Состояние, действие, история и свойства
Состояние параллельной программы состоит из значений переменных программы в некоторый момент времени. Переменные могут быть явно определенными программистом или неявными (вроде программного счетчика каждого процесса), хранящими скрытую информацию о состоянии. Параллельная программа начинает выполнение в некотором исходном состоянии. Каждый процесс программы выполняется независимо, и по мере выполнения он проверяет и изменяет состояние программы.
Процесс выполняет последовательность операторов. Оператор, в свою очередь, реализуется последовательностью неделимых действий. Эти действия проверяют или изменяют со-
50 Часть 1. Программирование с разделяемыми переменными
стояние программы неделимым образом. Примерами неделимых действий являются непрерываемые машинные инструкции, которые загружают и сохраняют слова памяти.
Выполнение параллельной программы приводит к чередованию последовательностей неделимых действий, производимых каждым процессом. Конкретное выполнение каждой программы может быть рассмотрено как история s0—> s, —>... —>sn, где s0— начальное состояние. Переходы между состояниями осуществляются неделимыми действиями, изменяющими состояние. Историю также называют трассой последовательности состояний. Даже параллельное выполнение можно представить в виде линейной истории, поскольку параллельная реализация набора неделимых действий эквивалентна их выполнению в некотором последовательном порядке. Изменение состояния, вызванное неделимым действием, неразделимо, и, следовательно, на него не могут повлиять неделимые действия, производимые примерно в это же время.
Каждое выполнение параллельной программы порождает историю. Для всех, кроме самых тривиальных программ, число возможных историй громадно. Дело в том, что следующим в истории может стать неделимое действие любого процесса. Следовательно, существует много способов чередования действий, даже если выполнение программы всегда начинается в одном и том же исходном состоянии.
Кроме того, в каждом процессе обычно есть условные операторы, и, следовательно, возможны различные действия при различных изменениях в состоянии.
Цель синхронизации — исключить нежелаемые истории параллельной программы. Взаимное исключение состоит в комбинировании неделимых действий, реализуемых непосредственно аппаратным обеспечением в виде последовательностей действий, которые называются критическими секциями. Они должны быть неделимыми, т.е. их нельзя прервать действия-• ми других процессов, которые ссылаются на те же переменные. Синхронизация по условию (условная синхронизация) означает, что действие будет осуществлено, когда состояние будет удовлетворять заданному логическому условию. Обе формы синхронизации могут приостанавливать процессы, ограничивая набор последующих неделимых действий.
Свойством программы называется атрибут, который является истинным при любой возмож--ной истории программы и, следовательно, при всех ее выполнениях. Есть два типа свойств: безопасность и живучесть. Свойство безопасности заключается в том, что программа никогда не попадает в "плохое" состояние (при котором некоторые переменные могут иметь нежелательные значения). Свойство живучести означает, что программа в конце концов всегда попадает в "хорошее" состояние, т.е. состояние, в котором все переменные имеют желаемые значения.
Примером свойства безопасности является частичная корректность (правильность). Программа частично корректна (правильна), если правильно ее заключительное состояние (при условии, что программа завершается). Если программе не удается завершить выполнение, она может никогда не выдать правильный результат, но не существует такой истории, при которой программа завершается, не выдавая правильного результата. Завершимость — пример свойства живучести. Программа завершается, если завершается каждый цикл или вызов процедуры, т.е. длина каждой истории конечна. Тотальная (полная) корректность программы — это свойство, объединяющее частичную корректность и завершимость: программа полностью корректна, если она всегда завершается, выдавая при этом правильный результат.
Взаимное исключение — это пример свойства безопасности в параллельной программе. При плохом состоянии два процесса такой программы одновременно выполняют действия в разных критических секциях. Возможность в конце концов войти в критическую секцию — пример свойства живучести в параллельной программе. В хорошем состоянии каждый процесс выполняется в своей критической секции.
Как же демонстрировать, что данная программа обладает желаемым свойством? Обычный подход состоит в тестировании, или отладке. Его можно охарактеризовать фразой "запусти программу и посмотри, что получится". Это соответствует перебору некоторых возможных историй программы и проверке их приемлемости. Недостаток такой проверки состоит в том, что каждый тест касается только одной истории выполнения, а ограниченное число тестов вряд ли способно продемонстрировать отсутствие плохих историй.
Глава 2. Процессы и синхронизация 51
Второй подход— использование операторных рассуждений, которые можно назвать "исчерпывающий анализ случаев" (перебираются все возможные истории выполнения программы). Для этого анализируются способы чередования неделимых действий процессов. К сожалению, в параллельной программе число возможных историй обычно очень велико (поэтому метод "изнурителен"5). Предположим, что параллельная программа содержит п процессов и каждый из них выполняет последовательность из m неделимых действий. Тогда число различных историй программы составит (n-m) !/(m!n). Для программы из трех процессов, каждый из которых выполняет всего две неделимые операции, возможны 90 различных историй! (Числитель в формуле — это количество возможных перестановок из n-m действий. Но, поскольку каждый процесс выполняет последовательность действий, для него возможен только один порядок следования m действий; знаменатель отбрасывает все варианты с неправильным порядком следования.
Эта формула дает количество, равное числу способов перемешать п колод по m карт в каждой, при условии, что относительный порядок карт в каждой колоде сохраняется.)
Третий подход— применение утвердительных рассуждений (assertional reasoning); его можно назвать "абстрактный анализ". В этом методе формулы логики предикатов называются утверждениями и используются для описания наборов состояний — например, всех состояний, у которых х > 0. Неделимые действия рассматриваются как предикатные преобразователи, поскольку они меняют состояние программы, удовлетворяющее одному предикату, на состояние, удовлетворяющее другому. Преимуществом данного подхода является компактное представление состояний и их преобразований. Но еще важнее то, что он приводит к методу построения и анализа программ, согласно которому объем работы прямо пропорционален числу неделимых действий в программе.
Используем метод утверждений как инструмент построения и анализа решений многих нетривиальных задач. При разработке алгоритмов также будет применяться метод операторных рассуждений. Наконец, многие программы этой книги были протестированы. Однако в результате тестирования можно только обнаружить наличие ошибок, а не гарантировать их отсутствие. Кроме того, параллельные программы очень сложны в тестировании и отладке, поскольку, во-первых, трудно остановить сразу все процессы и проверить их состояние, и, во-вторых, в общем случае каждое выполнение программы приводит к новой истории.
Структуры аппаратного обеспечения
В данной главе дается обзор основных атрибутов архитектуры современных компьютеров. В следующем разделе описаны приложения параллельного программирования и использование архитектуры в них. Описание начинается с однопроцессорных систем и кэш-памяти. Затем рассматриваются мультипроцессоры с разделяемой памятью. В конце описываются машины с распределенной памятью, к которым относятся многомашинные системы с распределенной памятью и сети машин.
1.2.1. Процессоры и кэш-память
Современная однопроцессорная машина состоит из нескольких компонентов: центрального процессорного устройства (ЦПУ), первичной памяти, одного или нескольких уровней кэш-памяти (кэш), вторичной (дисковой) памяти и набора периферийных устройств (дисплей, клавиатура, мышь, модем, CD, принтер и т.д.). Основными компонентами для выполнения программ являются ЦПУ, кэш и память. Отношения между ними изображены на рис. 1.1.
Процессор выбирает инструкции из памяти, декодирует их и выполняет. Он содержит управляющее устройство (УУ), арифметико-логическое устройство (АЛУ) и регистры. УУ вырабатывает сигналы, управляющие действиями АЛУ, системой памяти и внешними устройствами. АЛУ выполняет арифметические и логические инструкции, определяемые набором инструкций процессора. В регистрах хранятся инструкции, данные и состояние машины (включая счетчик команд).
Кэш — это небольшой по объему, но скоростной модуль памяти, используемый для ускорения выполнения программы. В нем хранится содержимое областей памяти, часто используемых процессором. Причина использования кэш-памяти состоит в том, что в большинстве программ наблюдается временная локальность, означающая, что если произошло обращение к некоторой области памяти, то, скорее всего, в ближайшем будущем обращения к этой области повторятся. Например,

инструкции внутри циклов выбираются и выполняются многократно.
Когда программа обращается к адресу в памяти, процессор сначала ищет его в кэше. Если данные находятся там (происходит попадание в кэш), то они считываются из кэша.
Если данных в кэше нет (промах), то данные считываются из первичной памяти и в процессор, и в кэш-память. Аналогично, когда программа записывает данные, они помещаются в первичную память и, возможно, в локальный кэш. В сквозном кэше данные помещаются в память немедленно, в кэше с обратной записью — позже. Ключевой момент состоит в том, что после записи содержимое первичной памяти временно может не соответствовать содержимому кэша.
Чтобы ускорить передачу (увеличить пропускную способность) между кэшем и первичной памятью, в элемент кэш-памяти обычно включают непрерывную последовательность слов из памяти. Эти элементы называются блоками или строками кэша. При промахе из памяти в кэш
22 Глава 1. Обзор области параллельных вычислений
передается полная строка. Это эффективно, поскольку в большинстве программ наблюдается пространственная локальность, т.е. за обращением к одному слову памяти вскоре последуют обращения к другим близлежащим словам.
В современных процессорах обычно есть два типа кэша. Кэш уровня 1 находится ближе к процессору, а кэш уровня 2 — между кэшем уровня 1 и первичной памятью. Кэш уровня 1 меньше и быстрее, чем кэш уровня 2, и зачастую иначе организован. Например, кэшпамять уровня 1 обычно отображается непосредственно, а кэш уровня 2 является множественно-ассоциативным.2
Кроме того, кэш уровня 1 часто содержит отдельные области кэшпамяти для инструкций и данных, в то время как кэш уровня 2 обычно унифицирован, т.е. в нем хранятся и данные, и инструкции.
Проиллюстрируем различия в скорости работы уровней иерархии памяти. Доступ к регистрам происходит за один такт работы процессора, поскольку они невелики и находятся внутри ЦПУ. Данные кэш-памяти уровня 1 также доступны за один-два такта. Однако для доступа к кэш-памяти уровня 2 необходимо порядка 10 тактов, а к первичной памяти — от 50 до 100 тактов. Аналогичны и различия в размере типов памяти: ЦПУ содержит несколько десятков регистров, кэш уровня 1 — несколько десятков килобайт, кэш уровня 2 — порядка мегабайта, а первичная память — десятки и сотни мегабайт.
1.2.2. Мультипроцессоры с разделяемой памятью
В мультипроцессоре с разделяемой памятью процессоры и модули памяти связаны с помощью соединительной сети (рис. 1.2). Процессоры совместно используют первичную память, но каждый из них имеет собственный кэш.
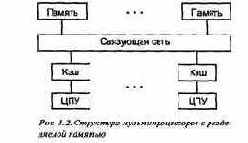
В небольшом мультипроцессоре, имеющем от двух до (порядка) 30 процессоров, соединительная сеть реализована в виде шины памяти или, возможно, матричного коммутатора. Такой мультипроцессор называется однородным (UMA machine — от "uniform memory access"), поскольку время доступа каждого из процессоров к любому участку памяти одинаково. Однородные машины также называются симметричными мультипроцессорами.
В больших мультипроцессорах с разделяемой памятью, включающих десятки или сотни процессоров, память организована иерархически. Соединительная сеть имеет вид древообразного набора переключателей и областей памяти. Следовательно, одна часть памяти ближе к определенному процессору, другая — дальше от него. Такая организация памяти
В непосредственно отображаемом кэше каждый адрес памяти отображается в один элемент кэша, а в множественно-ассоциативном — во множество элементов (обычно два или четыре). Таким образом, если два адреса памяти отображаются в одну и ту же ячейку, в непосредственно отображаемом кэше может находиться только ячейка, к которой производилось самое последнее обращение, а в ассоциативном — обе ячейки. С другой стороны, непосредственно отображаемый кэш быстрее, поскольку проще выяснить, есть ли данное слово в кэше.
1.2. Структуры аппаратного обеспечения 23
позволяет избежать перегрузки, возникающей при использовании одной шины или коммутатора, и приводит к неравным временам доступа, поэтому такие мультипроцессоры называются неоднородными (NUMA machines).
В машинах обоих типов у каждого процессора есть собственный кэш. Если два процессора ссылаются на разные области памяти, их содержимое можно безопасно поместить в кэш каждого из них.
Проблема возникает, когда два процессора обращаются к одной области памяти примерно одновременно. Если оба процессора только считывают данные, в кэш каждого из них можно поместить копию данных. Но если один из процессоров записывает в память, возникает проблема согласованности кэша: в кэш-памяти другого процессора теперь содержатся неверные данные. Значит, необходимо либо обновить кэш другого процессора, либо признать содержимое кэша недействительным. В каждом мультипроцессоре протокол согласования кэшпамяти должен быть реализован аппаратно. Один из способов состоит в том, чтобы каждый кэш "следил" за адресной шиной, отлавливая ссылки на области памяти, находящиеся в нем.
Запись в память также приводит к проблеме согласованности памяти: когда в действительности обновляется первичная память? Например, если один процессор выполняет запись в область памяти, а другой позже считывает данные из этой области, будет ли считано обновленное значение? Существует несколько различных моделей согласованности памяти. Последовательная согласованность — это наиболее сильная модель. Она гарантирует, что обновления памяти будут происходить в некоторой последовательности, причем каждому процессору будет "видна" одна и та же последовательность. Согласованность процессоров — более слабая модель. Она обеспечивает, что записи в память, выполняемые каждым процессом, совершаются в том порядке, в котором их производит процессор, но записи, инициированные различными процессорами, для других процессоров могут выглядеть по-разному. Еще более слабая модель— согласование освобождения, при которой первичная память обновляется в указанных программистом точках синхронизации.
Проблема согласования памяти представляет противоречия между простотой программирования и расходами на реализацию. Программист интуитивно ожидает последовательного согласования, поскольку программа считывает и записывает переменные независимо от того, в какой части машины они хранятся в действительности.
Когда процесс присваивает переменной значение, программист ожидает, что результаты этого присваивания станут немедленно известными всем процессам программы. С другой стороны, последовательное согласование очень дорого в реализации и замедляет работу машины. Дело в том, что при каждой записи аппаратная часть должна проверить все кэши (и, возможно, обновить их или сделать недействительными) и модифицировать первичную память. Вдобавок, эти действия должны быть неделимыми. Вот почему в мультипроцессорах обычно реализуется более слабая модель согласования памяти, а программистам необходимо вставлять инструкции синхронизации памяти. Это часто обеспечивают компиляторы и библиотеки, так что прикладной программист этим может не заниматься.
Как было отмечено, строки кэш-памяти часто содержат последовательности слов, которые блоками передаются из памяти и обратно. Предположим, что переменные х и у занимают по одному слову и хранятся в соседних ячейках памяти, отображенных в одну и ту же строку кэш-памяти. Пусть некоторый процесс выполняется на процессоре 1 мультипроцессора и производит записи и чтения переменной х. Наконец, допустим, что еще один процесс, выполняемый на процессоре 2, считывает и записывает переменную у. Тогда при каждом обращении процессора 1 к переменной х строка кэш-памяти этого процессора будет содержать и копию переменной у. Аналогичная картина будет и в кэше процессора 2.
Ситуация, описанная выше, называется ложным разделением: процессы в действительности не разделяют переменные х и у, но аппаратная часть кэш-памяти интерпретирует обе переменные как один блок. Следовательно, когда процессор 1 обновляет переменную х, должна быть признана недействительной и обновиться строка кэша в процессоре 2, содержащая их, ну. Таким же образом, когда процессор 2 обновляет значение у, строка кэш-памяти, содержащая значения х и у, в процессоре 1 тоже должна быть обновлена или признана недействительной. Эти операции замедляют работу системы памяти, поэтому программа будет выполняться намного
24 Глава 1. Обзор области параллельных вычислений
медленнее, чем тогда, когда две переменные попадают в разные строки кэша. Главное здесь — чтобы программист ясно понимал, что процессы не разделяют переменные, когда фактически система памяти вынуждена обеспечивать их разделение и тратить время на управление им.
Чтобы избежать ложного разделения, программист должен гарантировать, что переменные, записываемые различными процессами, не будут находиться в смежных областях памяти. Одно из решений этой проблемы заключается в выравнивании, т.е. резервировании фиктивных переменных, которые просто занимают место и отделяют реальные переменные друг от друга. Это пример противоречия между временем и пространством: для сокращения времени выполнения приходится тратить пространство.
Итак, мультипроцессоры используют кэш-память для повышения производительности. Однако иерархичность памяти порождает проблемы согласованности кэша и памяти, а также возможность ложного разделения. Следовательно, для получения максимальной производительности на данной машине программист должен знать характеристики системы памяти и писать программы, учитывая их. К этим вопросам мы еще вернемся.
1.2.3. Мультикомпьютеры с распределенной памятью и сети
В мультипроцессоре с распределенной памятью тоже есть соединительная сеть, но каждый процессор имеет собственную память. Как показано на рис. 1.3, соединительная сеть и модули памяти меняются местами по сравнению с их положением в мультипроцессоре с разделяемой памятью. Соединительная сеть поддерживает передачу сообщений, а не чтение и запись в память. Следовательно, процессоры взаимодействуют, передавая и принимая сообщения. У каждого процессора есть свой кэш, но из-за отсутствия разделения памяти нет проблем согласованности кэша и памяти.

Мультикомпьютер (многомашинная система) — это мультипроцессор с распределенной памятью, в котором процессоры и сеть расположены физически близко (в одном помещении).
По этой причине такую многомашинную систему часто называют тесно связанной (спаренной) машиной. Она одновременно используется одним или небольшим количеством приложений; каждое приложение задействует выделенный набор процессоров. Соединительная сеть с большой пропускной способностью предоставляет высокоскоростной путь связи между процессорами. Обычно она организована в гиперкуб или матричную структуру. (Машины со структурой типа гиперкуб были одними из первых многомашинных систем.)
Сетевая система — это многомашинная система с распределенной памятью, узлы которой связаны с помощью локальной сети типа Ethernet или такой глобальной сети, как Internet. Сетевые системы называются слабо связанными мультикомпьютерами. Здесь процессоры взаимодействуют также с помощью передачи сообщений, но время их доставки больше, чем в многомашинных системах, и в сети больше конфликтов. С другой стороны, сетевая система строится на основе обычных рабочих станций и сетей, тогда как в многомашинной системе часто есть специализированные компоненты, особенно у связующей сети.
1 3 Приложения и стили программирования 25
Сетевая система, состоящая из набора рабочих станций, часто называется сетью рабочих станций (network of workstations — NOW) или кластером рабочих станций (cluster of workstations — COW). Все рабочие станции выполняют одно или несколько приложений, возможно, связанных между собой. Популярный сейчас способ построения недорогого мультипроцессора с распределенной памятью — собрать так называемую машину Беовулфа (Beowulf). Она состоит из базового аппаратного обеспечения и таких бесплатных программ, как чипы к процессорам Pentium, сетевые карты, диски и операционная система Linux. (Имя Беовулф взято из старинной английской поэмы, первого шедевра английской литературы.)
Существуют также гибридные сочетания мультипроцессоров с распределенной и разделяемой памятью. Узлами системы с распределенной памятью могут быть мультипроцессоры с разделяемой памятью, а не обычные процессоры.Возможен вариант, когда связующая сеть поддерживает и механизмы передачи сообщений, и механизмы прямого доступа к удаленной памяти (на сегодня это наиболее мощные машины). Наиболее общая комбинация — машина с поддержкой распределенной разделяемой памяти, т.е. распределенной реализации абстракции разделяемой памяти. Она облегчает программирование многих приложений, но ставит проблемы согласованности кэша и памяти. (В главе 10 описана распределенная разделяемая память и ее реализация в программном обеспечении.)
Суть параллельного программирования
Параллельная программа содержит несколько процессов, работающих совместно над выполнением некоторой задачи. Каждый процесс — это последовательная программа, а точнее — последовательность операторов, выполняемых один за другим. Последовательная программа имеет один поток управления, а параллельная — несколько.
Совместная работа процессов параллельной программы осуществляется с помощью их взаимодействия. Взаимодействие программируется с применением разделяемых переменных или пересылки сообщений. Если используются разделяемые переменные, то один процесс осуществляет запись в переменную, считываемую другим процессом. При пересылке сообщений один процесс отправляет сообщение, которое получает другой.
При любом виде взаимодействия процессам необходима взаимная синхронизация. Существуют два основных вида синхронизации — взаимное исключение и условная синхрониза-
20 Глава 1. Обзор области параллельных вычислений
ция. Взаимное исключение обеспечивает, чтобы критические секции операторов не выполнялись одновременно. Условная синхронизация задерживает процесс до тех пор, пока не выполнится определенное условие. Например, взаимодействие процессов производителя и потребителя часто обеспечивается с помощью буфера в разделяемой памяти. Производитель записывает в буфер, потребитель читает из него. Чтобы предотвратить одновременное использование буфера и производителем, и потребителем (тогда может быть считано не полностью записанное сообщение), используется взаимное исключение. Условная синхронизация используется для проверки, было ли считано потребителем последнее записанное в буфер сообщение.
Как и другие прикладные области компьютерных наук, параллельное программирование прошло несколько стадий. Оно возникло благодаря новым возможностям, предоставленным развитием аппаратного обеспечения, и развилось в соответствии с технологическими изменениями. Через некоторое время специализированные методы были объединены в набор основных принципов и общих методов программирования.
Параллельное программирование возникло в 1960-е годы в сфере операционных систем. Причиной стало изобретение аппаратных модулей, названных каналами, или контроллерами устройств. Они работают независимо от управляющего процессора и позволяют выполнять операции ввода-вывода параллельно с инструкциями центрального процессора. Канал взаимодействует с процессором с помощью прерывания — аппаратного сигнала, который говорит: "Останови свою работу и начни выполнять другую последовательность инструкций".
Результатом появления каналов стала проблема программирования (настоящая интеллектуальная проблема) — теперь части программы могли быть выполнены в непредсказуемом '''порядке. Следовательно, пока одна часть программы обновляет значение некоторой переменной, может возникнуть прерывание, приводящее к выполнению другой части программы, которая тоже попытается изменить значение этой переменной. Эта специфическая проблема (задача критической секции) подробно рассматривается в главе 3.
Вскоре после изобретения каналов началась разработка многопроцессорных машин, хотя в течение двух десятилетий они были слишком дороги для широкого использования. Однако сейчас все крупные машины являются многопроцессорными, а самые большие имеют сотни процессоров и часто называются машинами с массовым параллелизмом (massively parallel processors). Скоро даже персональные компьютеры будут иметь несколько процессоров.
Многопроцессорные машины позволяют разным прикладным программам выполняться одновременно на разных процессорах. Они также ускоряют выполнение приложения, если оно написано (или переписано) для многопроцессорной машины. Но как синхронизировать работу параллельных процессов? Как использовать многопроцессорные системы для ускорения выполнения программ?
Итак, при использовании каналов и многопроцессорных систем возникают и возможности, и трудности. При написании параллельной программы необходимо решать, сколько процессов и какого типа нужно использовать, и как они должны взаимодействовать.
Эти ре шения зависят как от конкретного приложения, так и от аппаратного обеспечения, на котором будет выполняться программа. В любом случае ключом к созданию корректной программы является правильная синхронизация взаимодействия процессов.
Эта книга охватывает все области параллельного программирования, но основное внимание уделяет императивным программам с явными параллельностью, взаимодействием и синхронизацией. Программист должен специфицировать действия всех процессов, а также их взаимодействие и синхронизацию. Это контрастирует с декларативными программами, например, функциональными или логическими, где параллелизм скрыт и отсутствуют чтение и запись состояния программы. В декларативных программах независимые части программы могут выполняться параллельно; их взаимодействие и синхронизация происходят неявно, когда одна часть программы зависит от результата выполнения другой. Декларативный подход тоже интересен и важен (см. главу 12), но императивный распространен гораздо шире. Кроме того, для реализации декларативной программы на стандартной машине необходимо писать императивную программу.
1.2. Структуры аппаратного обеспечения 21
Изучаются также параллельные программы, в которых процессы выполняются асинхронно, т.е. каждый со своей скоростью. Такие программы могут выполняться с помощью чередования процессов на одном процессоре или их параллельного выполнения на мультипроцессоре со многими командами и многими данными (MIMD-процессоре). К этому классу машин относятся также мультипроцессоры с разделяемой памятью, многомашинные системы с распределенной памятью и сети рабочих станций (см. следующий раздел). Несмотря на внимание к асинхронным параллельным вычислениям, в главе 3 мы описываем синхронную мультиобработку (SIMD-машины), а в главах 3 и 12 — связанный с ней стиль программирования, параллельного по данным.
Свойства безопасности и живучести
Свойство программы — это ее атрибут, истинный для любой возможной истории выполнения (см. раздел 2.1). Каждое интересующее нас свойство можно сформулировать как свойство безопасности или живучести. Свойство безопасности утверждает, что во время выполнения программы не происходит ничего плохого; свойство живучести утверждает, что в конечном счете происходит что-то хорошее. В последовательных программах основное свойство безопасности состоит в корректности заключительного состояния, а живучести — в завершимости про-
Глава 2 Процессы и синхронизация 73
граммы. Для параллельных программ эти свойства одинаково важны. Однако есть и другие интересные свойства безопасности и живучести, применимые к параллельным программам.
Два важных свойства безопасности параллельных программ — взаимные исключения и отсутствие взаимоблокировок (deadlock). Для взаимного исключения плохо, когда несколько процессов одновременно выполняют критические секции операторов. Для взаимоблокировки плохо, когда все процессы ожидают условий, которые никогда не выполнятся.
Вот примеры свойств живучести параллельных программ: процесс в конце концов войдет в критическую секцию, запрос на обработку будет принят, а сообщение достигнет места назначения. Свойства живучести зависят от стратегии планирования, которая определяет, какое из неделимых действий должно быть выполнено следующим.
В данном разделе представлены два метода обоснования свойств безопасности. Затем описаны различные типы стратегий планирования процессора и их влияние на свойства живучести.
2.8.1. Доказательство свойств безопасности
Каждое выполняемое программой действие основано на ее состоянии. Если программа не удовлетворяет свойству безопасности, должно существовать некоторое "плохое" состояние, не удовлетворяющее этому свойству. Например, если не удовлетворяется свойство взаимного исключения, то должно быть некоторое состояние, в котором два (или более) процесса одновременно находятся в своих критических секциях.
Или если процессы заблокировали друг друга (вошли в клинч), то должно быть состояние, в котором это происходит.
Эти замечания ведут к простому методу доказательства, что программа удовлетворяет свойству безопасности. Пусть предикат BAD описывает плохое состояние программы. Тогда программа удовлетворяет соответствующему свойству безопасности, если BAD ложен в каждом состоянии любой возможной истории выполнения программы. Чтобы по данной программе S показать, что предикат BAD не является истинным в любом состоянии, нужно доказать, что он ложен в начальном состоянии, во втором состоянии и т.д., причем состояние изменяется в результате выполнения неделимых действий.
Если программа не должна попадать в BAD-состояние, она всегда должна быть в GOOD-состоянии, где предикат GOOD эквивалентен -<BAD. Следовательно, эффективный способ обеспечить свойства безопасности — определить предикат BAD и его отрицание, чтобы получить GOOD, а затем проверить, является ли предикат GOOD глобальным инвариантом, т.е. предикатом, истинным в каждом состоянии программы. Чтобы сделать предикат глобальным инвариантом, можно использовать синхронизацию (как это уже было и еще не раз будет показано в дальнейших главах).
Вышеописанный метод является общим для доказательства свойств безопасности. Существует связанный с ним, но несколько более специализированный метод, также весьма полезный. Рассмотрим следующий фрагмент программы.
со # процесс 1
...; {pre(Sl)} SI; ...
// # процесс 2
. ..,- {pre(S2)> S2; ...
ос
Здесь есть два оператора, по одному в каждом процессе, и два связанных с ними предусловия (предикаты, истинные перед выполнением каждого оператора). Предположим, что эти предикаты не подвержены вмешательству, а их конъюнкция ложна:
pre(Sl) л pre(S2) == false
Это значит, что оба процесса одновременно не могут выполнять данные операторы, поскольку предикат, который ложен, не характеризует ни одного состояния программы (пустое множество состояний, если хотите).
Этот метод называется исключением конфигураций, поскольку
74 Часть 1. Программирование с разделяемыми переменными
он исключает конфигурации программы, в которых первый процесс находится в состоянии pre (S1), а второй в это же время — в состоянии pre (S2).
В качестве примера рассмотрим схему доказательства корректности программы копирования массива (см. листинг 2.3). Оператор await в каждом процессе может стать причиной задержки. Процессы заблокируют друг друга ("войдут в клинч"), если оба будут приостановлены и ни один не сможет продолжить работу. Процесс Producer приостанавливается, если он находится в операторе await, а условие (окончания) задержки ложно; в этом состоянии истинным является следующий предикат. PC ^р<п^р ' = с
Следовательно, когда приостановлен процесс Producer, истинно условие р > с. Аналогично приостанавливается процесс Consumer, если он находится в операторе await, а условие (окончания) задержки ложно; это состояние удовлетворяет такому предикату.
/Слс<плр<=с
Поскольку условия р > сир <= с не могут быть истинными одновременно, процессы не могут одновременно находиться в этих состояниях, т.е. взаимоблокировка возникнуть не может.
2.8.2. Стратегии планирования и справедливость
Большинство свойств живучести зависит от справедливости (fairness), связанной с гарантиями, что каждый процесс получает шанс на продолжение выполнения независимо от действий других процессов. Каждый процесс выполняет последовательность неделимых действий. Неделимое действие в процессе называется подходящим, или возможным (eligible), если оно является следующим неделимым действием в процессе, которое может быть выполнено. При наличии нескольких процессов существует несколько возможных неделимых действий. Стратегия планирования (scheduling policy) определяет, какое из них будет выполнено следующим. В этом разделе определены три степени справедливости, которые могут быть обеспечены стратегией планирования.
Напомним, что безусловное неделимое действие — это действие, не имеющее условия задержки. Рассмотрим следующую простую программу, в которой процессы выполняют безусловные неделимые действия.
bool continue = true; со while (continue); // continue = false; oc
Допустим, что стратегия планирования назначает процессор для процесса до тех пор, пока тот не завершится или не будет приостановлен (задержан). При одном процессоре данная программа не завершится, если вначале будет выполняться первый процесс. Однако, если второй процесс в конце концов получит право на выполнение, программа будет завершена. Данная ситуация отражена в следующем определении.
(2.6) Безусловная справедливость (unconditional fairness). Стратегия планирования безусловно справедлива, если любое подходящее безусловное неделимое действие в конце концов выполняется.
Для программы, приведенной выше, безусловно справедливой стратегией планирования на одном процессоре было бы циклическое (round-robin) выполнение, а на мультипроцессоре — синхронное.
Если программа содержит условные неделимые действия— операторы await с логическими условиями в, необходимо делать более сильные предположения, чтобы гарантировать продвижение процесса. Причина в том, что условное неделимое действие не может быть выполнено, пока условие в не станет истинным.
Глава 2. Процессы и синхронизация 75
(2.7) Справедливость в слабом смысле (weak fairness). Стратегия планирования справедлива в слабом смысле, если: 1) она безусловно справедлива, и 2) каждое подходящее условное неделимое действие в конце концов выполняется, если его условие становится и затем остается истинным, пока его видит процесс, выполняющий условное неделимое действие.
Таким образом, если действие (await (В) S;) является подходящим и условие В становится истинным, то в остается истинным по крайней мере до окончания выполнения условного неделимого действия.
Циклическая стратегия и стратегия квантования времени являются справедливыми в слабом смысле, если каждому процессу дается возможность выполнения. Причина в том, что любой приостановленный процесс в конце концов увидит, что условие (окончания) его задержки истинно.
Справедливости в слабом смысле, однако, недостаточно для гарантии, что любой подходящий оператор await в конце концов выполняется. Это связано с тем, что условие может изменить свое значение (от ложного к истинному и обратно к ложному), пока процесс приостановлен. В этом случае необходима более сильная стратегия планирования.
(2.8) Справедливость в сильном смысле (strong fairness). Стратегия планирования справедлива в сильном смысле, если: 1) она безусловно справедлива, и 2) любое подходящее условное неделимое действие в конце концов выполняется в предположении, что его условие бывает истинным бесконечно часто.
Условие бывает истинным бесконечно часто, если оно истинно бесконечное число раз в каждой истории (не завершающейся) программы. Чтобы стратегия планирования была справедливой в сильном смысле, действие должно выбираться для выполнения не только тогда, когда его условие ложно, но и когда оно истинно.
Чтобы увидеть различия между справедливостью в слабом и сильном смысле, рассмотрим следующую программу.
bool continue = true, try = false;
со while (continue) (try = true; try = false;}
// (await (try) continue = false;)
oc
При стратегии, справедливой в сильном смысле, эта программа в конце концов завершится, поскольку значение переменной try бесконечно часто истинно. Однако при стратегии планирования, справедливой в слабом смысле, программа может не завершиться, поскольку значение переменной try также бесконечно часто является ложным.
К сожалению, невозможно разработать стратегию планирования процессора, которая была бы и практичной, и справедливой в сильном смысле. Еще раз рассмотрим программу, приведенную выше. На одном процессоре диспетчер, чередующий действия двух процессов, будет справедливым в сильном смысле, поскольку второй процесс будет видеть состояние, в котором значение переменной try истинно.
Однако такой планировщик невозможно реализовать практически. Циклическое планирование и планирование с квантованием времени практичны, но в общем случае не являются справедливыми в сильном смысле, поскольку процессы выполняются в непредсказуемом порядке. Диспетчер мультипроцессора, выполняющего процессы параллельно, также практичен, но не является справедливым в сильном смысле. Причина в том, что второй процесс может проверять значение переменной try только тогда, когда оно ложно. Это, конечно, маловероятно, но теоретически возможно.
Для дальнейшего объяснения различных видов стратегий планирования вернемся к программе копирования массива в листингах 2.2 и 2.3. Как отмечалось выше, эта программа свободна от блокировок. Таким образом, программа будет завершена, поскольку каждый процесс регулярно получает возможность продвинуться в своем выполнении. Процесс будет продвигаться, поскольку стратегия справедлива в слабом смысле. Дело в том, что, когда один процесс делает истинным условие (окончания) задержки другого процесса, это условие остается истинным, пока другой процесс не будет продолжен и не изменит разделяемые переменные.
76 Часть 1. Программирование с разделяемыми переменными
Оба оператора await в программе копирования массива имеют вид (await (В) ;), а условие в ссылается только на одну переменную, изменяемую другим процессом. Следовательно, оба оператора await могут быть реализованы циклами активного ожидания. Например, (await (р == с) ;) в процессе Producer может быть реализован следующим оператором. while (р != с);
Программа завершится, если стратегия планирования безусловно справедлива, поскольку теперь нет условных неделимых действий и процессы чередуют доступ к разделяемому буферу. Однако в общем случае не верно, что безусловно справедливая стратегия планирования гарантирует завершение цикла активного ожидания. Причина в том, что при безусловно справедливой стратегии всегда может быть запланировано к выполнению неделимое действие, проверяющее условие цикла как раз тогда, когда оно истинно (как в приведенной выше программе).
Если все циклы активного ожидания программы зациклились навсегда, о программе говорят, что она вошла в активный тупик (livelock) — программа работает, но процессы не продвигаются. Активный тупик — это активно ожидающий аналог взаимоблокировки (клинча). Отсутствие активного тупика, как и отсутствие клинча, является свойством безопасности. Плохим считается состояние, в котором все процессы зациклены, но не выполняется ни одно из условий (окончания) задержки. С другой стороны, продвижение любого из процессов является свойством живучести. Хорошим в этом случае является то, что цикл активного ожидания отдельного процесса когда-нибудь завершится.
Техника устранения взаимного вмешательства
Процессы в параллельной программе работают вместе над вычислением результата. Ключевое требование для получения правильной программы состоит в том, что процессы не должны влиять друг на друга. Совокупность процессов свободна от взаимного влияния, когда в одном процессе нет действий присваивания, вмешивающихся в критические утверждения другого процесса.
В данном разделе описаны четыре основных метода устранения взаимного вмешательства, которые можно использовать для разработки правильных параллельных программ: непересекающиеся множества переменных, ослабленные утверждения, глобальные инварианты и синхронизация. Эти методы широко применяются в оставшейся части книги. Все они включают запись утверждений и действий присваивания в форме, обеспечивающей истинность формулам (2.5).
2.7.1. Непересекающиеся множества переменных
Напомним, что множество записи процесса — это множество переменных, которым он присваивает значения (и, возможно, считывает их), а множество чтения процесса — это множество переменных, которые процесс считывает, но не изменяет. Множество ссылок процесса — это множество переменных, которые встречаются в утверждениях доказательства корректности данного процесса. Множество ссылок процесса часто (но не всегда) будет совпадать с объединением множеств чтения и записи. По отношению к взаимному вмешательству критические переменные — это переменные в утверждениях.
Если множество записи одного процесса не пересекается со множеством ссылок другого процесса и наоборот, то эти два процесса не могут влиять друг на друга. Формально это происходит потому, что в аксиоме присваивания используется текстуальная подстановка, которая не влияет на предикат, не содержащий ссылок на целевую переменную присваивания. (Локальные переменные в различных процессах, даже если и имеют одинаковые имена, все равно являются разными переменными; поэтому перед применением аксиомы присваивания их можно переименовать.)
В качестве примера рассмотрим следующую программу.
Другие процессы добавляют операции в очередь. Когда диск незанят, планировщик проверяет очередь, выбирает по некоторому критерию наилучшую операцию и начинает ее выполнять. В действительности диск не всегда будет выполнять наилучшую операцию, даже если она была таковой во время просмотра очереди. Это происходит потому, что процесс может добавить еще одну, лучшую, операцию в очередь сразу после того, как был сделан выбор, и даже до того, как диск начал выполнение операции. Таким образом, "наилучшая" в данном случае — это свойство, зависящее от времени, хотя для задачи планирования вроде приведенной этого достаточно.
Еще один пример — многие параллельные алгоритмы приближенного решения дифференциальных уравнений имеют следующий вид. (Более конкретный пример приводится в главе 11.) Пространство задачи аппроксимируется конечной сеткой точек, скажем, grid[n,n]. Каждой точке или (что типичнее) блоку точек сетки назначается процесс, как в следующем фрагменте программы.

Глава 2 Процессы и синхронизация
Функция f, вычисляемая на каждой итерации, может быть, например, усреднением значений в четырех соседних точках той же строки и того же столбца. Во многих задачах значение, присваиваемое элементу grid [ i, j ] на одной итерации, зависит от значений соседних элементов на предыдущей. Таким образом, инвариант цикла должен характеризовать отношения между старыми и новыми значениями точек сетки.
Чтобы гарантировать, что инвариант цикла в каждом процессе не подвержен влиянию извне, процессы должны использовать две матрицы и после каждой итерации синхронизироваться. На каждой итерации каждый процесс pde считывает значения из матрицы, вычисляет f, а затем записывает результат во вторую матрицу. Потом он ждет, пока остальные процессы вычислят новые значения для своих точек сетки. (В следующей главе показано, как реализовать этот тип синхронизации, называемый барьером.) Затем роли матриц меняются местами, и процессы выполняют следующую итерацию.
Второй способ синхронизации процессов состоит в их пошаговом выполнении, когда все процессы одновременно выполняют одни и те же действия. Этот тип синхронизации поддерживается в синхронных процессорах. Данный метод позволяет избежать взаимного вмешательства, поскольку каждый процесс считывает старые значения из массива grid до того, как какой-либо из процессов присвоит новое значение.
2.7.3. Глобальные инварианты
Еще один, очень эффективный способ избежать взаимного вмешательства состоит в использовании глобального инварианта для учета всех отношений между разделяемыми переменными. Как показано в начале главы 3, глобальный инвариант можно использовать при разработке решения любой задачи синхронизации.
Предположим, что I — предикат, который ссылается на глобальные переменные. Тогда I называется глобальным инвариантом по отношению ко множеству процессов, если: 1) I истинен в начале выполнения процессов, 2) I сохраняется каждым действием присваивания. Условие 1 удовлетворяется, если предикат I истинен в начальном состоянии каждого процесса. Условие 2 удовлетворяется, если для любого действия присваивания а предикат I истинен после выполнения а при условии, что I был истинным до выполнения а. Таким образом, эти два условия образуют пример использования математической индукции.
Предположим, что предикат I является глобальным инвариантом. Допустим, что любое критическое утверждение С в обосновании каждого процесса Рэ
имеет вид I L, где L — предикат относительно локальных переменных. В частности, каждая переменная, на которую ссылается предикат L, является либо локальной переменной для процесса Р:, либо глобальной, которой присваивает только процесс Р:. Если все критические утверждения можно представить в форме I L, то доказательства правильности процессов будут свободны от взаимного вмешательства. Дело в том, что: 1) предикат I инвариантен относительно каждого действия присваивания а, и 2) ни одно действие присваивания в одном процессе не может повлиять на локальный предикат L в другом процессе, поскольку левая часть присваивания а отличается от переменных в предикате L.
Если все утверждения используют глобальный инвариант и локальный предикат так, как описано выше, требование взаимного невмешательства (2.5) выполняется для каждой пары действий присваивания и критических утверждений. Кроме того, нам нужно проверить только тройки в каждом процессе, чтобы удостовериться, что каждое критическое утверждение имеет вышеописанный вид, а предикат I является глобальным инвариантом. Нам даже нет необходимости просматривать утверждения или операторы в других процессах. Фактически из массива идентичных процессов достаточно проверить только один. В любом случае нужно проверить лишь линейное число операторов и утверждений. Сравните это с необходимостью проверки экспоненциального количества историй программы (см. раздел 2.1).
70 Часть 1 Программирование с разделяемыми переменными
Техника глобальных инвариантов широко используется в остальной части книги. Ее полезность и мощность мы продемонстрируем в конце данного раздела после знакомства с четвертым способом избежать взаимного вмешательства — синхронизацией.
2.7.4. Синхронизация
Последовательность операторов внутри оператора await для других процессов выступает как неделимая единица. Это значит, что, определяя, вмешиваются ли процессы друг в друга, можно не обращать внимание на результаты выполнения отдельных операторов. Достаточно выяснить, может ли вся последовательность вызывать вмешательство. Например, рассмотрим следующее неделимое действие:
{х = х+1; у = у+1;>
Ни одно присваивание само по себе не может вызвать вмешательства, поскольку никакой другой процесс не может увидеть состояния, в котором переменная х уже была увеличена на единицу, а у — еще нет. Причиной вмешательства может стать только пара присваиваний.
Внутренние состояния сегментов программы внутри угловых скобок также неделимы. Следовательно, ни одно утверждение о внутреннем состоянии программы не может подвергаться вмешательству со стороны другого процесса.
Например, утверждение в середине сле дующего неделимого действия не является критическим.
{х == О л у == 0}
(х = х+1; {х == 1 л у == 0} у = у+1;> I
{х == 1 л у == 1}
Эти два свойства неделимых действий приводят к двум способам использования синхронизации для устранения взаимного влияния: взаимному исключению и условной синхронизации. Рассмотрим следующий фрагмент.
со Р1: ... а; ...
// Р2: ... S1; {С} S2; ...
ос
Здесь а — это оператор присваивания в процессе PI, a S1 и S2 — операторы в процессе Р2. Критическое утверждение С является предусловием оператора S2.
Предположим, что а влияет на С. Один способ избавиться от этого — использовать взаимное исключение, чтобы "скрыть" утверждение С от оператора а. Для этого операторы S1 и S2 второго процесса можно собрать в единое неделимое действие.
(SI; S2;>
Теперь операторы S1 и S2 выполняются неделимым образом, и состояние с становится невидимым для других процессов.
Другой способ избежать взаимного влияния процессов — использовать условную синхронизацию, чтобы усилить предусловие оператора а. В частности, можно заменить а следующим условным неделимым действием.
(await ('С or В) а;)
Здесь в — предикат, характеризующий множество состояний, при которых выполнение а сделает с истинным. Таким образом, в данном выражении вмешательство устраняется либо ожиданием того, что С станет ложным (тогда оператор S2 не сможет выполняться), либо обеспечением того, что выполнение а сделает с истинным (что будет приемлемым для выполнения S2).
2.7.5. Пример: еще раз о задаче копирования массива
В большинстве параллельных программ используется сочетание представленных выше методов. Здесь все они иллюстрируются в одной простой программе: задаче копирования массива
Глава 2. Процессы и синхронизация 71
(см. листинг 2.2). Напомним, что эта программа использует разделяемый буфер buf для копирования содержимого массива а (в процессе производителя) в массив Ь (в процессе потребителя).
Процессы Producer и Consumer в листинге 2. 2 по очереди получают доступ к переменной buf. Сначала Producer помещает первый элемент массива а в переменную buf, затем Consumer извлекает ее, a Producer помещает в переменную buf следующий элемент массива а и так далее. В переменных р и с ведется подсчет числа помещенных и извлеченных элементов, соответственно. Для синхронизации доступа к переменной buf используются операторы await. Когда выполняется условие р == с, буфер пуст (последний помещенный в него элемент был извлечен). Когда выполняется условие р > с, буфер заполнен.
Допустим, что вначале элементы массива а[п] содержат некоторый набор значений А [п]. (А [ i ] — это просто заменители произвольных действительных значений.) Цель — доказать, что при условии завершения программы, представленной выше, значения элементов b[n] будут совпадать с А[n], т.е. значениями элементов массива а. Это утверждение можно доказать с помощью следующего глобального инварианта.
PC: с <= р <= с+1 л а[0:n-1] == А[0:п-1] Л (р == с+1) => (buf == А[р-1])
Процессы чередуют доступ к переменной buf, поэтому в любой момент значение р равно с или на 1 больше, чем с. Массив а не изменяется, так что значением a[i] всегда является A[i]. Наконец, когда буфер полон (т.е. р == с+1), он содержит А [р-1].
Предикат PC в начальном состоянии является истинным, поскольку переменные рис равны нулю. Его истинность сохраняется каждым оператором присваивания, что показано в схеме доказательства (листинг 2.3). В листинге IP является инвариантом цикла в процессе Producer, а 1C— в Consumer. Как показано, предикаты 1Ри 1C связаны с предикатом PC.
Листинг 2.3 — это еще один пример схемы доказательства, поскольку перед каждым оператором и после него находятся утверждения, и каждая тройка в схеме доказательства истинна. Тройки в каждом процессе образуются непосредственно вокруг операторов присваивания в каждом процессе. Если каждый процесс непрерывно получает возможность выполняться, то операторы await завершаются, поскольку сначала истинно одно условие задержки, затем другое и так далее.
Таким образом, каждый процесс завершается после n итераций. Когда программа завершается, постусловия обоих процессов истинны. Следовательно, заключительное состояние программы удовлетворяет предикату:
PC ^ р == n ^ IC ^ с == n
Таким образом, массив b содержит копию массива а.
Утверждения в двух указанных процессах не оказывают взаимного влияния. Большинство из них являются комбинациями глобального инварианта PC и локальных предикатов. Следовательно, они соответствуют требованиям взаимного невмешательства, описанным в начале раздела о глобальных инвариантах. Четырьмя исключениями являются утверждения, которые определяют отношения между значениями разделяемых переменных рис. Но они не подвержены влиянию из-за операторов await.
Роль операторов await в программе копирования массива— обеспечить чередование доступа к буферу процесса-потребителя и процесса-производителя. В устранении взаимного вмешательства чередование играет двоякую роль. Во-первых, оно гарантирует, что два процесса не получат доступ к переменной buf одновременно (это пример взаимного исключения). Во-вторых, оно гарантирует, что производитель не перезаписывает элементы (переполнение), а потребитель не читает их дважды ("антипереполнение") — это пример условной синхронизации.
Подводя итоги, отметим, что этот пример, несмотря на простоту, иллюстрирует все четыре способа избежать взаимного влияния. Во-первых, многие операторы и многие части утверждений в каждом процессе не пересекаются. Во-вторых, использованы ослабленные утверждения о разделяемых переменных; например, говорится, что условие buf == А [р-1]
72 Часть 1 Программирование с разделяемыми переменными
истинно, только если истинно р == с+1. В-третьих, для выражения отношения между значениями разделяемых переменных использован глобальный инвариант PC; хотя при выполнении программы изменяется каждая переменная, это отношение не меняется! И, наконец, чтобы обеспечить взаимное исключение и условную синхронизацию, необходимые в этой программе, использована синхронизация, выраженная операторами await.

Точечные вычисления
Сеточные вычисления обычно используются для моделирования непрерывных систем, которые описываются дифференциальными уравнениями в частных производных. Для моделирования дискретных систем, состоящих из отдельных частиц (точек), воздействующих друг на друга, применяются точечные методы. Примерами являются заряженные частицы, взаимодействующие с помощью электрических и магнитных сил, молекулы (их взаимодействие обусловлено химическим строением) и астрономические тела, воздействующие друг на друга благодаря гравитации. Здесь рассматривается типичное приложение, называемое гравитационной задачей п тел. После постановки задачи представлены последовательная и параллельная программы, основанные на алгоритме сложности О(«2), затем описаны два приближенных метода сложности 0(п Iog2n): метод Барнса—Хата (Barnes—Hut) и быстрый метод мультиполей.
11.2.1. Гравитационная задача п тел
Предположим, что дано большое число астрономических тел галактики (звезд, пылевых облаков и черных дыр), и нужно промоделировать ее эволюцию.


Глава 11. Научные вычисления 425
11.2.2. Программа с разделяемыми переменными
Рассмотрим, как распараллелить программу для задачи п тел. Как всегда, вначале нужно решить, как распределить работу. Предположим, что есть PR процессоров, и, следовательно, будут использованы PR рабочих процессов. В реальных задачах п намного больше PR. Предположим, что п кратно pr.
Большая часть расчетов в последовательной программе проводится в цикле for процедуры calculateForces. В методе итераций Якоби работа просто распределялась по полосам, и на каждый рабочий процесс приходилось по n/PR строк сетки. В результате вычислительная нагрузка была сбалансированной, поскольку по методу итераций Якоби в каждой точке сетки выполняется один и тот же объем работы.
Для задачи п тел соответствующим разделением было бы назначение каждому рабочему процессу непрерывного блока тел: процесс 1 обрабатывает первые n/PR тел, 2— следующие n/PR тел и т.д.
Однако это привело бы к слишком несбалансированной нагрузке. Процессу 1 придется вычислить силы взаимодействия тела 1 со всеми остальными, затем — тела 2 со всеми, кроме тела 1, и т.д. С другой стороны, последнему процессу нужно вычислить только те силы, которые не были вычислены предыдущими процессами, т.е. лишь между последними n/PR телами.
Пусть для конкретного примера п равно 8, a pr — 2, т.е. используются два рабочих процесса. Назовем их черным (black — в) и белым (white — W). На рис. 11.4 показаны три способа назначения тел процессам. При блочном распределении первые четыре тела назначаются процессу В, последние четыре — W. Таким образом, число пар сил, вычисляемых В, равно 22 (7 + 6 + 5+4), а вычисляемых W, — 6 (3 + 2 +1).

Вычислительная нагрузка будет более сбалансированной, если назначать тела иначе: 1 — процессу В, 2 — W, 3 — В и т.д. Эта схема называется распределением по полосам по аналогии с полосами зебры. (Она называется еще циклическим распределением, поскольку схема повторяется.) Распределение по полосам приводит к следующей нагрузке процессов: 16 пар сил для В и 12 — для W.
Нагрузку можно еще больше сбалансировать, если распределить тела по схеме, похожей на ту, которая обычно используется при выборе команд в спортивных играх: назначим тело 1 процессу В, тела 2 и 3 — W, тела 4 и 5 — В и т.д. Эта схема называется распределением по обратным полосам, поскольку полосы каждый раз меняют порядок: черный, белый; белый, черный; черный, белый и т.д. Например, на рис. 11.4 нагрузка полностью сбалансирована — по 14 пар сил на каждый процесс.
Любая из приведенных выше стратегий распределения легко обобщается на любое число pr рабочих процессов. Блочная стратегия тривиальна. Для полос используется PR различных цветов. Первым цветом окрашивается тело 1, вторым — тело 2 и т.д. Цикл повторяется, пока все тела не будут окрашены. При использовании обратных полос порядок цветов меняется, когда начинается новый цикл, т.е. после окраски pr тел.
Для этой и любой другой задачи с похожей схемой индексов в главном вычислительном цикле распределение данных по схеме обратных полос дает наиболее сбалансированную вычислительную нагрузку. Однако схема полос программируется намного легче, чем схема обратных полос, и для больших значений п дает практически сбалансированную нагрузку. Поэтому в дальнейшем используем схему полос.
426 Часть 3. Синхронное параллельное программирование
Следующие вопросы связаны с синхронизацией. Есть ли критические секции? Нужна ли барьерная синхронизация? Ответ на оба вопроса утвердительный.
Сначала рассмотрим процедуру calculateForces. В цикле for рассматривается каждая пара тел i и j. Пока один процесс вычисляет силы между телами i и j, другой вычисляет силы между телами i' и j '. Некоторые из этих номеров могут быть равными: например, j в одном процессе может совпадать с i' в другом. Следовательно, процессы могут мешать друг другу при обновлении вектора сил f. Таким образом, четыре оператора присваивания, обновляющих f, образуют код критической секции.
Один из способов защитить критическую секцию — использовать одну переменную блокировки. Однако это неэффективно, поскольку критическая секция выполняется много раз каждым процессом. В другом предельном случае можно использовать массив переменных блокировки, по одной на тело. Это почти устраняет конфликты при блокировке, но за счет использования гораздо большего объема памяти. Промежуточный способ — использовать одну переменную блокировки на каждый блок из в тел, но и тут возникают конфликты блокировки.
Для хорошей производительности лучше всего вообще устранить накладные расходы на блокировку, избавившись от критических секций (если возможно). Это можно сделать двумя способами. При первом каждый рабочий процесс берет на себя полную ответственность за назначенные ему тела, т.е. процесс, отвечающий за тело i, вычисляет все силы, действующие на тело i, но не обновляет вектор сил для любого другого тела j.
Взамен, процесс, отвечающий за тело j, вычисляет все силы, действующие на него, в том числе и со стороны тела i. Такой способ можно запрограммировать, используя индексную переменную j в for цикле calculateForces со значениями в диапазоне от 1 до п, а не от i+1 до п, и исключая присваивания f [ j ]. Однако при этом не используется симметричность сил между двумя телами, так что все силы вычисляются дважды.
Второй способ устранения критических секций — вектор сил заменить матрицей сил, каждая строка которой соответствует одному процессу. Вычисляя силу между телами i и j, процесс w обновляет два элемента своей строки в матрице сил. А когда нужно будет вычислить новые положение и скорость тела, он сначала сложит все силы, действующие на данное тело и вычисленные ранее всеми остальными процессами.
Оба способа устранения критических секций используют дублирование. В первом методе дублируются вычисления, во втором — данные. Это еще один пример пространственно-временного противоречия. Поскольку целью параллельной программы обычно является уменьшение времени выполнения, то лучший выбор — использовать как можно больше пространства (разумеется, в пределах доступной памяти).
Осталось рассмотреть еще один важный момент — нужны ли барьеры, и если да, то где именно. Значения новых скоростей и положений, вычисляемых в moveBodies, зависят от сил, вычисленных в calculateForces. Поэтому, пока не будут вычислены все силы, нельзя перемещать тела. Аналогично силы зависят от положений и скоростей, поэтому нельзя пересчитывать силы, пока не перемещены тела. Таким образом, после каждого вызова процедур calculateForces и moveBodies нужна барьерная синхронизация.
Итак, здесь описаны три способа назначения тел процессам. Использование схемы полос приводит к вполне сбалансированной и легко программируемой вычислительной нагрузке. Рассмотрена проблема критической секции, показано, как применять блокировку и избегать ее. Наиболее эффективен следующий подход: исключить критические секции, чтобы каждый процесс обновлял свой собственный вектор сил.
Наконец, независимо от распределения рабочей нагрузки и управления критическими секциями нужны барьеры после вычисления сил и перемещения тел.
Все представленные решения включены в код в листинге 11.7. В основном структура программы совпадает со структурой последовательной программы (см. листинг 11.6). Для реализации барьерной синхронизации добавлена третья процедура barrier. Единый главный цикл имитации заменен имитацией на PR рабочих процессорах, и каждый из них выполняет цикл имитации. Процедура barrier вызывается после как вычисления сил, так и перемещения тел. Во всех вызовах процедур содержится аргумент w, который указывает на вызывающий процесс.

428 Часть 3. Синхронное параллельное программирование
Тела процедур, вычисляющих силы и перемещающих тела, изменены так, как описано выше. Наконец, главные циклы в этих процедурах изменены так, что приращение по i равно PR, а не 1 (этого достаточно, чтобы присваивать тела рабочим по схеме полос). Код в листинге 11.7 можно сделать более эффективным, оптимизировав его, как и последовательную программу.
11.2.3. Программы с передачей сообщений
Рассмотрим, как решить задачу п тел, используя передачу сообщений. Нам нужно построить метод распределения вычислений между рабочими процессами, чтобы рабочая нагрузка была сбалансированной. Необходимо также минимизировать накладные расходы на взаимодействие или хотя бы снизить их по сравнению с объемом полезной работы. Эти проблемы непросты, поскольку в задаче « тел вычисляются силы для всех пар тел, и, следовательно, каждому процессу приходится взаимодействовать со всеми остальными.
Вначале полезно разобраться, можно ли использовать парадигмы взаимодействия между процессами, описанные в начале главы 9, — "управляющий-рабочие" (распределенный портфель задач), алгоритм пульсации и конвейер. Поскольку задачи достаточно хорошо определены, а нагрузку сбалансировать сложно, подходит парадигма "управляющий-рабочие".
Можно также применить алгоритм пульсации, используя распределение тел и обмен данными между процессами. Однако явно не достаточно того, что каждый процесс обменивается информацией только с одним или двумя соседями. Наконец, можно использовать конвейер, в котором тела переходят от процесса к процессу. Ниже приведены решения задачи п тел с помощью каждой из этих парадигм, затем обсуждаются их преимущества и недостатки.
Программа типа "управляющий-рабочие"
Применим парадигму "управляющий-рабочие" (см. раздел 9.1). Управляющий обслуживает портфель задач; рабочие многократно получают задачу, выполняют ее и возвращают результат управляющему. В задаче п тел есть две фазы. В задачах первой фазы вычисляются силы между всеми парами тел, в задачах второй — перемещаются тела. Вычисление сил является основной частью работы, которая может оказаться несбалансированной. Поэтому есть смысл при вычислении сил использовать динамические задачи, а и при перемещении тел — статические (по одной на рабочего).
Предположим, что у нас есть PR процессоров и используются PR рабочих процессов. (Управляющий процесс работает на том же процессоре, что и один из рабочих.) Предположим для простоты, что п кратно PR. При использовании парадигмы "управляющий-рабочие" для сбалансированности нагрузки нужно, чтобы задач было хотя бы вдвое больше, чем рабочих процессов. Однако очень большое число задач или рабочих процессов нежелательно, поскольку рабочие процессы потратят слишком много времени на взаимодействие с менеджером. Один из способов распределить вычисления сил, действующих на n тел, состоит в следующем.
Множество тел разделяется на PR блоков размером n/PR. Первый блок содержит первые n/ PR тел, второй — следующие n/PR тел и т.д.
Образуются пары (i,J) для всех возможных комбинаций номеров блоков. Таких пар будет PR* (PR+1) /2 (сумма целых чисел от 1 до pr).
Пусть каждая пара представляет задачу, например, для пары (i,f) — вычислить силы, действующие между телами в блоках i hj.
В качестве конкретного примера предположим, что pr равно 4. Тогда десять задач представлены парами
(1, 1), (1, 2), (1, 3), (1,4), (2, 2), (2, 3), (2, 4), (3, 3), (3, 4), (4, 4).
Глава 11. Научные вычисления 429
этого рабочему нужны данные о положениях, скоростях и массах тел в одном или двух блоках. Управляющий мог бы передавать эти данные вместе с задачей, но можно значительно сократить длину сообщений, если у каждого рабочего процесса будет своя собственная копия данных о всех телах. Аналогично можно избавиться и от необходимости отправлять результаты управляющему, если каждый рабочий процесс отслеживает силы, которые он вычислил для каждого тела.
После вычисления всех сил, т.е. когда портфель задач пуст, рабочим процессам нужно обменяться силами и затем переместить тела. Простейшее статическое назначение работы в фазе перемещения тел состоит в том, чтобы каждый рабочий перемещал тела в одном блоке: рабочий процесс 1 перемещает тела в блоке 1, рабочий 2 — в блоке 2 и т. д. Следовательно, каждому рабочему w нужны векторы сил для тел блока w.

430 Часть 3. Синхронное параллельное программирование
Собирать и распределять силы, вычисленные каждым рабочим процессом, мог бы управляющий, но эффективность повысится, если каждый рабочий будет отправлять силы для блока тел непосредственно тому рабочему, который будет перемещать эти тела. Если же доступны глобальные примитивы взаимодействия (как в библиотеке MPI), возможен другой вариант: рабочие используют их для рассылки и удаления (добавления) значений в векторах сил. После того как все рабочие переместят тела в своих блоках, им нужно обменяться новыми положениями и скоростями тел. Для этого можно использовать сообщения "от точки к точке" или глобальное взаимодействие.
Листинг 11.8 содержит эскиз кода для программы типа "управляющий-рабочие".
Внешний цикл в каждом процессе выполняется один раз на каждом временном шаге имитации. Внутренний цикл в управляющем процессе выполняется numTasks+PR раз, где numTasks — число задач в портфеле. На последних pr итерациях портфель пуст, и управляющий отправляет пару (0, 0) как сигнал о том, что портфель пуст. Получая этот сигнал, каждый из PR процессов выходит из цикла вычисления сил.
Программа пульсации
Аналогом алгоритма с разделяемыми переменными является алгоритм пульсации, использующий передачу сообщений (раздел 9.2); вычислительные фазы в нем чередуются с барьерами. Программа с разделяемыми переменными (см. листинг 11.7) имеет соответствующую структуру, поэтому, чтобы использовать передачу сообщений, программу можно изменить: 1) каждому рабочему процессу назначается подмножество тел; 2) каждый рабочий сначала вычисляет силы в своем подмножестве, а затем обменивается силами с другими рабочими; 3) каждый рабочий перемещает свои тела; 4) рабочие обмениваются новыми положениями и скоростями тел. При имитации эти действия повторяются на каждом шаге по времени.
Назначать тела рабочим процессам можно по любой схеме распределения (см. рис. 11.4): по блокам, полосам или обратным полосам. Распределение по полосам или обратным полосам дает гораздо более сбалансированную вычислительную нагрузку, чем по блокам фиксированного размера. Однако каждому рабочему процессу придется иметь свою собственную копию векторов положений, скоростей, сил и масс. Кроме того, после каждой фазы необходим обмен целыми векторами со всеми остальными рабочими. Все это приводит к большому числу длинных сообщений.
Если рабочим назначать блоки тел, то будет использоваться приблизительно вдвое меньше сообщений, причем они будут короче. (Рабочим процессам также нужно меньше локальной памяти.) Чтобы понять, почему так происходит, рассмотрим пример из предыдущего раздела, в котором четыре процесса и десять задач. При назначении по блокам процесс 1 обрабатывает первые четыре задачи: (1, 1), (1, 2), (1, 3) и (1, 4).
Он вычисляет все силы, связанные с телами блока 1. Для этого ему необходимы положения и скорости тел из блоков 2, 3 и 4, и в эти же блоки ему нужно возвратить силы. Однако процесс 1 никогда не передает другим процессам положения и скорости своих тел, и ему не нужна информация о силах от любого другого процесса. С другой стороны, процесс 4 отвечает только за задачу (4,4). Ему не нужны положения или скорости остальных тел, и он не должен отправлять силы остальным рабочим.
Если все блоки одного размера, то рабочая нагрузка оказывается несбалансированной; затраты времени при этом могут даже превысить выигрыш от отправки меньшего числа сообщений. Но нет и причин, по которым все блоки должны быть одного размера, как в программе с разделяемыми переменными. Более того, тела можно переместить за линейное время, поэтому использование блоков разных размеров приведет к относительно небольшому дисбалансу нагрузки в фазе перемещения тел.
В листинге 11.9 представлена схема кода для программы пульсации, в которой рабочим процессам назначаются блоки разных размеров. Как показано, части кода, связанные с передачей сообщений, не симметричны. Разные рабочие отправляют неодинаковое число сообщений в различные моменты времени. Однако этот недостаток превращен в преимущество с помощью совмещения взаимодействий и вычислений во времени. Каждый рабочий процесс отправляет сообщения и затем до получения и обработки сообщений выполняет локальные вычисления.

Программа с конвейером
Рассмотрим решение задачи п тел с помощью конвейерного алгоритма (раздел 9.3). Напомним, что в конвейере информация двигается в одном направлении от процесса к процессу. Конвейер бывает открытым, круговым и замкнутым (см. рис. 9.1). Здесь нужна информация о телах, циркулирующая между рабочими процессами, поэтому следует использовать или круговой, или замкнутый конвейер. Управляющий процесс не нужен (за исключением, возможно, лишь инициализации рабочих процессов и сбора конечных результатов), поэтому достаточно кругового конвейера.
Рассмотрим идею использования кругового конвейера. Предположим, что каждому рабочему процессу назначен блок тел и каждый рабочий вычисляет силы, действующие только на тела в своем блоке. (Таким образом, сейчас выполняются лишние вычисления; позже мы используем симметрию сил между телами.) Каждому рабочему для вычисления сил, создаваемых "чужими" телами, нужна информация о них. Таким образом, достаточно, чтобы блоки тел циркулировали между рабочими процессами. Это можно сделать следующим образом..
Отправить р и v своего блока тел следующему рабочему процессу; вычислить силы, действующие между телами своего блока; for [i = 1 to PR-1] {
получить р и v блока тел от предыдущего рабочего процесса;
отправить этот блок тел следующему рабочему процессу;
432 Часть 3. Синхронное параллельное программирование
вычислить силы, с которыми тела нового блока действуют на тела своего блока -, }
получить обратно свой блок тел; переместить тела; реинициализировать силы, действующие на свои тела, нулями;
Каждый рабочий процесс выполняет данный код на каждом временном шаге имитации. (Последняя отправка и получение не обязательны в приведенном коде, однако они понадобятся позже.)
При описанном подходе выполняется вдвое больше вычислений сил, чем необходимо. Следовательно, нам желательно рассматривать каждую пару тел только один раз и пропускать силы, уже вычисленные для какой-либо группы тел. Чтобы сбалансировать вычислительную нагрузку, нужно или назначать разные количества тел каждому процессу (как в программе пульсации), или назначать тела по полосам или обратным полосам, как в программе с разделяемыми переменными. Применим одну из схем назначения тел по полосам, которая даст наиболее сбалансированную нагрузку.
В листинге 11.10 приведен код кругового конвейера, использующий схему присваивания тел по полосам. Каждое сообщение содержит положения, скорости и силы, уже вычисленные для подмножества тел.
В коде не показаны все подробности учета, необходимые, чтобы точно отслеживать, какие тела принадлежат каждому подмножеству; однако это можно определить по идентификатору владельца подмножества. Каждое подмножество тел циркулирует по конвейеру, пока не вернется к своему владельцу, который затем переместит эти тела.

Сравнение программ
Приведенные три программы с передачей сообщений отличаются друг от друга по нескольким параметрам: легкость программирования, сбалансированность нагрузки, число сообщений и объем локальных данных. Легкость программирования субъективна; она зависит от того, насколько программист знаком с каждым из стилей. Тем не менее, если сравнить длину и сложность программ, простейшей окажется программа с конвейером. Она короче
Глава 11. Научные вычисления 433
других, отчасти потому, что в ней используется наиболее регулярная схема взаимодействия. Программа типа "управляющий-рабочие" также весьма проста, хотя ей нужен дополнительный процесс. Программа пульсации сложнее других (хотя и не намного), поскольку в ней используются блоки тел разных размеров и асимметричная схема взаимодействия.
Рабочая нагрузка у всех трех программ будет достаточно сбалансированной. Программа типа "управляющий-рабочие" динамически распределяет работу, поэтому нагрузка здесь почти сбалансирована, даже если процессоры имеют разные скорости или некоторые из них одновременно выполняют другие программы. При выполнении на специализированной однородной архитектуре у конвейерной программы с назначением по полосам рабочая нагрузка будет сбалансирована достаточно, а с назначением по обратным полосам— почти идеально. Программа пульсации использует блоки разных размеров, поэтому нагрузка окажется не идеально, но все-таки почти сбалансированной; кроме того, асимметричная схема взаимодействия и перекрытие взаимодействия и вычислений во времени отчасти скроет несбалансированность вычисления сил.
Во всех программах на каждом шаге по времени отправляются (и получаются) 0(PR2) сообщений. Однако действительные количества сообщений отличаются, как и их размеры (табл. 11.1). Алгоритм пульсации дает наименьшее число сообщений. Конвейер — на PR сообщений больше, но они самые короткие. Больше всего сообщений в программе типа "управляющий-рабочие", однако здесь обмен значениями между рабочими процессами можно реализовать с помощью операций группового взаимодействия.

Наконец, программы отличаются объемом локальной памяти каждого рабочего процесса. В программе типа "управляющий-рабочие" каждый рабочий процесс имеет копию данных о всех телах; ему также нужна временная память для сообщений, число которых может достигать 2п. В программе пульсации каждому процессу нужна память для своего подмножества тел и временная память для наибольшего из блоков, которые он может получить от других. В конвейерной программе каждому рабочему процессу нужна память для своего подмножества тел и рабочая память для еще одного подмножества, размер которого — n/PR. Следовательно, конвейерной программе нужно меньше всего памяти на один рабочий процесс.
Подведем итог: для задачи п тел наиболее привлекательной выглядит программа с конвейером. Она сравнительно легко пишется, дает почти сбалансированную нагрузку, требует наименьшего объема локальной памяти и почти минимального числа сообщений. Кроме того, конвейерная программа будет эффективнее работать на некоторых типах коммуникационных сетей, поскольку каждый рабочий процесс взаимодействует только с двумя соседями. Однако различия между программами относительно невелики, поэтому приемлема любая из них. Оставим читателю интересную задачу реализации всех трех программ и экспериментального сравнения их производительности.
434 Часть 3. Синхронное параллельное программирование
11.2.4. Приближенные методы
В задаче п тел доминируют вычисления сил.
В реальных приложениях для очень больших значений и на вычисление сил приходится более 95 процентов всего времени. Поскольку каждое тело взаимодействует со всеми остальными, на каждом шаге по времени выполняется О(пг) вычислений сил. Однако величина гравитационной силы между двумя телами обратно пропорциональна квадрату расстояния между ними. Поэтому, если два тела находятся далеко друг от друга, то силой их притяжения можно пренебречь.
Рассмотрим конкретный пример: на движение Земли влияют другие тела Солнечной системы, в большей степени Солнце и Луна и в меньшей — остальные планеты. Гравитационная сила воздействия на Солнечную систему со стороны других тел пренебрежимо мала, но оказывается достаточно большой, чтобы вызвать движение Солнечной системы по галактике Млечного пути.
Ньютон доказал, что группу тел можно рассматривать как одно тело по отношению к другим, удаленным, телам. Например, группу тел В можно заменить одним телом Ь, которое имеет массу, равную сумме масс всех тел в В, и расположено в центре масс В. Тогда силу между отдаленным телом /' и всеми телами В можно заменить силой между / и Ь.
Ньютоновский подход приводит к приближенным методам имитации п тел. Первым распространенным методом был алгоритм Барнса—Хата (Barnes—Hut), но теперь чаще используется более эффективный быстрый метод мулыпиполей. Оба метода являются примерами так называемых древесных кодов, поскольку лежащая в их основе структура данных представляет собой дерево тел. Время работы алгоритма Барнса—Хата равно О(п \ogri); для однородных распределений тел время работы быстрого метода мультиполей равно О(п). Ниже кратко описана работа этих методов. Подробности можно найти в работах, указанных в исторической справке в конце данной главы.
Основой иерархических методов является древовидное представление физического пространства. Корень дерева представляет клетку, которая содержит все тела. Дерево строится рекурсивно с помощью разбиения клеток. В двухмерном варианте сначала корневую клетку делят на четыре одинаковые клетки, а затем дробят полученные клетки.
Клетка делится, если количество тел в ней больше некоторого фиксированного числа. Полученное таким образом дерево называется деревом квадрантов (quadtree), поскольку у каждого нелистового узла по четыре сына. Форма дерева соответствует распределению тел, поскольку дерево имеет больше уровней в тех областях, где больше тел. (В трехмерном пространстве родительские клетки делятся на восемь меньших, и структура данных называется деревом октантов.)
На рис. 11.5 проиллюстрирован процесс деления двухмерного пространства на клетки и соответствующее дерево квадрантов. Каждая группа из четырех клеток одинакового размера нумеруется по часовой стрелке, начиная с верхней левой и заканчивая нижней левой, 'и представлена деревом в том же порядке. Каждый узел-лист представляет клетку либо пустую, либо с одним телом.

Глава 11. Научные вычисления 435
Алгоритм Барнса—Хата
Алгоритм сложности я'на каждом шаге по времени имеет две фазы вычислений — вычисление сил и перемещение тел. В алгоритме Барнса—Хата есть еще две фазы предварительной обработки. Таким образом, на каждом временном шаге вычисления проводятся в четыре этапа.
1. Строится дерево квадрантов, представляющее текущее распределение тел.
2. Вычисляется полная масса и центр масс каждой клетки. Полученные значения записываются в соответствующем узле дерева квадрантов. Это делается с помощью прохода от листовых узлов к корню.
3. С использованием дерева вычисляются силы, связанные с каждым телом. Начиная с корня дерева, для каждого посещаемого узла рекурсивно выполняют следующую проверку. Если центр масс клетки "достаточно удален" от тела, то клеткой аппроксимируется все соответствующее ей поддерево; иначе обходятся все четыре подклетки. Чтобы определить, "достаточно ли удалена" клетка, используется параметр, заданный пользователем.
4. Тела перемещаются, как и раньше.
На каждом временном шаге дерево перестраивается, поскольку тела перемещаются, и, следовательно, их распределение изменяется.
Однако перемещения, в основном, малы, поэтому дерево можно перестраивать, если только какое-нибудь тело перемещается за пределы своей клетки. В любом случае центры масс всех клеток нужно пересчитывать на каждом временном шаге.
Число узлов в дереве квадрантов равно О(п log//), поэтому фазы 1 и 2 имеют такую же временную сложность. Вычисление сил также имеет сложность О(п logn), поскольку в дереве обходятся только клетки, расположенные близко к телу. Перемещение тел является, как обычно, самой быстрой фазой с временной сложностью О(п).
В алгоритме Барнса—Хата не учитывается свойство симметрии сил между телами, т.е. в фазе вычисления сил каждое тело рассматривается отдельно. (Учет получится слишком громоздким, если пытаться отслеживать все уже вычисленные пары тел.) Тем не менее алгоритм эффективен, поскольку его временная сложность меньше О(п2).
Алгоритм Барнса—Хата сложнее эффективно распараллелить, чем основной алгоритм, из-за следующих дополнительных проблем: 1) пространственное распределение тел в общем случае неоднородно, и, соответственно, дерево не сбалансировано; 2) дерево приходится обновлять на каждом временном шаге, поскольку тела перемещаются; 3) дерево является связанной структурой данных, которую гораздо сложнее распределить (и использовать), чем простые массивы. Эти проблемы затрудняют балансировку рабочей нагрузки и ослабление требований памяти. Например, процессорам нужно было бы назначить поровну тел, но это не будет соответствовать каким бы то ни было регулярным разбиениям пространства на клетки. Более того, процессорам нужно работать вместе, чтобы построить дерево, и при вычислении сил им может понадобиться все дерево. В результате многолетних исследований по имитации задачи п тел были разработаны эффективные методы ее параллельной реализации (см. историческую справку в конце главы). В настоящее время можно имитировать эволюцию систем, содержащих сотни миллионов тел, и на тысячах процессоров получать существенное ускорение.
Быстрый метод мультиполей
Быстрый метод мультиполей (Fast Multipole Method — FMM) является усовершенствованием метода Барнса-Хата и требует намного меньше вычислений сил. Метод Барнса-Хата рассматривает только взаимодействия типа тело-тело и тело-клетка. В FMM также вычисляются взаимодействия типа клетка-клетка. Если внутренняя клетка дерева квадрантов находится достаточно далеко от другой внутренней клетки, то в FMM вычисляются силы между двумя клетками, и полученный результат переносится на всех потомков обеих клеток.
Второе основное отличие FMM от метода Барнса-Хата состоит в способе, по которому методы управляют точностью аппроксимации сил. Метод Барнса-Хата представляет каждую клетку точкой, размещенной в центре масс клетки, и для аппроксимации силы учитывает
436 Часть 3. Синхронное параллельное программирование
расстояние между телом и данной точкой. В FMM распределение массы в клетке представляется с помощью ряда разложений и считается, что две клетки достаточно удалены друг от друга, если расстояние между ними намного превосходит длину большей из их сторон. Таким образом, аппроксимации в FMM используются намного чаще, чем в методе Барнса—Хата, но это компенсируется более точным описанием распределения массы внутри клетки.
Фазы на временном шаге в FMM такие же, как и в методе Барнса—Хата, но фазы 2 и 3 реализуются иначе. Благодаря вычислению взаимодействий типа клетка-клетка и аппроксимации гораздо большего числа сил, временная сложность FMM равна О(п) для однородных распределений тел в пространстве. FMM трудно распараллелить, но применение такой же техники, как в методе Барнса—Хата, все-таки позволяет сделать это достаточно эффективно.
Учебные примеры: библиотека Pthreads
Напомним, что поток — это "облегченный" процесс, т.е. процесс с собственным программным счетчиком и стеком выполнения, но без "тяжелого" контекста (типа таблиц страниц), связанного с работой приложения. Некоторые операционные системы уже давно предоставляли механизмы, позволявшие программистам писать многопоточные приложения. Но эти механизмы отличались, поэтому приложения нельзя было переносить между разными операционными системами или даже между разными типами одной операционной системы. Чтобы исправить эту ситуацию, большая группа людей в середине 1990-х годов определила стандартный набор функций языка С для многопоточного программирования. Эта группа работала под покровительством организации POSIX (Portable Operating System Interface — интерфейс переносимой операционной системы), поэтому библиотека называется Pthreads для потоков POSIX. Сейчас эта библиотека широко распространена и доступна на самых разных типах операционных систем UNIX и некоторых других системах
Библиотека Pthreads содержит много функций для управления потоками и их синхронизации. Здесь описан только базовый набор функций, достаточный для создания и соединения потоков, а также для синхронизации работы потоков с помощью семафоров. (В разделе 5.5 описаны функции для блокировки и переменных условия.) Также представлен простой, но достаточно полный пример приложения типа "производитель-потребитель". Он может служить базовым шаблоном для других приложений, в которых используется библиотека Pthreads.

Глава 4. Семафоры 155
нием области планирования. Часто программист хочет, чтобы планирование потока происходило глобально, а не локально, т.е. чтобы поток конкурировал за процессор со всеми потоками, а не только с созданными его родительским потоком. В вызове функции pthread_attr_setscope, приведенном выше, это учтено.10 Новый поток создается вызовом функции pthread_create:
pthread_create(&tid, &tattr, start_func, arg);
Первый аргумент — это адрес дескриптора потока, заполняемый при его успешном создании. Второй — адрес дескриптора атрибутов потока, который был инициализирован предыдущим. Новый поток начинает работу вызовом функции start_func с единственным аргументом arg. Если поток создан успешно, функция pthread_create возвращает нуль. Другие значения указывают на ошибку.
Поток завершает свою работу следующим вызовом: pthread_exit(value);
Параметр value — это скалярное возвращаемое значение (или NULL). Процедура exit вызывается неявно, если поток возвращается из функции, выполнение которой он начал.
Родительский процесс может ждать завершения работы сыновнего процесса, выполняя функцию
pthread_join(tid, value_ptr);
Здесь tid является дескриптором сыновнего процесса, а параметр value_ptr — адресом переменной для возвращаемого значения, которая заполняется, когда сыновний процесс вызывает функцию exit.
4.6.2. Семафоры
Потоки взаимодействуют с помощью переменных, объявленных глобальными по отношению к функциям, выполняемым потоками. Потоки могут синхронизироваться с помощью активного ожидания, блокировок, семафоров или условных переменных. Здесь описаны семафоры; блокировки и мониторы представлены в разделе 5.5.
Заголовочный файл semaphore.h содержит определения и прототипы операций для семафоров. Дескрипторы семафоров определены как глобальные относительно потоков, которые будут их использовать, например: sem_t mutex;
Дескриптор инициализируется вызовом функции sem_init. Например, следующий вызов присваивает семафору mutex значение 1:
sem_init(&mutex, SHARED, 1) ;
Если параметр shared не равен нулю, то семафор может быть разделяемым между процессами, иначе семафор могут использовать только потоки одного процесса. Эквивалент операции Р в библиотеке Pthreads— функция sem_wait, а операции V— функция sem_post. Итак, один из способов защиты критической секции с помощью семафоров выглядит следующим образом.
sem_wait(umutex); /* Р(mutex) */
критическая секция;
sem_post(fcmutex); /* V(mutex) */
Кроме того, в библиотеке Pthreads есть функции для условного ожидания на семафоре, получения текущего значения семафора и его уничтожения.
10
Программы, приведенные в книге и использующие библиотеку Pthreads, тестировались с помощью операционной системы Solaris. На других системах для некоторых атрибутов могут понадобиться другие значения. Например, в системе IRIX видимость для планирования должна быть указана как PTHREAD_SCOPE_PROCESS, и это значение установлено по умолчанию.
156 Часть 1 Программирование с разделяемыми переменными
4.6.3. Пример: простая программа типа "производитель-потребитель"
В листинге 4.14 приведена простая программа типа производитель-потребитель, аналогичная программе в листинге 4.3. Функции Producer и Consumer выполняются как независимые потоки. Они разделяют доступ к буферу data. Функция Producer помещает в буфер последовательность целых чисел от 1 до значения numlters. Функция Consumer извлекает и складывает эти значения. Для обеспечения попеременного доступа к буферу процесса-производителя и процесса-потребителя использованы два семафора, empty и full.
Функция main инициализирует дескрипторы и семафоры, создает два потока и ожидает завершения их работы. При завершении потоки неявно вызывают функцию pthread_exit. В данной программе аргументы потокам не передаются, поэтому в функции pthread_create использован адрес NULL. Пример, в котором используются аргументы потоков, приведен в разделе 5.5.

Глава 4 Семафоры
}
printf{"Сумма равна %d\n", total);
}___________________________________________________________________
Учебные примеры: язык Ada
Язык Ada бьи создан при содействии министерства обороны США в качестве стандартного языка программирования приложений для обороны (от встроенных систем реального времени до больших информационных систем). Возможности параллелизма языка Ada являются его важной частью; они критичны для его использования по назначению. В языке Ada также есть большой набор механизмов для последовательного программирования.
Язык Ada стал результатом широкого международного конкурса разработок в конце 1970-х годов и впервые был стандартизован в 1983 г. В языке Ada 83 был представлен механизм рандеву для межпроцессного взаимодействия. Сам термин рандеву был выбран потому, что руководителем группы разработчиков был француз. Вторая версия языка Ada была стандартизована в 1995 г. Язык Ada 95 совместим снизу вверх с языком Ada 83 (поэтому старые программы остались работоспособными), но в нем появилось несколько новых свойств. Два самых интересных свойства, связанных с параллельным программированием, — это защищенные типы, подобные мониторам, и оператор requeue, позволяющий программисту более полно управлять синхронизацией и планированием.
В данном разделе сначала представлен обзор основных механизмов параллельности в языке Ada: задачи, рандеву и защищенные типы. Далее показано, как запрограммировать барьер в виде защищенного типа, а решение задачи об обедающих философах — в виде набора задач, которые взаимодействуют с помощью рандеву. В примерах также демонстрируются возможности языка Ada для последовательного программирования.
8.6.1. Задачи
Программа на языке Ada состоит из подпрограмм, модулей (пакетов) и задач. Подпрограмма — это процедура или функция, пакет — набор деклараций, а задача — независимый процесс. Каждый компонент имеет раздел определений и тело. Определения объявляют ви-
310 Часть 2. Распределенное программирование
димые объекты, тело содержит локальные декларации и операторы.
Подпрограммы и модули могут быть настраиваемыми (generic), т.е. параметризоваться типами данных. Базовая форма определения задачи имеет следующий вид. task Name is
декларации точек входа; end;
Декларации точек входа аналогичны декларациям ор в модулях. Они определяют операции, которые обслуживает задача, и имеют такой вид.
entry Identifier (параметры) ;
Параметры передаются путем копирования в подпрограмму (по умолчанию), копирования из подпрограммы или обоими способами. Язык Ada поддерживает массивы точек входа, которые называются семействами точек входа.
Базовая форма тела задачи имеет следующий вид. task body Name is
локальные декларации begin
операторы; end Name;
Задача должна быть объявлена внутри подпрограммы или пакета. Простейшая параллельная программа на языке Ada является, таким образом, процедурой, содержащей определения задач и их тела. Объявления в любом компоненте обрабатываются по одному в порядке их появления. Обработка объявления задачи приводит к созданию экземпляра задачи. После обработки всех объявлений начинают выполняться последовательные операторы подпрограммы в виде безымянной задачи.
Пара "определение задачи-тело" определяет одну задачу. Язык Ada также поддерживает массивы задач, но способ поддержки не такой, как в других языках программирования. Программист сначала объявляет тип задачи, а затем — массив экземпляров этого типа. Для динамического создания задач программист может использовать типы задач совместно с указателями (в языке Ada они называются типами доступа).
8.6.2. Рандеву
В языке Ada 83 первичным механизмом взаимодействия и единственной схемой синхронизации было рандеву. (Задачи на одной машине могли также считывать и записывать значения разделяемых переменных.) Все остальные схемы взаимодействия нужно было программировать с помощью рандеву. Язык Ada 95 также поддерживает защищенные типы для синхронизированного доступа к разделяемым объектам; это описано в следующем разделе.
Предположим, что в задаче т объявлена точка входа Е. Задачи из области видимости задачи т могут вызвать Е следующим образом. cal 1 Т. Е (аргументы) ;
Как обычно, выполнение call приостанавливает работу вызывающего процесса до тех пор, пока не завершится Е (будет уничтожена или вызовет исключение).
Задача Т обслуживает вызовы точки входа Е с помощью оператора accept, имеющего следующий вид.
accept E (параметры) do
список операторов; end;
Выполнение оператора accept приостанавливает задачу, пока не появится вызов Е, копирует значения входных аргументов во входные параметры и выполняет список операторов. Когда выполнение списка операторов завершается, значения выходных параметров копируются
Глава 8. Удаленный вызов процедур и рандеву 311
в выходные аргументы. В этот момент продолжают работу и процесс, вызвавший точку входа, и процесс, выполняющий ее. Оператор accept, таким образом, похож на оператор ввода (раздел 8.2) с одной защитой, без условия синхронизации и выражения планирования.
Для поддержки недетерминированного взаимодействия задач в языке Ada используются операторы select трех типов: селективное ожидание, условный вызов точки входа и синхронизированный вызов точки входа. Оператор селективного ожидания поддерживает защищенное взаимодействие. Его обычная форма такова.
select when Bi => accept оператор; дополнительные операторы; or ...
or when Bn => accept оператор; дополнительные операторы;
end select;
Каждая строка называется альтернативой. Каждое бд. — это логическое выражение, части when необязательны. Говорят, что альтернатива открыта, если условие B1. истинно или часть when отсутствует.
Эта форма селективного ожидания приостанавливает выполняющий процесс до тех пор, пока не сможет выполниться оператор accept в одной из открытых альтернатив, т.е. если есть ожидающий вызов точки входа, указанной в операторе accept. Поскольку каждая защита Вл, предшествует оператору accept, защита не может ссылаться на параметры вызова точки входа.
Также язык Ada не поддерживает выражения планирования. Как отмечалось в разделе 8.2 и будет видно из примеров следующих двух разделов, это усложняет решение многих задач синхронизации и планирования.
Оператор селективного ожидания может содержать необязательную альтернативу else, которая выбирается, если нельзя выбрать ни одну из остальных альтернатив. Вместо оператора accept программист может использовать оператор delay или альтернативу terminate. Открытая альтернатива с оператором delay выбирается, если истек интервал ожидания; этим обеспечивается механизм управления временем простоя. Альтернатива terminate выбирается, если завершились или ожидают в своих альтернативах terminate все задачи, которые взаимодействуют с помощью рандеву с данной задачей (см. пример в листинге 8.18).
Условный вызов точки входа используется, если одна задача должна опросить другую. Он имеет такой вид.
select вызов точки входа; дополнительные операторы; else операторы; end select;
Вызов точки входа выбирается, если его можно выполнить немедленно, иначе выбирается альтернатива else.
Синхронизированный вызов точки входа используется, когда вызывающая задача должна ожидать не дольше заданного интервала времени. По форме такой вызов аналогичен условному вызову точки входа.
select вызов точки входа; дополнительные операторы; or delay оператор; дополнительные операторы;
end select;
Здесь выбирается вызов точки входа, если он может быть выполнен до истечения заданного интервала времени задержки.
Языки Ada 83 и Ada 95 обеспечивают несколько дополнительных механизмов для параллельного программирования. Задачи могут разделять переменные, однако обновление значений этих переменных гарантированно происходит только в точках синхронизации (например, в операторах рандеву). Оператор abort позволяет одной задаче прекращать выполнение другой. Существует механизм установки приоритета задачи. Кроме того, задача имеет так называемые атрибуты. Они позволяют определить, можно ли вызвать задачу, или она уже прекращена, а также узнать количество ожидающих вызовов точек входа.
312 Часть 2. Распределенное программирование
8.6.3. Защищенные типы
Язык Ada 95 развил механизмы параллельного программирования языка Ada 83 по нескольким направлениям. Наиболее существенные дополнения — защищенные типы, которые поддерживают синхронизированный доступ к разделяемым данным, и оператор requeue, обеспечивающий планирование и синхронизацию в зависимости от аргументов вызова. Защищенный тип инкапсулирует разделяемые данные и синхронизирует доступ к ним. Экземпляр защищенного типа аналогичен монитору, а его раздел определений имеет следующий вид. protected type Name is
декларации функций, процедур или точек входа; private
декларации переменных; end Name;
Тело имеет такой вид.
protected body Name is
тела функций, процедур или точек входа;
end Name;
Защищенные функции обеспечивают доступ только для чтения к скрытым переменным; следовательно, функцию могут вызвать одновременно несколько задач. Защищенные процедуры обеспечивают исключительный доступ к скрытым переменным для чтения и записи. Защищенные точки входа похожи на защищенные процедуры, но имеют еще часть when, которая определяет логическое условие синхронизации. Защищенная процедура или точка входа в любой момент времени может выполняться только для одной вызвавшей ее задачи. Вызов защищенной точки входа приостанавливается, пока условие синхронизации не станет истинным и вызывающая задача не получит исключительный доступ к скрытым переменным. Условие синхронизации не может зависеть от параметров вызова.
Вызовы защищенных процедур и точек входа обслуживаются в порядке FIFO, но в зависимости от условий синхронизации точек входа. Чтобы отложить завершение обслуживаемого вызова, в теле защищенной процедуры или точки входа можно использовать оператор requeue. (Его можно использовать и в теле оператора accept.) Он имеет следующий вид. requeue Opname;
Opname — это имя точки входа или защищенной процедуры, которая или не имеет параметров или имеет те же параметры, что и обслуживаемая операция.
В результате выполнения оператора requeue вызов помещается в очередь операции Opname, как если бы задача непосредственно вызвала операцию Opname.
В качестве примера использования защищенного типа и оператора requeue рассмотрим код N-задачного барьера-счетчика в листинге 8.16. Предполагается, что N — глобальная константа. Экземпляр барьера объявляется и используется следующим образом. В : Barrier; -- декларация барьера
В.Arrive; — или "call В.Arrive;"
Первые N-1 задач, подходя к барьеру, увеличивают значение счетчика барьера count и задерживаются в очереди на скрытой точке входа Go. Последняя прибывшая к барьеру задача присваивает переменной time_to_leave значение True; это позволяет запускать по одному процессы, задержанные в очереди операции Go. Каждая задача перед выходом из барьера уменьшает значение count, а последняя уходящая задача переустанавливает значение переменной time_to_leave, поэтому барьер можно использовать снова. (Семантика защищенных типов гарантирует, что каждая приостановленная в очереди Go задача будет выполняться до обслуживания любого последующего вызова процедуры Arrive.) Читателю полезно сравнить этот барьер с барьером в листинге 5.12, который запрограммирован с использованием библиотеки Pthreads.

U.4. Пример: обедающие философы
В данном разделе представлена законченная Ada-программа для задачи об обедающих философах (см. раздел 4.3). Программа иллюстрирует использование как задач и рандеву, гак и некоторых общих свойств языка Ada. Для удобства предполагается, что существуют две функции left(i) и right (i), которые возвращают индексы соседей философа i аева и справа.
В листинге 8.17 представлена главная процедура Dining_Philosophers. Перед процедурой находятся декларации with и use. В декларации with сообщается, что эта процедура использует объекты пакета Ada. Text_IO, a use делает имена экспортируемых объектов этого пакета непосредственно видимыми (т.е. их не нужно уточнять именем пакета).
яистинг 8.17. Решение задачи об обедающих философах на языке Ada; равная программа"
nth Ada.Text_IO; use Ada.Text_IO; procedure Dining_Philosophers is subtype ID is Integer range 1..5;
task Waiter is -- спецификация задачи-официанта
entry Pickup(I : in ID);
entry Putdownd : in ID) ; end task body Waiter is separate;
task type Philosopher is -- тип задачи-философа
"В теле задачи-философа отсутствует имитация случайных промежутков времени, в течение которых философы едят или думают. — Прим. ред.


В листинге 8.17 имя Philosopher определено как тип задачи, чтобы можно было объявить массив dp из пяти таких задач. Экземпляры пяти задач-философов создаются при обработке декларации массива DP. Каждый философ сначала ждет, чтобы принять вызов своей инициализирующей точки входа init, затем выполняет rounds итераций. Переменная rounds объявлена глобальной по отношению к телу задач философов, поэтому все они могут ее читать. Переменная rounds инициализируется вводимым значением в теле главной процедуры (конец листинга 8.17). Затем каждому философу передается его индекс с помощью вызова DP (j) . init (j).
Листинг 8.18 содержит тело задачи Waiter (официант). Оно сложнее, чем процесс Waiter в листинге 8.6, поскольку условие when в операторе select языка Ada не может ссылаться на входные параметры. Waiter многократно принимает вызовы операций Pickup и Putdown. Принимая вызов Pickup, официант проверяет, ест ли хотя бы один сосед философа i, вызвавшего эту операцию. Если нет, то философ i может есть. Но если хотя бы один сосед ест, то вызов Pickup должен быть вновь поставлен в очередь так, чтобы задача-философ не была слишком рано запущена вновь. Для приостановки ожидающих философов используется локальный массив из пяти точек входа wait (ID); каждый философ ставится в очередь отдельного элемента этого массива.
Поев, философ вызывает операцию Putdown. Принимая этот вызов, официант проверяет, хочет ли есть каждый сосед данного философа и может ли он приступить к еде.Если да, официант принимает отложенный вызов операции Wait, чтобы запустить задачу-философ, вызов операции Pickup которой был поставлен в очередь. Оператор accept, обслуживающий операцию Putdown, мог бы охватывать всю альтернативу в операторе select, т.е. заканчиваться после двух операторов if. Однако он заканчивается раньше, поскольку незачем приостанавливать задачу-философ, вызвавшую операцию Putdown.
Учебные примеры: язык Java
В разделе 5.4 был представлен язык Java и программы для чтения и записи простой разделяемой базы данных. В разделе 7.9 было показано, как создать приложение типа "клиент-сервер", используя передачу сообщений через сокеты и модуль j ava. net. Язык Java также поддерживает RPC для распределенных программ. Поскольку операции с объектами языка Java называются методами, а не процедурами, RPC в языке Java называется удаленным вызовом метода (remote method invocation — RMI). Он поддерживается модулями j ava. rmi и j ava. rmi. server.
Ниже приведен обзор удаленного вызова методов, а его использование иллюстрируется реализацией простой удаленной базы данных. База данных имеет тот же интерфейс, что и в предыдущих примерах на языке Java из главы 5, но в ее реализации использованы клиент и сервер, которые выполняются на разных машинах.
8.5.1. Удаленный вызов методов
Приложение, использующее удаленный вызов методов, состоит из трех компонентов: интерфейса, в котором объявлены заголовки удаленных методов, серверного класса, реализующего этот интерфейс, и одного или нескольких клиентов, которые вызывают удаленные методы. Приложение программируется следующим образом.
• Пишется интерфейс Java, который расширяет интерфейс Remote, определенный в модуле Java. rmi. Для каждого метода интерфейса нужно объявить, что он возбуждает удаленные исключительные ситуации.
• Строится серверный класс, расширяющий класс UniclassRemoteObject и реализующий методы интерфейса. (Сервер, конечно же, может содержать также защищенные поля и методы.) Пишется код, который создает экземпляр сервера и регистрирует его имя с помощью службы регистрации (см. ниже). Этот код может находиться в главном методе серверного класса или в другом классе.
• Пишется класс клиента, взаимодействующий с сервером. Клиент должен сначала установить диспетчер безопасности RMI, чтобы защитить себя от ошибочного кода заглушки (stub code, см. ниже), который может быть загружен через сеть.
После этого клиент вызывает метод Naming. lookup, чтобы получить объект-сервер от службы регистрации. Теперь клиент может вызывать удаленные методы сервера.
Как компилировать и выполнять эти компоненты, показано ниже. Конкретный пример рассматривается в следующем разделе.
Программа-клиент вызывает методы сервера так, как если бы они были локальными (на той же виртуальной Java-машине). Но когда вызываются удаленные методы, взаимодействие
Глава 8 Удаленный вызов процедур и рандеву 307
между клиентом и сервером в действительности управляется серверной заглушкой и скелетом сервера. Они создаются после компиляции программы при выполнении команды rmic. Заглушка и скелет — это части кода, которые включаются в программу автоматически. Они находятся между реальным клиентом и кодом сервера в исходной Java-программе. Когда клиент вызывает удаленный метод, он в действительности вызывает метод в заглушке. Заглушка упорядочивает аргументы удаленного вызова, собирая их в единое сообщение, и отсылает по сети скелету. Скелет получает сообщение с аргументами, генерирует локальный вызов метода сервера, ждет результатов и отсылает их назад заглушке. Наконец заглушка возвращает результаты коду клиента. Таким образом, заглушки и скелет скрывают подробности сетевого взаимодействия.
Еще одно следствие использования удаленных методов состоит в том, что клиент и сервер являются отдельными программами, которые выполняются на разных узлах сети. Следовательно, им нужен способ именования друг друга, причем имена серверов должны быть уникальными, поскольку одновременно могут работать многие серверы. По соглашению удаленные серверы именуются с помощью схемы URL. Имя имеет вид: rmi://hostname:port/ pathname, где hostname— доменное имя узла, на котором будет выполняться сервер, port — номер порта, a pathname — путевое имя на сервере, выбираемые пользователем.
Служба регистрации — это специализированная программа, которая управляет списком имен серверов, зарегистрированных на узле.
Она запускается на серверной машине в фоновом режиме командой "rmiregistry port &". (Программа-сервер может также обеспечивать собственную службу регистрации, используя модуль Java. rmi. registry.) Интерфейс для службы регистрации обеспечивается объектом Naming; основные методы этого объекта — bind для регистрации имени и сервера и lookup для поиска сервера, связанного с именем.
Последний шаг в выполнении программы типа "клиент-удаленный сервер" — запуск сервера и клиента (клиентов) с помощью интерпретатора Java. Сначала запускается сервер на машине hostname. Клиент запускается на любом узле, подключенном к серверу. Но тут есть два предостережения: пользователь должен иметь разрешение на чтение файлов . class языка Java на обеих машинах, а на серверной машине должны быть разрешены удаленные вызовы с клиентских машин.
8.5.2. Пример: удаленная база данных
В листинге 8.15 представлена законченная программа для простого, но интересного примера использования удаленного вызова методов. Интерфейс RemoteDatabase определяет методы read и write, реализуемые сервером. Эти методы будут выполняться удаленно по отношению к клиенту, поэтому они объявлены как возбуждающие исключительную ситуацию RemoteException.
Листинг 8.15. Интерфейс удаленной базы данных, клиент и сервер
import java.rmi.*;
import j ava.rmi.server.*;
public interface RemoteDatabase extends Remote {
public int read() throws RemoteException;
public void write(int value) throws RemoteException; }
class Client {
public static void main(String[] args) { try {
// установить стандартный диспетчер безопасности RMI System.setSecurityManager(new RMISecurityManager()); // получить объект удаленной базы данных

Класс Client определяет клиентскую часть программы. Он состоит из метода main, который можно запускать на любой машине. Клиент сначала устанавливает диспетчер безопасности RMI для защиты от ошибочного кода заглушки сервера. Затем клиент ищет имя сервера и получает ссылку на сервер.
В остальной части программы клиента циклически вызыва-
Глава 8. Удаленный вызов процедур и рандеву 309
ются методы read и write сервера. Число round повторений цикла задается как аргумент в командной строке при запуске клиента.
Серверный класс RemoteDatabaseServer реализует интерфейс сервера. Сама "база данных" представляет собой просто защищенную целочисленную переменную. Метод ma in сервера создает экземпляр сервера, регистрирует его имя и, чтобы показать, что сервер работает, выводит строку на терминал узла сервера. Сервер работает, пока его процесс не уничтожат. В программе используются такие имя и номер порта сервера: paloverde: 9999 (рабочая станция автора). Обе части программы должны быть записаны в одном файле, который называется Remot-eDatabase. Java, поскольку это имя интерфейса. Чтобы откомпилировать программу, создать заглушки, запустить службу регистрации и сервер, на узле paloverde нужно выполнить следующие команды.
javac RemoteDatabase.Java
rmic RemoteDatabaseServer
rmiregistry 9999 &
Java RemoteDatabaseServer
Клиентская программа запускается на машине paloverde или на другой машине той же сети с помощью такой команды.
Java Client rounds
Читателю рекомендуется поэкспериментировать с этой программой, чтобы понять, как она себя ведет. Например, что происходит, если выполняются несколько клиентов или если запустить клиентскую программу до запуска сервера?
Учебные примеры: язык SR
Язык синхронизирующих ресурсов (synchronizing resources — SR) был создан в 1980-х годах. В его первой версии был представлен механизм рандеву (см. раздел 8.2), затем он был дополнен поддержкой совместно используемых примитивов (см. раздел 8.3). Язык SR поддерживает разделяемые переменные и распределенное программирование, его можно использовать для непосредственной реализации почти всех программ изданной книги. SR-программы могут выполняться на мультипроцессорах с разделяемой памятью и в сетях рабочих станций, а также на однопроцессорных машинах.
Хотя язык SR содержит множество различных механизмов, все они основаны на нескольких ортогональных концепциях. Последовательный и параллельный механизмы объединены,
316 Часть 2. Распределенное программирование
чтобы похожие результаты достигались аналогичными способами. В разделах 8.2 и 8.3 уже были представлены и продемонстрированы многие аспекты языка SR, хотя явно об этом не говорилось. В данном разделе описываются такие вопросы, как структура программы, динамическое создание и размещение, дополнительные операторы. В качестве примера представлена программа, имитирующая выполнение процессов, которые входят в критические секции и выходят из них.
8.7.1. Ресурсы и глобальные объекты
Программа на языке SR состоит из ресурсов и глобальных компонентов. Декларация ресурса определяет схему модуля и имеет почти такую же структуру, как и module, resource name # раздел описаний
описания импортируемых объектов
декларации операций и типов body name (параметры) # тело
декларации переменных и других локальных объектов
код инициализации
процедуры и процессы
код завершения end name
Декларация ресурса содержит описания импортируемых объектов, если ресурс использует декларации, экспортируемые другими ресурсами или глобальными компонентами. Декларации и код инициализации в теле могут перемежаться; это позволяет использовать динамические массивы и управлять порядком инициализации переменных и создания процессов.
Раздел описаний может быть опущен. Раздел описаний и тело могут компилироваться отдельно.
Экземпляры ресурса создаются динамически с помощью оператора create. Например, код
reap := create name (аргументы)
передает аргументы (по значению) новому экземпляру ресурса name и затем выполняет код инициализации ресурса. Когда код инициализации завершается, возвращается мандат доступа к ресурсу, который присваивается переменной reap. В дальнейшем эту переменную можно использовать для вызова операций, экспортируемых ресурсом, или для уничтожения экземпляра ресурса. Ресурсы уничтожаются динамически с помощью оператора destroy. Выполнение destroy останавливает любую работу в указанном ресурсе, выполняет его код завершения (если есть) и освобождает выделенную ему память.
По умолчанию компоненты SR-программы размещаются в одном адресном пространстве. Оператор create можно также использовать для создания дополнительных адресных пространств, которые называются виртуальными машинами. vmcap := create vm() on machine
Этот оператор создает на указанном узле виртуальную машину и возвращает мандат доступа к ней. Последующие операторы создания ресурса могут использовать конструкцию "on vmcap", чтобы размещать новые ресурсы в этом адресном пространстве. Таким образом, язык SR, в отличие от Ada, дает программисту полный контроль над распределением ресурсов по машинам, которое может зависеть от входных данных программы.
Для объявления типов, переменных, операций и процедур, разделяемых ресурсами, применяется глобальный компонент. Это, по существу, одиночный экземпляр ресурса. На каждой виртуальной машине, использующей глобальный компонент, хранится одна его копия. Для
Глава 8. Удаленный вызов процедур и рандеву 317
этого при создании ресурса неявно создаются все глобальные объекты, из которых он импортирует (если они не были созданы ранее).
SR-программа содержит один отдельный главный ресурс.
Выполнение программы начинается с неявного создания одного экземпляра этого ресурса. Затем выполняется код инициализации главного ресурса; обычно он создает экземпляры других ресурсов.
SR-программа завершается, когда завершаются или блокируются все процессы, или когда выполняется оператор stop. В этот момент система поддержки программы (run-time system) выполняет код завершения (если он есть) главного ресурса и затем коды завершения (если есть) глобальных компонентов. Это обеспечивает программисту управление, чтобы, например, напечатать результаты или данные о времени работы программы.
В качестве простого примера приведем SR-программу, которая печатает две строки. resource silly()
write("Hello world.") final
write("Goodbye world.") end end
Этот ресурс создается автоматически. Он выводит строку и завершается. Тогда выполняется код завершения, выводящий вторую строку. Результат будет тем же, если убрать слова final и первое end.
8.7.2. Взаимодействие и синхронизация
Отличительным свойством языка SR является многообразие механизмов взаимодействия и синхронизации. Переменные могут разделяться процессами одного ресурса, а также ресурсами в одном адресном пространстве (с помощью глобальных компонентов). Процессы также могут взаимодействовать и синхронизироваться, используя все примитивы, описанные в разделе 8.3, — семафоры, асинхронную передачу сообщений, RPC и рандеву. Таким образом, язык SR можно использовать для реализации параллельных программ как на мультипроцессорных машинах с разделяемой памятью, так и в распределенных системах.
Декларации операций начинаются ключевым словом ор; их вид уже был представлен в данной главе. Такие декларации можно записывать в разделе описаний ресурса, в теле ресурса и даже в процессах. Операция, объявленная в процессе, называется локальной. Процесс, который объявляет операцию, может передавать мандат доступа к локальной операции другому процессу, позволяя ему вызывать эту операцию.
Эта возможность поддерживает непрерывность диалога (см. раздел 7.3).
Операция вызывается с помощью синхронного оператора call или асинхронного send. Для указания вызываемой операции оператор вызова использует мандат доступа к операции или поле мандата доступа к ресурсу. Внутри ресурса, объявившего операцию, ее мандатом фактически является ее имя, поэтому в операторе вызова можно использовать непосредственно имя операции. Мандаты ресурсов и операций можно передавать между ресурсами, поэтому пути взаимодействия могут изменяться динамически.
Операцию обслуживает либо процедура (ргос), либо оператор ввода (in). Для обслуживания каждого удаленного вызова ргос создается новый процесс; вызовы в пределах одного адресного пространства оптимизируются так, чтобы тело процедуры выполнял процесс, который ее вызвал. Все процессы ресурса работают параллельно, по крайней мере, теоретически.
Оператор ввода in поддерживает рандеву. Его вид указан в разделе 8.2; он может содержать условия синхронизации и выражения планирования, зависящие от параметров. Оператор ввода может содержать необязательную часть else, которая выбирается, если не пропускает ни одна из защит.
318 Часть 2. Распределенное программирование
Язык SR содержит несколько механизмов, являющихся сокращениями других конструкций. Декларация process — это сокращение декларации ор и определения ргос для обслуживания вызовов операции. Один экземпляр процесса создается неявным оператором send при создании ресурса. (Программист может объявлять и массивы процессов.) Декларация procedure также является сокращением декларации ор и определения ргос для обслуживания вызовов операции.
Еще два сокращения — это оператор receive и семафоры. Оператор receive выполняется так же, как оператор ввода, который обслуживает одну операцию и просто записывает значения аргументов в локальные переменные. Декларация семафора (sem) является сокращенной формой объявления операции без параметров.
Оператор Р представляет собой частный случай оператора receive, a V — оператора send.
Язык SR обеспечивает несколько дополнительных полезных операторов. Оператор reply — это вариант оператора return. Он возвращает значения, но выполняющий его процесс продолжает работу. Оператор forward можно использовать, передавая вызов другому процессу для последующего обслуживания. Он аналогичен оператору requeue языка Ada. Наконец, в языке SR есть оператор со для параллельного вызова операций.

Глава 8 Удаленный вызов процедур и рандеву 319
Глобальный компонент CS экспортирует две операции: CSenter и CSexit. Тело CS содержит процесс arbitrator, реализующий эти операции. Для ожидания вызова операции CSenter в нем использован оператор ввода.
in CSenter(id) by id ->
write( "user", id, "in its CS at", ageO) ni
Это механизм рандеву языка SR. Если есть несколько вызовов операции CSenter, то выбирается вызов с наименьшим значением параметра id, после чего печатается сообщение. Затем процесс arbitrator использует оператор receive для ожидания вызова операции CSexit. В этой программе процесс arbitrator и его операции можно было бы поместить внутрь ресурса main. Однако, находясь в глобальном компоненте, они могут использоваться другими ресурсами в большей программе.
Ресурс main считывает из командной строки два аргумента, после чего создает numus-ers экземпляров процесса user. Каждый процесс с индексом i выполняет цикл "для всех" (for all — fa), в котором вызывает операцию Csenter с аргументом i, чтобы получить разрешение на вход в критическую секцию. Длительность критической и некритической секций кода имитируется "сном" (пар) каждого процесса user в течение случайного числа миллисекунд. После "сна" процесс вызывает операцию CSexit. Операцию CSenter можно вызвать только синхронным оператором call, поскольку процесс user должен ожидать получения разрешения на вход в критическую секцию.
Это выражено ограничением {call} в объявлении операции CSenter. Однако операцию CSexit можно вызывать асинхронным оператором send, поскольку процесс user может не задерживаться, покидая критическую секцию.
В программе использованы несколько предопределенных функций языка SR. Оператор write печатает строку, a getarg считывает аргумент из командной строки. Функция age в операторе write возвращает длительность работы программы в миллисекундах. Функция пар заставляет процесс "спать" в течение времени, заданного ее аргументом в миллисекундах. Функция random возвращает псевдослучайное число в промежутке от О до значения ее аргумента. Использована также функция преобразования типа int, чтобы преобразовать результат, возвращаемый функцией random, к целому типу, необходимому для аргумента функции пар.
Историческая справка
Удаленный вызов процедур (RPC) и рандеву появились в конце 1970-х годов. Исследования по семантике, использованию и реализации RPC были начаты и продолжаются разработчиками операционных систем. Нельсон (Bruce Nelson) провел много экспериментов по этой теме в исследовательском центре фирмы Xerox в Пало-Альто (PARC) и написал отличную диссертацию [Nelson, 1981]. Эффективная реализация RPC в ядре операционной системы представлена в работе [Birrell and Nelson, 1984]. Перейдя из PARC в Стэнфорд-ский университет, Спектор [Alfred Spector, 1982] написал диссертацию по семантике и реализации RPC.
Бринч Хансен [Brinch Hansen, 1978] выдвинул основные идеи RPC (хотя и не дал этого названия) и разработал первый язык программирования, основанный на удаленном вызове процедур. Он назвал свой язык "Распределенные процессы" (Distributed Processes— DP). Процессы в DP могут экспортировать процедуры. Процедура, вызванная другим процессом, выполняется в новом потоке управления. Процесс может также иметь один "фоновый" поток, который выполняется первым и может продолжать работу в цикле. Потоки в процессе
32в Часть 2. Распределенное программирование
выполняются со взаимным исключением. Они синхронизируются с помощью разделяемых переменных и оператора when, аналогичного оператору await (глава 2).
RPC был включен в некоторые другие языки программирования, такие как Cedar, Eden, Emerald и Lynx. На RPC основаны языки Argus, Aeolus, Avalon и другие. В этих трех языках RPC объединен с так называемыми неделимыми транзакциями. Транзакция — это группа операций (вызовов процедур). Транзакция неделима, если ее нельзя прервать и она обратима. Если транзакция совершается (commit), выполнение все* операций выглядит единым и неделимым. Если транзакция прекращается (abort), то никаких видимых результатов ее выполнения нет. Неделимые транзакции возникли в области баз данных и использовались для программирования отказоустойчивых распределенных приложений.
В статье [Stamos and Gifford, 1990] представлено интересное обобщение RPC, которое названо удаленными вычислениями (remote evaluation — REV). С помощью RPC серверный модуль обеспечивает фиксированный набор предопределенных сервисных функций. С помощью REV клиент может в аргументы удаленного вызова включить программу. Получая вызов, сервер выполняет программу и возвращает результаты. Это позволяет серверу обеспечивать неограниченный набор сервисных функций. В работе Стамоса и Гиффорда показано, как использование REV может упростить разработку многих распределенных систем, и описан опыт разработчиков с реализацией прототипа. Аналогичные возможности (хотя чаще всего для клиентской стороны) предоставляют аплеты Java. Например, аплет обычно возвращается сервером и выполняется на машине клиента.
Рандеву были предложены в 1978 г. параллельно и независимо Жаном-Раймоном Абриалем (Jean-Raymond Abrial) из команды Ada и автором этой книги при разработке SR.' Термин рандеву был введен разработчиками Ada (многие из них были французами).
На ран деву основан еще один язык — Concurrent С [Gehani and Roome, 1986, 1989]. Он дополняет язык С процессами, рандеву (с помощью оператора accept) и защищенным взаимодействием (с помощью select). Оператор select похож на одноименный оператор в языке Ada, а оператор accept обладает большей мощью. Concurrent С позаимствовал из SR две идеи: условия синхронизации могут ссылаться на параметры, а оператор accept — содержать выражение планирования (часть by). Concurrent С также допускает вызов операций с помощью send и call, как и в SR. Позже Джехани и Руми [Gehani and Roome, 1988] разработали Concurrent C++, сочетавший черты Concurrent С и C++.
Совместно используемые примитивы включены в несколько языков программирования, самый известный из которых — SR. Язык StarMod (расширение Modula) поддерживает синхронную передачу сообщений, RPC, рандеву и динамическое создание процессов. Язык Lynx поддерживает RPC и рандеву. Новизна Lynx заключается в том, что он поддерживает динамическую реконфигурацию программы и защиту с помощью так называемых связей.
Обзор [Bal, Steiner and Tanenbaum, 1989] представляет исчерпывающую информацию и ссылки по всем упомянутым здесь языкам. Антология [Gehani and McGettrick, 1988] содержит перепечатки основных работ по нескольким языкам (Ada, Argus, Concurrent С, DP, SR), сравнительные обзоры и оценки языка Ada.
Кэширование файлов на клиентских рабочих станциях реализовано в большинстве распределенных операционных систем. Файловая система, представленная схематически в листинге 8.2, по сути та же, что в операционной системе Amoeba. В статье [Tanenbaum et al., 1990] дан обзор системы Amoeba и описан опыт работы с ней. Система Amoeba использует RPC в качестве базовой системы взаимодействия. Внутри модуля потоки выполняются параллельно и синхронизируются с помощью блокировок и семафоров.
В разделе 8.4 были описаны способы реализации дублируемых файлов. Техника взвешенного голосования подробно рассмотрена в работе [Gifford, 1979].
Основная причина использования дублирования — необходимость отказоустойчивости файловой системы. Отказоустойчивость и дополнительные способы реализации дублируемых файлов рассматриваются в исторической справке к главе 9.
Глава 8. Удаленный вызов процедур и рандеву 321
\
Удаленный вызов методов (RMI) появился в языке Java, начиная с версии 1.1. Пояснения к RMI и примеры его использования можно найти в книгах [Flanagan, 1997] и [Hartley, 1998]. (Подробнее об этих книгах и их Web-узлах сказано в конце исторической справки к главе 7.) Дополнительную информацию по RMI можно найти на главном Web-узле языка Java www. Javasoft. com.
В 1974 году Министерство обороны США (МО США) начало программу "универсального языка программирования высокого уровня" (как ответ на рост стоимости разработки и поддержки программного обеспечения). На ранних этапах программы появилась серия документов с основными требованиями, которые вылились в так называемые спецификации Стил-мена (Steelman). Четыре команды разработчиков, связанных с промышленностью и университетами, представили проекты языков весной 1978 г. Для завершающей стадии были выбраны два из них, названные Красным и Зеленым. На доработку им было дано несколько месяцев. "Красной" командой разработчиков руководил Intermetrics, "зеленой" — Cii Honey Bull. Обе команды сотрудничали с многочисленными внешними экспертами. Весной 1979 г. был выбран Зеленый проект. (Интересно, что вначале Зеленый проект основывался на синхронной передаче сообщений, аналогичной используемой в CSP; разработчики заменили ее рандеву летом и осенью 1978 г.)
МО США назвало новый язык Ada в честь Августы Ады Лавлейс, дочери поэта Байрона и помощницы Чарльза Бэббеджа, изобретателя аналитической машины. Первая версия языка Ada с учетом замечаний и опыта использования была усовершенствована и стандартизована в 1983 г. Новый язык был встречен и похвалой, и критикой; похвалой за превосходство над другими языками, которые использовались в МО США, а критикой — за размеры и сложность.
Оглядываясь в прошлое, можно заметить, что этот язык уже не кажется таким сложным. Некоторые замечания по Ada 83 и опыт его использования в следующем десятилетии привели к появлению языка Ada 95, который содержит новые механизмы параллельного программирования, описанные в разделе 8.6.
Реализации языка Ada и среды разработки для множества различных аппаратных платформ производятся несколькими компаниями. Этот язык описан во многих книгах. Особое внимание на большие возможности языка Ada обращено в книге [Gehani, 1983]; алгоритм решения задачи об обедающих философах (см. листинги 8.17 и 8.18) в своей основе был взят именно оттуда. В книге [Burns and Wellings, 1995] описаны механизмы параллельного программирования языка Ada 95 и показано, как его использовать для программирования систем реального времени и распределенных систем. Исчерпывающий Web-источник информации по языку Ada находится по адресу www. adahome. com.
Основные идеи языка SR (ресурсы, операции, операторы ввода, синхронные и асинхронные вызовы) были задуманы автором этой книги в 1978 г. и описаны в статье [Andrews, 1981]. Полностью язык был определен в начале 1980-х и реализован несколькими студентами. Энд-рюс и Олсон (Olsson) разработали новую версию этого языка в середине 1980-х годов. Были добавлены RFC, семафоры, быстрый ответ и некоторые дополнительные механизмы [Andrews et al., 1988]. Последующий опыт и желание обеспечить оптимальную поддержку для параллельного программирования привели к разработке версии 2.0. SR 2.0 представлен в книге [Andrews and Olsson, 1992], где также приведены многочисленные примеры и обзор реализации. Параллельное программирование на SR описано в книге [Hartley, 1995], задуманной как учебное руководство по операционным системам и параллельному программированию. Адрес домашний страницы проекта SR и реализаций: www. cs. arizona. edu/sr.
Основная тема этой книги — как писать многопоточные, параллельные и/или распределенные программы. Близкая тема, но имеющая более высокий уровень, — как связывать существующие или будущие прикладные программы, чтобы они совместно работали в распределенном окружении, основанном на Web.
Программные системы, которые обеспечивают такую связь, называются микропрограммными средствами (middleware). CORBA, Active-X и DCOM — это три наиболее известные системы. Они и большинство других основаны на
322 Часть 2. Распределенное программирование
объектно-ориентированных технологиях. CORBA (Common Object Request Broker Architecture — технология построения распределенных объектных приложений) — это набор спецификаций и инструментальных средств для обеспечения возможности взаимодействия программ в распределенных системах. Active-X— это технология для объединения таких приложений Web, как броузеры и Java-аплеты с настольными сервисами типа процессоров документов и таблиц. DCOM (Distributed Component Object Model — распределенная модель компонентных объектов) служит основой для удаленных взаимодействий, например, между компонентами Active-X. Эти и многие другие технологии описаны в книге [Umar, 1997). Полезным Web-узлом по CORBA является www. omg. org, а по Active-X и DCOM — www.activex.org.

Глава 8. Удаленный вызов процедур и рандеву 323
Stamos, J. W, and D. К. Gifford. 1990. Remote evaluation. ACM Trans, on Prog. Languages and Systems 12, 4 (October): 537-565.
Tanenbaum, A. S, R. van Renesse, H. van Staveren, G. i. Sharp, S. J. Mullender, J. Jansen, and G. van Rossum. 1990. Experiences with the Amoeba distributed operating system. Comm. ACM 33, 12 (December): 46-63.
Umar, A. 1997. Object-Oriented Client/Server Internet Environments. Englewood Cliffs, NJ: Prentice-Hall.
Упражнения
8.1. Измените модуль сервера времени в листинге 8.1 так, чтобы процесс часов не запускался при каждом "тике" часов. Вместо этого процесс часов должен устанавливать аппаратный таймер на срабатывание при наступлении следующего интересующего события. Предполагается, что время суток исчисляется в миллисекундах, а таймер можно устанавливать на любое число миллисекунд. Кроме того, процессы могут считывать количество времени, оставшееся до срабатывания аппаратного таймера, и таймер можно переустанавливать в любой момент времени.
8.2. Рассмотрим распределенную файловую систему в листинге 8.2:
а) разработайте законченные программы модулей кэширования файлов и файлового сервера. Разработайте реализацию кэша, добавьте код синхронизации и т.д.;
б) модули распределенной файловой системы запрограммированы с помощью RPC. Перепрограммируйте файловую систему, используя примитивы рандеву, определенные в разделе 8.2. Уточните программу, чтобы по степени детализациии она была сравнима с программой в листинге 8.2.
8.3. Предположим, что модули имеют вид, показанный в разделе 8.1, а процессы разных модулей взаимодействуют с помощью RPC. Кроме того, пусть процессы, которые обслуживают удаленные вызовы, выполняются со взаимным исключением (как в мониторах). Условная синхронизация программируется с помощью оператора when В, который приостанавливает выполняемый процесс до тех пор, пока логическое условие в не станет истинным. Условие В может использовать любые переменные из области видимости выражения:
а) перепишите модуль сервера времени (см. листинг 8.1), чтобы он использовал эти механизмы;
б) перепрограммируйте модуль фильтра слияния (см. листинг 8.3), используя эти механизмы.
8.4. Модуль Merge (см. листинг 8.3) имеет три процедуры и локальный процесс. Измените реализацию, чтобы избавиться от процесса М (процессы, обслуживающие вызовы операций inl и in2, должны взять на себя роль процессам).
8.5. Перепишите процесс TimeServer (см. листинг 8.7), чтобы операция delay задавала интервал времени, как в листинге 8.1, а не действительное время запуска программы. Используйте только примитивы рандеву, определенные в разделе 8.2. (Указание. Вам понадобится одна или несколько дополнительных операций, а клиенты не смогут просто вызывать операцию delay.)
8.6. Рассмотрим процесс планирующего драйвера диска (см. листинг 7.7). Предположим, что процесс экспортирует только операцию request (cylinder, . . .). Покажите, как использовать рандеву и оператор in для реализации каждого из следующих алгоритмов планирования работы диска: наименьшего времени поиска, циклического сканирования (CSCAN) и лифта. (Указание. Используйте выражения планирования.)
324 Часть 2. Распределенное программирование
8.7. Язык Ada обеспечивает примитивы рандеву, аналогичные определенным в разделе 8.2 (подробности — в разделе 8.6). Но в эквиваленте оператора in в языке Ada условия синхронизации не могут ссылаться на параметры операций. Кроме того, язык Ada не поддерживает выражения планирования.
Используя примитивы рандеву, определенные в разделе 8.2, и указанную ограниченную форму оператора in или примитивы языка Ada select и accept, перепрограммируйте следующие алгоритмы:
а) централизованное решение задачи об обедающих философах (см. листинг 8.6);
б) сервер времени (см. листинг 8.7);
в) диспетчер распределения ресурсов по принципу "кратчайшее задание" (см. листинг 8.8).
8.8. Рассмотрим следующее описание программы поиска минимального числа в наборе целых чисел. Дан массив процессов Min[l:n]. Вначале каждый процесс имеет одно целое значение. Процессы многократно взаимодействуют, и при взаимодействии каждый процесс пытается передать другому минимальное из увиденных им значений. Отдавая свое минимальное значение, процесс завершается. В конце концов останется
' один процесс, и он будет знать минимальное число исходного множества:
а) разработайте программу решения этой задачи, используя только примитивы RPC, описанные в разделе 8.1;
б) напишите программу решения задачи с помощью только примитивов рандеву (см. раздел 8.2);
в) разработайте программу с помощью совместно используемых примитивов, описанных в разделе 8.3. Ваша программа должна быть максимально простой.
8.9. В алгоритме работы читателей и писателей (см. листинг 8.13), предпочтение отдается читателям:
а) измените оператор ввода в процессе Writer, чтобы преимущество имели писатели;
б) измените оператор ввода в процессе Writer так, чтобы читатели и писатели получали доступ к базе данных по очереди.
8.10. В модуле FileServer (см. листинг 8.14) для обновления удаленных копий использован оператор call.
Предположим, что его заменили асинхронным оператором send. Работает ли программа? Если да, объясните, почему. Если нет, объясните, в чем ошибка.
8.11. Предположим, что процессы взаимодействуют только с помощью механизмов RPC, определенных в разделе 8.1, а процессы внутри модуля— с помощью семафоров. Перепрограммируйте каждый из указанных ниже алгоритмов:
а) модуль BoundedBuf f er (см. листинг 8.5); •б) модуль Table (см. листинг 8.6);
в) модуль SJN_Allocator (см. листинг 8.8);
г) модуль ReadersWriters (см. листинг 8.13);
д) модуль FileServer (см. листинг 8.14).
8.12. Разработайте серверный процесс, который реализует повторно используемый барьер для п рабочих процессов. Сервер имеет одну операцию — arrive (). Рабочий процесс вызывает операцию arrive, когда приходит к барьеру. Вызов завершается, когда к барьеру приходят все n процессов. Для программирования сервера и рабочих процессов используйте примитивы рандеву из раздела 8.2. Предположим, что
Глава 8. Удаленный вызов процедур и рандеву 325
доступна функция ?opname, определенная в разделе 8.3, которая возвращает число задержанных вызовов операции opname.
8.13. В листинге 7.12 был представлен алгоритм проверки простоты чисел с помощью решета из процессов-фильтров, написанный с использованием синхронной передачи сообщений языка CSP. Другой алгоритм, представленный в листинге 7.13, использовал управляющий процесс и портфель задач. Он был написан с помощью пространства кортежей языка Linda:
а) перепишите алгоритм из листинга 7.12 с помощью совместно используемых примитивов, определенных в разделе 8.3;
б) измените алгоритм из листинга 7.13 с помощью совместно используемых примитивов (см. раздел 8.3);
в) сравните производительность ответов к пунктам а и б. Сколько сообщений необходимо отправить для проверки всех нечетных чисел от 3 до п? Пара операторов send-receive учитывается как одно сообщение, а оператор call — как два, даже если нет возвращаемых значений.
8.14. Задача о счете. Несколько людей (процессов) используют общий счет. Каждый из них может помещать средства на счет и снимать их. Текущий баланс равен сумме всех вложенных средств минус сумма всех снятых. Баланс никогда не должен становиться отрицательным.
Используя составную нотацию, разработайте сервер для решения этой задачи, представьте его клиентский интерфейс. Сервер экспортирует две операции: deposit (amount) и withdraw (amount). Предполагается, что значение amount положительно, а выполнение операции withdraw откладывается, если на счету недостаточно денег.
8.15. В комнату входят процессы двух типов А и в. Процесс типа А не может выйти, пока не встретит два процесса в, а процесс в не может выйти, пока не встретит один процесс А. Встретив необходимое число процессов другого типа, процесс сразу выходит из комнаты:
а) разработайте серверный процесс для реализации такой синхронизации. Представьте серверный интерфейс процессов А и в. Используйте составную нотацию, определенную в разделе 8.3;
б) измените ответ к пункту а так, чтобы первый из двух процессов в, встретившихся с процессом А, не выходил из комнаты, пока процесс А не встретит второй процесс в.
8.16. Предположим, что в компьютерном центре есть два принтера, а и в, которые похожи, но не одинаковы. Есть три типа процессов, использующих принтеры: только типа А, только типа в, обоих типов.
Используя составную нотацию, разработайте код клиентов каждого типа для получения и освобождения принтера, а также серверный процесс для распределения принтеров. Ваше решение должно быть справедливым при условии, что принтеры в конце концов освобождаются.
8.17. Американские горки. Есть n процессов-пассажиров и один процесс-вагончик. Пассажиры ждут очереди проехать в вагончике, который вмещает с человек, С < п. Вагончик может ехать только заполненным:
а) разработайте коды процессов-пассажиров и процесса-вагончика с помощью составной нотации;
б) обобщите ответ к пункту а, чтобы использовались m процессов-вагончиков, m > 1.
Поскольку есть только одна дорога, обгон вагончиков невозможен, т.е. заканчивать
326 Часть 2. Распределенное программирование
движение по дороге вагончики должны в том же порядке, в котором начали. Как и ранее, вагончик может ехать только заполненным.
8.18. Задача об устойчивом паросочетании (о стабильных браках) состоит в следующем. Пусть Мап[1:п] и Woman[l:n] — массивы процессов. Каждый мужчина (man) оценивает женщин (woman) числами от 1 до п, и каждая женщина так же оценивает мужчин. Паросочетание — это взаимно однозначное соответствие между мужчинами и женщинами. Паросочетание устойчиво, если для любых двух мужчин mi и т2 и двух женщин wi и w2, соответствующих им в этом паросочетании, выполняются оба следующих условия:
• mi оценивает wi выше, чем w2, или w2 оценивает m2 выше, чем mi;
• m2 оценивает w2
выше, чем wi, или wi оценивает mi выше, чем т2.
Иными словами, Паросочетание неустойчиво, если найдутся мужчина и женщина, предпочитающие друг друга своей текущей паре. Решением задачи является множество n-паросочетаний, каждое из которых устойчиво:
а) с помощью совместно используемых примитивов напишите программу для решения задачи устойчивого брака;
б) обобщением этой задачи является задача об устойчивом соседстве. Есть 2п человек. У каждого из них есть список предпочтения возможных соседей. Решением задачи об устойчивом соседстве является набор из п пар, каждая из которых стабильна в том же смысле, что и в задаче об устойчивых браках. Используя составную нотацию, напишите программу решения задачи об устойчивом соседстве.
8.19. Модуль FileServer в листинге 8.14 использует по одной блокировке на каждую копию файла. Измените программу так, чтобы в ней использовалось взвешенное голосование, определенное в конце раздела 8.4.
8.20. В листинге 8.14 показано, как реализовать дублируемые файлы, используя составную нотацию (см. раздел 8.3). Для решения этой же задачи напишите программу на языке:
а) Java. Используйте RMI и синхронизированные методы;
б) Ada;
в) SR.
Поэкспериментируйте с программой, помещая различные файловые серверы на разные машины сети. Составьте краткий отчет с описанием программы, проведенных экспериментов и полученных результатов.
8.21. Проведите эксперименты с Java-программой для удаленной базы данных (см. листинг 8.15). Запустите программу и посмотрите, что происходит. Измените программу для работы с несколькими клиентами. Измените программу для работы с более реалистичной базой данных (по крайней мере, чтобы операции занимали больше времени). Составьте краткий отчет с описанием ваших действий и полученных результатов.
8.22. В листинге 8.15 представлена Java-программа, реализующая простую удаленную базу данных. Перепишите программу на языке Ada или SR, проведите эксперименты с ней. Например, добавьте возможность работы с несколькими клиентами, сделайте базу данных более реалистичной (по крайней мере, чтобы операции занимали больше времени). Составьте краткий отчет о том, как вы реализовали программу на SR или Ada, какие эксперименты провели, что узнали.
8.23. В листингах 8.17 и 8.18 представлена программа на языке Ada, которая реализует имитацию задачи об обедающих философах:
а) запустите программу;
б) перепишите программу на Java или SR.
Глава 8 Удаленный вызов процедур и рандеву 327
Проведите эксперименты с программой. Например, пусть философы засыпают на случайные промежутки времени во время еды или размышлений. Попробуйте использовать разные количества циклов. Составьте краткий отчет о том, как вы реализовали программу на SR или Java (для пункта б), какие эксперименты провели, что изучили.
8.24. В листинге 8.19 показана SR-программа моделирования решения задачи критической секции:
а) запустите программу;
б) перепишите программу на языке Java или Ada.
Поэкспериментируйте с программой. Например, измените интервалы задержки или приоритеты планирования.
Составьте краткий отчет о том, как вы реализовали программу на SR или Ada (для пункта б), какие эксперименты провели, что изучили.
8.25. В упражнении 7.26 описаны несколько проектов для параллельного и распределенного программирования. Выберите один из них или подобный им, разработайте и реализуйте решение, используя язык Java, Ada, SR или библиотеку подпрограмм, которая поддерживает RPC или рандеву. Закончив работу, составьте отчет с описанием вашей задачи и решения, продемонстрируйте работу программы.
Удаленный вызов процедур
Глава 8
Удаленный вызов процедур
и рандеву
Передача сообщений идеально подходит для программирования фильтров и взаимодействующих равных, поскольку в этих случаях процессы отсылают данные по каналам связи водном направлении. Как было показано, передача сообщений применяется также в программировании клиентов и серверов. Но двусторонний поток данных между клиентом и сервером приходится программировать с помощью двух явных передач сообщений по двум отдельным каналам. Кроме того, каждому клиенту нужен отдельный канал ответа; все это ведет к увеличению числа каналов.
В данной главе рассмотрены две дополнительные программные нотации — удаленный вызов процедур (remote procedure call — RPC) и рандеву, идеально подходящие для программирования взаимодействий типа "клиент-сервер". Они совмещают свойства мониторов и синхронной передачи сообщений Как и при использовании мониторов, модуль или процесс экспортирует операции, а операции запускаются с помощью оператора call. Как и синхронизированная отправка сообщения, выполнение оператора call приостанавливает работу процесса Новизна RPC и рандеву состоит в том, что они работают с двусторонним каналом связи от процесса, вызывающего функцию, к процессу, который обслуживает вызов, и в обратном направлении Вызвавший функцию процесс ждет, пока будет выполнена необходимая операция и возвращены ее результаты.
RPC и рандеву различаются способом обслуживания вызовов операций. Первый способ — для каждой операции объявлять процедуру и для обработки вызова создавать новый процесс (по крайней мере, теоретически). Этот способ называется удаленным вызовом процедуры (RPC), поскольку вызывающий процедуру процесс и ее тело могут находиться на разных машинах. Второй способ — назначить встречу (рандеву) с существующим процессом. Рандеву обслуживается с помощью оператора ввода (приема), который ждет вызова, обрабатывает его и возвращает результаты. (Иногда этот тип взаимодействия называется расширенным рандеву в отличие от простого рандеву, при котором встречаются операторы передачи и приема при синхронной передаче сообщений.)
В разделах 8.1 и 8 2 описаны типичные примеры программной нотации для RPC и рандеву, продемонстрировано их использование. Как упоминалось, эти методы упрощают программирование взаимодействий типа "клиент-сервер". Их можно использовать и при программировании фильтров, но мы увидим, что это трудоемкое занятие, поскольку ни RPC, ни рандеву напрямую не поддерживают асинхронную связь. К счастью, эту проблему можно решить, если объединить RPC, рандеву и асинхронную передачу сообщений в мощный, но достаточно простой язык, представленный в разделе 8.3.
Использование нотаций, их преимущества и недостатки демонстрируются на нескольких примерах В некоторых из них использованы задачи, рассмотренные ранее, что помогает сравнить различные виды передачи сообщений. Некоторые задачи приводятся впервые и демонстрируют применимость RPC и рандеву в программировании взаимодействий типа "клиент-сервер". Например, в разделе 8.4 показано, как реализовать инкапсулированную базу данных и дублирование файлов. В разделах 8 5—8.7 дан обзор механизмов распределенного программирования трех языков. Java (RPC), Ada (рандеву) и SR (совместно используемые примитивы).
284 Часть 2. Распределенное программирование
Следующая диаграмма иллюстрирует взаимодействие между процессом, вызывающим процедуру, и процессом-сервером.

Ось времени проходит по рисунку вниз, волнистые линии показывают ход выполнения процесса. Когда вызывающий процесс доходит до оператора call, он приостанавливается, пока сервер выполняет тело вызванной процедуры. После того как сервер возвратит результаты, вызвавший процесс продолжается.
8.1.1. Синхронизация в модулях
Сам по себе RPC — это механизм взаимодействия. Хотя вызывающий процесс синхронизируется со своим сервером, единственная роль сервера — действовать от имени вызывающего процесса. Теоретически все происходит так же, как если бы вызывающий процесс сам выполнял процедуру, поэтому синхронизация между вызывающим процессом и сервером происходит неявно.
Нужен также способ обеспечивать взаимно исключающий доступ процессов модуля к разделяемым переменным и их синхронизацию. Процессы модуля— это процессы-серверы, выполняющие удаленные вызовы, и фоновые процессы, объявленные в модуле.
Существует два подхода к обеспечению синхронизации в модулях. Первый — считать, что все процессы одного модуля должны выполняться со взаимным исключением, т.е. в любой момент времени может быть активен только один процесс. Этот метод аналогичен неявному исключению, определенному для мониторов, и гарантирует защиту разделяемых переменных от одновременного доступа. Но при этом нужен способ программирования условной синхронизации процессов, для чего можно использовать условные переменные (как в мониторах) или семафоры.
Второй подход — считать, что все процессы выполняются параллельно, и явным образом программировать взаимное исключение и условную синхронизацию. Тогда каждый модуль сам становится параллельной программой, и можно применить любой описанный метод. Например, можно использовать семафоры или локальные мониторы. В действительности, как будет показано в этой главе ниже, можно использовать рандеву (или даже передачу сообщений).
Программа, содержащая модули, выполняется, начиная с кода инициализации каждого из модулей. Коды инициализации разных модулей могут выполняться параллельно при условии,
286 Часть 2. Распределенное программирование
что в них нет удаленных вызовов. Затем запускаются фоновые процессы. Если исключение неявное, то одновременно в модуле выполняется только один фоновый процесс; когда он приостанавливается или завершается, может выполняться другой фоновый процесс. Если процессы модуля выполняются параллельно, то все фоновые процессы модуля могут начинаться одновременно.
У неявной формы исключения есть два преимущества. Первое — модули проще программировать, поскольку разделяемые переменные автоматически защищаются от конфликтов одновременного доступа. Второе — реализация модулей, выполняемых на однопроцессорных машинах, может быть более эффективной. Дело в том, что переключение контекста происходит только в точках входа, возврата или приостановки процедур или процессов, а не в произвольных точках, когда регистры могут содержать результаты промежуточных вычислений.
С другой стороны, предположение о параллельном выполнении процессов является более общим. Параллельное выполнение — это естественная модель для программ, работающих на обычных теперь мультипроцессорах с разделяемой памятью. Кроме того, с помощью параллельной модели выполнения можно реализовать квантование времени, чтобы разделять его между процессами и "обуздывать" неуправляемые процессы (например, зациклившиеся). Это невозможно при использовании исключающей модели выполнения, если только процессы сами не освобождают процессор через разумные промежутки времени, поскольку контекст можно переключить, только когда выполняемый процесс достигает точки выхода или приостановки.
Итак, будем предполагать, что процессы внутри модуля выполняются параллельно, и поэтому необходимо программировать взаимное исключение и условную синхронизацию.
В следующих двух разделах показано, как программировать сервер времени и кэширование в распределенной файловой системе с использованием семафоров.
8.1.2. Сервер времени
Рассмотрим задачу реализации сервера времени — модуля, который обслуживает работу с временными интервалами клиентских процессов из других модулей. Предположим, что в сервере времени определены две видимые операции: get_time и delay. Клиентский процесс получает время суток, вызывая операцию get_time, и блокируется на interval единиц времени с помощью операции delay. Сервер времени также содержит внутренний процесс, который постоянно запускает аппаратный таймер и при возникновении прерывания от таймера увеличивает время суток.
Листинг 8.1 содержит программу модуля сервера времени. Время суток хранится в переменной tod (time of day). Несколько клиентов могут вызывать функции get_time и delay одновременно, поэтому несколько процессов могут одновременно обслуживать вызовы. Такое обслуживание нескольких вызовов операции get_time безопасно для процессов, поскольку они просто считывают значение tod. Но операции delay и tick должны выполняться со взаимным исключением, обрабатывая очередь "уснувших" клиентских процессов napQ. Вместе с тем, в операции delay присваивание значения переменной wake_time может не быть критической секцией, поскольку переменная tod — это единственная разделяемая переменная, которая просто считывается. Кроме того, увеличение tod в процессе Clock также может не быть критической секцией, поскольку только процесс Clock может присваивать значение этой переменной..


Предполагается, что значение переменной myid в процессе delay является уникальным целым числом в промежутке от 0 до п-1. Оно используется для указания скрытого семафора, на котором приостановлен клиент. После прерывания от часов процесс Clock выполняет цикл проверки очереди napQ; он сигнализирует соответствующему семафору задержки, когда заданный интервал задержки заканчивается.
Может быть несколько процессов, ожидающих одно и то же время запуска, поэтому используется цикл.
8.1.3. Кэширование в распределенной файловой системе
Рассмотрим упрощенную версию задачи, возникающей в распределенных файловых системах и базах данных. Предположим, что прикладные процессы выполняются на рабочей станции, а файлы данных хранятся на файловом сервере. Не будем останавливаться на том, как файлы открываются и закрываются, а сосредоточимся на их чтении и записи. Когда прикладной процесс хочет получить доступ к файлу, он вызывает процедуру read или write влокальном модуле FileCache. Будем считать, что приложения читают и записывают массивы символов (байтов). Иногда это может быть несколько символов, а иногда — тысячи.
Файлы хранятся на диске файлового сервера в блоках фиксированного размера (например, по 1024 байт). Модуль FileServer управляет доступом к блокам диска. Для чтения и записи целых блоков он обеспечивает две операции, readblk и writeblk.
Модуль FileCache кэширует последние считанные блоки данных. Когда приложение запрашивает чтение части файла, модуль FileCache сначала проверяет, есть ли эти данные в его кэш-памяти. Если есть, то он может быстро обработать запрос клиента. Если нет, он должен вызвать процедуру readblk из модуля FileServer для получения блоков диска с запрашиваемыми данными. (Модуль FileCache может производить упреждающее чтение, если определит, что происходят последовательные обращения к файлу. А это бывает часто.)


При условии, что у каждого прикладного процесса есть отдельный модуль FileCache, внутренняя синхронизация в этом модуле не нужна, поскольку в любой момент времени может выполняться только один запрос чтения или записи. Но если несколько прикладных процессов используют один модуль FileCache или в нем есть процесс, который реализует упреждающее чтение, то для обеспечения взаимно исключающего доступа к разделяемой кэш-памяти в этом модуле необходимо использовать семафоры.
В модуле FileServer внутренняя синхронизация необходима, поскольку он совместно используется несколькими модулями FileCache и содержит внутренний процесс Disk-Driver.
В частности, необходимо синхронизировать процессы, обрабатывающие вызовы операций writeblk и readblk, и процесс DiskDriver, чтобы защитить доступ к кэшпамяти дисковых блоков и планировать операции доступа к диску. В листинге 8.2 код синхронизации не показан, но его нетрудно написать, используя методы из главы 4.
8.1.4. Сортирующая сеть из фильтров слияния
Хотя RPC упрощает программирование взаимодействий "клиент-сервер", его неудобно использовать для программирования фильтров и взаимодействующих равных. В этом разделе еще раз рассматривается задача реализации сортирующей сети из фильтров слияния, представленной в разделе 7.2, и показан способ поддержки динамических каналов связи с помощью указателей на операции в других модулях.
Напомним, что фильтр слияния получает два входных потока и производит один выходной. Предполагается, что каждый входной поток отсортирован, и задача фильтра — объединить значения из входных потоков в отсортированный выходной. Как и в разделе 7.2, предположим, что конец входного потока обозначен маркером EOS.
Первая проблема при программировании фильтра слияния с помощью RPC состоит в том, что RPC не поддерживает непосредственное взаимодействие процесс-процесс. Вместо этого в программе нужно явно реализовывать межпроцессное взаимодействие, поскольку для него нет примитивов, аналогичных примитивам для передачи сообщений.
290 Часть 2. Распределенное программирование
Еще одна проблема — связать между собой экземпляры фильтров. Каждый фильтр должен направить свой выходной поток во входной поток другого фильтра, но имена операций, представляющих каналы взаимодействия, являются различными идентификаторами. Таким образом, каждый входной поток должен быть реализован отдельной процедурой. Это затрудняет использование статического именования, поскольку фильтр слияния должен знать символьное имя операции, которую нужно вызвать для передачи выходного значения следующему фильтру.
Намного удобнее использовать динамическое именование, при котором каждому фильтру передается ссылка на операцию, используемую для вывода. Динамическая ссылка представляется мандатом доступа (capability), который можно рассматривать как указатель на операцию.
Листинг 8.3 содержит модуль, реализующий массив фильтров Merge. В первой строке модуля дано глобальное определение типа операций stream, получающих в качестве аргумента одно целое число. Каждый модуль экспортирует две операции, inl и in2. Они обеспечивают входные потоки и могут использоваться другими модулями для получения входных значений. Модули экспортируют третью операцию, initialize, которую вызывает главный модуль (не показан), чтобы передать фильтру мандат доступа к используемому выходному потоку. Например, главный модуль может дать фильтру Merge [ i ] мандат доступа к операции in2 фильтра Merge [ j ] с помощью следующего кода:

Глава 8. Удаленный вызов процедур и рандеву 291
else # v2 == EOS while (vl != EOS)
{ call out(vl); V(emptyl); P(fulll); } call out(EOS); # присоединить маркер конца } end Merge
Остальная часть модуля аналогична процессу Merge (см. листинг 7.2). Переменные vl и v2 соответствуют одноименным переменным в листинге 7.2, а процесс м повторяет действия процесса Merge. Однако процесс М для помещения следующего значения в выходной канал out использует оператор call, а не send. Процесс м для получения следующего числа из соответствующего входного потока использует операции семафора. Внутри модуля неявные серверные процессы, которые обрабатывают вызовы операций inl и in2, являются производителями, а процесс М — потребителем. Эти процессы синхронизируются так же, как процессы производителей и потребителей в листинге 4.3.
Сравнение программ в листингах 8.3 и 7.2 четко показывает недостатки PRC по отношению к передаче сообщений при программировании фильтров. Хотя процессы в обоих листингах похожи, для работы программы 8.3 необходимы дополнительные фрагменты.
В результате программа«работает примерно с такой же производительностью, но, используя RPC, программист должен написать намного больше.
8.1.5. Взаимодействующие равные: обмен значений
RPC можно использовать и для программирования обмена информацией, возникающего при взаимодействии равных процессов. Однако по сравнению с использованием передачи сообщений программы получаются громоздкими. В качестве примера рассмотрим взаимодействие двух процессов из разных модулей, которым необходимо обменять значения. Чтобы связаться с другим модулем, каждый процесс должен использовать RPC, поэтому каждый модуль должен экспортировать процедуру, вызываемую из другого модуля.
В листинге 8.4 показан один из способов программирования обмена значений. Для пересылки значения из одного модуля в другой используется операция deposit. Для реализации обмена каждый из рабочих процессов выполняет два шага: передает значение myvalue в другой модуль, а затем ждет, пока другой процесс не присвоит это значение своей локальной переменной. (Выражение З-i в каждом модуле задает номер модуля, с которым нужно взаимодействовать; например, модуль 1 должен обратиться к модулю с номером 3-1, т.е. 2.) В модулях используется семафор ready; он гарантирует, что рабочий процесс не получит доступ к переменной othervalue до того, как ей будет присвоено значение в операции deposit.
Листинг 8.4. Обмен значений с использованием R PC
module Exchange[i = 1 to 2]
op deposit(int); body
int othervalue;
sem ready =0; # используется для сигнализации proc deposit(other) { # вызывается из другого модуля othervalue = other; # сохранить полученное значение V(ready); # разрешить процессу Worker забрать его }
process Worker { int myvalue; call Exchange[3-i].deposit(myvalue); # отослать другому
292 Часть 2. Распределенное программирование
Р(ready); # ждать получения значения из другого процесса
} end Exchange____________________________________________________________
8.2. Рандеву
Сам по себе RPC обеспечивает только механизм межмодульного взаимодействия. Внутри модуля все равно нужно программировать синхронизацию. Иногда приходится определять дополнительные процессы, чтобы обрабатывать данные, передаваемые с помощью RPC. Это было показано в модуле Merge (см. листинг 8.3).
Рандеву сочетает взаимодействие и синхронизацию. Как и при PRC, клиентский процесс вызывает операцию с помощью оператора call. Но операцию обслуживает уже существующий, а не вновь создаваемый процесс. В частности, процесс-сервер использует оператор ввода, чтобы ожидать и затем действовать в пределах одного вызова. Следовательно, операции обслуживаются по одной, а не параллельно.
Как и в предыдущем разделе, часть модуля с определениями содержит объявления заголовков операций, экспортируемых модулем, но тело модуля теперь состоит из одного процесса, обслуживающего операции. (В следующем разделе это обобщается.) Используются также массивы операций, объявляемые с помощью добавления диапазона значений индекса к имени операции.
8.2.1. Операторы ввода
Предположим, что модуль экспортирует следующую операцию. op opname (типы параметров) ;
Процесс-сервер этого модуля осуществляет рандеву с процессом, вызвавшим операцию op-name, выполняя оператор ввода. Простейший вариант оператора ввода имеет вид:
in opname (параметры) -> S; ni
Область между ключевыми словами in и ni называется защищенной операцией. Защита именует операцию и обеспечивает идентификаторы для ее параметров (если они есть). S обозначает список операторов, обслуживающих вызов операции. Областью видимости параметров является вся защищенная операция, поэтому операторы из S могут считывать и записывать значения параметров.
Оператор ввода приостанавливает работу процесса-сервера до появления хотя бы одного вызова операции opname. Затем процесс выбирает самый старый из ожидающих вызовов, копирует значения его аргументов в параметры, выполняет список операторов S и, наконец, возвращает результирующие параметры вызвавшему процессу.
В этот момент и процесс-сервер, выполняющий in, и клиентский процесс, который вызывал opname, могут продолжать работу.
Следующая диаграмма отражает отношения между вызывающим и серверным процессами. Время возрастает в диаграмме сверху вниз, а волнистые линии показывают, когда процесс выполняется.

Глава 8. Удаленный вызов процедур и рандеву 293
Как и при использовании RPC, процесс, достигший оператора call, приостанавливается и возобновляется после того, как процесс-сервер выполнит вызванную операцию. Однако при использовании рандеву сервер является активным процессом, который работает и до, и после обслуживания удаленного вызова. Как было указано выше, сервер также задерживается, достигая оператора in, если нет ожидающих выполнения вызовов. Читателю было бы полезно сравнить приведенную диаграмму с аналогичной диаграммой для RPC.
Приведенный выше оператор ввода обслуживает одну операцию. Как сказано в разделе 7.6, защищенное взаимодействие полезно тем, что позволяет процессу ожидать выполнения одного из нескольких условий. Можно объединить рандеву и защищенное взаимодействие, используя общую форму оператора ввода.
in opi(параметры) and В1. by ei -> Si;
[] ...
[] оръ(параметрып) and В„ by en
-> Sn;
ni
Каждая ветвь оператора in является защищенной операцией. Часть кода перед символами -> называется защитой; каждое Si обозначает последовательность операторов. Защита содержит имя операции, ее параметры, необязательное условие синхронизации and Bj. и необязательное выражение планирования by e^.. В этих условиях и выражениях могут использоваться параметры операции.
В языке Ada (раздел 8.6) поддержка рандеву реализована с помощью оператора accept, а защищенное взаимодействие— оператора select. Оператор accept очень похож на in в простой форме, а оператор select — на общую форму in. Но in в общей форме предоставляет больше возможностей, чем select, поскольку в операторе select нельзя использовать аргументы операции и выражения планирования.
Эти различия обсуждаются в разделе 8.6.
Защита в операторе ввода пропускает, если была вызвана операция и соответствующее условие синхронизации истинно (или отсутствует). Область видимости параметров включает всю защищенную операцию, поэтому условие синхронизации может зависеть от значений параметров, т.е. от значений аргументов в вызове операции. Таким образом, один вызов операции может привести к тому, что защита пропустит, а другой — что не пропустит.
Выполнение оператора in приостанавливает работу процесса, пока не пропустит какая-нибудь защита. Если пропускают несколько защит (и нет условий планирования), то оператор in обслуживает первый (по времени) вызов, пропускаемый защитой. Аргументы этого вызова копируются в параметры, и затем выполняется соответствующий список операторов. По завершении операторов результирующие параметры и возвращаемое значение (если есть) возвращаются процессу, вызвавшему операцию. В этот момент операторы call и in завершаются.
Выражение планирования используется для изменения порядка обработки вызовов, используемого по умолчанию (первым обслуживается самый старый вызов). Если есть несколько вызовов, пропускаемых защитой, то первым обслуживается самый старый вызов, у которого выражение планирования имеет минимальное значение. Как и условие синхронизации, выражение планирования может ссылаться на параметры операции, и, следовательно, его значение может зависеть от аргументов вызова операции. В действительности, если в выражении планирования используются только локальные переменные, его значение одинаково для всех вызовов и не влияет на порядок обслуживания вызовов.
Как мы увидим далее, условия синхронизации и выражения планирования очень полезны. Они используются не только в рандеву, но и в синхронной и асинхронной передаче сообщений. Например, можно позволить операторам receive задействовать свои параметры, и многие библиотеки передачи сообщений обеспечивают средства для управления порядком получения сообщений.
Например, в библиотеке MPI получатель сообщения может определять отправителя и тип сообщения.
294 Часть 2 Распределенное программирование
8.2.2. Примеры взаимодействий типа "клиент-сервер"
В данном разделе представлены небольшие примеры, иллюстрирующие использование операторов ввода. Вернемся к задаче реализации кольцевого буфера. Нам нужен процесс, который имеет локальный буфер на п элементов и обслуживает две операции: deposit и fetch. Вызывая операцию deposit, производитель помещает элемент в буфер, а с помощью операции fetch потребитель извлекает элемент из буфера. Как обычно, операция deposit должна задерживаться, если в буфере уже есть n элементов, а операция fetch — пока в буфере не появится хотя бы один элемент.
Листинг 8.5 содержит модуль, реализующий кольцевой буфер. Процесс Buffer объявляет локальные переменные, которые представляют буфер, и затем циклически выполняет оператор ввода. На каждой итерации процесс Buffer ждет вызова операции deposit или fetch. Условия синхронизации в защитах обеспечивают необходимые задержки операций deposit и fetch.

Полезно сравнить процесс Buffer и монитор в листинге 5.3. Интерфейсы клиентских процессов и результаты вызова операций deposit и fetch у них одинаковые, а реализации совершенно разные. Тела процедур в реализации монитора превратились в список операторов в операторе ввода, и условие синхронизации выражается с помощью логических выражений, а не условных переменных.
Еще один пример: листинг 8.6 содержит модуль, реализующий централизованное решение задачи об обедающих философах. Структура процесса Waiter аналогична структуре процесса Buffer. Вызов операции getf orks может быть обслужен, если ни один из соседей не ест, а вызов операции relforks— всегда. Философ передает свой индекс i процессу Waiter, который использует этот индекс в условии синхронизации защиты для getf orks. Предполагается, что в этой защите вызовы функций left (i) и right (i) возвращают индексы соседей слева и справа философа Philosopher [ i ].


______________________________________________________________________________________________________________________________________________________________
Листинг8. 7 содержит модуль сервера времени, по назначению аналогичный модулю влистинге 8.1. Операции get_time и delay экспортируются для клиентов, a tick— для обработчика прерывания часов. В листинге 8.7 аргументом операции delay является время, в которое должен быть запущен клиентский процесс. Клиентский интерфейс данного модуля несколько отличается от интерфейса, приведенного в листинге 8.1. Клиентские процессы должны передавать время запуска, чтобы для управления порядком обслуживания вызовов delay можно было использовать условие синхронизации. В программе с применением рандеву процесс Timer может не поддерживать очередь приостановленных процессов; вместо этого приостановленными являются те процессы, время запуска которых еще не пришло. (Их вызовы остаются в очереди канала delay.)


8.2.3. Сортирующая сеть из фильтров слияния
Снова рассмотрим задачу реализации сортирующей сети с использованием фильтров слияния и решим ее, используя механизм рандеву. Есть два пути. Первый — использовать два вида процессов: один для реализации фильтров слияния и один для реализации буферов взаимодействия. Между каждой парой фильтров поместим процесс-буфер, реализованный в листинге 8.5. Каждый процесс-фильтр будет извлекать новые значения из буферов между этим процессом и его предшественниками в сети фильтров, сливать их и помещать свой выход в буфер между ним и следующим фильтром сети.
Аналогично описанному сети фильтров реализованы в операционной системе UNIX, где буферы обеспечиваются так называемыми каналами UNIX. Фильтр получает входные значения, читая из входного канала (или файла), а отсылает результаты, записывая их в выходной канал (или файл). Каналы реализуются не процессами; они больше похожи на мониторы, но пррцессы фильтров используют их таким же образом.
Второй путь для программирования фильтров — использовать операторы ввода для извлечения входных значений и операторы call для передачи выходных.
При таком подходе фильтры взаимодействуют между собой напрямую. В листинге 8.9 показан массив фильтров для сортировки слиянием, запрограммированных по второму методу. Как и в листинге 8.3, фильтр получает значения из двух входных потоков и отсылает результаты в выходной поток. Здесь также используется динамическое именование, чтобы с помощью операции initialize дать каждому процессу мандат доступа к выходному потоку, который он должен использовать. Этот поток связан со входным потоком другого элемента массива модулей Merge. Несмотря на эти общие черты, программы в листингах 8.3 и 8.8 совершенно разные, поскольку рандеву, в отличие от RPC, поддерживает прямую связь между процессами. Поэтому для программирования процессов-фильтров легче использовать рандеву


Процесс в листинге 8.9 похож на процесс из программы в листинге 7.2, который был запрограммирован с помощью асинхронной передачи сообщений. Операторы взаимодействия запрограммированы по-разному, но находятся в одних и тех же местах программ. Однако, поскольку оператор call является блокирующим, выполнение процесса гораздо теснее связано с рандеву, чем с асинхронной передачей сообщений. В частности, разные процессы Filter будут выполняться примерно с одинаковой скоростью, поскольку каждый поток будет всегда содержать не больше одного числа. (Процесс-фильтр не может вывести в поток второе значение, пока другой фильтр не получит первое.)
8.2.4. Взаимодействующие равные: обмен значений
Вернемся к задаче о процессах из двух модулей, которые обмениваются значениями переменных. Из листинга 8.4 видно, насколько сложно решить эту задачу с использованием RPC. Упростить решение можно, используя рандеву, хотя это хуже, чем передача сообщений.
Используя рандеву, процессы могут связываться между собой напрямую. Но, если оба процесса сделают вызовы одновременно, они заблокируют друг друга. Аналогично процессы одновременно не могут выполнять операторы in. Таким образом, решение должно быть асимметричным; один процесс должен выполнить оператор call и затем in, а другой — сначала in, а затем call.Это решение представлено в листинге 8.10. Требование асимметрии процессов приводит к появлению оператора i f в каждом процессе Worker. (Асимметричное __ решение можно получить, имитируя программу с RPC в листинге 8.4, но это еще сложнее.)

298 Часть 2. Распределенное программирование
Удаленный вызов процедур и рандеву
В данном разделе показано, как реализовать RPC и совместно используемые примитивы (включая рандеву) в ядре, а рандеву — с помощью асинхронной передачи сообщений. Ядро, поддерживающее RPC, иллюстрирует, как управлять двусторонним взаимодействием в ядре. На примере реализации рандеву с помощью передачи сообщений представлены дополнительные операции взаимодействия, необходимые для поддержки синхронизации в стиле рандеву. Ядро, обеспечивающее совместно используемые примитивы, демонстрирует реализацию всех различных примитивов взаимодействия одним унифицированным способом.
10.3.1. Реализация RPC в ядре
RPC поддерживает только взаимодействие и не заботится о синхронизации, поэтому реализуется проще всего. Напомним, что программа, использующая RPC, состоит из набора модулей, которые содержат процедуры и процессы. Процедуры (операции), объявленные в части определений модуля, можно вызывать из процессов, которые выполняются в других модулях. Все части модуля располагаются на одной машине, но разные модули могут находиться на разных машинах. (Здесь не рассматривается, как программист указывает размещение модуля; один из таких механизмов был описан в разделе 8.7.)
Процессы, выполняемые в одном модуле, взаимодействуют с помощью разделяемых переменных и синхронизируются, используя семафоры. Предполагается, что на каждой машине есть локальное ядро, реализующее процессы и семафоры, как описано в главе 6, и что ядра содержат процедуры сетевого интерфейса (см. листинг 10.2). Задача состоит в том, чтобы дополнить ядро процедурами и примитивами для реализации RPC.
Между вызывающим процедуру процессом и процедурой возможны три типа отношений.
• Они находятся в одном модуле и, следовательно, на одной машине.
• Они находятся в разных модулях, но на одной машине.
• Они находятся на разных машинах.
В первой ситуации можно использовать обычный вызов процедуры. Нет необходимости использовать ядро, если на этапе компиляции известно, что процедура является локальной.
Вы зывающий процедуру процесс может просто поместить аргументы в стек и перейти к выполнению процедуры, а после выхода из нее — извлечь из стека ее результаты и продолжить работу. Для межмодульных вызовов каждую процедуру можно однозначно идентифицировать парой (machine, address), где machine указывает место хранения тела процедуры, a address — точку входа в процедуру. Оператор вызова можно реализовать следующим образом.
if (machine локальная)
выполнить обычный вызов по адресу address ; else
rpc (machine, address, аргументы-значения);
388 Часть 2 Распределенное программирование
Для использования обычного вызова процедура обязательно должна существовать. Это условие выполняется, если нельзя изменять идентификатор процедуры или динамически уничтожать модули. В противном случае, чтобы перед вызовом процедуры убедиться в ее существовании, понадобится входить в локальное ядро.
Чтобы выполнить удаленный вызов процедуры, процесс должен передать на удаленную машину аргументы-значения и приостановить работу до получения результатов. Когда удаленная машина получает сообщение CALL, она создает процесс для выполнения тела процедуры. Перед завершением этого процесса вызывается примитив удаленного ядра, который передает результаты на первую машину.
В листинге 10.7 приведены ядровые примитивы для реализации rpc, а также новый обработчик прерывания чтения. В этих подпрограммах используется процедура распределенного ядра для асинхронной передачи сообщений netWrite (см. листинг 10.2), которая, в свою очередь, взаимодействует с соответствующим обработчиком прерывания.
При обработке удаленного вызова происходят следующие события.
• Вызывающий процесс инициирует примитив грс, который передает идентификатор вызывающего процесса, адрес процедуры и ее аргументы-значения на удаленную машину.
• Обработчик прерывания чтения в удаленном ядре получает сообщение и вызывает примитив handle_rpc, который создает процесс для обслуживания вызова.
• Серверный процесс выполняет тело процедуры и затем запускает примитив rpcRe-turn, чтобы возвратить результаты в ядро вызывающего процесса.
• Обработчик прерывания чтения в ядре вызывающего процесса получает возвращаемое сообщение и вызывает процедуру handleReturn, которая снимает блокировку вызывающей процедуры.
В примитиве handle_rpc предполагается, что существует список заранее созданных дескрипторов процессов, обслуживающих вызовы. Это ускоряет обработку удаленного вызова, поскольку не требует накладных расходов на динамическое выделение памяти и инициализацию дескрипторов. Также предполагается, что каждый серверный процесс запрограммирован так, что его первым действием является переход на соответствующую процедуру, а последним — вызов примитива ядра rpcReturn.


10.3.2. Реализация рандеву с помощью асинхронной передачи сообщений
Рассмотрим, как реализовать рандеву, используя асинхронную передачу сообщений. Напомним, что в рандеву участвуют два партнера: вызывающий процесс, который инициирует операцию с помощью оператора вызова, и сервер, обслуживающий операцию, используя оператор ввода. В разделе 7.3 было показано, как имитировать вызывающий процесс (клиент) и сервер с помощью асинхронной передачи сообщений (см. листинги 7.3 и 7.4). Здесь эта имитация развивается для реализации рандеву.
Главное — реализовать операторы ввода. Напомним, что оператор ввода содержит одну или несколько защищенных операций. Выполнение оператора in приостанавливает процесс до появления приемлемого вызова — оператор ввода обслужит тот вызов, для которого выполняется условие синхронизации. Пока не будем обращать внимания на выражения планирования.
Операцию можно обслужить только тем процессом, в котором она объявлена, поэтому ожидающие вызовы можно сохранить в этом процессе. Существует два основных способа сохранения вызовов' с отдельной очередью для каждой операции или с отдельной очередью для каждого процесса. (В действительности существует еще один вариант, который используется в следующем разделе по причинам, объясняемым здесь.) Используем способ с отдельной очередью для каждого процесса, поскольку это приводит к более простой реализации.
К тому же, во многих примерах главы 8 использовался один оператор ввода на серверный процесс. Однако у сервера может быть и несколько операторов ввода, обслуживающих разные операции. В таком случае появится необходимость просматривать вызовы, которые не могут быть выбраны в данном операторе ввода.
В листинге 10.8 иллюстрируется реализация рандеву с помощью асинхронной передачи сообщений. Каждый процесс с, выполняющий оператор вызова, имеет канал reply, из которого он получает результаты вызовов процедур. У каждого серверного процесса s, выполняющего оператор ввода, есть канал invoke, из которого он получает вызовы, и локальная очередь

Чтобы реализовать оператор ввода, серверный процесс S сначала просматривает ожидающие вызовы. Если он находит приемлемый вызов (операцию, соответствующую оператору вызова, для которой истинно условие синхронизации), то s удаляет самый старый из таких вызовов в очереди pending. Иначе S получает новые вызовы до тех пор, пока не найдет приемлемый вызов (сохраняя при этом неприемлемые). Найдя приемлемый вызов, S выполняет тело защищенной операции и после этого передает ответ вызвавшему процессу.
Напомним, что выражение планирования влияет на выбор вызова, если приемлемых вызовов несколько. Выражения планирования можно реализовать, дополнив листинг 10.8 следующим образом. Во-первых, чтобы планировать обработку ожидающих вызовов, серверный процесс должен сначала узнать обо всех таких вызовах. Это вызовы из очереди pending и других очередей, которые могут собираться в канале invoke процесса. Таким образом, перед просмотром очереди pending сервер S должен выполнить такой код.
while (not empty(invoke[S])) {
receive invoke[S](caller, opid, values);
вставить (caller, opid, values) в очередь pending; }
Во-вторых, если сервер находит приемлемый вызов в очереди pending, он должен просмотреть всю очередь в поисках приемлемого вызова этой же операции с минимальным значением выражения планирования.
Если такой вызов найден, то серверный процесс удаляет его из pending и обслуживает вместо первого найденного вызова. Однако цикл в листинге 10.8 изменять не нужно. Если в очереди pending нет приемлемых вызовов, то первый полученный сервером вызов как раз и будет иметь наименьшее значение выражения планирования.
Глава 10. Реализация языковых механизмов 39
10.3.3. Реализация совместно используемых примитивов в ядре
Рассмотрим реализацию в ядре совместно используемых примитивов (см. раздел 8.3) В ней свойства распределенных ядер для передачи сообщений и RPC сочетаются со свойст вами реализации рандеву с помощью асинхронной передачи сообщений. Она также иллюст рирует один из способов реализации рандеву в ядре.
Используя составную нотацию примитивов, операции можно вызывать двумя способами с помощью синхронных операторов вызова (call) и асинхронных— передачи (send). Об служивать операции можно тоже двумя способами, используя процедуры или операторы вво да (но не обоими одновременно). Таким образом, в ядре должно быть известно, какие методь используются для вызова и обслуживания каждой операции. Предположим, что ссылка н; операцию имеет вид записи с тремя полями. Первое поле указывает способ обработки операции. Второе определяет машину, на которой должна быть обслужена операция. Для операции, обслуживаемой процедурой ргос, третье поле записи указывает точку входа процедурь в ядре для RPC. Если же операция обслуживается операторами ввода, третье поле содержи! адрес дескриптора операции (его содержимое уточняется через два абзаца).
В рандеву каждая операция обслуживается тем процессом, в котором она объявлена. Следовательно, в реализации рандеву используется по одному набору ожидающих вызовов на каждый серверный процесс. Однако при использовании составной нотации примитивов операцию можно обслуживать операторами ввода в нескольких процессах модуля, в котором она объявлена.
Таким образом, серверным процессам одного модуля может понадобиться совместный доступ к ожидающим вызовам. Можно реализовать одно множество ожидающих вызовов для каждого модуля, но тогда все процессы модуля должны будут соперничать в доступе к этому множеству, даже если они обслуживают разные операции. Это приведет к задержкам, связанным с ожиданием доступа ко множеству и просмотром вызовов, которые наверняка не могут быть обслужены. Поэтому для ожидающих вызовов используем несколько множеств, по одному для каждого класса операций, как определено ниже.
Класс операции — это класс эквивалентности транзитивного замыкания отношения "обслуживаются одним и тем же оператором ввода". Например, если в одном операторе ввода есть операции а и Ь, то они принадлежат одному классу. Если в другом операторе ввода (в этом же модуле) есть операции а и с, то операция с также принадлежит классу, содержащему а и Ь. В худшем случае все операции модуля принадлежат одному классу. В лучшем — каждая находится в своем классе (например, если все они обслуживаются операторами receive).
Ссылка на операцию, которую обслуживают операторы ввода, содержит указатель на дескриптор операции. Дескриптор операции, в свою очередь, содержит указатель на дескриптор класса операции. Оба дескриптора хранятся на машине, обслуживающей эту операцию. Дескриптор класса содержит следующую информацию:
блокировка — используется для взаимоисключающего доступа; список задержанных — задержанные вызовы операций данного класса; список новых — вызовы, пришедшие, пока класс был заблокирован; список доступа — процессы, ожидающие блокировки; список ожидания — процессы, ожидающие появления новых вызовов.
Блокировка используется для того, чтобы в любой момент времени только один процесс мог просматривать ожидающие вызовы. Использование других полей описано ниже.
Операторы вызова и передачи реализуются следующим образом. Если операцию обслуживает процедура, которая находится на той же машине, то оператор вызова преобразуется в прямой вызов процедуры.
Процесс может определить это, просмотрев поля описанной выше ссылки на операцию. Если операция относится к другой машине или обслуживается опе-
i
392 Часть 2. Распределенное программирование
раторами ввода, то оператор вызова запускает на локальной машине примитив invoke. Независимо от того, как обслуживается операция, оператор send выполняет примитив invoke.
Листинг 10.9 содержит код примитива invoke и двух процедур ядра, которые он использует. Первый аргумент определяет вид вызова. При вызове CALL ядро блокирует выполняемый процесс до завершения обслуживания вызова. Затем ядро определяет, на локальной или удаленной машине должна быть обслужена операция. Если на удаленной, ядро отсылает сообщение INVOKE удаленному ядру, выполняющему затем процедуру ядра locallnvoke.
Подпрограмма locallnvoke проверяет, процедурой ли обслуживается операция. Если да, то она получает свободный дескриптор процесса и дает серверному процессу указание выполнить процедуру, как в ядре для RPC. Ядро также записывает в дескрипторе, как вызывалась операция. Эти данные используются позже для определения, есть ли вызвавший процедуру процесс, который нужно запустить после выхода из нее.


Если операция обслуживается оператором ввода, процедура local Invoke проверяет дескриптор класса. Если класс заблокирован (процесс выполняет оператор ввода и проверяет задержанные вызовы), ядро сохраняет вызов в списке новых вызовов и перемещает все процессы, ожидающие новых вызовов, в список доступа к классу. Если класс не заблокирован, ядро добавляет вызов ко множеству задержанных вызовов и проверяет список ожидания. (Список доступа пуст, если класс не заблокирован.) Если есть процессы, ожидающие новых вызовов, то один из них запускается, устанавливается блокировка, а остальные ожидающие процессы перемещаются в список доступа.
Заканчивая выполнение процедуры, процесс вызывает примитив ядра procDone (листинг 10.10).
Этот примитив освобождает дескриптор процесса и запускает вызвавший процедуру процесс (если такой есть). Примитив awakenCaller выполняется ядром на той машине, на которой размещен вызывающий процесс.

• Для операторов ввода процесс выполняет код, приведенный в листинге 10.11. В этом коде вызываются примитивы оператора ввода (листинг 10.12).'Процесс сначала получает исключительный доступ к дескриптору класса операции и затем ищет приемлемые задержанные вызовы. Если ни один из них принять нельзя, процесс вызывает процедуру waitNew, чтобы приостановить работу до прихода нового вызова. Этот примитив может закончиться немедленно, если новый вызов приходит во время поиска задержанных вызовов (и, следовательно, при заблокированном дескрипторе класса).
Найдя приемлемый вызов, процесс выполняет соответствующую защищенную операцию и вызывает процедуру inDone. Ядро запускает вызвавший процедуру процесс (если он есть)
394 Часть 2 Распределенное программирование
и обновляет состояние дескриптора класса Если во время выполнения оператора ввода прибывают новые вызовы, они перемещаются в список задержанных, а процессы, ожидающие доступа к классу, перемещаются в список доступа Затем, если есть процессы, ожидающие доступ к классу, запускается один из них, иначе блокировка снимается.


396 Часть 2. Распределенное программирование
сообщений. Частично это связано с тем, что понятие разделяемых переменных близко последовательному программированию. Однако РРП требует дополнительных затрат на обработку ситуаций, связанных с отсутствием страниц в локальной памяти, а также на получение и передачу удаленных страниц.
Ниже описана реализация РРП, которая сама по себе является еще одним примером распределенной программы. Затем рассматриваются некоторые из общепринятых протоколов согласования страниц и то, как они поддерживают схемы доступа к данным в прикладных программах.
10.4.1. Обзор реализации
РРП — это программная прослойка между прикладными программами и операционной системой или специализированным ядром. Ее общая структура показана на рис. 10.3. Адресное пространство каждого процессора (узла) состоит из разделяемой и скрытой областей. Разделяемые переменные прикладной программы хранятся в разделяемой области, а код и скрытые данные — в скрытой. Таким образом, можно считать, что в разделяемой области памяти находится "куча" программы, а в скрытой — сегменты кода и стеки процессов. В скрытой области каждого узла также расположена копия программного обеспечения РРП и операционная система узла или ядро взаимодействия.
РРП управляет разделяемой областью адресного пространства. Это линейный массив байтов, который теоретически дублируется на каждом узле. Разделяемая область памяти разбивается на модули, каждый из которых защищается отдельно и находится на одном или нескольких узлах. Обычно модули являются страницами фиксированного размера, хотя они могут быть и страницами переменного размера или отдельными объектами данных. Здесь предполагается, что размеры модулей зафиксированы. Управление страницами аналогично управлению страничной виртуальной памятью одиночного процессора. Страница может быть или резидентной (присутствующей) или нет. Резидентная страница может быть доступной только для чтения или для чтения и записи.
Каждая разделяемая переменная в приложении отображается в адрес в разделяемой области памяти и, следовательно, имеет один и тот же адрес на всех узлах. Вначале страницы разделяемой области некоторым образом распределены по узлам. Пока будем считать, что существует одна копия каждой страницы, и страница доступна для чтения и записи на узле ее расположения.
Обращаясь к разделяемой переменной в резидентной странице, процесс получает к ней прямой доступ. Но обращение к нерезидентной странице приводит к ошибке обращения к странице. Эту ошибку обрабатывает программное обеспечение РРП.
Оно определяет расположение страницы и отправляет сообщение на запросивший ее (первый) узел. Второй узел (на котором была страница) помечает ее как нерезидентную и передает на первый узел. Первый узел, получив страницу, обновляет ее защиту и возвращается к прикладному процессу. Как и в системе виртуальной памяти, прикладной процесс повторно выполняет инструкцию, вызвавшую ошибку обращения к странице, и обращение к разделяемой переменной заканчивается успешно.
Для иллюстрации описанных выше действий рассмотрим следующий простой пример.

Процессы могли бы работать синхронно или в произвольном порядке, но предположим, что Р1 выполняется первым и присваивает х. Поскольку страница с х в данный момент находится на узле 1, запись выполняется успешно и процесс завершается. Теперь начинается Р2. Он пытается записать в у, но содержащая у страница нерезидентная, и возникает ошибка. Обработчик ошибки узла 2 передает запрос страницы на узел 1, который отсылает страницу узлу 2. Получив страницу, узел 2 запускает процесс Р2; теперь запись в у завершается успешно. В заключительном состоянии страница является резидентной для узла 2 и обе переменные имеют новые значения.
Когда РРП реализуется на основе операционной системы Unix, защита разделяемых страниц устанавливается системным вызовом mprotect. Защита резидентной страницы устанавливается в состояние read или READ и WRITE. Защита нерезидентных страниц устанавливается в состояние none. При запросе нерезидентной страницы вырабатывается сигнал о нарушении сегментации (sigsegv). Обработчик ошибок обращения к страницам в РРП получает этот сигнал и посылает сообщение о запросе страницы, используя примитивы взаимодействия Unix (или им подобные программы). По прибытии сообщения на узел генерируется сигнал ввода-вывода (SIGIO). Обработчик сигналов ввода-вывода определяет тип сообщения (запрос страницы или ответ) и предпринимает соответствующие действия. Обработчики сигналов должны выполняться в критических секциях, поскольку во время обработки одного сигнала может прийти другой, например во время обработки ошибки обращения к странице может прийти запрос на страницу.
РРП может быть однопоточной или многопоточной. Однопоточная РРП поддерживает только один прикладной процесс на каждом узле. Процесс, вызвавший ошибку обращения к странице, приостанавливается до разрешения ошибки. Многопоточная РРП поддерживает несколько приложений на каждом узле, поэтому, когда один процесс вызывает ошибку обращения к странице, другой может выполняться, пока первый ожидает разрешения ошибки. Однопоточную РРП реализовать проще, поскольку в ней меньше критических секций. Однако многопоточная РРП гораздо лучше скрывает задержки при обращениях к удаленной странице и, следовательно, может обеспечить более высокую производительность.
398 Часть 2. Распределенное программирование
10.4.2. Протоколы согласования страниц
Производительность приложения, выполняемого на базе РРП, зависит от эффективности реализации самой РРП. Сюда входят и возможность маскирования ожидания при доступе к памяти, и эффективность обработчиков сигналов, и, в особенности, свойства протоколов взаимодействия. Производительность приложения также существенно зависит от методов управления страницами, а именно — от используемого протокола согласования страниц. Далее описаны три таких протокола: блуждания, или переноса (migratory), денонсирующей записи (write invalidate) и совместной записи (write shared).
В примере в листинге 10.4 предполагалось, что существует одна копия каждой страницы. Когда страница нужна другому узлу, копия перемещается. Это называется протоколом переноса. Содержание страницы всегда согласованно, поскольку есть только одна ее копия. Но что случится, когда два процесса на двух узлах просто захотят прочесть переменную на этой странице? Тогда страница будет прыгать между ними; этот процесс называется замусориванием (trashing).
Протокол денонсирующей записи позволяет дублировать страницы при чтении. У каждой страницы есть владелец. Пытаясь прочитать удаленную страницу, процесс получает от ее _владельца неизменяемую копию (только для чтения).
Копия владельца на это время тоже помечается как доступная только для чтения. Пытаясь записать в страницу, процесс получает копию (при необходимости), делает недействительными (денонсирует) остальные копии и записывает в полученную страницу. Обработчик ошибки обращения к странице узла, выполняющего запись, при этом совершает следующие действия: 1) связывается с владельцем, 2) получает страницу и владение ею, 3) отправляет денонсирующие сообщения узлам, на которых есть копии этой страницы (они устанавливают защиту своей копии страницы в состояние NONE), 4) устанавливает защиту своей копии в состояние READ и WRITE, 5) возобновляет прикладной процесс.
Протокол денонсирующей записи очень эффективен для страниц, которые доступны только для чтения (после их инициализации) или редко изменяются. Однако при появлении ложного разделения этот протокол приводит к замусориванию. Вернемся к рис. 10.4. Переменные х и у не разделяются процессами, но находятся на одной разделяемой странице. Следовательно, эта страница будет перемещаться между двумя узлами так же, как и при использовании протокола переноса.
Ложное разделение можно исключить, размещая такие переменные, как х и у в примере на разных страницах. Это можно делать статически во время компиляции программы или динамически во'время выполнения. Вместе с тем, ложное разделение можно допустить, используя протокол совместной записи. Этот процесс позволяет выполнять несколько параллельных записей на одну страницу. Например, когда процесс Р2, выполняемый на узле 2 (см. рис. 10.4), записывает в у, узел 2 получает копию страницы от узла 1, и оба узла получают разрешение записать на эту страницу. Ясно, что копии становятся несогласованными. В таких точках синхронизации, определенных в приложении, как барьеры, копии объединяются. При ложном разделении страницы объединенная копия будет правильной и согласованной. Однако при действительном разделении объединенная копия будет неопределенной комбинацией записанных значений.
Для обработки таких ситуаций каждый узел поддерживает список изменений, сделанных им на странице с совместной записью. Эти списки используются при объединении копий для учета последовательности записей, сделанных разными процессами.
Историческая справка
Реализации примитивов взаимодействия существовали столько же, сколько и сами примитивы. В исторических справках к главам 7—9 упоминались статьи с описаниями новых примитивов; во многих из этих работ представлена и реализация примитивов. Два хороших
Глава 10 Реализация языковых механизмов 399
источника информации по данной теме— книги [Bacon, 1998] и [Tanenbaum, 1992]. В них описаны примитивы взаимодействия и вопросы их реализации в целом, рассмотрены примеры важных операционных систем.
В распределенном ядре (раздел 10.1) предполагалось, что передача по сети происходит без ошибок, и не учитывалось управление буферами и потоками. Решение этих вопросов представлено в книгах по компьютерным сетям, например [Tanenbaum, 1988] или [Paterson and Davie, 1996].
Централизованная реализация синхронной передачи сообщений (см. рис. 10.2, листинги 10.5 и 10.6) была разработана автором этой книги. Существуют и децентрализованные решения без центрального управляющего. В работе [Silberschatz, 1979] рассмотрены процессы, образующие кольцо, а в [Van de Snepscheut, 1981] — иерархические системы. В [Bernstein, 1980] представлена реализация, работающая при любой топологии связи, а в [Schneider, 1982] — алгоритм рассылки, который, по существу, повторяет множества ожидания нашего учетного процесса (листинг 10.6). Алгоритм Шнейдера прост и справедлив, но требует обмена большим количеством сообщений, поскольку каждый процесс должен подтверждать каждую передачу. В статье [Buckley and Silberschatz, 1983] предложен справедливый децентрализованный алгоритм, обобщающий алгоритм из [Bernstein, 1980]. Этот алгоритм эффективнее, чем алгоритм Шнейдера, но намного сложнее. (Все упомянутые алгоритмы описаны в книге [Raynal, 1988].) В работе [Bagrodia, 1989] представлен еще один алгоритм, более простой и эффективный, чем алгоритм из [Buckley and Silberschatz, 1983].
В разделе 10. 3 были представлены реализации рандеву с использованием асинхронной передачи сообщений и ядра. Из-за сложности механизма рандеву его производительность в целом ниже, чем других механизмов синхронизации. Во многих программах рандеву можно заменить более простыми механизмами, такими как процедуры и семафоры. Многочисленные примеры таких преобразований (для языка Ада) приведены в статье [Roberts et al., 1981]. В [McNamee and Olsson, 1990] представлено больше преобразований и проведен анализ получаемого роста производительности, который в некоторых случаях достигал 95 процентов.
Концепцию распределенной разделяемой памяти (РРП) разработал Кай Ли (Kai Li) в свой докторской диссертации в Йельском университете под руководством Пола Хьюдака (Paul Hu-dak). В статье [Li and Hudak, 1989] представлен протокол денонсирующей записи для согласования страниц. Ли внес решающий вклад в развитие этой темы, поскольку до его публикации никто не верил, что с помощью передачи сообщений можно моделировать разделяемую память с приемлемой производительностью. Теперь РРП занимает прочные позиции и даже поддерживается многими производителями суперкомпьютеров.
Две важнейшие из последних РРП-систем — Munin и TreadMarks, разработанные в университете Раиса (Rice). Реализация и производительность системы Munin, в которой появился протокол совместной записи, описана в статье [Carter, Bennett and Zwaenepoel, 1991], а система TreadMarks— в [Amza et al., 1996]. Производительность PVM и TreadMarks сравнивается в работе [Lu et al., 1997]. Книга [Tanenbaum, 1995] содержит отличный обзор по РРП, включая работу Ли, систему Munin и другие. За более новой информацией по вопросам РРП обращайтесь к специализированному изданию Proceedings of IEEE (март 1999).
Литература
Amza, С., A. L. Cox, S. Dwarkadas, P. Keleher, H. Lu, R. Rajamony, W. Yu, and W. Zwaenepoel. 1996. TreadMarks: Shared memory computing on networks of workstations. IEEE Computer 29, 2 (February): 18-28.

Управляющий-рабочие (распределенный портфель задач)
В разделе 3.6 представлена парадигма портфеля задач и показано, как реализовать ее, используя для синхронизации и взаимодействия разделяемые переменные. Напомним основную идею: несколько рабочих процессов совместно используют портфель независимых задач. Рабочий многократно берет из портфеля задачу, выполняет ее и, возможно, порождает одну или несколько новых задач, помещая их в портфель. Преимуществами этого подхода к реализации параллельных вычислений являются легкость варьирования числа рабочих процессов и относительная простота обеспечения того, что процессы выполняют приблизительно одинаковые объемы работы.
Глава 9. Модели взаимодействия процессов 329
Здесь показано, как реализовать парадигму портфеля задач с помощью передачи сообщений вместо разделяемых переменных. Для этого портфель задач реализуется управляющим процессом, который выбирает задачи, собирает результаты и определяет завершение работы. Рабочие процессы получают задачи и возвращают результаты, взаимодействуя с управляющим, который, по сути, является сервером, а рабочие процессы — клиентами.
В первом примере, приведенном ниже, показано, как умножаются разреженные матрицы (большинство их элементов равны нулю). Во втором примере используется сочетание интервалов статического и адаптивного интегрирования в уже знакомой задаче квадратуры. В обоих примерах общее число задач фиксировано, а объем работы, выполняемой каждой задачей, изменяется.
9.1.1. Умножение разреженных матриц
Пусть А и В — матрицы размером n x п. Нужно определить произведение матриц А х в = С. Для этого необходимо вычислить п2 скалярных произведений векторов (сумм, образованных произведениями соответствующих элементов двух векторов длины п).
Матрица называется плотной, если большинство ее элементов не равны нулю, ч разреженной, если большинство элементов нулевые. Если А и в — плотные матрицы, то матрица с тоже будет плотной (если только в скалярных произведениях не произойдет значительного сокращения).
С другой стороны, если А или в — разреженные матрицы, то с тоже будет разреженной, поскольку каждый нуль в А или в даст нулевой вклад в n скалярных произведений. Например, если в строке матрицы А есть только нули, то и вся соответствующая строка с будет состоять из нулей.
Разреженные матрицы возникают во многих задачах, например, при численной аппроксимации решений дифференциальных уравнений в частных производных или в больших системах линейных уравнений. Примером разреженной матрицы является трехдиагональная матрица, у которой равны нулю все элементы, кроме главной диагонали и двух диагоналей непосредственно над и под ней. Если известно, что матрицы разреженные, то запоминание только ненулевых элементов экономит память, а игнорирование нулевых элементов при умножении уменьшает затраты времени.
Разреженная матрица А представляется информацией о ее строках:
int lengthA[n]; pair *elementsA[n];
Значение lengthAfi] является числом ненулевых элементов в строке i матрицы А. Переменная elementsAfi] указывает на список ненулевых элементов строки 1. Каждый элемент представлен парой значений (записью): целочисленным индексом столбца и значением соответствующего элемента матрицы (числом удвоенной точности). Таким образом, если значение lengthAfi] равно 3, то в списке elementsAfi] есть три пары. Они упорядочены по возрастанию индексов столбцов. Рассмотрим конкретный пример. lengthA elementsA
1 (3, 2.5) О
О
2 (1, -1.5) (4, 0.6) О
1 (0, 3.4)
Здесь записана матрица размерами 6 на б, в которой есть четыре ненулевых элемента: в строке 0 и столбце 3, в строке 3 и столбце 1, в строке 3 и столбце 4, в строке 5 и столбце 0.
Матрицу с представим так же, как и А. Чтобы упростить умножение, представим матрицу в не строками, а столбцами. Тогда значения в lengths будут указывать число ненулевых элементов в каждом столбце матрицы в, а в elementsB — храниться пары вида (номер строки, значение элемента).
330 Часть 2. Распределенное программирование
Для вычисления произведения матриц а и в, как обычно, нужно просмотреть п2 пар строк и столбцов. Для разреженных матриц самый подходящий объем задачи соответствует одной строке результирующей матрицы с, поскольку вся эта строка представляется одним вектором пар (столбец, значение). Таким образом, нужно столько задач, сколько строк в матрице А. (Очевидно, что для оптимизации можно пропускать строки матрицы А, полностью состоящие из нулей, т.е. строки, для которых lengthA [ i ] равно 0, поскольку соответствующие строки матрицы С тоже будут нулевыми. Но в реальных задачах это встречается редко.)
В листинге 9.1 показан код, реализующий умножение разреженных матриц с помощью одного управляющего и нескольких рабочих процессов. Предполагается, что матрица А в управляющем процессе уже инициализирована, а у каждого рабочего есть инициализированная копия матрицы в. Процессы взаимодействуют с помощью примитивов рандеву (см. главу 8), что упрощает программу. Для использования асинхронной передачи сообщений управляющий процесс должен быть запрограммирован в стиле активного монитора (см. раздел 7.3), а вызовы call в рабочих процессах нужно заменить вызовами send и receive.


332 Часть 2. Распределенное программирование
фала функции f (х) на интервале от а до Ь. В разделе 3.6 было показано, как реализовать адаптивную квадратуру с помощью разделяемого портфеля задач.
Здесь для реализации распределенного портфеля задач используется управляющий процесс. Но вместо "чистого" алгоритма адаптивной квадратуры, использованного в листинге 3.18, применяется комбинация статического и динамического алгоритмов. Интервал от а до Ь делится на фиксированное число подынтервалов, и для каждого из них используется алгоритм адаптивной квадратуры. Такое решение сочетает простоту итерационного алгоритма и высокую точность адаптивного.
Использование фиксированного числа задач упрощает программы управляющего и рабочих процессов, а также уменьшает число взаимодействий между ними.
В листинге 9.2 приведен код управляющего и рабочих процессов. Поскольку управляющий процесс, по существу, является серверным, для его взаимодействия с рабочими процессами здесь также используются рандеву. Таким образом, управляющий процесс имеет ту же структуру, что и в листинге 9.1, а, и также экспортирует операции getTask и putResult, но параметры операций отличаются. Теперь задача определяется конечными точками интервала (переменные left и right), а результатом вычислений является площадь под графиком f (х) на этом интервале. Предполагается, что значения переменных а, Ь и numlntervals заданы, например, как аргументы командной строки. По этим значениям управляющий процесс вычисляет ширину интервалов. Затем он выполняет цикл, принимая вызовы операций getTask и putTask, пока не получит по одному результату вычислений для каждого интервала (каждой задачи). Отметим использование условия синхронизации "st x< Ь" в ветви ••для операции getTask оператора ввода— оно предохраняет операцию getTask от выдачи следующей задачи, когда портфель задач уже пуст.


Рабочие процессы в листинге 9.2 разделяют или имеют собственные копии кода функций f и quad (рекурсивная функция quad приведена в разделе 1.5). Рабочий процесс циклически получает задачу от управляющего, вычисляет необходимые для функции quad аргументы, вызывает ее для аппроксимации значения площади под графиком функции от f (left) до f (right), а затем отсылает результат управляющему процессу.
Когда программа в листинге 9.2 завершается, рабочие процессы блокируются в своих вызовах функции getTask. Обычно это безопасно, как и здесь, но в некоторых случаях этот способ завершения выполнения рабочих процессов может привести к зависанию. Задача реализации нормального завершения рабочих процессов оставляется читателю. (Указание. Измените функцию getTask, чтобы она возвращала true или false.)
В рассматриваемой программе объем работы, приходящейся на одну задачу, зависит от скорости изменения функции f. Таким образом, если число задач приблизительно равно числу рабочих процессов, то вычислительная нагрузка почти наверняка будет несбалансированной. С другой стороны, если задач слишком много, то между управляющим и рабочими процессами будут происходить ненужные взаимодействия, что приведет к излишним накладным расходам. Было бы идеально иметь такое число задач, при котором общий объем работы приблизительно одинаков для всех рабочих процессов. Разумным является число задач, которое в два-три раза больше, чем число рабочих процессов (в данной программе значение пи-mlntervals должно быть в два-три раза больше значения numWorkers).
Определите характеристики доступных вам многопроцессорных
1.1. Определите характеристики доступных вам многопроцессорных машин. Сколько процессоров в каждой машине и каковы их рабочие частоты? Насколько велик размер их кэш-памяти, как она организована? Каково время доступа? Какой используется протокол согласования памяти? Как организована связующая сеть? Каково время удаленного доступа к памяти или передачи сообщения?
1.2. Многие задачи можно решить более эффективно с помощью параллельной, а не последовательной программы (конечно, при наличии соответствующего аппаратного обеспечения). Рассмотрите программы, которые вы писали раньше, и выберите две из них, которые можно переписать как параллельные. Одна из них должна быть итеративной, а другая— рекурсивной. Затем: а) запишите кратко условия задач и б) разработайте псевдокод параллельных программ, решающих поставленные задачи.
1.3. Рассмотрите умножение матриц в разделе 1.4:
а) напишите последовательную программу для решения этой задачи. Размер матрицы п должен быть аргументом командной строки. Инициализируйте каждый элемент матриц а и Ь значением 1. О (тогда значение каждого элемента результирующей матрицы с будет п);
б) напишите параллельную программу для решения этой задачи. Вычислите полосы результата параллельно, используя Р рабочих процессов. Размер матрицы п и число рабочих процессов Р должны быть аргументами командной строки. Вновь инициализируйте каждый элемент матриц а и b значением 1.0;
в) сравните производительность ваших программ. Поэкспериментируйте с разными значениями параметров n и р. Подготовьте график результатов и объясните, что вы заметили;
44 Глава 1. Обзор области параллельных вычислений
г) преобразуйте ваши программы для умножения прямоугольных матриц. Размер матрицы а должен быть pxq, а матрицы b — qxr. Тогда размер результирующей матрицы будет рхг. Повторите часть в данного упражнения для новых программ.
1.4.
2.1. Разберите эскиз программы в листинге 2.1, выводящей все строки с шаблоном pattern в файл:
а) разработайте недостающий код для синхронизации доступа к буферу buffer. Для программирования синхронизации используйте оператор await;
б) расширьте программу так, чтобы она читала два файла и выводила все строки, содержащие шаблон pattern. Определите независимые операции и используйте отдельный процесс для каждой из них. Напишите весь необходимый код синхронизации.
2.2. Рассмотрите решение задачи копирования массива в листинге 2.2. Измените код так, чтобы переменная р была локальной для процесса-производителя, а с — для потребителя. Следовательно, эти переменные нельзя использовать для синхронизации доступа к буферу buf. Вместо них используйте для синхронизации процессов две новые булевы переменные empty и full. В начальном состоянии переменная empty имеет значение true, full — false. Добавьте новый код для процессов потребителя и производителя. Для программирования синхронизации используйте оператор await.
2.3. Команда ОС Unix tee вызывается выполнением:
tee filename
Эта команда читает стандартный ввод и записывает его в стандартный вывод и в файл filename, т.е. создает две копии ввода:
а) запишите последовательную программу для реализации этой команды;
б) распараллельте вашу последовательную программу, чтобы она использовала три процесса: чтения из стандартного ввода, записи в стандартный вывод и записи в файл filename. Используйте стиль "со внутри while";
80 Часть 1. Программирование с разделяемыми переменными
в) измените свое решение из пункта 6, используя стиль "while внутри со". В частности, создайте процессы один раз. Используйте двойную буферизацию, чтобы можно было параллельно читать и писать. Для синхронизации доступа к буферам используйте оператор await.
2.4. Рассмотрите упрощенную версию команды ОС Unix di ff для сравнения двух текстовых файлов.
6.1. В многопроцессорном ядре, описанном в разделе 6.2, процессор выполняет процесс Idle (см. листинг 6.2), когда определяет, что список готовых к работе процессов пуст. На некоторых машинах есть бит в регистре (слове) состояния процессора. Его установка означает, что процессор должен бездействовать до возникновения прерывания (бит бездействия). В таких машинах есть и межпроцессорные прерывания, т.е. один процессор может быть прерван другим, в результате чего он входит в обработчик прерывания ядра на центральном процессоре.
• Измените многопроцессорное ядро в листинге 6.3 так, чтобы процессор сам устанавливал бит бездействия, когда список готовых к работе процессов пуст. Таким образом, для запуска процесса на одном процессоре потребуется выполнить команду на другом.
6.2. Предположим, что планирование процессов ведется одним главным процессором, выполняющим только процесс-диспетчер. Другие процессоры выполняют обычные процессы и процедуры ядра.
Разработайте процесс-диспетчер и соответственно измените многопроцессорное ядро в листинге 6.3. Определите все необходимые структуры данных. Помните, что бездействующий процессор не должен блокироваться внутри ядра, поскольку тогда в ядро не смогут войти остальные процессы.
6.3. Предположим, что все процессоры мультипроцессорной системы имеют собственные списки готовых к работе процессов и выполняют процессы только из них. Как было отмечено в тексте, возникает проблема балансировки нагрузки процессоров, поскольку новый процесс приходится назначать какому-нибудь из процессоров.
Существует много схем балансировки нагрузки процессоров, например, можно назначать новый процесс случайному процессору, "соседу" или поддерживать приблизительно одинаковую длину списков готовых к работе процессов. Выберите одну из схем, обоснуйте свой выбор и измените многопроцессорное ядро в листинге 6.3 так, чтобы в нем использовались несколько списков готовых к работе процессов и выбранная схема балансировки нагрузки процессоров.
10.1. Рассмотрим распределенное ядро в листингах 10.2 и 10.3:
а) расширьте реализацию, чтобы у канала могло быть несколько получателей. В частности, измените примитивы receiveChan и emptyChan, чтобы процесс на одной машине мог получать доступ к каналу, расположенному на другой;
б) измените ядро, чтобы примитив sendChan стал полу синхронным, т.е., вызывая sendChan, процесс должен дождаться постановки сообщения в очередь канала (или передачи получателю), даже если канал расположен на другой машине;
в) добавьте в ядро код определения окончания программы. Можно не учитывать ожидающий ввод-вывод. Вычисления завершены, когда все списки готовых к работе процессов пусты и сеть бездействует.
10.2. Реализация синхронной передачи сообщений в листинге 10.4 предполагает, что и процесс-источник, и процесс-приемник именуют друг друга. Обычно же процесс-приемник должен либо указывать источник, либо принимать сообщения от любого ис-
Глава 10. Реализация языковых механизмов 401
точника. Предположим, что процессы пронумерованы от 1 до п и индекс 0 используется процессом-приемником для указания, что он готов принять сообщение от любого источника. В последнем случае оператор ввода присваивает параметру source идентификатор процесса, приславшего сообщение.
Измените протоколы взаимодействия в листинге 10.4, чтобы они обрабатывали описанную ситуацию. Как и в листинге, основой для реализации описанной выше формы синхронной передачи сообщений должна служить асинхронная передача сообщений.
10.3. Разработайте реализацию в ядре примитивов синхронной передачи сообщений synch_send и synch_receive, определенных в начале раздела 10.2. Сначала постройте однопроцессорное ядро. Затем разработайте распределенное ядро со структурой, показанной в листинге 10.1. Все необходимые процедуры можно брать из листингов 10.2 и 10.3.
10.4. Даны процессы Р[ 1:п], каждый из которых содержит значение элемента a[i] массива из п значений.
11.1. В начале подраздела по последовательным итерациям Якоби представлена простая последовательная программа. Затем описаны четыре оптимизации, приводящие к программе в листинге 11.1, и еще две оптимизации:
а) постройте серию экспериментов для измерения индивидуального и совокупного эффекта от данных шести оптимизаций. Начните с измерения времени выполнения главного цикла вычислений в программе для метода итераций Якоби на сетках различных размеров, например 64x64, 128x128 и 256x256. Подберите такие значения EPSILON и/или iters, чтобы вычисления занимали несколько минут. (Время должно быть достаточно большим, чтобы заметить эффект от улучшений.) Затем добавляйте в код по одной оптимизации и измеряйте повышение производительности. Составьте краткий отчет с результатами измерений и выводами;
б) проведите эксперименты, позволяющие оценить все шесть оптимизаций по отдельности и в различных комбинациях друг с другом, в отличие от пункта а, где оптимизации добавлялись одна за другой. Какие оптимизации оказались наиболее продуктивными? Укажите, имеет ли значение порядок их применения;
в) рассмотрите другие способы оптимизации программы. Ваша цель — получить максимально быструю программу. Опишите и измерьте эффект от каждой дополнительной оптимизации, которую вы придумали.
11.2. Реализуйте программу для метода итераций Якоби с разделяемыми переменными (см. листинг 11.2) и измерьте ее производительность. Используйте разные размеры сеток и количества процессоров. Оптимизируйте программу своим способом и измерьте производительность улучшенной программы. Составьте отчет, в котором будут описаны все проделанные изменения, представлены результаты измерений и выводы.
11.3. Реализуйте неоптимизированную и оптимизированные программы для метода итераций Якоби с передачей сообщений (см. листинги 11.3 и 11.4) и измерьте их производительность. Используйте сетки разных размеров и разное количество процессоров. Затем оптимизируйте программы своим способом и измерьте производительность улучшенных программ.
12.1. В разделе 12. 1 представлены реализации метода итераций Якоби, в которых используются библиотеки Pthreads, MPI и ОрепМР. С помощью библиотек Pthreads, MPI и ОрепМР составьте параллельные программы:
а) для задачи п тел;
б) для реализации LU-разложения.
Для программ с Pthreads и ОрепМР используйте разделяемые переменные, а с MPI — обмен сообщениями. Последовательные части своих программ напишите на С для Pthreads и на С или Фортране для MPI и ОрепМР.
12.2. Рассмотрите последовательные программы для следующих задач:
а) метод итераций Якоби (листинг 11.1);
б) задача п тел (листинг 11.6);
в) LU-разложение (листинг 11.11);
г) прямой и обратный ход (листинг 11.12).
В каждой программе выделите все случаи: 1) потоковых зависимостей, 2) антизависимостей, 3) зависимостей по выходу. Укажите, какие из зависимостей находятся в циклах, а какие создаются циклами.
12.3. Рассмотрим следующие последовательные программы:
а) метод итераций Якоби (листинг 11.1);
б) задача п тел (листинг 11.6);
в) LU-разложение (листинг 11.11);
г) прямой и обратный ход (листинг 11.12).
На рис. 12.1 перечислены некоторые типы преобразований программ в распараллеливающих компиляторах. Для каждого преобразования и каждой из перечисленных выше последовательных программ определите, можно ли применить преобразование к программе, и, если можно, покажите, как это сделать. Каждое преобразование рассматривайте независимо от других.
12.4. Повторите предыдущее упражнение, применяя в каждой программе несколько преобразований. Предположим, что программа пишется для машины с разделяемой памятью, имеющей восемь процессоров, а размер задачи п кратен восьми. Ваша цель — создать программу, которую совсем просто превратить в параллельную программу со сбалансированной вычислительной нагрузкой, удачным распределением данных и небольшими накладными расходами синхронизации. Для каждой программы: 1) подберите последовательность преобразований, 2) покажите, как изменяется программа после каждого преобразования, и 3) объясните, почему вы считаете, что либо полученный код приведет к хорошей параллельной программе, либо из исходной программы получить хорошую параллельную программу нельзя.
Взаимодействующие равные: распределенное умножение матриц
Ранее было показано, как реализовать параллельное умножение матриц с помощью процессов, разделяющих переменные. Здесь представлены два способа решения этой задачи с использованием процессов, взаимодействующих с помощью пересылки сообщений. Более сложные алгоритмы представлены в главе 9. Первая программа использует управляющий процесс и массив независимых рабочих процессов. Во второй программе рабочие процессы равны и их взаимодействие обеспечивается круговым конвейером. Рис. 1.7 иллюстрирует структуру схем взаимодействия этих процессов. Как показано в части 2, они часто встречаются в распределенных параллельных вычислениях.

На машинах с распределенной памятью каждый процессор имеет доступ только к собственной локальной памяти. Это значит, что программа не может использовать глобальные переменные, поэтому любая переменная должна быть локальной для некоторого процесса и может быть доступной только этому процессу или процедуре. Следовательно, для взаимодействия процессы должны использовать передачу сообщений.
Допустим, что нам необходимо получить произведение матриц а и Ь, а результат поместить в матрицу с. Предположим, что каждая из них имеет размер пхп и существует п процессоров. Можно использовать массив из п рабочих процессов, поместив по одному на каждый процессор и заставив каждый рабочий процесс вычислять одну строку результирующей матрицы с. Программа для рабочих процессов будет выглядеть следующим образом.
process worker[i = 0 to n-1] {
double a[n]; # строка i матрицы а double b[n,n]; # вся матрица b double c[n],- # строка i матрицы с receive начальные значения вектора а и матрицы Ъ; for [j = 0 to n-1] { c[j] = 0.0; for [k = 0 to n-1]
c[j] = c[j] + a[k] * b[k,j]; }
send вектор-результат с управляющему процессу; }
Рабочий процесс i вычисляет строку i результирующей матрицы с. Чтобы это сделать, он должен получить строку i исходной матрицы а и всю исходную матрицу Ь.
Каждый рабочий процесс сначала получает эти значения от отдельного управляющего процесса. Затем рабочий процесс вычисляет свою строку результатов и отсылает ее обратно управляющему. (Или, возможно, исходные матрицы являются результатом предшествующих вычислений, а результирующая — входом для последующих; это пример распределенного конвейера.)
Управляющий процесс инициирует вычисления, собирает и выводит их результаты. В частности, сначала управляющий процесс посылает каждому рабочему соответствующую строку матрицы а и всю матрицу Ь. Затем управляющий процесс ожидает получения строк матрицы с от каждого рабочего. Схема управляющего процесса такова.

36 Глава 1. Обзор области параллельных вычислений
receive строку i матрицы с от процесса worker [i],-вывести результат, который теперь в матрице с ;
}
Операторы send и receive, используемые управляющим процессом, — это примитивы (элементарные действия) передачи сообщений. Операция send упаковывает сообщение и пересылает его другому процессу; операция receive ожидает сообщение от другого процесса, а затем сохраняет его в локальных переменных. Подробно передача сообщений будет описана в главе 7 и использована в программировании многочисленных приложений в частях 2 и 3.
Как и ранее, предположим, что каждый рабочий процесс получает одну строку матрицы а и должен вычислить одну строку матрицы с. Однако теперь допустим, что у каждого процесса есть только один столбец, а не вся матрица Ь. Итак, в начальном состоянии рабочий процесс i имеет столбец i матрицы Ь. Имея лишь эти исходные данные, рабочий процесс может вычислить только значение с [ i, i ]. Для того чтобы рабочий процесс i мог вычислить всю строку матрицы с, он должен получить все столбцы матрицы Ь. Для этого можно использовать круговой конвейер (см. рис. 1.7,б), в котором по рабочим процессам циркулируют, столбцы. Каждый рабочий процесс выполняет последовательность раундов; в каждом раунде ' он отсылает свой столбец матрицы Ь следующему процессу и получает другой ее столбец от предыдущего.
Программа имеет следующий вид.

В данной программе рабочие процессы упорядочены в соответствии с их индексами. (Для процесса п-1 следующим является процесс 0, а предыдущим для 0 — п-1.) Столбцы матрицы Ь передаются по кругу между рабочими процессами, поэтому каждый процесс в конце концов получит каждый столбец. Переменная nextCol отслеживает, куда в векторе с поместить очередное промежуточное произведение. Как и в первом вычислении, предполагается, что управляющий процесс отправляет строки матрицы а и столбцы матрицы Ь рабочим, а затем получает от них строки матрицы с.
1 9. Обзор программной нотации 37
Во второй программе использовано отношение между процессорами, которое называется взаимодействующие равные (interacting peers), или просто равные. Каждый рабочий процесс выполняет один и тот же алгоритм и взаимодействует с другими рабочими, чтобы вычислить свою часть необходимого результата. Дальнейшие примеры взаимодействующих равных мы увидим в частях 2 и 3. В одних случаях, как и здесь, каждый из рабочих процессов общается только с двумя своими соседями, в других — каждый из рабочих взаимодействует со всеми остальными процессами.
В первой из приведенных выше программ значения из матрицы Ь дублируются в каждом рабочем процессе. Во второй программе в любой момент времени у каждого процесса есть одна строка матрицы а и только один столбец матрицы Ь. Это снижает затраты памяти для каждого процесса, но вторая программа выполняется дольше первой, поскольку на каждой ее итерации каждый рабочий процесс должен отослать сообщение одному соседу и получить сообщение от другого. Данные программы иллюстрируют классическое противоречие между временем и пространством в вычислениях. В разделе 9.3 представлены другие алгоритмы для распределенного умножения матриц, иллюстрирующие дополнительные противоречия между временем и пространством.
Задача об обедающих философах
В предыдущем разделе было показано, как использовать семафоры для решения задачи критической секции. В этом и следующем разделах на основе этого решения строится реализация выборочного взаимного исключения для двух классических задач: об обедающих философах и о читателях и писателях. Решение задачи об обедающих философах иллюстрирует реализацию взаимного исключения между процессами, конкурирующими за доступ к пересекающимся множествам разделяемых переменных, а читателей и писателей — реализацию комбинации параллельного и исключительного доступа к разделяемым переменным. В упражнениях есть дополнительные задачи выборочного взаимного исключения.
Хотя задача об обедающих философах скорее занимательная, чем практическая, она аналогична реальным проблемам, в которых процессу необходим одновременный доступ более, чем к одному ресурсу. Поэтому она часто используется для иллюстрации и сравнения различных механизмов синхронизации.
4.1) Задача об обедающих философах. Пять философов сидят возле круглого стола. Они проводят жизнь, чередуя приемы пищи и размышления. В центре стола находится большое блюдо спагетти. Спагетти длинные и запутанные, философам тяжело управляться с ними, поэтому каждый из них, чтобы съесть порцию, должен пользоваться двумя вилками. К несчастью, философам дали всего пять вилок. Между каждой парой философов лежит одна вилка, поэтому они договорились, что каждый будет пользоваться только теми вилками, которые лежат рядом с ним (слева и справа). Задача — написать программу, моделирующую поведение философов. Программа должна избегать неудачной (и в итоге роковой) ситуации, в которой все философы голодны, но ни один из них не может взять обе вилки — например, когда каждый из них держит по одной вилке и не хочет отдавать ее.
Задача проиллюстрирована на рис. 4.1. Ясно, что два сидящих рядом философа не могут есть одновременно. Кроме того, раз вилок всего пять, одновременно могут есть не более, чем двое философов.

Предположим, что периоды раздумий и приемов пищи различны — для их имитации в программе можно использовать генератор случайных чисел. Проимитируем поведение философов следующим образом.
140 Часть 1. Программирование с разделяемыми переменными
process Philosopher[i = 0 to 4] { while (true) { поразмыслить; взять вилки; поесть -, отдать вилки; } }
Для решения задачи нужно запрограммировать операции "взять вилки" и "отдать (освободить) вилки". Вилки являются разделяемым ресурсом, поэтому сосредоточимся на их взятии и освобождении. (Можно решать эту задачу, отслеживая, едят ли философы; см. упражнения в конце главы.)
Каждая вилка похожа на блокировку критической секции: в любой момент времени владеть ею может только один философ. Следовательно, вилки можно представить массивом семафоров, инициализированных значением 1. Взятие вилки имитируется операцией Р для соответствующего семафора, а освобождение — операцией V.
Процессы, по существу, идентичны, поэтому естественно предполагать, что они выполняют одинаковые действия. Например, каждый процесс может сначала взять левую вилку, потому правую. Однако это может привести ко взаимной блокировке процессов. Например, если все философы возьмут свои левые вилки, то они навсегда останутся в ожидании воз-.. можности взять правую вилку.
Необходимое условие взаимной блокировки — возможность кругового ожидания, т.е. когда один процесс ждет ресурс, занятый вторым процессом, который ждет ресурс, занятый третьим, и так далее до некоторого процесса, ожидающего ресурс, занятый первым процессом. Таким образом, чтобы избежать взаимной блокировки, достаточно обеспечить невозможность возникновения кругового ожидания. Для этого можно заставить один из процессов, скажем, Philosopher [4], сначала взять правую вилку. Это решение показано в листинге 4.6. Возможен также вариант решения, в котором философы с четным номером берут вилки в одном порядке, а с нечетным — в другом.

Глава 4 Семафоры 141
4.4. Задача о читателях и писателях
Задача о читателях и писателях — это еще одна классическая задача синхронизации. Как и задачу об обедающих философах, ее часто используют для сравнения механизмов синхронизации. Она также весьма важна для практического применения.
(4.2) Задача о читателях и писателях. Базу данных разделяют два типа процессов — читатели и писатели Читатели выполняют транзакции, которые просматривают записи базы данных, а транзакции писателей и просматривают, и изменяют записи. Предполагается, что вначале база данных находится в непротиворечивом состоянии (т.е. отношения между данными имеют .смысл). Каждая отдельная транзакция переводит базу данных из одного непротиворечивого состояния в другое. Для предотвращения взаимного влияния транзакций процесс-писатель должен иметь исключительный доступ к базе данных Если к базе данных не обращается ни один из процессов-писателей, то выполнять транзакции могут одновременно сколько угодно читателей.
Приведенное выше определение касается разделяемой базы данных, но ею может быть файл, связанный список, таблица и т.д
Задача о читателях и писателях — это еще один пример выборочного взаимного исключения. В задаче об обедающих философах пары процессов конкурировали за доступ к вилкам. Здесь за доступ к базе данных соревнуются классы процессов. Процессы-читатели конкурируют с писателями, а отдельные процессы-писатели — между собой. Задача о читателях и писателях — это также пример задачи общей условной синхронизации: процессы-читатели должны ждать, пока к базе данных имеет доступ хотя бы один процесс-писатель; процессы-писатели должны ждать, пока к базе данных имеют доступ процессы-читатели или другой процесс-писатель.
В этом разделе представлены два различных решения задачи о читателях и писателях. В первом она рассматривается как задача взаимного исключения.
Это решение является коротким, и его легко реализовать. Однако в нем читатели получают преимущество перед писателями (почему— сказано ниже), и его трудно модифицировать, например, для достижения справедливости. Во втором решении задача рассматривается как задача условной синхронизации Это решение длиннее, оно кажется более сложным, но на самом деле его тоже легко реализовать. Более того, оно без труда изменяется для того, чтобы реализовать для читателей и писателей различные стратегии планирования. Важнее то, что во втором решении представлен мощный метод программирования, который называется передачей эстафеты и применим для решения любой задачи условной синхронизации.
4.4.1. Задача о читателях и писателях как задача исключения
Процессам-писателям нужен взаимоисключающий доступ к базе данных. Доступ процессов-читателей как группы также должен быть взаимоисключающим по отношению к любому процессу-писателю. Полезный для любой задачи избирательного взаимного исключения подход — вначале ввести дополнительные ограничения, реализовав больше исключений, чем требуется, а затем ослабить ограничения. Представим задачу как частный случай задачи критической секции. Очевидное дополнительное ограничение — обеспечить исключительный доступ к базе данных каждому читателю и писателю. Пусть переменная rw — это семафор взаимного исключения с начальным значением 1. В результате получим решение с дополнительным ограничением (листинг 4.7).
Рассмотрим, как ослабить ограничения в программе листинга 4.7, чтобы процессы-читатели могли работать параллельно. Читатели как группа должны блокировать работу писателей, но только первый читатель должен захватить блокировку взаимного исключения путем, выполнив операцию р (rw). Остальные читатели могут сразу обращаться к базе данных. Аналогично читатель, заканчивая работу, должен снимать блокировку, только если является последним активным процессом-читателем. Эти замечания приводят к решению, представленному в листинге 4.8.

Глава 4. Семафоры 143
вычитание и проверка значения переменной пг в протоколе выхода должны выполняться неделимым образом, поэтому протокол выхода тоже заключен в угловые скобки.
Для уточнения схемы решения в листинге 4.8 до полного решения, использующего семафоры, нужно просто реализовать неделимые действия с помощью семафоров. Каждое действие является критической секцией, а реализация критических секций представлена в листинге 4.1. Пусть mutexR— семафор, обеспечивающий взаимное исключение процессов-читателей в законченном решении задачи о читателях и писателях (листинг 4.9). Отметим, что mutexR инициализируется значением 1, начало каждого неделимого действия реализовано операцией Р (mutexR), а конец — операцией V (mutexR).

Алгоритм в листинге 4.9 реализует решение задачи с преимуществом читателей. Если некоторый процесс-читатель обращается к базе данных, а другой читатель и писатель достигают протоколов входа, то новый читатель получает преимущество перед писателем. Следовательно, это решение не является справедливым, поскольку бесконечный поток процессов-читателей может постоянно блокировать доступ писателей к базе данных. Чтобы получить справедливое решение, программу в листинге 4.9 изменить весьма сложно (см. историческую справку), но далее будет разработано другое решение, которое легко преобразуется к справедливому.
4.4.2. Решение задачи о читателях и писателях с использованием условной синхронизации
Задача о читателях и писателях рассматривалась с точки зрения взаимного исключения. Целью было гарантировать, что писатели исключают друг друга, а читатели как класс — писателей. Решение (см. листинг 4.9) получено было в результате объединения решений для двух
144 Часть 1 Программирование с разделяемыми переменными
задач критической секции: одно — для доступа к базе данных читателей и писателей, другое — для доступа читателей к переменной пг.
Построим другое решение поставленной задачи, начав с более простого определения необходимой синхронизации. В этом решении будет представлен общий метод программирования, который называется передачей эстафеты и использует разделенные двоичные семафоры как для исключения, так и для сигнализации приостановленным процессам. Метод передачи эстафеты можно применить для реализации любых операторов типа await и, таким образом, для реализации произвольной условной синхронизации. Этот метод можно также использовать для точного управления порядком, в котором возобновляются приостановленные процессы.
В соответствии с определением (4.2) процессы-читатели просматривают базу данных, а процессы-писатели и читают, и изменяют ее. Для сохранения непротиворечивости (целостности) базы данных писателям необходим исключительный доступ, но процессы-читатели могут работать параллельно в любом количестве. Простой способ описания такой синхронизации состоит в подсчете процессов каждого типа, которые обращаются к базе данных, и ограничении значений счетчиков. Например, пусть пг и nw — переменные с неотрицательными целыми значениями, хранящие соответственно число процессов-читателей и процессов-писателей, получивших доступ к базе данных. Нужно избегать плохих состояний, в которых значения обеих переменных положительны или значение nw больше 1:
BAD: (nr > 0 л nw > 0) v nw > 1
Дополняющее множество хороших состояний описывается отрицанием приведенного выше предиката, упрощенным до такого выражения:
RW: (пг == 0 v nw == 0) л nw <= 1
Первая часть формулы определяет, что читатели и писатели не могут получать доступ к базе данных одновременно. Вторая часть говорит, что не может быть больше одного активного писателя. В соответствии с этим описанием задачи схема основной части процесса-читателя выглядит так.
(пг = пг+1;) читать базу данных; (пг = пг-1;) Соответствующая схема процесса-писателя такова.
(nw = nw+1;} записать в базу данных;
(nw = nw-1;}
Чтобы уточнить эти схемы до крупномодульного решения, нужно защитить операции присваивания разделяемым переменным, гарантируя тем самым, что предикат RWявляется глобальным инвариантом. В процессах-читателях для этого необходимо защитить увеличение nr условием (nw == 0), поскольку при увеличении переменной nr значением nw должен быть 0. В процессах-писателях необходимо соблюдение условия (пг == 0 and nw == 0), поскольку при увеличении nw желательно нулевое значение как пг, так и nw. Однако в защите операций вычитания нет необходимости, поскольку никогда не нужно задерживать процесс, освобождающий ресурс. После вставки необходимых для защиты условий получим крупномодульное решение, показанное в листинге 4.10.
Листинг 4.10. Крупномодульное решение задачи о читателях и писателях"1
int nr = 0, nw = 0;
##RW: (nr == 0 v nw == 0) л nw <= 1
process Reader[i = 1 to M] { while (true) {
(await (nw ==0) nr = nr+1;)

4.4.3. Метод передачи эстафеты
Иногда операторы await можно реализовать путем прямого использования семафоров или других элементарных операций, но в общем случае это невозможно. Рассмотрим два условия защиты операторов await в листинге 4.10. Эти условия перекрываются: условие защиты в протоколе входа писателя требует, чтобы и nw, и пг равнялись 0, а в протоколе входа читателя — чтобы nw была равна 0. Ни один семафор не может различить эти условия, поэтому для реализации таких операторов await, как указанный здесь, нужен общий метод. Представленный здесь метод называется передачей эстафеты (появление названия объяснено ниже). Этот метод достаточно мощен, чтобы реализовать любой оператор await.
В листинге 4.10 присутствуют четыре неделимых оператора. Первые два (в процессах читателя и писателя) имеют вид:
(await (В) S;}
Как обычно, В обозначает логическое выражение, as— список операторов. Последние два неделимых оператора в обоих процессах имеют вид:
<S;>
Как было сказано в разделе 2.4, в первой форме может быть представлена любая условная синхронизация, а вторая форма является просто ее сокращением для частного случая, когда значение условия В неизменно и истинно.
Следовательно, если знать, как с помощью сема форов реализуются операторы await, можно решить любую задачу условной синхронизации.
Для реализации операторов await из листинга4.10 можно использовать разделенные двоичные семафоры. Пусть е — двоичный семафор с начальным значением 1. Он будет применяться для управления входом (entry) в любое неделимое действие.
С каждым условием защиты в свяжем один семафор и один счетчик с нулевыми начальными значениями. Семафор будем использовать для приостановки процесса до момента, когда условие защиты станет истинным. В счетчике будет храниться число приостановленных процессов. В программе (см. листинг 4.10) есть два разных условия защиты, по одному в протоколах входа писателей и читателей, поэтому нужны два семафора и два счетчика. Пусть г — семафор, связанный с условием защиты в процессе-читателе, a dr — соответствующий ему счетчик приостановленных процессов-читателей. Аналогично пусть с условием защиты в процессе-писателе связаны семафор w и счетчик приостановленных процессов-писателей dw. Вначале нет ожидающих читателей и писателей, поэтому значения г, dr, w и dw равны 0.
Использование трех семафоров (е, г и w) и двух счетчиков (dr и dw) описано в листинге 4.11. Комментарии поясняют, как реализованы крупномодульные неделимые действия из листинга 4.10. Для выхода из неделимых действий использован следующий код, помеченный SIGNAL.

Глава 4 Семафоры 147 •
Три семафора в листинге 4.11 образуют разделенный двоичный семафор, поскольку в любой момент времени только один из них может иметь значение 1, а все выполняемые ветви начинаются операциями Р и заканчиваются операциями V. Следовательно, операторы между каждой парой Р и V выполняются со взаимным исключением. Инвариант синхронизации RW является истинным в начале работы программы и перед каждой операцией V, так что он истинен, если один из семафоров имеет значение 1.
Кроме того, при выполнении защищенного оператора истинно его условие защиты В, поскольку его проверил /либо сам процесс и обнаружил, что оно истинно, либо семафор, который сигнализировал о продолжении приостановленного процесса, если только в истинно. Наконец, рассматриваемое преобразование кода не приводит ко взаимной блокировке, поскольку семафор задержки получает сигнал, только если некоторый процесс находится в состоянии ожидания или должен в него перейти. (Процесс может увеличить счетчик ожидающих процессов и выполнить операцию V(e), но не может выполнить операцию Р для семафора задержки.)
Описанный метод программирования называется передачей эстафеты из-за способа выработки сигналов семафорами. Когда процесс выполняется внутри критической секции, считается, что он получил эстафету, которая подтверждает его право на выполнение. Передача эстафеты происходит, когда процесс доходит до фрагмента программы SIGNAL. Если некоторый процесс ожидает условия, которое теперь стало истинным, эстафета передается одному из таких процессов, который в свою очередь выполняет критическую секцию и передает эстафету следующему процессу. Если ни один из процессов не ожидает условия, которое стало истинным, эстафета передается следующему процессу, который впервые пытается войти в критическую секцию, т.е. следующему процессу, выполняющему Р (е).
В листинге 4.11, как и в общем случае, многие экземпляры кода SIGNAL можно упростить или опустить. В процессе-читателе, например, перед выполнением первого экземпляра кода SIGNAL, т.е. в конце протокола входа процесса-читателя, пг больше нуля и nw равна нулю. Это значит, что фрагмент программы SIGNAL можно упростить:

Перед вторым экземпляром кода SIGNAL в процессах-читателях обе переменные nw и dr равны нулю В процессах-писателях пг равна нулю и nw больше нуля перед кодом SIGNAL в конце протокола входа писателя Наконец, обе переменные nw и пг равны нулю перед последним экземпляром кода SIGNAL процесса-писателя.
С помощью этих закономерностей упростим сигнальные протоколы и получим окончательное решение, использующее передачу эстафеты (листинг 4.12).
В этом варианте программы, если в момент завершения работы писателя несколько процессов-читателей отложены и один продолжает работу, то остальные возобновятся последовательно. Первый читатель увеличит пг и возобновит работу второго приостановленного процесса-читателя, который тоже увеличит nг и запустит третий процесс, и так далее. Эстафета передается от одного приостановленного процесса другому до тех пор, пока все они не возобновятся, т.е. значение переменной пг не станет равным 0. Последний оператор if процесса-писателя в листинге 4.12 сначала проверяет, есть ли приостановленные читатели, затем — есть ли приостановленные писатели. Порядок этих проверок можно свободно изменять, поскольку, если есть приостановленные процессы обоих типов, то после завершения протокола выхода писателя сигнал может получить любой из них.
4.4.4. Другие стратегии планирования
Решение задачи о читателях и писателях в листинге 4.12, конечно, длиннее, чем решение 4.8. Однако оно основано на многократном применении простого принципа — всегда передавать эстафету взаимного исключения только одному процессу. Оба решения дают преимущество чита-

Глава 4. Семафоры 149
Для выполнения второго условия изменим порядок первых двух ветвей оператора if процессов-писателей:

Теперь читатель может продолжить работу, только если нет ожидающих писателей; этот читатель, в свою очередь, может возобновить работу следующего читателя, и так далее. (Может появиться новый писатель, но, пока он не пройдет семафор входа, об этом не узнает ни один процесс.)
Ни одно из описанных выше преобразований не изменяет структуру программы. В этом заключается преимущество метода передачи эстафеты: для управления порядком запуска процессов можно изменять условия защиты, не влияя при этом на правильность решения.
При условии, что справедливы сами операции с семафорами, можно обеспечить справедливый доступ к базе данных, изменив программу 4.12.'Например, когда в состоянии ожидания находятся и читатели и писатели, можно запускать их по очереди. Для этого нужно:
• если ожидает писатель, приостанавливать работу нового читателя;
• если ожидает читатель, приостанавливать работу нового писателя;
• когда заканчивает работу читатель, запускать один ожидающий процесс-писатель (если он есть);
• когда заканчивает работу писатель, запускать все ожидающие процессы-читатели (если они есть); иначе запускать один ожидающий процесс-писатель (если он есть).
Можно приостанавливать работу новых читателей и писателей, как показано выше. (Программа в листинге 4.12 удовлетворяет двум последним требованиям.) И здесь структура решения не изменяется.
Метод передачи эстафеты можно применить, чтобы управление порядком, в котором процессы используют ресурсы, сделать более мелкомодульным. Это демонстрируется в следующем разделе. Единственное, чем мы не можем управлять — это порядок запуска процессов, остановленных на входном семафоре, но это зависит от реализации семафоров.
