Content-Transfer- Encoding используется пять видов кодировки (третий вид полей в приведенном выше списке):
7-бит (NVT ASCII, по умолчанию);
Набор печатных символов (полезен, когда только небольшая часть символов использует 8-ой бит);
64-символьный набор (Base64 см. выше в таблице 4.5.10.3);
8-битный набор символов, включающий псевдографику, с использованием построчного представления;
Двоичная кодировка (8-битное представление без построчного представления).
Только первые три типа согласуются с требованиями RFC-821. MIME позволяет снять с электронной почты привычные ограничения и предоставляет возможность пересылать любую информацию. Техника приложений (Attachment) позволяет пересылать через электронную почту любые файлы без какого-либо специального преобразования, выполняемого пользователем. При этом необходимо только, чтобы и приемник и передатчик поддерживали это расширение электронной почты. В MIME предусмотрены следующие типы и субтипы содержимого почтового сообщения:
Таблица 4.5.10.4. Типы и субтипы почтовых сообщений.
| Тип почтового сообщения | Субтип почтового сообщения | Описание |
| text | plain | Неформатированный текст |
| richtext | Текст с простым форматированием, таким как курсив, жирный, с подчеркиванием и т.д. | |
| enriched | Упрощение, прояснение и усовершенствование richtext | |
| multipart | mixed | Сообщение содержит несколько частей, которые обрабатываются последовательно |
| parallel | Сообщение содержит несколько частей, обрабатываемых параллельно | |
| digest | Краткое содержание почтового сообщения | |
| alternative | Сообщение содержит несколько частей с идентичным семантическим содержимым | |
| message | RFC822 | Содержимое является почтовым сообщением в стандарте RFC-822 |
| partial | Содержимое является фрагментом почтового сообщения | |
| external-body | Содержимое является указателем на действительный текст сообщения | |
| application | octet-stream | Произвольная двоичная информация |
| postscript | PostScript программа | |
| image | jpeg | Формат ISO 10918. |
| gif | Формат обмена CompuServe (Graphic Interchange Format). | |
| audio | basic | Формат ISO 11172 |
Текст электронного сообщения не передает всех оттенков мыслей и эмоций отправителя, что может вызвать неверное восприятие. Для решения этой проблемы хотя бы частично используются символьные обозначения эмоций. Таблица таких обозначений приведена ниже. Чтобы легче воспринять и запомнить их, посмотрите на страницу, где напечатана таблица, справа.
| Символ | Значение |
| :-) | Улыбка |
| :-D | Смех |
| ;-) | Подмигивание |
| :-( | Неудовольствие |
| :-< | Огорчение |
| 8-) | Удивление |
| :-o | О, нет! |
| :-I | Безразличие |
| :-# | Вынужденная улыбка |
| :-] | Ухмылка |
| :-{) | Улыбка с усами |
| {:-) | Улыбка с париком |
| :-X | Мой рот на замке |
| =:-) | Панк-рокер |
| =:-( | Настоящий панк-рокер никогда не улыбается |
| %^) | Название для этой улыбки читателям предлагается придумать самостоятельно |
В последнее время большинство почтовых серверов реализуется в среде UNIX, где функцию почтового демона (фонового процесса) выполняет программа sendmail. Эта программа осуществляет переадресацию сообщений от пользователя пользователю и от сервера серверу. Программа эта имеет большие возможности, но ее конфигурирование и использование представляет немалые трудности.
Элемент А
<!element a - - (%inline)* -(a)>
<!attlist a
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| charset cdata #implied | -- перекодировка символов в подключенном ресурсе -- | |
| name cdata #implied | -- именованный конец связи -- | |
| href %url #implied | -- url для подключенного ресурса -- | |
| target cdata #implied | -- где развернуть ресурс -- | |
| rel cdata #implied | -- типы прямых связей -- | |
| rev cdata #implied | -- типы обратных связей -- | |
| accesskey cdata #implied | -- символ ключа доступа -- | |
| shape %shape rect | -- для использования с object shapes -- | |
| coords %coords #implied | -- для использования с object shapes -- | |
| tabindex number #implied | -- положения табуляции -- > |
Описания атрибутов
name = cdata
Этот атрибут указывает на то, что элемент использован для описания якоря. Значение этого атрибута является уникальным именем якоря. Это имя действительно в пределах данного документа. Атрибут name работает в том же пространстве имен, что и атрибут ID.
href = url
Этот атрибут указывает на то, что элемент использован для описания связи. Значение атрибута равно положению одного из концов связи (другой конец задан положением этого элемента).
rel = cdata
Этот атрибут указывает на то, что источником связи является текущая позиция в документе. Значение Href в этом случае определяет место назначения связи. Значение rel специфицирует тип связи. Этот атрибут может включать в себя список типов связей, разделенных пробелами.
rev = cdata
Этот атрибут указывает на то, что место назначения связи соответствует текущей позиции в документе. Значение Href в этом случае определяет положение источника. Значение rev специфицирует тип связи. Этот атрибут может включать в себя список типов связей, разделенных пробелами.
charset = cdata
Этот атрибут специфицирует перекодировку символов для данной связи. Значение этого атрибута должно быть именем "charset" описанным в RFC-2045. Значение по умолчанию этого атрибута равно "ISO-8859-1".
Ниже приведен пример использования А-элемента.
<a href=>w3c web site</a>
Эта ссылка указывает на базовую страницу консорциума WWW. Когда пользователь активирует эту связь, агент пользователя обратится к указанному ресурсу и откроет HTML-документ. Агент пользователя представляет ссылки в документе так, чтобы выделить их из текста (например, подчеркивает их). Чтобы сообщить агенту пользователя в явном виде, какой набор символов следует использовать при отображении, следует установить соответствующее значение атрибута charset.
<a href = charset="ISO-8859-1">w3c web site</a>
Ниже приведен пример, иллюстрирующий описание якоря с именем "anchor-one" в файле "one.html".
… текст до якоря …
<a name="anchor-oner">this is the location of anchor one.</a>
… текст после якоря …
Это определение присваивает якорь зоне документа, содержащей текст "This is the location of anchor one". Определив якорь, мы можем установить с ним связь из того же или постороннего документа. URL, который указывает на якорь, завершаются символом #, за которым следует имя якоря. Ниже приведены примеры такого URL.
Абсолютный URL: http://www.mycompany.com/one.html">http://www.mycompany.com/one.html#anchor-one
Относительный URL: ../one.html#anchor-one
Когда связь задана в пределах документа: #anchor-one
Таким образом, связь, определенная в файле "two.html", который находится в том же каталоге, что и "one.html" имеет ссылку на якорь в виде:
<a href="./one.html#anchor-one" anchor one</a>
Элемент А в следующем примере определяет якорь и связь в одно и то же время.
<a name="anchor-two" href="html://wwwsomecompany.com/people/ian/vocation/family.png">
</a>
Этот пример содержит связь с www-ресурсом другого типа (png-изображение). Активация связи должна извлечь это изображение из сети и отобразить его.
15.4. Связи mailto
Автор может сформировать связи, которые не ведут к какому-либо документу, а реализуют отправку e-mail сообщения по некоторому адресу.
Когда такая связь активизируется, агент пользователя вызывает почтовую программу. Для реализации таких связей введено значение mailto атрибута Href.
<a href="mailto:semenov@ns.itep.ru"> yury semenov</a>
Когда пользователь активизирует эту связь, агент пользователя открывает почтовую программу и заносит в поле "to:" значение "semenov@ns.itep.ru".
15.5. Вложенные связи
Связи и якоря, описанные элементом А не допускают вложения. Например, ниже приведенная запись недопустима.
<a name="outer-anchor" href="next-outer.html"> an outer anchor and link <a name="inner-anchor" href="next-inner.html">an inner anchor and link.</a></a>
15.6. Якоря с атрибутом id
Атрибут id может использоваться для размещения якоря в области начальной метки любого элемента. Ниже приведен пример использования id для размещения якоря в элементе Н2. Якорь подвязан здесь посредством А-элемента.
<h2 id="section2">section two</h2>
… позднее в документе …
please refer to <a href="#section2">section two</a> above for more details.
Атрибуты ID и name работают в общем пространстве имен (см. ISO10646). Это означает, что они не могут описать якоря с идентичными именами в пределах одного документа.
15.7. Элемент link
<!element link - o empty>
<!attlist link
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| href %url #implied | -- url для подключаемого ресурса -- | |
| rel cdata #implied | -- forward link types -- | |
| rev cdata #implied | -- reverse link types -- | |
| type %contenttype #implied | -- advisory internet content type -- | |
| media cdata #implied | -- для представления в этой среде -- | |
| target cdata #implied | -- место, где производится отображение -- > |
Этот элемент, который должен использоваться в Head-секции документа (любое число раз), определяет связь, независящую от среды. Хотя Link не имеет содержимого, он предоставляет информацию, обрабатываемую агентами пользователя.
Ниже в предлагаемом примере показано как в секции head документа могут появиться несколько определений Link. Атрибуты rel и rev определяют, откуда связь начинается и где кончается.
<html>
<head>
<link rel ="index" href="../index.html">
<link rel ="next" href="chapter_3.html">
<link rev ="previous" href="chapter_1.html">
</head>
……
15.8. Типы связей
Атрибуты rel и rev определяют начало и конец связи, но их значение или значения задают также природу связи. Если для элемента А атрибуты rel и rev не являются обязательными для link, хотя бы один из них присутствовать должен. Агент пользователя может интерпретировать эти атрибуты множеством путей, например, через меню или "клавишу next". Ниже перечислены некоторые типы связей.
| Содержимое | соединение выполняет функцию оглавления документа. |
| Индекс | соединение предлагает индекс документа. |
| Глоссарий | соединение предлагает глоссарий терминов для данного документа. |
| copyright | соединение воспроизводит заявление о защите авторских прав. |
| Следующий | связь осуществляет переход к следующему документу из списка (next) |
| Предыдущий | связь осуществляет переход к предыдущему документу из списка (previous) |
| Содержание | связь вызывает переход к первому из ряда документов. |
| Справка | связь производит вызов документов, дающих дополнительную информацию по некоторым вопросам (help) |
| Закладка | связь реализует переход в определенную точку документа, часто такой точкой является заголовок главы или раздела (bookmark). |
| Стилевой лист | связь указывает на внешний стилевой лист. |
| Альтернатива | связь указывает на различные версии того же самого документа, например, на переводы данного документа на иностранные языки (alternate). |
Элемент button
<!element button - - (%flow;)* -(a|%formctrl;|form|fieldset) -- клавиша -->
<!attlist button
| %attrs | -- %coreattrs, %i18n, %events -- | |
| name cdata #implied | ||
| value cdata #implied | -- при представлении посылать серверу -- | |
| type (button|submit|reset) submit | -- для использования в качестве кнопки -- | |
| disabled (disabled) #implied | -- в данном контексте недоступно -- | |
| tabindex number #implied | -- position in tabbing order -- | |
| accesskey %character; #implied | -- клавиша доступа -- | |
| onfocus %script; #implied | -- элемент выделен -- | |
| onblur %script; #implied | -- элемент не выделен -- > |
Описание атрибутов
name = cdata
Этот атрибут присваивает имя кнопке.
value = cdata
Этот атрибут присваивает значение кнопке.
type = button | submit | reset
Этот атрибут декларирует тип кнопки. Когда атрибут не задан, поведение кнопки не определено. Возможные значения:
| button: | Создает простую кнопку, которая может запускать скрипт. | |
| submit: | Создает кнопку, которая служит для отправки формы серверу (значение по умолчанию). | |
| reset: | Создает кнопку сброса для формы. |
Элемент button с типом "submit", содержащий изображение (т.е. элемент img), очень похож на элемент input с типом "image". Но их поведение на фазе отображения различно. В этом контексте элемент input предполагает плоское изображение, а button - объемное (кнопка нажимается и отбрасывает тень). Ниже приведен пример использования элементов input и button:
<form action="http://somesite.com/prog/adduser" method="post"><p>
first name: <input type="text" name="firstname"><br>
last name: <input type="text" name="lastname"><br>
email: <input type="text" name="email"><br>
<input type="radio" name="sex" value="male"> male<br>
<input type="radio" name="sex" value="female"> female<br>
<button name="submit" value="submit" type="submit">
send<img src="/icons/wow.gif" alt="wow"></button>
<button name="reset" type="reset">
reset<img src="/icons/oops.gif" alt="oops"></button>
</p>
</form>
Если используется button с элементом img, рекомендуется применение img-элемента с атрибутом alt, чтобы обеспечить совместимость с агентами пользователя, не поддерживающими графику. Недопустимо использование карты изображения с img в элементе button:
<button>
<img src="foo.gif" usemap="…">
</button>
Элемент button с типом "reset" очень похож на элемент input с типом "reset".
Элемент col
<!element col - o empty>
| <!attlist col | -- группы колонок и свойства -- | |
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| span number 1 | -- число колонок в группе -- | |
| width cdata #implied | -- спецификация ширин колонок -- | |
| %CEllhalign; | -- горизонтальное выравнивание в ячейках -- | |
| %CEllvalign; | -- вертикальное выравнивание в ячейках -- > | |
Определение атрибута
width = length
Этот атрибут задает значение по умолчанию для ширины колонок в группе. Атрибут может также принимать значение "0*" (смотри выше) и "i*", где i - целое. Это называется относительной шириной. Когда агент пользователя выделяет место для таблицы, он сначала определяет габариты, а уже затем делит выделенное пространство, определяя относительные ширины рядов и колонок. Число i при этом определяет относительную долю, выделяемую данной колонке. Значение "*" эквивалентно "1*".
Каждая группа колонок может содержать нуль или более элементов col. Элемент col не определяет группу колонок в том смысле, как это делает colgroup, он предоставляет способ задать значения атрибутов для всех колонок группы. Атрибут span элемента col имеет следующее значение.
В отсутствии декларации span каждый элемент col представляет одну колонку. Если атрибут span имеет значение n>0, текущий элемент col действует на n колонок таблицы. Если атрибут span равен нулю, текущий элемент col имеет воздействие на все оставшиеся колонки таблицы, начиная с текущей. Что же касается colgroup, атрибут width для col воздействует на ширины колонок, к которым относится этот элемент. Если элемент cal действует на несколько колонок, тогда его атрибут width специфицирует ширину каждой колонки в его зоне ответственности.
Ниже приведен пример таблицы, имеющей две группы колонок. Первая группа содержит три колонки, вторая - две колонки. Доступное место по горизонтали определяется следующим образом. Сначала агент пользователя выделяет 30 пикселей для первой колонки. Затем будет выделено минимально возможное место для второй колонки.
Оставшееся место по горизонтали будет поделено на 6 равных частей. Колонка 3 получит 2 такие порции, колонка 4 - одну, а колонка 5 получит 3.
<table>
<colgroup>
| <col width="30"> | |
| <col width="0*"> | |
| <col width="2*"> |
<colgroup align="center">
| <col width="1*"> | |
<col width="3*" align="char" char=":"> |
<thead>
<tr> …..
</table>
Мы установили значение атрибута align во второй группе колонок равным "center". Все ячейки в каждой колонке этой группы наследуют это значение. Но оно может быть изменено. В действительности последний элемент col делает это, специфицируя то, что все колонки, которыми он управляет, будут выровнены по символу ":".
Элемент frame
<!element frame - o empty>
<!attlist frame
| name cdata #implied | -- имя рамки -- | |
| src %url #implied |
-- источник содержимого рамки -- | |
| frameborder (1|0) 1 | -- request frame border? -- | |
| marginwidth %pixels #implied |
-- ширина полей в пикселях -- | |
| marginheight %pixels #implied | -- высота полей в пикселях -- | |
| noresize (noresize) #implied |
-- позволить пользователям изменять размеры рамок? -- | |
| scrolling (yes/no/auto) auto | -- делать полосу прокрутки или нет? -- > |
Определения атрибутов
name = cdata
Атрибут присваивает имя текущей рамке. К этому имени можно адресоваться.
src = url
Этот атрибут специфицирует положение исходного документа, содержимое которого заключено в рамку.
noresize
Этот булев атрибут говорит агенту пользователя, что размер окна рамки не может быть изменен.
scrolling = auto|yes|no
Этот атрибут специфицирует информацию о возможности прокрутки информации в данной рамке. Возможные значения:
| auto: | говорит агенту пользователя, что он может организовывать скроллинг по своему усмотрению (значение по умолчанию) | |
| yes: | говорит агенту пользователя, что он должен обеспечить скроллинг информации в окне. | |
| no: | говорит агенту пользователя, что скроллинг делать не нужно. |
frameborder=1|0
Этот атрибут предоставляет агенту пользователя информацию о рамке вокруг текущего окошка. 1 означает, что агент пользователя должен прочертить границу вокруг текущей рамки (значение по умолчанию). 0 означает, что агент пользователя не должен прочерчивать границу вокруг текущей рамки.
marginwidth = length
Этот атрибут специфицирует правое и левое поля между текстом и границей рамки. Значение должно быть больше одного пикселя. Значение по умолчанию определяет агент пользователя.
marginheight = length
Этот атрибут специфицирует размер верхнего и нижнего поля между текстом и границей рамки. Значение должно быть больше одного пикселя. Значение по умолчанию определяет агент пользователя.
Атрибут SRC определяет источник текста, помещаемого в рамку. Содержимое рамки не может быть записано в том же документе, в котором описана сама рамка.
Пример:
<html>
<frameset cols="33%, 33%, 33%">
<frameset rows="*,200"> | ||
<frame src="contents_of_frame1.html"> | ||
<frame src="contents_of_frame2.gif"> | ||
| </frameset> | ||
<frame> src="contents_of_frame3.html"> | ||
<frame> src="contents_of_frame4.html"> | ||
</frameset>
</html>
В результате будет получена раскладка рамок, показанная ниже не рисунке.
Ниже приведенный пример содержит в себе ошибку, так как текст второй рамки включен в описание самой рамки.
<html>
<frameset cols="50%,50%">
| <frame src="contents_of_frame1.html"> | |
| <frame src="#anchor_in_same_document"> |
</frameset>
<body>
… некоторый текст…
<h2><a name="anchor_in_same_document">important section</a></h2>
… некоторый текст…
</body>
</html>
Существует атрибут target = cdata, который специфицирует имя рамки, где должна быть размещена информация. Путем присвоения с помощью атрибута name имени рамке разработчик может ссылаться на нее, как на адрес связей. Атрибут target может быть установлен для элементов, создающих связи (А, link), карты изображения (area) и формы (form). Ниже предлагается пример, где target позволяет динамически изменять содержимое рамки:
<html>
<frameset rows="50%,50%">
<frame name="fixed" src="init_fixed.html"> | |
<frame name="dynamic" src="init_dynamic.html"> |
</frameset>
</html>
Затем в init_dynamic.html мы организуем связь с рамкой под именем "dynamic"
<html>
<body >
… начало документа …
now you may advance to
<a href="slide2.html" target="dynamic">slide 2.</a> |
… продолжение документа …
you're doing great. now on to
<a href="slide3.html" target="dynamic">slide 3.</a> |
</body>
</html>
Активирование любой связи приводит к открытию документа в рамке с именем "dynamic", в то время как другие рамки ("fixed") остаются со своим исходным содержимым.
Элемент iframe
| <!element iframe - - (%flow;)* | -- субокно в блоке текста --> |
<!attlist iframe
| %coreattrs; | -- id, class, style, title -- | |
| longdesc %uri; #implied | -- указатель на более длинное описание (дополнение к title) -- | |
| name cdata #implied | -- имя файла для адресации -- | |
| src %uri; #implied | -- источник содержимого рамки -- | |
| frameborder (1|0) 1 | -- request frame borders? -- | |
| marginwidth %pixels; #implied | -- ширина поля в пикселях -- | |
| marginheight %pixels; #implied | -- высота поля в пикселях -- | |
| scrolling (yes|no|auto) auto | -- наличие поля прокрутки -- | |
| align %ialign; #implied | -- вертикальное и горизонтальное выравнивание -- | |
| height %length; #implied | -- высота рамки -- | |
| width %length; #implied | -- ширина рамки -- > |
Описание атрибутов
longdesc = uri
Этот атрибут специфицирует связь с длинным описанием рамки. Это описание должно быть дополнением короткого описания, данного в атрибуте title.
name = cdata
Этот атрибут присваивает имя текущей рамке. Это имя может использоваться в последующих ссылках.
width = length
Ширина рамки.
height = length
Высота рамки.
Элемент Iframe позволяет разработчику ввести рамку в блок текста. Эта процедура схожа с введением одного HTML-документа в другой с помощью элемента object. Информация, которая должна быть введена, определяется атрибутом src этого элемента. Содержимое элемента Iframe отображается только агентами пользователя, которые не поддерживают рамки. Пример, когда рамка вводится внутрь текста, приведен ниже.
<iframe src="foo.html" width="400" height="500"
scrolling="auto" frameborder="1">
[Ваш агент пользователя не поддерживает рамки или сконфигурирован без поддержки рамок]. Кликните для извлечения <a href="foo.html"> сопряженного документа. </a>]
</iframe>
Размеры этих рамок не могут быть изменены.
Элемент isindex
<!element isindex - o empty>
<!attlist isindex
| %coreattrs; | -- id, class, style, title -- | |
| %i18n; | -- lang, dir -- | |
| prompt cdata @implied | -- сообщение-приглашение (prompt) --> |
Элемент использовать не рекомендуется, вместо него лучше применять элемент input.
Описание атрибута
prompt = cdata
Атрибут специфицирует строку приглашения для ввода. Служит для ввода одной строки пользователем. Например:
<isindex prompt="enter your name: ">
Та же задача решается с использованием элемента input следующим образом (рекомендуемый вариант):
<form action="…" method="post">
enter your name: <input type="text">
</form>
Элемент label
<!element label - - (%inline;)* -(label) -- form field label text -->
<!attlist label
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| for idref #implied | -- matches field id value -- | |
| accesskey %character; #implied | -- клавиша доступа -- | |
| onfocus %script; #implied | -- элемент выделен -- | |
| onblur %script; #implied | -- элемент не выделен --> |
Определение атрибута
for = idref [cs]
Этот атрибут устанавливает соответствие между меткой и control. При наличии этого атрибута его значение должно совпадать с атрибутом id другого control того же документа. При отсутствии этого атрибута метка ставится в соответствие содержимому элемента.
Элемент label может использоваться для привязки информации к другим элементам control (за исключением других элементов label). Ниже приведены два примера использования элемента label.
<form action="..." method="post">
<table>
<tr>
<td><label for="fname">first name</label>
<td><input type="text" name="firstname" id="fname">
<tr>
<td><label for="lname">last name</label>
<td><input type="text" name="lastname" id="lname">
</table>
</form>
<form action="http://somesite.com/prog/adduser" method="post">
<p>
<label for="firstname">first name: </label>
<input type="text" id="firstname"><br>
<label for="lastname">last name: </label>
<input type="text" id="lastname"><br>
<label for="email">email: </label>
<input type="text" id="email"><br>
<input type="radio" name="sex" value="male"> male<br>
<input type="radio" name="sex" value="female"> female<br>
<input type="submit" value="send"> <input type="reset">
</p>
</form>
Для установления неявной связи между меткой и другим control контрольный элемент должен находиться внутри содержимого элемента label. В этом случае label может содержать только один контрольный элемент. В примере две метки неявно поставлены в соответствие двум вводимым текстам:
<form action="..." method="post">
<p>
<label>
first name
<input type="text" name="firstname">
</label>
<label>
<input type="text" name="lastname">
last name
</label>
</p>
</form>
Элемент noframes
<!element noframes - - (#pcdata, ((body,#pcdata)|
| (((%blocklevel)|%font|%phrase|%special|%formctrl),%block)))> |
Элемент noframes специфицирует содержимое, которое должно быть отображено, только когда не отображаются рамки. Агенты пользователя могут отображать содержимое только в случае, когда они сконфигурированы с блокировкой поддержки рамок.
Предположим, что имеется frameset, определенный в "top.html", который отображает документ "main.html", и оглавление этого документа ("table_of_contents.html"). Тогда содержимое "top.html":
<html>
<frameset cols="50%,50%">
| <frame src="main.html"> | |
|
<frame src="table_of_contents.html"> |
</frameset>
</html>
Когда пользователь читает "top.html", а агент пользователя не поддерживает работу с рамками, на экране ничего не появится, если в секции body ("top.html") нет альтернативного текста. Если мы введем "table_of_contents.html" и "main.html" непосредственно в body, задача ассоциации документов будет решена. Но при этом мы можем заставить агента пользователя, который поддерживает рамки, скопировать один и тот же документ дважды. Более экономно включить оглавление в начало "main.html", в элемент noframes:
<html>
<body>
<noframes>
… оглавление …
</noframes>
… остальная часть документа …
</body>
</html>
Элемент noframes может использоваться в frameset-секции документа. Например:
<!doctype html public "-//w3c//dtd HTML 4.0 frameset//en"
"http://www.w3.org/tr/rec-html40">
<html>
<head>
<title>a frameset document with noframes</title>
</head>
<frameset cols="50%, 50%">
<frame src="main.html">
<frame src="table_of_contents.html">
<noframes>
<p>here is the <a href="main-noframes.html">
версия документа non-frame.</a>
</noframes>
</frameset>
</html>
Элемент noscript
<!element noscript - - (%block;)+
-- альтернативный текст для случая безскриптового отображения -->
<!attlist noscript
| %attrs; | -- %coreattrs, %i18n, %events -- > |
Элемент noscript позволяет разработчику варьировать содержимое, даже когда скрипт не исполняется. Содержимое элемента noscript должно отображаться соответствующим агентом пользователя в следующих случаях:
Агент пользователя сконфигурирован так, что он не поддерживает скрипты.
Агент пользователя не поддерживает язык скрипта, использованный в элементе script.
Агент пользователя, не поддерживающий скрипты для стороны клиента, должен осуществлять разборку и представление содержимого элемента. В следующем примере агент пользователя, который исполняет script, включит некоторую динамически созданную информацию, в текст документа. Если агент пользователя не поддерживает скрипты, пользователь может, тем не менее, получить эту информацию через сеть.
<script type="text/tcl">
...некоторый tcl-скрипт для введения данных...
</script>
<noscript>
<p>access the <a href="http://someplace.com/data">data.</a>
</noscript>
Агент пользователя, который не распознает элемент script, вероятно будет разбирать и отображать содержимое элемента, как текст. Некоторые интерпретаторы скриптов, включая те, которые ориентированы на Javascript, VBscript и TCL, позволяют помещать фрагменты текстов скриптов в SGML-комментарии. Тогда агент пользователя, не узнавший элемент script, игнорирует его текст, считая его комментарием, а продвинутый интерпретатор скриптов распознает скрипт, помещенный в комментарий, и исполнит его. Другим решением проблемы является помещение скрипта во внешний документ.
Элемент object
<!entity % oalign "(texttop|middltextmiddle|baseline|textbottom|left|center|right)">
<!element object - - (param | %block)*>
<!attlist object
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| declare (declare) #implied |
-- декларирует но не присваивает конкретных значений флагу -- | |
| classid %url #implied | -- идентифицирует приложение -- | |
| codebase %url #implied | -- некоторые системы требуют дополнительного url -- | |
| data %url #implied | -- ссылка на объектные данные -- | |
| type %contenttype #implied | -- Интернетовский тип данных -- | |
| codetype %contenttype #implied | -- Интернетовский тип для кодов -- | |
| standby cdata #implied | -- сообщение, отображаемое при загрузке -- | |
| align %oalign #implied | -- позиционирование в пределах документа -- | |
| height %length #implied | -- предлагаемая высота -- | |
| width %length #implied | -- предлагаемая ширина -- | |
| border %length #implied | -- предлагаемая ширина рамки -- | |
| hspace %length #implied | -- предлагаемый горизонтальный пробел -- | |
| vspace %length #implied | -- предлагаемый вертикальный пробел -- | |
| usemap %url #implied | -- reference to image map -- | |
| shapes (shapes) #implied | -- объект имеет сформированные гипертекстные связи -- | |
| name %url #implied | -- представить, как часть формы -- | |
| tabindex number #implied | -- position in tabbing order -- > |
Определения атрибутов
codebase = url
Этот атрибут специфицирует базовый проход для определения относительного URL, описанного classid. Если атрибут не задан, значением по умолчанию является базовый URL данного документа.
classid = URL
Этот атрибут специфицирует положение механизма отображения через url.
codetype = cdata
Этот атрибут специфицирует internet media type данных, ожидаемых механизмом отображения, определенным classid. Атрибут является опционным, но рекомендуемым, когда имеется classid, так как это позволяет агенту пользователя избежать загрузки информации для неподдерживаемого типа среды. Если явно величина не задана, его значение по умолчанию соответствует значению атрибута type.
data = URL
Этот атрибут специфицирует положение данных, которые должны быть отображены.
type = cdata
Этот атрибут специфицирует Internet media type для данных, заданных атрибутом data. Атрибут является опционным, но рекомендуемым, когда задан атрибут data, так как это позволяет агенту пользователя избежать загрузки информации с типом, неподдерживаемым средой.
declare
Если присутствует, этот булев атрибут делает текущее определение object лишь декларацией.
standby = cdata
Этот атрибут специфицирует сообщение, которое агент пользователя может отобразить при загрузке объектных приложений и данных.
align = texttop|middle|textmiddle|baseline|textbottom|left|center|right
Не рекомендуется к использованию. Этот атрибут специфицирует положение объекта по отношению к окружающему контексту.
Большинство агентов пользователей снабжены механизмом для отображения базовых типов информации, таких как текст, картинки в GIF-формате, цвета, шрифты и т.д. В HTML элемент object определяет положение механизма отображения и положение данных, необходимых для механизма отображения. Агент пользователя интерпретирует элемент object согласно следующим правилам.
Агент пользователя должен сначала попробовать механизм отображения, заданный атрибутом элемента. Если агент пользователя не может поддержать этот механизм по какой-либо причине, он должен попытаться работать с содержимым элемента.
Важным следствием конструкции элемента object является то, что он предлагает механизм для описания альтернативного механизма отображения различных объектов. Каждая декларация object может предлагать альтернативный механизм отображения. Если агент пользователя не может воспользоваться имеющимся механизмом, он может обратиться к тексту, который может представлять собой другой элемент object. В ниже приведенном примере использовано несколько деклараций object для иллюстрации альтернативных способов отображения. Агент пользователя сначала попробует отобразить первый элемент object, а далее будет пытаться воспользоваться: аплетом eath, написанным на языке python, mpeg анимацией, изображением земли в формате GIF и, наконец, альтернативным текстом.
<object title=" the earth as seen from space"
classid="http://www.observer.mars/theearth.py">
<object data="theearth.mpeg" type="application/mpeg">
| <object src="theearth.gif"> |
the <strong> "earth"</strong> as seen from space.
| </object> | |||
| </object> | |||
</object>
Самая внешняя декларация специфицирует аплет, который не требует данных или начальных параметров. Вторая декларация специфицирует MPEG-анимацию и не определяет механизм отображения, предполагая, что с этой работой справится агент пользователя. Здесь установлен атрибут type, таким образом, что в случае если агент пользователя не может отобразить MPEG, он может не копировать "theearth.mpeg" из сети. Третья декларация специфицирует позицию GIF-файла и предлагает альтернативный текст на случай, когда другие механизмы не приведут к успеху.
Отображаемая информация может извлекаться двумя путями: из текущей строки илиb из внешнего источника. Первый способ дает большее быстродействие, но требует много места.
Элемент optgroup
| <!element optgroup - - (option)+ | -- группа опции --> | |||
| <!attlist optgroup | ||||
| %attrs; | -- %coreattrs, %i18n, %events -- | |||
| disabled (disabled) #implied | -- недоступно в данном контексте -- | |||
Определение атрибута
label = text [cs]
Этот атрибут специфицирует метку опции для группы опций.
Когда форма передается на обработку, каждый из выборов группируется с именем "component-select".
Элемент script
| <!element script - - %script; | -- текст скрипта --> |
<!attlist script
| charset %charset; #implied | -- кодировка символов, подключенного ресурса -- |
| type %contenttype; #required | -- тип содержимого языка скрипта -- |
| src %uri; #implied | -- URI для внешнего скрипта -- |
| defer (defer) #implied | -- ua может отложить исполнение скрипта --> |
Определение атрибутов
src = URI [ct]
Этот атрибут специфицирует местонахождения внешнего скрипта.
type = content-type
Этот атрибут специфицирует язык скрипта, включенного в элемент. Язык специфицируется в содержимом content-type (напр., "text/javascript"). Разработчик должен выдать значения этого атрибута, так как не существует никакого значения по умолчанию.
language = cdata
Не рекомендуется к применению. Этот атрибут специфицирует язык скрипта, включенного в элемент. Его содержимое представляет собой идентификатор языка. Но из-за отсутствия стандарта атрибут type предпочтительнее.
defer
Установка этого булева атрибута сообщает агенту пользователя о том, что скрипт не будет генерировать какого-либо текста документа, что позволяет агенту пользователя продолжить разборку и представление документа.
Элемент script размещает скрипт внутри документа. Этот элемент может встретиться в head или body HTML-документа любое число раз. Сам скрипт может находиться в содержательной части элемента script или во внешнем файле. Если атрибут src не установлен, агент пользователя должен интерпретировать содержимое элемента, как скрипт. Если же src содержит URL, то агент пользователя должен игнорировать содержимое элемента и получить скрипт через URL. Разработчик должен идентифицировать язык скрипта. Для того чтобы определить язык всех скриптов в документе, необходимо включить следующую meta-декларацию в head документа:
<meta http-equiv="content-script-type" content="type">
где "type" соответствует internet media type, именующему язык скрипта. В отсутствии META-декларации, значение по умолчанию может быть установлено с помощью HTTP-заголовка "content-script-type"
content-script-type: type
где "type" соответствует internet media type.
27.2. Локальная декларация языка скрипта
Можно описать язык скрипта в каждом элементе script независимо с помощью атрибута type. В отсутствии значения языка по умолчанию этот атрибут должен быть обязательно установлен. При наличии значения по умолчанию атрибут type переписывает это значение. Ниже приведен пример, где значение языка скриптов по умолчанию равно "text/tcl". Один скрипт включен в заголовок, он размещен во внешнем файле и написан на языке "text/vbscript". Включен скрипт и в тело script (написан на "text/javascript").
<!doctype html public "-//w3c//dtd html 4.0//en"
"http://www.w3.org/tr/rec-html40/strict.dtd">z
<html>
<head>
<title>a document with script</title>
<meta http-equiv="content-script-type" content="text/tcl">
<script type="text/vbscript" src="http://someplace.com/progs/vbcalc">
</script>
</head>
<body>
<script type="text/javascript">
...some javascript...
</script>
</body>
</html>
27.3. Ссылки на html-документы из скрипта
В каждом языке имеется соглашение относительно взаимодействия с HTML-объектами. Содержимым элемента script является скрипт и по этой причине агент пользователя не должен рассматривать его как часть HTML-текста. Текст скрипта начинается сразу после начальной метки и завершается любой меткой, которая начинается с символов "</". Ниже следующий пример не является корректным из-за наличия "</em>" символов внутри элемента script (эта комбинация указывает на окончание скрипта):
<scipt type="text/javascript">
document.write ("<em> this won't work</em>" |
Корректная версия записи выглядит как:
<scipt type="text/javascript">
document.write ("<em> this will work<\/em>" |
</script>
В tcl можно это записать как:
<scipt type="text/tcl">
document.write ("<em> this will work<\/em>" |
Определения атрибутов
onload = script [ct]
Событие onload происходит, когда пользователь заканчивает загрузку окна в рамках frameset. Этот атрибут может использоваться с элементами body и frameset.
onunload = script [ct]
Событие onunload происходит, когда агент пользователя удаляет документ из окна или рамки. Этот атрибут может использоваться с элементами BODY и frameset.
onclick = script [ct]
Событие onclick происходит, когда на устройстве (например, мышке), указывающем на клавишу, нажата кнопка. Этот атрибут может использоваться с большинством элементов.
ondblclick = script
Событие ondblclick происходит, когда на устройстве, указывающем на клавишу, кнопка нажата дважды. Этот атрибут может использоваться с большинством элементов.
onmousedown = script
Событие onmousedown происходит, когда на устройстве, указывающем на клавишу, кнопка находится в нажатом состоянии. Этот атрибут может использоваться с большинством элементов.
onmouseup = script
Событие onmouseup происходит, когда на устройстве, указывающем на клавишу, кнопка отпущена. Этот атрибут может использоваться с большинством элементов.
onmouseover = script
Событие onmouseover происходит, когда указатель устройства, наезжает на клавишу (элемент). Этот атрибут может использоваться с большинством элементов.
onmousemove = script
Событие onmousemove происходит, когда устройство указывающее на элемент, перемещено. Этот атрибут может использоваться с большинством элементов.
onmouseout = script
Событие onmouseout происходит, когда позиционер указателя сдвигается с поля элемента. Этот атрибут может использоваться с большинством элементов.
onfocus = script
Событие onfocus происходит, когда элемент оказывается выделен с помощью прибора-указателя или каким-либо другим способом (например, с помощью клавиш). Этот атрибут может использоваться с: label, input, select, textarea, и button.
onblur = script
Событие onblur происходит, когда элемент перестает быть выделенным с помощью прибора-указателя или каким-либо другим способом. navigation. Этот атрибут может использоваться с теми же элементами, что и onfocus.
onkeypress = script
Событие onkeypress происходит, когда клавиша нажата и отпущена на элементе. Этот атрибут может использоваться с большинством элементов.
onkeydown = script
Событие onkeydown происходит, когда клавиша нажата на элементе. Этот атрибут может использоваться с большинством элементов.
onkeyup = script
Событие onkeyup происходит, когда клавиша отпущена на элементе. Этот атрибут может использоваться с большинством элементов.
onsubmit = script
Событие onsubmit происходит, когда форма передана. Этот атрибут используется с элементом form.
onreset = script
Событие onreset происходит, когда форма сброшена. Этот атрибут используется с элементом form.
onselect = script
Событие onselect происходит, когда пользователь выбирает некоторый текст втекстовом поле. Этот атрибут может использоваться с элементами input и textarea.
onchange = script
Событие onchange происходит, когда control перестает быть выбранным и его значение модифицировано с момента выбора. Этот атрибут может использоваться с элементами input, select и textarea.
Имеется возможность установить соответствие между определенными действиями и несколькими событиями, когда пользователь взаимодействует с агентом пользователя. Управляющие элементы, такие как input, select, button, textarea и label реагируют на те или иные события. В следующем примере необходимо ввести имя пользователя в текстовое поле. Когда пользователь пытается покинуть это поле, событие onblur вызывает функцию javascript, которая проверяет корректность введенного имени.
<input name="num"
onchange="if (!checknum(this.value, 1, 10))
{this.focus();this.select();} else {thanks()}"
value="0">
Вот пример скрипта vbscript для обработки событий в текстовом поле:
<input name="edit1" size="50">
<script type="text/vbscript">
sub edit1_changed()
if edit1.value = "abc" then
button1.enabled = true
else
button1.enabled = false
end if
end sub
</script>
Ниже прведен пример с использованием tcl:
<input name="edit1" size="50">
<script type="text/tcl">
proc edit1_changed {} {
if {[edit value] == abc} {
button1 enable 1
} else {
button1 enable 0
}
}
edit1 onchange edit1_changed
</script>
Здесь приведен пример Javascript для демонстрации установки связи между скриптом и событием (в случае нажатия клавиши на мышке):
<button type="button" name="mybutton" value="10">
<script type="text/javascript">
function my_onclick() {
. . .
}
document.form.mybutton.onclick = my_onclick
</script>
</button>
Ниже представлен более интересный хандлер окна:
<script type="text/javascript">
function my_onload() {
. . .
}
var win = window.open("some/other/uri")
if (win) win.onload = my_onload
</script>
На tcl это выглядит как:
<script type="text/tcl">
proc my_onload {} {
. . .
}
set win [window open "some/other/uri"]
if {$win != ""} {
$win onload my_onload
}
</script>
Атрибуты скриптов для событий определяются как cdata. Значение атрибута должно быть заключено в одинарные или двойные кавычки. С учетом ограничений, налагаемых программой лексической разборки, случаи появления (") и "&" в атрибуте хандлера событий должны быть записаны следующим образом:
'"' должно быть записано как """ или """
'&' должно быть записано как "&" или "&"
Поэтому ниже представленный пример должен быть записан как:
<input name="num" value="0"
onchange="if (compare(this.value, "help")) {gethelp()}">
sgml разрешает введение (') в строку атрибута следующим образом:
"this is 'fine' " and "so is "this" '
28. Динамическая модификация документов
Скрипты, которые исполняются в процессе загрузки документа, могут динамически модифицировать его содержимое. Эта возможность зависит от языка, используемого для написания скрипта. Динамическая модификация документов осуществляется следующим образом:
Сначала определяются все элементы script для того, чтобы загрузить документ.
Определяются все конструкции скрипта в пределах данного элемента script, которые генерируют SGML cdata. Полученный в результате текст загружается в документ в месте размещения элемента script.
Сгененированная cdata подвергается обратному преобразованию.
Следующий пример иллюстрирует то, как скрипты могут динамически модифицировать текст.
<title>test document</title>
<script type="text/javascript">
document.write("<p><b>hello world!<\/b>")
</script>
Приведенный выше текст дает тот же результат, что и html-текст:
<title>test document</title>
<p><b>hello world!</b>
Элемент select
<!element select - - (optgroup|option)+ -- селектор опции -->
<!attlist select
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| name cdata #implied | -- имя поля -- | |
| size number #implied | -- rows visible -- | |
| multiple (multiple) #implied | -- по умолчанию один выбор -- | |
| disabled (disabled) #implied | -- недоступно в данном контексте -- | |
| tabindex number #implied | -- position in tabbing order -- | |
| onfocus %script; #implied | -- элемент выделен -- | |
| onblur %script; #implied | -- элемент не выделен -- | |
| onchange %script; #implied | -- значение элемента изменено --> |
Определение атрибутов
name = cdataЭтот атрибут присваивает имя control.
size = number
Если элемент select представлен в виде окна с полосой прокрутки, этот атрибут специфицирует число рядов в списке, которые должны быть видны одновременно. Визуальный агент пользователя не должен представлять элемент select в качестве окна; он может использовать и другой механизм, например, выпадающее меню.
multiple
Этот булев атрибут позволяет обеспечить множественный выбор. При отсутствии этого атрибута допускается только один выбор.
Элемент select создает список вариантов, из которых может выбирать пользователь. Каждый элемент select должен предложить как минимум один вариант. Каждый вариант специфицируется с помощью элемента option.
| <!element option - o (#pcdata) | -- доступный выбор --> | |
| <!attlist option | -- %coreattrs, %i18n, %events -- | |
| %attrs; | ||
| selected (selected) #implied | ||
| disabled (disabled) #implied | -- недоступно в данном контексте -- | |
| label %text; #implied | -- для использования иерархического меню -- | |
| value cdata #implied | -- содержимое элемента по умолчанию --> | |
Описание атрибутов элемента option selected
Этот булев атрибут определяет то, что данная опция является уже выбранной (pre-selected).
value = cdata
Этот атрибут специфицирует исходное значение control. Если атрибут не установлен, исходное значение определяется содержимым элемента option.
label = text
Этот атрибут позволяет разработчику специфицировать более короткую метку, чем содержимое элемента option.
Если атрибут задан, агент пользователя должен использовать в качестве метки опции значение атрибута, а не содержимое элемента option.
Элемент select помогает создать меню, с помощью которого осуществляется выбор опции. Ниже приведен пример создания такого меню.
<form action="http://somesite.com/prog/component-select" method="post">
<p>
<select multiple size="4" name="component-select">
<option selected value="component_1_a">component_1</option>
<option selected value="component_1_b">component_2</option>
<option>component_3</option>
<option>component_4</option>
<option>component_5</option>
<option>component_6</option>
<option>component_7</option>
</select>
<input type="submit" value="send"><input type="reset">
</p>
</form>
Атрибут size определяет, что в окне должно быть видно 4 опции. Реальное число опций равно 7, по этой причине выбор остальных опций возможен с помощью механизма скролинга.
Элемент optgroup позволяет разработчику логически сгруппировать опции. Это особенно удобно, когда пользователь должен сделать выбор из длинного списка опций. В HTML 4.0 все элементы optgroup должны быть специфицированы в пределах элемента select (т.е., группы не могут вкладываться друг в друга). В ниже приведенном примере показано использование элемента optgroup:
<form action="http://somesite.com/prog/someprog" method="post">
<p>
<select name="comos">
<optgroup label="portmaster 3">
<option label="3.7.1" value="pm3_3.7.1">portmaster 3 with comos 3.7.1
<option label="3.7" value="pm3_3.7">portmaster 3 with comos 3.7
<option label="3.5" value="pm3_3.5">portmaster 3 with comos 3.5
</optgroup>
<option label="3.7" value="pm2_3.7">portmaster 2 with comos 3.7
<option label="3.5" value="pm2_3.5">portmaster 2 with comos 3.5
</optgroup>
<optgroup label="irx">
<option label="3.7r" value="irx_3.7r">irx with comos 3.7r
<option label="3.5r" value="irx_3.5r">irx with comos 3.5r
</optgroup>
</select>
</form>
Элемент table
<!element table - - (caption?, (col*|colgroup*), thead?, tfoot?, tbody+)>
<!attlist table -- элемент таблицы -
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| align %talign; #implied | -- положение таблицы относительно окна -- | |
| bgcolor %color #implied | -- фоновый цвет ячейки -- | |
| width cdata #implied | -- ширина таблицы относительно окна -- | |
| cols number #implied | -- используется для режима немедленного отображения -- | |
| borrder cdata #implied | -- управляет шириной рамки вокруг таблицы -- | |
| frame %tframe; #implied | -- какую часть таблицы заключить в рамку -- | |
| rules %trules #implied | -- линии между рядами и колонками -- | |
| cellspacing cdata #implied | -- зазоры между ячейками -- | |
| cellpadding cdata #iplied | -- отступы внутри ячеек -- > |
Определение атрибутов
align = left | center | right
Этот атрибут определяет положение таблицы в документе. Возможные значения:
left: Таблица сдвинута к левому краю документа.
center: Таблица размещена по центральной оси документа.
right: Таблица сдвинута к правому краю документа.
width = length
Этот атрибут определяет желательную ширину всей таблицы для агента пользователя. В отсутствии этого атрибута размер таблицы определяется агентом пользователя.
cols = integer
Этот атрибут задает число колонок в таблице. Если он задан, агент пользователя разворачивает таблицу по мере получения данных.
Элемент textarea
| -- поле многострочного текста --> |
<!attlist textarea
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| name cdata #implied | ||
| rows number #required | ||
| cols number #required | ||
| disabled (disabled) #implied | -- недоступно в данном контексте -- | |
| readonly (readonly) #implied | ||
| tabindex number #implied | -- position in tabbing order -- | |
| accesskey %character; #implied | -- клавиша доступа -- | |
| onfocus %script; #implied | -- элемент выделен -- | |
| onblur %script; #implied | -- элемент не выделен -- | |
| onselect %script; #implied | -- некоторый текст выбран -- | |
| onchange %script; #implied | -- значение элемента изменено -- > |
Определение атрибутов
name = cdata [ci]
Этот атрибут присваивает имя control.
rows = number [cn]
Этот атрибут специфицирует номер видимой строки текста. Пользователь может ввести больше строк, чем это число, по этой причине агент пользователя должен предоставить средства для скролирования текста, чтобы обеспечить доступ к строкам за пределами видимости окна.
cols = number [cn]
Этот атрибут специфицирует видимую ширину строки (в символах). Пользователь может иметь возможность ввести более длинные строки, так что агент пользователя должен обеспечить средства для скролирования текста по горизонтали. Агент пользователя может разрывать строки, чтобы их сделать видимыми по всей длине без горизонтального скролинга.
Пример использования элемента textarea для создания текстовой области размером 20 строк по 80 колонок. В исходный момент зона содержит только две строки.
<form action="http://somesite.com/prog/text-read" method="post">
<p>
<textarea name="thetext" rows="20" cols="80">
first line of initial text.
second line of initial text.
</textarea>
<input type="submit" value="send"><input type="reset">
</p>
</form>
Элементарные свойства систем с большим числом состояний
Оставшаяся часть этого раздела будет посвящена анализу следующих трех проблем многих состояний.
Кратчайший путь
Исходные данные: Граф G=(V,E) с вершинами s и t
Случайный параметр: Le= длина ребра е
Системная величина: ФPATH= кратчайший путь от s до t
Максимальный поток
Исходные данные: Ориентированный граф G=(V,E) с вершинами s и t
Случайный параметр: Ce=пропускная способность связи е
Системная величина: ФFLOW= максимальный поток (s,t) в G
Работоспособность сети PERT
|
Исходные данные: |
Ориентированный граф без циклов G=(V,E) с исходящей вершиной s и входящей вершиной t |
|
Случайный параметр: |
Te = время завершения задания, ассоциированного с ребром е |
|
Системная величина: |
ФPERT= минимальное время завершения проекта, когда проект стартует в точке s и финиширует в t, и где никакое задание не может быть начато в вершине v, до тех пор, пока все задания, сопряженные с v, не будут завершены. Это условие можно переписать в виде: ФPERT= длине самого длинного пути с Te , представляющим длины ребер от s до t. |
Более проработанные модели могут включать в себя информацию, как о стоимости, так и пропускной способности (случайные величины или детерминистские) и самые разные метрики характеристик системы. Некоторые примеры являются стохастическими вариантами минимальной стоимости потоков, наилучшего соответствия или минимального дерева связей. Данный раздел будет концентрировать внимание на названных выше трех моделях.
Все три перечисленные выше проблемы имеют специальный случай, который в точности соответствует метрике надежности связности Rel2(G,s,t,p), рассмотренной в разделе 1.3. В частности, каждый параметр связи принимает значения 0 или 1, соответствующие рабочему состоянию связи в двоичном представлении. Функция надежности (s,t)-связности имеет тогда следующую интерпретацию:
Кратчайший путь: Если обрыв связи соответствует Le=1, а рабочее состояние связи соответствует Le=0, тогда Rel2(G,s,t,p)=Pr[ФPATH=0].
Максимальный поток: Если отсутствие связи соответствует Се=0, а рабочее состояние - Се=1, тогда Rel2(G,s,t,p)=Pr[ФFLOW ?1].
Работоспособность сети PERT: Если обрыв связи соответствует Te=0, а рабочее состояние связи соответствует Te=1 и каждый путь в G имеет идентичную длину n, тогда Rel2(G,s,t,p)=Pr[ФPERT=n].
Отсюда следует, что эти проблемы являются #P-полными для любого класса графа, для которого ассоциированная проблема надежности (s,t)-связности является #P-полной. (сюда входят и проблемы, которые удовлетворяют дополнительным требованиям соответствия PERT). Аналогичные рассуждения показывают, что вычисление E[Ф] является также #P-полным для этих классов графов.
Тип распределения, допустимый для случайных переменных связи, является критическим обстоятельством для эффективности вычислительных методов, обсуждаемых здесь, и, следовательно, необходимо рассмотреть базовые аспекты вычислительной эффективности при расчетах и манипулировании распределениями в процессе решения сетевых проблем. Следующие две операции играют главную роль в большинстве вычислительных схем расчета надежности сетей с большим числом состояний, а вычислительные трудности выполнения этих операций имеют первостепенную важность.
· свертка двух независимых случайных переменных Х1 и Х2, т.е. распределение их суммы Х1 + Х2;
· max (min) двух независимых случайных переменных Х1 и Х2, т.е. распределение max(Х1,Х2) или min(Х1,Х2).
Класс распределений связей для проблем сетей с большим числом состояний должен критически удовлетворять одному или более из следующих трех критериев, в зависимости от типа выполняемого анализа:
1. Вычисление данного значения интегральной функции распределения cdf (cumulative distribution function) элемента в фиксированном классе должно допускать расчет за полиномиальное время с нужным числом значащих цифр при заданной точности входного описания распределения.
2. Заданный набор распределений в классе и последовательность k операций min/max/свертки, выполняемых на основе этих распределений, распределение, полученное в результате последовательности операций должно принадлежать этому же классу, и далее, должно быть можно за полиномиальное время найти описание результирующих распределений при фиксированных исходных распределениях.
3. Ожидаемое значение, вариация или более общо любой специфицированный момент должны быть вычислимы (с точки зрения требуемой точности) в рамках полиномиальной оценки времени вычисления.
Обычно предполагается, что случайные величины имеют дискретное распределение, то есть, могут иметь конечное число значений. Хотя вычисление одной свертки или распределения min/max является элементарным, вычисление распределения для серии k таких операций считается #P-полным, даже если каждая исходная переменная имеет только два значения. Что необходимо, чтобы гарантировать эффективное вычисление свертки и min/max распределения, так это то, чтобы случайные переменные принимали последовательные значения {1, 2,…, xq} (или в более общем случае последовательные значения, кратные некоторому общему знаменателю) для всех ребер графа, для некоторого фиксированного q.
Существует два класса распределений с бесконечным числом состояний, которые относятся к наиболее известным и удовлетворяют сформулированным выше требованиям (1-3). Первое является дискретным и может быть описано как смесь геометрических распределений, имеющих форму pdf(probability distribution function)

для 0 < p < 1 и при соответствующем выборе значений aij. Существует также класс непрерывных распределений, которые имеют нужные свойства. Эти распределения могут быть описаны как “смесь Эрланговых” распределений (известных также как Coxian-распределения). Они являются аналогом “смеси геометрических” распределений, описанных выше. Они имеют форму cdf (cumulative distribution function):

при соответствующем выборе aij.
Дадим краткое описание методик основных оценок и ограничений для сетей с большим числом состояний. В большинстве случаев оказывается, что одна и та же техника используется для двух или более упомянутых выше проблем. Большинство методик имеют варианты для двоичных версий, которые представлены в разделах 3 и 4. Таким образом, мы организовали обсуждения методики, а не предмета, и следуем, когда возможно, формату для двоичной версии проблемы.Для большей части обсуждения мы концентрируемся на расчете Pr[Фіa] для конкретного системного значения функции Ф и специфической величины a.
Элементы fieldset и legend
<!-- #pcdata служит для решения проблемы смешанных данных, согласно спецификации здесь допустимы только whitespace! -->
<!element fieldset - - (#pcdata,legend,(%flow;)*) >
<!attlist fieldset
| %attrs; | -- %coreattrs, %i18n, %events -- > |
| <!element legend - - (%inline;)* | -- легенда поля --> |
<!entity % lalign "(top|bottom|left|right)">
<!attlist legend
| %attrs; | -- %coreattrs, %i18n, %events -- > |
| accesskey %character; #implied | -- клавиша доступа -- > |
Определение атрибута элемента legend
align = top|bottom|left|right
Не рекомендуется к применению. Этот атрибут специфицирует положение легенды по отношению к набору полей. Возможные значения:
| top: | Легенда размещается сверху (значение по умолчанию). |
| bottom: | Легенда размещается внизу. |
| left: | Легенда размещается слева. |
| right: | Легенда размещается справа. |
Элемент fieldset позволяет разработчику тематически группировать управляющие элементы. Группирование облегчает пользователю понимание их функций и в то же время упрощает графическому агенту пользователя их размещение.
Элемент legend позволяет разработчику поставить в соответствие надпись, поясняющую назначение полей, и fieldset. Ниже представлен пример использования этих элементов.
<form action="..." method="post">
<p>
<fieldset>
<legend>personal information</legend>
last name: <input name="personal_lastname" type="text" tabindex="1">
first name: <input name="personal_firstname" type="text" tabindex="2">
address: <input name="personal_address" type="text" tabindex="3">
...more personal information...
</fieldset>
<fieldset>
<legend>medical history</legend>
<input name="history_illness"
type="checkbox"
value="smallpox" tabindex="20"> smallpox
<input name="history_illness"
type="checkbox"
value="mumps" tabindex="21"> mumps
<input name="history_illness"
type="checkbox"
value="dizziness" tabindex="22"> dizziness
<input name="history_illness"
type="checkbox"
value="sneezing" tabindex="23"> sneezing
...more medical history...
</fieldset>
<fieldset>
<legend>current medication</legend>
are you currently taking any medication?
<input name="medication_now"
type="radio"
value="yes" tabindex="35">yes
<input name="medication_now"
type="radio"
value="no" tabindex="35">no
if you are currently taking medication, please indicate
it in the space below:
<textarea name="current_medication"
rows="20" cols="50"
tabindex="40">
</textarea>
</fieldset>
</form>
Обратите внимание на то, что в этом примере можно улучшить представление формы путем выравнивания элементов в пределах каждого fieldset (с помощью стилевых листов), добавив цвета, подобрав шрифты и используя скрипты.
Элементы, определяющие якоря
Существует два способа специфицировать якоря в HTML-документах.
Использовать элемент А (служит для формирования связей и якорей).
Применить атрибут id любого элемента.
Так как документы могут быть написаны на разных языках, link и a поддерживают атрибуты lang, dir и charset.
Эталонные символьные объекты для символов ISO -
Эталонные символьные объекты в этой секции формируют символы, чьи цифровые эквиваленты должны поддерживаться агентами пользователя HTML 2.0. Таким образом, эталонный символьный объект ÷ более удобная форма, чем ? для получения знака деления (/).
Чтобы поддержать эти именованные объекты агенты пользователя должны только распознать имя объекта и преобразовать его в символ из таблицы ISO88591.
Символ 65533 (FFFD в шестнадцатеричной нотации) является последним допустимым символом в UCS-2. 65534 (fffe в шестнадцатеричной нотации) не имеет какого-либо соответствия и зарезервирован для "неразрывного пробела нулевой ширины" для целей детектирования порядка байт. 65535 (FFFF в шестнадцатеричной нотации) вообще не имеет смысла.
Эталонные символьные объекты в HTML Введение
Эталонные символьные объекты представляют собой SGML конструкцию, которая соответствует набору символов документа. Эта версия HTML поддерживает несколько наборов эталонных последовательностей символов:
Символы ISO 8859-1 (Latin-1). В соответствии с секцией 14 RFC-1866, набор Latin-1 был расширен с тем, чтобы покрыть всю правую часть ISO-8859-1 (все позиции кодов с 1 в старшем бите), включая широко используемые , © и ®. Имена символьных объектов взяты из приложений SGML (определено в ISO8879).
Символы, математические символы и греческие буквы. Эти символы могут быть представлены глифами в шрифте adobe "symbol".
Символы разметки (markup) и символы интернационализации (напр., для двунаправленного текста).
Следующие разделы представляют собой полные списки эталонных символьных объектов. Хотя по соглашению ISO10646 комментарии пишутся большими буквами, мы для целей лучшей читаемости преобразовали их в строчные.
K терминалов
Набор путей с минимальной мощностью для k-терминальной меры является деревом Штейнера с минимальной мощностью. Известно, что задача распознавания является NP сложной для ориентированных и неориентированных сетей. Из теоремы 2.3 следует, что анализ функциональной и рациональной надежности для задачи анализа имеют NP сложность. Валиант [L.G.Valiant, “The complexity the enumeration and reliability problems”, SIAM, J. Computing, 8 (1979), 410-421] приводит альтернативное доказательство, заключающееся в демонстрации того, что вычисление SN(K)=? Fi = |{S : S соответствует субграфу, который содержит путь до каждого узла в К}|, имеет сложность NP. Здесь K является набором терминалов.
Кадровая аутентификация пользователя посредством CHAP
Сервер NAS с адресом 192.168.1.16 посылает запрос Access-Request в UDP-пакете серверу RADIUS для пользователя с именем VANYA для подключения к порту 20 в рамках протокола PPP. Аутентификация осуществляется посредством CHAP. NAS посылает атрибуты Service-Type и Framed-Protocol в качестве рекомендаций серверу RADIUS воспользоваться PPP, хотя NAS необязательно этому последует.
Code = 1 (Access-Request)
ID = 1
Request Authenticator = {16-октетное случайное число, используется также в вызове CHAP (CHAP challenge)}
Атрибуты:
User-Name = " VANYA"
CHAP-Password = {1 октет идентификатора CHAP, за которым следует 16 октетов CHAP-отклика}
NAS-IP-Address = 192.168.1.16
NAS-Port = 20
Service-Type = Framed-User
Framed-Protocol = PPP
Сервер RADIUS аутентифицирует VANYA и посылает запрос Access-Accept в UDP-пакете серверу NAS, сообщая, что он отрывает PPP-сессию и приписывает адрес пользователю из имеющегося у него списка.
Code = 2 (Access-Accept)
ID = 1 (тот же, что и в Access-Request)
Response Authenticator = {16-октетов контрольной суммы MD-5 кода (2), ID (1), Request Authenticator, приведенного выше, атрибутов этого отклика и общего секретного пароля}
Атрибуты:
Service-Type = Framed-User
Framed-Protocol = PPP
Framed-IP-Address = 255.255.255.254
Framed-Routing = None
Framed-Compression = 1 (Компрессия заголовка VJ TCP/IP)
Framed-MTU = 1500
Как специфицировать альтернативный текст?
Описание атрибута
alt = cdata
Для агента пользователя, который не может отображать изображения, формы или аплеты, этот атрибут позволяет ввести альтернативный текст. Язык этого текста задается атрибутом lang. Атрибут alt является обязательным для элемента area и опционным для img, applet и input.
Карты изображения клиента
Ниже описаны атрибуты элементов A и AREA, которые позволяют разработчику специфицировать ряд геометрических областей и ассоциировать их с определенными URL.
Описания атрибутов
shape = default|rect|circle|poly
Этот атрибут специфицирует форму области. Возможные значения:
| default | специфицирует всю область. | |
| rect | выделяет прямоугольную область. | |
| circle | выделяет круговую область. | |
| poly | выделяет область, ограниченную многогранником. |
coords = length-list
Этот атрибут специфицирует положение и форму области на экране. Число и порядок значений зависит от определенной формы. Возможны комбинации:
| rect: | левый-х, верхний-у, правый-х, нижний-у. | |
| circle: | х центра, у центра, радиус. | |
| poly: | х1, у1, х2, у2,…хn, yn. |
Начало координат размещено в верхнем левом углу объекта. Значения координат выражаются в пикселях или в процентах.
Для элемента object описан также булев атрибут shapes, который определяет то, что объект является картой изображения. Ниже представлен пример с картой изображения клиента.
<object data=:navbar.gif" shapes>
<a href="guide.html" shape="rect" coords="0,0,118,28">access guide</a> |
<a href="shotcut.html" shape="rect" coords="118,0,184,28">go</a> |
<a href="search.html" shape="circ" coords="184,200,60">search</a> |
<a href="top10.html" shape="poly" coords="276,0,373,28,50,50,276,0">top ten</a>
</object>
Если элемент object содержит атрибут shapes, агент пользователя должен анализировать содержимое элемента с целью поиска якорей. Если две или более областей перекрываются, область, определенная первой, имеет приоритет.
Карты изображения клиента с map и area
Элементы map и area предоставляют альтернативный механизм для карт изображения клиента.
<!element map - - (area)*>
| <!attrlist map %coreattrs; | -- id, class, style, title -- |
| name cdata #implied > |
<!element area - o empty>
<!attrlist area
| shape %shape rect | -- контролирует интерпретацию координат -- | |
| coords %coords #implied | -- список значений, разделенных запятыми -- | |
| href %url #implied |
-- эта область используется как гипертекстная связь -- | |
| target cdata #implied | -- где отображать подключенный ресурс -- | |
| nohref (nohref) #implied | -- эта область не вызывает никаких действий -- | |
| alt cdata #implied | -- описание для исключительно текстовых броузеров -- | |
| tabindex number #implied | -- position in tabbing order -- > |
Определение атрибута
| nohref | Этот булев атрибут (если =true) указывает на то, что данная область не имеет никаких связей. |
Несколько элементов (object, img и input) имеют атрибут usemap = URL для спецификации карты изображения клиента описанной элементами map и area.
Рассмотрим пример, представленный выше, переписанный в терминах MAP и AREA.
<object data=:navbar1.gif" usemap="#map></object>
<map name="map1">
| <area href="guide.html" | ||
| alt="search" | ||
| shape="rect" | ||
| coords="184,0,276,28"> | ||
<area href="top10.html"
| alt="top ten" | |
| shape="poly" | |
| coords="276,0,373,28,50,50,276,0"> |
</map>
Атрибут alt специфицирует альтернативный текст на случай, когда карта изображения не может быть отображена. map не совместима с версией HTML 2.0.
Карты изображения сервера
Карты изображения сервера могут представлять интерес в случае, когда карта изображения слишком сложна для стороны клиента. Такая карта может быть создана с помощью элемента img. Для того чтобы сделать это, нужно установить булев атрибут ismap в описании элемента IMG. Соответствующие области должны быть описаны с помощью атрибута usemap. Когда пользователь активирует область карты изображения, соответствующие координаты посылаются непосредственно серверу, где помещен документ.
Координаты на экране выражаются в пикселях. Агент пользователя берет новый URL из URL, описанного атрибутом HREF, присоединив к нему символ "?", за которым следуют координаты х и у, разделенные запятой. Например, в предыдущем примере, если пользователь кликнет в области x=10, y=27, то будет получен URL=/cgibin/navbar.map?10,27.
В следующем примере первая активная область определяет связь со стороны клиента. Вторая - определяет связь со стороны сервера, но не определяет ее форму и размер (это осуществляется значением по умолчанию атрибута shape). Так как области этих связей перекрываются, первая имеет более высокий приоритет. Таким образом, кликнув мышкой где-либо в прямоугольной области, мы пошлем соответствующие координаты серверу.
<object data="game.gif" shapes>
<a href="guide.html" shape="rect" coords="0,0,118,28"> | ||
| rules of the game </a> | ||
<a href= | ||
| ismap | ||
| shape="default"> | ||
| guess the location </a> | ||
</object>
Кодировки содержимого
Значения кодировки содержимого указывают на кодовое преобразование, которое было или может быть выполнено над объектом. Кодировки содержимого первоначально применены для того, чтобы иметь возможность архивировать документ или преобразовать его каким-то другим способом без потери идентичности или информации. Часто объект запоминается закодированным, передается и только получателем декодируется.
content-coding = token
Все значения кодировок содержимого не зависят от того, используются строчные или прописные символы. HTTP/1.1 использует значения кодировок содержимого в полях заголовка Accept-Encoding (раздел 13.3) и Content-Encoding (раздел 13.12). Хотя значение описывает кодирование содержимого, более важным является то, что оно определяет механизм декодирования.
Комитет по стандартным числам Интернет IANA (Internet Assigned Numbers Authority) выполняет функции регистра для значений лексем кодирования содержимого, этот регистр хранит следующие лексемы:
gzip
Формат кодирования, реализуемый программой архивации файлов "gzip" (GNU zip), как описано в RFC 1952 [25]. Этот формат соответствует кодированию Lempel-Ziv (LZ77) с 32 битным CRC.
compress
Формат кодирования, реализуемый стандартной программой UNIX для архивации файлов "compress". Этот формат соответствует адаптивному методу кодирования Lempel-Ziv-Welch (LZW).
Замечание: Использование имен программ для идентификации форматов кодирования не является желательным и будет в будущем заменено. Их использование здесь является следствием исторической практики. Для совместимости с предшествующими реализациями HTTP, приложения должны считать "x-gzip" и "x-compress" эквивалентными "gzip" и "compress" соответственно.
deflate
Формат "zlib" определен документом RFC 1950 [31] в комбинации с механизмом сжатия "deflate", описанным в RFC 1951 [29].
Новые значения лексем кодирования содержимого должны регистрироваться. Для обеспечения взаимодействия между клиентами и серверами спецификации алгоритмов кодирования содержимого должны быть общедоступны.
2.6. Транспортное кодирование
Значения транспортного кодирования используются для определения кодового преобразования, которому был подвергнут или желательно подвергнуть объект для того, чтобы гарантировать безопасную его транспортировку через сеть. Этот вид преобразования отличен от кодирования содержимого, так как относится к сообщению, а не исходному объекту.
| Transfer-coding | = "chunked" | transfer-extension |
| Transfer-extension | = token |
Все значения транспортного кодирования не зависят от того, строчные или прописные буквы здесь использованы. HTTP/1.1 несет значения транспортного кодирования в поле заголовка Transfer-Encoding (раздел 13.40).
Транспортные кодировки аналогичны используемым значениям Content-Transfer-Encoding MIME, которые были введены для обеспечения безопасной передачи двоичных данных через 7-битную транспортную среду. Однако безопасная транспортировка имеет другие аспекты в рамках 8-битного протокола передачи сообщений. В HTTP, единственной небезопасной характеристикой тела сообщения является неопределенность его длины (раздел 6.2.2), или желание зашифровать данные при передаче по общему каналу.
Блочное кодирование фрагментов модифицирует тело сообщения для того, чтобы передать его в виде последовательности пакетов, каждый со своим индикатором размера, за которым следует опционная завершающая запись (footer), содержащая поля заголовка объекта. Это позволяет передать динамически сформированное содержимое, снабдив его необходимой информацией для получателя, который, в конце концов, сможет восстановить все сообщение.
| Chunked | Body = *chunk "0" CRLF footer CRLF | |
| Chunk | = chunk-size [ chunk-ext ] CRLF chunk-data CRLF | |
| Hex-no-zero | = | |
| Chunk-size | = hex-no-zero *HEX | |
| Chunk-ext | = *( ";" chunk-ext-name [ "=" chunk-ext-value ] ) | |
| Chunk-ext-name | = token | |
| Chunk-ext-val | = token | quoted-string | |
| Chunk-data | = chunk-size(OCTET) | |
| footer | = *entity-header | |
Блочное кодирование фрагментов завершается пакетом нулевой длины, за которыми следует завершающая запись и пустая строка.
Назначение завершающей записи заключается в том, чтобы дать информацию о динамически сформированном объекте; приложения не должны пересылать поля заголовка в завершающей записи, кроме тех, которые специально оговорены, например, такие как Content-MD5 или будущие расширения HTTP для цифровой подписи. Пример процесса такого кодирования представлен в приложении 16.4.6.
Все приложения HTTP/1.1 должны быть способны получать и декодировать получаемые фрагменты ("chunked"-кодирование), и должны игнорировать расширения транспортного кодирования, которые они не понимают. Сервер, получающий тело объекта с транспортной кодировкой, которую он не понимает, должен отослать отклик c кодом 501 (Unimplemented - не применимо), и закрыть соединение. Сервер не должен использовать транспортное кодирование при посылке данных клиенту HTTP/1.0.
2.7. Типы среды
HTTP использует типы среды Интернет (Internet Media Types) в полях заголовка Content-Type (раздел 13.18) и Accept (раздел 13.1) для того, чтобы обеспечить широкий и открытый обмен с самыми разными типа среды.
| Media-type | = type "/" subtype *( ";" parameter ) |
| type | = token |
| subtype | = token |
Параметры могут следовать за type/subtype в форме пар атрибут/значение.
| Parameter | = attribute "=" value | |
| attribute | = token | |
| value | = token | quoted-string |
Имена типа, субтипа и атрибутов параметра могут набираться, как строчными, так и прописными буквами. Значения параметров могут быть и чувствительны к используемому регистру, в зависимости от семантики и имени параметра. Строчный пробел (LWS) не должен использоваться ни между типом и субтипом, ни между атрибутом и значением. Агенты пользователя, которые распознают тип среды, должны обрабатывать (или обеспечить обработку с использованием внешнего приложения для работы агента пользователя с типом/субтипом) параметры для типа MIME так, как это описано для данного типа/субтипа, и информировать пользователя о любых возникающих проблемах.
Замечание. Некоторые старые приложения HTTP не узнают параметры типа среды.
При посылке данных старому HTTP-приложению, программы должны использовать параметры типа среды, только когда они необходимы по описанию типа/субтипа. Значения типа среды регистрируются IANA (Internet Assigned Number Authority). Процесс регистрации типа среды описан в RFC 2048 [17]. Использование незарегистрированных типов среды настоятельно не рекомендуется.
2.7.1. Канонизация и текст по умолчанию
Типы среды Интернет регистрируются каноническим образом. Вообще, тело объекта, передаваемого с помощью HTTP сообщений, должно быть представлено соответствующим каноническим способом, прежде чем будет послано, исключение составляет тип "text", как это описано в следующем параграфе.
В случае канонической формы субтип среды "text" использует CRLF для завершения строки текста. HTTP ослабляет это требование и позволяет передавать текст, используя просто CR или LF, представляющие разрыв строки. HTTP приложения должны воспринимать CRLF, "голое" CR и LF как завершение строки для текстовой среды полученной через HTTP. Кроме того, если текст представлен в символьном наборе, где нет октетов 13 и 10 для CR и LF соответственно, как это имеет место в случае мультибайтных символьных наборов, HTTP позволяет использовать соответствующие символьные представления для CR и LF. Эта гибкость в отношении разрыва строк относится только к текстовой среде в теле объекта; CR или LF не должны подставляться вместо CRLF в любые управляющие структуры HTTP (такие как поля заголовка).
Если тело объекта закодировано с помощью Content-Encoding, исходные данные, прежде чем подвергнуться кодированию должны были иметь форму, указанную выше.
Параметр "charset" используется с некоторыми типами среды, чтобы определить символьный набор (раздел 2.4). Когда параметр charset не задан отправителем явно, субтип среды "text" определяется так, что используется символьный набор по умолчанию "ISO-8859-1". Данные с набором символов, отличным от "ISO-8859-1" или его субнабора, должны помечаться соответствующим значением charset.
Некоторые программы HTTP/1.0 интерпретируют заголовок Content- Type без параметра charset, неправильно предполагая, что "получатель должен решить сам, какой это набор". Отправители, желающие заблокировать такое поведение, могут включать параметр charset, даже когда charset равен ISO-8859-1 и должны делать так, когда известно, что это не запутает получателя.
К сожалению, некоторые старые HTTP/1.0 клиенты не обрабатывают корректно параметр charset. HTTP/1.1 получатели должны учитывать метку charset, присланную отправителем, и те агенты пользователя, которые умеют делать предположение относительно символьного набора, должны использовать символьный набор из поля content-type, если они поддерживают этот набор, а не набор, предпочитаемый получателем.
2.7.2. Составные типы
MIME обеспечивает нескольких составных типов - инкапсуляция одного или более объектов в общее тело сообщения. Все составные типы имеют общий синтаксис, как это определено в MIME [7], и должны включать граничный параметр, являющийся частью значения типа среды. Тело сообщения является само протокольным элементом и, следовательно, должно использовать только CRLF для обозначения разрывов строки. В отличии от MIME, завершающая часть любого составного cообщения должна быть пустой. HTTP приложения не должны передавать завершающую часть (даже если исходное составное сообщение содержит такую завершающую часть (эпилог-подпись).
В HTTP, составляющие части тела могут содержать поля заголовка, которые существенны для значения этих частей. Рекомендуется, чтобы поле заголовка Content-Location (раздел 13.15) было включено в часть тела каждого вложенного объекта, который может быть идентифицирован URL.
Вообще, рекомендуется, чтобы агент пользователя HTTP имел идентичное или схожее поведение с агентом пользователя MIME при получении составного типа. Если приложение получает неузнаваемый составной субтип, оно должно обрабатывать его также как "multipart/mixed".
Замечание: Тип "multipart/form-data" специально определен для переноса данных совместимого с методом обработки почтовых запросов, как это описано в RFC 1867 [15].
2.8. Лексемы (token) продукта
Лексемы продукта служат для того, чтобы позволить взаимодействующим приложениям идентифицировать себя с помощью имени и версии программного продукта. Большинство полей, использующих лексемы продукта допускают также включение в список субпродуктов, которые образуют существенную часть приложения, их лексемы отделяются пробелом. По договоренности, продукты перечисляются в порядке их важности для идентификации приложения.
| Product | = token ["/" product-version] |
| Product-version | = token |
Примеры:
User-Agent: CERN-LineMode/2.15 libwww/2.17b3
Server: Apache/0.8.4
Лексемы продукта должны быть короткими и, кроме того, использование их для оповещения или передачи маловажной информации абсолютно запрещено. Хотя любой символ лексемы может присутствовать в версии продукта, рекомендуется, чтобы эта лексема использовалась только для идентификации версии (то есть, последовательные версии одного и того же продукта должны отличаться только в части версии продукта).
2.9. Значения качества (Quality values)
HTTP согласование параметров содержимого (раздел 12) использует короткие числа с плавающей запятой для указания относительной важности (веса) различных согласуемых параметров. Вес нормализуется на истинное число в диапазоне 0 - 1, где 0 равен минимальному, а 1 максимальному значению. Приложения HTTP/1.1 не должны генерировать более трех чисел после запятой. Рекомендуется, чтобы конфигурация пользователя для этих значений удовлетворяла тем же ограничениям.
qvalue = ( "0" [ "." 0*3DIGIT ] ) | ( "1" [ "." 0*3("0") ] )
"Quality values" (значения качества) является неверным названием, так как эти значения в большей степени отражают относительную деградацию желательного качества.
2.10. Языковые метки
Языковая метка идентифицирует естественный язык. Компьютерные языки в этот перечень не входят. HTTP использует языковые метки в полях Accept-Language и Content-Language.
Синтаксис и регистр языковых меток HTTP тот же, что и определенный в RFC 1766 [1].
Языковая метка содержит одну или более частей: первичная языковая метка и последовательность субметок, которая может и отсутствовать:
| language-tag | = primary-tag *( "-" sub-tag ) |
| primary-tag | = 1*8ALPHA |
| sub-tag | = 1*8ALPHA |
Пробел не допустим в метке, применение строчных и прописных букв не играет никакой роли. Перечень языковых меток контролируется IANA. Ниже приведены примеры языковых меток:
en, en-US, en-cockney, i-cherokee, x-pig-latin
где любые две буквы первичной метки представляют собой языковую аббревиатуру ISO 639 и две буквы исходной субметки соответствуют коду страны ISO 3166 (последние три метки не являются зарегистрированными; все кроме последней могут быть зарегистрированы в будущем).
2.11. Метки объектов
Метки объектов служат для сравнения двух или более объектов из одного и того же запрошенного ресурса. HTTP/1.1 использует метки объектов в полях заголовков ETag (раздел 13.20), If-Match (раздел 13.25), If-None-Match (раздел 13.26) и If-Range (раздел 13.27). Метки объекта состоят из строк, заключенных в кавычки, перед ней может размещаться индикатор слабости.
| entity-tag | = [ weak ] opaque-tag |
| Weak | = "W/" |
| opaque-tag | = quoted-string |
"Сильная метка объекта" (strong entity tag) может принадлежать двум объектам ресурса, если они эквивалентны на октетном уровне.
"Слабая метка объекта " (weak entity tag) отмечается префиксом "W/", может относиться к двум объектам ресурса, только если объекты эквивалентны и могут быть взаимозаменяемы. Слабая метка объекта может использоваться для "слабого" сравнения.
Метка объекта должна быть уникальной для всех версий всех объектов, сопряженных с конкретным ресурсом. Значение данной метки объекта может использоваться для объектов, полученных в результате запросов для различных URI без использования данных об эквивалентности этих объектов.
2.12. Структурные единицы
HTTP/1.1 позволяет клиенту запросить только часть объекта (диапазон). HTTP/1.1 использует структурные единицы, определяющие выделение части объекта, в полях заголовка Range (раздел 13.36) и Content-Range (раздел 13.17).
Объект может быть разбит на фрагменты с использованием различных структурных единиц.
| range-unit | = bytesunit | other-range-unit |
| bytes-unit | = "bytes" |
| other-range-unit | = token |
Единственной структурной единицей, определенной в HTTP/1.1, является "bytes". HTTP/1.1 реализации могут игнорировать диапазоны, специфицированные с использованием других структурных единиц. HTTP/1.1 сконструирован так, чтобы позволить реализацию приложений, которые не зависят от знания диапазонов.
4.5.6.1.3. HTTP сообщение
3.1. Типы сообщений
Сообщения HTTP включают в себя запросы клиента к серверу и отклики сервера клиенту.
HTTP-message = Request | Response ; HTTP/1.1 messages
Сообщения запрос (раздел 5) и отклик (раздел 6) используют общий формат сообщений RFC-822 [9] для передачи объектов (поле данных сообщения). Оба типа сообщений состоят из стартовой строки, одного или более полей заголовка (также известные как "заголовки"), пустой строки (то есть, строка, содержащая CRLF), отмечающей конец полей заголовка, а также опционного тела сообщения.
generic-message = start-line
*message-header
CRLF
[ message-body ]
start-line = Request-Line | Status-Line
В интересах надежности, рекомендуется серверам игнорировать любые пустые строки, полученные, когда ожидается Request-Line (строка запроса). Другими словами, если сервер читает протокольный поток в начале сообщения и получает сначала CRLF, он должен игнорировать CRLF.
Замечание: Определенные не корректные реализации HTTP/1.0 клиентов генерируют дополнительные CRLF после запроса POST. Клиент HTTP/1.1 не должен посылать CRLF до или после запроса.
3.2. Заголовки сообщений
Поля заголовка HTTP, которые включают в себя поля общего заголовка (раздел 3.5), заголовка запроса (раздел 4.3), заголовка отклика (раздел 6.2), и заголовка объекта (раздел 6.1), следуют тому же общему формату, что дан в разделе 3.1 RFC 822 [9]. Каждое поле заголовка состоит из имени, за которым следует двоеточие (":"), и поля значения.
Поля имен безразличны в отношении использования строчных и прописных букв. Поле значения может начинаться с любого числа LWS, хотя один SP предпочтительнее. Поля заголовка могут занимать несколько строк, каждая новая строка должна открываться, по крайней мере, одним SP или HT. Рекомендуется, чтобы приложения следовали общему формату, если они создаются конструкциями HTTP, так как могут существовать некоторые реализации, которые не могут воспринимать ничего кроме общих форматов.
| Message-header | = field-name ":" [ field-value ] CRLF |
| field-name | = token |
| field-value | = *( field-content | LWS ) |
field-content = < OCTET'ы образуют значения поля и состоят из *TEXT или комбинаций лексем, tspecials и закавыченных строк >
Порядок, в котором приходят поля заголовка с отличающимися именами, не играет значения. Однако, хорошей практикой считается посылка сначала поля общего заголовка, за которым следует заголовок запроса или отклика, а в заключение поля заголовка объекта.
Множественные поля заголовка сообщения с идентичными именами могут присутствовать тогда и только тогда, когда значение поля определяется как список из элементов, разделенных запятыми [то есть, #(значения)]. Должна быть предусмотрена возможность объединять множественные поля заголовка в одну пару "имя_поля: значение_поля", без изменения семантики сообщения, путем добавления каждой последующей пары поле-значение, отделенных друг от друга запятыми. Порядок, в котором следуют поля заголовка с идентичными именами, влияет на последующую интерпретацию значения комбинированного поля, по этой причине прокси-сервер не должен менять порядок значений этих полей при переадресации сообщения.
3.3. Тело сообщения
Тело сообщения HTTP (если имеется) используется для переноса тела объекта, сопряженного с запросом или откликом. Тело сообщения отличается от тела объекта, только когда используется транспортное кодирование, как это указано в поле заголовка Transfer-Encoding (раздел 13.40).
message-body = entity-body
|
Transfer- Encoding должно использоваться для указания любого транспортного кодирования, реализованного приложением с целью гарантированной неискаженной доставки сообщения. Транспортное кодирование лежит в зоне ответственности сообщения, а не объекта и по этой причине может быть реализовано любым приложением в цепочке запрос/отклик.
Присутствие тела сообщения в запросе отмечается с помощью включения полей заголовка Content-Length или Transfer-Encoding в заголовки сообщений-запросов. Тело сообщения может быть включено в запрос, только когда метод запроса допускает наличие тела объекта (раздел 4.1.1).
Для сообщений-откликов включение в них тела сообщения зависит от метода запроса и статусного кода отклика (раздел 5.1.1). Все отклики в случае метода запроса HEAD не должны включать тела сообщения, даже если присутствуют поля заголовка объекта, позволяющие предположить его присутствие. Все отклики 1xx (информационные), 204 (никакого содержимого) и 304 (не модифицировано) не должны включать тела сообщения. Все другие отклики включают в себя тело сообщения, хотя оно может иметь и нулевую длину.
3.4. Длина сообщения
Когда тело включено в сообщение, его длина определяется следующим образом (в порядке приоритета):
Любое сообщение-отклик, которое не должно включать в себя тело сообщения (такое как отклик 1xx, 204 и 304, а также любые отклики на запрос HEAD) всегда завершаются первой пустой строкой после полей заголовка, вне зависимости от присутствующих в сообщении полей заголовка объекта.
Если присутствует поле заголовка Transfer-Encoding (раздел 13.40) и указано, что использовано по фрагментное ("chunked") транспортное кодирование, тогда длина тела определяется выбранной схемой кодирования (раздел 2.6).
Если присутствует поле заголовка Content-Length (раздел 13.14), его значение в байтах и определяет длину тела сообщения.
Если сообщение использует тип cреды "multipart/byteranges", который является самоограничивающим, тогда он и определяет длину.
Этот тип среды не должен использоваться, если отправитель не знает, может ли получатель разобрать его. Присутствие в запросе заголовка Range с множественными спецификаторами диапазона подразумевает, что клиент может разобрать отклики типа multipart/byteranges.
Определяется сервером при закрытии связи. (Закрытие соединения не может использоваться для обозначения конца тела запроса, так как это не оставит возможности для сервера послать отклик.)
Для совместимости с приложениями HTTP/1.0, запросы HTTP/1.1, содержащие тело запроса, должны включать корректное поле заголовка Content-Length. Если запрос содержит тело сообщения, а поле Content-Length отсутствует, рекомендуется, чтобы сервер реагировал откликом 400 (плохой запрос), если он не может определить длину сообщения, или 411 (необходима длина), если он настаивает на получении корректного поля Content-Length.
Все приложения HTTP/1.1, которые получают объект (entity) должны понимать блочное ("chunked") транспортное кодирование (раздел 2.6), таким образом, разрешая использование этого механизма для сообщений, когда длина сообщения не может быть определена заранее.
Сообщения не должны включать поле заголовка Content-Length и блочное транспортное кодирование одновременно. Если такое сообщение получено, поле Content-Length должно игнорироваться.
Когда в сообщении присутствует поле Content-Length и разрешено наличие тела сообщения, его значение поля должно строго соответствовать числу октетов в теле сообщения. Агенты пользователя HTTP/1.1 должны оповещать пользователя, если получено сообщение некорректной длины.
3.5. Общие поля заголовка
Существует несколько полей заголовка, которые имеют применимость, как для запросов, так и откликов, но которые не используются для передачи объектов. Эти поля заголовков служат только для пересылаемых сообщений.
| general-header | = Cache-Control | ; Раздел 13.9 |
| | Connection | ; Раздел 13.10 | |
| | Date | ; Раздел 13.19 | |
| | Pragma | ; Раздел 13.32 | |
| | Transfer-Encoding | ; Раздел 13.40 | |
| | Upgrade | ; Раздел 13.41 | |
| | Via | ; Раздел 13.44 |
Имена полей общего заголовка могут быть расширены только при изменении версии протокола. Однако, новые или экспериментальные поля заголовка могут использоваться при условии, если партнеры обмена способны их распознавать, как поля общего заголовка. Не узнанные поля заголовка считаются полями заголовка объекта (entity).
4.5.6.1.4. Запрос
Сообщение-запрос от клиента к серверу включает в себя, в пределах первой строки сообщения, метод, который должен быть использован для ресурса, идентификатор ресурса и код версии используемого протокола.
| Request | = Request-Line | |
| *( generalheader | ||
| | requestheader | ||
| | entityheader ) | ||
| CRLF | ||
| [ messagebody ] |
4.1. Строка запроса
Строка запроса начинается с лексемы метода, за которой следует Request-URI, версия протокола, завершается строка последовательностью CRLF. Элементы разделяются символами SP. Символы CR или LF запрещены кроме завершающей последовательности CRLF.
| Request | Line = Method SP Request-URI SP HTTP-Version CRLF |
4.1.1. Метод
Лексема Method указывает на метод, который должен быть применен к ресурсу, обозначенному Request-URI. При записи метода использование строчных или прописных букв не безразлично.
| Method | = "OPTIONS" | ; Раздел 9.2 |
| | "GET" | ; Раздел 9.3 | |
| | "HEAD" | ; Раздел 9.4 | |
| | "POST" | ; Раздел 9.5 | |
| | "PUT" | ; Раздел 9.6 | |
| | "DELETE" | ; Раздел 9.7 | |
| | "TRACE" | ; Раздел 9.8 | |
| extension-method extension-method = token |
Список методов допустимых для ресурса может быть специфицирован полем заголовка Allow (раздел 13.7). Возвращаемый код отклика всегда оповещает клиента, допустим ли метод для ресурса, так как набор допустимых методов может меняться динамически. Серверам рекомендуется возвращать статусный код 405 (Метод не допустим), если метод известен серверу, но не приемлем для запрашиваемого ресурса и 501 (Не применим), если метод не узнан или не приемлем для сервера. Список методов, известных серверу может быть представлен в поле заголовка отклика Public (раздел 13.35).
Методы GET и HEAD должны поддерживаться всеми серверами общего назначения. Все другие методы являются опционными; однако, если применены вышеназванные методы, они должны быть применены с той же семантикой, что специфицирована в разделе 8.
4.1.2 URI запроса
URI запроса является универсальным идентификатором ресурса (раздел 2.2) и идентифицирует ресурс, который запрашивается.
Request-URI = "*" | absoluteURI | abs_path
Три опции для Request-URI зависят от природы запроса. Звездочка "*" означает, что запрос приложим не к заданному ресурсу, но к самому серверу, и допустим только, когда используемый метод не обязательно приложим к ресурсу. Примером может служить
OPTIONS * HTTP/1.1
Форма абсолютного URI необходима, когда запрос адресован к прокси-серверу. Прокси-серверу посылается запрос переадресации с целью получения отклика. Заметьте, что прокси может переадресовать запрос другому прокси или серверу, указанному абсолютным URI. Для того, чтобы избежать петель запросов прокси-сервер должен быть способен распознавать все имена серверов, включая любые псевдонимы, локальные вариации и численные IP-адреса. Пример строки запроса представлен ниже:
GET http://www.w3.org/pub/WWW/TheProject.html HTTP/1.1
Для того чтобы разрешить передачу абсолютных URI в запросах будущих версий HTTP, все серверы HTTP/1.1 должны уметь работать с запросами абсолютных форм URI.
Наиболее общей формой Request-URI является та, которая используется для идентификации ресурса на исходном сервере или внешнем порту сети. В этом случае абсолютный проход к URI должен быть занесен в abs_path (см. раздел 2.2.1) как Request-URI, а сетевой адрес URI (net_loc) должен быть занесен в поле заголовка Host. Например, клиент, желающий извлечь ресурс из выше приведенного примера непосредственно с базового сервера, установит TCP-соединение через порт 80 с ЭВМ "www.w3.org" и пошлет строки:
GET /pub/WWW/TheProject.html HTTP/1.1
Host: www.w3.org
за которыми следует остальная часть запроса.
Заметьте, что абсолютный проход не может быть пустым; если его нет в исходном URI, он должен быть задан в виде "/" (корневой каталог сервера).
Если прокси получает запрос без какого-либо прохода в Request-URI, а метод, специфицирован так, чтобы быть способным поддерживать форму "*" запросов, тогда последний прокси в цепочке запроса должен переадресовать запрос с "*" в качестве финального Request-URI. Например, запрос
OPTIONS http://www.ics.uci.edu:8001 HTTP/1.1
будет переадресован прокси как
OPTIONS * HTTP/1.1
Host: www.ics.uci.edu:8001
после подключения к порту 8001 ЭВМ "www.ics.uci.edu".
Request-URI передается в формате, описанном в разделе 3.2.1. Исходный сервер должен декодировать Request-URI, для того чтобы правильно интерпретировать запрос. Серверам рекомендуется откликаться на некорректный запрос Request-URI соответствующим статусным кодом.
В запросах, которые они переадресуют, прокси-серверы не должны переписывать "abs_path" часть Request-URI каким-либо способом, за исключением случая, описанного выше, когда нулевой abs_path заменяется на "*".
Замечание: Правило "no rewrite" препятствует прокси изменить смысл запроса, когда исходный сервер некорректно использует незарезервированный URL символ для зарезервированных целей. Следует остерегаться того, что некоторые предшествующие варианты прокси-серверов HTTP/1.1 допускали перезапись Request-URI.
4.2. Ресурс, идентифицируемый запросом
Исходному серверу HTTP/1.1 рекомендуется заботиться о точном определении ресурса, идентифицированного Интернет-запросом путем анализа Request-URI и поля заголовка Host.
Исходный сервер, который не разделяет ресурсы по запрашиваемого ЭВМ, может игнорировать значение поля заголовка Host. (См. раздел 16.5.1 по поводу других требований по поддержке Host в HTTP/1.1.)
Исходный сервер, который различает ресурсы с использованием имени ЭВМ, должен использовать следующие правила для определения ресурса в запросе HTTP/1.1:
Если Request- URI является absoluteURI, ЭВМ определена частью Request-URI. Любое значение поля заголовка Host в запросе должно игнорироваться.
Если Request-URI не является absoluteURI, а запрос содержит поле заголовка Host, ЭВМ определяется значением поля заголовка Host.
Если ЭВМ, так как это определено правилами 1 или 2, не является ЭВМ сервера, откликом должно быть сообщение об ошибке с кодом 400 (Плохой запрос - Bad Request).
Получатели HTTP/1.0-запроса, где отсутствует поле заголовка Host, могут попытаться использовать эвристику (напр., рассмотрение прохода URI на предмет уникальной конкретной ЭВМ) для того, чтобы определить, какой конкретный ресурс запрошен.
4.3. Поля заголовка запроса
Поля заголовка запроса позволяют клиенту передавать серверу дополнительную информацию о запросе и о самом клиенте. Эти поля действуют как модификаторы запроса, с семантикой, эквивалентной параметрам, характеризующими метод языка программирования.
| Request-header | = Accept | ; Раздел 13.1 |
| | Accept-Charset | ; Раздел 13.2 | |
| | Accept-Encoding | ; Раздел 13.3 | |
| | Accept-Language | ; Раздел 13.4 | |
| | Authorization | ; Раздел 13.8 | |
| | From | ; Раздел 13.22 | |
| | Host | ; Раздел 13.23 | |
| | If-Modified-Since | ; Раздел 13.24 | |
| | If-Match | ; Раздел 13.25 | |
| | If-None-Match | ; Раздел 13.26 | |
| | If-Range | ; Раздел 13.27 | |
| | If-Unmodified-Since | ; Раздел 13.28 | |
| | Max-Forwards | ; Раздел 13.31 | |
| | Proxy-Authorization | ; Раздел 13.34 | |
| | Range | ; Раздел 13.36 | |
| | Referer | ; Раздел 13.37 | |
| | User-Agent | ; Раздел 13.42 |
Поля имен заголовка запроса могут быть безопасно расширены в сочетании с изменением версии протокола. Однако новым или экспериментальным полям может быть придана семантика полей заголовка запроса, если все участники обмена способны их распознать. Не узнанные поля заголовка рассматриваются как поля заголовка объекта.
4.5.6.1.5. Отклик
После получения и интерпретации сообщения-запроса, сервер реагирует, посылая HTTP сообщение отклик.
| Response | = Status-Line | ; Раздел 5.1 |
| *( general-header | ; Раздел 3.5 | |
| | response-header | ; Раздел 5.2 | |
| | entity-header ) | ; Раздел 6.1 | |
| CRLF | ||
| [ message-body ] | ; Раздел 6.2 |
5.1. Статусная строка
Первая строка сообщения- отклика является статусной строкой, состоящей из кода версии протокола, за которым следует числовой статусный код и его текстовое представление, все элементы разделяются символами SP (пробел). Никакие CR или LF не допустимы, за исключением завершающей последовательности CRLF.
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
5.1.1. Статусный код и словесный комментарий
Элемент Status-Code представляет собой 3-значный цифровой результирующий код попытки понять и исполнить запрос. Эти коды полностью определены в разделе 9. Словесный комментарий (Reason-Phrase) предназначен для того, чтобы дать краткое описание статусного кода. Статусный код служит для использования автоматами, а словесный комментарий для пользователей. Клиент не обязан рассматривать или отображать словесный комментарий.
Первая цифра статусного кода определяет класс отклика. Последние две цифры не имеют четко определенной функции. Существует 5 значений первой цифры:
1xx: Информационный - Запрос получен, процесс продолжается
2xx: Успех (Success) - Запрос успешно получен, понят и воспринят
3xx: Переадресация (Redirection) - Нужны дополнительные действия для завершения выполнения запроса
4xx: Ошибка клиента (Client Error) - Запрос содержит синтаксическую ошибку или не может быть выполнен
5xx: Ошибка сервера (Server Error) - Сервер не смог выполнить корректный запрос
Индивидуальные значения числовых статусных кодов определены в HTTP/1.1, а набор примеров, соответствующих причинам, представлен ниже. Комментарии причин, предлагаемые здесь, являются лишь рекомендательными - они могут быть заменены местными аналогами без последствий для протокола.
| Status-Code | = "100" | ; Continue |
| | "101" | ; Switching Protocols | |
| | "200" | ; OK | |
| | "201" | ; Created | |
| | "202" | ; Accepted | |
| | "203" | ; Non-Authoritative Information | |
| | "204" | ; No Content | |
| | "205" | ; Reset Content | |
| | "206" | ; Partial Content | |
| | "300" | ; Multiple Choices | |
| | "301" | ; Moved Permanently | |
| | "302" | ; Moved Temporarily | |
| | "303" | ; See Other | |
| | "304" | ; Not Modified | |
| | "305" | ; Use Proxy | |
| | "400" | ; Bad Request | |
| | "401" | ; Unauthorized | |
| | "402" | ; Payment Required | |
| | "403" | ; Forbidden | |
| | "404" | ; Not Found | |
| | "405" | ; Method Not Allowed | |
| | "406" | ; Not Acceptable | |
| | "407" | ; Proxy Authentication Required | |
| | "408" | ; Request Time-out | |
| | "409" | ; Conflict | |
| | "410" | ; Gone | |
| | "411" | ; Length Required | |
| | "412" | ; Precondition Failed | |
| | "413" | ; Request Entity Too Large | |
| | "414" | ; Request-URI Too Large | |
| | "415" | ; Unsupported Media Type | |
| | "500" | ; Internal Server Error | |
| | "501" | ; Not Implemented | |
| | "502" | ; Bad Gateway | |
| | "503" | ; Service Unavailable | |
| | "504" | ; Gateway Time-out | |
| | "505" | ; HTTP Version not supported | |
| | extension-code |
| Extension-code | = 3DIGIT |
| Reason-Phrase | = * |
Статусные коды HTTP допускают расширение. HTTP приложения могут не понимать значение всех зарегистрированных статусных кодов, хотя их понимание, очевидно, является желательным. Однако, приложения должны понимать класс любого статусного кода, который задается его первой цифрой, и воспринимать не узнанный отклик как x00. Не узнанный статусный отклик не должен заноситься в буфер. Например, если клиентом получен не распознаваемый статусный код 431, он может предположить, что произошло что-то с запросом и рассматривать отклик так, как если бы он равнялся 400. В таких случаях агентам пользователя рекомендуется предоставлять пользователю объект с откликом, который содержит текст, поясняющий причину создавшейся ситуации.
5.2 Поля заголовка отклика
Поля заголовка отклика позволяют серверу передавать дополнительную информацию об отклике, который не может быть помещен в статусную строку. Эти поля заголовка дают информацию о сервере и доступе к ресурсу, идентифицированному Request-URI.
| Response-header | = Age | ; Раздел 13.6 |
| | Location | ; Раздел 13.30 | |
| | Proxy-Authenticate | ; Раздел 13.33 | |
| | Public | ; Раздел 13.35 | |
| | Retry-After | ; Раздел 13.38 | |
| | Server | ; Раздел 13.39 | |
| | Vary | ; Раздел 13.43 | |
| | Warning | ; Раздел 13.45 | |
| | WWW-Authenticate | ; Раздел 13.46 |
Имена полей заголовка отклика могут быть расширены только в случае изменения версии протокола. Однако новые или экспериментальные поля могут быть введены с учетом семантики полей заголовка отклика, если все участники обмена способны распознавать эти поля. Не узнанные поля заголовка рассматриваются, как поля заголовка объекта (entity-header fields).
4.5.6.1.6. Объект (Entity)
Сообщения запрос и отклик могут нести в себе объект, если это не запрещено методом запроса или статусным кодом отклика. Объект состоит из полей заголовка объекта и тела объекта, хотя некоторые отклики включают в себя только заголовки объектов.
В данном разделе, как отправитель, так и получатель соотносятся к клиенту или серверу, в зависимости от того, кто отправляет и кто получает объект.
6.1. Поля заголовка объекта
Поля заголовка объекта определяют опционную метаинформацию о теле объекта или, если тело отсутствует, о ресурсе, идентифицированном в запросе.
| Entity-header | = Allow | ; Раздел 13.7 |
| | Content-Base | ; Раздел 13.11 | |
| Entity-header | | Content- | ; Раздел 13.12 |
| Entity-header | | Content-Language | ; Раздел 13.13 |
| Entity-header | | Content-Length | ; Раздел 13.14 |
| Entity-header | | Content-Location | ; Раздел 13.15 |
| Entity-header | | Content-MD5 | ; Раздел 13.16 |
| Entity-header | | Content-Range | ; Раздел 13.17 |
| Entity-header | | Content-Type | ; Раздел 13.18 |
| Entity-header | | Etag | ; Раздел 13.20 |
| Entity-header | | Expires | ; Раздел 13.21 |
| Entity-header | | Last-Modified | ; Раздел 13.29 |
| Entity-header | | extension-header |
extension-header = message-header
Механизм расширения заголовка позволяет определить дополнительные полязаголовка объекта без изменения версии протокола, но эти поля не могут считаться заведомо распознаваемыми получателем. Неузнанные поля заголовка рекомендуется получателю игнорировать и переадресовывать прокси-серверам.
6.2. Тело объекта
Тела объекта (если они имеются), пересылаемые HTTP-запросом или откликом, имеют формат и кодировку, определенную полями заголовка объекта.
| entity-body | = *OCTET |
Тело объекта присутствует в сообщении только когда имеется тело сообщения, как это описано в разделе 3.3. Тело объекта получается из тела сообщения путем декодирования любого транспортного кода (Transfer-Encoding), который может быть применен для обеспечения безопасной и корректной доставки.
6.2.1. Тип
Когда тело объекта включено в сообщение, тип данных этого тела определяется полями заголовка Content-Type и Content-Encoding. Они определяют два слоя, заданных моделью кодирования:
entity-body := Content-Encoding( Content-Type( данные ) )
Content-Type специфицирует тип среды данных.
Content-Encoding может использоваться для индикации любого дополнительного кодирования содержимого поля данных, обычно для целей архивации, которая является особенностью запрашиваемого ресурса. По умолчанию никакого кодирования не используется.
Любое HTTP/1. 1 сообщение, содержащее тело объекта, должно включать поле заголовка Content-Type, определяющее тип среды для данного тела. Только в случае, когда тип среды не задан полем Content-Type, получатель может попытаться предположить, каким является тип среды, просмотрев содержимое и/или расширения имен URL, использованного для идентификации ресурса. Если тип среды остается неизвестным, получателю следует рассматривать его как "application/octet-stream" (поток октетов).
6.2.2. Длина
Длина тела объекта равна длине тела сообщения, после того как произведено транспортное декодирование. Раздел 4.4 определяет то, как определяется длина тела сообщения.
4.5.6.1.7. Соединения
7.1. Постоянные соединения
7.1.1. Цель
Прежде чем установить постоянную связь должно быть реализовано отдельное TCP соединение с тем, чтобы получить URL. Это увеличивает нагрузку HTTP серверов и вызывает перегрузку каналов Интернет. Использование изображений и другой связанной с этим информации часто требует от клиента множественных запросов, направленных определенным серверам за достаточно короткое время. Анализ этих проблем содержится в [30][27], а результаты макетирования представлены в [26].
Постоянное HTTP соединение имеет много преимуществ:
При открытии и закрытии TCP соединений можно сэкономить время CPU и память, занимаемую управляющими блоками протокола TCP.
HTTP запросы и отклики могут при установлении связи буферизоваться (pipelining), образуя очередь. Буферизация позволяет клиенту выполнять множественные запросы, не ожидая каждый раз отклика на запрос, используя одно соединение TCP более эффективно и с меньшими потерями времени.
Перегрузка сети уменьшается за счет сокращения числа пакетов, сопряженных с открытием и закрытием TCP соединений, предоставляя достаточно времени для детектирования состояния перегрузки.
HTTP может функционировать более эффективно, так как сообщения об ошибках могут доставляться без потери TCP связи. Клиенты, использующие будущие версии HTTP, могут испытывать новые возможности, взаимодействуя со старым сервером, они могут после неудачи попробовать старую семантику.
HTTP реализациям следует пользоваться постоянными соединениями.
7.1.2. Общие процедуры
Заметным различием между HTTP/1.1 и более ранними версиями HTTP является постоянное соединение, которое в HTTP/1.1 является вариантом, реализуемым по умолчанию. Поэтому, если не указано обратное, клиент может предполагать, что сервер будет поддерживать постоянное соединение.
Постоянное соединение обеспечивает механизм, с помощью которого клиент и сервер могут сигнализировать о закрытии TCP-соединения. Эта система сигнализации использует поле заголовка Connection. Как только поступил сигнал о закрытии канала, клиент не должен посылать какие-либо запросы по этому каналу.
7.1.2.1. Согласование
HTTP/1.1 сервер может предполагать, что HTTP/1.1 клиент намерен поддерживать постоянное соединение, если только в поле заголовка Connection не записана лексема "close". Если сервер принял решение закрыть связь немедленно после посылки отклика, ему рекомендуется послать заголовок Connection, включающий лексему связи close.
Клиент HTTP/1.1 может ожидать, что соединение останется открытым, но примет решение оставлять ли его открытым на основе того, содержит ли отклик сервера заголовок Connection с лексемой close.
Если клиент или сервер посылает лексему close в заголовке Connection, этот запрос становится последним для данного соединения.
Клиентам и серверам не следует предполагать, что соединение будет оставаться постоянным для версий HTTP, меньше 1.1, если только не получено соответствующее уведомление.
7.1.2.2. Буферизация
Клиенты, которые поддерживают постоянное соединение, могут буферизовать свои запросы (то есть, посылать несколько запросов не дожидаясь отклика для каждого из них). Серверы должны посылать свои отклики на эти запросы в том же порядке, в каком они их получили.
Клиенты, которые предполагают постоянство соединения и буферизацию немедленно после установления соединения должны быть готовы совершить повторную попытку установить связь, если первая буферизованная попытка не удалась.
Если клиент совершает повторную попытку установления связи, он не должен выполнять буферизацию запросов, пока не получит подтверждения об установления постоянного соединения. Клиенты должны также быть готовы послать повторно свои запросы, если сервер закрывает соединение прежде, чем пришлет соответствующие отклики.
7.1.3. Прокси-серверы
Особенно важно то, чтобы прокси-серверы корректно использовали свойства поля заголовка Connection, как это специфицировано в 13.2.1.
Прокси-сервер должен сигнализировать о постоянном соединении отдельно своему клиенту и исходному серверу (origin server) или другому прокси, с которым связан. Каждое постоянное соединение устанавливается только для одной транспортной связи.
Прокси-сервер не должен устанавливать постоянное соединение с HTTP/1.0 клиентом.
7.1.4. Практические соображения
Серверы обычно имеют некоторое значение таймаута, за пределами которого они уже не поддерживают более неактивное соединение. Прокси-серверы могут сделать эту величины больше, так как весьма вероятно, что клиент создаст больше соединений через один и тот же сервер. Использование постоянных соединений не устанавливает никаких требований на величину этого таймаута для клиента или сервера.
Когда клиент или сервер хочет прервать связь по таймауту, ему следует послать корректное оповещение о закрытии соединения. Клиенты и серверы должны постоянно следить, не выдала ли противоположная сторона сигнал на закрытие канала и соответственно реагировать на него. Если клиент или сервер не зафиксирует сигнал противоположной стороны, то будут бессмысленно тратиться ресурсы сети.
Клиент, сервер или прокси могут закрыть транспортный канал в любое время. Например, клиент может послать новый запрос во время, когда сервер решит закрыть "пассивное" соединение. С точки зрения сервера, состояние которое предлагается закрыть, является пассивным, но с точки зрения клиента идет обработка запроса.
Это означает, что клиенты, серверы и прокси должны быть способны восстанавливаться после случаев асинхронного закрытия.
Программа клиента должна заново открыть транспортное соединение и повторно передать неисполненный запрос без вмешательства пользователя (см. раздел 1.2), хотя агент пользователя может предложить оператору выбор, сопряженный с повторением запроса. Однако эта повторная попытка не должна повторяться при повторной неудаче.
Серверам следует всегда реагировать, по крайней мере, на один запрос при соединении, если это возможно. Серверам не следует закрывать соединение в процессе передачи отклика, если только не имеет место отказ в сети или выключение клиента.
Клиенты, которые используют постоянные соединения, должны ограничивать число одновременных связей, которые они поддерживают с конкретным сервером. Однопользовательскому клиенту рекомендуется поддерживать не более двух соединений с любым сервером или прокси. Прокси следует использовать до 2*N соединений с другим сервером или прокси, где N равно числу активных пользователей. Эти рекомендации призваны улучшить время отклика HTTP и исключить перегрузки Интернет и других сетей.
7.2. Требования к передаче сообщений
Общие требования:
HTTP/1.1 серверам следует поддерживать постоянные соединения и использовать TCP механизмы контроля информационного потока для преодоления временных перегрузок, а не разрывать соединение в расчете на то, что клиент совершит повторную попытку. Последнее может усугубить сетевую перегрузку.
Клиент HTTP/1.1 (или позднее), посылая тело сообщения, должен мониторировать сетевое соединение на наличие сигнала ошибки. Если клиент обнаружил состояние ошибки, он должен немедленно прервать передачу. Если тело передается с использованием блочной кодировки ("chunked" encoding, раздел 2.6), возможно применение фрагмента нулевой длины и пустой завершающей секции для обозначения преждевременного конца сообщения. Если телу предшествовал заголовок Content-Length, клиент должен разорвать соединение.
Клиент HTTP/1.1 (или позднее) должен быть готов принять код статуса 100 (Continue - продолжить), за которым следует обычный отклик.
Сервер HTTP/1.1 (или позднее), который получает запрос от клиента HTTP/1.0 (или ранее), не должен передавать отклик 100 (continue - продолжение), ему следует или ждать нормального завершения запроса (таким образом, избегая его прерывания) или преждевременно разрывать соединение.
Клиентам следует запомнить номер версии, по крайней мере, сервера, с которым проводилась работа последним, если клиент HTTP/1.1 получил отклик от сервера HTTP/1.1 (или позднее) и обнаружил разрыв соединения до получения какого-либо статусного кода, клиенту следует повторно попытаться направить запрос без участия пользователя (см. раздел 9.1.2). Если клиент действительно повторяет запрос, то клиент:
Должен сначала послать поля заголовка запроса, а затем
Должен ждать, того, что сервер пришлет отклик 100 (Continue), тогда клиент продолжит работу, или код статуса, сигнализирующего об ошибке.
Если клиент HTTP/1.1 не получил отклика от сервера HTTP/1.1 (или более поздней версии), ему следует считать, что сервер поддерживает версию HTTP/1.0 или более раннюю и не использует отклик 100 (Continue). Если в этом случае клиент обнаруживает закрытие соединения до получения какого-либо статусного кода от сервера, клиенту следует повторить запрос. Если клиент повторил запрос серверу HTTP/1.0, ему следует использовать следующий алгоритм получения надежного отклика:
Инициировать новое соединение с сервером
Передать заголовок запроса
Инициализировать переменную R для оценки задержки отклика сервера (round-trip time) (напр., на основе времени установления соединения), если RTT не доступно, ему присваивается значение 5 секунд.
Вычислить T = R * (2**N), где N равно числу предыдущих попыток запроса.
Ждать в течение Т секунд или до прихода статуса ошибки (что наступит раньше)
Если не получен сигнал ошибки, после T секунд передается тело запроса.
Если клиент обнаруживает преждевременное прерывание связи, повторяется шаг 1 до тех пор, пока запрос не будет принят или будет получен сигнал ошибки, или пока нетерпеливый пользователь не завершит процесс посылки повторных запросов.
Вне зависимости от версии сервера, если получен статус ошибки, то клиент
Не должен продолжать операции и
Должен прервать соединение, если процедура не завершена посылкой сообщения.
Клиент HTTP/1.1 (или позднее), который обнаруживает разрыв соединения после получения флага 100 (Continue), но до получения какого-либо статусного кода, должен повторить запрос и не должен ждать отклика 100 (Continue), но может и делать это, если это упрощает реализацию программы.
4.5.6.1.8. Метод определений
Набор общих методов для HTTP/1.1 определен ниже. Хотя этот набор может быть расширен, нельзя предполагать, что дополнительные методы следуют той же семантике для разных клиентов и серверов. Поле заголовка запроса Host (раздел 13.23) должно присутствовать во всех запросах HTTP/1.1.
8.1. Безопасные и Idempotent методы
8.1.1. Безопасные методы
Программисты должны заботиться о том, чтобы избегать операций, которые могут иметь неожиданное значение для них самих или их соседей по сети Интернет.
В частности, установлено соглашение, что методы GET и HEAD никогда не должны выполнять какие либо функции помимо доставки информации. Эти методы должны рассматриваться как вполне безопасные. Это позволяет агентам пользователя представлять другие методы, такие как POST, PUT и DELETE, особым способом, так что пользователь сам будет заботиться о возможности опасных операций, которые могут быть выполнены в результате реализации запроса.
Естественно, невозможно гарантировать, что сервер не будет вызывать побочные эффекты, как следствие выполнения запроса GET; в действительности, некоторые динамические ресурсы предусматривают такую возможность. Важным отличием здесь является то, что пользователь не запрашивал побочные эффекты и, следовательно, не может нести ответственность за них.
8.1.2. Подобные методы
Методы могут также иметь свойство "idempotence", при котором (помимо ошибок и таймаутов) побочный эффект от N > 0 идентичных запросов является таким же, как и от одного запроса.Методы GET, HEAD, PUT и DELETE имеют это свойство.
Когерентность
Ограничение неизвестного Ni сильно зависит от знания комбинаторной структуры набора работающих субграфов. Большинство проблем надежности, представляющих для нас интерес, имеют свойство когерентности. Имея это в виду, рассмотрим набор D={D1, D2,D3,…,Dr}, в котором каждый Di является набором ребер, для которого E - Di является рабочим. Набор D имеет набор для каждого работающего субграфа, в который входят ребра, не перечисленные в работающем субграфе. Определив так D, мы сформировали наследственное семейство наборов (или комплекс), называемый F-комплексом (то есть, если SОD и S’ НS, тогда S’О D. Тот факт, что сформированное семейство наборов является наследственным, означает, что оно имеет свойство когерентности. Не является совпадением и тот факт, что Fi, определенное ранее, в точности равно числу наборов мощности i в D. Фактически полином надежности для наследственного семейства D полностью определяется его F-вектором (F0,F1,…,Fd), где d=m-1.
Ключом к использованию когерентности при нахождении ограничений является следующее. Рассмотрим все i-наборы в семействе наследования D. Так как семейство является наследственным, в коллекции i-наборов должно быть несколько i-1-наборов; минимальное число таких индуцированных наборов является нижней границей для Fi-1. Минимизация Fi-1 как функции Fi является известной проблемой в теории экстремальных наборов. Здесь имеет место неравенство

Теорема Спернера может использоваться при небольших вычислительных усилиях для улучшения простых ограничений. Мы предполагаем, что доступны l, c, Fm-1 и Fc. Тогда
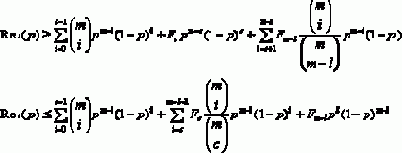
Эта техника ограничений применяется к любым когерентным системам и позволяет получить существенные улучшения для простых ограничений.
Одним из таких методов является улучшение теоремы Спернера. Теорема Крускала-Катона помещает нижнюю границу


Напомним, что Fс равно

Нижние границы получаются симметрично. Мы эффективно вычисляем некоторую последовательность коэффициентов Fm-l, Fm-l+1,…,Fm. Для всетерминальной и двухтерминальной надежности Fm-l равно числу деревьев связи и кратчайших путей, соответственно. В k-терминальной проблеме, для того чтобы вычислить эту последовательность, мы можем задать, например, l=k-1. В любом случае пусть d=m-l. При известном Fd, теорема Крускала-Катона выдает нижнюю границу для Fd-1, а именно

Комментирование скриптов в javascript
Интерпретатор javascript позволяет вводить строку "<!--" в начало элемента script и игнорировать все символы, следующие за ней вплоть до конца строки. javascript интерпретирует "//" как начало комментария, который следует до конца текущей строки. Это необходимо, для того чтобы скрыть строку "-->" от интерпретатора javascript.
<script type="text/javascript">
<!-- to hide script contents from old browsers
function square(i) {
document.write("the call passed ", i ," to the function.","<br>")
return i * i
}
document.write("the function returned ",square(5),".")
// end hiding contents from old browsers -->
</script>
Комментирование скриптов в tcl
В TCL для начала строки комментария используется символ "#" (действует до конца строки).
<script type="text/tcl">
<!-- чтобы скрыть содержимое скрипта от старых броузеров
proc square {i} {
document write "the call passed $i to the function.<br>"
return [expr $i * $i]
}
document write "the function returned [square 5]."
# end hiding contents from old browsers -->
</script>
Некоторые броузеры считают комментарий завершившимся на первом символе ">".
