Конвейерные алгоритмы
Напомним, что процесс-фильтр получает данные из входного порта, обрабатывает их и отсылает результаты в выходной порт. Конвейер — это линейно упорядоченный набор процессов-фильтров. Данная концепция уже рассматривалась в виде каналов Unix (раздел 1.6), сортирующей сети (раздел 7.2), а также как способ циркуляции значений между процессами (раздел 7.4). Здесь показано, что эта парадигма полезна и в синхронных параллельных вычислениях.
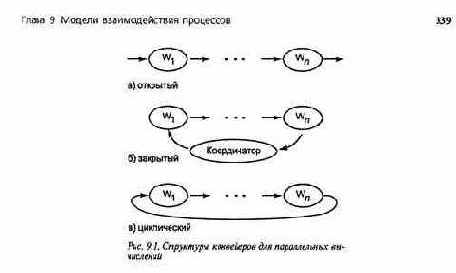
В решении задач параллельных вычислений обычно используется несколько рабочих процессов. Иногда их можно программировать в виде фильтров и соединять в конвейер параллельных вычислений. Есть три базовые структуры таких конвейеров (рис. 9.1): открытая, закрытая и циклическая (круговая). Рабочие процессы обозначены символами от Wt до Wf В открытом конвейере входной источник и выходной адресат не определены. Такой конвейер можно включить в любую цепь, для которой он подходит. Закрытый конвейер — это открытый конвейер, соединенный с, управляющим процессом, который производит входные данные для первого рабочего процесса и потребляет результаты, вырабатываемые последним рабочим процессом. Пример открытого конвейера — команда Unix "grep pattern file | we", которую можно поместить в самые разные места. Выполняясь в командной строке, эта команда становится частью закрытого конвейера с пользователем в качестве управляющего процесса. Конвейер называется циклическим (круговым), если его концы соединены; в этой ситуации данные циркулируют между рабочими процессами.
В разделе 1.8 были представлены две распределенные реализации умножения матриц а х Ь = с, где а, Ь и с — плотные матрицы размерами n x п. В первом решении работа просто делилась между n рабочими процессами, по одному на строку матриц а и с, но каждый процесс должен был хранить всю матрицу Ь. Во втором решении также использовались n рабочих процессов, но каждый из них должен был хранить только один столбец матрицы Ь. В этом решении в действительности применялся круговой конвейер, в котором между рабочими процессами циркулировали столбцы матрицы Ь.
Здесь будут рассмотрены еще две распределенные реализации умножения плотных матриц. В первом решении используется закрытый конвейер, во втором — сеть циклических конвейеров. Оба решения имеют интересные особенности по сравнению с рассмотренными ранее алгоритмами, они также демонстрируют шаблоны, применимые к другим задачам.

340 Часть 2 Распределенное программирование
чения а [ i, * ]. Во второй фазе рабочие процессы получают столбцы матрицы Ь, сразу передают их следующему рабочему процессу и вычисляют одно промежуточное произведение. Эту фазу каждый рабочий процесс повторяет п раз, получая в результате значения с [ i, * ]. В третьей фазе каждый рабочий процесс отсылает свою строку матрицы с следующему рабочему процессу, затем получает и передает далее строки матрицы с от предшествующих процессов конвейера. Последний рабочий процесс передает свою и остальные полученные строки матрицы с управляющему. При этом строки передаются в порядке от с[п-1,*] до с [ 0, * ], поскольку в этом порядке их получает последний рабочий процесс конвейера. При таком порядке передачи снижаются задержки взаимодействия, а последнему рабочему процессу не нужна локальная память для хранения всей матрицы с.
Действия рабочих процессов показаны в листинге 9.5, б. Три фазы работы процессов отмечены комментариями. Учтены отличия последнего рабочего процесса от остальных.

Глава 9. Модели взаимодействия процессов 341
ния идут непрерывно. Вычисляя промежуточное произведение, рабочий процесс уже передал используемый столбец, поэтому следующий процесс может его получить, передать дальше и начать вычисление своего собственного промежуточного произведения.
Во-вторых, чтобы первый рабочий процесс получил все строки матрицы а и передал их далее, нужно n циклов передачи сообщений. Еще п-1 циклов нужно, чтобы заполнить конвейер, т.е.
чтобы каждый рабочий процесс получил свою строку матрицы а. Однако после заполнения конвейера промежуточные произведения вычисляются почти с той же скоростью, с какой могут приходить сообщения. Причина, как уже отмечалось, в том, что столбцы матрицы Ь следуют сразу за строками матрицы а и передаются рабочими процессами сразу после получения. Если вычисление промежуточного произведения занимает больше времени, чем передача и прием сообщения, то после заполнения конвейера определяющим фактором станет время выполнения вычислений. Оставляем читателю решение интересных задач по выводу уравнений производительности и проведение опытов с пропускной способностью конвейера.
Еще одно интересное свойство рассматриваемого решения — возможность легко изменять число столбцов матрицы Ь. Для этого достаточно изменить верхние пределы в циклах обработки столбцов. Фактически такой же код можно использовать для умножения матрицы а на любой поток векторов, чтобы получить в результате поток векторов. Например, матрица а может представлять набор коэффициентов линейных уравнений, а поток векторов — различные комбинации значений переменных.
Конвейер также можно "сократить", чтобы использовать меньше рабочих процессов. Для этого каждый рабочий процесс должен хранить полосу строк матрицы а. Можно точно так же передавать по конвейеру столбцы матрицы Ь и строки с или, уменьшив количество сообщений, сделать их длиннее.
Закрытый конвейер, показанный в листинге 9.5, можно открыть и поместить его рабочие процессы в цепочку другого конвейера. Например, вместо управляющего процесса для соз-чания исходных векторов можно использовать еще один конвейер умножения матриц, а для юлучения результатов — еще один процесс. Однако, чтобы придать конвейеру наиболее об-ций вид, через него нужно передавать все векторы (даже строки матрицы а) — тогда на выхо-(е из конвейера эти данные будут доступны какому-нибудь другому процессу.
J.3.2. Блочное умножение матриц
Производительность предыдущего алгоритма определяется длиной конвейера и временем, «обходимым для передачи и приема сообщений.
Сеть связи некоторых высокопроизводитель-шх машин организована в виде двухмерной сетки или структуры, которая называется гиперкубом. Эти виды сетей связи позволяют одновременно передавать сообщения между различными парами соседствующих процессов. Кроме того, они уменьшают расстояние между процессора-пи по сравнению с их линейным упорядочением, что сокращает время передачи сообщения.
Для эффективного умножения матриц на машинах с такими структурами сети связи нужно делить матрицы на прямоугольные блоки и для обработки каждого блока использовать отдельный рабочий процесс. Таким образом, рабочие процессы и данные распределяются по процессорам в виде двухмерной сетки. У каждого рабочего процесса есть по четыре соседа: сверху, снизу, слева и справа. Соседями считаются рабочие процессы в верхнем и нижнем рядах сетки, а также в ее левом и правом столбцах.
Вернемся к задаче вычисления произведения двух матриц а и Ь с размерами n x n и сохранения результата в матрице с. Чтобы упростить код, используем отдельный рабочий процесс для каждого элемента матрицы и пронумеруем строки и столбцы от 1 до п. (В конце раздела описано использование блоков значений.) Пусть массив Worker [ 1.- n, 1.- n ] — это матрица рабочих процессов. Матрицы а и Ь вначале распределены так, что у каждого процесса Worker [ i, j ] есть соответствующие элементы матриц а и Ь.
342 Часть 2. Распределенное программирование
Для вычисления с I i, j ] рабочему процессу Worker [ i, j ] нужно умножить каждый элемент строки i матрицы а на соответствующий элемент столбца j матрицы b и сложить результаты. Однако порядок выполнения операций умножения на результат не влияет! Вопрос в том, как организовать циркуляцию данных между рабочими процессами, чтобы каждый из них получил все необходимые пары чисел.
Для начала рассмотрим процесс Worker [1,1]. Для вычисления значения с [ 1,1 ] этому процессу нужны все элементы строки 1 матрицы а и столбца 1 матрицы Ь.
Вначале у процесса есть а[1,1] и Ь [ 1,1 ], поэтому их можно сразу перемножить. Если теперь переместиться на 1 вправо по строке матрицы а и вниз по столбцу матрицы Ь, то процесс Worker [1,1] получит значения элементов а[1,2] и Ь[2,1 ], которые можно умножить и прибавить к значению с [ 1,1 ]. Если эти действия повторить еще п-2 раза, перемещаясь вправо по строке матрицы а и вниз по столбцу матрицы Ь, то процесс Worker [1,1] получит все необходимые ему данные.
К сожалению, такая последовательность сдвигов и умножений годится только для процесса, обрабатывающего диагональные элементы матрицы. Другие рабочие процессы тоже увидят необходимые им значения элементов матриц, но в неправильной последовательности. Однако перед началом умножений и перемещений элементы матриц а и Ь можно переупорядочить. Для этого нужно сначала циклически сдвинуть строку i матрицы а влево на i столбцов, а столбец j матрицы Ь вверх на j строк. (Причины, по которым такое перемещение элементов работает, не очевидны; этот порядок перемещения элементов был получен после исследований, проведенных для небольших матриц, и обобщения результатов.) Ниже показан результат предварительной перестановки значений матриц а и Ь с размерами 4x4. ai,2, b2,i ai,3, Ьз,2 ai,4, bi,3 ai,i, bi,i
32,3, Ьз,1 32,4, bt,2 32,1/ t>l,3 32,2. Ь2,4
аз,4, b4,i аз,1, bi,2 аз,2, Ь2,з аз,з, Ьз,4
a4,i, bi.i 34,2, Ь2,2 а4,з, Ьз,з а4,4, Ьа,4
После предварительной перестановки значений каждый рабочий процесс имеет два значения, которые он записывает в локальные переменные aij и bij. Затем рабочий процесс инициализирует переменную cij значением aij *bij и выполняет п-1 циклов сдвига и умножения. В каждом цикле значения aij передаются на один столбец влево, а значения bij — на строку выше; процесс получает новые значения, перемножает их и прибавляет произведение к текущему значению переменной cij.
Когда рабочие процессы завершаются, произведение матриц хранится в переменных cij всех рабочих процессов.
В листинге 9.6 показан код, реализующий этот алгоритм умножения матриц. Рабочие процессы совместно используют п2 каналов для циркуляции данных влево и еще п2 каналов для циркуляции данных вверх. Из каналов формируются 2п пересекающихся циклических конвейеров. Рабочие процессы одной строки связаны в циклический конвейер, через который данные перемещаются влево; рабочие процессы одного столбца связаны в циклический конвейер, по которому данные идут вверх. Константы LEFT1, UP1, LEFTI и UPJ в каждом рабочем процессе инициализируются соответствующими значениями и используются в операторах send для индексации массивов каналов.

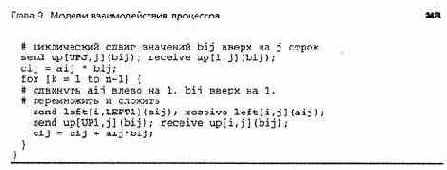
программа в листинге у.о явно неэффективна (если только она не реализована аппарат-но). В ней используется слишком много процессов и сообщений, а каждый процесс производит слишком мало вычислений. Но этот алгоритм легко обобщается для использования квадратных или прямоугольных блоков. Каждый рабочий процесс назначается для блоков матриц а и Ь Рабочие процессы сначала сдвигают свои блоки матрицы а влево на i блоков столбцов, а блоки матрицы Ь — вверх на j блоков строк. Затем каждый рабочий процесс инициализирует свой блок результирующей матрицы с промежуточными произведениями своих новых блоков матриц а и Ь. Затем рабочие процессы выполняют п-1 циклов сдвига матрицы а на блок влево и сдвига матрицы Ь на блок вверх, вычисляют новые промежуточные произведения и прибавляют их к с. Подробности этого процесса читатель может выяснить самостоятельно (см. упражнения в конце главы).
Дополнительный способ повысить эффективность кода в листинге 9.6 — выполнять при сдвиге данных оба оператора send до выполнения операторов receive. Изменим последовательность операторов
send/receive/send/receive на
send/send/receive/receive.
Это снижает вероятность того, что оператор receive заблокирует работу программы, и делает возможной параллельную передачу сообщений (если она обеспечена сетью связи).
Критические секции: решения со справедливой стратегией
Решения задачи критической секции с циклической блокировкой обеспечивают взаимное исключение, отсутствие взаимных блокировок, активных тупиков и нежелательных пауз. Однако для обеспечения свойства возможности входа (3.5) им необходима справедливая в сильном смысле стратегия планирования. Как сказано в разделе 2.8, стратегии планирования, применяемые на практике, являются справедливыми только в слабом смысле. Маловероятно, что процесс, пытающийся войти в критическую секцию, никогда этого не сделает, однако может случиться, что несколько процессов будут без конца состязаться за вход. В частности, решения с циклической блокировкой не управляют порядком, в котором несколько приостановленных процессов пытаются войти в критические секции.
В данном разделе представлены три решения задачи критической секции со справедливой стратегией планирования: алгоритмы разрыва узла, поликлиники и билета. Они зависят только от справедливой в слабом смысле стратегии планирования, например, от кругового (round-robin) планирования, при котором каждый процесс периодически получает возможность выполнения, а условия задержки, став истинными, остаются таковыми. Алгоритм разрыва узла достаточно прост для двух процессов и не зависит от специальных машинных инструкций, но сложен для n процессов. Алгоритм билета прост для любого числа процессов, но требует специальной инструкции "извлечь и сложить". Алгоритм поликлиники — это вариант алгоритма билета, для которого не нужны специальные машинные инструкции. Поэтому он более сложен (хотя и проще, чем алгоритм разрыва узла для n процессов).
3.3.1. Алгоритм разрыва узла
Рассмотрим решение задачи критической секции для двух процессов (листинг 3.1). Его недостаток в том, что оно не решает, какой из процессов, пытающихся войти в критическую секцию, туда действительно попадет. Например, один процесс может войти в критическую
96 Часть 1. Программирование с разделяемыми переменными
секцию, выполнить ее, затем вернуться к протоколу входа и снова успешно войти в критиче скую секцию. Чтобы решение было справедливым, должна соблюдаться очередность входа в критическую секцию, если несколько процессоров пытаются туда войти.
Алгоритм разрыва узла (также называемый алгоритмом Питерсона) — это вариант протокола критической секции (см. листинг 3.1), который "разрывает узел", когда два процесса пытаются войти в критическую секцию. Для этого используется дополнительная переменная, которая фиксирует, какой из процессов вошел в критическую секцию последним.
Чтобы пояснить алгоритм разрыва узла, вернемся к крупномодульной программе в листинге 3.1. Сейчас цель — реализовать условные неделимые действия в протоколах входа с использованием только простых переменных и последовательных операторов. Для начала рассмотрим реализацию оператора await, в которой сначала выполняется цикл, пока не будет снята блокировка, а затем присваивание. Протокол входа процесса CS1 должен выглядеть следующим образом.
while (in2) skip; inl = true;
Протокол входа процесса CS2 аналогичен:
while (inl) skip; in2 = true;
Соответствующий протокол выхода процесса CS1 должен присвоить значение "ложь" переменной inl, aCS2 —переменной in2.
В этом "решении" есть проблема — два действия в протоколе входа не выполняются неде-•лимым образом, поэтому не обеспечено взаимное исключение. Например, желательным постусловием для цикла задержки в процессе CS1 является in2 == false. К сожалению, на него влияет операция присваивания in2 = true;, поскольку оба процесса, вычислив свои условия задержки примерно в одно и то же время, могут обнаружить, что оба условия выполняются.
Когда завершается цикл while, каждый из процессов должен быть уверен в том, что другой не находится в критической секции. Поэтому рассмотрим протоколы входа с обратным порядком следования операторов. Для процесса CS1:
inl = true; while (in2) skip;
Аналогично и для CS2:
in2 = true; while (inl) skip;
Но этим проблема не решается. Взаимное исключение гарантируется, но появляется возможность взаимной блокировки: если обе переменные inl и in2 истинны, то ни один из циклов ожидания не завершится. Однако есть простой способ избежать взаимной блокировки — использовать дополнительную переменную, чтобы "разорвать узел", если приостановлены оба процесса.
Пусть last — целочисленная переменная, которая показывает, какой из процессов CS1 и CS2 начал выполнять протокол входа последним. Если оба процесса пытаются войти в критические секции, т.е. inl и in2 истинны, выполнение последнего из них приостанавливается. Это приводит к крупномодульному решению, показанному в листинге 3.5.
Алгоритм программы в листинге 3.5 очень близок к мелкомодульному решению, для которого не нужны операторы await. В частности, если все операторы await удовлетворяют условию "не больше одного" (2.2), то их можно реализовать в виде циклов активного ожидания. К сожалению, операторы await в листинге 3.5 обращаются к двум переменным, каждую из которых изменяет другой процесс. Однако в данном случае нет необходимости в неделимом вычислении условий задержки. Докажем это.
Предположим, процесс CS1 вычисляет свое условие задержки и обнаруживает, что оно истинно. Если CS1 обнаружил, что in2 ложна, то теперь in2 может быть истинной. Но в этом случае процесс CS2 только что присвоил переменной last значение 2; следовательно, условие задержки остается истинным, если даже значение переменной in2 изменилось. Если

Поскольку условие окончания задержки не обязательно вычислять неделимым образом, каждый оператор await можно заменить циклом while, который повторяется, пока условие окончания задержки ложно. Таким образом, получаем мелкомодульный алгоритм разрыва узла (листинг 3.6).
В этой программе решается проблема критических секций для двух процессов. Такую же основную идею можно использовать для решения задачи при любом числе процессов.
В частности, для каждого из п процессов протокол входа должен состоять из цикла, который проходит п-1 этапов. На каждом этапе используются экземпляры алгоритма разрыва узла для двух процессов, чтобы определить, какие процессы проходят на следующий этап. Если гарантируется, что все п-1 этапов может пройти не более, чем один процесс, то в критической секции одновременно будет находиться не больше одного процесса.
Пусть in[l:n] и last[l:n] — целочисленные массивы. Значение элемента in[i] показывает, какой этап выполняет процесс CS [i]. Значение last [ j ] показывает, какой процесс последним начал выполнять этап j. Эти переменные используются, как показано в листинге 3.7. Внешний цикл for выполняется п-1 раз. Внутренний цикл for процесса CS[i] проверяет все остальные процессы. Процесс CS [ i ] ждет, если некоторый другой процесс находится на этапе с равным или большим номером этапа, а процесс CS[i] был последним процессом, достигшим этапа j. Как только этапа j достигнет еще один процесс, или все процессы "перед" процессом CS [ i ] выйдут из своих критических секций, процесс CS [ i ] получит возможность выполняться на следующем этапе. Таким образом, не более п-1 процессов могут пройти первый этап, п-2 — второй и так далее. Это гарантирует, что пройти все n этапов и выполнять свою критическую секцию процессы могут только по одному.

Глава 3. Блокировки и барьеры
3.3.2. Алгоритм билета
Алгоритм разрыва узла для n процессов весьма сложен и неясен, и отчасти потому, что не очевидно обобщение алгоритма для двух процессов на случай n процессов. Построим более прозрачное решение задачи критической секции для n процессов, иллюстрирующее, как для упорядочения процессов используются целочисленные счетчики. Это решение называется алгоритмом билета, поскольку основано на вытягивании билетов (номеров) и последующего ожидания очереди.
В некоторых магазинах используется следующий метод обслуживания покупателей (посетителей) в порядке их прибытия: входя в магазин, посетитель получает номер, который больше номера любого из ранее вошедших.
Затем посетитель ждет, пока обслужат всех людей, получивших меньшие номера. Этот алгоритм реализован с помощью автомата для выдачи номеров и счетчика, отображающего номер обслуживаемого посетителя. Если за счетчиком следит один работник, посетители обслуживаются по одному в порядке прибытия. Описанную идею можно использовать и для реализации справедливого протокола критической секции.
Пусть number и next — целые переменные с начальными значениями 1, a turn[1:n] — массив целых с начальными значениями 0. Чтобы войти в критическую секцию, процесс cs [i ] сначала присваивает элементу turn [ i ] текущее значение number и увеличивает значение number на 1. Чтобы процессы (посетители) получали уникальные номера, эти действия должны выполняться неделимым образом. После этого процесс cs [ i ] ожидает, пока значение next не станет равным полученному им номеру. При завершении критической секции процесс CS [ i ] увеличивает на 1 значение next, снова в неделимом действии.
Описанный протокол реализован в алгоритме, приведенном в листинге 3.8. Поскольку значения number и next считываются и увеличиваются в неделимых действиях, следующий предикат будет глобальным инвариантом.
TICKET: next > 0 л (VI: 1 <= i <= n:
(CS[i] в своей критической секции) => (turn[i] == next) л (turn[i] >0) => (V j : I <= j <= n, j != i:
turnfi] != turnfj]) )
Последняя строка гласит, что ненулевые значения элементов массива turn уникальны. Следовательно, только один turn [ i ] может быть равен next, т.е. только один процесс может находиться в критической секции. Отсюда же следует отсутствие взаимоблокировок и ненужных задержек. Этот алгоритм гарантирует возможность входа при стратегии планирования, справедливой в слабом смысле, поскольку условие окончания задержки, ставшее истинным, таким и остается.
Листинг 3.8. Алгоритм билета: крупномодульное решение
int number = 1, next = 1, turn[l:n] = ( [n] 0);
И глобальный инвариант — предикат TICKET (см. текст)
process CS[i = 1 to n] { while (true) {
(turn[i) = number; number = number + 1;) (await (turnfi] == next);) критическая секция; (next = next + 1;) некритическая секция; } _}__________________________________________________________________________________
В отличие от алгоритма разрыва узла, алгоритм билета имеет потенциальный недостаток, общий для алгоритмов, использующих увеличение счетчиков: значения number и next не ограниче-
100 Часть 1. Программирование с разделяемыми переменными
ны. Если алгоритм билета выполнять достаточно долго, увеличение счетчиков приведет к арифметическому переполнению. Однако на практике это крайне маловероятно и не является проблемой.
Алгоритм в листинге 3.8 содержит три крупномодульных действия. Оператор await легко реализуется циклом с активным ожиданием, поскольку в булевом выражении использована только одна разделяемая переменная. Последнее неделимое действие, увеличение next, можно реализовать с помощью обычных инструкций загрузки и сохранения, поскольку в любой момент времени только один процесс выполняет протокол выхода. К сожалению, первое неделимое действие (чтение значения number и его увеличение) реализовать непросто.
У некоторых машин есть инструкции, которые возвращают старое значение переменной и увеличивают или уменьшают ее в одном неделимом действии. Эти инструкции выполняют именно то, что нужно для реализации алгоритма билета. В качестве примера приведем инструкцию "извлечь и сложить" (Fetch-and-Add — FA), которая работает следующим образом.

Для машин, не имеющих инструкции типа "извлечь и сложить", необходим другой метод. Главное требование алгоритма билета — каждый процесс должен получить уникальный номер. Если у машины есть инструкция неделимого увеличения, первый шаг протокола входа можно реализовать так:
turn[i] = number; (number = number + 1;)
Переменная number гарантированно увеличивается правильно, но процессы могут не получить уникальных номеров. Например, каждый из процессов может выполнить первое присваивание примерно в одно и то же время и получить один и тот же номер! Поэтому важно, чтобы оба присваивания выполнялись в одном неделимом действии.
Нам уже известны два других способа решения задачи критической секции: циклические блокировки и алгоритм разрыва узла. Чтобы обеспечить неделимость получения номеров, можно воспользоваться любым из них. Например, пусть CSenter — протокол входа критической секции, a CSexit— соответствующий протокол выхода. Тогда в программе 3.9 инструкцию "извлечь и сложить" можно заменить следующей последовательностью.
(3.10) CSenter, turn[i] = number; number = number+1; CSexif,
Такой подход выглядит необычным, но на практике он работает хорошо, особенно если для реализации протоколов входа и выхода доступна инструкция типа "проверить-установить". При использовании инструкции "проверить-установить" процессы получают номера не обязательно в соответствии с порядком, в котором они пытаются это сделать, и теоретически процесс может зациклиться навсегда. Но с очень высокой вероятностью каждый процесс получит номер, и большинство номеров будут выбраны по порядку. Причина в том, что крити-
Глава 3 Блокировки и барьеры 101
ческая секция в (3.10) очень коротка, и процесс не должен задерживаться в протоколе входа CSenter. Основной источник задержек в алгоритме билета — это ожидание, пока значение переменной next не станет равно значению turn [ i ].
3.3.3. Алгоритм поликлиники
Алгоритм билета можно непосредственно реализовать на машинах, имеющих операцию типа "извлечь и сложить". Если такая инструкция недоступна, можно промоделировать часть алгоритма билета, в которой происходит получение номера с использованием (3.10).
Но для этого нужен еще один протокол критической секции, и решение не обязательно будет обладать свойством справедливости. Здесь представлен алгоритм поликлиники, подобный алгоритму билета. Он обеспечивает справедливость планирования и не требует специальных машинных инструкций. Естественно, он сложнее, чем алгоритм билета (см. листинг 3.9).
По алгоритму билета каждый посетитель получает уникальный номер и ожидает, пока значение next не станет равным этому номеру. Алгоритм поликлиники использует другой подход. Входя, посетитель смотрит на всех остальных и выбирает номер, который больше любого другого. Все посетители должны ждать, пока назовут их номер. Как и в алгоритме билета, следующим обслуживается посетитель с наименьшим номером. Отличие состоит в том, что для определения очередности обслуживания посетители сверяются друг с другом, а не с общим счетчиком.
Как и в алгоритме билета, пусть turn [ 1: п] — массив целых с начальными значениями 0. Чтобы войти в критическую секцию, процесс CS [ i ] сначала присваивает переменной turn [ i ] значение, которое на 1 больше, чем максимальное среди текущих значений элементов массива turn. Затем CS [ i ] ожидает, пока значение turn [ i ] не станет наименьшим среди ненулевых элементов массива turn. Таким образом, инвариант алгоритма поликлиники выражается следующим предикатом.
CLINIC: (V i: I <= i <= n:
(CS[i] в своей критической секции) => (turn[i] > 0) л (turn[i] > 0) => (V j: 1<= j <= n, d '= i:
turntj] == 0 v turn[i] < turn[j]) )
Выходя из критической секции, процесс CS [ i ] присваивает turn [ i ] значение 0.
В листинге 3.10 показан крупномодульный вариант алгоритма поликлиники, соблюдающий поставленные условия. Первое неделимое действие обеспечивает уникальность всех ненулевых значений элементов массива turn. Оператор for гарантирует, что следствие предиката CLINIC истинно, когда процесс Р [ i ] выполняет свою критическую секцию.
Этот алго ритм удовлетворяет условию взаимного исключения, поскольку одновременно не могут быть истинными условия turn [ i ] i=0 для всех i и CLINIC. Ненулевые значения элементов массива turn уникальны и, как обычно, предполагается, что каждый процесс в конце концов выходит из своей критической секции, поэтому взаимных блокировок нет. Отсутствуют также излишние задержки процессов, поскольку сразу после выхода процесса CS [ i ] из критической секции turn[i] получает значение 0. Наконец, алгоритм поликлиники гарантирует возможность входа в критическую секцию, если планирование справедливо в слабом смысле, поскольку ставшее истинным условие окончания задержки остается таковым. (Значения элементов массива turn в алгоритме поликлиники могут быть как угодно велики, но значения элементов массива turn продолжают возрастать, только если всегда есть хотя бы один процесс, пытающийся войти в критическую секцию. Однако на практике это маловероятно.)
Алгоритм поликлиники в листинге 3.10 нельзя непосредственно реализовать на современных машинах. Чтобы присвоить переменной turn [ i ], необходимо найти максимальное из n значений, а оператор await дважды обращается к разделяемой переменной turn [ j ]. Эти операции можно было бы реализовать неделимым образом, используя еще один протокол критической секции, например, алгоритм разрыва узла, но это слишком неэффективно. К счастью, есть более простой выход.
102 Часть 1. Программирование с разделяемыми переменными
Листинг 3.10. Алгоритм поликлиники: крупномодульное решение
int turn[l:n] = ([n] 0);
i# глобальный инвариант — предикат CLINIC (си. текст)
process CS[i = 1 to n] { while (true) {
(turn[i] = max(turn[l:n]) + 1;} for [j = 1 to n st j != i]
(await (turn[j] == 0 or turn[i] < turn[j]);) критическая секция -, turn[i] = 0; некритическая секция -, } }____________________________________________________________________________________
Если необходимо синхронизировать n процессов, полезно сначала разработать решение для двух процессов, а затем обобщить его (так мы поступили с алгоритмом разрыва узла). Итак, рассмотрим следующий протокол входа для процесса csi.
turnl = turn2 + 1;
while (turn2 != 0 and turnl > turn2) skip;
Аналогичен и следующий протокол входа для процесса CS2.
turn2 = turnl + 1;
while (turnl != 0 and turn2 > turnl) skip,-
Каждый процесс присваивает значение своей переменной turn в соответствии с оптимизированным вариантом (ЗЛО), а операторы await реализованы в виде цикла с активным ожиданием.
Проблема этого "решения" в том, что ни операторы присваивания, ни циклы while не выполняются неделимым образом. Следовательно, процессы могут начать выполнение своих протоколов входа приблизительно одновременно, и оба присвоят переменным turnl и turn2 значение 1. Если это случится, оба процесса окажутся в своих критических секциях в одно и то же время.
Частично решить эту проблему можно по аналогии с алгоритмом 3.6: если обе переменные turnl и turn2 имеют значения 1, то один из процессов должен выполняться, а другой — приостанавливаться. Например, пусть выполняется процесс с меньшим номером; тогда в условии цикла задержки процесса CS2 изменим второй конъюнкт: turn2 >= turnl.
К сожалению, оба процесса все еще могут одновременно оказаться в критической секции. Допустим, что процесс csi считывает значение turn2 и получает 0. Процесс CS2 начинает выполнять свой протокол входа, определяет, что переменная turnl все еще имеет значение О, присваивает turn2 значение 1 и входит в критическую секцию. В этот момент CS1 может продолжить выполнение своего протокола входа, присвоить turnl значение 1 и затем войти в критическую секцию, поскольку переменные turnl и turn2 имеют значение 1, и процесс CS1 в этом случае получает преимущество. Такая ситуация называется состоянием гонок, поскольку процесс CS1 "обгоняет" CS2 и не учитывает, что процесс CS2 изменил переменную turn2.
Чтобы избежать состояния гонок, необходимо, чтобы каждый процесс присваивал своей переменной turn значение 1 (или любое отличное от нуля) в самом начале протокола входа. После этого процесс должен проверить значение переменной turn других процессов и переприсвоить значение своей переменной, т.е. протокол входа процесса CS1 выглядит следующим образом.
turnl = 1; turnl = turn2 + 1;
while (turn2 != 0 and turnl > turn2) skip;
Протокол входа процесса CS2 аналогичен.
turn2 = 1; turn2 = turnl + 1;
while (turnl != 0 and turn2 >= turnl) skip,-
Глава 3. Блокировки и барьеры 103
Теперь один процесс не может выйти из цикла whi 1е, пока другой не закончит начатое ранее присваивание turn. В этом решении процессу CS1 отдается преимущество перед CS2, когда у обоих процессов ненулевые значения переменной turn.
Протоколы входа процессов несимметричны, поскольку условие задержки второго цикла слегка отличается. Однако их можно записать и в симметричном виде. Пусть (а,Ь) и (с, d) — пары целых чисел. Определим отношение сравнения для них таким образом:
(a,b) > (c,d) == true, если а > с или а == с и b > d == false, иначе
Теперь можно переписать условие turnl > turn2 процесса CS1 в виде (turnl,!) > (turn2,2), аусловие turn2 >= turnl в процессе CS2 — (turn2, 2) > (turnl,!).
Достоинство симметричной записи в том, что теперь алгоритм поликлиники для двух процессов легко обобщить на случай п процессов (листинг 3.11). Каждый из процессов сначала показывает, что он собирается войти в критическую секцию, присваивая своей переменной turn значение 1. Затем он находит максимальное значение из всех turn [ i ] и прибавляет к нему 1. Наконец, процесс запускает цикл for и, как в крупномодульном решении, ожидает своей очереди. Отметим, что максимальное значение массива определяется считыванием всех его элементов и выбором наибольшего.Эти действия не являются неделимыми, поэтому точный результат не гарантируется. Однако, если несколько процессов получают одно и то же значение, они упорядочиваются в соответствии с правилом, описанным выше.
Листинг 3.11. Алгоритм поликлиники: мелкомодульное решение
mt turn[l:n] = ([n] 0);
process CS[i = 1 to n] { while (true) {
turn[i] = 1; turn[i] = max(turn[1:n])+1; for [j = 1 to n st j '= i] while (turntj] '= 0 and
(turn[i],i) > (turn[j],j)) skip; критическая секция; turn[i] = 0; некритическая секция; } _}_______________________________________________________________________________
Матричные вычисления
Сеточные и точечные вычисления являются фундаментальными в научных вычислениях. Третий основной вид вычислений — матричные. Умножение плотных и разреженных матриц уже рассматривалось. В данном разделе представлено использование матриц для решения систем линейных уравнений. Задачи такого типа составляют основу многих научных и инженерных приложений, а также задач экономического моделирования и многих других. (В действительности уравнение Лапласа, рассмотренное в разделе 11.1, можно заменить большой системой уравнений. Однако эта система получится очень разреженной, поэтому уравнение Лапласа обычно решают с помощью итерационных сеточных вычислений.)
Вначале рассмотрен метод исключений Гаусса. Затем описан более общий метод, который называется LU-разложением, и для него построена последовательная программа. Наконец разработаны параллельные программы для LU-разложения с разделяемыми переменными и с передачей сообщений. В упражнениях представлены другие матричные вычисления, в том числе обращение матриц.

Стандартный способ решения данной системы с неизвестными а, Ь и с — переписать одно из уравнений относительно какой-либо переменной, скажем, а, и полученное для нее выражение подставить в два других уравнения. Получим два новых уравнения с двумя неизвестными. ' Затем выполним с ними те же действия — перепишем одно уравнение относительно одной из переменных, скажем, Ь, и подставим полученное для b выражение во второе уравнение. Решим полученное уравнение относительно с, затем найдем Ь и, наконец, а.
Метод (процедура) исключений Гаусса является систематическим методом решения систем линейных уравнений любых размеров. Для указанных выше трех уравнений он работает следующим образом. Первый шаг: умножим первое уравнение на 2 и вычтем его из второго. Из второго уравнения исключается а. Второй шаг: умножим первое уравнение на -1 и вычтем его из третьего (т.е. сложим первое и третье уравнения); а исключается из третьего уравнения. Итак, получены уравнения

Глава 11. Научные вычисления 437
Повторим описанные выше действия для двух последних уравнений. Умножим второе уравнение на 2/3 и сложим его с третьим. В третьем уравнении исчезает Ь (и появляется с). Получается система уравнений
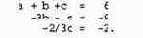
Описанные выше действия систематически исключают одну переменную из оставшихся уравнений и называются прямым ходом (фазой исключений). Во второй фазе выполняется обратный ход, в котором неизвестные находятся в обратном порядке, начиная с последнего уравнения и заканчивая первым. В нашем примере из последнего уравнения получим с = 3. Затем во второе уравнение вместо с подставим 3 и найдем значение b: b = 2. Наконец подставим полученные для b и с значения в первое уравнение и найдем а: а = 1. Итак, решение данной системы уравнений — а = 1,Ь = 2ис = 3.
Решение системы линейных уравнений эквивалентно решению матричного уравнения Ах = Ь, где а — квадратная матрица коэффициентов, b — вектор-столбец правых частей уравнений, ах— вектор-столбец неизвестных. Строка с номером i матрицы А содержит коэффициенты для неизвестных 1-го уравнения, а i-й элемент в столбце Ь— значение правой части 1-го уравнения.
Метод исключений Гаусса реализуется серией преобразований матрицы А и вектора Ь. Матрица А приводится к верхней треугольной матрице, у которой все элементы, расположенные ниже главной диагонали, равны нулю. В нашем примере начальное значение матрицы А таково:
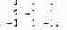
Соответствующие значения в Ь— (6, 3, -2). Прямой ход начинается с левого столбца и преобразует а и b следующим образом. Первый шаг: вычисляем множитель А[2,1]/А[1,1], умножаем на него первую строку матрицы А и первый элемент Ь; полученные строку и элемент вычитаем из второй строки А и второго элемента Ь. Второй шаг: вычисляем множитель А[3,1]/А[1,1], умножаем на него первую строку матрицы А и первый элемент Ь, и вычитаем их из третьей строки А и третьего элемента Ь. После этих двух шагов в первом столбце А будут нули во второй и третьей строках.
Последний шаг прямого хода в нашем несложном примере — вычисляем множитель А[3,2]/А[2,2], умножаем на него вторую строку А и второй элемент b и вычитаем их из третьей строки А и третьего элемента Ь. В итоге матрица А примет вид
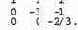
Соответствующие значения для b — (б, -9, -2).
Метод исключений Гаусса можно использовать при решении многих систем п уравнений с п неизвестными.23 Однако на каждом шаге прямого хода вычисляются множители вида A[k,i]/A[i,i]. Элемент А [ i, i ] называется ведущим элементом столбца i. Если он равен нулю, то получится "деление на ноль". Кроме того, если ведущий элемент слишком мал, то множитель будет слишком большим. Это может сделать алгоритм численно неустойчивым.
Обе проблемы можно решить, используя метод главных элементов. В каждом столбце i выбирается главный элемент A[k,i], имеющий наибольшее абсолютное значение. Перед следующим шагом исключений выполняется перестановка строк k и i. Ее лучше реализовать с помощью перестановки указателей на строки, а не путем реальных обменов значений их элементов.
" При этом уравнения должны быть независимыми, т.е. никакое уравнение системы не может быть получено из других. Точнее, А должна быть несингулярной (неособенной) матрицей.
438 Часть 3. Синхронное параллельное программирование
11.3.2. LU-разложение
Метод исключений Гаусса преобразует уравнение Ах = b в эквивалентное ему уравнение Ux = у, где и— верхняя треугольная матрица. При этом вычисляется последовательность множителей. Вместо того, чтобы отбрасывать их, предположим, что они сохраняются в третьей матрице L. Пусть матрица L — нижняя треугольная матрица, в которой все элементы, расположенные выше главной диагонали, равны нулю. Каждый элемент L [ j , i ] на диагонали и под ней имеет значение вида А [ j , i ] /pivot, где pivot — значение ведущего элемента для столбца i. После заполнения матрицы L произведение матриц L и и будет в точности равно исходной матрице А (если не учитывать возможных ошибок округления).
В частности, для нашей системы уравнений получим:
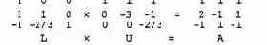



11.3.3. Программа с разделяемыми переменными
Рассмотрим, как распараллелить программы в листингах 11.11 и 11.12, используя pr процессоров и, соответственно, pr рабочих процессов. Вначале рассмотрим LU-разложение (см. листинг 11.11). В нем есть две фазы: инициализация ps и ш, а затем прямой ход исключений Гаусса. В фазе инициализации тела циклов независимы, поэтому их можно разделить
440 Часть 3. Синхронное параллельное программирование
между рабочими, используя любую схему распределения, которая каждому рабочему назначает поровну элементов данных.
Внешний цикл (по k) в фазе исключений должен выполняться последовательно каждым рабочим процессом, поскольку LU-разложение происходит итеративно вниз по главной диагонали и разлагает подматрицу LU[k:n,k:n]. Тело внешнего цикла имеет две фазы — выбор ведущего элемента и ведущей строки, затем сокращение строк под ведущей. Ведущий элемент можно выбрать следующими тремя способами.
• Каждый процесс просматривает все элементы в LU[k:n,k] и выбирает наибольший. Если каждый процесс сохраняет свою собственную копию индексов ведущих элементов ps, то после завершения этой фазы барьер не нужен.
• Один процесс просматривает все элементы в LU [ k: n, k ], выбирает наибольший и меняет местами ведущую строку и строку k. Здесь нужна точка барьерной синхронизации.
• Каждый рабочий процесс проверяет свое подмножество элементов из LU[k:n,k], выбирает наибольший элемент из подмножества и затем согласовывает с другими выбор ведущего элемента. Здесь также нужна точка барьерной синхронизации и в зависимости от того, как она запрограммирована, собственные копии ps.
Для малых значений n более быстрым будет первый подход, поскольку в нем нет барьеров. Для больших значений n более быстрым, вероятно, окажется третий подход. Точка пересечения (графиков сложности) зависит от того, как накладные расходы, связанные с барьером, соотносятся с временем выбора наибольшего элемента.
После выбора ведущего элемента все строки под ведущей строкой можно исключить параллельно. Для каждой строки сначала вычисляется и сохраняется множитель mult, затем выполняются итерации по столбцам, находящимся справа от столбца с ведущим элементом. По мере выполнения LU-разложения подматрица, в которой проводятся исключения, уменьшается, как и объем работы в фазах исключений. Таким образом, LU-матрицу нужно назначить рабочим процессам по полосам или обратным полосам, чтобы у каждого процесса постоянно была какая-то работа, кроме последних нескольких итераций в главном цикле. Вновь используем схему распределения по полосам, поскольку она проще программируется, чем схема с обратными полосами, и приводит к достаточно сбалансированной нагрузке.
В листинге 11.13 представлен эскиз параллельной программы LU-разложения с разделяемыми переменными. По сравнению с последовательной программой она имеет следующие основные отличия: 1) в фазах инициализации и исключений используются полосы строк; 2) после инициализации, каждой фазы выбора ведущего элемента (если необходимо) и каждого шага исключений установлены барьеры. Кроме того, каждому рабочему, возможно, нужна своя собственная локальная копия ведущих индексов, поскольку это упрощает перестановку строк и не требует синхронизации.


Рассмотрим, как распараллелить прямой и обратный проходы (см. листинг 11.12). К сожалению, в каждой фазе есть вложенные циклы, и каждый внутренний цикл зависит от значений, вычисленных на предыдущих итерациях соответствующего внешнего цикла. По определению прямой ход вычисляет элементы у по одному, а обратный — элементы х, также по одному.
В эти циклы можно внести независимость. Например, в фазе прямого хода можно развернуть внутренние циклы и переписать код, чтобы значения х [ i ] вычислялись в терминах ш и Ь. Вручную это делать утомительно, лучше использовать компилятор (см. раздел 12.2).
Другой способ получить параллельность — использовать так называемую синхронизацию фронта волны (wave front synchronization).
В фазе прямого хода итерации назначаются рабочим по полосам. Поскольку вычисления х [ i ] зависят от предыдущих значений х [ 1.- i -1 ], с каждым элементом х можно связать флаг (или семафор). Закончив вычисление х [ i ], процесс устанавливает флаг для этого элемента. Когда процессу нужно прочитать значение х [ i ], он сначала ждет, пока для этого элемента не будет установлен флаг. Например, код, выполняемый рабочим процессом w в прямом ходе, мог бы быть таким.

Фронт волны представляет собой установку флагов по мере вычисления новых элементов. (Термин фронт волны обычно используется для матриц; волна, как правило, представляет собой диагональную линию, движущуюся по матрице.)
Волновые фронты эффективны, если накладные расходы при синхронизации невелики по сравнению с объемом вычислений. Здесь же на каждый элемент приходится очень мало вычислений, поэтому синхронизацию можно запрограммировать с помощью простых флагов и активного ожидания. Это должно дать небольшое увеличение производительности данного приложения.
11.3.4. Программа с передачей сообщений
Рассмотрим, как реализовать LU-разложение с помощью передачи сообщений. Вновь рассмотрим три подхода — управляющий-рабочие, алгоритмы пульсации и конвейера. Можно использовать все три парадигмы, однако если в программе с разделяемыми переменными
442 Часть 3. Синхронное параллельное программирование
для некоторого приложения применяются барьеры, то естественнее всего построить распределенную программу на основе алгоритма пульсации. Ниже приведен эскиз программы пульсации для LU-разложения. Две другие парадигмы рассмотрены в упражнениях в конце главы.
Как обычно, при создании распределенной программы сначала нужно решить, как распределить данные, чтобы вычислительная нагрузка оказалась сбалансированной. Поскольку LU-разложение работает с уменьшающимися подматрицами, объем работы также уменьшается по мере выполнения исключений.
Поэтому можно назначить строки по полосам. Если предположить, что есть PR рабочих процессов, то рабочему процессу назначается каждая PR-я строка lu, по n/PR строк на каждый процесс.
Первый шаг в Ш-разложении — инициализация локальных строк ш и индексов ведущих элементов ps. Все процессы могут выполнить этот шаг параллельно. После инициализации барьер не нужен, поскольку здесь нет разделяемых переменных.
Главный шаг в LU-разложении — многократное повторение выбора ведущего элемента и ведущей строки с последующим исключением всех строк, расположенных ниже ведущей. Каждый рабочий процесс может выбрать наибольший элемент в столбце k своих n/PR строк в матрице lu. Однако для выбора глобального максимума рабочим нужно взаимодействовать. Можно использовать один процесс в качестве управляющего, который собирает максимальные значения от всех процессов, выбирает наибольшее из них и рассылает его копии. Или же, если доступны такие глобальные примитивы взаимодействия, как в библиотеке MPI, то для вычисления ведущего значения можно использовать примитив редукции.
После выбора ведущего значения процесс, которому принадлежит ведущая строка, должен передать ее другим, поскольку она им нужна в фазе исключения. Получив ведущие значение и строку, каждый рабочий процесс может выполнить исключение строк своей области под ведущей строкой.
В листинге 11.14 содержится эскиз программы с передачей сообщений для LU-разложения. Все шаги в программе такие, как описано выше. Явные барьеры здесь не нужны, поскольку обмен сообщениями, необходимый при выборе ведущего значения и ведущей строки, по сути, является барьером. В фазе исключений используется переменная myRow, чтобы отображать глобальный индекс i-й строки (который находится в диапазоне от 1 до п) в индекс соответствующей строки в локальном массиве строк.


Когда программа в листинге 11.14 завершается, результаты LU-разложения размещаются в локальных массивах рабочих процессов. Чтобы решить систему уравнений, нужно выполнить как прямой, так и обратный ход, т.е.
действия, требующие доступа ко всем элементам LU-разложения. Первый подход состоит в использовании процесса, который собирает все строки LU и затем выполняет код из листинга 11.12. При втором используется круговой конвейер, чтобы реализовать синхронизацию фронта волны с помощью передачи сообщений.
В круговом конвейере первый рабочий процесс вычисляет х [ 1 ] и передает его второму. Второй процесс вычисляет х [ 2 ] и передает х [ 2 ] и х [ 1 ] третьему. Последний процесс вычисляет х[ PR] и передает его и все предыдущие значения первому. Это продолжается до тех пор, пока не будет вычислен х [п]. Можно использовать такой же конвейер для обратного хода, вычисляя окончательные значения х[п],х[п-1] и так вплоть до х [ 1 ] и передавая их по конвейеру.
Конвейер для прямого и обратного хода относительно легко программируется, параллелен по существу и не требует сбора всех элементов Ш. Однако ему нужно много сообщений, поэтому вполне вероятно, что он может оказаться менее эффективным, чем алгоритм с одним процессом.
Методы синхронизации
В этом разделе разработаны решения пяти задач: о кольцевых буферах, читателях и писателях, планировании типа "кратчайшее задание", интервальных таймерах и спящем парикмахере. Каждая из задач по-своему интересна и иллюстрирует технику программирования с мониторами.
5.2.1. Кольцевые буферы: базовая условная синхронизация
Вернемся к задаче о кольцевом буфере (см. раздел 4.2). Процесс-производитель и процесс-потребитель взаимодействуют с помощью разделяемого буфера, состоящего из п ячеек. Буфер содержит очередь сообщений. Производитель передает сообщение потребителю, помещая его в конец очереди. Потребитель получает сообщение, извлекая его из начала очереди. Чтобы сообщение нельзя было извлечь из пустой очереди или поместить в заполненный буфер, нужна синхронизация.
В листинге 5.3 приведен монитор, реализующий кольцевой буфер. Для представления очереди сообщений вновь использованы массив buf и две целочисленные переменные front и rear, которые указывают соответственно на первую заполненную и первую пустую ячейку. В целочисленной переменной count хранится количество сообщений в буфере. Операции с буфером deposit и fetch становятся процедурами монитора. Взаимное исключение неявно, поэтому семафорам не нужно защищать критические секции. Условная синхронизация, как показано, реализована с помощью двух условных переменных.
В листинге 5.3 оба оператора wait находятся в циклах. Это безопасный способ обеспечить истинность необходимого условия перед тем, как произойдет обращение к постоянным переменным. Это необходимо также при наличии нескольких производителей и потребителей. (Напомним, что используется порядок "сигнализировать и продолжить".)

Выполняя операцию signal, процесс просто сообщает, что теперь некоторое условие истинно. Поскольку процесс-сигнализатор и, возможно, другие процессы могут выполняться в мониторе до возобновления процесса, запущенного операцией signal, в момент начала его работы условие запуска может уже не выполняться.
Например, процесс-производитель был приостановлен в ожидании свободной ячейки, затем процесс-потребитель извлек сообщение и запустил приостановленный процесс. Однако до того, как этому производителю пришла очередь выполняться, другой процесс-производитель мог уже войти в процедуру deposit и занять пустую ячейку. Аналогичная ситуация может возникнуть и с потребителями. Таким образом, условие приостановки необходимо перепроверять.
Операторы signal в процедурах deposit и fetch выполняются безусловно, поскольку в момент их выполнения условие, о котором они сигнализируют, является истинным. В действительности операторы wait находятся в циклах, поэтому операторы signal могут выполняться в любой момент времени, поскольку они просто дают подсказку приостановленным процессам. Однако программа выполняется более эффективно, когда signal выполняется, только если известно наверняка (или хотя бы с большой вероятностью), что некоторый приостановленный процесс может быть продолжен.
5.2.2. Читатели и писатели: сигнал оповещения
Задача о читателях и писателях была представлена в разделе 4.4. Напомним, что процесс-читатель может только читать записи базы данных, а процесс-писатель просматривает их и изменяет. Читатели могут обращаться к базе данных одновременно, писателям необходим исключительный доступ. Хотя база данных — общий ресурс, ее нельзя представить монитором, поскольку тогда читатели не смогут работать с ней параллельно (весь код внутри монитора выполняется со взаимным исключением). Вместо этого монитор используется для упорядочения доступа к базе данных. Сама база глобальна по отношению к читателям и писателям, она может находиться, например, в разделяемой памяти или во внешнем файле. Как будет показано ниже, такая базовая структура часто применяется в программах, основанных на мониторах.
В задаче о читателях и писателях упорядочивающий монитор дает разрешение на доступ к базе данных. Для этого необходимо, чтобы процессы информировали монитор о своем же-
Глава 5. Мониторы
ланий получить доступ и о завершении работы с базой данных. Есть два типа процессов и по два вида действий на процесс, поэтому получаем четыре процедуры монитора: ге-guest_read, release_read, request_write, release_write. Использование этих процедур очевидно. Например, процесс-читатель перед чтением базы данных должен вызвать .процедуру request_read, а после чтения — release_read.
Для синхронизации доступа к базе данных необходимо вести учет числа записывающих и читающих процессов. Как и раньше, пусть значение переменной nг — это число читателей, a nw — писателей. Это постоянные переменные монитора; при правильной синхронизации они должны удовлетворять инварианту монитора:
RW: (пг == 0 v nw == 0) л nw <= 1
В начальном состоянии пг и nw равны 0. Их значения увеличиваются при вызове процедур запроса и уменьшаются при вызове процедур освобождения.
В листинге 5.4 представлен монитор, соответствующий этой спецификации. Для обеспечения инварианта RWиспользованы циклы while и операторы wait. В начале процедуры request_read процесс-читатель должен приостановиться, пока nw не станет равной 0; эта задержка происходит на условной переменной oktoread. Аналогично процесс-писатель вначале процедуры reguest_write до обнуления переменных пг и nw должен приостановиться на условной переменной oktowrite. В процедуре release_read для процесса-писателя вырабатывается сигнал, когда значение nг равно нулю. Поскольку писатели выполняют перепроверку условия своей задержки, данное решение является правильным, даже если процессы-писатели всегда получают сигнал. Однако это решение будет менее эффективным, поскольку получивший сигнал процесс-писатель при нулевом значении nr должен сно-

178 Часть 1. Программирование с разделяемыми переменными
ва приостановиться. С другой стороны, в конце процедуры release_write точно известно, что значения обеих переменных пг и nw равны нулю. Следовательно, может продолжить работу любой приостановленный процесс.
Решение в листинге 5. 4 не устанавливает порядок чередования процессов-читателей и процессов-писателей. Вместо этого данная программа запускает все приостановленные процессы и позволяет стратегии планирования процессов определить, какой из них первым получит доступ к базе данных. Если это процесс-писатель, то приостановятся все запускаемые процессы-читатели. Если же первым получит доступ процесс-читатель, то приостановится запускаемый процесс-писатель.
5.2.3. Распределение ресурсов по схеме "кратчайшее задание": приоритетное ожидание
Условная переменная по умолчанию является FIFO-очередью, поэтому, выполняя оператор wait, процесс попадает в конец очереди ожидания. Оператор приоритетного ожидания wait (cv, rank) располагает приостановленные процессы в порядке возрастания ранга. Он используется для реализации стратегий планирования, отличных от FIFO. Здесь мы вновь обратимся к задаче распределения ресурсов по схеме "кратчайшее задание", представленной в разделе 4.5.
Для распределения ресурсов по схеме "кратчайшее задание" нужны две операции: request и release. Вызывая процедуру request, процесс либо приостанавливается до освобождения ресурса, либо получает затребованный ресурс. После получения и использования ресурса про-'•цесс вызывает процедуру release. Затем ресурс отдается тому процессу, который будет использовать его самое короткое время. Если ожидающих запросов нет, ресурс освобождается.
В листинге 5.5 представлен монитор, реализующий распределение ресурсов согласно стратегии КЗ. Постоянными переменными являются логическая переменная free для индикации того, что ресурс свободен, и условная переменная turn для приостановки процессов. Вместе они соответствуют инварианту монитора:
SJN: turn упорядочена по времени л (free => turn пуста)
Процедуры в листинге 5.5 используют метод передачи условия. Приоритетный оператор wait применяется для сортировки приостановленных процессов по количеству времени, в течение которого они будут использовать ресурс.
Функция empty используется для проверки, есть ли приостановленные процессы. Когда ресурс освобождается, при наличии приостановленных процессов запускается тот, которому нужно меньше всего времени, иначе ресурс помечается как свободный. Если процесс получает сигнал, то отметки об освобождении ресурса не делается, чтобы другой процесс не получил к нему доступ первым.

Глава 5. Мониторы
free = true; else
signal(turn); }
_}__________________________________________________________________
5.2.4. Интервальный таймер: покрывающие условия
Обратимся к новой задаче — разработке интервального таймера, который позволяет процессу перейти в состояние сна на некоторое количество единиц времени. Такая возможность часто обеспечивается операционными системами, чтобы позволить пользователям, например, периодически выполнять служебные команды. Разработаем два решения, иллюстрирующие два полезных метода. В первом решении использованы так называемые покрывающие условия; во втором (для создания компактного и эффективного механизма задержки) — приоритетный оператор wait.
Монитор, реализующий интервальный таймер, представляет собой еще один пример контроллера ресурсов. Ресурсом являются логические часы. Возможны две операции с часами: delay (interval), которая приостанавливает процесс на отрезок времени длительностью interval "тиков" таймера, и tick, инкрементирующая значение логических часов. Возможны и другие операции, например, получение значения часов или приостановка процесса до момента, когда часы достигнут определенного значения.
Прикладные процессы вызывают операцию delay (interval) с неотрицательным значением interval. Операцию tick вызывает процесс, который периодически запускается аппаратным таймером. Этот процесс обычно имеет большой приоритет выполнения, чтобы значение логических часов оставалось точным.
Для представления значения логических часов используем целочисленную переменную tod (time of day — время дня).
Вначале ее значение равно нулю и удовлетворяет простому инварианту:
CLOCK: tod >= 0 л tod монотонно увеличивается на 1
Вызвав операцию delay, процесс не должен возвращаться из нее, пока часы не "натикают" как минимум interval раз. Абсолютная точность не нужна, поскольку приостановленный процесс не может начать работу до того, как высокоприоритетный процесс, вызывающий tick, сделает это еще раз.
Процесс, вызывающий операцию delay, сначала должен вычислить желаемое время запуска. Это делается с помощью очевидного кода: wake_time = tod + interval;
Здесь переменная wake_time локальна по отношению к телу функции delay; следовательно, каждый процесс, вызывающий delay, вычисляет собственное значение времени запуска. Далее процесс должен ожидать, пока не будет достаточное число раз вызвана процедура tick. Для этого используется цикл while с условием окончания wake_time >= tod. Тело процедуры tick еще проще: она лишь увеличивает значение переменной tod и затем запускает приостановленные процессы.
Остается реализовать синхронизацию между приостановленными процессами и процессом, вызывающим tick. Один из методов состоит в использовании отдельной условной переменной для каждого условия задержки. Приостановленные процессы могут ожидать в течение разных промежутков времени, так что каждому из них нужна собственная (скрытая) условная переменная. Перед задержкой процесс записывает в постоянные переменные время, через которое он должен быть запущен. При вызове операции tick проверяются постоянные переменные, и при необходимости запуска процессов для их скрытых условных переменных вырабатываются сигналы. Описанный подход необходим для некоторых задач, но он более сложен и менее эффективен, чем необходимо для монитора Timer.
180 Часть 1. Программирование с разделяемыми переменными
Требуемую синхронизацию намного проще реализовать, используя одну условную переменную и метод так называемого покрывающего условия. Логическое выражение, связанное с условной переменной, "покрывает" условия запуска всех ожидающих процессов.
Когда какое- либо из покрываемых условий выполняется, запускаются все ожидающие процессы. Каждый такой процесс перепроверяет свое условие и возобновляется или вновь ожидает.
В мониторе Timer можно использовать одну условную переменную check, связанную с покрывающим условием "значение tod увеличено". Процессы ожидают на переменной check в теле функции delay. При каждом вызове процедуры tick запускаются все ожидающие процессы. Соответствующий этому описанию монитор Timer показан в листинге 5.6. В процедуре tick для запуска всех приостановленных процессов использована оповещающая операция signal_all.

Компактное и простое решение, представленное в листинге 5.6, не достаточно эффективно для данной задачи. Применение покрывающих условий подходит только для ситуаций, когда затраты на ложные сигналы (запускается процесс, который определяет, что его условие ложно, и сразу возвращается в состояние ожидания) меньше, чем затраты на обслуживание условий всех ожидающих процессов и запуск только того процесса, для которого условие выполняется. Именно так обычно и бывает (см. упражнения в конце главы), но в данной ситуации вероятно, что процессы задерживаются на длительное время и, следовательно, будут без нужды многократно запускаться.
Используя приоритетный оператор wait, можно преобразовать программу в листинге 5.6 в более простую и эффективную. Для этого используем приоритетный wait везде, где есть статическая упорядоченность условий для различных ожидающих процессов. В данной ситуации ожидающие процессы можно упорядочить по времени их запуска. Вызванная процедура tick использует функцию minrank, чтобы определить, пришло ли время запустить первый процесс, приостановленный на переменной check. Если да, этот процесс получает сигнал. Этим поправкам соответствует новая версия монитора Timer (листинг 5.7). В процедуре delay теперь не нужен цикл while, поскольку tick запускает процесс только при выполнении его условия запуска.
Однако операцию signal в процедуре tick нужно заключить в цикл, поскольку одного и того же времени запуска могут ожидать несколько процессов.
Итак, у нас есть три основных способа реализации условной синхронизации, при которых условия задержки зависят от переменных, локальных для ожидающих процессов. Лучше использовать приоритетное ожидание, поскольку оно дает эффективные и компактные решения, как в листингах 5.7 и 5.5. Этот способ можно применять всегда, когда условия задержки упорядочены статически.

Второй по качеству способ — использовать переменную покрывающего условия. Он также позволяет получить компактное решение, когда у приостановленных процессов есть возможность перепроверять условия своей приостановки. Однако он неприменим, когда условия ожидания процессов зависят от состояний других ожидающих процессов. Использование переменных покрывающего условия приемлемо, пока затраты на ложные сигналы ниже, чем на ведение записей об условиях ожидания в постоянных переменных.
Третий способ — записывать условия ожидания процессов в постоянные переменные и использовать скрытые переменные условий для запуска приостановленных процессов в нужное время. Этот способ приводит к более сложным решениям, но необходим, если первые два способа неприменимы или эффективность второго способа слишком низка. В упражнениях приведены задачи, демонстрирующие преимущества и недостатки всех трех способов.
5.2.5. Спящий парикмахер: рандеву
В качестве последнего базового примера рассмотрим еще одну классическую задачу синхронизации: задачу о спящем парикмахере. У нее колоритное условие, как и у задачи об обедающих философах. Она представляет практические задачи, например планирование работы головки дискового накопителя, описанное в следующем разделе. Эта задача иллюстрирует важность отношений клиент-сервер, которые часто существуют между процессами. Для нее необходим особый тип синхронизации, называемый рандеву. Наконец, она прекрасно демонстрирует необходимость систематического подхода к решению задач синхронизации.
Спе циализированные методы слишком подвержены ошибкам, чтобы использоваться для решения таких сложных задач, как эта.
(5.1) Задача о спящем парикмахере. В тихом городке есть парикмахерская с двумя дверями и несколькими креслами. Посетители входят через одну дверь и выходят через другую. Салон парикмахерской мал, и ходить по нему может только парикмахер и один посетитель. Парикмахер всю жизнь обслуживает посетителей. Когда в салоне никого нет, он спит в своем кресле. Когда посетитель приходит и видит спящего парикмахера, он будит его, садится в кресло и спит, пока тот занят стрижкой. Если парикмахер занят, когда приходит посетитель, тот садится в одно из свободных кресел и засыпает. После стрижки парикмахер открывает посетителю выходную дверь и закрывает ее за ним. Если есть ожидающие посетители, парикмахер будит одного из них и ждет, пока тот сядет в кресло парикмахера. Если никого нет, он снова идет спать до прихода следующего посетителя.
182 Часть 1. Программирование с разделяемыми переменными
Посетители и парикмахер являются процессами, взаимодействующими в мониторе — парикмахерской (рис. 5.2). Посетители — это клиенты, которые запрашивают сервис (стрижку) у парикмахера. Парикмахер — это сервер, постоянно обеспечивающий сервис. Данный тип взаимодействия представляет собой пример отношений клиент-сервер.
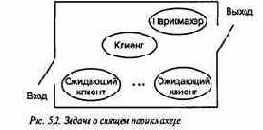
Для реализации описанных взаимодействий парикмахерскую можно промоделировать монитором с тремя процедурами: get_haircut (постричься), get_next_customer (позвать следующего) и f inished_cut (закончить стрижку). Посетители вызывают процедуру get_haircut; выход из нее происходит после того, как парикмахер закончит стрижку данного посетителя. Парикмахер циклически вызывает процедуру get_next_customer, приглашая клиента в свое кресло, стрижет его и выпускает из парикмахерской с помощью вызова процедуры f inished_cut. Постоянные переменные служат для хранения состояния процессов и представления кресел, в которых процессы спят.
Действия парикмахера и посетителей необходимо синхронизировать в мониторе. Во-первых, парикмахеру и посетителю необходима встреча — рандеву, т.е. парикмахер должен дождаться прихода посетителя, а посетитель — освобождения парикмахера. Рандеву аналогично барьеру для двух процессов, поскольку для продолжения работы к нему должны прийти обе стороны. Однако рандеву отличается от двухпроцессного барьера тем, что парикмахер может встретиться с любым из посетителей.
Во-вторых, посетителю необходимо ждать, пока парикмахер закончит его стричь, что определяется открытием выходной двери для посетителя. Наконец, перед тем, как закрыть выходную дверь, парикмахер должен подождать, пока уйдет посетитель. Таким образом, парикмахер и посетитель проходят через последовательность синхронизированных этапов, начинающихся с рандеву.
Самый простой способ определить подобные этапы синхронизации — использовать возрастающие счетчики для запоминания числа процессов, достигших каждого этапа. У посетителей есть два важных этапа: пребывание в кресле парикмахера и выход из парикмахерской. Для этих этапов будем использовать счетчики cinchair и cleave. Парикмахер циклически проходит через три этапа: освобождение от работы, стрижка и завершение стрижки. Используем для них счетчики bavail, bbusy и bdone. Все счетчики в начальном состоянии имеют значение нуль. Поскольку процессы проходят свои этапы последовательно, для счетчиков выполняется следующий инвариант:
Cl: cinchair >= cleave л bavail >= bbusy >= bdone
Чтобы обеспечить рандеву посетителя и парикмахера перед началом стрижки, посетитель не может садиться в кресло парикмахера чаще, чем парикмахер освобождается от работы. Кроме того, парикмахер не может начинать стрижку чаще, чем посетители садятся в его кресло. Итак, выполняется условие:
С2: cinchair <= bavail л bbusy <= cinchair
Наконец, посетители не могут выходить из парикмахерской чаще, чем парикмахер завершает стрижку:
СЗ: cleave <= bdone
Глава 5 Мониторы 183
Инвариант монитора для парикмахерской, таким образом, является конъюнкцией трех предикатов:
BARBER: С1 ^ С2 ^ СЗ
Возрастающие счетчики применимы для запоминания этапов, через которые проходят процессы, однако их значения могут возрастать неограниченно. Если синхронизация зависит только от разницы значений счетчиков, возрастания можно избежать, изменив переменные. В данной задаче есть три ключевые разности, для которых выделим три новые переменные barber, chair и open.
barber == bavail - cinchair chair == cinchair - bbusy open == bdone - cleave
Они инициализируются 0, а во время работы программы могут принимать значения 0 или 1. Значение barber равно 1, если парикмахер ожидает посетителя и сидит в своем кресле. Переменная chair имеет значение 1, если посетитель уже сел в кресло, но парикмахер еще не занят, а переменная open принимает значение 1, когда выходная дверь уже открыта, но посетитель еще не вышел.
Остается использовать эти условные переменные для реализации необходимой синхронизации между парикмахером и посетителями". Существуют четыре условия синхронизации: посетители дожидаются освобождения парикмахера; посетители ждут, когда парикмахер откроет дверь; парикмахер ждет прихода посетителя; парикмахер ждет ухода посетителя. Для представления этих условий нужны четыре условных переменных. Процессы ждут выполнения условий с помощью операторов wait, заключенных в циклы. В моменты, когда условия становятся истинными, процессы выполняют операцию signal.
Полное решение представлено в листинге 5.8. Эта задача значительно сложнее, чем рассмотренные ранее, поэтому имеет более сложное и длинное решение. Однако с помощью систематического подхода удается разделить всю синхронизацию на маленькие части, разработать решение для каждой из них и затем "склеить" решения.

184 Часть 1 Программирование с разделяемыми переменными
В приведенном мониторе мы впервые видим процедуру get_haircut, содержащую два оператора wait. Дело в том, что посетитель проходит через два этапа: сначала он ждет, пока не освободится парикмахер, потом — пока не закончится стрижка.
Модели взаимодействия процессов
_______________________________Глава 9
Модели взаимодействия процессов
Как уже отмечалось, существуют три основные схемы взаимодействия процессов: производитель-потребитель, клиент-сервер и взаимодействующие равные. В главе 7 было показано, как их программировать с помощью передачи сообщений, в главе 8 — с помощью RPC и рандеву.
Эти три основные схемы можно сочетать различными способами. В данной главе описаны некоторые из таких укрупненных схем и проиллюстрировано их использование. Каждая схема является парадигмой (моделью) взаимодействия процессов; она имеет уникальную структуру, которую можно использовать для решения многих задач. В этой главе описаны следующие парадигмы:
• управляющий-рабочие, представляющая собой распределенную реализацию портфеля задач;
• алгоритмы пульсации, в которых процессы периодически обмениваются информацией, используя передачу, а затем прием сообщений;
• конвейерные алгоритмы, пересылающие информацию от одного процесса к другому с помощью приема, а затем передачи;
• зонды (посылки) и эхо (приемы), которые рассылают и собирают информацию в деревьях и графах;
• алгоритмы рассылки, используемые для децентрализованного принятия решений;
• алгоритмы передачи маркера — еще один способ децентрализованного принятия решений;
• дублируемые серверные процессы, которые управляют несколькими экземплярами такого ресурса, как файл.
Первые три парадигмы обычно используются в синхронных параллельных вычислениях, остальные четыре — в распределенных системах. В данной главе показано, как эти парадигмы применяются для решения различных задач, включая умножение разреженных матриц, обработку изображений, распределенное умножение матриц, построение топологии сети, распределенное взаимное исключение, распределенное определение завершения и децентрализованное решение задачи об обедающих философах. Далее, в главе 11, три парадигмы синхронных параллельных вычислений используются для решения научных вычислительных задач. В упражнениях описаны дополнительные приложения, включая задачи сортировки и коммивояжера.
Мониторы
_______________________________Глава 5
Мониторы
Семафоры являются фундаментальным механизмом синхронизации. Как показано в главе 4, их использование облегчает программирование взаимного исключения и сигнализации, причем их можно применять систематически при решении любых задач синхронизации. Однако семафоры — низкоуррвневый механизм; пользуясь ими, легко наделать ошибок. Например, программист должен следить затем, чтобы случайно не пропустить вызовы операций Р и V или задать их больше, чем нужно. Можно неправильно выбрать тип семафора или защитить не все критические секции. Семафоры глобальны по отношению ко всем процессам, поэтому, чтобы разобраться, как используется семафор или другая разделяемая переменная, необходимо просмотреть всю программу. Наконец, при использовании семафоров взаимное исключение и условная синхронизация программируются одной и той же парой примитивов. Из-за этого трудно понять, для чего предназначены конкретные Р и V, не посмотрев на другие операции с данным семафором. Взаимное исключение и условная синхронизация — это разные понятия, потому и программировать их лучше разными способами.
Мониторы — это программные модули, которые обеспечивают большую структурированность, чем семафоры, хотя реализуются так же эффективно. В первую очередь, мониторы являются механизмом абстракции данных. Монитор инкапсулирует представление абстрактного объекта и обеспечивает набор операций, только с помощью которых оно обрабатывается. Монитор содержит переменные, хранящие состояние объекта, и процедуры, реализующие операции над ним. Процесс получает доступ к переменным в мониторе только путем вызова процедур этого монитора. Взаимное исключение обеспечивается неявно тем, что процедуры в одном мониторе не могут выполняться параллельно. Это похоже на неявное взаимное исключение, гарантируемое операторами await. Условная синхронизация в мониторах обеспечивается явно с помощью условных переменных (condition variable).
Они аналогичны семафорам, но имеют существенные отличия в определении и, следовательно, в использовании для сигнализации.
Параллельная программа, использующая мониторы для взаимодействия и синхронизации, содержит два типа модулей: активные процессы и пассивные мониторы. При условии, что все разделяемые переменные находятся внутри мониторов, два процесса взаимодействуют, вызывая процедуры одного и того же монитора. Получаемая модульность имеет два важных преимущества. Первое — процесс, вызывающий процедуру монитора, может не знать о конкретной реализации процедуры; роль играют лишь видимые результаты вызова процедуры. Второе — программист монитора может не заботиться о том, где и как используются процедуры монитора, и свободно изменять его реализацию, не меняя при этом видимых процедур и результатов их работы. Эти преимущества позволяют разрабатывать процессы и мониторы относительно независимо, что облегчает создание и понимание параллельной программы.
В данной главе подробно описаны мониторы и на примерах показано их использование Часть примеров уже встречалась, но есть и новые. В разделе 5.1 определены синтаксис и семантика мониторов. В разделе 5.2 представлен ряд полезных методов программирования и примеров их применения: кольцевые буферы, читатели и писатели, планирование типа "кратчайшая задача", интервальный таймер и классическая задача о спящем парикмахере. В разделе 5.3 взято несколько другое направление — в нем рассматривается структура решений задач параллельного программирования. Для демонстрации различных методов решения используется еще одна интересная задача — планирование доступа к диску с перемещаемыми головками.
Глава 5. Мониторы 169
Благодаря своей полезности и эффективности мониторы применяются в нескольких языках программирования. Примечательно их использование в языке Java, описанное в разделе 5.4.
Лежащие в основе мониторов механизмы синхронизации (неявное исключение и условные переменные для сигнализации) реализованы также в операционной системе Unix. Наконец, условные переменные поддерживаются несколькими библиотеками программирования. В разделе 5.5 описаны соответствующие процедуры библиотеки потоков POSK (Pthreads).
5.1. Синтаксис и семантика
Монитор используется, чтобы сгруппировать представление и реализацию разделяемого ресурса (класса). Он состоит из интерфейса и тела. Интерфейс определяет предоставляемые ресурсом операции (методы). Тело содержит переменные, представляющие состояние ресурса, и процедуры, реализующие операции интерфейса.
В разных языках программирования мониторы объявляются и создаются по-разному. Для простоты будем считать, что монитор является статичным объектом, а его тело и интерфейс описаны таким образом.
monitor raname {
объявления постоянных переменных операторы инициализации процедуры }
Процедуры реализуют видимые операции. Постоянные переменные разделяются всеми процедурами тела монитора. Они называются постоянными, поскольку существуют и сохраняют свое значение, пока существует монитор. В процедурах, как обычно, можно использовать локальные переменные, копии которых создаются для каждого вызова функции.
Монитор как представитель абстрактных типов данных обладает тремя свойствами. Во-первых, вне монитора видны только имена процедур — они представляют собой одно-единственное "окно в стене" объявления монитора. Таким образом, чтобы изменить состояние ресурса, представленное постоянными переменными, процесс должен вызвать одну из процедур монитора. Вызов процедуры монитора имеет следующий вид. call mname.opname(arguments)
Здесь mnаmе — имя монитора, opname — имя одной из его операций (процедур), вызываемой с аргументами arguments. Если имя opname уникально в области видимости вызывающего процедуру процесса, то часть "mname. " в вызове процедуры не обязательна.
Во-вторых, операторы внутри монитора (в объявлениях и процедурах) не могут обращаться к переменным, объявленным вне монитора.
В-третьих, постоянные переменные инициализируются до вызова его процедур. Это реализовано путем выполнения инициализирующих операторов при создании монитора и, следовательно, до вызова его процедур.
Одно из привлекательных свойств монитора, как и любого абстрактного типа данных, — возможность его относительно независимой разработки. Это означает, однако, что программист монитора может не знать заранее порядка вызова процедур. Поэтому полезно определить предикат, истинный независимо от порядка выполнения вызовов. Инвариант монитора — это предикат, определяющий "разумные" состояния постоянных переменных, когда процессы не обращаются к ним. Код инициализации монитора должен создать состояние, соответствующее инварианту, а каждая процедура должна его поддерживать. (Инвариант монитора аналогичен глобальному инварианту, но для переменных в пределах одного монитора.) Инварианты мониторов включены во все примеры главы. Строка инварианта начинается символами ##.
Монитор отличается от механизма абстракции данных в языках последовательного программирования тем, что совместно используется параллельно выполняемыми процессами. По-
170 Часть 1 Программирование с разделяемыми переменными
этому, чтобы избежать взаимного влияния в процессах, выполняемых в мониторах, может потребоваться взаимное исключение, а для приостановки работы до выполнения определенного условия — условная синхронизация. Рассмотрим, как процессы синхронизируются в мониторах.
5.1.1. Взаимное исключение
Синхронизацию проще всего понять и запрограммировать, если взаимное исключение и условная синхронизация выполняются разными способами. Лучше всего, если взаимное исключение происходит неявно, чем автоматически устраняется взаимное влияние. Кроме того, программы легче читать, поскольку в них нет явных протоколов входа в критические секции и выхода из них.
В отличие от взаимного исключения, условную синхронизацию нужно программировать явно, поскольку разные программы требуют различных условий синхронизации.
Хотя зачастую проще синхронизировать с помощью логических условий, как в операторах await, низкоуровневые механизмы можно реализовать намного эффективнее. Они позволяют программисту более точно управлять порядком выполнения программы, что помогает в решении проблем распределения ресурсов и планирования.
В соответствии с этими замечаниями взаимное исключение в мониторах обеспечивается неявно, а условная синхронизация программируется с помощью так называемых условных переменных.
Внешний процесс вызывает процедуру монитора. Пока некоторый процесс выполняет операторы процедуры, она активна. В любой момент времени может быть активным только один экземпляр только одной процедуры монитора, т.е. одновременно не могут быть активными ни два вызова разных процедур, ни два вызова одной и той же процедуры.
Процедуры мониторов по определению выполняются со взаимным исключением. Оно обеспечивается реализацией языка, библиотекой или операционной системой, но не программистом, использующим мониторы. На практике взаимное исключение в языках и библиотеках реализуется с помощью блокировок и семафоров, в однопроцессорных операционных системах — запрета внешних прерываний, а в многопроцессорных операционных системах — межпроцессорных блокировок и запрета прерываний на уровне процессора. В главе 6 подробно описаны вопросы и методы реализации.
5.1.2. Условные переменные
Условная переменная используется для приостановки работы процесса, безопасное выполнение которого невозможно до перехода монитора в состояние, удовлетворяющее некоторому логическому условию. Условные переменные также применяются для запуска приостановленных процессов, когда условие становится истинным. Условная переменная объявляется следующим образом. cond cv;
Таким образом, cond — это новый тип данных. Массив условных переменных объявляется, как обычно, указанием интервала индексов после имени переменной. Условные переменные можно объявлять и использовать только в пределах мониторов.
Значением условной переменной cv является очередь приостановленных процессов (очередь задержки). Вначале она пуста. Программист не может напрямую обращаться к значению переменной cv. Вместо этого он получает косвенный доступ к очереди с помощью нескольких специальных операций, описанных ниже.
Процесс может запросить состояние условной переменной с помощью вызова
empty(cv) ; Если очередь переменной cv пуста, эта функция возвращает значение "истина", иначе — "ложь"
Глава 5. Мониторы 171
Процесс блокируется на условной переменной cv с помощью вызова wait(cv);
Выполнение операции wait заставляет работающий процесс задержаться в конце очереди переменной cv. Чтобы другой процесс мог в конце концов войти в монитор для запуска приостановленного процесса, выполнение операции wait отбирает у процесса, вызвавшего ее, исключительный доступ к монитору.
Процессы, заблокированные на условных переменных, запускаются операторами signal. При выполнении вызова signal(cv);
проверяется очередь задержки переменной cv. Если она пуста, никакие действия не производятся. Однако, если приостановленные процессы есть, оператор signal запускает процесс вначале очереди. Таким образом, операции wait и signal обеспечивают порядок сигнализации FIFO: процессы приостанавливаются в порядке вызовов операции wait, а запускаются в порядке вызовов операции signal. Позже будет показано, как добавить к очереди задержки приоритеты планирования, но по умолчанию принимается порядок FIFO.
5.1.3. Дисциплины сигнализации
Выполняя операцию signal, процесс работает в мониторе и, следовательно, может управлять блокировкой, неявно связанной с монитором. В результате возникает дилемма. Если операция signal запускает другой процесс, то получается, что могли бы выполняться два процесса: вызвавший операцию signal и запущенный ею. Но следующим может выполняться только один из них (даже на мультипроцессорах), поскольку лишь один процесс может иметь исключительный доступ к монитору.
Таким образом, возможны два варианта:
• • сигнализировать и продолжить: сигнализатор продолжает работу, а процесс, получив-
ший сигнал, выполняется позже;
• сигнализировать и ожидать: сигнализатор ждет некоторое время, а процесс, получивший сигнал, выполняется сразу.
Дисциплина (порядок) "сигнализировать и продолжить" не прерывает обслуживания. Процесс, выполняющий операцию signal, сохраняет исключительный доступ к монитору, а запускаемый процесс начнет работу несколько позже, когда получит исключительный доступ к монитору. По существу, операция signal просто указывает запускаемому процессу на возможность выполнения, после чего он возвращается в очередь процессов, ожидающих на блокировке монитора.
Порядок "сигнализировать и ожидать" имеет свойство прерывания обслуживания. Процесс, выполняющий операцию signal, передает управление блокировкой монитора запускаемому процессу, т.е. запускаемый процесс прерывает работу процесса-сигнализатора. В этом случае сигнализатор переходит в очередь процессов, ожидающих на блокировке монитора. (Возможен вариант, когда сигнализатор помещается в начало очереди ожидающих процессов; это называется "сигнализировать и срочно (urgent) ожидать".)
Диаграмма состояний на рис. 5.1 иллюстрирует работу синхронизации в мониторах. Вызывая процедуру монитора, процесс помещается во входную очередь, если в мониторе выполняется еще один процесс; в противном случае вызвавший операцию процесс немедленно начинает выполнение в мониторе. Когда монитор освобождается (после возврата из процедуры или выполнения операции wait), один процесс из входной очереди может перейти к работе в мониторе. Выполняя операцию wait (cv), процесс переходит от работы в мониторе в очередь, связанную с условной переменной. Если процесс выполняет операцию signal (cv), то при порядке "сигнализировать и продолжить" (Signal and Continue — SC) процесс из начала очереди услов-
172 Часть 1 Программирование с разделяемыми переменными
ной переменной переходит во входную. При порядке "сигнализировать и ожидать" (Signal and Wait — SW) процесс, выполняемый в мониторе, переходит во входную очередь, а процесс из начала очереди условной переменной переходит к выполнению в мониторе.
В листинге 5.1 показан монитор, реализующий семафор. Здесь представлены все компоненты монитора, поясняющие различия между порядком выработки сигналов SC и SW. Хотя вряд ли кому-нибудь потребуются мониторы для реализации семафоров, этот пример демонстрирует такую возможность. В главе 6 будет показано, как реализовать мониторы с помощью семафоров. Монитор и семафор дуальны в том смысле, что с помощью одного из них можно реализовать другой, и, следовательно, их можно использовать для решения одних и тех же задач синхронизации. Однако мониторы являются механизмом более высокого уровня, чем семафоры, по причинам, описанным в начале главы.

В листинге 5.1 целочисленная переменная s представляет значение семафора. Вызывая операцию Psem, процесс приостанавливается, пока значение переменной s не станет положительным, затем уменьшает его на 1. Задержка программируется с помощью цикла while, который приводит процесс к ожиданию на условной переменной роз, если s равна 0. Операция Vsem увеличивает s на 1 и вырабатывает сигнал для переменной роз. Если есть приостановленные процессы, запускается "самый старый" из них.
Программа 5.1 корректно работает как при порядке "сигнализировать и ожидать" (SW), так и при "сигнализировать и продолжить" (SC). Под корректностью работы понимается сохранение истинности инварианта семафора s >= 0. Порядки работы отличаются только последовательностью выполнения процессов. Вызывая Psem, процесс ждет, если s равна О, а после запуска уменьшает значение з. Вызывая Vsem, процесс сначала увеличивает s, после чего запускает приостановленный процесс, если такой есть.
При порядке SW запускаемый
Глава 5. Мониторы 173
процесс выполняется сразу и уменьшает значение семафора s. При порядке SC запускаемый процесс выполняется через некоторое время после процесса, выработавшего сигнал. Запускаемый процесс должен перепроверить значение семафора s и убедиться, что оно все еще положительно. Это необходимо сделать, поскольку возможно, что другой процесс из очереди входа до этого вызвал действие Psem и уменьшил s. Таким образом, код в листинге 5.1 обеспечивает последовательность обслуживания FIFO для порядка SW, но не для порядка SC.
Листинг 5.1 демонстрирует еще одно различие между порядками выработки сигналов SW и SC. При порядке SW цикл while в действии Psem можно заменить простым оператором i f: if (s == 0) wait(pos);
При этом процесс, получивший сигнал, сразу начинает работу. Это гарантирует, что значение s положительно, когда данный процесс его уменьшает.
Монитор, показанный в листинге 5.1, можно изменить так, чтобы он корректно работал при обоих порядках запуска процессов (SC и SW), не использовал цикл while и реализовывал семафор с порядком обслуживания FIFO. Чтобы понять, как это сделать, вернемся кпрограмме в листинге 5.1. Когда процесс впервые вызывает операцию Psem, он должен приостановиться, если значение s равно нулю. Вызывая операцию Vsem, процесс собирается запустить приостановленный процесс, если такой есть. Различие между выработкой сигналов в порядке SC и SW состоит в том, что если процесс-сигнализатор продолжает выполняться, то уже увеличенное на единицу значение семафора s может прочитать не тот процесс, который только что был запущен. Избежать этой проблемы можно, если вызывающий операцию Vsem процесс примет следующее решение: если есть приостановленный процесс, то нужно сигнализировать для переменной роз, не увеличивая значение семафора s, иначе увеличить s. Соответственно, если процесс, вызывающий операцию Psem, должен ожидать, то в дальнейшем он не уменьшит s, поскольку к тому времени оно не будет увеличено процессом, выработавшим сигнал.
Монитор, использующий описанный способ, представлен в листинге 5.2. Этот метод на зывается передачей условия, поскольку, по существу, сигнализатор неявно передает значение условия (переменная s положительна) процессу, который он запускает. Условие не делается видимым, поэтому никакой другой процесс, кроме запускаемого операцией signal, не увидит, что условие стало истинным и не прекратит ожидания.

174 Часть 1. Программирование с разделяемыми переменными
ной s в процедуре Psem и ее уменьшение в процедуре Vsem. В разделах 5.2 и 5.3 будут приведены дополнительные примеры с использованием этого метода в решении задач планирования.
Из листингов 5.1 и 5.2 видно, что условные переменные аналогичны операциям Р и V с семафорами. Операция wait, подобно Р, приостанавливает процесс, а операция signal, как и V, запускает его. Однако есть два существенных отличия. Первое — операция wait всегда приостанавливает процесс до последующего выполнения операции signal, тогда как операция Р вызывает остановку процесса, только если текущее значение семафора равно нулю. Второе — операция signal не производит никаких действий, если нет процессов, приостановленных на условной переменной, тогда как V либо запускает приостановленный процесс, либо увеличивает значение семафора, т.е. факт выполнения операции signal не запоминается. Из-за этих отличий условная синхронизация с мониторами программируется не так, как с семафорами.
В оставшейся части данной главы будем предполагать, что мониторы используют порядок "сигнализировать и продолжить". Первым для мониторов был предложен порядок "сигнализировать и ожидать", однако SC был принят в операционной системе Unix, языке программирования Java и библиотеке Pthreads. Порядку SC было отдано предпочтение, поскольку он совместим с планированием процессов на основе приоритетов и имеет более простую формальную семантику. (Эти вопросы обсуждаются в исторической справке.)
5.1.4. Дополнительные операции с условными переменными
До сих пор с условными переменными использовались три операции: empty, wait и signal. Полезны еще три: приоритетная wait, minrank и signal_all. Все они имеют простую семантику и могут быть эффективно реализованы, поскольку обеспечивают лишь дополнительные действия над очередью, связанной с условной переменной. Все шесть операций представлены в табл. 5.1.
Таблица 5.1. Операции над условными переменными
wait(cv) Ждать в конце очереди
waitlcv, rank) Ждать в порядке возрастания значения ранга (rank)
signal (cv) Запустить процесс из начала очереди и продолжить
signal_all (cv) Запустить все процессы очереди и продолжить
empty (cv) Истина, если очередь ожидания пуста, иначе — ложь
minrank (cv) Значение ранга процесса в начале очереди ожидания
С помощью операций wait и signal приостановленные процессы запускаются в том же порядке, в котором они были задержаны, т.е. очередь задержки является FIFO-очередью. Приоритетный оператор wait позволяет программисту влиять на порядок постановки процессов в очередь и их запуска. Оператор имеет вид:
wait(cv, rank)
Параметр cv— это условная переменная, a rank— целочисленное выражение. Процессы приостанавливаются на переменной cv в порядке возрастания значения rank и, следовательно, в этом же порядке запускаются. При равенстве рангов запускается процесс, ожидавший дольше всех. Во избежание потенциальных проблем, связанных с совместным применением обычного и приоритетного операторов wait для одной переменной, программист должен всегда использовать только один тип оператора wait.
Для задач планирования, в которых используется приоритетный оператор wait, часто полезно иметь возможность определить ранг процесса в начале очереди задержки. Из вызова minrank(cv)
175
возвращается ранг приостановки процесса в начале очереди задержки условной переменной cv при условии, что очередь не пуста и для процесса в начале очереди был использован приоритетный оператор wait.
В противном случае возвращается некоторое произвольное целое число. Оповещающая операция signal — последняя с условными переменными. Она используется, если можно возобновить более одного приостановленного процесса или если процесс-сигнализатор не знает, какие из приостановленных процессов могли бы продолжать работу (поскольку им самим нужно перепроверить условия приостановки). Эта операция имеет вид: signal_all(cv)
Выполнение оператора signal_all запускает все процессы, приостановленные на условной переменной cv. При порядке "сигнализировать и продолжить" он аналогичен коду: while (.'empty (cv) ) signal(cv);
Запускаемые процессы возобновляют выполнение в мониторе через некоторое время в соответствии с ограничениями взаимного исключения. Как и оператор signal, оператор sig-nal_al 1 не дает результата, если нет процессов, приостановленных на условной переменной cv. Процесс, выработавший сигнал, также продолжает выполняться в мониторе.
Операция signal_all вполне определена, когда мониторы используют порядок "сигнализировать и продолжить", поскольку процесс, выработавший сигнал, всегда продолжает работать в мониторе. Но при использовании порядка "сигнализировать и ожидать" эта операция определена не точно, поскольку становится возможным передать управление более, чем одному процессу, и дать каждому процессу исключительный доступ к монитору. Это еще одна причина, по которой в операционной системе Unix, языке Java, библиотеке Pthreads иданной книге используется порядок запуска "сигнализировать и продолжить".
Неделимые действия и операторы ожидания
Как упоминалось выше, выполнение параллельной программы можно представить как чередование неделимых действий, выполняемых отдельными процессами. При взаимодействии процессов не все чередования допустимы. Цель синхронизации — предотвратить нежелательные чередования. Это осуществляется путем объединения мелкомодульных неделимых операций в крупномодульные (составные) действия или задержки выполнения процесса до достижения программой состояния, удовлетворяющего некоторому предикату. Первая форма синхронизации называется взаимным исключением; вторая — условной синхронизацией. В данном разделе рассмотрены аспекты неделимых действий и представлена нотация для определения синхронизации.
2.4.1. Мелкомодульная неделимость
Напомним, что неделимое действие выполняет неделимое преобразование состояния. Это значит, что любое промежуточное состояние, которое может возникнуть при выполнении этого действия, не должно быть видимым для других процессов. Мелкомодульное недели-
Глава 2. Процессы и синхронизация 57
мое действие — это действие, реализуемое непосредственно аппаратным обеспечением, на котором выполняется программа.
В последовательной программе неделимыми оказываются операторы присваивания, поскольку при их выполнении нет промежуточных состояний, видимых программе (за исключением, возможно, случаев, когда происходит ошибка, определяемая аппаратным обеспечением). Однако в параллельных программах оператор присваивания не является неделимым действием, поскольку он может быть реализован в виде последовательности мелкомодульных машинных инструкций. В качестве примера рассмотрим следующую программу и предположим, что мелкомодульные неделимые действия — это чтение и запись переменных.
int у = 0, z = 0;
со х = y+z; // у = 1; z = 2; ос;
Если выражение х = y+z реализовано загрузкой значения у в регистр и последующим прибавлением значения z, то конечными значениями переменной х могут быть 0,1,2 или 3.
Это про исходит потому, что мы можем получить как начальные значения у и z, так и их конечные значения или некоторую комбинацию, в зависимости от степени выполнения второго процесса. Еще одна особенность приведенной программы в том, что конечным значением х может быть и 2, хотя невозможно остановить программу и увидеть состояние, в котором сумма y+z имеет значение 2. Предполагается, что машины обладают следующими характеристиками.
• Значения базовых типов (например int) хранятся в элементах памяти (например словах), которые считываются и записываются неделимыми операциями.
• Значения обрабатываются так: их помещают в регистры, там к ним применяют операции и затем записывают результаты обратно в память.
• Каждый процесс имеет собственный набор регистров. Это реализуется или путем предоставления каждому процессу отдельного набора регистров, или путем сохранения и восстановления значений регистров при выполнении различных процессов. (Это называется переключением контекста, поскольку регистры образуют контекст выполнения процесса.)
• Любые промежуточные результаты, появляющиеся при вычислении сложных выражений, сохраняются в регистрах или областях памяти, принадлежащих исполняемому процессу, например, в его стеке.
В этой модели машины, если выражение е в одном процессе не обращается к переменной, измененной другим процессом, вычисление выражения всегда будет неделимой операцией, даже если для этого необходимо выполнить несколько мелкомодульных действий. Это происходит потому, что при вычислении выражения е ни одно значение, от которого зависит е, не изменяет своего значения, и ни один процесс не может видеть временные значения, которые создаются при вычислении выражения. Аналогично, если присваивание х = е в одном процессе не ссылается на переменные, изменяемые другим процессом (например, ссылается только на локальные переменные), то выполнение присваивания будет неделимой операцией.
К сожалению, многие операторы в параллельных программах, ссылающиеся на разделяемые переменные, не удовлетворяют этим условиям непересекаемости.
Однако часто выполняются более мягкие условия.
(2.2) Условие "не больше одного". Критической ссылкой в выражении называется ссылка на переменную, изменяемую другим процессом. Предположим, что любая критическая ссылка — это ссылка на простую переменную, которая хранится в элементе памяти и может быть считана и записана автоматически. Оператор присваивания х = е удовлетворяет условию "не больше одного", если либо выражение е содержит не больше одной критической ссылки, а переменная х не считывается другим процессом, либо выражение е не содержит критических ссылок, а другие процессы могут считывать переменную х.
58 Часть 1 Программирование с разделяемыми переменными
Это условие называется "не больше одного", поскольку в таком случае возможна только одна разделяемая переменная, и на нее ссылаются не более одного раза. Аналогичное определение применяется к выражениям, которые не являются операторами присваивания. Такое выражение удовлетворяет условию "не больше одного", если содержит не более одной критической ссылки.
Если оператор присваивания удовлетворяет требованиям условия "не больше одного", то выполнение оператора присваивания будет казаться неделимой операцией, поскольку одна-единственная разделяемая переменная в выражении будет записываться или считываться только один раз. Например, если выражение е не содержит критических ссылок, а переменная х — простая переменная, читаемая другими процессами, то они не могут распознать, вычисляется ли выражение неделимым образом. Аналогично, если е содержит одну критическую ссылку, то процесс, выполняющий присваивание, не сможет различить, каким образом изменяется значение переменной; он увидит только некоторое конечное значение.
Чтобы пояснить определение условия "не больше одного", приведем несколько примеров. В следующей программе оба присваивания удовлетворяют этому условию. int х = О, у = 0; со х = х+1; // у = у+1; ос;
Здесь нет критических ссылок ни в один процесс, поэтому конечным значением и х, и у будет 1. Оба присваивания в следующей программе также удовлетворяют условию. int х = 0, у = 0; со х = у+1; // у = у+1; ос;
•Первый процесс ссылается на у (одна критическая ссылка), но переменная х не читается вторым процессом, и во втором процессе нет критических ссылок. Конечным значением переменной х будет или 1, или 2, а конечным значением у — 1. Первый процесс увидит переменную у или перед ее увеличением, или после, но в параллельной программе он никогда не знает, какое из значений он видит, поскольку порядок выполнения программы недетерминирован.
В следующем примере ни одно присваивание не соответствует требованию "не больше одного".
int х = 0, у = 0;
со х = у+1; // у = х+1; ос;
Выражение в каждом процессе содержит критическую ссылку, и каждый процесс присваивает значение переменной, считываемой другим процессом. Действительно, конечными значениями переменных х и у могут быть 1 и 2, 2 и 1, или даже 1 и 1 (если процессы считывают значения переменных х и у до присвоения им значений). Однако, поскольку каждое присваивание ссылается только один раз и только на одну переменную, изменяемую другим процессом, конечными будут те значения, которые действительно существовали в некотором состоянии. Это отличается от примера, приведенного ранее, в котором выражение y+z ссылалось на две переменные, изменяемые другим процессом.
2.4.2. Задание синхронизации: оператор ожидания
Возможно, выражение или оператор присваивания не удовлетворяет условию "не больше одного", однако необходимо выполнить его как неделимое. В более общем случае в одном неделимом действии необходимо выполнить последовательность операторов. В любом случае нужен механизм синхронизации, позволяющий задать крупномодульное неделимое действие, — последовательность мелкомодульных неделимых операций, которая выглядит как неделимая.
В качестве конкретного примера представим, что база данных содержит два значения х и у, которые всегда должны быть одинаковы в том смысле, что ни один процесс, использующий базу данных, не должен видеть состояния, в котором х и у различаются. Следовательно, если процесс изменяет х, он должен изменить и у в том же самом неделимом действии.
Еще один пример: пусть один процесс вставляет элементы в очередь, представленную связанным списком. Другой процесс удаляет элементы из списка при условии, что они там есть.
Глава 2. Процессы и синхронизация 59
Одна переменная указывает на начало списка, а другая — на его конец. Вставка и удаление элементов требуют обработки двух значений. Например, для вставки элемента нужно изменить ссылку в предыдущем элементе и указатель конца списка так, чтобы они указывали на новый элемент. Если в списке содержится только один элемент, одновременные вставка и удаление могут вызвать конфликт и привести список к непригодному для использования состоянию. Таким образом, вставка и удаление элемента должны быть неделимыми действиями. К тому же, если список пуст, необходимо отложить выполнение операции удаления до того, как в список будет вставлен элемент.
Неделимые действия задаются с помощью угловых скобок (и}. Например, <е) указывает, что выражение е должно быть вычислено неделимым образом.
Синхронизация определяется с помощью оператора await:
(2.3) (await (В) S;>
Булево выражение В задает условие задержки (delay condition), as— это список последовательных операторов, завершение которых гарантированно (например, последовательность операторов присваивания). Оператор await заключен в угловые скобки для указания, что он выполняется как неделимое действие. В частности, выражение В гарантированно имеет значение "истина"6, когда начинается выполнение S, и ни одно.промежуточное состояние в s не видно другим процессам.
Например, выполнение кода
(await (s > 0) s = s-1;)
откладывается до момента, когда значение s станет положительным, а затем оно уменьшается на 1. Гарантируется, что перед вычитанием значение s положительно.
Оператор await является очень мощным, поскольку может быть использован для определения любых крупномодульных неделимых действий. Это делает его удобным для выражения синхронизации, поэтому будем использовать оператор await для разработки первоначальных решений задач синхронизации. Вместе с тем, выразительная мощность оператора await делает очень дорогой его реализацию в общей форме. Однако, как показано в этой и нескольких последующих главах, существует множество частных случаев оператора await, допускающих эффективную реализацию. Например, последний приведенный выше оператор await является частным случаем операции Р над семафором s (см. главу 4).
Общая форма оператора await определяет как взаимное исключение, так и синхронизацию по условию. Для определения только взаимного исключения можно использовать сокращенную форму оператора await:
<S;>
Например, в следующем операторе значения х и у увеличиваются в неделимом действии: (х = х+1; у * у+1;>
Промежуточное состояние, в котором х была увеличена на единицу, а у — еще нет, по определению не будет видимым для других процессов, ссылающихся на переменные х или у. Если последовательность s — это одиночный оператор присваивания, удовлетворяющий условию (2.2) "не больше одного", или если последовательность s реализована одной машинной инструкцией, то s будет выполнена как неделимая; таким образом, (S;) имеет тот же эффект, что и S. Для задания только условной синхронизации сократим оператор await так:
(await (B);>
Например, следующим оператором выполнение процесса откладывается до момента, когда значение переменной count станет положительным.
(await (count > 0);) 6 Условие задержки лучше было бы называть условием окончания задержки. — Прим.
ред.
60 Часть 1. Программирование с разделяемыми переменными
Если выражение в удовлетворяет условию "не больше одного", как в данном примере, то выражение (await (В) ;) может быть реализовано как
while (not В);
Это пример так называемого цикла ожидания (spin loop). Тело оператора while пусто, поэтому он просто зацикливается до тех пор, когда значением в станет "ложь".
Безусловное неделимое действие — это действие, которое не содержит в теле условия задержки в. Такое действие может быть выполнено немедленно, конечно, в соответствии с требованием неделимости его выполнения. Аппаратно реализуемые (мелкомодульные) действия, выражения в угловых скобках и операторы await, в которых условие опущено или является константой "истина", являются безусловными неделимыми действиями.
Условное неделимое действие — это оператор await с условием В. Такое действие не может быть выполнено, пока условие в не станет истинным. Если в ложно, оно может стать истинным только в результате действий других процессов. Таким образом, процесс, ожидающий выполнения условного неделимого действия, может оказаться задержанным непредсказуемо долго.
Нотация совместно используемых примитивов
При использовании RPC и рандеву процесс инициирует взаимодействие, выполняя оператор call, который блокирует вызвавший процесс до того, как вызов будет обслужен и результаты возвращены. Такая последовательность действий идеальна для программирования взаимодействий типа "клиент-сервер", но, как видно из двух последних разделов, усложняет программирование фильтров и взаимодействующих равных. С другой стороны, односторонний поток информации между фильтрами и равными процессами легче программировать с помощью асинхронной передачи сообщений.
В данном разделе описана программная нотация, которая объединяет RPC, рандеву и асинхронную передачу сообщений в единое целое. Такая составная нотация (нотация совместно используемых примитивов) сочетает преимущества всех трех ее компонентов и обеспечивает дополнительные возможности.
8.3.1. Вызов и обслуживание операций
По своей структуре программа будет набором модулей. Видимые операции объявляются в области определений модуля. Эти операции могут вызываться процессами из других модулей, а обслуживаются процессом или процедурой модуля, в котором объявлены. Могут использоваться также локальные операции, которые объявляются, вызываются и обслу-•• живаются в теле одного модуля.
В составной нотации операция может быть вызвана либо синхронным оператором call, либо асинхронным send. Они имеют следующий вид.
' call Mname. opname (аргументы) ;
send Mname.opname (аргументы);
Оператор call завершается, когда операция обслужена и возвращены результирующие аргументы, а оператор send — как только вычислены аргументы. Если операция возвращает результат, ее можно вызывать в выражении; ключевое слово call опускается. Если операция имеет результирующие параметры и вызывается оператором send, или функция вызывается оператором send, или вызов функции находится не в выражении, то возвращаемое значение игнорируется.
В составной нотации операция может быть обслужена либо в процедуре (ргос), либо с помощью рандеву (операторы in).
Выбор — за программистом, который объявляет операцию в модуле. Это зависит от того, нужен ли программисту новый процесс для обслуживания вызова, или удобнее использовать рандеву с существующим процессом. Преимущества и недостатки каждого способа демонстрируются в дальнейших примерах.
Когда операцию обслуживает процедура (ргос), для обработки вызова создается новый ' процесс. Вызов операции даст тот же результат, что и при использовании RPC. Если операция вызвана оператором send, результат будет тем же, что и при создании нового процесса, поскольку вызвавший операцию процесс продолжается асинхронно по отношению к процессу, обслуживающему вызов. В обоих случаях вызов обслуживается немедленно, и очереди ожидающих обработки вызовов нет.
Другой способ обслуживания операций состоит в использовании операторов ввода, которые имеют вид, указанный в разделе 8.2. С каждой операцией связана очередь ожидающих обработки вызовов, и доступ к этой очереди является неделимым. Выбор операции для обслуживания происходит в соответствии с семантикой операторов ввода. При вызове такой операции процесс приостанавливается, поэтому результат аналогичен использованию рандеву. Если такую операцию вызвать с помощью оператора send, результат будет аналогичным использованию асинхронной передачи сообщений, поскольку отправитель сообщения продолжает работу.
Итак, есть два способа вызова операции (операторы call и send) и два способа обслуживания вызова — ргос и in. Эти четыре комбинации приводят к таким результатам.
Глава 8 Удаленный вызов процедур и рандеву 299
Вызов Обслуживание Результат
call proc Вызов процедуры
call in Рандеву
send proc Динамическое создание процесса
send in Асинхронная передача сообщения
Если вызывающий процесс и процедура proc находятся в одном модуле, то вызов является локальным, иначе — удаленным. Операцию нельзя обслуживать как с помощью proc, так и в операторе in, поскольку тогда возникает неопределенность — обслужить операцию немедленно или поместить в очередь. Но операцию можно обслуживать в нескольких операторах ввода; они могут находиться в нескольких процессах модуля, в котором объявлена операция. В этом случае процессы совместно используют очередь ожидающих вызовов, но доступ к ней является неделимым.
Для мониторов и асинхронной передачи сообщений был определен примитив empty, который проверяет, есть ли объекты в канале сообщений или очереди условной переменной. В этой главе будет использован аналогичный, но несколько отличающийся примитив. Если opname является операцией, то ?opname — это функция, которая возвращает число ожидающих вызовов этой операции. Эту функцию удобно использовать в операторах ввода. Например, в следующем фрагменте кода операция ор1 имеет приоритет перед операцией ор2.
in opl(...) -> SI;
[] ор2(...) and ?opl == 0 -> S2;
_
Условие синхронизации во второй защите разрешает выбор операции ор2, только если при вычислении ?opl определено, что вызовов операции opl нет.
8.3.2. Примеры
Различные способы вызова и обслуживания операций проиллюстрируем тремя небольшими, тесно связанными примерами. Вначале рассмотрим реализацию очереди (листинг 8.11). Когда вызывается операция deposit, Bbuf помещается новый элемент. Если deposit вызвана оператором call, то вызывающий процесс ждет; если deposit вызвана оператором send, то вызывающий процесс продолжает работу (в этом случае процессу, вызывающему операцию, возможно, стоило бы убедиться, не переполнен ли буфер). Когда вызывается операция fetch, из массива buf извлекается элемент. Ее необходимо вызывать оператором call, иначе вызывающий процесс не получит результат.
Модуль Queue пригоден для использования одним процессом в другом модуле. Его не могут совместно использовать несколько процессов, поскольку в модуле нет критических секций для защиты переменных модуля. При параллельном вызове операций может возникнуть взаимное влияние.
Если нужна синхронизированная очередь, модуль Queue можно изменить так, чтобы он реализовывал кольцевой буфер. В листинге 8.5 был представлен именно такой модуль. Видимые операции в этом модуле те же, что и в модуле Queue. Но их вызовы обслуживаются оператором ввода в одном процессе, т.е. по одному. Операция fetch должна вызываться оператором call, однако для операции deposit вполне можно использовать оператор send.
Модули в листингах 8.5 и 8.11 демонстрируют два разных способа реализации одного итого же интерфейса. Выбор определяется программистом и зависит от того, как именно используется очередь. Но есть еще один способ реализации кольцевого буфера, иллюстрирующий еще одно сочетание различных способов вызова и обслуживания операций в нотации совместно используемых примитивов.

Поскольку оператор receive является просто сокращенной формой оператора in, будем использовать receive, когда нужно обработать вызов именно таким образом.
Теперь рассмотрим операцию, которая не имеет аргументов, вызывается оператором send и обслуживается оператором receive (или эквивалентным in). Такая операция эквивалентна семафору, причем send выступает в качестве V, a receive — Р. Начальное значение семафора равно нулю. Его текущее значение — это число "пустых" сообщений, переданных операции, минус число полученных сообщений.
В листинге 8.12 представлена еще одна реализация модуля BoundedBuf f er, в которой для синхронизации использованы семафоры. Операции deposit и fetch обслуживаются процедурами так же, как в листинге 8.11. Следовательно, одновременно может существовать несколько активных экземпляров этих процедур. Однако для реализации взаимного исключения и условной синхронизации в этой программе используются семафорные операции, как в листинге 4.5.
Структура этого модуля аналогична структуре монитора (см. листинг 5.3), но синхронизация реализована с помощью семафоров, а не исключений монитора и условных переменных.

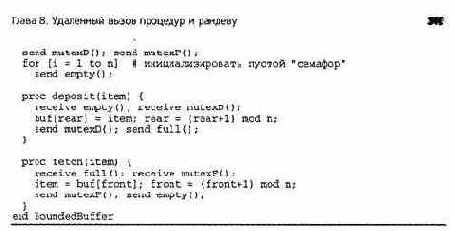
Две реализации кольцевого буфера (см. листинги 8.5 и 8.11) иллюстрируют важную взаимосвязь между условиями синхронизации в операторах ввода и явной синхронизацией в процедурах. Во-первых, их часто используют с одинаковой целью. Во-вторых, поскольку условия синхронизации операторов ввода могут зависеть от аргументов ожидающих вызовов, эти два метода синхронизации обладают равной мощью. Но пока не нужна параллельность, которую обеспечивают несколько вызовов процедур, эффективнее использовать рандеву клиентов с одним процессом.
Новые решения задачи о читателях и писателях
С применением нотации совместно используемых примитивов можно программировать фильтры и взаимодействующие равные так же, как в главе 7. Поскольку эта нотация включает и RPC, и рандеву, можно программировать процессы-клиенты и процессы-серверы, как в разделах 8.1 и 8.2. Совместно используемые примитивы обеспечивают дополнительную гибкость, которая демонстрируется здесь. Сначала разработаем еще одно решение задачи о читателях и писателях (см. раздел 4.4). В отличие от предыдущих решений, здесь инкапсулирован доступ к базе данных. Затем расширим решение до распределенной реализации дублируемых файлов или баз данных. Обсудим также, как можно программировать эти решения, используя только RPC и локальную синхронизацию или только рандеву.
8.4.1. Инкапсулированный доступ
Напомним, что в задаче о читателях и писателях читательские процессы просматривают базу данных, возможно, параллельно. Процессы-писатели могут изменять базу данных, поэтому им нужен исключающий доступ к базе данных. В предыдущих решениях (с помощью семафоров в листингах 4.9 и 4.12 или с помощью мониторов в листинге 5.4) база данных была глобальной по отношению к процессам читателей и писателей, чтобы читатели могли обращаться к ней параллельно. При этом процессы должны были перед доступом к базе данных запрашивать разрешение, а после работы с ней освобождать доступ. Намного лучше инкапсулировать доступ к базе данных в модуле, чтобы спрятать протоколы запроса и освобождения, тем самым гарантируя их выполнение. Такой подход поддерживается в языке Java (это показано в конце раздела 5.4), поскольку программист может выбирать, будут методы (экспортируемые операции) выполняться параллельно или по одному. При использовании составной нотации решение можно структурировать аналогичным образом, причем полученное решение будет еще короче, а синхронизация — яснее.
302 Часть 2. Распределенное программирование
В листинге 8. 13 представлен модуль, инкапсулирующий доступ к базе данных. Клиентские процессы просто вызывают операции read или write, а вся синхронизация скрыта внутри модуля. В реализации модуля использованы и RPC, и рандеву. Операция read реализована в виде ргос, поэтому несколько процессов-читателей могут выполняться параллельно, но операция write реализована на основе рандеву с процессом Writer, поэтому операции записи обслуживаются по очереди. Модуль также содержит две локальные операции, star tread и endread, которые используются, чтобы обеспечить взаимное исключение операций чтения и записи. Их также обслуживает процесс Writer, поэтому он может отслеживать количество активных процессов-читателей и при необходимости откладывать выполнение операции write. Благодаря использованию рандеву в процессе Writer ограничения синхронизации выражаются непосредственно в виде логических условий, без обращений к условным переменным или семафорам. Отметим, что локальная операция endread вызывается оператором send, а не call, поскольку процесс-читатель не обязан ждать завершения обслуживания endread.

В языке, поддерживающем RPC, но не рандеву, этот модуль пришлось бы запрограммировать иначе. Например, обе операции read и write должны быть реализованы как экспортируемые процедуры, которые в свою очередь должны вызывать локальные процедуры для запроса разрешения на доступ к базе данных и для освобождения доступа. Внутренняя синхронизация должна обеспечиваться семафорами или мониторами.
Хуже, если язык поддерживает только рандеву. Операции обслуживаются существующими процессами, и каждый процесс может обслуживать одновременно только одну операцию. Таким образом, есть только один способ обеспечить параллельное чтение базы данных — экспортировать массив операций чтения, по одной для каждого клиента, и для их обслуживания использовать отдельные процессы. Такое решение по меньшей мере неуклюже и неэффективно.
Решение в листинге 8.13 отдает предпочтение читателям.
Приоритет писателям можно дать, изменив оператор ввода с помощью функции ? для приостановки вызовов операции startread, когда есть задержанные вызовы операции write.

газраоотка решения со справедливым планированием оставляется читателю.
Модуль в листинге 8.13 блокирует для читателей или для писателей всю базу данных. Обычно этого достаточно для небольших файлов данных. Однако для транзакций в базах данных обычно нужно блокировать отдельные записи по мере их обработки, поскольку заранее не известно, какие конкретно записи понадобятся в транзакции. Например, транзакции нужно просмотреть некоторые записи, чтобы определить, какие именно считывать далее. Для реализации такого вида динамической блокировки можно использовать много модулей, по одному на каждую запись. Но тогда не будет инкапсулирован доступ к базе данных. Вместо этого в модуле ReadersWriters можно применить более сложную схему блокировки с мелкомодульной структурой. Например, выделять необходимые блокировки для каждой операции read и write. Именно этот подход типичен для систем управления базами данных.
8.4.2. Дублируемые файлы
Простой способ повысить доступность файла с критическими данными — хранить его резервную копию на другом диске, обычно расположенном на другой машине. Пользователь может делать это вручную, периодически копируя файлы, либо файловая система будет автоматически поддерживать копию таких файлов. В любом случае при необходимости доступа к файлу пользователь должен сначала проверить доступность основной копии файла и, если она недоступна, использовать резервную копию. (С этой задачей связана проблема обновления основной копии, когда она вновь становится доступной.)
Третий подход состоит в том, что файловая система обеспечивает прозрачное копирование. Предположим, что есть п копий файла данных и n серверных модулей. Каждый сервер обеспечивает доступ к одной копии файла. Клиент взаимодействует с одним из серверных модулей, например, с тем, который выполняется на одном процессоре с клиентом.
Серверы взаимодействуют между собой, создавая у клиентов иллюзию работы с файлом. На рис. 8.1 показана структура такой схемы взаимодействия.
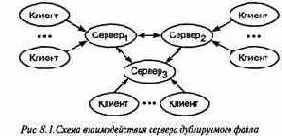
Каждый модуль сервера экспортирует четыре операции: open, close, read и write. Желая обратиться к файлу, клиент вызывает операцию open своего сервера с указанием, собирается он записывать в файл или читать из него. Затем клиент общается с тем же сервером, вызывая операции read и write. Если файл был открыт для чтения, можно использовать только операции read, а если для записи — и read, и write. В конце концов клиент заканчивает диалог, вызвав операцию close. (Эта схема взаимодействия совпадает с приведенной в конце раздела 7.3.)
Файловые серверы взаимодействуют, чтобы поддерживать согласованность копий файла и не давать делать записи в файл одновременно нескольким процессам. В каждом файловом
304 , Часть 2. Распределенное программирование
сервере есть локальный процесс-диспетчер блокировок, реализующий решение задачи о читателях и писателях. Когда клиент открывает файл для чтения, операция open вызывает операцию s tar tread локального диспетчера блокировок. Но когда клиентский процесс открывает файл для записи, операция open вызывает startwrite для всех n диспетчеров блокировок.
В листинге 8.14 представлен модуль FileServer. Для простоты использован массив и статическое именование, хотя на практике серверы должны создаваться динамически и размещаться на разных процессорах. Так или иначе, в реализации этого модуля есть несколько интересных аспектов.


• каждый модуль Fiieserver экспортирует два наоора операции: вызываемые его клиентами и вызываемые другими файловыми серверами. Операции open, close, read и write реализованы процедурами, но read— единственная, которая должна быть реализована процедурой, чтобы допустить параллельное чтение. Операции блокировки реализованы с помощью рандеву с диспетчером блокировок.
• Каждый модуль следит за текущим режимом доступа (каким образом файл был открыт последний раз), чтобы не разрешать записывать в файл, открытый для чтения, и определять, какие действия нужно выполнить при закрытии файла.
Но модуль не защищен от клиента, получившего доступ к файлу, предварительно не открыв его. Эту проблему можно решить с помощью динамического именования или дополнительных проверок в других операциях.
• В процедуре write модуль сначала обновляет свою локальную копию файла, а затем параллельно обновляет все удаленные копии. Это аналогично использованию стратегии сквозного обновления кэш-памяти. Вместо этого можно использовать стратегию с обратной записью, при которой операция write обновляет только локальную копию, а удаленные копии файла обновляются при его закрытии.
• В операции open клиент получает блокировки записи, по одной от каждого блокирующего процесса. Чтобы не возникла взаимоблокировка клиентов, все клиенты получают блокировку в одном и том же порядке. В операции close клиент освобождает блокировки записи с помощью оператора send, а не call, поскольку процессу не нужно ждать освобождения блокировок.
• Диспетчер блокировок реализует решение задачи о читателях и писателях с классическим предпочтением для читателей. Это активный монитор, поэтому инвариант его цикла тот же, что инвариант монитора в листинге 5.4.
В программе в листинге 8.14 читатель для чтения файла должен получить только одну блокировку чтения. Писатель же должен получить все n блокировок записи, по одной от каждого экземпляра модуля FileServer. В обобщении этой схемы нужно использовать так называемое взвешенное голосование.
Пусть readWeight — это число блокировок, необходимых для чтения файла, awriteWeight — для записи в файл. В нашем примере readWeight равно 1, awriteWeight — п. Можно было бы использовать другие значения — для readWeight значение 2, а для writeWeight — n-2. Это означало бы, что читатель должен получить две блокировки чтения и п-2 блокировок записи. Можно использовать любые весовые значения, лишь бы выполнялись следующие условия.
writeWeight > n/2 и (readWeight + writeWeight) > n
306 Часть 2.Распределенное программирование
При использовании взвешенного голосования, когда писатель закрывает файл, нужно обновить только копии, заблокированные для записи. Но каждая копия должна иметь метку времени последней записи в файл. Первое указанное выше требование гарантирует, что самые свежие данные и последние метки времени будут по меньшей мере у половины копий. (Как реализовать глобальные часы и метки времени последнего доступа к файлам, описывается в разделе 9.4.)
Открывая файл и получая блокировки чтения, читатель также должен прочитать метки времени последних изменений в каждой копии файла и использовать копию с самой последней меткой. Второе из указанных выше требований гарантирует, что будет хотя бы одна копия с самым последним временем изменений и, следовательно, с самыми последними данными. В нашей программе в листинге 8.14 не нужно было заботиться о метках времени, поскольку при закрытии файла обновлялись все его копии.
Обзор аксиоматической семантики
В конце раздела 2.1 было описано, как утвердительные рассуждения позволяют понять свойства параллельной программы. Но, что еще важнее, они могут помочь в разработке правильных программ. Поэтому утвердительные рассуждения будут интенсивно использоваться в оставшейся части книги. В этом и следующих двух разделах представлена формальная база для них. В дальнейших главах эти понятия будут использоваться неформально.
Основой для утвердительных рассуждений является так называемая логика программирования — формальная логическая система, которая обеспечивает порождение точных утверждений о выполнении программы. В этом разделе представлены основные понятия данной темы. В исторической справке указаны источники более подробной информации, включающей много различных примеров.
2.6.1. Формальные логические системы
Любая формальная логическая система состоит из правил, определенных в терминах следующих множеств:
• символов',
• формул, построенных из этих символов;
• выделенных формул, называемых аксиомами;
• правил вывода.
Формулами являются правильно построенные последовательности символов. Аксиомы — это особые формулы, которые априори предполагаются истинными. Правила вывода определяют, как получить истинные формулы из аксиом и других истинных формул. Правила вывода имеют вид
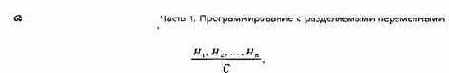
Каждая Я является гипотезой, С — заключением. Значение правила вывода состоит в том, что если все гипотезы истинны, то и заключение истинно. И гипотезы, и заключение являются формулами или их схематическим представлением.
Доказательство в формальной логической системе — это последовательность строк, каждая из которых является аксиомой или может быть получена из предыдущих строк путем применения к ним правила вывода. Теорема — это любая строка в доказательстве. Таким образом, теоремы либо являются аксиомами, либо получены с помощью применения правил вывода к другим теоремам.
Сама по себе формальная логическая система является математической абстракцией — набором символов и отношений между ними.
Логическая система становится интересной, когда формулы представляют утверждения о некоторой обсуждаемой области, а формулы, являющиеся теоремами, — истинные утверждения. Для этого нужно обеспечить интерпретацию формулы.
Интерпретация логики отображает каждую формулу в ложь или истину. Логика является непротиворечивой относительно интерпретации, если непротиворечивы все ее аксиомы и правила вывода. Аксиома непротиворечива, если она отображается в истину. Правило вывода непротиворечиво, если его следствие отображается в истину, при условии, что все его гипотезы отображаются в истину. Следовательно, если логика непротиворечива, то все теоремы являются истинными утверждениями в данной рассматриваемой области. В таком случае ин-'* терпретация называется моделью логики.
Понятие полноты дуально понятию непротиворечивости. Логика является полной относительно интерпретации, если формула, отображаемая в истину, является теоремой, т.е. в данной логике доказуема любая (истинная) формула. Таким образом, если ФАКТЫ— это множество истинных утверждений, выразимых формулами логики, а ТЕОРЕМЫ— множество теорем логики, то непротиворечивость означает, что ТЕОРЕМЫ ФАКТЫ, а полнота— ФАКТЫ с, ТЕОРЕМЫ. Полная и непротиворечивая логика позволяет доказать все ее истинные утверждения.
Как доказал немецкий математик Курт Гедель в своей знаменитой теореме о неполноте, любая логика, которая включает арифметику, не может быть полной. Однако логика, которая расширяет другую логику, может быть относительно полной. Это значит, что она не добавляет неполноту к той, которая присуща расширяемой логике. К счастью, относительной полноты вполне достаточно для логики программирования, представленной здесь, поскольку используемые свойства арифметики безусловно истинны.
2.6.2. Логика программирования
Логика программирования (ЛП) является формальной логической системой, которая позволяет устанавливать и обосновываты(доказывать) свойства программ.
Как и в любой формальной логической системе, в ЛП есть символы, формулы, аксиомы и правила вывода.
Символы ЛП— это предикаты, фигурные скобки и операторы языка программирования. Формулы в Ж? называются тройками. Они имеют вид7 (Р> S {Q}.
Предикаты р и Q определяют отношения между значениями переменных программы; S — это оператор или список операторов.
7 Предикаты в тройках заключаются в фигурные скобки, поскольку это традиционный способ их записи в логиках программирования Однако такие скобки используются в нашей программной нотации и для выделения последовательностей операторов. Во избежание возможных недоразумений предикаты в программе будут записываться с помощью символов ##. Напомним, что одиночный символ # используется для однострочного комментария, т.е. предикат можно рассматривать как предельно точный и четкий комментарий.
Глава 2. Процессы и синхронизация 63
Цель логики программирования состоит в том, чтобы обеспечить возможность обосновывать (доказывать) свойства выполнения программы. Следовательно, интерпретация тройки характеризует отношение между предикатами {Р} и {Q} и списком операторов S.
(2.4) Интерпретация тройки. Тройка {Р} S {Q} истинна при условии, что если выполнение S начинается в состоянии, удовлетворяющем Р, и завершается, то результирующее состояние удовлетворяет Q.
Эта интерпретация называется частичной корректностью, которая является свойством безопасности в соответствии с определением из раздела 2.1. Она утверждает, что если начальное состояние программы удовлетворяет Р, то заключительное состояние будет удовлетворять Q при условии, что выполнение S завершится. Соответствующее свойство живучести — это тотальная (полная) корректность, т.е. частичная корректность плюс завершимость (все истории конечны).
Предикаты Р и Q в тройке часто называются утверждениями, поскольку они утверждают, что состояние программы должно удовлетворять предикату, чтобы интерпретация тройки была истинной. Таким образом, утверждение характеризует допустимое состояние программы.
Предикат Р называется предусловием S. Он описывает условие, которому должно удовлетворять состояние перед началом выполнения S. Предикат Q называется постусловием S. Он описывает состояние после выполнения S при условии, что выполнение S завершается. Двумя особыми утверждениями являются true (истина), характеризующее все состояния программы, и false (ложь), которое не описывает ни одного состояния программы.
Для того чтобы интерпретация (2.4) была моделью нашей логики программирования, аксиомы и правила вывода ЛП должны быть непротиворечивыми относительно (2.4). Это гарантирует, что все доказуемые в ЛП теоремы непротиворечивы. Например, такая тройка должна быть теоремой:
{х == 0} х = х+1; {х == 1}
Однако следующая тройка не будет теоремой, поскольку присваивание значения переменной х не может чудесным образом изменить значение у на 1:
{х == 0} х = х+1; {у == 1}
В дополнение к непротиворечивости логика должна быть (относительно) полной, чтобы истинные тройки в действительности были доказуемыми теоремами.
Важнейшей аксиомой логики программирования, такой как ЛП, является аксиома, связанная с присваиванием.
Аксиома присваивания. {Рх <_ е} х = е {Р}
Запись Рх <_ е определяет текстуальную подстановку: заменить все свободные вхождения переменной х в предикат Р выражением е. (Переменная является свободной в предикате, если она не входит в область действия квантора существования или всеобщности, имеющего переменную с тем же именем.) Аксиома присваивания гласит, что если нужно, чтобы присваивание приводило к состоянию, удовлетворяющему предикату Р, то предшествующее состояние должно удовлетворять предикату Р, в котором вместо переменной х записано выражение е. В качестве примера для этой аксиомы приведем следующую тройку: {1 == 1} х = 1; {х == 1}
Предусловие упрощается до предиката true, характеризующего все состояния. Таким образом, эта тройка означает, что, независимо от начального состояния, после присваивания х значения 1 получается состояние, удовлетворяющее предикату х == 1.
Более общий способ рассматривать присваивание — "идти вперед", т.е. начать с некоторого предиката, характеризующего текущее состояние, а затем записать предикат, истинный для состояния после выполнения присваивания. Например, если начать в состоянии, в котором х == О, и прибавить 1 к х, то в результирующем состоянии значением х будет 1. Это описывается тройкой {х == 0} х = 1; {х == 1}.
64 Часть 1. Программирование с разделяемыми переменными
Аксиома присваивания описывает изменение состояния. Правила вывода в такой логике программирования, как ЛП, позволяют сочетать теоремы, полученные из частных случаев аксиомы присваивания. В частности, правила вывода используются для описания действия композиции операторов (списков операторов) и управляющих операторов, например if и while. Они также позволяют изменять предикаты в тройках.
На рис. 2.1 представлены четыре наиболее важных правила вывода. Правило композиции позволяет склеить тройки для двух операторов, выполняемых один за другим. Первая гипотеза в правиле оператора if характеризует результат выполнения оператора s, когда условие В истинно; вторая описывает, что является истинным, когда в ложно; заключение объединяет эти два случая. В качестве простого примера использования этих правил рассмотрим программу, которая присваивает переменной m максимальное из значений х и у.

Для правила оператора while требуется инвариант цикла I. Это предикат, значение которого истинно перед каждым повторением цикла и после него. Если инвариант I и условие цикла в истинны перед выполнением тела цикла S, то выполнение S должно снова сделать I истинным. Таким образом, когда оператор цикла завершается, инвариант I остается истинным, а В становится ложным. В качестве примера приведем следующую программу, которая просматривает массив а и ищет в нем первое вхождение значения х. При условии, что х встречается в а, цикл завершается присвоением переменной i индекса первого вхождения.
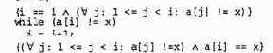
Здесь инвариантом цикла является предикат с квантором. Он истинен перед выполнением цикла, поскольку область определения квантора пуста. Он также истинен перед каждым вы-
Глава 2 Процессы и синхронизация 65
полнением тела цикла и после него. Когда выполнение оператора цикла завершается, а [ i ] равно х, и х ранее не встречался в массиве а.
Правило следования позволяет усиливать предусловия и ослаблять постусловия. В качестве примера рассмотрим истинную тройку:
{х = = 0} х = х+1; {х = = 1). По правилу следования истинной будет и такая тройка:
{х = = 0} х = х+1; {х > 0}.
Во второй тройке постусловие слабее, чем в первой, поскольку оно характеризует больше состояний; значение х может как равняться 1, так и вообще быть неотрицательным.
2.6.3. Семантика параллельного выполнения
Оператор параллельного выполнения со (или объявление процесса) является управляющим оператором. Следовательно, его действие описывается правилом вывода, учитывающим воздействие параллельного выполнения. Процессы состоят из последовательных операторов и операторов синхронизации, таких как оператор await.
С точки зрения частичной корректности действие оператора await
(await (В) S;>
больше всего похоже на действие оператора if, для которого условие в истинно, когда начинается выполнение S. Следовательно, правило вывода для оператора await аналогично правилу вывода для оператора if.
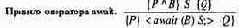
Гипотеза гласит: "если выполнение S начинается в состоянии, когда и Р, и В истинны, и S завершается, то Q будет истинным". Заключение позволяет сделать вывод о том, что оператор await приводит к состоянию, удовлетворяющему Q, если начинается в состоянии, удовлетворяющем Р (при условии, что выполнение оператора await завершается). Правила вывода ничего не говорят о возможных задержках выполнения, поскольку задержки влияют на свойства живучести, а не на свойства безопасности.
Теперь рассмотрим влияние параллельного выполнения, заданного, например, таким оператором:
со Si; // S2; // ... // Sn; ос; Предположим, что для каждого оператора истинно следующее выражение:
{Р,} S1 {Q,}
В соответствии с интерпретацией троек (2.4) это означает, что если зх начинается в состоянии, удовлетворяющем р!, и зх завершается, то состояние удовлетворяет qi. Для того чтобы эта интерпретация оставалась верной при параллельном выполнении, процессы должны начинаться в состоянии, удовлетворяющем конъюнкции предикатов Pi. Если все процессы завершаются, заключительное состояние будет удовлетворять конъюнкции предикатов ql Таким образом, получается следующее правило вывода.
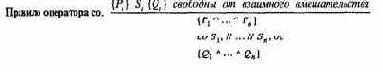
66 Часть 1. Программирование с разделяемыми переменными
Отметим фразу в гипотезе. Чтобы заключение было истинным, процессы и их обоснования не должны влиять друг на друга.
Один процесс вмешивается в другой (влияет на другой), если он выполняет присваивание, нарушающее утверждение в другом процессе. Утверждения характеризуют, что в процессе предполагается истинным до и после выполнения каждого оператора. Таким образом, если один процесс присваивает значение разделяемой переменной и тем самым делает недействительным предположение другого процесса, то обоснование другого процесса становится ложным. В качестве примера рассмотрим следующую простую программу: {х == 0}
со (х = х+1;} // <х = х+2;} ос {х == 3}
Если выполнение программы начинается состоянием, в котором значение х равно 0, то при завершении программы значение х будет равно 3. Но что же будет истинным для каждого процесса? Нельзя предполагать, что значение х будет 0 в начале каждого из них, поскольку порядок выполнения операторов недетерминирован. В частности, на предположение, что в начале выполнения процесса х имеет значение 0, влияет другой процесс, если выполняется первым. Однако то, что является истинным, учитывается следующими утверждениями.
Глава 2. Процессы и синхронизация 67
В качестве примера использования (2.5) рассмотрим последнюю из приведенных выше программ. Предусловие первого процесса является критическим утверждением. На него не влияет оператор присваивания во втором процессе, поскольку истинна такая тройка:
{ (х == 0 v х == 2) л (х == 0 v х == 1)}
х = х+2;
{х == 0 v х == 2}
Первый предикат упрощается до х == 0, поэтому после прибавления 2 к х значение переменной х будет или 0, или 2. Эта тройка выражает следующий факт: если второй процесс выполняется перед первым, то в начале выполнения первого процесса переменная х будет иметь значение 2. В данной программе есть еще три критических утверждения: постусловие первого процесса, пред- и постусловие второго процесса. Все доказательства взаимного невмешательства аналогичны приведенному.
Обзор области параллельных вычислений
Обзор области параллельных
вычислений
Представьте себе такую картину: несколько автомобилей едут из пункта А в пункт В. Машины могут бороться за дорожное пространство и либо следуют в колонне, либо обгоняют друг друга (попадая при этом в аварии!). Они могут также ехать по параллельным полосам дороги и прибыть почти одновременно, не "переезжая" дорогу друг другу. Возможен вариант, когда все машины поедут разными маршрутами и по разным дорогам.
Эта картина демонстрирует суть параллельных вычислений: есть несколько задач, которые должны быть выполнены (едущие машины). Можно выполнять их по одной на одном процессоре (дороге), параллельно на нескольких процессорах (дорожных полосах) или на распределенных процессорах (отдельных дорогах). Однако задачам нужно синхронизироваться, чтобы ..избежать столкновений или задержки на знаках остановки и светофорах.
Данная книга — это "атлас" параллельных вычислений. В ней рассматриваются типы автомашин (процессов), возможные пути их следования (приложения), схемы дорог (аппаратного обеспечения) и правила дорожного движения (взаимодействие и синхронизация). Так что заправьте полный бак и приготовьтесь к старту.
В данной главе рассказывается о надписях на карте параллельного программирования. Вразделе 1.1 представлены основные понятия. В разделах 1.2 и 1.3 описаны виды аппаратной части и приложения, которые делают параллельное программирование интересным и перспективным. В разделах с 1.4 по 1.8 описываются и иллюстрируются пять стилей программирования циклических вычислений: итеративный параллелизм, рекурсивный параллелизм, "производители и потребители", "клиенты и серверы" и, наконец, взаимодействующие каналы. В последнем разделе определена нотация программ, используемая в дальнейшем.
В следующих главах подробно рассмотрены приложения и методы программирования. Книга состоит из трех частей, в которых описано программирование с разделяемыми переменными, распределенное (основанное на сообщениях) и синхронное параллельное. Введение в каждую часть и главу служит картой маршрута, подводя итоги пройденного и предстоящего пути.
Обзор программной нотации
В пяти предыдущих разделах были представлены примеры циклических схем в параллельном программировании: итеративный параллелизм, рекурсивный параллелизм, производители и потребители, клиенты и серверы, а также взаимодействующие равные. Многочисленные примеры этих схем еще будут приведены. В примерах также была введена программная нотация. В данном разделе дается ее обзор, хотя она очевидна из примеров.
Напомним, что параллельная программа содержит один или несколько процессов, а каждый процесс — это последовательная программа. Таким образом, наш язык программирования содержит механизмы и параллельного, и последовательного программирования. Нотация последовательных программ основана на базовых понятиях языков С, C++ и Java. В нотации параллельного программирования используются операторы со и декларации process. Они были представлены ранее и определяются ниже. В следующих главах будут определены механизмы синхронизации и межпроцессного взаимодействия.
1.9.1. Декларации
Декларация (объявление, или определение) переменной задает тип данных и перечисляет имена одной или нескольких переменных этого типа. При объявлении переменную можно инициализировать, например: int i, j = 3; double sum = 0.0;
Массив объявляется добавлением размера каждого измерения к имени массива. Диапазон индексов массива по умолчанию находится в пределах от 0 до значения, меньшего на 1, чем размер измерения. В качестве альтернативы можно непосредственно указать нижнюю и верхнюю границы диапазона. Массивы также можно инициализировать при их объявлении. Вот примеры:
int a[n]; # то же, что и "int a[0:n-l];"
int b[l:n]; # массив из п целых, Ь[1] ... Ь[п]
int c[l:n]=([п]0); # вектор нулей
double c[n,n] = ([n] ([n] 1.0)); # матрица единиц
Каждая декларация сопровождается комментарием, который начинается знаком # (см. раздел 1.9.4). Последняя декларация говорит, что с — это матрица чисел двойной точности.
Ин дексы каждого ее измерения находятся в пределах от 0 до п-1, а начальное значение каждого ее элемента — 1.0.

Если условие имеет значение "истина", то выполняются вложенные операторы (тело цик ла), а затем оператор while повторяется. Цикл while завершается, если условие имеет зна чение "ложь". Если в теле цикла только один оператор, фигурные скобки опускаются.
Операторы if и while идентичны соответствующим операторам в языках С, C++ и Java, но оператор for записывается более компактно. Его общий вид таков.
for [квантификатор!, ..., квантификаторМ] { оператор!;
операторы,-}
Каждый квантификатор вводит новую индексную переменную (параметр цикла), инициализирует ее и указывает диапазон ее значений. Квадратные скобки вокруг квантификаторов используются для определения диапазона значений, как и в декларациях массивов.
В действительности его общий вид— while (условие) оператор;. Это же относится и к следующему оператору for. — Прим, перев
1.9. Обзор программной нотации 39
Предположим, что а [п] — это массив целых чисел. Тогда следующий оператор инициализирует каждый элемент массива а [ i ] значением 1. for [i = 0 to n-1] a[i] = i;
Здесь i — новая переменная; ее не обязательно определять выше в программе. Область видимости переменной i — тело данного цикла for. Ее начальное значение 0, и она принимает по порядку значения от 0 до п-1.
Предположим, что m[n,n] — массив целых чисел. Рассмотрим оператор for с двумя квантификаторами.
for [i = 0 to n-1, j = 0 to n-1] m[i,j] = 0;
Этому оператору эквивалентны вложенные операторы for.
for [i = 0 to n-1] for [j = 0 to n-1] m[i,j] = 0;
В обоих случаях п2 значений матрицы m инициализируются нулями. Рассмотрим еще два примера квантификаторов.
[i = 1 to n by 2] #нечетные значения от 1 до п
[i = 0 to n-1 st i!=x] каждое значение, кроме i==x
Обозначение st во втором квантификаторе — это сокращение слов "such that" ("такой, для которого").
Операторы for записываются с использованием синтаксиса, приведенного выше, по нескольким причинам. Во-первых, этим подчеркивается отличие наших операторов for от тех же операторов в языках С, C++ и Java. Во-вторых, такая нотация предполагает их использование с массивами, у которых индексы заключаются в квадратные, а не круглые скобки. В-третьих, наша запись упрощает программы, поскольку избавляет от необходимости объявлять индексную переменную. (Сколько раз вы забывали это сделать?) В-четвертых, зачастую удобнее использовать несколько индексных переменных, т.е. записывать несколько квантификаторов. И, наконец, те же формы квантификаторов используются в операторах со и декларациях process.
1.9.3. Параллельные операторы, процессы и процедуры
.По умолчанию операторы выполняются последовательно, т.е. один за другим. Оператор со (concurrent — параллельный, происходящий одновременно) указывает, что несколько операторов могут выполняться параллельно. В одной форме оператор со имеет несколько ветвей (arms).
со оператор!;
// .. .
// onepaтopN;
ос
Каждая ветвь содержит оператор (или список операторов). Ветви отделяются символом параллелизма //. Оператор, приведенный выше, означает следующее: начать параллельное выполнение всех операторов, затем ожидать их завершения. Оператор со, таким образом, завершается после выполнения всех его операторов.
В другой форме оператор со использует один или несколько квантификаторов, которые указывают, что набор операторов должен выполняться параллельно для каждой комбинации
40 Глава 1. Обзор области параллельных вычислений
значений параметров цикла. Например, следующий тривиальный оператор инициализирует массивы а [п] иЬ[п] нулями.
co[i = 0 to n-1] {
a[i] = 0; b[i] = 0; }
Этот оператор создает п процессов, по одному для каждого значения переменной i.
Область видимости счетчика — описание процесса, и у каждого процесса свое, отличное от других, значение переменной i. Две формы оператора со можно смешивать. Например, одна ветвь может иметь квантификатор в квадратных скобках, а другая — нет.
Декларация процесса является, по существу, сокращенной формой оператора со с одной ветвью и/или одним квантификатором. Она начинается ключевым словом process и именем процесса, а заканчивается ключевым словом end. Тело процесса содержит определения локальных переменных, если такие есть, и список операторов.
В следующем простом примере определяется процесс f оо, который суммирует числа от 1 до 10, записывая результат в глобальную переменную х.
process foo {
int sum = 0;
for [i = 1 to 10] sum += i;
x = sum; }
Декларация process записывается на синтаксическом уровне декларации procedure; это не оператор, в отличие от со. Кроме того, объявляемые процессы выполняются в фоновом режиме, тогда как выполнение оператора, следующего за оператором со, начинается после завершения процессов, созданных этим со.
Еще один простой пример: следующий процесс записывает значения от 1 до п в стандартный файл вывода.
process barl { for [i = 1 to n]
write(i); # то же, что "printf("%d\n",i);" }
Массив процессов объявляется добавлением квантификатора (в квадратных скобках) к имени процесса.
process bar2[i = 1 to n] {
write(i); }
И barl, и bar2 записывают в стандартный вывод значения от 1 до п. Однако порядок в котором их записывает массив процессов Ьаг2, недетерминирован, поскольку массив Ьаг2 состоит из п отдельных процессов, выполняемых в произвольном порядке. Существует п! различных порядков, в которых этот массив процессов мог бы записать числа (п! — число перестановок п значений).
Процедуры и функции объявляются и вызываются так же, как это делается в языке С, например, так.
int addOne(int v) { # функция возвращает целое число
return (v + 1); }
main() { # "void"-процедура int n, sum;
read(n); # прочитать целое число из stdin for [i = 1 to n]
sum = sum + addOne(i);
Историческая справка 41
write("Окончательным значением является ", sum); }
Если входное значение п равно 5, эта программа выведет такую строку.
Окончательным значением является 20
1.9.4. Комментарии
Комментарии записываются двумя способами. Однострочные комментарии начинаются символом # и завершаются в конце строки. Многострочные комментарии начинаются символами /* и оканчиваются символами */. Для однострочных комментариев используется символ #, поскольку символ однострочных комментариев // языков C++ и Java уже давно использовался в параллельном программировании как разделитель ветвей в параллельных операторах.
Утверждение — это предикат, определяющий условие, которое должно выполняться в некоторой точке программы. (Утверждения подробно описаны в главе 2.) Утверждения можно рассматривать как предельно точные комментарии, поэтому они записываются в отдельных строках, начинающихся двумя символами #:
## х > О Данный комментарий утверждает, что значение х положительно.
Однопроцессорное ядро
В предыдущих главах для определения параллельной работы использовались операторы со и декларации process. Процессы — это просто частные случаи операторов со, поэтому здесь основное внимание уделяется реализации операторов со. Рассмотрим следующий фрагмент программы.
SO;
СО PI: S1; // ... // Pn: Sn; ос
Sn+1;
Pi — это имена процессов, si обозначают списки операторов и необязательные декларации локальных переменных процесса pi.
Для реализации приведенного фрагмента программы необходимы три механизма:
• создания процессов и их запуска на выполнение;
• остановки (и уничтожения) процесса;
• определения момента завершения оператора со.
Примитив — это процедура, реализованная ядром так, что она выполняется как неделимое действие. Процессы создаются и уничтожаются с помощью двух примитивов ядра: fork и quit.
214 Часть 1. Программирование с разделяемыми переменными
Когда процесс запускает примитив fork, создается еще один процесс, готовый к запуску. Аргументы примитива fork передают адрес первой выполнимой инструкции нового процесса и любые другие данные, необходимые для определения его начального состояния, например, параметры процесса. Новый процесс называется сыновним, а процесс, выполняющий примитив fork, —родительским. Вызывая примитив quit, процесс прекращает свое существование. У примитива quit аргументов нет.
Третий примитив ядра, join, используется для ожидания завершения процессов и, следовательно, для определения момента завершения оператора со. В частности, когда родительский процесс выполняет примитив join, он ждет завершения сыновнего процесса, который до этого был порожден операцией fork. Аргументом операции join является имя сыновнего процесса. (Примитив join используется и без аргументов— тогда процесс ждет завершения любого из сыновних процессов и, возможно, возвращает его идентификатор.)
Итак, для реализации указанного выше фрагмента можно использовать три описанных примитива fork, j oin и quit.
Каждый сыновний процесс Pi выполняет следующий код:
Si; quit О;
Главный процесс выполняет такой код. SO; for [i = 1 to n] # создать сыновние процессы
fork(Pi) ; for [i = 1 to n] # ожидать завершения каждого из них
join(Pi); Sn+1 ;
Предполагается, что главный процесс создается неявно и автоматически начинает выполняться. Считается также, что к моменту запуска главного процесса код и данные всех процессов уже записаны в память.
Во втором цикле for приведенная программа ждет выхода из сыновнего процесса 1, затем выхода из процесса 2 и т.д. При использовании примитива join без параметров ожидается завершение всех n сыновних процессов в произвольном порядке. Если сыновние процессы были объявлены с помощью декларации process и, следовательно, должны выполняться в фоновом режиме, то главный процесс создаст их таким же образом, но не будет ждать выхода из них.
Теперь представим однопроцессорное ядро, реализующее операции fork, join и quit. Также опишем, как планировать процессы, чтобы каждый процесс периодически получал возможность выполняться, т.е. представим диспетчер со стратегией планирования, справедливой в слабом смысле (см. определение в разделе 2.8).
Любое ядро содержит структуры данных, которые представляют процессы и три базовых типа процедур: обработчики прерываний, сами примитивы и диспетчер. Ядро может включать и другие структуры данных или функции — например, дескрипторы файлов и процедуры доступа к файлам. Сосредоточимся, однако, на той части ядра, которая реализует процессы.
Есть два основных способа организовать ядро:
• в виде монолитного модуля, в котором каждый примитив ядра выполняется неделимым образом;
• в виде параллельной программы, в которой несколько пользовательских процессов одновременно могут выполнять примитивы ядра.
Здесь используется первый метод, поскольку для небольшого однопроцессорного ядра он самый простой. Второй метод будет использован для многопроцессорного ядра в следующем разделе.
В ядре каждый процесс представлен дескриптором процесса. Когда процесс простаивает, его дескриптор хранит состояние процесса, или контекст, — всю информацию, необходимую для выполнения процесса. Состояние (контекст) включает адрес следующей инструкции, которую должен выполнять процесс, и содержимое регистров процессора.
Глава б Реализация 215
Ядро начинает выполняться, когда происходит прерывание. Прерывания можно разделить на две широкие категории: внешние прерывания от периферийных устройств и внутренние прерывания, или ловушки, которые возбуждаются выполняемым процессом. Когда происходит прерывание, процессор автоматически сохраняет необходимую информацию о состоянии процесса, чтобы прерываемый процесс можно было продолжить. Затем процессор входит в обработчик прерывания; обычно каждый тип прерываний имеет свой обработчик.
Для запуска примитива ядра процесс вызывает внутреннее прерывание, выполняя машинную инструкцию, которая называется вызовом супервизора (supervisor call — SVC) или ловушкой (trap). В инструкции SVC процесс передает аргумент, который задает вызываемый примитив; остальные аргументы передаются в регистрах. Обработчик прерывания SVC сначала сохраняет состояние выполняемого процесса, затем вызывает соответствующий примитив, реализованный в виде процедуры ядра. Примитив, завершаясь, вызывает процедуру dispatcher (процессорный диспетчер). Процедура dispatcher выбирает процесс для выполнения и загружает его состояние. Состояние процесса называется контекстом, поэтому последнее действие процедуры dispatcher носит название переключение контекста.
Чтобы обеспечить неделимое выполнение примитивов, обработчик прерывания в начале своей работы должен запретить дальнейшие прерывания, а диспетчер в конце — разрешить их. Когда возникает прерывание, все остальные прерывания автоматически запрещаются аппаратной частью; в качестве побочного эффекта нагрузки состояния процесса ядро вновь разрешает прерывания. (В некоторых машинах прерывания разделены на несколько уровней, или классов.
В этой ситуации обработчик прерывания запрещает только те прерывания, которые могут повлиять на обрабатываемое.)
На рис. 6.1 показаны компоненты ядра и поток управления внутри него. Поток идет в одном направлении, от обработчиков прерываний через примитивы к процедуре dispatcher и затем обратно к активному процессу. Следовательно, возвращений из вызовов внутри ядра не происходит, поскольку вместо возврата к тому процессу, который выполнялся при входе в ядро, оно часто начинает выполнение другого процесса.

Тип processType — это тип структуры (записи), описывающий поля в дескрипторе процесса. Родительский процесс просит ядро создать сыновний процесс, вызывая примитив fork, который выделяет и инициализирует пустой дескриптор. Когда процедура ядра dispatcher планирует процессы, она ищет дескриптор процесса, имеющий право выполнения. Процедуры fork и dispatcher можно реализовать путем поиска в массиве дескрипторов процессов при условии, что каждая запись содержит поле, указывающее, занят ли данный элемент массива. Однако обычно используются два списка: список свободных (пустых дескрипторов) и список готовых к работе (там содержатся дескрипторы процессов, ожидающих своей очереди на выполнение). Родительские процессы, ожидающие завершения работы сыновних процессов, запоминаются в дополнительном списке ожидания. Наконец, ядро содержит переменную executing, значением которой является индекс дескриптора процесса, выполняемого в данный момент.
Предполагается, что при инициализации ядра, которая происходит при "загрузке" процессора, создается один процесс и переменная executing указывает на его дескриптор. Все остальные дескрипторы помещаются в список свободных. Таким образом, в начале выполнения списки готовых и ожидающих процессов пусты.
216 Часть 1 Программирование с разделяемыми переменными
При описанном представлении структур данных ядра примитив fork удаляет дескриптор из списка свободных, инициализирует его и вставляет в конец списка готовых к выполнению.
Примитив join проверяет, произошел ли уже выход из сыновнего процесса, и, если нет, блокирует выполняющийся (родительский) процесс. Примитив quit запоминает, что произошел выход из процесса, помещает дескриптор выполняемого процесса в список свободных, запускает родительский процесс, если он ждет, и присваивает переменной executing значение нуль, чтобы указать процедуре dispatcher, что процесс больше не будет выполняться.
Процедура dispatcher, вызываемая в конце примитива, проверяет значение переменной executing. Если это значение не равно нулю, то текущий процесс должен продолжить работу. Иначе процедура dispatcher удаляет первый дескриптор из списка готовых к выполнению и присваивает переменной executing значение, указывающее на этот процесс. Затем процедура dispatcher загружает состояние этого процесса. Здесь предполагается, что список готовых к выполнению процессов является очередью с обработкой типа "первым пришел — первым ушел" (FIFO).
Осталось обеспечить справедливость выполнения процесса. Если бы выполняемые процессы всегда завершались за конечное время, то описанная реализация ядра обеспечивала бы справедливость, поскольку список готовых к выполнению процессов имеет очередность FIFO. Но если есть процесс, ожидающий выполнения некоторого условия, которое в данный момент ложно, он заблокируется навсегда, если только его не заставить освободить процессор. (Процесс также зацикливается навсегда, если в результате ошибки программирования содержит бесконечный цикл.) Для того чтобы процесс периодически освобождал управление процессором, можно использовать интервальный таймер, если, конечно, он реализован ап-паратно. Тогда в сочетании с очередностью FIFO обработки списка готовых процессов каждый процесс периодически будет получать возможность выполнения, т.е. стратегия планирования будет справедливой в слабом смысле.
Интервальный таймер — это аппаратное устройство, которое инициализируется положительным целым числом, затем уменьшает свое значение с определенной частотой и возбуждает прерывание таймера, когда значение становится нулевым.
Такой таймер используется в ядре следующим образом. Вначале, перед загрузкой состояния следующего выполняемого процесса, процедура dispatcher инициализирует таймер. Затем, когда возникает прерывание таймера, обработчик этого прерывания помещает дескриптор процесса, на который указывает переменная executing, в конец списка готовых к выполнению процессов, присваивает переменной executing значение 0 и вызывает процедуру dispatcher. В результате образуется круговая очередность выполнения процессов.
Собрав вместе все описанные выше части, получим схему однопроцессорного ядра (листинг 6.1). Предполагается, что побочный результат запуска интервального таймера в процедуре dispatcher состоит в запрете всех прерываний, которые могут возникнуть в результате достижения таймером нулевого значения во время выполнения ядра. При таком необходимом дополнительном условии выбранный для выполнения процесс не будет прерван немедленно и не потеряет управления процессором
Листинг 6.1. Схема однопроцессорного ядр]
processType processDescriptor[maxProcs];
int executing =0; # индекс выполняемого процесса
объявления переменных для списков свободных, готовых к работе и ожидающих процессов;
SVC_Handler: { # вход с запрещенными прерываниями сохранить состояние выполняемого процесса (с индексом executing) ; определить, какой примитив был вызван, и запустить его;
}

В ядре (см. листинг 6.1) игнорируются такие возможные особые ситуации, как пустой список свободных дескрипторов при вызове примитива fork. В данной реализации также предполагается, что всегда есть хотя бы один готовый к работе процесс. На практике ядро всегда имеет один процесс-"бездельник", который запускается, когда другой работы нет; как это сделать, показано в следующем разделе Не учтено еще несколько моментов, возникающих на практике, — например, обработка прерываний ввода-вывода, управление устройствами, доступ к файлам и управление памятью.
6.2.
Многопроцессорное ядро
Мультипроцессор с разделяемой памятью содержит несколько процессоров и память, доступную каждому из них. Расширить однопроцессорное ядро для работы на мультипроцессорных машинах относительно нетрудно. Вот наиболее важные изменения:
218 Часть 1. Программирование с разделяемыми переменными
• процедуры и структуры данных ядра должны храниться в разделяемой памяти;
• доступ к структурам данных должен осуществляться со взаимным исключением, когда необходимо избегать взаимного влияния;
• процедуру dispatcher следует преобразовать для использования с несколькими процессорами.
Однако есть нюансы, которые связаны с особенностями мультипроцессоров и описаны ниже.
Предположим, что внутренние прерывания (ловушки) обслуживаются тем процессором, на котором выполняется процесс, вызвавший такое прерывание, и у каждого процессора есть интервальный таймер. Допустим также, что операции ядра и процессы могут быть выполнены на любом процессоре. (В конце раздела описано, как привязать процессы к процессорам, что делать с эффектами кэширования и неодинаковыми временами доступа к памяти.)
Когда процессор прерывается, он входит в ядро и запрещает дальнейшие прерывания для данного процессора. Вследствие этого выполнение в ядре становится неделимым на данном процессоре, но остальные процессоры, тем не менее, могут одновременно выполняться в ядре.
Чтобы предотвратить взаимное влияние процессоров, можно сделать критической секцией все ядро, но это плохо по двум причинам. Во-первых, нет необходимости запрещать некоторые безопасные параллельные операции, поскольку критичен только доступ к таким разделяемым ресурсам, как списки дескрипторов свободных и готовых к работе процессов. Во-вторых, если все ядро заключить в критическую секцию, она будет слишком длинной, что '• снижает производительность и увеличивает число конфликтов в памяти из-за переменных, реализующих протокол критической секции.
Следующий принцип позволяет получить на много более удачный вариант решения.
(6.1) Принцип блокировки мультипроцессора. Делайте критические секции короткими, за щищая каждую критическую структуру данных отдельно. Для каждой структуры дан ных используйте отдельные критические секции с отдельными переменными для протоколов входа и выхода.
В нашем ядре критическими данными являются списки дескрипторов свободных, готовых к работ! и ожидающих процессов. Для защиты доступа к ним можно использовать любой из протоколе! критической секции, описанных выше в книге. Для конкретного мультипроцессора выбор делается на основе доступных машинных инструкций. Например, если есть инструкция "извлеч! и сложить", можно использовать простой и справедливый алгоритм билета (см. листинг 3.9).
Предполагается, что ловушки обрабатываются тем же процессором, в котором они возникают, и каждый процессор имеет свой собственный интервальный таймер, поэтому обработчики прерываний от ловушек и от таймера остаются почти такими же, как и для однопроцессорного ядра. У них есть только два отличия: переменная executing теперь должна быть массивом с отдельным элементом для каждого из процессоров, а процедура Timer_Handler должна блокировать и освобождать список готовых к выполнению процессов.
Код всех трех примитивов ядра в основном также остается неизменным. Здесь нужно учесть, что переменная executing стала массивом, и защитить критическими секциями списки дескрипторов свободных, готовых к работе и ожидающих процессов.
Наибольшие изменения касаются процедуры dispatcher. До этого в нашем распоряжении был один процессор, и предполагалось, что всегда есть процесс для выполнения на нем, Теперь процессов может быть меньше, чем процессоров, поэтому некоторые процессоры могут простаивать. Когда создается новый процесс (или запускается после прерывания ввода-вывода), он должен быть привязан к незанятому процессору, если такой есть. Это можно сделать одним из трех способов:
• заставить каждый незанятый процессор выполнять специальный процесс, который периодически просматривает список дескрипторов готовых к работе процессов, пои не найдет готовый к работе процесс;
Глава б. Реализация 219
• заставить процессор, выполняющий fork, искать свободный процессор и назначать ему новый процесс;
• использовать отдельный процесс-диспетчер, который выполняется на отдельном процессоре и постоянно пытается назначать свободным процессорам готовые к работе процессы.
Первый метод наиболее эффективен, в частности, поскольку свободным процессорам нечего делать до тех пор, пока они не найдут процесс для выполнения.
Когда диспетчер определяет, что список готовых к работе процессов пуст, он присваивает переменной executing [ i ] значение, указывающее на дескриптор бездействующего процесса, и загружает его состояние. Код бездействующего процесса показан в листинге 6.2. По существу, процесс idle — "сам себе диспетчер". Сначала, пока в списке готовых к работе процессов нет элементов, он зацикливается, затем удаляет из списка дескриптор процесса и начинает выполнение этого процесса. Чтобы не было конфликтов в памяти, процесс Idle не должен непрерывно просматривать или блокировать и разблокировать список готовых к работе процессов, поэтому используем протокол "проверить-проверить-установить", аналогичный по структуре приведенному в листинге ЗА. Поскольку список готовых к работе процессов может стать пустым после того, как процесс idle захватит его блокировку, необходима повторная проверка.
Листинг 6.2. Код бездействующего процесса
process Idle {
while (executing [i] == бездействующий процесс) { while (список готовых пуст) Задержка; заблокировать список готовых; i f (список готовых не пуст) { удалить дескриптор из начала списка готовых; установить executingti] нанего; }
снять блокировку со списка готовых; }
запустить интервальный таймер на процессоре i;
загрузить состояние executing [i] ; # с разрешенными прерываниями }___________________________________________________________________________
Осталось обеспечить справедливость планирования. Вновь используем таймеры, чтобы заставить процессы, выполняемые вне ядра, освобождать процессоры. Предполагаем, что каждый процессор имеет свой таймер, который используется так же, как и в однопроцессорном ядре. Но одних таймеров недостаточно, поскольку теперь процессы могут быть приостановлены в ядре в ожидании доступа к разделяемым структурам данных ядра. Таким образом, нужно использовать справедливое решение для задачи критической секции, например, алгоритм разрыва узлов, алгоритм билета или алгоритм поликлиники (глава 3). Если вместо этого использовать протокол "проверить-установить", появится возможность "зависания" процессов. Однако это маловероятно, поскольку критические секции в ядре являются очень короткими.
В листинге 6.3 показана схема многопроцессорного ядра, включающая все перечисленные выше предположения и решения. Переменная i используется как индекс процессора, на котором выполняются процедуры, а операции "заблокировать" и "освободить" реализуют протоколы входа в критические секции и выхода из них. В этом решении не учтены возможные особые ситуации, а также не включен код для обработки прерываний ввода-вывода, управления памятью и т.д.
Листинг 6.3. Схема*ядра"для мультипроцессора с разделяемой памятью
processType processDescriptor[maxProcs];
int executing[maxProcs]; # по одному элементу для процессора


В многопроцессорном ядре в листинге 6.3 использован один список готовых к работе процессов с очередностью обработки FIFO. Если процессы имеют разные приоритеты, то список готовых к работе процессов должен обслуживаться с учетом приоритетов. Однако тогда процессор будет затрачивать больше времени на работу со списком готовых, по крайней мере, на вставку элементов в список, поскольку новый процесс нужно вставить в позицию очереди, соответствующую его приоритету.
Таким образом, список готовых к работе процессов может стать " узким местом" программы. Если число уровней приоритетов фиксировано, то эффективное решение — использовать по одной очереди на каждый уровень приоритета и по одной блокировке на каждую очередь. При таком представлении вставка процесса в список готовых к работе требует только вставки в конец соответствующей очереди. Но если число уровней приоритета изменяется динамически, то чаще всего используют единый список готовых к работе процессов.
В ядре (см. листинг 6.3) также предполагается, что процесс может выполняться на любом процессоре, поэтому диспетчер всегда выбирает первый готовый к выполнению процесс. В некоторых мультипроцессорах такие процессы, как драйверы устройств или файловые серверы, могут работать только на специальном процессоре, к которому присоединены периферийные устройства. В этой ситуации для такого процессора создается отдельный список готовых к работе процессов и, возможно, собственный диспетчер. (Ситуация значительно усложняется, если на специализированном процессоре могут выполняться и обычные процессы, поскольку их тоже нужно планировать.)
Даже если процессу подходит любой процессор, может быть очень неэффективно планировать его для случайного процессора. На машине с неоднородным доступом к памяти, например, процессоры могут получать доступ к локальной памяти значительно быстрее, чем к удаленной. Следовательно, процесс в идеальном случае должен выполняться на том же процессоре, в локальной памяти которого находится его код. Это предполагает наличие отдельного списка готовых к работе процессов для каждого из процессоров и назначение процессов на процессоры в зависимости от того, где хранится их код. Но тогда возникает вопрос балансировки нагрузки, т.е. процессоры должны нагружаться работой примерно одинаково. Просто назначать всем процессорам поровну процессов неэффективно; обычно различные процессы создают неодинаковую нагрузку, которая динамически изменяется.
Независимо от того, однородно или нет время доступа к памяти, процессоры обычно имеют кэш-память и буферы трансляции адресов виртуальной памяти. В этой ситуации процесс должен планироваться на тот процессор, на котором он выполнялся последний раз (предполагается, что часть состояния процесса находится в кэш-памяти и буферах трансляции процессора). Кроме того, если два процесса разделяют данные, находящиеся в кэшпамяти, гораздо эффективнее выполнять эти процессы по очереди на одном процессоре, чем на разных. Это называется совместным планированием. Здесь также предполагается наличие отдельного списка готовых к работе процессов у каждого процессора, что в свою очередь приводит к необходимости балансировки нагрузки. Дополнительная информация по этим вопросам дана в ссылках и упражнениях в конце главы.
222 Часть 1 Программирование с разделяемыми переменными
Планирование работы диска: программные структуры
В предыдущих примерах были рассмотрены несколько небольших задач и представлены разнообразные полезные методы синхронизации. В данном разделе описаны способы организации процессов и мониторов для решения одной более крупной задачи. Затрагиваются вопросы "большого программирования", точнее, различные способы структурирования программы. Это смещение акцентов делается и в оставшейся части книги.
В качестве примера рассмотрим задачу планирования доступа к диску с перемещаемыми головками, который используется для хранения файлов. Покажем, как в разработке решения задачи применяются методы, описанные в предыдущих разделах. Особо важно, что рассматриваются три различных способа структурирования решения. Задача планирования доступа к диску — типичный представитель ряда задач планирования, и каждая из структур ее решения применима во многих других ситуациях. Вначале опишем диски с подвижными головками.
На рис. 5.3 приведена общая схема диска с подвижными головками. Он содержит несколько соединенных с центральным шпинделем пластин, которые вращаются с постоянной скоростью. Данные хранятся на поверхностях пластин. Пластины похожи на граммофонные пластинки, за исключением того, что дорожки на них образуют отдельные концентрические кольца, а не спираль. Дорожки с одинаковым относительным положением на пластинах образуют цилиндр. Доступ к данным осуществляется так: головка чтения-записи перемещается на нужную дорожку, затем ожидает, когда пластина повернется и необходимые данные пройдут у головки. Обычно одна пластина имеет одну головку чтения-записи. Головки объединены в рычаг выборки, который может двигаться по'радиусу так, что их можно перемещать на любой цилиндр и, следовательно, на любую дорожку.
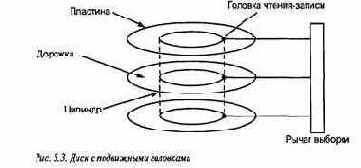
Физический адрес данных, записанных на диске, состоит из цилиндра, номера дорожки, определяющего пластину, и смещения, задающего расстояние от фиксированной точки отсчета на дорожке. Для обращения к диску программа выполняет машиннозависимую инструкцию ввода-вывода.
Параметрами инструкции являются физический дисковый адрес, число байтов для передачи, тип передачи (чтение или запись) и адрес буфера данных.
Время доступа к диску состоит из трех частей: времени поиска (перемещение головки чтения-записи на соответствующий цилиндр), задержки вращения и времени передачи данных. Время пе-
Глава 5 Мониторы 185
редачи данных целиком определяется количеством байтов передаваемых данных, а другие два интервала зависят от состояния диска. В лучшем случае головка чтения-записи уже находится на нужном цилиндре, а требуемая часть дорожки как раз начинает проходить под ней. В худшем случае головку чтения-записи нужно переместить через весь диск, а требуемая дорожка должна совершить полный оборот. Для дисков характерно то, что время перемещения головки от одного цилиндра к другому прямо пропорционально расстоянию между цилиндрами. Важно также, что время перемещения головки даже на один цилиндр намного больше, чем период вращения пластины. Таким образом, наиболее эффективный способ сократить время обращения к диску— минимизировать передвижения головки, сократив время поиска. (Можно сокращать и задержки вращения, но это сложно и неэффективно, поскольку они обычно очень малы.)
Предполагается, что диск используют несколько клиентов. Например, в мультипрограммной операционной системе это могут быть процессы, выполняющие команды пользователя, или системные процессы, реализующие управление виртуальной памятью. Если доступ к диску запрашивает всего один клиент, то ничего нельзя выиграть, не дав ему доступ немедленно, поскольку неизвестно, когда к диску обратится еще один клиент. Таким образом, планирование доступа к диску применяется, только когда приблизительно в одно время доступ запрашивают как минимум два процесса.
Напрашивается следующая стратегия планирования: всегда выбирать тот ожидающий запрос, который обращается к ближайшему относительно текущего положения головок цилиндру.
Эта стратегия называется стратегией кратчайшего времени поиска (shortest-seek-time — SST), поскольку помогает минимизировать время поиска. Однако SST— несправедливая стратегия, поскольку непрерывный поток запросов для цилиндров, находящихся рядом с текущей позицией головки, может остановить обработку запросов к отдаленным цилиндрам. Хотя такая остановка обработки запросов крайне маловероятна, длительность ожидания обработки запроса здесь ничем не ограничена. Стратегия SST используется в операционной системе UNIX; системный администратор с причудами, желая добиться справедливости планирования, наверное, купил бы побольше дисков .
Еще одна, уже справедливая, стратегия планирования — перемещать головки в одном направлении, пока не будут обслужены все запросы в этом направлении движения. Выбирается клиентский запрос, ближайший к текущей позиции головки в направлении, в котором она двигалась перед этим. Если для этого направления запросов больше нет, оно изменяется. Эта стратегия встречается под разными названиями — SCAN (сканирование), LOOK (просмотр) или алгоритм лифта, поскольку перемещения головки похожи на работу лифта, который ездит по этажам, забирая и высаживая пассажиров. Единственная проблема этой стратегии — запрос, которому соответствует позиция сразу за текущим положением головки, не будет обслужен, пока головка не пойдет назад. Это приводит к большому разбросу времени ожидания выполнения запроса.
Третья стратегия аналогична второй, но существенно уменьшает разброс времени ожидания выполнения запроса. Ее называют CSCAN или CLOOK (буква С взята от "circular" — циклический). Запросы обслуживаются только в одном направлении, например, от внешнего к внутреннему цилиндру. Таким образом, существует только одно направление поиска, и выбирается запрос, ближайший к текущему положению головки в этом направлении. Когда запросов в направлении движения головки не остается, поиск возобновляется с внешнего цилиндра.
Это похоже на лифт, который только поднимает пассажиров. (Вероятно, вниз они должны были бы идти пешком или прыгать!) В отношении сокращения времени поиска стратегия CSCAN эффективна почти так же, как и алгоритм лифта, поскольку для большинства дисков перемещение головок через все цилиндры занимает примерно вдвое больше времени, чем перемещение между соседними цилиндрами. Кроме того, стратегия CSCAN справедлива, если только поток запросов к текущей позиции головки не останавливает выполнение остальных запросов (что крайне маловероятно).
В оставшейся части данного раздела разработаны три различных по структуре решения задачи планирования доступа к диску. В первом решении планировщик (диспетчер) реализован отдельным монитором, как в решении задачи о читателях и писателях (см. листинг 5.4).
186 Часть 1. Программирование с разделяемыми переменными
Во втором он реализован монитором, который работает как посредник между пользователями диска и процессом, выполняющим непосредственный доступ к диску. По структуре это решение аналогично решению задачи о спящем парикмахере (см. листинг 5.8). В третьем решении использованы вложенные мониторы: первый из них осуществляет планирование, а второй — доступ к диску.
Все три монитора-диспетчера реализуют стратегию CSCAN, но их нетрудно модифицировать для реализации любой стратегии планирования. Например, реализация стратегии SST приведена в главе 7.
5.3.1. Использование отдельного монитора
Реализуем диспетчер монитором, который отделен от управляемого им ресурса, т.е. диска (рис. 5.4). В решении есть три вида компонентов: пользовательские процессы, диспетчер, а также процедуры или процесс, выполняющие обмен данными с диском. Диспетчер реализован монитором, чтобы данные планирования были доступны одновременно только одному процессу. Монитор поддерживает две операции: request (запросить) и release (освободить).
Для получения доступа к цилиндру cyl пользовательский процесс сначала вызывает процедуру request (cyl), из которой возвращается только после того, как диспетчер выберет этот запрос.
Затем пользовательский процесс работает с диском, например, вызывает соответствующие процедуры или взаимодействует с процессом драйвера диска. После работы с диском пользователь вызывает процедуру release, чтобы диспетчер мог выбрать новый запрос. Таким образом, диспетчер имеет следующий пользовательский интерфейс.
Disk_Scheduler.request(cyl)
работа с диском
Disk_Scheduler.release()
Монитор Disk_Scheduler играет двойную роль: он планирует обращения к диску и обеспечивает в любой момент времени доступ к диску только одному процессу. Таким образом, пользователи обязаны следовать указанному выше протоколу.
Предположим, что цилиндры диска пронумерованы от 0 до maxcyl, и диспетчер использует стратегию CSCAN с направлением поиска от 0 до maxcyl. Как обычно, важнейший шаг в разработке правильного решения — точно сформулировать его свойства. Здесь в любой момент времени только один процесс может использовать диск, а ожидающие запросы обслуживаются в порядке CSCAN.
Пусть переменная position указывает текущую позицию головки диска, т.е. номер цилиндра, к которому обращался процесс, использующий диск. Когда к диску нет обращений, переменной cylinder присваивается значение -1. (Можно использовать любой неправильный номер цилиндра или ввести дополнительную переменную.)
Для реализации стратегии планирования CSCAN необходимо различать запросы, которые нужно выполнить за текущий и за следующий проход через диск. Пусть эти запросы хранятся в непересекающихся множествах с и N. Оба множества упорядочены по возрастанию значе-
Глава 5. Мониторы 187
ния cyl, запросы к одному и тому же цилиндру упорядочены по времени вставки в множество. Таким образом, множество с содержит запросы для цилиндров, номера которых больше или равны текущей позиции, а N — для цилиндров с номерами, которые меньше или равны текущей позиции. Это выражается следующим предикатом, который является инвариантом монитора.
DISK: С и N являются упорядоченными множествами л все элементы множества С >= position л все элементы множества N <= position л (position == -1} => (С == 0 л N == 0)
Ожидающий запрос, для которого cyl равно position, мог бы быть в любом из множеств, но помещается в N, как описано в следующем абзаце.
Вызывая процедуру request, процесс выполняет одно из трех действий. Если переменная position имеет значение -1, диск свободен; процесс присваивает переменной position значение cyl и работает с диском. Если диск занят и выполняется условие cyl > position, то процесс вставляет значение cyl в с, иначе (cyl < position) — в N. При равенстве значений cyl и position используется N, чтобы избежать возможной несправедливости планирования, поэтому запрос будет ожидать следующего прохода по диску. После записи значения cyl в подходящее множество процесс приостанавливается до тех пор, пока не получит доступ к диску, т.е. до момента, когда значения переменных pos it ion и cyl станут равными.
Вызывая процедуру release, процесс обновляет постоянные переменные так, чтобы выполнялось условие DISK. Если множество с не пусто, то еще есть запросы для текущего прохода. В этом случае процесс, освобождающий доступ к диску, удаляет первый элемент множества с и присваивает это значение переменной position. Если с пусто, а N — нет, то нужно начать новый проход, который становится текущим. Для этого освобождающий процесс меняет местами множества с и N (N при этом становится пустым), затем извлекает первый элемент из С и присваивает его значение переменной position. Если оба множества пусты, то для индикации освобождения диска процесс присваивает переменной position значение -1.
Последний шаг в разработке решения — реализовать синхронизацию между процедурами request и release. Здесь та же ситуация, что и в задаче с интервальным таймером: между условиями ожидания есть статический порядок, поэтому для реализации упорядоченных множеств можно использовать приоритетный оператор wait.
Запросы в множествах С и N обслуживаются в порядке возрастания значения cyl. Эта ситуация похожа и на семафор FIFO: когда освобождается диск, разрешение на доступ к нему передается одному ожидающему процессу. Переменной position нужно присваивать значение того ожидающего запроса, который будет обработан следующим. По этим двум причинам синхронизацию можно реализовать эффективно, объединив свойства мониторов Timer (см. листинг 5.7) и FIFOsemaphore (см. листинг 5.2).
Для представления множеств с и N используем массив условных переменных scan [2], индексированный целыми сип. Когда запрашивающий доступ процесс должен вставить свой параметр cyl в множество С и ждать, пока станут равны position и cyl, он просто выполняет процедуру wait(scan[c] ,cyl). Аналогично процесс вставляет свой запрос вмножество N и приостанавливается, выполняя wait(scan[n] ,cyl). Кроме того, чтобы определить, пусто ли множество, используется функция empty, чтобы вычислить наименьшее значение в множестве — функция minrank, а для удаления первого элемента с одновременным запуском соответствующего процесса — процедура signal. Множества с и N меняются местами, когда это нужно, с помощью простого обмена значений сип. (Именно поэтому для представления множеств выбран массив.)
Объединив перечисленные изменения, получим программу в листинге 5.9. В конце процедуры release значением с является индекс текущего множества обрабатываемых запросов, поэтому достаточно вставить только один оператор signal. Если в этот момент переменная position имеет значение -1, то множество scan [с] будет пустым, и вызов signal не даст результата.

Задачи планирования, подобные рассмотренной, наиболее трудны, какой бы механизм синхронизации не использовался. Главное в решении— точно определить порядок обслуживания процессов. Когда порядок статичен, как здесь, можно использовать приоритетные операторы wait. Но, как отмечалось ранее, при динамическом порядке обслуживания необходимо использовать либо скрытые условные переменные для запуска отдельных процессов, либо покрывающие условия, позволяя приостановленным процессам осуществлять планирование самостоятельно.
5.3.2. Использование посредника
Чтобы привести структуру решения к задаче планирования и распределения, желательно реализовать монитор Disk_Scheduler или другой контроллер ресурсов в виде отдельного монитора. Поскольку диспетчер изолирован, его можно разрабатывать независимо от других компонентов. Однако чрезмерная изоляция обычно приводит к двум проблемам:
• присутствие диспетчера видно процессам, использующим диск. Если удалить диспетчер, изменятся пользовательские процессы;
• все пользовательские процессы должны следовать необходимому протоколу: запрос диска, его использование, освобождение. Если хотя бы один процесс нарушает этот протокол, планирование невозможно.
Обе проблемы можно смягчить, если протокол использования диска поместить в процедуру, а пользовательским процессам не давать прямого доступа ни к диску, ни к диспетчеру. Однако это приводит к дополнительному уровню процедур и соответствующему снижению эффективности. Еще одна проблема возникает, когда к диску обращается процесс драйвера диска, а не процедуры, напрямую вызываемые пользовательскими процессами. Получив доступ к диску, пользовательский процесс должен передать драйверу аргументы и получить результаты (см.
Глава 5. Мониторы 189
рис. 5.4). Взаимодействие пользовательского процесса и драйвера можно реализовать с помощью двух экземпляров монитора кольцевого буфера (см. листинг 5.3). Но тогда пользовательский интерфейс будет состоять из трех мониторов — диспетчера и двух кольцевых буферов, а пользователь при каждом использовании устройства должен будет делать по четыре вызова процедур монитора. Поскольку между пользователями и драйвером диска поддерживаются отношения клиент-сервер, интерфейс взаимодействия можно реализовать, используя вариант решения задачи о спящем парикмахере. Но все еще остаются два монитора — для планирования и для взаимодействия пользовательского процесса с драйвером диска.
Когда диск управляется процессом драйвера, лучше всего объединить диспетчер и интерфейс взаимодействия в один монитор. По существу, диспетчер становится посредником между пользовательскими процессами и драйвером диска, как показано на рис. 5.5. Монитор перенаправляет запросы пользователя драйверу в нужном порядке. Этот способ дает три преимущества. Первое: интерфейс диска использует только один монитор, и пользователь для получения доступа к диску должен сделать только один вызов процедуры монитора. Второе: не видно присутствия или отсутствия диспетчера. Третье: нет многошагового протокола, которому должен следовать пользователь. Таким образом, этот подход позволяет преодолеть все трудности, возникающие при выделении диспетчера в отдельный монитор.

В оставшейся части этого раздела показано, как преобразовать решение задачи о спящем парикмахере (листинг 5.8) в интерфейс драйвера диска, который и обеспечивает взаимодействие между клиентами и драйвером диска, и реализует стратегию планирования CSCAN. Решение задачи о спящем парикмахере нужно немного изменить. Первое: переименовать процессы, монитор и процедуры монитора, как описано ниже и показано в листинге 5.10. Второе: в процедуры монитора добавить параметры для передачи запросов пользователей (посетителей) к драйверу диска (парикмахеру) и обратной передачи результатов. По сути, "кресло парикмахера" и "выходную дверь" нужно превратить в буферы взаимодействия. Наконец, нужно добавить планирование к рандеву пользователь—драйвер диска, чтобы драйвер обслуживал предпочтительный запрос пользователя. Перечисленные изменения приводят к интерфейсу диска, схема которого показана в листинге 5.10.
Листинг 5.10. Схема монитора интерфейса диска
monitor Disk_Interface {
постоянные переменные для состояния, планирования и передачи данных
procedure use_disk(int cyl, параметры передачи и результата) {
ждать очереди использовать драйвер
сохранить параметры передачи в постоянных переменных
ждать завершения передачи
получить результаты из постоянных переменных
}
procedure get_next_request(someType &results) {
выбрать следующий запрос
ждать сохранения параметров передачи
присвоить переменной results параметры передачи
}
190 Часть 1. Программирование с разделяемыми переменными
procedure finished_transfer(someType results) { сохранить результаты в постоянные переменные ждать получения клиентом значения results }
_}_______________________________________________________________________________
Чтобы уточнить схему до полноценного решения, используем ту же базовую синхронизацию, что и в решении задачи о спящем парикмахере (см. листинг 5.8). К ней добавим планирование, как в мониторе Disk_Scheduler (см. листинг 5.9), и передачу параметров, как в кольцевом буфере (см. листинг 5.3). Инвариант монитора Disk_Interf асе становится, по существу, конъюнкцией инварианта для парикмахерской BARBER, инварианта диспетчера DISK и инварианта кольцевого буфера ВВ (упрощенного для одной ячейки).
Пользовательский процесс ждет очереди на доступ к диску, выполняя те же действия, что и процедура request монитора Disk_Scheduler (см. листинг 5.9). Аналогично процесс драйвера показывает, что он доступен, выполняя те же действия, что и процедура release монитора Disk_Scheduler. В начальном состоянии, однако, переменной position будет присваиваться значение -2, чтобы показать, что диск недоступен и не используется до того, как драйвер впервые вызовет процедуру get_next_request. Следовательно, пользователи должны ждать начала первого прохода.
Когда приходит очередь пользователя на доступ к диску, пользовательский процесс помещает свои аргументы передачи в постоянные переменные и ждет, чтобы затем извлечь результаты. После выбора следующего запроса пользователя процесс драйвера ждет получения аргументов пользователя. Затем драйвер выполняет требуемую дисковую передачу данных. После ее завершения драйвер помещает результаты и ждет их извлечения.
Информация помещается и извлекается с помощью буфера с одной ячейкой. Перечисленные уточнения приводят к монитору, изображенному в листинге 5.11.
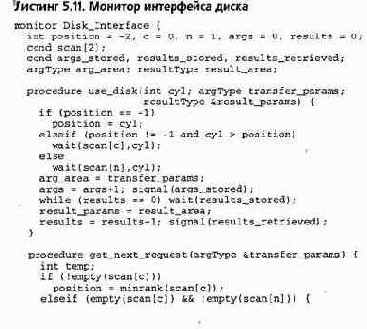

С помощью двух сравнительно простых изменений этот интерфейс между пользователем и драйвером диска можно сделать еще эффективнее. Во-первых, драйвер диска может быстрее начать обработку следующего пользовательского запроса, если в процедуре f inished_transf er исключить ожидание извлечения результатов предыдущей передачи. Но это нужно делать осторожно, чтобы область результатов не была перезаписана, когда драйвер завершает следующую передачу данных, а результаты предыдущей еще не извлечены. Во-вторых, можно объединить две процедуры, вызываемые драйвером диска. Тогда при обращении к диску экономится один вызов процедуры монитора. Реализация этих преобразований требует изменить инициализацию переменной results. Внесение обеих поправок предоставляется читателю.
5.3.3. Использование вложенного монитора
Если диспетчер доступа к диску является отдельным монитором, пользовательские процессы должны следовать протоколу: запрос диска, работа с ним, освобождение. Сам по себе диск управляется процессом или монитором. Когда диспетчер доступа к диску является посредником, пользовательский интерфейс упрощается (пользователю достаточно сделать всего один запрос), но монитор становится значительно сложнее, как видно из сравнения листингов 5.9 и 5.11. Кроме того, решение в листинге 5.11 предполагает, что диском управляет процесс драйвера.
Третий способ состоит в объединении двух стилей с помощью двух мониторов: одного для планирования и одного для доступа к диску (рис. 5.6). Однако при использовании такой структуры необходимо, чтобы вызовы из монитора диспетчера освобождали исключение в мониторе доступа. Ниже мы исследуем это свойство вложенных вызовов мониторов и разработаем схему решения задачи планирования доступа к диску.
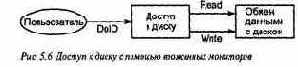
Несколько процессов не могут получить одновременный доступ к постоянным переменным монитора, поскольку в процедурах монитора процессы выполняются со взаимным исключением.
Но что произойдет, если процесс, выполняющий процедуру в одном мониторе, вызовет процедуру в другом мониторе и, следовательно, на время покинет первый? Если исключение монитора при таком вложенном вызове сохраняется, то вложенный вызов называется закрытым. Если при вложенном вызове исключение монитора снимается, а после него восстанавливается, то он называется открытым.
192 Часть 1. Программирование с разделяемыми переменными
Ясно, что при закрытом вызове постоянные переменные монитора защищены от параллельного доступа, поскольку никакой другой процесс не может войти в монитор во время выполнения вложенного вызова. Постоянные переменные защищены от параллельного доступа и при открытом вызове, если только они не передаются по ссылке в качестве аргументов вызова. Однако открытый вызов снимает исключение, поэтому инвариант монитора должен быть истинным перед вызовом. Таким образом, у открытых вызовов семантика сложнее, чем у закрытых. С другой стороны, закрытый вызов в большей степени чреват тупиком. Например, если процесс после вложенного вызова приостановлен оператором wait, его уже не сможет запустить другой процесс, который должен выполнить тот же набор вложенных вызовов.
Задача планирования доступа к диску является конкретным примером, в котором возникают описанные проблемы. Как уже отмечалось, решение задачи можно изменить в соответствии с рис. 5.6. Монитор Disk_Scheduler из программы в листинге 5.9 заменен двумя мониторами. Пользовательский процесс делает один вызов операции doIO монитора Disk_Access. Этот монитор планирует доступ, как в листинге 5.9. Когда приходит очередь процесса на доступ к диску, он делает второй вызов операции read или write монитора Disk_Transf er. Этот второй вызов происходит из монитора Disk_Access, имеющего следующую структуру, monitor Disk_Access {
постоянные переменные такие же, как в мониторе Disk_Scheduler ;
procedure doIOfint cyl; аргументы передачи и результата) { действия процедуры Disk_Scheduler.
request; вызов Disk_Transfer. read или Disk_Transf er .write ; действия процедуры Disk_Scheduler. release; } >
Вызовы монитора Disk_Transf er являются вложенными. Для планирования доступа к диску они должны быть открытыми, иначе в процедуре doIO не смогут одновременно находиться несколько процессов, и действия request и release станут ненужными. Здесь можно использовать открытые вызовы, поскольку в качестве аргументов для монитора Disk_Transf er передаются только локальные переменные (параметры процедуры doIO), а инвариант диспетчера доступа DISK перед вызовом операций read или wr i te остается истинным.
Независимо от семантики вложенных вызовов, остается проблема взаимного исключения внутри монитора. При последовательном выполнении процедур монитора параллельный доступ к его постоянным переменным невозможен. Однако это не всегда обязательно для исключения взаимного влияния процедур. Если процедура считывает, но не изменяет постоянные переменные, то ее разные вызовы могут выполняться параллельно. Или, если процедура просто возвращает значение некоторой постоянной переменной, и оно может читаться неделимым образом, . з эта процедура может выполняться параллельно с другими процедурами монитора. Значение, возвращенное вызвавшему процедуру процессу, может не совпадать с текущим значением постоянной переменной, но так всегда бывает в параллельных программах. К примеру, можно добавить процедуру read_clock к монитору Timer в листинге 5.6 или 5.7. Независимо от того, выполняется процедура read_clock со взаимным исключением или нет, вызвавший ее процесс знает лишь, что возвращаемое значение не больше текущего значения переменной tod.
Иногда возможно одновременное безопасное выполнение даже разных процедур монитора, изменяющих постоянные переменные. Например, в предыдущих главах было показано, что потребитель и производитель могут одновременно обращаться к разным ячейкам кольцевого буфера (например, см. листинг 4.5).
Если процедуры монитора должны выполняться со взаимным исключением, то такой буфер запрограммировать очень сложно. Необходимо либо представить каждую ячейку буфера в отдельном мониторе, либо буфер должен быть глобальным по отношению к процессам, которые синхронизируются с помощью мониторов, реализующих семафоры. К счастью, такие ситуации встречаются редко.

Глава 5. Мониторы 195
Это простой пример программирования мониторов на языке Java: постоянные переменные являются скрытыми данными класса, а процедуры монитора реализованы с помощью синхронизированных методов. В языке Java на один объект приходится по одной блокировке. Когда вызывается метод, определенный с ключевым словом synchronized, он ждет получения этой блокировки, выполняет тело метода и снимает блокировку.
Указанный выше пример можно запрограммировать иначе, используя ключевое слово synchronized для операторов внутри метода.
class Interfere {
private int data = 0; public void update() {
synchronized (this) { // блокировка данного объекта
data+ " } } }
Ключевое слово this ссылается на объект, для которого был вызван метод update, и, следовательно, на блокировку этого объекта. Синхронизированный оператор (с ключевым словом synchronized), таким образом, аналогичен оператору await, а синхронизированный метод — процедуре монитора.
Язык Java поддерживает условную синхронизацию с помощью операторов wait Hnotify; они очень похожи на операторы wait и signal, использованные ранее в этой главе. Но операторы wait и notify в действительности являются методами класса Object, родительского для всех классов языка Java. И метод wait, и метод notify должны выполняться внутри кода с описанием synchronized, т.е. при заблокированном объекте.
Метод wait снимает блокировку объекта и приостанавливает выполнение потока. У каждого объекта есть одна очередь задержки. Обычно (но не обязательно) это FIFO-очередь.
Язык Java не поддерживает условные переменные , но можно считать, что на каждый синхронизированный объект приходится по одной (неявно объявленной) условной переменной.
Метод notify запускает поток из начала очереди задержки, если он есть. Поток, вызвавший метод notify, продолжает удерживать блокировку объекта, так что запускаемый поток начнет работу через некоторое время, когда получит блокировку объекта. Это значит, что метод notify имеет семантику "сигнализировать и продолжить". Язык Java также поддерживает оповещающий сигнал с помощью метода noti f yAll, аналогичного процедуре signal_all. Поскольку у объекта есть только одна (неявная) переменная, методы wait, not i f у и not i f yAl 1 не имеют параметров.
Если синхронизированный метод (или оператор) одного объекта содержит вызов метода в другом объекте, то блокировка первого объекта во время выполнения вызова удерживается. Таким образом, вложенные вызовы из синхронизированных методов в языке Java являются закрытыми. Это не позволяет для решения задачи планирования доступа к диску с вложенными мониторами использовать струк^ру, изображенную на рис. 5.6. Это также может привести к зависанию программы, если изсинхронизированного метода одного объекта вызывается синхронизированный метод другого объекта и наоборот.
5.4.3. Читатели и писатели с параллельным доступом
В данном и следующих двух подразделах представлен ряд примеров, иллюстрирующих аспекты параллелизма и синхронизации программ на языке Java, использование классов, деклараций и операторов. Все три программы являются завершенными: их можно откомпилировать компилятором javac и выполнить с помощью интерпретатора Java. (За подробностями использования языка Java обращайтесь к своей локальной инсталляции; на Web-странице этой книги также есть исходные коды программ.)
196 Часть 1. Программирование с разделяемыми переменными
Сначала рассмотрим параллельную версию программы читателей и писателей, в которой читатели и писатели могут обращаться к базе данных параллельно.
Хотя в этой программе возможно взаимное влияние процессов, она служит для иллюстрации структуры программ на языке Java и использования потоков.
Исходный пункт программы — это класс, инкапсулирующий базу данных. Используем очень простую базу данных — одно целочисленное значение. Класс предоставляет две операции (метода), read и write. Класс определен так.

Членами класса являются поле data и два метода, read и write. Поле data объявлено с ключевым словом protected, т.е. оно доступно только внутри класса или в подклассах, наследующих этот класс (или в других классах, определенных в том же модуле). Методы read и write объявлены с ключевым словом public; это значит, что они доступны везде, где доступен класс. Каждый метод при запуске выводит одну строку, которая показывает текущее значение поля data; метод write увеличивает его значение.
Следующие классы в нашем примере — Reader и Writer. Они содержат коды процессов читателя и писателя и являются расширениями класса Thread. Каждый из них содержит метод инициализации с тем же именем, что и у класса; этот метод выполняется при создании нового экземпляра класса. Каждый класс имеет метод run, в котором находится код потока. Класс Reader определен так.

Когда создается экземпляр любого из этих классов, новый объект получает два параметра: число циклов выполнения rounds и экземпляр класса RWbasic. Методы инициализации сохраняют параметры в постоянные переменные rounds и RW. Внутри методов инициализации имена переменных предваряются ключевым словом this, чтобы различать постоянную переменную и параметр с тем же именем.
Три определенных выше класса Rwbasic, Reader и Writer — это "строительные блоки" программы для задачи о читателях и писателях, в которой читатели и писатели могут параллельно обращаться к одному экземпляру класса RWbasic. Чтобы закончить программу, нужен главный класс, который создает по одному экземпляру каждого класса и запускает потоки Reader и Writer на выполнение.

Программа начинает выполнение с метода main, который имеет параметр args, содержащий аргументы командной строки. Здесь это один аргумент, задающий число циклов, которые должен выполнить каждый поток. Программа выводит последовательность строк со считанными и записанными значениями. Всего выводится 2*rounds строк, поскольку работают два потока и каждый выполняет rounds итераций цикла.
5.4.4. Читатели и писатели с исключительным доступом
Приведенная выше программа позволяет потокам параллельно работать с полем data. Изменим ее, чтобы обе|спечить взаимно исключающий доступ к этому полю. Сначала определим новый класс RWexclusive, который расширяет класс RWbasic для использования синхронизированных методов read и write.


Глава 5. Мониторы , 199
while (nr > 0) //приостановка, если есть активные потоки Reader
try { wait(); }
catch (InterruptedException ex) {return;} data++;
System.out.println("записано: " + data); notify(); // запустить еще один ожидающий Writer } }
Нужно также изменить классы Reader, Writer и Main, чтобы они использовали этот класс вместо RWexclusive, но больше ничего менять не нужно. (Это одно из преимуществ объектно-ориентированных языков программирования.)
В классе ReadersWriters появились два новых локальных (с ключевым словом private) метода: startRead и endRead. Их вызывает метод read перед обращением к базе данных и после него. Метод startRead увеличивает значение скрытой переменной nr, которая учитывает число активных потоков-читателей. Метод endRead уменьшает значение переменной nr. Если она становится равной нулю, то для запуска ожидающего писателя (если он есть) вызывается процедура notify.
Методы startRead, endRead и write синхронизированы, поэтому в любой момент времени может выполняться только один из них. Следовательно, когда активен метод startRead или endRead, поток писателя выполняться не может.
Метод read не синхронизирован, поэтому его одновременно могут вызывать несколько потоков. Если поток писателя вызывает метод write, когда поток читателя считывает данные, значение nr положительно, поэтому писатель перейдет в состояние ожидания. Писатель запускается, когда значение nr становится равным нулю. После работы с полем data писатель запускает следующий ожидающий процесс-писатель с помощью метода notify. Поскольку метод notify имеет семантику "сигнализировать и продолжить", писатель не сможет выполняться, если еще один читатель увеличит значение nr, поэтому писатель перепроверяет значение nr.
В приведенном выше методе write вызов wait находится внутри так называемого оператора try. Это механизм обработки исключений языка Java, который помогает программисту обрабатывать нештатные ситуации. Поскольку ожидающий поток может быть остановлен или завершен ненормально, оператор wait необходимо использовать внутри оператора try, обрабатывающего исключительную ситуацию InterruptedException. В данном коде просто происходит выход из метода wr i te, если во время ожидания потока возникла исключительная ситуация.
Преимущество приведенного решения задачи о читателях и писателях по отношению к показанному ранее в листинге 5.4 состоит в том, что интерфейс потоков писателей организован в одну процедуру write, а не в две, request_write () и release_write (). Тем не менее в обоих решениях читатели имеют преимущество перед писателями. Подумайте, как изменить приведенное решение, чтобы отдать преимущество писателям или сделать решение справедливым (см. упражнения в конце главы).
мых аппаратных контроллеров, позволявших центральному
Предисловие
Параллельное программирование возникло в 1962 г. с изобретением каналов — независи мых аппаратных контроллеров, позволявших центральному процессору выполнять новую прикладную программу одновременно с операциями ввода-вывода других (приостановленных) программ. Параллельное программирование (слово параллельное в данном случае означает "происходящее одновременно"') первоначально было уделом разработчиков операционных систем. В конце 60-х годов были созданы многопроцессорные машины. В результате не только были поставлены новые задачи разработчикам операционных систем, но и появились новые возможности у прикладных программистов.
Первой важной задачей параллельного программирования стало решение проблемы так называемой критической секции. Эта и сопутствующие ей задачи ("обедающих философов", "читателей и писателей" и т.д.) привели к появлению в 60-е годы огромного числа научных работ. Для решения данной проблемы и упрощения работы программиста были разработаны такие элементы синхронизации, как семафоры и мониторы. К середине 70-х годов стало ясно, что для преодоления сложности, присущей параллельным программам, необходимо использовать формальные методы.
На рубеже 70-х и 80-х годов появились компьютерные сети. Для глобальных сетей стандартом стал Arpanet, а для локальных— Ethernet. Сети привели к росту распределенного программирования, которое стало основной темой в 80-х и, особенно, в 90-х годах. Суть рас-пределенног9 программирования состоит во взаимодействии процессов путем передачи сообщений, а не записи и чтения разделяемых переменных.
Сейчас, на заре нового века, стала заметной необходимость обработки с массовым параллелизмом, при которой для решения одной задачи используются десятки, сотни и даже тысячи процессоров. Также видна потребность в технологии клиент-сервер, сети Internet и World Wide Web. Наконец, стали появляться многопроцессорные рабочие станции и ПК. Параллельное аппаратное обеспечение используется больше, чем когда-либо, а параллельное программирование становится необходимым.
Это моя третья книга, в которой предпринята попытка охватить часть истории параллельного программирования. Первая книга — Concurrent Programming: Principles and Practice, опубликованная в 1991 г., — дает достаточно полное описание периода между 1960 и 1990 годами. Основное внимание в ней уделяется новым задачам, механизмам программирования и формальным методам.
Вторая книга — The SR Programming Language: Concurrency in Practice, опубликованная в 1993 году, —-подводит итог моей работы с Роном Одеоном (Ron Olsson) в конце 80-х и начале 90-х годов над специальным языком программирования, который может использоваться при написании параллельных программ для систем как с разделяемой, так и с распределенной памятью. Книга о языке SR является скорее практическим руководством, чем формальным описанием языка, поскольку демонстрирует пути решения многих проблем с использованием одного языка программирования.
Данная книга выросла из предыдущих и является отражением моих мыслей о том, что важно сейчас и в будущем. Многое почерпнуто из книги Concurrent Programming, но полностью переработан каждый раздел, взятый из нее, и переписаны все примеры программ на псевдоС вместо языка SR. Все разделы дополнены новым материалом; особенно это каса-
1 Слово "параллельный" в большинстве случаев является переводом английского "concurrent". Применительно к программам, вычислениям и программированию его смысл, возможно, лучше передавался бы словом "многопроцессный", но этого термина в русскоязычной литературе нет. Перевод английского "parallel" связан с синхронным параллелизмом, и его смысл определяется в разделах 1.3 и 3.5 и уточняется в самом начале части 3. Отметим, что смысл слова "concurrent" шире, чем "parallel". — Прим. ред.
14 Предисловие
ется параллельного научного программирования.
Также добавлены учебные примеры по наиболее важным языкам программирования и библиотекам программ, содержащие завершенные учебные программы. И, наконец, я по-новому вижу использование этой книги — в аудиториях и личных библиотеках.
Новое видение и новая роль
Идеи параллельных и распределенных вычислений сегодня распространены повсеместно. Как обычно в вычислительной технике, прогресс исходит от разработчиков аппаратного обеспечения, которые создают все более быстрые, большие и мощные компьютеры и коммуникационные сети. Большей частью, они достигают успеха, и лучшее доказательство тому — фондовая биржа!
Новые компьютеры и сети создают новые проблемы и возможности, а разработчики программного обеспечения по-прежнему не отстают. Вспомните Web-броузеры, Internet-коммерцию, потоки Pthread, язык Java, MPI, и вновь доказательством служит фондовая биржа! Эти программные продукты разрабатываются специально для того, чтобы использовать все преимущества параллельности в аппаратной и программной части. Короче говоря, большая часть мира вычислительной техники сейчас параллельна!
Аспекты параллельных вычислений — многопоточных, параллельных или распределенных — теперь рассматриваются почти в каждом углубленном курсе по вычислительной технике. Отражая историю, курсы по операционным системам охватывают такие темы, как многопоточность, протоколы взаимодействия и распределенные файловые системы. Курсы по архитектуре вычислительной техники — многопроцессорность и сети, по компиляторам — вопросы компиляции для параллельных машин, а теоретические курсы — модели параллельной обработки данных. В курсах по алгоритмам изучаются параллельные алгоритмы, а по базам данных — блокировка и распределенные базы данных. В курсах по графике используется параллелизм при визуализации и трассировке лучей Этот список можно продолжить. Кроме того, параллельные вычисления стали фундаментальным инструментом в широкой области научных и инженерных дисциплин.
Главная цель книги, как видно из ее названия, — заложить основу для программирования многопоточных, параллельных и распределенных вычислений. Частная цель — создать текст, который можно использовать в углубленном курсе для студентов и магистров. Когда некоторая тема становится распространенной, как это произошло с параллелизмом, вводятся учебные курсы по ее основам. Аналогично, когда тема становится хорошо изученной, как сейчас параллелизм, она переносится в нормативный курс.
Я пытался охватить те вопросы параллельной и распределенной обработки данных, которые, по моему мнению, должен знать любой студент, изучающий вычислительную технику. Сюда включены основные принципы, методы программирования, наиболее важные приложения, реализации и вопросы производительности. Я добавил также материал по важнейшим языкам программирования и библиотекам программ — потоки Pthread (три главы), язык Java (три главы), CSP, Linda, MPI (две главы), языки Ада, SR и ОрепМР. В каждом примере сначала описаны соответствующие части языка программирования или библиотеки, а затем представлена полная программа. Исходные тексты программ доступны на Web-сайте этой книги. Кроме того, в главе 12 приведен обзор нескольких дополнительных языков, моделей и инструментов для научных расчетов.
С другой стороны, ни в одной книге нельзя охватить все, поэтому, возможно, студенты и преподаватели захотят дополнить данный текст. Исторические справки и списки литературы в конце каждой главы описывают дополнительные материалы и содержат указания для дальнейшего изучения. Информация для дальнейшего изучения и ссылки на соответствующие материалы представлены на Web-сайте этой книги.
Предисловие 15
Обзор содержания
Эта книга состоит из 12 глав. В главе 1 дается обзор основных идей параллелизма, аппаратной части и приложений. Затем рассматриваются пять типичных приложений: умножение матриц, адаптивная квадратура, каналы ОС Unix, файловые системы и распределенное умножение матриц.
Каждое приложение просто, но, тем не менее, полезно: вместе они иллюстрируют некоторый диапазон задач и пять стилей программирования многократных вычислений. В последнем разделе главы 1 резюмируется программная нотация, использованная в книге.
Оставшиеся главы разделены на три части. Часть 1 описывает механизмы параллельного программирования, которые используют разделяемые переменные и поэтому непосредственно применяются к машинам с разделяемой памятью. В главе 2 представлены базовые понятия процессов и синхронизации; основные моменты иллюстрируются рядом примеров. Заканчивается глава обсуждением формальной семантики параллелизма. Понимание семантических концепций поможет вам разобраться в некоторых разделах последующих глав. В главе 3 показано, как реализовать и использовать блокировки и барьеры, описаны алгоритмы, параллельные по данным, и метод параллельного программирования, называемый "портфель задач". В главе 4 представлены семафоры и многочисленные примеры их использования. Семафор был первым механизмом параллельного программирования высокого уровня и остается одним из важнейших. В главе 5 подробно описаны мониторы. Они появились в 1974г.; в 80-е и в начале 90-х годов внимание к ним несколько угасло, но появление языка Java возобновило интерес к ним. Наконец, в главе 6 представлена реализация процессов, семафоров и мониторов на одно- и многопроцессорных машинах.
Часть 2 посвящена распределенному программированию, в котором процессы взаимодействуют и синхронизируются, используя сообщения. В главе 7 описана передача сообщений с помощью элементарных операций send и receive. Демонстрируется, как использовать эти операции для программирования фильтров (программ с односторонней связью), клиентов и серверов (с двусторонней связью), а также взаимодействующих равных (с передачей в обоих направлениях). В главе 8 рассматриваются два дополнительных примитива взаимодействия: удаленный вызов процедуры (RPC) и рандеву.
Процесс- клиент инициирует связь, посылая сообщение call (неявно оно является последовательностью сообщений send и receive). Взаимодействие обслуживается или новым процессом (RPC), или с помощью рандеву с существующим процессом. В главе 9 описано несколько моделей взаимодействия процессов в распределенных программах. Три из них обычно используются в параллельных вычислениях— "управляющий-рабочие", алгоритм пульсации и конвейер. Еще четыре возникли в распределенных системах — зонд-эхо, оповещение (рассылка), передача маркера и дублируемые серверы. Наконец, в главе 10 описана реализация передачи сообщений, RPC и рандеву. Показано, как реализовать так называемую распределенную разделяемую память, которая поддерживает модель программирования с разделяемой памятью в распределенной среде.
Часть 3 посвящена синхронному параллельному программированию, особенно его применению к высокопроизводительным научным вычислениям. (Многие другие типы синхронных параллельных вычислений рассмотрены в предыдущих главах и в упражнениях к нескольким из них.) Цель параллельной программы — ускорение, т.е. более быстрое решение задачи с помощью большого числа процессоров. Синхронные параллельные программы пишутся с использованием разделяемых переменных или передачи сообщений, следовательно, в них применяется методика, описанная в частях 1 и 2. В главе 11 рассматриваются три основных класса приложений для научных вычислений: сеточные, точечные и матричные. Они возникают при моделировании физических и биологических систем; матричные вычисления используются и для таких задач, как экономическое прогнозирование. В главе 12 дан обзор наиболее важных инструментов для написания научных параллельных вычислительных программ: библиотеки (Pthread, MPI, OpenMP), распараллеливающие компиляторы, языки и модели, а также такие инструменты более высокого уровня, как метавычисления.
16 Предисловие
В конце каждой главы размещены историческая справка, ссылки на литературу и упражнения. В исторической справке резюмируются происхождение, развитие и связи каждой темы с другими темами, а также описываются статьи и книги из списка литературы. В упражнениях представлены вопросы, поднятые в главе, и дополнительные приложения.
Использование в учебном процессе
Я использую эту книгу каждой весной в университете штата Аризона, читая курс примерно для 60 студентов. Около половины из них — магистры; остальные — студенты старших курсов. В основном это студенты специальности "computer science". Данный курс для них не обязателен, но большинство студентов его изучают. Также каждый год курс проходят несколько аспирантов других отделений, интересующихся вычислительной техникой и параллельными вычислениями. Большинство студентов одновременно проходят и наш курс по операционным системам.
В наших курсах по ОС, как и везде, рассматриваются потребности ОС в синхронизации и изучается реализация синхронизации, процессов и других элементов ОС, в основном, на однопроцессорных машинах. Мой курс демонстрирует, как использовать параллельность в качестве общего инструмента программирования для широкого диапазона приложений. Я рассматриваю методы программирования, концепции высокого уровня, параллельную и распределенную обработку данных. По существу, мой курс относится к курсу по ОС примерно так же, как сравнительный курс языков программирования относится к курсу по компиляторам.
В первой половине моего курса я подробно излагаю главу 2, а затем быстро прохожу по остальным главам первой части, акцентируя внимание на темах, не рассматриваемых в курсе по ОС, — протокол "проверить-проверить-установить" (Test-and-Test-and-Set), алгоритм билета, барьеры, передача эстафеты для семафоров, некоторые способы программирования мониторов и многопроцессорное ядро. В дополнение к этому студенты самостоятельно изучают библиотеку Pthread, потоки языка Java и синхронизированные методы.
После лекций по барьерам они выполняют проект по синхронным параллельным вычислениям (на основе материала главы 11).
Во второй половине курса я использую многое из материала части 2 книги, касающегося распределенного программирования. Мы рассматриваем передачу сообщений и ее использование в программировании как распределенных систем, так и распределенных параллельных вычислений. Затем мы изучаем RPC и рандеву, их воплощение в языках Java и Ada и приложения в распределенных системах. Наконец, мы рассматриваем каждую парадигму из главы 9, вновь используя для иллюстрации и мотивировки приложения из области синхронных параллельных и распределенных систем. Самостоятельно студенты изучают библиотеку MPI и снова используют язык Java.
В течение семестра я даю четыре домашних задания, два аудиторных экзамена, проект по параллельным вычислениям и заключительный проект. (Примеры представлены на Web-сайте книги.) Каждое домашнее задание состоит из письменных упражнений и одной или двух задач по программированию. Магистры должны выполнить все упражнения, другие студенты — две трети задач (по своему выбору). Экзамены проводятся аналогично: магистры решают все задачи, а остальные выбирают вопросы, на которые хотят отвечать. В Аризонском университете начальные задачи по программированию мы решаем с помощью языка SR, который студенты могут использовать и в дальнейшем, но поощряется использование таких языков и библиотек, как Pthreads, Java и MPI.
Проект по синхронному параллельному программированию связан с задачами из главы 11 (обычно это сеточные вычисления). Студенты пишут программы и экспериментируют на небольшом мультипроцессоре с разделяемой памятью. Магистры реализуют более сложные алгоритмы и обязаны написать подробный отчет о своих опытах. Заключительный проект — это статья или программный проект по какому-либо вопросу распределенного программирования. Студенты выбирают тему, которую я утверждаю. Большинство студентов выполняют
Предисловие 17
проекты по реализации, многие из них работают парами. Студенты создают разнообразные интересные системы, в основном, с графическим интерфейсом.
Несмотря на то что студенты, изучающие мой курс, имеют различную подготовку, почти все оценивают его отлично. Студенты часто отмечают, насколько хорошо курс согласуется с их курсом по ОС; им нравится взгляд на параллельность с другой точки зрения, изучение многопроцессорных систем, им интересно рассматривать широкий спектр приложений и инструментов. Магистры отмечают, что курс связывает воедино разные вещи, о которых они уже что-то слышали, и вводит их в область параллельного программирования. Однако многим из них было бы интересно изучить параллельные вычисления более подробно Со временем мы надеемся сделать отдельные курсы для магистров и студентов. Я не буду значительно изменять курс для студентов, но в нем будет меньше углубленных тем. В курсе для магистров я буду тратить меньше времени на материал, с которым они уже знакомы (часть 1), и больше времени посвящать синхронным параллельным приложениям и инструментарию синхронных вычислений (часть 3).
Эта книга идеально подходит для курса, который охватывает область механизмов параллельного программирования, средств и приложений. Почти все студенты смогут использовать что-то из рассмотренного здесь, но не все будут заниматься только параллельной обработкой данных, только распределенными системами или программировать только на языке Java. Тем не менее книгу можно использовать и как пособие в более специализированных курсах, например, в курсе синхронных параллельных вычислений, вместе с книгами по параллельным алгоритмам и приложениям.
Информация в Internet
"Домашняя страничка" этой книги находится по адресу:
http://www.cs.arizona.edu/people/greg/mpdbook
На этом сайте есть исходные тексты программ из книги, ссылки на программное обеспечение и информацию о языках программирования и библиотеках, описанных в примерах; большое число других полезных ссылок.
Также сайт содержит обширную информацию о моем курсе в Аризонском университете, включая программу курса, конспекты лекций, копии домашних заданий, проектов и экзаменационных вопросов. Информация об этой книге также доступна по адресу:
http://www.awlonline.com/cs
Несмотря на мои усилия, книга, без сомнения, содержит ошибки, так что по этому адресу появится (уверен, что скоро) их список. Безусловно, в будущем добавятся и другие материалы.
Благодарности
Я получил множество полезных замечаний от читателей чернового варианта этой книги. Марте Тиенари (Martti Tienary) и его студенты из университета Хельсинки обнаружили несколько неочевидных ошибок. Мои последние аспиранты, Вине Фрих (Vince Freeh) и Дейв Ловентал (Dave Lowenthal), прокомментировали новые главы и за последние несколько лет помогли отладить если не мои программы, то мои мысли. Студенты, изучавшие мой курс весной 1999 г., служили "подопытными кроликами" и нашли несколько досадных ошибок. Энди Бернат (Andy Bernat) предоставил отзыв о своем курсе в университете в Эль-Пасо, Техас, который он провел весной 1999 г. Благодарю следующих рецензентов за их бесценные отзывы: Джаспал Субхлок (Jaspal Subhlok) из университета Carnegy Mellon, Болеслав Жимански (Boleslaw Szymansky) из политехнического института Rensselaer, Дж. С. Стайлс (G. S. Stiles) из Utah State University, Нарсингх Део (Narsingh Deo) из Central Florida University, Джанет Харт-ман (Janet Hartman) из Illinois State University, Нэн Шаллер (Nan С. Schaller) из Технологического института Рочестера и Марк Файнап (Mark Fineup) из университета Северной Айовы.
В течение многих лет организация National Science Foundation поддерживает мои исследования, в основном по грантам CCR-9415303 и ACR-9720738. Грант от NSF (CDA-9500991) помог обеспечить оборудование для подготовки книги и проверки программ.
И главное — я хочу поблагодарить мою жену Мэри, еще раз смирившуюся с долгими часами, которые я провел, работая над этой книгой (несмотря на клятвы вроде "больше никогда" после завершения книги о языке SR).
Приложения и стили программирования
Параллельное программирование обеспечивает способ организации программного обеспечения, состоящего из относительно независимых частей. Оно также позволяет использовать множественные процессоры. Существует три обширных перекрывающихся класса приложений — многопоточные системы, распределенные системы и синхронные параллельные вычисления — и три соответствующих им типа параллельных программ.
Напомним, что процесс— это последовательная программа, которая при выполнении имеет собственный поток управления. Каждая параллельная программа содержит несколько процессов, поэтому имеет несколько потоков. Однако термин многопоточный обычно означает, что программа содержит больше процессов (потоков), чем существует процессоров для их выполнения. Следовательно, процессы на процессорах выполняются по очереди. Многопоточная программная система управляет множеством независимых процессов, например таких:
• оконные системы на персональных компьютерах или рабочих станциях;
• многопроцессорные операционные системы и системы с разделением времени;
• системы реального времени, управляющие электростанциями, космическими аппаратами и т.д.
Эти системы разработаны как многопоточные программы, поскольку организовать код и структуры данных в виде набора процессов намного проще, чем реализовать огромную последовательную программу. Кроме того, каждый процесс может планироваться и выполняться независимо. Например, когда пользователь нажимает кнопку мыши персонального компьютера, посылается сигнал процессу, управляющему окном, в котором в данный момент находится курсор мыши. Этот процесс (поток) может выполняться и отвечать на щелчок мыши. Приложения в других окнах могут продолжать при этом свое выполнение в фоновом режиме. Второй широкий класс приложений образуют распределенные вычисления, в которых компоненты выполняются на машинах, связанных локальной или глобальной сетью. По этой причине процессы взаимодействуют, обмениваясь сообщениями.
Вот примеры:
• файловые серверы в сети;
• системы баз данных для банков, заказа авиабилетов и т.д.;
• Web-серверы сети Internet;
26 Глава 1. Обзор области параллельных вычислений
• предпринимательские системы, объединяющие компоненты производства;
• отказоустойчивые системы, которые продолжают работать независимо от сбоев в компонентах.
Такие системы пишутся для распределения обработки (как в файловых серверах), обеспечения доступа к удаленным данным (как в базах данных и в Web), интеграции и управления данными, распределенными по своей сути (как в промышленных системах), или повышения надежности (как в отказоустойчивых системах). Многие распределенные системы организованы как системы типа клиент-сервер. Например, файловый сервер предоставляет файлы данных для процессов, выполняемых на клиентских машинах. Компоненты распределенных систем часто сами являются многопоточными программами.
Синхронные параллельные вычисления — третий широкий класс приложений. Их цель — быстро решить данную задачу или за то же время решить большую задачу. Примеры синхронных вычислений:
• научные вычисления, которые моделируют и имитируют такие явления, как глобальный климат, эволюция солнечной системы или результат действия нового лекарства;
• графика и обработка изображений, включая создание спецэффектов в кино;
• крупные комбинаторные или оптимизационные задачи, например, планирование авиаперелетов или экономическое моделирование.
Программы решения таких задач требуют больших вычислительных мощностей. Для дости-••жения высокой производительности они выполняются на параллельных процессорах, причем обычно количество процессов (потоков) равно числу процессоров. Параллельные вычисления описываются в виде программ, параллельных по данным, в которых все процессы выполняют одни и те же действия, но с собственной частью данных, или в виде программ, параллельных по задачам, в которых различные процессы решают различные задачи.
В данной книге рассмотрены все три вида приложений и, что более важно, показано, как их программировать. В многопоточных программах процессы (потоки) взаимодействуют, используя разделяемые переменные. В распределенных системах взаимодействие процессов обеспечивается с помощью обмена сообщениями или удаленного вызова операций. При выполнении синхронных параллельных вычислений процессы взаимодействуют, используя или разделяемые переменные, или передачу сообщений, в зависимости от аппаратного обеспечения, на котором выполняется программа. В части 1 этой книги показано, как написать программу, использующую для взаимодействия и синхронизации разделяемые переменные. Часть 2 описывает передачу сообщений и удаленные операции. В части 3 подробно рассмотрено синхронное параллельное программирование, ориентированное на научные вычисления.
Существует немало параллельных программных приложений, однако в них используется лишь небольшое число моделей решений, или парадигм. В частности, существует пять основных парадигм: 1) итеративный параллелизм, 2) рекурсивный параллелизм, 3) "производители и потребители" (конвейеры), 4) "клиенты и серверы", 5) взаимодействующие равные. С использованием одной или нескольких из этих парадигм и программируются приложения.
Итеративный параллелизм используется, когда в программе есть несколько процессов (часто идентичных), каждый из которых содержит один или несколько циклов. Таким образом, каждый процесс является итеративной программой. Процессы программы работают совместно над решением одной задачи; они взаимодействуют и синхронизируются с помощью разделяемых переменных или передачи сообщений. Итеративный параллелизм чаще всего встречается в научных вычислениях, выполняемых на нескольких процессорах.
Рекурсивный параллелизм может использоваться, когда в программе есть одна или несколько рекурсивных процедур, и их вызовы независимы, т.е. каждый из них работает над своей частью общих данных.
Рекурсия часто применяется в императивных языках программирования, особенно при реализации алгоритмов типа "разделяй и властвуй" или "перебор с воз-
1 4. Итеративный параллелизм: умножение матриц 27
вращением" (backtracking). Рекурсия является одной из фундаментальных парадигм и в символических, логических, функциональных языках программирования. Рекурсивный параллелизм используется для решения таких комбинаторных проблем, как сортировка, планирование (задача коммивояжера) и игры (шахматы и другие).
Производители и потребители — это взаимодействующие процессы. Они часто организуются в конвейер, через который проходит информация. Каждый процесс конвейера является фильтром, который потребляет выход своего предшественника и производит входные данные для своего последователя. Фильтры встречаются на уровне приложений (оболочки) в операционных системах типа ОС Unix, внутри самих операционных систем, внутри прикладных программ, если один процесс производит выходные данные, которые потребляет (читает) другой процесс.
Клиенты и серверы — наиболее распространенная модель взаимодействия в распределенных системах, от локальных сетей до World Wide Web. Клиентский процесс запрашивает сервис и ждет ответа. Сервер ожидает запросов от клиентов, а затем действует в соответствии с этими запросами. Сервер может быть реализован как одиночный процесс, который не может обрабатывать одновременно несколько клиентских запросов, или (при необходимости параллельного обслуживания запросов) как многопоточная программа. Клиенты и серверы представляют собой параллельное программное обобщение процедур и их вызовов: сервер выполняет роль процедуры, а клиенты ее вызывают. Но если код клиента и код сервера расположены на разных машинах, обычный вызов процедуры использовать нельзя. Вместо этого необходимо использовать удаленный вызов процедуры или рандеву, как это описано в главе 8.
Взаимодействующие равные — последняя парадигма взаимодействия. Она встречается в распределенных программах, в которых несколько процессов для решения задачи выполняют один и тот же код и обмениваются сообщениями. Взаимодействующие равные используются для реализации распределенных параллельных программ, особенно при итеративном параллелизме и децентрализованном принятии решений в распределенных системах. Некоторые приложения и схемы взаимодействия описаны в главе 9.
В следующих пяти разделах приводятся примеры, иллюстрирующие применение каждой модели. В примерах представлена программная нотация, используемая во всей книге. (Обзор нотации дается в разделе 1.9.) Еще больше примеров приведено в тексте и упражнениях последующих глав.
