Эффективность предвыборки в многозадачных системах
Процессы, исполняющиеся в многозадачных системах, владеют кэш-памятью не единолично, а вынуждены делить ее между собой. Снижает ли это эффективность предвыборки? Эффективность предвыборки в кэш первого уровня – однозначно нет. Промежуток времени между переключением задач – это целая вечность для процессора, соответствующая, по меньшей мере, миллионам тактов. В любом случае, независимо от того, будет ли вытеснено содержимое L1-кэша или нет, – предвыборка позволяет конвейеризовать загрузку данных из памяти, предотвращая тем самым возможное падение производительности.
С L2-кэшем ситуация не так однозначна. Если оптимизируемый алгоритм позволяет распараллелить загрузку данных с их обработкой, то состояние L2-кэша вообще не играет никакой роли, поскольку быстродействие программы ограничивается именно скоростью вычислений, но пропускной способностью подсистемы памяти (подробнее см. "Практическое использование предвыборки. Планирование дистанции предвыборки"). Однако если время обработки данных меньше времени их загрузки из основной памяти, падения производительности никак не избежать. Предвыборка, конечно, увеличит производительность программы и в этом случае, но – увы – ненамного, максимум в два-три раза.
С другой стороны, одновременное выполнение двух или более приложений, интенсивно обменивающихся с памятью, на рабочих станциях случается очень редко (для серверов, правда, это – норма жизни). В большинстве случаев пользователь активно работает лишь с одним приложениям, другие же находятся в фоне и довольствуются минимальным количеством памяти, а порой и вовсе "спят", не трогая L2-кэш и практически не снижая эффективности предвыборки.
Эволюция динамической памяти.
В микросхемах памяти, выпускаемых вплоть до середины девяностых, все три задержки (RASto CAS Delay, CAS Delay и RAS precharge) в сумме составляли порядка 200 нс., что соответствовало двум тактам в 10 мегагерцовой системе и, соответственно, двенадцати – в 60 мегагерцовой. С появлением Intel Pentium 60 (1993 год) и Intel 486DX4 100 (1994 год) возникла потребность в совершенствовании динамической памяти – прежнее быстродействие уже никого не устраивало.
Как компиляторы выравнивают данные
Большинство компиляторов все заботы о выравнивании данных берут на себя – прикладной программист об этих проблемах может даже не задумываться. Однако, стратегия, используемая компиляторами, не всегда эффективна, и в критических ситуациях без живой головы не обойтись!
Стратегия выравнивания для каждого типа переменных своя: статические (static) и глобальные переменные большинство компиляторов насильно выравнивают в соответствии с их размером, игнорируя при этом кратность выравнивая, заданную прагмой pack или соответствующим ключом компилятора! Во всяком случае, именно так поступают Microsoft Visual C++ и Borland C++. Причем оба этих компилятора (как, впрочем, и подавляющее большинство других) не дают себе труда организовать переменные оптимальным образом, и размещают их в памяти в строгом соответствии с порядком объявления в программе. Что отсюда следует? Рассмотрим следующий пример:
// ….
static int a;
static char b;
static int c;
static char d;
// …
Компилятор, выравнивая переменную 'c' по адресу, кратному четырем, пропускает три байта, следующих за переменной 'b', образуя незанятую "дырку", по напрасно отъедающую память. А вот если объявить переменные так:
// ….
static int a;
static int c;
static char b;
static char d;
// …
…компилятор расположит их вплотную друг другу, не оставляя никаких дыр! Обязательно возьмите этот трюк на вооружение! (Однако, помните, что в этом случае цикл наподобие for(;;) b = d
будет выполняться достаточно неэффективно – т.к. переменные b и d попадут в один банк, это делает невозможной их синхронную обработку – подробнее см. "Стратегия распределения данных по кэш-банкам").
Автоматические переменные (т.е. обыкновенные локальные переменные) независимо от своего размера большинством компиляторов выравниваются по адресам кратным четырем. Это связано с тем, что машинные команды закидывания и стягивания данных со стека работают с один типом данных – 4-байтным двойными словами, поэтому переменные типа char
занимают в стеке ровно столько же места, как и int. И никакой перегруппировкой переменных при их объявлении от "пустот" избавиться не удастся. Локальные массивы так же всегда расширяются до размеров, кратным четырем, т.е. char a[11] и char b[12]
занимают в памяти одинаковое количество места. (Впрочем, это утверждение не относятся к массивам переменных типа int, т.к. поскольку размер каждого элемента массива равен четырем байт – длина массива всегда кратна четырем).
Другой тонкий момент – поскольку локальные переменные адресуются относительно вершины стека, на этапе компиляции адрес их размещения еще неизвестен! Он определяется значительно позже – в ходе исполнения программы и зависит и от операционной системы, и от потребностей в стеке всех ранее вызванных функций, и… да мало ли еще от чего! Как же в этом ситуации осуществить выравнивание?
Компилятор Borland C++, не мудрствуя лукаво, при входе в функцию просто обнуляет четыре младших бита регистра-указателя вершины стека, округляя его тем самым до адреса, кратного шестнадцати. Компилятор же Microsoft Visual C++ пускает все на самотек, рассуждая так: поскольку размеры всех локальных переменных насильно округляются до величин, кратным четырем, а начальное значение регистра-указателя стека так же гарантированно кратно четырем (за это ручается операционная система), то в любой точке программы значение регистра указателя вершины стека всегда кратно четырем и никакого дополнительного выравнивания ему не требуется.
Динамические переменные размешаются в куче – области памяти выделенной специальной функцией наподобие malloc. Степень выравнивания (если таковая имеется) у каждой функции может быть своя. Например, malloc выравнивает выделяемые ей регионы памяти по адресам кратным 16.
Структуры. По умолчанию каждый элемент структуры выравнивается на величину, равную его размеру (т.е. char – вообще не выравниваются, short int – выравниваются по четным адресам, int и float – адресам, кратным четырем и double c __int64 – восьми).
Как уже отмечалось выше, это не самая лучшая стратегия, к тому же выравнивание структур, работающих с сетевыми протоколами, оборудованием, типизированными фалами категорически недопустимо! Как же запретить компилятору самовольничать? Универсальных решений нет – управление выравниванием не стандартизовано и специфично для каждого компилятора. Например, компиляторы Microsoft Visual C++ и Borland C++ поддерживают прагрму pack, задающую требую степень выравнивания. Например, "#pragma pack(1)" заставляет компилятор выравнивать элементы всех последующих структур по адресам, кратным единице – т.е. не выравнивать их вообще. Аналогичную роль играют ключи командной строки: /Zn? (Microsoft Visual C++) и –a? (Borland C++), где – "?" степень выравнивания.
Однако было бы неразумно полностью отказываться от выравнивания структур – если внутреннее представление структуры некритично, выравнивание ее элементов может значительно ускорить работу программы. К счастью, действие прагмы pack, в отличие от соответствующих ей ключей командой строки, - локально. Т.е. в тексте программы pack
может встречаться неоднократно и с различными степенями выравнивания. Более того, прагма pack
может сохранить предыдущее значение степени выравнивания, а затем восстановить его – pack(push)
запоминает, а pack(pop) вытаивает значение выравнивания из внутреннего стека компилятора. Разумеется, вызовы push/pop
могут быть вложенными. Пример их использования приведен ниже.
#pragma pack(push)
#pragma pack(1)
struct IP_HEADER{
// …
}
#pragma pack(pop)
Если программу не предполагается использовать на процессорах ниже чем P-II, достаточно выровнять начало структуры по адресу, кратному 32 и, если размер структуры не превышает 32 байт, о выравнивании каждого элемента можно вообще забыть.
Как опубликовать рекламную статью бесплатно?
Редакторы – народ строгий. На рекламу у них глаз наметан. Только появится рекламный подтекст, как сразу – публикация на правах рекламы, см. расценки. Недостаточно опытных редакторов легко обмануть, написав откровенно-рекламную статью в критической форме. Например, о программе с интуитивно-понятным интерфейсом, можно высказываться как о программе "для дурака", не забыв, конечно, привести все копии экрана. Клиент пропустит "дурака" мимо ушей, а вот описание интерфейса ему может понравиться!
Вообще же, основной признак рекламных статей – отсутствие информации о предмете рекламы. Зато отношения к этому предмету – хоть отбавляй. Например, "неотразимый дизайн". Простите, какой-какой? Угловатый, обтекаемый, тошнотворно-прозрачный? Оставьте же человеку права на собственный вкус! А "неотразимый" лучше вообще заменить на какое ни будь другое не броское прилагательное с частицей "не". Скажем: "недурной, выполненный в классическом угловатом стиле".
Никогда не стоит в рекламе бояться говорить о недостатках продукта – это не отвернет покупателя, зато крепче уверит его в беспристрастность описания достоинств. Ну, как такое горячее доверие не обмануть?! Так, где тут у нас лапша, пока он растопырил уши…
Как привлечь к себе внимание?
О! Привлечь к себе внимание очень просто – стоит ляпнуть какую-нибудь глупость или затронуть национальное или какое-нибудь другое достоинство. Ну, например, объявить, что в будущем при регистрации вашей копии программы потребуется указывать номер паспорта или, скажем, расписываться в лицензионном соглашении, заверять его у нотариуса, отсылать ценным письмом на фирму и только после этого ожидать регистрационного ключа, "отпирающего" программу.
Поднимется буря! Все журналисты встанут на уши и начнут смаковать, дескать, какой же идиот-клиент на это пойдет?! Да в новой программе нет никаких сногсшибательных возможностей, так, косметическая доводка по мелочам – стоит ли переходить на нее ценой такой головной боли?
Но, нет, фирма не потеряет своих клиентов – она их приобретет! Спустя некоторое время будет объявлено: мол, идя на встречу общественности, отменяем все эти нововведения, возвращая все на круги своя. Но, пока длится скандал, потребитель узнает и о самой программе, и о новых возможностях и, вполне вероятно, что приобретет!
Такую тактику применяют практически все "отцы-основатели" компьютерной индустрии: и Intel, и Microsoft, и многие другие копании.
Несколько видоизмененный вариант на ту же тему – публично заявить, что конкуренты украли такую-то "фенечку" и подать на них в суд. Исход разбирательства не важен. Главное – привлечение внимания общественности к собственной персоне. Пример: компания Sun, в стремлении донести до потребителя для чего вообще нужна эта Java (что это за серверный олень такой?), затеяла долгое препирательство с Microsoft. И это притом, что реализация VM Java от Microsoft была едва ли не самой лучшей, а Sun и сама не знала на какую ногу встать – то ли вопить о несовместимости с Java, то ли обвинять в незаконном распространении фрагментов исходных текстов в составе SDK.
Мотив этого и многих других судебных разборок один – широкомасштабная бесплатная реклама. И только потом – щелчок по носу конкурента.
Как с ними борются?
Было бы по меньшей мере удивительно, если бы с ошибками переполнения никто не пытался бы бороться. Такие попытки предпринимались неоднократно, но конечный результат во всех случаях оставлял желать лучшего.
Очевидное "лобовое" решение проблемы заключается в синтаксической проверке выхода за границы массива при каждом обращении к нему. Такие проверки опционально реализованы в некоторых компиляторах Си, например, в компиляторе "Compaq C" для Tru64 Unix и Alpha Linux. Они не предотвращают возможности переполнения вообще и обеспечивают лишь контроль непосредственных ссылок на элементы массивов, но бессильны предсказать значение указателей.
Проверка корректности указателей вообще не может быть реализована синтаксически, а осуществима только на машинном уровне. "Bounds Checker" – специальное дополнение для компилятора gcc – именно так и поступает, гарантированно исключая всякую возможность переполнения. Платой за надежность становится значительное, доходящее до тридцати
(!) и более раз падение производительности программы. В большинстве случаев это не приемлемо, поэтому, такой подход не сыскал популярности и практически никем не применяется. "Bounds Checker" хорошо подходит (и широко используется!) для облегчения отладки приложений, но вовсе не факт, что все допущенные ошибки проявят себя еще на стадии отладки и будут замечены beta-тестерами.
В рамках проекта Synthetix удалось найти несколько простых и надежных решений, не спасающих от ошибок переполнения, но затрудняющих их использование злоумышленниками для несанкционированного вторжения в систему. "StackGuard” – еще одно расширение к компилятору gcc, дополняет пролог и эпилог каждой функции особым кодом, контролирующим целостность адреса возврата.
Алгоритм в общих чертах следующий: в стек вместе с адресом возврата заносится, так называемый, “Canary Word”, расположенный до адреса возврата. Искажение адреса возврата обычно сопровождается и искажением Canary Word, что легко проконтролировать.
Соль в том, что Canary Word содержит символы “\0”, CR, LF, EOF, которые не могут быть обычным путем введены с клавиатуры. А для усиления защиты добавляется случайная привязка, генерируемая при каждом запуске программы.
Компилятор Microsoft Visual C++ так же способен контролировать сбалансированность стека на выходе из функции: сразу после входа в функцию он копирует содержимое регистра-указателя вершины стека в один из регистров общего назначения, а затем сверяет их перед выходом из функции. Недостаток: впустую расходуется один из семи регистров и совсем не проверяется целостность стека, а лишь его сбалансированность.
"Bounds Checker", выпущенный фирмой NuMega для операционной системы Microsoft Windows 9x\NT, довольно неплохо отлавливает ошибки переполнения, но, поскольку, он выполнен не в виде расширения к какому-нибудь компилятору, а представляет собой отдельное приложение, к тому же требующее для своей работы исходных текстов "подопытной" программы, он может быть использован лишь для отладки, и не пригоден для распространения.
Таким образом, никаких готовых "волшебных" решений проблемы переполнения не существует и сомнительно, чтобы они появилось в обозримом будущем. Да и так ли это необходимо при наличие поддержки структурных исключений со стороны операционной системы и современных компиляторов? Такая технология при правильном применении обгоняет в легкости применения, надежности и производительности все остальные, по крайней мере, существующие на сегодняшний день контролирующие алгоритмы.
Как сделать свои программы надежнее?
Просматривая популярную рассылку по информационной безопасности BUGTRAQ (или любую другую), легко убедиться, что подавляющее большинство уязвимостей приложений и операционных систем связано с ошибками переполнения буфера (buffers overfull). Ошибки этого типа настолько распространены, что вряд ли существует хотя бы один полностью свободный от них программный продукт.
Переполнение приводит не только к некорректной работе программы, но и возможности удаленного вторжения в систему с наследованием всех привилегий уязвимой программы. Это обстоятельство широко используется злоумышленниками для атак на телекоммуникационные службы.
Проблема настольно серьезна, что попытки ее решения предпринимаются как на уровне самих языков программирования, так и на уровне компиляторов. К сожалению, достигнутый результат до сих пор оставляет желать лучшего, и ошибки переполнения продолжают появляться даже в современных приложениях – ярким примером могут служить: Internet Information Service 5.0 (Microsoft Security Bulletin MS01-016), Outlook Express 5.5 (Microsoft Security Bulletin MS01-012), Netscape Directory Server 4.1x (L0PHT A030701-1), APPLE: QuickTime Player 4.1 (SPSadvisory#41), ISC BIND 8 (CERT: Advisory CA-2001-02, Lotus Domino 5.0 (Security Research Team, Security Bulletin 010123.EXP.1.10) – список можно было бы продолжать до бесконечности. А ведь это серьезные продукты солидных производителей, не скупящихся на тестирование!
Ниже вы найдете описание приемов программирования, следование которым значительно уменьшает вероятность появления ошибок переполнения, в то же время не требуя от разработчика никаких дополнительных усилий.
Как создать иллюзию устойчивости, когда делать идут хуже некуда?
Отличительная черта крупных, устойчиво стоящих на ногах компаний, – потребность в критике. Объективная критика позволяет выявить свои слабые стороны и приносит неоценимую пользу (это не аналитиков нанимать, которые требуют много денег, но все равно ничего путного не делают). Необъективная критика – лучшая похвала. Раз оппонент ни за что конструктивное ухватиться не может – значит, и ухватываться-то не за что (ну, во всяком случае, на его, - критика, - умственном уровне развития). Похвала, напротив, внушает чувство неуверенности и ее информационная ценность равна нулю. Мало ли, что кому понравилось? А, может быть, 99% остальным – это как раз и не нравится?
Мелкие, готовые вот-вот развалиться, компании ведут себя диаметрально противоположно. Они очень болезненно реагируют на критику, хватают критикующих их журналистов за грудки и с воплями "клевета, клевета", устраивают чуть ли не судебные разборки, дескать, сейчас же напечатайте опровержение!
Народ же обиженных любит! Товар фирмы-великомученика могут брать охотнее только за ее "мученичества" ("поможем братьям нашим китайцам завалить паразитов Янок!"). Словом, обильная порция грязи, критики и клеветы никогда не повредит. Напротив, чем больше критики, тем сильнее уверенность потребителя, что истинная причина критики не в действительных недостатках товара, а опасениях конкурентов, что этот самый товар может пошатнуть их позицию на рынке.
Чем плоха идея лить грязь на самих себя? Причем грязь откровенно сумасбродную, типа "эту программу писали сатанисты". Клиенту до того, кто ее писал, никакого дела нет. Но, не зная кем инсценирована эта критика, он может склониться к такому продукту, здраво рассуждая – если никаких других недостатков у него нет – он идеален.
Как учатся оптимизации
Было бы слишком наивно ожидать от книги, что она научит
вас писать эффективный код. Нет! По этому поводу уместно вспоминать детский анекдот, когда верзила-двоечник говорит своему "очкаристому" однокласснику "Дай мне твою самую толстую книгу – я ее прочитаю и буду таким же умным как ты". Книгу – извольте, но
Как удержать клиента в своих руках?
Клиента мало завоевать, его необходимо еще и удержать. Самая прочная сеть – закрытые и постоянно меняющиеся стандарты. Взять, к примеру, ICQ или Microsoft Office. Чтобы написать своего ICQ-клиента или свой редактор документов Office необходимо знать их формат. А он – секрет фирмы. Выяснить его можно только утомительным и трудоемким дизассемблированием, но весь труд полетит впустую, если этот формат будет хотя бы незначительно изменен в новой версии программы.
В результате – монополизация рынка: хочешь работать с нашими файлами? – Пользуйся нашими приложениями! Любопытно, что Билл Гейтс, во всю критикуя этот прием в своей книге "Дорога в будущее", сам является его горячим поклонником!
Как заставить клиента купить лицензионную копию ПО?
Законов, по которым было бы можно привлечь к ответственности физическое лицо, использующее нелегальное программное обеспечение в нашей стране не существует. С юридическими лицами в этом плане несколько легче, но удовлетворенные судебные иски все же очень редки. Разработчикам остается полагаться лишь на стойкость защитных механизмов, препятствующих несанкционированному копированию, да совесть пользователей, понимающих, что пиратство, в конечном счете, оборачивается против них. Но нет такой защиты, которую нельзя было бы взломать, а своя рубашка всегда ближе к телу – программное обеспечение воровали, воруют и будут воровать!
Придется идти на хитрость. Защита должна быть полностью интегрирована с программой, как бы "размазана" по ней и иметь, по крайней мере, два уровня обороны: на первом – блокирование работы, а на втором – искажение результата, выдаваемого программой. Взломщик легко нейтрализует блокировку, но вот дальше его будет ждать сюрприз – придется тщательно проанализировать весь код программы, полностью
разобраться с логикой ее работы, но даже тогда нельзя быть уверенным, что в какой-то момент программа не сделает из чисел "винегрет". В результате, у пользователя взломанная программа будет работать нестабильно, например, выводить на экран один цифры, а на принтер – другие. Вероятнее всего, большинство не будут искать хороший "кряк", а приобретут лицензионную копию.
На всякий случай можно затруднить поиски хорошего "кряка", наводнив хакерские сайты специально изготовленными низкокачественными "ломками", написанными самим же автором программы. Такая тактика особенно характерна для разработчиков бухгалтерских пакетов, т.к. рядовой хакер не слишком осведомлен в тонкостях дебита и кредита, а, потому, проверить корректность работы такой программы не может.
Как заставить клиента купить новую версию ПО?
Не секрет: чаще всего свежие версии ПО устанавливаются не ради новых функциональных особенностей, а в надежде, что большинство (или хотя бы основные) ошибки старых версий были устранены.
Так сделаем же превосходный маркетинговый ход! Допускаем (не обязательно умышленно) в каждой версии некоторое количество не смертельных ошибок; исправляем их в следующей версии, попутно внося свежие ляпы, и… потребитель приобретет такой продукт без конца.
Эту тактику, даже не стараясь замаскировать, взяли на вооружение практически все крупные и мелкие компании. И не безуспешно! Например, скажите: какое основное качество Windows 98? Правильно, не считая красивых бирюлек и мелких несущественных доделок ядра (о которых не всякий рядовой пользователь и знает), основное отличие от Windows 95 – надежность. А какое основное качество Windows Me? Вот, вот, - аналогично!
Наивно думать, что ошибки в ПО приносят убыток компании. Напротив, они оборачиваются выгодой, порой весьма значительной. Тщательное же "вылизывание" продукта чрезвычайно невыгодно. Это не только лишние затраты на beta-тестеров, но и отсрочка выхода программы на рынок – прямая угроза его захвата конкурентами.
Попутно – пусть новая версия сохраняет документы в формате, не поддерживаемом прежними версиями программы. Если хотя бы один – два процента пользователей установят новый продукт на свои компьютеры, начнется цепная реакция – всем остальным придется переходить на нее не в силу каких-то особенных достоинств, а из-за необходимости читать документы, созданные другими пользователями.
Именно так и поступила Microsoft со своим Word 7.0, документы которого не читались младшими версиями. Официальная тому причина – переход на UNICODE-кодировку с целью обеспечения многоязыковой поддержки. Но неужто ради этого стоило отказываться от совместимости? Разработчики предлагали встраивать в документ макрос, который, будучи запущен на Word 6.0, автоматически бы конвертировал текст. Так ведь нет! Выпустили отдельный конвертор, о существовании которого до сих пор знают не все пользователи. Сдается, что причина такого решения ни в чем ином, как в принудительном навязывании пользователям нового Word 7.0
Кэш-подсистема современных процессоров
Кэш подсистема процессоров P-II, P-III, P-4 и AMDAthlon представляет собой многоуровневую иерархию, состоящую из следующих компонентов: кэша данных первого уровня, кэша команд первого уровня, общего кэша второго уровня, TLB-кэша страниц данных, TLB-кэша страниц кода, буфера упорядочивая записи и буферов записи (см. рис. 0х016).
MOB: Данные, сходящие с вычислительного конвейера, первым делом попадают на MOB (Memory Order Buffer – буфер упорядочивая записи к памяти) где они, постепенно накаливаясь, ожидают своей очереди выгрузки в паять. Грубо говоря, буфер упорядоченной записи играет тут же самую роль, что и зал ожидания в аэропорту. Пассажиры прибывают туда в более или менее случайном порядке, но улетают в строгом соответствии со временем, указанном в билете, да и то при условии, что к этому моменту выдастся летная погода и самолету предоставят "коридор" (кто летал – тот поймет).
Данные, находящиеся в MOB, всегда доступы процессору, даже если они еще не выгружены в память, однако емкость буфера упорядоченной записи довольно невелика (40 входов на P6) и при его переполнении вычислительный конвейер блокируется. Поэтому, содержимое MOB должно при всякой возможности незамедлительно выгружаться оттуда. Это происходит по крайней мере тремя путями:
а) если модифицируемая ячейка уже присутствует в кэш-памяти первого уровня, то она прямиком направляется в соответствующую ей кэш-строку, на что уходит всего один такт, в течении которого в кэш может быть записана одна или даже две любых несмежные ячейки (максимальное количество одновременно записываемых ячеек определяется архитектурой кэш-подсистемы конкретного процессора, –см "Оптимизация обращения к памяти и кэшу. Влияние размера обрабатываемых данных на производительность. В кэше первого уровня");
б) если модифицируемая ячейка отсутствует в кэш-памяти первого уровня, она, при наличии хотя бы одного свободного буфера записи, попадает туда. Это так же занимает всего один такт, причем, максимальное количество параллельно записываемых ячеек определяется количеством портов, имеющихся в "распоряжении" у буферов записи (например, процессоры AMD K5 и Athlon содержат только один такой порт);
с) если модифицируемая ячейка отсутствует в кэш-памяти первого уровня и ни одного свободного буфера записи нет, – процессор самостоятельно загружает соответствующую копию данных в кэш-первого уровня, после чего переходит к пункту а). В зависимости от ряда обстоятельств, загрузка данных занимает от десятков до сотен (а то и десятков тысяч!) тактов процессора, поэтому, таких ситуаций по возможности следует избегать.
L1 CAHE. Кэш первого уровня размещается непосредственно на кристалле и реализуется на базе двух портовой статической памяти. Он состоит из двух независимых банков сверхоперативной памяти, каждый из которых управляется "своим" кэш-контроллером. Один кэширует машинные инструкции, другой – обрабатываемые ими данные. В кратной технической спецификации процессора обычно указывается суммарный объем кэш-памяти первого уровня, что приводит к некоторой неопределенности, т.к. емкости кэша инструкций и кэша данных не обязательно должны быть равны (а на последних процессорах они и не равны).
Каждый банк кэш-первого уровня помимо собственно данных и инструкций содержит и буфера ассоциативной трансляции (TLB) страниц данных и страниц кода соответственно. Под буфера ассоциативной трансляции отводятся фиксированные линейки кэша и занимаемое ими пространство "официально" исключено из емкости кэш-памяти. Т.е. если в спецификации сказано, что на процессоре установлен 8 Кб кэш данных, – все эти 8 Кб непосредственно доступны для кэширования данных, а реальная емкость кэш-памяти в действительности же превосходит 8 Кб.
Буфера Записи. Если честно, то у автора нет полной ясности где конкретно в кэш-иерархии расположены буфера записи. На блок-диаграммах процессоров Intel Pentium и AMD Athlon, приведенных в документации, они вообще отсутствуют, а в § 9.1 "INTERNAL CACHES, TLBS, AND BUFFERS" главы "MEMORY CACHE CONTROL" руководства по системному программирования от Intel, буфера записи изображены чисто условно и явно не в том месте, где им положено быть (сам Intel пишет, что "буфера записи связны с исполнительным блоком процессора", а на рисунке подсоединяет их к блоку интерфейсов с шиной – с каких это пор последний стал "вычислительным устройством"?!).
Проанализировав всю документированную информацию, так или иначе касающуюся буферов и основываясь на результат собственных экспериментов, автор склоняется к мысли, что буфера записи напрямую связаны как минимум с Буфером Упорядоченной Записи (ROB Wb), Блоком Интерфейса с Памятью (MIU) и Блоком Интерфейсов с Шиной (BIU). А на K5 (K6/Athlon) Буфера Записи связаны еще с кэш-памятью первого уровня.
Но, так или иначе, Буфера Записи позволяют на некоторое время откладывать фактическую запись в кэш и/или основную память, осуществляя эту операцию по мере освобождения кэш-контроллера, внутренней или системной шины, что ликвидирует целый ряд задержек и тем самым увеличивает производительность процессора.
Блок Интерфейсов с Памятью (MIU). Блок Интерфейсов с Памятью представляет собой одно из исполнительных устройств процессора и функционально состоит из двух компонентов: устройства чтения памяти и устройства записи памяти. Устройство чтения соединено с буферами записи и кэшем первого уровня. Если требуемая ячейка памяти присутствует хотя бы в одном из этих устройств, на ее чтение расходуется всего один такт. Причем независимо от типа обрабатываемых данных, вся кэш-линейка загружается целиком. Хотя Intel и AMD умалчивают об этой детали, она легко обнаруживается экспериментально. Действительно, имея всего одно устройство для работы с памятью, процессоры Pentium и AMD Athlon ухитряются спускать несколько инструкций чтения памяти за каждый такт, правда при условии, что данные выровнены по границе четырех байт и находятся в одной кэш-линейке. Отсюда следует, что шина, связывающая MIU и L1-Cache должна быть как минимум 256?битной, что (учитывая близость кэш-памяти первого уровня к ядру процессора) реализовать без особых затрат и труда.
Устройство записи памяти соединено с Блоком Упорядоченной Записи (ROB Wb), уже рассмотренным выше.
Блок Интерфейсов с Шиной Блок Интерфейсов с Шиной (BIU) является единственным звеном, связующим процессор с внешним миром, эдакое своеобразное "окно в Европу".
Сюда стекается все информация, вытесняемая из Буферов Записи и кэш-памяти первого уровня, сюда же поступают запросы за загрузку данных и машинных команд от кэша данных и кэша команд соответственно. Со стороны "Европы" к Блоку Интерфейсов с Шиной примыкает кэш-память второго уровня и основная оперативная память. Понятно, что от поворотливости BIU зависит быстродействие всей системы в целом.
Кэш второго уровня. В зависимости от конструктивных особенностей процессора кэш второго уровня может размещаться либо непосредственно на самом кристалле, либо монтироваться на отдельной плате вне его.
Однокристальная
(On Die) реализация обладает практически неограниченным быстродействием, – поскольку длины проводников, соединяющих кэш второго уровня с Блоком Интерфейсов с Шиной относительно невелики, кэш свободно работает на полной процессорной частоте, а разрядность его шины в процессорах P-III и P-4 достигает 256-бит. С другой стороны, такое решение значительно увеличивает площадь кристалла, а значит и его себестоимость (процент брака с увеличением площади кристалла растет экспоненциально). Тем не менее, благодаря совершенству производственных технологий (и не в последнюю очередь – жесточайшей конкурентной борьбе), – интегрированных кэшем второго уровня обладают все современные процессы.
Процессоры P-II и первые модели процессоров P-III и AMD Athlon имели
Двойная независимая шина (DIB – Dual Independent Bus). Для увеличения производительности системы, кэш второго уровня "общается" с BIU через свою собственную локальную шину, что значительно сокращает нагрузку, выпадающую на долю FSB.
В силу геометрической близости кэша второго уровня к процессорному ядру, длина локальной шины относительно невелика, а потому она может работать на значительно более высоких тактовых частотах, чем системная шина. Разрядность локальной шины долгое время оставалась равной разрядности системной шины и составляла 64 бита.
Впервые эта традиция нарушилась лишь с выходом Pentium-III Copper mine, оснащенным 256 битной локальной шиной, позволяющей загружать целую 32 байтную кэш-линейку всего за один такт! Это фактически уравняло кэш первого и кэш второго уровня в правах! (см. "Оптимизация обращения к памяти и кэшу. Влияние размера обрабатываемых данных на производительность. Особенности кэш-подсистемы процессоров P-II и P-III") К сожалению, процессоры AMD Athlon не могут похвастаться шириной своей шины…
Архитектура двойной независимой шины значительно снижает нагрузку на FSB, т.к. большая часть запросов к памяти обрабатывается локально. По статистике, коэффициент загрузки системной шины в однопроцессорных рабочих станциях, составляет порядка 10% от ее максимальной пропускной способности, а остальные 90% запросов ложатся на локальную шину. Даже в четырех процессорном сервере нагрузка на системную шину не превышает 60%, создавая тем самым обманчивую видимость, что производительность системной шины перестает быть самым узким местом системы, ограничивающим ее производительность.
Несмотря на то, что статистика не лжет, интерпретация казалось бы самоочевидных фактов, мягко говоря не совсем соответствует действительности. Низкая загрузка системной шины объясняется высокой латентностью основной оперативной памяти, приводящей к тому, что по меньшей мере половину времени шина тратит не на передачу, а на ожидание выполнения запроса. Помните как в анекдоте, – почему у вас нет черной икры? Да потому что спроса нет! К счастью, в старших моделях процессоров появились команды предвыборки, позволяющие предотвратить латентность и разогнать шину на всю мощь (см. так же "Оптимизация обращения к памяти и кэшу. Практическое использование предвыборки. Планирование дистанции предвыборки").

Рисунок 14 0х016 Кэш-подсистема современных процессоров (кэш кода не показан)

Рисунок 15 0x024 Блок-схема подсистемы кэш-памяти процессоров семейства Intel P6

Рисунок 16 0x023 Физическое воплощение подсистемы кэш-памяти на примере процессора Intel Pentium-III Coppermain
Кэш – принципы функционирования
Краткое описание архитектуры кэш-подсистемы, включенное в настоящую книгу, не претендует на исчерпывающее изложение материала и ориентировано в первую очередь на неподготовленных программистов, помогая им разобраться с устройством кэш-памяти хотя бы в общих чертах. Тем не менее, определенную ценность эта глава представляет и для профессионалов, позволяя им освежить свои знания и, возможно, даже восполнить некоторые пробелы и/или распутать темные места документации.
Несмотря на то, что приведенного здесь материла для грамотной работы с кэш-памятью более чем достаточно, автор настоятельно рекомендует не пренебрегать и чтением технической документации по процессорам, распространяемой их производителями, поскольку там содержится множество интереснейших сведений, не включенных в данную книгу по тем или иным соображениям (ну хотя бы уже потому, что нельзя объять необъятное и это все-таки руководство по оптимизации, но не энциклопедия компьютерного железа).
Комбинирование операций чтения с операциями записи
___Разнесение инструкций записи/чтения (см. Ител P-4)
Комбинирование операция записи с вычислительными операциями
Буферизация записи позволяет откалывать физическую выгрузку данных в сверхоперативную и/или основную оперативную память до того момента, когда процессору это будет наиболее "удобно". До тех пор, пока в наличии имеется по крайней мере один свободный буфер, такой прием существенно увеличивает производительность. В противном случае, процессор вынужден простаивать в ожидании выгрузки содержимого буферов и тогда запись с буферизацией ведет себя как обычная запись.
Другая не менее значимая функциональная обязанность буферов – упорядочивание записи. Данные, поступающие в буфера, неупорядочены и попадают в них по мере завершения команд микрокода. Здесь они сортируются и вытесняются с буферов уже в порядке следования оригинальных машинных команд программы.
Отсюда: переполнение буферов автоматически влечет за собой блокировку кэш-памяти,– до тех пор, пока не завершится выгрузка данных, вызвавших кэш-промах, все остальные попытки записи в память (независимо завершаются ли они кэш-попаданием или нет) будут временно заблокированы. Не очень-то хорошая перспектива, не правда ли?
Этой ситуации можно избежать, если планировать обработку данных так, чтобы скорость заполнения буферов не превышала скорости их выгрузки в кэш и/или оперативную память. Процессоры P-II и P-III содержат двенадцать 256-битных буферов, каждый из которых может соответствовать любой 32-байтовой области памяти, выровненной по границе 32 байт. Другими словами, буфера записи представляют собой 384-байтовый полностью ассоциативный кэш, состоящий из 12 кэш-линеек по 32 байта каждая. Так, надеюсь, будет понятно?
Процессор P-4 содержат аж 24 буфера записи, каждый из которых, по всей видимости, вмещает 512 бит данных.
Процессор AMD Athlon, так же, как и P-II/P-III содержит 12 буферов записи, совмещенных с буферами чтения. Об их длине в документации ничего не говориться (или просто я не нашел?), но можно предположить, что вместимость каждого из буферов составляет 64 байта.
Конечно, это вдовое меньше, чем у P-4, но AMD Athlon в отличии от своего конкурента, всегда выгружает содержимое буферов в кэш-первого уровня, в то время как процессоры P6 и P-4 при отсутствии записываемых данных в кэше первого уровня, выгружают их в кэш второго.
Трудно сказать, чья политика лучше. С одной стороны, при записи большого количества данных, обращений к которым в обозримом будущем не планируется, Intel заметно выигрывает, поскольку не "засоряет" кэш-первого уровня. С другой: выгрузка буферов на AMD Athlon происходит несколько быстрее, что уменьшает вероятность возникновения "заторов". Но, в то же время, 256-битная шина P-III и P-4, соединяющая кэш первого с кэшем второго уровня, практически стирает разницу в их производительности и буфера выгружаются даже с большей скоростью, чем на Athlon. Правда, Athlon, умеющий вытеснять содержимое кэша первого уровня параллельно с записью в него новых данных, от такого расклада вещей ничуть не страдает и… В общем, этот поединок детей двух гигантов процессорной индустрии можно продолжать бесконечно. Да и есть ли в этом смысл? Ведь при оптимизации программы все равно приходится закладываться на худшую конфигурацию, т.е. в данном случае на двенадцать 32-байтовых буферов записи.
Посмотрим (см. "Intel® Architecture Optimization Reference Manual Order Number: 245127-001"), что говорит Intel по этому поводу. "Write hits cannot pass write misses, so performance of critical loops can be improved by scheduling the writes to memory. When you expect to see write misses, schedule the write instructions in groups no larger than twelve, and schedule other instructions before scheduling further write instructions"
("Попадания /* hit */ записи не преодолевают промахи записи, поэтому, производительность критических циклов может быть увеличена планированием записей в память. Когда вы ожидаете промах записи, объединяйте инструкции записи в группы не более чем по двенадцать
и разделяйте их группами других инструкций").
Эта рекомендация содержит по крайней мере три неточности. Первая и наименее существенная из них: на самом деле, количество членов группы может быть и более двенадцати, ведь выгрузка буферов осуществляется параллельно с их заполнением. Объединение 14 команд записи не несет никакого риска, во всяком случае при выполнении программы под P-II/P-III/AMD Athlon и уже тем более P-4.
Другой момент. Под словом "двенадцать" авторы документации подразумевали "двенадцать команд записи с различными установочными адресами". На P-II/P-III в установочный адрес входят биты с 4 по 31 линейного адреса, а на P-4/AMD Athlon – с 5 по 31. Т.е. при последовательной записи 32-разрядных значений, "штатная" численность каждого группы команд составляет не двенадцать, а девяносто шесть "душ".
Наконец, третье и последнее. Поскольку, все записываемые данные в обязательном порядке проходят через буфера, предыдущее замечание не в меньшей степени справедливо и для модификации данных, уже находящихся в кэш-памяти перового уровня. С другой стороны, к данным, еще не вытесненным из буфера, можно обращаться многократно и "записью" это не считается.
Боюсь, что своими уточнениями я вас окончательно запутал… Но блуждание в трущобах непонимания, все таки лучше столбовой дороги грубого заблуждения. Давайте рассмотрим следующий пример Как вы думайте, можно ли назвать его оптимальным?
/*------------------------------------------------------------------------
*
* НЕОПТИМИЗИРОВАННЫЙ ВАРИАНТ
*
------------------------------------------------------------------------*/
// 192 ячейки типа DWORD дают в сумме 776 байт памяти,
// что вдвое превышает емкость буфером записи на
// процессорах PII/PIII. Где-то на половине исполнения
// возникнет затор и дальнейшие операции записи будут
// исполняться гораздо медленнее, т.е. им придется
// всякий раз дожидаться выгрузки буферов
for(a = 0; a < 192; a += 8)
{
// для устранения накладных расходов цикл
// должен быть развернут, иначе его
// расщепление снизит производительность
p[a + 0] = (a + 0);
p[a + 1] = (a + 1);
p[a + 2] = (a + 2);
p[a + 3] = (a + 3);
p[a + 4] = (a + 4);
p[a + 5] = (a + 5);
p[a + 6] = (a + 6);
p[a + 7] = (a + 7);
}
// делаем некоторые вычисления
for(b = 0; b < 66; b++)
x += x/cos(x);
Листинг 17 [Cache/write_sin.c] Кандидат на оптимизацию посредством совмещения команд записи с вычислительными операциями
Конечно же, цикл for a
на P-II/P-III исполняется весьма не оптимально. Даже если предположить, что на момент его начала все буфера девственно чисты (что вовсе не факт!), не успеет он перевалить за половину, как свободные буфера действительно кончатся и начнутся сильные тормоза, поскольку все последующие операции записи будут вынуждены ждать освобождения буферов. Ввиду постоянной занятости шины ждать придется довольно долго. Зато потом, в вычислительном цикле, она (шина) будет простаивать. Экий не рационализм!
Давайте реорганизуем наш цикл так, разбив его на несколько под–циклов, каждый из которых заполнял бы не более двенадцати-четырнадцати буферов. В данном случае, как нетрудно рассчитать, потребуется всего два цикла (192/96 == 2). Между циклами записи памяти мы разместим вычислительный цикл. Желательно спланировать его так, чтобы за время вычислений все буфера гарантированно успевали бы освободиться. Попутно отметим, если время вычислений значительно превосходит время выгрузки буферов, такую перегруппировку выполнять бессмысленно, т.к. в этом случае производительность в основном определяется скоростью вычислений, но не записью памяти.
Кстати, вычислительный цикл так же целесообразно разбить на две половинки, поместив первую из них перед циклом записи, а вторую позади него. Это гарантирует, что независимо от состояния буферов записи на момент начала выполнения записывающего цикла, все буфера будут действительно пусты. (Между прочим, этот факт не отмечен ни в одном известной мне инструкции по оптимизации, включая оригинальные руководства от Intel и AMD).
/*------------------------------------------------------------------------
*
* ОПТИМИЗИРОВАННЫЙ ВАРИАНТ
*
------------------------------------------------------------------------*/
// выполняем часть запланированных вычислений,
// с таким расчетом, что бы буферам хватило времени
// на сброс их текущего содержимого, ведь отнюдь
// не факт, что на момент начала выполнения цикла
// буфера пусты
for(b = 0; b < 33; b++)
x += x/cos(x);
// выполняем 96 записей ячеек типа DWORD, что
// соответствует емкости буферов записи; к моменту
// завершения цикла практически все буфера будут
// забиты. "Практически" -потому что какая-то часть
// из них уже успеет выгрузится
for(a = 0; a < 96; a += 8)
{
p[a + 0] = (a + 0);
p[a + 1] = (a + 1);
p[a + 2] = (a + 2);
p[a + 3] = (a + 3);
p[a + 4] = (a + 4);
p[a + 5] = (a + 5);
p[a + 6] = (a + 6);
p[a + 7] = (a + 7);
}
// выполняем оставшуюся часть вычислений. Будет
// просто замечательно, если за это время все буфера
// успеют аккурат выгрузится, - тогда мы достигнет
// полного параллелизма!
for(b = 0; b < 33; b++)
x += x/cos(x);
// выполняем оставшиеся 96 записей. Поскольку они
// к этому моменту уже освободились, запись
// протекает так быстро, как это только возможно
for(a = 96; a < 192; a += 8)
{
p[a + 0] = (a+0);
p[a + 1] = (a+1);
p[a + 2] = (a+2);
p[a + 3] = (a+3);
p[a + 4] = (a+4);
p[a + 5] = (a+5);
p[a + 6] = (a+6);
p[a + 7] = (a+7);
}
Листинг 18 [Cache/write_sin.c] Оптимизированный вариант, комбинирующий запись в память с вычислительными операциями
Результаты прогона оптимизированного варианта программы не то, чтобы очень впечатляющие, но и скромными их никак не назовешь (см. рис. graph 0x012). И на P-III, и на AMD Athlon достигается приблизительно двукратный прирост производительности вне зависимости от того: находятся ли ячейки записываемой памяти в кэше первого уровня или нет.
Более пристальный осмотр показывает, что в каждой группы составляет по кр
Как мы помним, кэш-память процессоров P6 и AMD K6 не блокируемая, – т.е. один промах не препятствует другим попаданиям. записываемые в буфера, попадают в порядке завершения команд микрокода, но в
Процессоры P-II/P-III имеют 12 32х-байтовых буферов,
то операции записи в некэшируемую память следует группировать количеством не более двенадцати записи с шагом более 32х байт и девяносто шести при записи с шагом равным четырем (12х32/4).
Рассмотрим следующий пример:
// Инициализируем 20 некэшируемых элементов массива
for (a=0;a<20;a++)
p[a*32]=0x666;
// Выполняем некоторые вычисления
for (b=0;b<10;b++)
tmp=tmp*13;
Казалось бы разумно расщепить цикл инициализации на два, разделенных вычислительным циклом. Тогда, первые двенадцать итераций инициализационного цикла выполняются без задержек (записываемые данные направляются в буфера), а пока процессор обрабатывает вычислительный цикл, буфера выгружаются в память, и оставшиеся десять операций присвоения вновь выполняются без задержек!
for (a=0;a<12;a++)
p[a*32]=0x666;
for (b=0;b<10;b++)
tmp=tmp*13;
for (a=12;a<20;a++)
p[a*32]=0x666;
Теоретически оно, может быть, и так, но на практике сколь ни будь значительного выигрыша добиться не получается. Взгляните на рисунок ???, – видите, оптимизация увеличила производительность на единичные проценты. Это объясняется тем, что, во-первых, расщепление циклов увеличивает количество ветвлений, "съедая" тем самым львиную долю выигрыша (см. "Декодер - Ветвления"). А, во-вторых, пока процессор вычисляет новое значение параметра цикла, проверяет условие продолжения цикла, наконец, выполняет условный переход – буфера выгружаются в память.
Поэтому, расщеплять циклы подобные этому не надо – значительного прироста производительности это все равно не даст, а вот отлаживать программу станет труднее.

Рисунок 38 graph 0x012 Демонстрация эффективности комбинирования операций записи памяти с вычислительными операциями
Напоследок – две пары расщепленных циклов можно, безо всякого ущерба для производительности, объединить в один – super-цикл. Особенно это актуально для тех случаев, когда цикл записи памяти разбивается не на два, а на множество под – циклов. Тогда можно поступить так:
/*------------------------------------------------------------------------
*
* ОПТИМИЗИРОВАННЫЙ СВЕРНУТЫЙ ВАРИАНТ
*
------------------------------------------------------------------------*/
for(d = 0;d<192;d += 96)
{
for(b = 0; b < 33; b++)
x += x/cos(x);
for(a = d; a < d+96; a += 8)
{
p[a + 0] = (a + 0);
p[a + 1] = (a + 1);
p[a + 2] = (a + 2);
p[a + 3] = (a + 3);
p[a + 4] = (a + 4);
p[a + 5] = (a + 5);
p[a + 6] = (a + 6);
p[a + 7] = (a + 7);
}
}
Листинг 19 Объединение двух расщепленных циклов в один
А как быть, если алгоритмом предусматриваются одни лишь операции записи, и кроме них нет никаких других вычислений? Стоит ли "искусственно" внедрять какую-нибудь команду для задержки? Нет! В лучшем случае – при правильном планировании – код выполнится за то же самое время – не медленнее, но и не быстрее. И неудивительно – ведь во время выгрузки буферов процессор занят бесполезными вычислениями!
Комбинирование вычислений с доступом к памяти
В современных процессорах обращение к оперативной памяти уже не приводит к остановке вычислительного конвейера. Отослав чипсету запрос на загрузку ячейки процессор временно приостанавливает выполнение текущей машинной инструкции и переходит к следующей. Это обстоятельство, в частности, позволяет посылать очередной запрос чипсету до завершения предыдущего (см. "Параллельная обработка данных"). Однако параллелизм чипсета весьма невысок и при обработке больших объемов данных процессор все равно вынужден простаивать, ожидая загрузки ячеек из оперативной памяти. Так почему бы не избавить процессор от скуки, и не занять его вычислениями?
Предположим, нам необходимо загрузить N ячеек памяти и k раз вычислить синус угла. Предпочтительнее выполнять эти действия не последовательно, а объединить их в одном цикле. Тогда вычисления синуса будут происходить параллельно с загрузкой ячеек из памяти, сокращая тем самым время выполнения задачи.
Сразу же возникает вопрос: в какой именно пропорции целесообразнее всего смешивать вычисления и обращения к памяти? Достаточно очевидно, что в идеале время выполнения вычислительных инструкций должно быть равно времени загрузки ячеек из памяти, – в этом случае достигается наивысшая степень параллелизм. Проблема в том, что соотношение скорости доступа к памяти и скорости выполнения машинных инструкций на различных системах варьируется в очень широких пределах, и потому универсальных решений поставленной задачи нет. (см. подробное обсуждение эта проблемы в главе "Кэш Предвыборка"). С другой стороны, полного параллелизма добиваться вовсе не обязательно. Да и зачастую он вообще невозможен в принципе, – так, например, количества вычислений может оказаться просто недостаточно для покрытия всех задержек загрузки данных из памяти.
Попробуем оценить выигрыш, достигаемый при полном и частичном параллелизме. Для этого напишем следующую несложную тестовую программу, исследующую различные "концентрации" вычислительных операций на ячейку памяти.
Ниже для экономии места приведен лишь ее фрагмент. Обратите внимание: цикл, обращающийся к памяти, в оптимизированном варианте должен быть развернут. В противном случае, мы не получим никакого выигрыша в производительности, и хорошо если еще не окажемся в убытке. Почему? Так ведь свернутый цикл нельзя исполнять параллельно. Это, во-первых. А, во-вторых, циклы с небольшим количеством итераций крайне невыгодны хотя бы уже потому, что исполняются на одну итерацию больше, чем следует. (Стратегия предсказания ветвлений такова, что в последней итерации цикла процессор, не догадываясь о том, что цикл уже завершен, действует "как раньше", передавая управление на первую команду цикла; потом, конечно, он распознает свою ошибку и выполняет откат, но время выполнения от этого не уменьшается). Необходимость разворота циклов приводит к колоссальному увеличению размеров тестовой программы, – поскольку язык Си не поддерживает циклические макросы, весь код приходится набивать на клавиатуре вручную. Вот, кстати, хороший пример задачи которую невозможно элегантно решить штатными средствами языка Си (макроассемблер с этим бы справился на ура). Но довольно лирики, перейдем к исследованиям…
/* ---------------------------------------------------------------------------
не оптимизированный вариант
--------------------------------------------------------------------------- */
per=16; // 16 загружаемых байт на одно вычисление синуса
// цикл загрузки ячеек из памяти
// этот цикл исполняется крайне не оптимально, поскольку неповоротливая
// подсистема памяти просто не успевает за процессором и тому приходится скучать
for(a = 0; a < BLOCK_SIZE; a+=4)
z += *(int*)((int)p1 + a);
// цикл вычисления синусов
for(a=0; a < (BLOCK_SIZE/per); a++)
x+=cos(x);
/* ---------------------------------------------------------------------------
не оптимизированный вариант
--------------------------------------------------------------------------- */
// общий цикл, комбинирующий обращение к памяти с вычислениями синуса
for(a = 0; a < BLOCK_SIZE; a += per)
{
// внимание: цикл обращения к памяти должен быть развернут,
// иначе оптимизация обернется проигрышем в производительности
z += *(int*)((int)p1 + a);
z += *(int*)((int)p1 + a + 4);
z += *(int*)((int)p1 + a + 8);
z += *(int*)((int)p1 + a + 12);
// вычисление синуса будет происходить параллельно с загрузкой предыдущих
// ячеек за счет чего достигается увеличение производительности
x+=cos(x);
}
Листинг 27 [Memory/mem.mix.c] Фрагмент программы, демонстрирующей эффективность комбинирования обращения к памяти с выполнением вычислений
Прогон данной программы под системой AMD Athlon 1050/100/100/VIA KT133 (см. рис. graph 22) позволил установить, что наивысший параллелизм достигается, когда на каждые тридцать два загруженных байта приходится одна операция вычисления синуса. В этом случае оптимизированный вариант исполняется практически на треть быстрее. Еще больший выигрыш наблюдается на P-III/733/133/100/I815EP: при концентрации 256 байт на один синус, мы добиваемся чуть ли не двукратного увеличения производительности!
Правда, платой за это становится размер программы. Развернутый цикл из 64 команд загрузки данных смотрится, прямо скажем, диковато. Попытка же его свернуть съедает весь выигрыш производительности подчистую. Крайняя правая точка графика graph 22 (на диаграмме она отмечена символом звездочки) как раз и иллюстрирует такую ситуацию. Легко подсчитать, что на свертке цикла мы теряем не много, ни мало – 40% производительности, в результате чего оптимизированный вариант обгоняет не оптимизированный всего на 5%.
Впрочем, в подавляющем большинстве случаев быстродействие более критично, чем размер приложения, поэтому, никаких поводов для расстройства у нас нет.

Рисунок 41 graph 22 Демонстрация эффективности комбинирования вычислительных операций с командами, обращающихся к памяти
Конвейеризация или пропускная способность vs латентность
Начнем с того, что в конвейерных системах такого понятия как "время выполнения одной команды" просто нет. Уместно провести такую аналогию. Допустим, некоторый приборостроительный завод выпускает шестьсот микросхем памяти в час. Ответьте: сколько времени занимает производство одной микросхемы? Шесть секунд? Ну конечно же нет! Полный технологический цикл составляет не секунды, и даже не дни, а месяцы! Мы не замечаем этого лишь благодаря конвейеризации
производства, т.е. разбиении его на отдельные стадии, через которые в каждый момент времени проходит по крайней мере одна микросхема.
Количество продукции, сходящей с конвейера в единицу времени, называют его пропускной способностью. Легко показать, что пропускная способность в общем случае обратно пропорциональна длительности одной стадии, – действительно, чем короче каждая стадия, тем чаще продукция сходит с конвейера. При этом количество самых стадий (попросту говоря длина конвейера) не играет абсолютно никакой роли. Кстати, обратите внимание, что практически на всех заводах каждая стадия представляет собой элементарную операцию, – вроде "накинуть ключ на гайку" или "стукнуть молотком". И не только потому, что человек лучше приспосабливается к однообразной монотонной работе (наоборот, он, в отличии от автоматов, ее терпеть не может!). Элементарные операции, занимая чрезвычайно короткое время, обеспечиваю конвейеру максимальную пропускную способность.
Той же самой тактики придерживаются и производители процессоров, причем заметна ярко выраженная тенденция увеличения длины конвейера в каждой новой модели. Так, если в первых Pentium длина конвейера составляла всего пять стадий, то в уже Pentium-II она была увеличена до четырнадцати стадий, а в Pentium-4– и вовсе до двадцати. Такая мера была вызвана чрезмерным наращиванием тактовой частоты ядра процессора и вытекающей отсюда необходимости как-то заставить конвейер на этой частоте работать.
С одной стороны и хорошо, – конвейер крутится как угорелый, спуская до 6 микроинструкций за такт и какое нам собственно дело до его длины? А вот какое! Вернемся к нашей аналоги с приборостроительным заводом.
Допустим, захотелось нам запустить в производство новую модель. Вопрос: через какое время она сойдет с конвейера? (Бюрократическими проволочками можно пренебречь). Ни через шесть секунд, ни через час новая модель готова не будет и придется ждать пока весь технологический цикл не завершится целиком.
Латентность – т.е. полное время прохождения продукции по конвейеру, может быть и не критична для неповоротливого технологического процесса производства (действительно, новые модели микросхем не возникают каждый день), но весьма ощутимо влияет на быстродействие динамичного процессора, обрабатывающего неоднородный по своей природе код. Продвижение машинных инструкций по конвейеру сопряжено с рядом принципиальных трудностей, – то не готовы операнды, то занято исполнительное устройство, то встретился условный переход (что равносильно переориентации нашего приборостроительного завода на производство новой модели) и… вместо безостановочного вращения конвейера мы наблюдаем его длительные простои, лишь изредка прерываемые короткими рывками, а затем вновь покой и тишина.
В лучшем случае время выполнения одной инструкции определяется пропускной способностью конвейера, а в худшем – его латентностью. Поскольку пропускная способность и латентность различаются где-то на порядок или около того, бессмысленно говорить о среднем времени выполнения инструкции. Оно не будет соответствовать никакой физической действительности.
Малоприятным следствием становится невозможность определения реального времени исполнения компактного участка кода (если, конечно, не прибегать к эмуляции процессора). До тех пор, пока время выполнения участка кода не превысит латентность конвейера (30 тактов на P6), мы вообще ничего не сможем сказать ни о коде, ни о времени, ни о конвейере!
Конвейерная статическая память
Конвейерная статическая память представляет собой синхронную статическую память, оснащенную специальными "защелками", удерживающими линии данных, что позволяет читать (записывать) содержимое одной ячейки параллельно с передачей адреса другой.
Так же, конвейерная память может обрабатывать несколько смежных ячеек за один рабочий цикл. Достаточно передать лишь адрес первой ячейки пакета, а адреса остальных микросхема вычислит самостоятельно, – только успевай подавать (забирать) записывание (считанные) данные!
За счет большей аппаратной сложности конвейерной памяти, время доступа к первой ячейке пакета увеличивается на один такт, однако, это практически не снижает производительности, т.к. все последующие ячейки пакета обрабатываются без задержек.
Конвейерная статическая память используется в частности в кэше второго уровня микропроцессоров Pentium-II и ее формула (см. "ЧастьI. Оперативная память. Устройство и принципы функционирования оперативной памяти Формула памяти ") выглядит так: 2 ? 1 ? 1 ? 1.
Краткая история создания данной книги
Настоящая книга задумывалась отнюдь не ради коммерческого успеха (который вообще сомнителен – ну много ли людей сегодня занимаются оптимизацией?), а писалась исключительно ради собственного удовольствия (как говорится: UTILE DULCI MISCERE – соединять приятно с полезным).
История ее создания вкратце такова: после сдачи моих первых шести книг, обеспечивших мне более или менее сносное существование, у меня появилось возможность неторопливо, без лишней спешки заняться теми исследованиями, которые меня уже давно волновали.
Вплотную столкнувшись с необходимостью оптимизации еще во времена древних и ныне скоропостижно почивших 8-рязрядных машин, я скорее по привычке, чем по насущной необходимости, сохранил преданность эффективному коду и настоящих дней. А потому, не без оснований считал, что "собаку съел" на оптимизации и искренне надеялся, что писать на эту тему мне будет очень легко. Вот только бы выяснить несколько "темных" мест и объяснить некоторые странности поведения процессора, до анализа которых раньше просто не доходили руки...
…уже к концу первого месяца своих изысканий я понял, что если и "съел собаку", то тухлую как мамонт, ибо за последние несколько лет техника оптимизации кардинально поменялась, а сами процессоры так усложнились, что особенности их поведения судя по всему перестали понимать и сами отцы-разработчики. В общем, вместо трех изначально запланированных на книгу месяцев, работа над ней растянулась более чем на год, причем за это время не было выполнено и десятой части запланированного проекта.
Поверьте! Я вовсе не мячик пинал и каждый день проводил за компьютером как минимум по 12– 15 часов, благодаря чему большая часть прежде темных мест выступила из мрака и теперь ярко освещена! Быть может, это и не очень производительный труд (и вообще крайний низкий выход в пересчете на символ – в – час), тем не менее проделанной рабой в целом я остался доволен. И не удивительно! Изучать "железки" – это до жути интересно. Перед вами – черный ящик и все, что вы можете – планировать и осуществлять различные эксперименты, пытаясь описать их результаты некоторой математической моделью, проверяя и уточняя ее последующими экспериментами. И вот так из черного ящика постепенно начинают проступать его внутренности и Вы уже буквально "чувствуете" как он работает и "дышит"! А какое вселенское удовлетворение наступает, когда бессмысленная и совершенно нелогичная паутина результатов замеров наконец-то ложится в стройную картину! Чувство, охватывающее вас при этом, можно сравнить разве что с оргазмом!
Краткий экскурс с историю или ассемблер – это всегда весна
До середины девяностых борьба ассемблера с компиляторами шла с переменным успехом. Верх одерживала то одна, то другая сторона. После выхода новых, более быстродействующих микропроцессоров, интерес к ассемблеру на какое-то время угасал – всем казалось, что наконец-то настала та счастливая пора, когда для решения подавляющего большинства задач достаточно одних лишь языков высокого уровня и нет нужды корпеть над кодом, сражаясь за каждый такт. Впрочем, эйфория никогда не длилась долго, – вслед за возросшими процессорными мощностями усложнялись и возлагаемые на них задачи. Возможностей языков высокого уровня вновь катастрофически не хватало, и интерес к ассемблеру незамедлительно вспыхивал с новой силой.
Практически ни один, сколь ни будь заметный проект тех лет, не обошелся без ассемблера. Ассемблерный код в изобилии присутствовал и в MS-DOS, и в Windows, и в Quake, и в Microsoft Office, и во многих других продуктах. Короче, слона шапками не закидать – плохой компилятор остается плохим и на быстрых процессорах, а потому рынок его сбыта будет сильно ограничен.
Жесточайшая конкуренция разработчиков компиляторов, в конечном счете, обернулась благом (и в первую очередь – для прикладных программистов), ибо привела к интенсивному совершенствованию алгоритмов машинной оптимизации. Уже к концу девяностых качество оптимизирующих компиляторов практически достигло теоретического идеала, сравнявшись в решении штатных задач с программистами средней квалификации.
Сегодня, когда редкий программист обходится без визуальных средств разработки и даже "чистые" высокоуровневые языки выходят из моды, ассемблер и вовсе выглядит архаичным рудиментом, задвинутым на одну полку с перфоратором и ламповой ЭВМ. Между тем, слухи о его скорой смерти сильно преувеличены. Ассемблер жив! И лучшее подтверждение этому – тот факт, что основным языком разработки драйверов Microsoft объявляет именно его, ассемблер, а вовсе не Си\Си++ или, скажем, Паскаль. Без ассемблера (или специализированных компиляторов) невозможно использовать преимущества новых мультимедийных команд параллельной обработки данных. Наконец, ассемблер по-прежнему незаменим в создании высокопроизводительных математических и графических библиотек. (Кстати, загляните в каталог CRT\SRC\Intel дистибьютива Microsoft Visual С++ – и здесь не обошлось без ассемблера, практически все функции, работающий со строками, реализованы именно на нем).
В общем, ситуация с вживлением ассемблера стабилизировалась, и на оставшуюся у него вотчину языки высокого уровня более не претендуют.
Краткий обзор современных профилировщиков
Существует не так уж и много профилировщиков, поэтому особой проблемы выбора у программистов и нет.
Если оптимизация – не ваш основной "хлеб", и эффективность для вас вообще не критична – вам подойдет практически любой профилировщик, например тот, что уже включен в ваш компилятор. Более сложные профилировщики для вас окажутся лишь обузой и вы все равно не разглядите заложенный в них потенциал, поскольку это требует глубоких знаний архитектуры процессора и всего компьютера в целом.
Если же вы всерьез озабоченны производительность и качеством оптимизации ваших программ и планируете посвятить профилировке значительное время, то кроме IntelVTune и AMD Code Analyst вам ничто не поможет. Обратите внимание: не "Intel VTune или AMD Code Analyst", а именно "Intel VTune и AMD Code Analyst". Оба этих профилировщика поддерживают процессоры исключительно "своих" фирм и потому использование лишь одного из них – не позволит оптимизировать программу более, чем наполовину.
Тем не менее, далеко не все читатели знакомы с этими продуктами и потому автор не может удержаться от соблазна, чтобы хотя бы кратко не описать их основные возможности.
Краткое описание профилировщика DoCPUClock
Подробное описание профилировщика DoCPU Clock содержится в Приложении ???, здесь же мы рассмотрим лишь его базовые функции да и то кратко.
Сердцем профилировщика являются всего две функции A1 и A2, которые, используя команду RDTSC, с высокой точностью определяют время выполнения исследуемого фрагмента программы. Функция A1 принимает единственный аргумент – указатель на переменную типа unsigned int, в которую и записывает текущее значение регистра времени. Функция A2 возвращает разницу значений переданного ей аргумента и регистра времени, при этом сам аргумент остается в полной неприкосновенности.
Рассмотрим простейший пример их использования:
Критерии оценки качества машинной оптимизации
Основные критерии качества кода это: быстродействие, компактность
и время, затраченное на его разработку. Причем, оптимизация программы по всем трем критериям невозможна в принципе. В частности, при выравнивании кода и структур данных по кратным адресам, производительность программы возрастает, но вместе с нею увеличивается и ее размер.
Считается, что скорость – более приоритетная характеристика, нежели объем. Сегодня, когда количество оперативной памяти измеряется сотнями мегабайт, а емкость диска – сотнями гигабайт, компактность программного кода, действительно, уже не столь критична, однако, конечному пользователю отнюдь не все равно: сколько мегабайт занимает программа – один или миллион. Поэтому, практически все современные компиляторы поддерживают как минимум два режима оптимизации: maximum speed и minimum space.
Однако скрупулезное тестирование не входит в наши планы. Оставим это на откуп читателям, а сами ограничимся компромиссным режимом максимальной оптимизации, пытающимся достичь наивысшей скорости при наименьшем объеме. Именно такой режим и используется в подавляющем большинстве случаев, а потому он наиболее интересен.
Отметим также, что манипулирование ключами тонкой настойки оптимизатора может значительно изменить результаты тестирования, причем, как в худшую, так и в лучшую сторону. Но в этом случае будут уже сравниваться не сами оптимизаторы, искусство их настройки, а это – тема совершенно другого разговора.
Важно понять: точно оценить общее
качество оптимизации на частных
случаях невозможно. Вот, например, MicrosoftVisual C++ умеет подменять константное деление умножением, (что в десятки раз быстрее!) а Borland C++ – нет. В зависимости от того, встречается ли константное деление в оптимизируемой программе или нет, соответствующим образом будет варьироваться и разница в быстродействии кода, сгенерированного обоими компиляторами.
Поэтому, в отсутствии конкретного примера, можно говорить лишь о приблизительной, прикидочной оценке качества компиляторов. Позднее (см. статью "Сравнительный анализ оптимизирующих компиляторов языка Си\Си++", опубликованную в N… журнала "Программист") мы рассмотрим этот вопрос во всех подробностях, а сейчас же нас в первую очередь будет интересовать усредненное качество машинной оптимизации на примере типовых алгоритмов.
Конечно, понятие "типовой алгоритм" очень относительное и субъективное. Для одних программистов, например, показательно Фурье-преобразование, другие же в своей практике могут и вовсе не сталкиваются с вещественной арифметикой. Нижеследующий выбор заведомо нерепрезентативен, но… определенную пищу для размышлений он все-таки дает.
Методики оценки качества машинной оптимизации
Задача оценки качества кодогенерации намного сложнее, чем может показаться на первый взгляд. Прежде всего, следует разделять, собственно, сам компилятор и его окружение (среду, библиотеки и т.д.). В частности совершенно некорректно сравнивать размер откомпилированного примера "Hello, World" с его ассемблерной реализацией. Вызов 'printf("xxx");' компилятор транслирует приблизительно в следующий код: "push offset xxx\call printf\pop eax" – круче уже не оптимизируешь!
Обратите внимание на размер объективного файла, сформированного компилятором. Не правда ли, он мало в чем не уступает объективному файлу ассемблерной реализации? Конечно, после подключения всех необходимых библиотек, размер откомпилированного файла увеличивается в десятки раз, в то время как объем ассемблерного модуля практически не изменяется. Да, это так, но при чем здесь компилятор?! Ему встретился вызов printf, – он и включил его в объективный файл. Если бы программист захотел вывести строку напрямую, – через соответствующую API функцию операционной системы (как он поступил в ассемблерной реализации), исполняемый файл сразу бы похудел на десяток-другой килобайт. Что еще остается? Ах да, среда, называемая так же RTL (Run Time Library
– библиотека времени исполнения), – служебные функции, вызываемые самим компилятором. Несмотря на то, что библиотеки времени исполнения являются неотъемлемым компонентом компилятора, к качеству кодогенерации они не имеют никакого отношения, т.к. с точки зрения компилятора функции RTL ничем не отличаются от обычных библиотечных функций.
Избыточность штатных библиотечных функций и библиотеки времени исполнения на крохотных проектах очевидна, – вывод строки "Hello, World" не использует и сотой доли возможностей функции printf, но в программе, состоящей из нескольких тысяч строк, соотношение между полезными и служебными функциями нормализуется и коэффициент полезного действия библиотек практически вплотную приближается к единице.
Таким образом, сравнивать эффективность компилятора и ассемблера на примере библиотечных функций – это вопиющая некорректность. Следует рассматривать лишь чистые реализации, не обращающиеся к внешнему коду. В противном случае, будет сравниваться не качество машинной и ручной оптимизации, а совершенство библиотек (написанных, кстати, в большинстве своем на ассемблере) с ручной оптимизацией. Совершенно бесполезно сравнивать и размеры объективных файлов, – помимо кода они содержат массу посторонней информации, причем в рассматриваемых ниже примерах ее объем превышает размер машинного кода в десятки раз!
Истинную картину вещей дает лишь дизассемблер, – загружаем в него объективный или исполняемый – без разницы – файл и от адреса конца функции вычитаем адрес ее начала. Полученная разность и будет подлинным размером исследуемого кода.
Измерять производительность еще проще – достаточно засечь время выполнения функции и… Правда, тут есть одно "но". Если уж мы взялись оценивать именно качество кодогенерации, а не быстродействие компьютера, следует учесть, и по возможности свести к нулю, все посторонние эффекты. Во-первых, к моменту вызова функции все, обрабатываемые ей данные, должны целиком находиться в кэше первого уровня, иначе неповоротливость памяти сотрет все различия в производительности тестируемого кода. Во-вторых, размер обрабатываемых данных должен быть достаточно велик для того, чтобы замаскировать накладные расходы на вызов функции, передачу аргументов, снятие показаний со счетчика производительности и т.д. Все нижеследующие примеры обрабатывают 4.000 элементов типа int, – это дает стабильный и хорошо воспроизводимый результат, т.к. "насыщение" наступает уже на 1.000 элементах, после чего накладные расходы уже не играют сколь ни будь заметной роли.
Microsoft Profile.exe

Рисунок 5 0x008 "Визитная карточка" профилировщика Microsoft Profile.exe
Профилировщик Microsoft Profile.exe настолько прост и незатейлив, что даже не имеет собственного имени и нам, на протяжении всей книги, придется называет его по имени исполняемого файла.
Profile.exe – чрезвычайно простой и минимально функциональный профилировщик, попадающий в этот обзор лишь потому, что он входит в штатную поставку компилятора Microsoft Visual C++ (редакции: Professional и Enterprise), а потому достается большинству из нас практически даров, в то время как остальные профилировщики приходится где-то искать/скачивать/покупать.
Основные его возможности перечислены в таблице ???, приведенной ниже.
Наглядная демонстрация качества машинной оптимизации
Разговор о качестве машинной оптимизации был бы неполным без конкретных примеров. Показатели производительности – слишком абстрактные величины. Они дают пищу для размышлений, но не объясняют: почему откомпилированный код оказался хуже. Как говорится, пока не увижу своими глазами, пока не пощупаю своими руками – не поверю!
Что ж, такая возможность у нас есть! Давайте изучим непосредственно сам ассемблерный код, сгенерированный компилятором. Для экономии бумажного пространства ниже приведен лишь один пример – результат компиляции программы пузырьковой сортировки компилятором MicrosoftVisual C++. Пример довольно показательный, ибо ощутимо улучшить его качество, не вывихнув при этом себе мозги, практически невозможно. Да вы смотрите сами. Если не владеете ассемблером – не расстраивайтесь, в листинге присутствуют подробные комментарии (надеюсь, вы понимаете, что их вставил не компилятор?).
.text:004013E0 ; ---------- S U B
R
O
U
T
I
N
E
----------
.text:004013E0
.text:004013E0
.text:004013E0 с_sort proc near ; CODE XREF: sub_401420+DAp
.text:004013E0
.text:004013E0 arg_0 = dword ptr 8
.text:004013E0 arg_4 = dword ptr 0Ch
.text:004013E0
.text:004013E0 push ebx
.text:004013E0 ; сохраняем регистр EBX, т.к. функция обязана сохранять
.text:004013E0 ; модифицируемые регистры, иначе программа рухнет
.text:004013E0 ;
.text:004013E1 mov ebx, [esp+arg_4]
.text:004013E1 ; загружаем в ebx самый правый аргумент – количество элементов
.text:004013E1 ; точно так поступил бы и человек
.text:004013E1 ; ага, локальные переменные адресуются непосредственно через ESP
.text:004013E1 ; это экономит один регистр (EBP), высвобождая его для других нужд
.text:004013E1 ; человек так не умеет… вернее, не то, что бы совсем не умеет,
.text:004013E1 ; но адресация через ESP
заставляет заново вычислять
.text:004013E1 ; местоположение локальных переменных при всяком перемещении
.text:004013E1 ; верхушки стека (в частности при передаче функции аргументов),
.text:004013E1 ; что ну очень утомительно…
.text:004013E1 ;
.text:004013E5 push ebp
.text:004013E6 push esi
.text:004013E6 ; сохраняем еще два регистра
.text:004013E6 ; вообще-то, человек мог воспользоваться и командой PUSHA,
.text:004013E6 ; сохраняющей все регистры общего назначения, что было бы
.text:004013E6 ; намного короче, но в то же время, увеличило бы потребности
.text:004013E6 ; программы в стековом пространстве и несколько снизило бы
.text:004013E6 ; ее скорость
.text:004013E6 ;
.text:004013E7 cmp ebx, 2
.text:004013E7 ; сравниваем значение аргумента n
с константой 2
.text:004013E7 ;
.text:004013EA push edi
.text:004013EB jl short loc_40141B
.text:004013EB ; а вот здесь пошла оптимизация кода под ранние процессоры P-P MMX
.text:004013EB ; сравнение содержимого EBX
и анализ результата сравнения разделен
.text:004013EB ; командой сохранения регистра EDI. Дело в том, что P-P MMX
.text:004013EB ; могли спаривать команды, если они имели зависимость по данным
.text:004013EB ; впрочем, в данном конкретном случае такая оптимизация излишня
.text:004013EB ; т.к. процессор пытается предсказать направление перехода еще до
.text:004013EB ; его реального исполнения. Впрочем, перестановка команд –
.text:004013EB ; карман не тянет и никому не мешает
.text:004013EB ;
.text:004013ED mov ebp, [esp+0Ch+arg_0]
.text:004013ED ; загружаем в EBP значение кране левого аргумента –
.text:004013ED ; указателя на сортируемый массив. Как уже сказано, так
.text:004013ED ; адресовать аргументы умеют только компиляторы,
.text:004013ED ; человеку это не под силу
.text:004013ED ;
.text:004013F1
.text:004013F1 loc_4013F1: ; CODE XREF: C_Sort+39j
.text:004013F1 ; цикл начинается с нечетного адреса. Плохо!
.text:004013F1 ; это весьма пагубно сказывается на производительность
.text:004013F1 ;
.text:004013F1 xor esi, esi
.text:004013F1 ; очищаем регистр ESI, выполняя логического XOR
над ним самим
.text:004013F1 ; вот на это человек – способен!
.text:004013F1 ;
.text:004013F3 cmp ebx, 1
.text:004013F6 jle short loc_40141B
.text:004013F6 ; эти две команды лишние.
.text:004013F6 ; Для человека очевидно, если EBX
>= 2, то он всегда больше одного
.text:004013F6 ; А вот для компилятора это – вовсе не факт! (Ну темный он)
.text:004013F6 ; Дело в том, что он превратил возрастающий цикл for
.text:004013F6 ; в убывающий цикл do/while с пост условием
.text:004013F6 ; /* убывающие циклы с постусловием реализуются на
.text:004013F6 ; х86-процессорах намного более эффективно */
.text:004013F6 ; но для этого компилятор должен быть уверен, что цикл
.text:004013F6 ; исполняется хотя бы раз – вот он и помещает
.text:004013F6 ; в код дополнительную и абсолютно лишнюю в данном случае
.text:004013F6 ; проверку. Впрочем, она не отнимает много времени
.text:004013F6 ;
.text:004013F8 lea eax, [ebp+4]
.text:004013F8 ; быстрое сложить EBP
с 4 и записать результат в EAX
.text:004013F8 ; об этом трюке знают далеко не все программисты,
.text:004013F8 ; и обычно выполняют данную задачу в два этапа
.text:004013F8 ; MOV EAX, EBX\ADD EAX, 4
.text:004013F8 ;
.text:004013FB lea edi, [ebx-1]
.text:004013FB ; быстро вычесть из EBX
единицу и записать результат в EDI
.text:004013FB ;
.text:004013FE
.text:004013FE loc_4013FE: ; CODE XREF: C_Sort+35j
.text:004013FE mov ecx, [eax-4]
.text:004013FE ; Оп
с! Команда, расположенная в начале цикла пересекает
.text:004013FE ; границу 0x10 байт, что приводит к ощутимым задержка исполнения
.text:004013FE ; Да, забыл сказать, эта инструкция загружает ячейку src[a-1]
.text:004013FE ; в регистр ECX
.text:004013FE ;
.text:00401401 mov edx, [eax]
.text:00401401 ; загружаем ячейку src[a] в регистр EDX
.text:00401401 ;
.text:00401403 cmp ecx, edx
.text:00401403 ; сравниваем ECX (src[a-1]) и
EDX (src[a])
.text:00401403 ; вообще-то, это можно было реализовать и короче
.text:00401403 ; CMP ECX, [EAX], избавлюсь от команды MOV EDX, [EAX]
.text:00401403 ; однако, это ни к чему, т.к. значение [EAX] нам потребуется ниже
.text:00401403 ; при обмене переменными и эта команда все равно бы вылезла там.
.text:00401403 ;
.text:00401405 jle short loc_401411
.text:00401405 ; переход на ветку loc_401411, если ECX
<= EDX
.text:00401405 ; в противном случае – выполнить обмен ячеек
.text:00401405 ;
.text:00401407 mov [eax-4], edx
.text:0040140A mov [eax], ecx
.text:0040140A ; обмен
ячейками. Вообще-то, можно было бы реализовать это и
.text:0040140A ; через XCHG, что было бы на несколько байт короче, но у этой
.text:0040140A ; инструкции свои проблемы – не на всех процессорах она работает
.text:0040140A ; быстрее…
.text:0040140A ;
.text:0040140C mov esi, 1
.text:0040140C ; устанавливаем ESI (флаг f) в
.text:0040140C ; человек мог бы сократить это на несколько байт, записав это так:
.text:0040140C ; MOV ESI, ECX. Поскольку ECX
> EDX, то ECX
!=0,
.text:0040140C ; при условии, конечно, что EDX
>= 0.
.text:0040140C ; разумеется, компиляторам такое не по зубам, однако, это
.text:0040140C ; алгоритмическая оптимизация и к качеству кодогенерации она
.text:0040140C ; не имеет никакого отношения
.text:0040140C ;
.text:00401411 loc_401411: ; CODE XREF: C_Sort+25j
.text:00401411 add eax, 4
.text:00401411 ; увеличиваем EAX (a) на
4 (sizeof(int))
.text:00401411 ;
.text:00401414 dec edi
.text:00401414 ; уменьшаем счетчик цикла на единицу
.text:00401414 ; (напоминаю, компилятор превратил наш for
в убывающий цикл)
.text:00401414 ;
.text:00401415 jnz short loc_4013FE
.text:00401415 ; переход к началу цикла, пока EDI
не равен нулю
.text:00401415 ; некоторые человеки здесь лепят LOOP, который хоть и компактнее
.text:00401415 ; но исполняется значительно медленнее
.text:00401415 ;
.text:00401417 test esi, esi
.text:00401417 ; проверка флага f на равенство нулю
.text:00401417 ;
.text:00401419 jnz short loc_4013F1
.text:00401419 ; повторять цикл, пока f
равен нулю
.text:0040141B
.text:0040141B loc_40141B:
.text:0040141B pop edi
.text:0040141C pop esi
.text:0040141D pop ebp
.text:0040141E pop ebx
.text:0040141E ; восстанавливаем все измененные регистры
.text:0040141E ;
.text:0040141F retn
.text:0040141F ; выходим из функции
.text:0040141F C_Sort endp
.text:0040141F
Итак, какие у противников компиляторов есть претензии к качеству кода? Смогли бы они реализовать эту же процедуру хотя бы процентов на десять эффективнее? Согласитесь, здесь есть чему поучиться даже весьма квалифицированным программистам!
Непостоянства времени выполнения
Если вы профилировали приложения и раньше, то наверняка сталкивались с тем, что результаты измерений времени выполнения варьируются от прогона к прогону, порой отличаясь один от другого более, чем значительно.
Причин такого непостоянства существует по меньшей мере две: программное непостоянство, связанное с тем, что в многозадачных операционных системах (в частности в Windows) профилируемая программа попадает под влияние чрезвычайно изменчивой окружающей среды, и аппаратное непостоянство, вызванное внутренней "многозадачностью" самого железа.
В силу огромной их значимости для результатов профилировке, обе этих причины ниже будет рассмотрены во всех подробностях.
Несколько советов по измерению производительности
1) "выкидывание" неиспользуемых переменных
2) размещение сравниваемых фрагментов в "своих" функциях
Неточность измерений
Одно из фундаментальных отличий цифровой от аналоговой техники заключается в том, что верхняя граница точности цифровых измерений определяется точностью измерительного инструмента (точность аналоговых измерительных инструментов, напротив, растет с увеличением количества замеров).
А чем можно измерять время работы отдельных участков программы? В персональных компьютерах семейства IBM PC AT имеются как минимум два таких механизма: системный таймер (штатная скорость: 18,2 тика в секунду, т.е. 55 мсек., максимальная скорость – 1.193.180 тиков в секунду или 0,84 мсек.), часы реального времени (скорость 1024 тика в секунду т.е. 0,98 мсек.). В дополнении к этому в процессорах семейства Pentium появился так называемый регистр счетчик - времени (Time Stamp Counter), увеличивающийся на единицу каждый такт процессорного ядра.
Теперь – разберемся со всем этим хозяйством подробнее. Системный таймер (с учетом времени, расходующего на считывание показаний) обеспечивает точность порядка 5 мсек., что составляет более двух десятков тысяч тактов даже в 500 MHz системе! Это – целая вечность для процессора. За это время он успевает перемолотить море данных, скажем, отсортировать сотни полторы чисел. Поэтому, системный таймер для профилирования отдельных функций непригоден. В частности, нечего и надеяться с его помощью найти узкие места функции quick sort! Да что там узкие места – при небольшом количестве обрабатываемых чисел он и общее время сортировки определяет весьма неуверенно.
Причем, прямого доступа к системному таймеру под нормальной операционной системой никто не даст, а минимальный временной интервал, еще засекаемый штатной Си-функций clock(), составляет всего лишь 1/100 сек, – а это годиться разве что для измерения времени выполнения всей программы целиком.
Точность часов реального времени так же вообще не идет ни в какое сравнение с точность системного таймера (перепрограммированного, разумеется).
Остается надеяться лишь на Time Stamp Counter.
Первое знакомство с ним вызывает просто бурю восторга и восхищения "ну наконец-то Intel подарила нам то, о чем мы так долго мечтали!". Судите сами: во-первых, операционные системы семейства Windows (в том числе и "драконическая" в этом плане NT) предоставляют беспрепятственный доступ к машинной команде RDTSC, читающий содержимое данного регистра. Во-вторых, поскольку он инкрементируется каждый такт, создается обманчивое впечатление, что с его помощью возможно точно определять время выполнения каждой команды процессора. Увы! На самом же деле это не далеко так!
Начнем с того, что в конвейерных системах (как мы уже помним) вообще нет такого понятия как время выполнения команды и следует говорить либо о пропускной способности, либо латентности. Сразу же возникает вопрос: а что же все-таки RDTSC меряет? Документация Intel не дает прямого ответа, но судя по всему, RDTSC считывает содержимое регистра счетчика-времени в момент прохождения данной инструкции через соответствующее исполнительное устройство. Причем, RDTSC – это неупорядоченная команда, т.е. она может завешаться даже раньше предшествующих ей команд. Именно так и произойдет если предшествующая команда простаивает в ожидании операндов.
Рассмотрим крайний случай, когда измеряется время выполнения минимальной порции кода (одна машинная команда уходит на то, чтобы сохранить считанное значение в первой итерации):
RDTSC ; читаем значение регистра времени
; и помещаем его в регистры EDX и EAX
MOV [clock], EAX ; сохраняем младшее двойное слово
; регистра времени в переменную clock
RDTSC ; читаем регистр времени еще раз
SUB EAX, [clock] ; вычисляем разницу замеров между
; первым и вторым замером
Листинг 5 Попытка замера времени выполнения одной машинной команды
При прогоне этого примера на P-III он выдаст 32 тактов, вызывая тем самым риторический вопрос: "а почему, собственно, так много?" Хорошо, оставим выяснение обстоятельств "похищения процессорных тактов до лучших времени", а сейчас попробуем измерять время выполнения какой-нибудь машинной команды, ну скажем, INC EAX, увеличивающий значение регистра EAX на единицу.
Поместим ее между инструкциями RDTSC и перекомпилируем программу.
Вот это да! Прогон показывает все те же 32 такта. Странно! Добавим-ка мы еще одну INC EAX. Как это так – снова 32 такта?! Зато при добавлении сразу трех
инструкций INC EAX контрольное время исполнения скачкообразно увеличивается на единицу, что составляет 33 такта. Четыре и пять инструкций INC EAX дадут аналогичный результат, а вот при добавлении шестой, результат изменений вновь подскакивает на один такт.
Но ведь процессор Pentium, имея в наличии всего лишь одно арифметическое устройство, никак не может выполнять более одного сложения за такт одновременно! Полученное нами значение в три команды за такт – это скорость их декодирования, но отнюдь не исполнения! Чтобы убедиться в этом запустим на выполнение следующий цикл:
MOV ECX,1000 ; поместить в регистр ECX значение 1000
@for: ; метка начала цикла
INC EAX ;\
INC EAX ; +- одна группа профилируемых инструкций
INC EAX ;/
INC EAX ;\
INC EAX ; +- вторая группа профилируемых инструкций
INC EAX ;/
DEC ECX ; уменьшить значение регистра ECX на 1
; (здесь он используется в качестве
; счетчика цикла)
JNZ @xxx ; до тех пор, пока ECX не обратится в ноль
; перепрыгивать на метку @for
Листинг 6 Измерение времени выполнения 6х1000 машинных команд INC
На P-III выполнение данного цикла займет отнюдь не ~2.000, а целых 6.781 тактов, что соответствует по меньшей мере одному такту, приходящемуся на каждую математическую инструкцию! Следовательно, в предыдущем случае, при измерении времени выполнения нескольких машинных команд, инструкция RDTSC "вперед батьки пролезла в пекло", сообщив нам совсем не тот результат, которого мы от нее ожидали!
Вот если бы существовал способ "притормозить" выполнение RDTSC до тех пор, пока полностью не будут завершены все предшествующие ей машинные инструкции… И такой способ есть! Достаточно поместить перед RDTSC одну из команд упорядоченного выполнения. Команды упорядоченного выполнения начинают обрабатываться только после схода с конвейера последней предшествующей ей неупорядоченной команды и, покуда команда упорядоченного выполнения не завершится, следующие за ней команды мирно дожидаются своей очереди, а не лезут как толпа дикарей вперед на конвейер.
Подавляющее большинство команд упорядоченного выполнения – это привилегированные
команды (например, инструкции чтения/записи портов ввода-вывода) и лишь очень немногие из них доступны с прикладного уровня. В частности, к таковым принадлежит инструкция идентификации процессора CPUID.
Многие руководства (в частности и Ангер Фог в своем руководстве "How to optimize for the Pentium family of microprocessors" и технический документ "Using the RDTSC Instruction for Performance Monitoring" от корпорации Intel) предлагают использовать приблизительно такой код:
XOR EAX,EAX ; вызываем машинную команду CPUID,
CPUID ; после выполнения которой все
; предыдущие машинные инструкции
; гарантированно сошли к конвейера
; и потому никак не могут повлиять
; на результаты наших замеров
RDTSC ; вызываем инструкцию RDTSC, которая
; возвращает в регистре EAX младшее
; двойное слово текущего значения
; Time Stamp Counter 'a
MOV [clock],EAX ; сохраняем полученное только что
; значение в переменной clock
// … ;\
// профилируемый код ; +-здесь исполняется профилируемый код
// … ;/
XOR EAX,EAX ; еще раз выполняем команду CPUID,
CPUID ; чтобы все предыдущие инструкции
; гарантированно успели покинуть
; конвейер
RDTSC ; вызываем инструкцию RDTSC для чтения
; нового значение Time Stamp Count 'a
SUB EAX,[clock] ; вычисляем разность второго и первого
; замеров, тем самым определяя реальное
; время выполнения профилируемого
; фрагмента кода
Листинг 7 Официально рекомендованный способ вызова RDTSC для измерения времени выполнения
К сожалению, даже этот, официально рекомендованный, код все равно не годится для измерения времени выполнения отдельных инструкций, поскольку полученный с его помощью результат представляет собой полное время выполнения инструкции, т.е. ее латентность, а отнюдь не пропускную способность, которая нас интересует больше всего. (Кстати, и у Intel, и Фрога есть одна грубая ошибка – в их варианте программы перед инструкцией CPUID отсутствует явное задание аргумента, который CPUID ожидает увидеть в регистре EAX. А, поскольку, время ее выполнения зависит от аргумента, то и время выполнения профилируемого фрагмента не постоянно, а зависит от состояния регистров на входе и выходе. В предлагаемом много варианте, инициализация EAX осуществляется явно, что страхует профилировщик от всяких там наведенных эффектов).
Имеется и другая проблема, еще более серьезная, чем первая. Вы помните постулат квантовой физики, сводящийся к тому, что всякое измерение свойств объекта неизбежно вносит в этот объект изменения, искажающие результат измерений? Причем, эти искажения невозможно устранить простой калибровкой, поскольку изменения могут носить не только количественный, но и качественный характер.
Если профилируемый код задействует те же самые узлы процессора, что и команды RDTSC/CPUID, время его выполнения окажется совсем иным нежели в "живой" действительности! Никаким ухищрениями нам не удастся достигнуть точности измерений до одного–двух тактов!
Поэтому, минимальный промежуток времени, которому еще можно верить, составляет, как показывает практика и личный опыт автора, по меньше мере пятьдесят – сто тактов.
Отсюда следствие: штатными средствами процессора измерять время выполнения отдельных команд невозможно.
Низкая "разрешающая способность"
Учитывая, что пропускная способность большинства инструкций составляет всего один такт, а минимальный промежуток времени, который еще можно измерять, находится в районе пятидесяти – ста тактов, предельная разрешающая способность не эмулирующих профилировщиков не превышает полста команд.
Под "разрешающей способностью" здесь и далее понимается протяженность "горячей" точки более или менее уверенно распознаваемой профилировщиком.
Строго говоря, не эмулирующие профилировщики показывают не саму горячую точку, а некоторую протяжную область к которой эта "горячая" точка принадлежит.
О чем и для кого предназначена эта книга
Настоящая книга описывает устройство и механизмы взаимодействия различных компонентов компьютера и рассказывает об эффективных приемах программирования и технике оптимизации программ, как на уровне машинного кода, так и на уровне структур данных.
Она ориентирована на прикладных программистов, владеющих (хотя бы в минимальном объеме) языком Си, а так же на системных программистов, знающих ассемблер. Описываемые техники не привязаны ни к какому языку и знание Си требуется лишь для чтения исходных текстов примеров, приведенных в книге.
В не меньшей степени "Техника оптимизации" будет интересна и лицам, занимающимся сборкой и настройкой компьютеров, поскольку подробно описывает устройство "железа" и разбирает "узкие места" распространенных моделей комплектующих.
В основу данной книги положена уникальная информация и методики, разработанные лично автором. Информация, почерпнутая из технической документации производителей комплектующих, операционных систем и компиляторов, тщательно проверена, в результате чего обнаружено большое количество ошибок, на которые и обращается внимание читателя (тем не менее, автор не гарантирует отсутствие вторичных и "наведенных" ошибок в самой книге).
Материал книги в основном ориентирован на микропроцессоры AMDAthlon и Intel Pentium-II, Pentium-III и Pentium-4, но местами описываются и более ранние процессоры.
Хотите заглянуть внутрь черного ящика подсистемы оперативной памяти? Хотите узнать, что чувствует, как "дышит" и какими мыслями живет каждая микросхема вашего компьютера? Тогда, вы не ошиблись в выборе книги!
Перед вами лежит уникальное практическое пособие по оптимизации программ под платформу IBM PC и операционные системы семейства Windows и UNIX. Его уникальность заключается в том, что оно показывает как эффективно реализовать на языке высокого уровня те трюки и приемы, которые всеми остальными руководствами осуществляются на ассемблере.
Это не только пособие по оптимизации программ, но и введение в философию компьютерного "железа".
О серии книг "Оптимизация"
Ну вот, – воскликнет, иной читатель, – опять серия! Да сколько же можно этому Касперски объявлять серий?! И что интересно: все серии разные! Выпущен первый том "Техники сетевых атак", но вот уже года три как нет второго. Объявлен трехтомник "Образ мышления – IDA", но до сих пор вышли только первый и третий тома книги, а второго по?прежнему нет и в обозримом будущем даже и не предвидится. Наконец, "Фундаментальные Основы Хакерства. Искусство Дизассемблирования"– это вновь всего лишь первый том! Так не лучше ли автору сконцентрироваться на чем ни будь одном, а не метаться по всей предметной области?
Кто-то даже сравнил меня с Кнутом – мол обещал семь томов, а выпустил только три. Но если Кнут выпустил три тома одной книги, то Касперски – по одному тому трех разных. Ситуация осложняется тем, что мой издатель по маркетинговым соображением наотрез отказался называть настоящую книгу томом. Хорошо, пусть это будет не "том", пусть это будет "первая книга серия". (Суть дела от этого все равно меняется).
Предвидя встречный вопрос читателя о причинах неполноты охвата информации (действительно, настоящий том ограничивается исключительно одной оперативной памятью и ни слова не обмолвливается о таких важных аспектах оптимизации как, например, планирование потока команд или векторизации вычислений), считаю своим долгом заявить, что в одной-единственной книге просто невозможно изложить все аспекты техники оптимизации и уж лучше подробно освещение узкого круга вопросов, чем поверхностный рассказ обо всем.
К тому же, с выпуском данной книги, работа над "Оптимизацией" не прекращается и на будущее запланировано как минимум пять томов. Ниже все они перечислены в предполагаемом хронологическом порядке.
Об авторе
Если говорить о себе кратко– "я просто познаю окружающий мир и получаю от этого удовольствие". Компьютерами одержим еще со старших классов средней школы (или еще раньше – уже, увы, не помню).
Основная специализация: разработка оптимизирующих компиляторов и операционных систем реального времени для управления производством.
Из всех языков программирования больше всего люблю ассемблер, но при разработке больших проектов предпочитаю С (реже – C++). Для создания сетевых приложений прибегаю к помощи Perl и Java, ну а макросы в Word'e и Visual Studio пишу на Бейсике. Эпизодически балуюсь Forth'ом и всякими "редкоземельными" языками наподобие Python'a. Впрочем, важен не сам язык, а мысли, которые этим языком выражают.
Но все-таки, компьютеры – не единственное и, вероятно, даже не самое главное увлечение в моей жизни. Помимо возни с железом и блужданий в непроходимых джунглях защитного кода, я не расстаюсь с миром звезд и моих телескопов, много читаю, да и пишу тоже (в последнее время как-то больше пишу, чем читаю).
"Техника оптимизации программ" – уже седьмая по счету моя книга. Предыдущие: "Техника и философия хакерских атак", "Техника сетевых атак", "Образ мышления – дизассемблер IDA", "Укрощение Интернет", "Фундаментальные основы хакерства. Искусство дизассемблирования" и "Предсказание погоды по местным атмосферным признакам" были горячо одобрены читателями и неплохо расходились, несмотря на то, что ориентированы на очень узкий круг читателей (гораздо более узкий, нежели "Техника оптимизации программ").
Помимо этому моему перу принадлежит свыше двухсот статей, опубликованных в журналах "Программист", "Открытые системы", "Инфо - бизнес", "Компьютерра", "LAN", "eCommerce World", "Mobile", "Byte", "Remont & Service", "Astronomy", "Домашний компьютер", "Интерфейс", "Мир Интернет", "Магия ПК", "Мегабайт", "Полный ПК", "Звездочет" и др.
Хакерские мотивы моего творчества не случайны и объясняются по-детски естественным желанием заглянуть "под капот" компьютера и малость потыкать его "ломом" и "молоточком", разумеется, фигурально - а как же иначе понять как эта штука работает? Если людей, одержимых познанием окружающего мира, считать хакерами, то я – хакер.
Адреса электронной почты для связи с автором: kpnc@programme.ru
kpnc@itech.ru
Об одном подходе к решению задач…
Все школьные приемы решения задач, так или иначе, сводятся к тому, что сначала каллиграфическим почерком ученик выписывает «Дано», потом «Найти», затем «Решение». Последнее обычно сопровождается ожесточенным покусываем авторучки, в поисках оптимального разбиения задачи на более мелкие, не представляющие по отдельности никакой трудности. То есть, говоря математическим языком, - решения с помощью декомпозиции.
Такой подход оптимален для школьных задач потому, что большинство из них составлялось композиционным образом, - то есть, автором учебника бралась за отправную точку некая идея (формула, теорема), а поверх насыпался добрый слой щебенки, который учащийся и должен был разобрать, проделывая обратный путь.
В жизни же подобной искусственности нет, и наиболее трудным моментом в решении задачи является (ну кто бы об этом мог подумать в школе!) именно определение что же именно нам дано, и что требуется найти.
Грубо говоря, часто бывает легче приложить усилия по получению дополнительных исходных данных, чем решать возникшую проблему в существующем виде. Точно так же можно изменить даже искомую величину, и выбрать другую, связанную с требуемой простой и легко решаемой зависимостью.
Например, как быстро в уме вычислить, сколько нечетных дней каждого месяца существует в году? Но только не делите 365 на два, потому что это очевидно неверное решение. Ведь нумерация дней в году идет не последовательно от одного до 365, а разбита на списки, в каждом из которых может находиться 28, 29, 30 или 31 дней. То есть, в одном случае за 30 днем месяца, наступает 1 число следующего, а в другом два нечетных числа «слипаются» если после 31 числа идет 1.
Хм, очевидно, что нечетных дней будет ощутимо больше. Но насколько больше? Давайте посчитаем! Так, «длинные» месяцы – Январь, Март, Май, Июль, Август, Октябрь, Декабрь. Итого, выходит нечетных чисел должно быть на семь больше.
Составим простое уравнение x+x-7==365, отсюда 2х==372, x=186. Гм, но нет ли более короткого решения (мы все же пытаемся это считать в уме!).
А почему бы и нет? Необходимо только чуть-чуть ( на время) изменить условия задачи. Попробуем найти количество четных
дней. В самом деле, оно (за исключением февраля) всегда постоянно и в каждом месяце равно пятнадцати. А в феврале, стало быть, четырнадцати. Умножим пятнадцать на десять и добавим еще двадцать девять, - получается 179. Не правда ли просто? А теперь несложно догадаться, что оставшиеся дни в году и будут искомыми нечетными!
Но в чем преимущество такого решения? Вспомним, что в условии не было оговорено, какой нас интересует год – простой или високосный? А, в самом деле, если ли разница? В первом решении да, ибо тогда формула должна была бы принять вид x+x-8==366. Но… посмотрите, что получается во втором случае – x==366-179! Или, если это записать в другом виде, x==Число_дней_в_году
– Константа_179.
Вряд ли можно усомниться, что последнее решение элегантнее. А первое и вовсе не верно. Почему? А разве нам кто-то оговаривал, какой именно требуется год? Нет же, верно? Следовательно, продолжительность его равна Y, а вовсе не 365 дней. Тогда… тогда первым уравнением задача не решается.
Кстати, говорят, что программист отличается от простого смертного тем, что пытается проверить задачу на всех, в том числе и бессмысленных, входных значениях. В нашем случае, оговаривается, что Y может быть принимать только два значения – либо 365, либо 366. Любое другое приведет к бессмысленному результату.
Выходит, что задача решена не в общем, а в частом виде? А каково количество нечетных дней на N-ый день произвольного месяца? То есть, сколько их будет, скажем от первого января 1990 года до 27 октября 2001?
Решая задачу де композиционным способом, пришлось бы для начала найти способ вычисления прошедших дней между двумя произвольными датами, но… может быть, существует иной способ решения? Попробуйте отыскать его. Уверяю, что это доставит Вам истинное удовольствие…
Обработка памяти байтами, двойными и четвертными словами
В своей повседневной практике программисты сталкиваются с самыми различными типами данных: байтами, двойными и четвертными словами… Какие же из них наиболее эффективны? Среди программистов нет единого мнения на этот счет. Одни руководства рекомендуют обрабатывать большие блоки памяти двойными словами и советуют навсегда забыть, что такое "байт". Другие же соблазняют командами мультимедийной обработки данных, способными "заглатывать" по крайней мере 64 бита (целое четвертное слово!) за один раз. Ближе всего к истине подобралось первое утверждение, да и то с некоторыми оговорками.
Несложная тестовая программа (см. [Memory/DWORD.c] – исходный текст который здесь не приводится ввиду ее простоты) убедительно доказывает, что чтение памяти двойными словами действительно, происходит на ~30% – ~40% быстрее побайтового чтения (см. рис. graph 25). А вот чтение памяти четвертными словами (с использованием команды MOVQ) на P?III 733/133/100/I815EP отстает от двойных слов на добрых 25%! Правда, на AMD Athlon 1050/100/100/VIA KT133 разрыв в производительности составляет всего ~5%, но это никак не меняет сути вещей. Чтение больших блоков памяти четвертными словами крайне нецелесообразно. (Вот компактные блоки памяти, – другое дело, но об этом мы поговорим позже, - см. "Кэш").
Интересная ситуация складывается с записью памяти. И байты, и двойные слова в этом случае оказывается одинаково эффективны! Поэтому, при записи данных смело выбирайте любой тип данных, – какой вам больше приходится по душе (читай: какой лучше подходит для описания конкретного алгоритма). Запись памяти четверными словами, как вы уже наверняка догадались, менее выгодна. И это действительно так! Забавно, но теперь наибольший разрыв в производительности наблюдается не на P?III (как это было при чтении памяти), а на AMD Athlon, который в 1,6 раз проигрывает двойными словам по скорости обработки.

Рисунок 34 graph 25 Сравнительная эффективность чтения/записи больших блоков памяти байтами, двойными и четверными словами.
Как видно: чтение памяти лучше всего осуществлять двойными словами, а запись – либо байтами, либо двойными словами. Обработка памяти четвертными словами всегда осуществляется наименее эффективно
Обработка байтовых потоков двойными словами.
В некоторых случаях байтовые потоки данных могут (не без ухищрений конечно) обрабатываться непосредственно двойными словами, что значительно (см. рис. graph 26) увеличивает производительность обрабатывающего их приложения.
Рассмотрим следующий пример, шифрующий байты тривиальной операцией XOR по постоянной маске:
simple_crypt(char *src, int mask, int n)
{
int a;
for (a = 0; a < n; a++)
src[a]^=mask;
}
Листинг 22 Пример обработки байтового потока
Поскольку, все байты обрабатываются однородно, – почему бы ни попробовать обрабатывать четыре байта одной командой? В данном случае для этого достаточно лишь "размножить" маску шифрования, скопировав ее в остальные три байта двойного слова.
Правда, еще потребуется предусмотреть возможность обработки блоков, размер которых не кратен четырем (а что, может же сложиться такая ситуация?). Кстати, это очень просто! Достаточно, получив остаток от деления размера блока на четыре, зашифровать оставшиеся "хвост" (если он есть) "вручную", – т.е. по байтам.
Это может выглядеть, например, так:
optimized_simple_crypt(char *src, int mask, int n)
{
int a;
// размножаем байтовую маску для получения двойного слова
supra_mask = mask+(mask<<8)+(mask<<16)+(mask<<24);
// обрабатываем байты двойными словами
for (a = 0; a < n; a += 4)
{
*(int *)src ^= supra_mask; src+=4;
}
// обрабатываем оставшийся "хвост" (если он есть)
for (a = (n & ~3); a < n; a++)
{
*src ^= mask; src += 1;
}
}
Листинг 23 Оптимизированный пример обработки байтового потока двойными словами
Разумеется, такой трюк применим не только к побайтовой шифровке! Оптимизации поддаются также алгоритмы копирования, инициализации, сравнения, поиска, обмена… словом все однородные способы обработки данных.
Обработка "расщепленных" (line-splint) данных
Чтение данных размером в байт, слово и двойное слово, целиком находящихся в одной кэш-линейке сверхоперативной памяти первого уровня, процессоры семейства P6 осуществляют за 1 такт. Если же данные выходят за границу 32- (64-/128-) байтной кэш-линейки и своим "хвостом" попадают в следующую кэш-линейку (см. рис. 0х020), – эта операция отнимает уже от 6 до 12 тактов, а сами данные называются "расщепленными" (от английского line-splint).
Так происходит потому, что: во-первых, процессор не может за один такт считать сразу две кэш-линейки, – хотя кэш-память и двух портовая (т.е. поддерживает параллельную обработку двух кэш-линеек), блок взаимодействия с памятью (Load Unit) способен загружать только одну ячейку за каждый такт. Точнее, полное время загрузки отнимает как минимум три такта, но при благоприятном стечении обстоятельств конвейер спускает по одной ячейка за каждый так, ликвидируя тем самым ее трех тактовую латентность.
Расщепленные данные блокируют конвейер и хвостовые ячейки начинают обрабатываться только после завершения обработки головы. Отсюда: минимальное время загрузки расщепленных данных составляет 2*Load.Unit.Latency == 2*3 == 6 тактов. Во-вторых, обрабатывая расщепленные данные, кэш-контроллер вынужден производить дополнительные расчеты, прикидывая как две половинки объединить в одну, что тоже обходится не бесплатно.
Гораздо лучше справляется с чтением расщепленных данных процессор AMD Athlon, теряющий при этом всего один такт, а то и вовсе не теряющий ничего (хотя, последнее утверждение и вступает в противоречие с документацией, оно подтверждается экспериментально). Это объясняется тем, что Athlon имеет две очереди запросов на загрузку данных из кэш-памяти первого уровня и потому может считывать сразу обе кэш-линейки. А вот с записью расщепленных данных Athlon справляется несравнимо хуже, поскольку очередь на запись у него всего одна. Тем не менее, за счет эффективного и грамотно спроектированной механизма буферизации записи, возникающая при этом задержка приблизительно в полтора раза меньше, чем на P-II/P-III.
На обоих процессорах запись расщепленных
На обоих процессорах запись расщепленных данных вызывает блокировку опережающей записи (store forwarding), что зачастую оборачивается весьма внушительным падением производительности (см "Особенности буферизации записи. Волчьи ямы опережающей записи").
Внимание: некоторые машинные инструкции (в частности MOVAPS) требуют обязательного выравнивания своих операндов. Попытка "скармливания" не выровненных данных (независимо от того, пересекают они границу кэш-линейки или нет) заканчивается выбрасываем исключения. В этом случае, необходимость выравнивания оговаривается в описании данной машинной инструкции.
Взять, например, описание уже упомянутой MOVAPS "…When the source or destination operand is a memory operand, the operand must be aligned on a 16-byte boundary or a general-protection exception (#GP) is generated" ("Когда операнд-источник или операнд-приемник представляет собой "операнд – в – памяти", он должен быть выровнен по 16-байтной границы, в противном случае сработает исключение общей защиты
– general-protection exception #GP").

Рисунок 23 0х020 Если читаемые данные начинаются в одной, а заканчиваются в другой строке кэша, при их обработке возникает задержка.
Обработка результатов измерений
Непосредственные результаты замеров времени исполнения программы в "сыром" виде, как было показано выше, ни на что ни годны. Очевидно, перед использованием их следует обработать. Как минимум откинуть пограничные значения, вызванные нерегулярными наведенными эффектами (ну, например, в самый ответственный для профилировки момент, операционная система принялась что-то сбрасывать на диск), а затем… Затем перед нами встает Буриданова проблема. Мы будет должны либо выбрать результат с минимальным временем исполнения – как наименее подвергнувшийся пагубному влиянию многозадачности, либо же вычислить наиболее типичное время выполнения – как время выполнения в реальных, а не идеализированных "лабораторных" условиях.
Мной опробован и успешно применяется компромиссный вариант, комбинирующий оба этих метода. Фактически я предлагаю вам отталкиваться от среде минимального времени исполнения. Сам алгоритм в общих чертах выглядит так: мы делаем N прогонов программы, а затем отбрасываем N/3 максимальных и N/3 минимальных результатов замеров. Для оставшиеся N/3 замеров мы находит среднее арифметическое, которое и берем за основной результат. Величина N варьируется в зависимости от конкретной ситуации, но обычно с лихвой хватает 9-12 прогонов – большее количество уже не увеличивает точности результатов.
Одна из возможных реализаций данного алгоритма приведена ниже:
unsigned int cycle_mid(unsigned int *buff, int nbuff)
{
int a,xa=0;
if (!nbuff) nbuff=A_NITER;
buff=buff+1; nbuff--; // Исключаем первый элемент
if (getargv("$NoSort",0)==-1)
qsort(buff,nbuff,sizeof(int), \
(int (*)(const void *,const void*))(_compare));
for (a=nbuff/3;a<(2*nbuff/3);a++)
xa+=buff[a];
xa/=(nbuff/3);
return xa;
}
Листинг 8 Нахождение средне типичного времени выполнения
Обработка структурных исключений
Приемы, описанные выше, реализуются с без особых усилий и излишних накладных расходов. Единственным серьезным недостатком является их несовместимость со стандартными библиотеками, т.к. они интенсивно используют завершающий символ нуля и не умеют по указателю на начало буфера определять его размер. Частично эта проблема может быть решена написанием "оберток" – слоя переходного кода, "посредничающего" между стандартными библиотеками и вашей программой.
Но следует помнить, что описанные подходы сам по себе еще не защищает от ошибок переполнения, а только уменьшают вероятность их появления. Они исправно работают в том, и только в том случае, когда разработчик всегда помнит необходимости постоянного контроля за границами массивов.
Практически гарантировать выполнение такого требования невозможно и в любой "полновесной" программе, состоящей из сотен и более тысяч строк, ошибки всегда есть. Это – аксиома, не требующая доказательств.
К тому же, чем больше проверок делает программа, тем "тяжелее" и медлительнее получается откомпилированный код и тем вероятнее, что хотя бы одна из проверок реализована неправильно или по забывчивости не реализована вообще!
Можно ли, избежав нудных проверок, в то же время получить высокопроизводительный код, гарантированно
защищенный от ошибок переполнения?
Несмотря на смелость вопроса, ответ положительный, да – можно! И поможет в этом обработка структурных исключений (SEH). В общих чертах смысл идеи следующий – выделяется некий буфер, с обоих сторон "окольцованный" несуществующими страницами памяти и устанавливается обработчик исключений, "отлавливающий" прерывания, вызываемые процессором при попытке доступа к несуществующей странице (вне зависимости от того, был ли запрос на запись или чтение).
Необходимость постоянного контроля границ массива при каждом к нему обращении отпадает! Точнее, теперь она ложится на плечи процессора, а от программиста требуется всего лишь написать несколько строк кода, возвращающего ошибку или увеличивающего размер буфера при его переполнении.
Единственным незакрытым лазом останется возможность прыгнув далеко-далеко за конец буфера случайно попасть на не имеющую к нему никакого отношения, но все-таки существующую страницу. В этом случае прерывание вызвано не будет и обработчик исключений ничего не узнает о факте нарушения. Однако, такая ситуация достаточно маловероятна, т.к. чаще всего буфера читаются и пишутся последовательно, а не в разброс, поэтому, ей можно пренебречь.
Преимущество от использования технологии обработки структурных исключений заключаются в надежности, компактности и ясности, использующего его программного кода, не отягощенного беспорядочно разбросанными проверками, затрудняющими его понимание.
Основной недостаток – плохая переносимость и системно - зависимость. Не всякие операционные системы позволяют прикладному коду манипулировать на низком уровне со страницами памяти, а те, что позволяют – реализуют это по-своему. Операционные системы семейства Windows такую возможность к счастью поддерживают, причем на довольно продвинутом уровне.
Функция VirtualAlloc обеспечивает выделение региона виртуальной памяти, (с которым можно обращаться в точности как и с обычным динамическим буфером), а вызов VirtualProtect позволят изменить его атрибуты защиты. Можно задавать любой требуемый тип доступа, например, разрешить только чтение памяти, но не запись или исполнение. Это позволяет защищать критически важные структуры данных от их разрушения некорректно работающими функциями. А запрет на исполнение кода в буфере даже при наличие ошибок переполнения не дает злоумышленнику никаких шансов запустить собственноручно переданный им код.
Использование функций, непосредственно работающих с виртуальной памятью, воистину позволяет творить настоящие чудеса, на которые принципиально не способны функции стандартной библиотеки Си/Cи ++.
Единственный их недостаток заключается в непереносимости. Однако, эта проблема может быть решена написанием собственной реализации функций VirtualAlloc, VirtualProtect и некоторых других, пускай в некоторых случаях на уровне компонентов ядра, а обработка структурных исключений изначально заложена в С++.
Таким образом, затраты на портирование приложений, построенных с учетом описанных выше технологий программирования, в принципе возможны, хотя и требует значительных усилий. Но эти усилия не настолько чрезмерны, что бы не окупить полученный результат.
Обращайтесь к памяти только когда это действительно необходимо
Наиболее эффективный способ оптимизации обмена с памятью заключается… в отказе от использования памяти. Нет, это не шутка! Большинство приложений используют память крайне нерационально, и грамотная алгоритмизация позволяет значительно умерять их аппетит.
Возьмем, к примеру, такой случай. Пусть у нас имеется текстовой или графический редактор, умеющий, среди прочего осуществлять копирование фрагментов текста (изображения) и их вставку. Традиционно эта задача сводится к вызову memmove (или memcpy), между тем существует масса более элегантных и производительных решений. Задумаемся: а зачем, собственно, вообще дублировать копируемый блок? До тех пор, пока скопированный фрагмент не будет изменен, мы вправе пользоваться ссылкой на оригинальный блок. Это может быть, не очень актуально для текстового редактора, но при обработке графических файлов высокого разрешения порой экономит миллиарды
обращений к памяти.
Более того, если пользователю захотелось изменить скопированный фрагмент, нет нужды дублировать его целиком! Достаточно "расщепить" непосредственно модифицированную часть, соответствующим образом скорректировав ссылки. Конечно, все это значительно "утяжеляет" алгоритм и затрудняет его отладку, но выигрыш стоит того!
Поскольку, данная проблема больше относится к алгоритмизации как таковой, чем к подсистеме памяти вообще, этот вопрос не будет здесь подробно рассматриваться.
Общее время исполнения
Сведения о времени, которое приложение тратит на выполнение каждой точки программы, позволяют выявить его наиболее горячие участки. Правда, здесь необходимо сделать одно уточнение. Непосредственный замер покажет, что по крайней мере 99,99% всего времени выполнения профилируемая программа проводит внутри функции main, но ведь очевидно, что "горячей" является отнюдь не main, а вызываемые ею функции! Чтобы не вызывать у программистов недоумения, профилировщики обычно вычитают время, потраченное на выполнение дочерних функций, из общего времени выполнения каждой функции программы.
Рассмотрим, например, результат профилировки некоторого приложения профилировщиком profile.exe, входящего в комплект поставки компилятора Microsoft Visual C++.
Func Func+Child Hit
Time % Time % Count Function
---------------------------------------------------------
350,192 95,9 360,982 98,9 10000 _do_pswd (pswd_x.obj)
5,700 1,6 5,700 1,6 10000 _CalculateCRC (pswd_x.obj)
5,090 1,4 10,790 3,0 10000 _CheckCRC (pswd_x.obj)
2,841 0,8 363,824 99,6 1 _gen_pswd (pswd_x.obj)
1,226 0,3 365,148 100,0 1 _main (pswd_x.obj)
0,098 0,0 0,098 0,0 1 _print_dot (pswd_x.obj)
В средней колонке (Func + Child Time) приводится полное время исполнения каждой функции, львиная доля которого принадлежит функции main (ну этого следовало ожидать), за ней с минимальным отрывом следует gen_pswd со своими 99,5%, далее идет do_pswd – 98,9% и, сильно отставая от нее, где-то там на отшибе плетется CheckCRC, оттягивая на себя всего лишь 3,0%. А функцией Calculate CRC, робко откусывающей 1,6%, на первый взгляд можно и вовсе пренебречь! Итак, судя по всему, мы имеем три горячих точки: main, gen_pswd и do_pswd (см. рис. graph 0x002).

Рисунок 1 graph 0x002 Диаграмма, иллюстрирующая общее время выполнения каждой из функций.
Кажется мы имеем три горячих точки, но на самом деле это не так.
Впрочем, main можно откинуть сразу. Она – понятное дело – ни в чем не "виновата". Остаются gen_pswd и do_pswd. Если бы это были абсолютно независимые функции, то горячих точек было бы и впрямь две, но в нашем случае это не так. И, если из полного времени выполнения функции gen_pswd, вычесть время выполнения ее дочерней функции do_pswd у матери останется всего лишь… 0,8%. Да! Меньше процента времени выполнения!
Обратимся к крайней левой колонке таблицы профилировщика (funct time), чтобы подтвердить наши предположения. Действительно, в программе присутствует всего лишь одна горячая точка – do_pswd, и только ее оптимизация способна существенно увеличить быстродействие приложения.

Рисунок 2 graph 0x003 Диаграмма, иллюстрирующие чистое время работы каждой из функций (т.е. с вычетом времени дочерних функций). Как видно, в программе есть одна, но чрезвычайно горячая точка.
Хорошо, будем считать, что наиболее горячая функция определена и теперь мы горим желанием ее оптимизировать. А для этого недурно бы узнать картину распределения температуры внутри самой функции. К сожалению, профилировщик profile.exe (и другие подобные ему) не сможет ничем нам помочь, поскольку его разрешающая способность ограничивается именно функциями.
Но, на наше счастье существуют и более продвинутые профилировщики, уверенно различающие отдельные строки и даже машинные команды! К таким профилировщикам в частности относится VTune от Intel. Давайте запустим его и заглянем внутрь функции do_pswd (подробнее о технике работы с VTune см. "Практический сеанс профилировки с VTune").
Line Clock ticks Source temperature
105 729 while((++pswd[p])>'z'){ **************************>>>
106 14 pswd[p] = '!'; **************
107 1 y = y | y << 8; *
108 2 x -= k; **
109 k = k << 8; *
110 3 k += 0x59; ***
111 2 p++; **
112 1 } *
Листинг 1 Карта распределения "температуры" внутри функции do_pswd, полученная с помощью профилировщика VTune.
Вот теперь совсем другое дело – сразу видно, что целесообразно оптимизировать, а что и без того уже вылизано по самые помидоры. Горячие точки главным образом сосредоточены вокруг конструкции pswd[p], – она очень медленно выполняется. Почему? Исходный текст не дает непосредственного ответа на поставленный вопрос и потому совсем не ясно: что конкретно следует сделать для понижения температуры горячих точек.
Приходится спускаться на уровень "голых" машинных команд (благо VTune это позволяет). Вот, например, во что компилятор превратил безобидный на вид оператор присвоения pswd[p] = '!'
Line Instructions Cycles Count temperature
107 mov edx, DWORD PTR [ebp+0ch] 143 11 *****************************
107 ^ загрузить в регистр EDX указатель pswd
107 add edx, DWORD PTR [ebp-4] 22 11 *****
107 ^ сложить EDX с переменной p
107 mov BYTE PTR [edx], 021h 33 11 *******
107 ^ по полученному смещению записать значение 0х21 ('!')
Листинг 2 Исследование температуры машинных команд внутри конструкции pswd[p]='!'
Смотрите! В одной строке исходного текста происходит целых три обращения к памяти! Сначала указатель pswd загружается в регистр EDX, затем он суммируется с переменной p, которая так же расположена в памяти, и лишь затем по рассчитанному смещению в память благополучно записывается константа '!' (021h). Тем не менее, все равно остается не ясно почему загрузка указателя pswd занимает столько времени. Может быть, кто-то постоянно вытесняет pswd из кэша, заставляя процессор обращаться к медленной оперативной памяти? Так ведь нет! Программа работает с небольшим количеством переменных, заведомо умещающихся в кэше второго уровня.
Обсуждение результатов тестирования
Итак, тестирование началось… Прогон "подопытных" примеров на процессорах Intel Pentium-III 733 и AMD Athlon 1.400 (см. рис. 1, рис. 2) говорит о достаточно высоком качестве кодогенерации современных компиляторов. В среднем (за вычетом особо оговариваемых исключений) производительность откомпилированных программ лишь на 20%?30% уступает вручную оптимизированному ассемблеру. Конечно, это весьма внушительная величина (особенно, если вспомнить, что эталонная ассемблерная программа достаточно далека от идеала). Эй, кто там говорил, что машинная оптимизация уступает человеку не более одно-двух процентов?! А ну подать сюда этого человека!
С другой стороны, разрыв производительности (за редкими исключениями) все же не настолько велик, чтобы перенос программы на ассемблер приводил к качественным изменениям.
А теперь обо всем этом подробнее. Как и следовало ожидать, наибольший разрыв в производительности наблюдается на копировании памяти. Впрочем, этот разрыв значительно сокращается с ростом тактовой частоты процессора. Если на P-III 733 наименьшее отставание составило целых 25%, то на Athlon 1.400 – всего 9%! Едва ли последняя цифра нуждается в комментариях – Microsoft рулит и жизнь прекрасна. Быстрота современных процессоров, помноженная на мощь современных компиляторов – и никаких ассемблерных вставок! Конечно, не все компиляторы одинаково хороши. Так, WATCOM – вообще в осадке; Borland уверенно держит позиции на Intel, но генерирует несколько неоптимальный код с точки зрения AMD.
С поиском минимума все компиляторы справились одинаково хорошо, а Microsoft Visual C++ вообще построил идеальный по своей красоте код, лишь из-за досадной случайности не дотянувшийся до 100% результата, – начало цикла пришлось на наихудший с точки зрения микропроцессора адрес: 0х4013FF. "Благодаря" этому каждая итерация облагается несколькими штрафными тактами, что, в конечном счете, выливается во вполне весомые потери. Чаще всего, впрочем, судьба оказывается не столь жестока, и код, сгенерированный компилятором, исполняется достаточно эффективно.
Однако нет никаких гарантий, что даже малейшее изменение программы, (да, да, – в том числе и выкидывание лишнего кода!), не ухудшит ее производительности (причем, под час весьма значительно). Увы, в этом смысле компиляторы все еще тупы до безобразия. Они либо вовсе не выравнивают переходы, либо выравнивают все
переходы, что неоправданно увеличивает размер программы и нередко дает обратный эффект, многократно снижая ее производительность (если программа в результате такого распухания не поместится в кэш). Между тем, правильное решение – выравнивать лишь часто выполняемые переходы, в частности циклы, но – увы – ни в одном известном мне компиляторе это не реализовано.
Заметно лучше сложилась ситуация с сортировкой. Компилятор Microsoft Visual C++ отстает от ассемблерного кода всего лишь на 13%-14%. За ним с минимальным отрывом идет Borland C++ со своими 15% и 24% для Athlon 1.400 и P-III 733 соответственно. Последнее место занимает WATCOM, ни в чем не уступающий Borland'у на Pentium'e, но безапелляционно сдающий свои позиции на Athlon'е. Ну не виноват он, что создавался в ту далекую эпоху, когда и процессоры, и техника оптимизации были совсем другими! В целом, WATCOM неплохой, но безнадежно устаревший оптимизатор, и любовь к нему (у тех, у кого она имеется) не должна слепить глаза, сегодня WATCOM'ом – уже не самый лучший выбор.
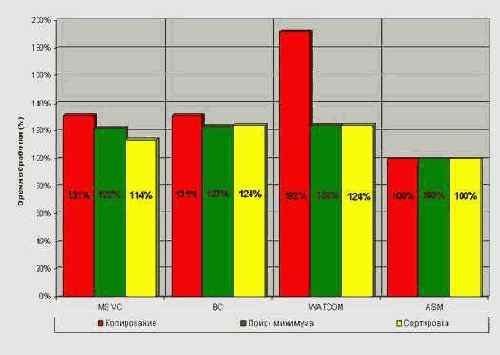
Рисунок 3 0х001 Сравнение качества машинной кодогенерации по скорости на Intel P-III 733

Рисунок 4 0х002 Сравнение качества машинной кодогенрации по скорости на AMD Athlon-1.400
Перейдем теперь к сравнению размера откомпилированного и ассемблерного кода. Первое, что бросается в глаза (см. рис. 3), – весьма внушительный отрыв Microsoft Visual C++ от своих конкурентов. Однако и он отстает от "ручного" кода, не дотягивая по меньшей мере 23%. Причем, по мере упрощения задач этот разрыв резко увеличивается, достигая в случае примера с копированием памяти целых 76%! Ух, ты! Ассемблерная реализация оказалась практически вдвое короче!
У конкурентов же ситуация еще хуже. Значительно хуже. Грубо говоря, можно утверждать, что перенос программы на ассемблер как минимум сокращает ее размер раза в полтора-два. Тем не менее, два раза – это не триста и с этим вполне можно жить.

Рисунок 5 0x003 Сравнение качества машинной кодогенерации по размеру
Операции с сентенциями
"Горячая" клавиша <Shift-Alt-L> удаляет весь текст, расположенный справа от курсора до следующей сентенции (пустой строки). Если пустые строки вставлены в листинг "с умом", – эта операция может оказаться весьма полезной.
Команды "SentenceLeft" и "SentenceRight" перемещают курсор на следующую и предыдущую сентенцию соответственно.
Операции со строками и словами
Клавишная комбинация <Shift-Alt-T> меняет местами текущую и предыдущую строку, что в некоторых ситуациях оказывается весьма сподручно. Ее ближайшая родственница <Shift-Ctrl-T> отличается лишь тем, что меняет местами не строки, а слова.
Пара команд "LineIndent" и "LineUnindent" сдвигают текущую строку на одну позицию табуляции назад и вперед соответственно. Какая от этого выгода? Не легче ли нажать <Tab> иди <Del>? Нет, не легче, и вот почему – указанные команды не требуют перемещать курсор в начало строки и выполняются из любой ее точки, что, согласитесь, ощутимо экономит время.
Команда "IndentToPrev" выравнивает текущую строку по образу и подобию предыдущей, что значительно упрощает форматирование листинга. Ее ближайшая родственница – "IndentSelectionToPrev", как и следует из ее названия, выравнивает сразу весь выделенный блок, что еще удобнее!
Определение количества вызовов
Как мы только что показали, определение количества вызовов профилируемой точки необходимо уже хотя бы для того, чтобы мы могли убедиться в достоверности изменений. К тому же, оценивать температуру точки можно не только по времени ее выполнения, но и частоте вызова.
Например, пусть у нас есть две "горячие" точки, в которых процессор проводит одинаковое время, но первая из них вызывается сто раз, а вторая – сто тысяч раз. Нетрудно догадаться, что оптимизировав последнюю хотя бы на 1% мы получим колоссальный выигрыш в производительности, в то время как сократив время выполнение первой из них вдвое, мы ускорим нашу программу всего лишь на четверть.
Часто вызываемые функции в большинстве случаев имеет смысл инлайнить
(от английского in-line), т.е. непосредственно вставить их код в тело вызываемых функций, что сэкономит какое-то количество времени.
Определять количество вызовов на умеют практически все профилировщики, и тут нет никаких проблем, заслуживающих нашего внимания.
Определение предпочтительной кэш-иерархии
Народная мудрость "положишь подальше – возьмешь поближе" в отношении предвыборки данных практически всегда неверна. Чем ближе к процессору в кэш-иерархии расположены данные, тем быстрее они могут быть получены. Т.е. если уж и осуществлять предвыборку – то предпочтительнее всего в кэш первого уровня (редкие исключения из этого правила будут рассмотрены ниже).
Если данные используются многократно, их предвыборку желательно осуществлять в кэш-уровни всех иерархий, – тогда при вытеснении из кэша первого уровня, данные за короткое время будут получены из кэша второго уровня и процессору не придется обращаться к медленной оперативной памяти. Напротив, однократно используемые данные (равно как и данные, гарантированно не вытесняемые из кэша первого уровня), загружать в кэш второго уровня нецелесообразно, особенно если в нем в это время хранится нечто полезное.
Сказанное в высшей степени справедливо для P-III, но не совсем верно в отношении P-4 (вернее, не верно совсем). Поскольку, вместо загрузки данных в кэш первого уровня, P-4 помещает их в первый банк кэша второго уровня, особенной свободы выбора у программистов и нет. И единственное отличие между командами prefetchnta и prefetchtx
заключается в том, что prefetchnta не может вытеснить из кэша второго уровня более одной восьмой объема его данных. (А по закону бутерброда вытесняются именно те данные, которые вам нужнее всего).
На K6 (VIA C3) никаких проблем с определение предпочтительной кэш-иерархии нет, поскольку нет и самой возможности ее выбора – данные всегда загружаются в кэш-уровни всех иерархий, вытесняя содержимое L2-кэша еще интенсивнее, чем на P-4! Поэтому, разработчики, оптимизирующие свои программы под K6\C3 не найдут в этой главе для себя ничего интересного.
Но довольно теории, перейдем к конкретным примерам. Вернемся к листингу N???2. Достаточно очевидно, что совершенно все равно: какой командой предвыборки пользоваться – prefetchnta или prefetcht0, поскольку к каждой ячейке обращение происходит лишь однократно, а в кэше второго уровня не хранится никаких ценных данных, которые было бы жалко вытеснять. (Впрочем, не стоит забывать, что в многозадачных операционных системах кэш приходится делить между несколькими приложениями и без острой надобности затирать его содержимое, право же, не стоит).
Достаточно лишь воспользоваться командой предвыборки не временных данных, убивая одним выстрелом двух зайцев наповал. Во-первых, предвыборка избавляет нас от ожидания загрузки ячеек блока BLOCK2, а, во-вторых, она позволяет подгружать блок BLOCK2 напрямую в кэш первого уровня (на P-4 в первый банк кэша второго уровня), не затирая содержимого блока BLOCK1, хранящегося в L2-кэше. (На P-4, – увы, – блок BLOCK1 все же будет частично затираться).
Следовательно, в данном случае выгоднее всего воспользоваться инструкцией prefetchnta, а не prefetchtx, поскольку она не затирает (на P-4 минимально затирает) кэш второго уровня:
for(...)
for(c=0;c<BLOCK2_SIZE;c+=STEP_SIZE)
{
// Обрабатываем блок BLOCK1 (находящийся в L2-кэше).
// Предвыборка в L1 кэш не нужна, т.к. это все равно
// не увеличит производительности, ввиду того, что на
// P-III время доступа к кэшу второго уровня
// пренебрежительно мало, а P-4 и вовсе не позволяет
// грузить данные в кэш первого уровня
b+=p1[d]; if ((d+=32) > BLOCK1_SIZE) d=0;
// Перед тем как заняться вычислениями отдаем команду на
// предвыборку данных блока BLICK2 в L1-кэш (в L2 на P-4)
// Во-первых, избавляясь тем самым от ожидания загрузки
// данных из медленной оперативной памяти, а во-вторых,
// предотвращая вытеснение данных блока BLOCK1 из L2-кэша
_prefetchnta(p2+c+STEP_SIZE);
// Обратите внимание, что загружаются данные, обращение
// к которым произойдет только в следующей итерации.
// Почему именно так? Дело в том, что время загрузки
// превышает время вычисления "b+=b % (c+1)" и...
// Загружая данные следующей итерации, мы теряем лишь
// первую итерацию цикла, а не через одну,
// как может показаться в начале, т.к. этот прием вполне
// законен и обеспечивает максимальный прирост
// быстродействия.
b+=b % (c+1);
// Теперь данные загружаются из L1-кэша! (из L2 на P-4)
b+=p2[c];
}
Листинг 23 Оптимизированный вариант с использованием предвыборки не временных данных
На P-III использование prefetchnta на 40% увеличивает производительность, в то время как prefetcht0 – на 20%, на prefetcht1 на 50% уменьшает ее, что и не удивительно, т.к. предвыборка временных данных приводит к вытеснению из кэша второго уровня содержимого блока BLOCK1, ничего не давая взамен. (см. рис. 0х016)

Рисунок 41 graph 0x016 Влияние различных типов предвыборки на производительность различных приложений
Определение ситуаций предпочтительного использования ассемблера
Наконец-то, мы вплотную подошли к ответу на главный вопрос: в каких именно случаях обращение к ассемблеру целесообразно, а в каких – нет. Часто программист (даже высококвалифицированный!) обнаружив профилировщиком "узкие" места в программе, автоматически принимает решение о переносе соответствующих функций на ассемблер. А напрасно! Как мы уже убедились, разница в производительности между ручной и машинной оптимизацией в подавляющем большинстве случаев очень невелика. Очень может статься так, что улучшать уже нечего, – за исключением мелких, "косметических" огрехов, результат работы компилятора идеален и никакие старания не увеличат производительность, более чем на 3%–5%. Печально, если это обстоятельство выясняется лишь после
переноса одной или нескольких таких функций на ассемблер. Потрачено время, затрачены силы… и все это впустую. Обидно, да?
Прежде, чем приступать к ручной оптимизации не мешало бы выяснить: насколько не оптимален код, сгенерированный компилятором, и оценить имеющийся резерв производительности. Но не стоит бросаться в другую крайность и полагать, что компилятор всегда генерирует оптимальный или близкий к тому код. Отнюдь! Все зависит от того, насколько хорошо вычислительный алгоритм ложиться в контекст языка высокого уровня. Некоторые задачи решаются одной машинной инструкцией, но целой группой команд на языках Си и Паскаль. Наивно надеяться, что компилятор поймет физический смысл компилируемой программы и догадается заменить эту группу инструкций одной машинной командой. Нет! Он будет тупо транслировать каждую инструкцию в одну или (чаще всего) несколько машинных команд, со всеми вытекающими отсюда последствиями…
Итак, правило номер один. Прежде, чем оптимизировать код, обязательно следует иметь надежно работающий не оптимизированный вариант. Создание оптимизированного кода "на ходу", по мере написания программы, невозможно! Такова уж специфика планирования команд – внесение даже малейших изменений в алгоритм практически всегда оборачивается кардинальными переделками кода.
Потому, приступайте к оптимизации только после тренировки на "кошках", – языке высокого уровня. Это поможет пояснить все неясности и темные места алгоритма. К тому же, при появлении ошибок в программе подозрение всегда падает именно на оптимизированные участки кода (оптимизированный код за редкими исключениями крайне ненагляден и чрезвычайно трудно читаем, потому его отладка – дело непростое), – вот тут-то и спасает "отлаженная кошка". Если после замены оптимизированного кода на неоптимизированный ошибки исчезнут, значит, и в самом деле виноват оптимизированный код. Ну, а нет, – ищите их где-нибудь в другом месте.
Правило номер два. Не путайте оптимизацию кода и ассемблерную реализацию. Обнаружив профилировщиком узкие места в программе, не торопитесь переписывать их на ассемблер. Сначала убедитесь, что все возможное для увеличения быстродействия кода в рамках языка высокого уровня уже сделано. В частности, следует избавиться от прожорливых арифметических операций (особенно обращая внимание на целочисленное деление и взятие остатка), свести к минимуму ветвления, развернуть циклы с малым количеством итераций… в крайнем случае, попробуйте сменить компилятор (как было показано выше – качество компиляторов очень разниться друг к другу). Если же все равно останетесь недовольны результатом тогда…
Правило номер три. Прежде, чем переписывать программу на ассемблер, изучите ассемблерный листинг компилятора на предмет оценки его совершенства.
Возможно, в неудовлетворительной производительности кода виноват не компилятор, а непосредственно сам процессор или подсистема памяти, например. Особенно это касается наукоемких приложений, жадных до математических расчетов и графических пакетов, нуждающихся в больших объемах памяти. Наивно думать, что перенос программы на ассемблер увеличит пропускную способность памяти или, скажем, заставит процессор вычислять синус угла быстрее. Получив ассемблерный листинг откомпилированной программы (для Microsoft Visual C++, например, это осуществляется ключом "/FA"), бегло просмотрите его глазами на предмет поиска явных ляпов и откровенно глупых конструкций наподобие: "MOV EAX,[EBX]\MOV [EBX],EAX".
Обычно гораздо проще не писать ассемблерную реализацию с чистого листа, а вычищать уже сгенерированный компилятором код. Это требует гораздо меньше времени, а результат дает ничуть не худший.
Правило номер четыре. Если ассемблерный листинг, выданный компилятором, идеален, но программа без видимых причин все равно исполняется медленно, не отчаивайтесь, а загрузите ее в дизассемблер. Как уже отмечалось выше, оптимизаторы крайне неаккуратно подходят к выравниванию переходов и кладут их куда глюк на душу положит. Наибольшая производительность достигается при выравнивании переходов по адресам, кратным шестнадцати, и будет уж совсем хорошо, если все тело цикла целиком поместиться в одну кэш-линейку (т.е. 32 байта). Впрочем, мы отвлеклись. Техника оптимизации машинного кода – тема совершенно другого разговора. Обратитесь к документации, распространяемой производителями процессоров – Intel и AMD.
Правило номер пять. Если существующие команды процессора позволяют реализовать ваш алгоритм проще и эффективнее, – вот тогда действительно, тяпнув для храбрости пивка, забросьте компилятор на полку и приступайте к ассемблерной реализации с чистого листа. Однако с такой ситуацией приходится встречаться крайне редко, и к тому же не стоит забывать, что вы – не на одиноком острове. Вокруг вас – огромное количество высокопроизводительных, тщательно отлаженных и великолепно оптимизированных библиотек. Так зачем же изобретать велосипед, если можно купить готовый?
И, наконец, последнее правило номер шесть. Если уж взялись писать на ассемблере, пишите максимально "красиво" и без излишнего трюкачества. Да, недокументированные возможности, нетрадиционные стили программирования, "черная магия", – все это безумно интересно и увлекательно, но… плохо переносимо, непонятно окружающим (в том числе и себе самому после возращения к исходнику десятилетней давности) и вообще несет в себе массу проблем. Автор этих строк неоднократно обжигался на своих же собственных трюках, причем самое обидное, что трюки эти были вызваны отнюдь не "производственной необходимостью", а… ну, скажем так, "любовью к искусству".За любовь же, как известно, всегда приходится платить. Не повторяете чужих ошибок! Не брезгуйте комментариями и непременно помещайте все ассемблерные функции в отдельный модуль. Никаких ассемблерных вставок – они практически непереносимы и создают очень много проблем при портировании приложений на другие платформы или даже при переходе на другой компилятор.
Единственная предметная область, не только оправдывающая, но, прямо скажем, провоцирующая ассемблерные извращения, это – защита программ. О чем мы и поговорим ниже…
Определение степени покрытия
Вообще-то говоря, определение степени покрытия не имеет никакого отношения к оптимизации приложений и это – побочная функция профилировщиков. Но, поскольку она все-таки есть, мораль обязывает автора рассмотреть ее – пускай и кратко.
Итак, покрытие – это процент реально выполненного кода программы в процессе его профилировки. Кому нужна такая информация? Ну, в первую очередь, тестерам, – должны же они убедиться, что весь код приложения протестирован целиком и в нем не осталось никаких "темных" мест.
С другой стороны, оптимизируя программу очень важно знать какие именно ее части были профилированы, а какие нет. В противном случае многих "горячих" точек можно просто не заметить только потому, что соответствующие им ветки программы вообще ни разу не получили управления!
Рассмотрим, например, как может выглядеть протокол покрытия функций, сгенерированный профилировщиком profile.exe для нашего тестового примера pswd.exe (о самом тестовом примере см. "Практический сеанс профилировки с VTune")
Program Statistics ; Статистика по программе
------------------
Command line at 2002 Aug 20 03:36: pswd ; командная
строка
Call depth: 2 ; глубина вызовов: 2
Total functions: 5 ; всего
функций: 5
Function coverage: 60,0% ; покрыто
функций: 60%
Module Statistics for pswd.exe ; статистика
по модулю pswd
------------------------------
Functions in module: 5 ; функций
в модуле: 5
Module function coverage: 60,0% ; функций
прокрыто: 60%
Covered Function ; порытые функции
----------------
. _DeCrypt (pswd.obj)
. __real@4@4008fa00000000000000 (pswd.obj)
* _gen_pswd (pswd.obj)
* _main (pswd.obj)
* _print_dot (pswd.obj)
Тут на чистейшем английском языке написано, что лишь 60% функций получили управление, а остальные 40% не были вызваны ни разу! Разумно убедиться: а вызываются ли эти функции когда ни будь вообще или представляют собой "мертвый" код, который можно безболезненно удалить из программы, практически на половину уменьшив ее в размерах?
Если же эти функции при каких-то определенных обстоятельствах все же получают управление, нам необходимо проанализировать исходный код, чтобы разобраться: что же это за обстоятельства и воссоздать их, чтобы профилировщик смог прогнать и остальные участки программы. Имена покрытых и непокрытых функций перечислены в секции Cover Function. Покрытые отмечаются знаком "*", а непокрытые – "."
Вообще же, для определения степени покрытия существует множество узкоспециализированных приложений (например, NuMega Code Coverage), изначально заточенных именно под эту задачу и со своей работой они справляются намного лучше любого профилировщика.
Оптимизация блочных алгоритмов
Если с потоковыми алгоритмами все было предельно просто (хотя и не без тонкостей), то оптимизация блочных алгоритмов – вещь сама по себе нетривиальная. Если потоковая обработка данных предполагает, что данные запрашиваются последовательно и ничего не стоит организовать оптимальную (с точки зрения подсистемы памяти) трансляцию виртуальных адресов, то блочные алгоритмы могут в хаотичном порядке запрашивать любые ячейки в границах отведенного им блока. До тех пор, пока размер блока не превосходит эти пресловутые (N? 1)c – т.е. составляет порядка 4х-6ти килобайт, – никаких проблем не возникает, особенно если разрядность обрабатываемых данных сопоставима с величиной пакетного цикла обмена с память. В противном случае, возникают штрафные задержки при попадании в регенерирующиеся DRAM-банки, плюс издержки от упреждающего чтения данных к которым никто не обращается.
В идеале следовало бы посоветовать сократить размер блоков до нескольких килобайт, но – увы – такое решение не всегда возможно. Что ж, тогда придется прибегать к механизму виртуализации адресов. Пусть слово "виртуальный" не вводит вас в заблуждение относительно механизма реализации такого приема. Для этого вовсе не обязательно иметь наивысшие привилегии и доступ к системным таблицам. Виртуальную трансляцию вполне можно организовать и программным способом, один из которых мы уже рассмотрели выше при оптимизации потоковых алгоритмов.
К сожалению, эта тема не имеет прямого отношения к подсистеме оперативной памяти, и не может быть подробно рассмотрена в рамках этой книги. Давайте отложим этот вопрос по крайней мере до третьего тома.
Спекулятивная загрузка данных Алгоритм спекулятивной загрузки данных родился в те незапамятные времена, когда вычислительными залами владели "динозавры", а роль внешней памяти выполняла до ужаса тормозная магнитная лента. Первые программы работали приблизительно так: ЗАГРУЗИТЬ БЛОК ДАННЫХ С ЛЕНТЫ, ОБРАБОТАТЬ ДАННЫЕ, ПОВТОРИТЬ. Во время загрузки данных бобины с лентой бешено вращались, а на время вычислений покорно останавливались.
На обывателя это зрелище, действительно, действовало неотразимо, но для достижения наибольшей производительности ленточный накопитель должен работать не урывками, а непрерывно.
История не сохранила имя первого человека, которого осенила блестящая мысль: совместить обработку данных с загрузкой следующего блока. Если время выполнения не оптимизированной программы в общем случае равно: T = N*(Ttype + Tdp), где Type – время загрузки блока данных с ленты, Tdp
– время обработки блока, а N – количество блоков, то оптимизированный алгоритм может быть выполнен за: Toptimize = N*(max((Ttype + Tdp))).
Максимальный выигрыш достигается в том случае, когда время загрузки данных с ленты в точности равно времени вычислений. Как нетрудно подсчитать: T/Toptimize = N*(Ttype + Tdp)/ N*Ttype
== 2, т.е. время обработки сокращается в два раза.
И хотя бобины магнитной ленты уже давно вышли из употребления, – они до сих пор готовы преподнести всем нам хороший урок. Задумайтесь: как работает подавляющее большинство современных блочных алгоритмов? Какую программу ни возьми, всюду встречаешь сценарий: "загрузить – обработать – повторить". Пускай, быстродействие оперативной памяти не идет ни в какое сравнение со скоростью магнитной ленты, но ведь и тактовая частота процессоров не стоит на месте!
Простое смешивание команд загрузки содержимого ячеек памяти с вычислительными инструкциями (подробнее см. "Группировка вычислений с доступом к памяти") еще не обеспечивает их параллельного выполнения, – ведь вычислительные инструкции начинают выполняться только после окончания загрузки обрабатываемых данных!
Вспоминая сценарий работы с лентой, давайте усовершенствуем стратегию загрузки данных, обращаясь к следующему обрабатываемому блоку задолго до того, как он будет реально востребован. Этим мы устраним зависимость между командами загрузки и обработки данных, благодаря чему они смогут выполнятся параллельно, и, если время обработки данных не превышает времени их загрузки (как часто и бывает), обмен с памятью станет происходить непрерывно, вплотную приближаясь к ее максимальной пропускной способности. (см.
так же "Параллельная загрузка данных").
Рассмотрим следующий пример:
/*--------------------------------------------------------------------
не оптимизированный вариант
------------------------------------------------------------------- */
for(a = 0; a < BLOCK_SIZE; a += 32)
{
// загружаем ячейки
x += (*(int *)((int ) p + a)); // ß эта команда блокирует все остальные
x += (*(int *)((int ) p + a + 4));
x += (*(int *)((int ) p + a + 8));
x += (*(int *)((int ) p + a + 12));
x += (*(int *)((int ) p + a + 16));
x += (*(int *)((int ) p + a + 20));
x += (*(int *)((int ) p + a + 24));
x += (*(int *)((int ) p + a + 28));
// выполняем некоторые вычисления
x += a/x/666;
}
Листинг 42 Типовой не оптимизированный алгоритм обработки данных
Основной его недостаток заключается в том, что вычислительная процедура "x += a/x/666" вынуждена дожидаться выполнения всех предыдущих команд, а они в свою очередь вынуждены дожидаться окончания загрузки требуемых данных из памяти. Т.е. первая строка цикла "x+=*(int*)((int)p + a)" блокирует все остальные (а еще говорят, что семеро одного не ждут).
Можно ли устранить такую зависимость по данным? Да, можно. Достаточно, например, загружать данные со сдвигом на одну или несколько итераций (подробнее о вычислении предпочтительной величины сдвига см. "Кэш. Предвыборка"). Образно говоря мы как бы смещаем команды загрузки данных относительно инструкций их обработки. (см. рис. 43).

Рисунок 53 0х43 Устранение зависимости по данным путем упреждающей загрузки следующего обрабатываемого блока
В результате этого мы получаем приблизительно следующий код (обратите внимание, исходный текст программы практически не изменен!):
/*--------------------------------------------------------------------
оптимизированный вариант
со спекулятивной загрузкой
------------------------------------------------------------------- */
// загружаем первую порцию данных
x += (*(int *)((int) p + a));
for(a = 0; a < BLOCK_SIZE; a += 32)
{
// упреждающая загрузка очередной порции данных
y = (*(int *)((int) p + a + 32)); // ß ***
// обрабатываем ранее загруженные ячейки
x += (*(int *)((int) p + a + 4));
x += (*(int *)((int) p + a + 8));
x += (*(int *)((int) p + a + 12));
x += (*(int *)((int) p + a + 16));
x += (*(int *)((int) p + a + 20));
x += (*(int *)((int) p + a + 24));
x += (*(int *)((int) p + a + 28));
// выполняем некоторые вычисления
x += a/x/666;
// востребуем упреждено - загруженные данные
x += y;
}
Листинг 43 [Memory/Speculative.read.c] Фрагмент программы, демонстрирующий эффективность использования спекулятивной загрузки данных
На P-III/133/100/I815EP такой несложный трюк уменьшает время обработки данного цикла приблизительно на ~25%.
Почему всего лишь на четверть, а не на половину, как это следует из рис. 43? Причина в том, что команда "x += a/x/666" выполняется вдвое быстрее, чем загрузка следующего блока данных, потому и

Рисунок 54 Univac Компьютер UNIVAC с ленточным накопителем (слева) и женщиной-оператором (справа)
Оптимизация инициализации строк
Компилятор Microsoft Visual C++ выгодно отличается от своих конкурентов – Borland С++ и WATCOM тем, что константные строки он инициирует, "заглатывая" их не байтами, а двойными словами. К тому же, только Microsoft Visual C++ умеет хранить короткие строки в регистрах.
Поэтому, программы, интересно манипулирующие со строками, выгоднее компилировать компилятором Microsoft Visual C++.
Оптимизация константных условий
Константные условия в изобилии встречаются во множестве программ. Например, бесконечный цикл (или цикл с условием в середине) подавляющим большинством программистов объявляется так:
while(1)
{
// тело цикла
}
Логично, что проверка 1 == 1 бессмысленна, и ее можно опустить. Компиляторы Microsoft Visual C++ и WATCOM именно так и поступают, но вот Borland C++ аккуратно проверяет: а равен ли один одному (ну мало ли…).
Оптимизация константных выражений
"Священные войны" вокруг констант и переменных ведутся уже давно[1]. Одни утверждают, что везде, где только можно, следует заменять переменные константами, другие же советуют поступать наоборот – использовать переменные вместо непосредственных значений. Давайте попробуем разобраться с этим вопросом.
Операндом машинной инструкции может быть либо регистр, либо непосредственное значение. В свою очередь, каждый из них может содержать либо готовое значение, либо указатель на ячейку памяти, из которой это значение следует извлечь. Причем, в силу архитектурных ограничений, только один из двух операндов инструкции может обращаться к памяти. Отсюда следует, что непосредственное присвоение одной переменной другой переменной – невозможно.
Приходится сначала загружать содержимое одной переменной в регистр общего назначения, а затем "перебрасывать" его в другую переменную. Платой за такое решение становится увеличение размера кода и снижение его быстродействия, не говоря уже о том, что для этой операции требуется один регистр, а регистры, как известно, нужно беречь, ибо на платформе Intel 80x86 их всего семь.
Замена переменной ее фактическим значением позволяет избавиться от промежуточной пересылки, увеличивая тем самым компактность кода. Однако если к данной переменной обращение происходит неоднократно – гораздо выгоднее поместить ее в регистр. В 32?разрядном режиме это сэкономит в среднем четыре байта на каждое обращение и увеличит скорость выполнения инструкции с двух тактов процессора до одного.
Таким образом, оптимальнее всего использовать следующую стратегию: наиболее интенсивно используемые константные переменные помещать в регистры, и только если свободных регистров нет, заменять переменные их непосредственными значениями.
Оптимизация копирования памяти
Для копирования памяти чаще всего используется штатная функция memcpy, входящая в стандартную библиотеку языка Си. Это очень быстрая функция, подавляющим большинством своих реализаций опирающаяся на команду циклической пересылки "REPMOVSD", копирующую по четыре байта за каждую итерацию. Но в некоторых ситуациях (например, при работе с блоками большого размера) производительности memcpy начинает катастрофически не хватать и у программистов появляется неудержимое стремление ну хоть немного оптимизировать ее.
Попробовать переписать memcpy на ассемблер? – Напрасный труд! Даже удалив весь обвязочный код, обеспечивающий копирование блоков с размером не кратным четырем, вам не удастся выиграть больше чем один-два процента! А вот правильный выбор адреса начала копируемого блока действительно ощутимо улучшает результат. Подтверждение тому – диаграмма, приведенная на рис. 0х017 и иллюстрирующая зависимость скорости копирования блоков памяти (вертикальная ось) от величины смещения относительно начала блока памяти, выделенного функцией malloc
(в данном случае возвращенный ею адрес заведомо кратен 0x10).
Смотрите – большие блоки памяти (т.е. такие, размер которых значительно превосходит кэш второго уровня), начинающиеся с адресов кратным четырем, обрабатываются практически в полтора раза быстрее, а блоки умеренного размера (целиком умещающиеся в кэше второго уровня) – практически втрое быстрее, чем блоки, начинающиеся с адресов, не кратным четырем!
И неудивительно – отсутствие выравнивания приводит к тому, что в каждом октете скопированных двойных слов, неизбежно будет присутствовать двойное слово, начинающиеся в одной кэш-линейке, а заканчивающиеся в другой. Процессоры Pentium шибко не любят такие "не правильные" слова и взыскивают за их обработку штрафные такты задержки.

Рисунок 48 graph 0x017 Зависимость относительной скорости копирования от адреса начала блока на процессоре Pentium-III 733/1333/100. За 100% принято время копирования блоков памяти, начинающихся с адреса, кратного 0х10.
Поэтому, при интенсивном копировании строк (структур, объектов, массивов) желательно добиться, чтобы они располагались в памяти по адресам, кратным четырем. (Подробнее об этом см. "Оптимизация обращения к памяти и кэшу. Выравнивание данных").
Однако в некоторых случаях выполнить выравнивание принципиально невозможно. Это бывает в частности тогда, когда адрес копируемого объекта поступает извне, например, возвращается операционной системой. Впрочем, это не повод для расстройства – увеличив начальный адрес до величины кратной четырем, мы избежим падения производительности. А пропущенный хвост можно скопировать и отдельно. Даже если это и вызовет штрафную задержку, потери времени будут ничтожно малы, т.к. максимальная протяженность "хвоста" никогда не повышает трех байт.
В копировании больших блоков памяти есть еще один фокус. – Если память копируется слева направо (т.е. с увеличением адресов), а скопированный блок обрабатывается от начала к концу (как чаще всего и бывает), то потребуются дополнительные такты ожидания на время пока начало блока не будет загружено в кэш. Если же схитрить и копировать память справа налево (т.е. от больших адресов к меньшим), то по завершению копирования начало блока окажется в кэше и может быть моментально использовано!
Но не спешите набрасываться на инструкцию "STD\REP MOVSD", копирующую двойные слова в обратном направлении! Подсистема памяти IBM PC оптимизирована именно под прямое копирование, а на обратном теряется до десяти-пятнадцати процентов производительности. Поэтому, приходится изощряться, обрабатывая блок справа налево небольшими "кусочками", копируя каждый из них в прямом направлении. Это можно сделать, например, следующим образом:
my_memcpy(char *dst, char *src, int len)
{
int a=STEP_SIZE; // Размер копируемых "кусочков"
while(len) // Копировать пока не скопируем все
{
if (len
< a) a=len; // Если оставшийся хвост меньше размера
// копируемого "кусочка", коррекрируем
// размер последнего
dst-=a;src-=a; // Уменьшаем указатели на
// требуемую величину
memcpy(dst,src,a); // Копируем очередной кусочек
len-=a; // Уменьшаем длину оставшегося блока
}
}
Листинг 35 Оптимизированное копирование памяти с помещением начала копируемого блока в кэш (Пригодно для любых процессоров)
Единственная проблема – правильно выбрать размер копируемых кусочков. С одной стороны: чем кусочки больше – тем лучше, т.к. это уменьшает накладные расходы на "обвязочный" код. А с другой – слишком большой блок может попросту не поместиться в кэш первого уровня (на P-4 его всего лишь восемь килобайт).
Учитывая, что в кэше находится и копируемый, и скопированный блок, размер кусочков не должен превышать половины размера самого маленького их кэшей, т.е. четырех килобайт. Но эта стратегия будет не самой оптимальной для P-III, а для P-II (CELERON) и вовсе окажется проигрышной, т.к. накладные расходы на выполнение обвязочного кода пересилят выигрыш от попадания в кэш.
По мнению автора, память выгоднее всего копировать 64-128 килобайтными кусками. В среднем это дает 10%-15% ускорение по сравнению со штатной функцией memcpy, но в отдельных случаях выигрыш может быть намного большим. Впрочем, размер кусочков нетрудно задавать и опционально – через файл настроек программы, конфигурируемый конечными пользователями (или определять тип и параметры процессора автоматически).
Вот, пожалуй, и все способны оптимизации копирования памяти на младших моделях процессоров Pentium. Гораздо больше существует популярных способов "пессимизации" копирования памяти. В первую очередь хотелось бы обратить внимание на широко распространенное заблуждение, связанное с машинной инструкцией MOVSQ. Эта MMX'овая команда оперирует 64-битными (8 байтовыми) операндами, что делает ее очень привлекательной в глазах множества программистов, наивно полагающих: чем больше размер операнда, тем быстрее происходит его копирование.
На самом же деле это не совсем так. При обработке больших блоков памяти (т.е. таких, размер которых намного превышает размер L2 кэша) на быстрых процессорах (в частности P-III), вы получите не худшую производительность, а на P-II скорость даже снизиться от 1.3 до 1.5 раз! Действительно, производительность MOVSD в первую очередь определяется не быстродействием процессора, а временем доступа к памяти, поэтому при копировании больших блоков памяти MOVSQ с учетом "обвязочного" кода быстрее никак не будет.
Обработка блоков памяти умеренного размера (целиком умещающихся в L2-кэше) посредством команды MOVSQ на P-II на 10%, а на P-III даже на 40% обгоняет MOVSD! Но при дальнейшем уменьшении размера копируемых блоков ситуация меняется на диаметрально противоположную. Блоки, не вылезающие за пределы L1-кэша, с помощью MOVSQ
на P-II копируется на 40%-80% медленнее (накладные расходы на обвязочный код дают о себе знать!), а на P-III лишь на несколько процентов быстрее, чем копируемые MOVSD. (см. рис. 0х21)
Таким образом, функцию копирования, базирующуюся на команде MOVSQ, в качестве основной функции переноса памяти использовать нерационально. Она оправдает себя лишь при многократной обработке блоков порядка 0x40-0x80 килобайт на момент копирования уже находящихся в кэше. В противном случае будет намного лучше воспользоваться шатанной функцией memcpy. (К тому же следует учитывать, что MOVSQ отсутствует на ранних процессорах Pentium без MMX, парк которых до сих пор еще достаточно широк, так стоит ли отсекать большое количество потенциальных пользователей ради незначительного увеличения скорости работы вашей программы?)

Рисунок 49 graph 0x021 Результаты тестирования функции копирования памяти четвертными словами на блоках различного размера на процессорах CELERON-300A/66/66 и Pentium-III 7333/133/100. Скорость копирования измеряется в относительных единицах в сравнении со штатной функцией memcpy, производительность которой принята на 100%.
Другое распространенное заблуждение гласит, что MOVSD вовсе не предел производительности и яко бы вручную можно создать супер-оптимизированный цикл, выполняющийся намного быстрее ее.
Действительно, линейки кэша первого уровня состоят из восьми независимых банков, которые могут обрабатываться параллельно (в частности, процессоры P-II способны за один такт обрабатывать два таких банка) и в правильно организованном цикле за вычетом обвязочного кода теоретически возможно копировать по 8 байт за каждые два такта. Инструкция REP MOVSD за это же время копирует только 4 байта.
На практике, однако, двукратного выигрыша достичь не удается – львиную долю прироста производительности "съедает" обвязочный код. Во всяком случае, автору так и не удалось создать цикл, который бы на всех моделях процессоров обгонял REP MOVSD
хотя бы на десяток-другой процентов. В лучшем случае код выполнялся не хуже, а зачастую в полтора-два раза медленнее штатной функции memcpy!
А, может быть, стоит обратиться к контроллеру DMA (про то, что современные операционные системы прикладным приложениям прав доступа к контроллеру просто не дадут, мы скромно промолчим)? Легенда об использовании DMA для копирования памяти давно уже будоражит умы программистов, но на самом деле она безосновательна. Тип передачи "память à память" ни в оригинальной IBM AT, ни в современных клонах оной не реализован. Возьмем, например, описание чипсета Intel 82801 и откроем его на странице 8-25, где содержится описание режимов передачи. Там, среди прочей полезной информации, мы найдем такие слова:
|
Bit |
Description |
|
3:2 |
DMA Transfer Type. These bits represent the direction of the DMA transfer. When the channel is programmed for cascade mode, (bits[7:6] = "11") the transfer type is irrelevant. 00 = Verify-No I/O or memory strobes generated 01 = Write-Data transferred from the I/O devices to memory 10 = Read-Data transferred from memory to the I/O device 11 = Illegal |
память". А раз его нет, то и говорить не о чем!
Оптимизация копирования в старших моделях процессоров Pentium. Команды управления кэшированием, впервые появившиеся в процессоре P-III, это, выражаясь словами известного юмориста, "не только ценный мех", но и превосходное средство ускорить копирование компактных блоков памяти вчетверо, а умеренных и больших – по крайней мере втрое!
Этот замечательный результат достигается, как ни странно, использованием всего двух команд: инструкции предвыборки данных в кэш первого (второго на P-4) уровня – prefetchnta и инструкции некэшируемой записи восьмерных (!) слов – movntps, выгружающей 128-битные операнды из SIMD-регистра в память. (Внимание: копируемые данные должны быть выровнены по 16-битной границе, в противном случае процессор сгенерирует исключение).
Поскольку, prefetchnta
– не блокируемая инструкция (т.е. молниеносно возвращающая управление задолго до своего фактического завершения), процессор может загружать очередную порцию данных из буфера-источника параллельно с переносом предыдущей порции в буфер-приемник. К тому же такая схема копирования не "загаживает" кэш второго уровня, оставляя скэшированные ранее данные в целости-сохранности, что немаловажно для большинства алгоритмов.
Но, как бы там все ни было хорошо, обязательно помните, что эти команды работают только на P-III+, а на более ранних процессорах (в т.ч. и AMD Athlon) генерируют исключение "неверный опкод".
Поскольку, компьютеры на базе P-II и P-MMX все еще продолжают использоваться (причем, достаточно широко), следует либо создавать отдельные версии программ для новых и старых процессоров (но это увеличит трудности по их тестированию и сопровождению), либо перехватывать исключение "неверный опкод" и программно эмулировать отсутствующие команды (что приведет к очень большим тормозам), либо автоматически определять процессор при старте программы и использовать соответствующую функцию копирования. (Хорошая идея поместить различные версии функций копирования в различные DLL, избавляясь от условных переходов внутри функции).
Последний способ, похоже, наиболее предпочтителен, хотя, все же и он не лишен недостатков.
Новые команды – это, конечно, хорошо, но есть ли от них хоть какая-то польза, пока на рынке не появятся компиляторы, обеспечивающие их поддержку? Ну, во-первых, такие компиляторы уже есть и распространяются самой Intel, а, во-вторых, ничто не мешает программисту использовать ассемблерные вставки в своем любимом компиляторе (правда, не все умеют программировать на ассемблере).
Будет большим заблуждением считать, что поддержка компилятором новых команд автоматически увеличит производительность приложения и вся оптимизация сведется к тривиальной перекомпиляции. Новые команды предлагают новые концепции программирования, что требует кардинального пересмотра алгоритмов программы. А решать алгоритмические задачи до сих пор способен лишь человек – компиляторам это не "по зубам".
Писать программы на ассемблере – тоже не лучший выход. Решение, предложенное Intel, носит компромиссный характер и заключается во введении встроенных операторов (intrinsic), функционально эквивалентных командам процессора, но обладающих высокоуровневым интерфейсом с "человеческим лицом". Например, конструкция "void _mm_prefetch(char *a, int sel)" на самом деле является не функцией, а завуалированным вызовом команды prefetchx. Встретив ее в тексте программы, компилятор отнюдь не станет вызывать подпрограмму, а непосредственно вставит соответствующую инструкцию в код, минимилизируя накладные расходы. (Некоторые операторы заменяются не на одну, а на целую группу совместно употребляемых машинных команд, но сути дела это не меняет).
Подробное описание intrinsic'сов и соответствующих им машинных инструкций можно найти в "Интел Инстракшен Сет" (Instruction Set Reference) и справочном руководстве, прилагаемом к компилятору (Intel C/C++ Compiler User's Guide With Support for the Streaming SIMD Extensions 2). Поясняющие примеры, приведенные в руководстве по оптимизации (Intel Architecture Optimization Reference Manual), в подавляющем большинстве написаны на Си с intrinsic'ами, и для их понимания необходимо знать: какой intrinsic какой команде процессора соответствует (их мнемоники очень часто не совпадают).
Поэтому, обращаться к таблице соответствий придется не зависимо от того: программируете ли вы на чистом ассемблере или Си (Фортране).
Хорошо, Intel справилась с проблемой, но как быть пользователям других компиляторов? Не отказываться же от своих любимых продуктов в угоду прогрессу (тем более, что Intel предоставляет компиляторы всего лишь двух языков – Си\Си++ и Фортрана, к тому же распространяет их отнюдь не бесплатно)!
Выход состоит в использовании ассемблерных вставок, а точнее даже не ассемблерных, а машинно-кодовых, поскольку сомнительно, чтобы ваш любимый транслятор понимал мнемоники, придуманные после его создания. В ассемблерах MASM и TASM ручной ввод кода обычно осуществляется через директиву "DB", а в компиляторах Microsoft Visual C++ и Borland C++ для той же цели служит директива "emit". К сожалению, синтаксис ее вызова различен для каждого из компиляторов, что приводит к проблемам переносимости.
Так, Microsoft Visual C++ предваряет emit одиночным символом прочерка и требует обязательного его помещения в ассемблерный блок. Например:
main()
{
__asm
{
; "рукотворное" создание инструкции INT 0x66 (опокд – CD 66)
_emit 0xCD
_emit 0x66
}
}
Компилятор Borland C++, напротив, предписывает окантовывать emit двойным символом прочерка с обеих сторон и ожидает его появления вне ассемблерного блока. Например:
main()
{
; "рукотворное" создание инструкции INT 0x66 (опокд – CD 66)
__emit__(0xCD, 0x66);
}
Разумеется, ручной ввод машинных кодов команд – утомительное и требующее определенной квалификации занятие. Проблема в том, что "Интел инстракшен сет" содержит лишь базовые опкоды инструкций, без перечисления всех возможных способов адресации. Например, опкод инструкции prefetchnta
выглядит так: 0F 18 /0. Если попытаться задать его с помощью emit как "__emit__(0xF, 0x18, 0x0)", то ничего не получится! (Кстати, это частая ошибка начинающих).
Ведь prefetchnta
ожидает операнда- указателя на адрес памяти, по которому следует произвести предвыборку. Где же он тут? А вот где: обратите внимание, что последний байт опкода инструкции предварен косой чертой – это обозначает, что приведено не все содержимое байта, а лишь те биты, которые хранят опкод инструкции. Остальные же определяют тип адресации, указывая процессору: где именно следует искать ее операнды (операнд).
В рамках данной книги вряд ли было бы целесообразно подробно рассказывать о формате машинных команд, поэтому автору ничего не остается, как отослать всех интересующихся к первым восьми страницам "Интел Инстракшен Сет", где это подробно описано. Во всяком случае, реализации двух необходимых для оптимизации копирования памяти команд, приведены ниже.
// Функция предвыбирает 32-байтовую строку в L1-кэш на P-III
// и 128-байтовую строку в L2-кэш на P-4
// Аналог _mm_prefetch((char*)mem, _MM_HINT_NTA)
__forceinline void __fastcall __prefetchnta(char *x)
{
__asm
{
mov eax,[x]
; prefetchnta [eax]
_emit 0xF
_emit 0x18
_emit 0x0
}
}
// Функция копирует 128-бит (16-байт) из src
в dst.
// Оба указателя должны быть выровнены по 16-байтной границе
// Аналог _mm_stream_ps((float*)dst,_mm_load_ps((float*)&src))
void __forceinline __fastcall __stream_cpy(char *dst,char *src)
{
__asm
{
mov eax, [src]
mov edx, [dst]
; movaps xmm0, oword ptr [eax]
_emit 0xF
_emit 0x28
_emit 0x0
; movntps oword ptr [edx], xmm0
_emit 0xF
_emit 0x2B
_emit 0x2
}
}
Листинг 36 Пример реализации команд процессора P-III+ ассемблерными вставками на Microsoft Visual C++.
Пару слов о способах вызова "рукотворных" команд. Это только кажется, что все просто, а на самом же деле, на этом пути сплошное нагромождение ловушек, трудностей и проблем. Вот только некоторые из них…
Достаточно очевидно, что оформлять одиночные процессорные команды в виде cdecl- или stdcall-функций невыгодно – зачем разбрасываться командами процессора? (Хотя, к чести P-III/P-4 стоит сказать, что при его скорости накладными расходами на вызовы функцией можно безболезненно пренебречь).
Отсюда и появляется квалификатор __forceinline, предписывающий компилятору встраивать вызываемую функцию непосредственно в тело вызывающей.
Правда, компилятор – животное упрямое и душа его – потемки. Встраиванию функции препятствует целый ряд противопоказаний (см. описание квалификатора inline
в прилагаемой к компилятору документации). Так, например, встраиваемыми не могут быть голые (naked) функции – т.е. функции без пролога и эпилога, часто используемые программистами, не полагающимися на удаление избыточного кода оптимизатором.
Кстати, об оптимизаторе. Соглашение Microsoft о быстрых вызовах (см. ключевое слово __fastcall) предписывает передавать первый аргумент функции в регистре ECX, а второй – в EDX. Так почему же в выше приведенных примерах автор перепихивает содержимое первого регистра в EAX, если можно преспокойно обратиться к ECX? Увы, коварство оптимизатора этого не позволяет. Обнаружив, что на аргументы функции явных ссылок нет (и, конечно же, благополучно забыв о регистрах), оптимизатор думает – а на кой передавать эти аргументы, если они не используются? И не только думает, но и не передает! В результате, в регистрах оказывается неинициализированный мусор, и функция, естественно, не работает! К сожалению, любое обращение к аргументам из ассемблерного блока приводит к автоматическому созданию фрейма, адресуемого через регистр EBP, т.е., аргументы функции передаются не через регистры, а через локальные стековые переменные!
Словом, избежать накладных расходов таким путем, увы, не удается… Впрочем, эти расходы не слишком велики и ими, скрепя сердце, можно пренебречь.
С алгоритмом оптимизированного копирования тоже не все безоблачно. Пример реализации, приведенный в "Intel® Architecture Optimization Reference Manual" – руководству по оптимизации под P-II и P-III (Order number 245127-001), содержит множество ошибок (вообще такое впечатление, что это руководство готовили в страшной спешке, – вот что значит первая ревизия!). К тому же, он не оптимален под P-4, а пример, приведенный в руководстве оптимизации по P-4, не оптимален под P-III! Поэтому, просто скопировать код программы в буфер обмена и откомпилировать – не получится.
Хочешь – не хочешь, а приходится доставать мозги с полки и мыслить самостоятельно. Значит, так…
На первом месте, конечно же, должен быть цикл предвыборки, дающий процессору задание на загрузку данных из основной памяти в кэш первого уровня (второго на P-4). Затем, загруженные в кэш данные могут быть мгновенно (в течении одного такта) прочитаны и занесены в SIMD-регистр, по эстафете передаваемый инструкции некэшируемой записи для выгрузки в память. (Использование промежуточного регистра объясняется тем, что адресация типа "память à
память" в микропроцессорах Intel 80x86 отродясь отсутствует).
Остается найти оптимальную стратегию предвыборки и записи. Решение, первым приходящее на ум, – перемежевать операции переноса данных с их предвыборкой, неверно. Правда, объяснить: почему оно неверно "на пальцах", не углубляясь в тонкости реализации шинных транзакций, невозможно. В общих чертах дело обстоит так: системная шина у процессора одна, но запросы на чтение/запись памяти делятся на множество фаз, которые могут перекрывать друг друга. Полного параллелизма в такой схеме, естественно, не достигается и неупорядоченная обработка запросов несет свои издержки. Уменьшение количества транзакций между чтением и записью данных позволяет значительно ускорить доступ к памяти, что, в свою очередь, существенно увеличивает производительность системы.
Следовательно, целесообразнее выполнять предвыборку в одном, а копировать память в другом цикле. Но, вот вопрос, – какими кусками "нарезать" память? В приведенном ею примере Intel рекомендует выбрать размер блока равным размеру кэша первого уровня для P-III и половине кэша второго для P-4 (т.к. у него команда предвыборки умеет загружать данные только в этот кэш). В то же время, описывая команду предвыборки в руководстве по оптимизации под P-4, Intel остерегает пересекать 4-килобайтовую границу страниц при предвыборке. (Такое впечатление, что авторы технической документации из Intel понимают в выпускаемых их фирмой процессорах меньше, чем сторонние разработчики).
Итак, у нас имеются два противоречащих друг другу утверждения, – какому же из них верить? Но зачем, собственно, верить? Наука – она тем от религии и отличается, что в первую очередь полагается не на авторитеты и логические умозаключения, а на эксперимент. Эксперимент же недвусмысленно скажет, что наилучшая производительность достигается при предвыборке блоков размером в 4 килобайта – т.е. одной страницы, а при увеличении размера начинает стремительно падать.
Так, с этим мы разобрались. Идем дальше. Реализация цикла предвыборки (между нами говоря) представляет собой достойный увековечивания пример как не надо программировать. Смотрите сами: "for (j=kk+4; j<kk+CACHESIZE; j+=4)". То, что вместо CACHESIZE
должно стоять PAGESIZE, мы уже выяснили, но вот величина шага приращения цикла очень интересна. Теоретически она должен быть равна размеру предвыбираемой строки – 32 байта на P-III и 128 байт на P-4. Откуда же здесь взялась четверка? Дело в том, что данный пример копирует массив, состоящий из элементов типа double, каждый из которых имеет размер 8 байт (про sizeof парни из Intel, конечно же, забыли), а 8 x 4 == 32! А если придется копировать данные другого типа? Так не лучше ли перейти от частностей к бестиповым указателям void? К тому же, данная реализация процессорно-зависима и не оптимальна на P-4. Правильным решением будет определять тип процессора при старте программы и выбирать соответствующий ему шаг цикла – 32 байта на P-III и 128 байт на P-4.
Следующий на очереди цикл копирования памяти. В Intel'ом примере допущена еще одна грубая ошибка (не иначе, как документацию писали под пивом) – "for (j=kk; j<kk+CACHESIZE; j+=4)" – конечно же, здесь должно быть не CACHESIZE, а, по крайней мере, CACHESIZE/sizeof(double), а точнее даже – PAGESIZE/sizeof(double). Этот ляп исправлен лишь в руководстве по оптимизации под P-4, где вместо CACHESIZE
фигурирует NUMPERPAGE
– количество элементов на страницу. Это уже лучше, но все же остается непонятным стремление авторов документации любой ценой избежать обращения к sizeof.
Тело цикла состоит из нескольких подряд идущих команд переноса 128-битного (16-байтового) блока памяти – в примере из руководства по P-III их два, а P-4 – аж восемь! Вакх! Зачем нам столько, когда достаточно и одной? А затем – чем больше операций копирования выполняется в каждой итерации цикла, тем меньше накладные расходы на организацию этого цикла. Различие же в количестве операций в обоих процессорах объясняется тем, что на P-III размер кэш-линий равен 32 байтам, а на P-4 – 128.
Поскольку, каждая операция копирования переносит 16 байт памяти, легко видеть, что в обоих случаях за одну итерацию цикла кэш-линия обрабатывается целиком, а задержки, связанные с поддержкой цикла, приурочиваются к переходу на следующую кэш–линию, что обеспечивает максимально возможную производительность. Любопытно, что цикл переноса памяти, оптимизированный под P-4, ничуть не хуже чувствует себя и на P-III, а вот пример, оптимизированный под P-III, попав на P-4, показывает далеко не лучший результат. Универсальным решением будет перенос 128–байтного блока памяти за каждую итерацию – это оптимально для обоих процессоров.
Теперь остается решить лишь технические проблемы. Во-первых, рассмотреть случай копирования блока памяти, размер которого не кратен размеру страницы – оставшийся хвост последней страницы придется переносить отдельно. Во-вторых, команда некэшируемой записи требует (а команда чтения рекомендует) чтобы данные были выровнены по 16-байтовой границе. В противном случае генерируется исключение. Вообще-то, требование выравнивания можно просто оговорить в спецификации функции, но будет лучше, если функция автоматически выровняет переданные ей указатели, не забыв, конечно, скопировать остаток обычным способом.
И, наконец, последнее: в фирменном примере присутствует бессмысленная на первый взгляд конструкция: "temp = a[kk+NUMPERPAGE]; // TLB priming" – для чего она предназначена? Программистам, знакомым с защищенным режимом, должно быть известно, что для трансляции виртуальных адресов в физические, процессор обращается к специальной структуре данных – страничному каталогу.
Страничный каталог формируется операционной системой и хранится в оперативной памяти. А оперативная память – это тормоза. Поэтому, данные страниц, к которым обращались в последнее время, автоматически запоминаются в специальном кэше – буфере ассоциативной трансляции (TLB - Transaction Look aside Buffer). Разумеется, данных о станицах, к которым еще не обращались, в TLB нет. Конструкция "temp = a[kk+NUMPERPAGE];"
как раз и загружает данные следующей копируемой страницы в TLB. Правда, остается непонятным, почему Intel выполняет упреждающую загрузку в TLB с одного лишь буфера-источника, забывая о приемнике. К тому же, загрузка данных страницы в TLB чтением ячейки памяти – блокируемая инструкция. Так какая разница: когда она произойдет сейчас или позже в ходе реального обращения к странице? (Правда, можно предположить, что с учетом внеочередного исполнения команд на P-III+ данная конструкция все же будет не блокируемой, но экспериментально подтвердить эту гипотезу не удается). К сожалению, это рождает проблему выхода за границы копируемого массива (ведь в последней итерации цикла мы обращаемся к возможно не существующей странице за его концом и если не предпринять дополнительных мер – операционная система может выбросить исключение, а дополнительные меры – это лишние накладные расходы). Ко всему прочему, оптимизирующий компилятор просто уничтожит бессмысленное (с его точки зрения!) присвоение – ведь переменная temp никак не используется в программе! Автором было экспериментально установлено, что удаление этой конструкции в не ухудшает производительности, поэтому, в своих разработках он рискнул ее не использовать.
Приведенный ниже пример реализации функции турбо-копирования для оптимизации под конкретный процессор использует два определения: _PAGE_SIZE, в обоих случаях равное 4 Кб, и _PREFETCH_SIZE – равное 32 байтам для P-III и 128 для P-4. Адреса источника и приемника должны быть выровнены по 16-байтовой границе, а размер копируемого блока – кратен размеру страницы.
Эти ограничения объясняются стремлением максимально упростить листинг для облегчения его понимания.
_turbo_memcpy(char *dst, char *src, int len)
{
int a, b, temp;
for (a=0; a < len; a += _PAGE_SIZE)
{
// Предвыбираем
temp = *(int *)((int) src + a + _page_size);
for (b = a; b < a + _PAGE_SIZE; a += _PREFETCH_SIZE)
__prefetchnta(src+b);
for (b = a; b < a + _PAGE_SIZE; b += 16 * 8)
{
__stream_cpy(dst + b + 16*0, src + b + 16*0);
__stream_cpy(dst + b + 16*1, src + b + 16*1);
__stream_cpy(dst + b + 16*2, src + b + 16*2);
__stream_cpy(dst + b + 16*3, src + b + 16*3);
__stream_cpy(dst + b + 16*4, src + b + 16*4);
__stream_cpy(dst + b + 16*5, src + b + 16*5);
__stream_cpy(dst + b + 16*6, src + b + 16*6);
__stream_cpy(dst + b + 16*7, src + b + 16*7);
}
}
return temp;
}
Листинг 37 [Cache/_turbo_memcpy.size.c] Функция турбо-копирования памяти, использующая новые команды управления кэшированием процессора P-III+.
Результаты тестирования функции турбо-копирования на блоках памяти различного размера приведены на рис. 0x02 (К сожалению, процессора P-4 в данный момент не оказалось под рукой и автору пришлось ограничится одним лишь P-III). Впечатляющее зрелище, не так ли? (Особенно в свете того, что функция копирования написана на чистом Си). Но и это еще не предел!
Во-первых, переписав код на ассемблер, можно на несколько процентов увеличить его производительность, добившись, по крайней мере, пяти кратного превосходства над штатной memcpy при копировании небольших блоков.
Во-вторых, представляет интерес рассмотреть частные случаи оптимизации. Например, если копируемые данные уже находятся к кэше (что очень часто и происходит при обработке блоков данных небольших размеров), цикл предвыборки можно исключить. (Особенно это актуально для программ, выполняющихся под P-4, команда предвыборки которого загружает данные в кэш второго, а не первого уровня).
При копировании блоков большого размера, обрабатываемых с начала, напротив, целесообразно использовать дополнительный цикл предвыборки, загружающий скопированные данные в кэш.
Впрочем, оптимальная стратегия копирования очень сильно зависит от конкретной ситуации и универсальных решений не существует – каждая программа требует своего подхода. Поэтому, не будем давать готовых решений, оставляя читателям полную свободу творчества.

Рисунок 50 graph 0x020 Результаты тестирования производительности функции турбо-копирования на блоках памяти различного размера под процессором Pentium-III 733/133/100. Скорость копирования измеряется в относительных единицах в сравнении со штатной функцией memcpy, производительность которой принята за 100%.

Рисунок 51 graph 0x022 График зависимости производительности функции турбо-копирования от размера предвыбираемого блока. [Pentium-III 733/133/100]
Заключение
…полученными результатами можно по праву гордиться: пятикратное ускорение – это что-то! Однако, копирование – не единственная базовая операция с памятью. Две другие – инициализация (заполнение) и сканирование (поиск) ничуть не в меньшей степени влияют на производительность, но требуют к себе совсем иных подходов, нежели копирование.
Об этом (и многом другом) мы и поговорим в следующей статье…
P.S. Да не будет сочтены небольшие придирки к Intel'овской документации за наезд на компанию. Автор, являясь горячим поклонником Intel, далек от мысли бросать в нее камни, но вот пару острых шуточек в ее адрес, все же себе позволяет.
Оптимизация "мертвого" кода
"Мертвым" называют код, никогда не получающий управления. Например, объявит программист функцию, но ни разу не использует, - ситуация знакомая, правда? Зачем же тогда этой функции впустую расходовать память? Увы, ни один из трех рассматриваемых компиляторов не удаляет "мертвые" функции оставляя эту работу на откуп линкеру. Умные линкеры действительно удаляют функции, на которые отсутствуют ссылки, но все же лучше, если это заблаговременно сделает компилятор.
Возьмем другой пример – пусть в программе присутствует следующий код, выводящий отладочное сообщение на экран, если макро DEBUG определен как TRUE:
if (DEBUG) printf("Некоторое отладочное сообщение");
При компиляции финальной версии DEBUG объявляется как FALSE и отладочный код никогда не выполняется, поэтому, имеет смысл его удалить. Компилятор Microsoft Visual C++ удаляет и проверку условия, и тело условного оператора (в данном случае – вызов функции printf), но забывает "вычистить" константную строку. Правда, есть надежда, что ее удалит продвинутый линкер, не обнаружив на нее ни одной ссылки. Вот компилятор WATCOM начисто удаляет весь мертвый код – и проверку условия, и тело условного оператора, и константную строку. А компилятор Borland C++ вообще не удаляет мертвый код, послушно выполняя проверку константы (константы!) FALSE на равенство TRUE.
Оптимизация передачи аргументов
Механизмы вызова и передачи аргументов функциями стандартных типов (как-то cdecl, stdcall, PASCAL) жестко декларированы, и никакой самодеятельности оптимизатор позволить себе не может. Стандарт предписывает передавать аргументы через стек, т.е. через жутко тормозную оперативную память, и, чем больше аргументов принимает функция, тем значительнее накладные расходы на каждый ее вызов.
Если же тип функции не задан явно, компилятор имеет право передавать ей аргументы так, как он сочтет нужным. Эффективнее всего передавать аргументы через регистры, чтение/запись которых укладывается в один такт процессора (обращение к памяти может потребовать не одного десятка тактов в зависимости от ряда факторов – быстродействия микросхем и контроллера памяти, частоты шины, наличия или отсутствия данных ячеек в кэше и т.д.). Беда в том, что даже у старших моделей микропроцессоров Pentium регистров общего назначения всего семь и их приходится делить между аргументами и возвращаемыми значениями функций, регистровыми и промежуточными переменными. Выделить все семь регистров под аргументы – было бы слишком глупым решением, ибо в этом случае переменные, содержавшие передаваемые аргументы пришлось бы размещать в оперативной памяти, сводя весь выигрыш на нет.
Компилятор Microsoft Visual C++ отводит для передачи аргументов два регистра, Borland C++ - три, а WATCOM – четыре. Вопрос: "чья стратегия лучше?" остается открыт и единого мнения нет. Автор этой статьи склоняется к мысли, что два регистра – действительно, наилучший компромисс. К слову сказать, Microsoft C 7.0 – "прародитель" Microsoft Visual C++ – использовал для передачи аргументов три регистра, но после серии испытаний, осуждений, споров и дебатов, его разработчики пришли к выводу, что два регистра обеспечивают лучшую производительность, нежели три.
Другой важный момент – тип вызова функции по умолчанию. Компилятор Microsoft Visual C++ задействует регистровую передачу аргументов только в том случае, если перед функцией указан квалификатор __fastcall (исключение составляет неявный аргумент this по умолчанию передаваемый через регистр). Компиляторы же Borland C++ и WATCOM по умолчанию используют регистровую передачу аргументов. Поэтому, если вы используете Microsoft Visual C++, вставляйте квалификатор __fastcall самостоятельно.
