Представление типа адреса
Специфический тип IPv6 адресов идентифицируется лидирующими битами адреса. Поле переменной длины, содержащее эти лидирующие биты, называется префиксом формата (Format Prefix - FP). Исходное назначение этих префиксов следующее (табл. 4.4.1.1.1):
Таблица 4.4.1.1.1
| Назначение |
Префикс (двоичный) | Часть адресного пространства |
| Зарезервировано | 0000 0000 | 1/256 |
| Не определено | 0000 0001 | 1/256 |
| Зарезервировано для NSAP | 0000 001 | 1/128 |
| Зарезервировано для IPX | 0000 010 | 1/128 |
| Не определено | 0000 011 | 1/128 |
| Не определено | 0000 1 | 1/32 |
| Не определено | 0001 | 1/16 |
| Не определено | 001 | 1/8 |
| Провайдерские уникаст-адреса | 010 | 1/8 |
| Не определено | 011 | 1/8 |
|
Зарезервировано для географических уникаст-адресов | 100 | 1/8 |
| Не определено | 101 | 1/8 |
| Не определено | 110 | 1/8 |
| Не определено | 1110 | 1/16 |
| Не определено | 1111 0 | 1/32 |
| Не определено | 1111 10 | 1/64 |
| Не определено | 1111 110 | 1/128 |
| Не определено | 1111 1110 0 | 1/512 |
| Локальные канальные адреса | 1111 1110 10 | 1/1024 |
| Локальные адреса (site) | 1111 1110 11 | 1/1024 |
| Мультикаст-адреса | 1111 1111 | 1/256 |
Замечание: Не специфицированные адреса, адреса обратной связи и IPv6 адреса со встроенными IPv4 адресами, определены вне “0000 0000” префиксного пространства.
Данное распределение адресов поддерживает прямое выделение адресов провайдера, адресов локального применения и мультикастинг-адресов. Зарезервировано место для адресов NSAP, IPX и географических адресов. Оставшаяся часть адресного пространства зарезервирована для будущего использования. Эти адреса могут использоваться для расширения имеющихся возможностей (например, дополнительных адресов провайдеров и т.д.) или новых приложений (например, отдельные локаторы и идентификаторы). Пятнадцать процентов адресного пространства уже распределено. Остальные 85% зарезервированы.
Уникастные адреса отличаются от мультикастных значением старшего октета: значение FF (11111111) идентифицирует мультикастинг-адрес; любые другие значения говорят о том, что адрес уникастный. Эникастные (anycast) адреса берутся из уникастного пространства, и синтаксически неотличимы от них.
Представление записи адресов (текстовое представление адресов)
Существует три стандартные формы для представления ipv6 адресов в виде текстовых строк:
Основная форма имеет вид x:x:x:x:x:x:x:x, где 'x' шестнадцатеричные 16-битовые числа.
Примеры:
fedc:ba98:7654:3210:FEDC:BA98:7654:3210
1080:0:0:0:8:800:200C:417A
Заметьте, что ненужно писать начальные нули в каждом из конкретных полей, но в каждом поле должна быть, по крайней мере, одна цифра (за исключением случая, описанного в пункте 2.).
Из-за метода записи некоторых типов IPv6 адресов, они часто содержат длинные последовательности нулевых бит. Для того чтобы сделать запись адресов, содержащих нулевые биты, более удобной, имеется специальный синтаксис для удаления лишних нулей. Использование записи "::" указывает на наличие групп из 16 нулевых бит. Комбинация "::" может появляться только при записи адреса. Последовательность "::" может также использоваться для удаления из записи начальных или завершающих нулей в адресе. Например:
| 1080:0:0:0:8:800:200c:417a | уникаст-адрес |
| ff01:0:0:0:0:0:0:43 | мультикаст адрес |
| 0:0:0:0:0:0:0:1 | адрес обратной связи |
| 0:0:0:0:0:0:0:0 | неспецифицированный адрес |
может быть представлено в виде:
| 1080::8:800:200c:417a | уникаст-адрес |
| ff01::43 | мультикаст адрес |
| ::1 | адрес обратной связи |
| :: | не специфицированный адрес |
Альтернативной формой записи, которая более удобна при работе с ipv4 и IPv6, является x:x:x:x:x:x:d.d.d.d, где 'x' шестнадцатеричные 16-битовые коды адреса, а 'd' десятичные 8-битовые, составляющие младшую часть адреса (стандартное IPv4 представление). Например:
0:0:0:0:0:0:13.1.68.3
0:0:0:0:0:FFFF:129.144.52.38
или в сжатом виде:
::13.1.68.3
::FFFF:129.144.52.38
Прерывание сессии
Прерывание сессии может быть инициировано LAC или LNS и выполняется путем посылки управляющего сообщения CDN. После того как последняя сессия прервана, управляющее соединение может быть также разорвано. Ниже приводится типовой обмен управляющими сообщениями:
LAC или LNS LAC или LNS
CDN ->
(Clean up)
| <- ZLB ACK | |
| (Clean up) |
a Рекомендации по формированию опций
Это приложение дает некоторые советы, как выкладывать поля, при формировании новых опций, предназначенных для использования в заголовке опций hop-by-hop или в заголовке опций места назначения. Эти рекомендации базируются на следующих предположениях:
Желательно, чтобы любые многооктетные поля в пределах данных опции были выровнены на их естественные границы, т.e., поля с длиной в n октетов следует помещать со смещением по отношению к началу заголовка (hop-by-hop или destination options), кратным n октетам, для n = 1, 2, 4 или 8.
Другим желательным требованием является минимальное место, занимаемое hop-by-hop или опциями места назначения, а длина заголовка должна быть кратной 8 октетам.
Можно предположить, что когда присутствует какой-то заголовок, содержащий опции, он несет в себе небольшое число опций, обычно одну.
Эти предположения определяют следующий подход к выкладке полей опций: порядок опций от коротких к длинным без внутреннего заполнения. Требования выравнивания границ для всей опции определяется требованием выравнивания наиболее длинного поля (до 8 октетов). Этот подход иллюстрируется на следующих примерах:
Пример 1
Если опция x требует двух полей данных, одно длиной 8 октетов, а другое длиной 4 октета, ее формат будет иметь вид (рис. 4.4.1.1.27):

Рис. 4.4.1.1.27.
Требование выравнивания соответствует 8n+2, для того чтобы гарантировать начало 8-октетного поля со смещением, кратным 8, от начала последнего заголовка. Полный заголовок (hop-by-hop или destination options), содержащий одну из этих опций будет иметь формат (рис. 4.4.1.1.28):

Рис. 4.4.1.1.28
Пример 2
Если опция y требует трех полей данных, одно длиной 4 октета, одно - 2 октета и одно - длиной один октет, она будет уложена следующим образом (рис. 4.4.1.1.29):

Рис. 4.4.1.1.29
Требование выравнивания выглядит как 4n+3, и призвано гарантировать, что 4-октетное поле начнется со смещением кратным 4 по отношению к началу завершающего заголовка. Полный заголовок (hop-by-hop или destination options), содержащий одну из указанных опций будет иметь вид (рис. 4.4.1.1.30):

Рис. 4.4.1.1.30
Пример 3
Заголовок с опциями hop-by-hop или destination options, содержащий обе опции x и y из примеров 1 и 2, будет иметь один из приведенных ниже форматов, в зависимости от того, какая из опций встречается первой (рис. 4.4.1.1.31, 4.4.1.1.32):

Рис. 4.4.1.1.31

Рис. 4.4.1.1.32
B Коды и значения ошибки
Нижеприведенные коды ошибок могут встретиться в объектах ERROR_SPEC, и предназначены для пересылки оконечным системам. За исключением специально оговоренных случаев эти коды могут использоваться только в сообщениях ResvErr. Код ошибки = 00: Подтверждение.
Это код зарезервирован для использования в объекте ERROR_SPEC сообщения ResvConf. Значение ошибки также будет равно нулю. Код ошибки = 01: Отказ системы управления допуском.
Запрос резервирования отвергнут системой управления допуском из-за недостатка ресурсов. Для этого кода ошибки 16 бит поля значение ошибки имеют формат:
ssur cccc cccc cccc
где биты имеют следующие значения:
ss = 00: Младшие 12 бит содержат глобально-определенный субкод (значение приведены ниже).
ss = 10: Младшие 12 бит содержат организационно-специфический субкод. Предполагается, что RSVP интерпретирует этот код как обычное число.
ss = 11: Младшие 12 бит содержат субкод, зависящий от вида услуг. Предполагается, что RSVP интерпретирует этот код как обычное число.
Так как механизм управления трафиком может предлагать различные услуги, кодирование может включать в себя некоторые особенности используемой услуги.
u = 0: RSVP отвергает сообщение без модификации локального состояния
u = 1: RSVP может использовать сообщение для модификации локального состояния и для последующей пересылки. Это означает, что сообщение является информационным.
r: зарезервированный бит, должен быть равен нулю.
cccc cccc cccc: 12 битовый код.
Следующие глобально-заданные субкоды могут появиться в младших 12 битах, когда ssur = 0000:
- Субкод = 1: Предел (bound) по задержке не может быть обеспечен.
- Субкод = 2: Запрашиваемая полоса пропускания недоступна.
- Субкод = 3: MTU в flowspec больше чем MTU интерфейса. Код ошибки = 02: Policy Control failure
Сообщение резервирования или path было отвергнуто по административным причинам, например, не выполнены условия аутентификации, недостаточная квота и т.д.. Этот код ошибки может появиться в сообщении PathErr или ResvErr.
Содержимое поля значение ошибки должно быть определено в будущем. Код ошибки = 03: Нет информации о проходе для этого сообщения Resv. Нет состояния прохода для данной сессии. Сообщение Resv не может быть переслано.Код ошибки = 04: Нет информации отправителя для этого сообщения Resv. Имеется состояние прохода для этой сессии, но оно не включает в себя записи отправителя, соответствующей дескриптору потока, который содержится в сообщении Resv. Сообщение Resv не может быть переслано.Код ошибки = 05: Конфликт со стилем резервирования. Стиль резервирования конфликтует со стилем существующего состояния резервирования. Поле значение ошибки содержит младшие 16 бит вектора опций существующего стиля, с которым произошел конфликт. Сообщение Resv не может быть переслано.Код ошибки = 06: Неизвестный стиль резервирования. Стиль резервирования неизвестен. Сообщение Resv не может быть переслано.Код ошибки = 07: Конфликт портов места назначения. Появились сессии для одного и того же адреса места назначения с нулевым и ненулевым значением полей порта назначения. Этот код ошибки может появиться в сообщении PathErr или ResvErr.Код ошибки = 08: Конфликт портов отправителя. Для одной и той же сессии имеются нулевые и ненулевые порты отправителя в сообщениях Path. Этот код ошибки может появиться только в сообщении PathErr.Код ошибки = 09, 10, 11: (зарезервировано)Код ошибки = 12: Привилегированное обслуживание. Запрос обслуживания, определенный объектом STYLE, и дескриптор потока были административно перехвачены.
Для этого кода ошибки 16 бит поля значения ошибки имеют формат:
ssur cccc cccc cccc
Ниже приведены значения старших бит ssur, как они определены при коде ошибки 01. Глобально-заданные субкоды, которые могут появиться в младших 12 битах, когда ssur = 0000 должны быть определены в будущем. Код ошибки = 13: Неизвестный класс объекта. Этот код ошибки содержит 16-битовое слово, состоящее из (Class-Num, C-тип) неизвестного объекта. Эта ошибка должна быть послана только в случае, когда RSVP намеревается отвергнуть сообщение, как это определено старшими битами Class-Num.
Этот код ошибки может появиться в сообщении PathErr или ResvErr.Код ошибки = 14: Неизвестный объект C-типа. Значение ошибки содержит 6-битовый код, состоящий из (Class-Num, C-тип) объекта.Код ошибки = 15-19: (зарезервировано)Код ошибки = 20: Зарезервировано для API. Поле значение ошибки содержит код ошибки API, которая была обнаружена асинхронно и о которой необходимо уведомить систему соответствующим откликом.Код ошибки = 21: Ошибка управления трафиком. Запрос управления трафиком не прошел из-за формата или содержимого параметров запроса. Сообщения Resv или Path, которые инициировали вызов, не могут быть пересланы, повторные вызовы бесполезны.
Для этого кода ошибки 16 бит поля значения ошибки имеют формат:
ss00 cccc cccc cccc
Ниже представлены значения старших бит ss, как это определено для кода ошибки 01.
Следующие глобально-заданные субкоды могут появляться в младших 12 битах (cccc cccc cccc), когда ss = 00: Субкод = 01: Конфликт сервиса. Попытка объединить два несовместимых запроса обслуживания.Субкод = 02: Сервис не поддерживается. Управление трафиком не может обеспечить запрашиваемый сервис или его приемлемую замену.Субкод = 03: Плохое значение Flowspec. Запрос неверного формата или неприемлемые требования.Субкод = 04: Плохое значение Tspec. Запрос неверного формата или неприемлемых требований.Субкод = 05: Плохое значение Adspec. Запрос неверного формата или неприемлемые требования.Код ошибки = 22: Ошибка системы управления трафиком. Модули управления трафиком обнаружели системную ошибку. Значение ошибки будет содержать специфический для системы код, предоставляющий дополнительную информацию об ошибке. Предполагается, что RSVP не может интерпретировать его значение.Код ошибки = 23: Системная ошибка RSVP
Поле значения ошибки предоставляет информацию об ошибке с учетом конкретной реализации приложения. Предполагается, что RSVP не может интерпретировать его значение.
Вообще каждое сообщение RSVP переформируется в каждом узле, а узел, в котором генерируется RSVP сообщение, несет ответственность за его правильную структуру.
Аналогично, каждый узел должен контролировать корректность структуры полученного им сообщения. В случае, когда из-за ошибки программы будет генерировано сообщение с некорректным форматом, оконечная система не обязательно будет проинформирована об этом. Ошибка, скорее всего, будет зафиксирована локально и передана через механизмы управления сетью.
Единственными ошибками формата сообщений, которые доводятся до сведения оконечной системы, являются несоответствия версии.
Ошибки формата сообщения, которые могут быть зафиксированы локально и сообщены приложению RSVP, относятся к числу специфических для данной реализации. Наиболее типичными из них можно считать следующие: Неверная длина сообщения: Поле длины RSVP не соответствует реальной длине сообщения.Неизвестная или неподдерживаемая версия RSVP.Ошибка в контрольной сумме RSVPОшибка в INTEGRITYНелегальный тип сообщения RSVPНелегальная длина объекта: не кратна 4, или меньше 4 байт.Адрес предыдущего/следующего узла в объекте HOP является нелегальным.Неверный номер порта источника: Порт источника не равен нулю в спецификации фильтра или шаблоне отправителя для сессии с нулевым портом назначения.Отсутствует необходимый класс объектаНелегальный класс объекта для данного типа сообщения.Нарушение регламентируемого порядка объектовНеверное число дескрипторов потока для данного типа сообщения или стиляНеверный дескриптор логического интерфейса Неизвестный объект Class-Num.Адрес места назначения сообщения ResvConf не согласуется с адресом получателя в объекте RESV_CONFIRM.
42. Приложение C. UDP-инкапсуляция
Реализации RSVP обычно требуют возможности выполнять любые сетевые операции ввода/вывода, т.е., посылать и получать IP-дейтограммы, используя код протокола 46. Однако, некоторые важные классы вычислительных систем могут не поддерживать такого рода операции. Для использования RSVP, такие ЭВМ должны инкапсулировать сообщения RSVP в UDP-дейтограммы.
Базовая схема UDP-инкапсуляции использует два предположения: Все ЭВМ способны посылать и получать мультикастные пакеты, если требуется поддержка мультикастных адресов назначения.Маршрутизаторы первого/последнего узлов должны поддерживать RSVP.
Пусть Hu является ЭВМ, которая нуждается в UDP-инкапсуляции, а Hr ЭВМ, способная выполнять любые сетевые операции ввода/вывода. Схема UDP-инкапсуляции должна допускать RSVP взаимодействие ЭВМ типа Hr, Hu и маршрутизаторов.
Сообщения Resv, ResvErr, ResvTear и PathErr посылаются по уникастным адресам, полученным из состояний прохода или резервирования узла. Если узел отслеживает, в каком из предыдущих узлов и в каком интерфейсе нужна UDP-инкапсуляция, эти сообщения при необходимости могут быть посланы с применением UDP инкапсуляции. С другой стороны, сообщения Path и PathTear могут посылаться адресату с применением как мультикастных, так и уникастных адресов.
В таблицах 4.4.9.6.1 и 4.4.9.6.2 приведены базовые правила UDP-инкапсуляции сообщений Path и PathTear, для уникастных и мультикастных DestAddress. Другие типы сообщений, которые работают с уникастными адресами, должны следовать правилам из табл. 4.4.9.6.1. Записи в колонке `RSVP посылает' имеют формат `mode(destaddr, destport)'.
Полезно определить две разновидности UDP-инкапсуляций, одна используется для посылки сообщений от Hu, другая от Hr и R. Это делается, для того чтобы избежать двойной обработки сообщения получателем. На практике эти два вида инкапсуляций разделяются по номерам UDP портов Pu и Pu'.
В таблицах используются следующие символы. D является портом назначения (DestAddress) конкретной сессии.G* является стандартным групповым адресом формата 224.0.0.14, т.е., группа ограничена пределами локальной сети.Pu и Pu' являются стандартными UDP-портами для UDP-инкапсуляции RSVP, с номерами 1698 и 1699.Ra равен IP-адресу интерфейса маршрутизатора `a'.Интерфейс маршрутизатора `a' локально доступен для Hu и Hr.
Таблица 4.4.9.6.1. Правила UDP-инкапсуляции для уникастных сообщений Path и Resv
(D – уникастный адрес места назначения; R – маршрутизатор; Raw – режим произвольных операций сетевого ввода/вывода.)
| Узел | RSVP посылает | RSVP получает |
| Hu | UDP(D/Ra,Pu) [1] | UDP(D,Pu) и UDP(D,Pu’) [2] |
| Hr | Raw(D) и, если (UDP), тогда UDP(D, Pu’) | RAW() и UDP(D, Pu) [2] (игнорировать Pu’) |
| R (интерфейс а) | Raw(D) и, если (UDP), тогда UDP(D, Pu’) | RAW() и UDP(Ra, Pu) (игнорировать Pu’) |
/p>
[1] | Hu посылает уникастные сообщения Path либо по адресу D, если D является локальным, либо по адресу Ra маршрутизатора первого узла. Ra предполагается известным. |
[2] | Здесь D является адресом локального интерфейса, через который приходит сообщение. |
[3] | Это предполагает, что приложение присоединилось к группе D. |
Таблица 4.4.9.6.2. Правила UDP-инкапсуляции для мультикастных сообщений Path
| Узел | RSVP посылает | RSVP получает |
| Hu | UDP(G*,Pu) | UDP(D,Pu’) [3] и UDP(G*,Pu) |
| Hr | Raw(D,Tr) и, если (UDP), тогда UDP(D, Pu’) | RAW() и UDP(G*, Pu) (игнорировать Pu’) |
R (интерфейс а) | Raw(D,Tr) и, если (UDP), тогда UDP(D, Pu’) | RAW() и UDP(G*, Pu) (игнорировать Pu’) |
Маршрутизатор может определить, нуждается ли его интерфейс Х в UDP-инкапсуляции, контролируя поступление UDP-инкапсулированных сообщений Path, которые были посланы либо G* (мультикаст D) либо по адресу интерфейса X (уникаст D). Для данной схемы существует один неудачный режим: если нет ни одной ЭВМ в сети, которая бы выполняла функцию RSVP отправителя, тогда не будет сообщений прохода (Path), чтобы запустить UDP-инкапсуляцию. В этом случае будет необходимо сконфигурировать UDP-инкапсуляцию для интерфейса локального маршрутизатора.
Когда получен UDP-инкапсулированный пакет, в большинстве систем TTL не доступно для приложения. Процесс RSVP, который получает UDP-инкапсулированное сообщение Path или PathTear должен использовать поле Send_TTL общего RSVP-заголовка для извлечения значения TTL. В тех случаях, когда это по каким-либо причинам не приемлемо, значение TTL может быть задано вручную при конфигурации.
Мы предположили, что первый маршрутизатор, поддерживающий RSVP, подключен непосредственно к локальной сети. Существует несколько подходов в случае, когда это не так. Hu может запускать как уникастные, так и мультикастные сессии в UDP(Ra,Pu) с TTL=Ta. Здесь Ta должно быть достаточным, чтобы достичь R. Если Ta слишком мало, сообщение Path не дойдет до R. Если Ta слишком велико, R и последующие маршрутизаторы могут переправлять UDP-пакет до тех пор, пока не иссякнет запас по TTL.
Это включит UDP-инкапсуляцию между маршрутизаторами в Интернет, возможно вызвав паразитный UDP трафик. ЭВМ Hu должна быть непосредственно сконфигурирована с использованием Ra и Ta.Конкретная ЭВМ локальной сети, соединенная с Hu может считаться “транспортной ЭВМ RSVP". Транспортная ЭВМ будет прослушивать (G*,Pu) и переправлять любое сообщение Path непосредственно R, хотя это и не будет маршрутом передачи данных. Транспортная ЭВМ должна быть сконфигурирована с использованием Ra и Ta.
Библиография
[Baker96] | Baker, F., "RSVP Cryptographic Authentication", Work in Progress. |
| [RFC 1633] | Braden, R., Clark, D., and S. Shenker, "Integrated Services in the Internet Architecture: an Overview", RFC 1633, ISI, MIT, and PARC, June 1994. |
| [FJ94] | Floyd, S. and V. Jacobson, "Synchronization of Periodic Routing Messages", IEEE/ACM Transactions on Networking, Vol. 2, No. 2, April, 1994. |
| [RFC 2207] | Berger, L. and T. O'Malley, "RSVP Extensions for IPSEC Data Flows", RFC 2207, September 1997. |
| [RFC-2208] | “Resource Reservation Protocol (RSVP) – Version 1. Applicability Statement”. |
| [RFC-2209] | “Resource Reservation Protocol (RSVP) – Version 1.Message Processing Rules” |
| [RFC 2113] | Katz, D., "IP Router Alert Option", RFC 2113, cisco Systems, February 1997. |
| [RFC 2210] | Wroclawski, J., "The Use of RSVP with Integrated Services", RFC 2210, September 1997. |
| [RFC-2211] | “Specification of the Controlled-Load Network Element Service” |
| [RFC-2212] | “Specification of Guarantied Quality of Service” |
| [PolArch96] | Herzog, S., "Policy Control for RSVP: Architectural Overview". Work in Progress. |
| [OPWA95] | Shenker, S. and L. Breslau, "Two Issues in Reservation Establishment", Proc. ACM SIGCOMM '95, Cambridge, MA, August 1995. |
Пример соединения IMAP
Последующее является записью для соединения IMAP 4.1. (Данный пример и нижеприведенное описание синтаксиса практически без изменения взято из документа RFC-2060).
S: * OK IMAP4rev1 Service Ready
C: a001 login mrc secret
S: a001 OK LOGIN completed
C: a002 select inbox
S: * 18 EXISTS
S: * FLAGS (\Answered \Flagged \Deleted \Seen \Draft)
S: * 2 RECENT
S: * OK [UNSEEN 17] Message 17 is the first unseen message
S: * OK [UIDVALIDITY 3857529045] UIDs valid
S: a002 OK [READ-WRITE] SELECT completed
C: a003 fetch 12 full
S: * 12 FETCH (FLAGS (\Seen) INTERNALDATE "17-Jul-1996 02:44:25 -0700"
RFC822.SIZE 4286 ENVELOPE ("Wed, 17 Jul 1996 02:23:25 -0700 (PDT)"
"IMAP4rev1 WG mtg summary and minutes"
(("Terry Gray" NIL "gray" "cac.washington.edu"))
(("Terry Gray" NIL "gray" "cac.washington.edu"))
(("Terry Gray" NIL "gray" "cac.washington.edu"))
((NIL NIL "imap" "cac.washington.edu"))
((NIL NIL "minutes" "CNRI.Reston.VA.US")
("John Klensin" NIL "KLENSIN" "INFOODS.MIT.EDU")) NIL NIL
"")
BODY ("TEXT" "PLAIN" ("CHARSET" "US-ASCII") NIL NIL "7BIT" 3028 92))
S: a003 OK FETCH completed
C: a004 fetch 12 body[header]
S: * 12 FETCH (BODY[HEADER] {350}
S: Date: Wed, 17 Jul 1996 02:23:25 -0700 (PDT)
S: From: Terry Gray gray@cac.washington.edu
S: Subject: IMAP4rev1 WG mtg summary and minutes
S: To: imap@cac.washington.edu
S: cc: minutes@CNRI.Reston.VA.US, John Klensin KLENSIN@INFOODS.MIT.EDU
S: Message-Id: B27397-0100000@cac.washington.edu
S: MIME-Version: 1.0
S: Content-Type: TEXT/PLAIN; CHARSET=US-ASCII
S:
S: )
S: a004 OK FETCH completed
C: a005 store 12 +flags \deleted
S: * 12 FETCH (FLAGS (\Seen \Deleted))
S: a005 OK +FLAGS completed
C: a006 logout
S: * BYE IMAP4rev1 server terminating connection
S: a006 OK LOGOUT completed
Примеры стилей
На рис. 4.4.9.6.2. показан пример маршрутизатора с двумя входными интерфейсами IА и IБ, через которые проходят входные потоки, и двумя выходными интерфейсами IВ и IГ, через которые осуществляется переадресация входных потоков. Пусть существует три отправителя S1 (S2 и S3), подключенные к интерфейсам IА и IБ, соответственно. Имеется три получателя R1 (R2 и R3), которые маршрутизированы через выходные интерфейсы IВ и IГ, соответственно. Будем также предполагать, что интерфейс IГ подключен к широковещательной сети, а R2 и R3 достижимы через разные маршрутизаторы, не показанные на рисунке.
Здесь нужно специфицировать мультикастные маршруты в пределах узла, отображенного на рис. 4.4.9.6.2. Предположим сначала, что информационные пакеты от каждого из отправителей Si, показанных на рисунке, маршрутизованы на оба выходных интерфейса. При этих предположениях на рисунках 4.4.9.6.3, 4.4.9.6.4 и 4.4.9.6.5 проиллюстрированы стили резервирования WF, FF и SE, соответственно.

Рис. 4.4.9.6.2. Конфигурация маршрутизатора
Для простоты эти примеры показывают flowspec как одномерное кратное повторение некоторого базового качества ресурса B. Колонка "Резервирует" показывает запросы резервирования RSVP, полученные через выходные интерфейсы IВ и IГ, а колонка "Получает" показывает результирующее состояние резервирования для каждого интерфейса. Колонка "Посылает" показывает запросы резервирования, посланные предшествующим узлам (IА и IБ). В колонке "Резервирует” каждая рамка представляет один зарезервированный виртуальный канал с соответствующим дескриптором потока.
Рис. 4.4.9.6.3, демонстрируя стиль WF, показывает две ситуации, в которых требуется объединение. Каждый из двух узлов, следующих за интерфейсом IГ посылают независимые запросы резервирования RSVP, эти два запроса должны быть объединены в одну спецификацию flowspec (3B), которая используется для выполнения резервирования в интерфейсе IГ.Резервирования для интерфейсов IB и IГ должны быть объединены, для того чтобы осуществить переадресацию запросов резервирования далее и получить спецификацию flowspec (4B).

Рис. 4.4.9.6.3. Пример резервирования WF (Wildcard-Filter)
На рис. 4.4.9.6. 4 проиллюстрирован стиль резервирования FF (Fixed-Filter). Для каждого выходного интерфейса, имеется отдельное резервирование для каждого запрошенного источника, но это резервирование будет общим для всех получателей, которые послали запрос. Дескрипторы для получателей S2 и S3, полученные через выходные интерфейсы IВ и IГ, вкладываются в пакеты запросов, направляемых предыдущему узлу (IБ). С другой стороны, три различных дескриптора потоков, специфицирующих отправителя S1, объединяются в один запрос FF( S1{4B} ), который посылается предыдущему узлу (IА).
На рис. 4.4.9.6.5 показан пример стиля резервирования SE. Когда резервирования стиля SE объединяются, результирующая спецификация фильтра является объединением исходных спецификаций, а результирующая спецификация flowspec равна наибольшей из flowspec.

Рис. 4.4.9.6.4. Пример резервирования FF (Fixed-Filter)

Рис. 4.4.9.6.5. Пример резервирования SE (Shared-Explicit)
Приведенные примеры предполагают, что информационные пакеты от S1, S2 и S3 маршрутизируются через оба выходных интерфейса. Нижняя часть рис. 4.4.9.6.2 показывает еще одно предположение о маршрутизации: информационные пакеты от S2 и S3 не переадресуются интерфейсу IВ, напр., из-за того что сеть обеспечивает более короткий путь для пакетов отправителя к R1. Рис. 4.4.9.6.3 показывает пример резервирования WF именно при этом предположении (стрелками отмечены допустимые маршруты). Так как нет пути от IБ к IВ, резервирование, переадресуемое интерфейсом IБ, рассматривает резервирование только для интерфейса IГ.
5. Механизмы протокола RSVP
5.1. Сообщения RSVP

Рис. 4.4.9.6.6. Маршрутизатор, использующий RSVP
На рис. 4.4.9.6.6 проиллюстрирована модель RSVP узла маршрутизатора. Каждый поток данных приходит со стороны предшествующего узла через соответствующий входной интерфейс и выходит из маршрутизатора через один или несколько выходных интерфейсов. Один и тот же интерфейс для разных потоков в пределах одной сессии может выполнять как входную, так и выходную роль.
Несколько предшествующих узлов и/ или последующих узлов могут для коммуникаций использовать один и тот же физический интерфейс; например, на рисунке два узла Г и Г' подключены к широковещательной сети через интерфейс IГ. Существует два фундаментальных типа сообщений RSVP: Resv и Path. Каждый получатель посылает свой RSVP запрос резервирования в виде сообщений (Resv) отправителям данных. Эти сообщения должны двигаться в точности тем же маршрутом с учетом выбора отправителей, что и данные только в противоположном направлении. Они создают и поддерживают состояние резервирования в каждом узле вдоль маршрута. Сообщения Resv должны быть, в конце концов, доставлены ЭВМ-отправителям, таким образом, ЭВМ устанавливают параметры управления трафиком.
Каждая ЭВМ отправитель передает RSVP сообщения "Path" вдоль уникаст/мультикаст маршрутов, сформированных с помощью маршрутных протоколов. Эти сообщения Path запоминают состояние пути в каждом узле вдоль маршрута. Это состояние пути включает в себя уникастный IP-адрес предыдущего узла, который используется для маршрутизации сообщений Resv от узла к узлу в противоположном направлении. Сообщение Path содержит помимо этого следующую информацию: Шаблон отправителя
Сообщение Path должно нести в себе шаблон отправителя (Sender Template), который описывает формат пакетов данных, посылаемых отправителем. Этот шаблон имеет форму спецификации фильтра, которая может использоваться для отделения пакетов данного отправителя от других пакетов в пределах сессии.
Шаблоны отправителя имеют тот же формат, что и спецификации фильтра, которые используются в сообщениях Resv. Следовательно, шаблон отправителя может специфицировать только его IP-адрес и опционно UDP/TCP порт, с учетом идентификатора протокола, заданного для сессии. Спецификация Tspec отправителя
Сообщения Path должны содержать спецификацию отправителя Tspec, которая определяет характеристики информационного трафика, формируемого отправителем. Спецификация Tspec используется для предотвращения избыточного резервирования. Спецификация Adspec
Сообщение Path может нести в себе пакет данных оповещения OPWA, известный, как "Adspec". Пакет Adspec, полученный с сообщением Path, передается системе управления трафиком, которая присылает скорректированную версию Adspec. Последняя пересылается далее в виде сообщения Path.
Сообщения Path посылаются с теми же адресами отправителя и получателя, что и данные, так что они будут корректно маршрутизироваться даже через сетевые области, не поддерживающие RSVP. С другой стороны, сообщения Resv посылаются от узла к узлу; каждый узел, поддерживающий RSVP, переправляет сообщение Resv по уникастному адресу предшествующего узла RSVP.
6. Объединение Flowspecs
Сообщение Resv, переадресованное предшествующему узлу, несет в себе спецификацию flowspec, которая является “наибольшей” из всех flowspec, запрошенных последующими узлами, которым будут посылаться данные.
Так как flowspecs непрозрачны для RSVP, действительные правила для сравнения flowspecs должны быть определены и реализованы вне рамок этого протокола. Реализация RSVP потребует обращения к специальной программе для выполнения объединения спецификаций flowspec.
Заметим, что спецификации flowspecs представляют собой в общем случае многомерные векторы; они могут содержать как Tspec, так и Rspec компоненты, каждая из которых может сама быть многомерной. Например, если один запрос требует высокой пропускной способности, а другой – жесткого ограничения задержек, один не может быть "больше" другого. В таком случае, вместо взятия большего, прикладная программа объединения должна быть способна сформировать такую спецификацию flowspec, которая по крайне мере столь же велика, как и каждая из составляющих; математически это наименьший верхний предел LUB (least upper bound). В некоторых случаях спецификация flowspec по крайне мере настолько мала насколько возможно; это наибольший верхний предел GLB (Greatest Lower Bound).
Для вычисления эффективного значения flowspec (Re, Te), инсталлируемого в интерфейс, используются следующие шаги [RFC 2210].
Здесь Te – эффективная спецификация Tspec, а Re – эффективная спецификация Rspec. Определяется эффективная спецификация flowspec для выходного интерфейса. В зависимости от технологии канального уровня, это может требовать объединения спецификаций flowspecs различных последующих узлов. Это означает вычисление эффективной спецификации flowspec, как LUB flowspecs. Какие спецификации следует объединять, определяется средой канального уровня, в то время как процедура объединения определяется используемой моделью обслуживания [RFC 2210]. В результате получается спецификация flowspec, которая непрозрачна для RSVP, но в действительности состоит из пары (Re, Resv_Te), где Re является эффективной спецификацией Rspec, а Resv_Te - эффективная спецификация Tspec.Производится вычисление спецификации Path_Te, зависящей от приложения и представляющей собой сумму всех Tspecs, которые были присланы в сообщениях Path, пришедших от различных предшествующих узлов (напр., некоторые или все узлы A, Б, и Б' на рис. 4.4.9.6.6).(Re, Resv_Te) и Path_Te передаются системе управления трафиком. Управление трафиком вычислит эффективную спецификацию flowspec, как минимум Path_Te и Resv_Te.
7. Гибкое состояние
RSVP использует подход "soft state" (гибкое состояние) для управления состоянием резервирования в маршрутизаторах и ЭВМ. Гибкое состояние RSVP создается и периодически освежается посредством сообщений Path и Resv. Состояние уничтожается, если не приходит подтверждения в течение заданного времени тайм-аута очистки. Состояние может быть стерто также посредством сообщения "teardown" (уничтожение). По истечении каждого таймаута обновления и после любых изменений состояния RSVP осуществляет проверку, для того чтобы подготовить и отправить сообщения обновления Path и Resv последующим узлам.
Сообщения Path и Resv практически эквивалентны (idempotent). Когда маршрут меняется, следующее сообщение Path инициализирует состояние прохода для нового маршрута, а последующие сообщения Resv установят для него резервирование.
Состояние же на неиспользованном в данный момент сегменте маршрута будет аннулировано по таймауту. Следовательно, определение того, является ли сообщение "новым" или "обновляющим" принимается отдельно для каждого узла в зависимости от его текущего состояния.
Протокол RSVP посылает свои сообщения в виде IP-дейтограмм без какого-либо улучшения надежности. Периодическая передача сообщений обновления от ЭВМ и маршрутизаторов позволяет компенсировать случайные потери отдельных RSVP сообщений. Если таймаут удаления установлен равным K периодам обновления, тогда RSVP может допускать потерю K-1 RSVP-пакетов подряд без аннулирования состояния. Механизм управления сетевым трафиком должен быть отконфигурирован так, чтобы предоставить минимальную полосу пропускания для сообщений RSVP, чтобы предотвратить их потерю из-за перегрузки канала.
Состояние, поддерживаемое RSVP, является динамическим. Для изменения набора отправителей Si или изменения любого запроса QoS, ЭВМ просто начинает посылать измененные сообщения Path и/или Resv. В результате будет осуществлено соответствующее изменение RSVP-состояния во всех узлах вдоль пути, неиспользуемые состояния будут аннулированы по таймауту, если не поступит прямых указаний по их ликвидации до этого.
В стабильном состоянии осуществляется обновление статуса узел за узлом. Когда полученное состояние отличается от хранящегося, последнее обновляется. О модификации состояния соседи оповещаются с помощью сообщений обновления, которые рассылаются сразу после изменения состояния. Но эта волна изменений может остановиться в узле, где в результате слияния получается состояние, которое не отличается от прежнего. Это минимизирует трафик управления RSVP, что весьма существенно для больших мультикастинг-групп.
Состояние, которое получено через конкретный интерфейс I* никогда не должно переадресовываться этому интерфейсу. Состояние, которое направляется интерфейсу I* должно вычисляться на основе состояний, полученных от других интерфейсов, исключая I*.
Тривиальный пример, поясняющий это правило приведен на рис. 4.4.9.6.7, на котором показан маршрутизатор с одним отправителем и одним получателем на каждом интерфейсе (R1, S1 и R2, S2). Интерфейсы IA и IБ выполняют как входные, так и выходные функции. Оба получателя используют WF-стиль резервирования, в котором сообщения Resv переадресуются всем предшествующим узлам группы вдоль маршрута, за исключением узла, от которого это сообщение получено. В результате достигается независимое резервирование для обоих направлений (на рис. 4.4.9.6.7 “Получает” и “Отправляет” подразумевает внешнее направление по отношению к маршрутизатору).

| Интерфейс IА | Интерфейс IБ | ||
| Получает | Отправляет | Получает | Отправляет |
| WF (* {4B}) | WF (* {3B}) | WF (* {3B}) | WF(*{4B}) |
| Резервирует | |||
| * {4B} | * {3B} | ||
Рис. 4.4.9.6.7. Независимые резервирования
Существует еще одно правило, которое управляет процессом переадресации сообщений Resv: состояние из сообщения Resv, полученное через выходной интерфейс Io, следует передавать входному интерфейсу Ii только в том случае, когда сообщение Path от Ii переадресовано к Io.
8. Аннулирование (Teardown)
Сообщения RSVP "аннулирование" удаляет проход или состояние резервирования. Хотя прямое уничтожение старого резервирования не является обязательным, оно настоятельно рекомендуется, так как ускоряет переходные процессы в сети.
Существует два типа RSVP сообщений аннулирования: PathTear и ResvTear. Сообщение PathTear направляется всем получателям и ликвидирует состояние прохода, а также все зависящие от него состояния резервирования. Сообщение ResvTear уничтожает состояние резервирования и направляется всем отправителям.
Запрос аннулирование (teardown) может посылаться приложением оконечной системы (получатель или отправитель), или маршрутизатором в результате таймаута или при появлении привилегированной задачи. После инициализации запрос-аннулирование должен переадресовываться от узла к узлу без задержки. Сообщение аннулирование уничтожает специфицированное состояние в узле-получателе.
Подобно другим сообщениям RSVP, запросы- аннулирования доставляются без гарантии надежности. Потеря такого запроса не вызовет катастрофы, так как не используемое состояние будет рано или поздно ликвидировано по таймауту. Если маршрутизатор не получил сообщения аннулирования, он ликвидирует соответствующее состояние по таймауту и формирует сообщение аннулирование, рассылаемое последующим узлам. Предполагая, что вероятность потери сообщения RSVP мала, наибольшее среднее время ликвидации ненужного состояния не превышает периода обновления.
Необходимо иметь возможность ликвидировать любой субнабор установленных состояний. Для состояний прохода минимально это может быть один отправитель. Для состояний резервирования таким объектом является спецификация фильтра. Например, в случае, показанном на рис. 4.4.9.6.7, получатель R1 может послать сообщение ResvTear только отправителю S2 (или любому субнабору из списка спецификаций фильтрации), оставляя S1 без изменений.
Сообщение ResvTear специфицирует стиль и фильтры, любая спецификация flowspec игнорируется. Любая рабочая спецификация flowspec будет убрана, если все ее спецификации фильтров будут ликвидированы.
9. Ошибки
Существует два типа RSVP сообщений об ошибках: ResvErr и PathErr. Сообщения PathErr очень просты, они посылаются отправителю виновнику ошибки и не изменяют состояния прохода в узлах, через которые проходят. Существует всего несколько причин ошибок прохода.
Однако для синтаксически верных запросов резервирования имеется много способов быть отвергнутыми. Узел может решить аннулировать установленное резервирование из-за более приоритетных заданий. Так как неудовлетворение запроса может быть вызвано объединением нескольких запросов, ошибка резервирования должна быть ретранслирована всем получателям группы. Кроме того, объединение разнородных запросов создает потенциальную трудность, известную как проблема "резервирования килера", в которой один запрос может блокировать услуги другого. В действительности существует две такие проблемы. Первая проблема резервирования килера (KR-I) возникает, когда уже имеется резервирование Q0.
Если другой получатель делает новое Q1 > Q0, результирующее объединенное резервирование Q0 и Q1 может быть отвергнуто системой контроля доступа в некотором последующем узле. Это не должно вредить услугам на уровне Q0. Решение этой проблемы весьма просто: когда контроль доступа не пропускает запрос резервирования, существующее состояние резервирования сохраняется.Вторая проблема (KR-II) противоположна первой: получатель, выполняющий резервирование Q1, сохраняется даже в случае не прохождения контроля доступа для Q1 в каком-то узле. Это не должно мешать другому получателю, установить меньшее резервирование Q0, которое бы прошло, если бы не было объединено с Q1.
Чтобы решить эту проблему сообщения ResvErr устанавливают дополнительное состояние, называемое, "состояние блокады", в каждом из узлов, через которые проходит это сообщение. Состояние блокады в узле модифицирует процедуру объединения, так чтобы игнорировать блокирующие спецификации flowspec (Q1 в вышеприведенном примере), позволяя скромным запросам проходить и осуществлять свое резервирование. Состояние резервирования Q1 считается в данном случае заблокированным.
Запрос резервирования, не прошедший контроль допуска создает состояние блокады в соответствующем узле, но остается действующим во всех предшествующих узлах. Было предложено, чтобы эти резервирования до точки отказа были удалены. Однако, эти резервирования были сохранены по следующим причинам: Имеется две возможные причины получателю настаивать на резервировании:
Заказываемый ресурс доступен по всей длине пути, или Нужно получить желаемый уровень QoS вдоль оговоренного пути так далеко, как это возможно. Конечно, во втором случае, а может быть и в первом, получатель захочет настаивать на резервировании, осуществленном вплоть до точки блокировки.
Если бы эти резервирования в предыдущих узлах не были сохранены, реагирование RSVP на некоторые переходные отказы станет хуже. Например, предположим, что маршрут переключился на альтернативный, который сильно перегружен, так что существующие резервирования не могут быть удовлетворены, и система возвращается к исходному маршруту.
Состояние блокады в каждом из маршрутизаторов до узкого места не должно быть немедленно удалено, так как не позволит системе быстро восстановиться.Если бы мы не обновляли резервирование в предшествующих узлах каждые Tb секунд, они могли бы быть удалены по таймауту (Tb время таймаута состояния блокады).
10. Подтверждение
Чтобы запросить подтверждение на свое резервирование, получатель Rj включает в сообщение Resv объект запроса подтверждения, содержащий IP-адрес Rj. В каждой точке объединения только наибольшая из спецификаций flowspec и соответствующий объект запроса подтверждения посылаются далее. Если запрос резервирования от Rj равен или меньше уже существующего резервирования, его Resv не переадресуется последующим узлам, и, если Resv включает в себя запрос подтверждения, отправителю Rj посылается сообщение ResvConf. Если запрос подтверждения переадресуется, это делается немедленно и не более одного раза на каждый запрос.
Этот механизм подтверждения имеет следующую последовательность: Новый запрос резервирования со спецификацией flowspec больше чем любая из действующих в данной точке спецификаций сессии обычно вызывает либо сообщение ResvErr, либо ResvConf, отправляемое получателю каждым из отправителей данных. В этом случае, сообщение ResvConf будет подтверждением, относящимся ко всему пути.Получение ResvConf не предоставляет никаких гарантий. Предположим, что два запроса резервирования от получателей R1 и R2 пришли в узел, где они были объединены. R2, чье резервирование было вторым по времени, может получить подтверждение ResvConf от данного узла, в то время как запрос R1 еще не прошел весь путь и он может еще быть отвергнут каким-то последующим узлом. Таким образом, R2 может получить ResvConf, когда не имеется полномасштабного резервирования вдоль всего пути; более того, R2 может получить ResvConf, за которым последует сообщение ResvErr.
11. Управление политикой
Механизм управления политикой определяет, каким пользователям или приложениям позволено осуществлять резервирование и в каком объеме.
RSVP- запросы QoS позволяют определенным пользователям получить предпочтительный доступ к сетевым ресурсам. Для предотвращения злоупотреблений, необходима некоторая обратная связь. Такого рода обратная связь может быть реализована с помощью административной политики обеспечения доступа, или путем введения прямой или виртуальной оплаты резервирования. В любом случае требуется идентификация пользователя.
Когда запрашивается новое резервирование, каждый узел должен ответить на два вопроса: "Имеется ли достаточно ресурсов, чтобы удовлетворить запрос?" и "Позволено ли данному пользователю осуществлять резервирование?" Эти два решения называются "управлением доступа" и "управлением политикой", соответственно. Различные административные домены в Интернет могут иметь разные политики резервирования.
На вход управления политикой поступают специфические блоки данных, которые заключены в объектах POLICY_DATA протокола RSVP. Эти блоки данных могут включать в себя параметры доступа пользователя, его класс, номер аккоунта, пределы квоты и пр. Подобно flowspecs, эти данные недоступны для RSVP, который просто передает их, когда требуется, системе управления политикой. Аналогично, объединение этих данных должно выполняться системой управления политикой, а не самим протоколом RSVP. Заметим, что точки объединения данных, характеризующих политику, должны находиться на границах административных доменов.
Перенос таких данных, поставляемых пользователями, в сообщениях Resv может представлять проблему в случае существенного увеличения числа пользователей. Когда мультикастинг-группа содержит большое число получателей, может оказаться невозможно или нежелательно транспортировать данные, описывающие политику, вдоль всего маршрута. Эти данные должны объединяться как можно ближе к получателям, чтобы избежать чрезмерного информационного потока.
12. Безопасность
При использовании протокола RSVP возникают определенные проблемы безопасности. Целостность сообщений и аутентификация узлов
Повреждение или фальсификация запросов резервирования может привести к получению услуг неавторизованными пользователями или к отказам в услугах. RSVP осуществляет защиту против таких атак с помощью механизма аутентификации, действующего в каждом из узлов и использующего шифрование с применением хэш-функций. Механизм поддерживается объектами INTEGRITY, которые могут быть включены в любое сообщение RSVP. Эти объекты используют технику криптографических дайджестов, которая предполагает, что соседи RSVP совместно владеют секретом шифрования (см. [Baker96]). Аутентификация пользователя
Управление политикой будет зависеть от положительного результата аутентификации для каждого из запросов резервирования. Информация, характеризующая политику, может быть включена в сообщение в виде криптографически защищенного сертификата пользователя. Безопасные потоки данных
Первые два пункта касались выполнения операций RSVP. Третий пункт касается резервирования для безопасных потоков данных. В частности, использование IPSEC (IP Security) в потоке данных создает проблему для RSVP: если транспортный и вышележащие заголовки зашифрованы, общие номера порта RSVP не могут использоваться для определения сессии или отправителя.
Для решения этой проблемы определено расширение RSVP, в котором идентификатор секретности (IPSEC SPI) играет ту же роль что и номер порта [RFC 2207].
13. Области, не поддерживающие RSVP
Невозможно развернуть протокол RSVP (или любой новый протокол) во всем Интернет одновременно. Более того, RSVP вероятно никогда не будет развернут повсеместно. RSVP должен гарантировать корректную работу, когда два RSVP маршрутизатора объединены друг с другом через сетевую область, не поддерживающую этот протокол. Конечно, промежуточная сетевая область, лишенная поддержки RSVP, не способна осуществлять резервирование ресурсов. Однако, если эта область обладает достаточной емкостью, она может обеспечить необходимый уровень услуг реального времени.
Протокол RSVP приспособлен для работы через такие, не поддерживающие его, сетевые области.
Как поддерживающие RSVP так и не поддерживающие RSVP маршрутизаторы переадресуют сообщения Path в соответствие с адресом места назначения, используя свои локальные таблицы маршрутизации. Следовательно, на маршрутизацию сообщений Path не оказывает влияние наличие промежуточных маршрутизаторов, лишенных RSVP поддержки. Когда сообщение Path проходит через сетевую область, не поддерживающую RSVP, оно, направляясь к следующему узлу, поддерживающему RSVP, несет в себе IP-адрес последнего RSVP-маршрутизатора. Сообщение Resv тогда переадресуется непосредственно следующему RSVP-маршрутизатору на пути к отправителю.
Хотя RSVP работает корректно и через сетевые области без поддержки RSVP, узлы из этой области могут внести искажения в QoS. При встрече области без поддержки RSVP протокол устанавливает бит-флаг `NonRSVP' и передает его механизму управления трафиком. Управление трафиком комбинирует этот однобитовый флаг со своей собственной информацией об источниках и передает ее вдоль транспортного пути получателям, используя спецификацию Adspecs [RFC 2210].
При некоторых топологиях маршрутизаторов с и без поддержки RSVP возможна доставка сообщений Resv в не тот узел, или не тот интерфейс. Процесс RSVP должен быть готов обрабатывать такие ситуации. Если адрес места назначения не соответствует ни одному локальному интерфейсу, а сообщение не является Path или PathTear, тогда оно должно передаваться далее без какой-либо обработки в данном узле. Чтобы обработать случай с неправильным интерфейсом, используется дескриптор логического интерфейса LIH (Logical Interface Handle). Информация предыдущего узла, включенная в сообщение Path, содержит не только IP-адрес предшествующего узла, но также и LIH, определяющий логический выходной интерфейс; обе величины записываются в состояние прохода. Сообщение Resv, пребывающее в адресуемый узел, несет в себе IP-адрес и LIH правильного выходного интерфейса, т.е., интерфейса, который должен получить запрошенное резервирование, вне зависимости от того, на какой интерфейс оно попало.
14. Модель ЭВМ
Прежде чем будет сформирована сессия, ей должен быть присвоен идентификатор (DestAddress, ProtocolId [, DstPort]), который рассылается всем отправителям и получателям. Когда RSVP сессия сформировалась, в оконечных системах должны произойти следующие события.
H1 | Получатель посредством IGMP подключается к мультикаст-группе, заданной адресом DestAddress. |
H2 | Потенциальный отправитель начинает посылать сообщения Path по адресу DestAddress. |
H3 | Приложение получателя принимает сообщение Path. |
H4 | Получатель начинает посылать соответствующие сообщения Resv, задавая дескрипторы нужных потоков. |
H5 | Приложение отправителя получает сообщение Resv. |
H6 | Отправитель начинает посылать информационные пакеты. |
Существует несколько соображений, касающихся синхронизации. H1 и H2 могут произойти в любом порядке.Предположим, что новый отправитель начинает отправку данных (H6), но пока нет мультикастинг маршрутов, так как ни один получатель не подключился к группе (H1). Тогда данные будут выбрасываться в некотором узловом маршрутизаторе (какой это будет узел, зависит от используемого протокола маршрутизации), пока не появится хотя бы один получатель.Предположим, что новый отправитель начинает рассылку сообщений Path (H2) и данных (H6) одновременно, и имеется некоторое число получателей, но сообщения Resv пока не достигли отправителя (напр., потому что его сообщения Path еще не дошли до получателей). Тогда исходные данные могут прийти к получателю без желаемого уровня QoS. Отправитель может немного облегчить эту проблему, подождав прибытия первого сообщения Resv (H5). Однако получатели, которые достаточно далеко, могут еще не получить необходимого резервирования.Если получатель начинает посылать сообщения Resv (H4) до получения какого-либо сообщения Path (H3), RSVP пришлет получателю сообщение об ошибке.
Получатель может просто игнорировать такие сообщения об ошибке или он может избежать их, ожидая сообщений, прежде чем посылать сообщения Resv. Программный интерфейс приложения (API) для RSVP в данной спецификации не определен, так как он может зависеть от ЭВМ и ОС.
15. Функциональная спецификация RSVP
15.1. Формат сообщений RSVP
Сообщение RSVP состоит из общего заголовка, за которым следует тело сообщения, состоящее из переменного числа объектов переменной длины. Для каждого типа сообщения RSVP, существует набор правил допустимого выбора типов объектов. Эти правила специфицированы с использованием стандартных форм Бакуса-Наура (BNF), дополняемых опционными субпоследовательностями, которые помещаются в квадратные скобки. Объекты следуют в определенном порядке. Однако, во многих случаях (но не во всех), порядок объектов не играет роли. Приложение должно создавать сообщения с порядком объектов, предлагаемом в данном документе. Но оно должно быть способно воспринимать объекты в любом порядке.
16. Общий заголовок

Рис. 4.4.9.6.8. Формат общего заголовка
В общем заголовке имеются следующие поля:
Vers. 4 бита – Номер версии протокола. В данном описании = 1.
Флаги: 4 бита - 0x01-0x08. Зарезервированы.
Флаги пока не определены.
Тип Msg. Тип сообщения (8 бит).
1 = Path
2 = Resv
3 = PathErr
4 = ResvErr
5 = PathTear
6 = ResvTear
7 = ResvConf
Контрольная сумма RSVP: 16 бит
Дополнение по модулю один контрольной суммы сообщения (в процессе вычисления поле контрольной суммы считается нулевым). Если в поле записан нуль, это означает, что контрольная сумма не вычислялась.
Send_TTL: 8 бит
Значение TTL для протокола IP, с которым было послано сообщение.
Длина RSVP: 16 бит
Полная длина RSVP сообщения в байтах, включая общий заголовок и объекты переменной длины, которые за ним следуют.
Примеры уникастных адресов
Примером уникастного адресного формата, который является стандартным для локальных сетей и других случаев, где применимы MAC адреса, может служить:

Рис. 4.4.1.1.3
Где 48-битовый идентификатор интерфейса представляет собой IEEE-802 MAC адрес. Использование IEEE 802 mac адресов в качестве идентификаторов интерфейсов будет стандартным в среде, где узлы имеют IEEE 802 MAC адреса. В других средах, где IEEE 802 MAC адреса не доступны, могут использоваться другие типы адресов связного уровня, такие как E.164 адреса, в качестве идентификаторов интерфейсов.
Включение уникального глобального идентификатора интерфейса, такого как IEEE MAC адрес, делает возможным очень простую форму авто-конфигурации адресов. Узел может узнать идентификатор субсети, получая информацию от маршрутизатора в виде сообщений оповещения, которые маршрутизатор посылает связанным с ним партнерам, и затем сформировать IPv6 адрес для себя, используя IEEE MAC адрес в качестве идентификатора интерфейса для данной субсети.
Другой формат уникастного адреса относится к случаю, когда локальная сеть или организация нуждаются в дополнительных уровнях иерархии. В этом примере идентификатор субсети делится на идентификатор области и идентификатор субсети. Формат такого адреса имеет вид:

Рис. 4.4.1.1.4
Эта схема может быть развита с тем, чтобы позволить локальной сети или организации добавлять новые уровни внутренней иерархии. Может быть, желательно использовать идентификатор интерфейса меньше чем 48-разрядный IEEE 802 MAC адрес, с тем, чтобы оставить больше места для полей, характеризующих уровни иерархии. Это могут быть идентификаторы интерфейсов, сформированные администрацией локальной сети или организации.
Приоритет
4-битовое поле приоритета в IPv6 заголовке позволяет отправителю идентифицировать относительный приоритет доставки пакетов. Значения приоритетов делятся на два диапазона. Коды от 0 до 7 используются для задания приоритета трафика, для которого отправитель осуществляет контроль перегрузки (например, снижает поток TCP в ответ на сигнал перегрузки). Значения с 8 до 15 используются для определения приоритета трафика, для которого не производится снижения потока в ответ на сигнал перегрузки, например, в случае пакетов “реального времени”, посылаемых с постоянной частотой.
Для трафика, управляемого сигналами перегрузки, рекомендуются следующие значения приоритета для конкретных категорий приложений (см. таблицу 4.4.1.1.2).
Таблица 4.4.1.1.2. Значения кодов приоритета
| Код приоритета | Назначение |
| 0 | Нехарактеризованный трафик |
| 1 | Заполняющий трафик (например, сетевые новости) |
| 2 | Несущественный информационный трафик (например, электронная почта) |
| 3 | Резерв |
| 4 | Существенный трафик (напр., FTP, HTTP, NFS) |
| 5 | Резерв |
| 6 | Интерактивный трафик (напр. telnet, x) |
| 7 | Управляющий трафик Интернет (напр., маршрутные протоколы, snmp) |
Предполагается, что чем больше код, тем выше приоритет данных, тем быстрее они должны быть доставлены. Так для передачи мультимедийной информации, где управление скоростью передачи не возможно, уровень приоритета должен лежать в пределах 8-15. Практически, уровни приоритета выше или равные 8 зарезервированы для передачи данных в реальном масштабе времени.
Для трафика, не контролируемого на перегрузки, нижнее значение приоритета (8) должно использоваться для тех пакетов, которые отправитель разрешает выбросить в случае перегрузки (например, видео трафик высокого качества), а высшее значение (15) следует использовать для пакетов, которые отправитель не хотел бы потерять (напр., аудио трафик с низкой надежностью). Не существует связи между относительными приоритетами обменов с и без контроля перегрузки.
Прочие ссылки
Geoff Husston, “Future for TCP” The Internet Protocol Journal, v3, N3, сентябрь 2000
( )
Huston, G., “TCP Performance”, The Internet Protocol Journal, Vol. 3, No. 2, Cisco Systems, June 2000.
T. V. Lakshman, Upamanyu Madhow, “The performance of TCP/IP for networks with high bandwidth-delay products and random loss” Infocom ’97, апрель, 1997, IEEE/ACM Trans. Networking, V5, N3, p.336-350, June 1997. (http://www.ece.ucsb.edu/Faculty/Madhow/publications.html/)
Kenji Kurata, Go Hasegawa, Masayuki Murata, “Fairness Comparisons Between TCP Reno and TCP Vegas for Future Deployment of TCP Vegas”, Университет Осаки, Япония,
T.N.Saadawi, M.H.Ammar, Ahmed El Hakeem, “Fundamentals of Telecommunication Networks”, Wiley-Interscience Publication, Jhon Wiley & sons, inc. 1995.
ATM Forum Trac Management Specication Version 4.0, Draft Specification ATM Forum/95-0013R11, ATM Forum, March 1996.
J. Bolot and A. U. Shankar, “Dynamical behavior of rate based flow control mechanisms”, Computer Communication Review pp. 35-49, April 1990.
J. Bolot, “End-to-end packet delay and loss behavior in the Internet”, Proc. ACM SIGCOMM ’93.
L. S. Brakmo, S. W. O’Malley, L. L. Peterson, “TCP Vegas: New techniques for congestion detection and avoidance”, Proc. ACM Sigcomm, August 1994.
H. Chaskar, T. V. Lakshman, U. Madhow, “On the Design of Interfaces for TCP/IP over Wireless”, Proceedings of IEEE Milcom ‘96.
A. Demers, S. Keshav, S. Shenker, “Analysis and simulation of affair queueing algorithm”, Proc. ACM SIGCOMM ‘89.
K. W. Fendick, D. Mitra, I. Mitrani, M. A. Rodrigues, J. B. Seery, A. Weiss, “An approach to high performance high speed data networks”, IEEE Communications Magazine, pp. 74-82, October 1991.
S. Floyd, “Connections with Multiple Congested Gateways in Packet Switched Networks Part 1: One-way Traffic”, Computer Communications Review, vol. 21 no.5 pp. 30-47,October 1991.
S. Floyd and V. Jacobson, “On Traffic Phase Effects in Packet Switched Gateways” Internetworking: Research and Experience vol.3 no.3 pp. 115-156, September 1992. (An earlier version of this paper appeared in Computer Communication Review, vol. 21 no.2 April 1991)
S. Floyd and V. Jacobson, “ Random Early Detection gateways for congestion avoidance”, IEEE/ACM Transactions of Networking vol. 1, no. 4, pp. 397-413, August 1993. .
V. Jacobson, “Congestion avoidance and control" Proc. ACM SIGCOMM ’88, pp. 314-329.
V. Jacobson, “Modified TCP congestion avoidance algorithm" message to end2end-interest mailing list, April 1990, URL .
V. Jacobson, “Berkeley TCP evolution from 4.3-tahoe to 4.3-reno” , Proc. of the 18th Internet Engineering Task Force, Vancouver, August, 1990.
P. Karn and C. Partridge, “Improving Round Trip Time Estimates in Reliable Transport Protocols" ACM Trans. on Computer Systems, vol. 9no. 4, pp. 364-373, November 1991.
T. V. Lakshman, U. Madhow, B. Suter, “Window-based error recovery and flow control with a slow acknowledgement channel: a study of TCP/IP performance”, Proceedings of IEEE Infocom 1997.
B. Makrucki, “On the performance of Submitting Excess Traffic to ATM Networks”, Proc. of Globecom 1991 pp. 281-288, December 1991.
D. Mitra, “Asymptotically optimal design of congestion control for high speed data networks”, IEEE Trans. Commun., vol. 40, no. 2, pp. 301-311, February 1992.
D. Mitra and J. B. Seery, “Dynamic adaptive windows for high speed data networks with multiple paths and propagation delays”, Computer Networks and ISDN Systems, vol. 25, pp. 663-679, 1993.
A. Mukherjee and J. C. Strikwerda, “Analysis of dynamic congestion control protocols - a Fokker-Planck approximation”, Proc. ACM SIGCOMM ‘91, pp. 159-169.
A. K. Parekh and R. G. Gallager, “A generalized processor sharing approach to flow control in integrated services networks - the multiple node case", Proc. IEEE Infocom ‘93.
K. K. Ramakrishnan and R. Jain, “A binary feedback scheme for congestion avoidance in computer networks with a connectionless network layer”, Proc. ACM SIGCOMM ’88, pp. 303-313.
S. Shenker, “A theoretical analysis of feedback flow control”, Proc. ACM SIGCOMM ’90, pp. 156-165.
S. Shenker, L. Zhang, and D. D. Clark, “ Some observations on the dynamics of a congestion control algorithm”, Computer Communication Review, pp. 30-39, October 1990.
L. Zhang, “A new architecture for packet switching network protocols”, Ph. D. dissertation, M.I.T. Lab. Comput. Sci. ,Cambridge, MA., 1989.
L. Zhang, S. Shenker, and D. D. Clark, “Observations on the dynamics of a congestion control algorithm the effects of two-way traffic” Proc. ACM SIGCOMM ’91, pp. 133-147.
M. Mathis, J. Semke, J. Mahdavi, “The Macroscopic Behavior of the TCP Congestion Avoidance Algorithm” ACM SIGCOMM, v27, N3, July 1997. Computer Communication Review, Vol.27, No.3, 1997
K. Fall, S. Floyd, “Simulation-based Comparisons of Tahoe, Reno, and SACK TCP”
B. Sikdar, S. Kalyanaraman, K.S. Vastola, “Analytic Models for the Latency and Steady-State Throughput of TCP Tahoe, Reno and SACK”, IEEE GLOBECOM’01, San Antonio, TX, USA.
H. Sawashima, Y.Hori, H. Sunahara, Y. Oie, “Characteristics of UDP Packet Loss: Effect of TCP Traffic”,
S. Floyd, K. Fall, “Promoting the Use of End-to-End Congestion Control in the Internet”, IEEE/ACM Transactions on Internetworking, V7, N4. August 1999.
Z. Jiang, L. Kleinrock, “A Packet Selection Algorithm for Adaptive Transmission of Smoothed Video Over a Wireless Channel”,
J. Padhye, V. Firoiu, D. Towsley, J. Kirose, “Modeling TCP Throughput: A Simple Model and Its Empirical Validation”, UMASS CMPSCI Tech. Report TR98-008, Feb.1998.
Описание канонической версии протокола ТСР в разделе
S. Floyd, “Multiplexing, TCP, and UDP: Pointers to the discussion”, 1999.
S. Floyd, K. Fall, “Router mechanisms to support end-to-end congestion control”,
S. Floyd, “TCP and successive Fast Retransmits”, February 1995.
S. Floyd, “TCP and successive Fast Retransmits”, February 1995.
M. Mathis, J Mahdavi, “TCP Rate-Halving with Bounding Parameters”, October 1996,
M. Mathis, “Internet Performance IP Provider Metrics information page”. , 1997
S. McCanne, S Floyd.
“NS LBL Network Simulator”, , 1995.
S. Ostermann, “tcptrace TCP dump-file analysis tool”, , 1996
T. Ott, J. Kempermann, M. Mathis, “ The stationary behavior of ideal TCP congestion avoidance”,
T. Ott, L.H.B. Kempermann, M. Mathis, “The stationary distribution of ideal TCP congestion avoidance”,
A.Romanow, S. Floyd, “Dynamics of TCP traffic over ATM networks”, IEEE J. Select. Areas Commun. V13, pp. 633-641, 1995,
J. Mahdavi, S. Floyd, “TCP-friendly unicast rate-based flow control”. 1997,
J. Padhye, V. Firoiu, D.Towsley, J. Kurose, “Modeling TCP througput: A simple model and its empirical validation”, Proc. SIGCOMM Symp. Communications Architectures and Protocols, Aug. 1998, pp.303-314,
H. Balakrishnan, V.N.Padanabhan, S. Seshan, S. Stemn, R.H.Katz, “TCP behavior of a busy internet server: Analysis and improvements”, Proc. Conf. Computer Communications. (IEEE INFOCOM), Mar. 1998,
Назад:
Оглавление:
Вперёд:
Прокси-ARP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Еще одна разновидность протокола ARP служит для того, чтобы один и тот же сетевой префикс адреса можно было использовать для двух сетей. Этот протокол называется смешанным протоколом ARP (proxy). Предположим, мы имеем сеть из четырех ЭВМ (1-4; рис. 4.4.7.1), которую бы мы хотели соединить с другой сетью из четырех ЭВМ (5-8), причем так, чтобы машины взаимодействовали друг с другом так, будто они принадлежат одной сети. Решить эту проблему можно, соединив эти сети через маршрутизатор M, работающий в соответствии со смешанным протоколом ARP (функционально это IP-мост). Маршрутизатор знает, какая из машин принадлежит какой физической сети. Он перехватывает широковещательные ARP-запросы из сети 1, относящиеся к сети 2, и наоборот. Во всех случаях в качестве физического адреса маршрутизатор возвращает свой адрес. В дальнейшем, получая дейтограммы, он маршрутизирует их на физические адреса по их IP-адресам.

Рис. 4.4.7.1. Использование протокола proxy ARP
Не трудно видеть, что в смешанном протоколе ARP нескольким IP-адресам ставится в соответствие один и тот же физический адрес. Поэтому системы, где предусмотрен контроль за соответствием физических и IP-адресов, не могут работать со смешанным протоколом ARP. Главным преимуществом этого протокола является то, что он позволяет путем добавления одного маршрутизатора (Gateway) подключить к Интернет еще одну сеть, не изменяя таблиц маршрутизации в других узлах. Этот протокол удобен для сети, где есть ЭВМ, не способная работать с субсетями. Протокол используется при построении сетей Интранет.
Протокол IGMP и передача мультимедиа по Интернет
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Передача мультимедийных данных по сетям Интернет является одним из наиболее важных направлений. Этот вид информации передается обычно в режиме без установления соединения (протокол UDP-RTP). Наиболее типичной схемой в этом случае является наличие одного передатчика и большого числа приемников. Эта схема реализуется с использованием мультикастинг-адресации. Мультикастинг-адресация может осуществляться на IP- и MAC-уровнях. В Ethernet для этих целей зарезервирован блок адресов в диапазоне от 01:00:5E:00:00:00 до 01:00:5E:7F:FF:FF. Первый байт адреса, равный 01, указывает на то, что адрес является мультикастным. Данная схема резервирования адресного пространства позволяет использовать 23 бита Ethernet-адреса для идентификации группы рассылки при IP-мультикастинге (см. рис. 4.4.9.1.).

Рис. 4.4.9.1. Соотношение мультикастинговых MAC- и IP-адресов
Область из 5 бит в IP-адресе, отмеченная *****, не используется при формировании Ethernet-адреса. Так как соотношение IP и MAC-адресов не является однозначным, драйверы должны обеспечивать обработку адресов с тем, чтобы интерфейсы получали только те кадры, которые действительно им предназначены. Для того чтобы информировать маршрутизатор о наличии участников мультикастинг-обмена в субсети, связанной с тем или иным интерфейсом, используется протокол IGMP.
Протокол IGMP (internet group management protocol, RFC-1112) используется для видеоконференций, передачи звуковых сообщений, а также группового исполнения команд различными ЭВМ. Этот протокол использует групповую адресацию (мультикастинг).
Групповая форма адресации нужна тогда, когда какое-то сообщение или последовательность сообщений необходимо послать нескольким (но не всем) адресатам одновременно. При этой форме адресации ЭВМ имеет возможность выбрать, хочет ли она участвовать в этой процедуре. Когда группа ЭВМ хочет взаимодействовать друг с другом, используется один групповой (мультикастинг) адрес. Групповая адресация может рассматриваться как обобщение обычной системы адресов, а традиционный IP-адрес - частный случай группового обращения при числе ЭВМ, равном 1.
При групповой адресации один и тот же пакет может быть доставлен заданной группе ЭВМ. Членство в этой группе может динамично меняться со временем. Любая ЭВМ может войти в группу и выйти из группы в любое время по своей инициативе. В то же время ЭВМ может быть членом большого числа таких групп. ЭВМ может посылать пакеты членам группы, не являясь им сама. Каждая группа имеет свой адрес класса D (рис. 4.4.9.2, см. также рис. 4.4.9.1).

Рис. 4.4.9.2. Формат группового адреса
Адрес 224.0.0.1 предназначен для обращения ко всем группам (все узлы и серверы, вовлеченные в данный момент в мультикастинг-обмен, например, участвующие в видеоконференции). ЭВМ может участвовать в мультикастинг-процессе на одном из следующих уровней:
Таблица 4.4.9.1. Коды мультикастинг-процессов
| Уровень мультикастинг-процесса | Описание |
| 0 | ЭВМ не может ни посылать, ни принимать данные |
| 1 | ЭВМ может только посылать пакеты в процессе IP-мултикастинга |
| 2 | ЭВМ в режиме мультикастинга может передавать и принимать пакеты |
Ряд мультикастинг-адресов зарезервировано строго для определенных целей.
Таблица 4.4.9.2. Зарезервированные мультикастинг-адреса
| Мультикастинг адрес | Описание |
| 224.0.0.0 | Зарезервировано |
| 224.0.0.1 | Все системы данной субсети |
| 224.0.0.2 | Все маршрутизаторы данной субсети |
| 224.0.0.4 | Все DVMRP-маршрутизаторы |
| 224.0.0.5-224.0.0.6 | OSPFIGP (MOSPF) |
| 224.0.0.9 | Маршрутизаторы RIP2 |
| 224.0.0.10 | IGRP маршрутизаторы |
| 224.0.1.0 | VMTP-группа менеджеров |
| 224.0.1.1 | NTP-network time protocol - сетевая службы времени |
| 224.0.1.6 | NSS - сервер имен |
| 224.0.1.7 | Audionews - audio news multicast (аудио служба новостей) |
| 224.0.1.9 | MTP (multicast transport protocol) - транспортный протокол мультикастинга |
| 224.0.1.10 | IETF-1-low-audio |
| 224.0.1.11 | IETF-1-audio |
| 224.0.1.12 | IETF-1-video |
| 224.1.0.0-224.1.255.255 | ST мультикастинг-группы |
| 224.2.0.0-224.2.255.255 | Вызовы при мультимедиа- конференциях |
| 232.0.0.0-232.255.255.255 | VMTP переходные группы |
Для того чтобы участвовать в коллективных обменах в локальной сети ЭВМ должна быть снабжена программой, которая поддерживает этот режим.
При этом сервер локальной сети (gateway) информируется о намерении использовать мультикастинг. Сервер передает эту информацию другим внешним серверам IP-сети. Следует иметь в виду, что мультикастинг также как и широковещательный режим, заметно загружает сеть. IGMP для передачи своих сообщений использует IP-дейтограммы (IGMP-пакеты инкапсулируются в них). Для подключения к группе сначала посылается IGMP-сообщение "всем ЭВМ" о включении в группу, при этом локальный мультикаст-сервер подготавливает маршрут. Локальный мультикаст-сервер время от времени проверяет ЭВМ и определяет, не покинули ли они группу (ЭВМ не подтверждает свое членство в группе). Все обмены между ЭВМ и мультикаст-сервером производятся в режиме ip-мультикастинга, те есть, любое сообщение адресуется всем ЭВМ группы. ЭВМ, не принадлежащая группе, IGMP-сообщений не получает, что сокращает загрузку сети. Формат сообщений в протоколе IGMP имеет вид, показанный ниже на рис. 4.4.9.3.

Рис. 4.4.9.3. Формат IGMP-сообщений
Поле версия определяет используемую версию протокола, поле тип=1 говорит о том, что это запрос, отправленный мультикастинг-маршрутизатором, тип=2 указывает, что этот отклик послан ЭВМ. ЭВМ использует групповой адрес, чтобы сообщить о своем подключении к группе. Контрольная сумма вычисляется по тому же алгоритму, что и для ICMP. IGMP-сообщения используются мультикастинг-маршрутизаторами для того, чтобы отслеживать членство в группе каждой из сетей, подключенных к нему. В группе может участвовать несколько активных процессов в одной и той же ЭВМ, но при этом посылается только один запрос для регистрации. Когда какой-то процесс покидает группу, ЭВМ не шлет сообщения об этом, даже в случае, когда это последний из процессов - членов группы на данной ЭВМ. Просто при очередном запросе ЭВМ не подтвердит членство в группе. Мультикастинг-маршрутизатор регулярно посылает запросы с требованием подтвердить участие в группе. ЭВМ посылает отклик- подтверждение для каждой из групп, если у нее есть хотя бы один процесс - член группы.
На основе этих запросов-откликов мультикастинг-маршрутизатор составляет и поддерживает таблицу интерфейсов, которые имеют одну или более ЭВМ, входящих в мультикастинг-группы.
Протокол IGMP используется при организации мультикастинг-туннелей для передачи звуковой и видеоинформации. Для решения проблем мультимедиа в сетях Интернет используется идея MBONE.
По умолчанию мультикаст-дейтограммы имеют значение поля TTL=1, что ограничивает их распространение одной субсетью. Приложения могут увеличивать значение TTL. Первая дейтограмма, тем не менее, всегда имеет TTL=1. Если получение этой дейтограммы не подтверждается сервером, посылается вторая - с TTL=2 и т.д. Таким образом попутно измеряется и число шагов между клиентом и сервером. Для случая, когда число шагов не более 1, зарезервирован блок адресов 224.0.0.0 - 224.0.0.255. Маршрутизатор не обрабатывает пакеты с такими адресами вне зависимости от кода поля TTL.
При использовании мультикастинга MAC-переключатели переадресуют пакеты через все имеющиеся интерфейсы, что заметно ухудшает эффективность сети. Чтобы решить эту проблему компания CISCO разработала протокол CGMP (Cisco Group Management Protocol), который позволяет взаимодействовать маршрутизаторам и переключателям, что позволяет передавать мультикаст-пакеты только на те интерфейсы, где имеются активные члены группы.
Протокол IGRP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Протокол IGRP разработан фирмой CISCO для своих многопротокольных маршрутизаторов в середине 80-х годов. Хотя этот протокол и не является стандартным, я счел возможным включить его описание, так как маршрутизаторы этой фирмы относятся к наиболее массовым. IGRP представляет собой протокол, который позволяет большому числу маршрутизаторов координировать свою работу. Основные достоинства протокола (описание протокола взято из депозитария FTP.CISCO.COM/pub/igrp.doc).
стабильность маршрутов даже в очень больших и сложных сетях;
быстрый отклик на изменения топологии сети;
минимальная избыточность. Поэтому IGRP не требует дополнительной пропускной способности каналов для своей работы;
разделение потока данных между несколькими параллельными маршрутами, примерно равного достоинства;
учет частоты ошибок и уровня загрузки каналов;
возможность реализовать различные виды сервиса для одного и того же набора информации.
Сегодняшняя реализация протокола ориентирована на TCP/IP. Однако, базовая конструкция системы позволяет использовать IGRP и с другими протоколами. IGRP имеет некоторое сходство со старыми протоколами, например с RIP и Hello. Здесь маршрутизатор обменивается маршрутной информацией только с непосредственными соседями. Поэтому задача маршрутизации решается всей совокупностью маршрутизаторов, а не каждым отдельно.
Для того чтобы исключить осцилляции маршрутов, протокол IGRP должен игнорировать новую информацию в течение нескольких минут после ее возникновения. OSPF-протокол вынужден использовать большую избыточность информации по сравнению с IGRP, как на уровне базы маршрутных данных, так и в процессе обмена с внешней средой.
IGRP используется в маршрутизаторах, которые имеют связи с несколькими сетями и выполняют функции переключателей пакетов. Когда какой-то объект в одной сети хочет послать пакет в другую сеть, он должен послать его соответствующему маршрутизатору. Если адресат находится в одной из сетей, непосредственно связанной с маршрутизатором, он отправляет этот пакет по месту назначения.
Если же адресат находится в более отдаленной сети, маршрутизатор перешлет пакет другому маршрутизатору, расположенному ближе к адресату. Здесь также как и в других протоколах для хранения маршрутных данных используются специализированные базы данных.
Протокол IGRP формирует эту базу данных на основе информации, которую он получит от соседних маршрутизаторов. В простейшем случае находится один путь для каждой из сетей. Сегменты пути характеризуются используемым сетевым интерфейсом, метрикой и маршрутизатором, куда следует сначала послать пакет. Метрика - то число, которое говорит о том, насколько хорош данный маршрут. Это число позволяет сравнить его с другими маршрутами, ведущими к тому же месту назначения и обеспечивающим тот же уровень QOS. Предусматривается возможность (как и в OSPF) разделять информационный поток между несколькими доступными эквивалентными маршрутами. Пользователь может сам разделить поток данных, если два или более пути оказались почти равными по метрике, при этом большая часть трафика будет послана по пути с лучшей метрикой. Метрика, используемая в IGRP, учитывает:
время задержки;
пропускную способность самого слабого сегмента пути (в битах в сек);
загруженность канала (относительную);
надежность канала (определяется долей пакетов, достигших места назначения неповрежденными).
Время задержки предполагается равным времени, необходимому для достижения места назначения при нулевой загрузке сети. Дополнительные задержки, связанные с загрузкой учитываются отдельно.
Среди параметров, которые контролируются, но не учитываются метрикой, находятся число шагов до цели и MTU (maximum transfer unit - размер пакета пересылаемого без фрагментации). Расчет метрики производится для каждого сегмента пути.
Время от времени каждый маршрутизатор широковещательно рассылает свою маршрутную информацию всем соседним маршрутизаторам. Получатель сравнивает эти данные с уже имеющимися и вносит, если требуется, необходимые коррекции. На основании вновь полученной информации могут быть приняты решения об изменении маршрутов.
Эта процедура типична для многих маршрутизаторов и этот алгоритм носит имя Белмана-Форда. (см. также описание протокола RIP, RFC-1058). Наилучший путь выбирается с использованием комбинированной метрики, вычисленной по формуле:
[(K1 / Be) + (K2 * Dc)] r [1],
где: K1, K2 = константы;
Be= пропускная способность канала (в отсутствии загрузки) * (1 - загрузка канала);
Dc = топологическая задержка;
r = относительная надежность. (% пакетов, успешно передаваемых по данному сегменту пути). Здесь загрузка измеряется как доля от 1.
Путь, имеющий наименьшую комбинированную метрику, считается лучшим. В такой схеме появляется возможность, используя весовые коэффициенты, адаптировать выбор маршрутов к задачам конечного пользователя.
Одним из преимуществ igrp является простота реконфигурации. В igrp маршрут по умолчанию не назначается, а выбирается из числа кандидатов.
Когда маршрутизатор включается, его маршрутные таблицы инициализируются оператором вручную или с использованием специальных файлов. На рис. 4.4.11.3.1 маршрутизатор S связан через соответствующие интерфейсы с сетями 2 и 3.

Рис. 4.4.11.3.1
Таким образом, в исходный момент маршрутизатор S знает только о доступности сетей 2 и 3. За счет обмена информацией, полученной при инициализации и присланной позднее соседями, маршрутизаторы познают окружающий мир. Так S спустя некоторое время получит информацию от маршрутизатора R о доступности сети 1 и от T - о сети 4. В свою очередь S проинформирует T о доступе к сети 1. Очень быстро информация о доступности дойдет до всех маршрутизаторов и разрозненные сети станут единым целым. Для пояснения выбора маршрута в условиях многовариантности рассмотрим схему на рис. 4.4.11.3.2.

Рис. 4.4.11.3.2. Пример с альтернативными маршрутами
Пусть каждый из маршрутизаторов уже вычислил комбинированную метрику для системы, изображенной на рис. 4.4.11.3.2. Для места назначения в сети 6 маршрутизатор A вычислит метрику для двух путей, через маршрутизаторы B и C. В действительности существует три маршрута из a в сеть 6:
- непосредственно в B
- в C и затем в B
- в C и затем в D
Маршрутизатору A не нужно выбирать между двумя маршрутами через C. Маршрутная таблица в A содержит только одну запись, соответствующую пути к C. Если маршрутизатор A посылает пакет маршрутизатору C, то именно C решает, использовать далее путь через маршрутизаторы B или D.
Для каждого типа канала используется свое стандартное значение комбинированной задержки. Ниже приведен пример того, как может выглядеть маршрутная таблица в маршрутизаторе A для сети, изображенной на рис. 4.4.11.3.3.
Номер сети | Интерфейс | Следующий Маршрутизатор | Метрика маршрута |
| Сеть 1 | NW 1 | Нет | Непосредственная связь |
| Сеть 2 | NW 2 | Нет | Непосредственная связь |
| Сеть 3 | NW 3 | Нет | Непосредственная связь |
| Сеть 4 | NW 2 | C | 1270 |
| NW 3 | B | 1180 | |
| Сеть 5 | NW 2 | C | 1270 |
| NW 3 | B | 2130 | |
| Сеть 6 | NW 2 | C | 2040 |
| NW 3 | B | 1180 |
Рис. 4.4.11.3.3. Пример маршрутной таблицы
Для того чтобы обеспечить работу с большими и сложными сетями, в IGRP введены три усовершенствования алгоритма Белмана-Форда:
Для описания путей вместо простой, введена векторная метрика. Расчет комбинированной метрики проводится с использованием формулы [1]. Применение векторной метрики позволяет адаптировать систему с учетом различных видов сервиса.
Вместо выбора одного пути с минимальной метрикой, информационный поток может быть поделен между несколькими путями с метрикой, лежащей в заданном интервале. Распределение потоков определяется соотношением величин комбинированной метрики. Таким образом, используются маршруты с комбинированной метрикой меньше некоторого предельного значения M, а также с метрикой меньше V*M, где V - значение вариации M (обычно задается оператором сети).
Существуют определенные проблемы с вариацией. Трудно определить стратегию использования вариации V>1 и избежать зацикливания пакетов. В современных реализациях V=1.
Разработан ряд мер, препятствующих осцилляциям маршрутов при изменении топологии сети.
Значения вариации, отличное от единицы, позволяет использовать одновременно два или более путей с разной пропускной способностью.
При дальнейшем увеличении вариации можно разрешить не только более "медленные" сегменты пути, но и ведущие в обратном направлении, что приведет с неизбежностью к "бесконечному" циклическому движению пакетов.
Протокол маршрутизации IGRP предназначен для работы с несколькими типами сервиса (TOS) и несколькими протоколами. Под типами сервиса в TCP/IP подразумевается оптимизация маршрутизации по пропускной способности, задержке, надежности и т.д. Для решения этой задачи можно использовать весовые коэффициента K1 и K2 (формула [1] данного раздела). При этом для каждого TOS подготавливается своя маршрутная таблица. Среди мер, обеспечивающих cтабильность топологии связей, следует отметить следующее правило, которое поясняется на приведенном ниже примере.

Маршрутизатор A сообщает B о маршруте к сети 1. Когда же B посылает сообщения об изменении маршрутов в A, он ни при каких обстоятельствах не должен упоминать сеть 1. Т.е. сообщения об изменении маршрута, направленные какому-то маршрутизатору, не должны содержать данных об объектах, непосредственно с ним связанных. Сообщения об изменении маршрутов должны содержать:
- адреса сетей, с которыми маршрутизатор связан непосредственно;
- пропускную способность каждой из сетей;
- топологическую задержку каждой из сетей;
- надежность передачи пакетов для каждой сети;
- загруженность канала для каждой сети;
- MTU для каждой сети.
Следует еще раз обратить ваше внимание, что в IGRP не используется измерение задержек, измеряется только надежность и коэффициент загрузки канала. Надежность определяется на основе сообщений интерфейсов о числе ошибок.
Существует 4 временные константы, управляющие процессом распространения маршрутной информации (эти константы определяются оператором сети):
- период широковещательных сообщений об изменении маршрутов (это время по умолчанию равно 90 сек);
- время существования - если за это время не поступило никаких сообщений о данном маршруте, он считается нерабочим. Это время в несколько раз больше периода сообщений об изменениях (по умолчанию в 3 раза).
- время удержания - когда какой- то адресат становится недостижим, он переходит в режим выдержки. В этом режиме никакие новые маршруты, ведущие к нему, не воспринимаются. Длительность этого режима и называется временем удержания. Обычно это время в три раза дольше периода сообщений об изменениях маршрутов.
- время удаления - если в течение данного времени не поступило сообщений о доступе к данному адресату, производится удаление записи о нем из маршрутной базы данных (по умолчанию это время в 7 раз больше периода сообщений об изменениях маршрутов).
IGRP-сообщение вкладывается в IP-пакет, это сообщение имеет следующие поля:
version номер версии протокола 4 байта
opcode код операции
edition код издания
asystem номер автономной системы
Ninterior, Nsystem, Nexterior числа субсетей в локальной сети, в автономной системе и вне автономной системы.
checksum контрольная сумма IGRP-заголовка и данных
Version - номер версии в настоящее время равен 1. Пакеты с другим номером версии игнорируются.
Opcode - код операции определяет тип сообщения и может принимать значения:
1 - изменение; 2 - запрос
Edition - (издание) является серийным номером, который увеличивается при каждом изменении маршрутной таблицы. Это позволяет маршрутизатору игнорировать информацию, которая уже содержится в его базе данных.
Asystem - номер автономной системы. Согласно нормам Сisco маршрутизатор может входить в более чем одну автономную систему. В каждой AS работает свой протокол и они могут иметь совершенно независимые таблицы маршрутизации. Хотя в IGRP допускается "утечка" маршрутной информации из одной автономной системы в другую, но это определяется не протоколом, а администратором.
Ninterior, nsystem, и nexterior определяют числа записей в каждой из трех секций сообщения об изменениях.
Checksum - контрольная сумма заголовка и маршрутной информации, для вычисления которой используется тот же алгоритм, что и в UDP, TCP и ICMP.
IGRP запрос требует от адресата прислать свою маршрутную таблицу.
Сообщение содержит только заголовок. Используются поля version, opcode и asystem, остальные поля обнуляются. IP-пакет, содержащий сообщение об изменении маршрутов, имеет 1500 байт (включая IP-заголовок). Для описанной выше схемы это позволяет включить в пакет до 104 записей. Если требуется больше записей, посылается несколько пакетов. Фрагментация пакетов не применяется.
Ниже приведено описание структуры для маршрута:
| Number | 3 октета IP-адреса |
| delay | задержка в десятках микросекунд 3 октета |
| bandwidth | Пропускная способность, в Кбит/с 3 октета |
| uchar mtu | MTU, в октетах 2 октета |
| reliability | процент успешно переданных пакетов tx/rx 1 октет |
| load | процент занятости канала 1 октет |
| hopcount | Число шагов 1 октет |
Субполе описание маршрута Number определяет IP-адрес места назначения, для экономии места здесь используется только 3 его байта. Если поле задержки содержит только единицы, место назначения недостижимо.
Пропускная способность измеряется в величинах, обратных бит/сек, умноженных на 1010. (Т.е., если пропускная способность равна N Кбит/с, то ее измерением в IGRP будет 10000000/N.). Надежность измеряется в долях от 255 (т.е. 255 соответствует 100%). Загрузка измеряется также в долях от 255, а задержка в десятках миллисекунд.
Ниже приведены значения по умолчанию для величин задержки и пропускной способности
Вид среды | Задержка | Пропускная способность |
| Спутник | 200,000 (2 сек) | 20 (500 Мбит/c) |
| Ethernet | 100 (1 мсек) | 1,000 |
1.544 Мбит/c | 2000 (20 мсек) | 6,476 |
| 64 Кбит/c | 2000 | 156,250 |
| 56 Кбит/c | 2000 | 178,571 |
| 10 Кбит/c | 2000 | 1,000,000 |
| 1 Кбит/c | 2000 | 10,000,000 |
Комбинированная метрика в действительности вычисляется по следующей формуле (для версии Cisco 8.0(3)):
Метрика = [K1*пропускная_способность + (K2*пропускная_способность)/(256 - загрузка) + K3*задержка] * [K5/(надежность + K4)].
Если K5 == 0, член надежности отбрасывается. По умолчанию в IGRP K1 == K3 == 1, K2 == K4 == K5 == 0, а загрузка лежит в интервале от 1 до 255.
В начале 90-х годов разработана новая версия протокола IGRP - EIGRP с улучшенным алгоритмом оптимизации маршрутов, сокращенным временем установления и масками субсетей переменной длины.
EIGRP поддерживает многие протоколы сетевого уровня. Рассылка маршрутной информации здесь производится лишь при измении маршрутной ситуации. Протокол периодически рассылает соседним маршрутизаторам короткие сообщения Hello. Получение отклика означает, что сосед функционален и можно осуществлять обмен маршрутной информацией. Протокол EIGRP использует таблицы соседей (адрес и интерфейс), топологические таблицы (адрес места назначения и список соседей, объявляющих о доступности этого адреса), состояния и метки маршрутов. Для каждого протокольного модуля создается своя таблица соседей. Протоколом используется сообщения типа hello (мультикастная адресация), подтверждени (acknowledgent), актуализация (update), запрос (query; всегда мультикастный) и отклик (reply; посылается отправителю запроса). Маршруты здесь делятся на внутренние и внешние - полученные от других протоколов или записанные в статических таблицах. Маршруты помечаются идентификаторами их начала. Внешние маршруты помечаются следующей информацией:
Идентификатор маршрутизатора EIGRP, который осуществляет рассылку информации о маршруте
Номер AS, где расположен адресат маршрута
Метка администратора
Идентификатор протокола
Метрика внешнего маршрута
Битовые флаги маршрута по умолчанию
Протокол EIGRP полностью совместим с IGRP, он обеспечивает работу в сетях IP, Apple Talk и Novell.
Протокол Интернет для работы с сообщениями IMAP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Протокол IMAP 4.1 (INTERNET MESSAGE ACCESS PROTOCOL - VERSION 4rev1, V.Crispin, RFC-2060, December 1996) базируется на транспортном протоколе TCP и использует порт 143. Протокол IMAP представляет собой альтернативу POP-3. Также как и последний он работает только с сообщениями и не требует каких-либо пакетов со специальными заголовками.
1.Команды и отклики
Соединение IMAP 4.1 подразумевает установление связи между клиентом и сервером. Клиент посылает серверу команды, сервер клиенту данные и уведомления о статусе выполнения запроса. Все сообщения, как клиента, так и сервера имеют форму строк, которые завершаются последовательностью CRLF. Получатель (клиент или сервер) воспринимает такую строку или последовательность октетов известной длины, за которой следует строка.
Протокол электронной почты SMTP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Главной целью протокола simple mail transfer protocol (SMTP, RFC-821, -822) служит надежная и эффективная доставка электронных почтовых сообщений. SMTP является довольно независимой субсистемой и требует только надежного канала связи. Средой для SMTP может служить отдельная локальная сеть, система сетей или весь Интернет.
SMTP базируется на следующей модели коммуникаций: в ответ на запрос пользователя почтовая программа-отправитель устанавливает двухстороннюю связь с программой-приемником (TCP, порт 25). Получателем может быть оконечный или промежуточный адресат. SMTP-команды генерируются отправителем и посылаются получателю. На каждую команду должен быть отправлен и получен отклик.
Когда канал организован, отправитель посылает команду MAIL, идентифицирую себя. Если получатель готов к приему сообщения, он посылает положительное подтверждение. Далее отправитель посылает команду RCPT, идентифицируя получателя почтового сообщения. Если получатель может принять сообщение для оконечного адресата, он выдает снова положительное подтверждение (схема формирования откликов помещена в приложении ). В противном случае он отвергает получение сообщения для данного адресата, но не вообще почтовой посылки. Взаимодействие с почтовым сервером возможно и в диалоговом режиме, например:
tn dxmint.cern.ch 25 (команда telnet с использованием порта 25)
220 dxmint.cern.ch sendmail ready at sun, 9 jul 1995 11:13:57 +0200 (связь установлена, код отклика 220 является положительным)
| EHLO dxmint.cern.ch | (поддерживает ли сервер расширение mime?) |
| 500 command unrecognized | (не поддерживает) |
| HELO crnvma.cern.ch | (команда выхода на конкретный сервер) |
250 dxmint.cern.ch hello crnvma.cern.ch, pleased to meet you (отклик 250 также является положительным)
mail from:<> (так как на моей PC нет резидентной почтовой программы, я не указываю обратного адреса)
| 250 <>... sender ok | (команда прошла успешно) |
| RCPT TO: ysemenov@cernvm.cern.ch | (указываем адрес места назначения) |
250 ... recipient ok
| DATA | (начало ввода текста сообщения) |
| nu-i-nu... | (текст сообщения) |
| . | (знак конца сообщения) |
| QUIT | (прерывание или завершение процедуры) |
221 dxmint.cern.ch closing connection (сообщение об успешном завершении процедуры)
Почтовое сообщение отправлено без использования доступа к локальной почтовой программе (mail на sun, например). Следует отметить, что работа через порт 25 в данном случае открывает богатые возможности для хакеров. Вообще умелый программист может многого достичь, используя номера портов. Здесь есть над чем поработать людям, ответственным за безопасность сетей. Аналогично, не имея авторизации, можно выявить клиентов почтового сервера, используя команду VRFY:
tn ns.itep.ru 25
220 ns.itep.ru 5.67a8/ida-1.5 sendmail is ready at sat, 29 jul 1995 13:53:03
vrfy bobyshev
250 andrey bobyshev
и т.д.
quit
SMTP-отправитель и SMTP-получатель могут вести диалог с несколькими оконечными пользователями (рис. 4.4.14.1). Любое почтовое сообщение завершается специальной последовательностью символов. Если получатель успешно завершил прием и обработку почтового сообщения, он посылает положительное подтверждение.
SMTP обеспечивает передачу почтового сообщения непосредственно конечному получателю, когда они соединены непосредственно. В противном случае пересылка может выполняться через одного или более промежуточных "почтовых станций".

Рис. 4.4.14.1 Схема взаимодействия различных частей почтовой системы
Для решения поставленной задачи SMTP-сервер должен знать имя конечного получателя и название почтового ящика места назначения. Аргументом команды MAIL является адрес отправителя (обратный адрес). Аргументом команды RCPT служит адрес конечного получателя. Обратный адрес используется для посылки сообщения в случае ошибки.
Все отклики имеют цифровые коды. Команды, отклики и имена ЭВМ не чувствительны к тому, строчные или прописные символы использованы при их написании. Это не всегда справедливо при написании имен и адресов получателя.
Многие почтовые системы работают только с ASCII-символами.
Если транспортный канал работает с октетами, 7- битные коды будут дополнены нулевым восьмым битом. Именно здесь коренилась проблема пересылки почтовых сообщений на русском языке несколько лет назад(русский алфавит требует 8-битового представления).
Как уже было сказано, процедура отправки почтового сообщения начинается с посылки команды MAIL, которая имеет формат:
MAIL <SP> FROM:<reverse-path> <CRLF>,
где <SP> - пробел, <CRLF> - комбинация кодов возврата каретки и перехода на новую строку, а <reverse-path> - обратный путь.
Эта команда сообщает SMTP-получателю, что стартует новая процедура и следует сбросить в исходное состояние все статусные таблицы, буферы и т.д. Если команда прошла, получатель реагирует откликом: 250 OK.
Аргумент может содержать не только адрес почтового ящика, в общем случае является списком адресов ЭВМ-серверов, через которые пришло данное сообщение, включая, разумеется, и адрес почтового ящика отправителя. Первым в списке <reverse-path> стоит адрес ЭВМ-отправителя.
После прохождения команды MAIL посылается команда RCPT:
RCPT <SP> TO:<forward-path> <CRLF>
Эта команда указывает адрес конечного получателя (<forward-path>). При благополучном прохождении команды получатель посылает код-отклик 250 OK, и запоминает полученный адрес. Если получатель неизвестен, SMTP-сервер пошлет отклик 550 Failure reply. Команда RCPT может повторяться сколько угодно раз, если адресат не один.
Аргумент может содержать не только адрес почтового ящика, но и маршрутный список ЭВМ по дороге к нему. Первым в этом списке должно стоять имя ЭВМ, получившей данную команду. По завершении этого этапа посылается собственно сообщение:
DATA <CRLF>
При правильном приеме этого сообщения SMTP-сервер реагирует посылкой отклика 354 Intermediate reply (промежуточный отклик), и рассматривает все последующие строки в качестве почтового текста. При получении кода конца текста отправляется отклик: 250 OK.
Признаком конца почтового сообщения является точка в самом начале строки, за которой следует <CRLF>.
Пользователям почтовых UNIX-систем это уже известно.
В некоторых случаях адрес места назначения может содержать ошибку, но получатель знает правильный адрес. Тогда возможны два варианта отклика:
1. 251 User not local; will forward to <forward-path>
Это означает, что получатель берет на себя ответственность за доставку сообщения. Это случается, когда адресат, например, мигрировал в другую субсеть в пределах зоны действия данного почтового сервера.
2. 551 User not local; please try <forward-path>
Получатель знает правильный адрес и предлагает отправителю переадресовать сообщение по адресу <forward-path>.
SMTP имеет команды для проверки корректности имени адресата (VRFY) и расширения списка адресов (EXPN). Обе команды в качестве аргументов используют строки символов (в некоторых реализациях эти две команды по своей функции идентичны). Для команды VRFY параметром является имя пользователя, а отклик может содержать его полное имя и адрес его почтового ящика.
Реакция на команду VRFY зависит от аргумента. Так если среди клиентов почтового сервера имеется два пользователя с именем Ivanov, откликом на команду "VRFY Ivanov" будет "553 User ambiguous". В общем случае команда VRFY Ivanov может получить в качестве откликов:
250 Vasja Ivanov Ivanov@cl.itep.ru
или:
251 User not local; will forward to Ivanov@cl.itep.ru
или:
550 String does not match anything (данная строка ничему не соответствует).
или:
551 User not local; please try Vasja@ns.itep.ru
или:
VRFY Chtozachertovchina
553 User ambiguous (несуществующее имя)
В случае пропечатки списка адресов отклик занимает несколько строк, например:
EXPN Example-People
250-Juri Semenov Semenov@ns.itep.ru
250-Alexey Sher Sher@suncom.itep.ru
250-Andrey Bobyshev Bobyshev@ns.itep.ru
250-Igor Gursky Gursky@ns.itep.ru
В некоторых системах аргументом команды EXPN может быть имя файла, содержащего список почтовых адресов.
Основной задачей почты служит доставка сообщений в почтовый ящик адресата.
Сходную форму услуги оказывают некоторые ЭВМ, доставляя сообщения на экран терминала (в рамках SMTP). Для посылки сообщений на экран терминала адресата предусмотрено три команды:
1. SEND <SP> FROM:<reverse-path> <CRLF>
Команда SEND требует, чтобы почтовое сообщение было доставлено на терминал. Если терминал адресата не активен в данный момент, то откликом на команду RCPT будет код 450.
2. SOML <SP> FROM:<reverse-path> <CRLF>
Команда Send Or MaiL (SOML) пересылает сообщение на экран адресата, если он активен, в противном случае сообщение будет уложено в его почтовый ящик.
3. SAML <SP> FROM:<reverse-path> <CRLF>
Команда Send And MaiL (SAML) предполагает доставку сообщение на экран терминала адресата и занесение в его почтовый ящик.
Если SMTP-сервер обнаружит, что доставка сообщения по адресу <forward-path> невозможна, тогда он формирует сообщение о "не доставленном письме", используя <reverse-path>. Следует также помнить, что ни прямой ни обратный адреса-маршруты, вообще говоря, могут не иметь ничего общего с текстом заголовка почтового сообщения.
При определенных условиях и ошибках в задании прямых и обратных адресов-маршрутов возможно зацикливание сообщений об этих ошибках. Чтобы заведомо избежать этого можно выдавать команду MAIL c нулевым обратным маршрутом:
MAIL FROM:< >
Если вы или ваша программа не указали обратного адреса, не следует думать, что это помешает работе почтовой программы и она не будет знать, куда посылать отклики. Ваш обратный IP-адрес указан в каждом пакете, посылаемом адресату!
Некоторые другие команды, используемые в SMTP:
Команда TURN используется для того, чтобы поменять местами функции программ, взаимодействовавших по телекоммуникационному каналу. Программа-отправитель становится получателем (после того как она выдаст команду TURN и получит отклик 250), а программа-получатель - отправителем. Если программа не хочет или не может поменять свою функцию, она пошлет отклик 502.
Команда RESET (RSET) прерывает текущую процедуру отправки почтового сообщения. Все буферы и таблицы очищаются, получатель должен послать отклик 250 OK.
Команда HELP вынуждает получателя послать справочную информацию отправителю команды HELP. Команда может содержать аргумент (имя команды). Команда не изменяет состояния таблиц или буферов.
Команда NOOP не оказывает влияния на какие-либо параметры или результаты предшествующих команд, она только вынуждает получателя послать отклик 250 OK. Может использоваться для проверки работоспособности TCP-канала.
Допустимо написание команд строчными или прописными символами, например: MAIL, Mail, mail, MaIl или mAIl.
Для того чтобы программа SMTP-сервера была работоспособна, она должна понимать следующий минимум команд: HELO, MAIL, RCPT, DATA, RSET, NOOP, QUIT.
Предельная длина имени пользователя или домена равна 64 символам. Максимальная длина <reverse-path> или <forward-path> составляет 256 символов, включая разделители (пробелы, точки, запятые и пр.). Командная строка не должна быть длиннее 512 символов. Максимальный размер строки отклика не должен превышать, включая его код и <CRLF>, 512 символов. Максимальная длина строки составляет, включая <CRLF>, 1000 символов. Предельно допустимое число адресатов равно 100, последнее полезно помнить, если вы храните этот список в файле.
Протокол мультикастинг-маршрутизации DVMRP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
DVMRP - (Distance Vector Multicast Routing Protocol) мультикастинг-протокол, где в качестве метрики применен вектор расстояния (см. также описание RIP, RFC-1058). DVMRP использует идеологию документа RFC-1054, а также алгоритм TRPB (Truncated Reverse Path Broadcasting). При получении первого пакета маршрутизатор не имеет информации о группе. Он посылает полученный пакет через все интерфейсы, кроме того, через который этот пакет получен. Если пакет пришел не через интерфейс, который используется маршрутизатором для посылки пакетов отправителю мультикаст-информации, полученный пакет выбрасывается. При получении пакета маршрутизатором, в зоне ответственности которого нет членов группы, он посылает сообщение об исключении (prun-команда). Эти сообщения используются для отсечения от дерева маршрутов веток, не содержащих членов группы. По истечении определенного времени "отрезанные" ветки дерева маршрутов "отрастают" вновь и снова могут быть отсечены (протокол TRPB). В настоящее время этот протокол рассматривается в качестве экспериментального и его широкое применение не рекомендуется. DVMRP относится к внутренним протоколам маршрутизации, пригодным для использования в пределах автономной системы.
Протокол DVMRP используется для построения дерева мультикасинг-маршрутов. Предполагается, что в дальнейшем принцип "вектора расстояния" может быть заменен алгоритмом "состояния канала" (MOSPF аналог OSPF). Целью протокола DVMRP является описание обратного пути к источнику мультикастинг-дейтограмм. Протоколы состояния канала предполагают широковещательную рассылку информации о членстве в группе. При получении мультикаст-пакета маршрутизатор определяет дерево кратчайших маршрутов.
DVMRP-дейтограмма состоит из небольшого заголовка фиксированного размера и длинного списка записей. Заголовок DVMRP-сообщений имеет формат IGMP (рис. 4.4.9.4.1):

Рис. 4.4.9.4.1 Формат заголовка DVMRP-сообщений
Поле версия равно 1.
Поле тип содержит всегда код 3. А поле субтип может принимать значения:
1 = Отклик; сообщение о маршрутах до некоторого (-ых) мест(а) назначения.
2 = Запрос; поиск маршрутов до определенного места назначения;
3 = Сообщение о выходе из членов группы;
4 = Отмена заявки о выходе из группы.
Контрольная сумма вычисляется также как и в других IP-протоколах. Отдельные записи в указанном списке выполняют роль команд и их размер должен быть кратен 16 бит (их границы соответствующим образом выравниваются). Максимальная длина DVMRP-сообщения, включая заголовок, не может превышать 512 байт.
В настоящее время IETF установлены следующие значения TTL и порогов при передаче видео- и аудио-информации по мультикастинг-каналам. Колонка TTL содержит значение времени жизни IP-пакета при его отправке для каждого из указанных приложений. В колонке порог записано значение TTL, при котором пакет будет пропущен дальше.
Таблица 4.4.9.4.1. Значения TTL для различных приложений
| Вид мультикастинг-туннеля | TTL | Порог |
IETF канал 1 GSM-аудио (~18кб/с) | 255 | 224 |
IETF канал 2 GSM-аудио | 223 | 192 |
IETF канал 1 видео | 127 | 96 |
IETF канал 2 видео | 95 | 64 |
Местное аудио | 63 | 32 |
Местное видео | 31 | 1 |
Мультикастинг-дейтограмма с исходным TTL=64 доступна для достаточно обширной области, а мультикастинг-дейтограмма с исходным TTL=128 доступна для целого континента, дейтограмма же с исходным TTL=255 дойдет до любой точки сети Интернет. Понятия "узкий регион" и "обширная область" достаточно неопределенные и будут уточняться позднее.
Маршрутные сообщения, посылаемые конкретному физическому интерфейсу, также как и запросы подтверждения членства в мультикастинг-группе должны иметь TTL=1. Цикл обмена маршрутной информацией между мультикастинг- маршрутизаторами (FULL_UPDATE_RATE) равен 60 сек. Подтверждение членства в группе должно посылаться каждые 120 сек (QUERY_RATE). Если подтверждение не получено в течение 2*QUERY_RATE+20 секунд, то членство в данной группе аннулируется. Соседний мультикастинг-маршрутизатор считается работающим при отсутствии подтверждений (UPDATE-сообщений) в течение 4*FULL_UPDATE_RATE.
Описанные выше протоколы DVMRP и MOSPF имеют общий недостаток - широко используют широковещательные режимы рассылки пакетов и требуют каналов с высокой пропускной способностью. Они удобны для компактных групп (например, все члены группа находятся в пределах одной автономной системы). Для обслуживания более широких групп предложен протокол PIM.
Протокол обмена UUCP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Этот протокол сыграл немалую роль в становлении современных телекоммуникационных технологий. Первые системы электронной почты использовали протокол UUCP (Unix-to-Unix Copy Program). Основополагающие идеи ОС UNIX расширили область взаимодействия вычислительных и управляющих процессов за рамки центрального процессора ЭВМ. Хотя большинство современных почтовых серверов базируется на протоколе SMTP, протокол UUCP продолжает применяться во многих приложениях, использующих ОС UNIX (см. ).
Современные программные пакеты UUCP поддерживают приоритеты для всех команд, которые варьируются от a (наивысший) до z и далее a-z. В UNIX эти коды приоритетов вставляются в имена командных файлов, создаваемых UUCP или UUX. Имя командного файла обычно имеет вид: c.nnnngssss, где g - код приоритета (от слова grade), nnnn - имя удаленной системы, а ssss - четырех символьный номер. Например, командный файл создаваемый системой sun2 с уровнем приоритета d может иметь имя c.sun2d1111. При этом в имени удаленной системы сохраняется лишь 7 символов, чтобы обеспечить совместимость с 14-символьным ограничением для имен файлов.

UUCP-протокол определяет взаимодействие между двумя программами. Этот диалог включает в себя три этапа: установление канала, последовательность запросов пересылки файлов и закрытие канала. Прежде чем начать диалог, инициатор обмена должен авторизоваться в ЭВМ, с которой планируется обмен, и активизировать тамошнюю систему UUCP. На рисунке инициатор обмена назван клиентом (в литературе можно также встретить также название master). Все сообщения начинаются с символа ^p (восьмеричный код ‘\020’) и завершаются нулевым байтом (\000). В некоторых системах для завершения сообщений используется код перевода строки (\012).
Установление канала инициируется сервером, который посылает сообщение \020shere=hostname\000, где hostname - имя ЭВМ сервера. В устаревших пакетах uucp можно встретить инициирующие сообщения вида \020shere\000.
Клиент должен откликнуться сообщением \020shostname options\000, где hostname соответствует имени клиента (инициатора обмена).
При этом допустимы следующие опции (опции могут и отсутствовать).
| Опция | Описание |
| -qseq | Сообщает порядковый номер сообщения. Порядковые номера запоминаются как клиентом, так и сервером их значения инкрементируются при каждом вызове. Порядковые номера контролируются, что обеспечивает дополнительную надежность |
| -xlevel | Требует, чтобы сервер установил требуемый отладочный уровень (поддерживается не всеми системами) |
| -vgrade=grade | Требует, чтобы сервер передавал файлы заданного сорта (grade) |
| -r | Указывает на то, что клиент знает, как повторно запустить обмен в случае сбоя |
| -ulimit | Сообщает предельный размер файла, который может создать клиент. Размер задается в шестнадцатеричном формате и обозначает число 512 байтных блоков в файле, например -ux300000. |
На запрос \020rok\000 возможно несколько откликов:
| rok | Запрос принимается, диалог переходит к согласованию протокола; |
| rlck | Сервер заблокирован, что говорит о том, что ЭВМ уже осуществляют обмен; |
| rcb | Сервер осуществляет обратный запрос клиенту, что позволяет исключить ложные вызовы; |
| rbadseq | Неверен порядковый номер сообщения; |
| rlogin | Клиент использовал неверное имя при авторизации; |
| ryou are unknown to me | Клиент неизвестен серверу (uucp не позволяет соединение с неизвестными системами). |
Если отклик не rok, то обе стороны прерывают сессию.
Запрос сервера \020pprotocols\000, где protocols характеризует список поддерживаемых протоколов, причем каждому протоколу соответствует лишь один символ. Клиент может послать сообщение \020uprotocols\000, где инициатор сессии выбирает протокол из предлагаемого сервером списка. Если в предлагаемом списке нет нужного протокола, посылается сообщение \020un\000 и обе стороны разрывают сессию.
Когда канал сформирован и определены его параметры, может начаться обмен командами. Если в процессе обмена командами выявляется ошибка, участники обмена переходят к диалогу для закрытия канала.
Клиент может послать команды: s, r, x, e, или h (команды посылает только клиент). В качестве параметров этих команд используются имена файлов.
Это могут быть абсолютные имена файлов, начинающиеся с символа /, файлы из публичного каталога с именами, которые начинаются с символов ~/, файлы из каталога пользователя, начинающиеся с строки ~user/, или файлы из временного буфера (spool). Собственно имена начинаются с c. для командных файлов, с d. для файлов данных, или с x. для исполнительных файлов.
Команда клиента s, предназначенная для посылки файлов серверу, имеет формат: s from to user -options temp mode notify size. Параметр from представляет собой имя посылаемого файла, to - имя файла на сервере, куда будет скопирован файл, user - имя пользователя, инициировавшего пересылку файла, options - список опций, управляющих обменом, temp - имя пересылаемого файла в случае использования опции С. После успешного завершения обмена сервер стирает файл temp. Параметр mode задает разновидность файла на сервере. Если файл не из каталога spool, клиент создает его с mode=0666. Параметр notify может отсутствовать, он имеет смысл лишь при наличии опции n. В этом случае при успешном завершении обмена посылается уведомление через электронную почту по адресу notify. Поле size задает размер файла в байтах.
| Опция | Описание |
| c | Файл копируется в каталог spool (клиент должен использовать temp, а не from) |
| c | Файл не должен копироваться в каталог spool (по умолчанию) |
| d | Сервер должен сформировать каталог, если необходимо (по умолчанию) |
| f | Сервер не должен формировать каталог, если необходимо, а вместо этого он должен оборвать связь |
| m | Клиент должен послать электронное почтовое сообщение пользователю (user) по завершении обмена |
| n | Сервер должен послать e-mail по адресу, указанному в параметре notify, по завершении обмена |
Сервер может откликнуться на s-команду следующими способами.
| Отклик | Описание |
| sy start | Сервер готов принять файл и обмен начинается. Поле start присутствует в случае использования рестарта и характеризует позицию в файле, с которой осуществляется рестарт. Для нового файла start=0x0 |
| sn2 | Сервер не выдает разрешение на пересылку файла. Это может означать, например, что недоступен нужный каталог. Такой отклик говорит о том, что пересылка принципиально невозможна. |
| sn4 | Сервер не может создать нужный временный файл, можно повторить попытку обмена позднее |
| sn6 | Используется версией taylor uucp. Сервер считает файл слишком длинным (в данный момент места нет, но возможно ситуация изменится в будущем) |
| sn7 | Используется версией taylor UUCP. Сервер считает файл настолько большим, что пересылка вообще невозможна |
| sn8 | Используется версией taylor UUCP. Означает, что файл был уже получен ранее. Это может произойти при потере подтверждения завершения обмена. |
| sn9 | Используется версией taylor UUCP и uuplus. Означает, что удаленная система не может открыть другой канал и можно позднее попытаться передать файл еще раз |
| sn10 | Используется только svr4 uucp и означает, что размер файла слишком велик |
| cy | Передача файла успешно завершилась |
| cym | Передача успешно завершена и сервер хочет стать клиентом |
| cn5 | Временный файл не может быть перемещен в окончательное положение, что означает невозможность завершения обмена. |
/p> Последние три отклика сервера называются С-командами. При получении С-команды клиент может послать новую команду-запрос. Такой командой может быть r-команда, которая имеет следующий формат.
r from to user -options size
Это запрос клиента на получение файла от сервера. Параметр from - имя файла на сервере. Это не может быть spool-файл, имя не может иметь символов подмены (wildcard). Параметр to - имя файла, который должен появиться у клиента, user - имя пользователя, инициировавшего обмен, options - список опций, контролирующих обмен, size - определяет максимальный размер файла, который может принять клиент. Допускаются следующие опции.
| d | клиент должен создать каталог, если необходимо (по умолчанию); |
| f | клиент не должен создать каталог, если необходимо,вместо этого он должен прервать сессию; |
| m | клиент должен послать e-mail по адресу user в случае успешного завершения обмена. |
Сервер может прислать следующие отклики на r-команду.
| Отклик | Описание |
| ry mode [size] | Сервер готов послать файл и начинает эту процедуру. Аргумент mode - восьмеричный код модификатора файла на сервере. Для некоторых версий bsd uucp аргумент mode может иметь в конце символ М, означающий, что сервер хочет стать клиентом и выдать команду-запрос |
| rn2 | Сервер не может послать файл, так как это запрещено или потому, что такой файл отсутствует |
| rn6 | Используется версией taylor uucp. Файл слишком велик (например, не соответствует ограничениям клиента) |
| rn9 | Используется версией taylor uucp и fsuucp. Удаленная система не может открыть еще один канал. Можно попробовать позднее |
По завершении обмена клиент может послать следующие команды (сервер их может проигнорировать).
cy файл благополучно передан;
cn5 временный файл не может быть перемещен в окончательную позицию.
Клиент может использовать команду x для запуска uucp на сервере. Команда может иметь формат x from to user -options. Параметр from - имя файла (или файлов) на ЭВМ-сервере, пересылку которого затребовал клиент. Команда может служить для пересылки файлов из сервера посторонней третьей системе.
Параметр to является именем файла или каталога, куда будут перенесен файл (или файлы). Например, если клиент хочет получить файлы сам, можно использовать запись master!path. Сервер может прислать следующие отклики на команду x.
xy запрос принят, соответствующие команды пересылки файлов поставлены в очередь для последующего исполнения.
xn Запрос отклонен (причина отклонения не сообщается, может быть сервер не поддерживает Х-запросы).
Клиент может послать команду Е, которая имеет следующий формат:
e from to user -options temp mode notify size command
Е-команда поддерживается системой taylor uucp и служит для реализации запросов исполнения без использования файлов x.*. Эта команда применяется в случае, когда исполняемая команда требует входного файла, который используется ей в качестве стандартного ввода. Основные параметры команды имеют то же значение, что и в случае команды s. Список опций, управляющих обменом, представлен в таблице.
| Опция | Описание |
| c | Файл копируется в каталог spool (клиент должен использовать temp, а не from) |
| c | Файл не копируется в каталог spool (по умолчанию) |
| n | e-mail сообщение не посылается даже в случае неудачи. Это эквивалентно n-команде в файле x.*. |
| z | Е-mail сообщение посылается, если при исполнении команды произошла ошибка (значение по умолчанию). Эквивалентно команде z в файле Х.* |
| r | Е-mail сообщение о результате выполнения посылается адресату, записанному в параметре notify. Эквивалентно команде r в файле Х.* |
| e | Исполнение должно проводиться с /bin/sh. Эквивалентно команде e файла Х.*. |
В поле command записывается команда, которая должна быть исполнена. Это эквивалентно команде c файла Х.*. Отклики сервера на Е-команду эквивалентны откликам на команду s, только начальное s заменяется на Е.
Для переведения соединения в пассивное состояние клиент может использовать h-команду (не имеет параметров или опций). Сервер реагирует на нее h-откликом.
| hy | сервер согласен заблокировать обмен. В некоторых пакетах uucp клиент также посылаете команду hy. После этого стартует процедура закрытия канала. |
| hn | Сервер не готов заблокировать обмен. После этого клиент и сервер меняются ролями, такой обмен ролями возможен несколько раз за время сессии. |
/p> Если обмен завершен и клиент не намерен выдавать какие-либо запросы, связь прерывается. Клиент посылает сообщение \020ОООООО\000, на что сервер откликается посылкой строки \02ООООООО\000 (6 символов ‘О’ в первом и 7 - во втором случае). Какой-либо смысловой нагрузки этот обмен не несет, по этой причине некоторые пакеты его не производят.
В рамках UUCP предусмотрено несколько вспомогательных протоколов.
g-протокол предназначен для коррекции ошибок и поддерживается всеми версиями UUCP. Стандартная ширина окна в этом протоколе равна 3, а размер пакета 64 байтам, но в принципе предусмотрена возможность расширения окна при реализации потоков до 7 при размере пакетов 4096 байт. Протокол базируется на стандартных пакетных драйверах. Для реализации g-протокола используются пакеты с 6-байтовыми заголовками (управляющие пакеты содержат только заголовок). Формат этих пакетов представлен на рис. 4.4.14.1.1.

Рис. 4.4.14.1. Формат пакетов g-протокола
Пакет начинается с восьмеричного кода 020, далее следует поле k (1 Ј k Ј 9). Для управляющих пакетов k=9. Для информационных пакетов k определяет размер поля данных. k=1 соответствует 32 байтам данных, а k=9 - 4096 байтам. Далее следуют два байта контрольной суммы, контрольный байт, определяющий тип пакета, и xor-байт. Последний равен результату операции xor для полей k, младшего байта контрольной суммы, старшего байта контрольной суммы и контрольного байта. Этот байт служит для контроля целостности заголовка пакета.
Управляющий байт заголовка содержит в себе три субполя (ttxxxyyy). Поле tt может принимать следующие значения.
| 0 | Указатель управляющего пакета (k должно быть равно 9). При этом поле xxx определяет тип управляющего пакета; |
| 1 | Не используется UUCP; |
| 2 | Информационный пакет; |
| 3 | Короткий информационный пакет. |
Пусть длина поля данных, заданная k, равна 1, пусть также первый байт поля данных равен b1. Если b1 меньше 128, тогда истинное число байт в поле данных равно 1 - b1, начиная со второго байта. Если b1і 128 и второй байт поля данных b2, то истинное число байт в поле данных равно 1 - ((b1 & 0x7f) + (b2 << 7)), начиная с третьего байта.
Контрольная сумма вычисляется для всех байтов поля данных.
Один байт данных пересылается в любом случае. Для всех типов информационных пакетов поле ххх определяет порядковый номер пакета, а поле yyy определяет номер последнего пакета, принятого без ошибки, что и определяет максимальный размер окна, равный 7. Каждая из сторон, участвующих в обмене, использует окно, чтобы регистрировать число пакетов, которое может быть послано без получения подтверждения. Размер этого окна может лежать в пределах 1-7. Пакеты посылаются строго по очереди, получение всех пакетов должно быть подтверждено в том порядке, в каком они были посланы.
В пакетах управления поле ххх может принимать следующие значения:
| CLOSE | Соединение должно быть оборвано немедленно (например, обнаружено слишком много ошибок). |
| RJ или NAK | Последний пакет доставлен с ошибкой. В поле ууу записан номер последнего пакета, доставленного корректно. |
| SRJ | Выборочный отказ. Поле ууу содержит номер пакета, доставленного с ошибкой. Пакет должен быть послан повторно. В UUCP обычно не используется. |
| RR или ACK | Подтверждение получения пакета. Поле ууу содержит код номера последнего пакета, полученного корректно. |
| INITA | Первый пакет инициализации. Поле ууу содержит код максимального размера окна. |
| INITB | Второй пакет инициализации. Поле ууу содержит код размера пакетов, который планируется использовать. |
| INITC | Третий пакет инициализации. Поле ууу содержит размер окна, который будет использован. |
Контрольная сумма управляющего пакета равна 0хаааа - с, где с - контрольный байт заголовка. Контрольная сумма информационного пакета равна 0хаааа - (check ^ c), где ^ обозначает операцию исключающее ИЛИ, а check результат работы программы, приведенной ниже и обрабатывающей поле данных. Исходными параметрами для этой программы является указатель на начало блока данных z и число байтов в блоке c.
Int
igchecksum (z, c)
register const char *z; | |
register int c; |
| register unsigned int ichk1, ichk2; | ||
| ichk1 = 0xffff; | ||
| ichk2 = 0; | ||
| do | ||
{ | ||
register unsigned int b; | ||
/* rotate ichk1 left. */
| if ((ichk1 & 0x8000) == 0) | ||
ichk1 <<= 1; | ||
else | ||
{ | ||
ichk1 <<= 1; | ||
++ichk1; | ||
| } | ||
/* add the next character to ichk1. */
| b = *z++ & 0xff; | |
| ichk1 += b; |
ichk2 += ichk1 ^ c; /* if the character was zero, or adding it to ichk1 caused an overflow, xor ichk2 to ichk1. */
if (b == 0 (ichk1 & 0xffff) < b) | |
ichk1 ^= ichk2; | |
} | |
while (--c > 0); | |
return ichk1 & 0xffff; |
Когда g-протокол запускается в работу, посылается управляющий пакет INITA с кодом желательного значения максимального размера окна. Сервер откликается пакетом INITA со своим предложением размера окна. После этого аналогичный обмен производится пакетами INITB и INITC. В результате каждая из сторон может использовать свой размер окна и длину посылаемых пакетов.
Когда UUCP выдает команду, посылается один или более пакетов. В конце команды всегда посылается нулевой байт, который указывает на завершение командной строки. Когда пересылается файл, его завершение отмечается коротким информационным пакетом, содержащим нули. Прекращение работы протокола осуществляется посылкой управляющего пакета close.
f-протокол. Этот протокол предназначен для пересылки 7-битных текстовых файлов. Здесь используются только символы от \040 (пробел) до \176 (~) и возврат каретки. Протокол весьма не эффективен для транспортировки 8-битовых данных. Его система контрольного суммирования не слишком надежна для больших файлов. Первоначально этот протокол предназначался для работы в сетях Х.25. В f-протоколе не предусмотрена процедура инициализации. При пересылке команды передается строка, завершающаяся символом возврат каретки. В процессе передачи файлов каждый байт b преобразуется в соответствии с таблицей.
0 | <= b <= 037: | 0172, b + 0100 | (0100 дo 0137) |
040 | <= b <= 0171: | b | (040 до 0171) |
0172 | <= b <= 0177: | 0173, b - 0100 | ( 072 до 077) |
0200 | <= b <= 0237: | 0174, b - 0100 | (0100 до 0137) |
0240 | <= b <= 0371: | 0175, b - 0200 | ( 040 до 0171) |
0372 | <= b <= 0377: | 0176, b - 0300 | ( 072 до 077) |
/p> Таким образом, байты между \040 и \ 171 включительно передаются без изменений, остальные перед отправкой преобразуются. Когда файл данных переслан, посылается 7-байтовая последовательность, включающая в себя два байта \176, за которыми следует 4 ASCII байта контрольной суммы (в шестнадцатеричном формате) и символ возврата каретки. Если контрольная сумма равна 0x1a2b, то будет послана последовательность \176\1761a2b\r.
При вычислении контрольной суммы туда сначала заносится код 0xffff. Для вычисления контрольной суммы (ichk) используется следующая программа, которая выполняется перед отправкой каждого байта.
/* rotate the checksum left. */
if ((ichk & 0x8000) == 0) | |
ichk <<= 1; | |
else | |
{ | |
ichk <<= 1; | |
++ichk; | |
} |
/* add the next byte into the checksum. */
ichk += b; |
Принимающая файл сторона также вычисляет контрольную сумму данных и сравнивает ее с полученной по каналу. По результату этого сравнения передающей стороне посылается одно-символьный отклик, за которым следует код возврата каретки.
| G | Файл принят без ошибок; |
| R | Ошибка в контрольной сумме, файл надо передать повторно; |
| Q | Контрольная сумма неверна, но уже совершено много попыток и сессию следует прервать |
t-протокол. Протокол предназначен для каналов, обеспечивающих надежную связь по схеме точка-точка (аналог TCP) для 8-битных данных. При посылке команды сначала определяется ее длина с. Затем посылается (с/512 +1)*512 байт, которые включают в себя строку команды и соответствующее число нулевых байтов. При пересылке файлов обмен идет блоками по 1024 байта. Каждый блок начинается с 4 байтов, характеризующих объем данных в блоке (формат аналогичен используемому UNIX-утилитой htonl). В конце файла передается блок нулевых байтов.
e-протокол. Протокол подобен t-протоколу. Но здесь нет управления потоком и контроля ошибок. При посылке команды передается командная строка, завершающаяся нулевым байтом. При пересылке файла сначала посылается код его размера в виде ASCII десятичных цифр. Эта строка дополняется до 20 символов нулевыми байтами.
Так, если длина файла 40000 байт, сначала посылается последовательность 40000\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0, после чего посылается собственно файл.
G-протокол. Протокол используется SVR4 UUCP. Он идентичен G-протоколу за исключением того, что можно модифицировать окно и размер пакетов. В SVR4 реализации G-протокола размер окна всегда равен 7 а длина пакета 64 байтам.
i-протокол. Протокол написан Яном Лансом Тейлором и использован в taylor UUCP. Это протокол пересылки данных со скользящим окном, подобно G-протоколу. Но в отличие от этого протокола i-протокол поддерживает обмен данными в двух направлениях одновременно. Пакеты в этом протоколе имеют 6-байтовый заголовок. За полем данных следует 4-байтовая контрольная сумма. Определено 5 типов пакетов: DATA, SYNC, ACK, NAK, SPOS и CLOSE. Все они могут содержать поле данных. Пакеты типа DATA, SPOS и CLOSE имеют порядковые номера. Каждая из сторон нумерует пакеты независимо по модулю 32. Каждый из пакетов характеризуется локальным и удаленным номерами каналов. Каждому типу команд в локальной системе ставится в соответствие ненулевой локальный номер канала. Аналогичное правило справедливо и для удаленной системы. Это позволяет решить проблему одновременного двухстороннего информационного обмена. Для каждого файла протокол формирует указатель, в исходный момент равный нулю. После получения очередного пакета указатель соответствующим образом инкрементируется. Исключение представляют пакеты типа spos, которые служат для изменения указателя файла. Формат пакета i-протокола представлен на рис. 4.4.14.1.2.

Рис. 4.4.14.1.2. Формат пакета i -протокола
Заголовок начинается с флага ^g (восьмеричный код \007), далее следует 5-битовое поле пакет. Пакеты DATA, SPOS и CLOSE используют это поле для номера пакета. В пакетах NAK сюда заносится номер пакета, подлежащий повторной пересылке. В пакетах же ACK и SYNC это поле заполняется нулями. Поле ACK содержит 5 бит и служит для записи номера последнего пакета, принятого без ошибки.
Это поле используется всеми типами пакетов. В трехбитовое поле тип определяет назначение пакета и может принимать следующие значения.
| 0 ‘DATA’ | Информационный пакет; |
| 1 ‘SYNC’ | Пакет sync используется при инициализации соединения, поле пакет в для этого типа обнуляется; |
| 2 ‘ACK’ | Пакет-отклик. Так как пакет типа data также может использоваться для отклика, ack предназначен для случая, когда одной из сторон нечего посылать. Пакеты ack не нумеруются. |
| 3 ‘NAK’ | Отрицательное подтверждение. Пакет посылается, когда при приеме произошла ошибка. В этом случае в поле пакет записывается номер пакета, подлежащего повторной пересылке. |
| 4 ‘SPOS’ | Пакет служит для изменения указателя файла. Пакет содержит 4 байта указателя файла (наиболее значащий байт первый). |
| 5 ‘CLOSE’ | Пакет служит для сообщения о прерывании связи. Противоположная сторона должна откликнуться пакетом CLOSE. |
Однобитовое поле d =1 для пакетов клиента и =0 для пакетов сервера. Поле длины поля данных состоит из двух секций (полный байт содержит младшую часть), имеет суммарную протяженность 12 бит, что позволяет варьировать поле данных в пределах от 0 до 4095 байт. Однобайтовое поле контрольная сумма содержит код, который представляет собой результат операции XOR, выполненной для байт заголовка, начиная со второго по пятый. После заголовка следует поле данных, за которым помещается 32-разрядная контрольная сумма информационного поля (CRC).
При инициализации i-протокола стороны обмениваются SYNC-пакетами, которые содержат по крайней мере 3 байта. Первые два байта несут в себе максимальный размер пакетов, посылаемых удаленной стороной (старший байт первый). Третий байт определяет размер окна, используемый удаленной стороной. При этом могут посылаться пакеты любого размера, но не больше указанного максимального. Если SYNC содержит четвертый байт, то он хранит в себе номер канала (1-7), который может использовать удаленная система. Размер окна определяет число пакетов, которое может быть послано, не дожидаясь подтверждения получения.
Подтверждаться может не каждый пакет. Если получено подтверждение получения пакета n, все предшествующие считаются полученными корректно. Если потерян пакет, посланный одной из сторон, другая может передавать пакеты, как ни в чем не бывало. Команды посылаются в виде последовательности информационных пакетов с ненулевым полем номера локального канала. Последний из пакетов в этом случае должен содержать нулевой байт в конце (обычно команда укладывается в один пакет). Файла передаются в виде последовательности пакетов, завершающейся пакетом нулевой длины. При получении отклика sn пересылка файла абортируется. Применение номеров каналов позволяет посылать команды и пересылать файлы одновременно.
j-протокол. Этот протокол является разновидностью i-протокола написанного тем же автором. Протокол предназначен для коммуникационных каналов с возможностью перехвата некоторых символов, например xon или xoff. Протокол не выполняет детектирования или исправления ошибок. При инициализации j-протокола системы обмениваются последовательностями печатных ascii-символов, чтобы указать, какие из них стороны хотят исключить из употребления. Такая последовательность должна начинаться с символа ^ (восьмеричный код 136) и завершаться символом ~ (восьмеричный код 176). После отправления такой строки система ждет аналогичной посылки с противоположной стороны. Строки состоят из esc-последовательностей типа \ooo, где o - восьмеричная цифра. Например, посылка последовательности ^\021\023~ означает, что следует избегать символов xon и xoff. Блокировка использования символов из диапазона \040 - \176 запрещена. После указанного обмена включается стандартный i-протокол, но пакеты i-протокола вкладываются в j-пакеты. Заголовок j-пакетов содержит 7 байт. Формат заголовка пакета j-протокола показан на рис. 4.4.14.1.3.

Рис. 4.4.14.1.3. Формат заголовка j-пакета
Заголовок начинается с кода символа ^. Далее следует два байта поля длина (первый из них старший), которые характеризуют полную длину пакета в байтах.
Запись в этом поле осуществляется в виде ascii-символов. Истинная длина пакета вычисляется согласно формуле: (l1 - 040)*0100 + (l2 - 040), где 040 Ј l1 < 0177 и 040 Ј l2 < 0140. После поля длина следует байт 075 (символ =), за которым следует два байта длины поля данных (равна размеру вложенного i-пакета в октетах). Заголовок завершается символом @ (восьмеричный код 0100). Все символы, запрещенные к использованию при инициализации, в случае их наличия в i-пакете подменяются печатными ASCII-символами. При этом для каждой такой подмены вводится два индексных байта (index-h и index_l). Индексные байты непосредственно следуют за байтами данных. В индексных байтах закодировано положение “запретного” символа в i-пакете. Преобразование запретных символов производится следующим образом. Если код символа больше или равно 0200, из него вычитается 0200, если при этом результат меньше 020 или равен 0177, над ним производится операция xor 020. Индексные байты представляют собой ASCII-символы. Истинное положение запретного символа вычисляется по формуле: (index-h - 040) * 040 + (index_l - 040). Значение index_l должно лежать в пределах 040 Ј index_l < 0100, а index-h - 040 Ј index-h < 0176.
x-протокол. Протокол ориентирован на машины со встроенными картами Х.25 и предназначен для непосредственной пересылки 8-битовых данных без взаимодействия со слоями Х.28 или Х.29. Пересылка осуществляется 512 байтными пакетами.
y-протокол. Протокол разработан Йоргом Квиком и используется в FX uucico. Протокол осуществляет контроль и коррекцию ошибок, он предназначен для передачи 8-битовых данных в поточном режиме. Здесь не предусмотрено подтверждения получения пакетов, по этой причине протокол удобен для полудуплексных каналов. Каждый пакет имеет 6-байтовый заголовок. Формат заголовка для y-пакетов показан на рис. 4.4.14.1.4.

Рис. 4.4.14.1.4. Формат заголовка для y-пакетов
Первое поле номер содержит два байта номера пакета, причем первый из байтов является младшей частью номера (это справедливо и для других полей заголовка).
Нумерация начинается с нуля. Так как первый пакет всегда SYNC, информационные пакеты имеют номера, начиная с 1. Каждая из систем, участвующих в обмене, нумеруют пакеты независимо. Если старший бит 16-битового поля длины равен нулю, то в этом поле записано число байт в поле данных, следующем за заголовком. Если же старший бит равен 1, то данных в пакете нет, а сам он является управляющим пакетом. В этом случае поле длина определяет тип пакета. Содержимое двухбайтового поля контрольная сумма вычисляется по программе, приведенной в описании протокола f. Для пакетов, не содержащих данных, контрольная сумма равна нулю. Инициализация протокола начинается с того, что стороны обмениваются SYNC-пакетами. SYNC-пакет должен содержать по меньшей мере 4 байта данных. Первый из них содержит код версии протокола. Далее следует байт длины пакета, которая измеряется в блоках по 256 байт (максимальный размер поля данных 32768 байт, что соответствует коду длины 128). Завершается блок данных пакета SYNC двумя байтами флагов. В настоящее время их функции не определены и их следует обнулять. Определены следующие типы управляющих пакетов.
| 0хFFFE ‘YPKT_ACK’ | подтверждение корректного приема файла; |
| 0xFFFD ‘YPKT_ERR’ | указывает на ошибку в контрольной сумме; |
| 0xFFFC ‘YPKT_BAD’ | указывает на ошибку в порядковом номере, в поле длины или какую-либо еще ошибку. |
Если получен управляющий пакет, отличный от ‘YPKT_ACK’, соединение обрывается (это же делается при обнаружении других ошибок). Команда в y-протоколе представляет собой последовательность пакетов, завершающаяся нулевым байтом. Конец передачи файла отмечается посылкой пакета с нулем в поле длина.
Существуют также d-, h- и v-протоколы UUCP, но они не имеют заметного применения.
Протокол обратного адресного преобразования RARP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Обычно IP-адреса хранятся на диске, откуда они считываются при загрузке системы. Проблема возникает тогда, когда необходимо инициализировать рабочую станцию, не имеющую диска. Бездисковые системы часто используют операции типа TFTP для переноса из сервера в память образа операционной системы, а это нельзя сделать, не зная IP-адресов сервера и ЭВМ-клиента. Записывать эти адреса в ПЗУ не представляется целесообразным, так как их значения зависят от точки подключения ЭВМ и могут меняться. Для решения данной проблемы был разработан протокол обратной трансляции адресов (RARP – Reverse Address Resolution Protocol, RFC-0903, смотри также ниже описание протокола ). Форматы сообщений RARP сходны с ARP (см. рис. 4.4.8.1), хотя сами протоколы принципиально различны. Протокол RARP предполагает наличие специального сервера, обслуживающего RARP-запросы и хранящего базу данных о соответствии аппаратных адресов протокольным. Этот протокол работает с любой транспортной средой, в случае же кадра Ethernet в поле тип будет записан код 803516 (смотри таблицу ).

Рис. 4.4.8.1. Формат RARP-сообщения
Здесь обозначения те же, что и в описании ARP-формата. Значение n определяется числом, записанным в поле HA-Len, а m - числом из поля PA-Len. Для Internet PA-Len=4 и тип протокола=2048, а для Ethernet равно HA-Len=6 и тип оборудования=1. В RARP используется два кода операции. Код операции=3 используется для RARP-запросов, а код операции=4 - для RARP-откликов. В первом случае поле протокольный адрес отправителя и протокольный адрес адресата не определены. Обычно локальная сеть имеет несколько RARP-серверов, что позволяет загрузиться бездисковым машинам, даже если какой-то из серверов выключен или не исправен.
Протокол OSPF (алгоритм Дикстры)
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Протокол OSPF (Open Shortest Pass First, RFC-1245-48, RFC-1583-1587, алгоритмы предложены Дикстрой) является альтернативой RIP в качестве внутреннего протокола маршрутизации. OSPF представляет собой протокол состояния маршрута (в качестве метрики используется - коэффициент качества обслуживания). Каждый маршрутизатор обладает полной информацией о состоянии всех интерфейсов всех маршрутизаторов (переключателей) автономной системы. Протокол OSPF реализован в демоне маршрутизации gated, который поддерживает также RIP и внешний протокол маршрутизации BGP.
Автономная система может быть разделена на несколько областей, куда могут входить как отдельные ЭВМ, так и целые сети. В этом случае внутренние маршрутизаторы области могут и не иметь информации о топологии остальной части AS. Сеть обычно имеет выделенный (designated) маршрутизатор, который является источником маршрутной информации для остальных маршрутизаторов AS. Каждый маршрутизатор самостоятельно решает задачу оптимизации маршрутов. Если к месту назначения ведут два или более эквивалентных маршрута, информационный поток будет поделен между ними поровну. Переходные процессы в OSPF завершаются быстрее, чем в RIP. В процессе выбора оптимального маршрута анализируется ориентированный граф сети. Ниже описан алгоритм Дикстры по выбору оптимального пути. На иллюстративном рис. 4.2.11.2.1 приведена схема узлов (A-J) со значениями метрики для каждого из отрезков пути. Анализ графа начинается с узла A (Старт). Пути с наименьшим суммарным значением метрики считаются наилучшими. Именно они оказываются выбранными в результате рассмотрения графа (“кратчайшие пути“).

Рис. 4.2.11.2.1 Иллюстрация работы алгоритма Дикстры
Ниже дается формальное описание алгоритма. Сначала вводим некоторые определения.
Пусть D(v) равно сумме весов связей для данного пути.
Пусть c(i,j) равно весу связи между узлами с номерами i и j.
Далее следует последовательность шагов, реализующих алгоритм.
Устанавливаем множество узлов N = {1}.
Для каждого узла v не из множества n устанавливаем D(v)= c(1,v).
Для каждого шага находим узел w не из множества N, для которого D(w) минимально, и добавляем узел w в множество N.
Актуализируем D(v) для всех узлов не из множества N
D(v)=min{D(v), D(v)+c(w,v)}.
Повторяем шаги 2-4, пока все узлы не окажутся в множестве N.
Топология маршрутов для узла a приведена на нижней части рис. 4.2.11.2.1. В скобках записаны числа, характеризующие метрику отобранного маршрута согласно критерию пункта 3.
Таблица 4.2.11.2.1. Реализация алгоритма
| Множество | Метрика связи узла a с узлами | |||||||||
| Шаг | N | B | C | D | E | F | G | H | I | J |
| 0 | {A} | 3 | - | 9 | - | - | - | - | - | - |
| 1 | {A,B} | (3) | 4 | 9 | 7 | - | 10 | - | - | - |
| 2 | {A,B,C} | 3 | (4) | 6 | 6 | 10 | 10 | 8 | - | 14 |
| 3 | {A,BC,D} | 3 | 4 | (6) | 6 | 10 | 10 | 8 | 9 | 14 |
| 4 | {A,B,C,D,E} | 3 | 4 | 6 | (6) | 10 | 10 | 8 | 9 | 14 |
| 5 | {A,B,C,D,E,H} | 3 | 4 | 6 | 6 | 10 | 10 | (8) | 9 | 14 |
| 6 | {A,B,C,D,E,H,I} | 3 | 4 | 6 | 6 | 10 | 10 | 8 | (9) | 14 |
| 7 | {A,B,C,D,E,H,I,F} | 3 | 4 | 6 | 6 | (10) | 10 | 8 | 9 | 14 |
| 8 | {A,B,C,D,E,H,I,F,G} | 3 | 4 | 6 | 6 | 10 | (10) | 8 | 9 | 14 |
| 9 | {A,B,C,D,E,H,I,F,G,J} | 3 | 4 | 6 | 6 | 10 | 10 | 8 | 9 | (14) |
Таблица 4.2.11.2.1 может иметь совершенно иное содержимое для какого-то другого вида сервиса, выбранные пути при этом могут иметь другую топологию. Качество сервиса (QoS) может характеризоваться следующими параметрами:
пропускной способностью канала;
задержкой (время распространения пакета);
числом дейтограмм, стоящих в очереди для передачи;
загрузкой канала;
требованиями безопасности;
типом трафика;
числом шагов до цели;
возможностями промежуточных связей (например, многовариантность достижения адресата).
Определяющими являются три характеристики: задержка, пропускная способность и надежность. Для транспортных целей OSPF использует IP непосредственно, т.е. не привлекает протоколы UDP или TCP. OSPF имеет свой код (89) в протокольном поле IP-заголовка. Код TOS (type of service) в IP-пакетах, содержащих OSPF-сообщения, равен нулю, значение TOS здесь задается в самих пакетах OSPF. Маршрутизация в этом протоколе определяется IP-адресом и типом сервиса. Так как протокол не требует инкапсуляции пакетов, сильно облегчается управление сетями с большим количеством бриджей и сложной топологией (исключается циркуляция пакетов, сокращается транзитный трафик).
Автономная система может быть поделена на отдельные области, каждая из которых становится объектом маршрутизации, а внутренняя структура снаружи не видна (узлы на рис. 4.2.11.2.1 могут представлять собой как отдельные ЭВМ или маршрутизаторы, так и целые сети). Этот прием позволяет значительно сократить необходимый объем маршрутной базы данных. В OSPF используется термин опорной сети (backbone) для коммуникаций между выделенными областями. Протокол работает лишь в пределах автономной системы. В пределах выделенной области может работать свой протокол маршрутизации.

Рис. 4.2.11.2.2 Пример выделения областей при ospf маршрутизации в автономной системе (М - маршрутизаторы; c - сети).
На рис 4.2.11.2.2 (см. также рис. 4.2.11.2.1) приведен пример выделения областей маршрутизации при ospf-маршрутизации в пределах автономной системы. На рис. 4.2.11.2.2 маршрутизаторы М4 и М2 выполняют функция опорной сети для других областей. В выделенных областях может быть любое число маршрутизаторов. Более толстыми линиями выделены связи с другими автономными системами.
При передаче OSPF-пакетов фрагментация не желательна, но не запрещается. Для передачи статусной информации OSPF использует широковещательные сообщения Hello. Для повышения безопасности предусмотрена авторизация процедур. OSPF-протокол требует резервирования двух мультикастинг-адресов:
| 224.0.0.5 | предназначен для обращения ко всем маршрутизаторам, поддерживающим этот протокол. |
| 224.0.0.6 | служит для обращения к специально выделенному маршрутизатору. |
Любое сообщение ospf начинается с 24-октетного заголовка:

Рис. 4.2.11.2.3 Формат заголовка сообщений для протокола маршрутизации ospf
Поле версия определяет версию протокола (= 2). Поле тип идентифицирует функцию сообщения согласно таблице 4.2.11.2.2:
Таблица 4.2.11.2.2. Коды поля тип
| Тип | Значение |
| 1 | Hello (используется для проверки доступности маршрутизатора). |
| 2 | Описание базы данных (топология). |
| 3 | Запрос состояния канала. |
| 4 | Изменение состояния канала. |
| 5 | Подтверждение получения сообщения о статусе канала. |
Поле длина пакета определяет длину блока в октетах, включая заголовок. Идентификатор области - 32-битный код, идентифицирующий область, которой данный пакет принадлежит. Все ospf-пакеты ассоциируются с той или иной областью. Большинство из них не преодолевает более одного шага. Пакеты, путешествующие по виртуальным каналам, помечаются идентификатором опорной области (backbone) 0.0.0.0. Поле контрольная сумма содержит контрольную сумму IP-пакета, включая поле типа идентификации. Контрольное суммирование производится по модулю 1. Поле тип идентификации может принимать значения 0 при отсутствии контроля доступа, и 1 при наличии контроля. В дальнейшем функции поля будут расширены. Важную функцию в OSPF-сообщениях выполняет одно-октетное поле опции, оно присутствует в сообщениях типа Hello, объявление состояния канала и описание базы данных. Особую роль в этом поле играют младшие биты e и Т:

Бит E характеризует возможность внешней маршрутизации и имеет значение только в сообщениях типа Hello, в остальных сообщениях этот бит должен быть обнулен. Если E=0, то данный маршрутизатор не будет посылать или принимать маршрутную информацию от внешних автономных систем. Бит T определяет сервисные возможности маршрутизатора (TOS). Если T=0, это означает, что маршрутизатор поддерживает только один вид услуг (TOS=0) и он не пригоден для маршрутизации с учетом вида услуг. Такие маршрутизаторы, как правило, не используются для транзитного трафика.
Протокол ospf использует сообщение типа Hello для взаимообмена данными между соседними маршрутизаторами. Структура пакетов этого типа показана на рис. 4.2.11.2.4.

Рис. 4.2.11.2.4 Формат сообщения Hello в протоколе OSPF
Поле сетевая маска соответствует маске субсети данного интерфейса. Например, если интерфейс принадлежит сети класса B и третий байт служит для выделения нужной субсети, то сетевая маска будет иметь вид 0xFFFFFF00.
Поле время между Hello содержит значение времени в секундах, между сообщениями Hello. Поле опции характеризует возможности, которые предоставляет данный маршрутизатор.
Поле приоритет характеризует уровень приоритета маршрутизатора (целое положительное число), используется при выборе резервного (backup) маршрутизатора. Если приоритет равен нулю, данный маршрутизатор никогда не будет использован в качестве резервного. Поле время отключения маршрутизатора определяет временной интервал в секундах, по истечении которого "молчащий" маршрутизатор считается вышедшим из строя. IP-адреса маршрутизаторов, записанные в последующих полях, указывают место, куда следует послать данное сообщение. Поля IP-адрес соседа k образуют список адресов соседних маршрутизаторов, откуда за последнее время были получены сообщения Hello.
Маршрутизаторы обмениваются сообщениями из баз данных OSPF, чтобы инициализировать, а в дальнейшем актуализовать свои базы данных, характеризующие топологию сети. Обмен происходит в режиме клиент-сервер. Клиент подтверждает получение каждого сообщения. Формат пересылки записей из базы данных представлен на рис. 4.2.11.2.5.

Рис. 4.2.11.2.5 Формат OSPF-сообщений о маршрутах
Поля, начиная с тип канала, повторяются для каждого описания канала. Так как размер базы данных может быть велик, ее содержимое может пересылаться по частям. Для реализации этого используются биты I и М. Бит I устанавливается в 1 в стартовом сообщении, а бит M принимает единичное состояние для сообщения, которые являются продолжением. Бит S определяет то, кем послано сообщение (S=1 для сервера, S=0 для клиента, этот бит иногда имеет имя MS). Поле номер сообщения по порядку служит для контроля пропущенных блоков. Первое сообщение содержит в этом поле случайное целое число M, последующие M+1, M+2,...M+L. Поле тип канала может принимать следующие значения:
Таблица 4.2.11.2.3. Коды типов состояния каналов (LS)
| LS-тип | Описание объявления о маршруте |
| 1 | Описание каналов маршрутизатора, то есть состояния его интерфейсов. |
| 2 | Описание сетевых каналов. Это перечень маршрутизаторов, непосредственно связанных с сетью. |
| 3 или 4 | Сводное описание каналов, куда входят маршруты между отдельными областями сети. Эта информация поступает от пограничных маршрутизаторов этих зон. Тип 3 приписан маршрутам, ведущим к сетям, а тип 4 характеризует маршруты, ведущие к пограничным маршрутизаторам автономной системы. |
| 5 | Описания внешних связей автономной системы. Такие маршруты начинаются в пограничных маршрутизаторах AS. |
/p> Поле идентификатор канала определяет его характер, в зависимости от этого идентификатором может быть IP-адрес маршрутизатора или сети. Маршрутизатор, рекламирующий канал определяет адрес этого маршрутизатора. Поле порядковый номер канала позволяет маршрутизатору контролировать порядок прихода сообщений и их потерю. Поле возраст канала определяет время в секундах с момента установления связи. После обмена сообщениями с соседями маршрутизатор может выяснить, что часть данных в его базе устарела. Он может послать своим соседям запрос с целью получения свежей маршрутной информации о каком-то конкретном канале связи. Сосед, получивший запрос, высылает необходимую информацию. Запрос посылается в соответствии с форматом, показанном ниже (рис. 4.2.11.2.6):

Рис. 4.2.11.2.6 Формат ospf-запроса маршрутной информации
Три поля этого запроса повторяются согласно числу каналов, информация о которых запрашивается. Если список достаточно длинен, может потребоваться несколько запросов. Маршрутизаторы посылают широковещательные (или мультикастинговые) сообщения об изменении состояния своих непосредственных связей. Такое сообщение содержит список объявлений, имеющих формат (рис. 4.2.11.2.7):

Рис. 4.2.11.2.7 Сообщение об изменении маршрутов
Сообщения об изменениях маршрутов могут быть вызваны следующими причинами:
1. Возраст маршрута достиг предельного значения (lsrefreshtime).
2. Изменилось состояние интерфейса.
3. Произошли изменения в маршрутизаторе сети.
4. Произошло изменение состояния одного из соседних маршрутизаторов.
5. Изменилось состояние одного из внутренних маршрутов (появление нового, исчезновение старого и т.д.)
6. Изменение состояния межзонного маршрута.
7. Появление нового маршрутизатора, подключенного к сети.
8. Вариация виртуального маршрута одним из маршрутизаторов.
9. Возникли изменения одного из внешних маршрутов.
10. Маршрутизатор перестал быть пограничным для данной as (например, перезагрузился).
Каждое сообщение о состоянии канала начинается с заголовка - "объявление состояния канала" (LS- link state).
Формат этого типа заголовка приведен ниже (20 октетов):

Рис. 4.2.11.2.8 Формат ospf-сообщения, описывающего состояние канала
Поле возраст ls информации (рис. 4.2.11.2.8) определяет время в секундах с момента объявления состояния канала. Поле опции содержит значения типов сервиса (TOS), поддерживаемые маршрутизатором, рассылающим маршрутную информацию. Поле тип LS (тип состояния канала) может принимать значения, описанные выше в табл. 4.2.11.2.3. Следует обратить внимание, что код, содержащийся в этом поле, определяет формат сообщения. Поле длина задает размер сообщения в октетах, включая заголовок. В результате получается сообщение с форматом, показанным на рис. 4.2.11.2.9. Зарезервированный октет должен быть обнулен. Идентификатор связи определяет тип маршрутизатора, подключенного к каналу. Действительное значение этого поля зависит от поля тип. В свою очередь информация о канале также зависит от поля тип. Число tos определяет многообразие метрик, соответствующих видам сервиса, для данного канала. Последовательность описания метрик задается величиной кода TOS. Таблица кодов TOS, принятых в OSPF протоколе приведена ниже.
Таблица 4.2.11.2.4. Коды типа сервиса (TOS)
| OSPF-код | TOS-коды | TOS(RFC-1349) |
| 0 | 0000 | Обычный сервис |
| 2 | 0001 | Минимизация денежной стоимости |
| 4 | 0010 | Максимальная надежность |
| 8 | 0100 | Максимальная пропускная способность |
| 16 | 1000 | Минимальная задержка |

Рис. 4.2.11.2.9 Формат описания типа канала с LS=1
Если бит V=1 (virtual), маршрутизатор является оконечной точкой активного виртуального канала. Если бит E (external) равен 1, маршрутизатор является пограничным для автономной системы. Бит B=1 (border) указывает на то, что маршрутизатор является пограничным для данной области. Поле тип может принимать значения, приведенные в таблице 4.2.11.2.5.
Таблица 4.2.11.2.5. Коды типов связей (см. рис. 4.2.11.2.9)
| Код типа связи | Описание |
| 1 | Связь с другим маршрутизатором по схеме точка-точка |
| 2 | Связь с транзитной сетью |
| 3 | Связь с оконечной сетью |
| 4 | Виртуальная связь (например, опорная сеть или туннель) |
Поле идентификатор канала характеризует объект, с которым связывается маршрутизатор. Примеры идентификаторов представлены в таблице:
Таблица 4.2.11.2.6. Коды идентификаторов канала
| Код идентификатора | Описание |
| 1 | Идентификатор соседнего маршрутизатора |
| 2 | IP-адрес основного маршрутизатора (по умолчанию) |
| 3 | IP-адрес сети/субсети |
| 4 | Идентификатор соседнего маршрутизатора |
Маршрутизатор, получивший OSPF-пакет, посылает подтверждение его приема. Этот вид пакетов имеет тип=5 и структуру, отображенную на рис. 4.2.11.2.10. Получение нескольких объявлений о состоянии линий может быть подтверждено одним пакетом. Адресом места назначения этого пакета может быть индивидуальный маршрутизатор, группа маршрутизаторов или все маршрутизаторы автономной системы.

Рис. 4.2.11.2.10 Формат сообщения о получении OSPF-пакета
Рекламирование сетевых связей относится к типу 2. Сообщения посылаются для каждой транзитной сети в автономной системе. Транзитной считается сеть, которая имеет более одного маршрутизатора. Сообщение о сетевых связях должно содержать информацию обо всех маршрутизаторах, подключенных к сети, включая тот, который рассылает эту информацию. Расстояние от сети до любого подключенного маршрутизатора равно нулю для всех видов сервиса (TOS), поэтому поля TOS и метрики в этих сообщениях отсутствуют. Формат сообщения о транзитных сетевых связях показан на рис. 4.2.11.2.11.
Следует помнить, что приведенные ниже сообщения должны быть снабжены стандартными 24-октетными OSPF-заголовками (на рис. 4.2.11.2.11 отсутствует).

Рис. 4.2.11.2.11 Формат сообщения о сетевых связях (тип LS=2)
Сетевая маска относится к описываемой сети, а поле подключенный маршрутизатор содержит идентификатор маршрутизатора, работающего в сети. Информация об адресатах в пределах автономной системы передается LS-сообщениями типа 3 и 4. Тип 3 работает для IP-сетей. В этом случае в качестве идентификатора состояния канала используется IP-адрес сети. Если же адресатом является пограничный маршрутизатор данной AS, то используется LS-сообщение типа 4, а в поле идентификатор состояния канала записывается OSPF-идентификатор этого маршрутизатора.
Во всех остальных отношениях сообщения 3 и 4 имеют идентичные форматы (рис. 4.2.11.2.12):

Рис. 4.2.11.2.12 Формат сообщений об адресатах в пределах автономной системы
Поля, следующие после заголовка, повторяются в соответствии с числом описываемых объектов. Рекламирование внешних маршрутов относится к пятому типу. Эта информация рассылается пограничными маршрутизаторами. Информация о каждом внешнем адресате, известном маршрутизатору, посылается независимо. Этот вид описания используется и для маршрутов по умолчанию, для которых идентификатор состояния канала устанавливается равным 0.0.0.0 (аналогичное значение принимает при этом и сетевая маска). Формат такого сообщения представлен на рис. 4.2.11.2.13.

Рис. 4.2.11.2.13 Формат описания внешних маршрутов
Сетевая маска характеризует место назначения рекламируемого маршрута. Так для сети класса A маска может иметь вид 0xFF000000. Последующий набор полей повторяется для каждого вида TOS. Поля для TOS=0 заполняются всегда, и это описание является первым. Бит E характеризует внешнюю метрику. Если E=0, то она может непосредственно (без преобразования) сравниваться с метриками других каналов. При E=1 метрика считается больше любой метрики. Поле адрес пересылки указывает на место, куда будут пересылаться данные, адресованные рекламируемым маршрутом. Если адрес пересылки равен 0.0.0.0, данные посылаются пограничному маршрутизатору автономной системы - источнику данного сообщения. Метка внешнего маршрута - 32-битовое число, присваиваемое каждому внешнему маршруту. Эта метка самим протоколом OSPF не используется и предназначена для информирования других автономных систем при работе внешних протоколов маршрутизации. Маршрутная таблица OSPF содержит в себе:
IP-адрес места назначения и маску;
тип места назначения (сеть, граничный маршрутизатор и т.д.);
тип функции (возможен набор маршрутизаторов для каждой из функций TOS);
область (описывает область, связь с которой ведет к цели, возможно несколько записей данного типа, если области действия граничных маршрутизаторов перекрываются);
тип пути ( характеризует путь как внутренний, межобластной или внешний, ведущий к AS);
цена маршрута до цели;
очередной маршрутизатор, куда следует послать дейтограмму;
объявляющий маршрутизатор (используется для межобластных обменов и для связей автономных систем друг с другом).
Преимущества OSPF:
Для каждого адреса может быть несколько маршрутных таблиц, по одной на каждый вид IP-операции (TOS).
Каждому интерфейсу присваивается безразмерная цена, учитывающая пропускную способность, время транспортировки сообщения. Для каждой IP-операции может быть присвоена своя цена (коэффициент качества).
При существовании эквивалентных маршрутов OSFP распределяет поток равномерно по этим маршрутам.
Поддерживается адресация субсетей (разные маски для разных маршрутов).
При связи точка-точка не требуется IP-адрес для каждого из концов. (Экономия адресов!)
Применение мультикастинга вместо широковещательных сообщений снижает загрузку не вовлеченных сегментов.
Недостатки:
Трудно получить информацию о предпочтительности каналов для узлов, поддерживающих другие протоколы, или со статической маршрутизацией.
OSPF является лишь внутренним протоколом.
Протокол передачи команд и сообщений об ошибках (ICMP)
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Протокол передачи команд и сообщений об ошибках (ICMP - internet control message protocol, RFC-792, - 1256) выполняет многие и не только диагностические функции, хотя у рядового пользователя именно этот протокол вызывает раздражение, сообщая об его ошибках или сбоях в сети. Именно этот протокол используется программным обеспечением ЭВМ при взаимодействии друг с другом в рамках идеологии TCP/IP. Осуществление повторной передачи пакета, если предшествующая попытка была неудачной, лежит на TCP или прикладной программе. При пересылке пакетов промежуточные узлы не информируются о возникших проблемах, поэтому ошибка в маршрутной таблице будет восприниматься как неисправность в узле адресата и достоверно диагностироваться не будет. ICMP-протокол сообщает об ошибках в IP-дейтограммах, но не дает информации об ошибках в самих ICMP-сообщениях. icmp использует IP, а IP-протокол должен использовать ICMP. В случае ICMP-фрагментации сообщение об ошибке будет выдано только один раз на дейтограмму, даже если ошибки были в нескольких фрагментах. Подводя итоги, можно сказать, что ICMP-протокол осуществляет:
передачу отклика на пакет или эхо на отклик;
контроль времени жизни дейтограмм в системе;
реализует переадресацию пакета;
выдает сообщения о недостижимости адресата или о некорректности параметров;
формирует и пересылает временные метки;
выдает запросы и отклики для адресных масок и другой информации.
ICMP-сообщения об ошибках никогда не выдаются в ответ на:
icmp-сообщение об ошибке.
При мультикастинг или широковещательной адресации.
Для фрагмента дейтограммы (кроме первого).
Для дейтограмм, чей адрес отправителя является нулевым, широковещательным или мультикастинговым.
Эти правила призваны блокировать потоки дейтограмм, посылаемым в отклик на мультикастинг или широковещательные ICMP-сообщения.
ICMP-сообщения имеют свой формат, а схема их вложения аналогична UDP или TCP и представлена на рис. 4.4.4.1.

Рис. 4.4.4.1. Схема вложения ICMP-пакетов в Ethernet-кадр
Все ICMP пакеты начинаются с 8-битного поля типа ICMP и его кода (15 значений). Код уточняет функцию ICMP-сообщения. Таблица этих кодов приведена ниже (символом * помечены сообщения об ошибках, остальные – являются запросами):
Таблица 4.4.4.1. Типы и коды ICMP-сообщений.
icmp-сообщение | Описание сообщения | |
| Тип | Код | |
| 0 | Эхо-ответ (ping-отклик) | |
| 3 | Адресат недостижим | |
| 0 | * Сеть недостижима | |
| 1 | * ЭВМ не достижима | |
| 2 | * Протокол не доступен | |
| 3 | * Порт не доступен | |
| 4 | * Необходима фрагментация сообщения | |
| 5 | * Исходный маршрут вышел из строя | |
| 6 | * Сеть места назначения не известна | |
| 7 | * ЭВМ места назначения не известна | |
| 8 | * Исходная ЭВМ изолирована | |
| 9 | * Связь с сетью места назначения административно запрещена | |
| 10 | * Связь с ЭВМ места назначения административно запрещена | |
| 11 | * Сеть не доступна для данного вида сервиса | |
| 12 | * ЭВМ не доступна для данного вида сервиса | |
| 13 | * Связь административно запрещена с помощью фильтра. | |
| 14 | * Нарушение старшинства ЭВМ | |
| 15 | * Дискриминация по старшинству | |
| 4 | 0 | * Отключение источника при переполнении очереди |
| 5 | Переадресовать (изменить маршрут) | |
| 0 | Переадресовать дейтограмму в сеть (устарело) | |
| 1 | Переадресовать дейтограмму на ЭВМ | |
| 2 | Переадресовать дейтограмму для типа сервиса (tos) и сети | |
| 3 | Переадресовать дейтограмму для типа сервиса и ЭВМ | |
| 8 | 0 | Эхо запроса (ping-запрос). |
| 9 | 0 | Объявление маршрутизатора |
| 10 | 0 | Запрос маршрутизатора |
| 11 | Для дейтограммы время жизни истекло (ttl=0): | |
| 0 | *при передаче | |
| 1 | * при сборке (случай фрагментации). | |
| 12 | * Проблема с параметрами дейтограммы | |
| 0 | * Ошибка в ip-заголовке | |
| 1 | * Отсутствует необходимая опция | |
| 13 | Запрос временной метки | |
| 14 | Временная метка-отклик | |
| 15 | Запрос информации (устарел) | |
| 16 | Информационный отклик (устарел) | |
| 17 | Запрос адресной маски | |
| 18 | Отклик на запрос адресной маски | |
Процедура "отключение источника" (quench, поле тип ICMP=4) позволяет управлять потоками данных в каналах Интернет. Не справляясь с обработкой дейтограмм, ЭВМ-адресат может послать запрос "отключить источник" отправителю, который может сократить темп посылки пакетов или вовсе прервать их посылку.
Специальной команды, отменяющей прежние запреты, не существует. Если сообщения об отключении прекращаются, источник может возобновить посылку пакетов или увеличить частоту их отправки. Ниже (на рис. 4.4.4.2) представлен формат эхо-запроса (ping) и отклика для протокола ICMP.
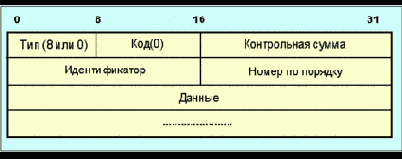
Рис. 4.4.4.2. Формат эхо-запроса и отклика ICMP

Поля идентификатор и номер по порядку служат для того, чтобы отправитель мог связать в пары запросы и отклики. Поле тип определяет, является ли этот пакет запросом (8) или откликом (0). Поле контрольная сумма представляет собой 16-разрядное дополнение по модулю 1 контрольной суммы всего ICMP-сообщения, начиная с поля тип. Поле данные служит для записи информации, возвращаемой отправителю. При выполнении процедуры ping эхо-запрос с временной меткой в поле данные посылается адресату. Если адресат активен, он принимает IP-пакет, меняет адрес отправителя и получателя местами и посылает его обратно. ЭВМ-отправитель, восприняв этот отклик, может сравнить временную метку, записанную им в пакет, с текущим показанием внутренних часов и определить время распространения пакета (RTT - round trip time). Размер поля данные не регламентирован и определяется предельным размером IP-пакета.
Время распространения ICMP-запроса, вообще говоря, не равно времени распространения отклика. Это связано не только с возможными изменениями в канале. В общем случае маршруты их движения могут быть различными.
Когда маршрутизатор не может доставить дейтограмму по месту назначения, он посылает отправителю сообщение "адресат не достижим" (destination unreachable). Формат такого сообщения показан ниже (на рис. 4.4.4.3).

Рис. 4.4.4.3. Формат ICMP-сообщения "адресат не достижим"
Поле код содержит целое число, проясняющее положение дел. Перечень кодов таких сообщений помещена в таблице 4.4.4.1. Поле MTU на следующем этапе характеризует максимальную длину пакетов на очередном шаге пересылки.
Так как в сообщении содержится Интернет-заголовок и первые 64-бита дейтограммы, легко понять, какой адрес оказался недостижим.
Этот тип ICMP-сообщения посылается и в случае, когда дейтограмма имеет флаг DF=1 ("не фрагментировать"), а фрагментация необходима. В поле код в этом случае будет записано число 4.
Если буфер приема сообщения переполнен, ЭВМ посылает сообщение типа 4 для каждого из не записанных в буфер сообщений.
Так как собственные часы различных ЭВМ имеют свое представление о времени, протокол ICMP, среди прочего, служит для синхронизации работы различных узлов, если это требуется (запросы временных меток). Протокол синхронизации NTP (network time protocol) описан в RFC-1119.
Когда дейтограммы поступают слишком часто и принимающая сторона не справляется с этим потоком, отправителю может быть послано сообщение с требованием резко сократить информационный поток (quench-запрос), снижение потока должно продолжаться до тех пор, пока не прекратятся quench-запросы. Такое сообщение имеет формат:

Рис. 4.4.4.4. Формат icmp-запроса снижения загрузки
В Internet таблицы маршрутизации остаются без изменений достаточно долгое время, но иногда таблицы все же меняются. Если маршрутизатор обнаружит, что ЭВМ использует неоптимальный маршрут, он может послать ей ICMP-запрос переадресации. Формат такого сообщения отображен на рисунке 4.4.4.5.

Рис. 4.4.4.5. Формат ICMP-запроса переадресации
Поле Internet-адрес маршрутизатора содержит адрес маршрутизатора, который ЭВМ должна использовать, чтобы посланная дейтограмма достигла места назначения, указанного в ее заголовке. В поле internet-заголовок кроме самого заголовка лежит 64 первых бита дейтограммы, вызвавшей это сообщение. Поле код специфицирует то, как нужно интерпретировать адрес места назначения (см. табл. 4.4.4.1).
Команды переадресации маршрутизатор посылает только ЭВМ и никогда другим маршрутизаторам. Рассмотрим конкретный пример. Пусть некоторая ЭВМ на основе своей маршрутной таблицы посылает пакет маршрутизатору M1. Он, просмотрев свою маршрутную таблицу, находит, что пакет следует переслать маршрутизатору M2. Причем выясняется, что пакет из M1 в M2 следует послать через тот же интерфейс, через который он попал в M1.
Это означает, что M2 доступен и непосредственно для ЭВМ-отправителя. В такой ситуации M1 посылает ICMP-запрос переадресации ЭВМ-отправителю указанного пакета с тем, чтобы она внесла соответствующие коррективы в свою маршрутную таблицу.
Маршрутная таблица может загружаться из файла, формироваться менеджером сети, но может создаваться и в результате запросов и объявлений, посылаемых маршрутизаторами. После загрузки системы маршрутизатор посылает широковещательный запрос. Один или более маршрутизаторов посылают в ответ сообщения об имеющейся маршрутной информации. Кроме того, маршрутизаторы периодически (раз в 450-600 сек.) широковещательно объявляют о своих маршрутах, что позволяет другим маршрутизаторам скорректировать свои маршрутные таблицы. В RFC-1256 описаны форматы ICMP-сообщений такого рода (см. рис. 4.4.4.6).

Рис. 4.4.4.6. Формат ICMP-сообщений об имеющихся маршрутах
Поле число адресов характеризует количество адресных записей в сообщении. Поле длина адреса содержит число 32-битных слов, необходимых для описания адреса маршрутизатора. Поле время жизни предназначено для записи продолжительности жизни объявленных маршрутов (адресов) в секундах. По умолчанию время жизни равно 30 мин. Поля уровень приоритета представляют собой меру приоритетности маршрута по отношению к другим маршрутам данной подсети. Чем больше этот код тем выше приоритет. Маршрут по умолчанию имеет уровень приоритета 0. Формат запроса маршрутной информации (8 октетов, рис. 4.4.4.7).

Рис. 4.4.4.7 Формат запроса маршрутной информации
Так как следующий прогон (hop) дейтограммы определяется на основании локальной маршрутной таблицы, ошибки в последней могут привести к зацикливанию пакетов. Для подавления таких циркуляций используется контроль по времени жизни пакета (TTL). При ликвидации пакета по истечении TTL маршрутизатор посылает отправителю сообщение "время истекло", которое имеет формат (рис. 4.4.4.8):

Рис. 4.4.4.8. Формат сообщения "время (ttl) истекло"
Значение поля код определяет природу тайм-аута (см.
табл. 4.4.4.1).
Когда маршрутизатор или ЭВМ выявили какую-либо ошибку, не из числа описанных выше (например, нелегальный заголовок дейтограммы), посылается сообщение "конфликт параметров". Это может произойти при неверных параметрах опций. При этом посылается сообщение вида (рис. 4.4.4.9):

Рис. 4.4.4.9. Формат сообщения типа "конфликт параметров"
Поле указатель отмечает октет дейтограммы, который создал проблему. Код=1 используется для сообщения о том, что отсутствует требуемая опция (например, опция безопасности при конфиденциальных обменах), поле указатель при значении поля код=1 не используется.
В процессе трассировки маршрутов возникает проблема синхронизации работы часов в различных ЭВМ. К счастью синхронизация внутренних часов ЭВМ требуется не так часто (например, при выполнении синхронных измерений), негативную роль здесь могут играть задержки в каналах связи. Для запроса временной метки другой ЭВМ используется сообщение запрос временной метки, которое вызывает отклик с форматом (рис. 4.4.4.10):

Рис. 4.4.4.10. Формат ICMP-запроса временной метки
Поле тип=13 указывает на то, что это запрос, а тип=14 - на то, что это отклик. Поле идентификатор и номер по порядку используются отправителем для связи запроса и отклика. Поле исходная временная метка заполняется отправителем непосредственно перед отправкой пакета. Поле временная метка на входе заполняется маршрутизатором при получении этого пакета, а Временная метка на выходе - непосредственно перед его отправкой. Именно этот формат используется в процедурах ping и traceroute. Эти процедуры позволяют не только диагностировать, но и оптимизировать маршруты. Например, команда traceroute cernvm.cern.ch, выданная в ЭВМ SUN (ИТЭФ), может отобразить на экране (в скобках указаны IP-адреса узлов и значения времени жизни дейтограмм, значения RTT приводится в миллисекундах):
| traceroute to crnvma.cern.ch | (128.141.2.4) 30 hops max, 40 byte packets | |
| 1 | itep-fddi-bbone | (193.124.224.50) 3 ms 2 ms 3 ms |
| 2 | msu-tower.moscow.ru.radio-msu.net | (193.124.137.13) 3 ms 3 ms 3 ms |
| 3 | npi-msu.moscow.ru.radio-msu.net | (193.124.137.9) 27 ms 3 ms 9 ms |
| 4 | desy.hamburg.de.radio-msu.net | (193.124.137.6) 556 ms 535 ms 535 ms |
| 5 | * 188.1.133.56 | (188.1.133.56) 637ms 670ms |
| 6 | duesseldorf2.empb.net | (193.172.4.12) 740ms(ttl=59!) 839ms(ttl=59!) 2066ms(ttl=59!) |
| 7 | bern3.empb.net | (193.172.4.30) 2135ms (ttl=58!) 1644ms (ttl=58!) 1409ms (ttl=58!) |
| 8 | cernh3.euro-hep.net | (193.172.24.10) 1808ms 1508ms 1830ms |
| 9 | cgate1.cern.ch | (192.65.185.1) 1116ms 1270ms 1278ms |
| 10 | crnvma.cern.ch | (128.141.2.4) 1132ms 1362ms 1524ms |
Отсюда видно, что наиболее узкими участками маршрута являются Гамбург-Дюссельдорф-Берн-CERN. Следует иметь в виду, что канал МГУ-Гамбург является спутниковым и 500мс задержки здесь вносит время распространения сигнала до спутника и обратно. Участок Гамбург-Дюссельдорф (X.25, квота 256кбит/с) является общим также и для потока данных из Германии в США. Передача IP поверх X.25 также снижает эффективную широкополосность канала. Остальные связи обладают недостаточной пропускной способностью. Программа ping показывает для данных участков в часы пик высокую долю потерянных пакетов. Таким образом, имея карту связей и используя указанные процедуры, вы можете успешно диагностировать ситуацию в сети. Продвинутые же программисты могут легко написать свои диагностические программы, базирующиеся на ICMP, как для локальной сети, так и для "окрестного" Интернет.
При работе с субсетью важно знать маску этой субсети. Как уже отмечалось выше, IP-адрес содержит секцию адреса ЭВМ и секцию адреса сети. Для получения маски субсети ЭВМ может послать "запрос маски" в маршрутизатор и получить отклик, содержащий эту маску. ЭВМ может это сделать непосредственно, если ей известен адрес маршрутизатора, либо прибегнув к широковещательному запросу. Ниже описан формат таких запросов-откликов (рис. 4.4.4.11).

Рис. 4.4.4.11. Формат запроса (отклика) маски субсети
Поле тип здесь специфицирует модификацию сообщения, тип=17 - это запрос, а тип=18 - отклик. Поля идентификатор и номер по порядку, как обычно, обеспечивают взаимную привязку запроса и отклика, а поле адресная маска содержит 32-разрядную маску сети.
Протокол PIM
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Протокол PIM (Protocol Independent Multicast) призван решить проблемы маршрутизации для произвольного числа и расположения членов группы и для произвольного числа отправителей информации. В настоящее время протокол не является стандартом.
Главным преимуществом данного протокола является эффективная поддержка работы "рассеянных" мультикастинг-групп. Такие группы могут включать не только членов из разных автономных систем, но и находящихся на разных континентах. Протоколы MOSPF и DVMRP хороши для сетей, где нет ограничений по пропускной способности каналов.
PIM базируется на традиционных маршрутных протоколах, конкретно не связан ни с каким из них, им используются сформированные этими протоколами маршрутные таблицы. Существует два режима работы протокола - DM (для компактных групп) и SM (Protocol Independent Multicast-Sparse Mode (PIM-SM)). Protocol Specification. D. Estrin, D. Farinacci, A. Helmy, D. Thaler, S. Deering, M. Handley, V. Jacobson, C. Liu, P. Sharma, L. Wei, RFC-2117, June 1997) (для рассеянных групп). В режиме DM протокол PIM строит дерево маршрутов аналогично DVMRP.
В режиме SM маршрутизаторы, имеющие членов мультикастинг-группы, посылают сообщения о присоединении к дереву рассылки в узлы, которые называются точками встречи (RP). Отправители используют RP для объявления о своем существовании, а получатели, чтобы узнать о новых отправителях. В качестве RP может использоваться любой маршрутизатор, поддерживающий протокол PIM.
Когда какой-то клиент хочет подключиться к некоторой группе, ближайший к нему маршрутизатор посылает специальное сообщение о включении в группу (PIM-joint) узлу, объявленному для данной группы точкой встречи (RP). Число RP в сети может быть произвольным. Узел RP пересылает сообщение о включении узлу-отправителю (или отправителям). Если маршрутизатор не имеет информации о RP, включается схема, работающая для компактных групп. При обработке сообщения о включении в группу промежуточные маршрутизаторы формируют часть дерева мультикастинг-маршрутов между RP и получателем.
При отправке мультикастинг- пакета соответствующий маршрутизатор посылает узлу RP регистрационное сообщение (PIM-register), куда вкладывается информационный пакет. Если используется несколько RP, отправитель должен посылать пакеты всем RP. Получатель же должен быть подключен лишь к одному из RP. В случае, когда сообщение о включении достигнет отправителя раньше, чем RP, подключение осуществляется, минуя RP. Если необходимо оптимизировать дерево доставки пакетов, маршрутизаторы-получатели должны послать сообщение о включении самому отправителю. После этого дерево соединений видоизменяется, некоторыми узлами, если требуется, посылается сообщение об отключении. Ниже приведен пример взаимодействия узлов при формировании дерева маршрутов в режиме SM-PIM (рис. 4.4.9.5.1).
Следует заметить, что большинство протоколов для маршрутизации мультимедийной информации формируют маршрут не от отправителя к получателю, а в обратном направлении. Это имеет под собой веские причины. Дерево рассылки должно быть построено так, чтобы поток отправителя как можно дольше и меньше разветвлялся. Желательно, чтобы разветвления происходили как можно ближе к получателю. Это соображение проиллюстрировано на рис. 4.4.9.5.2. На рисунке условно, в виде сетки маршрутизаторов (желтые кружочки) показан фрагмент сети Интернет. Зеленым прямоугольником отмечен передатчик, а голубыми кружочками приемники - члены группы. Маршруты от передатчика к приемникам можно проложить индивидуально (выделены зеленым цветом), а можно и "коллективно" (синий цвет). От передатчика до маршрутизатора отмеченного красным цветом следует один поток для всех приемников. Такое решение приводит к минимизации сетевой загрузки, ведь всем приемникам посылаются одни и те же пакеты. Чем позже их пути разойдутся, тем лучше. Именно этот алгоритм и реализует протокол PIM. Точки разветвления потоков на рис. 4.4.9.5.2 отмечены крестами (RP).

Рис. 4.4.9.5.1. Иллюстрация реализации протокола мультикастинг маршрутизации PIM
Получатель посылает PIM-joint пакет в RP, устанавливая канал от RP до получателя.
Из рисунка видно, что исходный маршрут d-c-b-a длиннее оптимального d-b-a. Последний может быть реализован после посылки PIM-joint команды от a к d.
При решении транспортных задач в мультимедиа чаще используется протокол UDP (малая избыточность и отсутствие подтверждений).

Рис. 4.4.9.5.2.
Ниже приводится более подробное, хотя и неполное описание протокола pim.
Используемые сокращения и термины
| Assert | Сообщения assert используются для принятия решения, какой из параллельных маршрутизаторов, подключенных к локальной сети с множественным доступом, должен быть ответственным за ретрансляцию пакетов в LAN. |
| bootstrap | Сообщения, посылаемые от узла к узлу в пределах домена. Все маршрутизаторы воспринимают эти сообщения для получения RP-информации. За рассылку сообщений в пределах домена bootstrap ответственен маршрутизатор BSR. |
| BSR | bootstrap router - маршрутизатор, ответственный за рассылку сообщений bootstrap |
| C-RP | candidate RP - кандидат в маршрутизаторы RP |
| DR | designated router - специально выделенный маршрутизатор для рассылки мультикастинг данных. |
| (*,g) | wild card мультикастная запись для группы g |
| Graft | Сообщение, используемое в режиме PIM для компактных групп. |
| Hello | Соседние маршрутизаторы шлют друг другу сообщения hello. Маршрутизатор с наибольшим IP-адресом выбирается в качестве dr. |
| IGMP | internet group management protocol - протокол управления группами |
| IIF | input interface - входной интерфейс |
| Join | Подключение к дереву маршрутов |
| MBR | Пограничный мультикастинг маршрутизатор |
| OIF | output interface - выходной интерфейс |
| PMBR | PIM multicast border router |
| Prune | Отключение от дерева маршрутов |
| Register | Когда источник отправляет данные группе в первый раз, его DR посылает уникастные сообщения register, в которые вкладывает информационные пакеты. |
| RP | rendezvous point - маршрутизатор разветвления маршрута для потока данных |
| (*,*,rp) | cпециальный тип маршрутных записей для поддержки совместной работы DVMRP и PIM. Запись (*,*,rp) представляет собой объединение всех групп, которые работают через данную RP. |
| RPF | reverse path forwarding - переадресация по пути возврата |
| RPT | RP-tree - дерево точек встречи |
| (s,g) | Маршрутная запись, характеризующее состояние системы группа-отправитель (source-group) |
| SPT | shortest pass tree - дерево кратчайших маршрутов |
| SP | shortest pass - кратчайший путь (обозначение фрагмента дерева маршрутов) |
| WC | wild card |
Целью протокола PIM является построение дерева маршрутов для рассылки мультикастных сообщений.
Маршрутизатор получает сообщения join/prune от соседних маршрутизаторов, которые обслуживают группы пользователей. Он переадресует информационные пакеты, адресованные группе G, только через те интерфейсы, через которые ранее было получено сообщение join.
Специальный маршрутизатор DR (designated router) рассылает периодически сообщения join/prune в точки встречи (RP) для каждой группы, в которой имеются активные участники. Для описания дерева маршрута используются маршрутные записи, содержащие адрес отправителя, групповой адрес, номер входного интерфейса, через который принимаются пакеты, список интерфейсов, через которые осуществляется рассылка, таймеры, флаги и пр. Выходные интерфейсы указывают на соседние маршрутизаторы, через которые пролегает путь к RP. В центре этого маршрутного дерева, включающего в себя всех членов группы, находится RP. Когда источник информации посылает что-то группе в первый раз, его DR отправляет уникастное сообщение register в RP.
Для того чтобы присоединиться к мультикатинг-группе G, ЭВМ передает IGMP-сообщение (или ICMP в случае IPv6). При этом предполагается, что ЭВМ будет выполнять функции получателя (R).
Когда DR получает уведомление о членстве новой группы от IGMP G, он просматривает соответствующие RP. DR формирует запись мультикастинг-маршрута для группы (*,g) [wild card мультикастная запись для группы G, определяющая ее состояние]. Адрес RP включается в специальное поле маршрутной записи, содержащейся в периодически рассылаемых сообщениях join/prune (см. рис. 4.4.9.5.9). При этом в список выходных интерфейсов включается тот, к которому подключен новый член группы, а в качестве входного интерфейса указывается тот, через который посылаются уникастные пакеты к RP.
Когда не остается ни одного непосредственно подключенного члена группы, протокол IGMP уведомляет об этом DR. Если DR не имеет ни локальных, ни удаленных получателей, запись (*,g) ликвидируется.
Запись (*,g), инициирует формирование DR сообщения join/prune с RP-адресом в его join-списке и установленными битами WC и RPT. Равенство WC=1 говорит о том, что согласно этой записи будут пересылаться пакеты любого отправителя. Список удаления (prune) остается пустым. Когда бит RPT=1, это указывает на то, что подключение осуществлено через общее RP-дерево и, следовательно, сообщение join/prune будет идти по этому RP-дереву. Когда бит WC= 1, это означает, что адрес принадлежит RP, а получатели предполагают получать пакеты от всех отправителей.
Каждый маршрутизатор, расположенный по пути к отправителю, создает и отслеживает изменения маршрутной записи для (*,g), когда он получает сообщения join/prune с RPT=WC=1. Интерфейс, через который получено сообщение join/prune, добавляется к списку выходных интерфейсов (OIF) для (*,g). На основе этой записи каждый маршрутизатор по пути между получателем и RP посылает сообщение join/prune, в котором RP включен в список join. Поле данных этого пакета содержит мультикаст-адрес=G, join=RP, wc-бит, RPT-бит, prune=null.
Когда ЭВМ начинает посылать мультикастинг-пакеты группе, сначала DR должен доставить их в RP для последующей раздачи по дереву RP. DR отправителя в начале инкапсулирует каждый информационный пакет в сообщение register (см. рис. 4.4.9.5.7) и отправляет его по уникастному адресу RP данной группы. RP извлекает каждое сообщение register и переадресует вложенные информационные пакеты вдоль RP-дерева.
Если поток данных позволяет использовать дерево кратчайшего пути до отправителя (SPT), RP может сформировать новую маршрутную запись для дерева мультикаст-маршрута, специфичного для данного отправителя (SP-дерево).
DR отправителя прекратит инкапсуляцию информация в пакеты registers, когда он получит сообщение register-stop от RP. RP отравляет сообщения register-stop в качестве отклика на сообщение registers, если RP не имеет более активных членов группы.
Новый приемник может подключиться к существующему RP-дереву, для которого установлено обрезание (prune state) (например, из-за того, что другие получатели переключились на SP-деревья).
В этом случае состояние обрезания аннулируется с тем, чтобы обеспечить доставку данных новому получателю.
В стабильном состоянии каждый маршрутизатор периодически посылает сообщения join/prune для каждой маршрутной записи PIM. Сообщения join/prune посылаются соседу, указанному в соответствующей записи. Такие сообщения позволяют отследить изменения состояния системы и топологию членства в группе.
Для того чтобы получить информацию о RP, все маршрутизаторы в пределах PIM-домена собирают сообщения bootstrap. Сообщения bootstrap пересылаются от узла к узлу в пределах домена. За организацию рассылки этих сообщений несет ответственность специальный маршрутизатор BSR (bootstrap router). Сообщения bootstrap используются для выполнения динамического выбора BSR, когда это необходимо, а также для получения информации об RP. Домен в этом контексте представляет собой набор смежных маршрутизаторов, поддерживающих PIM, и сконфигурированных для совместной работы в рамках границ, определенных пограничными маршрутизаторами PMBR (PIM multicast border router), соединяющими PIM-домен с остальным Интернет.
Маршрутизаторы используют набор доступных RP (называемый {RP-set}), для того чтобы осуществить связь отдельных групп с соответствующими RP. Некоторое число маршрутизаторов в домене конфигурируется как кандидаты для выполнения функций BSR. Для назначения BSR в домене существуют простые правила выбора. Часть маршрутизаторов в домене конфигурируются также как кандидаты для работы в качестве RP (C-RP); как правило, это те же маршрутизаторы, что и кандидаты в BSR. Кандидат в RP периодически посылает BSR домена уникастное сообщение candidate-rp-advertisement (C-RP-ADVS). C-RP-ADVS включает в себя адрес C-RP, а также опционный групповой адрес и поле длины маски. BSR включает набор этих кандидатов в RP (набор RP), вместе с соответствующим групповым префиксом периодически рассылаемых сообщений.
Маршрутизаторы получают и запоминают содержимое сообщений bootstrap. Когда DR получает указание о членстве в группе от IGMP, DR использует хэш-функцию для установления соответствия между групповым адресом и одним из C-RP, чей префикс включает в себя данную группу.
Для конкретной группы G, хэш-функция использует только те C-RP, чьи групповые префиксы покрывают G. Когда соответствие установлено, DR посылает сообщение join/prune (или уникастный пакет register) соответствующему rp.
Сообщения bootstrap информирует о работоспособности точек встречи (rp), обслуживающих сессию. Если RP включен в сообщение, он считается рабочим, в то время как отсутствие rp в сообщении, приводит к удалению его из списка, с которым работает алгоритм. Каждый маршрутизатор продолжает использовать содержимое, полученное в последнем сообщении bootstrap, пока не будет получено новое сообщение bootstrap.
Если зона PIM-домена теряют доступ к старому BSR, они выберут новый BSR, который разошлет RP-набор, содержащий RP, доступные в пределах данной зоны. Любая область в любой заданный момент времени обслуживается только одним BSR, который и осуществляет посылку сообщений bootstrap.
Для того чтобы обеспечить совместимость с сетями, работающими в режиме DM, с протоколами типа DVMRP, все пакеты, генерируемые в области PIM-SM, должны быть переправлены мультикастным пограничным маршрутизаторам области PMBR (multicast border router) и переадресованы в сеть DVMRP. Маршрутизатор PMBR размещается на границе домена PIM-SM и взаимодействует с другими типами мультикаст-маршрутизаторов, например, такими, которые поддерживают протокол DVMRP. Таким образом, PMBR должен поддерживать оба протокола. Для поддержки совместной работы все маршрутизаторы должны поддерживать специальный тип маршрутных записей, обозначаемых (*,*,rp).
Информационные пакеты, соответствуют записи (*,*,rp), если нет никаких других записи, например, (s,g) или (*,g), групповой адрес места назначения пакета согласуется с RP, указанным в записи (*,*,rp). В этом смысле запись (*,*,rp) представляет собой объединение всех групп, которые работают через данную точку встречи RP. PMBR инициализируют состояние (*,*,rp) для каждой RP в каждом доменном наборе RP. Состояние (*,*,rp) заставляет pmbr посылать сообщения (*,*,rp) join/prune каждой активной RP в домене.
В результате деревья рассылки строятся так, что передают все пакеты, возникающие в пределах PIM-домена (и ретранслируются в точки встречи) в направлении пограничных маршрутизаторов PMBR.
PMBR осуществляют также доставку внешних пакетов маршрутизаторам в пределах PIM-домена. Для решения этой задачи эти маршрутизаторы инкапсулируют внешние пакеты, полученные через интерфейсы DVMRP, в сообщения register, после чего уникастным образом переадресуют их в точку встречи RP PIM-домена. Сообщение register имеет бит, указывающий на то, что пакет сформирован пограничным маршрутизатором.
Информационные пакеты обрабатываются также как и при других мультикаст-схемах. Маршрутизатор сначала проверяет адреса отправителя и группы. Затем определяется адрес RP, если непосредственная передача невозможна. Если пути доставки не существует, пакет выбрасывается. При наличии пути выясняется интерфейс, через который должна производиться передача, и пакет переадресуется.
Информационные пакеты никогда не вызывают обрезания ветвей маршрутного дерева. Однако информационные пакеты могут запустить процессы, которые в конечном итоге приведут к такому результату.
Когда имеется несколько маршрутизаторов, соединенных с сетью, имеющей много каналов доступа, один из них должен быть выбран в качестве ретранслятора (DR; обычно это маршрутизатор с наибольшим IP-адресом). Это справедливо для любой точки сети в любое время. Процедуре выбора предшествует обмен сообщениями Hello.
При наличии параллельных проходов к источнику или RP для выбора маршрута применяются сообщения assert. Используя сообщения assert, адресованные `224.0.0.13' (группа all-pim-routers) в локальной сети, вышестоящий маршрутизатор может узнать, где осуществляется переадресация сообщений. Нижестоящие маршрутизаторы, получая сообщения assert, узнают, какой маршрутизатор выбран в качестве ретранслятора, и куда следует посылать сообщение join. Обычно это тот же нижележащий маршрутизатор-сосед (reverse path forwarding), но иногда это может быть и не так, например, когда в локальной сети используется несколько протоколов маршрутизации.
RPF- сосед для конкретного отправителя или RP является следующим маршрутизатором, которому переправляются пакеты по пути к отправителю или RP. По этой причине он может рассматриваться как хорошая промежуточная инстанция для пересылки пакетов отправителем.
Когда приходит пакет в выходной интерфейс, маршрутизатор посылает сообщение assert в локальную сеть с множественным доступом, указывая, какую метрику он использует для достижения отправителя информационных пакетов. Маршрутизатор с наименьшим значением метрики и станет базовым ретранслятором. Все прочие вышестоящие маршрутизаторы вычеркнут этот интерфейс из своего списка выходных интерфейсов. Нижестоящие маршрутизаторы также производят сравнение, если ретранслятором не является RPF-сосед.
С понятием метрики связано и значение предпочтения метрики. Оно введено, чтобы решать проблемы в случае, когда вышестоящие маршрутизаторы использует другие уникастные протоколы маршрутизации. Численно меньшее значение предпочтения соответствует более высокому приоритету. Значение предпочтения рассматривается в качестве старшей части метрики при сравнении, которое осуществляется при обработке сообщений assert. Предпочтение может быть присвоено уникастному протоколу маршрутизации и должно быть взаимосогласованным для всех маршрутизаторов локальной сети с множественным доступом.
Сообщения assert нужны для маршрутных записей (*,g), так как деревья RP и SP для некоторых групп могут возникать зоны перекрытия в сетях с множественным доступом. Когда assert посылается для записи (*,g), RPT-бит устанавливается равным 1. Первый бит поля предпочтения всегда устанавливается равным 1, для того чтобы отметить, что проход соответствует RP-дереву. RPT-бит всегда обнуляется для предпочтения, которое относится к записям SP-деревьев. Это приводит к тому, что проход через SP-дерево выглядит всегда редпочтительнее, чем проход через RP-дерево. Когда деревья SP и RP перекрываются для какой-то LAN, этот механизм устраняет дублирование для данной сети.
DR может уступить процесс (*,g) assert другому маршрутизатору LAN, если существует несколько проходов к rp через lan.
В этом случае DR не является более "ближайшим" маршрутизатором для местных получателей и он удаляет LAN из своего (*,g) списка выходных интерфейсов. Маршрутизатор-победитель становится "ближайшим" и ответственным за рассылку сообщений (*,g) join для RP.
Подавление join/prune может использоваться в локальных сетях с множественным доступом, для того чтобы сократить число дублирующих управляющих сообщений. Для нормальной работы протокола этого не требуется. Если получено сообщение join/prune, которое соответствует существующим маршрутным записям (s,g), (*,g) или (*,*,rp) для данного входного интерфейса, а поле holdtime сообщения join/prune больше, чем join/prune-holdtime получателя, может быть запущен таймер (join/prune-suppression-таймер) маршрутной записи получателя с тем, чтобы заблокировать последующие сообщения join/prune. После завершения работы таймера получатель отправляет сообщение join/prune, и возобновляет периодическую посылку join/prune, для данной записи. Таймер join/prune-suppression должен перезапускаться каждый раз, когда приходит сообщение join/prune с большим значением holdtime.
Когда уникастная маршрутизация претерпевает изменения, RPF производит проверку активных маршрутных записей (s,g), (*,g) и (*,*,rp) и вносит необходимые поправки. В частности, если в списке выходных интерфейсов появляется новый принимающий интерфейс, то он удаляется из этого списка. Предшествующий входной интерфейс может быть добавлен в список выходных интерфейсов с помощью последующих сообщений join/prune, поступающих от нижестоящих узлов. Сообщения join/prune, полученные текущим входным интерфейсом, игнорируются, а сообщения, полученные новыми или существующими выходными интерфейсами, обрабатываются. Остальные выходные интерфейсы останутся в прежнем состоянии до тех пор, пока не будут отключены нижележащими маршрутизаторами или по таймауту из-за отсутствия соответствующих сообщений join/prune. Если маршрутизатор имеет запись (s,g) с установленным битом spt, а обновленная запись IIF(s,g) не отличается от IIF(*,g) или IIF(*,*,rp), тогда маршрутизатор переводит бит SPT в нулевое состояние.
Соседи-маршрутизаторы, поддерживающие протокол pim, периодически обмениваются сообщениями Hello (см. рис. 4.4.9.5.6). Сообщения Hello могут также рассылаться мультикастным образом с использованием адреса 224.0.0.13 (группа all-pim-routers). Пакет содержит значение holdtime (время сохранения информации).
Когда маршрутизатор получает сообщение hello, он запоминает IP-адрес соседа, устанавливает таймер отправки на время, соответствующее holdtime, заключенное в Hello, и определяет выделенный маршрутизатор (DR) для данного интерфейса. В качестве DR выбирается объект с наибольшим Ip.
Когда маршрутизатор, который является активным DR, получает Hello от нового соседа (например, от IP-адреса, которого нет в таблице DR), DR уникастным образом передает RP-информацию новому соседу.
PIM-соседи, от которых в течение определенного времени не поступало сообщений Hello, считаются отключившимися. Если DR отключился, выбирается новый DR из числа соседей с наибольшим IP-адресом.
Сообщения join/prune служат, для того чтобы подключить или удалить ветвь мультикастинг-дерева рассылки. Сообщение содержит как join-, так и prune-списки, любой из них может иметь нулевую длину. Эти сообщения содержат все подключенные и отсоединенные источники данных, достижимые через данный узел адресат сообщения. Период отправки сообщений join/prune определяется значением [join/prune-period].
Маршрутизатор периодически посылает сообщения join/prune каждому конкретному RPF-соседу, соответствующему каждой маршрутной записи (s,g), (*,g) и (*,*,rp). Сообщения join/prune посылаются только тогда, когда RPF-сосед является PIM-соседом.
Кроме периодически рассылаемых сообщений некоторые из join/prune пакетов могут генерироваться как следствие следующих событий:
создана новая маршрутная запись или
список выходных интерфейсов изменился из нулевого в ненулевое состояние или наоборот.
Может так случиться, что размер сообщения join/prune превысит MTU сети. В этом случае сообщение может быть фрагментировано, информация, относящаяся к различным группам, будет послана в разных пакетах.
Однако, если сообщение join/ prune должно быть фрагментировано, полный prune-список, соответствующий группе G, должен быть включен в одно сообщение join/prune согласно RP-дереву join для G. Если такая семантическая фрагментация невозможна, при транспортировке пакетов от соседа к соседу должна использоваться IP-фрагментация.
Для любой новой записи (s,g), (*,g) или (*,*,rp), сформированной входящим сообщение join/prune, бит SPT сбрасывается.
Если запись имеет таймер join/prune-suppression, полученное сообщение join/prune не указывает на маршрутизатор в качестве места назначения, тогда принимающий маршрутизатор рассматривает join- и prune-списки, с тем чтобы выяснить, нет ли там адресов полностью соответствующих существующим состояниям (s,g), (*,g) или (*,*,rp), для которых принимающий маршрутизатор осуществляет рассылку сообщений join/prune. Элемент join- или prune-списка полностью соответствует маршрутной записи, только тогда, когда их IP-адреса и RPT-флаги тождественны. Если приходящее сообщение join/prune полностью соответствует существующим записям (s,g), (*,g) или (*,*,rp), а сообщение join/prune приходит на входной интерфейс для данной записи, маршрутизатор сравнивает holdtime сообщения со своим собственным значением join/prune-holdtime. Если его значение join/prune-holdtime меньше, запускается таймер join/prune-suppression. Если join/prune-holdtime равно holdtime сообщения, коллизия разрешается в пользу отправителя сообщения join/prune, который имеет больший ip-адрес. Когда время join/prune таймера истекает, маршрутизатор отправляет сообщение join/prune для соответствующей маршрутной записи.
Когда отправитель начинает отправку данных группе, его пакеты инкапсулируются в сообщения register и посылаются в RP. Если скорость передачи гарантируется каналом, RP устанавливает соответствующее состояние для отправителя и начинает посылать сообщения (s,g) join/prune отправителю с S в join-списке.
Когда DR получает сообщение register-stop, он перезапускает таймер register-suppression в соответствующей записи (s,g) на register-suppression-timeout секунд.
Если имеются данные, которые должны быть зарегистрированы, DR может послать RP сообщение register нулевой длины, за probe-time секунд до истечения времени таймера register- suppression.
Сообщения assert используются для принятия решения, какой из параллельных маршрутизаторов, подключенных к локальной сети с множественным доступом, должен быть ответственным за ретрансляцию пакетов в LAN.
Все управляющие сообщения PIM имеют номер протокола 103. Сообщения PIM являются либо уникастными (например, registers и register-stop), либо мультикастными для группы `all-pim-routers' `224.0.0.13' (например, join/prune, asserts, и т.д.). Формат заголовка пакета протокола PIM показан на рис. 4.4.9.5.3.

Рис. 4.4.9.5.3. Формат заголовка сообщения PIM
Поле OIM VER - версия протокола (в настоящее время = 2). Поле тип характеризует PIM-сообщение. Возможные значения поля тип представлены в таблице 4.4.9.5.1.
Таблица 4.4.9.5.1. Коды типа сообщений
| Код поля тип | Тип сообщения pim |
| 0 | hello |
| 1 | register |
| 2 | register-stop |
| 3 | join/prune |
| 4 | bootstrap |
| 5 | assert |
| 6 | graft (используется только в pim-dm) |
| 7 | graft-ack (используется только в pim-dm) |
| 8 | candidate-rp-advertisement |
Поле длина адреса характеризует длину кода адреса в байтах. Поле контрольная сумма вычисляется методом суммирования всего pim-сообщения по модулю 1, это поле имеет длину 16 бит. Формат закодированного группового адреса показан на рис. 4.4.9.5.4.

Рис. 4.4.9.5.4. Формат закодированного группового адреса
Поле длина маски имеет 8 бит. Значение поля определяет число последовательных бит, выровненных по левому краю, которые определяют адрес. Маска равна или меньше длины адреса * 8 (то есть 32 бита для IPv4 и 128 для IPv6). Поле групповой мультикаст адрес содержит адрес группы и имеет число байт, равное указанному в поле длина адреса. Формат кодированного адреса отправителя показан на рис. 4.4.9.5.5.

Рис. 4.4.9.5.5. Формат кодированного адреса отправителя
Поле бит s (бит рассеянности) содержит 1 для PIM-SM. Этот бит используется для обеспечения совместимости с PIM v.1.
Поле бит W (бит WC). Бит WC =1, если подключение (join) или удаление (prune) используются для маршрутной записи (*,g) или (*,*,rp). Если wc=0, join или prune используются для маршрутной записи (s,g), где s - адрес отправителя. Сообщения join и prune, посылаемые в RP, должны иметь этот бит равным 1.
Поле бит R (бит RPT). Бит RPT=1, если информация о (s,g) послана в RP. Если RPT=0, информация должна быть послана S, где S - адрес отправителя.
Поле длина маски имеет длину 8 бит. Значение этого поля охарактеризовано выше в комментарии к рисунку 4.4.9.5.4.
Поле адрес отправителя имеет длину, определяемую полем заголовка длина адреса. Для IPv4, она равна 4 октетам. Формат сообщения Hello показан на рис. 4.4.9.5.6.
Первые два байта представляют собой заголовок PIM-сообщения. Поле optiontype определяет тип опции, значение которой задано в поле optionvalue. Поле optionlength задает длину поля optionvalue в байтах. Поле optionvalue имеет переменную длину и содержит значение опции. Поле опция может содержать следующие значения:

Рис. 4.4.9.5.6. Формат сообщения Hello
optiontype = 1; optionlength = 2; optionvalue = holdtime; где holdtime равно времени в секундах, в течение которого получатель должен сохранять доступность к соседу. Если holdtime установлено равным `0xFFFF', получатель этого сообщения никогда не прервет соединение с соседом по таймауту. Это может использоваться для каналов ISDN, для того чтобы избежать поддержания канала путем периодической посылки сообщений Hello. Более того, если holdtime= 0, информация объявляется устаревшей немедленно. Диапазон значений optiontype 2 - 16 зарезервирован на будущее. Сообщение register посылается DR или PMBR в RP, когда необходимо передать мультикаст-пакет по rp-дереву. IP-адрес отправителя при этом равен адресу DR, а адрес места назначения - адресу RP. Формат сообщения register показан на рис. 4.4.9.5.7. Постоянная часть заголовка здесь идентична, показанной на рис. 4.4.9.5.3.

Рис. 4.4.9.5.7. Формат сообщения register
Поле B - (бит border) пограничный бит. B=1, если маршрутизатор непосредственно соединен с отправителем. Поле N - бит нулевого регистра. n устанавливается DR равным 1 при тестировании RP до истечения времени регистрации (register-suppression timer). Поле информационный мультикаст-пакет представляет собой оригинальное сообщение, посланное отправителем.
Сообщение register-stop является уникастным, направляемым от RP к отправителю сообщения register. IP-адрес отправителя является адресом, к которому направлялось сообщение регистрации. IP-адрес места назначения равен адресу отправителя сообщения register. Формат сообщения register-stop показан на рис. 4.4.9.5.8.

Рис. 4.4.9.5.8. Формат сообщения register-stop
Поле закодированный групповой адрес имеет тот же смысл, что и на рис. 4.4.9.5.4. Для сообщений register-stop поле длины маски содержит длину адреса * 8 (32 для IPv4), если сообщение послано для одной группы.
Поле уникастный адрес отправителя представляет собой IP-адрес ЭВМ отправителя из мультикастного информационного пакета. Длина этого поля в байтах задано полем длина адреса. Значение (0.0.0.0) может быть использовано для обозначения любого адреса.
Сообщение join/prune посылается маршрутизаторами в направлении вышестоящих отправителей и RP. Сообщения join служит для построения совместно используемых маршрутных деревьев (RP-деревьев) или деревьев отправителей (SPT). Сообщения prune посылаются для отключения деревьев отправителей, когда участники покидают группу, а также для отправителей, которые не используют общее дерево. Формат сообщения join/prune показан на рис. 4.4.9.5.9.

Рис. 4.4.9.5.9. Формат сообщения join/prune
Поле адрес вышестоящего соседа представляет собой IP-адрес RPF или вышестоящего соседа. Поле holdtime характеризует время в секундах, в течение которого получатель должен поддерживать активное состояние join/prune. Если holdtime сделано равным `0xffff', получатель сообщения отключает таймаут для данного выходного интерфейса. Если holdtime сделано равным `0', таймаут происходит немедленно.
Поле число групп равно количеству мультикаст-групп, содержащихся в сообщении.
Поле закодированный мультикастный групповой адрес имеет формат, показанный на рис. 4.4.9.5.4. Произвольная группа (wildcard) (*,*,rp) характеризуется адресом 224.0.0.0 и `4' в поле длина маски. Подключение (*,*,rp) имеет биты WC и RPT равные 1.
Поле число подключенных отправителей равно количеству адресов подключенных отправителей для данной группы. Поля адрес подключенного отправителя -1 .. N представляют собой список отправителей, которым посылающий маршрутизатор переправляет мультикастные дейтограммы при получении их через интерфейс, на который пришло данное сообщение. Формат полей кодированного адреса отправителя следует описанию на рис. 4.4.9.5.5.

Рис. 4.4.9.5.10. Формат сообщения bootstrap
Сообщения bootstrap пересылаются мультикастным способом группе `all-pim-routers', через все интерфейсы, имеющие PIM-соседей (за исключением того, через который получено сообщение). Сообщения bootstrap генерируются в BSR и посылаются с TTL=1. Формат сообщения bootstrap показан на рис. 4.4.9.5.10.
Сообщение bootstrap делится на семантические фрагменты, если исходное сообщение превосходит предельный размер пакета. Формат этих фрагментов представлен ниже (см. также рис. 4.4.9.5.10):
Поле метка фрагмента является случайным числом и служит для идентификации фрагментов принадлежащих одному и тому же сообщению. Фрагменты одного и того же сообщения имеют идентичные метки фрагмента. Поле длина хэш-маски - это длина маски хэш функции в битах. Для IPv4 рекомендуется значение 30, а для IPv6 - 126. Поле BSR-приоритет содержит значение BSR-приоритета для включенного BSR. Это поле рассматривается как старший байт при сравнении BSR-адресов. Поле уникастный BSR-адрес является IP-адресом маршрутизатора (bootstrap) домена. Размер этого поля в байтах специфицирован в поле длина адреса. Поля закодированный групповой адрес -1..n является групповым префиксом (адрес и маска), с которым ассоциируются кандидаты RP.
Поля число RP -1..N равны числу адресов кандидатов RP, включенных в сообщение bootstrap для соответствующего группового префикса. Маршрутизатор не замещает старый RP-набор для данного группового префикса до тех пор, пока не получит новое число RP-адресов для этого префикса. Адреса могут содержаться в нескольких фрагментах. Если получена только часть RP-набора для данного префикса, маршрутизатор эту часть выбрасывает, не изменяя RP-набора. Поля FRAG RP-cnt-1..m представляет собой число адресов кандидатов RP, включенных в этот фрагмент сообщения bootstrap, для соответствующего группового префикса. Поле `FRAG RP-cnt' облегчает разбор RP-набора для данного группового префикса, когда он размещается в более чем одном фрагменте. Поля уникастные rp-адреса -1..m представляют собой адреса кандидатов RP, для соответствующего группового префикса. Длина поля в байтах специфицировано полем длина адреса. Поля rp1..m-holdtime характеризуют значения holdtime для соответствующих RP. Это поле копируется из поля `holdtime' RP, записанного в BSR.
Сообщение assert посылается когда мультикастный информационный пакет получен выходным интерфейсом, соответствующим (s,g) или (*,g), относящимся к отправителю. Формат такого сообщения представлен на рис. 4.4.9.5.11.

Рис. 4.4.9.5.11. Формат сообщения assert
Поле закодированный групповой адрес характеризует групповой адрес места назначения пакетов, который явился причиной посылки сообщения assert. Поле уникастный адрес отправителя содержит IP-адрес отправителя из дейтограммы, вызвавшей посылку мультикастного пакета Assert. Длина поля в байтах определена полем длины адреса. Поле R представляет собой RPT-бит. Если IP мультикастинг дейтограмма, вызвавшая посылку пакета assert направляется вниз по RP-дереву, тогда RPT-бит равен 1. Если маршрутизация осуществляется вдоль SPT, бит равен 0. Поле предпочтение несет в себе значения кода предпочтения, присвоенного уникастному протоколу маршрутизации, который организует проход до ЭВМ. Поле метрика содержит значение метрики для таблицы маршрутизации.
Единицы измерения должны соответствовать требованиям маршрутного протокола.
Сообщения кандидата RP посылаются периодически C-RP способом и уникастно адресуются к BSR. Формат таких сообщений показан на рис. 4.4.9.5.12.

Рис. 4.4.9.5.12. Формат сообщения кандидата RP (C-RP)
Поле # префиксов (Prefix-Cnt) содержит количество кодированных групповых адресов, включенных в сообщение, указывая групповые префиксы, для которых производится C-RP оповещение. Значение поля Prefix-Cnt = `0' предполагает использование префикса 224.0.0.0 с длиной маски 4, что означает - все мультикастные группы. Если C-RP не снабжена информацией о групповом префиксе, C-RP заносит в поле значение по умолчанию равное `0'. Поле A характеризует бит указания. Этот бит указывает, что BSR не должен переписывать информацию о групповых префиксах, приведенную в C-RP оповещении. В большинстве случаев C-RP устанавливает этот бит, равным 0. Поле Holdtime содержит значение времени, в течение которого оповещение корректно. Это поле позволяет определить время, когда оповещение устареет. Поле уникастный RP-адрес представляет собой адрес интерфейса, который объявляется кандидатом в RP. Длина этого поля в байтах определена полем длина адреса. Поле закодированный групповой адрес -1..n является групповым префиксом, для которого производится уведомление кандидатом в RP.
Литература
| 1 | Deering, S., D.Estrin, D.Farinacci, V.Jacobson, C.Liu, L.Wei, P.Sharma, and A.Helmy. Protocol independent multicast (pim) : Motivation and architecture. Work in Progress. |
| 2 | Deering, S., D.Estrin, D.Farinacci, V.Jacobson, C.Liu, and L.Wei. The PIM architecture for wide-area multicast routing. ACM Transactions on Networks, April 1996. |
| 3 | Estrin, D., D.Farinacci, V.Jacobson, C.Liu, L.Wei, P.Sharma, and A.Helmy. Protocol independent multicast-dense mode (pim-dm): Protocol specification. Work in Progress. |
| 4 | Deering, S. Host extensions for ip multicasting, Aug 1989. RFC1112. |
| 5 | Fenner, W. Internet group management protocol, version 2. Work in Progress. |
| 6 | Atkinson, R. Security architecture for the internet protocol, August 1995. RFC-1825. |
| 7 | Ballardie, A.J., P.F. Francis, and J.Crowcroft. Core based trees. In Proceedings of the ACM SIGCOMM, San Francisco, 1993. |
Протокол преобразования адресов ARP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Любое устройство, подключенное к локальной сети (Ethernet, FDDI и т.д.), имеет уникальный физический сетевой адрес, заданный аппаратным образом. 6-байтовый Ethernet-адрес выбирает изготовитель сетевого интерфейсного оборудования из выделенного для него по лицензии адресного пространства. Если у машины меняется сетевой адаптер, то меняется и ее Ethernet-адрес.
4-байтовый IP-адрес задает менеджер сети с учетом положения машины в сети Интернет. Если машина перемещается в другую часть сети Интернет, то ее IP-адрес должен быть изменен. Преобразование IP-адресов в сетевые выполняется с помощью arp-таблицы. Каждая машина сети имеет отдельную ARP-таблицу для каждого своего сетевого адаптера. Не трудно видеть, что существует проблема отображения физического адреса (6 байт для Ethernet) в пространство сетевых IP-адресов (4 байта) и наоборот.
Протокол ARP (address resolution protocol, RFC-826) решает именно эту проблему - преобразует ARP- в Ethernet-адреса.
Рассмотрим процедуру преобразования адресов при отправлении сообщения. Пусть прикладная программа одной ЭВМ отправляет сообщение другой. Прикладной программе IP-адрес места назначения обычно известен. Для определения Ethernet-адреса просматривается ARP-таблица. Если для требуемого IP-адреса в ней присутствует Ethernet-адрес, то формируется и посылается соответствующий пакет. Если же с помощью ARP-таблицы не удается преобразовать адрес, то выполняется следующее:
1. Всем машинам в сети посылается пакет с ARP-запросом (с широковещательным Ethernet-адресом места назначения).
2. Исходящий IP-пакет ставится в очередь.
Каждая машина, принявшая ARP-запрос, в своем ARP-модуле сравнивает собственный IP-адрес с IP-адресом в запросе. Если IP-адрес совпал, то прямо по Ethernet-адресу отправителя запроса посылается ответ, содержащий как IP-адрес ответившей машины, так и ее Ethernet-адрес. После получения ответа на свой ARP-запрос машина имеет требуемую информацию о соответствии IP и Ethernet-адресов, формирует соответствующий элемент ARP-таблицы и отправляет IP-пакет, ранее поставленный в очередь.
Если же в сети нет машины с искомым IP-адресом, то ARP-ответа не будет и не будет записи в ARP-таблицу. Протокол IP будет уничтожать IP-пакеты, предназначенные для отправки по этому адресу. Протоколы верхнего уровня не могут отличить случай повреждения в среде ethernet от случая отсутствия машины с искомым IP-адресом. Во многих реализациях в случае, если IP-адрес не принадлежит локальной сети, внешний порт сети (gateway) или маршрутизатор откликается, выдавая свой физический адрес (режим прокси-ARP). Функционально, ARP делится на две части. Одна - определяет физический адрес при посылке пакета, другая отвечает на запросы других машин. ARP-таблицы имеют динамический характер, каждая запись в ней "живет" определенное время после чего удаляется. Менеджер сети может осуществить запись в ARP-таблицу, которая там будет храниться "вечно". ARP-пакеты вкладываются непосредственно в ethernet-кадры. Формат arp-пакета показан на рис. 4.4.6.1.

Рис. 4.4.6.1. Формат пакета ARP HA-Len - длина аппаратного адреса; PA-Len – длина протокольного адреса (длина в байтах, например, для IP-адреса PA-Len=4). Тип оборудования - это тип интерфейса, для которого отправитель ищет адрес; код содержит 1 для Ethernet. Ниже представлена таблица 4.4.6.1 кодов оборудования. Таблица 4.4.6.1. Коды оборудования
| Код типа оборудования | Описание |
| 1 | Ethernet (10 Мбит/с) |
| 2 | Экспериментальный Ethernet (3 Мбит/с) |
| 3 | Радиолюбительская связь через X.25 |
| 4 | Proteon ProNET маркерная кольцевая сеть (Token Ring) |
| 5 | Chaos |
| 6 | Сети IEEE 802 |
| 7 | ARCNET |
Таблица 4.4.6.2. Коды протоколов (для IP это 0800H).
| Код типа протокола | Описание | |
| Десятичное значение | Hex | |
| 512 | 0200 | XEROX PUP |
| 513 | 0201 | PUP трансляция адреса |
| 1536 | 0600 | XEROX NS IDP |
| 2048 | 0800 | DOD Internet протокол (IP) |
| 2049 | 0801 | X.75 Internet |
| 2050 | 0802 | NBS Internet |
| 2051 | 0803 | ECMA Internet |
| 2052 | 0804 | Chaosnet |
| 2053 | 0805 | X.25 уровень 3 |
| 2054 | 0806 | Протокол трансляции адреса (ARP) |
| 2055 | 0807 | XNS совместимость |
| 2560 | 0A00 | Xerox IEEE-802.3 PUP |
| 4096 | 1000 | Bercley Trailer |
| 21000 | 5208 | BBN Simnet |
| 24577 | 6001 | DEC MOP Dump/Load |
| 24578 | 6002 | DEC MOP удаленный терминал |
| 24579 | 6003 | DEC DECnet фаза IV |
| 24580 | 6004 | DEC LAT |
| 24582 | 6005 | DEC |
| 24583 | 6006 | DEC |
| 32773 | 8005 | HP Probe |
| 32784 | 8010 | Excelan |
| 32821 | 8035 | Реверсивный протокол ARP (RARP) |
| 32824 | 8038 | DEC LANbridge |
| 32923 | 8098 | Appletalk |
| 33100 | 814C | SNMP |
Поле код операции определяет, является ли данный пакет ARP-запросом (код = 1), ARP-откликом (2), RARP-запросом (3), или RARP-откликом (4). Это поле необходимо, как поле тип кадра в Ethernet пакетах, они идентичны для ARP-запроса и отклика. ARP-таблицы строятся согласно документу RFC-1213 и для каждого IP-адреса содержит четыре кода:
| ifindex | Физический порт (интерфейс), соответствующий данному адресу; |
| Физический адрес | MAC-адрес, например Ethernet-адрес; |
| IP-адрес | IP-адрес, соответствующий физическому адресу; |
| тип адресного соответствия | это поле может принимать 4 значения: 1 - вариант не стандартный и не подходит ни к одному из описанных ниже типов; 2 - данная запись уже не соответствует действительности; 3 - постоянная привязка; 4 - динамическая привязка; |
В SUN и некоторых других ЭВМ имеется программа arp, которая позволяет отобразить ARP-таблицу на экране. С флагом -a команда отображает всю таблицу, флаг –d позволяет стереть запись, а -s - служит для внесения записей в таблицу (последние два флага доступны для операторов с системными привилегиями). Команда ARP без флагов с адресом или именем ЭВМ выдаст соответствующую строку таблицы: arp 192.148.166.129
Name: semenov.itep.ru
Address: 192.148.166.129 (IP-адрес моей персональной ЭВМ)
Aliases: yas
А команда
arp nb
выдаст запись
nb (193.124.224.60) at 0:80:ad:2:24:b7 (запись для NetBlazer ИТЭФ) ARP запросы могут решать и другие задачи. Так при загрузке сетевого обеспечения ЭВМ такой запрос может выяснить, а не присвоен ли идентичный IP-адрес какому-то еще объекту в сети. При смене физического интерфейса такой запрос может инициировать смену записи в ARP-таблице.
В рамках протокола ARP возможны самообращенные запросы (gratuitous ARP). При таком запросе инициатор формирует пакет, где в качестве IP используется его собственный адрес. Это бывает нужно, когда осуществляется стартовая конфигурация сетевого интерфейса. В таком запросе IP-адреса отправителя и получателя совпадают.
Самообращенный запрос позволяет ЭВМ решить две проблемы.Во-первых, определить, нет ли в сети объекта, имеющего тот же IР-адрес. Если на такой запрос придет отклик, то ЭВМ выдаст на консоль сообщение Dublicate IP address sent from Ethernet address <...>. Во-вторых, в случае смены сетевой карты производится корректировка записи в АRP-таблицах ЭВМ, которые содержали старый МАС-адрес инициатора. Машина, получающая ARP-запрос c адресом, который содержится в ее таблице, должна обновить эту запись.
Вторая особенность такого запроса позволяет резервному файловому серверу заменить основной, послав самообращенный запрос со своим МАС-адресом, но с IP вышедшего из строя сервера. Этот запрос вынудит перенаправление кадров, адресованных основному серверу на резервный. Клиенты сервера при этом могут и не знать о выходе основного сервера из строя. При этом возможны и неудачи, если программные реализании в ЭВМ не в полной мере следуют регламентациям протокола ARP.
Протокол реального времени RTP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
В Интернет, также как и в некоторых других сетях, возможна потеря пакетов изменение их порядка в процессе транспортировки, а также вариация времени доставки в достаточно широких пределах. Мультимедийные приложения накладывают достаточно жесткие требования на транспортную среду. Для согласования таких требований с возможностями Интернет был разработан протокол RTP. Протокол RTP (См. RFC-2205, -2209, -2210, -1990, -1889; "RTP: A Transport Protocol for Real-Time Applications" H. Schulzrinne, S. Casner, R. Frederick, V. Jacobson) базируется на идеях, предложенных Кларком и Тенненхаузом [1], и предназначен для доставки данных в реальном масштабе времени (например, аудио- или видео). При этом определяется тип поля данных, производится нумерация посылок, присвоение временных меток и мониторирование доставки. Приложения обычно используют RTP поверх протокола UDP для того, чтобы использовать его возможности мультиплексирования и контрольного суммирования. Но RTP может использоваться и поверх любой другой сетевой транспортной среды. RTP поддерживает одновременную доставку по многим адресам, если мультикастинг поддерживается нижележащим сетевым уровнем.
Следует иметь в виду, что сам по себе RTP не обеспечивает своевременной доставки и не предоставляет каких-либо гарантий уровня сервиса (QoS. Этот протокол не может гарантировать также корректного порядка доставки данных. Правильный порядок выкладки информации может быть обеспечен принимающей стороной с помощью порядковых номеров пакетов. Такая возможность крайне важна практически всегда, но особое внимание этому уделяется при восстановлении передаваемого изображения.
На практике протокол RTP не отделим от протокола RTCP (RTP control protocol). Последний служит для мониторинга qos и для передачи информации об участниках обмена в ходе сессии.
RTP гибкий протокол, который может доставить приложению нужную информацию, его функциональные модули не образуют отдельный слой, а чаще встраиваются в прикладную программу.
Протокол RTP не является жестко регламентирующим.
При организации аудио-конференции каждый участник должен иметь адрес и два порта, один для звуковых данных, другой для управляющих RTCP-пакетов. Эти параметры должны быть известны всем участникам конференции. При необходимости соблюдения конфиденциальности информация и пакеты управления могут быть зашифрованы. При аудио конференциях каждый из участников пересылает небольшие закодированные звуковые фрагменты длительностью порядка 20 мсек. Каждый из таких фрагментов помещается в поле данных RTP-пакета, который в свою очередь вкладывается в UDP-дейтограмму.
Заголовок пакета RTP определяет, какой вид кодирования звука применен (PCM, ADPCM или LPC), что позволяет отправителю при необходимости сменить метод кодирования, если к конференции подключился новый потребитель с определенными ограничениями или сеть требует снижения скорости передачи.
При передаче звука весьма важным становится взаимное положение закодированных фрагментов во времени. Для решения задачи корректного воспроизведения заголовки пакетов RTP содержат временную информацию и порядковые номера. Порядковые номера позволяют не только восстановить правильный порядок фрагментов, но и определить число потерянных пакетов-фрагментов.
Так как участники конференции могут появляться и исчезать по своему усмотрению, полезно знать, кто из них присутствует в сети в данный момент, и как до них доходят передаваемые данные. Для этой цели периодически каждый из участников транслирует через порт RTCP мультикастинг-сообщение, содержащее имя участника и диагностические данные. Узел-участник конференции шлет пакет BUY (RTCP), если он покидает сессию.
Если в ходе конференции передается не только звук но и изображение, они передаются как два независимых потока с использованием двух пар UDP-портов. RTCP-пакеты посылаются независимо для каждой из этих двух сессий.
На уровне RTP не существует какой-либо взаимосвязи между аудио- и видео сессиями. Только RTCP-пакеты несут в себе одни и те же канонические имена участников.
В некоторых случаях можно столкнуться с ситуацией, когда один из участников конференции подключен к сети через узкополосный канал. Было бы не слишком хорошо требовать от всех участников перехода на кодировку, соответствующую этой малой полосе. Для того чтобы этого избежать, можно установить преобразователь, называемый смесителем, в непосредственной близости от узкополосной области.
Смеситель преобразует поток аудио-пакетов в следовательность пакетов, которая соответствует возможностям узкополосного канала. Эти пакеты могут быть уникастными (адресованными одному получателю) или мультикастными. Заголовок RTP включает в себя средства, которые позволяют мультиплексорам идентифицировать источники, внесшие вклад. Так что получатель может правильно идентифицировать источник звукового сигнала.
Некоторые участники конференции, использующие широкополосные каналы, не доступны для IP-мультикастинга (например, находятся за Firewall). Для таких узлов смесители не нужны, здесь используется другой RTP-уровень передачи, называемый трансляцией. Устанавливается два транслятора по одному с каждой из сторон Firewall. Внешний транслятор передает мультикастинг-пакеты по безопасному каналу внутреннему транслятору. Внутренний же транслятор рассылает их подписчикам локальной сети обычным образом.
Смесители и трансляторы могут выполнять и другие функции, например, преобразование IP/UDP пакетов в ST-II при видео конференциях.
Определения
Поле данных RTP: Информация, пересылаемая в пакете RTP, например фрагменты звука или сжатые видео данные.
Пакет RTP: Информационный пакет, содержащий фиксированный заголовок. Один пакет транспортного нижнего уровня, например UDP, обычно содержит один RTP-пакет, но это требование не является обязательным. Поле источников информации может быть пустым.
Пакет RTCP: Управляющий пакет, содержащий фиксированный заголовок сходный с RTP, за которым следуют структурные элементы, зависящие от типа RTCP-пакета. Обычно несколько RTCP-пакетов посылаются как составной RTCP-пакет, вложенный в дейтограмму нижележащего уровня.
Транспортный адрес: Комбинация сетевого адреса и порта, которая идентифицирует конечную точку канала (например, IP-адрес и UDP-порт). Пакеты следуют от транспортного адреса отправителя к транспортному адресу получателя.
Сессия RTP: Период с момента установления группы участников RTP-обмена до ее исчезновения. Для каждого из участников сессия определяется конкретной парой транспортных адресов (сетевой адрес и номера портов для RTP и RTCP). Транспортный адрес места назначения может быть общим для всех участников сессии. Допускается реализация нескольких сессий для каждого из участников одновременно.
Источник синхронизации (SSRC): Источник потока RTP-пакетов, определяется 32-битным числовым SSRC-идентификатором, который записывается в заголовок RTP-пакета и не зависит от сетевого адреса. Все пакеты от источника синхронизации образуют часть с идентичной временной привязкой и нумерацией. Эти данные используются принимающей стороной при воспроизведении. Источниками синхронизации могут служить источники первичного сигнала (микрофоны или видеокамеры), а также RTP-смесители. SSRC-идентификатор представляет собой случайное число, которое является уникальным для данной RTP-сессии. Участник сессии не должен использовать один и тот же SSRC-идентификатор для всех RTP-сессий мультимедийного набора. Если участник формирует несколько потоков в рамках одной RTP-сессии (например, от нескольких видеокамер), каждый участник должен быть снабжен уникальным SSRC-идентификатором.
Информационный источник CSRC (contributing source): Источник потока RTP-пакетов, который вносит вклад в общий поток, формируемый RTP-смесителем. Смеситель вставляет список SSRC-идентификаторов, которые идентифицируют парциальные источники, в заголовок RTP-пакетов. Этот список называется CSRC-списком. Примером приложения может быть аудио-конференция, где смеситель отмечает всех говорящих, чей голос порождает исходящие пакеты. Это позволяет принимающей стороне идентифицировать говорящего, хотя все пакеты имеют один и тот же SSRC-идентификатор.
Оконечная система: Приложение, которое генерирует или воспринимает данные, посылаемые в виде RTP-пакетов. Оконечная система может выступать в качестве одного или нескольких источников синхронизации для конкретной сессии.
Смеситель: Промежуточная система, которая получает RTP-пакеты от одного или нескольких источников, при необходимости меняет их формат, объединяет и пересылает их адресатам. Так как временная привязка входных пакетов может отличаться, смеситель осуществляет их синхронизацию и генерирует свой собственный поток RTP-пакетов. Таким образом все посылаемые пакеты имеют в качестве источника синхронизации смеситель.
Транслятор: Промежуточная система, которая переадресует RTP-пакеты, не изменяя их идентификаторы источника синхронизации. Такие устройства используются для преобразования системы кодирования, перехода от мультикастинг- к традиционной уникаст-адресации или при работе с Firewall.
Монитор: Приложение, которое получает RTCP-пакеты, посланные участниками RTP-сессии, в частности диагностические сообщения, производит оценку состояния связи, копит долгосрочную статистику обмена.
Все целочисленные поля передаются в соответствии c сетевым порядком, т.е. старший байт следует первым (big-endian). Порядок передачи описан подробно в работе [3]. Если не оговорено обратного все цифровые константы являются десятичными. Все поля заголовка выравниваются по их естественным границам, т.е. 16-битовые поля имеют четное смещение, а 32-битные имеют адрес, кратный 4. Октеты-заполнители содержат нули.
Абсолютное время представляется с помощью временных меток в соответствии с форматом NTP (network time protocol), который характеризует время в секундах от начала суток (UTC) 1 января 1900 [4]. Полное разрешение временной метки NTP определяется 64-битовым числом с фиксированной запятой без знака. Целочисленная часть задается первыми 32 битами, а дробная часть последними. В некоторых полях, где допустимо более компактное представление, используются только средние 32 бита (16 бит целочисленная часть и 16 бит дробная).
Заголовок RTP-пакета имеет следующий формат (см. рис. 4.4.9.2.1).

Рис. 4.4.9.2.1. Заголовок пакета RTP
Первые 12 октетов присутствуют во всех RTP-пакетах, в то время как список CSRC-идентификаторов присутствует только, когда пакет формируется смесителем. Поля имеют следующие назначения:
v (Версия): 2 бита
Это поле идентифицирует версию протокола RTP. В настоящее время в это поле записывается код 2. Значение 1 использовалось в опытной версии RTP, а код 0 - в аудио приложении "vat".
p (Заполнитель): 1 бит
Если Р=1, пакет содержит один или более дополнительных октетов-заполнителей в конце поля данных (заполнители не являются частью поля данных). Последний октет заполнителя содержит число октетов, которые должны игнорироваться. Заполнитель нужен при использовании некоторых алгоритмов шифрования при фиксированном размере блоков или при укладке нескольких RTP-пакетов в один UDP.
x (Расширение): 1 бит
Если бит Х=1, далее следует фиксированный заголовок, за которым размещается одно расширение заголовка.
CC(CSRC count - число CSRC): 4 бита
Число CSRC содержит код количества csrc-идентификаторов, которые записаны в пакете.
M (маркер): 1 бит
Интерпретация маркера определяется профайлом. Предполагается разрешить выделять в потоке пакетов существенные события, такие как границы кадра. Профайл может определить дополнительные маркерные биты или специфицировать отсутствие маркерных битов путем изменения числа битов в поле PT.
PT(Тип данных): 7 бит
Это поле идентифицирует формат поля данных RTP-пакета и определяет интерпретацию его приложением. Могут быть определены дополнительные коды типа данных. Исходный набор кодов по умолчанию для аудио и видео задан в профайле Internet-draft draft-ietf-avt-profile, и может быть расширен в следующих редакциях стандарта assigned numbers (RFC-1700) [5].
Номер по порядку: 16 бит
Номер по порядку инкрементируется на 1 при посылке очередного RTP-пакета данных, этот код может использоваться получателем для регистрации потерь пакетов и для восстановления истинного порядка присланных фрагментов.
Начальное значение кода является случайным. Алгоритм генерации таких кодов рассмотрен в [6].
Временная метка: 32 бита
Временная метка соответствует времени стробирования для первого октета в информационном RTP-пакете. Время стробирования должно быть получено от часов, показания которых увеличиваются монотонно и линейно, чтобы обеспечить синхронизацию и вычисление временного разброса. Разрешающая способность часов должна быть достаточной для обеспечения приемлемой точности синхронизации (одного тика на видео кадр обычно не достаточно). Частота часов зависит от формата данных и задается статически в профайле, в спецификации поля данных, или динамически средствами, выходящими за пределы спецификации протокола RTP. Если RTP-пакеты генерируются периодически, используется временная привязка, определенная задающим генератором стробирования, а не показаниями системных часов.
Начальное значение временной метки является случайным. Несколько последовательных RTP-пакетов могут иметь идентичные временные метки, если логически они генерируются одновременно (например, относятся к и тому же видео кадру).
SSRC: 32 бита
Поле SSRC идентифицирует источник синхронизации. Этот идентификатор выбирается случайным образом, так чтобы в пределах одной RTP-сессии не было двух равных SSRC-кодов. Все приложения должны быть способны выявлять случаи равенства SSRC-кодов. Если отправитель изменяет свой транспортный адрес, он должен также сменить и SSRC-идентификатор.
CSRC-список: от 0 до 15 элементов, по 32 бита каждый
CSRC-список идентифицирует источники информации, которые внесли свой вклад в поле данных пакета. Число идентификаторов задается полем CC. Если число источников больше 15, только 15 из них могут быть идентифицированы.
Для эффективной реализации протокола число точек мультиплексирования должно быть минимизировано. В RTP, мультиплексирование осуществляется по транспортным адресам мест назначения, которые определены RTP-сессией. Использование пакетов с различным типом поля данных но с идентичным ssrc создает определенные проблемы:
1. Если один из типов данных будет изменен в ходе сессии, нет универсальных средств для определения, какое из старых значений следует заменить на новое.
2. ssrc определено для идентификации одного пространства номеров и временных меток. Совместное использование нескольких типов данных в общем потоке может потребовать разных средств синхронизации и разной нумерации, чтобы определять, какой из типов пакетов потерян.
3. RTCP-сообщения отправителя и получателя могут описать только одно пространство номеров и временных меток для каждого SSRC и не имеют поля типа данных.
4. RTP-смеситель не сможет объединять перекрывающиеся потоки при условии их несовместимости.
5. Работа со многими средами в пределах одной RTP-сессии предполагает: использование различных сетевых путей или разного размещения сетевых ресурсов; приема только одного субнабора, например аудио, когда видео недоступно из-за недостатка широкополосности.
Использование различных ssrc для каждого вида среды, при посылке их в пределах одной RTP-сессии позволяет преодолеть первые три проблемы.
Хотя существующие RTP-заголовки позволяют решать широкий круг проблем, предусмотрена возможность их модификации с помощью профайлов. При этом сохраняется возможность контроля и мониторирования с использованием стандартных средств.
Бит маркера и поле типа данных содержат информацию, задаваемую профайлом, но они размещаются в стандартном заголовке, так как нужны многим приложениям. Октет, где размещаются эти поля, может быть переопределен профайлом. При любом числе маркерных битов один должен размещаться в старшем разряде октета, так как это необходимо для мониторирования потока.
Дополнительная информация, которая необходима для конкретного формата поля данных, такая как тип видео-кодирования, должна транспортироваться в поле данных пакета. Это может быть заголовок, присутствующий в начале поля данных.
Если конкретное приложение нуждается в дополнительных возможностях, которые не зависят от содержимого поля данных, профайл данного приложения должен определить дополнительные фиксированные поля, следующие непосредственно после поля SSRC существующего заголовка пакета.
Эти приложения смогут получить доступ к этим дополнительным полям, при этом сохраняются все стандартные средства контроля и мониторинга, так как они базируются на первых 12 октетах заголовка.
В протоколе RTP предусмотрен механизм расширений заголовка, который позволяет модифицировать заголовок и экспериментировать с новыми форматами поля данных. Этот механизм устроен так, что расширения заголовка могут игнорироваться приложениями, которые не нуждаются в расширениях.
Расширения заголовка предназначены для ограниченного использования. И многие приложения лучше реализовать, используя профайл. Формат реализации расширений показан на рис. 4.4.9.2.2.

Рис. 4.4.9.2.2. Формат расширения заголовка
Если бит x в RTP-заголовке равен 1, то к заголовку добавлено расширение переменной длины, за которым может следовать список csrc. Расширение заголовка содержит 16-битовое поле длины, определяющее число 32-битных слов в расширении, исключая 4-октета заголовка расширения (т.о. значения поля длина, равное нулю вполне допустимо). Информационный заголовок RTP может иметь только одно расширение. Для того чтобы обеспечить работу различных приложений с различными расширениями заголовка или чтобы обеспечить работу с более чем одним типом расширений, первые 16 бит расширения заголовка остаются свободными для выбора идентификаторов или параметров. Формат этих 16 бит определяется спецификацией профайла, с которым работает приложение.
Кроме оконечных систем RTP поддерживает трансляторы и смесители, которые рассматриваются как промежуточные системы на уровне RTP.
RTP транслятор/смеситель соединяет две или более области на транспортном уровне. Обычно каждая область определяется сетью и транспортным протоколом (например, ip/udp), мультикаст-адресом или парой уникаст-адресов, а также портом назначения транспортного уровня. Одна система может служить транслятором или смесителем для нескольких RTP сессий.
Для того чтобы исключить зацикливание при использовании транслятора или смесителя следует придерживаться следующих правил:
Каждая из областей, соединенных транслятором или смесителем, участвующих в одной RTP-сессии должна отличаться от всех других, по крайней мере, одним параметром (протоколом, адресом, портом) или должна быть изолирована от других на сетевом уровне.
Следствием первого правила является то, что области не должны быть соединены более чем одним смесителем или транслятором.
Аналогично все оконечные системы RTP, которые взаимодействуют через один или более трансляторов или смесителей, принадлежат одной и той же ssrc-области, т.е., ssrc-идентификаторы должны быть уникальными для задействованных оконечных систем. Существует большое разнообразие трансляторов и смесителей, спроектированных для решения различных задач и приложений. Некоторые служат для шифрования/дешифрования несущих дейтограмм. Различие между смесителями и трансляторами заключается в том, что последние пропускают через себя потоки данных, при необходимости их преобразуя, а смесители объединяют несколько потоков в один.
Транслятор. Переадресует RTP-пакеты, не изменяя их SSRC-идентификаторы. Это позволяет получателям идентифицировать отдельные источники, даже если пакеты от всех источников проходят через один общий транслятор и имеют сетевой адрес транслятора. Некоторые типы трансляторов передают данные без изменений, другие кодируют данные и соответственно изменяют коды типа данных и временные метки. Приемник не может заметить присутствия транслятора.
Смеситель. Принимает потоки RTP-данных от одного или нескольких источников, может изменять формат данных, определенным образом объединяет потоки и затем формирует из них один общий поток. Так как объединяемые потоки не синхронизованы, смеситель производит синхронизацию потоков и формирует свою собственную временную шкалу для исходящего потока. Смеситель является источником синхронизации. Таким образом, все пакеты данных, переадресованные смесителем, будут помечены SSRC-идентификатором смесителя. Для того чтобы сохранить информацию об источниках исходных данных, смеситель должен внести свои SSRC-идентификаторы в список CSRC-идентификаторов, который следует за фиксированным RTP-заголовком пакета.
Смеситель, который, кроме того, вносит в общий поток свою составляющую, должен включить свой собственный SSRC-идентификатор в CSRC-список для данного пакета.
Для некоторых приложений смеситель может не идентифицировать источники в CSRC-списке. Однако это создает опасность того, что петли, включающие эти источники, не смогут быть выявлены.
Преимуществом смесителя перед транслятором для аудио- приложений является то, что выходная полоса не превосходит полосы одного источника, даже когда в сессии на входе смесителя присутствуют несколько участников. Недостатком является то, что получатели с выходной стороны не имеют никаких средств для контроля того, какой из источников передает данные даже в случае наличия дистанционного управления смесителем.

Рис. 4.4.9.2.3 Пример RTP сети с оконечными системами, смесителями и трансляторами
Некоторый набор смесителей и трансляторов представлен на рис. 4.4.9.2.3. Здесь показано их влияние на SSRC и CSRC-идентификаторы. Оконечные системы обозначены символами ES и выделены желтым цветом. Трансляторы обозначены буквами TRS (на рисунке овалы голубого цвета) и смесители обозначены как MUX (прямоугольники сиреневого цвета). Запись "M1:13(1,17)" обозначает пакет отправленный смесителем MUX1, который идентифицируется случайным значением SSRC 13 и двумя CSRC-идентификаторами 1 и 17, скопированными с SSRC-идентификаторов пакетов оконечных систем ES1 и ES2.
Последовательное включение смесителей
В RTP-сессии могут быть задействованы несколько смесителей и трансляторов, как это показано на рис. 4.4.9.2.3. Если два смесителя включены последовательно, так как MUX2 и MUX3, пакеты полученные смесителем могут быть уже объединены и включать CSRC-список со многими идентификаторами. Cмеситель (MUX3) должен формировать CSRC-список для исходящих пакетов, используя CSRC-идентификаторы уже смешанных входных пакетов (выход MUX2) и SSRC-идентификаторы несмешанных входных пакетов, поступивших от ES9 (E:36). Это отмечено на рисунке для выходных пакетов смесителя MUX3 как M3:99(9,11,36).
Если число идентификаторов в списке CSRC превышает 15, остальные не могут быть туда включены.
SSRC-идентификаторы в RTP-заголовках и в различных полях RTCP-пакетов являются случайными 32-битовыми числами, которые должны быть уникальными в рамках RTP-сессии. Очень важно, чтобы одни и те же числа не были использованы несколькими участниками сессии.
Недостаточно использовать в качестве идентификатора локальный сетевой адрес (такой как IPv4), так как может быть не уникальным. Так как RTP трансляторы и смесители допускают работу с сетями, использующими различные адресные пространства, это допускает их случайное совпадение с большей вероятностью, чем в случае использования случайных чисел.
Не приемлемо также получать идентификаторы SSRC путем простого обращения к функции random() без тщательной инициализации.
Так как идентификаторы выбраны случайным образом, существует малая, но конечная вероятность того, что два или более источников выберут одно и то же число. Столкновение более вероятно, если все источники стартуют одновременно. Если N число источников, а L длина идентификатора (в нашем случае, 32 бита), вероятность того, что два источника независимо выберут одно и то же значение (для больших N [8]) составляет 1 - exp(-N2 / 2(L+1)). Для N=1000, вероятность примерно равна 10-4.
Типовое значение вероятности столкновения много меньше худшего случая, рассмотренного выше. Рассмотрим случай, когда новый источник подключается к RTP-сессии, в которой все остальные источники уже имеют уникальные идентификаторы. Если N равно числу источников, а L длина идентификатора, вероятность столкновения равна N / 2L. Для N=1000, вероятность составит около 2*10-7.
Вероятность столкновения уменьшается еще больше в случае, когда новый источник получает пакеты других участников до того, как передаст свой первый пакет. Если новый источник отслеживает идентификаторы других участников, он легко может устранить вероятность конфликта.
Преодоление столкновений и детектирование петель
Хотя вероятность столкновения идентификаторов SSRC довольно мала, все RTP реализации должны быть готовы обнаруживать столкновения и предпринимать адекватные меры для их преодоления.
Если источник обнаруживает в какой- либо момент, что другой источник использует тот же идентификатор SSRC, он посылает пакет RTCP BYE для старого идентификатора и выбирает новый. Если получатель обнаруживает, что два других источника имеют равные идентификаторы (столкновение), он может воспринимать пакеты от одного и игнорировать от другого до тех пор, пока это не будет зарегистрировано отправителями или CNAME.
Так как идентификаторы уникальны, они могут использоваться для детектирования петель, которые могут создаваться смесителем или транслятором. Петля приводит к дублированию данных и управляющей информации:
Транслятор может некорректно переадресовать пакет некоторой мультикастинг-группе, откуда этот пакет получен. Это может быть сделано непосредственно или через цепочку трансляторов. В этом случае один и тот же пакет появится несколько раз, приходя от разных сетевых источников.
Два транслятора некорректно поставленные в параллель, т.е., с одними и теми же мультикастными группами на обеих сторонах будут направлять пакеты от одной мультикастной группы к другой. Однонаправленные трансляторы могут создать две копии; двунаправленные трансляторы могут образовать петлю.
Смеситель может замкнуть петлю путем посылки пакета по адресу, откуда он был получен. Это может быть выполнено непосредственно, через смеситель или через транслятор.
Источник может обнаружить, что его собственный пакет движется по кругу, или что пакеты других источников осуществляют циклическое движение.
Оба вида петель и столкновения приводят к тому, что пакеты приходят с тем же самым SSRC-идентификатором, но с разными транспортными адресами, которые могут принадлежать оконечной или какой-то промежуточной системе. Следовательно, если источник меняет свой транспортный адрес, он должен также выбрать новый SSRC-идентификатор с тем, чтобы ситуация не была интерпретирована, как зацикливание. Петли или столкновения, происходящие на дальней стороне транслятора или смесителя, не могут быть детектированы с использованием транспортного адреса источника, если все копии пакетов идут через транслятор или смеситель.
Однако, столкновения могут быть детектированы, когда фрагменты двух RTCP SDES пакетов содержат равные SSRC-идентификаторы, но разные коды CNAME (см. описание протокола ).
Для того чтобы детектировать и устранять конфликты, реализации RTP должны содержать алгоритм, аналогичный описанному ниже. Он игнорирует пакеты от нового источника, которые входят в противоречие с работающим источником. Алгоритм разрешает конфликты с SSRC-идентификаторами участников путем выбора нового идентификатора и посылки RTCP BYE для старого. Однако, когда столкновение вызвано зацикливанием собственных пакетов участников сессии, алгоритм выбирает новый идентификатор только раз и после этого игнорирует пакеты от транспортного адреса, вызвавшего зацикливание. Это требуется для того, чтобы избежать потока пакетов BYE.
Этот алгоритм зависит от равенства транспортных адресов для RTP и RTCP пакетов источника. Алгоритм требует модификации приложений, которые не отвечают этому ограничению.
Этот алгоритм требует наличия таблицы транспортных адресов источников, упорядоченных по их идентификаторам. В таблицу заносятся адреса, откуда данный идентификатор был впервые получен. Каждый SSRC или CSRC идентификатор, полученный с информационным или управляющим пакетом ищется в этой таблице, для того чтобы корректно обработать полученные данные. Для управляющих пакетов каждый элемент с его собственным SSRC, например, фрагмент SDES, требует отдельного просмотра. SSRC в сообщениях-отчетах составляют исключение. Если SSRC или CSRC не найдены, создается новая запись в таблице. Эти записи в таблице удаляются, когда приходит пакет RTCP BYE с соответствующим кодом SSRC, или когда достаточно долго не приходит вообще никаких пакетов.
Для того чтобы отслеживать зацикливание собственных пакетов участников, необходимо также завести отдельный список транспортных адресов источников, которые считаются конфликтными. Заметим, что это должен быть короткий список, обычно пустой. Каждый элемент этого списка хранит адрес источника и время, когда был получен последний конфликтный пакет.
Элемент может быть удален из списка, когда за время 10 периодов посылки RTCP сообщений-отчетов не прибыло ни одного конфликтного пакета.
Предполагается, что собственные идентификаторы и состояния участников записаны в таблицу идентификаторов источников.
IF SSRC или CSRC-идентификатор не найден в таблице идентификаторов источников:
THEN создать новую запись и внести туда транспортный адрес источника и SSRC или
CSRC вместе с кодом состояния.
CONTINUE (продолжить) обычную процедуру обработки.
Идентификатор найден в таблице
IF транспортный адрес источника из пакета совпадает с одним из записанных в таблице:
THEN CONTINUE Продолжить обычную процедуру обработки.
Обнаружено столкновение идентификаторов или зацикливание
IF идентификатор источника не совпадает с собственным идентификатором участника:
THEN IF идентификатор источника совпадает с тем, что содержится в фрагменте RTCP SDES содержащем элемент CNAME, который отличается от CNAME из рекорда таблицы:
THEN (опционно) Случилось столкновение посторонних идентификаторов.
ELSE (опционно) Случилось зацикливание.
ABORT Прервать обработку информационного или управляющего пакета.
Столкновение для идентификатора участника или зацикливание его пакетов
IF транспортный адрес найден в списке конфликтных адресов:
THEN IF идентификатор источника не найден во фрагменте RTCP SDES, содержащем CNAME, или если CNAME принадлежит участнику:
THEN (опционно) случилось зацикливание собственного трафика.
Записать текущее время в соответствующую запись таблицы конфликтных адресов.
ABORT (прервать) обработку информационного или управляющего пакета.
Зафиксировать факт столкновения.
Внести новую запись в таблицу конфликтных адресов и зафиксировать время записи.
Послать пакет RTCP BYE с идентификатором SSRC.
Выбрать новый идентификатор.
Внести новую запись в таблицу идентификаторов источников со старым SSRC, транспортным адресом источника обработанного пакета.
CONTINUE Продолжить обычную процедуру обработки.
В этом алгоритме все пакеты от вновь конфликтующих источников будут игнорироваться, а пакеты от исходного источника будут приниматься.
Если в течение достаточно протяженного периода времени пакеты от исходного источника не приходят, соответствующая запись в таблице будет аннулирована.
Когда из-за столкновения выбран новый SSRC-идентификатор, кандидат-идентификатор должен быть сверен с содержимым таблицы идентификаторов. Если такой код там уже имеется, должен быть выбран другой кандидат и процедура сверки повторена.
Зацикливание информационных мультикастинг-пакетов может вызвать сильную перегрузку сети. Все смесители и трансляторы должны реализовывать алгоритм детектирования зацикливания с тем, чтобы немедленно прервать этот опасный процесс. Это должно уменьшить лишний трафик. Однако, в крайних случаях, где смеситель или транслятор не прерывают зацикливание, может быть необходимо для оконечных систем прервать передачу.
Когда необходимо шифрование RTP или RTCP, все октеты будут инкапсулированы в одну дейтограмму нижележащего уровня и зашифрованы как единое целое. Для RTCP в начало последовательности перед шифрованием добавляется 32-битное случайное число, чтобы предотвратить возможные атаки. В случае RTP никаких префиксов не требуется, так как порядковый номер и временная метка и без того являются случайными числами.
Алгоритмом шифрования по умолчанию является DES (Data Encryption Standard), работающий в режиме CBC (Cipher Block Chaining), как это описано в RFC 1423 [9], за исключением того, что используется заполнение кратное 8 октетам. Инициализационный вектор равен нулю, так как для RTP-заголовка используются случайные числа. Более подробно о векторах инициализации можно прочесть в [10]. Приложения, которые используют шифрование должны поддерживать алгоритм DES в режиме CBC. Этот метод выбран потому, что он показал на практике свою эффективность при работе с аудио и видео приложениями в Интернет. Возможно применение и других криптографических средств.
В качестве альтернативы шифрованию на уровне RTP, можно определить дополнительные типы поля данных для шифрованных полей данных в профайлах. Этот метод позволяет шифровать только данные, в то время как заголовки остаются незашифрованными.
Это может оказаться полезным для реализации шифрования и дешифрования.
Для обеспечения демультиплексирования RTP полагается на нижележащий протокольный уровень. Для UDP и сходных с ним протоколов, RTP использует четные номера портов, а соответствующие RTCP-потоки используют нечетные номера портов. Если приложению предлагается использовать нечетный номер RTP-порта, этот номер должен быть заменен на ближайший четный меньше исходного.
Информационные RTP-пакеты не имеют поля длины или каких-либо других средств ограничения размеров пакета, по этой причине RTP полагается на нижележащий протокол при задании размера поля данных. Максимальная длина RTP-пакетов ограничена размером используемых транспортных пакетов (например, UDP).
Если RTP-пакеты переносятся посредством протокола, который поддерживает поточный метод передачи, должен быть определен механизм вложения. Механизм вложения должен быть детализован и в случае, когда транспортный протокол использует в поле данных заполнители.
Механизм вложения может быть определен в профайле даже в случае, когда для транспортировки RTP используется не поточный протокол, это позволяет укладывать несколько RTP-пакетов в одну дейтограмму транспортного протокола (например, UDP). Передача нескольких RTP-пакетов в одном транспортном уменьшает издержки, связанные с заголовком и может упростить синхронизацию различных потоков.
Константы, определяющие тип данных (PT) RTP-пакета, задаются профайлом а не самим протоколом. Однако, значение октета RTP-заголовка, который содержит бит(ы) маркера не должно ни при каких обстоятельствах равняться 200 и 201 (десятичные), для того чтобы отличить RTP-пакеты от RTCP-пакетов типа SR и RR.
Использование протокола RTP в различных приложениях может предъявлять различные требования. Адаптация протокола к этим требованиям осуществляется путем выбора определенных параметров, использования различных расширений (см. рис. 4.4.9.2.2) или путем вариации формата на основе профайлов. Типовое приложение использует только один профайл.
Спецификация формата поля данных определяет то, например, как, закодированный видеосигнал (H.261) должен переноситься RTP-пакетами.
В рамках RTP-стандарта определены следующие элементы поля данных (этот список не следует рассматривать, как окончательный):
Заголовок поля данных RTP. Октет RTP заголовка, содержащий маркер тип поля данных, может быть переопределен с помощью профайла (например, можно изменить число маркерных битов).
Типы поля данных. Профайл обычно определяет набор форматов поля данных (напр., типов кодирования исходных данных) и соответствие между этими форматами и кодами типа поля данных. Для каждого описанного типа поля данных должна быть определена частота временных меток.
Дополнения к заголовку RTP. К стандартному RTP-заголовку могут быть добавлены новые поля, расширяющие функциональность приложения.
Расширения заголовка RTP. Структура содержимого первых 16 бит расширения RTP-заголовка должна быть определена профайлом (см. рис. 4.4.9.2.2).
Безопасность. Профайл может специфицировать, какие услуги и алгоритмы безопасности должно обеспечить приложение.
Установка соответствия между строкой и ключом. Профайл может специфицировать, какому ключу шифрования соответствует введенный пользователем пароль.
Нижележащий протокол. Определяется нижележащий транспортный протокол, который служит для пересылки RTP-пакетов.
Транспортное соответствие. Соответствие RTP и RTCP адресам транспортного уровня, например, UDP-портам.
Инкапсуляция. Инкапсуляция RTP-пакетов может быть определена для того, чтобы позволить транспортировку нескольких RTP-пакетов в одной дейтограмме нижележащего протокола.
Не предполагается, что для каждого приложения требуется свой профайл. В пределах одного класса приложений целесообразно использовать расширения одного и того же профайла. Простое расширение, такое как введение дополнительного типа поля данных или нового типа RTCP-пакета, может быть выполнено путем регистрации их через комитет по стандартным числам Интернет и публикации их описаний в приложении к профайлу.
Алгоритмы работы отправителя и получателя RTP-пакетов описаны в RFC- 1889 на примере кодов, написанных на языке СИ.
Нижеприведенные определения заимствованы целиком из RFC, ссылка на который приведена в начале данного раздела. Все цифра представлены в формате, где первым является старший октет. Предполагается, что битовые поля размещаются без заполнителей в том же порядке, что и октеты.
/*
* rtp.h -- Файл заголовка RTP (RFC 1889)
*/
#include <sys/types.h>
/*
* Нижеприведенные определения предполагают 32-битовое представление, а в случаях
* 16- или 64-битового представлений необходимы соответствующие модификации.
*/
typedef unsigned char u_int8;
typedef unsigned short u_int16;
typedef unsigned int u_int32;
typedef short int16;
/*
* Текущая версия протокола.
*/
#define RTP_VERSION 2
#define RTP_SEQ_MOD (1<<16)
#define RTP_MAX_SDES 255 /* максимальная длина текста для SDES */
typedef enum {
RTCP_SR = 200,
RTCP_RR = 201,
RTCP_SDES = 202,
RTCP_BYE = 203,
RTCP_APP = 204
} rtcp_type_t;
typedef enum {
RTCP_SDES_END = 0,
RTCP_SDES_CNAME = 1,
RTCP_SDES_NAME = 2,
RTCP_SDES_EMAIL = 3,
RTCP_SDES_PHONE = 4,
RTCP_SDES_LOC = 5,
RTCP_SDES_TOOL = 6,
RTCP_SDES_NOTE = 7,
RTCP_SDES_PRIV = 8
} rtcp_sdes_type_t;
/*
* Заголовок RTP-пакета
*/
typedef struct {
unsigned int version:2; /* версия протокола */
unsigned int p:1; /* флаг заполнителя */
unsigned int x:1; /* Флаг расширения заголовка */
unsigned int cc:4; /* число CSRC */
unsigned int m:1; /* Бит маркера */
unsigned int pt:7; /* тип поля данных */
u_int16 seq; /* номер по порядку */
u_int32 ts; /* временная метка */
u_int32 ssrc; /* источник синхронизации */
u_int32 csrc[1]; /* опционный список CSRC */
} rtp_hdr_t;
/*
* Общее слово RTCP-заголовка
*/
typedef struct {
unsigned int version:2; /* версия протокола */
unsigned int p:1; /* флаг заполнителя */
unsigned int count:5; /* варьируется в зависимости от типа пакета */
unsigned int pt:8; /* тип пакета RTCP */
u_int16 length; /* Длина пакета в словах */
} rtcp_common_t;
/*
* Маска версии, бита заполнителя и типа пакета
*/
#define RTCP_VALID_MASK (0xc000 | 0x2000 | 0xfe)
#define RTCP_VALID_VALUE ((RTP_VERSION << 14) | RTCP_SR)
/*
* Блок отчета о приеме
*/
typedef struct {
u_int32 ssrc; /* Источник, для которого составлен отчет */
unsigned int fraction:8; /* доля потерянных пакетов с момента последнего SR/RR */
int lost:24; /* полное число потерянных пакетов */
u_int32 last_seq; /* номер последнего полученного пакета */
u_int32 jitter; /* разброс времени прихода пакетов */
u_int32 lsr; /* последний SR-пакет от этого источника */
u_int32 dlsr; /* задержка с момента последнего SR пакета */
} rtcp_rr_t;
/*
* элемент SDES
*/
typedef struct {
u_int8 type; /* тип элемента (rtcp_sdes_type_t) */
u_int8 length; /* Длина элемента (в октетах) */
char data[1]; /* текст */
} rtcp_sdes_item_t;
/*
* One RTCP packet
*/
typedef struct {
rtcp_common_t common; /* общий заголовок */
union {
/* sender report (SR) */
struct {
u_int32 ssrc; /* Отправитель, генерирующий этот отчет */
u_int32 ntp_sec; /* временная метка NTP */
u_int32 ntp_frac;
u_int32 rtp_ts; /* временная метка RTP */
u_int32 psent; /* послано пакетов */
u_int32 osent; /* послано октетов */
rtcp_rr_t rr[1]; /* список переменной длины */
} sr;
/* Отчет о приеме (RR) */
struct {
u_int32 ssrc; /* приемник, формирующий данный отчет */
rtcp_rr_t rr[1]; /* список переменной длины */
} rr;
/* описание источника (SDES) */
struct rtcp_sdes {
u_int32 src; /* первый SSRC/CSRC */
rtcp_sdes_item_t item[1]; /* список элементов SDES */
} sdes;
/* BYE */
struct {
u_int32 src[1]; /* список источников */
/* can't express trailing text for reason */
} bye;
} r;
} rtcp_t;
typedef struct rtcp_sdes rtcp_sdes_t;
/*
* Информация состояния источников
*/
typedef struct {
u_int16 max_seq; /* наибольший зарегистрированный номер */
u_int32 cycles; /* shifted count of seq. number cycles */
u_int32 base_seq; /* основной порядковый номер */
u_int32 bad_seq; /* последний 'плохой' порядковый номер + 1 */
u_int32 probation; /* sequ.
packets till source is valid */
u_int32 received; /* пакетов получено */
u_int32 expected_prior; /* пакет, ожидаемый в последнем интервале */
u_int32 received_prior; /* пакет, полученный за последний интервал */
u_int32 transit; /* относительное время передачи для предыдущего пакета */
u_int32 jitter; /* оценка временного разброса */
/* ... */
} source;
Получатель RTP-пакета должен проверить корректность заголовка. Здесь следует учитывать, что пакет может быть зашифрован. Если пакет не пройдет данную проверку (например, неверно дешифрован, ошибка в адресе или обнаружен неизвестный тип поля данных), должно быть выработано соответствующее сообщение. Ограниченная проверка допустима только для нового источника:
В поле версии RTP должен быть записан код 2.
Тип поля данных должен быть из числа известных, в частности он не должен быть равным SR или RR.
Если бит P=1, тогда последний октет пакета должен содержать правильное число октетов, в частности оно должно быть меньше полной длины пакета минус размер заголовка.
Бит X должен быть равен нулю, если профайл не указывает на использование механизма расширения. В противном случае длина поля расширения должна быть меньше полной длины пакета минус длина стандартного заголовка вместе с заполнителем.
Длина пакета должна согласовываться с CC и типом поля данных (если длина поля данных известна).
Последние три проверки достаточно сложны и не всегда возможны. Если SSRC-идентификатор в пакете соответствует одному из полученных ранее, тогда пакет вероятно корректен и следует проверить то, что его порядковый номер лежит в нужном диапазоне. Если SSRC-идентификатор ранее не встречался, тогда данный пакет может рассматриваться некорректным до тех пор, пока не будет получено несколько таких последовательно пронумерованных пакетов.
Программа update_seq, приведенная ниже гарантирует, что источник декларирован правильно после получения MIN_SEQUENTIAL последовательно пронумерованных пакетов. Она также проверяет номера пакетов SEQ и актуализует состояние источника пакетов в структуре, на которую указывает S.
Когда новый источник дает о себе знать впервые (т.е. его SSRC-идентификатор отсутствует в таблице), и для описания его состояния выделено место в памяти, S->probation должно быть сделано равным числу последовательных пакетов, которые должны быть зарегистрированы до того, как источник будет объявлен легальным (параметр MIN_SEQUENTIAL ), а переменной s->max_seq присваивается значение SEQ-1. s->probation помечает источник как еще нелегальный, так что описание его состояния может быть выброшено после короткой выдержки.
После того как источник признан легальным, номер по порядку считается корректным, если он не больше чем на MAX_DROPOUT впереди S->max_seq и не больше на MAX_MISORDER после.
В противном случае возвращается нуль, что означает неудачу проверки, а плохой последовательный номер запоминается. Если номер очередного полученного пакета имеет следующий номер по порядку, то он рассматривается как начало новой последовательности (возможно источник рестартовал). Так как при этом теряется много циклов, статистика потерь пакетов сбрасывается.
Приведенные типовые значения параметров базируются на максимальном времени сбоя нумерации равном 2 секундам при скорости 50 пакетов/сек и времени таймаута 1 минута. Параметр таймаута MAX_DROPOUT должен соответствовать небольшой доле от 16-битового диапазона нумерации. Таким образом, после рестарта новый номер пакета с большой вероятностью не должен попасть в допустимый диапазон.
void init_seq(source *s, u_int16 seq)
{
s->base_seq = seq - 1;
s->max_seq = seq;
s->bad_seq = RTP_SEQ_MOD + 1;
s->cycles = 0;
s->received = 0;
s->received_prior = 0;
s->expected_prior = 0;
/* other initialization */
}
int update_seq(source *s, u_int16 seq)
{
u_int16 udelta = seq - s->max_seq;
const int MAX_DROPOUT = 3000;
const int MAX_MISORDER = 100;
const int MIN_SEQUENTIAL = 2;
*
* Источник нелегален до тех пор, пока не будет получено MIN_SEQUENTIAL пакетов
* с последовательно нарастающими номерами.
*/
if (s->probation) {
/* пакет соответствует последовательности */
if (seq == s->max_seq + 1) {
s->probation--;
s->max_seq = seq;
if (s->probation == 0) {
init_seq(s, seq);
s->received++;
return 1;
}
} else {
s->probation = MIN_SEQUENTIAL - 1;
s->max_seq = seq;
}
return 0;
} else if (udelta < MAX_DROPOUT) {
/* в порядке, с допустимым зазором */
if (seq < s->max_seq) {
/*
* Порядковый номер переполнен - начинаем новый 64K цикл.
*/
s->cycles += RTP_SEQ_MOD;
}
s->max_seq = seq;
} else if (udelta <= RTP_SEQ_MOD - MAX_MISORDER) {
/* порядковый номер изменился слишком сильно */
if (seq == s->bad_seq) {
/*
* Два последовательных пакета - предполагается, что другая сторона рестартовала, не
* предупредив нас об этом. re-sync (т.е., считаем, что получили первый пакет).
*/
init_seq(s, seq);
}
else {
s->bad_seq = (seq + 1) & (RTP_SEQ_MOD-1);
return 0;
}
} else {
/* задублированные пакеты или пакеты с перепутанным порядком прихода */
}
s->received++;
return 1;
}
Проверка корректности может быть и жестче, требуя более двух пакетов с последовательными номерами подряд. Недостатком такого подхода будут трудности, связанные с каналами, где вероятность потери пакета велика. Однако, так как проверка корректности заголовка RTCP-пакета достаточно строга, можно ограничиться требованием двух последовательных информационных пакетов. Если начальная потеря данных в течение нескольких секунд приемлема, приложение может выбрасывать все информационные пакеты до тех пор, пока не будет получен от источника корректный RTCP-пакет.
В зависимости от приложения и используемого кодирования для проверки можно использовать дополнительную информацию о структуре поля данных. Например, для типов данных, где используются временные метки, можно с некоторой точностью предсказывать очередное значение метки на основании знания предыдущей и разности номеров пакетов.
Для того чтобы посчитать частоту потерь пакетов, нужно знать ожидаемое и реально полученное число пакетов для каждого из источников.
Число полученных пакетов получается простым их подсчетом с учетом возможного дублирования и запаздывания. Ожидаемое число пакетов может быть подсчитано получателем как разность между наибольшим порядковым номером пакета (s->max_seq) и номером первого пакета в последовательности (S->base_seq). При этом нужно учитывать то, что номера имеют 16 бит, и по этой причине могут переполниться (число переполнений хранится в переменной s->cycles).
extended_max = s->cycles + s->max_seq;
expected = extended_max - s->base_seq + 1;
Число потерянных пакетов определяется как разность между ожидаемым и реально полученным числом пакетов:
lost = expected - s->received;
Доля потерянных пакетов за отчетный период (с момента посылки предыдущего SR или RR пакета) вычисляется из разности ожидаемого и реально полученного числа пакетов за отчетный период, где expected_prior и received_prior представляют собой значения, записанные в момент подготовки предыдущего отчета.:
expected_interval = expected - s->expected_prior;
s->expected_prior = expected;
received_interval = s->received - s->received_prior;
s->received_prior = s->received;
lost_interval = expected_interval - received_interval;
if (expected_interval == 0 lost_interval <= 0) fraction = 0;
else fraction = (lost_interval << 8) / expected_interval;
Результирующее значение доли равно 8-битовому числу с фиксированной запятой, расположенной слева.
Генерирование псевдослучайных 32-битовых идентификаторов
Ниже приведенная подпрограмма (заимствована из RFC-1889) генерирует псевдослучайные 32-битовые идентификаторы, используя программы MD5, опубликованные в RFC-1321 [11]. Системные программы могут и не присутствовать во всех операционных системах, но они помогают понять, какого рода информация может использоваться.
o getdomainname() ,
o getwd() , или
o getrusage()
"Живые" видео или аудио сигналы могут быть также не плохим источником случайных числе, при этом только следует позаботиться о том, чтобы микрофон не был отключен, а объектив камеры не был закрыт [7].
Использование этой или другой подобной программы предполагает определенную процедуру инициализации, которая нужна для получения первых псевдослучайных чисел. Так как эта программа заметно загружает процессор, ее непосредственное использование для генерации RTCP-периодов нельзя считать приемлемым. Следует заметить, что данная программа выдает один и тот же результат при последовательных вызовах до тех пор, пока не изменится показание системных часов или не будет задано другое значение аргумента type.
/*
* Генерация псевдослучайного 32-битового числа.
*/
#include <sys/types.h> u_long */
#include <sys/time.h> /* gettimeofday() */
#include <unistd.h> /* get..() */
#include <stdio.h> /* printf() */
#include <time.h> /* clock() */
#include <sys/utsname.h> /* uname() */
#include "global.h" /* from RFC 1321 */
#include "md5.h" /* from RFC 1321 */
#define MD_CTX MD5_CTX
#define MDInit MD5Init
#define MDUpdate MD5Update
#define MDFinal MD5Final
static u_long md_32(char *string, int length)
{
MD_CTX context;
union {
char c[16];
u_long x[4];
} digest;
u_long r;
int i;
MDInit (&context);
MDUpdate (&context, string, length);
MDFinal ((unsigned char *)&digest, &context);
r = 0;
for (i = 0; i < 3; i++) {
r ^= digest.x[i];
}
return r;
} /* md_32 */
/*
* Полученный результат - 32-битовое число без знака. Используйте аргумент 'type' если вам
* нужно получить несколько разных величин подряд.
*/
u_int32 random32(int type)
{
struct {
int type;
struct timeval tv;
clock_t cpu;
pid_t pid;
u_long hid;
uid_t uid;
gid_t gid;
struct utsname name;
} s;
gettimeofday(&s.tv, 0);
uname(&s.name);
s.type = type;
s.cpu = clock();
s.pid = getpid();
s.hid = gethostid();
s.uid = getuid();
s.gid = getgid();
return md_32((char *)&s, sizeof(s));
} /* random32 */
Библиография
| [1] | D. D. Clark и D. L. Tennenhouse, "Architectural considerations for a new generation of protocols," in SIGCOMM Symposium on Communications Architectures и Protocols , (Philadelphia, Pennsylvania), pp. 200--208, IEEE, Sept. 1990. Computer Communications Review, Vol. 20(4), Sept. 1990. |
| [2] | D. E. Comer, Internetworking with TCP/IP , vol. 1. Englewood Cliffs, New Jersey: Prentice Hall, 1991. |
| [3] | Postel, J., "Internet Protocol", STD 5, RFC 791, USC/Information Sciences Institute, September 1981. |
| [4] | Mills, D., "Network Time Protocol Version 3", RFC 1305, UDEL, March 1992. |
| [5] | Reynolds, J., и J. Postel, "Assigned Numbers", STD 2, RFC 1700, USC/Information Sciences Institute, October 1994. |
| [6] | Eastlake, D., Crocker, S., и J. Schiller, "Randomness Recommendations for Security", RFC 1750, DEC, Cybercash, MIT, December 1994. |
| [7] | J.-C. Bolot, T. Turletti, и I. Wakeman, "Scalable feedback control for multicast video distribution in the internet," in SIGCOMM Symposium on Communications Architectures и Protocols, (London, England), pp. 58--67, ACM, Aug. 1994. |
| [8] | Balenson, D., "Privacy Enhancement for Internet Electronic Mail: Part III: Algorithms, Modes, и Identifiers", RFC 1423, TIS, IAB IRTF PSRG, IETF PEM WG, February 1993. |
| [9] | V. L. Voydock и S. T. Kent, "Security mechanisms in high-level network protocols," ACM Computing Surveys, vol. 15, pp. 135--171, June 1983. |
| [10] | Rivest, R., "The MD5 Message-Digest Algorithm", RFC 1321, MIT Laboratory for Computer Science и RSA Data Security, Inc., April 1992. |
| [11] | S. Stubblebine, "Security services for multimedia conferencing," in 16th National Computer Security Conference , (Baltimore, Maryland), pp. 391--395, Sept. 1993. |
| [12] | S. Floyd и V. Jacobson, "The synchronization of periodic routing messages," IEEE/ACM Transactions on Networking , vol. 2, pp. 122-136, April 1994. |
Протокол резервирования ресурсов RSVP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Протокол RSVP (L. Zhang, R. Braden, Ed., S. Berson, S. Herzog, S. Jamin “Resource ReSerVation Protocol”, RFC-2205) используется ЭВМ для того, чтобы запросить для приложения определенный уровень качества сетевых услуг QoS (Quality of Service, например, определенный уровень полосы пропускания). RSVP используется также маршрутизаторами для доставки QOS-запросов всем узлам вдоль пути информационного потока, а также для установки и поддержания необходимого уровня услуг. RSVP-запросы обеспечивают резервирование определенных сетевых ресурсов, которые нужны, чтобы обеспечить конкретный уровень QOS вдоль всего маршрута транспортировки данных. Функция этого протокола крайне важна и многообразна, именно по этой причине это один из самых сложных протоколов.
RSVP запрашивает ресурсы только для одного из направлений трафика и только по указанию получателя. RSVP работает поверх IPv4 или IPv6. Протокол относится к числу управляющих, а не транспортных.
RSVP предназначен для работы с существующими и будущими маршрутными протоколами, управляющими как обычными, так и мультикастными потоками. В последнем случае ЭВМ сначала посылает IGMP-запрос, для того чтобы подключиться к мультикастинг-группе, а затем уже RSVP-сообщение для резервирования ресурсов по маршруту доставки.
Механизм обеспечения QOS включает в себя классификацию пакетов, административный контроль и диспетчеризацию. Классификатор пакетов определяет QoS класс (а иногда и маршрут движения) для каждого пакета. В процессе реализации резервирования RSVP-запрос проходит два местных управляющих модуля: "контроль доступа" и "управление политикой". Контроль доступа определяет, имеет ли узел достаточно ресурсов для удовлетворения поступившей заявки. Управление политикой определяет, имеет ли пользователь административное разрешение сделать данное резервирование. Если обе проверки завершились успешно, параметры передаются классификатору пакетов и интерфейсу канального уровня (диспетчеру пакетов).
Если же какой- либо из тестов не прошел, программа RSVP присылает прикладному процессу сообщение об ошибке.
Структура и содержимое параметров QoS документировано в спецификации RFC-2210. Так как число участников группы, а также топология связей меняется со временем, структура RSVP предполагает адаптацию ЭВМ и маршрутизаторов к этим изменениям. Для этой цели RSVP периодически посылает сообщения для поддержания необходимого состояния вдоль всего маршрута обмена. При отсутствии этих сообщений происходит тайм-аут и резервирование аннулируется. Обобщая, можно сказать, что RSVP имеет следующие атрибуты: RSVP выполняет резервирование для уникастных и мультикастных приложений, динамически адаптируясь к изменениям членства в группе вдоль маршрута.RSVP является симплексным протоколом, т.е., он выполняет резервирование для однонаправленного потока данных.RSVP ориентирован на получателя, т.е., получатель данных инициирует и поддерживает резервирование ресурсов для потока.RSVP поддерживает динамическое членство в группе и автоматически адаптируется к изменениям маршрутов.RSVP не является маршрутным протоколом, но зависит от существующих и будущих маршрутных протоколов.RSVP транспортирует и поддерживает параметры управления трафиком и политикой, которые остаются непрозрачными для RSVP.RSVP обеспечивает несколько моделей резервирования или стилей, для того чтобы удовлетворить требованиям различных приложений.RSVP обеспечивает прозрачность операций для маршрутизаторов, которые его не поддерживают.RSVP может работать с IPv4 и IPv6.
Подобно приложениям маршрутизации и протоколам управления, программы RSVP исполняется в фоновом режиме. Схема работы процесса RSVP показана на рис. 4.4.9.6.1.

Рис. 4.4.9.6.1. RSVP в ЭВМ и маршрутизаторе
Протокол SNTP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Протокол SNTP V 4 отличается от предыдущей версии NTP и SNTP (Simple Network Time Protocol (SNTP) V.4 for IPv4, IPv6 and OSI, D. Mills, RFC-2030) модификацией интерпретации заголовка с целью осуществления совместимости адресации с IPv6 [DEE96] и OSI [COL94].
Протокол TCP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Протокол TCP (transmission control protocol, RFC-793, -1323, -1644[T/TCP], -2018, -2581, -2582[RENO], -2861, -2873, -2883[SACK], -2923[MTU], -2988[RTO], -3293[GSMP], -3448[TFRC], -3465, -3481) в отличии от UDP осуществляет доставку дейтаграмм, называемых сегментами, в виде байтовых потоков с установлением соединения. Протокол TCP применяется в тех случаях, когда требуется гарантированная доставка сообщений. Он использует контрольные суммы пакетов для проверки их целостности и освобождает прикладные процессы от необходимости таймаутов и повторных передач для обеспечения надежности. Для отслеживания подтверждения доставки в TCP реализуется алгоритм "скользящего" окна. Наиболее типичными прикладными процессами, использующими TCP, являются FTP (file transfer protocol - протокол передачи файлов) и telnet. Кроме того, TCP используют системы SMTP, HTTP, X-window, RCP (remote copy), а также "r"-команды. Внутренняя структура модуля TCP гораздо сложнее структуры UDP. Подобно UDP прикладные процессы взаимодействуют с модулем TCP через порты (см. в предыдущей главе). Под байтовыми потоками здесь подразумевается то, что один примитив, например, read или write (см. ) может вызвать посылку адресату последовательности сегментов, которые образуют некоторый блок данных (сообщение). Использование портов открывает возможность осуществлять несколько соединений между двумя сетевыми объектами (работать с разными процессами).
Примером прикладного процесса, использующего TCP, может служить FTP, при этом будет работать стек протоколов ftp/tcp/ip/ethernet. Хотя протоколы UDP и TCP могли бы для сходных задач использовать разные номера портов, обычно этого не происходит. Модули TCP и UDP выполняют функции мультиплексоров/демультиплексоров между прикладными процессами и IP-модулем. При поступлении пакета в модуль IP он будет передан в TCP- или UDP-модуль согласно коду, записанному в поле протокола данного IP-пакета. Формат сегмента (пакета) TCP представлен ниже на рис. 4.4.3.1.
Если вы хотите глубже разобраться с особенностями работы этого протокола, рекомендуется воспользоваться услугами программы tcpdump, которая позволяет отслеживать содержимое отправляемых и приходящих пакетов в ходе реализации сессии.
Если IP-протокол работает с адресами, то TCP, также как и UDP, с портами. Именно с номеров портов отправителя и получателя начинается заголовок TCP-сегмента. 32-битовое поле код позиции в сообщении определяет порядковый номер первого октета в поле данных пользователя. В приложениях передатчика и приемника этому полю соответствуют 32-разрядные счетчики числа байт, которые при переполнении обнуляются. При значении флага syn=1 в этом поле лежит код ISN (Initial Sequence Number; смотри ниже описание процедуры установления связи), выбираемый для конкретного соединения. Первому байту, передаваемому через созданное соединение, присваивается номер ISN+1. Значение ISN может задаваться случайным образом. Но в UNIX 4.4BSD при загрузке ОС ISN делается равнм 1 (это нарушает требования RFC), а далее увеличивается на 640000 каждые полсекунды. Аналогичная инкрементация осуществляется при установлении нового соединения. В RFC рекомендуется увеличивать счетчик ISN на 1 каждые 4 микросекунды.
32-битовое поле номер октета, который должен прийти следующим содержит код, который на единицу больше номера номера последнего успешно доставленного (принятого) байта. Содержимое этого поля интерпретируется получателем сегмента, только если присутствует флаг ACK. В заголовках всех сегментов, передаваемых после установления соединения это поле заполняется, а флаг AСK=1.
В ТСР предусмотрен режим полнодуплексной передачи. При этом данные могут передаваться в обоих направлениях независимо. В ходе обмена каждая из сторон должна отслеживать позиционные номера передаваемых и принимаемых байт. Если получен сегмент с некоторым кодом поля номер октета, который должен прийти следующим, это означает, что все октеты с номерами меньше указанного в данном поле, доставлены благополучно.
Если благополучно доставлены байты с номерами 0-N, а затем получен сегмент с номерами байтов (N+k) - (N+k+m), такой сегмент будет буферизован, но подтверждения его получения не последует. Вместо этого посылается отклик, с кодом номер октета, который должен прийти следующим =(N+1). В случае получения сегмента с неверной контрольной суммой будет послан отклик, идентичный предыдущему. Дублированные отклики позволяют детектировать потерю пакета.
Поле HLEN - определяет длину заголовка сегмента, которая измеряется в 32-разрядных словах. Это поле нужно, так как в заголовке могут содержаться поля опций пееременной длины. Далее следует поле резерв, предназначенное для будущего использования, в настоящее время должно обнуляться. Поле размер окна сообщает, сколько октетов готов принять получатель (флаг ACK=1) вслед за байтом, указанным в поле номер октета, который должен прийти следующим. Окно имеет принципиальное значение, оно определяет число сегментов, которые могут быть посланы без получения подтверждения. Значение ширины окна может варьироваться во время сессии (смотри описание процедуры "медленного старта"). Значение этого поля равное нулю также допустимо и указывает, что байты вплоть до указанного в поле номер октета, который должен прийти следующим, получены, но адресат временно не может принимать данные. Разрешение на посылку новой информации может быть дано с помощью посылки сегмента с тем же значением поля номер октета, который должен прийти следующим, но ненулевым значением поля ширины окна. Поле контрольная сумма предназначено для обеспечения целостности сообщения. Контрольное суммирование производится по модулю 1. Перед контрольным суммированием к TCP-сегменту добавляется псевдозаголовок, как и в случае протокола , который включает в себя адреса отправителя и получателя, код протокола и длину сегмента, исключая псевдозаголовок. Поле указатель важной информации представляет собой указатель последнего байта, содержащий информацию, которая требует немедленного реагирования.
Поле имеет смысл лишь при флаге URG=1, отмечающем сегмент с первым байтом "важной информации". Значение разрядов в 6-битовом коде флаги описано в таблице 4.4.3.1. Если флаг ACK=0, значение поля номер октета, который должен прийти следующим, игнорируется. Флаг URG=1 устанавливается в случае нажатия пользователем клавиш Del или Ctrl-С.
Таблица 4.4.3.1 Значения бит поля флаги
| Обозначение битов (слева на право) поля флаги | Значение бита, если он равен 1 |
| URG | Флаг важной информации, поле Указатель важной информации имеет смысл, если urg=1. |
| ACK | Номер октета, который должен прийти следующим, правилен. |
| PSH | Этот сегмент требует выполнения операции push. Получатель должен передать эти данные прикладной программе как можно быстрее. |
| RST | Прерывание связи. |
| SYN | Флаг для синхронизации номеров сегментов, используется при установлении связи. |
| FIN | Отправитель закончил посылку байтов. |

Рис. 4.4.3.1 Формат TCP-сегмента
Поле опции зарезервировано на будущее и в заголовке может отсутствовать, его размер переменен и дополняется до кратного 32-бит с помощью поля заполнитель. Формат поля опции представлен на рис. 4.4.3.2. В настоящее время определены опции:
0 Конец списка опций.
1 Никаких операций. Используется для заполнения поля опции до числа октетов, кратного 4.
2 Максимальный размер сегмента (MSS).
В поле вид записывается код опции, поле LEN содержит число октетов в описании опции, включая поля вид и LEN. Определены также опции со значением вид=4,5,6,7. В предложении T/TCP (RFC-1644) описаны опции 11, 12 и 13. Поле данные может иметь переменную длину, верхняя его граница задается значением MSS (Maximum Segment Size). Значение MSS может быть задано при установлении соединения каждой из сторон независимо. Для Ethernet MSS=1452 байта.

Рис. 4.4.3.2. Формат опций для TCP-сегментов
Поле данные в TCP-сегменте может и отсутствовать, характер и формат передаваемой информации задается исключительно прикладной программой, теоретически максимальный размер этого поля составляет в отсутствии опций 65495 байт (на практике, помимо MSS, нужно помнить, например, о значении MTU для Ethernet, которое немногим больше 1500 байт).
TCP является протоколом, который ориентируется на согласованную работу ЭВМ и программного обеспечения партнеров, участвующих в обмене информацией. Установление связи клиент-сервер осуществляется в три этапа:
Клиент посылает SYN-сегмент с указанием номера порта сервера, который предлагается использовать для организации канала связи (active open).
Сервер откликается, посылая свой SYN-сегмент, содержащий идентификатор (ISN - Initial Sequence Number). Начальное значение ISN не равно нулю. Процедура называется passive open.
Клиент отправляет подтверждение получения SYN-сегмента от сервера с идентификатором равным ISN (сервера)+1.
Стандартная процедура установления связи представлена на рисунке 4.4.3.3 (под словом “стандартная” подразумевается отсутствие каких-либо отклонений от штатного режима, например, одновременного открывание соединения со стороны сервера и клиента). Если же соединение одновременно инициируется клиентом и сервером, в конечном итоге будет создан только один виртуальный канал.

Рис. 4.4.3.3. Алгоритм установления связи. В рамках представлены состояния клиента и сервера; пунктиром отмечены изменения cостояния после посылки сообщения (см. также рис. 4.4.3.4)
Префикс S на рисунке указывает на сервер, а С - на клиента. Параметры в скобках обозначают относительные значения ISN. После установления соединения ISN(S) = s_seq_1, а ISN(C) = c_seq_1.
Каждое соединение должно иметь свой неповторимый код ISN. Для реализации режима соединения прикладная программа на одном конце канала устанавливается в режим пассивного доступа ("passive open"), а операционная система на другом конце ставится в режим активного доступа ("active open"). Протокол TCP предполагает реализацию 11 состояний (established, closed, listen, syn_sent, syn_received и т.д.; см. также RFC-793), переход между которыми строго регламентирован. Машина состояний для протокола TCP может быть описана диаграммой, представленной на рис. 4.4.3.4. Здесь состояние closed является начальной и конечной точкой последовательности переходов.
Каждое соединение стартует из состояния closed. Из диаграммы машины состояний видно, что ни одному из состояний не поставлен в соответствие какой-либо таймер. Это означает, что машина состояний TCP может оставаться в любом из состояний сколь угодно долго. Исключение составляет keep-alive таймер, но его работа является опционной, а время по умолчанию составляет 2 часа. Это означает, что машина состояния может оставаться 2 часа без движения. В случае, когда две ЭВМ (C и S) попытаются установить связь друг с другом одновременно, реализуется режим simultaneous connection (RFC-793). Обе ЭВМ посылают друг другу сигналы SYN. При поучении этого сигнала партнеры посылают отклики SYN+ACK. Обе ЭВМ должны обнаружить, что SYN и SYN+ACK относятся к одному и тому же соединению. Когда C и S обнаружат, что SYN+ACK соответствует посланному ранее SYN, они выключат таймер установления соединения и перейдут непосредственно в состояние syn_recvd (смотри рис. 4.4.3.4).
В состоянии established пакет будет принят сервером, если его ISN лежит в пределах s_ack, s_ack+s_wind (s_wind - ширина окна для сервера; см. рис. 4.4.3.5). Аналогичный диапазон ISN для клиента выглядит как: c_ack, c_ack+c_wind (c_wind - ширина окна для клиента). c_wind и s_wind могут быть не равны. Пакеты, для которых эти условия не выполняются, будут отброшены.
Рассмотрим пример установления соединения для случая FTP-запроса (См. также ). Пусть клиент С запускает процесс установления FTP-соединения с сервером s. Обычный порядок установления соединения показан ниже (см. рис. 4.4.3.3):
c -> s:syn(isnc)
s -> c:syn(isns), ack(isnc)
c -> s: ack(isns) (Связь установлена)
c -> s: данные
и/или
s -> c: данные
ISN - идентификатор пакета, посылаемого клиентом (С) или сервером (S). Клиент, послав SYN серверу S, переходит в состояние syn_sent. При этом запускается таймер установления соединения. Как при установлении соединения так и при его разрыве приходится сталкиваться с проблемой двух армий. Представим себе, что имеется две армии А и Б, причем Б больше по численности чем А.
Армия Б разделена на две части, размещенные по разные стороны от армии А. Если две части армии Б одновременно нападут на армию А, победа гарантирована. В то же время нападение на А одной из частей армии Б обрекает ее на поражение. Но как обеспечить одновременность? Здесь предполагается, что радио еще не изобретено и передача сообщений осуществляется вестовыми, которые в нашем случае могут быть перехвачены врагом. Как убедиться, что вестовой дошел? Первое, что приходит в голову, это послать другого вестового с подтверждением. Но он также с некоторой вероятностью может быть перехвачен. А отправитель не будет знать, дошел ли он. Ведь если сообщение перехвачено, отправитель первичного запроса не выдаст команды на начало, так как не уверен, дошло ли его первое сообщение. Возникает вопрос, существует ли алгоритм, который бы гарантировал надежность синхронизации решений путем обмена сообщениями при ненадежной доставке? Повысит ли достоверность увеличение числа обменов между партнерами? Ответом на этот вопрос будет - нет, не существует. В этом читатель, порассуждав логически, может убедиться самостоятельно. Не трудно видеть, что схожие проблемы возникают в любом протоколе, работающем через установление соединения. Чаще всего эта проблема решается путем таймаутов и повторных попыток (это, слава богу, не война и все обходится без людских жертв).
Сервер, получив SYN, откликается посылкой другого SYN. Когда С получает SYN от S (но не получает ACK, например, из-за его потери или злого умысла), он предполагает, что имеет место случай одновременного открытия соединения. В результате он посылает syn_ack, отключает таймер установления соединения и переходит в состояние syn_received. Сервер получает syn_ack от C, но не посылает отклика. Тогда С ожидает получения syn_ack в состоянии syn_received. Так как время пребывания в этом состоянии не контролируется таймером, С может остаться в состоянии syn_received вечно. Из-за того, что переходы из состояния в состояние не всегда четко определены, протокол TCP допускает и другие виды атак (некоторые из них описаны в разделе ), там же рассмотрены алгоритмы задания и изменения ISN.
Хотя TCP- соединение является полнодуплексным, при рассмотрении процесса разрыва связи проще его рассматривать как два полудуплексных канала, каждый из которых каналов ликвидируется независимо. Сначала инициатор разрыва посылает сегмент с флагом FIN, сообщая этим партнеру, что не намерен более что-либо передавать (FIN посылается, как правило в результате вызова приложением функции close). Когда получение этого сегмента будет подтверждено (ACK), данное направление передачи считается ликвидированным (реализуется полузакрытие соединения). При этом передача информации в противоположном направлении может беспрепятственно продолжаться. Когда партнер закончит посылку данных, он также пошлет сегмент с флагом FIN. По получении отклика ACK виртуальный канал считается окончательно ликвидированным. Таким образом, для установление связи требуется обмен тремя сегментами, а для разрыва - четырьмя. Но протокол допускает совмещение первого ACK и второго FIN в одном сегменте, сокращая полное число закрывающих сегментов с четырех до трех. Партнер, пославший флаг FIN первым, производит активное закрытие соедиения, а противоположный партнер (получивший FIN) отвечает на него своим FIN, осуществляя пассивное закрытие соединения. Инициатором посылки первого FIN может любая из сторон, но чаще это делается клиентом (например, путем ввода команды quit). Полузакрытие используется, например при реализации команды rsh (запуск операций в удаленном узле).
Машина состояний для протокола TCP не предусматривает изменения состояний при посылке или получении обычных пакетов, содержащих данные.
Всего в машине конечных состояний протокола TCP имеется 11 состояний (CLOSED, LISTEN, SYN_RCVD, SYN_SENT и т.д., введены в RFC-793). Состояние CLOSED является начальной и конечной точкой диаграммы. ESTABLISHED указывает на то, что система находится в состоянии с установленным соединением. Четыре состояния в левом углу помещены в границы зеленой зоны и соответствуют активному закрытию. Состояния CLOSE_WAIT и LAST_ACK относятся к пассивному закрытию.
Переход из состояния SYN_RCVD в LISTEN возможно, если переход в SYN_RCVD осуществлен из состояния LISTEN, а не из состояния SYN_SENT (одновременное открытие двух соединений, получение RST вместо финального ACK).

Рис. 4.4.3.4. Машина состояний для протокола tcp (W.R. Stivens, TCP/IP Illustrated. V1. Addison-Wesley publishing company. 1993. Имеется обновленная версия книги, переведенная на русский язык: У.Ричард Стивенс, "Протоколы TCP/IP. Практическое руководство", BHV, Санкт-Петербург, 2003)
Состояние TIME_WAIT часто называется ожиданием длительностью 2MSL (Maximum Segment Lifetime). Значение MSL задается конкретной реализацией и определяет предельную величину пребывания сегмента в сети. В RFC-793 рекомендуется задавать MSL равным 2 мин. Но нужно помнить, что ТСР-сегмент транспортируется в IP-дейтаграмме, содержащем поле TTL. Когда модуль выполнил активное закрытие и в ответ на FIN послал ACK, соединение должно оставаться в состоянии TIME_WAIT в течение времени, в два раза превышающем MSL. Сокет, используемый данным соединение не может быть задействован другим соединением в продолжении указанного времени. Все сегменты данного соединения, задержавшиеся в пути, во время TIMR_WAITотбрасываются. Это гарантирует то, что сегменты старого соединения не будут восприняты новым соедиением. Такая процедура препятствует перезапуску серверов в течение 1-4 минут, так как в течение данного времени не могут использоваться стандартные значения номеров портов.
Состояние FIN_WAIT_2 сопряжено со случаем, когда одна сторона послала сегмент FIN, а другая сторона подтвердила его получение. Если данное соединение не нужно, можно ждать, когда приложение другой стороны получит код конца файла и пришлет свой флаг FIN. Только после этого система перейдет из состояний FIN_WAIT_2 в состояние TIME_WAIT. Теоретически такое ожидание может быть бесконечным. Другая сторона при этом остается в состоянии CLOSE_WAIT, пока приложение не вызовет функцию close. Для решения проблемы часто вводят дополнительный таймер.
В ТСР возможна ситуация, когда обе стороны запускают процедуру закрытия одновременно (посылают FIN), что в протоколе ТСР вполне допустимо. Каждая из сторон при этом переходит из состояния ESTABLISHED в состояние FIN_WAIT_1 (после вызова операции closed). По получении FIN стороны переходят из состояния FIN_WAIT_1 в состояние CLOSING и посылают ACK. После получения ACK происходит переход в состояние TIME_WAIT.
Когда оператор, работая в диалоговом режиме, нажимает командную клавишу, сегмент, в который помещается эта управляющая последовательность, помечается флагом PSH (push). Это говорит приемнику, что информация из этого сегмента должна быть передана прикладному процессу как можно скорее, не дожидаясь прихода еще какой-либо информации. Сходную функцию выполняет флаг URG. URG позволяет выделить целый массив данных, так как активизирует указатель последнего байта важной информации. Будет ли какая-либо реакция на эту "важную" информацию определяет прикладная программа получателя. urg-режим используется для прерываний при работе с FTP, telnet или rlogin. Если до завершения обработки "важной" информации придет еще один сегмент с флагом URG, значение старого указателя конца "важного" сообщения будет утеряно. Это обстоятельство должно учитываться прикладными процессами. Так telnet в командных последовательностях всегда помещает префиксный байт с кодом 255.
В режиме удаленного терминала (telnet/ssh) при нажатии любой клавиши формируется и поcылается 41-октетный сегмент (здесь не учитываются издержки Ethernet), который содержит всего один байт полезной информации. В локальной сети здесь проблем не возникает, но в буферах маршрутизаторов в среде Интернет могут возникнуть заторы. Эффективность работы может быть улучшена с помощью алгоритма Нагля (Nagle, 1984; RFC-896). Нагль предложил при однобайтовом обмене посылать первый байт, а последующие буферизовать до прихода подтверждения получения посланного. После этого посылаются все буферизованные октеты, а запись в буфер вводимых кодов возобновляется.
Если оператор вводит символы быстро, а сеть работает медленно, этот алгоритм позволяет заметно понизить загрузку канала. Встречаются, впрочем, случаи, когда алгоритм Нагля желательно отключить, например, при работе в Интернет в режиме Х-терминала, где сигналы перемещения мышки должны пересылаться немедленно, чтобы не ввести в заблуждение пользователя относительно истинного положения маркера.
Существует еще одна проблема при пересылке данных по каналам TCP, которая называется синдром узкого окна (silly window syndrome; Clark, 1982). Такого рода проблема возникает в том случае, когда данные поступают отправителю крупными блоками, а интерактивное приложение адресата считывает информацию побайтно. Предположим, что в исходный момент времени буфер адресата полон и передающая сторона знает об этом (window=0). Интерактивное приложение считывает очередной октет из TCP-потока, при этом TCP-агент адресата поcылает уведомление отправителю, разрешающее ему послать один байт. Этот байт будет послан и снова заполнит до краев буфер получателя, что вызовет отправку ACK со значением window=0. Этот процесс может продолжаться сколь угодно долго, понижая коэффициент использования канала ниже паровозного уровня.
Кларк предложил не посылать уведомление о ненулевом значении ширины окна при считывании одного байта, а лишь после освобождения достаточно большого пространства в буфере. Например, когда адресат готов принять MSS байтов или когда буфер наполовину пуст.
Предполагается, что получатель пакета практически всегда посылает отправителю пакет-отклик. Отправитель может послать очередной пакет, не дожидаясь получения подтверждения для предшествующего. Таким образом, может быть послано k пакетов, прежде чем будет получен отклик на первый пакет (протокол "скользящего окна"). В протоколе TCP "скользящее окно" используется для регулировки трафика и препятствия переполнения буферов. Идея скользящего окна отображена на рис. 4.4.3.5. Здесь предполагается, что ширина окна равна 7 (k=7; это число может меняться в очень широких пределах).

Рис. 4.4.3.5. Схема использования скользящего окна
После прихода отклика на пакет окно смещается вправо на одну позицию. Теперь отправитель может послать и пакет . Если порядок прихода откликов нарушается, сдвиг окна может задержаться. Размер окна в сегментах определяется соотношением:
window > RTT*B/MSS,
где B - полоса пропускания канала в бит/с, а MSS - максимальный размер сегмента в битах, а window - в сегментах.
Для протокола TCP механизм скользящего окна может работать на уровне октетов или сегментов. В первом случае нужно учитывать каждый раз размер поля данных переданного и подтвержденного сегмента. В TCP-протоколе используется три указателя (стрелки на рис. 4.4.3.3б):
Первый указатель определяет положение левого края окна, отделяя посланный сегмент, получивший подтверждение, от посланного сегмента, получение которого не подтверждено. Второй указатель отмечает правый край окна и указывает на сегмент, который может быть послан до получения очередного подтверждения. Третий указатель помечает границу внутри скользящего окна между уже посланными сегментами и теми, которые еще предстоит послать. Получатель организует аналогичные окна для обеспечения контроля потока данных. Если указатель 3 совпадет с указателем 2, отправитель должен прервать дальнейшее отправление пакетов до получения хотя бы одного подтверждения. Обычно получатель посылает одно подтверждение (ACK) на два полученных сегмента.
Регулирование трафика в TCP подразумевает существование двух независимых процессов: контроль доставки, управляемый получателем с помощью параметра window, и контроль перегрузки, управляемый отправителем с помощью окна перегрузки cwnd (congestion window) и ssthreth (slow start threshold). Первый процесс отслеживает заполнение входного буфера получателя, второй - регистрирует перегрузку канала, а также связанные с этим потери и понижает уровень трафика. В исходный момент времени при установлении соединения cwnd делается равным одному MSS, а ssthreth=65535 байтам.
Программа, управляющая пересылкой, никогда не пошлет больше байт, чем это задано cwnd и объявленным получателем значением window. Когда получение очередного блока данных подтверждено, значение cwnd увеличивается. Характер этого увеличения зависит от того, осуществляется медленный старт или реализуется процедура подавления перегрузки. Если cwnd меньше или равно ssthreth, выполняется медленный старт, в противном случае осуществляется подавление перегрузки. В последнем случае cwndi+1 = cwndi + MSS/8 +(MSS*MSS)/cwnd. Если возникает состояние перегрузки канала значение cwnd снова делается равным одному MSS.
В качестве модуля приращения cwnd используется MSS. При получении подтверждения (ACK) окно перегрузки увеличивается на один сегмент ("медленный старт", CWNDi+1 = CWNDi + размер_сегмента, последнее слагаемое нужно, если размер окна задан в октетах, в противном случае вместо него следует использовать 1) и теперь отправитель может послать, не дожидаясь ACK, уже два сегмента и т.д.. Ширина окна, в конце концов, может стать настолько большой, что ошибка доставки в пределах окна станет заметной. Тогда будет запущена процедура “медленного старта” или другой алгоритм, который определит новое, уменьшенное значение окна. Окно перегрузки позволяет управлять информационным потоком со стороны отправителя, блокируя возможные перегрузки и потери данных в промежуточных узлах сети (о других методах подавления перегрузки канала смотри ). Если переполнения не происходит, CWND становится больше окна, объявленного получателем, и именно последнее будет ограничивать поток данных в канале. Размер окна, объявленный получателем, ограничивается произведением полосы пропускания канала (бит/с) на RTT (время распространения пакета туда и обратно). Максимально допустимый размер окна в TCP равен 65535 байт (задается размером поля). Конечной целью регулирования трафика является установление соответствия между темпом передачи и возможностями приема. Причиной перегрузки может быть не только ограниченность размера буфера, но и недостаточная пропускная способность какого-то участка канала.
С учетом этого обстоятельства каждый отправитель формирует два окна: окно получателя и окно перегрузки (ширина этого окна равна cwnd). Каждое из этих окон задает число байтов, которое может послать отправитель. Реальное число байтов, которое разрешено послать, равно минимальному из этих окон. При инициализации соединения окно перегрузки имеет ширину равную максимальному сегменту, который может быть использован в данном канале. Отправитель посылает такой сегмент. Если будет прислано подтверждение до истечения времени таймаута, размер окна перегрузки удваивается и посылается два сегмента максимальной длины. При получении подтверждения доставки каждого из сегментов окно перегрузки увеличивается на один сегмент максимальной длины. Когда ширина окна перегрузки становится равной B сегментов и все B посланных сегментов получают подтверждение, окно перегрузки возрастает на число байт, содержащихся в этих сегментах. Таким образом, ширина окна перегрузки последовательно удваивается, пока доставка всех сегментов подтверждается. Рост ширины окна перегрузки при этом имеет экспоненциальный характер. Это продолжается до тех пор, пока не наступит таймаут или окно перегрузки не сравняется с окном получателя. Именно эта процедура и называется медленным стартом (Джекобсон, 1988).
Как было сказано выше, помимо окон перегрузки и получателя в TCP используется третий параметр - порог (иногда он называется порогом медленного старта ssthresh). При установлении соединения ssthresh=64 Kбайт. В случае возникновения таймаута значение ssthresh делается равным CWND/2, а само значение CWND приравнивается MSS (см. рис. 4.4.3.6). Далее запускается процедура медленного старта, чтобы выяснить возможности канала. При этом экспоненциальный рост cwnd осуществляется вплоть до значения ssthresh. Когда этот уровень cwnd достигнут, дальнейший рост происходит линейно с приращением на каждом шагу равным MSS (рис. 4.4.3.6).

Рис. 4.4.3.6. Эволюция ширины окна при медленном старте
Здесь предполагается, что MSS=1 Кбайт.
Началу диаграммы соответствует установка значения ssthresh=16 Kбайт. Данная схема позволяет более точно выбрать значение cwnd. После таймаута, который на рисунке произошел при передаче c номером 12, значение порога понижается до 12 Кбайт (=cwnd/2). Ширина окна cwnd снова начинает расти от передачи к передаче, начиная с одного сегмента, вплоть до нового значения порога ssthresh=12 Кбайт. Стратегия с экспоненциальным и линейным участками изменения ширины окна переполнения позволяет несколько приблизить среднее его значение к оптимальному. Для локальных сетей, где значение RTT невелико, а вероятность потери пакета мала, оптимизация задания cwnd не так существенна, как в случае протяженных внешних (например, спутниковых) каналов. Ситуация может поменяться, если в локальной сети имеется фрагмент, где вероятность потерь пакетов велика. Таким фрагментом может быть МАС-бридж (или переключатель), один из каналов которого подключен к сегменту Fast Ethernet, а другой к обычному Ethernet на 10 Мбит/c. Если такой мост не снабжен системой подавления перегрузки (до сих пор такие приборы не имели подобных систем), то каждый из пакетов будет потерян в среднем 9 раз, прежде чем будет передан (здесь предполагается, что передача идет из сегмента FE). При этом cwnd будет практически все время равно MSS, что крайне неэффективно при передаче по каналам Интернет. Такие потери вызовут определенные ошибки при вычислении среднего значения и дисперсии RTT, а как следствие и величин таймаутов. Применение в таких местах маршрутизаторов или других приборов, способных реагировать на перегрузку посредством ICMP(4), решает эту проблему.
Для взаимного согласования операций в рамках TCP-протокола используется четыре таймера:
Таймер повторных передач (retransmission; RTO) контролирует время прихода подтверждений (ACK). Таймер запускается в момент посылки сегмента. При получении отклика ACK до истечения времени таймера, он сбраcывается. Если же время таймера истекает до прихода ACK, сегмент посылается адресату повторно, а таймер перезапускается.
Таймер запросов (persist timer), контролирующий размер окна даже в случае, когда приемное окно закрыто. При window=0 получатель при изменении ситуации посылает сегмент с ненулевым значением ширины окна, что позволит отправителю возобновить свою работу. Но если этот пакет будет потерян, возникнет тупик, тогда каждая из сторон ждет сигнала от партнера. Именно в этой ситуации и используется таймер запросов. По истечении времени этого таймера отправитель пошлет сегмент адресату. Отклик на этот сегмент будет содержать новое значение ширины окна. Таймер запускается каждый раз, когда получен сегмент с window=0.
Таймер контроля работоспособности (keepalive), который регистрирует факты выхода из строя или перезагрузки ЭВМ-партнеров. Время по умолчанию равно 2 часам. Keepalive-таймер не является частью TCP-спецификации. Таймер полезен для выявления состояний сервера half-open при условии, что клиент отключился (например, пользователь выключил свою персональную ЭВМ, не выполнив LOGOUT). По истечении времени таймера клиенту посылается сегмент проверки состояния. Если в течение 75 секунд будет получен отклик, сервер повторяет запрос 10 раз с периодом 75 сек, после чего соединение разрывается. При получении любого сегмента от клиента таймер сбрасывается и запускается вновь.
2MSL-таймер (Maximum Segment Lifetime) контролирует время пребывания канала в состоянии TIME_WAIT. Выдержка таймера по умолчанию равно 2 мин (FIN_WAIT-таймер). См. рис. 4.4.3.4. и RFC-793. Таймер запускается при выполнении процедуры active close в момент посылки последнего ACK.
Важным параметром, определяющим рабочие параметры таймеров, является RTT (время путешествия пакета до адресата и обратно). TCP-агент самостоятельно измеряет RTT. Такие измерения производятся периодически и по их результатам корректируется среднее значение RTT:
RTTm = a*RTTm + (1-a)*RTTi,
где RTTi - результат очередного измерения, RTTm - величина, полученная в результате усреднения предыдущих измерений, а - коэффициент сглаживания, обычно равный 0.9.
RFC- 793 рекомендует устанавливать время таймаута для ретрансмиссии (повторной передачи), значение RTO - Retransmission TimeOut равно RTO=RTTm*b, где b равно 2. От корректного выбора этих параметров зависит эффективная работа каналов. Так занижение времени ретрансмиссии приводит к неоправданным повторным посылкам сегментов, перегружая каналы связи. Для более точного выбора RTO необходимо знать дисперсию RTT. Несколько более корректную оценку RTO можно получить из следующих соотношений (предложено Джекобсоном в 1988 году, он же позднее предложил целочисленный алгоритм реализации этих вычислений):
RTTm = RTTm + g(RTTi-RTTm)
D = D + d(|RTTi - RTTm| - D)
RTO = RTTm + 4D,
где D - среднее отклонение RTT от равновесного значения, а коэффициенты g = 0,125, D = 0,25. Чем больше g, тем быстрее растет RTO по отношению к RTT. Это хорошо работает до тех пор, пока не произойдет таймаут и ретрансмиссия. В этом случае, получив ACK, трудно решить, какому сегменту соответствует это подтверждение, первому или второму. На эту проблему впервые обратил внимание Фил Карн. Решением проблемы является приостановка коррекции RTTm при таймауте и ретрансмиссиях. Значение RTO зависит от пропускной способности канала и от специфических задержек, например в случае спутниковых каналов. В основном RTO лежит в секундном диапазоне (5-15 сек). Наиболее вероятная причина потери пакетов - это перегрузка канала на участках между отправителем и приемником. Указанием на то, что пакет потерян, может служить таймаут или получение дубликата сегмента ACK. Если произошел таймаут, система переходит в режим "медленного старта" (ширина окна перегрузки делается равной 1 сегменту, а значение порога медленного старта - ssthresh делается равным двум сегментам). При инициализации канала переменная ssthresh обычно равна 65535. Дублирование ACK индицирует потерю пакета до наступления таймаута. В этом случае сначала меняется алгоритм приращения величины окна перегрузки cwnd (замедляется темп его роста). После прихода очередного ACK новое значение cwnd вычисляется по формуле:
cwndi+1 = cwndi + (размер_сегмента*размер_сегмента)/cwndi + размер_сегмента/8
Если же в этот момент величина окна перегрузки меньше или равна некоторому порогу (ssthresh - slow start threshold, обычно измеряется в байтах), осуществляется "медленный старт". Следует помнить, что TCP требует посылки немедленного подтверждения (дублированного ACK) при обнаружении прихода сегментов с нарушением порядка следования. Причиной нарушения порядка следования может быть флуктуация задержки в сети или потеря пакета. Если получено три или более задублированных ACK, это является убедительным указанием на потерю пакета и, не дожидаясь таймаута, осуществляется его повторная передача. Перехода в режим медленного старта в этом случае не производится, но понижаются значения cwnd и ssthresh (почти вдвое).
Когда TCP-канал закрывается и за время сессии переслано более 16 полых окон, а адресат достижим не через маршрут по умолчанию, то в таблицу маршрутизации заносится следующая информация: усредненное значение RTT, значение дисперсии RTT и ssthresh.
Если в ходе TCP-сессии получено сообщение ICMP(4) (переполнение канала - quench), требующее снижения потока данных, то cwdn делается равным одному сегменту, а величина порога медленного старта ssthresh не изменяется. На ICMP-сообщения о недостижимости сети или ЭВМ программы TCP-уровня не реагируют вообще.
Нулевой размер окна блокирует посылку информации и этим система время от времени пользуется. Что произойдет, если получатель послал сегмент, объявляющий окно ненулевым, а подтверждение получения этого сегмента не прошло? TCP-протокол не предусматривает посылки ACK на само подтверждение. Адресат ждет в этом случае данных, так как он уже объявил о существовании ненулевого окна с помощью соответствующего ACK, а отправитель ждет этого недошедшего ACK, чтобы начать передачу данных. Для разрешения этой тупиковой ситуации используется таймер запросов, который периодически посылает зондирующие сегменты получателю. Цель этого зондирования - выяснение существования окна ненулевой ширины.
Таймер запросов запускается при получении информации об обнулении ширины окна приемником. Если за определенное время не поступает сегмента, сообщающего об изменении размера окна, таймер начинает посылать зондирующие сегменты. Таймер запросов использует базовую временную шкалу с периодом в 500 мсек, а период посылки зондирующих сегментов лежит в диапазоне 5-60 сек. Такой сегмент содержит только один байт данных. Таймер запросов не прерывает своей работы до тех пор, пока не будет подтверждено открытие окна или пока прикладная задача не завершит свою работу, выключив канал связи.
Будучи однажды создан, канал TCP может существовать "вечно". Если клиент и сервер пассивны, они не заметят того, например, что какой-то бульдозер оборвал кабель или спутник связи покоится на дне океана. Чтобы это обнаружить, либо клиент либо сервер должны попытаться послать какую-то информацию. Чтобы информировать систему об этих и подобных им жизненных неурядицах, предусмотрен таймер контроля работоспособности (keepalive). Многим читателям, возможно, приходилось легкомысленно выключать питание своего персонального компьютера, не позаботившись о корректном logout из процедуры telnet или FTP. Если бы не существовало этого таймера, включив ЭВМ, вы бы обнаружили, что "находитесь" в заморском депозитарии, где были вчера. Но таймер контроля работоспособности может и прервать сессию, если какой-то промежуточный маршрутизатор произвел перезагрузку или был вынужден поменять маршрут. Принцип работы таймера работоспособности предельно прост. Если канал пассивен, например, 2 часа, сервер посылает клиенту сегмент-зонд. При этом ЭВМ-клиент может быть в одном из четырех состояний.
Работоспособен и достижим для сервера. Отклик от клиента сбросит таймер работоспособности в ноль (начало отсчета очередных двух часов).
Вышел из строя, выключен или перезагружается. Сервер посылает 10 запросов с интервалом 75 сек. Если отклика нет, канал закрывается и со стороны сервера.
Перезагрузился. Сервер получит отклик типа RESET и канал будет закрыт.
Работоспособен, но не достижим для сервера. Случай тождественен, описанному во втором по порядку пункте.
Временная постоянная таймера keepalive является системной переменной единой для всех пользователей ЭВМ или даже локальной сети.
Расширение пропускной способности и надежности телекоммуникационных каналов делает актуальной совершенствование протоколов. Так как TCP является основным транспортным протоколом, попытки усовершенствовать его предпринимаются, начиная с 1992 года (RFC-1323, Якобсон, Браден и Борман). Целью этих усовершенствований служит повышение эффективности и пропускной способности канала, а также обеспечение безопасности. При этом рассматриваются следующие возможности:
увеличение MTU (максимальный передаваемый блок данных);
расширение окна за пределы 65535 байт;
исключение "трех-сегментного" процесса установления связи и "четырехсегментного" ее прерывания (T/TCP, RFC-1644);
совершенствование механизма измерения RTT. оптимизация отслеживания CWND.
Оптимальный выбор MTU позволяет минимизировать или исключить фрагментацию (и последующую сборку) сегментов. Верхняя граница на MTU налагается значением MSS (максимальный размер сегмента). Разумно находить и запоминать оптимальные значения MTU для каждого конкретного маршрута. Так как в современных системах используются динамические протоколы маршрутизации, поиск оптимального MTU рекомендуется повторять каждые 10 мин (RFC-1191).
Как уже отмечалось, размер TCP-окна определяется произведением полосы канала (в бит/с) на RTT в сек. Для Ethernet c полосой 10 Мбит/с и RTT=3 мсек это произведение равно 3750 байт, а для канала ИТЭФ-ДЕЗИ с пропускной способностью 1,5 Мбит/с и RTT=710 мсек (спутник) - 88750 байт, а это отнюдь не предел современной телекоммуникационной технологии. Но уже эти примеры говорят о том, что максимально возможный размер окна должен быть увеличен в раз 10-100 уже сегодня. Протокол же разрешает 65535 байт. Появление столь мощных каналов порождает и другие проблемы - потеря пакетов в них обходится слишком дорого, так как "медленный старт" и другие связанные с этим издержки сильно снижают пропускную способность.
В последнее время алгоритм медленного старта заменяется более эффективными алгоритмами.
Простое увеличение ширины окна до тех пор, пока не произойдет сбой, плохая стратегия при использовании традиционного медленного старта, так как заметную часть времени ширина окна будет неоптимальной - то слишком большой, то слишком малой. Оптимальная стратегия должна включать в себя прогнозирование оптимальной ширины окна. В новых версиях модулей TCP реализуются именно такие алгоритмы. В 1994 году Бракмо предложил вариант стратегии изменения параметров передачи, который на 40-70% повышает пропускную способность TCP-канала.
Существуют и другие, могущие показаться забавными проблемы. Каждый сегмент в TCP-протоколе снабжается 32-битным идентификатором. Время жизни IP-пакета (TTL) определяется по максимуму 255 шагами или 255 секундами в зависимости оттого, что раньше наступит. Трудно предсказуемая ситуация может произойти, когда канал ликвидирован, затем создан снова (для той же комбинации IP-адресов и портов), а какой-то пакет из предшествующей сессии, погуляв по Интернет, придет уже во время следующей. Есть ли гарантия, что он будет верно идентифицирован? Одной из мер, упомянутых ранее, можно считать использование ограничения по максимальному времени жизни сегмента (MSL) или TTL, хотя снижение значения TTL не всегда возможно - ведь IP-пакетами пользуется не только TCP-протокол и нужна очень гибкая система задания его величины. Во многих приложениях MSL=30 сек (рекомендуемое значение 2 мин слишком велико). Технический прогресс ставит и некоторые новые проблемы. Высокопроизводительные каналы (1 Гбит/с) уже сегодня могут исчерпать разнообразие идентификационных кодов пакетов за один сеанс связи. Появление же двух пакетов с равными идентификаторами может породить неразрешимые трудности. Для передачи мегабайтного файла по гигабитному каналу требуется около 40 мсек (при этом предполагается, что задержка в канале составляет 32 мсек (RTT=64 мсек)). Собственно передача этой информации занимает 8 мсек.
Из этих цифр видно, что традиционные протоколы, размеры окон и пр. могут свести на нет преимущества скоростного (дорогостоящего) канала. Пропускная способность такого канала определяется уже не его полосой, а задержкой. Понятно также, что необходимо расширить поле размера окна с 16 до 32 бит. Чтобы не изменять формат TCP-сегментов, можно сделать код размера окна в программе 32-разрядным, сохранив соответствующее поле в сегменте неизменным. Размер окна в этом случае задается как бы в формате с плавающей запятой. При установлении канала определяется масштабный коэффициент n (порядок) лежащий в интервале 0-14. Передача этого коэффициента (один байт) осуществляется сегментом SYN в поле опций. В результате размер окна оказывается равным 65535*2n. Если один из партнеров послал ненулевой масштабный коэффициент, но не получил такого коэффициента от своего партнера по каналу, то n считается равным нулю. Эта схема позволит сосуществовать старым и новым системам. Выбор n возлагается на TCP-модуль системы.
Для того чтобы точнее отслеживать вариации RTT, предлагается помещать временные метки в каждый посылаемый сегмент. Так как в TCP используется одно подтверждение ACK на несколько сегментов, правильнее будет сказать, что RTT измеряется при посылке каждого ACK. Способность и готовность партнеров работать в таком режиме временных меток определяется на фазе установления канала. Более точное вычисление RTT позволяет не только корректно выбрать временные постоянные для таймеров, правильно вычислить задержку TIME_WAIT (TIME_WAIT=8*RTO), но и отфильтровать "старые" сегменты. Идеология временных меток используется и в алгоритме PAWS (Protection Against Wrapped Sequence Numbers) для защиты против перепутывания номеров сегментов.
Предлагаемое усовершенствование TCP - T/TCP модифицирует алгоритмы выполнения операций. T/TCP вводит новую 32-битную системную переменную - число соединений (CC). СС позволяет сократить число пересылаемых сегментов при установлении канала, а также отфильтровывать "старые" сегменты, не принадлежащие данной сессии (установленной связи).
Время отклика клиента в рамках указанных алгоритмов сокращается до суммы RTT и времени обработки запроса процессором. Данные пришедшие до SYN-сегмента должны буферизоваться для последующей обработки, а не отбрасываться.
Ethernet (10 Мбит/c) в идеальных условиях позволяет осуществить обмен в рамках протокола TCP (например, при FTP-сессии) со скоростью 1,18 Мбайт/с.
Как уже отмечалось, максимальная длина сегмента (MSS - Maximum Segment Size) в TCP-обменах величина переменная. Длина сегмента определяет длину кадра, в который он вложен. Для локальных Ethernet-сетей MSS=1460 октетов. Чем длиннее кадр, тем выше пропускная способность сети (меньше накладные расходы на заголовок кадра). С другой стороны, при передаче дейтаграмм по внешним каналам, где размер пакета не столь велик, большое значение MSS приведет к фрагментации пакетов, которая замедлит обмен, поэтому администратор сети должен взвешивать последствия, задавая значения размера сегментов. Если MSS явно не задан, устанавливается значение по умолчанию (536 байт), что соответствует 576-байтной IP-дейтаграмме. Для нелокальных адресов - это, как правило, разумный выбор.
Ликвидация связи требует посылки четырех сегментов. TCP-протокол допускает возможность, когда один из концов канала объявляет о прекращении посылки данных (посылает FIN-сегмент), продолжая их получать (режим частичного закрытия - half-close). Посылка сегмента FIN означает выполнение операции active close. Получатель FIN-сегмента должен послать подтверждение его получения. Когда противоположный конец, получивший FIN, закончит пересылку данных, он пошлет свой FIN-сегмент. Прием подтверждения на получение этого сегмента означает закрытие данного канала связи. Возможно прерывание связи и с помощью посылки RST-сегмента. В этом случае все буферы и очереди очищаются немедленно и часть информации будет потеряна.
Протокол UDP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Протокол UDP (User Datagram Protocol, RFC-768) является одним из основных протоколов, расположенных непосредственно над IP. Он предоставляет прикладным процессам транспортные услуги, немногим отличающиеся от услуг протокола IP. Протокол UDP обеспечивает доставку дейтограмм, но не требует подтверждения их получения. Протокол UDP не требует соединения с удаленным модулем UDP ("бессвязный" протокол). К заголовку IP-пакета udp добавляет поля порт отправителя и порт получателя, которые обеспечивают мультиплексирование информации между различными прикладными процессами, а также поля длина udp-дейтограммы и контрольная сумма, позволяющие поддерживать целостность данных. Таким образом, если на уровне ip для определения места доставки пакета используется адрес, на уровне UDP - номер порта.
Примерами сетевых приложений, использующих UDP, являются NFS (Network File System), TFTP (Trivial File Transfer protocol, RFC-1350), RPC (Remote Procedure Call, RFC-1057) и SNMP (Simple Network Management Protocol, RFC-1157). Малые накладные расходы, связанные с форматом UDP, а также отсутствие необходимости подтверждения получения пакета, делают этот протокол наиболее популярным при реализации приложений мультимедиа, но главное его место работы - локальные сети и мультимедиа.
Прикладные процессы и модули UDP взаимодействуют через UDP-порты. Эти порты нумеруются, начиная с нуля. Прикладной процесс, предоставляющий некоторые услуги (сервер), ожидает сообщений, направленных в порт, специально выделенный для этих услуг. Программа-сервер ждет, когда какая-нибудь программа-клиент запросит услугу.
Например, сервер snmp всегда ожидает сообщения, адресованного в порт 161. Если клиент snmp желает получить услугу, он посылает запрос в UDP-порт 161 на машину, где работает сервер. На каждой машине может быть только один агент SNMP, т.к. существует только один порт 161. Данный номер порта является общеизвестным, т.е. фиксированным номером, официально выделенным в сети Internet для услуг SNMP.
Общеизвестные номера портов определяются стандартами Internet (см. табл. 4.4.2.1).
Данные, отправляемые прикладным процессом через модуль UDP, достигают места назначения как единое целое. Например, если процесс-отправитель производит 5 записей в порт, то процесс-получатель должен будет сделать 5 чтений. Размер каждого записанного сообщения будет совпадать с размером каждого прочитанного. Протокол UDP сохраняет границы сообщений, определяемые прикладным процессом. Он никогда не объединяет несколько сообщений в одно и не делит одно сообщение на части. Формат UDP-сообщений представлен ниже на рис. 4.4.2.1:

Длина сообщения равна числу байт в UDP-дейтограмме, включая заголовок. Поле UDP контрольная сумма содержит код, полученный в результате контрольного суммирования UDP-заголовка и поля данные. Не трудно видеть, что этот протокол использует заголовок минимального размера (8 байт). Таблица номеров UDP-портов приведена ниже (4.4.2.1). Номера портов от 0 до 255 стандартизованы и использовать их в прикладных задачах не рекомендуется. Но и в интервале 255-1023 многие номера портов заняты, поэтому прежде чем использовать какой-то порт в своей программе, следует заглянуть в RFC-1700. Во второй колонке содержится стандартное имя, принятое в Internet, а в третей - записаны имена, принятые в unix.
Таблица 4.4.2.1 Номера UDP-портов (более полный перечень в RFC-1700; Если какой-то номер порта в перечне отсутствует, это не означает, что он не зарезервирован и его можно использовать, просто я сэкономил место)
| Десятич. номер порта | Обозначение порта | Описание | |
| в Интернет | в Unix | ||
| 0 | - | - | Зарезервировано |
| 1 | TCPmux | - | tcp Мультиплексор |
| 2 | Compressnet | - | Программа управления |
| 3 | Compressnet | - | Процесс сжатия |
| 5 | RJE | - | Вход в удаленную задачу |
| 7 | Echo | echo | Эхо |
| 9 | Discard | discard | Сброс |
| 11 | Users | systat | Активные пользователи |
| 13 | Daytime | daytime | Время дня |
| 15 | - | Netstat | Кто работает или netstat |
| 19 | Chargen | chargen | Генератор символов |
| 20 | FTP-data | ftp-data | FTP (данные) |
| 21 | FTP | ftp | Протокол пересылки файлов (управление) |
| 23 | telnet | telnet | Подключение терминала |
| 24 | - | - | Любая частная почтовая система |
| 25 | SMTP | smtp | Протокол передачи почтовых сообщений |
| 31 | MSG-auth | Распознавание сообщения (аутентификация) | |
| 35 | - | - | Любой частный принт-сервер |
| 37 | Time | time | Время |
| 39 | RLP | - | Протокол поиска ресурсов |
| 41 | Graphics | Графика | |
| 42 | nameserver | name | Сервер имен |
| 43 | Nicname | whois | Кто это? (whois-сервис) |
| 45 | MPM | - | Блок обработки входных сообщений |
| 46 | MPM-snd | - | Блок обработки выходных сообщений |
| 48 | Auditd | - | Демон цифрового аудита |
| 49 | login | - | Протокол входа в ЭВМ |
| 50 | RE-mail-ck | - | Протокол удаленного контроля почтовым обменом |
| 53 | Domain | nameserver | Сервер имен доменов (dns) |
| 57 | - | - | Любой частный терминальный доступ |
| 59 | - | - | Любой частный файл-сервер |
| 64 | covia | - | Коммуникационный интегратор (ci) |
| 66 | SQL*net | - | Oracle SQL*net |
| 67 | Bootps | Bootps | Протокол загрузки сервера |
| 68 | Bootpc | bootpc | Протокол загрузки клиента |
| 69 | TFTP | tftp | Упрощенная пересылка файлов |
| 70 | Gopher | - | Gopher (поисковая система) |
| 71 | - | Netrjs-1 | Сервис удаленных услуг |
| 77 | - | rje | Любой частный RJE-сервис |
| 79 | Finger | finger | finger |
| 80 | WWW-HTTP | World Wide Web HTTP | |
| 81 | Hosts2-NS | - | Сервер имен 2 |
| 87 | - | - | Любая частная терминальная связь |
| 88 | Kerberos | Kerberos | |
| 92 | NPP | - | Протокол сетевой печати |
| 93 | DCP | - | Протокол управления приборами |
| 95 | Supdup | supdup | Supdup протокол |
| 97 | Swift-rvf | - | swift-протокол удаленных виртуальных файлов |
| 101 | Hostname | hostnames | Сервер имен ЭВМ для сетевого информационного центра |
| 102 | ISO-Tsap | iso-tsap | ISO-Tsap |
| 103 | GPPitnp | Сети точка-точка | |
| 104 | ACR-nema | ACR-nema digital IMAG. & comm. 300 | |
| 108 | Snagas | sna-сервер доступа | |
| 109 | POP2 | - | Почтовый протокол pop2 |
| 110 | POP3 | - | Почтовый протокол POP3 |
| 111 | SUNRPC | sunrpc | SUN microsystem RPC |
| 113 | Auth | auth | Служба распознавания |
| 114 | Audionews | Аудио-новости | |
| 115 | SFTP | Простой протокол передачи файлов | |
| 117 | UUCP-path | uucp-path | Служба паролей uucp |
| 118 | SQLserv | SQL-сервер | |
| 119 | NNTP | NNTP | Протокол передачи новостей |
| 123 | NTP | NTP | Сетевой протокол синхронизации |
| 129 | PWDgen | Протокол генерации паролей | |
| 130-132 | Cisco | ||
| 133 | Statsrv | Сервер статистики | |
| 134 | Ingres-net | Ingres-net-сервис | |
| 135 | LOC-srv | Поисковый сервис | |
| 137 | Netbios-SSN | - | Служба имен Netbios |
| 138 | Netbios-DGM | Служба дейтограмм netbios | |
| 139 | Netbios-SSN | Служба сессий Netbios | |
| 147 | ISO-IP | ISO-IP | |
| 150 | SQL-net | SQL net | |
| 152 | BFTP | Протокол фоновой пересылки файлов | |
| 156 | SQLsrv | SQL-сервер | |
| 158 | PCmail-srv | PC почтовый сервер | |
| 161 | - | SNMP | Сетевой монитор SNMP |
| 162 | - | SNMP-trap | SNMP-ловушки |
| 170 | Print-srv | postscript сетевой сервер печати | |
| 179 | BGP | Динамический протокол внешней маршрутизации | |
| 191 | Prospero | Служба каталогов Prospero | |
| 194 | IRC | Протокол Интернет для удаленных переговоров | |
| 201-206 | Протоколы сетей Apple talk | ||
| 213 | IPX | ipx | |
| 348 | CSI-SGWP | Протокол управления cabletron | |
| 396 | Netware-IP | Novell-Netware через IP | |
| 398 | Kryptolan | Kryptolan | |
| 414 | Infoseek | Infoseek (информационный поиск) | |
| 418 | Hyper-g | Hyper-g | |
| 444 | SNPP | Простой протокол работы со страницами | |
| 512 | - | biff (exec) | Unix Comsat (удаленное исполнение) |
| 513 | - | Who | Unix Rwho daemon |
| 514 | - | syslog | Дневник системы |
| 515 | Printer | Работа с буфером печати (spooler) | |
| 525 | - | Timed | Драйвер времени |
Зарегистрировано ряд портов для стандартного применения и в диапазоне 1024-65535. Например:
| Номер порта | Обозначение | Назначение |
| 1397 | Аudio-activmail | Активная звуковая почта |
| 1398 | Video-activmail | Активная видео-почта |
| 5002 | RFE | Радио-Ethernet |
| 6000-6063 | X11 | Система X Window |
| 7008 | AFS3-update | Сервер-сервер актуализация |
Модуль IP передает поступающий IP-пакет модулю UDP, если в заголовке этого пакета указан код протокола UDP. Когда модуль UDP получает дейтограмму от модуля IP, он проверяет контрольную сумму, содержащуюся в ее заголовке. Если контрольная сумма равна нулю, это означает, что отправитель ее не подсчитал. ICMP, IGMP, UDP и TCP протоколы имеют один и тот же алгоритм вычисления контрольной суммы (RFC-1071). Но вычисление контрольной суммы для UDP имеет некоторые особенности. Во-первых, длина UDP-дейтограммы может содержать нечетное число байт, в этом случае к ней добавляется нулевой байт, который служит лишь для унификации алгоритма и никуда не пересылается. Во-вторых, при расчете контрольной суммы для UDP и TCP добавляются 12-байтные псевдо-заголовки, содержащие IP-адреса отправителя и получателя, код протокола и длину дейтограммы (см. рис. 4.4.2.2). Как и в случае IP-дейтограммы, если вычисленная контрольная сумма равна нулю, в соответствующее поле будет записан код 65535.

Рис. 4.4.2.2. Псевдозаголовок, используемый при расчете контрольной суммы
Если контрольная сумма правильная (или равна 0), то проверяется порт назначения, указанный в заголовке дейтограммы. Если прикладной процесс подключен к этому порту, то прикладное сообщение, содержащиеся в дейтограмме, становится в очередь к прикладному процессу для прочтения. В остальных случаях дейтограмма отбрасывается. Если дейтограммы поступают быстрее, чем их успевает обрабатывать прикладной процесс, то при переполнении очереди сообщений поступающие дейтограммы отбрасываются модулем UDP. Следует учитывать, что во многих посылках контрольное суммирование не охватывает адреса отправителя и места назначения. При некоторых схемах маршрутизации это приводит к зацикливанию пакетов в случае повреждения его адресной части (адресат не признает его "своим").
Так как максимальная длина IP-дейтограммы равна 65535 байтам, максимальная протяженность информационного поля UDP-дейтограммы составляет 65507 байт. На практике большинство систем работает с UDP-дейтограммами с длиной 8192 байта или менее. Детальное описание форматов, полей пакетов и пр. читатель может найти в RFC-768.
Протокол управления SNMP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Интернет - гигантская сеть. Напрашивается вопрос, как она сохраняет свою целостность и функциональность без единого управления? Если же учесть разнородность ЭВМ, маршрутизаторов и программного обеспечения, используемых в сети, само существование Интернет представится просто чудом. Так как же решаются проблемы управления в Интернет? Отчасти на этот вопрос уже дан ответ - сеть сохраняет работоспособность за счет жесткой протокольной регламентации. "Запас прочности" заложен в самих протоколах. Функции диагностики возложены, как было сказано выше, на протокол ICMP. Учитывая важность функции управления, для этих целей создано два протокола SNMP(Simple Network Management Protocol, RFC-1157, -1215, -1187, -1089 разработан в 1988 году) и CMOT (Common Management Information services and protocol over TCP/IP, RFC-1095, в последнее время применение этого протокола ограничено). Обычно управляющая прикладная программа воздействует на сеть по цепочке SNMP-UDP-IP-Ethernet. Наиболее важным объектом управления обычно является внешний порт сети (gateway) или маршрутизатор сети. Каждому управляемому объекту присваивается уникальный идентификатор.
Протокол SNMP работает на базе транспортных возможностей UDP (возможны реализации и на основе ТСР) и предназначен для использования сетевыми управляющими станциями. Он позволяет управляющим станциям собирать информацию о положении в сети Интернет. Протокол определяет формат данных, а их обработка и интерпретация остаются на усмотрение управляющих станций или менеджера сети. SNMP-сообщения не имеют фиксированного формата и фиксированных полей. При своей работе SNMP использует управляющую базу данных (MIB - management information base, RFC-1213, -1212).
Алгоритмы управления в Интернет обычно описывают в нотации ASN.1 (Abstract Syntax Notation). Все объекты в Интернет разделены на 10 групп и описаны в MIB: система, интерфейсы, обмены, трансляция адресов, IP, ICMP, TCP, UDP, EGP, SNMP. В группу "система" входит название и версия оборудования, операционной системы, сетевого программного обеспечения и пр..
В группу "интерфейсы" входит число поддерживаемых интерфейсов, тип интерфейса, работающего под IP (Ethernet, LAPB etc.), размер дейтограмм, скорость обмена, адрес интерфейса. IP-группа включает в себя время жизни дейтограмм, информация о фрагментации, маски субсетей и т.д. В TCP-группу входит алгоритм повторной пересылки, максимальное число повторных пересылок и пр.. Ниже приведена таблица (4.4.13.1) команд (pdu - protocol data unit) SNMP:
Таблица 4.4.13.1 Команды SNMP
| Команда SNMP | Тип PDU | Назначение |
| GET-request | 0 | Получить значение указанной переменной или информацию о состоянии сетевого элемента; |
| GET_next_request | 1 | Получить значение переменной, не зная точного ее имени (следующий логический идентификатор на дереве MIB); |
| SET-request | 2 | Присвоить переменной соответствующее значение. Используется для описания действия, которое должно быть выполнено; |
| GET response | 3 | Отклик на GET-request, GET_next_request и SET-request. Содержит также информацию о состоянии (коды ошибок и другие данные); |
| TRAP | 4 | Отклик сетевого объекта на событие или на изменение состояния. |
| GetBulkRequest | 5 | Запрос пересылки больших объемов данных, например, таблиц. |
| InformRequest | 6 | Менеджер обращает внимание партнера на определенную информацию в MIB. |
| SNMPv3-Trap | 7 | Отклик на событие (расширение по отношению v1 и v2). |
| Report | 8 | Отчет (функция пока не задана). |

Рис. 4.4.13.1 Схема запросов/откликов SNMP
Формат SNMP-сообщений, вкладываемых в UDP-дейтограммы, имеет вид (рис. 4.4.13.2):
Поле версия содержит значение, равное номеру версии SNMP минус один. Поле пароль (community - определяет группу доступа) содержит последовательность символов, которая является пропуском при взаимодействии менеджера и объекта управления. Обычно это поле содержит 6-байтовую строку public, что означает общедоступность. Для запросов GET, GET-next и SET значение идентификатора запроса устанавливается менеджером и возвращается объектом управления в отклике GET, что позволяет связывать в пары запросы и отклики.
Поле фирма (enterprise) = sysobjectid объекта. Поле статус ошибки характеризуется целым числом, присланным объектом управления:
Таблица 4.4.13.2. Номера и назначения используемых портов
| Назначение | Порт | Пояснение |
| SNMP | 161/TCP | Simple Network Management Protocol |
| SNMP | 162/TCP | Trap |
| SMUX | 199/TCP | SNMP Unix Multiplexer |
| SMUX | 199/UDP | SNMP Unix Multiplexer |
| synoptics-relay | 391/TCP | SynOptics SNMP Relay Port |
| synoptics-relay | 391/UDP | SynOptics SNMP Relay Port |
| agentx | 705/TCP | AgentX |
| snmp-tcp-port | 1993/TCP | cisco SNMP TCP port |
| snmp-tcp-port | 1993/UDP | cisco SNMP TCP port |
| Статус ошибки | Имя ошибки | Описание |
| 0 | Noerror | Все в порядке; |
| 1 | Toobig | Объект не может уложить отклик в одно сообщение; |
| 2 | Nosuchname | В операции указана неизвестная переменная; |
| 3 | badvalue | В команде set использована недопустимая величина или неправильный синтаксис; |
| 4 | Readonly | Менеджер попытался изменить константу; |
| 5 | Generr | Прочие ошибки. |
Таблица 4.4.13.4. Коды TRAP
| Тип TRAP | Имя TRAP | Описание |
| 0 | Coldstart | Установка начального состояния объекта. |
| 1 | Warmstart | Восстановление начального состояния объекта. |
| 2 | Linkdown | Интерфейс выключился. Первая переменная в сообщении идентифицирует интерфейс. |
| 3 | Linkup | Интерфейс включился. Первая переменная в сообщении идентифицирует интерфейс. |
| 4 | Authenticationfailure | От менеджера получено snmp-сообщение с неверным паролем (community). |
| 5 | EGPneighborloss | R$GP-партнер отключился. Первая переменная в сообщении определяет IP-адрес партнера. |
| 6 | Entrprisespecific | Информация о TRAP содержится в поле специальный код. |
Поле временная метка содержит число сотых долей секунды (число тиков) с момента инициализации объекта управления. Так прерывание coldstart выдается объектом через 200 мс после инициализации.
В последнее время широкое распространение получила идеология распределенного протокольного интерфейса DPI (Distributed Protocol Interface). Для транспортировки snmp-запросов может использоваться не только UDP-, но и TCP-протокол. Это дает возможность применять SNMP-протокол не только в локальных сетях. Форматы SNMP-DPI-запросов (версия 2.0) описаны в документе RFC-1592. Пример заголовка snmp-запроса (изображенные поля образуют единый массив; см. рис. 4.4.13.3):
Поле Флаг=0x30 является признаком ASN.1-заголовка. Коды Ln - представляют собой длины полей, начинающиеся с байта, который следует за кодом длины, вплоть до конца сообщения-запроса (n - номер поля длины), если не оговорено другое. Так L1 - длина пакета-запроса, начиная с T1 и до конца пакета, а L3 - длина поля пароля. Субполя Tn - поля типа следующего за ними субполя запроса. Так T1=2 означает, что поле характеризуется целым числом, а T2=4 указывает на то, что далее следует пароль (поле community, в приведенном примере = public). Цифры под рисунками означают типовые значения субполей. Код 0xA - является признаком GET-запроса, за ним следует поле кода PDU (=0-4, см. табл. 4.4.13.1) Блок субполей идентификатора запроса служит для тех же целей, что и другие идентификаторы - для определения пары запрос-отклик. Собственно идентификатор запроса может занимать один или два байта, что определяется значением Lиз. СО - статус ошибки (СО=0 - ошибки нет); ТМ - тип MIB-переменной (в приведенном примере = 0x2B); ИО - индекс ошибки. Цифровой код MIB-переменной отображается последовательностью цифровых субполей, характеризующих переменную, например: переменная 1.3.6.1.2.1.5 (в символьном выражении iso.org.dod.internet.mgmt.mib.icmp) характеризуется последовательностью кодов 0x2B 0x06 0x01 0x02 0x01 0x05 0x00.
Начиная с января 1998 года, выпущен набор документов, посвященных SNMPv3.
В этой версии существенно расширена функциональность (см. таблицу 1 тип PDU=5-8), разработана система безопасности. В данной версии реализована модель, базирующаяся на процессоре SNMP (SNMP Engene) и содержащая несколько подсистем (дипетчер, система обработки сообщений, безопасности и управления доступом, см. рис. 4.4.13.4). Перечисленные подсистемы служат основой функционирования генератора и обработчика команд, отправителя и обработчика уведомлений и прокси-сервера (Proxy Forwarder), работающих на прикладном уровне. Процессор SNMP идентифицируется с помощью snmpEngineID. Обеспечение безопасности модели работы SNMP упрощается обычно тем, что обмен запросами-откликами осуществляется в локальной сети, а источники запросов-откликов легко идентифицируются.

Рис. 4.4.13.4. Архитектура сущности SNMP (SNMP-entity)
Компоненты процессора SNMP перечислены в таблице 4.4.13.5 (смотри RFC 2571 и -2573)
Таблица 4.4.13.5. Компоненты процессора SNMP
| Название компонента | Функция компонента |
| Диспетчер | Позволяет одновременную поддержку нескольких версий SNMP-сообщений в процессоре SNMP. Этот компонент ответственен за прием протокольных блоков данных (PDU), за передачу PDU подсистеме обработки сообщений, за передачу и прием сетевых SNMP-сообщений |
| Подсистема обработки сообщений | Ответственна за подготовку сообщений для отправки и за извлечение данных из входных сообщений |
| Подсистема безопасности | Предоставляет услуги, обеспечивающие безопасность: аутентификацию и защищенность сообщений от перехвата и искажения. Допускается реализация нескольких моджелей безопасности |
| Подсистема управления доступом | Предоставляет ряд услуг авторизации, которые могут использоваться приложениями для проверки прав доступа. |
| Генератор команд | Инициирует SNMP-запросы Get, GetNext, GetBulk или Set, предназначенные для локальной системы, которые могут использоваться приложениями для проверки прав доступа. |
| Обработчик команд | Воспринимает SNMP-запросы Get, GetNext, GetBulk или Set, предназначенные для локальной системы, это индицируется тем, что contextEngeneID в полученном запросе равно соответствующему значению в процессоре SNMP. Приложение обработчика команд выполняет соответствующие протокольные операции, генерирует сообщения отклика и посылает их откправителю запроса. |
| Отправитель уведомлений | Мониторирует систему на предмет выявления определенных событий или условий и генерирует сообщения Trap или Inform. Источник уведомлений должен иметь механизм определения адресата таких сообщений, а также параметров безопасности |
| Получатель уведомлений | Прослушивает сообщения уведомления и формирует сообщения-отклики, когда приходит сообщение с PDU Inform |
| Прокси-сервер | Переадресует SNMP-сообщения. Реализация этогог модуля является опционной |
br>
На рис. 4.4.13. 5 показан формат сообщений SNMPv3, реализующий модель безопасности UBM (User-Based Security Model).
Первые пять полей формируются отправителем в рамках модели обработки сообщений и обрабатываются получателем. Следующие шесть полей несут в себе параметры безопасности. Далее следует PDU (блок поля данных) с contextEngeneID и contextName.
.
msgVersion (для SNMPv3)=3
msgID - уникальный идентификатор, используемый SNMP-сущностями для установления соответствия между запросом и откликом. Значение msgID лежит в диапазоне 0 - (231-1)
msgMaxSize - определяет максимальный размер сообщения в октетах, поддерживаемый отправителем. Его значение лежит в диапазоне 484 - (231-1) и равно максимальному размеру сегмента, который может воспринять отправитель.
msgFlags - 1-октетная строка, содержащая три флага в младших битах: reportableFlag, privFlag, authFlag. Если reportableFlag=1, должно быть прислано сообщение с PDU Report; когда флаг =0, Report посылать не следует. Флаг reportableFlag=1 устанавливается отправителем во всех сообщениях запроса (Get, Set) или Inform. Флаг устанавливается равным нулю в откликах, уведомлениях Trap или сообщениях Report. Флаги privFlag и authFlag устанавливаются отправителем для индикации уровня безопасности для данного сообщения. Для privFlag=1 используется шифрование, а для authFlag=0 - аутентификация. Допустимы любые комбинации значений флагов кроме privFlag=1 AND authFlag=0 (шифрование бех аутентификации).
msgSecurityModel - идентификатор со значением в диапазоне 0 - (231-1), который указывает на модель безопасности, использованную при формировании данного сообщения. Зарезервированы значения 1 для SNMPv1,2 и 3 - для SNMPv3.
Модель безопасности USM (User-Based Security Model) использует концепцию авторизованного сервера (authoritative Engene). При любой передаче сообщения одна или две сущности, передатчик или приемник, рассматриваются в качестве авторизованного SNMP-сервера. Это делается согласно следующим правилам:
Когда SNMP-сообщение содержит поле данных, которое предполагает отклик (например, Get, GetNext, GetBulk, Set или Inform), получатель такого сообщения считается авторизованным.
Когда SNMP- сообщение содержит поле данных, которое не предполагает посылку отклика (например, SNMPv2-Trap, Response или Report), тогда отправитель такого сообщения считается авторизованным.
Таким образом, сообщения, посланные генератором команд, и сообщения Inform, посланные отправителем уведомлений, получатель является авторизованным. Для сообщений, посланных обработчиком команд или отправителем уведомлений Trap, отправитель является авторизованным. Такой подход имеет две цели:
Своевременность сообщения определяется с учетом показания часов авторизованного сервера. Когда авторизованный сервер посылает сообщение (Trap, Response, Report), оно содержит текущее показание часов, так что неавторизованный получатель может синхронизовать свои часы. Когда неавторизованный сервер посылает посылает сообщение (Get, GetNext, GetBulk, Set, Inform), он помещает туда текущую оценку показания часов места назначения, позволяя получателю оценить своевременность прихода сообщения.
Процесс локализации ключа, описанный ниже, устанавливает единственного принципала, который может владеть ключем. Ключи могут храниться только в авторизованном сервере, исключая хранение нескольких копий ключа в разных местах.
Когда исходящее сообщение передается процессором сообщений в USM, USM заполняет поля параметров безопасности в заголовке сообщения. Когда входное сообщение передается обработчиком сообщений в USM, обрабатываются значения параметров безопасности, содержащихся в заголоке сообщения. В параметрах безопасности содержатся:
msgAuthoritativeEngeneID - snmpEngeneID авторизованного сервера, участвующего в обмене. Таким образом, это значение идентификатора отправителя для Trap, Response или Report или адресата для Get, GetNext, GetBulk, Set или Inform.
msgAuthoritativeEngeneBoots - snmpEngeneBoots авторизованного сервера, участвующего в обмене. Объект snmpEngeneBoots является целым в диапазоне 0 - (231-1). Этот код характеризует число раз, которое SNMP-сервер был перезагружен с момента конфигурирования.
msgAuthoritativeEngeneTime - nmpEngeneTime авторизованного сервера, участвующего в обмене. Значение этого кода лежит в диапазоне 0 - (231-1). Этот код характеризует число секунд, которое прошло с момента последней перезагрузки. Каждый авторизованный сервер должен инкрементировать этот код один раз в секунду.
msgUserName - идентификатор пользователя от имени которого послано сообщение.
msgAuthenticationParameters - нуль, если при обмене не используется аутентификация. В противном случае - это аутентификационный параметр.
msgPrivacyParameters - нуль - если не требуется соблюдения конфимденциальности. В противном случае - это параметр безопасности. В действующей модели USM используется алгоритм шифрования DES.
Механизм аутентификации в SNMPv3 предполагает, что полученное сообщение действительно послано принципалом, идентификатор которого содержится в заголовке сообщения, и он не был модифицирован по дороге. Для реализации аутентификации каждый из принципалов, участвующих в обмене должен иметь секретный ключ аутентификации, общий для всех участников (определяется на фазе конфигурации системы). В посылаемое сообщение отправитель должен включить код, который является функцией содержимого сообщения и секретного ключа. Одним из принципов USM является прверка своевременности сообщения (смотри выше), что делает маловероятной атаку с использованием копий сообщения.
Система конфигурирования агентов позволяет обеспечить разные уровни доступа к MIB для различных SNMP-менеджеров. Это делается путем ограничения доступа некоторым агантам к определенным частям MIB, а также с помощью ограничения перечня допустимых операций для заданной части MIB. Такая схема управления доступом называется VACM (View-Based Access Control Model). В процессе управления доступом анализируется контекст (vacmContextTable), а также специализированные таблицы vacmSecurityToGroupTable, vacmTreeFamilyTable и vacmAccessTable.
SNMP-протокол служит примером системы управления, где для достижения нужного результата выдается не команда, а осуществляется обмен информацией, решение же принимается "на месте" в соответствии с полученными данными.
Внедрены подситемы аутентификации, информационной безопасности и управления доступом.
Таблица 4.4.13.6. RFC-документы по протоколу SNMP
| Название | Дата | Наименование документа |
| STD-15 | май 1990 г | Simple Network Management Protocol (RFC-1157) |
| STD-16 | май 1990 г | Structure and Identification of Management Information for TCP/IP-based Internets (RFC-1155) |
| SNMPv2 | ||
| RFC 1902 | январь 1996 г | Structure of Management Information for Version 2 of the Simple Network Management Protocol (SNMPv2) |
| RFC 1903 | январь 1996 г | Textual Conventions for Version 2 of the Simple Network Management Protocol (SNMPv2) |
| RFC 1904 | январь 1996 г | Conformance Statements for Version 2 of the Simple Network Management Protocol (SNMPv2) |
| RFC 1905 | январь 1996 г | Protocol Operations for Version 2 of the Simple Network Management Protocol (SNMPv2) |
| RFC 1906 | январь 1996 г | Transport Mappings for Version 2 of the Simple Network Management Protocol (SNMPv2) |
| RFC 1907 | январь 1996 г | Management Information Base for Version 2 of the Simple Network Management Protocol (SNMPv2) |
| RFC 1908 | январь 1996 г | Coexistence between Version 1 and Version 2 of the Internet-standard Network Management Framework |
| SNMPv3 | ||
| RFC 2570 | апрель 1999 г | Introduction to Version 3 of the Internet-standard Network Management Framework |
| RFC2571 | апрель 1999 г | An Architecture for Describing SNMP Management Frameworks |
| RFC2572 | апрель 1999 г | Message Processing and Dispatching for the Simple Network Management Protocol (SNMP) |
| RFC2573 | апрель 1999 г | SNMP Applications |
| RFC2574 | апрель 1999 г | The User-Based Security Model for Version 3 of the Simple Network Management Protocol (SNMPv3). Безопасность уровня сообщений (MD5 и SHA + DES CBC) |
| RFC2575 | апрель 1999 г | View-based Access Control Model (VACM) for the Simple Network Management Protocol (SNMP) |
Протокол управляющих сообщений
Протокол IPv6 является новой версией IP. IPv6использует протокол управляющих сообщений (ICMP) так, как это определено для IPv4 [RFC-792], но с некоторым количеством изменений. Протокол подключения к группам (IGMP), специфицированный для IPv4 [RFC-1112] был также пересмотрен и включен в протокол ICMP для IPv6. Результирующий протокол называется ICMPv6, и имеет код следующего заголовка 58.
Протокол XTP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Транспортный протокол XTP (xpress transport protocol; ) разработан в 1992 году, является протоколом нового поколения и имеет целью преодолеть недостатки такого популярного протокола как TCP (медленный старт, неэффективная работа при возникновении потерь пакетов). В XTP функции обеспечения надежной передачи данных и управления разделены, протокол допускает управление пропускной способностью канала и успешно справляется с перегрузкой канала. Принципиальной особенностью XTP является независимость от числа участников информационного обмена (обычный режим эквивалентен мультикастингу, по этой причине XTP может использоваться и как мультикастинг-протокол) и возможность работы с MAC, IP или AAL5. Протокол призван в перспективе заменить TCP, UDP, Appletalk и IPX. Мультикастинг в XTP в отличии от других протоколов может гарантировать доставку информации, что может оказаться важным при многоточечном управлении или в некоторых распределенных базах данных.
При передаче больших массивов информации последовательные пакеты нумеруются. В случае потери принимающая сторона посылает отправителю список не доставленных пакетов (TCP повторяет пересылку всех пакетов, начиная с потерянного). Именно алгоритм селективной ретрансмиссии и позволяет повысить эффективность использования канала. Длина пакетов XTP кратна 64 бит. Совокупность информации, описывающей состояние XTP, называется контекстом. Каждый контекст управляет как входящим, так и исходящим потоками данных. Два активных контекста и поток данных образуют ассоциацию. В исходном состоянии контекст оконечной системы пассивен и находится в состоянии ожидания. Первый передаваемый пакет содержит полную адресную информацию. После получения первого пакета контекст становится активным. С этого момента ассоциация сформирована и обмен может происходить в обоих направлениях. Каждый последующий пакет несет в себе ключевой код, определяющий его принадлежность к данному контексту. При завершении передачи устанавливаются соответствующие биты опций, связь разрывается, а контексты возвращаются в пассивное состояние.
Все виды XTP-пакетов имеют один и тот же формат заголовков. Управление контекстом осуществляется с помощью флагов, содержащихся в заголовке. Всего предусмотрено 15 флагов.
На рис. 4.4.5.1 показана зависимость пропускной способности канала для сети ATM при использовании транспортных протоколов TCP и XTP, в обоих случая использовался в качестве базового протокол IP. Измерения производились для приложений типа FTP. Из рисунка видно, что даже 1% потерянных или поврежденных пакетов понижает пропускную способность на 30% при работе с протоколом TCP. XTP требует только три пакета, чтобы сформировать виртуальный канал, в то время как XTP требует для тех же целей семь пакетов. Благодаря своей простоте XTP может легко подменить любой транспортный протокол в любом существующем телекоммуникационном приложении. Протокол предоставляет некоторые услуги недоступные в других протоколах, что оказывается особенно привлекательным для приложений мультимедиа.

Рис. 4.4.5.1. Зависимость пропускной способности канала при использовании протоколов TCP и XTP ( и xtpdata.html XTP 95-20, Xpress Transport Protocol Specification (XTP revision 4.0), 1995, XTP Forum, Santa Barbara, CA 93108 USA )
При 5% потерях пакетов XTP обеспечивает в 6 раз большую пропускную способность, чем TCP. В таблице 4.4.5.1 приведены сравнительные результаты измерения пропускной способности канала ATM (155 Мбит/с) при использовании протоколов TCP, UDP и XTP (использовались пакеты длиной 8190 байт).
Таблица 4.4.5.1. Сравнительные характеристики протоколов TCP, UDPи XTP
| Название протокола | Пропускная способность в Мбит/с |
| TCP | 89-93 |
| UDP | 93-94 |
| XTP | 112-115 |
Из таблицы видно, что в нормальных условиях протокол XTP гарантирует пропускную способность на 25% выше, чем TCP или UDP.
Все поля в XTP-пакетах передаются так, что наиболее значимый байт передается первым (порядок байт - "big-endian"). Формат заголовка XTP-пакета показан на рис. 4.4.5.2. Поле ключ определяет принадлежность пакета к тому или иному контексту, поле команда (CMD) задает процедуру обработки пакета.
Поле длина (DLEN) определяет объем данных в пакете, а поле номер по порядку (SEQ) представляет собой порядковый номер пакета в последовательности. Поля контрольная сумма и синхронизация используются для проверки корректности доставки. Старший бит поля ключ (RTN - возврат, рис. 4.4.5.3) зарезервирован в качестве флага, указывающего на контекст передающей (=0) или принимающей стороны (принимающая сторона, посылая пакеты, ставит RTN=1). Код поля ключ должен быть уникальным. Для обеспечения этого остальная часть поля делится на два субполя: индекс и инстанция (распределение бит между ними зависит от реализации и реальных потребностей). Индекс служит для выбора контекста, а инстанция подтверждает корректность кода индекс. Так при получении пакета сначала по индексу определяется контекст, а затем производится сравнение кодов инстанции в пакете и в таблице контекстов.

Рис. 4.4.5.2 Формат кадра протокола XTP

Рис. 4.4.5.3 Структура поля ключ
32-разрядное поле команды содержит в себе субполе опции. Названия различных бит этого поля показаны на рис. 4.4.5.4.

Рис. 4.4.5.4. Формат поля команда
| btag=1 | указывает на то, что первые восемь байт сегмента данных стали полем btag (beginning tag field - начальная метка). Служит для постановки меток для прикладных программ. BTAG имеет смысл только для информационных пакетов и должен быть обнулен для всех остальных. |
| dreq=1 | |
| edge | при получении пакета значение этого бита сравнивается с со значение бита edge предыдущего пакета. Если их величины отличаются, посылается управляющий пакет. Отправитель может изменять значения этого бита, чтобы вызвать присылку управляющего пакета, не привлекая механизма SREQ или DREQ. |
| end=1 | указывает на прекращение использования данного контекста, устанавливается в последнем пакете, завершающем диалог, а также при ликвидации ассоциации. |
| EOM | служит для обозначения границ сообщения в потоке данных. Если EOM=1, то этот пакет завершает сообщение. Управляющие пакеты не должны иметь EOM=1. Этот бит устанавливается прикладной, а не протокольной программой. |
| fastnak | показывает, что получатель должен обеспечивать быстрое отрицательное подтверждение (если необходимо). Этот бит устанавливается отправителем лишь тогда, когда протокольный уровень ниже XTP не меняет часто порядок пакетов. |
| multi=1 | указывает на использование режима мульткастинга. Значение этого бита должно быть идентичным для всех пакетов в период жизни ассоциации. |
| noerr=1 | информирует получателя о том, что отправитель не будет повторно присылать пакеты и рекомендует получателю отключить контроль ошибок. |
| Nocheck=1 | указывает на то, что контрольная сумма вычислена только для полей заголовка, в противном случае - для всего пакета. |
| Noflow=1 | указывает на то, что отправитель не следит за ограничениями потока данных (например, игнорирует значение alloc). |
| RES=1 | позволяет режим резервирования. Устанавливая его, отправитель обращает внимание получателя на то, что значение alloc, присланные получателем в контрольных пакетах, должно соответствовать реальному объему свободного буферного пространства. |
| Sort=1 | указывает, что значение кода в поле sort заголовка должно интерпретироваться и использоваться для приоритетного отбора пакетов. |
| sreq=1 | указывает получателю, что он должен немедленно послать контрольный пакет. Бит SREQ устанавливается отправителем в соответствии со своей политикой подтверждений или в случае возникновения ошибок. |
| Wclose и Rclose | используются при диалоге отсоединения. wclose-бит указывает на то, что не будет больше записей в выходной информационный поток. rclose-бит служит для того, чтобы сообщить, что все биты, занесенные во входной поток, доставлены. |
/p> XTP- передатчик контролирует все биты поля опции для каждого пакета. Некоторые дополнительные данные о битах субполя опции можно найти в таблице 4.4.5.2.
Таблица 4.4.5.2. Значения битов субполя опции
| Бит поля опции | Маска | Возможность изменения | Использование | Описание |
| 0x800000 | Не используется, должно обнуляться | |||
| nocheck | 0x400000 | по-пакетно | Раз на контекст | Отключение контрольной суммы |
| edge | 0x200000 | по-пакетно | Пограничный запрос статуса | |
| noerr | 0x100000 | по-пакетно | Раз на контекст | Отключение контроля ошибок |
| multi | 0x080000 | Раз на ассоциацию | Режим мультикастинга | |
| res | 0x040000 | по-пакетно | Раз на контекст | Режим резервирования |
| Sort | 0x020000 | по-пакетно | Раз на контекст | Допускает сортировку |
| Noflow | 0x010000 | по-пакетно | Раз на контекст | Отключает управление потоком данных |
| Fastnack | 0x008000 | по-пакетно | Раз на контекст | Разрешает жесткий контроль ошибок |
| SRREQ | 0x004000 | по-пакетно | Запрос статуса | |
| DREQ | 0x002000 | по-пакетно | Запрос доставки статуса | |
| Rclose | 0x001000 | по-пакетно | Получатель отключен | |
| Wclose | 0x000800 | по-пакетно | Отправитель отключен | |
| EOM | 0x000400 | по-пакетно | Конец сообщения | |
| End | 0x000200 | один раз | Конец контекста или ассоциации | |
| Btag | 0x000100 | по-пакетно | Начало метки поля данных |
"По-пакетно" означает, что бит может изменяться от пакета к пакету. "Раз на ассоциацию" означает, что все контексты ассоциации должны иметь этот бит идентичным. "Один раз" означает, что бит может быть установлен один раз за время жизни контекста
Таблица 4.4.5.3. Коды типов пакетов XTP (Pformat)
| Формат пакета | Код типа | Описание |
| data | 0 | Информационный пакет пользователя |
| cntl | 1 | Пакет управления состоянием |
| first | 2 | Исходный пакет ассоциации (содержит адресный сегмент) |
| ecntl | 3 | Пакет управления (ошибка) |
| tcntl | 5 | Пакет управления трафиком |
| join | 6 | Мультикастинг-пакет включения в группу |
| diag | 8 | Диагностический пакет |
Младший байт поля команда содержит субполе типа пакета (ptype). Биты 0-4 этого субполя содержат код формата пакета (Pformat, см. таблицу 4.4.5.3). Биты 5-7 определяют версию протокола (ver).
Для XTP 4.0 код версии равен 001.
Поле DLEN содержит число байт в массиве данных пакета, следующем непосредственно за заголовком. Так как информационные пакеты с нулевым объемом данных запрещены, код dlen не может быть равен нулю.
Поле Check содержит контрольную сумму. Если бит nochek=1, то в поле записана контрольная сумма только заголовка, в противном случае - всего пакета.
Поле приоритет (sort) предназначено для задания приоритета пересылаемой информации. Это поле интерпретируется лишь в случае, если бит sort=1. При sort=0 поле приоритет должно быть обнулено. Контексты с приоритетным трафиком посылают пакеты с sort=1 и с определенным кодом в поле приоритет. Бесприоритетные контексты шлют пакеты с sort=0 и нулевым полем приоритета. На приемной стороне информация доставляется в соответствии с кодом приоритета. Поле приоритет характеризуется беззнаковым 16-разрядным числом. Код приоритет, равный нулю, указывает на самый низкий приоритет, чем больше этот код, тем выше приоритет. XTP обслуживает активные контексты в соответствии с присвоенными им приоритетами. Высокоприоритетная информация посылается раньше низкоприоритетной. Аналогичный порядок обслуживания работает и на принимающей стороне.
32-битовое поле синхронизация (Sync) служит для синхронизации диалога. Каждый контекст хранит код последнего посланного значения Sync в переменной Saved_sync. Когда пакет послан с Sreq=1, значение переменной Saved_sync увеличивается на единицу и этот код заносится в поле Sync отправляемого пакета. Получатель запоминает последний полученный код Sync в контекстной переменной Rcvd_sync. Значение этой переменной записывается в поле эхо каждого посылаемого управляющего пакета. Когда управляющий пакет получен, код поля sync сравнивается со значением Rcvd_sync. Если sync і Rcvd_sync, то управляющий пакет обрабатывается нормально. В противном случае управляющий пакет содержит информацию, которая старее полученной с предыдущими пакетами, и обрабатываться не должен.
Поле номер по прядку (SEQ) характеризуется 64-разрядным числом без знака и представляет собой порядковый номер байта в передаваемом потоке.
Для первого пакета (first) поле SEQ характеризует объем буферов для потока откликов, а для пакетов Join это поле содержит дентификатор получателя (ключ контекста). Join-пакет отклик на запрос содержит в поле SEQ порядковый номер байта для текущей ассоциации. Диапазон значений поля номер по порядку для информационных пакетов начинается с SEQ и простирается вплоть до SEQ+ DLEN - 1. Для DIAG пакетов поле SEQ содержит код SEQ входного пакета, который вызвал ошибку. Если посылка пакета DIAG вызвана не входным пакетом, код SEQ должен быть равен нулю.
Вслед за заголовком обычно следует его расширение (сегмент), формат которого зависит от типа пакета. Используются управляющие и информационные сегменты.
Управляющие сегменты несут в себе информацию о состоянии контекста, его приславшего. XTP пакеты, содержащие управляющие сегменты называются контрольными пакетами. Управляющие сегменты содержат пакеты типа Cntl, Ecntl и Tcntl. Управляющий сегмент Cntl-пакета несет в себе информацию об управлении обменом. Ecntl-пакеты включают в себя сегменты управления ошибками, а Tcntl-пакеты - сегменты управления трафиком. Формат управляющего сегмента показан на рис. 4.4.5.5.

Рис. 4.4.5.5 Формат общего управляющего сегмента пакета XTP
Три поля общего управляющего сегмента представляют статусную информацию и содержатся во всех трех типах контрольных пакетов. Первые два поля RSEQ и alloc являются параметрами управления обменом. Поле Echo используется для идентификации контрольных пакетов, которые являются откликом на пакеты с битом SREQ=1. Поле RSEQ содержит в себе номер очередного байта, подлежащего пересылке, и определяет начало окна, управляющего обменом. Поле Alloc интерпретируется, когда разрешено управление обменом. Код поля Alloc определяет объем данных, который отправитель может послать (а получатель принять). Если бит RES=1, то поле Alloc задает размер буфера, зарезервированного для данной ассоциации. Поле Echo используется для установления соответствия между запросом статуса и контрольными пакетами.
Код поля Echo равен наибольшему значению sync для полученных пакетов. Это значение хранится в контекстной переменной rcvd_sync. Когда формируется контрольный пакет, значение rcvd_sync заносится в поле Echo этого пакета.
Формат сегмента управления ошибками показан на рис. 4.4.5.6. Этот сегмент включает в себя все поля общего управляющего сегмента, дополнительно использовано только два поля Nspan и Spans, которые сообщают о том, какие пакеты потеряны.

Рис. 4.4.5.6 Формат сегмента управления ошибками
Сегмент управления ошибками используется в пакетах Ecntl. Поле Nspan определяет число Spans в Ecntl-пакете. Так как пакет Ecntl посылается только в случае потери информации, поле Nspan несет в себе код не меньше 1. Поле Spans содержит в себе Nspan пар чисел, которые характеризуют интервалы номеров байт, переданных корректно. Речь здесь идет о данных, имеющих номера больше того, который указан в поле RSEQ. На основании этих данных можно вычислить, какая именно информация потеряна.
Формат сегмента управления трафиком показан на рис. 4.4.5.7. Помимо полей общего управляющего сегмента здесь присутствуют поля RSVD и XKEY, а также спецификация трафика. Поле RSVD является резервным и должно содержать нуль. Поле XKEY является обязательной принадлежностью всех Tcntl-пакетов, величина этого поля должна равняться значению ключа для контекста, посылающего пакет (бит RTN=1). Спецификация трафика используется в пакетах типа first и Tcnnl. Пакет first предлагает параметры режима обмена, а Tcntl несет в себе отклик на это предложение.

Рис. 4.4.5.7 Формат сегмента управления трафиком
Поле tlen определяет длину спецификации трафика, включая 4-байтовый дескриптор (tlen і ). Поле service используется для задания типа транспортного сервиса на фазе установления режима обмена. Коды доступных видов сервиса представлены в таблице 4.4.5.4. Эта информация передается в пакете типа first.
Таблица 4.4.5.4. Коды поля тип сервиса (service)
| Код типа сервиса | Описание |
| 0x00 | Не специфицировано |
| 0x01 | Традиционная передача дейтограмм без подтверждения |
| 0x02 | Передача дейтограмм с подтверждением |
| 0x03 | Реализация транзакций |
| 0x04 | Традиционная передача потока данных с гарантированной доставкой |
| 0x05 | Передача потока данных в мультикастинг-режиме без подтверждения |
| 0x06 | Мультикастинг режим передачи потока данных с гарантированной доставкой |
Поле tformat определяет формат поля traffic. Код tformat=0 используется тогда, когда не нужно ни какой спецификации трафика, в 4-байтовое поле traffic в этом случае записываются нули. В противном случае используется код tformat=0x01. Формат поля traffic для этого арианта показан на рис. 4.4.5.8.

Рис. 4.4.5.8 Формат поля traffic
Поле maxdata несет в себе код максимального размера информационного сегмента, который отправитель может послать за время жизни ассоциации. Поля inrate и inburst представляют собой параметры, определяющие входной поток данных. Поля outrate и outburst являются параметрами, задающими выходной поток данных.
Информационный сегмент включает в себя пользовательскую и другую протокольную и диагностическую информацию. XTP-пакеты, содержащие информационный сегмент, называются информационными пакетами. К их числу относятся пакеты типа data, first, join и diag. Информационные пакеты могут включать в себя сегмент данных, адресный сегмент, спецификатор трафика и диагностический сегмент. Формат полей адресного сегмента показан на рис. 4.4.5.9.

Рис. 4.4.5.9 Формат полей адресного сегмента
Адресный сегмент используется в пакетах типа first и join. Протокол XTP использует параметрическую схему адресации, возможны несколько форматов адресов отправителя и места назначения. Поле Alen определяет полную длину адресного сегмента. Поле Adomain представляет собой адресный демультиплексор, допуская работу с несколькими адресными доменами. Поле Adomain используется в частности для того, чтобы обеспечить совместимость с протоколами UDP и TCP (для TCP Adomain=6, для UDP 17, а для XTP 36). Поле Aformat идентифицирует адресный синтаксис в соответствии с таблицей 4.4.5.5.
Таблица 4.4.5.5. Значения кодов поля Aformat
| Код поля aformat | Синтаксис адреса |
| 0x00 | Нулевой адрес |
| 0x01 | ip-адрес |
| 0x02 | ISO адрес протокольного сетевого уровня для передачи без установления связи |
| 0x03 | Адрес сети Ксерокс |
| 0x04 | IPX-адрес |
| 0x05 | Локальный адрес |
| 0x06 | IP-адрес версии 6 |
Поле адрес несет в себе адреса отправителя и получателя пакетов, форматы которых заданы полем Aformat.
Формат полей сегмента данных показан на рис. 4.4.5.10. Эти сегменты предназначены для применения на прикладных пользовательских уровнях и программами поддержки протокола XTP не интерпретируются. Сегмент включается в пакеты типа first и data.

Рис. 4.4.5.10 Формат полей сегмента данных
Размер поля Data имеет произвольное значение, первые 8 байт (поле Btag) представляют собой специальную метку (если бит опций заголовка btag=1). При Btag=0 метка отсутствует. Интерпретация поля Btag осуществляется исключительно прикладной программой и для XTP его значение безразлично.
Формат полей диагностического сегмента показан на рис. 4.4.5.11. Этот сегмент используется пакетами типа DIAG для информирования протокольной или прикладной программы о случаях ошибок. Поле Code определяет тип и категорию ошибки, вызвавшей отправку пакета типа DIAG. Поле val позволяет уточнить причину ошибки. Поле message является опционным и может иметь произвольную длину. Обычно это поле содержит текстовую интерпретацию полей Code и VAL.

Рис. 4.4.5.11 Форматы полей диагностического сегмента
Протокол загрузки BOOTP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
В больших сетях некоторые рабочие станции (например, Х-терминалы) могут не иметь системного диска, а операционная система и сетевое программное обеспечение загружается через сеть. Для этого рабочая станция должна иметь стартовую программу, записанную в ПЗУ. Такое постоянное запоминающее устройство часто производится на фирме, изготовившей эту рабочую станцию, и по этой причине не содержат информации ни об адресе сервера, ни даже о своем IP-адресе. Выше был описан протокол RARP, который способен решать подобные задачи для случая, когда сервер находится в пределах данной локальной сети. Ведь RARP выдает широковещательный запрос на связном уровне, а он не ретранслируется маршрутизаторами. Более мощным средством для загрузки бездисковых станций является протокол BOOTP (Bootstrap протокол, RFC-951, -1048, -1532). BOOTP пригоден и для загрузки бездисковых маршрутизаторов. BOOTP в качестве транспортного использует UDP-протокол. ЭВМ-клиент (порт=68), которая хочет воспользоваться BOOTP, посылает широковещательное сообщение (по адресу = 255.255.255.255). Сервер (порт=67) в отличии от случая RARP не обязательно должен находиться в пределах данной локальной сети. В поле IP-адрес клиента будет записано 0.0.0.0, так как клиент пока не знает своего адреса. Получив запрос через порт 67, маршрутизатор помещает свой IP-адрес в поле IP-адрес маршрутизатора (см. формат запроса на рис. 4.4.10.1) и пересылает запрос действительному BOOTP-серверу, увеличив на 1 значение поля Hop#. По пути к серверу может быть несколько маршрутизаторов (но обычно не больше 3). Сервер не знает физического адреса клиента. Воспользоваться ARP-запросом он не может, так как клиент пока не знает своего IP-адреса и на ARP-запрос не откликнется. У сервера, получившего запрос, имеется две возможности.
1. Проанализировать пакет, извлечь из него физический адрес клиента и скорректировать ARP-таблицу.
2. Послать отклик, используя широковещательный адрес.
Так как программа загрузки находится на прикладном уровне, и ей запрещено исправлять ARP-таблицы, реально доступен только второй путь.
Использование разных номеров портов для сервера и клиента делает работу системы более эффективной. Когда отклик сервера является широковещательным, это позволяет не прерывать работу прикладных программ, работающих с номерами портов, отличными от 68 (порт Bootp-клиента). В Bootp ответственность за надежность связи лежит на ЭВМ-клиенте. При отсутствии отклика в отведенное время клиент повторяет Bootp-запрос. На IP-уровне, где данные не имеют контрольной суммы, целостность сообщения не гарантирована. Bootp требует, чтобы проверка контрольной суммы обязательно проводилась на UDP-уровне (следует заметить, что обычно это не является обязательным). Сервер читает UDP-дейтограммы через порт 67. Для повышения надежности обменов, как правило, блокируется фрагментация дейтограмм.
Загрузка рабочих станций часто запускается броском напряжения сетевого питания. При этом несколько Bootp-процессов стартуют одновременно. Для того чтобы снизить вероятность столкновений, величина времени тайм-аута выбирается случайно в интервале 0-4сек. После каждого повторного запроса это время удваивается. Верхнее значение тайм-аута равно 60сек. Для справок время загрузки бездискового x-терминала при благоприятных условиях может составлять около 20 сек.
bootp осуществляет загрузку в два этапа. На первом этапе bootp лишь снабжает клиента информацией, где лежит нужные ему данные. Далее ЭВМ-клиент использует протокол TFTP для получения искомого загружаемого файла. Bootp-сервер не обязательно должен работать на той же машине, где хранятся загружаемые файлы, но он должен знать их имена. Формат Bootp-сообщений представлен на рис. 4.4.10.1.

Рис. 4.4.10.1. Формат сообщений BOOTP
Поле операция=1 говорит о том, что данное сообщение запрос, а значение операция=2 указывает на то, что сообщение является откликом. Поля H-тип и Hlen определяют тип используемого оборудования и длину аппаратного адреса (для Ethernet H-тип=1, а HLen=6). ЭВМ-клиент кладет в поле Hop# (число шагов) нуль. Если BOOTP-сервер, получив запрос, решит передать его другой ЭВМ, он увеличит значение этого поля на 1, и так далее.
Поле идентификатор операции содержит целое число, которое на бездисковых машинах позволяет связать в пары запросы и отклики. Поле секунды хранит время с момента начала процедуры загрузки (BOOT).
ЭВМ-клиент заполняет все последующие поля, если она этой информацией владеет, в противном случае поля обнуляются. Возможность указания имени BOOT(загрузочного)-файла позволяет учесть индивидуальность конфигурации конкретной ЭВМ и пожелания относительно загружаемой операционной системы. Поле специфическая информация поставщика содержит информацию, которая передается от сервера к ЭВМ-клиенту. Первые 4 октета этого поля носят название "волшебное печенье" (magic cookie) и определяют формат остальных субполей. Если в указанном поле имеется информация, субполе волшебное печенье имеет значение 99.130.83.99. Вслед за этим субполем следует последовательность субполей, содержащих один октет тип, опционный октет длина и многооктетное субполе значение. Стандарт предусматривает следующие разновидности субполей:
Таблица 4.4.10.1 Разновидности субполей и их коды (BOOTP)
| Тип субполя | Код субполя | Длина субполя в октетах | Содержимое субполя |
| Заполнитель | 0 | - | Нули - используются для заполнения неиспользуемых полей |
| Маска субсети | 1 | 4 | Маска субсети в локальной сети |
| Время дня | 2 | 4 | Время дня по универсальной шкале |
| Маршрутизаторы | 3 | N | Список IP-адресов N/4 маршрутизаторов |
| Временные серверы | 4 | N | IP-адреса N/4 временных серверов |
| IEN116 сервер | 5 | N | IP-адреса N/4 IEN116 серверов |
| Домейн-сервер | 6 | N | IP-адреса N/4 DNS-серверов |
| Log-сервер | 7 | N | IP-адреса N/4 log-серверов |
| Сервер квот | 8 | N | IP-адреса N/4 серверов квот |
| Сервер принтера | 9 | N | IP-адреса N/4 серверов печати |
| Impress | 10 | N | IP-адреса N/4 impress-серверов |
| RLP-сервер | 11 | N | IP-адреса N/4 RLP серверов |
| Имя ЭВМ | 12 | N | N байтов имени ЭВМ-клиента |
| Размер Boot-файла | 13 | 2 | 2-октетный размер boot-файла |
| Зарезервировано | 128-254 | - | Зарезервировано для местного применения |
| Конец | 255 | - | Конец списка |
Определены и другие субполя (RFC-1533), субполе конец (255) помечает конец поля.Хотя маска субсети может быть получена с помощью ICMP-запроса, стандарт требует, чтобы маска присылалась BOOT-сервером в ответ на каждый запрос, что исключает лишние ICMP-сообщения. Маска субсети может быть записана в поле специфическая информация поставщика, как это видно из таблицы. Время дня (тип=2) отсчитывается в секундах от 1-го января 1900 года. В новом протоколе DHCP (Dynamic Host Configuration Protocol, RFC-1531, протокол динамического конфигурирования системы) размер поля специфическая информация поставщика расширен до 312 байт.
Протокольная спецификация контрольного соединения
Следующие сообщения управляющего соединения используются для установления, ликвидации и поддержания L2TP-туннелей. Вся информация посылается в порядке, определенном для сети (старший октет первый). Любые "резервные" или "пустые" поля для обеспечения протокольной масштабируемости должны содержать 0.
Протокольные операции
Необходимая процедура установления PPP-сессии туннелирования L2TP включает в себя два этапа:
Установление управляющего канала для туннеля, и
Формирование сессии в соответствии с запросом входящего или исходящего вызова.
Туннель и соответствующий управляющий канал должны быть сформированы до инициализации входящего или исходящего вызовов. L2TP-сессия должна быть реализована до того, как L2TP сможет передавать PPP-кадры через туннель. В одном туннеле могут существовать несколько сессий между одними и теми же LAC и LNS.

Рис. 18. PPP-туннелирование
Протокольные операции контрольного соединения
Этот раздел описывает работу различных функций управляющего соединения L2TP и сообщения управляющего соединения, которые используются для их поддержания.
Получение некорректного или неправильно сформатированного управляющего сообщения должно регистрироваться соответствующим образом, а управляющее соединение возвращается в исходное состояние, чтобы гарантировать восстановление заданного состояния. Управляющее соединение может затем перезапуститься инициатором операции.
Некорректное управляющее сообщение определяется как сообщение, которое содержит тип сообщения, помеченное как обязательное (смотри раздел 4.4.1) и неизвестное программе управляющее сообщение, которое получено в правильной последовательности (например, в ответ на SCCRQ послано SCCCN).
Примеры управляющих сообщений с некорректным форматом включают те, которые имеют неверное значение в своем заголовке, содержат AVP, сформированную некорректно или чье значение находится вне допустимых пределов, или сообщение, которое не имеет необходимого AVP. Управляющее сообщение с некорректным заголовком должно быть отброшено. Управляющее сообщение с некорректным AVP должно проверить M-бит для этого AVP, чтобы определить, является ли ошибка исправимой или нет.
Неверно сформатированное, но исправимое необязательное (M-бит равен нулю) AVP в управляющем сообщении должно рассматриваться, также как нераспознанное необязательное AVP. Таким образом, если получена AVP с неверным форматом и битом M=1, сессия или туннель должны быть разорваны с соответствующим кодом результата или ошибки. Если M-бит не равен 1, AVP должно игнорироваться (за исключением записи об ошибке в местном журнале).
Это не должно рассматриваться, как разрешение посылать неверно сформатированные AVP, а лишь как указание на то, как реагировать на неверно сформатированное сообщение в случае его получения. Невозможно перечислить все возможные ошибки в сообщениях и дать совет, как с ними обходиться. Примером исправимой неверно сформатированной AVP может быть случай, когда получена AVP скорости соединения Rx, атрибут 38, с полем длина 8, а не 10 и BPS с двумя, а не четырьмя октетами. Так как Rx Connect Speed не является обязательным, такое условие не может рассматриваться как катастрофическое. Как таковое, управляющее сообщение должно быть воспринято, как если бы AVP не было получено (за исключением записи в локальный журнал ошибок). В нескольких случаях в последующих таблицах, посылается протокольное сообщение, а затем случается "сброс". Заметим, что, несмотря на ликвидацию туннеля одним из партнеров, в течение определенного времени механизм надежной доставки должен быть сохранен (смотри раздел 5.8) вплоть до окончательного закрытия туннеля. Это позволяет сообщениям управления туннеля надежно доставляться партнеру.
Протокольный отправитель клиента и протокольный получатель сервера
Любая процедура начинается с команды клиента. Любая команда клиента начинается с префикса-идентификатора (обычно короткая буквенно-цифровая строка, например A0001, A0002 и т.д.), называемого меткой (tag). Для каждой команды клиент генерирует свою метку. Имеется два случая, когда строка, посланная клиентом, не представляет собой законченную команду. В первом - аргумент команды снабжается кодом, определяющим число октетов в строке (см. описание литеральных строк в разделе “Форматы данных”). Во втором – аргументы команды требуют отклика со стороны сервера (см. описание команды authenticate). В обоих вариантах сервер посылает запрос продолжения команды, если он готов. Такой отклик сервера начинается с символа "+".
Замечание: Если, вместо этого, сервер детектирует ошибку в команде, посылается отклик завершения bad с меткой, требующей игнорирования команды и предотвращения посылки клиентом каких-либо еще запросов.
Отправитель может послать отклик завершения и в случае некоторых других команд (если одновременно исполняется несколько команд) или если данные не имеют меток. В любом случае, ожидается запрос продолжения, клиент предпринимает в ответ соответствующие действия и читает следующий отклик сервера. Во всех вариантах клиент должен завершить отправку одной команды прежде чем послать новую.
Протокольный приемник IMAP 4.1 сервера читает строку команды, пришедшей от клиента, осуществляет ее разбор, выделяет ее параметры и передает серверу данные. По завершении команды сервер посылает отклик.
Протокольный отправитель сервера и протокольный получатель клиента
Данные, передаваемые сервером клиенту, а также статусные отклики, которые не указывают на завершение выполнения команды, имеют префикс "*" и называются непомеченными откликами.
Данные сервера могут быть посланы в ответ на команду клиента или отправлены сервером по своей инициативе. Формат данных не зависит от причины посылки.
Отклик указывает на успешное выполнение операции или на ее неудачу. Отклик использует ту же метку, что и команда клиента, запустившая процедуру. Таким образом, если осуществляется более чем одна команда, метка сервера указывает на команду, вызвавшую данный отклик. Имеется три вида отклика завершения сервера: ok (указывает на успешное выполнение), no (отмечает неуспех) или bad (указывает на протокольную ошибку, например, не узнана команда или зафиксирована синтаксическая ошибка).
Протокольный приемник клиента IMAP 4.1 читает строку отклика от сервера. Он должен предпринять действия, в соответствии с первым символом метки "*" или "+".
Клиент должен быть готов принять любой отклик сервера в любое время. Это касается и не запрошенных данных, присланных сервером. Данные сервера должны быть записаны так, чтобы клиент мог их непосредственно использовать, не посылая серверу уточняющих запросов.
Каждое сообщение имеет несколько связанных с ним атрибутов. Эти атрибуты могут быть определены индивидуально или совместно с другими атрибутами.
Доступ к сообщениям в IMAP 4.1 осуществляется с помощью уникального идентификатора или порядкового номера сообщения.
Протоколы маршрутизации (обзор, таблицы маршрутизации, вектор расстояния)
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Основная задача сетей - транспортировка информации от ЭВМ-отправителя к ЭВМ-получателю. В большинстве случаев для этого нужно совершить несколько пересылок. Проблему выбора пути решают алгоритмы маршрутизации. Если транспортировка данных осуществляется дейтограммами, для каждой из них эта задача решается независимо. При использовании виртуальных каналов выбор пути выполняется на этапе формирования этого канала. В Интернет с его IP-дейтограммами реализуется первый вариант, а в ISDN - второй.
Алгоритм маршрутизации должен обладать вполне определенными свойствами: надежностью, корректностью, стабильностью, простотой и оптимальностью. Последнее свойство не так прозрачно, как это может показаться на первый взгляд, все зависит от того, по какому или каким параметрам производится оптимизация. Эта задача иногда совсем не проста даже для сравнительно простых локальных сетей (смотри, например, рис. 4.4.11.1). Предположим, что поток данных между ЭВМ b и d, соединенных через концентратор (К) весьма высок, что окажет ощутимое влияние на скорость обмена между ЭВМ А и С. Но этот факт довольно трудно выявить, находясь в ЭВМ А или С. Внешне это проявится лишь как повышенная задержка и пониженная пропускная способность участка А-С.

Рис. 4.4.11.1
Среди параметров оптимизации может быть минимальная задержка доставки, максимальная пропускная способность, минимальная цена, максимальная надежность или минимальная вероятность ошибки.
Алгоритмы маршрутизации бывают адаптивными и неадаптивными. Вторые, осуществляя выбор маршрута, не принимают во внимание существующую в данный момент топологию или загрузку каналов. Такие алгоритмы называются также статическими. Адаптивные же алгоритмы предполагают периодическое измерение характеристик каналов и постоянное исследование топологии маршрутов. Выбор того или иного маршрута здесь производится на основании этих измерений.
Практически все методы маршрутизации базируются на следующем утверждении (принцип оптимальности).
Если маршрутизатор M находится на оптимальном пути от маршрутизатора I к маршрутизатору J, тогда оптимальный путь от М к J проходит по этому пути. Чтобы убедиться в этом обозначим маршрут I-M R1, а m-j - R2. Если существует маршрут оптимальнее, чем R2, то он должен быть объединен с R1, чтобы образовать более оптимальный путь I-J, что противоречит исходному утверждению об оптимальности пути J-J. Следствием принципа оптимальности является утверждение, что оптимальные маршруты от всех отправителей к общему месту назначения образуют дерево, лишенное циклов (см. разделы и ). Такое дерево (называется sink tree) может быть не единственным, могут существовать другие деревья с теми же длинами пути. А это, в свою очередь означает, что любой пакет будет доставлен за строго ограниченное время, пройдя однократно определенное число маршрутизаторов
Главным параметром при маршрутизации пакета в Интернет является ip-адрес его места назначения. Проблема оптимальной маршрутизации в современном Интернет, насчитывающем уже более десяти миллионов узлов, весьма сложна. Полная таблица маршрутов может содержать 107! записей (здесь ! означает знак факториала, а не выражение эмоций), что не по плечу не только сегодняшним ЭВМ.
Обычный пользователь не задумывается и не должен задумываться над проблемами маршрутизации, но даже ему иногда может оказаться полезным понимать, что возможно, а что невозможно в Интернет. Нужно только четко разделять работу протоколов маршрутизации, которые формируют маршрутные таблицы, и процесс маршрутизации пакетов, когда эти таблицы используются.
IP делит все ЭВМ на маршрутизаторы и обычные ЭВМ (host), последние, как правило, не рассылают свои маршрутные таблицы. Предполагается, что маршрутизатор владеет исчерпывающей информацией о правильных маршрутах (хотя это и не совсем так). Обычная ЭВМ имеет минимальную маршрутную информацию (например, адрес маршрутизатора локальной сети и сервера имен). Автономная система может содержать множество маршрутизаторов, но взаимодействие с другими as она осуществляет только через один маршрутизатор, называемый пограничным (border gateway, именно он дал название протоколу bgp).
Пограничный маршрутизатор нужен лишь тогда, когда автономная система имеет более одного внешнего канала, в противном случае его функции выполняет порт внешнего подключения (gateway). Если адресат достижим более чем одним путем, маршрутизатор должен сделать выбор, этот выбор осуществляется на основании оценки маршрутов-кандидатов. Обычно каждому сегменту, составляющему маршрут, присваивается некоторая величина - оценка этого сегмента. Каждый протокол маршрутизации использует свою систему оценки маршрутов. Оценка сегмента маршрута называется метрикой. Здесь следует обратить внимание на то, что при выборе маршрута всем сегментам пути должны быть даны сопоставимые значения метрики. Недопустимо, чтобы одни сегменты оценивались числом шагов, а другие - по величине задержки в миллисекундах. В пределах автономной системы это обычно не создает проблем, ведь это зона ответственности одного администратора. Но в региональных сетях, где работает много администраторов, проблема выбора метрики может стать реальной трудностью. Именно по этой причине в таких сетях часто используется вектор расстояния, исключающий субъективность оценок метрики.
Помимо классической схемы маршрутизации по адресу места назначения, часто используется вариант выбора маршрута отправителем (данный вариант получил дальнейшее развитие при введении стандарта IPv6). В этом случае IP-пакет содержит соответствующий код опции и список промежуточных адресов узлов, которые он должен посетить по пути к месту назначения.
Существуют и другие схемы, например, использующие широковещательные методы адресации (flooding), где каждый приходящий пакет посылается по всем имеющимся исходящим каналам, за исключением того, по которому он получен. С тем чтобы исключить беспредельное размножение пакетов в заголовок вводится поле-счетчик числа шагов. В каждом узле содержимое поле уменьшается на единицу. Когда значение поля становится равным нулю, пакет ликвидируется. Исходное значение счетчика определяется размером субсети. Предпринимаются специальные меры против возможного зацикливания пакетов.
Существует усовершенствованная версия широковещательной маршрутизации, называемая селективной широковещательной рассылкой. В этом алгоритме рассылка производится не по всем возможным направлениям, а только по тем, которые предположительно ведут в правильную сторону. Широковещательные методы не относятся к широко применимым. Но они используются там, где нужна предельно возможная надежность, например в военных приложениях, когда весьма вероятно повреждение тех или иных каналов. Данные методы могут использоваться лишь при формировании виртуального канала, ведь они всегда обеспечивают наикратчайший путь, так как перебираются все возможности. Если путь записывается в пакете, получатель может выбрать оптимальный проход и уведомить об этом отправителя.
Большинство алгоритмов учитывают топологию связей, а не их качество (пропускную способность, загрузку и пр.). Но существуют подходы к решению проблемы статической маршрутизации, учитывающие как топологию, так и загрузку (flow-based routing). В некоторых сетях потоки между узлами относительно стабильны и предсказуемы. В этом случае появляется возможность вычислить оптимальную схему маршрутов заранее. Здесь на основе теории массового обслуживания производится оценка средней задержки доставки для каждой связи. Топология маршрутов оптимизируется по значению задержки доставки пакета. Исходными данными при расчете считается описание топологии связей, матрица трафика для всех узлов Ti,j (в пакетах в секунду) и матрица пропускных способностей каналов Bi,j в битах в секунду. Задержка t для каждой из связей оценивается по формуле
ti,j = 1/(p*bi,j - ti,j),
где 1/Р - среднее значение ширины пакета в битах, произведение p*bi,j выражается в пакетах в секунду, а t измеряется в мсек. Сформировав матрицу ti,j, можно получить граф кратчайших связей. Так как вычисления производятся не в реальном масштабе времени, особых трудностей здесь не возникает.
Статические протоколы (примером реализации статических протоколов может служить первая версия маршрутизатора Netblazer) предполагают, что любые изменения в маршрутные таблицы вносит администратор сети.
Рассмотрим для примера сеть, изображенную на рис. 4.4.11.2.

Рис. 4.4.11.2 Схема для иллюстрации методики составления маршрутных таблиц.
g1, g2, g3 - Маршрутизаторы
Примитивная таблица маршрутизации для приведенного примера может иметь вид (для маршрутизатора g2):
| Сеть-адресат | Маршрут к этой сети |
| 193.0.0.0 | Прямая доставка |
| 193.148.0.0 | Прямая доставка |
| 192.0.0.0 | Через адрес 193.0.0.1 |
| 192.166.0.0 | Через адрес 193.148.0.7 |
Заметно сокращает размер маршрутной таблицы маршруты по умолчанию. В этой схеме сначала ищется маршрут в таблицах, а если он не найден, пакет посылается в узел, специально выбранный для данного случая. Так, когда имеется только один канал за рубеж, неудачный поиск в таблице маршрутов по России означает, что пакет следует послать по этому каналу и пусть там с ним разбираются. Маршруты по умолчанию используются обычно тогда, когда маршрутизатор имеет ограниченный объем памяти или по какой-то иной причине не имеет полной таблицы маршрутизации. Маршрут по умолчанию может помочь реализовать связь даже при ошибках в маршрутной таблице. Это может не иметь никаких последствий для малых сетей, но для региональных сетей с ограниченной пропускной способностью такое решение может повлечь серьезные последствия. Экономия на памяти для маршрутных таблиц - дурной стиль, который не доведет до добра. Например, из-за такого рода ошибки довольно долго пакеты из Ярославля в Москву шли через США, я уже не говорю о случае, когда машины, размещенные в соседних комнатах Президиума РАН, вели обмен через Амстердам (правда, это было достаточно давно). Алгоритм выбора маршрута универсален и не зависит от протокола маршрутизации, который используется лишь для формирования маршрутной таблицы. Описание алгоритма выбора маршрута представлено ниже:
Извлечь IP-адрес (ID) места назначения из дейтограммы.
Вычислить IP-адрес сети назначения (IN)
IF INсоответствует какому-либо адресу локальной сети, послать дейтограмму по этому адресу;
else if in присутствует в маршрутной таблице, то послать дейтограмму к серверу, указанному в таблице;
else if описан маршрут по умолчанию, то послать дейтограмму к этому серверу;
else выдать сообщение об ошибке маршрутизации.
Если сеть включает в себя субсети, то для каждой записи в маршрутной таблице производится побитная операция <И> для ID и маски субсети. Если результат этой операции совпадет с содержимым адресного поля сети, дейтограмма посылается серверу субсети. На практике при наличии субсетей в маршрутную таблицу добавляются соответствующие записи с масками и адресами сетей.
Одна из базовых идей маршрутизации заключается в том, чтобы сконцентрировать маршрутную информацию в ограниченном числе (в идеале в одном) узловых маршрутизаторов-диспетчеров. Эта замечательная идея ведет к заметному увеличению числа шагов при пересылке пакетов. Оптимизировать решение позволяет backbone (опорная сеть), к которой подключаются узловые маршрутизаторы. Любая as подключается к backbone через узловой маршрутизатор.
"Прозрачные" backbone не работают с адресами класса С (все объекты такой сети должны иметь один адрес, а для c-класса число объектов слишком ограничено). "Прозрачные" мосты трудно диагностировать, так как они не следуют протоколу ICMP (команда ping не работает, в последнее время такие объекты снабжаются snmp-поддержкой). За то они позволяют перераспределять нагрузку через несколько маршрутизаторов, что невозможно для большинства протоколов.

Рис. 4.4.11.3.
В примере, приведенном на рис. 4.4.11.3, задача маршрутизации достаточно сложна. ЭВМ1,2 и ЭВМ6,1 можно связать многими путями: ЭВМ1,2 - GW1 - ЭВМ6,1; ЭВМ1,2 - GW2 - ЭВМ6,1; ЭВМ1,2 - GW3 - ЭВМ6,1; ЭВМ1,2 - GW4 - ЭВМ6,1; ЭВМ1,2 - GW1 - GW2 - GW3 - ЭВМ6,1; и т.д. Трафик между двумя географически близкими узлами должен направляться кратчайшим путем, вне зависимости от направления глобальных потоков. Так ЭВМ1,2 и ЭВМ1,1 должны соединяться через GW1. Маршрутизация через опорные сети (backbone) требует индивидуального подхода для каждого узла. Администраторы опорных сетей должны согласовывать свои принципы маршрутизации.
Ситуация, когда узел не владеет исчерпывающей маршрутной информацией, в сочетании с использованием маршрутов по умолчанию может привести к зацикливанию пакетов. Например, если маршрут по умолчанию в GW1 указывает на GW2, а в GW2 на GW1, то пакет с несуществующим адресом будет циркулировать между gw1 и gw2 пока не истечет ttl (время жизни пакета), полностью блокируя канал. По этой причине желательно иметь полную таблицу маршрутизации, и, если не вынуждают обстоятельства, избегать использования маршрутов по умолчанию.

Рис. 4.4.11.4.
Протоколы маршрутизации отличаются друг от друга тем, где хранится и как формируется маршрутная информация. Оптимальность маршрута достижима лишь при полной информации обо всех возможных маршрутах, но такие данные потребуют слишком большого объема памяти. Полная маршрутная информация доступна для внутренних протоколов при ограниченном объеме сети. Чаще приходится иметь дело с распределенной схемой представления маршрутной информации. Маршрутизатор может быть информирован лишь о состоянии близлежащих каналов и маршрутизаторов.
Динамические протоколы (обычно используются именно они, наиболее известным разработчиком является компания CISCO):
В маршрутизаторе с динамическим протоколом (например, BGP-4) резидентно загруженная программа-драйвер изменяет таблицы маршрутизации на основе информации, полученной от соседних маршрутизаторов. В ЭВМ, работающей под UNIX и выполняющей функции маршрутизатора, эту задачу часто решает резидентная программа gated или routed (демон). Последняя - поддерживает только внутренние протоколы маршрутизации.
Применение динамической маршрутизации не изменяет алгоритм маршрутизации, осуществляемой на IP-уровне. Программа-драйвер при поиске маршрутизатора-адресата по-прежнему просматривает таблицы. Любой маршрутизатор может использовать два протокола маршрутизации одновременно, один для внешних связей, другой - для внутренних.
Любая автономная система (AS, система маршрутизаторов, ЭВМ или сетей, имеющая единую политику маршрутизации) может выбрать свой собственный протокол маршрутизации.
Внутренний протокол маршрутизации IGP ( Interior Gateway Protocol) определяет маршруты внутри автономной системы. Наиболее популярный IGP - RIP (Routing Information Protocol, RFC-1058), разработан Фордом, Фулкерсоном и Белманом (фирма XEROX). Существует более новый протокол OSPF (Open Shortest Pass First, RFC-1131, -1245, -1247, -1253). Наиболее старые системы (IGP) используют протокол HELLO. Протокол HELLO поддерживался фирмой DEC, в качестве метрики он использует время, а не число шагов до цели. Для взаимодействия маршрутизаторов используются внешние протоколы (EGP - Exterior Gateway Protocols).
Одной из разновидностей EGP является протокол BGP (Border Gateway Protocol, RFC-1268 [BGP-3], RFC-1467 [BGP-4]).
Протокол IGRP (Interior Gateway Routing Protocol) разработан компанией CISCO для больших сетей со сложной топологией и сегментами, которые обладают различной полосой пропускания и задержкой. Это внутренний протокол маршрутизации имеет некоторые черты сходства с OSPF.
IGRP использует несколько типов метрики, по одной на каждый вид QOS. Метрика характеризуется 32-разрядным числом. В однородных средах этот вид метрики вырождается в число шагов до цели. Маршрут с минимальным значением метрики является предпочтительным. Актуализация маршрутной информации для этого протокола производится каждые 90 секунд. Если какой-либо маршрут не подтверждает своей работоспособности в течение 270 сек, он считается недоступным. После семи циклов (630 сек) актуализации такой маршрут удаляется из маршрутных таблиц. IGRP аналогично OSPF производит расчет метрики для каждого вида сервиса (TOS) отдельно.
Протокол IDPR (InterDomain Policy Routing Protocol, RFC-1477, -1479) представляет собой разновидность BGP-протокола. Протокол IS-IS (Intermediate System to Intermediate System Protocol, RFC-1195, -1142) является еще одним внутренним протоколом, который используется для маршрутизации CLNP (Connectionless Network Protocol, RFC-1575, -1561, -1526). IS-IS имеет много общего с OSPF. Смотри также .
Сразу после включения маршрутизатор не имеет информации о возможностях соседних маршрутизаторов. Статичесикие маршрутные таблицы могут храниться в постоянной памяти или загружаться из какого-то сетевого сервера. По этой причине первейшей задачей маршрутизатора является получение маршрутной информации от соседей, а для начала выявление наличия соседей и их адресов. Для этой цели посылается специальный пакет Hello через каждый из своих внешних интерфейсов. В ответ предполагается получить отклик, содержащий идентификационную информацию соответствующего маршрутизатора. Когда два или более маршрутизаторов объединены через локальную сеть, ситуация несколько усложняется. Смотри рис. 4.4.11.5. Маршрутизаторы E, F, G и H подключены непосредственно к локальной сети, некоторые из них имеют связи с другими маршрутизаторами (сети, которые они обслуживают, на рисунке не показаны).
Одним из способов смоделировать локальную сеть - рассматривать маршрутизаторы E, F, G и H, как соединеные непосредственно, введя виртуальный узел сети L (выделен зеленым цветом). На правой части рисунка показан граф такой сети. Возможность прохода из узла F к G обозначена путем FLG. Для протоколов, учитывающих состояние канала, желательно иметь исчерпывающую информацию о нем (загрузка, задержка, пропускная способность, надежность, стоимость и т.д.). Некоторые из перечисленных параметров довольно легко измерить, например, задержку. Для этого вполне пригоден протокол ICMP. К сожалению многие из указанных параметров довольно сильно коррелированы и подвержены флуктуациям. В частности результаты измерения задержки зависят от загрузки канала (вариация времени ожидания в очереди).

Рис. 4.4.11.5. Маршрутизаторы, подключенные к локальной сети
Рассмотрим трафик на пути А-Н. Допустим на основании анализа состояния канал выбран путь через узел Е. В этом случае он может оказаться перегружен, что приведет к большим задаржкам пакетов на пути А-Н. Последующий анализ ситуации может привести к тому, что более оптимальным может оказаться маршрут через узел F.
Если будет принято решение переключить трафик на маршрут ACFH, может перегрузиться участок АСF и история повторится. Данный сценарий описывает типичную ситуацию с осцилляциями маршрута. Осцилляции маршрутов не так безобидны, как это может показаться. Маршрутные таблицы в маршрутизаторах актуализуются вдоль пути с заметными задержками и отнюдь не синхронно. Такие осцилляции могут в разы понизить пропускную способность сети, что необходимо учитывать, выбирая параметры протоколов маршрутизации.
К сожалению многие современные протоколы маршрутизации не имеют встроенных средств аутентификации (контроля доступа), что делает их уязвимыми для различных злоупотреблений.
В последнее время все больше людей обзаводятся компактными переносимыми ЭВМ, которые они берут с собой в деловые поездки, и хотели бы использовать в привычном режиме для работы в Интернет. Конечно, можно заставить модем дозвониться до вашего модемного пула в офисе, но это не всегда лучшее решение как по надежности так и по цене. Пользователи с точки зрения их подвижности могут быть разделены на три группы:
стационарные, работающие всегда на своем постоянном месте в локальной сети
мигрирующие, меняющие время от времени свое рабочее место в рамках локальной сети или даже переходящие из одной LAN в другую.
подвижные, перемещающиеся в пространстве и желающие работать в процессе перемещения.
Предполагается, что все эти пользователи имеют свою постоянную приписку к какой-то сети и соответствующий постоянный IP-адрес. (см. RFC-2794 "Mobile IP Network Access Identifier Extension for IPv4. P. Calhoun, C. Perkins. March 2000). На рис. 4.4.11.6 показана схема подключения подвижных пользователей к Интернет. В этой схеме предполагается наличие в каждой области сети Интернет внешнего агента, обеспечивающего доступ к этой зоне подвижных ЭВМ (на рисунке такой агент помечен надписью "чужая LAN"). Доступ может осуществляться через мобильную телефонную сеть. Предполагается также наличие соответствующего агента в "домашней" LAN, куда стационарно приписана данная ЭВМ.
Домашний агент отслеживает все перемещения своих пользователей, в том числе и тех, кто подключается к "чужим" LAN.

Рис. 4.4.11.6. Схема подключения к Интернет подвижных объектов
Когда к локальной сети подключается новый пользователь (непосредственно физически или через модем сотовой телефонной сети), он должен там зарегистрироваться. Процедура регистрации включает в себя следующие операции:
Каждый внешний агент периодически широковещательно рассылает пакет-сообщение, содержащее его IP-адрес. "Вновь прибывшая ЭВМ" может подождать такого сообщения или сама послать широковещательный запрос наличия внешнего агента.
Мобильный пользователь регистрируется внешним агентом, сообщая ему свой IP- и MAC-адрес, а также некоторые параметры системы безопасности.
Внешний агент устанавливает связь с LAN постоянной приписки зарегистрированного мобильного пользователя, сообщая необходимую адресную информацию и некоторые параметры аутентификации.
Домашний агент анализирует параметры аутентификации и, если все в порядке, процедура установления связи будет продолжена.
Когда внешний агент получает положительный отклик от домашнего агента, он сообщает мобильной ЭВМ, что она зарегистрирована.
Когда пользователь покидает зону обслуживания данной LAN или MAN, регистрация должна быть анулирована, а ЭВМ должна быть автоматически зарегистрирована в новой зоне. Когда посылается пакет мобильному пользователю, "домашняя LAN", получив его, маршрутизирует пакет внешнему агенту, зарегистрировавшему данного пользователя. Этот агент переправит пакет адресату.
Процедуры переадресации выполняются с привлечением технологии IP-туннелей. Домашний агент предлагает отправителю посылать пакеты непосредственно внешнему агенту области, где зарегистрирована подвижная ЭВМ. Существует много вариантов реализации протокола с разным распределением функций между маршрутизаторами и ЭВМ. Существуют схемы и временным выделением резервного IP-адреса подвижному пользователю. Международный стандарт для решения проблемы работы с подвижными пользователями пока не разработан.
В локальных или корпоративных сетях иной раз возникает необходимость разослать некоторую информацию всем остальным ЭВМ-пользователям сети (штормовое предупреждение, изменение курса акций и т.д.). Отправителю достаточно знать адреса всех N заинтересованных пользователей и послать им соответствующее сообщение. Данная схема крайне не эффективна, ведь обычная широковещательная адресация предлагает решение в N раз лучше с точки зрения загрузки сети (посылается одно а не N сообщений). Широковещательная адресация сработает, если в локальной сети нет маршрутизаторов, в противном случае широковещательные адреса МАС-типа заменяются на IP-адреса (что, впрочем, не слишком изящное решение) или применяется мультикастинг адресация. Маршрутизация для мультикастинга представляет собой отдельную задачу. Ведь здесь надо проложить маршрут от отправителя к большому числу получателей. Традиционные методы маршрутизации здесь применимы, но до крайности не эффективны. Здесь для целей выбора маршрута можно с успехом применить алгоритм "расширяющееся дерево" (spanning tree; не имеет циклических структур). Когда на вход маршрутизатора приходит широковещательный пакет, он проверяет, является ли интерфейс, через который он пришел, оптимальным направлением к источнику пакета. Если это так, пакет направляется через все внешние интерфейсы кроме того, через который он пришел. В противном случае пакет игнорируется (так как скорее всего это дубликат). Этот алгоритм называется Reverse Path Forwarding (переадресация в обратном направлении). Пояснение работы алгоритма представлено на рис. 4.4.11.7 (прямоугольниками на рис. обозначены маршрутизаторы). Секция I характеризует топологию сети. Справа показано дерево маршрутов для маршрутизатора I (sink tree). Секция III демонстрирует то, как работает алгоритм Reverse Path Forwarding. Сначала I посылает пакеты маршрутизаторам B, F, H, J и L. Далее посылка пакетов определяется алгоритмом.

Рис. 4.4.11.7. Алгоритм Reverse Path Forwarding
При передаче мультимедиа информации используются принципиально другие протоколы маршрутизации.
Здесь путь прокладывается от получателя к отправителю, а не наоборот. Это связано с тем, что там при доставке применяется мультикастинговый метод. Здесь, как правило, один отправитель посылает пакеты многим потребителям. При этом важно, чтобы размножение пакета происходило как можно ближе к кластеру адресатов. Такая стратегия иной раз удлинняет маршрут, но всегда снижает результирующую загрузку сети. Смотри описания протоколов и .
В последнее время конфигурирование сетевого оборудования (маршрутизаторов, DNS и почтовых серверов усложнилось нкастолько, что это стало составлять заметную часть издержек при формировании коммуникационного узла. Заметного упрощенияи удешевления маршрутизаторов можно ожидать при внедрении IPv6. Следующим шагом станет внедрение объектно-ориентированного языка описания маршрутной политики RPSL (Routing Policy Specification Language). Здесь конфигурирование маршрутизатора будет осуществляться на основе описанной маршрутной политики.
Теперь немного подробнее о наиболее популярных протоколах маршрутизации - RIP, OSPF, IGRP и BGP-4. Начнем с внутреннего протокола маршрутизации RIP.
Провайдерские глобальные уникаст-адреса
Глобальный уникаст-адрес провайдера имеет назначение, описанное в [ALLOC]. Исходное назначение этих уникаст-адресов аналогично функции IPv4 адресов в схеме CIDR [см. CIDR]. Глобальный IPv6 уникаст-адрес провайдера имеет формат, отображенный ниже на рис. 4.4.1.1.9:

Рис. 4.4.1.1.9. Глобальный адрес провайдера
Старшая часть адреса предназначена для определения того, кто определяет часть адреса провайдера, подписчика и т.д.
Идентификатор регистрации определяет регистратора, который задает провайдерскую часть адреса. Термин "префикс регистрации" относится к старшей части адреса, включая поле идентификатор регистрации (ID).
Идентификатор провайдера задает специфического провайдера, который определяет часть адреса подписчика. Термин "префикс провайдера" относится к старшей части адреса включая идентификатора провайдера.
Идентификатор подписчика позволяет разделить подписчиков, подключенных к одному и тому же провайдеру. Термин "префикс подписчика" относится к старшей части адреса, включая идентификатор подписчика.
Часть адреса интра-подписчик определяется подписчиком и организована согласно местной топологии Интернет подписчика. Возможно, что несколько подписчиков пожелают использовать область адреса интра-подписчик для одной и той же субсети и интерфейса. В этом случае идентификатор субсети определяет специфический физический канал, а идентификатор интерфейса - определенный интерфейс субсети.
Рабочие режимы и адресация
SNTP v.4 может работать в уникастном (точка-точка), мультикастном (один передатчик - много приемников) или эникаст (несколько передатчиков - один приемник). Уникастный клиент посылает запросы специально выделенному серверу по его уникастному адресу и ожидает отклика, из которого он может определить время и опционно RTT, а также сдвижку временной шкалы местных часов по отношению к шкале сервера. Мультикастный сервер периодически посылает сообщения по локальному мультикаст-адресу (IPv4 или IPv6). Мультикастный клиент воспринимает получаемые данные и не посылает никаких запросов. Эникастный клиент посылает запрос по локальному специально выделенному мультикастному (IPv4 или IPv6) адресу, при этом один или более эникатных серверов отправляют клиенту отклик. Клиент связывается с первым из них и в дальнейшем продолжает работу уже в уникастном режиме адресации.
Мультикастные серверы должны реагировать на уникастные запросы клиентов, а также самостоятельно посылать мультикастные сообщения. Мультикастные клиенты могут посылать уникастные запросы, чтобы определить задержку распространения пакетов в сети между сервером и клиентом с тем, чтобы в дальнейшем продолжить работу в мультикастном режиме.
В уникастном режиме адреса клиенту и серверу присваиваются согласно обычной схеме IPv4, IPv6 или OSI. В мультикастном режиме сервер использует локальный широковещательный адрес или мультикастный групповой адрес. Локальный широковещательный IP-адрес имеет область действия, ограниченную субсетью, так как маршрутизаторы не ретранслируют широковещательные IP-дейтограммы. С другой стороны IP-адрес мультикастинг-группы имеет область действия, распространяющуюся потенциально на весь Интернет. Для IPv4 iana для целей NTP выделила мультикастный групповой адрес 224.0.1.1, который используется как для мультикаст серверов, так и для эникаст клиентов.
Мультикастные клиенты прослушивают выделенный локальный широковещательный адрес или мультикастный групповой адрес. В случае мультикастного IP-адреса, мультикастный клиент и эникастный сервер должны реализовать протокол IGMP (Internet Group Management Protocol) [DEE89], для того чтобы местный маршрутизатор подключился к мультикаст-группе и ретранслировал сообщения, направленные по IPv4 или IPv6 мультикастным групповым адресам, присвоенным IANA.
Очень важно оптимально выбрать значение поля TTL в IP-заголовке мультикастинг-сообщения, для того чтобы ограничить сетевые ресурсы, используемые данным видом сервиса.
Режим эникаст сконструирован для использования с набором взаимодействующих серверов, чьи адреса не известны клиенту заранее. Эникастный клиент посылает запрос по локальному широковещательному адресу или групповому мультикастинг-адресу. Для этой цели используется групповой адрес NTP специально выделенный iana для этих целей. Один или более эникастных серверов воспринимают этот запрос и отправляют отклик по уникастному адресу клиента. Клиент устанавливает связь с сервером, от которого получил отклик раньше. Последующие отклики эникаст-серверов игнорируются.
В случае SNTP, существует реальная угроза того, что SNTP мультикаст-клиент может быть введен в заблуждение поведением SNTP или NTP-серверов (возможно и преднамеренным), так как все они используют один и тот же групповой мультикаст-адрес, выделенный для этих целей IANA. Где необходимо, для выбора сервера, известного клиенту может проводиться отбор по адресу. Опционной является схема криптографической аутентификации, описанной в документе RFC-1305.
Расширение DNS для поддержки IP-версии (DNS Extensions to Support IP Version S Thomson RFC-)
Существующая поддержка записи адресов Интернет в DNS (Domain Name System) [1,2] не может быть легко расширена для поддержки IPv6-адресов [3], так как приложение предполагает, что адресный запрос вернет только 32-битовый IPv4-адрес.
Для того чтобы запоминать IPv6-адреса, определены следующие расширения:
Определен новый тип ресурсной записи, для того чтобы установить соответствие между именами доменов и адресами IPv6.
Определен новый домен, предназначенный для обработки запросов по новым адресам.
Существующие запросы, которые выполняют выявление IPv4-адресов, переопределены для получения как IPv4, так и IPv6-адресов.
Изменения выполнены так, чтобы быть совместимыми с имеющимся программным обеспечением. Существующая поддержка IPv4-адресов сохраняется. Переходное состояние осуществования IPv4 и IPv6-адресов обсуждается в [4].
Размер почтового ящика и актуализации состояния сообщений
В любое время сервер может послать данные, которые клиент не запрашивал. Иногда, такое поведение системы является необходимым. Например, агенты, внешние по отношению к серверу, могут положить сообщения в почтовый ящик, изменить флаги сообщения в почтовом ящике (например, одновременный доступ в почтовый ящик нескольких агентов), или даже удалить сообщения из почтового ящика. Сервер должен автоматически послать уведомление об изменении размера почтового ящика, если такое изменение произошло в процессе выполнения команды. Сервер должен автоматически послать уведомление об изменении флагов сообщений, не требуя соответствующего запроса клиента. Имеются специальные правила для оповещения клиента сервером об удалении сообщений, чтобы избежать ошибок синхронизации (смотри также описание EXPUNGE). Программа клиента должна своевременно фиксировать изменения размера почтового ящика. Она не должна полагаться на то, что любая команда после начального выбора почтового ящика возвращает значение его размера.
Разрыв контрольного соединения
Разрыв контрольного соединения может быть инициирован LAC или LNS и выполняется путем посылки одного управляющего сообщения StopCCN. Получатель StopCCN должен послать ZLB ACK, чтобы подтвердить получение сообщения, и поддерживает состояние управляющего соединения на уровне достаточном для корректного приема StopCCN, а также повторения цикла, если ZLB ACK потеряно. Рекомендуемое время повторения цикла равно 31 секунде (смотри раздел 5.8). Ниже приводится типовой обмен управляющими сообщениями:
LAC или LNS LAC или LNS
StopCCN ->
(Clean up)
| <- ZLB ACK | |
| (Wait) | |
| (Clean up) |
Программа может ликвидировать туннель и все сессии туннеля путем посылки StopCCN. Таким образом, не нужно прерывать каждую сессию, если разорван туннель.
Реализация LTP через специфическую среду
Протокол L2TP является само документируемым, работающим поверх уровня, который служит для транспортировки. Однако, необходимы некоторые детали подключения к среде, для того чтобы обеспечить совместимость различных реализаций.
Set-Link-Info (SLI)
Сообщение Set-Link-Info является управляющим сообщением L2TP, посланным от LNS к LAC для установления согласуемых опций PPP. Эти опции можно изменять в любое время на протяжении реализации вызова, таким образом, LAC должен быть способен обновлять свою собственную информацию вызова и поведение на протяжении активной PPP-сессии. Следующие AVP должны присутствовать в SLI:
Тип сообщения (Message Type)
ACCM
Сетевой протокол времени NTP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Время – самый важный и невосполнимый ресурс любого человека. Проблема эта занимала людей всегда, и уже более 4 тысяч лет люди пытаются как-то упорядочить учет расходования этого ресурса, создавая различные календарные системы и устройства измерения времени. Календарные системы древнего мира отражали сельскохозяйственные, политические и ритуальные нужды, характерные для того времени. Астрономические наблюдения для установления зимнего и летнего солнцестояния производились еще 4000 лет тому назад. Проблема создания календаря возникала только в обществах, где государственная стабильность поддерживалась в течение достаточно долгого времени (Китай, Египет, государство Майя). В 14-ом столетии до Рождества Христова в Китае была определена длительность солнечного года - 365.25 дней, а лунный месяц - 29.5 дней. Солнечно-лунный календарь действовал на ближнем востоке (за исключением Египта) и в Греции, начиная с 3-го тысячелетия до нашей эры. Ранние календари использовали либо 13 лунных месяцев по 28 дней или 12 месяцев с чередующейся протяженностью 29 и 30 дней.
Древнеегипетский календарь имел 12 30-дневных лунных месяцев, но был привязан к сезонному появлению звезды Сириус (sirius – sothis). Для того чтобы примирить этот календарь с солнечным годом, был изобретен гражданский календарь, в котором добавлено 5 дней, доводящих длительность года до 365 дней. Однако со временем было замечено, что гражданский год примерно на одну четверть дня короче, чем солнечный год. Выбранная длительность года обеспечивала полное совпадение с солнечным годом раз за 1460 лет. Этот период называется циклом Сотиса (sothic-цикл). Так же как и shang chinese, древние египтяне установили длительность солнечного года равной 365,25 дней, что с точностью 11 минут совпадает с результатами современных вычислений. В 432 году до рождества Христа, около столетия после китайцев греческий астроном Метон вычислил, что 110 лунных месяцев по 29 дней и 125 лунных месяцев по 30 дней соответствуют 6940 солнечным дням, что лишь немного превышает 19 лет. 19-летний цикл, названный циклом Метона, установил длительность лунного месяца равной 29,532 солнечных дней, что с точностью 2 минут совпадает результатами современных измерений.
В древнем Риме использовался лунный календарь. Юлий Цезарь пригласилалександрийского астронома Сосигенса, который разработал календарь (который по понятным причинам стал называться юлианским), принятый в 46 году до Рождества Христова. Календарь содержал 365 дней в году с добавлением одного дня каждые 4 года. Однако первые 36 лет по ошибке дополнительный день добавлялся каждые три года. В результате набежало лишних три дня, которые пришлось компенсировать вплоть до 8 года нашей эры.
Семидневная неделя была введена лишь в четвертом столетии нашей эры императором Константином I.
Во время романской эры 15-летний цикл переписи использовался при исчислении налогов. Последовательность имен дней недели воспроизводится через 28 лет, этот период называется солнечным циклом. Таким образом, учитывая 28-летний солнечный цикл, 19-летний цикл Метона и 15-летний переписи, получаем суперцикл протяженностью 7980-лет, называемый юлианской эрой, которая начинается в 4713 году до рождества христова.
К 1545 году расхождение между юлианским календарем и солнечным годом достигло 10 дней. В 1582, астрономы Кристофер Клавиус и Луиджи Лилио предложили новую схему календаря. Папа Грегорий XIII выпусти указ, где среди прочего указывалось, что в году содержится 365.2422 дней. Для того чтобы более точно аппроксимировать эту новую величину, только столетние годы, которые делятся без остатка на 400, объявляются високосными, что предполагает длительность года 365,2425 дней. В настоящее время григорианский календарь принят большинством стран мира.
Для того чтобы мерить расширение вселенной или распад протона необходимо стандартную схему нумерации дней. По решению Международного астрономического Союза был принят стандарт на секунду и юлианская система нумерации дней (jdn). Стандартный день содержит 86,400 стандартных секунд, а стандартный год состоит из 365,25 стандартных дней.
В схеме (JDN), предложенной в 1583 французским ученым Джозефом Юлиусом Скалигером, JDN 0.0 соответствует 12 часам (полдень) первого дня юлианской эры - 1 января 4713 до нашей эры.
Годы до нашей эры подсчитываются согласно юлианскому календарю, в то время как годы нашей эры нумеруются по григорианскому календарю. 1 января 1 года после рождества христова в григорианском календаре соответствует 3 января 1 года юлианского календаря [DER90], в JDN 1.721.426,0 день соответствует 12 часам первого дня нашей эры.
Эталоном времени может стать любой циклический процесс с достаточно стабильным периодом. Для измерения времни сначала использовали солнечные часы (Вавилон, 3,5 тысячи лет назад), которые были пригодны только днем при безоблачном небе. Им на смену пришли водяные часы, способные работать круглые сутки (если позволял объем сосуда). Позднее были изобретены песочные часы (появились примерно тысячу лет назад), которые могли обеспечить точность около 15-20 минут за сутки. Именно от этого типа часов пошла морская единица измерения времени - "склянки". Революцию в сфере измерения времени вызвало изобретение механических часов (Вестмистерские куранты 1288 год). Первые часы с маятником были изготовлены Х. Гюйгенсом в 1657 году, через 13 лет был изобретен анкерный механизм. Механическим хронометрам человечество обязано великим географическим открытиям 18 века (Дж.Кук). Первые часы с использованием электричества был разработаны А. Бейном в 1840 году, а первые кварцевые часы увидели свет в 1918 году. В 1937 году кварцевые часы Л.Эссена были установлены в Гринвичской лаборатории (GMT), они имели точность 2мсек в сутки. В 1944 году радиостанция BBC стала передавать сигналы точного времени с погрешностью около 0,1 мсек.сутки. Сейчас кварцевые часы можно увидеть на запястьях людей и в любом комьютере. Первые атомные часы были изготовлены в 1949 году. Без этих технологических свершений технический прогресс 20-го века был бы невозможен. Кварцевые часы побывали в космосе и на Луне.
В 1967 году был принят цезиевый (Cs133) стандарт времени, где одна секунда соответствует 9192631770 периодам перихода между уровнями в атоме цезия UTC (Universal Time Coordinated).
UTC почти в миллион раз точнее астрономического среднего времени по Гринвичу. Ошибка UTC составляет менее 0,3 нсек/сутки .
Не исключено, что со врменем эталоном времени станет излучение миллисекундного пульсара (открыт в 1982 году), имеющего период 1,55780645169838 миллисекунды. Этот пульсар предположительно имеет массу Солнца, радиус 10 км и вращается со скоростью 642 оборота в секунду.
С 1 января 2001 года английским правительством было официально объявлено о новом стандарте времени Grinwich e-time (GET), который будет использоваться для обеспечения глобальных электронных платежей через Интернет.
Для оценки времени природа снабдила человека, как и некоторых других живых существ, так называемыми биологическими часами. Эти часы отсчитывают циклы длительностью около 24 часов. У нас, правда, есть природный генератор - это сердце, с периодом около 1 секунды. За отсчет времени ответственен теменной участок коры больших полушарий мозга. Механизмы оценки коротких временных интервалов и упорядочение наших жизненных событий происходит разными способами. Но эти механизмы хороши, пожалуй, лишь для определния времени обеда.
Калиброванный эталон времени, например атомные часы, довольно сложное и дорогостоящее устройство, требующее квалифицированного обслуживания. По этой причине многие пользователи не могут позволить себе такие издержки и вынуждены обращаться к услугам удаленных эталонов. Это может быть первичный эталон, размещенный где-то в локальной сети, или радио-часы. Условия доступа к сети уже предполагают наличие определенной дисперсии для времени доставки калибровочной информации. Если же эталон размещен далеко в Интернет, значения задержки и дисперсии могут возрасти многократно. Для обеспечения большей надежности калибровки обычно используют несколько эталонов, а для снижения влияния временных разбросов привлекают довольно сложные алгоритмы усреднения.
Сетевой протокол задания времени NTP (network time protocol; Network Time Protocol Version 3 Specification, Implementation and Analysis, David L.
Mills, RFC-1305, March 1992) служит для осуществления синхронизации работы различных процессов в серверах и программах клиента. Он определяет архитектуру, алгоритмы, объекты и протоколы, используемые для указанных целей. NTP был впервые определен в документе RFC-958 [MIL85c], но с тех пор несколько раз переделан и усовершенствован (RFC-1119 [MIL89]). Протокол использует для транспортных целей UDP [POS80]. Целью протокола является обеспечение максимально возможной точности и надежности, несмотря на значительный разброс задержек при прохождении через большое число промежуточных маршрутизаторов.
Протокол NTP обеспечивает механизмы синхронизации с точностью до наносекунд. Протокол предлагает средства для определения характеристик и оценки ошибок локальных часов и временного сервера, который осуществляет синхронизацию. Предусмотрены возможности работы с иерархически распределенными первичными эталонами, такими как синхронизуемые радио-часы.
Точность, достижимая с помощью NTP, сильно зависит от точности локальных часов и характерных скрытых задержек. Алгоритм коррекции временной шкалы включает внесение задержек, коррекцию частоты часов и ряд механизмов, позволяющих достичь точности порядка нескольких миллисекунд, даже после длительных периодов, когда потеряна связь с синхронизирующими источниками.
Существует ряд механизмов в Интернет, которые позволяют передавать и записывать время, когда произошло какое-то событие. Это протокол daytime [POS83a], time protocol [POS83b], сообщения ICMP “временная метка” [DAR81b] и опция IP “временная метка” [SU81].
Маршрутный протокол fuzzball [MIL83b], иногда называемый hellospeak, встраивает синхронизацию непосредственно в алгоритм маршрутного протокола. Он не является протоколом из стека IP.
Юниксовский (4.3BSD) времязадающий демон [GUS85a] измеряет временные сдвиги различных клиентских процессов и рассылает им соответствующие поправки.
В этой модели сервер определен с помощью алгоритма выбора [GUS85b], который исключает ситуации, где сервер не выбран или выбрано более одного сервера.
Процесс выбора требует возможности рассылки широковещательных сообщений.
Архитектура системы

В модели NTP некоторое число первичных эталонов времени, синхронизованных по кабелю или с помощью национальных радио служб времени, подключено к широкодоступным ресурсам, таким как порты опорной сети. Эти устройства функционируют как первичные серверы времени. Целью NTP является передача информации о точном времени от этих серверов к другим серверам через Интернет и коррекция ошибок, связанных с флуктуациями задержек в сети. Некоторое число локальных ЭВМ или внешних шлюзов могут выполнять функции вторичных серверов времени, общающихся с первичными эталонами на основе протокола NTP. Вторичные серверы позволяют минимизировать избыточность протокола, рассылая нужную временную информацию локально. В целях обеспечения надежности выбранные вторичные источники могут быть снабжены менее точными, зато более дешевыми радио-часами, используемыми в ситуациях, когда откажет первичный эталон или выйдет из строя ведущий к нему канал.
Под стабильностью подразумевается степень постоянства задающей частоты часов, а под точностью – соответствие этой частоты национальным стандартам времени. Если не указано обратного, под временным сдвигом между часами подразумевается разница показаний этих часов. В то время как под сбоем (skew) подразумевается различие их рабочих частот (первая производная). Настоящие часы имеют конечную стабильность частоты (вторая производная не равна нулю). Нестабильность частоты называется дрейфом, но в рамках протокола NTP дрейф предполагается равным нулю.
Протокол NTP создан с целью определения трех величин: смещения часов (clock offset), RTT и дисперсии, все они вычисляются по отношению к выбранным эталонным часам. Смещение часов определяет поправку, которую необходимо внести в показания местных часов, чтобы результат совпал показанием эталонных часов. Дисперсия характеризует максимальную ошибку локальных часов по отношению к эталонным.
В протоколе NTP нет средств для нахождения партнера или управления.
Целостность данных обеспечивается с помощью IP и UDP контрольных сумм. Система может работать в симметричном режиме, когда сервер и клиент неразличимы, и в режиме клиент-сервер, где сервер выполняет только то, что требует клиент. Используется только один формат сообщений NTP. В рамках модели необходимо определить минимально возможную частоту коррекций часов, обеспечивающую требуемую временную точность.
Реализация модели
Клиент посылает NTP-сообщения одному или нескольким серверам и обрабатывает отклики по мере их получения. Сервер изменяет адреса и номера портов, переписывает содержимое некоторых полей, заново вычисляет контрольную сумму и немедленно посылает отклик. Информация, заключенная в сообщение NTP, позволяет клиенту определить показания часов сервера по отношению к часам клиента и соответствующим образом скорректировать рабочие параметры местных часов. Кроме того, эта информация содержит данные, позволяющие оценить точность и надежность часов сервера и выбрать наилучший эталон времени.
Модель клиент-сервер может быть вполне достаточна для локальных сетей, где один сервер обслуживает некоторое количество клиентов. В общем случае NTP требует одновременной работы большого числа распределенных пар партнеров (клиент-сервер), конфигурация которых изменяется динамически. Нужны достаточно сложные алгоритмы управления такой ассоциацией, для обработки данных и контроля множества локальных часов.
Процесс передачи, управляемый независимыми таймерами для каждого из партнеров, осуществляет накопление информации в базе данных и посылает сообщения NTP. Каждое сообщение содержит локальную временную метку момента отправки сообщения, ранее полученные временные метки, а также необходимую вспомогательную информацию. Частота посылки сообщений определяется требуемой точностью локальных часов, а также предельными точностями часов партнеров.
Процесс приема осуществляет получение сообщений NTP и, возможно, сообщений других протоколов, а также информации от непосредственно подключенных радио-часов.
Когда получено сообщение NTP, вычисляется сдвиг между часами партнера и локальными часами, результат заносится в базу данных вместе с другой информацией, необходимой для вычисления ошибок и выбора партнера.
Конфигурации сети
Субсеть синхронизации представляет собой соединение первичных и вторичных серверов времени, клиентов и каналов передачи данных. Первичные серверы времени синхронизованы непосредственно от эталонов времени, обычно от радио-часов. Вторичные серверы могут быть синхронизованы от первичных серверов или других вторичных серверов времени. Система серверов имеет иерархическую структуру, построенную по схеме клиент-сервер. Понятно, что вторичные серверы обеспечивают более низкую временную точность.
Следуя принципам, принятым в телефонной промышленности [BEl86], точность каждого сервера определяется номером слоя (stratum), наивысший уровень (для первичного сервера) имеет номер 1. На современном уровне технологий (радио-часы) точность однократной сверки имеет порядок одной миллисекунды.
Точность однократной сверки падает по мере роста значения RTT и его разброса. Для того чтобы избежать сложных расчетов [BRA80], необходимых для оценки точности в каждом конкретном случае, полезно предположить, что средняя ошибка измерения пропорциональна RTT и ее дисперсии. Предполагая, что первичные серверы синхронизованы стандартами времени с известной точностью, можно получить вполне надежную оценку точности синхронизации субсети.
Дополнительным фактором является то, что каждый переход от одного слоя к другому предполагает наличие ненадежного сервера времени, который вносит дополнительные ошибки. Алгоритм выбора серверов времени использует разновидность алгоритма маршрутизации , при этом формируется дерево минимальных весов, основанием которого являются первичные сервера. Метрикой расстояния служит номер слоя плюс расстояние синхронизации, которое характеризуется суммой дисперсии и половины абсолютного значения задержки.
Такая конструкция способствует тому, что субсеть автоматически реконфигурируется и настраивается на максимально достижимую точность даже при выходе из строя первичных или вторичных серверов времени.
Если даже все первичные серверы выйдут из строя или станут недоступными, их функции будут выполнять вторичные серверы, если расстояние до них согласно алгоритму Беллмана-Форда не превышает значения метрики, соответствующего бесконечности (разрыву связи). Если все серверы окажутся на больших расстояниях, субсеть продолжит работу при установках, выполненных при последней синхронизации (коррекции внутренних часов). Даже в этом случае достижима точность порядка миллисекунд в сутки.
Если два сервера находятся согласно алгоритму на равных расстояниях, допускается случайный выбор.
Форматы данных
Все арифметические операции в рамках протокола выполняются в формате с фиксированной запятой. По этой причине все переменные в NTP имеют именно этот формат. Биты пронумерованы слева на право (со старшего бита), начиная с нуля. Жестких требований на число разрядов после запятой не установлено. Если не оговорено обратного, все числа не имеют знака и занимают все отведенное для них поле (при необходимости в качестве заполнителей старших разрядов используются нули).
Временные метки NTP представляют собой 64-битные числа с фиксированной запятой без знака, которое указывает число секунд с нуля часов 1-го января 1900 года. Целая часть содержит первые 32 разряда, а дробная часть остальные 32 разряда. Этот формат не совпадает с форматом меток ICMP, где время измеряется в миллисекундах. Точность представления составляет 200 пикосекунд, что должно удовлетворить самым экзотическим требованиям.
Временная метка формируется путем копирования показания местных часов. Это производится в момент времени, заданный каким-то событием, например, приходом сообщения. Для поддержания наивысшей точности, важно, чтобы это делалось как можно ближе к оборудованию или программному обеспечению, инициирующего этот процесс. В случае, когда временная метка недоступна, например, производится перезагрузка машин, поле метки характеризуется 64 нулями.
Заметим, что с 1968 года старший бит (бит 0 целой части) равен единице, а где-то в 2036 году 64-битовое поле переполнится.
Переменные состояния и параметры
Ниже приводится обзор различных переменных и параметров, используемых протоколом. Они распределены по классам системных переменных, которые имеют отношение к операционной среде и механизму реализации местных часов. Сюда входят переменные партнеров, которые характеризуют состояние протокольных машин участников обмена, переменные пакетов, описывающие содержимое пересылаемых NTP-сообщений, а также параметры, задающие конфигурацию текущей версии программного обеспечения. Имена переменных записываются строчными буквами, а имена параметров - прописными.
Общие переменные
Следующие переменные являются общими для двух или более систем, партнеров и классов пакетов. Когда необходимо отличить общие переменные с идентичными именами, вводится идентификатор переменной.
Адрес партнера (peer.peeraddr, pkt.peeraddr), порт партнера (peer.peerport, pkt.peerport). 32-битный ip-адрес и 16-битный номер порта партнера.
Адрес ЭВМ (peer.hostaddr, pkt.hostaddr), порт ЭВМ (peer.hostport, pkt.hostport). 32-битный IP-адрес и 16-битный номер порта ЭВМ. Эти переменные включаются в переменные состояния для поддержки мультиинтерфейсных систем.
Индикатор приращения (sys.leap, peer.leap, pkt.leap) - это двухбитный код предупреждения о включении дополнительных секунд во временную шкалу NTP. Эти биты устанавливаются до 23:59 дня добавления и сбрасываются после 00:00 следующего дня. В результате день, для которого проведена эта процедура, окажется длиннее или короче на одну секунду. Для вторичных серверов эти биты устанавливаются протоколом NTP. Биты 0 и 1 (LI) принимают значения, перечисленные в таблице 4.4.15.1:
Таблица 4.4.15.1 Значения кодов индикатора LI
| LI | Величина | Значение |
| 00 | 0 | предупреждения нет |
| 01 | 1 | последняя минута содержит 61 секунду |
| 10 | 2 | последняя минута содержит 59 секунд |
| 11 | 3 | аварийный сигнал (часы не синхронизованы) |
Во всех случаях за исключением аварийного сигнала (alarm = 112), протокол NTP никак не изменяет эти биты, а только передает их программам преобразования времени, которые не являются частью протокола.
Аварийная ситуация возникает, когда по какой-либо причине локальные часы оказываются не синхронизованными. Это может случиться в ходе инициализации системы или в случае, когда первичные часы оказываются недоступны в течение длительного времени.
Режим (peer.mode, pkt.mode) - это целое 3-битовое число, обозначающее код режима ассоциации, который может принимать значения, приведенные в таблице 4.4.15.2:
Таблица 4.4.15.2. Значения кодов Режим
| Режим | Значение |
| 0 | зарезервировано |
| 1 | симметричный активный |
| 2 | симметричный пассивный |
| 3 | клиент |
| 4 | сервер |
| 5 | широковещательный |
| 6 | для управляющих сообщений NTP |
| 7 | зарезервировано для частного использования |
Слой (sys.stratum, peer.stratum, pkt.stratum) - это целое число, указывающее код слоя локальных часов, который может принимать значения приведенные в таблице 4.4.15.3.
Таблица 4.4.15.3. Значения кодов слой
| Слой | Значение |
| 0 | Не специфицирован или недоступен |
| 1 | Первичный эталон (например, радио часы) |
| 2-15 | Вторичный эталон (через NTP или sntp) |
| 16-255 | Зарезервировано на будущее |
Для целей сравнения значение нуль для кода слоя считается выше, чем любая другая величина. Заметим, что максимальное значение целого, закодированное как пакетная переменная, ограничено параметром ntp.maxstratum.
Период обмена (sys.poll, peer.hostpoll, peer.peerpoll, pkt.poll). Это целая переменная со знаком, указывающая минимальный интервал между передаваемыми сообщениями, измеренный в секундах и представленный как степень 2. Например, значение 6 указывает на минимальный интервал в 64 секунды.
Точность (sys.precision, peer.precision, pkt.precision). Это целая переменная со знаком, обозначающая точность часов в секундах и выраженная как ближайшая степень числа 2. Значение должно быть округлено в большую сторону до ближайшего значения степени 2, например, сетевой частоте 50-Гц (20 мс) или 60-Гц (16.67 мс) будет поставлено в соответствие величина -5 (31.25 мс), в то время как кварцевой частоте 1000-Гц (1 мс) будет поставлено в соответствие значение -9 (1.95 мс).
Базовая задержка (sys.rootdelay, peer.rootdelay, pkt.rootdelay).
Это число с фиксированной запятой со знаком, указывающее на величину полной циклической задержки (RTT) до первичного эталона частоты, выраженной в секундах.
Базовая дисперсия (sys.rootdispersion, peer.rootdispersion, pkt.rootdispersion). Это число с фиксированной запятой больше нуля, указывающее на максимальное значение временной ошибки по отношению к первичному эталону в секундах.
Идентификатор эталонных часов (sys.refid, peer.refid, pkt.refid). Это 32-битовый код, идентифицирующий конкретные эталонные часы. В случае слоя 0 (не специфицирован) или слоя 1 (первичный эталонный источник), 4-октетная ASCII-строка, выровненная по левому краю и дополненная при необходимости нулями, например:
Таблица 4.4.15.4. Коды идентификаторов часов
| Слой | Код | Значение |
| 0 | dcn | Протокол маршрутизации dcn |
| 0 | dts | Цифровая служба времени (digital time service) |
| 0 | nist | Общий модем nist |
| 0 | tsp | Временной протокол tsp |
| 1 | atom | Атомные часы (калиброванные) |
| 1 | vlf | vlf-радио (omega, и пр.) |
| 1 | callsign | Общее радио |
| 1 | gps | gps УВЧ позиционирование спутников |
| 1 | lorc | loran-c радионавигация |
| 1 | wwvb | Радио wwvb НЧ (диапазон 5) |
| 1 | goes | Спутник goes УВЧ (диапазон 9) |
| 1 | wwv | Радио wwv ВЧ (диапазон 7) |
В случае слоя 2 и выше (вторичный эталон) - это 4-октетный IP-адрес партнера, выбранного для синхронизации.
Эталонная временная метка (sys.reftime, peer.reftime, pkt.reftime) - локальное время в формате временных меток, соответствующее моменту последней коррекции показаний часов. Если локальные часы не были синхронизованы, переменная содержит нуль.
Базовая временная метка (peer.org, pkt.org) - локальное время в формате временных меток, соответствующее моменту посылки последнего NTP-сообщения. Если партнер недостижим, переменная принимает нулевое значение.
Временная метка получения (peer.rec, pkt.rec) - локальное время в формате временных меток, соответствующее моменту прихода последнего NTP-сообщения, полученного от партнера. Если партнер недостижим, переменная принимает нулевое значение.
Временная метка передачи (peer.xmt, pkt.xmt) - локальное время в формате временных меток, соответствующее моменту отправки NTP-сообщения.
Системные переменные
Следующие переменные используются операционной системой для синхронизации локальных часов.
Переменная локальные часы (sys.clock) содержит показание локальных часов в формате временных меток. Локальное время получается от аппаратных часов конкретной ЭВМ и дискретно увеличивается с конструктивно заданными приращениями.
Переменная Базовые часы (sys.peer) представляет собой селектор, идентифицирующий используемый источник синхронизации. Обычно это указатель на структуру, содержащую переменные партнера. Значение нуль указывает, что в настоящее время источник синхронизации отсутствует.
Переменные партнера
Ниже перечислены все переменные партнера, которые используются для управления и реализации измерительных процедур.
Бит конфигурации (peer.config) - бит, индицирующий, что ассоциация была сформирована на основе конфигурационной информации и не должна быть расформирована, когда партнер становится недоступен.
Временная метка актуализации (peer.update) - локальное время в формате временной метки, отмечающее момент, когда было получено последнее NTP сообщение. Переменная используется для вычисления дисперсии временного сдвига.
Регистр достижимости (peer.reach) - сдвиговый регистр битов ntp.window, используемых для определения статуса достижимости партнера. Ввод данных производится со стороны младших бит (справа). Партнер считается достижимым, если как минимум один бит этого регистра равен 1.
Таймер партнера (peer.timer) - целочисленный счетчик, используемый для управления интервалом между последовательно посылаемыми NTP-сообщениями. После установки значения счетчика его содержимое уменьшается на 1 (1сек) пока не достигнет нуля. При этом вызывается процедура передачи. Заметим, что работа этого таймера не должна зависеть от локальных часов.
Пакетные переменные
Номер версии (pkt.version) - целое число индицирующее номер версии отправителя. NTP сообщения всегда посылаются с текущим значением версии ntp.version и будут восприняты лишь при условии совпадения кодов версии (ntp.version).
Исключения допускаются лишь при смене номера версии.
Переменные фильтра часов
Когда используются фильтры и алгоритмы отбора, дополнительно привлекаются следующие переменные состояния.
Регистр фильтра (peer.filter) - сдвиговый регистр каскадов ntp.shift, где каждый каскад запоминает значения измеренной задержки, смещения и вычисленной дисперсии, соответствующих одному наблюдению. Эти три параметра вводятся со стороны старших разрядов и сдвигаются в направлении младших разрядов (направо). При получении результатов нового наблюдения старые результаты теряются.
Счетчик корректных данных (peer.valid) - целочисленный счетчик, указывающий на корректные образцы, остающиеся в регистре фильтра. Он используется для определения состояния доступности и для управления увеличением и уменьшением периода рассылки сообщений.
Смещение (peer.offset) - число с фиксированной запятой со знаком, индицирующее значение смещение часов партнера по отношению к локальным часам в секундах.
Задержка (peer.delay) - число с фиксированной запятой со знаком, индицирующее полную циклическую задержку (RTT) часов партнера по отношению к локальным часам с учетом времени распространения сообщения и отклика в сети в секундах. Заметим, что переменная может принимать как положительное, так и отрицательное значение в зависимости от точности часов и накопившейся ошибки смещения.
Дисперсия (peer.dispersion) - число с фиксированной запятой, индицирующее максимальную ошибку часов партнера по отношению к локальным часам с учетом сетевой задержки в секундах. Допускаются только значения больше нуля.
Переменные аутентификации
При использовании механизма аутентификации привлекаются следующие переменные состояния.
Бит разрешения аутентификации (peer.authenable) - бит, указывающий, что ассоциация должна работать в режиме аутентификации.
Бит аутентификации (peer.authentic) - бит, индицирующий то, что последнее сообщение, полученное от партнера, было корректно аутентифицировано.
Идентификатор ключа (peer.hostkeyid, peer.peerkeyid, pkt.keyid) - целое число, идентифицирующее криптографический ключ, использованный при генерации аутентификационного кода сообщения.
Криптографические ключи (sys.key) - набор 64- битных ключей DES. Каждый ключ создается в соответствии с берклиевскими UNIX-распределениями, которые состоят из 8 октетов, где 7 младших бит каждого октета соответствуют битам des 1-7, а старший бит соответствует биту четности DES.
Контрольная крипто-сумма (pkt.check) - криптографическая контрольная сумма, вычисляемая процедурой шифрации.
Параметры
Ниже описаны параметры для всех реализаций, работающих в сети Интернет. Необходимо договориться относительно значений этих параметров для того, чтобы исключить ненужную избыточность и стабилизировать ассоциации партнеров. Приведенные параметры применимы для всех ассоциаций.
Номер версии (ntp.version) - текущий номер версии NTP (3).
Порт NTP (ntp.port) - стандартный номер порта (123), присвоенный протоколу NTP.
Максимальный номер слоя (ntp.maxstratum) - максимальный номер слоя, который может быть использован при кодировании пакетной переменной. Этот параметр обычно интерпретируется как определение бесконечности (недостижимости для протокола маршрутизации в субсети).
Максимальный возраст часов (ntp.maxage) - максимальный интервал в секундах, в течение которого эталонные часы будут рассматриваться корректными после последней сверки.
Максимальный сбой (ntp.maxskew) - максимальная ошибка смещения, связанная со сбоем локальных часов за время ntp.maxage, в секундах. Отношение ntp.maxskew к ntp.maxage интерпретируется как максимальный сбой, вызванный всей совокупностью факторов.
Максимальное расстояние (ntp.maxdistance) - максимально допустимое расстояние между партнерами при синхронизации с использованием алгоритма отбора.
Минимальный период рассылки (ntp.minpoll) - минимальный период рассылки, допустимый для любого из партнеров в сети Интернет. Этот период выражается в секундах и представляет собой степень 2.
Максимальный период рассылки (ntp.maxpoll) -максимальный период рассылки, допустимый для любого из партнеров в сети Интернет. Этот период выражается в секундах и представляет собой степень 2.
Минимум избранных часов (ntp.minclock) - минимальное число партнеров, необходимое для синхронизации (при использовании алгоритма отбора).
Максимум избранных часов (ntp.maxclock) - максимальное число партнеров, необходимое для организации отбора (при использовании алгоритма селекции).
Минимальная дисперсия (ntp.mindisperse) - минимальное значение приращения дисперсии для каждого из слоев в секундах (при использовании алгоритма фильтрации).
Максимальная дисперсия (ntp.maxdisperse) - максимальная дисперсия в секундах с учетом потерянных данных (при использовании алгоритма фильтрации).
Размер регистра доступности (ntp.window) - размер регистра доступности (peer.reach) в битах.
Размер фильтра (ntp.shift) - размер сдвигового регистра фильтра часов (peer.filter) в каскадах.
Вес фильтра (ntp.filter) - вес, используемый при вычислении дисперсии фильтра (применяется при работе с алгоритмом фильтрации).
Выбранный вес (ntp.select) - вес, используемый при вычислении выбранной дисперсии (применяется при работе алгоритма селекции).
Режимы работы
За исключением широковещательного режима, NTP-ассоциация формируется, когда два партнера обмениваются сообщениями и один или оба из них создает и поддерживает протокольную машину, называемую ассоциацией. Ассоциация может работать в одном из 5 режимов, заданных переменной peer.mode: симметрично активный, симметрично пассивный, клиент, сервер и широковещательный:
Симметрично активный (1). ЭВМ, работающая в этом режиме, периодически посылает сообщения вне зависимости от достижимости или слоя своего партнера. При работе в этом режиме ЭВМ оповещает о своем намерении синхронизовать и быть синхронизованной партнером.
Симметрично пассивный (2). Этот тип ассоциации первоначально создается по прибытии сообщения от партнера, работающего в симметрично активном режиме. Он сохраняется, пока партнер достижим и функционирует в слое ниже или равном данной ЭВМ. В противном случае ассоциация распадается. Однако ассоциация будет существовать до тех пор, пока, по крайней мере, одно сообщение не будет послано в качестве отклика.
При работе в этом режиме ЭВМ оповещает о своем намерении синхронизовать и быть синхронизованной партнером.
Клиент (3). ЭВМ, работающая в этом режиме, периодически посылает сообщения вне зависимости от достижимости или слоя своего партнера. При работе в этом режиме ЭВМ, обычно это сетевая рабочая станция, оповещает о своем намерении быть синхронизованной партнером.
Сервер (4). Этот тип ассоциации первоначально создается по прибытии запроса клиента и существует только для отклика на этот запрос. После отклика ассоциация ликвидируется. При работе в этом режиме ЭВМ, обычно рабочая сетевая станция, оповещает о намерении синхронизовать партнера.
Широковещательный (5). ЭВМ, работающая в этом режиме, периодически посылает сообщения вне зависимости от доступности или слоя партнеров. При работе в этом режиме ЭВМ, обычно сетевой сервер времени, который работает в широковещательной среде, оповещает о намерении синхронизовать всех партнеров.
ЭВМ, работающая в режиме клиента, иногда посылает NTP-сообщение ЭВМ, работающей в режиме сервера, например, сразу после перезагрузки и периодически после этого. Сервер откликается, меняя адреса и номера портов, занося необходимую информацию и отправляя сообщение назад клиенту. Серверы не должны хранить какую-либо статусную информацию в паузах между запросами клиента, в то время как клиенты могут варьировать интервалы между NTP сообщениями, для того чтобы удовлетворить локальным требованиям. В этих режимах протокольная машина, описанная в этой статье, может быть существенно упрощена без заметной потери точности или надежности особенно при работе в быстродействующей локальной сети.
В симметричных режимах отличие клиента от сервера практически исчезает. Симметрично пассивный режим предназначен для использования временными серверами, работающими вблизи базовых узлов (нижний слой) субсети синхронизации и со сравнительно большим числом партнеров. В этом режиме идентификации партнера не требуется заранее, так как ассоциация с ее переменными состояния создана, только когда получено NTP-сообщение.
Более того, запомненное состояние может быть использовано позднее, когда партнер станет недостижим или будет работать на более высоком уровне и по этой причине будет непригоден в качестве источника синхронизации.
Симметрично активный режим предназначен для использования серверами времени, работающими вблизи оконечных узлов (наивысший слой) синхронизации. Надежный временной сервис обычно может быть реализован с помощью двух партнеров на ближайшем нижележащем слое и одном партнере в том же слое. По этой причине поток сообщений обычно невелик, даже когда связь потеряна, и на каждый запрос приходит отклик об ошибке.
В норме, один партнер работает в активном режиме (симметричный активный, клиент или широковещательный), как это сконфигурировано в стартовом файле, в то время как другие работают в пассивном режиме (симметричный пассивный или сервер), часто без предварительной конфигурации. Однако оба партнера могут быть сконфигурированы для работы в симметричном режиме. Условие ошибки возникает, когда оба партнера работают в одном и том же режиме, но не в симметричном активном. В таких случаях каждый партнер будет игнорировать сообщения, поступающие от другого, и ассоциация, если она существовала, будет ликвидирована из-за недостижимости партнера.
Широковещательный режим предназначен для работы в скоростных локальных сетях с большим числом рабочих станций, где не требуется высокая точность. При типичном сценарии один или более временных серверов LAN периодически посылают широковещательные сообщения рабочим станциям, которые затем определяют время на основе предварительно заданной задержки распространения порядка нескольких миллисекунд.
Обработка событий
Существенные события с точки зрения протокола NTP происходят при истечении времени таймеров партнера (peer.timer), один из которых ориентирован специально на данного партнера в активной ассоциации, а также при получении NTP-сообщения от различных партнеров. Событие может произойти как результат команды оператора или обнаруженной ошибки, такой как отказ первичного эталона.
Обозначения
Алгоритмы фильтрации и селекции NTP используют несколько переменных для хранения значений сдвига часов, RTT и дисперсии. Переменные, относящиеся к партнерам, обычно обозначаются строчными греческими буквами, а для первичного эталона времени используются прописные буквы. Эти алгоритмы базируются на параметре, называемом расстояние синхронизации (l) и вычисляемом с использованием rtt и дисперсии.
Дисперсия партнера (e) содержит вклады от ошибок измерения (r) и накопления ошибок дрейфа (skew-error).
Каждый раз, когда соответствующие переменные партнеров изменяются, значения дисперсии корректируются. Ниже приводятся основные определения переменных и формулы их вычисления:
q = peer.offset,
d = peer.delay,
e = peer.dispersion = r + jt + es,
l = e + |d|/2,
где d = rtt, q - сдвиг часов, jt - накопление сбоя, j = ntp.maxskew/ntp.maxage, t - момент времени передачи исходной временной метки (на основе t вычисляется q и d), e s - дисперсия фильтра. Переменные, относящиеся к партнеру i, определяются следующим образом:
q i = j i,
d i = peer.rootdelay + d i,
e i = peer.rootdispersion + e i + j ti (максимальная дисперсия часов партнера),
li= ei + |di|/2,
Окончательно, предполагая, что для синхронизации выбран i-ый партнер, система переменных определяется следующим образом:
q = комбинированное окончательное смещение (combined final offset),
d = di,
e = ei + ex + q,
l = li,
где ex дисперсия выбора (select dispersion).
Приводимые ниже тексты программ, реализующие вычисления переменных, записаны на условном языке, напоминающем СИ.
Процедура передачи
Процедура передачи запускается, когда таймер партнера станет равным нулю. В режиме клиента с широковещательным сервером сообщения вообще не посылаются. В режиме сервера сообщения посылаются только в качестве отклика на полученные запросы.
Нижеприведенный фрагмент программы инициализирует пакетный буфер и копирует пакетные переменные.
| pkt.peeraddr <- peer.hostaddr; | /* копирование системных и партнерских переменных */ |
pkt.peerport <- peer.hostport;
pkt.hostaddr <- peer.peeraddr;
pkt.hostport <- peer.peerport;
pkt.leap <- sys.leap;
pkt.version <- ntp.version;
pkt.mode <- peer.mode;
pkt.stratum <- sys.stratum;
pkt.poll <- peer.hostpoll;
pkt.precision <- sys.precision;
pkt.rootdelay <- sys.rootdelay;
if (sys.leap = 112 or (sys.clock - sys.reftime) > ntp.maxage)
skew <- ntp.maxskew;
else
skew <- j (sys.clock - sys.reftime);
{pkt.rootdispersion <- sys.rootdispersion + (1 << sys.precision)} + skew;
pkt.refid <- sys.refid;
pkt.reftime <- sys.reftime;
Временная метка передачи pkt. xmt будет использована позднее, для того чтобы проконтролировать отклик. Таким образом, программа должна сохранить точное переданное значение. Кроме того, порядок копирования временных меток должен быть выбран так, чтобы не понизить точность.
| pkt.org <- peer.org; | /* копирование временных меток */ |
pkt.rec <- peer.rec;
pkt.xmt <- sys.clock;
peer.xmt <- pkt.xmt;
Регистр доступности сдвигается на одну позицию влево, в освободившийся разряд записывается нуль. Если все биты регистра равны нулю, вызывается процедура очистки (clear procedure) для обнуления фильтра часов и выбора, если необходимо, нового источника синхронизации. Если ассоциация не была сконфигурирована при инициализации, то она ликвидируется.
| peer.reach <- peer.reach <<1; | /* актуализация доступности */ |
if (peer.reach = 0 and peer.config =0)
begin
ликвидируем ассоциацию;
exit;
endif
Если корректные данные введены в сдвиговый регистр фильтра хотя бы раз за время предыдущих двух периодов рассылки (младший бит peer.reach равен 1), счетчик корректных данных увеличивается на 1. После восьми таких удачных периодов интервал рассылки увеличивается. Процедура выбора часов вызывается, если необходимо заменить источник синхронизации.
| if (peer.reach & 6 ? 0) | /* Проверка младших двух бит */ |
| if (peer.valid << ntp.shift) | /* получены корректные данные */ |
peer.valid <- peer.valid + 1;
else peer.hostpoll <- peer.hostpoll + 1;
else begin
| peer.valid <- peer.valid - 1; | /* ничего не слышно */ |
peer.hostpoll <- peer.hostpoll - 1;
call clock-filter(0, 0, ntp.maxdisperse);
| call clock-select; | /* выбираем источник синхронизации */ |
endif
call poll-update;
end transmit procedure;
Процедура получения
Процедура получения выполняется по приходу NTP-сообщения. Она проверяет сообщения, интерпретирует различные режимы и вызывает другие процедуры для фильтрации данных и выбора источника синхронизации. Если номер версии в пакете не соответствует текущей версии, сообщение может быть отброшено. Если получено управляющее сообщение NTP и код режима пакета равен 6 (управление), вызывается процедура управляющего сообщения. IP-адреса отправителя и адресата, а также номера портов устанавливаются соответствующими заданному партнеру. Если соответствия нет, производится новая инсталляция протокольной машины и формируется новая ассоциация.
begin receive procedure
if (pkt.version ? ntp.version>) exit;
#ifdef (control messages implemented)
if (pkt.mode = 6) call control-message;
#endef
| for (all associations) | /* Здесь выполняется управление доступом */ |
match addresses and ports to associations;
if (no matching association)
| call receive-instantiation procedure; | /* создаем ассоциацию */ |
Вызов процедуры дешифровки осуществляется только в случае применения аутентификации.
#ifdef (authentication implemented)
call decrypt;
#endef
Если код режима пакета не равен нулю, он определяет режим на следующем этапе; в противном случае, режим определяется по номеру порта.
| if (pkt.mode = 0) | /* для совместимости со старыми версиями */ |
mode;
else
mode <- pkt.mode;
case (mode, peer.hostmode)
В случае ошибки пакет просто игнорируется, а ассоциация, если она не была предварительно сконфигурирована, ликвидируется.
error: if (peer.config = 0) demobilize association;
break;
В случае recv пакет обрабатывается, а ассоциация помечается как достижимая при условии 5-8 успешных проверок.
Если и проверки с первой по 4-ую проходят успешно (данные корректны), вызывается процедура коррекции показания локальных часов. В противном случае, если ассоциация не была предварительно сконфигурирована, она ликвидируется.
recv: call packet; | /* обработать пакет */ |
| if (valid header) begin | /* если правильный заголовок, актуализовать внутренние часы */ |
peer.reach <- peer.reach | 1;
if (valid data) call clock-update;
endif
else
if (peer.config = 0) ликвидировать ассоциацию;
break;
В случае xmit, пакет обрабатывается и посылается промежуточный отклик. Ассоциация затем ликвидируется.
| xmit: call packet; | /* обработать пакет */ |
| peer.hostpoll <- peer.peerpoll; | /* послать немедленно отклик */ |
call poll-update;
call transmit;
if (peer.config = 0) ликвидировать ассоциацию;
break;
В случае pkt, пакет обрабатывается, а ассоциация помечается как достижимая при условии, что тесты 5-8 (правильный заголовок), перечисленные в пакетной процедуре, прошли успешно. Если, кроме того, прошли тесты 1-4 (корректные данные), вызывается процедура коррекции показаний локальных часов. В противном случае, если ассоциация не была предварительно сконфигурирована, она сразу после отклика ликвидируется.
| pkt: call packet; | /* обработка пакета */ |
.reach <- peer.reach | 1;
if (valid data) call clock-update;
endif
else if (peer.config = 0) begin
poll-update;
call transmit;
ликвидировать ассоциацию;
endif
endcase
end receive procedure;
Пакетная процедура
Пакетная процедура проверяет корректность сообщения, вычисляет задержку/смещение и вызывает другие процедуры для отбора данных и выбора источника синхронизации. Тест 1 требует, чтобы переданная временная метка отличалась от последней, полученной от того же партнера. Тест 2 требует, чтобы исходная временная метка соответствовала последней метке, посланной тому же партнеру. В случае широковещательного режима (5) rtt=0 и полная точность операции передачи времени будет недостижимой. Однако, полученная точность может быть вполне приемлемой для многих целей.
Процедура вызова коррекции времени использует в качестве параметра peer.hostpoll (peer.peerpoll может быть изменено).
begin packet procedure
| peer.rec <- sys.clock; | /* забрать полученную временную метку */ |
if (pkt.mode ? 5) begin
| test1 <- (pkt.xmt ? peer.org); | /* Тест 1 */ |
| test2 <- (pkt.org = peer.xmt); | /* Тест 2 */ |
else begin
| pkt.org <- peer.rec; | /* потеря временной метки из-за ошибки */ |
| test1; | /* ложные тесты */ |
endif
| peer.org <- pkt.xmt; | |
poll-update(peer.hostpoll);
Тест 3 требует, чтобы исходная и полученная временные метки не были равны нулю. Если любая из них равна нулю, ассоциация не синхронизирована или потеряла доступ в одном или обоих направлениях.
test3 <- (pkt.org ? 0 and pkt.rec ? 0); /* Тест 3 */
rtt и временное смещение по отношению партнера вычисляется следующим образом. Пусть i четное целое число.
Тогда ti-3, ti-2, ti-1 и ti - содержимое переменных pkt.org, pkt.rec, pkt.xmt и peer.rec, соответственно. Смещение часов j, rtt=d и дисперсия e ЭВМ по отношению к партнеру равны:
d = (ti - ti-3) - (ti-1 - ti - 2),
j = ((ti - 2 - ti-3) + ( ti-1 - ti))/2,
e = (1 << sys.precision) + j (ti - ti-3),
где, как и прежде, j = ntp.maxskew/ntp.maxage. << - обозначает сдвиг кода влево. Значение e представляет собой максимальную ошибку или дисперсию, связанную с ошибкой измерения на стороне ЭВМ, а также накопление ошибок из-за дрейфа локальных часов за время после посылки последнего сообщения, посланного партнером. Дисперсия корректируется процедурой фильтра часов (clock-filter).
Рассмотренный метод эквивалентен непрерывному стробированию, которое используется в некоторых телефонных сетях [bel86]. Преимуществом метода является полная независимость от порядка и времени прихода сообщений, а также допустимость потери некоторых пакетов. Очевидно, что достижимые точности зависят от статистических свойств каналов связи.
Тест 4 требует, чтобы вычисленная задержка лежала в допустимых пределах:
test4 <- (|d| < ntp.maxdisperse И e
Тест 5 используется, только если реализован механизм аутентификации. Он требует, чтобы либо аутентификация была явно блокирована, либо чтобы аутентификатор в точности соответствовал тому, что описано в процедуре дешифровки.
#ifdef (authentication implemented) /* Тест 5 */
test5 <- ((peer.config = 1 и peer.authenable = 0) или peer.authentic = 1);
#endef
Тест 6 требует, чтобы часы партнера были синхронизованы, и время с момента последней коррекции было положительным и меньше чем ntp.maxage.
Тест 7 гарантирует, что ЭВМ не будет синхронизовано от партнера с большим кодом номера слоя.
Тест 8 требует, чтобы заголовок содержал соответствующие коды в полях pkt.rootdelay и pkt.rootdispersion.
| test6 <- (pkt.leap ? 112 and | /* Тест 6 */ |
{pkt.reftime ? pkt.xmt << pkt.reftime + ntp.maxage})
| test7 <- {pkt.stratum ? sys.stratum} and | /* Тест 7 */ |
{pkt.stratum << ntp.maxstratum};
| test8 <- (| pkt.rootdelay | << ntp.maxdisperse and | /* Тест 8 */ |
{pkt.rootdispersion << ntp.maxdisperse});
С точки зрения последующей обработки пакеты содержат корректные данные, если успешно проходят тесты 1-4 (test1 & test2 & test3 & test4 = 1), вне зависимости от результатов других тестов. Только пакеты с корректными данными могут использоваться для вычисления смещения (offset), задержки (delay) и дисперсии. Пакеты имеют корректные заголовки, если успешно проходят тесты 5-8 (test5 & test6 & test7 & test8 = 1), вне зависимости от результатов остальных тестов. Только пакеты с корректными заголовками могут использоваться для определения того, может ли партнер быть выбран в качестве источника синхронизации. Заметим, что тесты 1-2 не используются в широковещательном режиме.
Процедура "часовой фильтр" вызывается для вычисления задержки (peer.delay), смещения (peer.offset) и дисперсии (peer.dispersion) для партнера. Спецификация алгоритма часового фильтра не является составной частью протокола NTP. По этой причине описания, приводимые ниже, следует рассматривать как рекомендательные.
if (not valid header) exit;
| peer.leap < pkt.leap; | /* Копирование переменных пакета */ |
peer.stratum <- pkt.stratum>;
peer.precision <- pkt.precision>;
peer.rootdelay <- pkt.rootdelay>;
peer.rootdispersion <- pkt.rootdispersion>;
peer.refid <- pkt.refid>;
peer.reftime <- pkt.reftime>;
if (valid data) call clock-filter(q, d, e); | /* обработка данных */ |
end packet procedure;
Процедура коррекции показаний часов
Процедура коррекции показания часов вызывается процедурой приема, когда процедура фильтрации определила корректные значения смещения задержки и дисперсии для данного партнера.
begin clock-update procedure
| call clock-select; | /* Выбор базовых часов */ |
if (sys.peer ? peer) exit;
Может так случиться, что локальные часы оказались сброшены. В этом случае вызывается процедура очистки (clear procedure) для каждого из партнеров, чтобы возвратить в исходное состояние фильтр часов, период рассылки и, если необходимо, осуществить выбор нового источника синхронизации.
Процедура расстояния вычисляет базовую (root) задержку d, базовую дисперсию e и базовое расстояние синхронизации l. ЭВМ не будет синхронизовать выбранного партнера, если расстояние больше чем ntp.maxdistance.
| l andistance(peer); | /* обновление системных переменных */ |
if (l ? ntp.maxdistance) exit;
sys.leap <- peer.leap;
sys.stratum <- peer.stratum + 1;
sys.refid <- peer.peeraddr;
call local-clock;
| if (local clock reset) begin | /* если сброс, очистить системные переменные */ |
sys.leap <- 112;
for (all peers) call clear;
endif
else begin
| sys.peer <- peer; | /* если нет, то подстроить локальные часы */ |
sys.rootdelay <- d;
sys.rootdispersion <- e + max (ex + |t|, ntp.mindisperse);
endif
sys.reftime <- sys.clock;
end clock-update procedure;
В некоторых конфигурациях системы прецизионный источник временной информации доступен в виде последовательности синхронизующих импульсов, следующих с периодом в одну секунду. Обычно это является дополнением к базовому источнику времязадающей информации, такому как радио-часы или даже сам протокол NTP, для того чтобы обеспечить подсчет секунд, минут, часов и дней.
В этих конфигурациях системные переменные устанавливаются с учетом источника, от которого поступают такие импульсы. Для конфигураций, которые поддерживают первичные эталонные источники, такие как радио-часы или калиброванные атомные часы код слоя устанавливается равным 1, поскольку именно он является действительным источником синхронизации.
Спецификация алгоритмов выбора часов и работы локальных часов не являются составной частью NTP. По этой причине описания этих алгоритмов, представленные ниже, следует рассматривать лишь как рекомендации.
Работа первичных часов (primary-clock procedure)
Когда ЭВМ связана с первичным эталоном времени, таким как радио-часы, удобно ввести информацию об этих часах в базу данных, как если бы это был обычный партнер. В процедуре первичных часов часы запрашиваются раз в минуту или около того, полученный же временной код используется для корректировки показаний местных часов. Когда обнуляется peer.timer для первичного партнера, процедура передачи не вызывается, а посылается запрос радио-часам с использованием ASCII-последовательности, предусмотренной для этого случая. Когда получен корректный временной код от радио-часов, он преобразуется в формат временной метки NTP и корректируются соответствующие переменные партнера. Величина peer.leap устанавливается в зависимости от состояния бита оповещения временного кода, если таковой имеется, или вручную оператором. Значение для peer.peeraddr, которое становится равно sys.refid, когда вызывается процедура корректировки показаний часов, делается равным ASCII-строке, описывающей часы.
begin primary-clock-update procedure
| peer.leap <- "from" radio or operator; | /* Копирование переменных */ |
peer.peeraddr <- ascii identifier;
peer.rec <- radio timestamp;
peer.reach <- 1;
call clock-filter({sys.clock - peer.rec, 0, 1 << peer.precision}); | /* образец процесса */ | |
| call clockupdate; | /* коррекция локальных часов */ | |
end primary-clock-update procedure;
Процедуры инициализации
Процедура инициализации вызывается при перезагрузке системы или при повторном запуске демона NTP. Состояние локальных часов при загрузке предполагается неопределенным; однако, некоторые виды оборудования обеспечивают доступ к локальным часам, как в ходе загрузки, так и сразу после нее. Переменная точности определяется внутренней архитектурой оборудования локальных часов. Аутентификационные переменные используются лишь при реализации механизма аутентификации. Значения этих переменных определяются процедурами, выходящими за рамки протокола NTP.
begin initialization procedure
#ifdef (authentication implemented)
sys.keys <- as required;
#endef;
| sys.leap <- 112; | /* копирование переменных */ |
sys.stratum <- 0 (undefined);
sys.precision <- host~precision;
sys.rootdelay <- 0(undefined);
sys.rootdispersion <- 0 (undefined);
sys.refid <- 0 (undefined);
sys.reftime <- 0 (undefined);
sys.clock <- external reference;
sys.peer <- null;
sys.poll <- ntp.minpoll;
| for (all configured peers) | /* создание конфигурированных ассоциаций */ |
call initialization-instantiation procedure;
end initialization procedure;
Процедура initialization-instantiation
Эта процедура является аппаратно-зависимой и служит, среди прочего, для формирования ассоциации. Адреса и режимы работы партнеров определяются в процессе чтения при перезагрузке или в результате обработки команд оператора. В случае привлечения механизма аутентификации только аутентифицированный партнер может стать источником синхронизации.
begin initialization-instantiation procedure
peer.config <- 1;
#ifdef (authentication implemented)
peer.authenable <- 1 (suggested);
peer.authentic <- 0;
peer.hostkeyid <- as required;
peer.peerkeyid <- 0;
#endef;
| peer.peeraddr <- peer ip address; | /* копирование переменных */ |
peer.peerport <- ntp.port;
peer.hostaddr <- host ip address;
peer.hostport <- ntp.port;
peer.mode <- host mode;
peer.peerpoll <- 0 (undefined);
peer.timer <- 0;
peer.delay <- 0 (undefined);
peer.offset <- 0 (undefined);
| call clear; | /* инициализация ассоциации */ |
end initialization-instantiation procedure;
Процедура receive-instantiation
Процедура receive- instantiation вызывается процедурой приема, когда обнаруживается новый партнер. Она инициализирует переменные партнера и формирует ассоциацию. Если сообщение получено от партнера, работающего в режиме клиента (3), ЭВМ переводится в режим сервера (4); в противном случае, она устанавливается в симметрично пассивный режим (2).
begin receive-instantiation procedure
#ifdef (authentication implemented)
peer.authenable <- 0;
peer.authentic <- 0;
peer.hostkeyid <- as required;
peer.peerkeyid <- 0;
#endef
| peer.config <- 0; | /* Копирование переменных */ |
peer.peeraddr <- pkt.peeraddr;
peer.peerport <- pkt.peerport;
peer.hostaddr <- pkt.hostaddr;
peer.hostport <- pkt.hostport;
| if (pkt.mode = 3) | /* Определение режима */ |
peer.mode <- 4;
else
peer.mode <- 2;
peer.peerpoll <- 0 (undefined);
peer.timer <- 0;
peer.delay <- 0 (undefined);
peer.offset <- 0 (undefined);
| call clear; | /* инициализация ассоциации */ |
end receive-instantiation procedure;
Процедура primary clock-instantiation
Эта процедура вызывается из процедуры инициализации для того, чтобы установить переменные состояния для первичных часов. Значение peer.precision определяется из спецификации радио-часов и аппаратного интерфейса. Значение peer.rootdispersion номинально равно удесятеренной максимальной ошибке радио-часов, например, 10 мсек для WWVB или радио-часов goes и 100 мсек для менее точных радио-часов WWV.
begin clock-instantiation procedure
| peer.config <- 1; | /* копирование переменных */ |
peer.peeraddr <- 0 undefined;
peer.peerport <- 0 (not used);
peer.hostaddr <- 0 (not used);
peer.hostport <- 0 (not used);
peer.leap <- 112;
peer.mode <- 0 (not used);
peer.stratum <- 0;
peer.peerpoll <- 0 (undefined);
peer.precision <- clock precision;
peer.rootdelay <- 0;
peer.rootdispersion <- clock dispersion;
peer.refid <- 0 (not used);
peer.reftime <- 0 (undefined);
peer.timer <- 0;
peer.delay <- 0 (undefined);
peer.offset <- 0 (undefined);
| call clear; | /* инициализация ассоциации */ |
end clock-instantiation procedure;
В некоторых конфигурациях, включающих в себя атомные часы или приемники LORAN-C, первичный эталон может выдавать только секундные импульсы и не предоставлять полного временного кода (числа секунд и пр.). В этих конфигурациях нумерация секунд может быть получена из других источников, таких как радио-часы или даже другие NTP-партнеры. В этих конфигурациях переменные первичных часов должны отражать особенности первичного эталона, а не источника нумерации секунд. Однако если источник нумерации секунд отказал или работает некорректно, актуализация локальных часов от первичного эталона должна быть заблокирована.
Процедура очистки
Процедура очистки вызывается, когда произошло событие, которое значительно изменило достижимость или вызвало поломку локальных часов.
begin clear procedure
| peer.org <- 0 (undefined); | /* пометка неопределенных временных меток */ |
peer.rec <- 0 (undefined);
peer.xmt <- 0 (undefined);
| peer.reach <- 0; | /* сброс переменных состояния */ | |
| peer.filter <- [0, ,0, ntp.maxdisperse]; | /* все ступени */ | |
peer.valid <- 0;
peer.dispersion <- ntp.maxdisperse;
| {peer.hostpoll <- ntp.minpoll}; | /* первичная установка периода рассылки */ |
call poll-update;
| call clock-select; | /* Выбор эталонных часов */ |
end clear procedure;
Процедура запроса-коррекции (poll-update)
Процедура запросов-коррекции вызывается, когда происходит событие, которое может вызвать изменение периода запросов (рассылки) или таймера партнера. Она проверяет значения периода запросов ЭВМ (peer.hostpoll) и партнера (peer.peerpoll), а также устанавливает их в заданных пределах.
begin poll-update procedure
| temp <- peer.hostpoll; | /* определение периода запросов ЭВМ */ |
if (peer = sys.peer)
temp <- min (temp, {sys.poll, ntp.maxpoll)};
else
temp <- min (temp, ntp.maxpoll);
peer.hostpoll <- max (temp, ntp.minpoll);
temp <- 1 <
Если интервал запросов (рассылок) не изменился, а таймер партнера на нуле, то таймер просто сбрасывается в начальное состояние. Если интервал запросов изменен, и новое значение таймера больше текущего значения, никаких дополнительных действий не требуется; в противном случае величина выдержки таймера партнера должна быть уменьшена. Когда время выдержки таймера партнера уменьшается, важно исключить тенденцию синхронизации обмена между партнерами. Благоразумной предосторожностью является рэндмизация первой передачи после уменьшения выдержки таймера.
| if (peer.timer = 0) | /* сброс таймера партнера */ |
peer.timer <- temp;
else if (peer.timer >temp)
peer.timer <- (sys.clock & (temp - 1)) + 1;
end poll-update procedure;
Процедура расстояния синхронизации (synchronization distance)
Процедура расстояния вычисляет расстояние синхронизации на основе переменных партнеров.
begin distance(peer) procedure;
d <- {peer.rootdelay + |peer.delay|};
e <- {peer.rootdispersion + peer.dispersion + f (sys.clock - peer.update)};
l<-e + |d|/2;
end distance procedure;
Заметим, что, в то время как d может быть в некоторых случаях отрицательной, e и l всегда положительны.
Замечания о контроле доступа
Конструкция NTP устроена так, что случайная или намеренная модификация данных временного сервера не должна привести к серьезным ошибкам синхронизации. Однако успех этого подхода зависит от дополнительных временных серверов и альтернативных сетевых маршрутов, а также от предположения, что искажения не охватывают большинство временных серверов одновременно. В принципе уязвимость субсети может быть улучшена разумным выбором временных серверов. Механизм аутентификации также позволяет повысить надежность синхронизации. Следует, правда, принимать во внимание, что шифрование/дешифрование данных заметно ухудшает точность синхронизации.
Если требуется более надежная модель, система может базироваться на списке доступа, в который включаются 32-битовый IP-адрес, 32-битовая маска и 3-битовый код режима работы. Если логическое И адреса эталона (pkt.peeraddr) и маски на входе ЭВМ соответствуют соответствующим адресу и режиму (pkt.mode), доступ разрешается, в противном случае отправителю запроса присылается ICMP-сообщение об ошибке. Список управления доступом служит фильтром, определяющим, какой из партнеров может сформировать ассоциацию.
Алгоритмы фильтрации и селекции
Наиболее важным фактором, влияющим на точность и надежность синхронизации, является набор алгоритмов, используемых для уменьшения статистических ошибок и искажений при сбоях в различных компонентах субсети. Алгоритмы, описанные в этой статье, не являются частью стандарта NTP, по этой причине допускается использование любых других алгоритмов.
Для того чтобы NTP алгоритмы фильтрации и отбора работали эффективно, полезно иметь меру вариации для каждого из партнеров. Принятая мера вариации базируется на разностях первого порядка, которые легко вычислить. Существует две меры, одна называемая дисперсией фильтра es, и другая дисперсия выбора (select dispersion) ez. Обе меры вычисляются как взвешенные суммы смещений из списка, сформированного на основе расстояний синхронизации. Если qi (0Ј i < n) смещение i-ой записи, тогда разность eij i-ой записи по отношению к j-ой записи определяется как |qi - q j|. Дисперсия относительно j-ой записи определяется как ej =

где w - весовой коэффициент, который служит для учета влияния расстояния синхронизации на дисперсию. В алгоритмах NTP w выбирается меньше 1/2: w = ntp.filter для дисперсии фильтра (filter dispersion) и w = NTP.SELECT для дисперсии выбора (select dispersion).
Дисперсия es и ex определены относительно 0-ой записи e0.
Существует две процедуры, описанные ниже, процедура "часовой-фильтр" (clock-filter), которая используется для выбора лучших записей смещения для данных часов, и процедура "выбора часов" (clock-selection), которая используется, чтобы выбрать наилучшие часы среди иерархического набора часов.
Процедура часовой фильтр (clock-filter)
Процедура часовой фильтр исполняется по прибытии сообщения NTP или другого события, в результате которого получены новые данные. Она использует аргументы (q, d, e), где q - результат измерения смещения часов, содержащийся в записи, а d и e соответственно RTT и дисперсия. Процедура определяет значение отфильтрованного смещения часов (filtered clock offset - peer.offset), RTT (peer.delay) и дисперсии (peer.dispersion). Она также корректирует дисперсию хранящихся записей и текущее показание часов (peer.update).
Процедура часового фильтра использует сдвиговый регистр (peer.filter), который состоит из NTP.SHIFT каскадов, каждый каскад содержит значения qi, di и e i, которые пронумерованы, начиная с нуля, слева направо. Фильтр инициализируется процедурой очистки при этом заносятся значения [0, 0, NTP.MAXDISPERSE] во всех каскадах. Новые данные записей вдвигаются в фильтр с левого конца. Пакетная процедура выдает записи в формате (q ,d, e), когда приходят новые корректирующие данные, в то время как процедура передачи выдает записи в форме [0, 0, NTP.MAXDISPERSE], когда истекает два периода запроса без поступления свежих данных. Когда одни и те же символы (q, d, e) используютсядля аргументов, содержимого часового фильтра и переменных партнера, их значения обычно понятно из контекста. Ниже представлена псевдопрограмма, поясняющая работу данной процедуры.
begin clock-filter procedure (q, d, e)
Дисперсия ei для всех корректных записей в регистре фильтра должна корректироваться с тем, чтобы отражать накопление смещения со времени последней коррекции. Эти записи заносятся также во временный список, следуя стандартному формату записей [расстояние, индекс]. Записи в регистре сдвигаются вправо, новые записи вводятся слева, а самая правая запись теряется. Временный список сортируется по значению расстояния. Если в списке не остается записей, процедура прерывается без корректировки переменных партнера.
| for (i from ntp.size 1 to 1) begin | /* коррекция дисперсии */ |
[qi, di, ei] <- [q{i-1}, d{i-1}, e{i-1}];
/* shift stage right */
ei = ei + ft;
add [li ? ei + {|di|}/2, i] to temporary list;
endfor;
[q0, d0, e0] <- [q, d, e]; | /* ввести новую запись */ |
add [l ? e + {|d|}/2, 0] to temporary list;
peer.update <- sys.clock; | /* сбросить показание часов */ |
sort temporary list by increasing [distance index];
где [distance index] представляет собой объединение полей расстояния и индекса (расстояние занимает старшую позицию). Дисперсия фильтра es вычисляется и включается в дисперсию партнера. Заметим, что временный список для этой цели уже упорядочен.
es <- 0;
| for (i from ntp.shift-1 to 0) | /* вычисление дисперсии фильтра */ |
if (peer.dispersionindex[i] ? NTP.MAXDISPERSE or |qi - q0 > NTP.MAXDISPERSE)
es <- (es + NTP.MAXDISPERSE) * NTP.FILTER;
else
es <- (es + |qi - q0|) * NTP.FILTER;
Смещение партнера q0, задержка d0 и дисперсия e0 выбираются как величины, соответствующие записи с минимальным расстоянием; другими словами, записи, соответствующей первому элементу временного списка (в данной нотации имеет индекс 0).
peer.offset <- q0; | /* корректировка переменных партнера */ |
peer.delay <- d0;
peer.dispersion <- min(e0 + es, NTP.MAXDISPERSE);
end clock-filter procedure
Переменные peer.offset и peer.delay представляют смещение шкалы часов и RTT для локальных часов, измеренные относительно часов партнера. Обе они усредняются по большому числу измерений в течение длительного периода времени. Переменная peer.dispersion характеризует максимальную ошибку из-за неточности измерений, дрейфа и вариации записей. Все три переменные используются при выборе часов для синхронизации.
Процедура выбора часов
Процедура выбора часов использует переменные партнера q, d, e и t, она вызывается, когда эти переменные изменились или изменился статус доступности. Процедура включает в себя две составные части: алгоритм пересечения (intersection algorithm) и алгоритм кластеризации (clustering algorithm). Алгоритм пересечения подготавливает список кандидатов партнеров, могущих стать источниками синхронизации и вычисляет доверительный интервал для каждого из них.
Алгоритм кластеризации сортирует список кандидатов по кодам слоя и расстояния синхронизации. Системная переменная sys.peer представляет собой указатель на наиболее вероятного кандидата, если таковой имеется, или на нулевую величину в противном случае.
Алгоритм пересечения
begin clock-selection procedure
Каждый из партнеров просматривается последовательно и добавляется в конец списка, если он прошел ряд тестов. Для каждого из m кандидатов в список заносятся 3 записи в форме [указатель, тип]: [q - l, - 1], [q, 0] и [q + l, 1]. В результате в списке будет 3m записей, которые будут позднее упорядочены.
m <- 0;
| for (each peer) | /*обращение ко всем партнерам */ |
if ({peer.reach ? 0 and peer.dispersion < ntp.maxdisperse} and not (peer.stratum > 1 И peer.refid = peer.hostaddr)) begin
l
| andistance (peer); | /* запись в список */ |
add [q - l, -1] to endpoint list;
add [q, 0] to endpoint list;
add [q + l, 1] to endpoint list;
m <- m + 1;
<B>endif
endfor
| if (m = 0) begin | /* уход, если кандидаты отсутствуют */ |
sys.peer <- null;
sys.stratum <- 0 (undefined);
exit;
endif
sort endpoint list by increasing endpointtype;
Ниже приведенный алгоритм представляет собой адаптированную версию DTS [DEC89] и сконструирован так, чтобы отбирать только истинных кандидатов. Алгоритм начинается с инициализации значения f и занесения нуля в счетчики i и c. Затем, начиная с конца упорядоченного, для каждой записи [указатель, тип] значение типа вычитается из кода счетчика i, который содержит число пересечений. Если код типа равен нулю, инкрементируется значение c, которое регистрирует число ложных кандидатов. Если для некоторых записей i і ? m - f, конец записи становится нижней границей пересечения; в противном случае, f увеличивается на 1 и процедура повторяется. Без сброса значений f или c, аналогичная процедура используется для нахождения верхней границы, за исключением того, что значение кода тип добавляется к счетчику. Если после того как обе границы определены c Ј f, процедура продолжается для найденных m - f кандидатов, в противном случае, f увеличивается на 1 и вся процедура повторяется.
| for (f from 0 to f ? m/2) begin | /* обращение ко всем кандидатам */ |
c <- 0;
i <- 0;
| for (each [endpoint, type] from lowest) begin | /* нахождение нижней границы */ |
i <- i - type;
low <- endpoint;
if (i ? m - f) break;
if (type = 0) c <- c + 1;
endfor;
i <- 0;
| for (each [endpoint, type] from highest) begin | /* нахождение верхней границы */ |
i <- i + type;
high <- endpoint;
if (i ? m - f) break;
if (type = 0 ) c <- c + 1;
endfor;
| if (c ? f) break; | /* продолжить, пока не будут найдены все ложные кандидаты */ |
endfor;
| if (low > high) begin | /* завершить, если не найдено ни одного пересечения */ |
sys.peer <- null;
exit;
endif;
Заметим, что работа продолжается далее данной точки, только если имеется более m/2 пересечений. Однако возможно, но не слишком вероятно, что в области пересечения окажется менее m/2 кандидатов.
Алгоритм кластеризации
В исходном алгоритме DTS процедура выбора часов прерывается в данной точке с выбором кандидатов из центра области пересечения. Однако это ведет к заметной потере точности и стабильности, так как не учитываются индивидуальные статистические свойства партнеров. Следовательно, в NTP только кандидаты, которые остаются в результате описанного выше отбора, могут участвовать в последующей обработке. Список кандидатов преобразуется к форме [расстояние, индекс], где расстояние вычисляется на основе кода слоя и расстояния синхронизации l партнера. Масштабный коэффициент позволяет реализовать механизм весового учета вкладов от кодов слоя и расстояния. Обычно, код слоя доминирует, если только один или более кандидатов имеют слишком большие расстояния. Список упорядочивается согласно величине расстояния.
m <- 0;
| for (each peer) begin | /* обращение ко всем партнерам */ |
if (low ? q ? high) begin
| l <- distance (peer); | /* сформировать запись в списке */ |
dist <- {peer.stratum * NTP.MAXDISPERSE + l}
add [dist, peer] to candidate list;
m <- m + 1;
endif;
endfor;
sort candidate list by increasing dist;
Последующие шаги служат для того, чтобы отсеять кандидатов со слишком большими дисперсиями.
Практика показывает, что число кандидатов здесь может быть достаточно велико. Это может привести к большому числу циклов повторения процедуры отбора, которые не дадут какого-либо улучшения результатов. Длина списка кандидатов ограничивается переменной ntp.maxclock.
Заметим, что exi представляет собой дисперсию относительно i-го партнера из списка кандидатов, которая может быть вычислена методом дисперсии фильтра, описанным выше. ej - дисперсия j-ого партнера из списка, включающая в себя вклады от ошибок измерения, от накопления дрейфа и из-за дисперсии фильтра. Если максимальное значение exi больше чем минимальное значение ej, а число кандидатов больше чем ntp.minclock, i-ый партнер удаляется из списка и процедура повторяется. Если текущий источник синхронизации является одним из членов списка и нет других кандидатов из более низкого слоя, процедура прерывается, и никакие другие последующие шаги не предпринимаются. В противном случае в качестве источника синхронизации берется первый кандидат из списка. В ниже приведенном тексте i, j, k, l - индексы партнеров, k - индекс текущего источника синхронизации (нуль, если такой источник отсутствует), l - индекс первого кандидата в списке.
while begin
| for (each survivor [distance, index]) begin | /* вычисление дисперсии */ |
find index i for max e{xi};
find index j for min ej;
endfor
if (e{xi} ? ej or m ? NTP.MINCLOCK) break;
| peer.survivor [i] <- 0; | /* отбрасывание i-го партнера */ |
if (i = k) sys.peer <- null;
delete the ith peer from the candidate list;
m <- m - 1;
endwhile
if (peer.survivor [k] = 0 or peer.stratum [k] >> peer.stratum [l]) begin
sys.peer <- l; /* новый источник часов */
call poll-update;
endif
end clock-select procedure;
Алгоритм сконструирован так, чтобы отдавать предпочтение партнерам из головной части списка, которые размещены в более низком слое, имеют наименьшее расстояние и могут обеспечить наибольшую точность и стабильность. С помощью правильного выбора весового коэффициента v (называемого ntp.select), можно удалить некоторые записи из финальной части списка.
Локальные часы
Для того чтобы иметь точные локальные часы, ЭВМ должна быть оборудована аппаратными часами, состоящими из задающего генератора и интерфейса, обеспечивающего необходимые операции установки и коррекции. Логические часы конструируются, используя эти компоненты и программы, которые осуществляют подстройку частоты и абсолютного показания локальных часов. Такая система позволяет достичь точности времени до 15 нс и стабильности частоты на уровне 0.3 мс в день. Предлагаемая модель удобна для применения как для компенсируемых, так и для некомпенсируемых кварцевых генераторов, пригодна она и для часов, использующих для создания временной шкалы частоту сети переменного тока.
Важно заметить, что конкретная описанная реализация является лишь одной из многих возможных.
Реализация "пушистый шарик" (Fuzzball)
Локальные часы "пушистый шарик" представляют собой комбинация аппаратных и программных регистров, а также алгоритмов, которые осуществляют функционирование часов - работу управляемого задающего генератора, синхронизуемого от внешнего источника. Долее следует описание его компонент и способа работы. Заметим, что все числа представлены в представлении дополнений до 2, а все сдвиги являются арифметическими (заполнение знаком при сдвиге вправо и нулем при сдвиге влево).
48-битовый часовой регистр (clock) и 32-битовый предварительный счетчик (prescaler) образуют управляемый задающий генератор с периодом 1 мс. Дробная часть кода времени представляет число миллисекунд с начала суток. 32-битовый регистр коррекций (Clock-Adjust) используется для подстройки фазы часов постепенными шагами, что исключает неоднородности временной шкалы. Его содержимое обозначается x. 32-битовый регистр компенсации дрейфа (Skew-Compensation) используется для подстройки частоты задающего генератора с помощью добавления небольших фазовых сдвигов (0,01%). Его содержимое обозначается символом y. 16-битовый счетчик оповещения (Watchdog) и 32-битный регистр согласования (Compliance) используются для определения корректности и служит также для задания периода рассылки запросов.
Содержимое регистра согласования обозначается символом z. 32-битовый регистр настройки (PPS-Adjust) служит для подстройки точности, когда имеется точный источник сигналов с периодом в одну секунду. 2-битовый регистр флагов управляет добавлением/вычитанием секунд к показаниям часов, когда это необходимо.
Все регистры кроме предварительного счетчика обычно размещаются в памяти. В типовом интерфейсе часов, таком как DEC KWV11-C, регистр prescaler реализован в виде 16-битового буферного счетчика, управляемого кварцевым генератором с частотой, кратной 1000 Гц. Переполнение счетчика вызывает прерывание процессора, которое осуществляет приращение содержимого регистра часов.
Когда наступает момент подстройки, CLOCK.ADJ секунд вычитается из содержимого PPS-счетчика, но это CLOCK.ADJ делается лишь при условии, что там лежит число больше нуля. CLOCK.ADJ добавляется к коду счетчика Watchdog. Этот код не должен превышать значения NTP.MAXAGE, поделенного на CLOCK.ADJ. Если счетчик Watchdog достигнет этой величины, часы считаются не синхронизованными, а Leap-биты устанавливаются равными 112.
Постепенная настройка фазы
Если локальные часы нескорректированы, они продолжают работать со смещением и частотой (при отсутствии дрейфа), установленными при последней коррекции. Корректирующая информация имеет формат 48-битного целого числа со знаком. Это число характеризует целое и дробное число миллисекунд (запятая располагается после 32-го двоичного разряда). Если полученная величина превосходит максимальное значение, заданное CLOCK.MAX, необходима постепенная пошаговая коррекция. В норме величина поправки вычисляется в рамках алгоритма NTP. Однако, если код счетчика PPS больше нуля, вместо него должен использоваться регистр PPS-ADJUST. Пусть u представляет собой 32-битовый код с битами 0-31 равными разрядам 16-47 корректирующего кода. Если некоторые младшие биты корректирующего кода не используются, они устанавливаются равными биту знака. Такие операции сдвигают положение запятой влево по отношению биту 16, что уменьшает влияние ошибок округления.
Пусть b число начальных нулей в коде регистра Compliance и пусть c - число начальных нулей в коде счетчика W@atchdog. Тогда b установится равным:
b = b - 16 + clock.comp
b не должно быть меньше нуля (это логарифм постоянной времени обратной связи). Затем установим c равным:
c = 10 - c
Величина c представляет собой логарифм времени интегрирования со времени последней коррекции. Затем вычисляются новые значения кодов для регистров CLOCK.ADJUST и Skew-Compensation.
x = u >> b,
y = y + (u >> (b + b - c)).
В заключение вычисляем экспоненциальное среднее
z = z + (u << (b + clock.mult) - z) >> clock.weight,
где сдвиг влево переносит положения запятой с целью достижения большей точности.
Для каждого периода подстройки определяется корректирующий код из двух составляющих. Первая составляющая (фаза) определяется как
x >> clock.phase,
эта величина затем вычитается из предшествующего значения регистра Clock-Adjust. Результат становится новым значением кода этого регистра. Вторая компонента - (частота) определяется как
y >> clock.freq.
Совокупность фазы и частоты представляет собой окончательный корректирующий код, который затем добавляется к коду регистра (clock). В заключение, счетчик Watchdog обнуляется.
Величина b вычисленная ранее может использоваться для изменения величины системной переменной, характеризующей период запросов (коррекций) sys.poll.
sys.poll <- b + NTP.MINPOLL.
При условии, что шум коррекций велик, частота аппаратного задающего генератора может меняться быстро из-за изменений условий окружающей среды. В этом случае период запросов укорачивается. Когда шум незначителен, задающий генератор стабилен и период запросов растет вплоть до NTP.MAXPOLL секунд.
Ступенчатая подстройка фазы
Когда величина поправки превышает CLOCK.MAX, имеется возможность того, что часы окажутся настолько не синхронизованы, что наилучшим решением будет немедленная замена содержимого регистра часов. Однако, в случаях, когда вариация записи весьма высока, разумно не поверить в возможность скачкообразного изменения, если только со времени последней коррекции не прошло достаточно много времени.
Следовательно, если обнаружено скачкообразное изменение, а счетчик Watchdog содержит код меньше предварительно установленного значения CLOCK.MINSTEP, корректирующее сообщение игнорируется.
Если обнаружено ступенчатое изменение, коррекция заносится непосредственно в регистры Clock, а содержимое регистров Clock-Adjust и Watchdog обнуляется. Другие же регистры остаются без изменений. Так как ступенчатое изменение показаний указывает на некорректность информации в часовых фильтрах (clock filters), биты добавления делаются равными 112 (не синхронизовано) и вызывается процедура очистки часовых фильтров и переменных состояния для всех партнеров. На практике необходимость корректировать показания часов скачкообразно случается крайне редко, когда, например, локальные часы или эталон перезагружаются.
Практически значения CLOCK.MAX могут быть превышены временным сервером лишь в условиях чрезмерной перегрузки канала или при сбоях оборудования. Наиболее часто встречаемый случай - это смена сервера при регистрации слишком большого числа ошибок или из-за сильной вариации задержки. Рекомендуется, чтобы реализации программ включали средства формирования значений CLOCK.MAX для особых случаев. Величина, на которую можно превысить CLOCK.MAX, не нарушая требования монотонности, зависит от значения приращения регистра часов (Clock Register).
Обсуждение реализации
Базовая модель надежности NTP предполагает, что не должно быть никаких других способов изменения показаний кроме предусмотренных самим протоколом NTP. Системы с часами-календарем, имеющие питание от батареи или аккумулятора, считаются надежными, но менее точными, чем использующие NTP-синхронизацию. При последовательных коррекциях, если величина поправки превышает конфигурационный параметр (напр., 1000 секунд), поправка отбрасывается и посылается сообщение об ошибке. Некоторые реализации периодически записывают содержимое регистра Skew-Compensation (компенсация дрейфа) в системный файл или в NVRAM (память, сохраняемая при отключении питания).
Преобразование из формата NTP в обычный информационный формат осуществляется прикладными программами. В день накануне добавления/вычитания секунды из показаний времени значение sys.leap устанавливается на первичном сервере вручную. Следует иметь в виду, что большинство радио-часов не имеет автоматических или ручных средств добавления/вычитания секунд. Но даже в случае некорректного добавления/вычитания секунды локальные часы будут вновь синхронизованы не позднее чем через число секунд, заданное CLOCK.MINSTEP.
Приложение А. Формат данных NTP - версия 3
Формат NTP-сообщения, которое следует сразу после UDP-заголовка, показан на рис 4.4.15.1.
Индикатор добавления (LI - leap indicator) - двухбитовое поле предупреждения о предстоящем добавлении/вычитании секунды к последней минуте текущего дня. Значения этих битов смотри в таблице 4.4.15.1.

Рис. 4.4.15.1. Формат сообщения NTP.
Номер версии (VN) - трехбитовое поле, указывающее на номер версии протокола NTP, в настоящее время (3).
Режим (Mode) - трехбитовое поле, определяющее режим, значения кодов режима приведены в таблице 4.4.15.2.
Слой (Stratum) - 8-битовое поле, определяющее код слоя, где работают локальные часы. Коды слоя представлены в таблице 4.4.15.3. Возможные значения кодов лежат в интервале от нуля до NTP.INFIN включительно.
Период запросов (poll interval) - 8-битовое поле, указывающее на максимальное значение интервала между запросами. Код, записанный в этом поле, интерпретируется как целое число со знаком и характеризует значение периода в секундах, как ближайшее к величине степени двух. Коды, которые могут быть записаны в этом поле, должны лежать в интервале между NTP.MAXPOLL и NTP.MAXPOLL включительно.
Точность (precision) - 8-битовое поле, обозначающее точность локальных часов в секундах. Код поля интерпретируется как целая степень со знаком числа 2.
Базовая задержка (Root Delay) - 32-битовое поле, характеризующее RTT до эталонного источника в секундах. Код поля интерпретируется как число с фиксированной запятой, размещенной между битами 15 и 16.
Заметим, что величина этого кода может иметь и отрицательное значение (зависит от точности часов и величины дрейфа).
Базовая дисперсия (Root Dispersion) - 32-битовое поле, определяющее максимальную ошибку по отношению к эталонному источнику в секундах. Код поля интерпретируется как число с фиксированной запятой (между 15 и 16 битами). Допустимы только положительные значения.
Идентификатор эталонных часов (Reference Clock Identifier) - 32-битовое поле, идентифицирующее конкретные эталонные часы. В случае кода слоя нуль (не специфицировано) или слоя 1 (первичный эталон), это 4-октетная комбинация выравнивается по левому краю и дополняется нулями (ASCII). Когда идентификатор в NTP не специфицирован, предлагаются ascii- идентификаторы, приведенные в таблице 4.4.15.4.
В случае слоя 2 и больше (вторичный эталон) - это 4-октетный IP-адрес ЭВМ - первичного эталона.
Эталонная временная метка (Reference Timestamp) - поле локального времени (64-битовый формат временных меток), когда часы корректировались в последний раз.
Исходная временная метка (Originate Timestamp) определяет время, когда запрос направлен серверу (стандартный 64-битовый формат временных меток).
Получаемая временная метка (Receive Timestamp) - время, когда запрос прибыл к серверу (стандартный 64-битовый формат временных меток).
Передаваемая временная метка (Transmit Timestamp) - локальное время, когда послан отклик сервером (стандартный 64-битовый формат временных меток).
Аутентификатор (authenticator) (опционно) - поле, содержащее аутентификационную информацию. Используется лишь в случае реализации NTP-аутентификации.
Приложение Б. Сообщения управления NTP
В сетевой среде должны быть средства управления программами NTP, такие как установка индикатора добавления секунды (Leap-Indicator) со стороны первичного сервера, настройка различных системных параметров и процедур мониторинга. Такие операции могут быть реализованы с привлечением протокола snmp и соответствующего расширения базы данных MIB. Однако в тех случаях, когда такие средства недоступны, эти функции могут быть реализованы с помощью специальных управляющих NTP-сообщений.
Управляющие сообщения NTP имеют код 6 в поле режима первого октета NTP-заголовка. Формат поля данных специфичен для каждой из команд или отклика. Однако, в большинстве случаев формат конструируется так, чтобы облегчить его непосредственное чтение. Как правило, он состоит из ASCII-строк. Если используется аутентификатор, поле данных дополняется нулями до границы, кратной целому числу 32-битных слов.
IP-ЭВМ не должны обрабатывать дейтограммы длиннее 576 октетов; однако, некоторые команды или отклики могут содержать данные, непомещающиеся в одну дейтограмму. Для решения данной проблемы все октеты сообщения нумеруются, начиная с нуля. При передаче фрагментов сообщения номер первого октета записывается в поле смещения (offset), а число октетов в поле длины. Бит (M - more) устанавливается во всех фрагментах за исключением последнего.
Большинство контрольных функций включает посылку команды и получение отклика. Отправитель выбирает ненулевой порядковый номер и устанавливает статусное поле и биты R и E равными нулю. Получатель интерпретирует код операции и дополнительную информацию, содержащуюся в поле данных, вносит изменение в поле статуса и устанавливает бит R=1, а также возвращает три 32-битного слова заголовка вместе с другой дополнительной информацией поля данных. В случае неверного формата сообщения или ошибки в поле данных получатель заносит соответствующий код в поле статуса, устанавливает биты R и E равными 1, и опционно записывает диагностическое сообщение в поле данных.
Некоторые команды осуществляют чтение или запись для системных переменных и переменных партнеров для ассоциации, идентифицированной в команде. Другие читают или записывают значения переменных, связанных с радио-часами и другими приборами, имеющими непосредственное отношение к эталонам времени. Для определения ассоциации используется ее 16-битовый идентификатор. Для системных переменных используется идентификатор нуль. Управляющий объект может затребовать текущий список идентификаторов с тем, чтобы их использовать в дальнейшем.
При попытке употребить уже недействительный идентификатор будет прислан соответствующий отклик, после чего необходимо запросить список идентификаторов еще раз.
Некоторые события, такие как изменение статуса доступа к партнеру, не сопряжены с какими-либо командами и происходят асинхронно. Программа может запоминать информацию о таких событиях и пересылать ее в откликах. Текущий статус и краткая аннотация чрезвычайных событий пересылаются каждым откликом. Биты в статусном поле указывают на то, произошло ли какое-либо событие с момента предыдущего отклика и было ли их больше одного.
Формат сообщений управления NTP
Формат заголовков управляющих NTP-сообщений показан на рис. 4.4.15.2. Этот заголовок располагается непосредственно вслед за UDP-заголовком.

Рис. 4.4.15.2. Формат управляющего сообщения ntp
Первые два бита, обозначенные ZZ, должны всегда содержать 0.
Номер версии (VN - version number) - трехбитовое поле, указывающее на номер версии протокола NTP, в настоящее время (3).
Режим (Mode) - трехбитовое поле, определяющее режим, значение кода режима для управляющих сообщений равно 6.
Бит отклика (R) - равен нулю для команд и 1 для откликов.
Бит ошибки (E) - равен нулю для нормального отклика и 1 в случае ошибки.
Бит продолжения (M - more) - равен нулю для последнего фрагмента и 1 - для всех остальных.
Код операции (OP) - 5-битовое поле, определяющее код команды. Значения кодов и их функции представлены в таблице 4.4.15.5.
Таблица 4.4.15.5. Коду операции управляющего сообщения
| Код | Функция |
| 0 | Зарезервировано |
| 1 | чтение статуса команда/отклик |
| 2 | чтение переменной команда/отклик |
| 3 | запись переменной команда/отклик |
| 4 | чтение переменных часов команда/отклик |
| 5 | запись переменных часов команда/отклик |
| 6 | установка адреса/порта trap команда/отклик |
| 7 | отклик на Trap |
| 8-31 | Зарезервировано на будущее |
Порядковый номер (Sequence) - 16-битовое поле, определяющее номер запроса или отклика, и облегчающее определения их соответствия.
Статус - 16-битовое поле, содержащее код статуса системы, партнера или часов.
Идентификатор ассоциации (Association ID) - 16-битовое поле, несущее в себе идентификатор ассоциации.
Смещение (Offset) - 16- битовое поле, определяющее положение первого октета поля данных в сообщении, передаваемом в нескольких дейтограммах (позиция задается в октетах).
Длина (Count) - 16-битовое поле, определяющее длину поля данных в октетах.
Данные - это поле содержит информацию сообщения, как для команды, так и для отклика. Максимальное число октетов в поле данных равно 468.
Аутентификатор (опционно). Поле, содержащие аутентификационную информацию. Используется лишь в случае реализации NTP-аутентификации.
Статусные слова
Статусные слова указывают на текущее состояние системы ассоциации и часов. Эти слова интерпретируются программами сетевого мониторинга и имеют 4 разных 16-битовых форматов. Статусные слова партнеров и системы соответствуют откликам для всех команд за исключением случая чтения/записи переменных часов и установки адреса/порта для TRAP. Идентификатор ассоциации нуль соответствует системным статусным словам, в то время как ненулевой идентификатор указывает на какую-то конкретную ассоциацию. Статусное слово, присланное в ответ на команду чтения или записи переменной часов, указывает на состояние оборудования и кодирующего программного обеспечения.
Системные статусные слова
Системное статусное слово может присутствовать в статусном поле отклика. Системное статусное слово имеет следующий формат.
Индикатор добавления (LI - leap indicator) - двухбитовое поле предупреждения о предстоящем добавлении/вычитании секунды к последней минуте текущего дня. Значения этих битов смотри в таблице 4.4.15.1.
Источник часов (clock source) - 6-битовое поле, указывающее на используемый в данный момент источник синхронизации. Назначение кодов этого поля описано в таблице 4.4.15.6.
Таблица 4.4.15.6. Коды источников временного эталона
| Код | Функция |
| 0 | Не специфицирован или неизвестен |
| 1 | Калиброванные атомные часы (напр., hp 5061) |
| 2 | vlf (диапазон 4) или НЧ (диапазон 5) радио (напр., omega, wwvb) |
| 3 | ВЧ (диапазон 7) радио (напр., chu, msf, wwv/h) |
| 4 | УВЧ (диапазон 9) спутник (напр., goes, gps) |
| 5 | Локальная сеть (напр., dcn, tsp, dts) |
| 6 | UDP/NTP |
| 7 | UDP/time |
| 8 | eyeball-and-wristwatch |
| 9 | Телефонный модем (напр., nist) |
| 10-63 | Зарезервировано на будущее |
Системный счетчик событий - четырех битовое целое число, обозначающее число событий, происшедших с момента последнего получения статусного слова системы. Счетчик обнуляется, когда присылается в статусном поле отклика и остается неизменным после достижения значения 15.
Код системного события - четырехбитовое число, идентифицирующее последнее системное событие, новое значение переписывает предыдущее. Коды событий перечислены в таблице 4.4.15.7.
Таблица 4.4.15.7. Коды системных событий
| Код | Функция |
| 0 | Не специфицировано |
| 1 | Рестарт системы |
| 2 | Системный или аппаратный сбой |
| 3 | Новое статусное слово системы (изменение битов добавления или синхронизации) |
| 4 | Новый источник синхронизации или слой (изменение sys.peer или sys.stratum) |
| 5 | Сброс системных часов (корректирующая добавка превысила clock.max) |
| 6 | Некорректное системное время или дата |
| 7 | system clock exception |
| 8-15 | Зарезервировано на будущее |
Статусное слово партнера
Статусное слово партнера возвращается в статусном поле отклика на команду чтения статуса, а также чтения или записи переменных. Это слово появляется в списке идентификаторов ассоциации и статусных слов, присылаемых в ответ на команду чтения статуса с нулевым идентификатором ассоциации. Формат статусного слова партнера содержит следующие поля (рис. 4.4.15.3)

Рис. 4.4.15.3. Форматы статусных слов
Статус партнера - 5-битный код, характеризующий состояние партнера, определяемого процедурой обмена. Значения этого поля представлены в таблице 4.4.15.8.
Таблица 4.4.15.8. Коды состояния партнера
| Значение кода | Функция |
| 0 | Сконфигурирован (peer.config) |
| 1 | Разрешена аутентификация (peer.authenable) |
| 2 | Аутентификация успешна (peer.authentic) |
| 3 | Партнер доступен (peer.reach) |
| 4 | Зарезервировано на будущее |
Выбор партнера (Sel) - 3-битный код, говорящий о состоянии партнера, определенного в результате процедуры выбора часов. Значения кодов представлены в таблице 4.4.15.9.
Таблица 4.4.15.9. Коды выбора партнера
| Значение кода | Функция |
| 0 | Отклонен |
| 1 | Проверка соответствия прошла успешно (тесты 1 - 8) |
| 2 | Прошел проверки корректности (алгоритм пересечения) |
| 3 | Прошел проверки, как кандидат |
| 4 | Проверка ресурсов прошла успешно (алгоритм кластеризации) |
| 5 | Текущий источник синхронизации; превышено максимальное расстояние (если используются предельные проверки) |
| 6 | Текущий источник синхронизации; максимальное расстояние в пределах нормы |
| 7 | Зарезервировано на будущее |
Счетчик событий партнера - 4-битовое число событий (exception) партнера, которые имели место со времени последнего получения статусного слова в рамках отклика или сообщения TRAP. Счетчик сбрасывается при занесении кода в поле статуса отклика, и перестает изменяться при достижении значения 15.
Код события партнера - 4-битовое целое число, идентифицирующее последнее событие партнера. Новое значение переписывает предыдущее. Значения кодов представлены в таблице 4.4.15.10.
Таблица 4.4.15.10. Коды события партнера
| Значение кода | Функция |
| 0 | Не специфицировано |
| 1 | IP-ошибка партнера |
| 2 | Ошибка аутентификации партнера (бит peer.authentic был равен 1, а теперь =0) |
| 3 | Партнер не достижим (peer.reach стал равен нулю) |
| 4 | Партнер достижим (peer.reach стал не равен нулю) |
| 5 | Проблема с часами партнера |
| 6-15 | Зарезервировано на будущее |
Слово состояния часов
Существует два способа подключить эталонные часы к NTP-серверу, как специальный прибор, поддерживаемый операционной системой или как партнера, управляемого NTP. Как и в случае команды чтения статуса идентификатор ассоциации определяет, часы какого из партнеров имеются в виду. При нулевом идентификаторе речь идет о системных часах. Протокол поддерживает только одни системные часы, число часов-партнеров практически не ограничено. Статусное слово часов системы или партнера записывается в поле статуса отклика на команды чтения или записи переменных, характеризующих часы. Это слово может рассматриваться как расширение системного статусного слова или статусного слова партнера. Формат слова описан ниже (См. также рис. 4.4.15.3).
Состояние часов - 8-битовое число, характеризующее текущее состояние часов. Допустимые значения этого числа и их смысл представлены в таблице 4.4.15.11.
Таблица 4.4.15.11. Коды состояния часов
| Код | Функция |
| 0 | Работа часов в пределах нормы |
| 1 | Таймаут ответа |
| 2 | Плохой формат ответа |
| 3 | Сбой оборудования или программы |
| 4 | Потеря при передаче |
| 5 | Неверный формат или значение даты |
| 6 | Неверный формат или значение времени |
| 7-255 | Зарезервировано на будущее |
Код события для часов - 8- битовый код, идентифицирующий последнее событие для данных часов (exception). Новое значение переписывает предыдущее значение кода. Когда значение кода становится ненулевым для поля статуса радио-часов, этот код копируется в статусное поле кода события и считается, что произошло событие для системных часов или часов партнера.
Слово состояния ошибки
Статусное слово ошибки присылается в поле статуса отклика, если обнаружена ошибка в формате сообщения или в его содержимом. Его присутствие указывается равенствами E (error) и R (response) битов 1. Коды ошибки и их значения собраны в таблице 4.4.15.12.
Таблица 4.4.15.12. Коды ошибки
| Код ошибки | Значение |
| 0 | Не специфицировано |
| 1 | Неудачная аутентификация |
| 2 | Неверный формат или длина сообщения |
| 3 | style="font-family:arial;font-size:12pt" Неверный код операции |
| 4 | Неизвестный идентификатор ассоциации |
| 5 | Неизвестное имя переменной |
| 6 | Неверное значение переменной |
| 7 | Административно запрещено |
| 8-255 | Зарезервировано на будущее |
Команды
Команды состоят из заголовка и опционного поля данных. Если поле данных присутствует, оно включает в себя список идентификаторов и, возможно, их значений.
<identifier>[=<value>],<identifier> =<value> ],...
где представляет собой имя переменной системы или партнера в форме ASCII-последовательности, а является десятичным или шестнадцатеричным числом, или строкой, соответствующей синтаксису языка C. Для большей читаемости допускается применение пробелов (Whitespace). IP-адреса представляются в формате [n.n.n.n], где n - десятичное число. Скобки являются опционными.
Команды интерпретируются следующим образом:
Чтение статуса (1). Поле данных команды пусто или содержит список идентификаторов, разделенных запятыми. Команда работает по-разному в зависимости от значения идентификатора. Если идентификатор не равен нулю, отклик содержит идентификатор партнера и статусное слово. Если идентификатор ассоциации равен нулю, отклик содержит системный идентификатор (0) и статусное слово, в то время как поле данных содержит список пар двоичных кодов:
<идентификатор ассоциации> <статусное слово>,
по одному на каждую, определенную в данный момент ассоциацию.
Чтение переменных (2). Поле данных команды пусто или содержит список идентификаторов, разделенных запятыми. Если идентификатор ассоциации не равен нулю, отклик включает в себя идентификатор запрашиваемого партнера и его статусное слово, в то время как в поле данных записывается список переменных партнера и их значения. Если идентификатор ассоциации равен нулю, поле данных содержит список системных переменных и их значения. Если партнер выбран в качестве источника синхронизации, отклик включает в себя идентификатор партнера и его статусное слово.
Запись переменных (3). Поле данных команды содержит список присвоений, описанный выше. Отклик идентичен отклику на команду чтения переменных.
Чтение переменных часов (4). Поле данных команды пусто или содержит список идентификаторов, разделенных запятыми. Идентификатор ассоциации выбирает переменные системных часов или партнера точно также, как в случае команды чтения переменных. Отклик включает в себя запрошенные идентификатор часов и статусное слово, а поле данных несет в себе список переменных часов и их значений, включая последний временной код, полученный от часов.
Запись переменных часов (5). Поле данных команды содержит список присвоений, как это описано выше. Отклик имеет формат, как в случае команду чтения переменных часов.
Установка адреса/порта Trap (6). Идентификатор ассоциации команды, статус и поле данных игнорируются. Адрес и номер порта для последующих TRAP-сообщений берутся из самого управляющего сообщения. Исходное значение счетчика TRAP для сообщений откликов заимствуется из поля номера по порядку. Идентификатор ассоциации, статус и поле данных в отклике несущественны.
Отклик на TRAP (7). Это сообщение посылается, когда происходит событие (exception) в систему, у партнера или для данных часов. Код команды равен 7, а бит R=1. Содержимое trap-счетчика увеличивается на 1 для каждого сообщения данного типа.
Поле номер по порядку сообщения равно содержимому этого счетчика. При посылке сообщения TRAP используется IP-адрес и номер порта, заданные командой установки адреса и порта TRAP. В случае системного TRAP идентификатор ассоциации устанавливается равным нулю, а поле статус содержит статусное слово системы. В случае TRAP партнера поле идентификатора ассоциации соответствует партнеру, а поле статус несет в себе его статусное слово. В поле данных опционно может быть включено любое символьное сообщение (ASCII).
Приложение В. Аутентификация
Требования надежности NTP подобны аналогичным для других протоколов, работающих с большим числом партнеров и служащих для маршрутизации, управления и доступа к файлам. Система должна противостоять случайным ошибкам и злонамеренным действиям.
Механизм управления доступом в NTP отвечает всем базовым требованиям. Различные проверки препятствуют большинству возможных атак, связанных с подменой временных меток.
Однако имеется возможность того, что хакер нарушит процедуру синхронизации путем модификации NTP-сообщений. Для подавления такой возможности нужно привлекать криптографические механизмы аутентификации (в частности сертификаты).
Механизм, который работает на прикладном уровне, служит для того, чтобы исключить неавторизованную модификацию потока сообщений. Это достигается с помощью контрольных крипто-сумм, вычисляемых отправителем и проверяемых получателем. Однако сам протокол NTP не имеет средств для работы с сертификатами и ключами.
Процедура вычисления контрольной крипто-суммы использует алгоритм DES (Data Encryption Standard) [NBS77].
Механизм аутентификации NTP
Когда предполагается использовать аутентификацию, инициализируется ряд переменных, определяющих выбор сертификата, алгоритма шифрования и крипто-ключ и, возможно, другие параметры. Процедуры инициализации и выбора этих переменных не регламентируются протоколом NTP. Набор переменных партнера и пакетов может включать в себя следующие компоненты:
Бит разрешения аутентификации (peer.authenable).
Этот бит указывает, что ассоциация работает в режиме аутентификации. Для сконфигурированных партнеров этот бит определяется на фазе инициализации. Для неконфигурированных - этот бит делается равным 1, если приходящее сообщение содержит аутентификатор, в противном случае =0.
Бит аутентификации (peer.authentic). Этот бит указывает, что последнее сообщение, полученное от партнера, было корректно аутентифицировано.
Идентификатор ключа (peer.hostkeyid, peer.peerkeyid, pkt.keyid). Это целое число идентифицирует криптографический ключ, используемый для генерации кода аутентификации сообщения. Системная переменная peer.hostkeyid используется для активной ассоциации. Переменная peer.peerkeyid инициализируется нулем, когда ассоциация сформирована.
Криптографические ключи (sys.key). Это набор 64-битовых ключей DES, где 7 младших бит каждого октета соответствуют битам 1-7 DES, а старший бит соответствует биту четности 8 (сумма нечетна).
Контрольная крипто-сумма (pkt.check). Крипто-сумма вычисляется процедурой шифрования.
Поле аутентификатора состоит из двух субполей, одно содержит переменную pkt.keyid, а другое переменную pkt.check, вычисленную программой шифрования, вызываемой процедурой передачи протокола NTP, а также программой дешифровки, которая вызывается процедурой приема NTP. Ее присутствия определяется по общей длине UDP-дейтограммы. Для целей аутентификации NTP-сообщение дополняется нулями, для того чтобы сделать ее длину кратной 64 битам. Аутентификатор содержит 96 бит, куда входят 32-битовый идентификатор ключа и 64-битовая крипто-сумма. Дополнительная информация (например, о сертификате и алгоритме шифрования), если необходимо, может быть вставлена между NTP-сообщением и идентификатором ключа. Подобно аутентификатору эта информация не включается в контрольное крипто-суммирование.
Процедуры аутентификации NTP
Когда используется аутентификация для реализации протокола NTP, привлекается две дополнительные процедуры. Одна из них формирует крипто-сумму для передаваемых сообщений, а другая дешифрует и проверяет корректность контрольной суммы получаемых сообщений.
Процедуры представляют собой варианты программ, используемых для реализации алгоритма DES и описанных в [NBS80]. На самом деле процедура не связана жестко с алгоритмом DES, а лишь предполагают работу с 64-битовыми блоками данных.
Приложение Г. Временная шкала NTP и ее хронометрия
Ниже рассматривается соответствие временной шкалы NTP и UTC (Coordinated Universal Time). Синхронизация часов предполагает их согласование по частоте и времени.
Для синхронизации необходимо уметь сравнить их частоты и показания. Базовыми источниками временных стандартов традиционно являлись периоды движения Земли, Луны и других космических объектов. К сожалению, они не слишком стабильны.
Первичная частота и стандарты времени
Первичными стандартами частоты являются осцилляторы с высокой стабильностью. Такие стандарты используют межуровневые переходы в атомах водорода, цезия и рубидия. В таблице 4.4.15.12 приведены характеристики типичных стандартов времени. Локальные же часы обычно используют некомпенсированные кварцевые генераторы. Такие генераторы не только подвержены дрейфам под действием изменения параметров окружающей среды, но систематически меняют свои свойства со временем (старение).
Даже если кварцевый генератор имеет температурную компенсацию, его частота должна время от времени сравниваться первичным стандартом для обеспечения высокой точности.
Сеть, в которой все часы фазированы и согласованы по частоте с единым стандартом, называется изохронной. Сети, где разные часы сфазированы с разными стандартами, но все они привязаны к одной базовой частоте называются плезиохронными. В плезиохронных системах фазы разных осцилляторов могут дрейфовать друг относительно друга, что может приводить к накоплению ошибок.
Обычно часовые осцилляторы классифицируются по трем параметрам: стабильность, разброс и блуждание. Стабильность определяется систематическими вариациями частоты со временем. Синонимом нестабильности является старение и дрейф. Разброс (называемый также временным дрожанием) характеризует кратковременные случайные вариации частоты с составляющими более 10 Гц, в то время как блуждание характеризует медленные вариации частоты с составляющими менее 10 Гц.
Таблица 4.4.15.12. Точность и стабильность часов для различных слоев
| Слой | Минимальная точность (за день) | Минимальная стабильность (за день) |
| 1 | 1 x 10-11 | Не специфицировано |
| 2 | 1.6 x 10-8 | 1 x 10-10 |
| 3 | 4.6 x 10-6 | 3.7 x 10-7 |
| 4 | 3.2 x 10-5 | Не специфицировано |
Конструкция, работа и характеристики осциллятора слоя 1 предполагаются сопоставимыми с национальными стандартами времени и часто базируются на цезиевом стандарте. Часы слоя 4 соответствуют требованиям обычных цифровых каналов и систем PBX. Слои 2-3 могут использоваться для работы с мощными синхронными каналами связи.
Раздача времени и частоты
Для того чтобы атомное и обычное время могли быть взаимосвязаны, национальные администрации обеспечивают работу первичных стандартов времени и частоты и совместно координируют их функционирование. Большинство морских держав поддерживают широковещательные радиослужбы времени.
Американский Национальный Институт Стандартов и Технологии (NIST – National Institute of Standards and Technology) поддерживает три радиослужбы для рассылки временной информации. Одна из них использует передачу (ВЧ или CCIR диапазон 7) на частотах 2.5, 5, 10, 15 и 20 Мгц. Сигнал распространяется, отражаясь от верхних слоев атмосферы, что неизбежно приводит к непредсказуемым вариациям задержки на принимающей стороне. С 60-секундным интервалом передается временной код, который транслируется на 100 килогерцной субнесущей со скоростью передачи 1 бит/с. Этот код содержит информацию об UTC времени и дате, но не включает в себя данных о текущем годе и оповещения о добавлении/вычитании секунды для последней минуты данного дня. Существуют и другие сходные службы времени (например, в Оттаве), гарантирующие точность на уровне 1-10 мсек.
Вторая служба времени NIST использует передачу (НЧ или CCIR диапазон 5) на частоте 60 КГц, она доступна на континентальной части США и вблизи берегов. Сигнал распространяется в нижней части атмосферы и по этой причине слабо подвержен вариациям времени распространения. Временной код передается с периодом в 60 секунд со скоростью 1 бит/с.
Достижимая точность составляет 50 миллисекунд [BLA74]. Ряд европейских стран предлагают аналогичные службы времени (Великобритания - MSF; Германия - DCF77). Коды времени здесь включают информацию о текущем годе и предупреждение о добавляемой/вычитаемой секунде. Третья служба NIST использует передачу на частоте 468 МГц (УВЧ или CCIR диапазон 9) с геостационарных спутников GOES, три из которых перекрывают западное полушарие. Временной код перемежается с сообщениями, адресованными удаленным датчикам и состоит из 600 4-битовых слов, передаваемых с периодом в 30 секунд. Временной код содержит информацию об UTC времени-дне-годе, а также предупреждение о добавлении/вычитании секунды в конце дня. Точность этой службы составляет 0,5 мсек.
Министерство обороны США разработало глобальную систему определения координат GPS (Global Positioning System). Эта система базируется на 24 спутниках, движущихся по орбитам с периодом 12 часов. Система GPS может обеспечить точность определения времени на уровне нескольких наносекунд [VAN84].
Американская береговая охрана в течение многих лет использует службу радионавигации LORAN-C [FRA82]. Эта служба обеспечивает временную точность менее 1 мксек.
Система радионавигации военно-морского флота США и других стран OMEGA [VAS78] состоит из 8 передатчиков, работающих на частотах от 10.2 до 13.1 КГц (УНЧ или CIR диапазон 4) и перекрывающих весь земной шар 24 часа в сутки. Точность этой системы составляет около 1 мсек. Система OMEGA обеспечивает высокую точность для частоты, но не передает временного кода. По этой причине приемник должен предварительно получить географические координаты с точностью до градуса и время UTC с точностью 5 секунд от независимых источников.
Заметим, что не все службы времени передают информацию о текущем годе и предупреждения о добавлении/вычитании секунды. Протокол NTP позволяет решить эту проблему.
Определение частоты
В течение многих лет наиболее важным использованием времени и частоты были всемирная навигация и космическая наука, которые зависят от наблюдений солнца, луны и звезд.
За стандартную секунду (в 1957 году) принята 1/31,556,925. 9747 периода вращения Земли вокруг Солнца (тропический год). Согласно этой шкалы тропический год длится 365.2421987 дней, а лунный месяц 29.53059 дней. Однако тропический год может быть определен лишь с точностью около 50 мсек.
С древнейших времен человечеству были известны три осциллятора (процесса задающих временную шкалу) - вращение земли вокруг своей оси, вращение Луны вокруг Земли и вращение Земли вокруг Солнца. К сожалению, с точки требований современных технологий все эти три осциллятора не обладают достаточной стабильностью. В 1967 стандартная секунда была переопределена и теперь равняется 9,192,631,770 периодов перехода в атоме цезия-133. С 1972 стандарты времени и частоты базируются на международном атомном времени TAI (International Atomic Time). Точность таких часов составляет около микросекунды в сутки. Важно то, что новая шкала абсолютно однородна и не подвержена дрейфам.
Определение времени и необходимости добавления/вычитания секунды
Международное бюро мер и стандартов IBWM (International Bureau of Weights and Measures) использует астрономические наблюдения, выполненные морской обсерваторией США и другими обсерваториями для определения UTC.
Для более точной временной привязки событий после 1972 года необходимо знать, когда вставлялись или удалялись секунды коррекции (удаление пока никогда не производилось). Как определено в докладе 517 CCIR, который воспроизведен в [BLA74], дополнительные секунды вставляются после 23:59:59 в последний день июня или декабря. Неоднородность во временную шкалу (TAI) помимо добавляемых секунд вносят также 100 миллисекундные коррекции UT1, называемые DUT1, которые служат для повышения точности при навигации. Следует признать, что момент добавления секунды является началом новой (однородной) временной шкалы.
Временная шкала NTP базируется на шкале UTC, но необязательно всегда совпадает с ней. В 0 часов 1 января 1972 начинается эра UTC, часы NTP были установлены на 2,272,060,800 стандартных секунд после 0 часов 1 января 1900.
Ссылки
| [ABA89] | Abate, et al. AT&T' s new approach to the synchronization of telecommunication networks. IEEE Communications Magazine (April 1989), 35-45. |
| [ALL74a] | Allan, D.W., J.H. Shoaf and D. Halford. Statistics of time and frequency data analysis. In: Blair, B.E. (Ed.). Time and Frequency Theory and Fundamentals. National Bureau of Standards Monograph 140, U.S. Department of Commerce, 1974, 151-204. |
| [ALL74b] | Allan, D.W., J.E. Gray and H.E. Machlan. The National Bureau of Standards atomic time scale: generation, stability, accuracy and accessibility. In: Blair, B.E. (Ed.). Time and Frequency Theory and Fundamentals. National Bureau of Standards Monograph 140, U.S. Department of Commerce, 1974, 205-231. |
| [BEL86] | Bell Communications Research. Digital Synchronization Network Plan. Technical Advisory TA-NPL-000436, 1 November 1986. |
| [BER87] | Bertsekas, D., and R. Gallager. Data Networks. Prentice-Hall, Englewood Cliffs, NJ, 1987. |
| [BLA74] | Blair, B.E. Time and frequency dissemination: an overview of principles and techniques. In: Blair, B.E. (Ed.). Time and Frequency Theory and Fundamentals. National Bureau of Standards Monograph 140, U.S. Department of Commerce, 1974, 233-314. |
| [BRA80] | Braun, W.B. Short term frequency effects in networks of coupled oscillators. IEEE Trans. Communications COM-28, 8 (August 1980), 1269-1275 |
| [COL88] | Cole, R., and C. Foxcroft. An experiment in clock synchronisation. The Computer Journal 31, 6 (1988), 496-502. |
| [DAR81a] | Defense Advanced Research Projects Agency. Internet Protocol. DARPA Network Working Group Report RFC-791, USC Information Sciences Institute, September 1981. |
| [DAR81b] | Defense Advanced Research Projects Agency. Internet Control Message Protocol. DARPA Network Working Group Report RFC-792, USC Information Sciences Institute, September 1981. |
| [DEC89] | Digital Time Service Functional Specification Version T.1.0.5. Digital Equipment Corporation, 1989 |
| [DER90] | Dershowitz, N., and E.M. Reingold. Calendrical Calculations. Software Practice and Experience 20, 9 (September 1990), 899-928. |
| [FRA82] | Frank, R.L. History of LORAN-C. Navigation 29, 1 (Spring 1982). |
| [GUS84] | Gusella, R., and S. Zatti. TEMPO - A network time controller for a distributed Berkeley UNIX system. IEEE Distributed Processing Technical Committee Newsletter 6, NoSI-2 (June 1984), 7-15. Also in: Proc. Summer USENIX Conference (June 1984, Salt Lake City). |
| [GUS85a] | Gusella, R., and S. Zatti. The Berkeley UNIX 4.3BSD time synchronization protocol: protocol specification. Technical Report UCB/CSD 85/250, University of California, Berkeley, June 1985. |
| [GUS85b] | Gusella, R., and S. Zatti. An election algorithm for a distributed clock synchronization program. Technical Report UCB/CSD 86/275, University of California, Berkeley, December 1985. |
| [HAL84] | Halpern, J.Y., B. Simons, R. Strong and D. Dolly. Fault-tolerant clock synchronization. Proc. Third Annual ACM Symposium on Principles of Distributed Computing (August 1984), 89-102. |
| [JOR85] | Jordan, E.C. (Ed). Reference Data for Engineers, Seventh Edition. H.W. Sams & Co., New York, 1985. |
| [KOP87] | Kopetz, H., and W. Ochsenreiter. Clock synchronization in distributed real-time systems. IEEE Trans. Computers C-36, 8 (August 1987), 933-939. |
| [LAM78] | Lamport, L., Time, clocks and the ordering of events in a distributed system. Comm. ACM 21, 7 (July 1978), 558-565. |
| [LAM85] | Lamport, L., and P.M. Melliar-Smith. Synchronizing clocks in the presence of faults. J. ACM 32, 1 (January 1985), 52-78. |
| [LIN80] | Lindsay, W.C., and A.V. Kantak. Network synchronization of random signals. IEEE Trans. Communications COM-28, 8 (August 1980), 1260-1266. |
| [LUN84] | Lundelius, J., and N.A. Lynch. A new fault-tolerant algorithm for clock synchronization. Proc. Third Annual ACM Symposium on Principles of Distributed Computing (August 1984), 75-88. |
| [MAR85] | Marzullo, K., and S. Owicki. Maintaining the time in a distributed system. ACM Operating Systems Review 19, 3 (July 1985), 44-54. |
| [MIL81a] | Mills, D.L. Time Synchronization in DCNET Hosts. DARPA Internet Project Report IEN-173, COMSAT Laboratories, February 1981. |
| [MIL81b] | Mills, D.L. DCNET Internet Clock Service. DARPA Network Working Group Report RFC-778, COMSAT Laboratories, April 1981. |
| [MIL83a] | Mills, D.L. Internet Delay Experiments. DARPA Network Working Group Report RFC-889, M/A-COM Linkabit, December 1983. |
| [MIL83b] | Mills, D.L. DCN local-network protocols. DARPA Network Working Group Report RFC-891, M/A-COM Linkabit, December 1983. |
| [MIL85a] | Mills, D.L. Algorithms for synchronizing network clocks. DARPA Network Working Group Report RFC-956, M/A-COM Linkabit, September 1985. |
| [MIL85b] | Mills, D.L. Experiments in network clock synchronization. DARPA Network Working Group Report RFC-957, M/A-COM Linkabit, September 1985. |
| [MIL85c] | Mills, D.L. Network Time Protocol (NTP). DARPA Network Working Group Report RFC-958, M/A-COM Linkabit, September 1985. |
| [MIL88a] | Mills, D.L. Network Time Protocol (version 1) - specification and implementation. DARPA Network Working Group Report RFC-1059, University of Delaware, July 1988. |
| [MIL88b] | Mills, D.L. The Fuzzball. Proc. ACM SIGCOMM 88 Symposium (Palo Alto, CA, August 1988), 115-122. |
| [MIL89] | Mills, D.L. Network Time Protocol (version 2) - specification and implementation. DARPA Network Working Group Report RFC-1119, University of Delaware, September 1989. |
| [MIL90] | Mills, D.L. Measured performance of the Network Time Protocol in the Internet system. ACM Computer Communication Review 20, 1 (January 1990), 65-75. |
| [MIL91a] | Mills, D.L. Internet time synchronization: the Network Time Protocol. IEEE Trans. Communications 39, 10 (October 1991), 1482-1493. |
| [MIL91b] | Mills, D.L. On the chronology and metrology of computer network timescales and their application to the Network Time Protocol. ACM Computer Communications Review 21, 5 (October 1991), 8-17. |
| [MIT80] | Mitra, D. Network synchronization: analysis of a hybrid of master-slave and mutual synchronization. IEEE Trans. Communications COM-28, 8 (August 1980), 1245-1259. |
| [NBS77] | Data Encryption Standard. Federal Information Processing Standards Publication 46. National Bureau of Standards, U.S. Department of Commerce, 1977. |
| [NBS79] | Time and Frequency Dissemination Services. NBS Special Publication 432, U.S. Department of Commerce, 1979 |
| [NBS80] | DES Modes of Operation. Federal Information Processing Standards Publication 81. National Bureau of Standards, U.S. Department of Commerce, December 1980. |
| [POS80] | Postel, J. User Datagram Protocol. DARPA Network Working Group Report RFC-768, USC Information Sciences Institute, August 1980. |
| [POS83a] | Postel, J. Daytime protocol. DARPA Network Working Group Report RFC-867, USC Information Sciences Institute, May 1983. |
| [POS83b] | Postel, J. Time protocol. DARPA Network Working Group Report RFC-868, USC Information Sciences Institute, May 1983. |
| [RIC88] | Rickert, N.W. Non Byzantine clock synchronization - a programming experiment. ACM Operating Systems Review 22, 1 (January 1988), 73-78. |
| [SCH86] | Schneider, F.B. A paradigm for reliable clock synchronization. Department of Computer Science Technical Report TR 86-735, Cornell University, February 1986. |
| [SMI86] | Smith, J. Modern Communications Circuits. McGraw-Hill, New York, NY, 1986. |
| [SRI87] | Srikanth, T.K., and S. Toueg. Optimal clock synchronization. J. ACM 34, 3 (July 1987), 626-645. |
| [STE88] | Steiner, J.G., C. Neuman, and J.I. Schiller. Kerberos: an authentication service for open network systems. Proc. Winter USENIX Conference (February 1988). |
| [SU81] | Su, Z. A specification of the Internet protocol (IP) timestamp option. DARPA Network Working Group Report RFC-781. SRI International, May 1981. |
| [TRI86] | Tripathi, S.K., and S.H. Chang. ETempo: a clock synchronization algorithm for hierarchical LANs - implementation and measurements. Systems Research Center Technical Report TR-86-48, University of Maryland, 1986. |
| [VAN84] | Van Dierendonck, A.J., and W.C. Melton. Applications of time transfer using NAVSTAR GPS. In: Global Positioning System, Papers Published in Navigation, Vol. II, Institute of Navigation, Washington, DC, 1984. |
| [VAS78] | Vass, E.R. OMEGA navigation system: present status and plans 1977-1980. Navigation 25, 1 (Spring 1978). |
Соглашение о пространстве имен почтовых ящиков
В соответствии с соглашением первый иерархический элемент любого имени почтового ящика, который начинается с символа "#" указывает на “пространство имен” остальной части имени. Например, реализации, которые предлагают доступ к группам новостей USENET могут использовать пространство имен "#news", для того чтобы отделить пространство имен групп новостей от имен других почтовых ящиков. Таким образом, группа новостей comp.mail.misc будет иметь имя почтового ящика "#news.comp.mail.misc", а имя "comp.mail.misc" может относиться к другому объекту (напр., к почтовому ящику пользователя).
Сокрытие значений атрибутов AVP
Бит H в заголовке каждой AVP предлагает механизм указания принимающему партнеру, представлено ли содержимое AVP скрытым или открытым текстом. Эта возможность применяется, чтобы скрыть важную информацию управляющих сообщений, такую как пароль пользователя или его ID.
Бит H должен быть равен 1, если имеется общий ключ для LAC и LNS. Этот ключ является тем же ключом, который использовался для аутентификации туннеля (смотри раздел 5.1.1). Если бит H =1 в любой AVP в данном управляющем сообщении, там должен также присутствовать случайный вектор AVP и должен предшествовать первому AVP, имеющему H = 1.
Сокрытие значения AVP делается за несколько шагов. Сначала берутся поля длины и значения оригинала (открытый текст) AVP и кодируются согласно субформата скрытого AVP:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | ||
| Длина значения оригинала | Значение оригинала атрибута | ||||||||||||||||||||||||||||||||
| Продолжение значения оригинала атрибута | Заполнитель |
Рис 5. Субформат скрытого AVP
Исходная длина значения атрибута. Это длина кода исходного значения атрибута, которое следует закрыть, в октетах. Необходимо определить исходную длину значения атрибута, так как ее значение теряется при добавлении заполнителя.
Исходное значение атрибута. Значение атрибута, которое должно быть скрыто.
Заполнитель. Произвольные дополнительные октеты, используемые для того, чтобы скрыть длину значения атрибута, когда необходимо скрыть само значение.
Чтобы замаскировать размер скрытого поля данных, используемый субформат может быть дополнен некоторым количеством произвольных октетов. Заполнитель не меняет значения поля, но изменяет величину поля длина AVP, которое было сформировано. Например, если значение атрибута, которое необходимо скрыть, занимает 4 октета, исходная длина AVP будет равна 10 октетам (6 + длина поля значения атрибута). После операции сокрытия, длина AVP станет равной 6 + длина атрибута + размер поля длины исходного значения атрибута + длина заполнителя. Таким образом, если заполнитель имеет 12 октетов, длина AVP будет равна 6 + 4 + 2 + 12 = 24 октетам.
Далее, производится хэширование (MD5) для полученного объединения:
+ 2 октета номера атрибута AVP
+ общий секретный ключ
+ случайный вектор произвольной длины
Значение случайного вектора, используемого в этом хэше, передается в поле случайный вектор AVP. Этот случайный вектор AVP должен быть помещен в сообщение отправителем до любого скрытого AVP. Тот же самый случайный вектор может быть использован для более чем одного скрытого AVP сообщения. Если для сокрытия последующих AVP используется другой случайный вектор, тогда новый случайный вектор AVP должен быть помещен в командное сообщение до первого его использования.
Значение хэша MD5 затем объединяется с помощью операции XOR с первыми 16 октетами сегмента субформата скрытого AVP и помещается в поле значения атрибута скрытого AVP. Если субформат скрытого AVP имеет менее 16 октетов, субформат преобразуется так, как если бы поле значения атрибута было дополнено до 16 октетов перед операцией XOR, но модифицируются только действительные октеты, присутствующие в субформате, а длина AVP не изменяется.
Если субформат длиннее 16 октетов, вычисляется второй хэш MD5 для потока октетов, состоящего из общего секретного ключа, за которым следует результат первой операции XOR. Этот хэш объединяется с помощью операции XOR со вторым 16 октетным (или менее) сегментом субформата, а результат помещается в соответствующие октеты поля значения скрытого AVP.
Если необходимо, эта операция повторяется, для общего секретного ключа, используемого совместно с каждым результатом операции XOR, чтобы получить очередной хэш, для которого будет выполняться XOR с кодом следующего сегмента.
Метод сокрытия был адаптирован из RFC 2138 [RFC2138], который был взят из секции "Mixing in the Plaintext" книги "Network Security" Кауфмана, Пелмана и Спенсера [KPS]. Ниже дается детальное пояснение метода:
Берется общий секретный ключ S, случайный вектор RV и значение атрибута AV. Поле значение делится на секции по 16 октетов p1, p2 и т.д..Последняя секция дополняется до границы в 16 октетов специальным заполнителем. Вычисляются блоки шифротекста c(1), c(2), и т.д.. Мы также определяем промежуточные значения b1, b2, и т.д.
| b1 = MD5(AV + S + RV) | c(1) = p1 xor b1 |
| b2 = MD5(S + c(1)) | c(2) = p2 xor b2 |
| . | . |
| . | . |
| . | . |
| bi = MD5(S + c(i-1)) | c(i) = pi xor bi |
строка будет содержать c(1)+c(2)+...+c(i) где + означает объединение.
По получение, случайный вектор берется из AVP, включенного в сообщение до AVP, подлежащего сокрытию. Описанный выше процесс реверсируется с целью получения исходного значения.
Соображения безопасности
Заголовок IP идентификации [RFC-1826] и безопасная IP инкапсуляция [RFC-1827] будут использоваться в IPv6, в соответствии с безопасной архитектурой протоколов Интернет [RFC-1825].
Протокол L2TP сталкивается при своей работе с несколькими проблемами безопасности. Ниже рассмотрены некоторые подходы для решения этих проблем.
Соображения IANA
Этот документ определяет ряд "магических" числе, которые определяются IANA. Эта секция объясняет критерии, которые должна использовать IANA при присвоении дополнительных чисел в каждый из этих списков. Следующие субсекции описывают политику присвоения для пространства имен, определенных в данном документе.
Сообщения об ошибках Resv
Сообщения ResvErr (reservation error) сообщают об ошибках при обработке сообщений Resv, или о спонтанном нарушении резервирования, напр., в результате административного вмешательства.
Сообщения ResvErr направляются соответствующим получателям, они маршрутизируются от узла к узлу с использованием состояния резервирования. В каждом из узлов в качестве IP-адреса места назначения используется уникастный адрес следующего узла.
<ResvErr Message> ::= <Common Header> [ <INTEGRITY> ]
<SESSION> <RSVP_HOP>
<ERROR_SPEC> [ <SCOPE> ]
[ <POLICY_DATA> ...]
<STYLE> [ <error flow descriptor> ]
Объект ERROR_SPEC специфицирует ошибку и включает в себя IP-адрес узла, который обнаружил ошибку (Error Node Address). Для приобщения необходимой информации в сообщение могут быть включены один или более объектов POLICY_DATA. Объект RSVP_HOP содержит адрес предыдущего узла, а объект STYLE копируется из сообщения Resv.
Следующие правила, зависящие от стиля, определяют структуру ошибки дескриптора потока. Стиль WF:
<error flow descriptor> ::= <WF flow descriptor> Стиль FF:
<error flow descriptor> ::= <FF flow descriptor>
Каждый дескриптор потока в сообщении Resv стиля FF должен обрабатываться независимо и для каждого из них, имеющего ошибку, должно посылаться отдельное сообщение ResvErr. Стиль SE:
<error flow descriptor> ::= <SE flow descriptor>
Сообщение ResvErr стиля SE может представит список субнабора спецификаций фильтрации, которые вызвали ошибки, в соответствующем сообщении Resv.
Заметим, что сообщение ResvErr содержит только один дескриптор потока. Следовательно, сообщение Resv, которое содержит N > 1 дескрипторов потока (стиль FF) может быть причиной N сообщений ResvErr.
Вообще говоря, сообщение ResvErr следует пересылать всем получателям, которые могут быть причиной данной ошибки. Конкретнее: Узел, который обнаружил ошибку в запросе резервирования посылает сообщение ResvErr узлу, от которого получен ошибочный запрос резервирования.
Это сообщение ResvErr должно содержать информацию, необходимую для определения ошибки и для маршрутизации сообщения об ошибке последующим узлам. Такое сообщение, следовательно, включает в себя объект ERROR_SPEC, копию объекта STYLE и соответствующий дескриптор потока, где зафиксирована ошибка. Если ошибка является результатом отказа при попытке увеличить резервирование, тогда существующее резервирование должно быть сохранено и должен быть установлен бит-флаг InPlace в ERROR_SPEC сообщения ResvErr. Узлы переадресуют сообщение ResvErr последующим узлам, которые имеют локальное состояние резервирования. Для резервирования с произвольным выбором отправителей имеется дополнительное ограничение на пересылку сообщений ResvErr, связанное с блокировкой возможных циклических маршрутов. Существует строгое правило рассылки сообщений при ошибке, связанной с разрешением доступа. Сообщение ResvErr, которое посылается, должно нести в себе спецификацию FILTER_SPEC соответствующего состояния резервирования.Когда сообщение ResvErr достигает получателя, приложение должно принять объект STYLE, список дескрипторов потока и объект ERROR_SPEC (включая его флаги).
