Протокол TFTP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
TFTP (Trivial FTP, RFC-1350, -783, RFC-906, STD0033) представляет собой упрощенную версию FTP. TFTP не имеет системы безопасности и идентификации, она в отличии от FTP базируется на протоколе UDP (порт 69), а не TCP. Обычно передача осуществляется блоками по 512 байт с ожиданием подтверждения приема каждого пакета (протокол "стой-и-жди"). TFTP используется при загрузке операционной системы в бездисковые рабочие станции (напр. X-терминалы, см. ) или для загрузки конфигурационных файлов в маршрутизатор. Возможно и непосредственное исполнение команды TFTP (TFTP имя_ЭВМ), хотя эта процедура и не дает каких-либо серьезных преимуществ перед FTP (кроме скорости обмена). При выполнении команды без параметров машина выдает приглашение TFTP> и вам предоставляется возможность выполнить определенные команды (ЭВМ SUN):
connect имя_ЭВМ [ порт ]
Задает имя ЭВМ, с которой будет осуществляться обмен, и, если это необходимо порт. Но реального соединения не производится, так как это не предусмотрено протоколом.
mode модификация_обмена.
В качестве модификаций обмена данными могут использоваться аргументы ASCII или BINARY. По умолчанию используется ASCII.
put имя_файла
put местный_файл удаленный_файл
put имя_файла1 имя_файла2 ... имя_файлаn удаленный_каталог
Копирование файла или группы файлов в указанный файл или каталог. Здесь предполагается, что имя удаленной ЭВМ было указано ранее. Если же это не так, возможно одновременное указание имени удаленной ЭВМ и имя файла-адресата: имя_ЭВМ:имя_файла. Имя_ЭВМ становится именем по умолчанию для последующих обменов. Субкоманда GET имеет аналогичную форму обращения. Субкоманда trace позволяет отследить путь пакетов, а команда status сообщит текущее состояние системы. Уход из TFTP по команде exit или quit.
Существует пять форматов пакетов tftp:

Рис. 68. Форматы TFTP-сообщений
Операции запросов (RRQ и WRQ) требуют присылки пакета-отклика (ACK). Сначала устанавливается связь между клиентом и сервером, для этого посылаются запросы read или write.
При этом сообщается имя файла и режим доступа (Mode). Предусмотрено три режима доступа, которые определяются значением поля MODE: NetASCII (американский стандарт для информационных обменов), побайтный (режим binary) и почтовый (данные поступают пользователю, а не заносятся в файл, при этом используется система кодов NetASCII). Предусмотрено шесть типов сообщений об ошибках:
0 - не определен;
1 - файл не найден;
2 - ошибка доступа;
3 - переполнение диска или превышение выделенной квоты;
4 - нелегальная TFTP-операция;
5 - неизвестный идентификатор обмена.
Если запросы read или write успешно выполнены, сервер использует IP-адрес и номер UDP-порта клиента для идентификации последующих операций. Таким образом, ни при пересылке данных, ни при передаче подтверждений (ACK) не нужно указывать явно имя файла. Блоки данных нумеруются, начиная с 1, подтверждение получения пакета имеет тот же номер. Получение блока с размером менее 512 байт означает конец файла. Получение сигнала об ошибке прерывает обмен. При возникновении тайм-аута производится повторная передача последнего блока данных или подтверждения. При задержке отклика, превышающей значение тайм-аута, возможно удвоение всех последующих блоков. Это происходит в некоторых реализациях программного обеспечения оттого, что из-за тайм-аута происходит повторная пересылка блока, а запоздавший отклик на блок i вызовет посылку блока i+1. Это будет продолжаться вплоть до конца пересылки файла. TFTP-протокол используется также и при реализации электронной почты (посылка файлов почтовой программе).
Отсутствие авторизации делает доступность TFTP одной из угроз безопасности. Именно по этой причине во многих инструкциях вы можете найти рекомендацию запретить применение этой утилиты.
Протокол X-Window
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Система X-window была разработана в Массачусетском Технологическом институте (сотрудники этого института внесли существенный вклад и в разработку всего комплекса TCP/IP-протоколов) в качестве многооконного программного интерфейса для ЭВМ с побитовым отображением графической информации. Система предполагала отображение результатов работы нескольких программ одновременно. Сегодня это одна из наиболее популярных систем. Для каждой программы выделялась отдельная область на экране - "окно". С самого начала система предназначалась для работы в различных сетях (TCP, IPX/SPX и т.д.). Система может управлять окнами как на локальной, так и удаленной ЭВМ. Для управления окнами используются специальные сообщения. Для обмена этими сообщениями разработан x-windows протокол. Система X-window состоит из двух частей Xlib и X-сервера (RFC-1198).
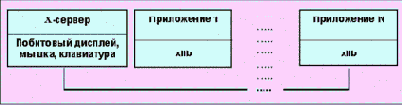
Рис. 4.5.5.1. Схема взаимодействия различных частей X-window
xlib является интерфейсом для любого прикладного процесса и обычно представляет собой программу, написанную на C. Xlib отвечает за обмен информацией между сервером и терминалом пользователя (X-клиент). Под приложениями здесь подразумеваются независимые процессы. Для каждого терминала инсталлируется отдельный X-сервер. Один X-сервер может обслуживать несколько клиентов. X-сервер осуществляет отображение на экране всех окон, в то время как функция клиентов - управление окнами. Для управления окнами используются структуры типа стеков.
Прикладная программа-клиент и сервер взаимодействуют друг с другом через системный протокол X-window (RFC-1013 и RFC-1198). При этом используется четыре вида сообщений:
Запрос: инструкция, направляемая серверу рабочей станции, например, нарисовать окружность.
Отклик: направляется от сервера в ответ на запрос.
Событие: используется сервером, чтобы сообщить прикладной программе об изменениях, которые могут повлиять на ее работу (например, нажатие клавиши на терминале или мышке, запрос из сети и т.д.).
Ошибка: посылается сервером прикладной программе, если что не так (переполнение памяти, неправильно заданные параметры делают выполнение задания невозможным и пр.).
Форматы таких сообщений представлены на рис. 4.5.5.2.
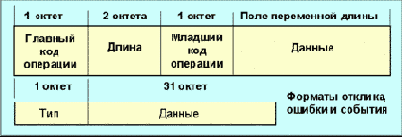
Рис. 4.5.5.2 Форматы сообщений об ошибках
Некоторые X-запросы не нуждаются в откликах (например, связанные с перемещением манипулятора мышь), такие сообщения могут группироваться и посылаться единым потоком (batch stream). Такой подход позволяет пользователю выдать Xlib-запрос и перейти к выполнению других операций, в то время как схема запрос-отклик требует ожидания.
Сообщение типа событие посылается прикладной программе только в случае, если она запрашивала такого рода информацию.
X-Window приложения должны установить канал связи между собой, прежде чем они смогут обмениваться сообщениями. Приложение для того, чтобы установить связь с рабочей станцией использует запрос XOpenDisplay из библиотеки Xlib. Xlib формирует структуру дисплея, которая содержит необходимую информацию, определяющую режим обмена прикладная программа <-> рабочая станция. После того как связь установлена прикладная программа и рабочая станция готовы к работе. Если была нажата клавиша мышки (событие - ButtonPress), а не известно, в каком из окон находится ее указатель, прикладная программа выдает в Xlib запрос XQueryPointer. Положение указателя будет прислано в отклике на этот запрос.
Данный протокол, строго говоря, не входит в набор TCP/IP хотя, как было сказано, он описан в RFC. Но мне представлялось важным дать в руки операторов сетей информацию, которая позволит им лучше понимать, что "гуляет" по их кабельным сегментам.
Работа
Когда клиент сконфигурирован для использования RADIUS, любой пользователь предоставляет аутентификационные данные клиенту. Это может быть сделано с помощью традиционной процедуры login, когда пользователь вводит свое имя и пароль. В качестве альтернативы может использоваться протокол типаPPP, который имеет специальные пакеты, несущие аутентификационную информацию.
Когда клиент получил такую информацию, он может выбрать для аутентификации протокол RADIUS. Для реализации этого клиент формирует запрос доступа (Access-Request), содержащий такие атрибуты как имя пользователя, его пароль, идентификатор клиента и идентификатор порта, к которому должен получить доступ пользователь. При передаче пароля используется метод, базирующийся на алгоритме MD5 (RSA Message Digest Algorithm [1]).
Запрос Access-Request направляется по сети серверу RADIUS. Если в пределах заданного временного интервала не поступает отклика, запрос повторяется. Клиент может переадресовать запрос альтернативному серверу, если первичный сервер вышел из строя или недоступен.
Когда сервер RADIUS получил запрос, он проверяет корректность клиента-отправителя. Запрос, для которого сервер RADIUS не имеет общего секретного ключа (пароля), молча отбрасывается. Если клиент корректен, сервер RADIUS обращается к базе данных пользователей, чтобы найти пользователя, чье имя соответствует запросу. Пользовательская запись в базе данных содержит список требований, которые должны быть удовлетворены, прежде чем будет позволен доступ. Сюда всегда входит сверка пароля, но можно специфицировать клиента или порт, к которому разрешен доступ пользователя. Сервер RADIUS может посылать запросы к другим серверам, для того чтобы выполнить запрос, в этом случае он выступает в качестве клиента.
Если хотя бы какое-то условие не выполнено, сервер посылает отклик "Access-Reject" (отклонение Access-Reject текст комментария.
Если все условия выполнены, сервер может послать отклик-приглашение (Access-Challenge). Этот отклик может содержать текстовое сообщение, которое отображается клиентом и предлагает пользователю откликнуться на приглашение.
Отклик- приглашение может содержать атрибут состояния (State). Если клиент получает Access-Challenge, он может отобразить текст сообщения и затем предложить пользователю ввести текст отклика. Клиент при этом повторно направляет свой Access-Request с новым идентификатором, с атрибутом пароля пользователя, замененным зашифрованным откликом. Этот запрос включает в себя атрибут состояния, содержащийся в приглашении Access-Challenge (если он там был). Сервер может реагировать на этот новый запрос откликами Access-Accept, Access-Reject, или новым Access-Challenge.
Если все условия выполнены, список конфигурационных значений для пользователя укладываются в отклик Access-Accept. Эти значения включают в себя тип услуги (например: SLIP, PPP, Login User) и все параметры, необходимые для обеспечения запрошенного сервиса. Для SLIP и PPP, сюда могут входить такие значения как IP-адрес, маска субсети, MTU, желательный тип компрессии, а также желательные идентификаторы пакетных фильтров. В случае символьного режима это список может включать в себя тип протокола и имя ЭВМ.
Работа с PAP и CHAP
Для PAP, NAS берет идентификатор PAP и пароль и посылает их в пакете Access-Request в полях имя пользователя и пароль пользователя.. NAS может содержать атрибуты Service-Type = Framed-User и Framed-Protocol = PPP в качестве подсказки серверу RADIUS, который предполагает использование услуг PPP.
Для CHAP NAS генерирует псевдослучайное приглашение (желательно 16 октетов) и посылает его пользователю, который возвращает CHAP-отклик вместе с идентификатором и именем пользователя CHAP. NAS посылает затем серверу RADIUS пакет Access-Request с именем CHAP-пользователя в качестве User-Name и с CHAP ID и CHAP-откликом в качестве CHAP-Password (атрибут 3). Случайный вызов может быть включен в атрибут CHAP-Challenge или, если он имеет длину 16 октетов, может быть помещен в поле аутентификатор запроса пакета запроса доступа. NAS может включать в себя атрибуты Service-Type = Framed-User и Framed-Protocol = PPP в качестве подсказки серверу RADIUS, указывая, что предполагается использование канала PPP.
Сервер RADIUS ищет пароль по имени пользователя, шифрует вызов и CHAP-вызов с помощью алгоритма MD5, затем сравнивает результат с CHAP-паролем. Если они совпадают, сервер посылает сообщение Access-Accept, в противном случае - Access-Reject.
Если сервер RADIUS не способен выполнить запрошенную аутентификацию, он должен прислать сообщение Access-Reject. Например, CHAP требует, чтобы пароль пользователя должен быть доступен серверу в открытом текстовом виде, чтобы он мог зашифровать CHAP-вызов и сравнить его с CHAP-откликом. Если пароль не доступен серверу RADIUS в таком виде, он должен послать клиенту сообщение Access-Reject.
Работа с сервером новостей
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
NETNEWS (или Usenet, RFC-1036) - всемирная система обмена сообщениями, использующая для этого единый формат. Сообщения рассортированы по темам, которые носят названия newsgroups (группы новостей). Эти сообщения имеют огромный суммарный объем и передаются от ЭВМ к ЭВМ. Они могут содержать текстовую или кодированную двоичную информацию. Сообщение имеет несколько строк заголовка, которые определяют, откуда пришло сообщение, через какие узлы поступило и т.д.
Основные группы новостей, рассылаемые по всему миру, это: alt, comp, misc, news, rec, sci, soc и talk. Существует много других базовых категорий новостей, например, bionet, biz, vmsnet, которые рассылаются также повсеместно или в рамках какого-то региона или организации (например, ieee), а также коммерческие (например, clari). Последние категории рассылаются только ограниченно. Сообщения многих Bitnet LISTSERV серверов также рассылаются в виде новостей и относятся к категории bit.
Наиболее важные группы новостей:
| Имя группы новостей | Тематика |
| alt | Много различных тем (альтернативные группы новостей) |
| bionet | Биология |
| bit | Многие темы: из подписного листа Bitnet |
| biz | Бизнес, маркетинг, реклама |
| comp | ЭВМ |
| ddn | Defense Data Network (сеть министерства обороны) |
| gnu | Фонд общедоступного программного обеспечения, проект GNU |
| ieee | Institute of Electrical and Electronics Engineers (Институт инженеров электриков и электронщиков) |
| info | Многие темы из листа рассылки Университета Иллинойса |
| k12 | От детских садов до высшей школы |
| misc | Все, что не попадает в одну из категорий news о самой Usenet |
| rec | Хобби, искусство, развлечения, отдых |
| sci | Науки всех направлений |
| soc | Социальная тематика |
| talk | Обсуждение полемических тем |
| u3b | AT&T 3B ЭВМ |
| vmsnet | DEC VAX/VMS и DECNET системы |
Базовые категории разбиваются на более чем 1200 групп новостей по различным вопросам и темам (от образования для инвалидов до Star Trek и от науки об окружающей среде до политики в странах бывшего Советского Союза). Качество дискуссий в этой среде не гарантируется.
Некоторые группы имеют посредников, которые просматривают сообщения перед рассылкой. Usenet была разработана в 1979 году для системы UNIX. В настоящее время в сети новостей работает несколько тысяч узлов, охватывающих практически весь земной шар.
Новости доступны как через локальный сервер, так и через телефонные коммутируемые сети. Программы для поддержки локального сервера новостей доступны в Интернет, UUCP, EARN/Bitnet и Fidonet. Если вам доступна только электронная почта, тогда для вас Usenet не доступна. Однако, многие группы новостей подключены к спискам почтовой рассылки и вы можете подписаться на них. Для этого шлите запрос в LISTSERV@AMERICAN.EDU со строкой: GET NETGATE GATELIST. Более того, многие документы, которые появляются в новостях, доступны по электронной почте в mail-server@rtfm.mit.edu. Для получения руководства по применению в поле subject напишите HELP.
Команды (базовые), используемые при выборе групп новостей
Основные команды
| h | Отобразить справочную информацию; |
| q | quit rn (чтение новостей) - прерывание чтения новостей; |
| x | quit rn, изменения, внесенные в ваш файл .newsrc, не будут сохранены; |
| v | Показать, c какой версией rn вы работаете. RN - прикладная программа, предназначенная для просмотра новостей. |
Начало чтения статей
| Space | Выполнение команды по умолчанию; |
| y | Чтение текущей группы новостей; |
| - | Тоже самое, что и y, но отображает список тем (subjects); |
| ^N | Переход к следующей нечитанной статье по тому же вопросу; |
| k | Пометить как читанные все статьи по текущей теме (subject). |
| = | Выдать список всех нечитанных статей; |
| число | Переход к статье с данным номером; |
| # | Отобразить номер последней статьи. |
Управление группами новостей
| n | Переход к следующей группе новостей с нечитанными статьями; |
| p | Переход к предшествующей группе с нечитанными статьями; |
| P | Назад к следующей статье читанной или не читанной; |
| ^P | Назад к предыдущей статье по той же теме; |
| ^ | Переход к первой группе новостей с нечитанными статьями; |
| ^R | Заново вывести на экран текущую статью; |
| $ | Переход в конец списка групп новостей; |
| g группа новостей | Переход к заданной группе новостей; |
| /эталон | Поиск в прямом направлении группы, содержащей эталон; |
| ? эталон | Поиск в обратном направлении группы, содержащей эталон; |
| / | Поиск в прямом направлении предшествующего эталона; |
| G | Повторить поиск с направлением вперед; |
| ? | Поиск в обратном направлении предшествующего эталона; |
| u | Ликвидация подписки на текущую группу новостей; |
| v | Заново вывести на экран текущую статью вместе с заголовком; |
| l эталон | Выдача списка неподписанных групп, содержащих эталон; |
| L | Выдача состояния групп новостей в файле .newsrc; |
| ^L | Заново вывести на экран текущую страницу; |
| b | Возврат назад на одну страницу; |
| c | Пометить все новости в группе как прочитанные; |
| A | Пренебречь всеми изменениями в данной группе новостей; |
| j | Пометить статью, как прочитанную и перейти в конец; |
| ^X | Декодировать текущую статью, используя ROT-13; |
| X | Декодировать текущую страницу, используя ROT-13; |
/p> Отклик на статью
| r | Послать отклик автору статьи по электронной почте; |
| R | То же, что и r, но в ответ включается исходный текст; |
| f | Запуск программы Pnews для написания статьи отклика; |
| F | То же, что и f, но с включением текста исходной статьи. |
Сохранение статей
| s файл | Запись статьи в файл; |
| w файл | То же, что и s, но без записи заголовка. |
Ввод Unix-команд
| ! команда | Выполнить данную Unix-команду; |
| ! | Прервать исполнение rn и уйти в Shell. |
Если Usenet доступен с вашего терминала, используйте один из многих программных пакетов, пригодных для чтения новостей. Эти пакеты используют либо доступ к местному серверу, либо работают на основе протокола доступа к новостям (NNTP Network News Transfer Protocol), осуществляя связь с другими ЭВМ сети. Рекомендуется прочесть брошюру "How to become a USENET site", которая посылается периодически в news.answers newsgroup. Она также доступна через анонимное FTP по адресу в каталоге /pub/usenet/news.answers/site-setup или по почте в mail-server@rtfm.mit.edu со строкой send usenet/news.answers/site-setup.
Существует поддержка Usenet в самых разных операционных системах: Unix, VMS, MS-DOS, OS/2, Macintosh, MVS, а также в различных средах: MS-Windows, X-Windows, Windows-NT, Emacs. Имеются интерфейсы для системы USENET и для электронной почты. Многие, реально почти все, программные продукты обеспечивают следующие возможности:
Подписка на группы новостей. Это означает, что именно новости данной группы будут немедленно доступны и вы сможете их просмотреть, когда пожелаете.
Аннулирование подписки на группы новостей. Группа удаляется из вашего списка.
Чтение оглавления групп новостей. Ваш локальный сервер выдает вам оглавление новостей и отслеживает, какие из них вы уже читали.
Нить дискуссии. Вы можете отслеживать оглавления групп новостей, имеющих отношение к одной и той же теме или предмету.
Посылка сообщения в группу новостей. Вы можете участвовать в дискуссии, ваш сервер новостей знает, куда послать ваше сообщение.
Отклик на сообщение.
Вы можете послать отклик на любое сообщение (это часто называется follow-up [отклик]) или обратиться к автору сообщения (это обычно называется replay [ответ]).
Выбрав с помощью стрелки группу новостей и нажав клавишу <Enter>, вы получите оглавление статей в группе. Символ "+" указывает на то, что не все сообщения в цепочке были прочитаны. После выбора конкретной статьи вам будет предоставлено ее содержание.
Когда вы введете TIN (программа просмотра новостей), вы получите список групп новостей, на которые вы подписались:
tin 1.2 PL2 [UNIX] (c) Copyright 1991-93 Iain Lea.
(загрузка просмотрщика новостей)
Reading news active file...
Reading attributes file...
Reading newsgroups file... h=help
| Group | Selection (3658) | (выдается базовое меню групп новостей) |
| 1 | 26 | alt.0d | |
| 2 | 72 | alt.1d ? | |
| 3 | 50426 | alt.2600 | |
| 4 | 79 | alt.3d | Dis |
| 5 | 496 | alt.abortion.inequity | Pat |
| 6 | 83 | alt.abuse.recovery | ? |
| 7 | 41087 | alt.activism | Act |
| 8 | 231 | alt.activism.d | A p |
| 9 | 106 | alt.activism.death-penalty | |
| 10 | 208 | alt.adoption | Ado |
| 11 | 37 | alt.aeffle.und.pferdle | Ger |
| 12 | 40 | alt.agriculture.fruit | ? |
| 13 | 26 | alt.agriculture.misc | Gen |
| 14 | 8 | alt.aldus.freehand | ? |
| 15 | 5 | alt.aldus.misc | ? |
| 16 | 78 | alt.aldus.pagemaker | ? |
Приведем краткий перечень возможных команд, для выполнения которых достаточно нажать клавишу-символ, отмеченную правой круглой скобкой.
| <n>=set current to n, | TAB=next unread, | /=search pattern, | c)atchup, | g)oto, |
| j=line down, | k=line up, | h)elp, | m)ove, | q)uit, |
| r=toggle all/unread, | s)ubscribe, | S)ub pattern, | u)nsubscribe, | U)nsub |
| pattern, | y)ank in/out |
Если выбрать команду g (goto), то предоставляется возможность ввести имя группы новостей, которая вас интересует. Например, выберем группу comp.inforsystems.gopher:
Goto newsgroup [comp.mail.misc]> comp.inforsystems.gopher
(получаем новое меню, выбранная тема помечена стрелкой на левом поле)
Group Selection (3658)
| 1825 | 189 comp.graphics.animation Tec | |
| 1826 | 26 comp.graphics.visualization Inf | |
| 1827 | 19 comp.groupware Har | |
| 1828 | 180 comp.groupware.lotus-notes.misc | |
| 1829 | 151 comp.home.automation | |
| 1830 | comp.home.misc | |
| 1831 | 53 comp.human-factors Iss | |
| 1832 | 27 comp.infosystems Any | |
| 1833 | comp.infosystems.announce | |
| 1834 | 130 comp.infosystems.gis All | |
| --> | 1835 | 8 comp.infosystems.gopher Dis |
| 1836 | 1 comp.infosystems.interpedia | |
| 1837 | comp.infosystems.kiosks | |
| 1838 | 27 comp.infosystems.wais The | |
| 1839 | 302 comp.infosystems.www.misc | |
| 1840 | 16 comp.internet.library Dis |
Нажимаем <Enter>> и входим в раздел comp.infosystems.gopher. Система выдает список имеющихся документов.
| 1 | + 3 mime-type Wolfgang Zekoll | |
| 2 | + Harmony Binary Release 1.1 Mansuet Gaisbauer | |
| 3 | + IRD Internet Gopher sites file Fritz Bohnet | |
| --> | 4 | + telnet via gopher Monty FullerDC |
| 5 | + WWW shop of British fine tea from Williamson webmaster@sswi.com | |
| 6 | + WWW shop of Billy Riggs' sermon tapes webmaster@sswi.com |
Выбираем сначала пункт 4. Там лежит сообщение:
Does anyone have a list of sights through which one can access telnet by way of gopher? Thanks for any help. Sincerely, Monty Fuller
Посмотрим следующее сообщение (пункт 5):
Hi,
I would like to invite everybody to visit our WWW shop of British fine tea from Williamson & Magor: Assam, Celebration Blend, Darjeeling, Earl Grey, English Breakfast, Lifeboat.
Go to http://www.sswi.com/, and look under "Shopping Mall": Have a nice holiday. Web Master
http://www.sswi.com/ (может быть интересно для любителей хорошего чая).
В документе 3 найдем полезную информацию об адресе, где лежит список Gopher-серверов:
I have found the IRD Gopher sites file to be a very useful tool for searching the Internet. For those of you who want to have a look, here is the download site:
or via FTP from:
ftp://ftp.mbmarktcons.com/pub/mbmarkt/ird/Fritz
Вернувшись назад в предыдущее меню и выбрав позицию 1838 (comp.infosystems.wais), мы получим другой список документов:
comp.infosystems.wais (19T 26A 0K 0H R)
| 1 | + searching for an underscore ("_") Thomas Carter |
| 2 | + Multi-field search w/freeWAIS-sf Paul Bingman |
| 3 | + 2 Help, compiling FreeWAIS under Sun OS 4.1.4 Adrian Blakey |
| 4 | + Harmony Binary Release 1.1 Mansuet Gaisbauer |
| 5 | + 2 freewais-sf BIO patches? Tak |
| 6 | + Indiceing single letters with freeWAIS-sf-2.0 B. D.O.Adams |
| 7 | + Wais database and html page question? Hans Baartmans |
| 8 | + Help on Virtual Warehousing Daniel Chang |
| 9 | + Question on freeWAIS and SFgate Anna Lee |
| 10 | + 2 Combining numeric fields in boolean search Frances Blomeley |
| 11 | + 2 Indexing PDF files Robert M. Ioffe |
| 12 | + extending length of filenames in freewais-sf Brenda Levesque |
| 13 | + Question: Timestamp problem with wais? Hans Baartmans |
| 14 | + 3 sockets.c - make errors Jason Wilkes |
| 15 | + freewais, wais, and Solaris Philippe Cuif |
| 16 | + 2 freeWAIS-sf Can't compile on BSD Jack Ellis |
Процесс этот почти беспределен.....
Серверы новостей взаимодействуют друг с другом согласно стандартным протоколам, некоторые из которых описаны в Internet RFC. В настоящее время в этом списке имеются:
RFC-977 описывает NNTP (Network News Transfer Protocol)
RFC-1036 определяет формат статей Usenet.
Некоторые группы новостей содержат статьи и дискуссионные материалы по использованию Usenet. Например: news.announce.newusers, news.answers и news.newusers.questions. Многие статьи, которые появляются в этих группах новостей доступны также с помощью анонимного FTP по адресу rtfm.mit.edu или по электронной почте по адресу: mail-server@rtfm.mit.edu.
Равные вероятности отказа ребер
В этом разделе мы работаем с ограничениями, которые верны, когда каждое ребро имеет одну и ту же вероятность работоспособности р; в этом случае, как мы видели, надежность может быть выражена в виде полинома от р. Субграф с рабочими ребрами Е’НE возникает с вероятностью p|E’|(1-p)|E-E’|. Следовательно, вероятность получения субграфа зависит только от числа ребер, которые он содержит. Тогда пусть Ni обозначает число рабочих субграфов с i ребрами. Вероятность работы сети обозначим Rel(G,p) или просто Rel(p) и тогда

Таким образом, вероятность является полиномом по р, который называется полиномом надежности. Это формулировка в терминах наборов маршрутов. Другая формулировка получается из рассмотрения наборов разрезов. Пусть Сi равно числу i-реберных наборов разрезов (оставляющим m-i рабочих ребер), тогда

Еще одна формулировка, вероятно наиболее общая, получается путем рассмотрения дополнений наборов маршрутов. Пусть Fi обозначает число наборов с i ребрами, для которых остальные m-i ребер образуют набор маршрутов. Тогда

Различные ограничения
Существует много других методик ограничений, которые были исследованы и которые не могут быть легко классифицированы как “группировка ребер” или как ограничения, базирующиеся на преобразованиях. Используя модель случайного графа, введенную Эрдёсом и Ренаем, Ломоносов [M.V.Lomonosov, “Bernoulli scheme with closure”, Problems of Information Transmission, 10 (1974), 73-81] рассмотрел процесс эволюции графа. Предположим, что в момент времени 0 каждое из ребер отсутствует, но имеет экспоненциально распределенную вероятность того, что оно появится в графе. Когда впервые граф станет связанным? Ломоносов установил эквивалентность между процессом эволюции графа и статической эволюцией всетерминальной надежности, путем рассмотрения ожидаемого времени, когда произойдет переход из состояния сети с l компонентами в состояние с l-1> компонентом (для l=n,…,2), он установил нижнюю границу всетерминальной надежности.
Рекомендуемые алгоритмы верстки
Если присутствуют элементы col или colgroup, они специфицируют число колонок и таблица может быть отображена с использованием фиксированной раскладки. В противном случае будет применен автоматический алгоритм раскладки, описанный ниже.
Если атрибут width не специфицирован, визуальные агенты пользователя должны предполагать значение по умолчанию, равное 100%.
Рекомендуется, чтобы агенты пользователя увеличивали ширину таблицы за пределы, специфицированные width в случаях, когда содержимое может не поместиться. Агенты пользователя, которые корректируют значение, заданное width должны делать это в пределах разумного. Агенты пользователя могут выбрать переносы строк, когда горизонтальный скролинг не желателен или не практичен.
Для целей раскладки агенты пользователя должны учитывать, что табличные надписи (специфицированные элементом caption) ведут себя подобно ячейкам таблицы. Каждая надпись является ячейкой, которая простирается через все колонки таблицы, если она размещена вверху или внизу таблицы, или через все ряды, если она находится справа или слева от таблицы.
Ряды таблицы Элемент tr
<!element tr - o (th|td)+>
| <!attlist tr | -- ряд таблицы -- | |
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| %CEllhalign; | -- горизонтальное выравнивание в ячейках -- | |
| %CEllvalign; | -- вертикальное выравнивание в ячейках -- | |
| bgcolor %color #implied | -- цвет фона в ряду -- > | |
Элементы TR действуют как контейнеры рядов ячеек таблицы. Ниже приведен пример таблицы, которая имеет три ряда, каждый из которых открывается элементом TR.
<table>
<caption>cups of coffee consumed by each senator</caption>
<tr> … Ряд заголовка …
<tr> … Первый ряд данных …
<tr> … Второй ряд данных …
… остальная часть таблицы …
</table>
Роботы и элементы meta
Элемент meta позволяет HTML разработчикам сообщить приходящим роботам, можно ли индексировать документы. В ниже приведенном примере робот не должен ни индексировать документ, ни анализировать его связи.
<meta name="robots" content="noindex, nofollow">
Список терминов в содержимом включает в себя all, index, nofollow, noindex. Имена и содержимое значений атрибутов не зависит от регистра, использованного при наборе текста.
Замечание. В начале 1997 только несколько роботов следовало этим правилам, но ожидается, что ситуация изменится в ближайшее время.
Серверы подписки (LISTSERV)
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
LISTSERV - система обслуживания и управления списками адресов электронной почты. Она работает в рамках SUN/UNIX, LINUX и др., в интернациональной сети NJE (EARN/Bitnet) и Интернет. Она позволяет группам пользователей, объединенных общим интересом общаться между собой, обеспечивая эффективное использование ресурсов сети. Система дает возможность пользователю найти интересующую его группу, присоединиться к ней и активно участвовать в ее функционировании. LISTSERV управляет почтовым трафиком, осуществляет поиск архивов и файлов. Спектр тем ничем не ограничен, число рубрик превышает 3000.
Доступ к LISTSERV может получить всякий пользователь, кто может посылать электронные сообщения по адресам EARN/Bitnet (в соответствии со стандартом RFC-822) и имеет пригодный к использованию адрес. Отличие от обычной электронной почты заключается в том, здесь вы можете обратиться не только к тем партнерам, адреса которых вы знаете, но и к тем о существовании которых и не подозреваете. Однажды по работе мне потребовалась информация по ультрафиолетовой дозиметрии, я послал запрос в один из серверов и в течение суток получил 6 ответов из США, Канады и Новой Зеландии (среди них Stephan Straus stephen@unicaat.yorku.ca, Martin Brown brauwnma@ucs.oust.edu). Неизвестные мне доселе люди снабдили меня необходимыми данными, указали адреса, где можно найти дополнительную информацию, прислали списки библиографии. Обратите внимание, чтобы однозначно определить, кого я имею в виду, достаточно указать электронный адрес.
Для того, чтобы наладить контакт с LISTSERV нужно послать запрос по адресу: LISTSERV@host-id, где host-id NJE-адрес ЭВМ (например, TAUNIVM.BITNET) или имя INTERNET-домена (в этом случае, VM.TAU.AC.IL). Серверу LISTSERV можно послать несколько команд в одном сообщении. Каждая команда должна начинаться с новой строки. Поле subject при этом игнорируется. Возможно взаимодействие с LISTSERV и в интерактивном режиме.
Для облегчения связи с сервером необходимо определить узловую ЭВМ в сети EARN/Bitnet.
Пользователи вне сети EARN/ Bitnet могут посылать свои запросы по адресу LISTSERV.NET. Заметьте, что если этот узел еще не определен для вашей сети, вы можете попробовать работать на LISTSERV%LISTSERV.BITNET@CUNYVM.CUNY.EDU. Вы можете также использовать специальный LISTSERV-адрес, чтобы послать e-mail в любой LISTSERV-список. Например, если вы хотите послать электронное сообщение в список BITFTP-L для того, чтобы получить копию программы BITFTP, вы можете сделать это, послав сообщение по адресу BITFTP-L@LISTSERV.NET. Ваше сообщение будет автоматически переадресовано по реальному адресу (в данном случае BITFTP-L@EARNCC.BITNET), когда оно попадет в узел LISTSERV. Существует (на конец 1994 года) более 250 узлов в более чем 30 странах мира, где работают серверы LISTSERV. Вот некоторые из них:
| Сервер | Место расположения | Страна |
| BITNIC | Информационный центр сети BITNET | США |
| DEARN | GMD, Бонн | Германия |
| EARNCC | Офис EARN, Париж | Франция |
| HEARN | Католический университет Nijmegen | Нидерланды |
| PUCC | Принстонский университет, Нью-Джерси | США |
| SEARN | Kungliga Tekniska Hoegskolan, Стокгольм | Швеция |
Ниже описаны наиболее часто используемые команды. Для получения полного списка команд извлеките LISTSERV User Guide из списка DOC FILELIST по адресу LISTSERV@EARNCC.BITNET.
Команды имеют следующий формат: заглавные буквы указывают на возможное сокращение, угловые скобки выделяют опционный параметр, а вертикальная черта отмечает значение этого параметра. Существует стандартный набор параметров ключевых слов, которые могут использоваться совместно с командами в качестве параметров. Важными ключевыми словами являются:
PW=пароль - это ключевое слово служит для описания слова-пароля. Если вы завели слово-пароль для данного LISTSERV-сервера, вы должны в дальнейшем записывать в командном тексте строку PW=, чтобы ваши команды были выполнены. Эта функция создана, чтобы блокировать возможность исполнения команд, используя ваш электронный адрес. Если вы зарегистрировали ваш пароль в сервере LISTSERV, вы обязаны включать PW= во все команды, где это требуется по описанию.
F=формат - это ключевое слово управляет форматом файла (или внутренней структурой файла), в котором он будет вам послан. Если вы не являетесь членом EARN/Bitnet, то LISTSERV будет всегда использовать формат MAIL. В противном случае формат файла зависит от информации, которая содержится в BITEARN NODES файле вашей ЭВМ. BITEARN NODES файл - это специальный файл описания сетей, используемый в EARN/Bitnet сетях. Любой пользователь может затребовать формат, отличный от описанного по умолчанию, посредством F=командное_ключевое_слово в командах, где это требуется опционно. Допустимы следующие форматы файлов:
В последние годы появилась возможность создания подписных листов на основе UNIX программы Majordomo. Количество таких списков резко возросло, их создают группы студенов оздоровительные клубы и т.д. Но свободный доступ к команде subscribe открывает также широкие возможности для злоупотреблений. Так фирмы и частные лица, занимающиеся рассылкой SPAM, могут воспользоваться такой возможностью, сформировать клиента подписного листа с именем, например, spam_sender. После этого от его имени cмогут посылать всем подписчикам соответствующие рекламные и прочие spam-сообщения. Возможны и другие варианты. По этоц причине команда subscribe должна исполняться либо только медиатором либо с привлечением пароля.
XXE UUe MIME/text MIME/Appl MAIL
Кроме того, пользователи EARN/Bitnet могут задать:
Netdata Card Disk Punch LPunch VMSdump
Первичной задачей LISTSERV является обслуживание списков электронных адресов (списки для рассылки). Эти списки используются, чтобы пересылать сообщения подписчикам. Таким образом, создаются форумы для обмена идеями и информацией по темам, интересующим подписчиков. Пользователю достаточно помнить только один адрес (адрес сервера), чтобы взаимодействовать с большим числом лиц, имеющим сходные интересы. Обсуждения или дебаты при этом могут иметь всемирный характер.
В рамках LISTSERV почтового списка могут использоваться следующие команды, которые служат для поиска нужного списка и адреса соответствующего сервера, для подписки или ее отмены и т.д.
SUBscribe имя_списка <полное_имя>
Эта команда служит для включения подписчика в список для рассылки. Вы можете использовать эту команду для изменения имени (но не электронного адреса), под которым вы уже известны в списке. имя_списка - это наименование списка, на который вы хотите подписаться. Например, EARN User Group список, находящийся в узле IRLEARN, имеет имя EARN-UG. Не следует путать имя списка с адресом сервера (EARN-UG@IRLEARN). Опционный параметр полное_имя позволяет вам выдать имя, под которым вы хотите фигурировать в списке (это может быть псевдоним). При посылке этой команды в LISTSERV по e-mail полное имя будет взято из поля From:. При посылке этой команды в сервер, где вы уже подписаны, это будет воспринято, как требование об изменении полного имени. Запрос о присоединении к подписному листу может быть обработан тремя путями: подписка может быть OPEN, CLOSED или BY-OWNER. Если это OPEN, вы будете автоматически добавлены в список и получите подтверждение этого. Если это CLOSED, вы будете вычеркнуты из списка рассылки. Если вас там не было, вы получите уведомление о том, что запрос не выполнен. Если же это BY-OWNER, ваш запрос будет переадресован собственнику списка, кто и решит добавлять вас к списку или нет. Адрес, куда будет переправлен ваш запрос, вам будет прислан. Для того, чтобы быть исключенным из списка посылайте команду:
UNSubscribe имя_списка | * <(NETWIDE>
Наличие круглой скобки только слева не является опечаткой. Для того, чтобы ликвидировать подписку по всем спискам LISTSERV, можете использовать "*" вместо имени списка. Если вы хотите, чтобы ваш запрос был передан всем серверам сети, используйте команду (NETWIDE. Эта версия команды рекомендуется при смене вашего электронного адреса или при длительном отпуске. Для получения списка имеющихся списков в сервере LISTSERV используйте команду List.
List <option> <F=формат>
Параметр option может принимать следующие значения:
Short
Отображается резюме всех списков, контролируемых LISTSERV, по одной строке на список.
Эта версия реализуется по умолчанию;
Long
(детально) пересылает вам файл (называемый node-name LISTS), содержащий исчерпывающие описания всех списков, поддерживаемых сервером.
Global <эталон>
Выдается полный список всех известных почтовых списков LISTSERV на текущий момент. Этот файл имеет имя LISTSERV LISTS и содержит имена, заголовки и e-mail адреса этих списков. Это очень большой файл, поэтому следует проверить, есть ли у вас достаточно места на диске, прежде чем использовать опцию Global. Опционный параметр эталон может использоваться для того, чтобы выбрать имя списка, заголовок или список адресов.
Для получения листинга почтовых списков используется команда REView. Формат команды:
REView имя_списка <(> <option>
Листинг будет вам переслан в виде файла с именем list-name LIST (или list-name node-name). Почтовый список состоит из двух частей: управляющая секция и подписная секция. Управляющая секция содержит параметры списка, которые включают в себя информацию о том, кто решает вопросы включения в список или его пересмотра, а также архивации. Подписная секция содержит e-mail адреса и имена всех членов списка. REView-команда позволяет вам получить листинг любой или обеих этих секций (по умолчанию - обеих) для любого из списков. Следует иметь в виду, что по решению владельца списка командой REView может выдаваться только список членов этого списка. В этом случае вам не будет позволено просматривать список e-mail адресов, если вы не член списка. Члены списка могут ограничить доступ к своему e-mail адресу по команде REView, если они установили опцию CANCEL. имя_списка - имя LISTSERV-списка, который вы хотите просмотреть. К важным опциям команды REView относятся:
Short
Получаемая информация ограничивается управляющей секцией (только параметры списка).
Countries
Выдается перечень членов списка упорядоченный с учетом национальной принадлежности.
LOCal
Если список имеет пару (соединен с другим списком того же имени, обслуживаемым другим сервером), вы получите полный листинг в отклик на команду REView.
Опция LOCal может использоваться для подавления распространения действия команды REView на другие серверы. В этом случае вы получите листинг только от сервера, куда вы послали запрос.
При подключении к какому-либо списку, вам будет поставлен в соответствие перечень параметров по умолчанию. Эти параметры могут быть вами изменены для любого из списков, где вы являетесь подписчиком. Команда Query позволяет просмотреть текущие значения параметров (опций) для любого списка. Формат команды:
Query имя_списка | *
Параметр имя_списка представляет собой наименование списка, на который вы подписались. Если вы используете символ "*" вместо имени списка, вы получите информацию о ваших личных параметрах для всех списков, на которые вы подписаны.
Для изменения параметров вашей подписки используется команда SET. Она имеет формат:
SET имя_списка | * options
После выполнения команды SET сервер пришлет вам подтверждение успешного изменения параметра по электронной почте. Важными опциями команды SET являются:
Mail | DIGests | INDex | NOMail
Эти опции варьируют способ, которым вы получаете сообщения. Mail означает, что вы хотите получать сообщения по электронной почте (значение по умолчанию).
DIGests и INDex доступны только в случае, если они разрешены собственником списка. DIGests сохраняет все сообщения посланные в список в течении определенного времени. Вместо того, чтобы получать сообщения одно за другим вы получите их единым кластером в определенный день недели или месяца. Обратите внимание, DIGests не редактирует почту и вы получите все сообщения. INDex передаст вам только дату, время, предмет, число строк, имя отправителя и адреса всех сообщений, посланных в список. Текст сообщений передан не будет. Вы можете выбрать и извлечь заинтересовавшие вас сообщения. NoMail означает, что вам не будут пересылаться сообщения. Это полезно при длительной командировке или отпуске. Вернувшись, вы можете послать команду SET c опцией Mail и возобновить присылку сообщений. Предусмотрена возможность изменения формата заголовков почтовых сообщений.
SHORThdr | FULLhdr | IETFhdr | DUALhdr
Все почтовые сообщения состоят из секции заголовка и тела сообщения. Заголовок содержит информацию об отправителе, получателе, дате и времени отправки. Перечисленные выше опции команды SET указывают на тип заголовка почтового сообщения, который вы хотите иметь. SHORThdr означает, что заголовок сообщения будет содержать только самую существенную информацию (например, Date:, To:, From:, Subject:, и Replay-to: поля). Этот вариант работает по умолчанию. Вы можете изменить это, используя опцию FULLhdr, которая означает, что все (даже не существенные) поля заголовка будут присутствовать в почтовом сообщении. Опция IETFhdr означает, что LISTSERV не изменит заголовок, за исключением того, что добавит в заголовок Received: (а также Message-id: и Sender:, если их там не было). Эта опция введена для обеспечения совместимости с SMTP. Наконец DUALhdr очень похожа на SHORThdr за исключением того, что LISTSERV введет заголовок в начало тела сообщения. Следовательно, когда сообщение получено и читается получателем с этой опцией, оно начнется с этой информации (например, первые три строки сообщения могут содержать To:. From:, и Subject). Эта опция удобна для таких почтовых пакетов на PC, где эта информация не отображается.
CONCEAL | NOCONCEAL
указывает на то, хотите вы или нет, чтобы ваше имя и почтовый адрес появлялся в ответ на команду REView, выданную одним из подписчиков списка. По умолчанию работает NONCONCEAL. Обратите внимание, что полный список подписчиков доступен владельцу списка и администратору LISTSERV, вне зависимости от установки этой опции.
Для возобновления вашей подписки необходимо выдать команду COMFIRM. Формат команды:
CONFIRM имя_списка
Некоторые подписные листы требуют регулярного подтверждения подписки (обычно раз в год). Система автоматически напоминает пользователям, что они должны подтвердить свою подписку, т.е. они должны послать команду CONFIRM в течение заданного числа дней. В противном случае клиент будет вычеркнут из списка.
Эта команда должна быть послана с того же адреса, по которому было послано напоминание. LISTSERV присылает подтверждение получения команды CONFIRM.
LISTSERV может работать также и как файл-сервер. Поэтому сервер может запоминать файлы и обеспечивать к ним доступ по запросам. Эти файлы запоминаются в рамках иерархической системы filelists. Как и предполагает его название filelist представляет собой специальный файл, который содержит список файлов. Каждая запись в filelist описывает файл, который можно затребовать, давая информацию о его имени, размере, а также коде доступа (File Access Code), который описывает, кто имеет доступ к нему. Эти файлы сами могут быть списками файлов. Таким образом, эта файловая система имеет древовидную структуру.
На LISTSERV существует два вида файлов-списков. Первый тип содержит файлы, которые помещены туда специально хозяином списка или его администратором. Это могут быть документы, карты, диаграммы или даже программы. Файлы-списки второго вида ассоциированы со списком адресов LISTSERV. Это списки файлов-списков, они состоят из серии файлов, каждый из которых хранит (обычно до месяца) копию сообщения, которое было ранее разослано. При желании в течение определенного времени эти файлы могут быть скопированы любым подписчиком.
LISTSERV может компоновать один или более файлов в пакет и в таком виде рассылать подписчикам. Это могут быть, например, файлы, необходимые для генерации определенной программы. Пакет декларируется в LISTSERV-filelist через файл, который именуется packet-name $PACKEGE. В нем хранятся описания всех файлов, которые представляют собой пакеты. Любой файл, представляющий собой пакет, может быть извлечен из хранилища с помощью запроса: packet-name PACKAGE. Обратите внимание, что в этом случае символ $ в имени опущен. Таким образом, одна команда позволяет извлечь из депозитария сразу несколько файлов, входящих в пакет.
Некоторые команды позволяют пользователю манипулировать файлами, которые хранятся в депозитарии LISTSERV.
Сюда входят команды подписки и извлечения файлов. При посылке команд файл-серверу вы должны адресовать их именно серверу, а не какому-либо почтовому списку.
Используйте команду INDex для получения списка файлов из определенного filelist. Формат команды:
INDex <список_файлов> <F=формат>
Параметр список_файлов определяет имя списка, который вас интересует. Если не указано ни какого имени, вам будет прислан индекс корневого списка файлов (именуемого LISTSERV FILELIST).
Команда GET используется для извлечения какого-то определенного файла или пакета файлов из списка файлов, если вам разрешено это делать. Формат команды:
GET имя_файла тип_файла <список_файлов> <F=формат>
Параметры имя_файла и тип_файла описывают файл или пакет файлов, который вы хотите получить. Параметр список_файлов определяет список файлов или пакетов, где лежит искомый файл. Если этот параметр не указан, LISTSERV будет определять его путем поиска в собственном индексе, что задержит выполнение запроса.
Для подписки на файлы или пакеты из определенного списка следует использовать команду AFD (Automatic File Distribution). Формат команды:
AFD options
Каждый раз, когда данный список или конкретный файл актуализуется (изменяется), вам будет выслана сервером его копия. Число файлов или пакетов, на которые вы подписаны, не лимитировано. Вы можете в любой момент просмотреть перечень подписки и ликвидировать ее частично или полностью. Параметр options команды AFD может принимать одно из следующих значений:
ADD имя_файла тип_файла <список_файлов> <текст>
<F=формат> <PW=password>
Опция ADD позволяет вам подписаться на файл или пакет, имя_файла и тип_файла характеризует при этом имя и тип файла, на который вы подписались. Если вы хотите, чтобы автоматически в начало каждого присылаемого файла или пакета добавлялся некоторый текст, используйте параметр текст. Если вы пропускаете параметр список_файлов, то параметр текст должен быть помещен в кавычки.
DELete filename filetype <filelist> <PW=password>
Эта опция служит для аннулирования подписки, имена могут содержать символы * (wildcard). Опция List показывает файлы или пакеты, на которые вы в данный момент подписаны. Формат опции:
List <(FORMAT>
Если вы включите опцию (FORMAT, то будет отображен и формат, в котором вам будет присылаться файлы или пакеты. Еще одна команда, которая позволяет осуществить подписку на файлы и пакеты, носит название FUI (File Update Information). Ее формат:
FUI options
Эта команда аналогична AFD за исключением того, что вы в данном случае получаете сообщение об изменении файла или пакета, а не его новую копию. Эта команда допускает следующие опции:
ADD имя_файла тип_файла <список_файлов> <PW=пароль>
Аналог ADD для команды AFD за исключением параметров формат и текст. Опция DELete является полным аналогом одноименной опции команды AFD:
Для получения информации об актуализации файлов или пакетов удобна команда Query File. Параметр список_файлов может быть опущен. Формат команды:
Query File имя_файла тип_файла <список_файлов> <(FLags>
Вы можете задать параметр (Flags, который позволит администрации LISTSERV получить дополнительную техническую информацию о файле, полезную при описании проблем, с которыми вы столкнулись.
Команда PW позволяет вам добавить, изменить или ликвидировать ваше персональное слово-пароль. Команда имеет следующий формат:
PW options
Слово-пароль блокирует возможность несанкционированного использования вашего электронного адреса. Настоятельно рекомендуется воспользоваться этой возможностью. Запрос на регистрацию слова-пароля может быть воспринят в любое время, аналогично оно может быть изменено и аннулировано также, когда вы захотите. Слово-пароль может включать в себя от одного до 8 алфавитно-цифровых символов. Среди опций этой команды могут быть:
ADD new-password
Добавляет новое слово-пароль. Если вы зарегистрировали свое слово-пароль, вы обязаны впредь его использовать всюду (вводить командное ключевое слово PW=), где это требуется опционно.
CHange old-password new-password
Изменяет ваше старое слово-пароль на новое.
DELete old-password
Удаляет ваше слово- пароль из сервера, если вы уже имели его. После этого вы уже не обязаны вводить впредь командное ключевое слово PW=.
Функции LISTSERV DATABASE
LISTSERV позволяет пользователям извлекать старые почтовые сообщения, которые рассылались по списку какое-то время назад. Каждый почтовый список имеет ассоциированную базу данных (обычно называемую notebook или база данных list archive), в которую производится запись рассылаемых сообщений. Такая возможность зависит от хозяина списка и присутствует не всегда. Практически каждый сервер имеет базу данных по узловым ЭВМ сети EARN/Bitnet, которая называется BITEARN. Эта база доступна для всех пользователей. Базовые серверы имеют также базы данных по всем узловым ЭВМ LISTSERV (база имеет название PEERS). Для того, чтобы определить, какие базы данных доступны на данном сервере выдайте команду DATABASE LIST. Для выполнения поиска в базе данных вы можете послать e-mail в LISTSERV c соответствующим запросом в базу данных. Кроме того, пользователи EARN/Bitnet на VM или VMS системах имеют интерактивный доступ к базам данных через программу LDBASE. Для получения более детальной информации пошлите команду Info DATABASE на ближайший сервер.
LISTSERV может выдать пользователю много и другой информации: статистика запросов, справочные и конфигурационные файлы и пр. При запросе этой информации следует адресоваться к серверам, а не к какому-либо списку. К числу команд, помогающих извлечь вспомогательную информацию, относится HELP. В ответ на эту команду вы получите по электронной почте описание наиболее употребимых команд LISTSERV, а также имя сервер-почтмейстера и его электронный адрес.
Для получения help-файла из LISTSERV можно выдать команду Info, которая имеет формат:
INFO <тема> <F=формат>
Опция тема должна характеризовать тематику файла, который вы получите в ответ. Если вы пошлете запрос в ближайший (или любой) LISTSERV без указания темы, то получите список возможных тем запросов.
Допустим вы хотите подписаться на список EARNEWS, который находится в узле FRMOP11. Ваше полное имя Yuri A. Semenov. Пошлите следующую команду по адресу LISTSERV@FRMOP11.BITNET:
SUBSCRIBE EARNEWS Yuri A. Semenov
Если вы хотите покинуть INFO-MAC список, где вы были подписчиком ранее, в узле CEARN, выдайте команду:
UNSUBSCRIBE INFO-MAC
которая должна быть послана серверу LISTSERV в CEARN, который управляет списком INFO_MAC. Для того чтобы покинуть все списки LISTSERV, пошлите команду в ближайший сервер LISTSERV:
UNSUBSCRIBE * (NETWIDE
Если вы хотите получить полный список всех списков рассылки, которые в своем названии содержат слово Europe. Пошлите следующую команду ближайшему серверу LISTSERV:
LIST GLOBAL EUROPE
Вы хотите прекратить получение сообщений из всех списков SEARN, где вы состоите подписчиком. Пошлите серверу LISTSERV в SEARN команду:
SET * NOMAIL
Предположим, что вы получили сообщение от сервера LISTSERV в IRLEARN с просьбой подтвердить вашу подписку на список EARN-UG и вы согласны это сделать. Пошлите серверу команду:
CONFIRM EARN-UG
Если вы хотите получить листинг файлов в DOC FILELIST, то следует послать команду INDEX DOC в LISTSERV-сервер EARNCC, где расположен этот список. Эта команда эквивалентна команде GET DOC FILELIST.
Допустим, вы хотите получить файл PCPROG ZIP из списка файлов в формате XXE. Пошлите команду серверу, где размещен этот файл:
GET PCPROG ZIP F=XXE
Предположим, что вы хотите извлечь все файлы, которые образуют пакет под названием PROGRAM (как видно из файла с названием PROGRAM $PACKAGE) из списка файлов SAMPLE. Пошлите команду:
GET PROGRAM PACKAGE SAMPLE
Если вы хотите подписаться на файл под названием BUDGET MEMO в списке файлов EXPENSES с помощью AFD, тогда воспользуйтесь командой:
AFD ADD BUDGET MEMO EXPENSES
Чтобы подписаться на файл с названием VM EMAIL в DOC FILELIST с помощью FUI, вам следует послать следующую команду в LISTSERV узла EARNCC:
FUI ADD VM EMAIL DOC
Ниже приведен пример реализации LIST-сервера, который использован для обмена информацией о московском опорном магистрали (LIST-сервер "FBONE-OP").
LIST-сервер "FBONE-OP" - система обслуживания и управления списком адресов электронной почты. Она позволяет группам ученых, пользующихся услугами южной части московской оптоволоконной магистрали, общаться между собой. Доступ к серверу может получить всякий пользователь, который имеет доступ к электронной почте. Система реализована на версии Majordomo. Это разработка Brent Chapman'а, версия 1.93.
В описании, приведенном ниже параметры, которые помещены в ] являются опционными. Если вы задаете эти параметры, не помещайте их в [ ].
Для того, чтобы наладить контакт с сервером нужно послать запрос по адресу: FBONE-OP-REQUEST@ITEP.RU. Серверу можно послать несколько команд в одном сообщении. Каждая команда должна начинаться с новой строки. Поле subject при этом игнорируется. Ниже описаны наиболее часто используемые команды. Команды имеют следующий формат: прописные буквы указывают на возможное сокращение, угловые скобки выделяют опционный параметр, а вертикальная черта отмечает значение этого параметра. Существует стандартный набор параметров ключевых слов, которые могут использоваться совместно с командами в качестве параметров.
При работе с LIST-сервером помимо уже описанных (subscribe, unsubscribe, get и index) могут использоваться следующие команды:
which [<address>]
Определить, на какой из списков вы подписаны (или адресат <address>).
who [<list>]
Определить список подписчиков <list>.
info [<list>]
Выдать общую вводную информацию для указанного списка <list>.
lists
Отображает список списков, которые обслуживаются Majordomo-сервером.
end
Блокирует дальнейшую обработку команд (полезно, если вы используете "подпись" в вашей почтовой программе).
Команды должны записываться в тело почтового сообщения (а не в поле Subject) FBONE-OP@ITEP.Ru или FBONE-OP-REQUEST@ITEP.Ru.
В ответ на запрос subscribe вы получите отклик вида:
Received: by ns.itep.ru id AA03442 (5.67a8/IDA-1.5 for semenov); Sun, 26 Feb 1995 12:29:44 +0300
Date: Sun, 26 Feb 1995 12:29:44 +0300
To: semenov
From: MailList
Subject: ITEP MailLists Server results
Reply-To: MailList
>>>> subscribe
Succeeded.
Параметр <list> является опционным, если запрос послан по адресу "<list>-request@ITEP.Ru". В ответ на запрос who сервер выдаст:
From maillist Sun Feb 26 15:46:16 1995
Received: by ns.itep.ru id AA07983
Date: Sun, 26 Feb 1995 15:46:15 +0300
To: semenov
From: MailList
Subject: ITEP MailLists Server results
Reply-To: MailList
>>>> who
Members of list 'fbone-op':
bobyshev
BOBYSHEV@vxdesy.desy.de
bobyshev@x4u2.desy.de
kent@top.rector.msu.su
ks@isf.ru
em@free.net
gonchar@ipsun.ras.ru
noc@radio-msu.net
sid@free.net
nelubov@oea.ihep.su
sakr@itp.ac.ru
leonid@egoshin.ihep.su
semenov
При работе c подписными листами следует прежде всего думать о партнерах по списку. Это занятые люди, поэтому для всеобщего внимания следует выносить лаконичные сообщения, представляющие всеобщий интерес. Частные сообщения лучше посылать только тому, или тем, адресатам, которым это важно знать.
Детальная документация по LISTSERV и связанных с ним услуг доступна в DOC FILELIST по адресу LISTSERV@EARNCC.BITNET. Сюда входит LISTSERV User Guide, который доступен в обычном и postscript форматах. Для получения списка доступной документации используйте команду INDex. Существует несколько списков для обсуждения технических вопросов LISTSERV. Они не предназначены для обычных пользователей, но и не закрыты для них. Это:
LSTSRV-L технический форум LISTSERV.
LSTOWN-L форум хозяев списков LISTSERV.
LDBASE-L форум возможностей баз данных в LISTSERV.
Сетевая надежность
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
M.O. Ball, C.J. Colbourn, J.S. Provan Network Reliability
Авторизованный перевод Семенова Ю.А. и Гончарова А.А. (ИТЭФ/ЦНТК)
Сетевое моделирование
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Ни один проект крупной сети со сложной топологией в настоящее время не обходится без исчерпывающего моделирования будущей сети (речь, разумеется, идет не о России). Программы, выполняющие эту задачу, достаточно сложны и дороги. Целью моделирования является определение оптимальной топологии, адекватный выбор сетевого оборудования, определение рабочих характеристик сети и возможных этапов будущего развития. Ведь сеть, слишком точно оптимизированная для решений задач текущего момента, может потребовать серьезных переделок в будущем. На модели можно опробовать влияние всплесков широковещательных запросов или реализовать режим коллапса (для Ethernet), что вряд ли кто-то может себе позволить в работающей сети. В процессе моделирования выясняются следующие параметры:
Предельные пропускные способности различных фрагментов сети и зависимости потерь пакетов от загрузки отдельных станций и внешних каналов.
Время отклика основных серверов в самых разных режимах, в том числе таких, которые в реальной сети крайне нежелательны.
Влияние установки новых серверов на перераспределение информационных потоков (Proxy, Firewall и т.д.).
Решение оптимизации топологии при возникновении узких мест в сети (размещение серверов, DNS, внешних шлюзов, организация опорных каналов и пр.).
Выбор того или иного типа сетевого оборудования (например, 10BaseTX или 100BaseFX) или режима его работы (например, cut-through, store-and-forward для мостов и переключателей и т.д.).
Выбор внутреннего протокола маршрутизации и его параметров (например, метрики).
Определение предельно допустимого числа пользователей того или иного сервера.
Оценка необходимой полосы пропускания внешнего канала для обеспечения требуемого уровня QOS.
Оценка влияния мультимедийного трафика на работу локальной сети, например, при подготовке видеоконференций.
Перечисленные задачи предъявляют различные требования к программам. В одних случаях достаточно провести моделирование на физическом (MAC) уровне, в других нужен уже уровень транспортных протоколов (например, UDP и TCP), а для наиболее сложных задач нужно воспроизвести поведение прикладных программ.
Все это должно учитываться при выборе или разработке моделирующей программы. Ведь нужно учесть, что ваша машина должна в той или иной мере воспроизвести действия всех машин в моделируемой сети. Таким образом, машина эта должна быть достаточно быстродействующей и, несмотря на это, моделирование одной секунды работы сети может занять при определенных условиях не один час.
Результаты моделирования должны иметь точность 10-20%, так как этого достаточно для большинства целей и не требует слишком много машинного времени. Следует иметь в виду, что для моделирования поведение реальной сети, надо знать все ее рабочие параметры: длины кабеля от концентратора до конкретной ЭВМ, задержки используемых кабелей, задержки концентраторов (этот параметр часто отсутствует в документации и его придется брать из документации на сетевой протокол, например из IEEE 802.3). Параметры могут быть определены и прямым измерением. Чем точнее вы воспроизводите поведение сети, тем больше машинного времени это потребует. Кроме того, вам предстоит сделать некоторые предположения относительно распределения загрузки для конкретных ЭВМ и других сетевых элементов, задержек в переключателях, мостах, времени обработки запросов в серверах. Здесь нужно учитывать и характер решаемых на ЭВМ задач. www/ftp-сервер или обычная персональная рабочая станция создают различные сетевые трафики. Определенное влияние на результат могут оказывать и используемые ОС. В случае моделирования реальной сети можно произвести соответствующие измерения, что иногда тоже не слишком просто. Учитывая сложность моделирования на одной ординарной ЭВМ, следует ограничиваться моделированием не более чем одной минуты для каждого из наборов параметров (этого времени достаточно для копирования практически любого файла через локальную сеть). Исключение может составлять моделирование внешнего трафика, но в этом случае весь локальный трафик должен рассматриваться как фоновый.
Сети с коммутацией пакетов, уровень опорной сети
Первые сети с коммутацией пакетов были разработаны в 1960х. Их создали с целью поделить высокоскоростные каналы между большим количеством пользователей. Трафик, порождаемый одним пользователем, имеет много всплесков и пауз. Трафик нескольких пользователей можно динамически разнести по времени и передавать по одному соединению. ARPANET была первой крупной сетью с коммутацией пакетов. Большая часть исследований в области сетевой надежности до и после 1970 велась именно для ARPANET. На рис. 1 представлена схема ARPANET по состоянию на 1979 год. Надежность ARPANET в основном рассматривалась с точки зрения связанности сети. Считалось, что сеть функционирует, если она остается связанной, т.е. пока каждый из пользователей специфицированного субнабора связан друг с другом. Такой подход был оправдан, так как в ARPANET использовалась динамическая маршрутизация, так что данные могли быть направлены в обход отказавших узлов. Хотя данные и могли быть направлены по другому маршруту, в сети могли возникнуть перегрузки и задержки, вызванные падением общей пропускной способности сети.
При сравнении ARPANET с коммерческими опорными сетями с коммутацией пакетов, используемыми в 1980-х годах, такими как Telnet и Tymnet ясно, что коммерческие сети много компактнее. Как следствие, вероятность нарушения связанности в коммерческих сетях много меньше, но, как правило, загрузка каналов там достаточно высока. Отсюда напрашивается вывод, что следует более детально подходить к вычислению параметров сетевой надежности и учитывать перегрузки и пропускную способность сети. Будем считать, что сеть работоспособна, если она связанна и параметры сетевой работоспособности, коими могут быть средние задержки, не превышают заданных пределов.
Сегодня сеть ArpaNet может показаться топологически достаточно простой, но даже для такой сети расчет надежности отнюдь не простая задача даже при оценке простой связности.
Для того чтобы минимизировать перебор можно использовать различные методы эквивалентного преобразования графа сети, минимизирующего число узлов или ребер при сохранении значения надежности.
SGML декларация
<!sgml "ISO 8879:1986"
-- SGML - предложениеHhypertext Markup Language версия 4.0. С поддержкой первых 17 плоскостей ISO10646 и увеличенными пределами для меток и литералов. --
charset
baseset "ISO registration number 177//charset
ISO/IEC 10646-1:1993 UCS-4 with
implementation level 3//esc 2/5 2/15 4/6"
| descset | 0 | 9 | unused |
| 9 | 2 | 9 | |
| 11 | 2 | unused | |
| 13 | 1 | 13 | |
| 14 | 18 | unused | |
| 32 | 95 | 32 | |
| 127 | 1 | unused | |
| 128 | 32 | unused | |
| 160 | 55136 | 160 | |
| 55296 | 2048 |
unused -- суррогаты -- | |
| 57344 | 1056768 | 57344 |
| capacity | sgmlref | |
| totalcap | 150000 | |
| grpcap | 150000 | |
| entcap | 150000 | |
| scope | document | |
syntax
| shunchar | controls | 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 127
| baseset | "ISO 646irv:1991//charset | |
|
international reference version (irv)//esc 2/8 4/2" |
descset 0 128 0
function
| re | 13 |
| rs | 10 |
| space | 32 |
| tab sepchar | 9 |
| naming | lcnmstrt "" | |||
| ucnmstrt "" | ||||
| lcnmchar ".-_:" | ||||
| ucnmchar ".-_:" | ||||
| namecase | general | yes | ||
| entity | no | |||
| delim | general | sgmlref | ||
| shortref | sgmlref | |||
| names | sgmlref | |||
| quantity | sgmlref | |||
| attcnt | 60 | |||
| attsplen | 65536 | -- Это наибольшие величины -- | ||
| litlen | 65536 | -- разрешенные в декларации -- | ||
| namelen | 65536 | -- Избегайте фиксированных пределов -- | ||
| pilen | 65536 | -- приложения агентов пользователя HTML -- | ||
| taglvl | 100 | |||
| taglen | 65536 | |||
| grpgtcnt | 150 | |||
| grpcnt | 64 | |||
features
| minimize | ||
| datatag | no | |
| omittag | yes | |
| rank | no | |
| shorttag | yes | |
| link | ||
| simple | no | |
| implicit | no | |
| explicit | no | |
| other | ||
| concur | no | |
| subdoc | no | |
| formal | yes | |
| appinfo | none | |
Sgml декларация html
Замечание. Набор символов SGML-деклараций документа включает в себя первые 17 плоскостей [ISO10646] (17 раз по 65536). Это ограничение связано с тем, что это число в текущей версии стандарта SGML имеет только 8 цифр.
Замечание. Строго говоря, регистрационный номер ISO 177 относится к исходному состоянию ISO 10646 в 1993 году, в то время как в этой спецификации мы базируемся на последней версии ISO 10646.
Символ & в значениях атрибута URI
URI, который создан при выдаче формы, может быть использован в качестве связи типа якорь (напр., атрибут Href для элемента A). К сожалению использование символа "&" для разделения полей формы противоречит его применению в значениях атрибутов SGML для выделения символьных объектов. Например, для того чтобы использовать URI "http://host/?x=1&y=2" в качестве связующего URI, его следует записать в виде <a Href="http://host/?x=1&y=2"> или <a Href="http://host/?x=1&y=2">.
Рекомендуется, чтобы пользователи сервера http, и в частности, пользователи CGI поддерживали применение ";" вместо "&" с целью избавления разработчиков от обхода символов "&".
Система поиска файлов Archie
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
ARCHIE - информационная система с наиболее эффективной системой поиска. Система разработана Аланом Эмтейджем, Питером Дойчем и Билом Хееланом из университетского вычислительного центра McGill, Канада. ARCHIE осуществляет поиск по более чем 1000 депозитариям мира допускающим анонимный доступ и содержащим более 2100000 файлов. ARCHIE работает под Windows, MS-DOS, Macintosh, Unix в рамках сети INTERNET. Рекомендуется следовать следующим правилам (в последнее время система стала менее популярна, ее функции взяли на себя поисковые сервера):
избегайте проводить поиск в рабочие часы, так как большинство ARCHIE- серверов выполняют и другие локальные функции.
запросы должны быть как можно конкретнее, это ускорит их выполнение.
интерфейс на вашей ЭВМ снизит нагрузку удаленных серверов, поэтому рекомендуется использовать локальные интерфейсы.
используйте ближайший к вам ARCHIE-сервер, это сократит нагрузку телекоммуникационных каналов и повысит надежность поиска.
Базы данных ARCHIE располагаются по адресам:
| Адрес ARCHIE | Страна | Число шагов из ITEPNet *) |
| archie.au (139.130.4.6) | Австралия | 23 |
| archie.edvz.uni-linz.ac.at (140.78.3.8) | Австрия | |
| archie.univie.ac.at (131.130.1.23) | Австрия | 17 |
| archie.uqam.ca (132.208.250.10) | Канада | 21 |
| archie.funet.fi (128.214.6.102) | Финляндия | 9 |
| archie.th-darmstadt.de (130.83.128.118) | Германия | 13 |
| archie.doc.ic.ac.uk (146.169.11.3) | Англия | 16 |
| archie.ac.il (132.65.16.8) | Израиль | 19 |
| archie.cs.huji.ac.il (132.65.6.15) | Израиль | |
| archie.unipi.it (131.114.21.10) | Италия | 12 |
| Archie.uninett.no (128.39.2.20) | Норвегия | |
| archie.kuis.kyoto-u.ac.jp | Япония | 29 |
| archie.wide.ad.jp (133.4.3.6) | Япония | |
| archie.kr | Корея | |
| archie.sogang.ac.kr (163.239.1.11) | Корея | |
| archie.rediris.es (130.206.1.2) | Испания | 12 |
| archie.nz (130.195.9.4) | Новая Зеландия | 25 |
| archie.luth.se (130.240.18.4) | Швеция | 15 |
| archie.switch.ch (130.59.1.40) | Швейцария | 15 |
| archie.ncu.edu.tw (140.115.19.24) | Тайвань | |
| archie.ans.net (147.225.1.10) | США | 23 |
| archie.internic.net (198.49.45.10) | США | 16 |
| archie.rutgers.edu (128.6.18.15) | США | |
| archie.sura.net (128.167.254.179) | США | |
| archie.unl.edu (129.93.1.14) | США | 20 |
*) Число шагов величина непостоянная и может изменяться со временем, сильно зависит от используемого маршрута.
Имеется возможность доступа к ARCHIE через локальный клиент-сервер, через команду telnet или с помощью электронной почты. В настоящее время доступна версия сервера 3.0. Команды, помеченные ниже (+) работают только с версией 3.0, помеченные же (*), работают только с предшествующими версиями. Для определения версии, с которой вы работаете, выдайте команду version. Локальные серверы работают быстрее и надежнее. В публичном доступе имеются версии для MS-DOS, OS/2, VMS, NeXT, Unix, X-windows и Macintosh. Клиент-серверы доступны через анонимный FTP в каталогах /pub/archie/clients ли /archie/clients, обычно это строчные варианты. Существует и графическая версия (xarchie) для X-windows. Стандартное обращение к ARCHIE имеет форму:
ARCHIE <-options> последовательность символов | образ
где options могут быть:
| o | определяет имя выходного файла для запоминания результата. |
| l | список найденных объектов по одной строке на документ. |
| t | сортирует результат поиска по датам. |
| m# | определяет максимальное число найденных документов (# от 0 до 1000), по умолчанию это число равно 95. |
| H archie-server | специфицирует сервер, куда посылается запрос, в отсутствии этого параметра используется сервер по умолчанию, если такой описан. |
| L | список известных серверов, включая текущий. |
Например, команда (SUN): archie -L выдаст на экран:
Known archie servers:
archie.ans.net (USA [NY])
archie.rutgers.edu (USA [NJ])
archie.sura.net (USA [MD])
archie.unl.edu (USA [NE])
archie.mcgill.ca (Canada)
archie.funet.fi (Finland/Mainland Europe)
archie.au (Australia)
archie.doc.ic.ac.uk (Great Britain/Ireland)
archie.wide.ad.jp (Japan)
archie.ncu.edu.tw (Taiwan)
* archie.funet.fi is the default Archie server.
* For the most up-to-date list, write to an Archie server and give it the command `servers'.
Следующая группа options определяет разновидность поиска.
| s | объект будет выбран, если имя файла/каталога содержит заданную последовательность символов. Поиск не зависит от того, строчные или заглавные буквы использованы в эталонной последовательности. |
| c | как и выше, но для поиска не безразличны строчные/заглавные буквы. |
| e | последовательность символов должна точно совпадать с образцом, с учетом использования заглавных и строчных символов. Это способ поиска по умолчанию. |
| r | поиск образов, которые включают в себя специальные символы, интерпретируемые до начала поиска. |
/p> Результатом поиска может стать список FTP-адресов файлов или каталогов, соответствующих критериям отбора, указывается размер файлов, дата последней модификации и имя каталога, где этот файл лежит.
Для интерактивного попадания в ARCHIE-сервер используется команда telnet, в ответ на login следует ввести archie. Для того чтобы покинуть ARCHIE-сервер используются команды: exit, quit, bye. Кроме того, существуют следующие команды:
| help ? | Выдает полный список команд |
| help <имя команды> | Выдает описание команды, возврат с помощью клавиши <Enter>. |
| help set variable | Выдает описание присвоения значения системной переменной. |
| list <образ> | Выдает список IP-адресов баз данных и дат их последней коррекции. Параметр, если он присутствует, обеспечивает отбор адресов с учетом соответствия этому параметру. Если нет параметра, то список будет содержать около 1000 адресов. list \.de$ даст адреса в Германии. |
| manpage | Отображение страницы руководства по использованию Archie |
| servers | Выдает список серверов Archie |
| site (*) site-name | Получение списка каталогов и субкаталогов депозитария с именем site-name. Обычно это очень длинный список. |
| whatis <строка> | Осуществляет поиск описания программы для string. |
prog <строка>|<образ> find(+)<строка>|<образ> | Осуществляет поиск строки <строка> или образа <образ>, представляющий название искомого ресурса. Поиск может выполняться несколькими способами, определяемыми переменной search (команда set), которая также определяет, следует ли интерпретировать параметр как string или pattern. Результат представляет собой список FTP- адресов, размеров найденных объектов и дат последней модификации. Число объектов в списке ограничивается переменной maxhits (команда set). Результат prog может быть отсортирован в соответствии с величиной переменной sortby (команда set). По умолчанию переменные search, maxhits и sortby устанавливаются соответственно на точное соответствие string, 1000 объектов без сортировки результата |
| mail <email> <,email2...> | Отсылает результат поиска по электронной почте по заданному адресу. При команде без параметров результат отсылается по адресу, заданному переменной mailo (команда set). |
| show <переменная> | Отображает значение переменной с данным именем. В отсутствии параметра отображаются все переменные. |
| set <переменная> <значение> | Устанавливает значение одной из переменных ARCHIE. |
/p> Используются следующие переменные:
compress(+) метод_архивации
Задает метод архивации (none или compress), используется до отправки почты командой mail. По умолчанию none.
encode(+) метод_кодирования
Определяет метод кодирования (none или uuencode), используется при отправке по почте. Эта переменная игнорируется, если компрессии нет. По умолчанию none.
mailo email <,email2...>
Определяет e-mail адрес, куда будет послан результат, при выдаче команды без аргумента.
maxhits number
Определяет максимальное число отобранных объектов командой prog (0-1000). По умолчанию эта переменная равна 1000.
search search-value
Определяет вид проводимого поиска: prog string | prog string | pattern. search-values равны:
| sub | Частичное совпадение и независимость от заглавная/сточная. | |
| subcase | То же, но не безразлично заглавный/сточный символы. | |
| exact | Точное соответствие образцу. | |
| regex pattern | Интерпретируется перед началом поиска. | |
| sortby sort-value | Описывает то, как сортировать результаты поиска по команде prog. Значения sort-values (параметр сортировки): | |
| hostname | Сортировка по FTP-адресам в лексическом порядке | |
| time | Сортировка по дате модификации, более поздние сначала. | |
| filename | Сортировка по именам файлов или каталогов в лексическом порядке | |
| none | Никакой сортировки | |
| size | Сортировка документов по размеру | |
term terminal-type <number-of-rows<number-of-columns>>
Сообщает ARCHIE, какой терминал используется.
Доступ через электронную почту
Пользователи могут получить доступ к ARCHIE через электронную почту, послав запрос по адресу archie@archie.ac.il. Команды посылаются в теле сообщения. Командные строки начинаются всегда с первой колонки. Поле subject рассматривается как строка самого сообщения. При этом допустимы следующие команды:
| help | Присылает файл HELP, при этом другие команды сообщения игнорируются. |
| path return-address set mailto(+) return-address | Определяет обратный адрес, отличный от того, что записан в заголовке |
| list pattern <pattern2...> | Выдает список адресов, где есть данные, соответствующие pattern, наиболее свежие по дате |
| site(*) site-name | Выдает список каталогов и субкаталогов по адресу site-name |
| whatis string <string2...> | Ищется в базе данных описание программных продуктов, где содержится string. Прописные или строчные буквы роли не играет |
| prog pattern <pattern2...> find(+) pattern <pattern2> | Поиск всех упоминаний ресурсов с именем pattern. Если несколько pattern помещено в одной строке, результат поиска будет прислан в одном сообщении. Если несколько prog помещено в строке, результат присылается в нескольких сообщениях, по одному на каждый prog. Результат представляет собой список адресов для FTP. Если pattern содержит пробелы, он должен быть заключен в кавычки. Поиск не зависит от того, заглавные или строчные буквы использованы в запросе. |
| compress(*) | Полученный результат будет архивирован и перекодирован с помощью uuencode. В результате будет получен файл с расширением .Z. Сначала по получении сообщения следует обработать с помощью uudecode, а после этого следует выполнить программу uncompress |
| set compress(+) compress-method | Специфицирует метод архивирования (none или compress) перед отправкой по почте. По умолчанию none |
| set encode(+) encode-method | Специфицирует метод кодирования (none или uuencode) перед отправкой по почте. По умолчанию none. |
| quit | Ничего не производит, полезна в случае автоматического добавления подписи в конце сообщения. |
| Description of pattern pattern | Описывает последовательность символов, включая специальные символы. Символ перестает быть специальным, если перед ним стоит "\". |
/p> К числу специальных символов относится:
| . (точка) | Заменяет любые другие символы (wildcard). |
| ^ | Появляется в начале pattern. При этом будет искаться будет последовательность, следующая за "^". Например: "^efgh" узнает "efgh" или "efghij" но не "abcdefgh". |
| $ | Появляется в конце pattern. Так, например: "efghi$" узнает "efghi" или "abcdefghi" но не узнает "efghijkl". |
Если вы послали команду list \.de$ по электронной почте или с помощью Telnet, вы получите следующий отклик:
| alice.fmi.uni-passau.de | 132.231.1.180 | 12:31 | 8 Aug 1993 |
| askhp.ask.uni-karlsruhe.de | 129.13.200.33 | 12:25 | 8 Aug 1993 |
| athene.uni-paderborn.de | 131.234.2.32 | 15:21 | 6 Aug 1993 |
| bseis.eis.cs.tu-bs.de | 134.169.33.1 | 00:18 | 31 Jul 1993 |
| clio.rz.uni-duesseldorf.de | 134.99.128.3 | 12:10 | 8 Aug 1993 |
| cns.wtza-berlin.de | 141.16.244.4 | 16:08 | 31 Jul 1993 |
и т.д.
Если вы пошлете команду whatis compression по почте или посредством Telnet, вы получите следующий результат:
| RFC 468 | Braden, R.T. FTP data compression 1973 March 8; 5p. |
| arc | PC compression program |
| deltac | Image compression using delta modulation |
| spl | Splay tree compression routines |
| squeeze | A file compression program |
| uncrunch | Uncompression program |
| unsqueeze | Uncompression programs (Пример взят из [1]) |
В ответ на команду find AMPS, вы получите:
| Host goliat.eik.bme.hu | (152.66.115.2) |
Last updated 00:02 3 Jan 1995
Location: /pub/win3/util
FILE -r--r--r-- 145312 bytes 11:18 22 Dec 1994 amps13.zip
| Host nic.switch.ch | (130.59.1.40) |
Last updated 01:17 11 Dec 1994
Location: /mirror/novell/netwire/novuser/01
FILE -rw-rw-r-- 177681 bytes 02:14 1 Nov 1994 amps15.zip
| Host faui43.informatik.uni.erlangen.de | (131.188.1.43) |
Last updated 01:31 11 Dec 1994
Location:
/mounts/epix/public/pub/pc/windows/cica_mirror/util
FILE -r--r--r-- 145312 bytes 00:00 2 Jun 1994 amps13.zip
| Host ftp.luth.se | (130.240.16.39) |
Last updated 17:53 13 Dec 1994
Location: /pub/msdos/.1/.util
FILE -r--r--r-- 145312 bytes 01:00 1 Jun 1994 amps13.zip
| Host ftp.cyf | kr.edu.pl (149.156.1.8) |
Last updated 17:50 3 Jan 1995
Location: /pub/mirror/ami/chipset_guides
FILE -rw-r--r-- 111858 bytes 00:00 4 Apr 1994 scampsx.z06
FILE -rw-r--r-- 46677 bytes 00:00 4 Apr 1994 scampsx.z07
Это лишь фрагмент выдачи реально она много длиннее. Видно, что один и тот же документ найден в нескольких депозитариях. Если у вас есть вопросы об ARCHIE, пишите Archie Group, Bunyip Information Systems Inc. по адресу info@bunyip.com. В случае обнаружения ошибок, а также с комментариями следует обращаться по адресу archie-admin@bunyip.com. По вопросам, связанным с конкретными серверами можно обратиться по адресу archie-admin@address.of.archie.server, например, archie-admin@archie.ac.il. Список адресов для рассылки информации находится по адресу: archie-people@bunyip.com; для включения в подписной лист можно послать запрос по адресу: archie-people-request@bunyip.com.
Система поиска NETFIND
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
NETFIND представляет собой прикладную программу для работы со справочниками и каталогами. Получив имя человека и некоторые данные о том, где он работает, NETFIND пытается найти его номер телефона, электронный адрес, используя базу данных доменов seed. NETFIND ищет информацию о людях с помощью Интернет-протоколов SMTP и finger. Netfind работает на ЭВМ SUN OS 4.0 или более новых. Могут быть найдены только лица, имеющие доступ к Интернет. Существует возможность работы с NETFIND через электронную почту. Доступ через telnet возможна по адресам (login: netfind):
| Адрес сервера | Страна | Адрес сервера | Страна |
| archie.ua | Австралия | bruno.cs.colorado.edu | США |
| dino.conicit.ve | Венесуэла | ds.internic.net | США |
| lincoln.technet.sg | Сингапур | macs.ee.mcgill.ca | Канада |
| malloco.ing.puc.cl | Чили | monolith.cc.ic.ac.uk | Англия |
| mudhoney.micro.umn.edu | США | netfind.oc.com | США |
| netfind.sjsu.edu | США | netfind.icm.edu.pl | Польша |
| netfind.vslib.cz | Чехия | nic.nm.kr | Корея |
| nic.uakom.sk | Словакия | redmont.cis.uab.edu | США |
| netfind.fnet.fr | Франция | eis.calstate.edu | США |
Место работы искомого человека может быть описано ключевыми словами. NETFIND просматривает свою базу данных seed, чтобы найти домен, отвечающий критериям отбора. Список таких доменов отображается и вам предлагается выбрать из них 1-3. Если обнаружено более 100 доменов, NETFIND выдаст имена некоторых из них и предложит повторить поиск с более жесткими условиями. Можно использовать часть названия организации или домена в качестве эталона в процессе поиска. При использовании более чем одного эталона можно применить знак логической операции AND. По завершении поиска или при прерывании его с помощью ^C NETFIND выдает полученный результат. Предлагаются не только данные о домене или организации, но и даты последних входов искомого человека в систему. Обращение к NETFIND имеет формат:
netfind <опции> фамилия (имя) место работы (ключевые слова)
где допустимы следующие опции:
| -h | Указывает NETFIND обойти фазу поиска домена и немедленно начать поиск индивидуальной ЭВМ в базе seed. Эта функция редко используется обычными пользователями |
| -s | Исключает применение протокола SMTP при поиске. Поиск происходит немного быстрее, но дает не полную информацию, так как не все ЭВМ пользователей поддерживают протокол finger |
| -t | Сообщает сколько случилось таймаутов. -T опция устанавливает время таймаута равным заданному числу секунд, что позволяет увеличить это время в некоторых случаях |
| -D | Устанавливает максимальное число доменов, где будет проводиться поиск. По умолчанию эта величина равна 3 (большее значение устанавливать не рекомендуется). Правильный выбор этого числа заметно ускоряет процесс поиска и снижает нагрузку на сеть. |
| -H | Устанавливает максимальное число ЭВМ, где будет проводиться поиск. По умолчанию это число равно 50. Устанавливать большую величину не рекомендуется |
| -m | Отображает измерительную информацию. Если не указано имя файла, то вывод производится в файл stderr |
| -d | Позволяет устанавливать различные классы отладочного вывода (в stderr), используя соответствующую букву для каждого из них, напр. -dsf. Могут использоваться любые комбинации этих букв |
/p> Существуют следующие классы/буквы:
| c: | Отображает управляющие сообщения ( позволяет контролировать, какой точки достигла программа). |
| f: | Отображает сообщения, связанные с finger. |
| h: | Выдает список ЭВМ, найденных в базе данных seed. |
| m: | Отображает сообщения протокола SMTP. |
| n: | Отображает сообщения о неисправности сети. |
| r: | Отображает имена ЭВМ из базы seed, которые были отброшены из-за выбора search scope. |
| s: | Отображает системные сообщения. |
| t: | Отображает сообщения, связанные с thrread. |
Обычным пользователям наиболее интересны буквы f, m, и n. По умолчанию работают именно эти функции. -d команда инвертирует текущее значение опции, поэтому использование этих трех команд под знаком -d, заблокирует их работу. В качестве имени можно применить фамилию, имя или ID. При выдаче имени домена или ЭВМ можно выдавать эту информацию без разделительных точек, например, cs colorado edu. NETFIND для входа не требует каких-либо слов-паролей, кроме NETFIND. Воспользуемся услугами сервера nic.uakom.sk:
| tn nic.uakom.sk | (обращение к серверу в Словакии) | ||
| SunOS UNIX (nic) | (произошло соединение) | ||
| login: | netfind | (подключаемся к NETFIND-серверу, далее следует текст, выдаваемый сервером) | |
UAKOM UMB
Slovakia, Banska Bystrica
Welcome to the Netfind server
questions/problems : Lubos.Elias@uakom.sk
Alternate Netfind servers:
I think that your terminal can display 24 lines. If this is wrong, please enter the "Options" menu and set the correct number of lines. (Если ваш терминал не работает с 24 строками, обратитесь в раздел "Options" и установите верное значение).
| Top level choices: | (Выдано базовое меню) | |
| 1. Help (Запрос справочной информации) | ||
| 2. Search (Поиск) | ||
3. Seed database lookup (просмотр базы данных SEED) | ||
| 4. Options (Дополнительные возможности) | ||
| 5. Quit (exit server) (Уход из сервера) | ||
| --> | 1 (Запрошена справочная информация) | |
Help choices: (Справочное меню)
| 1. Netfind search help (Работа с NETFIND) | |
| 2. Usage restrictions (Используемые команды) | |
| 3. Frequently asked questions (Часто задаваемые вопросы) | |
| 4. For more information (Дополнительная информация) | |
| 5. Quit menu (back to top level) (Возврат в предыдущее меню) | |
| --> | 1 (Запрошена информация о работе с NETFIND) |
/p> Система выдает запрошенную справочную информацию (ниже приведен сокращенный перевод):
По имени и приблизительному описанию места работы Netfind пытается найти информацию о данном лице. В качестве имени может быть введена фамилия или имя. Одновременно могут быть выданы ключевые слова: место работы, имя домена, город или страна. Найдя домен, Netfind отображает список доменов и просит вас выбрать от одного до трех из них, где следует провести поиск.
Поиск проходит в два этапа. На первом - Netfind выполняет поиск в каждом из выбранных доменов. На втором этапе проводится более детальное исследование с помощью finger. Имеется возможность прервать поиск с помощью ^C.
По завершении знакомства со справочной информации система возвращается к базовому меню. На этот раз выбираем пункт 2 (Поиск). Система выдает предупреждение:
| NOTE: | Received no responses, and some host or network failures occurred. Maybe try this search again later. (В случае неуспеха можно позднее попытать счастья снова). |
Предлагается ввести имя и ключевые слова.
Enter person and keys (blank to exit) --> Burov DESY Germany
(Введено задание на поиск: фамилия, место работы, страна)
Найдено три домена, отвечающие критериям отбора.
Please select at most 3 of the following domains to search:
(предлагается провести поиск по этим трем доменам)
| 0. | desy.de (desy zeus central data acquisition, germany) |
| 1. | dsyibm.desy.de (desy, hamburg, germany) |
| 2. | info.desy.de (desy zeus central data acquisition, germany) |
Enter selection (e.g., 2 0 1)--> 2 0 1
(введен список доменов, где будет проведен поиск)
( 3) SMTP_Finger_Search: checking domain dsyibm.desy.de
( 3) do_connect:
Finger service not available on host dsyibm.desy.de -> cannot do user lookup.
(Поиск с помощью Finger не доступен на dsyibm.desy.de)
( 1) SMTP_Finger_Search: checking domain info.desy.de
( 2) got nameserver operator.desy.de
( 2) got nameserver sun01a.desy.de
( 2) SMTP_Finger_Search: checking domain desy.de
Mail for Sergei Bourov is forwarded to burov@x4u2.desy.de
Поиск завершился успехом - найден адрес, куда пересылается почта для Бурова, далее на экран выводится следующий текст:
NOTE:
this is a domain mail forwarding arrangement to an outside domain, possibly indicating that "burov" has moved to another department or institution. Hence, mail should be addressed to "burov@x4u2.desy.de" (почта должна посылаться Бурову по адресу).
( 1) SMTP_Finger_Search: checking host x4u2.desy.de
SYSTEM: x4u2.desy.de
| Login name: burov In real life: | Sergei Bourov | |
| (Полное имя: Сергей Буров) | ||
| Office: 1d/39, 2081/2747 | Home phone: none |
Directory: /home/dice/burov Shell: /bin/zsh
Last login at Tue Sep 26 09:04 from UNKNOWN@AXDSYB.desy.de
(последний раз входил в систему во вторник 26-го сентября)
No Plan.
FINGER SUMMARY (результат исследования с помощью Finger):
- Remote user queries (finger) were not supported on host(s) searched in the domain 'dsyibm.desy.de'.
- The most promising email address for "burov" based on the above finger search is burov@x4u2.desy.de.
Continue the search ([n]/y) ? --> n (хотим ли мы продолжить поиск?)
При удаленном доступе к NETFIND имеется служба HELP. В секции каталога DOC обычно имеется также файл "часто задаваемые вопросы" (frequently asked questions - FAQ). Большую пользу может оказать статья "Experience with a Semantically Cognizant Internet White Pages Directory Tool", написанная M.F.Schwartz и P.G.Tsirigotis, Journal of Internetworking Research and Experience, март 1991, стр. 23-50. Существует список адресов подписчиков NETFIND. Для включения вас в этот список необходимо послать запрос по адресу netfind-users-request@cs.colorado.edu, где в тексте сообщения (не в строке subject!) написать: subscribe netfind-users. Исчерпывающую информацию о NETFIND можно найти посредством:
FTP ftp.cs.colorado.edu /pub/cs/distribs/netfind
WWW www.earn.net gnrt/netfind.html alpha.acast.nova.edu netfind.html
Telnet ds.internic.net (Login: netfind).
Сложность анализа сетевой надежности
Приведем результаты, полученные для сложности анализа сетевой надежности в трех частных задачах: k-терминальной 2-терминальной и всетерминальной.
Соображения безопасности для форм
Агент пользователя не должен посылать какой-либо файл, который пользователь не указал явно, как подлежащий пересылке. Таким образом, агенты пользователя HTML должны требовать подтверждения для любых имен файлов по умолчанию, которые могут быть указаны значениями атрибутов элемента INPUT.
Эта спецификация не содержит механизма шифрования данных. Раз файл загружен, агент должен обработать и записать его соответствующим образом.
Сообщение Access-Challenge
Если сервер RADIUS хочет послать пользователю вызов, требующий отклика, то сервер должен реагировать на запрос Access-Request посылкой пакета с полем код=11 (Access-Challenge). Поле атрибуты может содержать один или более атрибутов Reply-Message, и может опционно включать атрибут состояния. Никакие другие атрибуты здесь не применимы.
При получении Access-Challenge, поле идентификатор соответствует содержимому пакета Access-Request. Кроме того, поле аутентификатор отклика должно содержать корректный отклик на обрабатываемый запрос Access-Request. Некорректные пакеты молча отбрасываются. Если NAS не поддерживает обмен вызов/отклик (challenge/response), он должен обрабатывать сообщение Access-Challenge, как если бы это был запрос Access-Reject.
Если сервер NAS поддерживает обмен вызов/отклик, получение корректного сообщения Access-Challenge указывает, что следует послать новый запрос Access-Request. Сервер NAS может отобразить текстовое сообщение для пользователя, если таковое имеется, а затем предложить ему ввести отклик. Затем сервер посылает исходное сообщение Access-Request с новым идентификатором запроса и аутентификатором отклика, с атрибутом пароля пользователя, содержащим зашифрованный отклик пользователя. Кроме того, это сообщение содержит атрибут состояния (State) сообщения Access-Challenge, если таковой имелся.
NAS, который поддерживает PAP может переадресовать сообщение Reply-Message клиенту, подключенному по модемному каналу, и принять PAP-отклик, который он может использовать как отклик, введенный пользователем. Если NAS этого сделать не может, он должен воспринимать Access-Challenge, как если бы он получил сообщение Access-Reject. Формат пакета Access-Challenge совпадает с форматом Access-Accept и Access-Request.
Поле идентификатор является копией одноименного поля пакета Access-Request, который вызвал посылку Access-Challenge.
Значение аутентификатора отклика вычисляется так, как это было описано выше. Поле атрибуты имеет переменную длину, и содержит список из нуля или более атрибутов.
Сообщение Access-Reject
Если какое-либо значение полученного атрибута неприемлемо, тогда сервер RADIUS должен послать пакет с полем код= 3 (Access-Reject). Пакет может содержать один или более атрибутов Reply-Message с текстом, который может быть отображен NAS для пользователя. Поле идентификатор для данного пакета копируется из одноименного поля пакета Access-Request, вызвавшего данный отклик.
Значение поля аутентификатор отклика вычисляется на основе содержимого сообщения Access-Request, как это описано выше.
Современные поисковые системы
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Развитие Интернет начиналось как средство общения и удаленного доступа (электронная почта, telnet, FTP). Но постепенно эта сеть превратилась в средство массовой информации, отличающееся тем, что операторы сети сами могут быть источниками информации и определяют, в свою очередь то, какую информацию они хотят получить.
Среди первых поисковых систем были archie, gopher и wais. Эти относительно простые системы казались тогда чудом. Использование этих систем показало их недостаточность и определенные врожденные недостатки: ограниченность зоны поиска и отсутствие управления этим процессом. Поиск проводился по ограниченному списку серверов и никогда не было известно, насколько исчерпывающую информацию получил клиент.
Первые WWW-системы работали в режиме меню (Mosaic появилась несколько позже) и обход дерева поиска производился вручную. Структура гиперсвязей могла иметь циклические пути, как, например, на рис. 4.5.14.1. Число входящих и исходящих гиперсвязей для любого узла дерева может быть произвольным.

Рис. 4.5.14.1. Пример дерева гиперсвязей
Связь, помеченная буквой А может явиться причиной образования цикла при обходе дерева. Исключить такие связи невозможно, так как они носят принципиально смысловой характер. По этой причине любая автоматизированная программа обхода дерева связей должна учитывать такую возможность и исключать циклы обхода.
Задача непроста даже в случае поиска нужного текста в пределах одного достаточно большого по емкости диска, когда вы заранее не знаете или не помните в каком субкаталоге или в каком файле содержится искомый текст. Для облегчения ручного поиска на серверах FTP в начале каждого субкаталога размещается индексный файл.
Для решения этой задачи в большинстве операционных систем имеются специальные утилиты (например, grep для UNIX). Но даже они требуют достаточно много времени, если, например, дисковое пространство лежит в пределах нескольких гигабайт, а каталог весьма разветвлен. В полнотекстных базах данных для ускорения поиска используется индексация по совокупности слов, составляющих текст.
Хотя индексация также является весьма времяемкой процедурой, но производить ее, как правило, приходится только один раз. Проблема здесь заключается в том, что объем индексного файла оказывается сравным (а в некоторых случаях превосходит) с исходным индексируемым файлом. Первоначально каждому документу ставился в соответствие индексный файл, в настоящее время индекс готовится для тематической группы документов или для поисковой системы в целом. Такая схема индексации экономит место в памяти и ускоряет поиск. Для документов очень большого размера может использоваться отдельный индекс, а в поисковой системе иерархический набор индексов. Индексированием называется процесс перевода с естественного языка на информационно-поисковый язык. В частности, под индексированием понимается отнесение документа в зависимости от содержимого к определенной рубрике некоторой классификации. Индексирование можно свести к проблеме распознавания образов. Классификация определяет разбиение пространства предметных областей на непересекающиеся классы. Каждый класс характеризуется набором признаков и специфических для него терминов (ключевых слов), выражающих основные понятия и отношения между ними.
Слова в любом тексте в информационном отношении весьма неравнозначны. И дело не только в том, что текст содержит много вспомогательных элементов предлогов или артиклей (напр., в англоязычных текстах). Часто для сокращения объема индексных регистров и ускорения самого процесса индексации вводятся так называемые стоп-листы. В эти стоп-листы вносятся слова, которые не несут смысловой нагрузки (например, предлоги или некоторые вводные слова). Но при использовании стоп-листов необходима определенная осторожность. Например, занеся в стоп-лист, неопределенный артикль английского языка "а", можно заблокировать нахождение ссылки на "витамин А".
Немалое влияние оказывает изменяемость слов из-за склонения или спряжения. Последнее делает необходимым лингвистический разбор текста перед индексацией.
Хорошо известно, что смысл слова может меняться в зависимости от контекста, что также усложняет проблему поиска. Практически все современные информационные системы для создания и обновления индексных файлов используют специальные программные средства.
Существующие поисковые системы успешно работают с HTML-документами, с обычными ASCII-текстами и новостями usenet. Трудности возникают для текстов Winword и даже для текстов Postscript. Связано это с тем, что такие тексты содержат большое количество управляющих символов и текстов. Трудно (практически невозможно) осуществлять поиск для текстов, которые представлены в графической форме. К сожалению, к их числу относятся и математические формулы, которые в HTML имеют формат рисунков (это уже недостаток самого языка). Так что можно без преувеличения сказать, что в этой крайне важной области, имеющей немалые успехи, мы находимся лишь в начале пути. Ведь море информации, уже загруженной в Интернет, требует эффективных средств навигации. Ведь оттого, что информации в сети много, мало толку, если мы не можем быстро найти то, что нужно. И в этом, я полагаю, убедились многие читатели, получив на свой запрос список из нескольких тысяч документов. Во многих случаях это эквивалентно списку нулевой длины, так как заказчик в обоих случая не получает того, что хотел.
Встроенная в язык HTML метка <meta> создана для предоставления информации о содержании документа для поисковых роботов, броузеров и других приложений. Структура метки: <meta http-equiv=response content=description name=description URL=url>. Параметр http-equiv=response ставит в соответствие элементу заголовок HTTP ответа. Значение параметра http-equiv интерпретируется приложением, обрабатывающим HTML документ. Значение параметра content определяется значением, содержащимся в http-equiv.
Современная поисковая система содержит в себе несколько подсистем.
web-агенты. Осуществляют поиск серверов, извлекают оттуда документы и передают их системе обработки.
Система обработки.
Индексирует полученные документы, используя синтаксический разбор и стоп-листы (где, помимо прочего, содержатся все стандартные операторы и атрибуты HTML).
Система поиска. Воспринимает запрос от системы обслуживания, осуществляет поиск в индексных файлах, формирует список найденных ссылок на документы.
Система обслуживания. Принимает запросы поиска от клиентов, преобразует их, направляет системе поиска, работающей с индексными файлами, возвращает результат поиска клиенту. Система в некоторых случаях может осуществлять поиск в пределах списка найденных ссылок на основе уточняющего запроса клиента (например, recall в системе altavista). Задание системе обслуживания передается WEB-клиентом в виде строки, присоединенной к URL, наример, http://altavista.com/cgi-bin/query?pg=q&what=web&fmt=/&q=plug+%26+play, где в поле поиска было записано plug & play)
Следует иметь в виду, что работа web-агентов и системы поиска напрямую независимы. WEB-агенты (роботы) работают постоянно, вне зависимости от поступающих запросов. Их задача - выявление новых информационных серверов, новых документов или новых версий уже существующих документов. Под документом здесь подразумевается HTML-, текстовый или nntp-документ. WEB-агенты имеют некоторый базовый список зарегистрированных серверов, с которых начинается просмотр. Этот список постоянно расширяется. При просмотре документов очередного сервера выявляются URL и по ним производится дополнительный поиск. Таким образом, WEB-агенты осуществляют обход дерева ссылок. Каждый новый или обновленный документ передается системе обработки. Роботы могут в качестве побочного продукта выявлять разорванные гиперсвязи, способствовать построению зеркальных серверов.
Обычно работа роботов приветствуется, ведь благодаря ним сервер может обрести новых клиентов, ради которых и создавался сервер. Но при определенных обстоятельствах может возникнуть желание ограничить неконтролируемый доступ роботов к серверам узла. Одной из причин может быть постоянное обновление информации каких-то серверов, другой причиной может стать то, что для доставки документов используются скрипты CGI.
Динамические вариации документа могут привести к бесконечному разрастанию индекса. Для управления роботами имеются разные возможности. Можно закрыть определенные каталоги или сервера с помощью специальной фильтрации по IP-адресам, можно потребовать идентификации с помощью имени и пароля, можно, наконец, спрятать часть сети за Firewall. Но существует другой, достаточно гибкий способ управления поведением роботов. Этот метод предполагает, что робот следует некоторым неформальным правилам поведения. Большинство из этих правил важны для самого робота (например, обхождение так называемых "черных дыр", где он может застрять), часть имеет нейтральный характер (игнорирование каталогов, где лежит информация, имеющая исключительно локальный характер, или страниц, которые находятся в состоянии формирования), некоторые запреты призваны ограничить загрузку локального сервера.
Когда воспитанный робот заходит в ЭВМ, он проверяет наличие в корневом каталоге файла robots.txt. Обнаружив его, робот копирует этот файл и следует изложенным в нем рекомендациям. Содержимое файла robots.txt в простейшем случае может выглядеть, например, следующим образом.
# robots.txt for http://store.in.ru
| user-agent: * | # * соответствует любому имени робота |
| disallow: /cgi-bin/ | # не допускает робот в каталог cgi-bin |
| disallow: /tmp/ | # не следует индексировать временные файлы |
| disallow: /private/ | # не следует заходить в частные каталоги |
Файл содержит обычный текст, который легко редактировать, после символа # следуют комментарии. Допускается две директивы. user-agent: - определяет имя робота, к которому обращены следующие далее инструкции, если не имеется в виду какой-то конкретный робот и инструкции должны выполняться всеми роботами, в поле параметра записывается символ *. disallow - указывает имя каталога, посещение которого роботу запрещено. Нужно учитывать, что не все роботы, как и люди, следуют правилам, и не слишком на это полагаться (см. ).
Автор исходного текста может заметно помочь поисковой системе, выбрав умело заголовок и подзаголовок, профессионально пользуясь терминологией и перечислив ключевые слова в подзаголовках.
Исследования показали, что автор (а иногда и просто посторонний эксперт) справляется с этой задачей быстрее и лучше, чем вычислительная машина. Но такое пожелание вряд ли станет руководством к действию для всех без исключения авторов. Ведь многие из них, давая своему тексту образный заголовок, рассчитывают (и не без успеха) привлечь к данному тексту внимание читателей. Но машинные системы поиска не воспринимают (во всяком случае, пока) образного языка. Например, в одном лабораторном проекте, разработанном для лексического разбора выражений, состоящих из существительных с определяющим прилагательным, и по своей теме связанных с компьютерной тематикой, система была не способна определить во фразе "иерархическая компьютерная архитектура" то, что прилагательное "иерархическая" относится к слову "архитектура", а не к "компьютерная" (Vickery & Vickery 1992). То есть система была не способна отличать образное использование слова в выражении от его буквального значения.
В свою очередь специалисты, занятые в области поисковых и информационных систем, способны заметно облегчить работу авторам, снабдив их необходимыми современными тезаурусами, где перечисляются нормативные значения базовых терминов в той или иной научно-технической области, а также устойчивых словосочетаний. Параллельно могут быть решены проблемы синонимов.
В настоящее время, несмотря на впечатляющий прогресс в области вычислительной техники, степень соответствия документа определенным критериям запроса надежнее всего может определить человек. Но темп появления электронных документов в сети достигает ошеломляющего уровня (частично это связано с преобразованием в электронную форму старых документов и книг методом сканирования). Написание рефератов для последующего их использование поисковыми системами достаточно изнурительное занятие, требующее к тому же достаточно высокой профессиональной подготовки. Именно по этой причине уже достаточно давно предпринимаются попытки перепоручить этот процесс ЭВМ.
Для этого нужно выработать критерии оценки важности отдельных слов и фраз, составляющих текст. Оценку значимости предложений выработал Г.Лун. Он предложил оценивать предложения текста в соответствии с параметром: Vпр =
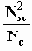
Автоматическая система выявления ключевых слов обычно использует статистический частотный анализ (методика В. Пурто). Пусть f - частота, с которой встречаются различные слова в тексте, а u - относительное значение полезности (важности).
Тогда зависимость f(u) апроксимируется формулой
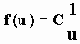
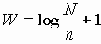
Одним из известных путей облегчения процедуры поиска является группирование документов по определенной достаточно узкой тематике в кластеры. В этом случае запрос с ключевым словом, фигурирующем в заголовке кластера, приведет к тому, что все документы кластера будут включены в список найденных. Кластерный метод наряду с очевидными преимуществами (прежде всего заметное ускорение поиска) имеет столь же явные недостатки. Документы, сгруппированные по одному признаку, могут быть случайно включены в перечень документов, отвечающих запросу, по той причине, что одно из ключевых слов кластера соответствует запросу. В результате в перечне найденных документов вы можете с удивлением обнаружить тексты, не имеющие никакого отношения к интересующей вас теме.
Некоторые поисковые системы предоставляют возможность нахождения документов, где определенные ключевые слова находятся на определенном расстоянии друг от друга (proximity search).
Наиболее эффективным инструментом при поиске можно считать возможность использования в запросе булевых логических операторов AND, OR и NOT. Объединение ключевых слов с помощью логических операторов может сузить или расширить зону поиска.
Проблема соответствия (релевантности) документа определенному запросу совсем не проста.
Индексные файлы, содержащие информацию о WEB-сайтах, занимают около 200 Гигабайт дискового пространства, поиск по содержимому которых производится за время, меньшее одной секунды (на самом деле, реальный поиск производится в более чем в десять раз меньшем объеме). Такой объем содержащейся информации делает Altavista неоценимым помощником в поиске нужных документов и серьезным конкурентом для остальных компаний, содержащих поисковые серверы. Поисковая система Altavista работает на самых мощных компьютерах, произведенных компанией Digital Equipment Corporation - это 16 серверов Alphaserver 8400 5/440, объединенных в сетевой кластер. Каждый из серверов имеет 8 Гбайт оперативной памяти (может иметь до 28 Гбайт), содержит 12 (до 14) процессоров Digital Alfa с тактовой частотой 437 МГц, в качестве жестких дисков используются высокоскоростные и надежные дисковые системы RAID с общим объемом 300 Гбайт.
Для обеспечения связи с Интернет используются каналы с суммарной пропускной способностью 100 Мбит/с через шлюз DEC Palo Alto - что является самым мощным корпоративным шлюзом в Интернет.
Пример широко известной поисковой системы alta vista, где задействовано большое число суперЭВМ, показывает, что дальнейшее движение по такому пути вряд ли можно считать разумным, хотя прогресс в вычислительной технике может и опровергнуть это утверждение. Тем не менее, даже в случае фантастических достижений в области создания еще более мощных ЭВМ, можно утверждать, что распределенные поисковые системы могут оказаться эффективнее. Во-первых, местный администратор быстрее может найти общий язык с авторами текстов, которые могут точнее выбрать набор ключевых слов. Во-вторых, распределенная система способна распараллелить обработку одного и того же информационного запроса. Распределенная система памяти и процессоров может, в конце концов, стать более адекватной потокам запросов к информации, содержащейся на том или ином сервере. Способствовать этому может также создание тематических серверов поиска, где концентрируется информация по относительно узкой области знаний. Для таких серверов возможен отбор документов экспертами, они же могут определить списки ключевых слов для многих документов. Здесь возможна автоматическая предварительная процедура фильтрации документов по наличию определенного набора ключевых слов. Способствует этому и существование тематических журналов, где сконцентрированы статьи по определенной тематике.
В случаях, когда поисковая система выдает заказчику большой список документов, отвечающих критериям его запроса, бывает важно, чтобы они были упорядочены согласно их степени соответствия (наличие ключевых слов в заголовке, большая частота использования ключевых слов в тексте документа и т.д.). Но простые критерии здесь не всегда срабатывают, так объемный документ имеет больше шансов попасть в список результата поиска, так как в нем много слов и с большой вероятностью там встречается ключевое слово.
По этому критерию Британская энциклопедия должна попасть в результирующий список любого запроса. Для компенсации искажений, вносимых длиной документов, используется нормализация весов индексных терминов.
Нормализация представляет собой способ уменьшения абсолютного значения веса индексных терминов, обнаруженных в документе. Одним из наиболее распространенных методов, решающих данную проблему, является косинусная нормализация. При использовании этого метода нормализации вес каждого индексного термина делится на Евклидову длину вектора оцениваемого документа. Евклидова длина вектора определяется формулой:
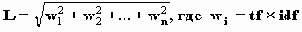
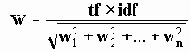
В работах Букштейна, Свенсона и Хартера было показано, что распределение функциональных слов в отличие от специфических слов с хорошей точностью описывается распределением Пуассона. То есть, если ищется распределение функционального слова w в некотором множестве документов, тогда вероятность f(n) того, что слово w будет встречено в тексте n раз представляется функцией:
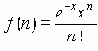
Для представления документов используется векторная модель, где любой документ характеризуется бинарным вектором x = x1,x2,…, xn, где значения xi = 0 или 1, в зависимости от того, присутствует в тексте i-ый индексный термин или нет.
Рассматриваются два взаимно исключающих события:
w1 - документ удовлетворяет запросу
w2 - документ удовлетворяет запросу
Для каждого документа необходимо вычислить условные вероятности P(w1|x) и P(w2|x) для определения, какие документы удовлетворяют запросу, а какие нет.
Непосредственно получить значения этих вероятностей нельзя, поэтому необходимо найти другой альтернативный подход для их определения с помощью известных нам величин. По формуле Байеса для дискретного распределения условных вероятностей:
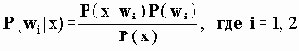
В приведенной формуле P(w1) - первоначальная вероятность соответствия (i = 1) или несоответствия (i = 2) запросу, величина P(x|wi) пропорциональна вероятности соответствия или несоответствия запросу для данного x; в недискретном случае она представляет собой функцию плотности распределения и обозначается как P(x|wi).
Окончательно:
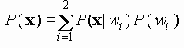
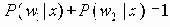
Для определения релевантности документа используется вполне очевидное правило:
Если
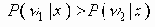
В противном случае считается, что документ не удовлетворяет запросу. При равенстве значений вероятности решение о релевантности документа принимается произвольно.
Правило [1] основано на том, что при его использовании просто минимизируется средняя вероятность ошибки принятия нерелевантного документа за релевантный и наоборот. То есть, для любого документа x вероятность ошибки
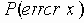

Таким образом, для минимизации средней вероятности ошибки необходимо минимизировать функцию
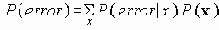
Не углубляясь в теорию вероятностного нахождения релевантных документов, укажем еще одно правило, которое можно использовать вместо [1]:

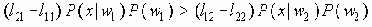
В формуле [2] коэффициенты lij стоимостной функции определяют потери, вносимые при ожидании события wi, когда на самом деле произошло событие wj.
Для практической реализации вероятностного поиска вводится упрощающее предположение относительно P(x|wi).
Принимается, что значения xi вектора x являются статистически независимыми. Данное утверждение математически представляется в виде:
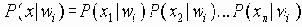
Определим переменные:
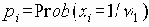
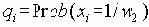
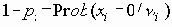
Вероятностные функции, используемые для подстановки в правило [1] имеют вид:
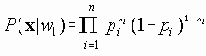
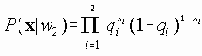
Подставляя значения
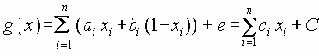
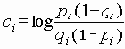
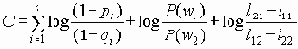
Функция G(x) представляет собой ничто иное, как весовую функцию, в которой коэффициенты Сi представляют собой веса присутствующих в документе индексных терминов. Константа С одинакова для всех документов x, но, конечно, различна для разных запросов и может рассматриваться в качестве порогового значения для поисковой функции. Единственными параметрами, которые могут меняться для данного запроса являются параметры стоимостной функции, вариации которых позволяют получать в ответе большее или меньшее число документов.
Теперь рассмотрим коэффициенты Сi функции G(x) с использованием следующей терминологии:
Таблица 4.5.14.1.
| Релевантные документы | Нерелевантные документы | Общее количество документов | |
 |  |  | 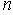 |
 | 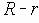 | 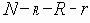 | 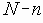 |
| Всего | 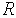 | 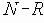 |  |
N - полное число документов в системе.
R - число релевантных документов
r - число релевантных документов, выданных в ответ на запрос
n - полное число документов, выданных в ответ на запрос
Таблица представляет результаты запроса, направленного системе поиска. Представленная таблица должна существовать для каждого из индексных терминов.
Если мы обладаем всей информацией о релевантных и нерелевантных документах в коллекции документов, то применимы следующие оценки:
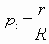
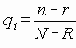
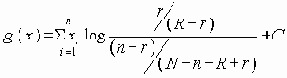
Коэффициент при xi показывает, до какой степени можно провести дискриминацию по i-тому термину в рассматриваемой коллекции документов. В действительности, N может рассматриваться не только как полное количество документов во всей коллекции, но и в некотором ее подмножестве.
Все приведенные формулы были выведены при условии, что индексные термины являются статистически независимыми. В общем случае это, конечно, не так. В теории вероятностного поиска моделируется зависимость между различными индексными формулами, в связи с чем, вид функции G(x) несколько меняется.
Многие системы поиска информации основаны на словарях и тезаурусах для корректировки запросов и представления индексируемых документов, чтобы увеличить шансы найти необходимый документ. На практике, большинство словарей составляется вручную. Словари создаются с помощью одного из двух основных способов:
Связываются слова, описывающие одну и ту же тему.
Связываются слова, описывающие похожие темы.
В первом случае связываются слова, являющиеся взаимозаменяемыми, то есть, в словарях и тезаурусах они принадлежат одному и тому же классу. То есть, можно выбрать по одному слову из каждого класса и совокупность выбранных слов может быть использована для создания контролируемого словаря. Выбирая слова из созданного контролируемого словаря можно проводить индексацию документов или создавать поисковые запросы.
Во втором случае для создания тезауруса используются семантические связи между словами для построения, например, иерархической структуры связей. Создание такого типа словарей является достаточно сложным и трудоемким процессом.
Однако, были предложены способы и для автоматического создания словарей. В то время как созданные вручную словари опираются на семантику (т.е. распознают синонимы, являются более обширными, используют более тонкие взаимосвязи), автоматически созданные тезаурусы, в основном, основаны на синтаксическом и статистическом анализе. Но, так как, использование синтаксиса не приводит к серьезному увеличению эффективности работы систем, то значительно большее внимание уделяется статистическим методам.
Основное допущение, используемое для автоматического создания классов ключевых слов, заключается в следующем. Если ключевые слова a и b могут быть взаимозаменяемы в том смысле, что мы готовы принять документ, содержащий ключевое слово b вместо ключевого слова a и наоборот, то данное обстоятельство имеет место из-за того, что слова a и b имеют одинаковое значение или ссылаются на одинаковые темы.
Основываясь на описанном принципе нетрудно видеть, что создание классификации слов может быть автоматизировано. Можно определить два основных приближения для использования классификации ключевых слов:
Производить замену каждого из ключевых слов, встречающегося в представлении документа или запроса, названием класса, которому оно принадлежит.
Заменять каждое из встреченных ключевых слов всеми словами, входящими в класс, которому принадлежит рассматриваемое ключевое слово.
Для простейшей поисковой стратегии, использующей только что описанные дескрипторы, независимо от того, являются ли они ключевыми словами или названиями классов, созданных на основе группы ключевых слов, "расширенное" представление документов и запросов с помощью любого из вышеописанных способов может существенно повысить число соответствий между документами и запросами и, следовательно, увеличить значение параметра recall. Правда, последнее обстоятельство не является определяющим, так как значение имеет только совокупность параметров (recall, precision), а одно лишь увеличение параметра recall может привести лишь к увеличению объема выдаваемых в ответ на запрос различных документов.
В отчетах об экспериментальных работах по использованию автоматической классификации ключевых слов, проведенных уже упоминавшимся ранее Спарком Джонсом, сообщается, что использование автоматической классификации приводит к увеличению эффективности работы системы по сравнению с системой, использующей неклассифицированные ключевые слова.
Работа Минкера и др. не подтвердила выводы Спарка Джонса и, фактически, показала, что в некоторых случаях использование классификации ключевых слов приводит к существенному ухудшению работы системы в целом. Д. Сальтон в своем отзыве о работе Минкера определил, что целесообразность использования классификации ключевых слов для улучшения эффективности работы поисковых систем еще полностью не определена и является объектом дальнейших экспериментальных исследований. Действительно, при работе в Интернет с поисковыми системами, использующими классификацию ключевых слов, (такими как lycos и excite) заметно существенное увеличение документов, не представляющих ничего общего с запросом, но, тем не менее, имеющих довольно высокий ранг и, следовательно, по мнению поисковой системы, наиболее точно соответствующих заданному запросу.
Для дальнейшего увеличения эффективности системы используется так называемая кластеризация документов.
Существуют две основные области применения методов классификации в системах поиска и локализации информации. Это - кластеризация (классификация) ключевых слов и кластеризация документов.
Под кластеризацией документов понимается создание групп документов, таких, что документы, принадлежащие одной группе, оказываются, в некоторой степени, связанными друг с другом. Другими словами, документы принадлежат одной группе потому, что ожидается, что эти документы будут находиться вместе в результате обработки запроса. Логическая организация документов достигается, в основном, двумя следующими способами.
Первый - путем непосредственной классификации документов и второй - посредством промежуточного вычисления некоторой величины соответствия между различными документами.
Было теоретически доказано, что первый метод является очень сложным для практической реализации, так что любые экспериментальные результаты не могут считаться достаточно надежными. Второй способ классификации заслуживает подробного внимания, и, по сути, является единственным реальным подходом к решению проблемы.
На практике почти невозможно сопоставить каждый из документов каждому из запросов из-за слишком больших затрат машинного времени на проведение таких операций. Было предложено много различных способов для уменьшения количества необходимых для выполнения запроса операций сравнения. Наиболее многообещающим было предложение использовать группы взаимосвязанных документов, используя процедуры автоматического определения соответствия документов. Проводя сравнения запроса всего лишь с одним документом, являющимся представителем группы (заранее определенным) и, таким образом, определяя группу документов, в которой и происходит дальнейший поиск, существенно уменьшается затрачиваемое на обработку запроса машинное время. Однако, Дж. Сальтон полагал, что, хотя использование кластеризации документов и уменьшает время поиска, но неизбежно снижает эффективность поисковой системы.
Точка зрения других исследователей несколько отличается от мнения Дж. Сальтона, так, в работе Jardine, N. и Van Rijsbergen, c.j., "The Use of Hierarchic Clustering in Information Retrieval", Information Storage and Retrieval, 7, 217-240 (1971) делаются выводы о достаточно высоком потенциале методов кластеризации для увеличения эффективности работы поисковых систем.
Для построения систем поиска информации с использованием кластеров необходимо использовать методы для определения степени взаимосвязи между объектами. На основе определенных взаимосвязей можно построить систему кластеров. Взаимосвязь между документами определяется понятиями "степень сходства", "степень различия" и "степень соответствия". Значение степени сходства и степени соответствия между документами увеличивается по мере увеличения количества совпадающих параметров. В рассмотрении могут участвовать совершенно разные параметры. Некоторыми исследователями отмечалось, что различие в производительности поисковых систем при использовании различных способов определения степени ассоциации является несущественным, при условии, что функции, используемые для ее определения, являются соответствующим образом нормализованными. Интуитивно, такой вывод можно понять, так как большинство методов определения взаимосвязи между документами используют одни и те же параметры (использующие, в большинстве, статистический анализ текстовых документов). Данное предположение подтверждается в работах И. Лермана, где показано, что многие из способов определения степени соответствия являются монотонными по отношению друг к другу.
В теории поиска информации используется пять основных способов определения степени соответствия. Документы и запросы представляются, в основном, с помощью индексных терминов или ключевых слов, поэтому для облегчения описания моделей обозначим посредством
Самая простая из моделей для определения степени соответствия - это так называемый простой коэффициент соответствия:
При вычислении коэффициента не берутся в рассмотрение размеры множеств X и Y.
В следующей таблице показаны другие подходы к определению степени соответствия, использующие коэффициенты, учитывающие размеры множеств
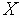
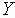
Таблица 4.5.14.2
| Коэффициент | Название |
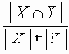 | Коэффициент Дайса (dice) |
 | Коэффициент Джаккарда (jaccard) |
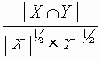 | Косинусный коэффициент |
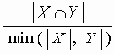 | Коэффициент перекрытия |
Приведенные коэффициенты, по сути, представляют собой нормализованные варианты простого коэффициента соответствия.
Скажем несколько слов о функциях, определяющих степень различия между документами. Причины использования в системах поиска информации функций, определяющих степень различия между документами, вместо степени соответствия являются чисто техническими. Добавим, что любая функция оценки степени различия между документами d может быть преобразована в функцию, определяющую степень соответствия s следующим образом:
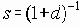
Если P - множество объектов, предназначенных для кластеризации, то функция D определения степени различия документов - это функция, ставящая в соответствие

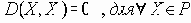
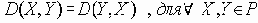
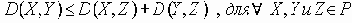
Четвертое свойство неявно отображает тот факт, что функция определения степени различия между документами является, в некоторой степени, функцией, определяющей "расстояние" между двумя объектами и, следовательно, логично предположить, что должна удовлетворять неравенству треугольника. Данное свойство выполняется практически для всех функций определения степени различия.
Пример функции, удовлетворяющей свойствам 1 - 4:
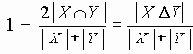
Наконец, представим функцию определения степени различия в альтернативной форме:
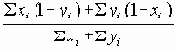
Используя векторное представление документов, для

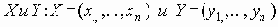
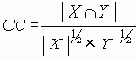
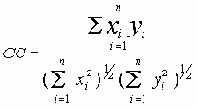
Скажем несколько слов о вероятностном подходе для функций, определяющих степень соответствия. Степень соответствия между объектами определяется по тому, насколько их распределения вероятности отличаются от статистически независимого. Для определения степени соответствия используется ожидаемая взаимная мера информации. Для двух дискретных распределений вероятности
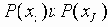
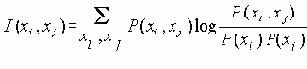
Если xi и xj - независимы, тогда
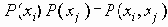
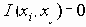
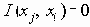
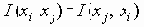
Функция
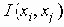
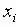
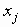
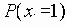
Та степень взаимосвязи, которая существует между индексными терминами i и j вычисляется затем функцией
Были предложены и другие функции, похожие на описанную выше функцию
Как и в случае автоматической классификации документов, использование вероятностных методов при формировании кластеров содержит в себе достаточно высокий потенциал и представляет крайне интересную область для исследований.
Итак, для формирования кластеров необходимо использовать некую функцию соответствия для определения степени связи между парами документов из коллекции.
Постулируем теперь основную идею, на которой, собственно говоря, и построена вся теория кластерного представления коллекции документов. Гипотеза, приведшая к появлению кластерных методов, называется Гипотезой Кластеров и может быть сформулирована следующим образом: "Связанные между собой документы имеют тенденцию быть релевантными одним и тем же запросам".
Базисом, на котором построены все системы автоматического поиска информации, является то, что документы, релевантные запросу, отличаются от нерелевантных документов. Гипотеза кластеров указывает на целесообразность разделения документов на группы до обработки поисковых запросов. Естественно, она ничего не говорит о том, каким образом должно проводиться это разделение.
Проводился ряд исследований по поводу применения кластерных методов в поисковых системах. Некоторые отчеты приведены в работах Б. Литофски, Д. Крауча, Н. Привеса и Д. Смита, а также М. Фритше.
Кластерные методы, выбираемые для использования в экспериментальных поисковых системах должны удовлетворять некоторым определенным требованиям. Это:
методы, создающие кластеры, не должны существенно их изменять при добавлении новых объектов. То есть, должны быть устойчивы по отношению к объему коллекции.
методы должны быть устойчивы и в том отношении, что небольшие ошибки в описании объектов приводят к небольшим изменениям результата процесса кластеризации.
результат, производимый методами кластеризации, должен быть независимым от начального порядка объектов.
Основной вывод из вышесказанного состоит в том, что любой кластерный метод, не удовлетворяющий приведенным условиям, не может производить сколько-нибудь значащие экспериментальные результаты. Надо сказать что, к сожалению, далеко не все работающие кластерные методы удовлетворяют приведенным требованиям. В основном, это происходит из-за значительных различий между реализованными методами кластеризации от теоретически разработанных ад-хок алгоритмов.
Другим критерием выбора является эффективность процесса создания кластеров с точки зрения производительности и требований к объему необходимого дискового пространства.
Необходимость учета данного критерия находится, естественно, в сильной зависимости от конкретных условий и требований.
Возможно, использование процедур фильтрации базы данных таким образом, что из базы данных будет удаляться информация об индексных терминах, встречающихся в более чем, скажем 80% проиндексированных документов.
Таким образом, список стоп- слов будет динамически изменяющимся. Как уже говорилось, использование списка стоп-слов может приводить к 30% уменьшению размеров индексных файлов. Для построения кластеров обычно используется два основных подхода:
кластеризация основывается на вычислении степени соответствия между подвергающимися кластеризации объектами.
кластерные методы применяются не к объектам непосредственно, а к их описаниям.
В первом случае кластеры можно представить с помощью графов, построенных с учетом значений функции соответствия для каждой пары документов.
Рассмотрим некоторое множество объектов, которые должны быть кластеризованы. Для каждой пары объектов из данного множества вычисляется значение функции соответствия, показывающее насколько эти объекты сходны.
Если полученное значение оказывается больше величины заранее определенного порогового значения, то объекты считаются связанными. Вычислив значения функции соответствия для каждой пары объектов, строится граф, по сути, представляющий собой кластер. То есть определение кластера строится в терминах графического представления.
Список литературы
| 1 | Salton, G., "Automatic Text Analysis", Science, 168, 335-343 (1970) |
| 2 | Luhn, H. P. "The automatic creation of literature abstracts", IBM Journal of Research and Development, 2, 159-165 (1958) |
| 3 | Gerard Salton, Chris Buckley and Edward A. Fox, "Automatic Query Formulations in Information Retrieval", Cornell University, |
| 4 | Tandem Computers Inc. "Three Query Parsers", |
| 5 | Object Design Inc., "Persistent Storage Engine PSE-Pro documentation", |
| 6 | Roger Whitney, "CS 660: Combinatorial Algorithms. Splay Tree", San Diego State University. |
Спецификация направления текста Атрибут dir
Описание атрибута
dir = ltr | rtl
Специфицирует направление размещения текста, возможные значения:
ltr: слева направо
rtl: справа налево.
Последнее значение атрибута может быть нужно для случая арабского или еврейского текстов. Агент пользователя не может использовать атрибут lang для определения направления текста.
Спецификация не HTML-данных
Текст скрипта и стилевые данные могут появиться в содержимом элемента или в качестве значения атрибута.
Замечание. DTD определяет данные скриптов и стилей как Cdata для содержимого элементов и значения атрибутов. Правила SGML не позволяют использование символьных объектов в Cdata элементах, но допускают их в Cdata значений атрибутов. Разработчикам следует обращать особое внимание на случаи обмена данными скриптов и стилей методом вырезания и вставления между элементами и значениями атрибутов.
Эта асимметрия означает также, что при кросскодировании (transcoding) из богатого кодового набора символов в более бедный, кодировщик не может просто заменить неконвертируемые символы в скрипте или стилевых данных соответствующим цифровыми кодами. Он должен произвести разборку (анализ) HTML-документа и узнать все о каждом скрипте и стилевом языке для того, чтобы правильно обработать соответствующие данные.
Содержимое элемента
Когда скрипт или стилевые данные являются содержимым элемента (script и style), данные начинаются немедленно после начальной метки элемента и кончаются на первом etago ("</") разграничителе, за которым следует имя символа ([a-za-z]), это может быть и не конечной меткой элемента. Разработчики должны избегать использования строк "</" в теле элемента.
Нелегальный пример:
Следующий текст скрипта содержит недопустимую последовательность "</" (в качестве части "</em>") перед конечной меткой script:
<script type="text/javascript">
document.write ("<em>this won't work</em>")
</script>
В javascript, этот код может быть представлен корректно, путем сокрытия разграничителя Etago перед начальным символом имени SGML:
<script type="text/javascript">
document.write ("<em>this will work<\/em>")
</script>
В tcl, можно выполнить это следующим образом:
<script type="text/tcl">
document write "<em>this will work<\/em>"
</script>
В vbscript эта проблема может быть обойдена с помощью функции chr():
"<em>this will work<" & chr(47) & "em>"
Значения атрибутов
Когда скриптовые или стилевые данные представляют собой значение атрибута, разработчики должны избегать случаев использования одиночных или двойных кавычек в значениях атрибута в соответствии с рекомендациями языка скрипта или описания стиля. Разработчики должны также избегать включения "&", если "&" не означает начало символьного объекта.
* '"' should be written as """ or """
* '&' should be written as "&" or "&"
Таким образом, например, можно написать:
<input name="num" value="0"
onchange="if (compare(this.value, "help")) {gethelp()}">
Списки определений Элементы dl, dt и dd
<!element dl - - (dt|dd)+>
| <!attlist dl %attrs | -- %coreattrs, %i18n, %events -- | |
| compact (compact) #implied | -- уменьшенное расстояние между элементами -- > | |
<!element dt - o (%inline) *>
<!element dd - o %block>
| <!attlist (dt|dd) %attrs | -- %coreattrs, %i18n, %events -- > |
Список определений отличается слабо от других списков, он состоит из двух частей: начальная этикетка (label) и описание. Этикетка инициируется элементом DT и может содержать только помеченный текст. Описание начинается с элемента DD и может содержать данные блочного уровня. Например:
<dl>
|
<dt> <em> daniel</em> | ||
| <dd> born in france, daniel's favorite food is foie gras. | ||
|
<p> in this paragraph we'll discuss daniel's girlfriends: audrey, laurie and alice. | ||
| <dt> <em> tim</em> | |
| <dd> born in new york, tim's favorite food is ice cream. |
</dl>
Представление списка определений зависит от агента пользователя. Агент пользователя может отобразить представленный список в виде:
daniel
born in france, daniel's favorite food is foie gras.
in this paragraph we'll discuss daniel's girlfriends: audrey, laurie and alice.
tim
born in new york, tim's favorite food is ice cream.
Ссылки на литературу и сервера
| [CSS1] |
"Cascading Style Sheets, level 1", H. W. Lie and B. Bos, 17 December 1996. Доступно по адресу: |
| [DATETIME] |
"Date and Time Formats", W3C Note, M. Wolf and C. Wicksteed, 15 September 1997. Доступно по адресу: |
| [IANA] |
"Assigned Numbers", STD 2, RFC 1700, USC/ISI, J. Reynolds and J. Postel, October 1994. Доступно по адресу: |
| [ISO639] |
"Codes for the representation of names of languages", ISO 639:1988. Дополнительная информация может быть получена по адресу: . См. также |
| [ISO3166] | "Codes for the representation of names of countries", ISO 3166:1993. |
| [ISO8601] | "Data elements and interchange formats -- Information interchange -- Representation of dates and times", ISO 8601:1988 |
| [ISO8879] |
"Information Processing -- Text and Office Systems -- Standard Generalized Markup Language (SGML)", ISO 8879:1986. Информация о стандарте может быть получена по адресу . |
| [ISO10646] |
"Information Technology -- Universal Multiple-Octet Coded Character Set (UCS) -- Part 1: Architecture and Basic Multilingual Plane", ISO/IEC 10646-1:1993. Данная спецификация учитывает также первые пять поправок к документу ISO/IEC 10646-1:1993 |
| [ISO88591] |
"Information Processing -- 8-bit single-byte coded graphic character sets -- Part 1: Latin alphabet No. 1", ISO 8859-1:1987 |
| [MIMETYPES] |
Список зарегистрированных типов содержимого (типы MIME). Список зарегистрированных типов можно найти по адресу /. |
| [RFC1555] |
"Hebrew Character Encoding for Internet Messages", H. Nussbacher and Y. Bourvine, December 1993. Доступно по адресу: . |
| [RFC1556] |
"Handling of Bi-directional Texts in MIME", H. Nussbacher, December 1993. Доступно по адресу: |
| [RFC1738] |
"Uniform Resource Locators", T. Berners-Lee, L. Masinter, and M. McCahill, December 1994. Доступно по адресу: . |
| [RFC1766] |
"Tags for the Identification of Languages", H. Alvestrand, March 1995. Доступно по адресу: |
| [RFC1808] |
"Relative Uniform Resource Locators", R. Fielding, June 1995. Доступно по адресу: . |
| [RFC2044] |
"UTF-8, a transformation format of Unicode and ISO 10646", F. Yergeau, October 1996. Доступно по адресу: |
| [RFC2045] |
"Multipurpose Internet Mail Extensions (MIME) Part One: Format of Internet Message Bodies", N. Freed and N. Borenstein, November 1996. Доступно по адресу: . Учтите, что это RFC замещает RFC1521, RFC1522 и RFC1590. |
| [RFC2046] |
"Multipurpose Internet Mail Extensions (MIME) Part Two: Media Types", N. Freed and N. Borenstein, November 1996. Доступно по адресу: . Учтите, что это RFC замещает RFC1521, RFC1522 и RFC1590. |
| [RFC2068] |
"HTTP Version 1.1 ", R. Fielding, J. Gettys, J. Mogul, H. Frystyk Nielsen, and T. Berners-Lee, January 1997. Доступно по адресу: |
| [RFC2119] |
"Key words for use in RFCs to Indicate Requirement Levels", S. Bradner, March 1997. Доступно по адресу: |
| [RFC2141] |
"URN Syntax", R. Moats, May 1997. Доступно по адресу: |
| [SRGB] |
"A Standard Default color Space for the Internet", version 1.10, M. Stokes, M. Anderson, S. Chandrasekar, and R. Motta, 5 November 1996. Доступно по адресу: |
| [UNICODE] |
"The Unicode Standard: Version 2.0", The Unicode Consortium, Addison-Wesley Developers Press, 1996. Спецификация учитывает также обнаруженные ошибки Для получения дополнительной информации, рекомендуется посмотреть базовую страницу Unicode Consortium's по адресу |
| [URI] |
"Uniform Resource Identifiers (URI): Generic Syntax and Semantics", T. Berners-Lee, R. Fielding, L. Masinter, 18 November 1997. Доступно по адресу: . Работа продолжается и ожидается, что тексты RFC-1738 и RFC-1808 будут пересмотрены. |
| WEBSGML] |
"Proposed TC for WebSGML Adaptations for SGML", C. F. Goldfarb, ed., 14 June 1997. Доступно по адресу: |
/p> Информационные ссылки
| [BRYAN88] | "SGML: An Author' s Guide to the Standard Generalized Markup Language", M. Bryan, Addison-Wesley Publishing Co., 1988 |
| [CALS] | Continuous Acquisition and Life-Cycle Support (CALS). CALS является стратегией Министерства обороны США для достижения эффективного создания, обмена и использования цифровых данных для оборудования и систем оружия. Дополнительная информация доступна на базовой странице CALS по адресу |
| [CHARSETS] | Registered charset values. Загрузка списка зарегистрированных наборов символов возможна по адресу |
| [CSS2] | "Cascading Style Sheets, level 2", B. Bos, H. W. Lie, C. Lilley, and I. Jacobs, November 1997. Доступно по адресу: |
| [DCORE] | The Dublin Core: дополнительная информация доступна по адресу |
| [ETHNO] | "Ethnologue, Languages of the World", 12th Edition, Barbara F. Grimes editor, Summer Institute of Linguistics, October 1992. |
| [GOLD90] | "The SGML Handbook", C. F. Goldfarb, Clarendon Press, 1991. |
| [HTML30] | "HyperText Markup Language Specification Version 3.0", Dave Raggett, September 1995. Доступно по адресу: |
| [HTML32] | "HTML 3.2 Reference Specification", Dave Raggett, 14 January 1997. Доступно по адресу: |
| [HTML3STYLE] | "HTML and Style Sheets", B. Bos, D. Raggett, and H. Lie, 24 March 1997. Доступно по адресу: |
| [LEXHTML] | "A Lexical Analyzer for HTML and Basic SGML", D. Connolly, 15 June 1996. Доступно по адресу: |
| [PICS] | Platform for Internet Content (PICS). Дополнительная информация доступна по адресу |
| [RDF] | The Resource Description Language: дополнительная информация доступна по адресу |
| [RFC822] | "Standard for the Format of ARPA Internet Text Messages", Revised by David H. Crocker, August 1982. Доступно по адресу: . |
| [RFC850] | "Standard for Interchange of USENET Messages", M. Horton, June 1983. Доступно по адресу: |
| [RFC1468] | "Japanese Character Encoding for Internet Messages", J. Murai, M. Crispin, and E. van der Poel, June 1993. Доступно по адресу: |
| [RFC1630] | "Universal Resource Identifiers in WWW: A Unifying Syntax for the Expression of Names and Addresses of Objects on the Network as used in the World-Wide Web", T. Berners-Lee, June 1994. Доступно по адресу: |
| [RFC1866] | "HyperText Markup Language 2.0", T. Berners-Lee and D. Connolly, November 1995. Доступно по адресу: |
| [RFC1867] | "Form-based File Upload in HTML", E. Nebel and L. Masinter, November 1995. Доступно по адресу: . Ожидается, что RFC1867 будет поправлено, см.: ftp://ftp.ietf.org/internet-drafts/draft-masinter-form-data-01.txt, в настоящее время ведутся работы |
| [RFC1942] | "HTML Tables", Dave Raggett, May 1996. Доступно по адресу: |
| [RFC2048] | "Multipurpose Internet Mail Extensions (MIME) Part Four: Registration Procedures", N. Freed, J. Klensin, and J. Postel, November 1996. Доступно по адресу: . Учтите, что это RFC замещает RFC-1521, RFC-1522 и RFC-1590. |
| [RFC2070] | "Internationalization of the HyperText Markup Language", F. Yergeau, G. Nicol, G. Adams, and M. Dьrst, January 1997. Доступно по адресу: |
| [SGMLOPEN] | SGML Consortium. Базовая страница консорциума находится по адресу |
| [SP] | SP представляет собой общедоступный интерпретатор SGML. Доступно по адресу: /. Дополнительная информация доступна по адресу: |
| [SQ91] | "The SGML Primer", 3rd Edition, SoftQuad Inc., 1991 |
| [TAKADA] | "Multilingual Information Exchange through the World-Wide Web", Toshihiro Takada, Computer Networks and ISDN Systems, Vol. 27, No. 2, pp. 235-241, November 1994. |
| [WAIGUIDE] | Базовая информация по формированию HTML документов доступна на сайте Web Accessibility Initiative (WAI): /. |
| [VANH90] | "Practical SGML", E. van Herwijnen, Kluwer Academic Publishers Group, Norwell and Dordrecht, 1990 |
Стандартная форма
Мы рассмотрим еще одну форму полинома надежности. До этого момента основой построения была идея нумерации состояний, где любое рабочее и нерабочее состояние пронумерованы. Многие алгоритмы надежности так не работают, а вместо этого используется нумерация проходов или разрезов.
Мы видели ранее, что один или более полезных точных алгоритмов используют теорию доминирования. Мы вернемся немного к этой теории, чтобы разработать интерпретацию коэффициентов в полиноме надежности. В развитие идеи доминирования следующим образом определена i-четность Pi(G). Пусть все Si являются i-реберными субграфами графа G. Тогда Pi(G)=

При получении значения надежности через наборы маршрутов каждое образование рассматривается только один раз. Пусть {G1,…,Gt} обозначает все K-субграфы графа G, Relk(G)=


Другими словами, четности являются просто коэффициентами этого полинома надежности (Р-вектор).
Описание Р-векторов, базирующееся на полиномах надежности, широко не изучалось. Р-вектор для полинома всетерминальной надежности удовлетворяет неравенству

Стилевая информация заголовка Элемент style
<!element style - - cdata -- стилевая информация --
<!attlist style
| %i18n; |
-- lang, dir, для использования с title -- | |
| type cdata #implied |
-- тип содержимого internet для стилевого языка -- | |
| media cdata #implied |
-- предназначено для использования в этих средах -- | |
| title cdata #implied |
-- рекомендуемый title -- > |
Описание атрибутов
type = cdata
Этот атрибут специфицирует язык стилевого листа (заменяет значение по умолчанию). Стилевой язык специфицируется также как и тип среды Интернет (internet media type) (т.е. "text/css").
media cdata-list
Этот атрибут специфицирует среду для стилевой информации. Это может быть одна среда или перечень, где отдельные элементы списка разделены запятыми. Возможные типы сред:
| screen: |
Вывод на экран дисплей (без многостраничной поддержки). Значение по умолчанию. | |
| print: | Постраничный вывод на непрозрачную бумагу. Предназначен также для вывода на экран в режиме preview. | |
| projection: | Вывод на проектор. | |
| braille: | Вывод кодов Брайля на тактильное устройство | |
| speach: | Вывод на речевой синтезатор. | |
| all: | Вывод на все устройства сразу. |
Элемент style позволяет разработчику установить стилевые правила в заголовке документа. HTML допускает любое число элементов style в секции head документа. Агент пользователя, который не поддерживает стилевые листы или специфический стилевой язык, используемый элементом style, должен прятать содержимое элемента style. Управление средой особенно интересно, когда применяются внешние стилевые листы, так как агент пользователя может сэкономить время, копируя через сеть только те стилевые листы, которые используются на данном устройстве вывода.
Следующая декларация CSS style устанавливает рамку вокруг каждого Н1 элемента в документе и центрирует ее на странице.
<head>
<style type="text/css">
|
h1 {border-width: 1; border: solid; text-align: center} | ||
| </style> | ||
</head>
Для спецификации того, что этот стиль информации должен применяться только для Н1-элементов определенного класса, модифицируем эту запись следующим образом.
<head>
<style type="text/css">
h1.myclass {border-width: 1; border: solid; text-align: center} | ||
| </style> | ||
</head>
<body>
| <h1 class="myclass"> this H1 is affected by our style </h1> | |
| <h1 this one is not affected by our style </h1> |
</body>
И наконец, для того чтобы ограничить зону действия стилевой информации одним случаем Н1, установим атрибут ID.
<head>
<style type="text/css"> | ||
h1.myid {border-width: 1; border: solid; text-align: center} | ||
| </style> | ||
</head>
<body>
| <H1 class="myclass"> this H1 is not affected </h1> | |
| <H1 this one is affected by style </H1> | |
| <H1> this h1 is not affected </H1> |
</body>
В следующем примере использован элемент span для определения шрифтового стиля первых нескольких слов.
<head>
<style type="text/css"> | ||
| span.sc-ex { font-variant: small-caps } | ||
| </style> | ||
</head>
<body>
<p><span id="sc-ex"> the first</span> few words of | ||
| this paragraph are in small-caps | ||
</body>
В следующем примере используется div и атрибут class для выравнивания последовательности параграфов. Эта стилевая информация может быть использована повторно, например, для форматирования резюме научных статей путем установки атрибута class в соответствующем месте документа.
<head>
| <style type="text/css"> | ||
| div.abstact {text-align: justify } | ||
| </style> | ||
</head>
<body>
| <div class="abstract"> | |
| <p>the chieftain product range is our market winner for the coming year. | |
| this report sets out how to position chieftain against competing products. | |
| <p>chieftain replaces the commander range, which will remain on the | |
| price list until further notice. |
</div>
</body>
23.2. Типы среды
HTML позволяет разработчику конструировать документы, структура которых не зависит от специфических свойств среды.
В результате пользователь может просматривать этот документ с использованием самых разных агентов пользователя: на персональной ЭВМ, рабочей станции, Х-терминале, специально приспособленном телефонном аппарате и т.д..
Атрибут media специфицирует среду вывода для формирования стилевых правил. Установив атрибут media, разработчик может позволить агенту пользователя избежать копирования через сеть стилевых листов, не используемых в данном документе. Ниже предлагается пример деклараций для элемента Н1. При отображении на экране текст будет голубым и выровненным по центру, при печати текст будет выровнен по центру. Предусмотрена возможность вывода и на речевой синтезатор.
<head>
<style type="text/css" media="screen"> | ||
| h1 { color: blue } | ||
| </style> | ||
<style type="text/css" media="screen, print">
h1 { text-align: center }
</style>
<style type="text/acss" media="speach">
h1 { cue-before: url(bell.aiff); cue-after: url(dong.wav)}
</style>
</head>
Предыдущий пример может быть переписан для случая применения внешних стилевых листов (вместо элемента style) в сочетании с атрибутом media. Агент пользователя на основе атрибута media принимает решение о копировании из сети тех или иных стилевых листов.
<head>
<link href="docl-screen.css" rel="stylesheet"
| type="text/css" media="screen"> |
| type="text/css" media="print"> |
<link href="docl-speach.css" rel="stylesheet"
| type="text/css" media="speach"> |
</head>
Стилевые листы
Стилевые листы являются главным инструментом при разработке дизайна HTML-страниц. Они дают разработчику возможность преобразовать текст в изображение, отображать таблицы, писать программы и делать многое другое. HTML 4.0 поддерживает следующие возможности:
Гибкое размещение стилевой информации. Помещение стилевых листов в отдельные файлы упрощает их повторное использование.
Независимость от стилевых особенностей используемого языка. Данная спецификация HTML не привязывает его к какому-то определенному языку.
Каскадирование стилевых листов. Эта особенность позволяет совместно использовать стилевую информацию из нескольких источников.
Зависимость от среды. HTML позволяет описать документ независимым от среды способом, что обеспечивает доступ широкому кругу людей, работающих в различных средах (Windows, X11, Mac, мультимедиа системы и пр.). Стилевые листы позволяют адаптироваться к среде наилучшим образом, используя все предоставляемые ей возможности.
Альтернативные стили. Разработчик может предложить пользователю несколько альтернативных стилей представления данных. Например, отображение с мелкими или крупными шрифтами, с или без графических объектов и т.д.
HTML-документ может содержать стилевые рекомендации внутри, но можно их импортировать и извне. Синтаксис стилевых правил определяется языком стилевых листов CSS (Cascading Style Sheets), который не является частью HTML. Так как агент пользователя должен осуществлять разбор стилевых инструкций, пользователь обязан декларировать, какой стилевой язык он использует. Можно использовать элемент META для установки стилевого языка по умолчанию. Так для установления в качестве стилевого языка по умолчанию CSS, в head документа нужно включить следующую декларацию.
<meta http-equiv="content-style-type" content="text/css">
Стилевой язык может быть задан также в http-заголовках. Например:
content-style-type: text/css
Если использовано несколько деклараций стилевого языка, работает самая последняя декларация. Если нет явной декларации стилевого языка, по умолчанию устанавливается CSS. HTML-элементы и атрибуты определяют начало стилевого листа. Конец стилевого листа определяется открытым разграничителем конечной метки, за которым следует начальный символ имени SGML [a-za-z]. Агент пользователя должен иметь соответствующий хандлер стилевого листа.
Одним из строчных стилевых атрибутов является style = Cdata. Этот атрибут специфицирует стилевую информацию для текущего элемента. Ниже приведен пример задания цвета и размера шрифта в тексте параграфа.
<p type="text/css" style="font-size: 12pt; color: fuschia">aren't style sheet wonderful?
Декларация типа имя: значение является конструкцией языка CSS. Если стиль планируется использовать повторно в нескольких элементах, более корректным будет применение элемента style, а не атрибута style, который носит одноразовый характер.
Строки и параграфы
Любой текст обычно представляется в виде последовательности параграфов. Для определения границ параграфа в HTML используется элемент p. Текст параграфа будет использоваться как единое целое при ряде процедур.
Структура и презентация
HTML различает структурную разметку, такую как параграфы и цитаты из идиом отображения (rendering idioms) таких как поля, шрифты, цвета, и т.д. Как это различие влияет на таблицы? С чисто теоретической точки зрения выравнивание текста внутри ячеек таблицы и определение границы между ячейками, проблема отображения, а не структуры. На практике полезно использовать обе возможности. Модель таблиц HTML оставляет большую часть управления отображением стилевым листам.
Современные издательские системы предоставляют очень богатые возможности управления отображением таблиц. Эти спецификации предлагают разработчику возможность выбора класса стиля границ. Атрибут frame управляет наличием разграничительных линий вокруг таблицы, в то время как атрибут rules определяет выбор разделительных линий внутри таблицы. Стилевой атрибут может быть использован для спецификации информации, управляющей процессом отображения для индивидуальных элементов. Дополнительная информация может быть получена через элемент style в заголовке документа или из подключенного стилевого листа.
Связи с поисковыми системами
Элемент Link может использоваться для решения задач поиска документов по ключевым словам и другим признакам, например, язык или представления документа в виде, допускающем печать. Ниже приведен пример, где сообщается поисковой системе о месте нахождения печатной копии руководства.
<head>
<link media="print" title="the manual in postscript"
| rel="alternate" | |
| href="http://someplace.com/manual/postscript.ps"> |
</head>
А в этом примере мы заставляем поисковую систему найти первую страницу собрания документов.
<head>
<link rel="start" title="the first page of the manual"
| href="html://someplace.com/manual/postscript.ps"> |
</head>
Связные сети
Особый случай сетей с коммутацией каналов возникает при проектировании связных сетей в параллельных вычислительных архитектурах для объединения параллельных процессоров и памяти. Модели, основанные на связанности сети, одинаково применимы и к отказам по причине перегрузок, и к отказам в работе сетевых узлов. Эквивалентом производительности системы считается среднее значение параметра связанности сети между ее входной и выходной точками.
Таблица атрибутов
В таблице собраны основные характеристики атрибутов, типы пакетов, где они используются, а также возможное число атрибутов в пакете.
Таблица .8. Основные характеристики атрибутов
| Request | Accept | Reject | Challenge | # | Атрибут |
| 1 | 0 | 0 | 0 | 1 | User-Name |
| 0-1 | 0 | 0 | 0 | 2 | User-Password [*] |
| 0-1 | 0 | 0 | 0 | 3 | CHAP-Password [*] |
| 0-1 | 0 | 0 | 0 | 4 | NAS-IP-Address |
| 01 | 0 | 0 | 5 | NASPort | |
| 0-1 | 0-1 | 0 | 0 | 6 | Service-Type |
| 0-1 | 0-1 | 0 | 0 | 7 | Framed-Protocol |
| 0-1 | 0-1 | 0 | 0 | 8 | Framed-IP-Address |
| 0-1 | 0-1 | 0 | 0 | 9 | Framed-IP-Netmask |
| 0 | 0-1 | 0 | 0 | 10 | Framed-Routing |
| 0 | 0+ | 0 | 0 | 11 | Filter-Id |
| 0 | 0-1 | 0 | 0 | 12 | Framed-MTU |
| 0+ | 0+ | 0 | 0 | 13 | Framed-Compression |
| 0+ | 0+ | 0 | 0 | 14 | Login-IP-Host |
| 0 | 0-1 | 0 | 0 | 15 | Login-Service |
| 0 | 0-1 | 0 | 0 | 16 | Login-TCP-Port |
| 0 | 0+ | 0+ | 0+ | 18 | Reply-Message |
| 0-1 | 0-1 | 0 | 0 | 19 | Callback-Number |
| 0 | 0-1 | 0 | 0 | 20 | Callback-Id |
| 0 | 0+ | 0 | 0 | 22 | Framed-Route |
| 0 | 0-1 | 0 | 0 | 23 | Framed-IPX-Network |
| 0-1 | 0-1 | 0 | 0-1 | 24 | State |
| 0 | 0+ | 0 | 0 | 25 | Class |
| 0+ | 0+ | 0 | 0+ | 26 | Vendor-Specific |
| 0 | 0-1 | 0 | 0-1 | 27 | Session-Timeout |
| 0 | 0-1 | 0 | 0-1 | 28 | Idle-Timeout |
| 0 | 0-1 | 0 | 0 | 29 | Termination-Action |
| 0-1 | 0 | 0 | 0 | 30 | Called-Station-Id |
| 0-1 | 0 | 0 | 0 | 31 | Calling-Station-Id |
| 0-1 | 0 | 0 | 0 | 32 | NAS-Identifier |
| 0+ | 0+ | 0+ | 0+ | 33 | Proxy-State |
| 0-1 | 0-1 | 0 | 0 | 34 | Login-LAT-Service |
| 0-1 | 0-1 | 0 | 0 | 35 | Login-LAT-Node |
| 0-1 | 0-1 | 0 | 0 | 36 | Login-LAT-Group |
| 0 | 0-1 | 0 | 0 | 37 | Framed-AppleTalk-Link |
| 0 | 0+ | 0 | 0 | 38 | Framed-AppleTalk-Network |
| 0 | 0-1 | 0 | 0 | 39 | Framed-AppleTalk-Zone |
| 0-1 | 0 | 0 | 0 | 60 | CHAP-Challenge |
| 0-1 | 0 | 0 | 0 | 61 | NAS-Port-Type |
| 0-1 | 0-1 | 0 | 0 | 62 | Port-Limit |
| 0-1 | 0-1 | 0 | 0 | 63 | Login-LAT-Port |
[*] Запрос Access-Request должен содержать пароль пользователя или CHAP-пароль, но не должен содержать и то и другое.
Ниже в таблице представлены обозначения, использованные в таблице 8.
| 0 | Этого атрибута не должно быть в пакете. |
| 0+ | Атрибут может использоваться в пакете нуль или более раз. |
| 0-1 | Атрибут может использоваться в пакете нуль или один раз. |
| 1 | Атрибут должен присутствовать в пакете обязательно один раз. |
Таблицы
Модель таблиц в HTML позволяет пользователям создавать достаточно сложные структуры таблиц. В этой модели ряды и колонки можно объединять в группы. При печати больших таблиц заголовки и нижние комментарии могут дублироваться для каждой части.
14.1. Структура таблиц
В HTML таблицы имеют следующую структуру
Допускается одна или более групп строк. Каждая группа состоит из опционной секции заголовка таблицы и опционной нижней секции.
Допускается одна или более групп колонок.
Каждая строка состоит из одной или более ячеек.
Каждая ячейка может содержать заголовок или информацию и занимать более одной строки и более одной колонки.
