Распространенные заблуждения
Оптимизация овеяна многочисленными заблуждениями, которые вызывают снисходительную улыбку у профессионалов, но зачастую необратимо уродуют психику и калечат мировоззрение новичков. Я думаю, профессионалы не обидятся на меня за то, что я потратил несколько страниц книги, чтобы их развеять (естественно, заблуждения, а не самих профессионалов):
Раздельное хранение кода и данных
Поскольку кодовый кэш тесно связан с декодером, в настоящей книге он не рассматривается, т.к. декодер и все, что с ним связано, – тема второго тома (см. "Введение в книгу. О серии книг "Оптимизация"), подробно рассказывающим об устройстве процессора и методиках планирования эффективного потока команд.
Разгон… Sound Blaster'а
Сказали бы мне некоторое время назад, что обычный Sound Blaster может наглым образом тормозить всю систему, я бы просто не поверил. Но… именно такой экземпляр Blaster'а мне попал недавно в руки. Причем, как показало небольшое расследование, это был дефект не конкретного экземпляра, а непосредственно самой модели, причем не одной, а сразу нескольких!
Изменением всего одного байта драйвера звуковой карты мне удалось значительно увеличить производительность системы, причем безо всякого ущерба для функциональности! О том, как был найден этот зловредный байт, и рассказывает настоящая статья.
…все началось с того, что я, заинтересовавшись новыми мультимедийными командами, решился-таки приобрести Pentium-III, поскольку мой старичок CELERON-300A их не поддерживал. Понятное дело, вместе с процессором потребовалось приобретать и новую материнскую плату, а, поскольку на современных матерях ISA-слоты отсутствуют, пришлось менять звуковую карту Gold Edison на что-нибудь поновее. Выбор пал на Sound Blaster-128 PCI <CT 4830/PCI> от Creative (собственно, ничего более стоящего в магазине и не было).
Ничуть не стремясь к чудесам производительности (и на прежнем процессоре все буквально "летало"), я все же ожидал, что Pentium-III 733 будет, по крайней мере, не медленнее. А вот как бы не так! Производительность системы после апгрейда существенно упала и работа с ней превратилась в сплошное мучение. Постоянно используемые мною приложения Adobe Acrobat Reader и компьютерный словарь Lingvo выдерживали пяти-семи секундную паузу при загрузке (тогда как прежде они запускались практически мгновенно), такая же пауза наблюдалась у Microsoft Word и Microsoft Visual Studio при первом обращении к панелям инструментов и меню. Особенно замедлилась скорость открывания файлов в "Универсальном проигрывателе" – прежде выполняясь практически мгновенно, теперь она отнимала несколько секунд.
Перерыв все настойки BIOS, и даже переустановив операционную систему (Windows 2000 для справки), я не добился ровным счетом ничего, правда выяснил, что на Windows 98 все работает отлично – ни задержек, ни тормозов там нет, и все приложения грузятся как из пушки, значительно быстрее, чем раньше.
В конце туннеля замаячил свет: раз под Windows 98 система работает, значит, это не аппаратный, а программный глюк Windows 2000. Что ж, будем лечить!
Первым делом требовалось установить – кто же вызывает задержку. Традиционно такие задачи решаются с помощью профилировщика, но как назло ни одного из них не оказалось под рукой, а бежать покупать диск среди глубокой ночи как-то не хотелось. На выручку пришел отладчик, интегрированный в Visual Studio (впрочем, подошел бы и любой другой, например, Soft-Ice или Windeb).
Рассуждал я следующим образом: "раз и Word, и Visual Studio, и многие другие приложения при первом обращении к меню вызывают задержку – очевидно, виновники не они, а какой-то системный компонент, загружаемый ими. Если этот зловредный компонент автоматически загружается вместе с самим приложением, то пауза возникает при его запуске (как, например, в Adobe Acrobat Reader). А если же он загружается динамически при возникновении в нем необходимости – задержка появляется при обращении к меню".
Загрузив Word в отладчик и щелкнув мышкой по меню, я с удовлетворением отметил, что в окне "DEBUG" появились следующие строки:
Loaded 'C:\WINNT\system32\winmm.dll', no matching symbolic information found.
Loaded 'C:\WINNT\system32\wdmaud.drv', no matching symbolic information found.
Loaded 'C:\WINNT\system32\wdmaud.drv', no matching symbolic information found.
Loaded 'C:\WINNT\system32\wdmaud.drv', no matching symbolic information found.
Ага! Все-таки что-то грузится! Остается только разобраться что… Заглянув в Platform SDK я выяснил, что динамическая библиотека "winmm.dll" обеспечивает работу со звуком и мультимедиа, а, загрузив ее в HEX-редактор, быстро нашел текстовую строку "wdmaud.drv", красноречиво свидетельствующую о том, что драйвер "wdmaud.drv" грузит никто иной, как "winmm.dll".
Логично, что "wdmaud.drv" предназначается для вывода звука, и это действительно так, поскольку его имя обнаружилось во вкладке "Драйвера" Sound Blaster'a в "Устройствах системы".
Может ли Blaster или его драйвер вызывать тормоза? А почему бы и нет! Чтобы проверить это предположение я решился временно удалить "winmm.dll" из папки SYSTEM32. Но под Windows 2000 это сделать не так-то просто! Во-первых, winmm.dll уже используется системой и, стало быть, доступ к ней заблокирован даже для администраторов, а, во-вторых, даже если ее и удалить, она все равно будет автоматически восстановлена операционной системой из резервной копии!
Чтобы воспрепятствовать этому, необходимо заблаговременно удалить winmm.dll из папки WINNT\system32\dllcache. А затем – переименовать "winmm.dll" во что-нибудь другое, скажем "winmm.dl_". Весь фокус в том, что переименования используемых динамических библиотек система не запрещает, автоматически корректируя все активные ссылки, но после перезагрузки приложения будут по-прежнему пытаться загрузить именно "winmm.dll" (откуда же им знать о переименовании?!) и… не найдут ее! (Что, мне собственно, и нужно).
После удаления "winmm.dll" все тормоза мигом исчезли, но… вместе с ними исчез и звук, а, согласитесь, что за компьютер без звука! С другой стороны, приложениям наподобие Word, Visual Studio, Adobe Acrobat Reader звук совсем ни к чему (во всяком случае у меня отключена озвучка пунктов меню и закрытия/открытия окон). Так почему бы не подсунуть им липовую "пустышку": динамическую библиотеку, имеющую то же самое имя, но не выполняющую никаких действий – просто возвращающую управление при вызове, а всем остальным приложениям (действительно нуждающимся в звуке) позволить обращаться к настоящей "winmm.dll"?
Сказано – сделано! Наскоро склепав dll'ку, не экспортирующую ни одной функции, я раскидал ее по всем каталогам, в которых находились исполняемые файлы Word, Visual Studio и других приложений. Дело в том, что при загрузке динамических библиотек система сначала ищет их в каталоге приложения, и только если ее там нет переходит к системному каталогу Windows.
C Word и Visual Studio этот фокус удался, а вот с Acrobat'ом не прошел – не понравилось ему, что в "пустышке" отсутствует функция "timeGetTime". Но трудно, что ль ее создать? (Тем более что ее прототип присутствует в SDK).
Наконец-то, с новым компьютером стало можно работать, а не мучаться как раньше! Разве не прелесть – ни тормозов, ни задержек! Все буквально летает – не успеваешь щелкнуть по иконке, как приложение уже появляется на экране! Но подобный "грязный хак" не мог вызвать у меня должного удовлетворения. Ведь я не нашел причину глюка, а всего лишь загнал его поглубже внутрь.
И вот на Новый год, когда чудом выдалось несколько часов свободного времени, я решил взять врага если не штурмом, то осадой. Пошагово трассируя стартовую процедуру этой злощастной DLL, я искал функцию, вызывающую задержку, а, находя такую, – перебирал все вложенные в нее функции одну за одной, а затем вложенные во вложенные... (В том, что тормоза вызвала именно стартовая процедура, у меня не было никаких сомнений, ибо задержка возникала именно при инициализации).
Через десяток минут я был вознагражден! Следы вели к функции OpenDriver, что выглядело логично, ибо наличие бага в штатной библиотеке "winmm.dll" производства Microsoft Corporation мне казалось сомнительным – она ведь одина на все карты, да и с прежним Blaster'ом работала без нареканий. Вот драйвер нового Blaster'а – дело другое! Нет ничего невероятного в том, что его инициализация (то бишь "открытие") происходит с задержкой. Круг "подозреваемых" сузился, но все же не было ясно кто истинный виновник – непосредственно железяка или ее родной драйвер.
Пройдясь несколько раз дизассемблером по драйверу Blaster'a я не нашел ничего, способного вызывать задержку, – напротив, очень аккуратный и профессионально составленный код. Выходит, все же железка?! Эх, если бы не Новый год было бы можно вернуть ее продавцу с претензией на обмен… А вдруг не железка? Может мать? Теоретически мог иметь место конфликт с контроллером PCI-шины или просто кривой контроллер…
Продолжая копаться в недрах драйвера, я неожиданно заметил, что OpenDriver вызывается четырежды
с последовательной инициализацией портов "wave", "midi", "mixer" и "aux", причем первые три инициализации пролетали на ура, а последняя-то и вызывала задержку.
Вот оно что! Виновата все же железка! AUX-порт на Blaster'е действительно был (хотя мною никак не использовался) и даже успешно функционировал, хотя до жути медленно инициализировался.
А зачем мне AUX-порт? Мне и обычных портов с лихвой хватает! Стоит ли ради него терпеть задержки?! В общем, я решил запретить драйверу инициализацию AUX'а (действительно, глупо инициализировать то, с чем все равно не работаешь). Конечно, правильнее всего было бы переписать код "winmm.dll", но… вносить исправления в двоичный файл чрезвычайно тяжело и весьма небезопасно. Поэтому я ограничился тем, что забил строку "AUX" нулями (в моей версии файла она расположена по адресу ".7752BB18"). Функция OpenDriver, получив на вход пустую строку, ничего не инициируя просто возвращает управление.
Итак, что же конкретно должны сделать читатели, желающие устранить этот дефект у себя? (Если, конечно, у них он есть). Распишу все действия по шагам:
Шаг первый: зайдя в систему под именем (или с правами) администратора, переместите "winmm.dll" из каталога WINNT\system32\dllcache
в какой-нибудь другой каталог, где вы храните резервные файлы. (Это на тот случай, если вы передумаете и захотите вернуть все на место)
Шаг второй: скопируйте WINNT\system32\winmm.dll
в winmm.dl1 и откройте его в любом HEX-редакторе (например, Hiew'e, Qview'e или на худой конец в том, что встроен в популярную файловую оболочку DOS Navigator)
Шаг третий: в winmm.dll найдите строку "AUX", завершаемую одним или несколькими нулями. Если эта та строка, которая вам действительно нужна, поблизости должны быть строки "Wave" и "Mixer" или "Midi" (в winmm.dll может быть несколько строк aux, использующихся различными ветвями программы)
Шаг четвертый: забейте строку "AUX" нулями (т.е. символами с кодом \x00, а не символами "0" с кодом \x30). Хотя, на самом деле, нулем достаточно затереть первую букву "A" – но это будет не так аккуратно.
Шаг пятый: создайте командный файл следующего содержания: "ren WINNT\system32\winmm.dll WINNT\system32\winmm.dl_ & ren WINNT\system32\winmm.dl1 WINNT\system32\winmm.dll" и запустите его на выполнение.
Шаг шестой: перезагрузитесь
Шаг седьмой: удалите WINNT\system32\winmm.dl_ и созданный вами командный файл.
Шаг восьмой: скопируйте измененную WINNT\system32\winmm.dll в папку WINNT\system32\dllcache
Вот и все! Счастливой работы! Если же у вас не все будет гладко получаться, то обращайтесь к автору этой статьи.
Разворачивание циклов
Разворот циклов, – простой и весьма эффективный способ оптимизации. Конвейерные микропроцессоры крайне болезненно реагируют на ветвления, значительно уменьшая скорость выполнения программ (а цикл как раз и представляет собой одну из разновидностей ветвления). Образно говоря, процессор – это гонщик, мчащийся по трассе (программному коду) и сбрасывающий газ на каждом повороте (ветвлении). Чем меньше поворотов содержит трасса (и чем протяженнее участки беспрепятственной прямой),– тем меньше времени требуется на ее прохождение.
Техника разворачивания циклов в общем случае сводится к уменьшению количества итераций за счет дублирования тела цикла соответствующее число раз. Рассмотрим следующий цикл:
for(a = 0; a < 666; a++)
x+=p[a];
Листинг 2 Не оптимизированный исходный цикл
С точки зрения процессора этот цикл представляет собой сплошной ухаб, не содержащий ни одного мало-мальски протяженного прямого участка. Разворот цикла позволяет частично смягчить ситуацию. Чтобы уменьшить количество поворотов вдвое следует реорганизовать цикл так:
for(a = 0; a < 666; a+=2)
{// обратите внимание ^^^ с разверткой цикла
// мы соответственно увеличиваем и шаг
x+=p[a];
x+=p[a + 1]; // продублированное тело цикла
/* ^^^ корректируем значение счетчика цикла */
}
Листинг 3 Пример реализации двукратного разворота цикла
Разворот цикла в четыре раза будет еще эффективнее, но непосредственно этого не сделать, ведь количество итераций цикла не кратно четырем: 666 на 4 нацело не делится! Один из возможных путей решения: округлить количество итераций до величины кратной четырем (или, в более общем случае, – кратности разворота цикла), а оставшиеся итерации поместить за концом цикла.
Оптимизированный код может выглядеть, например, так:
for(a = 0; a < 664; a+=4)
{ // округляем ^^^ количество итераций до величины
// кратной четырем
x+=p[a]; // четырежды
x+=p[a + 1]; // дублируем
x+=p[a + 2]; // тело
x+=p[a + 3]; // цикла
}
x+=p[a]; // оставшиеся две итерации добавляем в конец
x+=p[a + 1]; // цикла
Листинг 4 Пример реализации четырехкратного разворота цикла в случае, когда количество итераций цикла не кратно четырем
Хорошо, а как быть, если количество итераций на стадии компиляции еще неизвестно? (То есть, количество итераций – переменная, а не константа). В этой ситуации разумнее всего прибегнуть к битовым операциям:
for(a = 0; a < (N & ~3); a += k)
{ // округляем ^^^ количество итераций до величины
// кратной степени разворота
x+=p[a];
x+=p[a + 1];
x+=p[a + 2];
x+=p[a + 3];
}
// оставшиеся итерации добавляем в конец цикла
for(a = (N & ~3)); a < N; a++)
x+=p[a];
Листинг 5 Пример реализации четырехкратного разворота цикла в случае заранее неизвестного количества итераций
Как нетрудно догадаться, выражение (N & ~3)) и осуществляет округление количества итераций до величины кратной четырем. А почему, собственно, четырем? Как вообще зависит скорость выполнения цикла от глубины его развертки? Что ж, давайте поставим эксперимент! Несколько забегая вперед отметим, что эффективность оптимизации зависит не только от глубины развертки цикла, но и рода обработки данных. Поэтому, циклы, читающие память, и циклы, записывающие память, должны тестироваться отдельно. Вот с чтения памяти мы, пожалуй, и начнем…
/* -----------------------------------------------------------------------
не оптимизированный вариант
(чтение)
----------------------------------------------------------------------- */
for (a = 0; a < BLOCK_SIZE; a += sizeof(int))
x += *(int *)((int)p + a);
/* -----------------------------------------------------------------------
разворот на четыре итерации
(чтение)
----------------------------------------------------------------------- */
for (a = 0; a < BLOCK_SIZE; a += 4*sizeof(int))
{
x += *(int *)((int)p + a );
x += *(int *)((int)p + a + 1*sizeof(int));
x += *(int *)((int)p + a + 2*sizeof(int));
x += *(int *)((int)p + a + 3*sizeof(int));
}
Листинг 6 [Memory/unroll.read.c] Фрагмент программы, исследующий влияние глубины развертки цикла, читающего память, на время его выполнения
Что ж, результаты тестирования нас не разочаровали! Оказывается, глубокая развертка цикла сокращает время его выполнения более чем в два раза. Впрочем, здесь главное – не переборщить! (Скупой, как хорошо известно, платит дважды). Чрезмерная глубина развертки ведет к катастрофическому увеличению размеров цикла и совершенно не оправдывает привносимый ей выигрыш. Шестидесяти четырех кратное дублирование тела цикла смотрится довольно таки жутковато. Хуже того, – такой монстр может просто не влезть в кэш, что вызовет просто обвальное падение производительности!
Целесообразнее всего, как следует из диаграммы graph 28, разворачивать цикл в восемь или шестнадцать раз. Дальнейшее увеличение степени развертки практически не добавляет производительности.
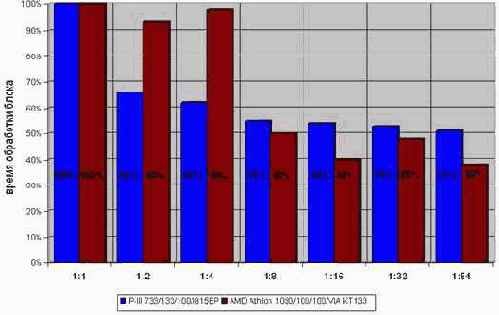
Рисунок 16 graph 28 Эффективность разворачивания циклов, читающих память. Видно, что время выполнения цикла резко уменьшается с его глубиной
С записью же картина совсем другая (см. рис. graph 29). /* Поскольку, тестовая программа мало чем отличается от предыдущей ради экономии места она опускается. */ На P?III/I815EP время выполнения цикла, записывающего память, вообще не зависит от глубины развертки. Ну, практически не зависит. Развернутый цикл выполняется на ~2% медленнее за счет потери компактности кода. Впрочем, этой величиной можно и пренебречь. Для увеличения эффективности выполнения программы под процессором Athlon следует развернуть записывающий цикл в шестнадцать раз. Это практически на четверть повысит его быстродействие!
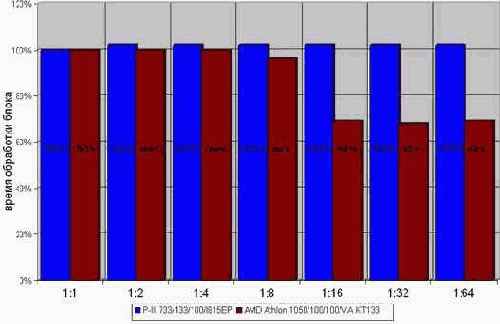
Рисунок 17 graph 29 Эффективность разворачивания циклов, записывающих память. Время выполнения цикла практически не зависит от глубины развертки и лишь на AMD Athlon шестнадцати кратная развертка несколько увеличивает его производительность
Что же касается смешанных циклов, обращающихся к памяти и на запись, и на чтение одновременно, – их так же рекомендуется разворачивать в восемь–шестнадцать раз. (см. так же "Группировка операций чтения с операциями записи").
Разворот циклов средствами макроассемблера. В заключении отметим одно печальное обстоятельство. Препроцессор языка Си не поддерживает циклических макросов и потому не позволяет реализовывать эффективную развертку циклов. Программист вынужден самостоятельно проделывать утомительную и чреватую ошибками работу по многократному дублированию тела цикла, не забывая к тому же о постоянной коррекции счетчика.
"Астматики" находятся гораздо в лучшем положении. Развитые макросредства ассемблеров MASM и TASM позволяют переложить всю рутинную работу на компилятор, и программисту ничего не стоит написать макрос разворачивающий цикл какое угодно количество раз. Это необычайно облегчает отладку и оптимизацию программы!
Одна из таких программ и приведена ниже в качестве наглядной иллюстрации. Согласитесь, элегантно решить эту (отнюдь не надуманную!) задачу средствами ANSI Cи/Си++ физически невозможно!
; /* -------------------------------------
; *
; * макрос, дублирующий свое тело N раз
; *
;
-------------------------------------- */
READ_BUFF MACRO N
MYN = N
MYA = 0
; // цикл дублирования своего тела
WHILE MYA NE MYN
; // тело цикла
; // макропроцессор продублирует его заданное число раз
MOV EDX, [EBX + 32 * MYA]
MYA = MYA + 1
ENDM
ENDM
UNROLL_POWER EQU 8 ; // глубина разворота цикла
Loop:
READ_BUFF UNROLL_POWER
; // ^^^^^^^^^^^^ обратите внимание, глубина разворота
; // задается препроцессорной константой!
; // никакой ручной работы!
ADD EAX, EDX
ADD EBX, 4 * UNROLL_POWER
; // коррекция ^^^^^^^^^^^^^^ количества итераций
DEC ECX
JNZ Loop
Листинг 7 Пример разворачивания цикла средствами макроассемблера. Макрос READ_BUFF позволяет разворачивать цикл произвольное количество раз
Разворот цикла средствами препроцессора Си. Хотя автоматически развернуть цикл директивами препроцессора ANSI Cи/Си++ невозможно, пути изгнания рутины из жизни программиста все-таки существуют! Стоит только подумать…
Одна из идей состоит в отказе от модификации счетчика цикла внутри заголовка цикла и выполнении этой операции внутри макроса "продразверстки". В результате, необходимость ручной коррекции счетчика отпадает и все копии тела цикла становятся идентичны друг другу. А раз так, – почему бы их не засунуть в препроцессорный макрос?
Это можно сделать, например, так:
#define BODY x+=p[a++]; // тело цикла
for(a=0; a < BLOCK_SIZE;)
{
// разворот цикла в 8 раз
BODY; BODY; BODY; BODY;
BODY; BODY; BODY; BODY;
}
Листинг 8 Пример разворачивания цикла средствами препроцессора языка Си. Это лучшее, что язык Си в состоянии нам предложить
RDRAM (Rambus DRAM) - Rambus-память
С DDR-SDRAM жесточайшим образом конкурирует Direct RDRAM, разработанная компанией Rambus. Вопреки распространенному мнению, ее архитектура довольно прозаична и не блещет какой бы то ни было революционной новизной. Основных отличий от памяти предыдущих поколений всего три:
а) увеличение тактовой частоты за счет сокращения разрядности шины,
б) одновременная передача номеров строки и столба ячейки,
в) увеличение количества банков для усиления параллелизма.
А теперь обо всем этом подробнее. Повышение тактовой частоты вызывает резкое усиление всевозможных помех и в первую очередь электромагнитной интерференции, интенсивность которой в общем случае пропорциональна квадрату частоты, а на частотах свыше 350 мегагерц вообще приближается к кубической. Это обстоятельство налагает чрезвычайно жесткие ограничения на топологию и качество изготовления печатных плат модулей микросхемы, что значительно усложняет технологию производства и себестоимость памяти. С другой стороны, уровень помех можно значительно понизить, если сократить количество проводников, т.е. уменьшить разрядность микросхемы. Именно по такому пути компания Rambus и пошла, компенсировав увеличение частоты до 400 MHz (с учетом технологии DDR эффективная частота составляет 800 MHz) уменьшением разрядности шины данных до 16 бит (плюс два бита на ECC). Таким образом, Direct RDRAM в четыре раза обгоняет DDR?1600 по частоте, но во столько же раз отстает от нее в разрядности! А от DDR?2100, Direct RDRAM отстает конкретно, и это при том, что себестоимость DDR заметно дешевле!
Второе (по списку) преимущество RDRAM – одновременная передача номеров строки и столбца ячейки – при ближайшем рассмотрении оказывается вовсе не преимуществом, а фичей – конструктивной особенностью. Это не уменьшает латентности чтения произвольной ячейки (т.е. интервалом времени между подачей адреса и получения данных), т.к. она в большей степени определяется скоростью ярда, а RDRAM функционирует на старом ядре.
Из спецификации RDRAM следует, что время доступа составляет 38,75 нс. (для сравнения время доступа 100 MHz SDRAM составляет 40 нс.). Ну, и стоило бы огород городить?
Стоило! Большое количество банков позволяет (теоретически) достичь идеальной конвейеризации запросов к памяти, – несмотря на то, что данные поступают на шину лишь спустя 40 нс. после запроса (что соответствует 320 тактам в 800 MHz системе), сам поток данных непрерывен.
Стоило?! Для потоковых алгоритмов последовательной обработки памяти это, допустим, хорошо, но во всех остальных случаях RDRAM не покажет никаких преимуществ перед DDR-SDRAM, а то и обычной SDRAM, работающей на скромной частоте в ~100 MHz. К тому же (как будет показано ниже, – см. "Кэш"), солидный объем кэш-памяти современных процессоров позволяет обрабатывать подавляющее большинство запросов локально, вообще не обращаясь к основной памяти или на худой конец, отложить это обращение до "лучших времен". Производительность RDRAM памяти реально ощущается лишь при обработке гигантских объемов данных, например, при редактировании изображений полиграфического качества в PhotoShop.
Таким образом, использование RDRAM в домашних и офисных компьютеров, ничем, кроме желания показать свою "крутость", не оправдано. Для высокопроизводительных рабочих станций лучший выбор – DDR-SDRAM, не уступающая RDRAM в производительности, но значительно выигрывающая у нее в себестоимости.
В этом свете не очень понятно стремление компании Intel к продвижению Rambus'а на рынке. Еще раз обращу внимание читателя: ничего революционного Rambus в себе не несет. Чрезвычайно сложная и требовательна к качеству производства интерфейсная обвязка обеспечивает высокую тактовую частоту, но не производительность! Соотношение 400x2 MHz на 16 бит оптимальным соотношением категорически не является уже хотя бы потому, что DDR?SDRAM без особых ухищрений тянет 133x2 MHz на 64 бит. Причем производители DDR?SDRAM в ближайшем будущем планируют взять барьер в 200x4 MHz на 128 бит, что увеличит пропускную способность до 12,8 Гбайт/с., что в восемь раз превосходит пропускную способность Direct RDRAM при меньшей себестоимости и аппаратной сложности!
Не стоит, однако, бросаться и в другую крайность, считая Rambus "кривой" и "идиотской" памятью. Отнюдь! Инженерный опыт, приобретенный в процессе создания этой, не побоюсь сказать, чрезвычайно высокотехнологичной памяти, несомненно, найдет себе применение в дальнейших разработках. Взять хотя бы машину Бэббиджа. Согласитесь, несмотря на передовые идеи, ее реальное воплощение проигрывало по всем позициям даже конторским счетам. Аналогично и с Direct RDRAM. Достичь пропускной способности в 1,6 Гбайт/с. можно и более простыми путями…

Рисунок 9 ramnus Внешний вид модулей Rambus памяти

Рисунок 10 1733rambus Модули Rambus-памяти установленные на материнской плате. Обратите внимание на близость контроллера памяти (большая микросхема слева, снабженная радиатором) к модулям памяти.
Самомодифицирующийся код как средство защиты приложений
И вот после стольких мытарств и ухищрений злополучный пример запущен и победно выводит на экран "Hello, World!". Резонный вопрос – а зачем, собственно, все это нужно? Какая выгода оттого, что функция будет исполнена в стеке? Ответ:– код функции, исполняющееся в стеке, можно прямо "на лету" изменять, например, расшифровывать ее.
Шифрованный код чрезвычайно затрудняет дизассемблирование и усиливает стойкость защиты, а какой разработчик не хочет уберечь свою программу от хакеров? Разумеется, одна лишь шифровка кода – не очень-то серьезное препятствие для взломщика, снабженного отладчиком или продвинутым дизассемблером, наподобие IDA Pro, но антиотладочные приемы (а они существуют и притом в изобилии) – тема отдельного разговора, выходящего за рамки настоящей статьи.
Простейший алгоритм шифрования заключается в последовательной обработке каждого элемента исходного текста операцией "ИЛИ-исключающее-И" (XOR). Повторное применение XOR к шифротексту позволяет вновь получить исходный текст.
Следующий пример (см. листинг 3) читает содержимое функции Demo, зашифровывает его и записывает полученный результат в файл.
void _bild()
{
FILE *f;
char buff[1000];
void (*_Demo) (int (*) (const char *,...));
void (*_Bild) ();
_Demo=Demo;
_Bild=_bild;
int func_len = (unsigned int) _Bild - (unsigned int) _Demo;
f=fopen("Demo32.bin","wb");
for (int a=0;a<func_len;a++)
fputc(((int) buff[a]) ^ 0x77,f);
fclose(f);
}
Листинг 5 Шифрование функции Demo
Теперь из исходного текста программы функцию Demo
можно удалить, взамен этого, разместив ее зашифрованное содержимое в строковой переменной (впрочем, не обязательно именно строковой). В нужный момент оно может быть расшифровано, скопировано в локальный буфер и вызвано для выполнения. Один из вариантов реализации приведен в листинге 4.
Обратите внимание, как функция printf
в листинге 2 выводит приветствие на экран. На первый взгляд ничего необычного, но, задумайтесь, где
размещена строка "Hello, World!". Разумеется, не в сегменте кода – там ей не место ( хотя некоторые компиляторы фирмы Borland помещают ее именно туда). Выходит, в сегменте данных, там, где ей и положено быть? Но если так, то одного лишь копирования тела функции окажется явно недостаточно – придется скопировать и саму строковую константу. А это – утомительно. Но существует и другой способ – создать локальный буфер и инициализировать его по ходу выполнения программы, например, так: …buf[666]; buff[0]='H'; buff[1]='e'; buff[2]='l'; buff[3]='l';buff[4]='o',… - не самый короткий, но, ввиду своей простоты, широко распространенный путь.
int main(int argc, char* argv[])
{
char buff[1000];
int (*_printf) (const char *,...);
void (*_Demo) (int (*) (const char *,...));
char code[]="\x22\xFC\x9B\xF4\x9B\x67\xB1\x32\x87\
\x3F\xB1\x32\x86\x12\xB1\x32\x85\x1B\xB1\
\x32\x84\x1B\xB1\x32\x83\x18\xB1\x32\x82\
\x5B\xB1\x32\x81\x57\xB1\x32\x80\x20\xB1\
\x32\x8F\x18\xB1\x32\x8E\x05\xB1\x32\x8D\
\x1B\xB1\x32\x8C\x13\xB1\x32\x8B\x56\xB1\
\x32\x8A\x7D\xB1\x32\x89\x77\xFA\x32\x87\
\x27\x88\x22\x7F\xF4\xB3\x73\xFC\x92\x2A\
\xB4";
_printf=printf;
int code_size=strlen(&code[0]);
strcpy(&buff[0],&code[0]);
for (int a=0;a<code_size;a++)
buff[a] = buff[a] ^ 0x77;
_Demo = (void (*) (int (*) (const char *,...))) &buff[0];
_Demo(_printf);
return 0;
}
Листинг 6 Зашифрованная программа
Теперь (см. листинг 4) даже при наличии исходных текстов алгоритм работы функции Demo будет представлять загадку! Этим обстоятельством можно воспользоваться для сокрытия некоторой критической информации, например, процедуры генерации ключа или проверки серийного номера.
Проверку серийного номера желательно организовать так, чтобы даже после расшифровки кода, ее алгоритм представлял бы головоломку для хакера. Один из примеров такого алгоритма предложен ниже.
Суть его заключается в том, что инструкция, отвечающая за преобразование бит, динамически изменяется в ходе выполнения программы, а вместе с нею, соответственно, изменяется и сам результат вычислений.
Поскольку при создании самомодифицирующегося кода требуется точно знать в какой ячейке памяти какой байт расположен, приходится отказываться от языков высокого уровня и прибегать к ассемблеру.
С этим связана одна проблема – чтобы модифицировать такой-то байт, инструкции mov требуется передать его абсолютный линейный адрес, а он, как было показано выше, заранее неизвестен. Однако его можно узнать непосредственно в ходе выполнения программы. Наибольшую популярность получила конструкция "CALL $+5\POP reg\mov [reg+relative_addres], xx" – т.е. вызова следующей инструкцией call
команды и извлечению из стека адреса возврата – абсолютного адреса этой команды, который в дальнейшем используется в качестве базы для адресации кода стековой функции. Вот, пожалуй, и все премудрости.
MyFunc:
push esi ; сохранение регистра esi
в стеке
mov esi, [esp+8] ; ESI = &username[0]
push ebx ; сохранение прочих регистров в стеке
push ecx
push edx
xor eax, eax ; обнуление рабочих регистров
xor edx, edx
RepeatString: ; цикл обработки строки байт-за-байтом
lodsb ; читаем очередной байт в AL
test al, al ; ?достигнут конец строки
jz short Exit
; Значение счетчика для обработки одного байта строки.
; Значение счетчика следует выбирать так, чтобы с одной стороны все биты
; полностью перемешались, а с другой - была обеспечена четность (нечтность)
; преобразований операции xor
mov ecx, 21h
RepeatChar:
xor edx, eax
; циклически меняется с xor
на adc
ror eax, 3
rol edx, 5
call $+5 ; ebx = eip
pop ebx ; /
xor byte ptr [ebx-0Dh], 26h; Эта команда обеспечивает цикл.
; изменение инструкции xor
на adc
loop RepeatChar
jmp short RepeatString
Exit:
xchg eax, edx ; результат
работы (ser.num) в eax
pop edx ; восстановление регистров
pop ecx
pop ebx
pop esi
retn ; возврат из функции
Листинг 7 Процедура генерации серийного номера, предназначенная для выполнения в стеке
Приведенный алгоритм интересен тем, что повторный вызов функции с передачей тех же самых аргументов может возвращать либо той же самый, либо совершенно другой результат – если длина имени пользователя нечетна, то при выходе из функции XOR меняется на ADC с очевидными последствиями. Если же длина имени четна – ничего подобного не происходит.
Разумеется, стойкость предложенной защиты относительно невелика. Однако она может быть значительно усилена. На то существует масса хитрых приемов программирования – динамическая асинхронная расшифровка, подстановка результатов сравнения вместо коэффициентов в различных вычислениях, помещение критической части кода непосредственно в ключ и т.д.
Но назначение статьи состоит не в том, чтобы предложить готовую к употреблению защиту (да и, зачем? чтобы хакерам ее было бы легче изучать?), а доказать (и показать!) принципиальную возможность создания самомодифицирующегося кода под управлением Windows 95/Windows NT/Windows 2000. Как именно предоставленной возможностью можно воспользоваться – надлежит решать читателю.
Самомодифицирующийся код в современных операционных системах
Лет десять-двадцать тому назад, в эпоху рассвета MS-DOS, программистами широко использовался самомодифицирующийся код, без которого не обходилась практически ни одна мало-мальски серьезная защита. Да и не только защита, - он встречался в компиляторах, компилирующих код в память, распаковщиках исполняемых файлов, полиморфных генераторах и т.д. и т.п.
В середине девяностых началась массовая миграция пользователей с MS-DOS на Windows 95\Windows NT, и разработчиком пришлось задуматься о переносе накопленного опыта и приемов программирования на новую платформу – от бесконтрольного доступа к "железу", памяти, компонентам операционной системы и связанным с ними хитроумными трюками программирования пришлось отвыкать. В частности стала невозможна непосредственная модификация исполняемого кода приложений, поскольку Windows защищает его от непреднамеренных изменений. Это привело к рождению нелепого убеждения, дескать, под Windows создание самомодифицирующегося кода вообще невозможно, по крайней мере, без использования VxD и недокументированных возможностей операционной системы.
На самом деле существует по крайней мере два документированных способа изменения кода приложений, одинаково хорошо работающих как под управлением Windows 95\Windows 98\Windows Me, так и под Windows NT\Windows 2000, и вполне удовлетворяющихся привилегиями гостевого пользователя.
Во-первых, kernel32.dll экспортирует функцию WriteProcessMemory, предназначенную, как и следует из ее названия, для модификации памяти процесса. Во-вторых, практически все операционные системы, включая Windows и LINUX, разрешают выполнение и модификацию кода, размещенного в стеке.
В принципе, задача создания самомодифицирующегося кода может быть решена исключительно средствами языков высокого уровня, таких, например, как Си, Си++, Паскаль без применения ассемблера.
Материал, изложенный в настоящей главе, большей частью ориентирован на компилятор Microsoft Visual C++ и 32-разрядный исполняемый код. Под Windows 3.x приведенные примеры работать не будут. Но это вряд ли представляет существенную проблему - доля машин с Windows 3.x на рынке очень невелика, поэтому, ими можно полностью пренебречь.
SDRAM (Synchronous DRAM) – синхронная DRAM
Появление микропроцессоров с шинами на 100 MHz привело к радикальному пересмотру механизма управления памятью, что привело к созданию синхронной динамической памяти – SDRAM (Synchronous-DRAM синхронная DRAM). Как и следует из ее названия, микросхемы SDRAM-памяти работают синхронно с контроллером, что гарантирует завершение цикла обмена в строго заданный срок. (Помните, "как хочешь, крутись, теща, но что бы к трем часам как штык была готова"). Кроме того, номера строк и столбцов подаются с таким расчетом, чтобы к приходу следующего тактового импульса сигналы уже успели стабилизироваться и были готовы к считыванию.
Также, в SDRAM реализован усовершенствованный пакетный режим обмена. Контроллер может запросить как одну, так и несколько последовательных ячеек памяти, а при желании – даже всю строку целиком! Это стало возможным благодаря использованию полноразрядного адресного счетчика уже не ограниченного, как в BEDO, двумя битами.
Другое усовершенствование. Количество матриц (банков) памяти в SDRAM было увеличено сначала с одного до двух, а затем и до четырех. Это позволило обращаться к ячейкам одного банка параллельно с перезарядкой внутренних цепей другого, что (при условии правильного планирования потоков данных см. "Оптимизация работы с памятью: стратегия распределения данных по DRAM банкам") приблизительно на ~30% увеличивает производительность.
Помимо этого появилась возможность одновременного открытия двух (четырех) страниц памяти, причем открытие одной страницы (т.е. передача номера строки) может происходить во время считывания информации с другой, что позволяет обращаться к новому столбцу ячейки памяти на каждом тактовом цикле.
В отличие от FPM-DRAM\EDO-DRAM\BEDO, выполняющих перезарядку внутренних цепей при закрытии страницы (т.е. при дезактивации сигнала RAS), синхронная память проделывает эту операцию автоматически, позволяя держать страницы открытыми столь долго, сколько это угодно.
Наконец, разрядность линий данных увеличилась с 32- до 64 бит, что еще вдвое увеличило ее производительность!
Формула чтения произвольной ячейки из закрытой строки для SDRAM обычно выглядит так: 4?1?x?x, а открытой так: 2?1?х?х.
В настоящее время (2002 год) подавляющее большинство персональных компьютеров оснащаются именно SDRAM-памятью, которая прочно удерживает свои позиции, несмотря на активный натиск современных разработок.
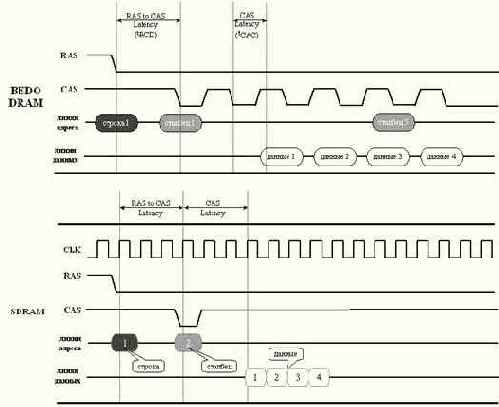
Рисунок 8 0x24 Временная диаграмма, иллюстрирующая работу некоторых типов памяти (окончание)
Секреты копирования памяти или
Обработка строк, структур, массивов, объектов, передача аргументов функциям, проигрывание звука или вывод изображения на экран – вот далеко не полный перечень областей применения функции копирования памяти. Разработчики компиляторов прилагают значительные усилия, чтобы штатная функция копирования памяти (например, в языке Си она называется memcpy) "летала" настолько быстро, насколько это вообще возможно. Но задачи оптимизации не имеют решений общего вида – алгоритм, оптимальный для одной ситуации, зачастую оказывается чрезвычайно неоптимальным в другой.
Копирование памяти – отнюдь не такая тривиальная операция, какой кажется с первого взгляда. Здесь есть свои тонкости и секреты… Им-то и посвящена настоящая глава. (см. так же. "Часть I Оптимизация работы с памятью. Оптимизация штатных Си-функций для работы с памятью").
Секреты Visual Studio
Современные программные интерфейсы заметно потеснили, если не сказать вытеснили, документацию, которая, по мнению большинства пользователей, никому кроме "ламеров" уже не нужна. Назначение большинства пунктов меню интуитивно понятно и так, а, если даже и непонятно, его нетрудно выяснить экспериментально.
На самом же деле, меню – лишь верхушка айсберга, а большая часть функциональных возможностей многих приложений скрыта под водой. Продвинутые программные пакеты, такие как, например, MicrosoftVisual Studio содержат тысячи команд, и, если бы все они были "втиснуты" в меню, его бы размеры выросли по меньшей мере до луны.… Вот и приходится помещать в меню лишь наиболее важные (с точки зрения разработчиков) команды, скрывая остальные от глаз пользователя.
Не стоит думать, что все скрытые команды – никому не нужный балласт. Среди них притаилось немало подлинных драгоценностей, значительно облегчающих жизнь программисту.
Данная глава посвящена малоизвестным, но чрезвычайно полезным секретам среды разработки Visual Studio 6.0. Поскольку, эта среда так же необъятна, как и мир, рассказать обо всех возможностях в рамках одной главы просто невозможно. Поэтому, ограничимся лишь встроенным редактором текстов – важнейшим компонентом любой среды разработки.
Маленькое замечание мимоходом: если вы пришли на Windows из UNIX и вам ужасно недостает возможностей тех сред разработки – эта статья для вас! Все, что было в UNIX, есть и в Windows, только скрытно от посторонних глаз. Но мы-то с вами не посторонние, правда? :-)
Семь китов оптимизации или Жизненный цикл оптимизации
Часто программист (даже высококвалифицированный!) обнаружив профилировщиком "узкие" места в программе, автоматически
принимает решение о переносе соответствующих функций на ассемблер. А напрасно! Как мы еще убедимся (см. "Часть III. Ассемблер vs компилятор"), разница в производительности между ручной и машинной оптимизацией в подавляющем большинстве случаев очень невелика. Очень может статься так, что улучшать уже нечего, – за исключением мелких, "косметических" огрехов, результат работы компилятора идеален и никакие старания не увеличат производительность, более чем на 3%–5%. Печально, если это обстоятельство выясняется лишь после переноса одной или нескольких таких функций на ассемблер. Потрачено время, затрачены силы… и все это впустую. Обидно, да?
Прежде, чем приступать к ручной оптимизации не мешало бы выяснить: насколько не оптимален код, сгенерированный компилятором, и оценить имеющийся резерв производительности. Но не стоит бросаться в другую крайность и полагать, что компилятор всегда генерирует оптимальный или близкий к тому код. Отнюдь! Все зависит от того, насколько хорошо вычислительный алгоритм ложиться в контекст языка высокого уровня. Некоторые задачи решаются одной машинной инструкцией, но целой группой команд на языках Си и Паскаль. Наивно надеяться, что компилятор поймет физический смысл компилируемой программы и догадается заменить эту группу инструкций одной машинной командой. Нет! Он будет тупо транслировать каждую инструкцию в одну или (чаще всего) несколько машинных команд, со всеми вытекающими отсюда последствиями…
четвертый. Избавление от strlen
Возвращаясь к рис. 0x004 отметим, что обращение к не выровненным данным – не единственная горячая точка функции Calculate CRC. С небольшим отрывом за ней следует инструкция PUSH, временно сохраняющая регистры в стеке и… опять та противная strlen
с которой мы уже столкнулись.
Действительно, вычисление длины пароля вполне сопоставимо по времени с подсчетом его контрольной суммы. Вот если бы этого удалось избежать… А для собственно, вообще вычислять длину каждого пароля? Ведь пароли перебираются не хаотично, а генерируется по вполне упорядоченной схеме и приращение длины пароля на единицу происходит не так уж и часто. Так, может быть, лучше возложить эту задачу на функцию gen_pswd? Пусть при первом вызове она определяет длину начального пароля, а затем при "растяжке" строки увеличивает глобальную переменную length на единицу. Сказано – сделано.
Теперь код gen_pswd выглядит так:
int a;
int p = 0;
length = strlen(pswd); // определение длины начального пароля
…
if (!pswd[p])
{
pswd[p]=' ';
pswd[p+1]=0;
length++; // "ручное" увеличение длины пароля
}
…
Листинг 16 Удаление функции strlen и "ручное" приращение длины пароля при его удлинении на один символ
А код Calculate CRC так:
for (a = 0; a <= length; a++)
Листинг 17 Использование глобальной переменной для определения длины пароля
В результате этих нехитрых преобразований мы получаем скорость в… восемь миллионов паролей в секунду. Много? Подождите! Самое интересное еще только начинается…
десятый. Заключительный
Все оставшиеся 17 горячих точек представляют собой издержки обращения к кэш-памяти и… штрафные такты ожидания за неудачную с точки зрения процессора группировку команд. Ладно, оставим обращения к памяти в стороне, вернее отдадим эту задачу на откуп неутомимым читателям (задумайтесь: зачем вообще теперь генерировать пароли, если их контрольная сумма считается без обращения к ним?) и займемся оптимальным планированием потока команд.
Обратимся к другому мощному средству профилировщика VTune – автоматическому оптимизатору, по праву носящему гордое имя "Assembly Coach" (Ассемблерный Тренер, – не путайте его с Инструктором!). Выделим, удерживая левую клавишу мыши, все тело функции gen_pswd
и найдем на панели инструментов кнопку с "учителем" (почему-то ярко-красного цвета), держащим указку на перевес. Нажмем ее.
На выбор нам предоставляется три варианта оптимизации, выбираемые в ниспадающем боксе "Mode of Operation" – Автоматическая Оптимизация (Automatic Optimization), Пошаговая Оптимизация (Single Step Optimization) и Интерактивная Оптимизация (Interactive Optimization). Первые два режима представляют собой сплошное барахло, не представляющего особого интереса, а вот качество Интерактивной Оптимизации – выше всяких похвал. Итак, выбираем интерактивную оптимизацию и нажимаем кнопку "Next" расположенную чуть правее ниспадающего бокса.
Содержимое экрана тут же преобразится (см. рис 0х005): в левой панели показан исходный ассемблерный код, в правой – оптимизируемый код. В нижнем углу экрана по ходу оптимизации будут отображаться так называемые "assumption" (буквально – допущения), за разрешением которых оптимизатор будет обращаться к программисту. Сейчас в этом окне горит следующее допущение: "Offset: 0x55 & 0x72: Instructions Reference to Same Memory" (Инструкции со смещениями 0x55 и 0x72 обращаются к одной и той же области памяти). Смотрим: что за инструкции расположены по таким смещениям. Ага:
1:55 mov ebp, DWORD PTR [esp+018h]
1:72 mov DWORD PTR [esp+010h], ecx
Несмотря на кажущееся различие в операндах, на самом деле они адресуют одну и ту же переменную, т.к. между ними расположены две машинные команды PUSH, уменьшающие значение регистра ESP на 8. Таким образом, это предположение верно и мы подтверждаем его нажатием "Apply".
Теперь обратим внимание на инструкции, залитые красным цветом и отмеченные красным огоньком светофора слева. Это отвратительно спланированные инструкции, обложенные штрафными тактами процессора.
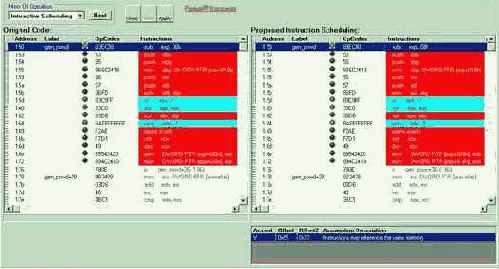
Рисунок 10 0x005 Использование Ассемблерного Тренера для оптимизации планирования машинных команд
Давайте щелкнем по самому нижнему "светофору" и посмотрим, как VTune перегруппирует наши команды… Ну вот, совсем другое дело! Теперь все инструкции залиты пастельным желтым цветом, что означает: никаких конфликтов и штрафных тактов – нет. Что в оптимизированном коде изменилось? Ну, во-первых, теперь команды PUSH (заталкивающие регистры в стек) отделены от команды, модифицирующей регистр указатель вершины стека, что уничтожает паразитную зависимость по данным (действительно, нельзя заталкивать свежие данные в стек пока не известно положение его вершины).
Во-вторых, арифметические команды теперь равномерно перемешаны с командами записи/чтения регистров, – поскольку вычислительное устройство (АЛУ – арифметически логическое устройство) у процессоров Pentium всего одно, то эта мера практически удваивает производительность.
В-третьих, процессоры Pentium содержат только один полноценный x86 декодер и потому заявленная скорость декодирования три инструкции за такт достигается только при строго определенном следовании инструкцией. Инструкции, декодируемые только полноценным x86-декодером, следует размещать в начале каждого триплета, заполняя "хвост" триплета командами, которые по зубам остальным двум декодерам. Как легко убедиться, компилятор MS VC генерирует весьма неоптимальный с точки зрения Pentium-процессора код и VTune перетасовывает его команды по своему.
sub esp, 08h sub esp, 08h
push ebx or ecx, -1
push ebp push ebx
mov ebp, DWORD PTR [esp+018h] push ebp
push esi mov ebp, DWORD PTR [esp+018h]
push edi xor eax, eax
mov edi, ebp push esi
or ecx, -1 push edi
xor eax, eax xor ebx, ebx
xor ebx, ebx mov edx, -1
mov edx, -1 mov edi, ebp
repne scasb repne scasb
not ecx mov DWORD PTR [esp+020h], edx
dec ecx not ecx
mov DWORD PTR [esp+020h], edx dec ecx
mov DWORD PTR [esp+010h], ecx mov DWORD PTR [esp+010h], ecx
Листинг 20 Ассемблерный код, оптимизированный компилятором Microsoft Visual C++ 6.0 в режиме максимальной оптимизации (слева) и его усовершенствованный вариант, переработанный VTune (справа).
Нажимаем еще раз "Next" и переходим к анализу следующего блока инструкций. Теперь VTune устраняет зависимость по данным, разделяя команды чтения и сложения регистра ESI командой увеличение регистра EAX
mov esi, DWORD PTR [eax+ebp] mov esi, DWORD PTR [eax+ebp]
add edx, esi inc eax
inc eax add edx, esi
cmp eax, ecx cmp eax, ecx
…и таким Макаром мы продолжаем до тех пор, пока весь код целиком не будет оптимизирован.
И тут возникает новая проблема. Как это ни прискорбно, но VTune не позволяет поместить оптимизированный код в исполняемый файл, видимо, полагая, что программист–ассемблерщик без труда перебьет его с клавиатуры и вручную. Но мы то с вами не ассемблерщики! (В смысле: среди нас с вами есть и не ассемблерщики).
И потом – куда прикажите перебивать код? Не резать же двоичный файл "в живую"? Конечно нет! Давайте поступим так (не самый лучший вариант, конечно, но ничего более умного мне в голову пока не пришло). Переместив курсор в панель оптимизированного кода в меню файл выберем пункт "печать". В окне "Field Selection" (выбор полей) снимем галочки со всего, кроме "Labels" (метки) и "Instructions" (инструкции) и зададим печать в файл или буфер обмена.
Тем временем, подготовим ассемблерный листинг нашей программы, задав в командной строке компилятора ключ "/FA" (в других компиляторах этот ключ, разумеется, может быть и иным). В результате мы станем обладателями файла pswd.asm, который даже можно откомпилировать ("ml /c /coff pswd.asm"), слинковать ("link /SUBSYSTEM:CONSLE pswd.obj LIBC.LIB") и запустить. Но что за черт! Мы получаем скорость всего ~65 миллионов паролей в секунду против 83 миллионов, которые получаются обычным путем. Оказывается, коварный MS VC просто не вставляет директивы выравнивания в ассемблерный текст! Это затрудняет оценку производительности качества оптимизации кода профилировщиков VTune. Ну да ладно, возьмем за основу данные 65 миллионов и посмотрим насколько VTune сможет улучшить этот результат.
Открываем файл, созданный профилировщиком и… еще одна проблема! Его синтаксис совершенно не совместим с синтаксисом популярных трансляторов ассемблера!
Label Instructions
gen_pswd sub esp, 08h
js gen_pswd+36 (1:86)
gen_pswd+28 mov esi, DWORD PTR [eax+ebp]
Листинг 21 Фрагмент ассемблерного файла, сгенерированного VTune
Во-первых, после меток не стоит знак двоеточия, во-вторых, в метках встречается запрещенный знак "плюс", в третьих, условные переходы содержат лишний адрес, заключенный в скобки на конце.
Словом нам предстоит много ручной работы, после которой "вычищенный" фрагмент программы будет выглядеть так:
Label Instructions
gen_pswd: sub esp, 08h
js gen_pswd+_36 (1:86)
gen_pswd+_28 mov esi, DWORD PTR [eax+ebp]
Листинг 22 Исправленный фрагмент сгенерированного VTune файла стал пригоден к трансляции ассемблером TASM или MASM
Остается заключить его в следующую "обвязку" и оттранслировать ассемблером TASM или MASM – это уже как вам по вкусу:
.386
.model FLAT
PUBLIC _gen_pswd
EXTERN _DeCrypt:PROC
EXTRN _printf:NEAR
EXTRN _malloc:NEAR
_DATA SEGMENT
my_string DB 'CRC %8X: try to decrypt: "%s"', 0aH, 00H
_DATA ENDS
_TEXT SEGMENT
_gen_pswd PROC NEAS
// код функции gen_pswd
_gen_pswd ENDP
_TEXT ENDS
END
Листинг 23 "Обвязка" ассемблерного файла в которую необходимо поместить оптимизированный код функции _gen_pswd для его последующей трансляции
А в самой программе pswd.c функцию gen_pswd объявить как внешнюю. Это можно сделать например так:
extern int _gen_pswd(char *crypteddata,
char *pswd, int max_iter, int validCRC);
Листинг 24 Объявление внешней функции gen_pswd в Си-программе
Теперь можно собирать наш проект воедино:
ml /c /coff gen_pswd.asm
cl /Ox pswd.c /link gen_pswd.obj
Листинг 25 Финальная сборка проекта pswd
Прогон оптимизированной программы показывает, что она выдает ~78 миллионов паролей в секунду, что на ~20% чем было до оптимизации. Что ж! Профилировщик VTune весьма не хило оптимизирует код! Тем не менее, полученный результат все же не дотягивает до скорости, достигнутой на предыдущем шаге.Конечно, камень преткновения не в профилировщике, а в компиляторе, но разве от этого нам легче?
Впрочем, на оптимизацию собственных ассемблерных программ эта проблема никак не отражается.
девятый. VTune – ваш персональный тренер
А теперь мы обратимся к наименее известному средству профилировщика VTune – Инструктору (в оригинале Coach так же переводимое как "тренер" или "учитель").
Фактически инструктор – это ни что иное как высококлассный интерактивный оптимизатор, поддерживающий целый ряд языков: C, C++, FORTRAN и Java. Он анализирует исходный текст программы на предмет поиска "слабых" мест, а обнаружив такие – дает подробные рекомендации по их устранению.
Разумеется, интеллектуальность Инструктора не идет ни в какое сравнение с сообразительностью живого программиста и вообще, как мы увидим в дальнейшем, Инструктор скорее туп, чем умен… все-таки рассмотреть его поближе будет небесполезно.
Несмотря на то, что Инструктор в первую очередь ориентирована на программистов-новичков (на что указывает полностью "разжеванный" стиль подсказок), и для профессионалов он под час оказывается не лишним, особенно когда приходится оптимизировать чужой код, в котором лень досконально разбираться.
Плохая новость (впрочем, ее и следовало ожидать)– при отсутствии отладочной информации в профилируемой программе инструктор не может работать с исходным текстом и опускается на уровень чистого ассемблера (см. "Шаг десятый"). Тем не менее, это обстоятельство не доставляет непреодолимых неудобств, т.к. текст программы именно анализируется, но не профилируется. Поэтому, пусть вас не смущает, что включение в исполняемый файл отладочной информации приводит к автоматическому "вырубанию" всех оптимизирующих опций компилятора. Инструктор, работая с исходным текстом программы, вообще не будет касаться скомпилированного машинного кода!
Итак, перекомпилируем нашу демонстрационный пример, добавив ключ "/Zi" в командную строку компилятора и ключ "/DEBIG" – в командную строку линкера. Загрузим полученный файл в VTune и, дождавшись появления диаграммы "Hot Spots", дважды щелкнем мышкой по самому высокому прямоугольнику, соответствующему, как мы уже знаем, функции gen_pswd, в которой программа проводит большую часть своего времени.
Loop unrolling
Examples: C, Fortran, Java*
The loop contains instructions that do not allow efficient instruction scheduling and pairing. The instructions are few or have dependencies that provide little scope for the compiler to schedule them in such a manner as to make optimal use of the processor's multiple pipelines. As a result, extra clock cycles are needed to execute these instructions.
Advice
Unroll the loop as suggested by the coach. Create a loop that contains more instructions, but is executed fewer times. If the unrolling factor suggested by the coach is not appropriate, use an unrolling factor that is more appropriate.
To unroll the loop, do the following:
– Replicate the body of the loop the recommended number of times.
– Adjust the index expressions to reference successive array elements.
–Adjust the loop control statements.
Result:
– Increases the number of machine instructions generated inside the loop.
– Provides more scope for the compiler to reorder and schedule instructions so that they pair and execute simultaneously in the processor's pipelines.
– Executes the loop fewer times.
Caution:
Be aware that increasing the number of instructions within the loop also increases the register pressure.
В переводе на русский язык все вышесказанное будет звучать приблизительно таким образом:
Разворачивание цикла:
Данный цикл содержит инструкции, которые не могут быть эффективно спланированы и распараллелены процессором, поскольку они малочисленны [то бишь кворума мы здесь не наберем – КК] или содержат зависимости, что сужает возможности компилятора в их группировке для достижения наиболее оптимального использования конвейеров процессора. В результате, на выполнение этих инструкций расходуется значительно большее количество циклов.
Совет:
Развертите цикл, согласно советам "Учителя". Создайте цикл, что содержит больше инструкций, но исполняется меньшее количество раз.
Если степень развертки, рекомендуемая "Учителем", кажется вам неподходящей, используйте более подходящую степень.
Для развертки цикла сделайте следующее:
– Продублируйте тело цикла соответствующее количество раз;
– Скорректируйте ссылки на продублированные элементы массива;
– Скорректируйте условие цикла.
Результат:
– Увеличивается количество машинных инструкций внутри цикла;
– Появляется место, где "развернуться" компилятору для переупорядочивания и планирования потока инструкций так, чтобы они спаривались и выполнялись параллельно в конвейерах процессора.
– Выполнение цикла занимает меньшее время.
Предостережение:
Знайте, что увеличение количества инструкций в теле цикла влечет за собой увеличение "регистрового давления".
Согласитесь, весьма исчерпывающее руководство по развертке циклов! Причем, если вам все равно не понятно как именно разворачиваются циклы, можно кликнуть по ссылке "Examples" (примеры) и увидеть конкретный пример "продразверстки" на Си, Java или Fortran. Давайте выберем "Си" и посмотрим, что нам еще посоветует VTune:
Original Code Optimized Code
for(i=0; i<n; i++) for(i=0; i<n-(n%3); i+=3)
a[i] = c[i] ; {
a[i] = c[i] ;
a[i+1] = c[i+1];
a[i+2] = c[i+2];
}
for(i;i < n; i++)
a[i] = c[i];
Тем не менее, мы этот цикл разворачивать не будем и пойдем дальше. Совет номер два вновь рекомендует развернуть тот же самый цикл, но уже находящийся внутри цикла while. Поскольку, этот цикл получает управление лишь при удлинении перебираемого пароля на один символ (что происходит прямо-таки скажем не часто) он, как и предыдущий, не оказывает практически никакого влияния на производительность, а потому рекомендацию по его развороту мы отправим в /dev/null.
Совет номер три придирается к с виду безобидной конструкции p++, увеличивающий переменную p на единицу:
114 p++;
115 if (!pswd[p])
116 {
117 pswd[p]='!';
118 pswd[p+1]=0;
119 length++;
120 x = -1;
121 for (b = 0; b <= length; b++)
122 x += *(int *)((int)pswd + b);
The loop whose index is incremented at line 114 should be interchanged with the loop whose index is incremented at line 121, for more efficient memory access
"Для достижения более эффективного доступа [к памяти] цикл, чей индекс увеличивается в строке 114, должен быть заменен циклом, чей индекс увеличивается в строке 121". ?! Инструктор судя по всему или пьян или от перегрева процессора спятил. Это вообще разные циклы. И индексы у них разные. И вообще они не имеют к друг другу никакого отношения, причем цикл, расположенный в строке 121, исполняется редко, так что совсем не понятно, что это VTune к нему так пристал?!
Может быть, дополнительная информация от Инструктора все разъяснит? Дважды щелкаем по строке 114 и читаем:
Loop interchange:
Loops with index variables referencing a multi-dimensional array are nested. The order in which the index variables are incremented causes out-of-sequence array referencing, resulting in many data cache misses. This increases the loop execution time.
Advice:
Do the following:
– Change the sequence of the array dimensions in the array declaration.
– Interchange the loop control statements.
Result:
The order in which the array elements are referenced is more sequential. Fewer data cache misses occur, significantly reducing the loop execution time.
Перестановка циклов:
Здесь наблюдается вложенные циклы с индексными переменными, обращающимися к многомерным массивам, Порядок, в котором увеличиваются индексные переменные, приводит к несвоевременному обращению к массивам, и как следствие этого – множественным кэш-промахам.
В результате увеличивается время выполнения цикла.
Совет:
Сделайте следующее:
– Измените последовательность измерений массивов в их объявлении;
– Поменяйте местами "измерения" управление цикла
[подразумевается: сделайте либо то, либо это, но ни в коем случае ни то и другое вместе – иначе "минус на минус даст плюс" и вы получите тот же самый результат – КК]
Результат:
Порядок, в котором обрабатываются элементы массива станет более последовательным. Меньше кэш-промахов будет происходить, от чего время выполнения цикла значительно сократиться.
Какие многомерные массивы? Какие кэш-промахи? Здесь у нас и близко нет ни того, ни другого! Судя по всему мы столкнулись с грубой ошибкой Инструктора (шаблонный поиск дает о себе знать!) но все же не поленимся, а заглянем в предлагаемый Инструктором пример, памятуя о том, что всегда в первую очередь следует искать ошибку у себя, а не у окружающих. Быть может, это мы чего-то недопонимаем…
|
Original Code |
Optimized Code |
|
|
int b[200][120]; void xmpl17(int *a) { int i, j; for (i = 0; i < 120; i++) for (j = 0; j < 200; j++) b[j][i]=b[j][i]+a[2*j]; } |
int b[200][120]; void ympl17(int *a) { int i, j; int atemp; for (j = 0; j < 200; j++) for (i = 0; i < 120;i++) b[j][i]=b[j][i]+a[2*j]; } |
Ну вот, все правильно. Приводимый VTune фрагмент кода наглядно демонстрирует, что к двухмерные массивы лучше обрабатывать по строкам, а не столбцам (см. "Часть II. Кэш"). Но ведь у нас нет двухмерных массивов, а – стало быть – и слушаться Инструктора в данном случае не надо.
Совет номер четыре и слова этот несчастный цикл подсчета контрольной суммы. Ну понравился от Инструктору – что поделаешь! Что же ему не понравилось на этот раз? Читаем…
121 for (b = 0; b <= length; b++)
122 x += *(int *)((int)pswd + b);
123 pswd[p]=' ';
124 y = 0;
125 }
126 } // end while(pswd)
Use the Intel C/C++ Compiler vectorizer to automatically generate highly optimized SIMD code. The statement on line 122 and others like it will be vectorized if the following program changes are made (double-click on any line for more information):
==> Simplify the pointer expression to indicate contiguous array accesses.
==> Restructure the loop to isolate the statement or construct that interferes with vectorization.
==> Try loop interchanging to obtain vector code in the innermost loop.
==> Simplify the pointer expression to indicate contiguous array accesses.
Используйте векторизатор компилятора Intel С/C++ для автоматической генерации высоко оптимизированного SIMD-кода. Оператор, находящийся в линии 122 и остальные подобные ему операторы, будут векторизованы при условии следующих изменений программы:
==> Упростите выражение указателя для индикации смежных доступов к массиву;
==> Реструктурируйте цикл для отделения выражения или логической конструкции, препятствующей векторизации;
==> Попытайтесь перестроить цикл для получения векторного кода во вложенном цикле;
==> Упростите выражение указателя для индикации смежных доступов к массиву;
Хорошие, однако, советы! А рекомендация упростить и без того примитивную форму адресации повторяется аж два раза! И это при том, что векторизовать данный цикл все равно не получится даже на Intel C/C++, а уж про все остальные компиляторы я и вовсе промолчу.
Тем не менее, все-таки заглянем в помощь – может быть, что-нибудь интересное скажут!
Intel C++ Compiler Vectorizer
The coach has identified an assignment or expression that is a candidate for SIMD technology code generation using Intel C++ Compiler vectorizer.
Advice
Use the Intel C++ Compiler vectorizer to automatically generate highly optimized SIMD code wherever appropriate in your application.
Use the following syntax to invoke the vectorizer from the command line: prompt> icl -O2 -QxW myprog.cpp.
The -QxW command enables vectorization of source code and provides access to other vectorization-related options.
Result
The Intel C++ Compiler vectorizer optimizes your application by processing data in parallel, using the Streaming SIMD Extensions of the Intel processors. Since the Streaming SIMD Extensions that the class library implements access and operate on 2, 4, 8, or 16 array elements at one time, the program executes much faster.
Векторизатор компилятора Intel C++
Инструктор идентифицирован присвоение или выражение, являющееся кандидатом для генерации кода по SIMD-технологии, используемой векторизатором компилятора Intel C++.
Совет:
Используйте векторизатор компилятора Intel C++ для автоматической генерации высоко оптимизированного SIMD-кода, подходящего к вашему приложению. Используйте следующий синтаксис для вызова векторизатора из командной строки: icl –O2 QxW myprog.cpp.
Ключ "-QxW" разрешает векторизацию исходного кода и предоставляет доступ к остальным векторным опциям.
Результат:
Векторизатор компилятора Intel C++ оптимизирует ваше приложение путем парализации обработки данных, с использованием поточного SIMD-расширения команд процессоров Intel. С тех пор как потоковые SIMD расширения библиотеки классов осуществляют доступ и обработку 2, 4, 8 или 16 элементов массива за один раз, скорость выполнения программы весьма значительно возрастает.
Бесспорно, векторизация – полезная штука, действительно позволяющая многократно увеличить скорость работы программы, но ее широкому внедрению в массы препятствует по меньшей мере два минуса: во-первых, подавляющее большинство x86-компилятор не умеют векторизовать код, а переход на компилятор Intel не всегда приемлем. Во-вторых, векторизация будет по настоящему эффективна лишь в том случае, если программа изначально заточена под эту технологию. И хотя в мире "больших" машин векторизация кода известна уже давно, для x86-программистов это еще тот конек!
Совет номер пять или еще один просчет Инструктора. Так, посмотрим, что за перл выдал Инструктор на этот раз.
91 if (x==validCRC)
92 {
93 // копируем шифроданные во временный буфер
94 buff = (char *) malloc(strlen(crypteddata));
95 strcpy(buff, crypteddata);
96
97 // расшифровываем
98 DeCrypt(pswd, buff);
99
The argument list for the function call to _malloc on line 94 appears to be loop-invariant. If there are no conflicts with other variables in the loop, and if the function has no side effects and no external dependencies, move the call out of the loop.
(Список аргументов функции malloc, находящейся в строке 94, вероятно, инвариантен относительно цикла. Если это не вызовет конфликта с остальными переменными цикла, и если не имеет посторонних эффектов и внешних зависимостей, вынесите ее за пределы цикла).
Вообще-то, формально Инструктор прав. Вынос инвариантных функций из тела цикла – хороший тон программирования, поскольку, находясь в теле цикла, функция вызывается множество раз, но, в силу своей независимости от параметров цикла, при каждом вызове дает один и тот же результат. Действительно, не проще ли единожды выделив память при входе в функцию, просто сохранить возращенный malloc указатель в специальной переменной, а затем использовать его по мере необходимости?
Возражения: ну и что мы в результате этого получим? Данная ветка вызывается лишь при совпадении контрольной суммы текущего перебираемого пароля с эталонной контрольной суммой, что происходит крайне редко – в лучшем случае несколько раз за все время выполнения программы.
Возражение номер два: перефразируя известный анекдот "я девушку кормил-поил, я ее и танцевать буду" можно сказать "та ветвь программы, которая выделила блок памяти, сама же его и освобождает, конечно, если это не приводит к неоправданному снижению производительности".
Таким образом, ничего за пределы цикла мы выносить не будем, что бы там нам не советовал Инструктор.
Совет номер шесть. Данный совет практически полностью повторяет предыдущий, однако, на этот раз, Инструктор посоветовал вынести за пределы цикла функцию De Crypt. Да, да! Счел ее инвариантом и посоветовал вынести куда подальше и это не смотря на то, что: а) код самой функции в принципе был в его распоряжении ("в принципе" потому, что мы приказали Инструктору анализировать только gen_pswd). б) функции De Crypt
передается указатель pswd, который явным образом изменяется в цикле! А раз так, то инвариантом De Crypt
быть ну никак не может! И как только Инструктору не стыдно давать такие советы? Или все-таки стыдно – а вы думали почему он красный такой?
Совет номер семь. Сейчас Инструктор обращает наше внимание, на то, что: "The value returned by De Crypt() on line 98 is not used…" ("Значение, возвращаемое функцией De Crypt, расположенной в строке 98, не используется..") и дает следующий совет "If the return value is being ignored, write an alternate version of the function which returns void" ("Если возвращенное значение игнорируется, создайте альтернативную версию данной функции, возвращающей значение void").
В основе данного совета лежит допущение Инспектора, что функция, не возвращающая никакого значения, будет работать быстрее функции такое значение возвращающей. На самом деле это более, чем спорно. Во-первых, возврат значения занимает не так уж много времени, во-вторых, большинство компиляторов при выходе из void
функций все равно возвращают "ноль", а вовсе ни "ничто". В-третьих, создание двух экземпляров одной функции обойдется много дороже, чем накладные расходы на возврат никому не нужного значения.
Так что игнорируем этот совет и идем дальше.
Совет номер восемь. Теперь Инспектор принял за инвариант функцию printf, распечатывающую содержимое буфера buff, только что возвращенного функцией De Crypt.
Мм… не ужели разработчикам VTune было трудно заложить в башку Инспектора смысловое значение хотя бы основных библиотечных функций? Функция printf
не зависимо от того является ли она инвариантом или нет, никогда не может быть вынесена за пределы цикла! И вряд ли стоит объяснять почему.
Совет номер девять. …Значение, возвращаемое функций printf не используется, поэтому…
Что ж! Результатами такого инструктажа трудно остаться удовлетворенным. Из девяти советов мы не воспользовались ни одним, поскольку это все равно бы не увеличило скорость выполнения программы. Тем не менее, Инструктора не стоит считать совсем уж никчемным чукчей. Во всяком случае он рассказывает о действительно интересных и эффективных приемах оптимизации, не все из которых известны новичкам.
Возможно мне возразят, что такая непроходимая тупость Инструктора объясняется тем, что мы подсунули ему уже до предела оптимизированную программу и ему ничего не осталось, как придираться к второстепенным мелочам. Хорошо, давайте напустим Инструктора на самый первый вариант программы, заставив его проанализировать весь код целиком. Он сделает нам 33 замечания, из которых полезных по прежнему не окажется ни одного!
первый. Удаление printf
Конечно, полностью отказываться от вывода текущего состояния программы – глупо (пользователю ведь интересно знать сколько паролей уже перебрано, и потом надо ведь как-то контролировать машину – не зависла ли?), но можно ведь отображать не каждый перебираемый пароль, а скажем, каждый шестисотый, а еще лучше – каждый шеститысячный. При этом, накладные расходы на вызов printf значительно упадут, а то и вовсе приблизятся к нулю.
Давайте перепишем фрагмент, ответственный за вывод текущего состояния следующим образом:
static int x=0;
// вывод текущего состояния на терминал
if (++x>6666)
{
x = 0;
printf("Current pswd : %10s [%d%%]\r",&pswd[0],progress);
}
Листинг 12 Сокращение количества вызова функции printf
Батюшки мои! После перекомпиляции мы получаем скорость перебора свыше полутора миллионов паролей в секунду! То есть скорость программы возросла более, чем в пять раз! Программа выполняется так быстро, что "чувствительности" функции clock уже оказывается недостаточно для измерений и количество итераций приходится увеличивать раз в сто! И это, как мы убедимся в самом непосредственном будущем, еще отнюдь не предел быстродействия!
пятый. Удаление операции деления
Теперь на первое место вырывается функция gen_pswd, в которой процессор проводит более половины всего времени исполнения программы.
За gen_pswd
с большим отрывом следует CalculateCRC – ~21% и Check CRC
– ~15%. Причем, ~40% от общего времени исполнения функции gen_pswd
сосредоточено в одной - единственной горячей точке. Непорядок! Надо оптимизировать!
Двойной щелчок по высоченному прямоугольнику приводит нас к… инструкции IDIV, выполняющий целочисленное деление. Постой, постой, а где у нас в gen_pswd
целочисленное деление? А вот, уже нашли!
do_pswd(crypteddata, pswd, validCRC, 100*a/max_iter);
Здесь мы вычисляем процент проделанной работы. Забавно, но на это уходит приблизительно столько же времени, сколько и на саму работу! А раз так – ну все эти "градусники" к черту! Удаляем команду деления, подставляя вместо значения прогресса "0" или любое другое понравившееся вам число.
Перекомпилируем, и…. четырнадцать с половиной миллионов паролей в секунду!
седьмой. Объединение функций
На этот раз самой горячей точкой становится сохранение регистра ESI где-то глубоко внутри функции CalculateCRC. Это компилятор "заботливо" бережет его содержимое от посторонних модификаций. Несмотря на то, что количество используемых переменных в программе довольно невелико и в принципе обращений к памяти можно было бы и избежать, разместив все переменные в регистра, компилятор не в состоянии этого сделать, т.к. оптимизирует каждую функцию по отдельности.
Так давайте же, плюнув на структурность, объединим все наиболее интенсивно используемые функции (gen_pswd, do_paswd, Check CRC и Calculate CRC) в одну "супер-функцию".
Ее реализация может выглядеть например так:
int gen_pswd(char *crypteddata, char *pswd, int max_iter, int validCRC)
{
int a, b, x;
int p = 0;
char *buff;
int length = strlen(pswd);
for(a = 0; a < max_iter; a++)
{
x = -1; for (b = 0; b <= length; b++) x += *(int *)((int)pswd + b);
if (x==validCRC)
{
buff = (char *) malloc(strlen(crypteddata));
strcpy(buff, crypteddata); DeCrypt(pswd, buff);
printf("CRC %8X: try to decrypt: \"%s\"\n", validCRC,buff);
}
while((++pswd[p])>'z')
{
pswd[p] = '!'; p++; if (!pswd[p])
{
pswd[p]=' '; pswd[p+1]=0;length++;
}
}; p = 0;
}
return 0;
}
Листинг 18 Объединение функций gen_pswd, do_paswd, Check CRC и Calculate CRC
в одну супер функцию
Компилируем, запускаем… ой! прямо не верим своим глазам – тридцать пять миллионов паролей в секунду! А ведь казалось, что резерв быстродействия уже исчерпан. Ну и кто теперь скажет, что Pentium – медленный процессор? Генерация очередного пароля, вычисление и проверка его контрольной суммы укладывается в каких-то двадцать тактов…
Двадцать тактов?! Хм! Тут еще есть над чем поработать!
шестой. Удаление мониторинга производительности
Несмотря на прямо-таки гигантскую скорость перебора, функция gen_pswd все еще оттягивает на себя ~22% времени исполнения программы, что не есть хорошо.
Двойной щелчок по ней показывает, что среди более или менее ровного ряда практически одинаковых по высоте диаграмм, возвышается всего лишь один красный прямоугольник. А ну-ка посмотрим что там!
Дизассемблирование позволяет установить, что за этой горячей точкой скрывается уже знакомая нам конструкция:
if (++x>66666)
{
x = 0;
printf("Current pswd : %10s [%d%%]\r",&pswd[0],progress);
}
Что ж! Во имя Ее Величества Производительности, мы решаемся полностью отказаться от мониторинга текущего состояния и выбрасываем эти шесть строк напрочь.
В результате скорость перебора повышается еще на пять миллионов паролей в секунду. Хм, вообще-то не такая уж и большая прибавка, так что не факт, что такую оптимизацию следовало выполнять…
третий. Выравнивание данных
Тем не менее профилировка показывает, что количество горячих точек не только сократилось, но даже возросло на одну! Почему? Так дело в том, что алгоритм подсчета горячих точек учитывает не абсолютное, а относительное быстродействие различных частей программы по отношению друг к другу. И по мере удаления самых больших пиков, на диаграмме появится более мелка "рябь".
Несмотря на оптимизацию, функция CalculateCRC, по прежнему идет "впереди планеты всей", отхватывая более 50% всего времени исполнения программы. Но теперь самой горячей точной становится пара команд:
mov edi, DWORD PTR [eax+esi]
add edx, edi
Хм! Что же в них такого особенного? Ну да, тут налицо обращение к памяти (x += *(int *)((int)pswd + a)), но ведь тестируемый пароль по идее должен находится в кэше первого уровня, доступ к которому занимает один такт. Может быть, кто-то вытеснил эти данные из кэша? Или произошел какой-нибудь конфликт? Попробуй тут разберись! Можно бесконечно ломать голову, поскольку причина вовсе не в этом коде, а совсем в другой ветке программы…
Вот тут самое время прибегнуть к одному из мощнейших средств VTune – динамическому анализу, позволяющему не только определить куда уходят такты, но и выяснить причины этого. Причем, динамический анализ выполняется отнюдь не на "живом" процессоре, а… его программном эмуляторе. Это здорово экономит ваши финансы! Для оптимизации вовсе не обязательно приобретать всю линейку процессоров – от Intel 486 до Pentium-4, – достаточно приобрести один VTune, и можете запросто оптимизировать свои программы под Pentium-4, имея в наличии всего лишь Pentium-II или Pentium-III.
Перед началом динамического анализа, вам требуется указать какую именно часть программы вы хотите профилировать. В частности, можно анализировать как одну "горячую" точку функции Calculate CRC, так и всю функцию целиком. Поскольку, наша подопечная функция содержит множество "горячих" точек, выберем последний вариант.
Прокручивая экран вверх, переместим курсор в строку с меткой "Calculate CRC" (метки отображаются в второй слева колонке экрана). Если же такой строки не окажется, найдем на панели инструментов кнопку, с голубым треугольником, направленным вверх (Scroll to Previous Portal) и нажмем ее. Теперь установим точку входа (Dynamic Analyses Entry Pont) которая задается кнопкой с желтой стрелкой, направленной вправо. Аналогичным образом задается и точка выхода (Dynamic Analyses Exit Pont) – прокручивая экран вниз, добираемся до последней строки Calculate CRC (она состоит всего из одной команды – ret) и, пометив ее курсором, нажимаем кнопку с желтой стрелкой, направленной налево. Теперь – "Run\Dynamic Analysis Session". В появившимся диалоговом окне выбираем эмулируемую модель процессора (в нашем случае – P-III) на нажимаем "Start". Поехали!
Профилировщик вновь запустит программу и, погоняя ее минуту-другую, выдаст приблизительно следующее окно (см. рис. 0x004).
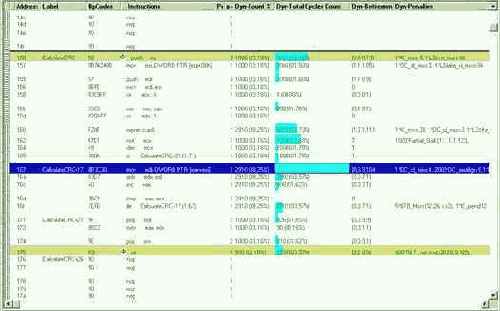
Рисунок 9 0х004 Динамический анализ программы не только определяет температуру каждой машинной инструкции, но и объясняет причины ее "нагрева"
Ага! Вот она наша горячая точка (на рисунке она отмечена курсором). Двойной щелчок мыши вызывает информационный диалог, подробно описывающий проблему :
Decoder Minimum Clocks = 0, ; // Минимальное время декодирования 0 тактов
Decoder Average Clocks = 0.7 ; // Среднее время декодирования 0.7 тактов
Decoder Maximum Clocks = 14 ; // Максимальное время декодирования 14 тактов
Retirement Minimum Clocks = 0, ; // Минимальное время завершения 0 тактов
Retirement Average Clocks = 6.9 ; // Среднее время завершения 6.9 тактов
Retirement Maximum Clocks = 104 ; // Максимальное время завершения 104 такта
Total Cycles = 20117 (35,88%) ; // Полное время исполнения 20.117 тактов (35,88%)
Micro-Ops for this instruction = 1 ; // Инструкция декодируется в одну микрооперацию
// Инструкция ждала (0, 0.1, 2) цикла пока ее операнды не были готовы
The instruction had to wait (0,0.1,2) cycles for it's sources to be ready
Warnings: 3*decode_slow:0 ; // Конфликтов декодеров – нет
Dynamic Penalty: DC_rd_miss
The operand of this load instruction was not in the data cache. The instruction stalls while the processor loads the specified address location from the L2 cache or main memory.
(Операнд этой инструкции отсутствовал в кэше данных. Инструкция ожидала пока процессор загрузит соответствующие данные из кэша второго уровня или основной памяти).
Occurrences = 1 ; // Случалось один раз
Dynamic Penalty: DC_misalign
The instruction stalls because it accessed data that was split across two data-cache lines.
(Инструкция простаивала, потому что она обращалась к данным "расщепленным" через две кэш-линии)
Occurrences = 2000 ; // Случалось 2000 раз
Dynamic Penalty: L2data_rd_miss
The operand of this load instruction was not in the L2 cache. The instruction stalls while the processor loads the specified address location from main memory.
(Операнд этой инструкции отсутствовал в кэше второго уровня. Инструкция ожидала пока процессор загрузит соответствующие данные из основной памяти).
Occurrences = 1 ; // Случалось один раз
Dynamic Penalty: No_BTB_info
The BTB does not contain information about this branch. The branch was predicted using the static branch prediction algorithm.
(BTB – Branch Target Buffer – буфер ветвлений не содержал информацию об этом ветвлении.
Ветка была предсказана статическим алгоритмов предсказаний).
Occurrences = 1 ; // Случалось один раз
Какая богатая кладезь информации! Оказывается, кэш тут действительно не причем (кэш-промах произошел всего один раз), а основной виновник – доступ к не выровненным данным, который имел место аж 2000 раз, – именно столько, сколько и прогонялась программа. Т.е. такое происшествие случалось на каждой итерации цикла – отсюда и тормоза.
Смотрим, – где в программе инициализируется указатель pswd? Ага, вот фрагмент кода из тела функции main (надеюсь, теперь вам понятно, почему статически анализ функции Calculate CRC был неспособен что-либо дать?):
pswd = (char *) malloc(512*1024);
pswd+=62;
Листинг 15 Выравнивание парольного буфера для предотвращения штрафных санкций со стороны процессора
Убираем строку "pswd += 62"
и перекомпилируем программу. Четыре с половиной миллиона паролей в секунду! Держи тигра за хвост!
восьмой. Сокращения операций обращение к памяти
Основная масса горячих точек теперь, как показывает профилировка, сосредоточена в цикле подсчета контрольной суммы пароля – на него приходится свыше 80% всего времени исполнения программы, из них 50% "съедает" условный переход, замыкающий цикл (Pentium-процессоры страсть как не любят коротких циклов и условных переходов), а остальные 50% расходуются на обращение к кэш-памяти. Тут уместно сделать небольшое пояснение.
Расхожее мнение утверждает, что чтение нерасщепленных данных, находящихся в кэш-памяти занимает всего один такт, – ровно столько же, сколько и чтение содержимого регистра. Это действительно так, но при более пристальном изучении проблемы выясняется, что "одна ячейка за такт", это пропускная способность кэш памяти, а полное время загрузки данных с учетом латентности составляет как минимум три такта. При чтении зависимых данных из кэша (как в нашем случае) полное время доступа к ячейке определяется не пропускной способностью, а его латентностью. К тому, на процессорах семейства P6 установлено всего лишь одно устройство чтения данных и поэтому, даже при благоприятном стечении обстоятельств они могут загружать всего лишь одну ячейку за такт. Напротив, на данные, хранящиеся в регистрах, это ограничение не распространяется.
Таким образом, для увеличения производительности мы должны избавиться от цикла и до минимума сократить количество обращений к памяти. К сожалению, мы не можем эффективно развернуть цикл, поскольку нам заранее неизвестно количество его итераций. Аналогичная ситуация складывается и с переменными: программируя на ассемблере, мы запросто смогли бы разместить парольный буфер в регистрах общего назначения (благо 16-символьный пароль – самый длинный пароль – который реально найти перебором – размешается всего в четырех регистрах, а в остающиеся три регистра вмещаются все остальные переменные). Но для прикладных программистов, владеющих одним лишь языком высокого уровня этот путь закрыт и им приходится искать другие решения.
И такие решения действительно есть! До сих пор мы увеличивали скорость выполнения программы за счет отказа от наиболее "тяжеловесных" операций, практически не меняя базовых вычислительных алгоритмов. Этот путь привел к колоссальному увеличению производительности, но сейчас он себя исчерпал и дальнейшая оптимизация возможна лишь на алгоритмическом
уровне.
В алгоритмической же оптимизации нет и не может быть универсальных советов и общих решений, – каждый случай должен рассматриваться индивидуально, в контексте своего окружения. Возвращаясь к нашим баранам, задумается: а так ли необходимо считать контрольные суммы каждого нового пароля? В силу слабости используемого алгоритма подсчета CRC, его можно заменить другим, – более быстродействующим, но эквивалентным алгоритмом.
Действительно, поскольку младший байт пароля суммируется всего лишь один раз, то при переходе к следующему паролю его контрольная сумма в большинстве случаев увеличивается ровно на единицу. "В большинстве" – потому, что при изменении второго и последующих байтов пароля, изменяемый байт уже суммируется как минимум дважды, к тому же постоянно попадает то в один, то в другой разряд. Это немного усложняет наш алгоритм, но все же не оставляет его далеко впереди "тупой" методики постоянного подсчета контрольной суммы, используемой ранее.
Словом, финальная реализация улучшенного переборщика паролей может выглядеть так:
int gen_pswd(char *crypteddata, char *pswd, int max_iter, int validCRC)
{
int a, b, x;
int p = 0;
char *buff;
int y=0;
int k;
int length = strlen(pswd);
int mask;
x = -1;
for (b = 0; b <= length; b++)
x += *(int *)((int)pswd + b);
for(a = 0; a < max_iter ; a++)
{
if (x==validCRC)
{
buff = (char *) malloc(strlen(crypteddata));
strcpy(buff, crypteddata); DeCrypt(pswd, buff);
printf("CRC %8X: try to decrypt: \"%s\"\n", validCRC,buff);
}
y = 1;
k = 'z'-'!';
while((++pswd[p])>'z')
{
pswd[p] = '!';
// следующий символ
y = y | y << 8;
x -= k;
k = k << 8;
k += ('z'-'!');
p++;
if (!pswd[p])
{
pswd[p]='!';
pswd[p+1]=0;
length++;
x = -1;
for (b = 0; b <= length; b++)
x += *(int *)((int)pswd + b);
y = 0;
pswd[p]=' ';
}
//printf("%x\n",y);
} // end while(pswd)
p = 0;
x+=y;
} // end for(a)
return 0;
}
Листинг 19 Алгоритмическая оптимизация алгоритма просчета CRC
Какой результат дала алгоритмическая оптимизация? Ни за что не догадаетесь –восемьдесят три миллиона паролей в секунду или ~1/10 пароля за такт. Фантастика!
И это при том, что программа написана на чистом Си! И ведь самое забавное, что хороший резерв производительности по-прежнему есть!
второй. Вынос strlen за тело цикла
Повторный запуск "обновленной" программы под профилировщиком показывает, что количество "горячих" точек в ней уменьшилось с 187 до 106. Конечно, это хорошо, но ведь горячие точки все еще есть! Кликнув в окне "View" расположенным в правом верхнем углу окна "Hot Spots" по радио – кнопке "Hotspots by function" (сортировать горячие точки по функциями), мы узнаем, что ~80% времени наша программа проводит в недрах функции Calculate CRC, затем с большим отрывом следует gen_pswd – ~12% и по ~3% делят функции Check CRK и do_pswd.
Ну это никуда не годится! Какая-то там задрипанная Calculate CRC без зазрения совести поглощает практически все быстродействие программы! Эх, вот бы еще узнать, какая именно часть функции в наибольшей степени влияет на производительность… И VTune позволяет это сделать!
Дважды кликнем по красному прямоугольнику, чтобы увеличить его на весь экран. Оказывается, внутри функции Calculate CRC насчитывается 18 горячих точек, три их которых наиболее горячи – ~30%, ~25% и ~10% соответственно (см. рис 0x003). Вот с первой из них мы и начнем. Дважды кликнем по самому высокому из прямоугольников и… VTune обижено пискнув сообщит, что "No source found for offset 0x69 into F:\.OPTIMIZE\src\Profil\pswd.exe. Proceed with disassembly only?" ("Исходные тексты не найдены. Продолжать с отображением только дизассемблерного текста?"). Действительно, поскольку программа откомпилирована без отладочной информации, то VTune не может знать, какой байт ассемблерного когда, какой строке соответствует, а компилятор не соглашается предоставить эту информацию в силу того, что в оптимизированной программе соответствие между исходным текстом и сгенерированным машинным кодов в общем-то не столь однозначно.
Конечно, можно профилировать и не оптимизированную программу, – но… какой в этом резон? Ведь это будет другая программа и с другими
горячими точками! По любому, качественная оптимизация без знаний ассемблера невозможна, поэтому, прогнав все страхи прочь, смело нажмем кнопочку, "ОК", то есть "Да, мы соглашаемся работать без исходных текстов непосредственно с ассемблерным кодом".
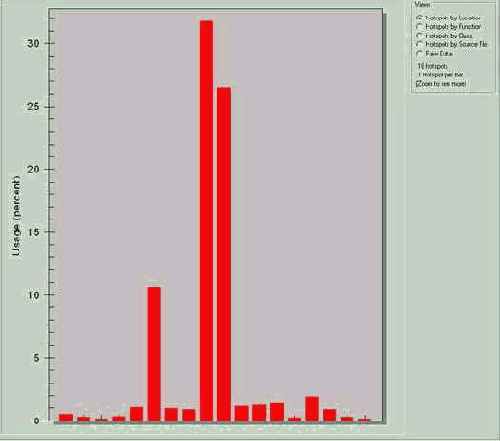
Рисунок 8 0x003 Распределение температуры внутри функции Calculate CRC (снимок сделан с высоким разрешением)
VTune тут же тыкает нас носом в инструкцию REPNE SCANB. Не нужно быть провидцем, чтобы распознать в ней ядро функции strlen. Использовали ли мы strlen в исходном тексте программы? А то как же! Смотрим сюда:
int CalculateCRC(char *pswd)
{
int a;
int x = -1; // ошибка вычисления CRC
for (a = 0; a <= strlen(pswd); a++)
x += *(int *)((int)pswd + a);
return x;
}
Листинг 13 Вызов функции strlen в заголовке цикла привел к тому, что компилятор, не распознав в ней инварианта, не вынес ее из цикла, "благодаря" чему длина одной и той же строки стала подсчитываться на каждой итерации
Судя по всему бестолковый компилятор не вынес вызов strlen за тело цикла, хотя ее аргумент – переменная pswd не модифицировалась в цикле! Хорошо, если гора не идет к Магомету, пойдем навстречу компилятору и перепишем этот участок кода так:
int length;
length=strlen(pswd);
for (a = 0; a <= length; a++)
Листинг 14 Вынос функции strlen за пределы цикла
Перекомпилировав программу, мы с удовлетворением отметим, что теперь ее быстродействие возросло до трех с половиной миллионов паролей в секунду, т.е. практически в два с половиной раза больше, чем было в предыдущем случае.
Силки для клиента или 7 таинств мистерий
Бизнес честным не бывает. Понятия "справедливости" в нем не существует. Сумма денег (пренебрегая инфляцией) величина постоянная и единственный способ заработать – отнять у других.
Конечная цель любого бизнесмена – заставить клиента расстаться с деньгами, а конкурента – с клиентами. Неприкрытый грабеж встречается достаточно редко (цивилизация мы или нет?), но хитрость и обман – сплошь и рядом.
Синхронная статическая память
Синхронная статическая память выполняет все операции одновременно с тактовыми сигналами, в результате чего время доступа к ячейке укладывается в один-единственный такт. Именно на синхронной статической памяти реализуется кэш первого уровня современных процессоров.
Слияние циклов
Если два цикла имеют идентичные заголовки, их можно объединить в один общий цикл. Например, пусть исходный код программы выглядел так:
for(b=0;b<10;b++)
x[b]=b;
for(b=0;b<10;b++)
y[b]=b;
Очевидно, что данный код можно без потери функциональности переписать так, увеличив производительность и компактность программы:
for(b=0;b<10;b++)
{
x[b]=b;
y[b]=b;
}
К сожалению, ни один из трех рассматриваемых компиляторов сливать циклы не способен.
Сложение и вычитание
Старшие модели микропроцессоров Intel Pentium могут выполнять до двух операций целочисленного сложения (вычитания) за каждый такт, – казалось бы, все оптимизировано по самые помидоры, но оказывается, что это далеко не предел! Инструкция LEA способна вычислять за один такт сумму двух регистров и одной константы, помещая результат в любой регистр, а не обязательно в один из операндов, как это делает команда ADD.
Использование LEA позволяет выполнить следующий код (int c=a+b+0x666; int d=e+f+0x777)
всего за один такт! (Конечно, при условии, что a, b, с, d, e и f – регистровые переменные). Весь фокус в том, что "официально" инструкция LEA предназначена для вычисления эффективного смещения ячейки памяти и по логике применима только к ближним (near) указателям. Но, поскольку в силу архитектурных особенностей микропроцессоров серии Intel 80x86 представление ближних указателей эквивалентно их фактическому значению, результат, возвращенный инструкцией LEA, равен алгебраической сумме ее операндов, и потому она может быть использована вместо ADD!
Все три рассматриваемых компилятора – Microsoft Visual C++, Borland C++ и WATCOM "знают" об этом трюке и активно прибегают к нему при необходимости.
Смертельная схватка: Ассемблер vs. Компилятор
"Сохраняй за собой право думать, даже неправильно - это лучше, чем не думать совсем".
приписывается Гиппатии
В статье приводится сравнительный анализ качества машинной кода и ручной ассемблерной оптимизации на примере широко распространенных компиляторов Microsoft Visual C++ 6.0, Borland C++ 5.5, WATCOM С++ 10.0
"Священные войны" вокруг компиляторов бушуют очень давно. Одни обожествляют машинную кодогенерацию, другие же стремятся все делать своими руками, порой реализуя программы на чистейшем ассемблере. Конечно, всякий имеет право на выбор, но этот выбор должен делаться осмысленно, а не вслепую. Между тем, каждая из сторон, распускает совершенно неправдоподобные слухи. Приверженцы компиляторов убеждают окружающих в том, что человек физически не способен учитывать все архитектурные особенности современных процессоров эта работа якобы по плечу одному лишь оптимизатору. Их противники в качестве контраргумента обычно приводят ассемблерную реализацию канонической программы "Hello, World!", – по объему раз в триста
меньшей "самого оптимального кода", сгенерированного компиляторами.
Вот и разберись: кому же верить, а кому нет? Такая неопределенность часто нервирует начинающих программистов, пытающихся разобраться: стоит ли изучать ассемблер или же это пустая трата времени?
Чтобы там ни говорили сторонники компиляторов, машинная оптимизация всегда будет проигрывать человеку, поскольку, действует по жесткому, заранее заложенному в нее шаблону, в то время как человек же способен на качественно новые решения. Касательно же невозможности учета архитектурных способностей современных процессоров, – тем, кто это утверждает, легко возразить: не стоит, право же, судить все человечество по себе. Оптимальное планирование потока команд вполне по силам программисту средней руки, конечно, при наличии соответствующей подготовки. К тому же, техника оптимизации процессоров последнего поколения стала значительно проще, чем была лет пять тому назад.
С другой стороны, ассемблер – это не волшебная лампа Паладина; он не способен творить чудеса. Во всяком случае, реализация полиномиального алгоритма на ассемблере еще никогда не превращала его в логарифмический. За исключением особо оговариваемых случаев речь может идти лишь о количественном, но отнюдь не качественном выигрыше (пример с "Hello, World!" – как раз и есть один из таких редких случаев, и ниже он будет рассмотрен во всех подробностях). К тому же, при неумелом обращении (или применении знаний, почерпнутых их книжек по оптимизации десятилетней давности) "ручная" оптимизация становится просто посмешищем компиляторов!
В общем, здесь есть, с чем разбираться…
Соглашения об условных обозначениях и наименованиях
Расшифровку всех непонятных терминов, если таковые встретятся вам по ходу чтения книги, можно узнать в глоссарии. Но, поскольку, в глоссарий по обыкновению все равно никто не заглядывает, ниже перечислены обозначения, которые с наибольшей степенью вероятности могут вызвать затруднение.
1) Под P6-процессорами понимаются все процессоры с ядром P6, построенные по архитектуре Pentium Pro. К ним принадлежат: сам Pentium Pro, Pentium-II и Pentium-III, а так же процессоры семейства CELERON.
2) Процессоры серии Pentium здесь сокращаются до первой буквы "P" и стоящей за ней суффиксом, уточняющим какая именно модель имеется ввиду. Например, "P Pro" обозначает "Pentium Pro", а "P?4" – "Pentium?4". Кстати, обратите особое внимание, что индексы "II" и "III" записываются римскими цифрами, а "4" – арабскими. Так хочет фирма Intel (она уже однажды сделала мне замечание по этому поводу), поэтому не будем ей противоречить. В конце концов, хозяин – барин.
3) Под "MS VC" или даже просто "VC" подразумевается Microsoft Visual C++ 6.0, а под "BC" – Borland C++ 5.5. Соответственно, "WPP" обозначает "WATCOM C++ 10.0".
4) Кабалистическое выражение наподобие "P-III 733/133/100/I815EP" расшифровывается так: "процессор Intel Pentium-III с тактовой частой 773 MHz, частой системной шины 133 MHz и частой памяти 100 MHz, установленный в материнскую плату, базирующуюся на чипсете Intel 815 EP".
Соответственно, "AMD Athlon 1050/100/100/VIA KT 133" обозначает: "процессор AMD Athlon с тактовой частотой 1050 MHz, частотой системной шины 100 MHz и частотой работы памяти 100 MHz, уставленный в материнскую плату, базирующуюся на чипсете VIA KT 133".
Да, чуть не забыл сказать. "Сверхоперативная память" – это русский эквивалент американского термина "cache memory". Здесь он будет использоваться вовсе не из-за самостийной гордости, а просто для того, чтобы избежать излишней тавтологии (частого повторения одних и тех же слов).
Создание таблицы переходов
Если значения ветвей выбора представляют собой арифметическую прогрессию, то можно сформировать таблицу переходов – массив, проиндексированный case-значениями и содержащий указатели на соответствующие им case-обработчики. В этом случае, сколько бы оператор switch ни содержал ветвей, – один или миллион – он выполняется за одну итерацию. Красота!
Создавать таблицы переходов умеют все три рассматриваемых компилятора, и следующий пример успешно оптимизирует каждый из них.
switch (a)
{
case 1 : …;
case 2 :…;
case 3 :…;
case 4 :…;
case 5 : …;
case 6 :…;
case 7 :…;
case 8 :…;
case 9 :…;
case 10 :…;
case 11 :…;
}
Однако WATCOM плохо справляется с переупорядоченной прогрессией и совсем не справляется с несколькими независимыми прогрессиями. Компиляторы Microsoft Visual C++ и Borland C++ успешно оптимизируют следующий пример, а WATCOM создаст обычное несбалансированное логическое дерево, в худшем случае выполняющееся за одиннадцать итераций, что на порядок хуже, чем у конкурентов.
switch (a)
{
case 11 : …;
case 2 : …;
case 13 : …;
case 4 : …;
case 15 : …;
case 6 : …;
case 17 : …;
case 8 : …;
case 19 : …;
case 10 : …;
case 21 : …;
}
Сравнительная характеристика основных типов памяти
С точки зрения пользователя PC главная характеристика памяти это – скорость
или, выражаясь другими словами, ее быстродействие. Казалось бы, что может быть проще, чем измерять быстродействие? Достаточно подсчитать количество информации, выдаваемой памятью в единицу времени (скажем, мегабайт в секунду), и… ничего не получится! Ведь, как мы уже знаем, время доступа к памяти непостоянно и, в зависимости от характера обращений, варьируется в очень широких пределах. Наибольшая скорость достигается при последовательном чтении, а наименьшая – при чтении в разброс. Но и это еще не все! Современные модули памяти имеют несколько независимых банков и потому позволяют обрабатывать несколько запросов параллельно.
Если запросы следуют друг за другом непрерывным потоком, непрерывно генерируются и ответы. Несмотря на то, что задержка между поступлением запроса и выдачей соответствующего ему ответа может быть весьма велика, в данном случае это не играет никакой роли, поскольку латентность (т.е. величина данной задержки) полностью маскируется конвейеризацией и производительность памяти определяется исключительно ее пропускной способностью. Можно провести следующую аналогию: пусть сборка одного отдельного взятого Мерседеса занимает ну, скажем, целый месяц. Однако если множество машин собирается параллельно, завод может выдавать хоть по сотне Мерседесов в день и его "пропускная способность" в большей степени определяется именно количеством сборочных линий, а не временем сборки каждой машины.
В настоящее время практически все производители оперативной памяти маркируют свою продукцию именно в пропускной способности, но наблюдающийся в последнее время стремительный рост пропускной способности (см. рис. graph 30), адекватного увеличения производительности приложений, как это ни странно, не вызывает. Почему?
Основной камень преткновения – фундаментальная проблема зависимости по данным (см. "Оптимизация работы с памятью: устранение зависимости по данным"). Рассмотрим следующую ситуацию.
Пусть ячейка N1 хранит указатель на ячейку N 2, содержащую обрабатываемые данные. До тех пор, пока мы не получим содержимое ячейки N 1, мы не сможем послать запрос на чтение ячейки N 2, поскольку, еще не знаем ее адреса. Следовательно, производительность памяти в данном случае будет определяться не пропускной способностью, а латентностью. Причем, не латентностью микросхемы памяти, а латентностью всей подсистемы памяти – кэш-контроллером, системной шиной, набором системной логики… Латентность всего это хозяйства очень велика и составляет порядка 20 тактов системной шины, что многократно превышает полное время доступа к ячейке оперативной памяти. Таким образом, при обработке зависимых данных быстродействие памяти вообще не играет никакой роли – и SDRAM PC100, и RDRAM-800 покажут практически идентичный результат!
Причем, описываемый случай отнюдь не является надуманным, скорее наоборот – это типичная ситуация. Основные структуры данных (такие как деревья и списки) имеют ярко выраженную зависимость по данным, поскольку объединяют свои элементы именно посредством указателей, что "съедает" весь выигрыш от быстродействия микросхем памяти.
Таким образом, теоретическая пропускная способность памяти, заявленная производителями, совсем ничего не говорит о ее реальной производительности.
|
Тип памяти |
Рабочая частота, MHz |
Разрядность, бит |
Время доступа, нс. |
Время рабочего цикла, нс. |
Пропускная способность, Мбайт/c |
|
FPM |
25, 33 |
32 |
70, 60 |
40, 35 |
100, 132 |
|
EDO |
40, 50 |
32 |
60, 50 |
25, 20 |
160, 200 |
|
SDRAM |
66, 100, 133 |
64 |
40, 30 |
10, 7.5 |
528, 800, 1064 |
|
DDR |
100, 133 |
64 |
30, 22.5 |
5, 3.75 |
1600, 2100 |
|
RDRAM |
400, 600, 800 |
16 |
,,30 |
,,2.5 |
1600, 2400, 3200 |
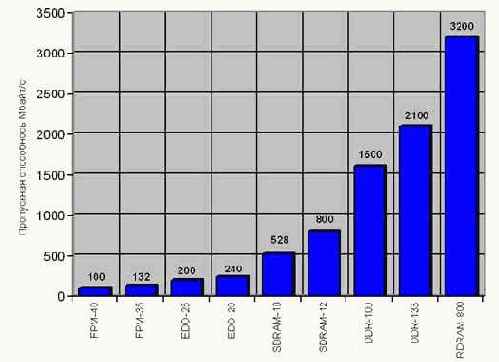
Рисунок graph 30 Максимально достижимая пропускная способность основных типов памяти
Сравнительная характеристика профилировщиков
1) профилируемые приложения
2) эмулируемые процессоры
3) разрешающая способность
4) диаграм левел
Сравнительный анализ оптимизирующих компиляторов языка Си\Си++
Количество Си/Си++ компиляторов огромно – какой же из них выбрать? Точнее, на какой критерий (критерии) следует обращать внимание при выборе компилятора?
Стоимость? Отнюдь, – для профессиональных разработчиков ценовой фактор вторичен, – вложенные в компилятор средства они с лихвой окупают одной – максимум двумя программами, а непрофессионалы в своей массе лицензионных продуктов вообще не приобретают.
Степень соответствия ANSI стандартам Си/Си ++? Да большинство разработчиков с этими стандартными знакомы лишь понаслышке! И потом, кто из нас удерживался от использования нестандартных расширений или библиотек, специфичных исключительно для данного компилятора?
Качество оптимизации кода – один из тех критериев, значимость которого разделяет подавляющее большинство программистов. Даже существует поверье, что "крутой" компилятор способен исправить кривой от рождения код. Отчасти это действительно так, – оптимизатор устраняет многие небрежности и ляпы программиста, но вот вопрос – какие именно?
Техника оптимизации – тайна за семью печатями. Далеко не каждый разработчик знает, что конкретно умеет оптимизировать его любимый компилятор и чем именно он отличается от своих конкурентов. Штатная документация об этом обычно умалчивает, ограничиваясь рекламными лозунгами, не несущими никакой информации. Доступной литературы, посвященной вопросам оптимизации, (насколько известно автору) не существует и единственным источником информации остается машинный код, сгенерированный компилятором.
Исследование ассемблерных листингов, плюс собственный опыт создания оптимизирующих Си-компиляторов – вот что легло в основу данной статьи. Ни рекламная информация, ни слухи, собранные в программистских кулуарах, автором не использовались. Конечно, это не страхует от ошибок, упущений и заблуждений, но, во всяком случае, значительно уменьшает их число.
К сожалению, в рамках одной главы невозможно рассказать о том, как
работает оптимизатор и придется ограничиться перечислением пунктов: что именно он оптимизирует.
В тестах принимали участие три популярнейших компилятора: Microsoft Visual C++ 6.0, Borland C++ 5.0 и WATCOM С 10.0, результаты тестирования представлены ниже.
Сравнительный анализ основных компиляторов
Давайте рассмотрим три довольно полярных алгоритма: копирование блока памяти, поиск минимума среди множества чисел и пузырьковую сортировку. Предложенный выбор совсем не случаен. Операции копирования (равно как сравнения и поиска в памяти) программисты всегда предпочитали реализовывать на чистом ассемблере, ибо микропроцессоры Intel80x86 поддерживают специальные машинные инструкции, изначально ориентированные на эти цели. В частности, копирование памяти осуществляется командой REP MOVS, – своеобразным аналогом функции memcpy. К сожалению, эквивалентные ей (команде REP MOVS) конструкции в языках Си/Си++ отсутствуют. Можно, конечно, вызвать саму memcpy, но это будет нечестно – мы же договорились библиотечные функции не использовать! (тем более что memcpy за редкими исключениями пишется отнюдь не на Си, а на ассемблере). На уровне чистого языка существует лишь один путь решения данной задачи – поэлементное копирование массива в цикле. Проблема в том, что компиляторы еще не научились понимать физический смысл компилируемой программы, и даже такой очевидный алгоритм копирования ни один из известных мне оптимизаторов ни в жизнь не распознает. Компилятор дословно переведет программу на язык машинного кода, сохранив при этом и сам цикл, и все временные переменные, используемые для пересылки данных. Как следствие – полученный код будет далеко не самым оптимальным, проигрывая ассемблеру и по скорости, и по размеру, да и по времени, затраченному на его создание, кстати. Поэтому, очень интересно знать: насколько эффективной окажется компиляция заведомо неоптимального кода. Данный пример позволяет оценить целесообразность использования ассемблера для решения задач, имеющих аппаратную поддержку со стороны процессора, в отсутствии эквивалентных конструкций в языке высокого уровня.
Поиск минимума – достаточно тривиальный алгоритм, элементарно укладывающийся в несколько строк как на ассемблере, так и на языке высокого уровня. Столь малое пространство не дает оптимизатору развернуться и показать себя во все красе.
Да этого нам, собственно, и не нужно! Напротив, представляет интерес установить: какое количество избыточного кода воткнул сюда компилятор! Благодаря тому, что объем полезного кода в нем очень мал, такой пример оказывается весьма чувствительным даже к микроскопическим порциям "мусора".
Наконец, сортировка представляет собой довольно типичный пример программистского кода, и по ней вполне можно судить о "средневзвешенном" качестве оптимизации конкретных компиляторов.
Сравнивать различные компиляторы между собой – проще всего. Сравнение же компилятора с человеком осуществить сложнее, поскольку сразу же возникает неопределенность: с каким именно человеком его сравнивать. С профессионалом экстра класса? Но будет ли показательным такое сравнение? Мы же говорим не о теоретическом превосходстве человеческого интеллекта над машинным, а о практических путях решения задач, стоящих перед рядовыми программистами. Может ли рядовой программист рассчитывать на помощь такого экстра профессионала? Вряд ли! Скорее всего, засучив рукава, ему придется взяться за кодирование самому.
Поэтому, приведенные ниже ассемблерные примеры умышленно составлены как средний по качеству и далеко не идеальный код. Причем, поскольку целевой процессор заранее не оговорен, при их подготовке использовались лишь самые общие приемы оптимизации, без учета оптимального планирования потока команд. Тем не менее, это действительно оптимизированный ассемблерный код, приблизительно соответствующий уровню программиста средней руки. (Кстати, интересно: кто из читателей сможет улучить качество кода хотя бы на процент?).
Хорошо, с человеком мы разобрались. Теперь дело – за компиляторами. Какие же из них выбрать? Давайте остановимся на следующем "джентльменском наборе": Microsoft Visual C++ 6.0, Borland C++ 5.5, WATCOM C++ 10.0.
Стратегия оптимального выравнивания
Если обращение к данным, пересекающим кэш-строку, происходит лишь эпизодически– никакого "криминала" в этом нет, и накладными расходами на дополнительную задержку можно смело пренебречь. Никакой осязаемой выгоды от выравнивания таких переменных мы все равно не получим.
Интенсивно используемые переменные
(например, счетчики цикла) – дело другое. В этом случае потери производительности скорее всего окажутся весьма велики, и по меньшей мере неразумно закрывать на это глаза! Чтобы окончательно убедиться в этом, запустим следующий контрольный пример, использующий в качестве счетчика цикла 32-разрядную переменную, смещенную на 62 байта от начала, гарантируя тем самым ее расщепление и на P?II/P-III, и на AMD Athlon.
#define N_ITER 1000 // кол-во итераций цикла
#define
_MAX_CACHE_LINE_SIZE 64 //максимально возможный размер кэш-линии
#define UN_FOX (*(int*)((int)fox + _MAX_CACHE_LINE_SIZE - sizeof(int)/2))
#define FOX (*fox) // определение выровненного (FOX) и
// не выровненного (UN_FOX) счетчиков
// выделяем память
fox = (int *) _malloc32(MAX_CACHE_LINE_SIZE*2);
/*------------------------------------------------------------------------
*
* ОПТИМИЗИРОВАННЫЙ ВАРИАНТ
* (счетчик цикла не разбивает кэш-строку)
*
------------------------------------------------------------------------*/
for(FOX = 0; FOX < N_ITER; FOX+=1) c++;
/*------------------------------------------------------------------------
*
* ПЕССИМИЗИРОВАННЫЙ ВАРИАНТ
* (счетчик цикла разбивает кэш-строку)
*
------------------------------------------------------------------------*/
for(UN_FOX = 0; UN_FOX < N_ITER; UN_FOX+=1) c++;
Листинг 5 [Cache/align.for.c] Демонстрация последствий использования расщепленного счетчика цикла
Прогон программы показывает (см. рис graph 0x009), что на P-III 733 расщепленный счетчик цикла снижает производительность практически в пять раз, а на AMD Athlon падение производительности не достигает и двух крат, подтверждая тем самым что Athlon – чрезвычайно непритязательный к выравниванию процессор.
И, если бы мир ограничивался одним Athlon'ом – данные можно было бы вообще не выравнивать (шутка).
Рисунок 25 graph 0x009 Снижение производительности при обработке расщемленных данных
Обработка массивов. Несколько иначе обстоят дела с последовательной обработкой массивов данных. Этот вопрос мы уже рассматривали в первой части настоящей книги, но тогда речь шла о взаимодействии с оперативной памятью, а время загрузки ячейки из основной оперативной памяти намного превышает штрафное пенальти конфликта кэш-линий, поэтому, мы, как помнится, пришли к выводу, что потоковые данные выравнивать бессмысленно.
Если же данные целиком умещаются в кэш-памяти первого (второго) уровня, то пагубное влияние кэш-конфликтов достигает весьма значительных величин, но… только на неразвернутых циклах. Воспользуемся несколько модернизированной программой Memory/aling.c чтобы изучить этот вопрос поподробнее. Уменьшим размер блока до 8-16 Кб и запустим программу…
На неразвернутом цикле чтения (см. рис. graph 0x007) даже P-III показал всего лишь 7% падение производительности, чего и следовало ожидать, т.к. во время кэш-конфликта процессор не простаивает, а обрабатывает команды, составляющие тело цикла, практически полностью маскируя задержку.
А вот неразвернутый цикл записи… ой-ой-ой! Четырехкратное отставание по скорости это вам не тигру хвост оторвать. Чем же вызвано это…. ну там мягко скажем безобразие? А вот чем: хитрый компилятор Microsoft Visual C++ заменил цикл записи всего одной машинной командой REP STOSD, чем к минимуму свел накладные расходы на организацию цикла. Кроме того, поскольку длина буферов записи равна длине кэш-линейке, совмещение начального адреса записи с адресом начала кэш линейки, обеспечивает эффективную трансляцию адресов, позволяя выгружать весь 32-байтный буфер всего за один такт.
На фоне этого 100% результат AMD Athlon выглядит весьма сильно, правда, при развороте циклов он все же начинает сдавать, отставая от выровненного варианта на 24% при чтении и на 48% при записи данных.Впрочем, P-III выглядит ее слабее: +74% и +133% соответственно.
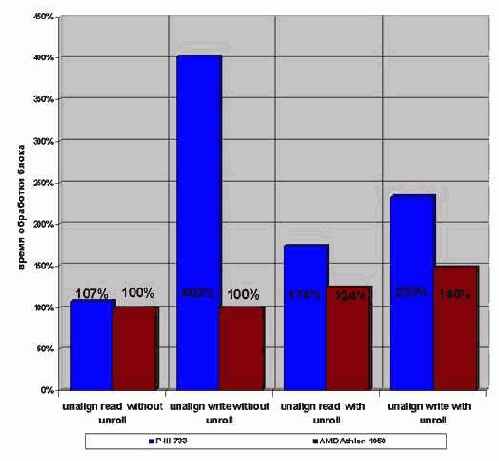
Рисунок 26 graph 0x07 Влияние выравнивания данных на производительность
Задержка окажется еще большей, если запрошенные данные в L1-кэше отсутствуют – тогда потребуется считать из L2-кэша обе кэш-линии, на что в среднем уйдет от 8 до 12 тактов. Если же и в L2-кэше этих злощасных данных нет, - придется ожидать загрузки аж 512 бит (64 байт) из основной памяти. А это в лучшем случае полсотни тактов процессора!
Впрочем,
Стратегия распределения данных по DRAM-банкам
Сформулированное в конце предыдущего параграфа правило ориентировано исключительно на потоковые алгоритмы, обращающиеся к каждой ячейке (и странице!) памяти всего один раз. А если обращение к некоторым страницам памяти происходит неоднократно, – имеет ли значение порядок их обработки или нет? На первый взгляд, если обрабатываемые страницы уже находятся в TLB, – шаг чтения данных никакого значения не имеет. А вот давайте проверим! Для этого добавим в нашу тестирующую программу Memory/list.step.c цикл for(i = 0; i <= BLOCK_SIZE; i += 4*K) x += *(int *)((int)p + i + 32), заставляющий систему спроецировать все страницы и загрузить их в TLB до начала замера времени исполнения. (Читателям достаточно лишь раскомментировать определение UNTLB). В результате получится следующее (см. рис. graph 11).
Рисунок 28 graph 11 График, иллюстрирующий время обработки блока данных в зависимости от шага чтения при отсутствии и присутствии страниц в TLB. Обратите внимание на "волнистость" нижней кривой. Это – прямое следствие регенерации DRAM банков оперативной памяти.
Смотри-ка, а ведь время трассировки списка и, правда, многократно уменьшилось! Зависимость скорости обработки от величины шага на первый взгляд как будто бы исчезла, но при внимательном изучении графика на нем все же обнаруживается мелкая "рябь". Строгая периодичность "волн" говорит нам о том, что это не ошибка эксперимента, а некая закономерность. Весь вопрос в том, – какая? Падение производительности на гребнях волны достигает ~30% и списывать эту величину на "мелкие брызги" побочных эффектов, – было бы с нашей стороны откровенной наглостью.
Характер кривой объясняется особенностями организации оперативной памяти. Как нам уже известно, время доступа к памяти непостоянно и зависит от множества факторов. Максимальная производительность достигается когда: а) запрашиваемые ячейки находятся в открытых страницах DRAM; б) ни страница, ни банк памяти в момент обращения к ним не находится на регенерации.
Исходя из пунктов а) и б) попробуйте ответить на вопрос: как изменяется время доступа к ячейкам памяти в зависимости от шага чтения?
Так – так – так… (глубоко затянувшись и откинувшись на спинку стула). Начнем с пункта а). Из самых общих рассуждений следует, что по мере увеличения шага время доступа будет пропорционально расти за счет более частого открытия страниц. Так будет продолжаться до тех пор, пока длина шага не достигнет длины одной DRAM-страницы (типичная длина которой 1, 2 и 4 Кб), после чего открытия страниц станут происходить при каждом доступе к ячейке и кривая, достигнув максимума насыщения, перейдет в горизонтальное положение. Попробуем проверить наше предположение на практике, запустив следующий тест (см. Memory/memory.hit.miss.c), поскольку масштаб графика graph 11 не очень-то подходит для точных измерений.
// шапка для Word'а
printf("STEP");
for(pg_size=STEP_SIZE;pg_size<=MAX_PG_SIZE;pg_size+=(STEP_SIZE*STEP_FACTOR))
printf("\t%d",pg_size);printf("\nTime");
// основной цикл, различные шаги чтения
for(pg_size=STEP_SIZE;pg_size<=MAX_PG_SIZE;pg_size+=(STEP_SIZE*STEP_FACTOR))
{
A_BEGIN(0) /* начало замера времени выполнения */
// цикл, читающий память с заданным шагом
// поскольку, количество физической памяти ограничено,
// а при большом шаге чтения все читаемые ячейки поместятся в кэше
// приходится хитрить и представлять память как кольцевой массив
// в общем, этот алгоритм нагляднее описывается кодом, чем словами
for (b=0;b<pg_size;b+=STEP_SIZE)
for(a=b;a<BLOCK_SIZE/sizeof(int);a+=(pg_size/sizeof(int)))
x+=p[a];
A_END(0) /* конец замера времени выполнения */
printf("\t%d",Ax_GET(0)); /* печать времени выполнения */
PRINT_PROGRESS(100*pg_size/MAX_PG_SIZE);
}
Листинг 17 [Memory/DRAM.wave.c] Фрагмент программы, предназначенной для детального изучения "волн" DRAM-памяти
Смотрите (см. рис. 0х29), – восходящая ветвь кривой действительно ведет себя в соответствии с нашими предположениями, но не достигает максимума насыщения, а переходит в чрезвычайно испещренную пиками и рытвинами местность. Время доступа к ячейкам с ростом шага меняется непрерывно, но график – к счастью! – обнаруживает строгую периодичность, что вселяет надежду на возможность его расшифровки. Собственно, это не график даже, а кладезь информации, раскрывающая секреты внутренней структуры и организации микросхем памяти. Итак, заправляемся пивом и начинаем…
Закон №1 (возьмите себе на заметку) где есть периодичность, там всегда есть структура. Значит, память, – это не просто длинная цепочка ячеек, а нечто более сложное и неоднородное. Да, мы знаем, что память состоит из страниц, но одного этого факта явно недостаточно для объяснения формы кривой. Требуется что-то еще… Не замешено ли здесь расслоение памяти на банки и их регенерация? Давайте прикинем. Время доступа к ячейке без регенерации занимает 2 (RAS to CAS Delay) + 2 (CAS Delay) + 1 + 1 + 1 == 7 тактов, а с регенерацией: 2 (RAS Precharge) + 2 (RAS to CAS Delay) + 2 (CAS Delay) + 1 + 1 + 1 == 9 тактов, что в 1.225 раз больше. Согласно графику 0x29 время обработки блока на "вершине" горы составляет 22.892.645 тактов, а у ее "подножия" – 18.610.240 тактов, что соответствует отношению в 1.23 раз. Цифры фантастическим образом сходятся! Значит, наше предположение на счет регенерации верно! (Точнее, как осторожные исследователи, мы должны сказать "скорее всего верно", но… это было бы слишком скучно)
Вообще-то, на этом можно было бы и остановится, поскольку закладываться на физическую организацию оперативной памяти столь же безрассудно, как и вкладывать свои ваучеры в МММ. С другой стороны: вполне можно выделить ряд рекомендаций, общих для всех или, по крайней мере, большинства моделей памяти. Особого прироста производительности их соблюдение, впрочем, не принесет, но вот избежать
более чем 20%-30% падения производительности – поможет.
Тонкая оптимизация для "гурманов" В первую очередь нас будет интересовать схема отображения физических ячеек памяти на адресное пространство процессора (см. "Отображение физических DRAM-адресов на логические"), а так же количество и размер банков, длина страниц и все остальные подробности.
Достаточно очевидно, что гребень волны соответствует той ситуации, когда каждое обращение к памяти попадает в регенерирующийся банк. Отсюда: расстояние между двумя соседними гребнями равно произведению длины одной DRAM страницы на количество банков (в нашем случае – 8 Кб), что удовлетворяет следующим комбинациям: 1 Кб (длина DRAM-страницы) x 8 (банков), 2 x 4, 4 x 8 и 8 x 1. Можно ли определить какой именно тип памяти используется в действительности? Да, можно и ключ к этому дает ширина склона "горы" (на рис. 29 она обозначена символом d). Легко доказать, что ширина склона "горы" в точности соответствует длине одной DRAM-страницы. Действительно, путь c – длина одной страницы, а N – количество банков. Тогда, расстояние между концом одной и началом другой страницы всякого банка равно (N-1) * c /* 1 */, соответственно, расстояние между двумя страницами одного банка равно Nc /* 2 */, а расстояние между началом одной и концом другой страниц – (N + 1) * c /* 3 */.
Ситуация /* 1 */ соответствует самому подножию горы, – если шаг чтения меньше чем (N ? 1) * c, то, независимо от смещения ячейки в странице, следующая запрашиваемая ячейка гарантированно не находится в том же самом банке. Но что произойдет, если шаг возрастет хотя бы на единицу? Правильно, при чтении последней ячейки одной DRAM-страницы, очередная ячейка придется на… следующую страницу того же самого банка! (Если не совсем понимаете, о чем идет речь, попробуйте изобразить это графически). Дальнейшее увеличение шага будет захватывать все больше и больше ячеек, вызывая неуклонное снижение производительности.
Так будет продолжаться до тех пор, пока шаг чтения не сравняется с /* 2 */, после чего начнется обратный процесс. Теперь, все больше и больше ячеек будут "вылетать" в страницы соседнего банка, уже готового к обработке запроса…
Отсюда: ширина склона "горы" равна N*c – (N ? 1)*c. Раскрываем скобки и получаем: N*c – N*c + c == c, что и требовалось доказать. Зная же c, вычислить N будет совсем не сложно: количество банков равно отношению расстояния между двумя пиками к ширине склона одной "горы", т.е. приведенный график соответствует четырех банковой памяти с длиной страницы в 2 Кб.
Бесспорно, эта методика весьма перспективна в плане создания тестирующей программы (надо же знать какое оборудование вам подсунули продавцы), но поможет ли она нам в оптимизации программ? Ввиду большого количества "разношерстных" моделей памяти, величина оптимального (неоптимального) шага чтения памяти на стадии разработки программы неизвестна
и должна определятся динамически на этапе исполнения, "затачиваясь" под конкретную аппаратную конфигурацию.
Причем, сказанное относится не только к трассировке списков и других ссылочных структур, но и к параллельной обработке нескольких потоков данных. Рассмотрим, например, такой код:
int *p1, int p2;
p1=malloc(BLOCK_SIZE*sizeof(int));
p2= malloc(BLOCK_SIZE*sizeof(int));
…
if (memcmp(p1,p2, BLOCK_SIZE*sizeof(int)) …
…
Листинг 18 Пример неоптимального программного кода, – оба блока памяти могут начинаться с одного и того же DRAM банка, вследствие чего их параллельная обработка окажется невозможна.
Как вы думаете: можно ли считать этот фрагмент программы оптимальным? А вот и нет! Ведь никто не гарантирует, что блоки памяти, возвращенные malloc-ом, не начинаются с одного и того же банка. Скорее, нам гарантированно обратное. Если размер блока превышает 512 Кб (а про обработку вот таких гигантских массивов памяти мы и говорим!), он не может быть размещен в куче и необходимую память приходится выделять с помощью win32 API?функции VirtualAlloc.
К несчастью, возвращаемый ей адрес всегда выравнивается на границу 64 Кб, т.е. величину, кратную любым разумным сочетаниям Nc. Т.е. попросту говоря, все выделяемые malloc-ом блоки памяти начинаются с одного и того же банка! А это не есть хорошо!!! Точнее – это просто кретинизм! Неужели разработчики системы проглядели такой ляп? Что ж, это не сложно проверить, – достаточно написать программку, выделяющую блоки памяти разного размера и анализирующую значения 11 и 12 битов (эти биты отвечают за выбор DRAM-банка).
#define N_ITER 9 // кол-во итераций
#define STEP_FACTOR (100*1024) // шаг приращения шага размера памяти
#define MAX_MEM_SIZE (1024*1024)
#define _one_bit 11 // эти биты отвечают...
#define _two_bit 12 // ...за выбор банка
#define MASK ((1<<_one_bit)+(1<<_two_bit))
#define zzz(a) (((int) malloc(a) & MASK) >> _one_bit)
main()
{
int a,b;
PRINT(_TEXT("= = = Определение номеров DRAM-банков = = =\n"));
PRINT_TITLE;
printf("BLOCK\n SIZE - - - n BANK - - -\n");
printf("----!----------------------------------------------------------\n");
for(a = STEP_FACTOR; a < MAX_MEM_SIZE; a += STEP_FACTOR)
{
printf("%04d:",a/1024);
for (b = 0; b < N_ITER; b++)
printf("\t%x",zzz(a));
printf("\n");
}
}
Листинг 19 [Memory/bank.malloc.c] Фрагмент программы, определяющий номера банков с которых начинаются блоки памяти, выделяемые функцией malloc
Результат ее работы будет следующим:
BLOCK
SIZE (Кб) - - - n BANK - - -
----!------------------------------------------------------------------
0100: 0 2 0 2 0 2 0 2 0
0200: 0 0 0 0 0 0 0 0 0
0300: 0 2 0 2 0 2 0 2 0
0400: 2 2 2 0 0 0 0 0 0
0500: 2 0 2 0 2 0 2 0 2
0600: 0 0 0 0 0 0 0 0 0
0700: 0 0 0 0 0 0 0 0 0
0800: 0 0 0 0 0 0 0 0 0
0900: 0 0 0 0 0 0 0 0 0
1000: 0 0 0 0 0 0 0 0 0
Смотрите, – до тех пор, пока размер выделяемых блоков не достиг 512 Кб, нам попадались как удачные, так и неудачные комбинации, но, начиная с 512 Кб, все выделенные блоки, действительно, начинаются с одного и того же банка.
Что же делать? Писать собственную реализацию malloc? Конечно же, нет! Достаточно динамически определив N и c, проверить соответствующие биты в адресах, возращенных malloc. И, если они вдруг окажутся равны, – увеличить любой из адресов на величину c (естественно, размер запрашиваемого блока необходимо заблаговременно увеличить на эту же самую величину). В результате мы теряем от 1- до 4 Кб, но получаем взамен, по крайней мере, 20%-30% выигрыш в производительности.
Это тот редкий случай, когда знание приемов "черной магии" позволяет совершенно непостижимым для окружающих способом увеличить быстродействие чужой программы, добавив в нее всего одну строку, даже без анализа исходных текстов. Маленькое лирическое отступление. Однажды поручили мне в порядке конкурсного задания оптимизацию одной программы, уже и без того оптимизированной – по понятиям заказчика – "по самые помидоры". Собственно, проблема заключалась в том, что львиная доля процессорного времени уходила не на вычисления, а на обмен с оперативной памятью, причем размер обрабатываемых данных был действительно сокращен до предела и Заказчик пребывал в абсолютной уверенности, что оптимизировать тут более нечего… Каково же было его удивление когда я прямо на его глазах, бегло пробежался контекстным поиском по исходным тестам и, даже не удосужившись запустить профилировщик, просто воткнул в нескольких местах код a'la p += 4*1024, после чего программа заработала приблизительно на треть быстрее.
Он (Заказчик) долго и недоверчиво спрашивал: уверен ли я, что это не случайность и под всяким ли железом и операционной системе это будет работать? Нет, не случайность. Уверен. Будет работать под любой OC семейства Windows и почти на любом железе: микросхемах памяти с организацией 2 x 4, 4 x 2, 4 x 2, 4 x 4, а на чипсетах серии Intel 815 (и других подобным им) вообще на всех
типах памяти. Эти чипсеты отображают 8- и 9-биты номера столбца на 25- и 26-биты линейного адреса, а вовсе не на 11- и 12-биты, как того следовало ожидать. Попросту говоря, программная длина DRAM-страниц на таких чипсетах всегда равна 2 Кб, потому на всех модулях памяти, имеющих по крайней мере четырех банковую организацию (а все модули емкостью от 64 и более мегабайт такую организацию и имеют), сдвиг указателя на 4 Кб гарантированно исключает попадание в тот же самый DRAM-банк.
Конечно, закладываться на такие особенности аппаратуры – дурной тон и в программах, рассчитанных на долговременное использование, настоятельно рекомендуется не лениться, а определять длину DRAM-страниц автоматически или, на худой конец, позволять изменять эту величину опционально.
Рисунок 29 0x029 / graph 0x004 "Волны" памяти несут чрезвычайно богатую информацию о конструктивных особенностях используемых микросхем памяти. Вот только основные характеристики: а. – расстояние между концом одной и началом следующей DRAM-страницы того же самого DRAM-банка; b. – расстояние между началом одной и началом другой DRAM-страницы того же самого DRAM-банка (т.е. размер всех DRAM-банков); c. и d. – размер одной DRAM-страницы. Кол-во DRAM банков равно b/d
Стратегия распределения данных по кэш-банкам
В выравнивании данных есть еще один далеко неочевидный момент, по непонятным обстоятельствам, упущенный составителями оригинальных руководств по оптимизации под процессоры Pentium и AMD, а потому практически не известный программистской общественности.
Руководство по оптимизации под Pentium MMX – Pentium-II (Order Number 242816-003) содержало лишь следующую скудную информацию: "The data cache consists of eight banks interleaved on four-byte boundaries. On Pentium processors with MMX technology, the data cache can be accessed simultaneously from both pipes, as long as the references are to different cache banks. On the P6-family processors, the data cache can be accessed simultaneously by a load instruction and a store instruction, as long as the references are to different cache banks….
…If both instructions access the same data-cache memory bank then the second request (V-pipe) must wait for the first request to complete. A bank conflict occurs when bits 2 through 4 are the same in the two physical addresses. A bank conflict incurs a one clock penalty on the V-pipe instruction"
("Кэш данных состоит из восьми банков, чередующихся по четырех байтовым адресам. Кэш данных процессоров Pentium MMX одновременно доступен с обоих конвейеров при условии, что они обращаются к различным кэш-банкам. На процессорах семейства P6 (Pentium Pro, Pentium-II), кэш данных доступен и на чтение, и на запись, при условии, что обращение происходит к различным кэш-банкам…
…если обе инструкции [речь идет о спариваемых инструкциях – КК] обращаются к одному и тому же банку кэш-памяти, следующей запрос (V-труба) будет вынужден дожидаться завершения выполнения предыдущего. Конфликт банков происходит всякий раз, когда биты со второго по четвертый в двух физических адресах совпадают. Конфликт банков возлагает штрафную задержку в один такт, задерживающую выполнение инструкции находящейся в V-трубе"
В руководстве оптимизации под P-III второй абзац загадочным образом исчезает.
Но это еще что, – "Intel Pentium 4 Processor Optimization Reference Manual P-4" о кэш-банках вообще не обмолвливается ни словом! Ничуть не разговорчивее оказывается и "AMD Athlon Processor x86 Code Optimization Guide", уделяющее этому вопросу едва ли не дюжину слов: "The data cache and instruction cache are both two-way set-associative and 64-Kbytes in size. It is divided into 8 banks where each bank is 8 bytes wide" ("Кэш данных и кэш инструкций двух ассоциативны и имеют размер по 64 Кб каждый. Они поделены на 8 банков, шириной по 8 байт"). Понять последнее предложение может только тот, кто хорошо знаком с архитектурой расслоенной памяти и хотя бы в общих чертах представляет себе как на аппаратном уровне устроен и работает кэш. К тому же возникает досадная терминологическая путаница: разновидностей кэш-банков насчитывается по меньшей мере две.
Ассоциативный кэш делится на независимые области, называемые банками, число которых и определяет его ассоциативность. На физическом уровне, эти банки состоят из нескольких матриц статической памяти, так же именуемых банками. Расслоение памяти подробно разбиралось на страницах данной книги (см. "Часть I. Оперативная память. Устройство и принципы функционирования оперативной памяти. SDRAM (Synchronous DRAM) – синхронная DRAM") и внимательным читателям навряд ли стоило большого труда догадаться какой именно "банк" составители руководства имели ввиду. Да! Но насколько хреново приходится тем, кто только начинает изучать программирование!
А ведь когда-то фирма AMD славилась качеством совей документации. Откроем, например, замечательное руководство "AMD-K5 Processor Technical Reference Manual", которое я частенько перелистываю перед сном, поскольку это гораздо больше, чем просто руководство по безнадежно устаревшему процессору. Это – исчерпывающее описание архитектуры, к которой вплоть до последних времен не добавилось ничего революционно нового.
Даже супер современный Hammer основан на тех же самых принципах и почти том же самом ядре.
В частности, организация и назначение кэш-банков объясняются так: "The data cache overcomes load/store bottlenecks by supporting simultaneous accesses to two lines in a single clock, if the lines are in separate banks. Each of the four cache banks contains eight bytes, or one-fourth of a 32-byte cache line. They are interleaved on a four-byte boundary. One instruction can be accessing bank 0 (bytes 0-3 and 16-19), while another instruction is accessing bank 1, 2, or 3 (bytes 4-7 and 20-23, 8-11 and 24-27, and 12-15 and 28-31 respectively)".
("Кэш данных преодолевает заторы чтения/записи путем поддержки возможности одновременной записи двух кэш-линеек за один такт, при условии, что эти линейки расположены в различных банках. Каждый из четырех кэш-банков состоит из восьми байтов, или другими словами говоря, одной четвертной длины 32?байтной кэш-линейки. Они (банки) чередуются с четырех байтовым диапазоном. Одна инструкция может обращаться к банку 0 (байты 0-3 и 16-19), в то время как другая инструкция может параллельно обращаться к банку 1, 2 или 3 (байты 4 – 7 и 20 – 23, 8 – 11, и 24 – 27, и 12 – 15, и 28 – 31 соответственно").
Вот теперь все более или менее ясно. Остается лишь вопрос: а для чего такие извращения? Ответ: реализация двух портовой матрицы статической памяти обходится дорого, т.к. требует для своего создания восьми CMOS-транзисторов вместо шести. Поэтому, конструкторы поступили проще: разбили статическую память на несколько независимых банков и подцепили к ней двух портовый интерфейс. Таким образом, на 64 Кб кэше экономится порядка миллиона транзисторов, правда временами такая экономия оборачивается дорогой ценой, – ведь двух портовое ядро памяти способно одновременно обрабатывать два любых запроса, а кэш с двух портовым интерфейсом может распараллеливать только те запросы, которые направляются в различные банки.
Итак, для достижения наивысшей скорости обработки данных, мы должны соблюдать ряд определенных предписаний и планировать поток данных с таким расчетом, чтобы не возникало паразитных задержек за счет по парного обращения к одним и тем же кэш-банкам.
Рисунок 27 0х021 Схема проецирования матриц кэш-памяти на кэш-линейки
Итак, кэш-линейка не представляет собой изотропное целое, а состоит их четырех или восьми независимых 32-, 64- или 128-битных банков (см. рис 0х021). Их независимость выражается в том, что чтение/запись в каждый из банков может происходить параллельно в течение одного такта процессора. Степень параллелизма зависит от количества функциональных устройств, подцепленных к исполнительным конвейерам микропроцессора и количества портов самого кэша. В частности, микропроцессоры P-II могут выполнить одну запись и одну чтение двух различных банков за каждый такт. Более подробные сведения об особенностях реализации кэш-банках в популярных моделях процессоров можно подчеркнуть из таблицы….
Таким образом, если у нас имеются две 32-битовых переменных, каждая из которых расположена в "своем" банке, операция присвоения одной переменной другой может быть выполнена всего за один такт! Напротив, если переменные пересекают границы банков – как показано на рис. 0х022 – возникает задержка: процессор не может писать в тот банк, который в данный момент обрабатывает запрос на чтение. Величина задержки варьируется в зависимости от модели процессора, например, на P-II составляет пять тактов.
Но вернемся к нашим баранам (оптимальной стратегии выравнивания данных). В свете новых воззрений, все данные (включая переменные размером в байт) лучше располагать по адресам кратным по меньшей мере четырем, тем самым обеспечивая возможность их параллельной обработки, т.к. каждая переменная будет "монопольно" владеть соответствующим ей банком. Правда, помимо собственно самого выравнивания еще потребуется убедиться, что биты, "ответственные" за смещение данных в кэш-линейке у параллельно обрабатываемых ячеек не равны, иначе они с неизбежностью попадут в одну и ту же матрицу статической памяти, хотя и будут находиться в различных линейках кэша. (Замечание: данное ограничение не распространяется на операцию чтения, последующую за записью, – в этом случае записываемые данные направляются в буфер записи и к кэш-памяти происходит только одно обращение, да и то, лишь когда считываемых данных не окажется в буфере, – подробнее см.
"Буфера записи").
С другой стороны: такое выравнивание приводит к "разрыхлению" упаковки данных и требует значительного большего количества памяти, в результате чего вполне может статься так, что данные просто не влезут в кэш первого (а то и второго) уровня. Тем самым мы рискуем вместо ожидаемого увеличения скорости нарваться на большие тормоза, съедающие весь выигрыш параллельной обработки!
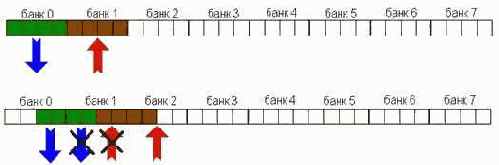
Рисунок 28 0х022 Чтение/запись ячеек, расположенных в различных кэш-банках (т.е. в различных матрицах статической памяти) осуществляется за один такт. В противном случае, каждая переменная будет обрабатываться последовательно, что потребует вдвое больше тактов.
Насколько значительными будут последствия конфликта кэш-банков? А вот сейчас и увидим! Чтобы выяснить это мы напишем следующую программу, учитывая при ее проектировании следующие обстоятельства:
а) на P-III конфликт кэш-банков приводит к падению производительности только
в случае комбинирования операций чтения с операциями записи (т.е. на P-III всего одно устройство чтения, загрузить две ячейки за такт даже из двух различных банков он увы не сможет);
б) цикл обработки памяти должен быть развернут минимум на четыре итерации, т.к. в противном случае буферизация записи позволит переждать задержки, вызванные конфликтом банков и отложить выгрузку данных "до лучших времен", а единственной инструкции записи просто будет не с чем спариваться!
Хорошо! Давайте же вызовем джина из бутыли. "Ало, джин ибн Конфликт Кэш Банков" появись!" Как вы думаете, он появится?
//============================================================================
// НЕТ КОНФЛИКТОВ
//----------------------------------------------------------------------------
// Распределение переменных по кэш-банкам на P-III
// ===============================================
// !<bank0>!<bank1>!<bank2>!<bank3>!<bank4>!<bank5>!<bank6>!<bank7>!
// !0 1 2 3!4 5 6 7!8 9 0 1!2 3 4 5!6 7 8 9!0 1 2 3!4 5 6 7!8 9 0 1!<- offset
// !-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!
// !*-*-*-*! ! ! ! ! ! <<-- ((int)_p32 + a + 0);
// ! !*-*-*-*! ! ! ! ! <<-- ((int)_p32 + a + 4);
// ! ! ! !*-*-*-*! ! ! <<-- ((int)_p32 + a +12);
// ! ! ! ! !*-*-*-*! ! <<-- ((int)_p32 + a +16);
//============================================================================
//
// Распределение переменных по кэш-банкам на AMD Athlon
// ====================================================
// !<-- bank 0 -->!<-- bank 1 -->!<-- bank 2 -->!<-- bank 3 -->!...
// !0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 ...
// !-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!-!...
// !*-*-*-* ! ! ! <<-- ((int)_p32 + a + 2);
// ! *-*-*-*! ! ! <<-- ((int)_p32 + a + 6);
// ! ! *-*-*-*! ! <<-- ((int)_p32 + a +12);
// ! ! !*-*-*-* ! <<-- ((int)_p32 + a +16);
//============================================================================
optimize(int *_p32)
{
int a;
int _tmp32 = 0;
for(a = 0; a < BLOCK_SIZE; a += 32)
{
_tmp32 += *(int *)((int)_p32 + a + 0); // bank 0 [Athlon: bank 0]
*(int *)((int)_p32 + a +12) = _tmp32; // bank 3 [Athlon: bank 1]
_tmp32 += *(int *)((int)_p32 + a + 4); // bank 1 [Athlon: bank 0]
*(int *)((int)_p32 + a +16) = _tmp32; // bank 4 [Athlon: bank 2]
}
}
//============================================================================
// ДЕМОНСТРАЦИЯ КОНФЛИКТА БАНКОВ
//----------------------------------------------------------------------------
// Распределение переменных по кэш-банкам на P-III
// ===============================================
// !<bank0>!<bank1>!<bank2>!<bank3>!<bank4>!<bank5>!<bank6>!<bank7>!
// !0 1 2 3!4 5 6 7!8 9 0 1!2 3 4 5!6 7 8 9!0 1 2 3!4 5 6 7! 8 9 0 1 <- offset
// !-+-+-+-+-+-+-+-!-+-+-+-+-+-+-+-!-+-+-+-+-+-+-+-!-+-+-+-+-+-+-+-
// ! *-*-*-* ! ! ! ! ! <<-- ((int)_p32 + a + 2);
// ! !^ *-*-*-* ! ! ! ! <<-- ((int)_p32 + a + 6);
// ! !| !^ !*-*-*-*! ! ! <<-- ((int)_p32 + a +12);
// ! !| !| ! !*-*-*-*! ! <<-- ((int)_p32 + a +16);
// | |
// +-------+--- <- КОНФЛИКТ
//============================================================================
//
// Распределение переменных по кэш-банкам на AMD Athlon
// ====================================================
// !<-- bank 0 -->!<-- bank 1 -->!<-- bank 2 -->!<-- bank 3 -->!
// !0 1 2 3 4 5 6 7!8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
// !-+-+-+-+-+-+-+-!-+-+-+-+-+-+-+-!-+-+-+-+-+-+-+-!-+-+-+-+-+-+-+-+
// ! *-*-*-* ! ! ! <<-- ((int)_p32 + a + 2);
// ! *-*-*-* ! ! <<-- ((int)_p32 + a + 6);
// ! ^ *-*-*-*! ! <<-- ((int)_p32 + a +12);
// ! | !*-*-*-* ! <<-- ((int)_p32 + a +16);
// ! КОНФЛИКТ ! !
//
//============================================================================
conflict(int *_p32)
{
int a;
int _tmp32 = 0;
for(a = 0; a < BLOCK_SIZE; a += 32)
{
_tmp32 += *(int *)((int)_p32+a+2); // bank 0 + 1 [Athlon: bank 0]
*(int *)((int)_p32+a+12) = _tmp32; // bank 3 * [Athlon: bank 1]
// *
// "*" MARK BANKS CONFLICT
// * *
_tmp32 += *(int *)((int)_p32+a+6); // bank 1 + 2 [Athlon: bank 0 + 1]
*(int *)((int)_p32+a+16) = _tmp32; // bank 4 [Athlon: bank 2]
}
}
Листинг 6 [Cache/banks.c] Демонстрация последствий конфликта кэш-банков
На P-III "джин" появляется, да какой джин (см. рис. graph 0x008)! Чтением двух смежных 32- разрядных ячеек, смещенных относительно начала первого банка на 16 бит, мы вызвали более чем трех кратное падение производительности, что и неудивительно, т.к. в этом случае чтение двух ячеек происходит не за два такта как это должно быть, а за 2 + penalty
тактов. Поскольку на P-III величина пенальти составляет пять тактов, мы проигрываем = 350%, что вполне близко к экспериментальному значению – 320% (завышенная оценка объясняется тем, что мы не учли накладных расходов на запись и организацию цикла).
На AMD Athlon последствия конфликта кэш-банков оказались гораздо меньшими, всего на 9% увеличив время выполнения программы. Такое преимущество над P-III объясняется тем, что благодаря двойному превосходству в ширине кэш-банков, мы перекрыли всего лишь два из них и вместо полного затора (как на P-III) на Athlon'e образовалась лишь маленькая, быстро рассасывающая пробка. Разумеется, это отнюдь не означает, что на AMD Athlon вызвать затор невозможно, – возможно, еще как! Достаточно добиться перекрытия сразу нескольких банков, но для этого понадобится совсем другая программа, которая окажется непригодной для тестирования P-III. Тем не менее, вероятность спонтанного конфликта кэш-банков на AMD Athlon все-таки ниже.
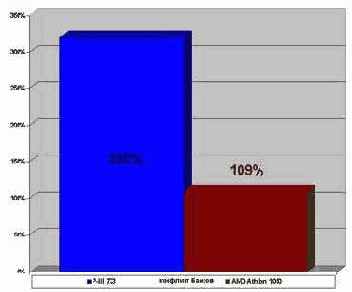
Рисунок 29 graph 0x008 Демонстрация конфликта кэш-банков на P-III и AMD Athlon
Сводная характеристика инструкций предвыборки различных процессоров
Для облегчения ориентирования среди множества команд предвыборки и особенностей их поведения на различных моделях процессоров, все основные характеристики собраны в следующей таблице:
| Инструкция | Характеристика | ||||||||
| K6 | C3-VIA | Athlon | P-III | P-4 | |||||
| prefetch | Загружает 32 байта в кэш-уровни всех кэш-иерархий и определяет состояние строки как исключительное | Загружает 64 байта в кэш-уровни всех кэш-иерархий и определяет состояние строки как исключительное | не поддерживается | ||||||
| prefetchw | Загружает 32 байта в кэш-уровни всех кэш-иерархий и определяет состояние строки как модифицируемое | Загружает 64 байта в кэш-уровни всех кэш-иерархий и определяет состояние строки как модифицируемое | |||||||
| prefetchnta | не поддерживается | Загружает 64 байта в L1 кэш | Загружает 32 байта в L1 кэш | Загружает 128 байт в первый банка L2 кэша | |||||
| prefetcht0 | Загружает 64 байта в L1 и L2 кэш | Загружает 32 байта в L1 и L2 кэш | Загружает 128 байт в кэш второго уровня | ||||||
| prefetcht1 | Загружает 64 байта в L2 кэш | Загружает 32 байта в L2 кэш | |||||||
| prefetcht2 | Загружает 64 байта в L3 кэш (если есть) | ||||||||
Таблица 5 Сводная характеристика инструкций предвыборки различных процессоров
Сводная характеристика качества оптимизации штатных Си функций и функций ОС для работы с памятью
Качество оптимизации штатных функций, поставляемых вместе с компилятором, – весьма актуальный вопрос, поскольку от этого напрямую зависит производительность откомпилированной программы.
Вообще же, отношения к штатным функциям у программистов самые разнообразные: от полного нежелания использовать что-либо стандартное (стандартные вещи редко бывают хорошими), до безоговорочного их обожания (не надо думать, что разработчики компилятора глупее нас с вами).
Как же действительно обстоят дела на практике? Об этом можно узнать из таблицы ???3, приведенной ниже и описывающие ключевые особенности оптимизации базовых memory-функций популярных компиляторов и операционной системы Windows 2000. (Операционная система приведена лишь в качестве примера, т.к. использование функций семейства RtlxxxMemory, как было показано выше нецелесообразно – см. "Особое замечание по функциями Win32 API"):
| memcpy/CopyMemory | |||||||||||
| Microsoft Visual C++ 6.0 | Borland C++ 5.5 | WATCOM C++ 10 | Windows 2000 | ||||||||
| LIB | intrinsic | ||||||||||
| копирование | DWORD | DWORD | DWORD | DWORD | –– | ||||||
| выравнивание адресов источника и/или приемника | выравнивает адрес приемника по границе 4 байт | не выравнивает | не выравнивает | не выравнивает | –– |
| memmove/MoveMemory | |||||||||||||
| Microsoft Visual C++ 6.0 | Borland C++ 5.5 | WATCOM C++ 10 | Windows 2000 | ||||||||||
| LIB | intrinsic | ||||||||||||
| копирование не перекрывающихся блоков памяти | DWORD, в прямом направлении | – | DWORD, в прямом направлении | DWORD, в прямом направлении | DWORD, в прямом направлении | ||||||||
| копирование перекрывающихся блоков памяти пр | src < dst | DWORD, в обратном направлении | – | DWORD, в обратном направлении | BYTE?, в обратном направлении | DWORD, в обратном направлении | |||||||
| src > dst | DWORD, в прямом направлении | – | DWORD, в прямом направлении | DWORD, в прямом направлении | DWORD, в прямом направлении | ||||||||
| выравнивание адресов источника и/или приемника | выравнивает адрес приемника по границе 4 байт | – | не выравнивает | не выравнивает | не выравнивает |
В таблицах, приведенных ниже, содержится краткая характеристика качества оптимизации штатных Си-функций и функций операционной системы для работы со строками. Обратите внимание: ни операционная система, ни библиотеки распространенных компиляторов не являются полностью оптимальными и резерв для повышения быстродействия еще есть!
Поэтому, целесообразнее пользоваться вашими собственными реализациями строковых функций, вылизанных "по самые помидоры". Если этого не сделаете вы, никто не оптимизирует вашу программу за вас!
| strlen/lstrlenA | |||||||||||||
| Microsoft Visual C++ 6.0 | Borland C++ 5.5 | WATCOM C++ 10 | Windows 2000 | ||||||||||
| LIB | intrinsic | ||||||||||||
| определение длины | align | unalign | BYTE, в прямом направлении | DWORD, в прямом направлении | BYTE, в прямом направлении | BYTE, в прямом направлении | |||||||
| dword | byte | ||||||||||||
| выравнивание адресов источника и/или приемника | не выравнивает | не выравнивает | выравнивает по границе 4 байт | не выравнивает | не выравнивает | ||||||||
| степень разворота цикла (итераций) | 1 | 1 | 1 | 1 | 1 |
| strcpy/lstrcpyA | |||||||||||||
| Microsoft Visual C++ 6.0 | Borland C++ 5.5 | WATCOM C++ 10 | Windows 2000 | ||||||||||
| LIB | intrinsic | ||||||||||||
| копирование | определение длины источника | не определяет | BYTE | BYTE | BYTE | BYTE | |||||||
| перенос строки | align | unalign | DWORD | DWORD | DWORD | ||||||||
| dword | byte | ||||||||||||
| выравнивание адресов источника и/или приемника | не выравнивает | не выравнивает | не выравнивает | не выравнивает | не выравнивает | ||||||||
| степень разворота цикла (итераций) | 1 | 1 | 1 | 2 | 1 |
| strcat/lstrcatA | |||||||||||||
| Microsoft Visual C++ 6.0 | Borland C++ 5.5 | WATCOM C++ 10 | Windows 2000 | ||||||||||
| LIB | intrinsic | ||||||||||||
| копирование | определение длины источника | не определяет | BYTE | BYTE | BYTE | BYTE | |||||||
| определение длины приемника | align | unalign | BYTE | BYTE | не определяет | BYTE | |||||||
| dword | byte | ||||||||||||
| перенос строки | align | unalign | DWORD | DWORD | BYTE | DWORD, в прямом направлении | |||||||
| dword | byte | ||||||||||||
| выравнивание адресов источника и/или приемника | не выравнивает | не выравнивает | не выравнивает | не выравнивает | не выравнивает | ||||||||
| степень разворота цикла (итераций) | 1 | 1 | 1 | 2 | 1 |
|
memset/FillMemory/ZeroMemory |
|||||
|
Microsoft Visual C++ 6.0 |
Borland C++ 5.5 |
WATCOM C++ 10 |
Windows 2000 |
||
|
LIB |
intrinsic |
||||
|
заполнение памяти |
DWORD, в прямом направлении |
DWORD, в прямом направлении |
DWORD, в прямом направлении |
DWORD, в прямом направлении |
DWORD, в прямом направлении |
|
выравнивание адреса приемника |
выравнивает адрес приемника по границе 4 байт |
не выравнивает |
не выравнивает |
не выравнивает |
не выравнивает |
|
memcmp/CompareMemory |
|||||
|
Microsoft Visual C++ 6.0 |
Borland C++ 5.5 |
WATCOM C++ 10 |
Windows 2000 |
||
|
LIB |
intrinsic |
||||
|
сравнение памяти |
BYTE, в прямом направлении |
BYTE, в прямом направлении |
BYTE, в прямом направлении |
BYTE, в прямом направлении |
DWORD, в прямом направлении |
|
выравнивание адресов источника и/или приемника |
не выравнивает |
не выравнивает |
не выравнивает |
не выравнивает |
не выравнивает |
Что полезного можно почерпнуть из этой таблицы? Первое, что сразу бросается в глаза: крайне небрежная оптимизация штатных функций в компиляторах от Borland и WATCOM. Создается впечатление, что их разработчики вообще не ставили перед собой задачу достичь если не максимальной, то хотя бы приемлемой производительности.
Гораздо качественнее оптимизированы memory-функции штатной библиотеки компилятора Microsoft Visual C++, которые выгодно отличаются тем, что выравнивают адрес приемника на границу 4 байт, что в ряде случаев значительно увеличивает производительность (правда, как было показано в главе "Выравнивание данных" гораздо предпочтительнее выравнивать адрес источника, а не приемника). Тем не менее Microsoft Visual C++ не использует никаких прогрессивных алгоритмов оптимизации, описанных в главе "Оптимизация штатных Си-функций для работы с памятью", а функции memcmp он не оптимизирует вообще!
Словом, если вам нужна скорость – используйте собственные реализации функций для работы с памятью!
|
strcmp/lstrcmpA |
|||||
|
Microsoft Visual C++ 6.0 |
Borland C++ 5.5 |
WATCOM C++ 10 |
Windows 2000 |
||
|
LIB |
intrinsic |
||||
|
проверка |
BYTE, в прямом направлении |
BYTE |
BYTE |
DWORD, в прямом направлении |
BYTE, в прямом направлении |
|
выравнивание адресов источника и/или приемника |
не выравнивает |
не выравнивает |
не выравнивает |
не выравнивает |
не выравнивает |
|
степень разворота цикла (итераций) |
2 |
2 |
2 |
8 (!) |
1 |
|
strstr/--- |
|||||
|
Microsoft Visual C++ 6.0 |
Borland C++ 5.5 |
WATCOM C++ 10 |
Windows 2000 |
||
|
LIB |
intrinsic |
||||
|
сравнение |
BYTE, в прямом направлении |
– |
DWORD, в прямом направлении |
BYTE, в прямом направлении |
– |
|
выравнивание адресов источника и/или приемника |
не выравнивает |
– |
не выравнивает |
не выравнивает |
– |
|
степень разворота цикла (итераций) |
1 |
– |
1 |
1 |
– |
Сводная таблица
| компилятор
действие | Microsoft Visual C++ 6 | Borland C++ 5 | WATCOM C 10 | ||||
| размножение констант | всегда размножает | никогда не размножает | всегда размножает | ||||
| свертка констант | всегда сворачивает | никогда не сворачивает | всегда сворачивает | ||||
| вычисление константных выражений | вычисляет | вычисляет | вычисляет | ||||
| свертка функций | никогда не сворачивает | никогда не сворачивает | никогда не сворачивает | ||||
| удаление неиспользуемых переменных | удаляет с все неявно неиспользуемые отслеживанием генетических связей | удаляет лишь явно неиспользуемые переменные. генетические связи не отслеживает | удаляет с все неявно неиспользуемые отслеживанием генетических связей | ||||
| удаление неиспользуемых присвоений | удаляет | удаляет | удаляет | ||||
| удаление копий переменных | удаляет | не удаляет | удаляет | ||||
| удаление лишних присвоение | удаляет | не удаляет | удаляет | ||||
| удаление лишних вызовов функций | не удаляет | не удаляет | не удаляет | ||||
| выполнение алгебраических упрощений | частично | не выполняет | не выполняет | ||||
| оптимизация подвыражений | вычислят идентичные выражения (с учетом перегруппировки) лишь раз | частично оптимизирует без учета перегруппировки | вычислят идентичные выражения (с учетом перегруппировки) лишь раз | ||||
| замена деления сдвигом | заменяет | заменяет | заменяет | ||||
| замена деления умножением | заменяет | не заменяет | не заменяет | ||||
| замена оператора взятия остатка битовыми операциями | заменяет | заменяет | заменяет | ||||
| быстрое вычисление остатка | не поддерживает | не поддерживает | не поддерживает | ||||
| замена умножения сдвигом | заменяет | заменяет | заменяет | ||||
| замена умножения сложением | заменяет | заменяет | не заменяет | ||||
| использование LEA для быстрого сложения (умножения, вычитания) | использует | использует | использует | ||||
| замена условных переходов арифметическими операциями | не заменяет | не заменяет | не заменяет | ||||
| удаление лишних условий | удаляет | не удаляет | не удаляет | ||||
| удаление заведомо ложных условий | частично | не удаляет | не удаляет | ||||
| балансировка дерева case-переходов | балансирует | балансирует | не балансирует | ||||
| создание таблицы переходов | создает | создает | частично | ||||
| разворот циклов | не разворачивает | не разворачивает | не разворачивает | ||||
| слияние циклов | не сливает | не сливает | не сливает | ||||
| вынос инвариантного кода за пределы цикла | выносит | не выносит | выносит | ||||
| замена циклов с предусловием на циклы с постусловием | заменяет | не заменяет | не заменяет | ||||
| замена возрастающих циклов на убывающие циклы | заменяет | не заменяет | не заменяет | ||||
| удаление ветвлений из цикла | удаляет | не удаляет | не удаляет | ||||
| учет частоты использования переменных при помещении их в регистр | не учитывает | учитывает | учитывает | ||||
| передача аргументов в регистрах по умолчанию | нет | да | да | ||||
| количество регистров, выделенных для передачи аргументов функции | 2 | 3 | 4 | ||||
| адресация локальных переменных через ESP | да | да | да | ||||
| оптимизация инициализации константных строк | да | нет | нет | ||||
| удаление "мертвого" кода | да | нет | частично | ||||
| оптимизация константных условий | да | нет | да |
Таблица 1 Поддержка основных методов оптимизации компиляторами Microsoft Visual C++, Borland C++ и WATCOM C++. Серым цветом для облегчения ориентации закрашены не поддерживаемые пункты
Сжатие файлов под Windows 9x\NT
Наступил девяносто пятый год – мир медленно, но неотвратимо пересаживался на новую операционную систему – Windows95. Пользователи осторожно осваивали мышь и графический интерфейс, а программисты тем временем лихорадочного переносили старое программное обеспечение на новую платформу. Объемы винчестеров к тому времени выросли настолько, что разработчики могли забыть слово "оптимизация", да они, судя по размеру современных приложений, его и забыли. Сто мегабайт – туда, триста сюда – эдак никаких гигабайт не хватит!
Вот тут-то и вспомнили о распаковке исполняемых файлов "на лету". На рынке появилось несколько программ - компрессоров, из которых наибольшую популярность завоевал ASPack, умеющий сжимать и разжимать не только "экзешники", но и динамические библиотеки. А в состав самой Windows 95 вошла динамическая библиотека "LZEXPAND.DLL", поддерживающая базовые операции упаковки-распаковки и "прозрачную" работу со сжатыми файлами. Пользователи и программисты не замедлили воспользоваться новыми средствами, но…
…в отличие от старушки MS-DOS, в Windows 9x\NT за автоматическую распаковку приходится платить больше, чем получать взамен. Вспомним, как в MS-DOS происходила загрузка исполняемых модулей? Файл целиком считывался с диска и копировался в оперативную память, причем наиболее узким местом была именно операция чтения с диска. Упаковка даже ускоряла загрузку, ибо физически читался меньший объем данных, а их распаковка занимала пренебрежительно короткое время.
В Windows же загрузчик читает лишь заголовок и таблицу импорта файла, а затем проецирует его на адресное пространство процесса так, будто бы файл является частью виртуальной памяти, хранящейся на диске. (Вообще-то, все происходит намного сложнее, но не будем вдаваться в не относящиеся к делу подробности). Подкачка с диска происходит динамически – по мере обращения к соответствующим страницам памяти, причем загружаются только те их них, что действительно нужны.
Например, если в текстовом редакторе есть модуль работы с таблицами, он не будет загружен с диска до тех пор, пока пользователь не захочет создать (или отобразить) свою таблицу. Причем неважно – находится ли этот модуль в динамической библиотеке или в основном файле! (Вот и попробуйте после этого сказать, что Windows глупые люди писали!). Загрузка таких "монстров" как Microsoft Visual Studio и Word как бы "размазывается" во времени и к работе с приложением можно приступать практически сразу же после его запуска. А что произойдет, если файл упаковать? Правильно, - он будет должен считаться с диска целиком (!) и затем – опять-таки, целиком – распаковаться в оперативную память.
Стоп! Откуда у нас столько оперативной памяти? Ее явно не хватит и распакованные такой ценой страницы придется вновь скидывать на диск! Как говорится, за что боролись, на то и напоролись. Причем, если при проецировании неупакованного exe - файла оперативная память не выделяется, (ну, во всяком случае, до тех пор, пока в ней не возникнет необходимость), распаковщику без памяти никак не обойтись! А поскольку оперативная память никогда не бывает в избытке (ну разве что у вас установлено 128-256 мегабайт RAM), она может быть выделена лишь за счет других приложений! Отметим также, что в силу конструктивных особенностей железа и архитектуры операционной системы, операция записи на диск заметно медленнее операции чтения.
Важно понять: Windows никогда не сбрасывает на диск не модифицированные страницы проецируемого файла. Зачем ей это? Ведь в любой момент их можно вновь считать с оригинального файла. Но ведь при распаковке модифицируются все страницы файла! Значит, система будет вынуждена "гонять" их между диском и памятью, что существенно снизит общую производительность всех приложений в целом.
Еще большие накладные расходы влечет за собой сжатие динамических библиотек. Для экономии памяти, страницы, занятые динамической библиотекой совместно используются всеми процессами, загрузившими эту DLL.
Но как только один из процессов пытается что-то записать в память, занятую DLL, система мгновенно создает копию модифицируемой страницы и предоставляет ее в "монопольное" распоряжение процесса-писателя. Поскольку, распаковка динамических библиотек происходит в контексте процесса, загрузившего эту DLL, система вынуждена многократно дублировать все страницы памяти, выделенные динамической библиотеке, фактически предоставляя каждому процессору свой собственный экземпляр DLL. Предположим, одна DLL размером в мегабайт, была загружена десятью процессами, - посчитайте: сколько памяти напрасно потеряется, если она сжата!
Таким образом, под Windows 9x\NT сжимать исполняемые файлы нецелесообразно, - вы платите гораздо больше, чем выручаете. Что же касается защиты от дизассемблирования… Да, когда ASPack только появился, он отвадил от взлома очень многих неквалифицированных хакеров, но – Woozl! – ненадолго! Сегодня в сети только слепой не найдет руководство по ручному снятию ASPack-а. Существует и масса готового инструментария – от автоматических распаковщиков до плагинов к дизассемблеру IDA Pro, позволяющих ему дизассемблировать сжатые файлы. Поэтому, надеяться, что ASPack спасет вашу программу от взлома несколько наивно.
Техника оптимизации программ Подсистема оперативной памяти ЭНЦИКЛОПЕДИЯ
Крис Касперски
"Память определяет быстродействие"
Фон-Нейман
"Самый медленный верблюд определяет скорость каравана"
Арабское народное
"Время работы программы определяется ее самой медленной частью"
Закон Амдала

Рисунок 1 mcap1 "Караван"

Рисунок 2 logo4.gif Память… Миллиарды битовых ячеек, упакованных в крошечную керамическую пластинку, свободно умещающуюся на ладони… вот как выглядит современная оперативная память!
ТЕХНИКА ОПТИМИЗАЦИИ ПРОГРАММ ТОМ
Крис Касперски
kpnc@programme.ru
kpnc@itech.ru
TEMPORA MUTANTUR, ET NOS MUTAMUR IN ILLIS
(Времена меняются и мы меняемся с ними лат.)
"Когда караван поворачивает назад, самый медленный верблюд оказывается впереди".
Арабское народное
Крис Касперски
kpnc@programme.ru
kpnc@itech.ru


Рисунок 1 0x000.gif 0x0025.gif DEUS EX MACHINA…
Типы статической памяти
Существует как минимум три типа статической памяти: асинхронная (только что рассмотренная выше), синхронная и конвейерная. Все они практически ничем не отличаются от соответствующих им типов динамической памяти (см. "Часть I Оперативная память: Устройство и принципы функционирования оперативной памяти"), поэтому, во избежание никому не нужного повторения ниже приведено лишь краткое их описание.
Том I Оперативная память
Оптимизация на уровне структур данных и алгоритмов их обработки. Ориентирована на прикладных и системных программистов.
Настоящая книга включает лишь половину запланированного материала первого тома. Остающаяся либо выйдет отдельной книгой, либо (что более вероятно) появится во втором издании настоящей книги.
Предполагаемый срок выхода: начало 2003 года
Том II Процессор
Оптимизация на уровне планирования потоков машинных команд. Ориентирована на системных программистов и прикладных программистов, владеющих ассемблером
Предполагаемый срок выхода: начало 2004 года
Том III Автоматическая кодогенерация
Устройство оптимизирующих компиляторов, алгоритмы оптимизации, сравнение качества кодогенерации различных компиляторов, как "помочь" оптимизатору. Ориентирована на прикладных и системных программистов.
Предполагаемый срок выхода: начало 2005 года
Том IV Ввод/вывод
Оптимизация работы с периферией (как-то жесткие и лазерные диски, коммуникации, параллельные и последовательные порты, видео подсистема) Ориентирована на прикладных и системных программистов.
Предполагаемый срок выхода: начало 2006 года
Том V Параллельные вычисления и суперкомпьютеры
Ориентирована на прикладных программистов. Вся информация уникальна, а многая даже засекречена. Поэтому книга будет читаться как самый настоящий детектив про разведчиков.
Предполагаемый срок выхода: не известен
Традиции vs надежность
Народная мудрость и здравый смысл утверждают, "если все очень хорошо, то что-то тут не так". Применительно к описанной ситуации – если описанные авторов приемы программирования столь хороши, почему же они не получили массового распространения? Видимо, на практике не все так хорошо, как на бумаге.
На самом деле основной "камень преткновения" – верность традициям. В сложившейся культуре программирования признаком хорошего тона считается использование везде, где только возможно, стандартных функций самого языка, а не специфических возможностей операционной системы, "привязывающих" продукт к одной платформе. Какой бы небесспорной эта рекомендация ни была, многие разработчики слепо следуют ей едва ли не с фанатичной приверженностью.
Но что лучше – мобильный, но нестабильно работающий и небезопасный код или– плохо переносимое (в худшем случае вообще непереносимое), зато устойчивое и безопасное приложение? Если отказ от использования стандартных библиотек позволит значительно уменьшить количество ошибок в приложении и многократно повысить его безопасность, стоит ли этим пренебрегать?
Удивительно, но существует и такое мнение, что непереносимость – более тяжкий грех, чем ошибки от которых, как водится, никто не застрахован. Аргументы: дескать, ошибки – явление временное и теоретически устранимое, а непереносимость – это навсегда.
Можно возразить – использование в своей программе функций, специфичных для какой-то одной операционной системы, не является непреодолимым препятствием для ее портирования на платформы, где этих функций нет, - достаточно лишь реализовать их самостоятельно (трудно, конечно, но в принципе осуществимо).
Другая причина не распространенности описанных выше приемов программирования – непопулярность обработки структурных исключений вообще. Несмотря на все усилия Microsoft, эта технология так и не получила массового распространения, а жаль! Ведь при возникновении нештатной ситуации любое приложение может если не исправить положение, то, по крайней мере, записать все не сохраненные данные на диск и затем корректно завершить свою работу. Напротив, если возникшее исключение не обрабатывается приложением, операционная система аварийно завершает его работу, а пользователь теряет все не сохраненные данные.
Не существует никаких объективных причин, препятствующих активному использованию структурной обработке исключений в ваших приложениях кроме желания держаться за старые традиции, игнорируя все новые технологии. Обработка структурных исключений – очень полезная возможность, области применения которой ограничены разве что фантазией разработчика. И предложенные выше приемы программирования – лучшее тому подтверждение.
Учет ограниченной ассоциативности кэша
До тех пор, пока в процессорах не появятся полностью ассоциативные кэши, оптимальная организация данных останется прерогативой программистов. В главе "Кэш – принципы функционирования: Организация кэша" было показано, что каждая ячейка кэшируемой памяти может претендовать не на любую, а всего лишь на несколько кэш-строк, число которых и определяется ассоциативностью кэша. Поскольку, ассоциативность кэш-памяти первого уровня обычно очень невелика (так, на P-II/P-III она равна четырем, а на AMDAthlon и вовсе двум), становится очевидным, что неудачная организация данных способна сократить размер кэш-памяти на один-два порядка, а то и более того!
Если установочные биты кэшируемых ячеек равны, они отображаются на одну и ту же кэш-строку, поэтому таких ситуаций следует избегать. Как вычисляются установочные адреса? Для этого можно воспользоваться следующей формулой. set.address = my.address & ((mask.bank – 1) & ~(mask.line-1)), где mask.line (маска кэш линей) определяется так: 2mask.line = CACHE.LINE.SIZE, а mask.bank (маска банка) определяется так: 2mask.bank == BANK.SIZE. В частности, 4х ассоциативный 16 Кб кэш процессоров P-II/P-III задействует под установочные адреса биты с 11 по 4 линейного адреса памяти.
Таким образом, обработка ячеек памяти с шагом равным или кратным размеру кэш банка крайне непроизводительна и этого любой ценой следует избегать. Касательно размера кэш-банков – позвольте поделиться наблюдением: на всех известных мне процессорах он равен или кратен 4 Кб. Эта цифра, конечно, не догма (см. "Определение ассоциативности"), но как рабочий вариант вполне сойдет.
А теперь скажите, как вы думаете, можно ли назвать следующий код оптимальным кодом?
for(a = 0; a < googol; a++)
{
// …
a1 += bar[4096*1];
a2 += bar[4096*2];
a3 += bar[4096*3];
a4 += bar[4096*4];
a5 += bar[4096*5];
// …
}
Листинг 7 Пример, демонстрирующий конфликт кэш-линеек за счет ограниченной степени ассоциативности
Увы, оптимальность здесь и не ночевала. Смотрите, что происходит: при исполнении программы под P-II/P-III: в первом проходе цикла for ячейки bar[4096]
еще не содержится в сверхоперативной памяти первого уровня и возникает задержка в два-четыре такта, на время загрузки данных из кэша второго уровня (а в худшем случае – из оперативной памяти). Поскольку установочный адрес ячейки равен нулю (условимся считать, что массив bar выровнено по 4 Кб границе, хотя это и не критично), кэш контроллер помещает считанные 32 байта в нулевую кэш-строку первого (точнее, условного первого) кэш-банка. Идем далее: установочный адрес ячейки bar[4096*2]
тоже равен нулю и очередная порция считанных данных также претендуют на нулевую кэш-строку! Поскольку, нулевая строка первого кэш-банк уже занята, кэш-контроллер задействует второй банк…
Но ведь количество кэш-банков не безгранично! Напротив, – оно очень мало, и на момент чтения пятой по счету ячейки – bar[4096*5]
нулевые кэш-строки всех четырех кэш- банков уже заняты, а данная ячейка претендует именно на нулевую кэш-строку! Кэш-контроллер (а что ему еще остается делать?) безжалостно "прибивает" наиболее "дряхлую" нулевую строку первого кэш-банка (к ней дольше всего не было обращения) и записывает в нее "свежие" данные. Как следствие – в следующем проходе цикла for ячейки bar[4096]
вновь не оказывается в сверхоперативной памяти первого уровня, и вновь возникнет задержка на время ее загрузки! Кэш контроллер, обнаружив, что свободных банков совсем нет (помните как в том анекдоте про бензин "Как нет? Совсем нет, да!"), прибивает нулевую строку теперь уже второго банка – ту, что хранила ячейку bar[4096*2]… Чувствуете, что происходит? Правильно, кэш работает на 100% вхолостую, не обеспечивая ни одного кэш-попадания – одни лишь промахи. А ведь обрабатываемых ячеек памяти всего лишь пять…
Во избежании падения производительности, обрабатываемые данные необходимо реорганизовать так, чтобы читаемые ячейки попадали в различные кэш-линии, а, если это невозможно, то обрабатывать их не в одном, а в нескольких последовательных циклах, например, так:
for(a = 0; a < googol; a++)
{
// …
a1=bar[4096];
a2=bar[4096*2];
a3=bar[4096*3];
// …
}
for(a = 0; a < googol; a++)
{
// …
a4=bar[4096*4];
a5=bar[4096*5];
// …
}
Листинг 8 Оптимизированный вариант программы, учитывающий особенности архитектуры наборно-ассоциативной кэш памяти
А теперь разберем как будет исполняться следующий код на процессоре AMD Athlon. На первый взгляд, все произойдет по сценарию, описанному выше, с той лишь разницей, что двух ассоциативный кэш Athlon'а "завалится" уже на третий итерации.
Точнее, мы думаем, что он "завалится", на самом же деле, никакого сколь ни будь заметного падения производительности не наблюдается.
for(a = 0; a < googol; a++)
{
// …
a1 += bar[4096];
a2 += bar[4096*2];
a3 += bar[4096*3];
a4 += bar[4096*4];
a5 += bar[4096*5];
// …
}
Листинг 9 Пример кода, вопреки "здравому смыслу" оптимальное для процессора AMD Athlon
Первое впечатление: Вот это номер! Ай да Athlon! Второе впечатление (немного остынув от щенячьего восторга, мы задаемся известным вопросом): но почему? Как это реализовано? Прочитав руководство по оптимизации от начала до конца, в приложении "А" мы находим междустрочный ответ на вопрос. Оказывается в процессорах AMD Athlon имеется очередь чтения/записи на 12 входов, которая временно сохраняет данные, считанные из кэша первого уровня. Конфликты кэш-линий все-таки возникают, но они маскируются системой буферизации данных. Выходит, что при оптимизации программы исключительно под Athlon нехватки ассоциативности можно не опасаться? Увы, не все так радужно… В данном случае падения производительности не наблюдается лишь только потому, что количество одновременно обрабатываемых ячеек не превышает двенадцати.
Особенно щепетильным следует быть при выборе величины шага чтения при обработке блочных алгоритмов. Если она окажется кратной размеру кэш-банка (или хотя бы производной от него), – многократного падения производительности не избежать.
Рассмотрим следующий пример:
#define N_ITER 466 // кол-во итераций
// теоретически будет востребовано
// LINE_SIZE*N_ITER байт кэш-памяти,
// т.е. в данном случае 466*64 = ~30 Kb
#define CACHE_BANK_SIZE (4*K ) // размер кэш-банка
#define LINE_SIZE 64 // максимально возможный размер кэш-линий
#define BLOCK_SIZE ((CACHE_BANK_SIZE+LINE_SIZE)*N_ITER) // размер бурка
/*----------------------------------------------------------------------------
*
* ВАРИАНТ, ИЛЛЮСТРИРУЮЩИЙ КОНФЛИКТЫ КЭШ-ЛИНИЙ
*
----------------------------------------------------------------------------*/
int over_assoc(int *p)
{
int a;
volatile int x=0;
// внимание: top-level цикл поскипан, поскольку профайлер
// и без того прокрутит этот цикл 10 раз
for(a=0; a < N_ITER; a++)
// читаем память с шагом 4 Kb, в результате
// и на P-II/P-III/P-4 и на AMD Athlon
// быстро наступает насыщение кэша и идет
// его перегруз;
// поскольку, обрабатывается более 12 ячеек
// буферизация чтения на Athlon положения
// уже не спасает
x+=*(int *)((int)p + a*CACHE_BANK_SIZE);
return x;
}
Листинг 10 [Cache/L1.overassoc] Пример, демонстрирующий возникновение конфликтов кэш-линий и их влияние на производительность
При шаге чтения, равным четырем килобайтам, данная программа будет "буксовать" на всех процессорах, поскольку в кэш-память не поместится вообще ни одной ячейки! (Чу! Слышу голоса: "почему ни одной ячейки? Ведь должны же сохранится четыре ячейки на P-II/P-III и две – на Athlon, в соответствии с величиной их ассоциативности". Увы! При очередном проходе цикла последние сохраненные ячейки будут выкинуты из кэша).
Как можно предотвратить кэш-конфликты? Для этого мы должны реструктурировать обрабатываемый массив с таким расчетом, чтобы установочные адреса всех загружаемых ячеек были бы различны. Один из возможных путей решения – увеличить величину шага на размер кэш-линейки. (Конечно, для этого необходимо изменить и сам массив, т.к. при этом будут читаться уже другие
данные).
Оптимизированный пример может выглядеть приблизительно так:
/*----------------------------------------------------------------------------
*
* ВАРИАНТ, ИСПОЛНЯЮЩИЙСЯ БЕЗ КОНФЛИКТОВ
*
----------------------------------------------------------------------------*/
int optimize(int *p)
{
int a=0;
volatile int x=0;
// внимание: top-level цикл поскипан, поскольку профайлер
// и без того прокрутит этот цикл 10 раз
for(a=0; a < N_ITER; a++)
{
// читаем паять с шагом CACHE_BANK_SIZE+LINE_SIZE
// т.е. в данном случае 4096+64=4160 байт;
// поскольку установочные адреса всех ячеек различны
// мы не имеем конфликтов и использует емкость
// кэш-память на все 100%
x+=*(int *)((int)p + a*(CACHE_BANK_SIZE+LINE_SIZE));
}
return x;
}
Листинг 11 [Cache/L1.overassoc.c] Оптимизированный пример, устраняющий конфликты кэш-линий
Прогон программы показывает, что в результате оптимизации ее скорость увеличилась более, чем в шесть раз на процессоре P-III 733 и более чем в пять раз на процессоре AMD Athlon 1050. Согласитесь, очень неплохая прибавка к производительности и это при том, что мы только читали конфликтующие ячейки, но не модифицировали их. Конфликт же записи обойдется вам приблизительно в полтора раза "дороже"!
Поэтому, если ваша программа не смотря на крошечный размер обрабатываемых данных работает на удивление медленно, – в первую очередь проверьте, – не замешен ли здесь конфликт кэш-линеек.
Рисунок 30 graph 0x010 Демонстрация падения производительности при попадании загружаемых данных в одну и ту же кэш-линейку. Конфликт записи обходится приблизительно в полтора раза дороже.
Удаление копий переменных
Если две и более переменных имеют одно и то же значение, – можно оставить лишь одну из них, а остальные удалить, заодно избавляясь от лишних присвоений. Рассмотрим следующий пример:
int a=b;
printf("%x %x \n",a, b);
Логично, что переменная 'a' совершенно не нужна и программа может работать и без нее, достаточно переписать ее так:
int a=b;
printf("%x %x \n",b, b);
Компиляторы Microsoft Visual C++ и WATCOM успешно справляются с удалением копий переменных, а вот Borland C++ этого не умеет.
Удаление лишних присвоений
Операция присвоения одной переменной другой переменной (т.е. что-то вроде a=b) бессмысленна – от нее всегда можно избавиться, заменив копию переменной ее оригиналом. Например, пусть не оптимизированный код выглядел так:
int a=b;
printf("%x %x \n",a, b);
a=a+1;
printf("%x %x \n",a, b);
Очевидно: переменная 'a' не является копией 'b' и не может быть удалена, но вот присвоение a=b удалить можно, смотрите:
int a=b;
printf("%x %x \n",b, b);
a=b+1;
printf("%x %x \n",a, b);
Компиляторы Microsoft Visual C++ и WATCOM всегда избавляются от лишних присвоений, а Borland C++ делать этого не умеет.
Удаление лишних условий
Упрощение логических условий чем-то сродни алгебраическим упрощения. Рассмотрим следующий пример:
if (a>0 && a<0x666 && a!=0) …
Очевидно, что проверка (a!=0) лишняя – т.к. если 'a' больше нуля, оно заведомо не равно нулю! Компилятор Microsoft Visual C++ умеет распознавать такие ситуации, избавляясь от избыточных проверок, а вот Borland C++ и WATCOM на это не способны.
Удаление лишних выражений[2]
Если результат вычисления некоторого выражения никак не используется в программе, то, очевидно, выполнять вычисление выражение нет никакой нужды. Как же возникает такой бессмысленный код? Чаще всего – из-за небрежности программиста, привыкшего сначала программировать, а потом думать, что он запрограммировал.
Рассмотрим следующий пример:
c = a/b;
c = a*b;
printf("%x\n",c);
Поскольку, результат вычислений выражения (a/b) никак не используется в программе, его можно удалить, избавляясь тем самым от одной операции деления и присвоения, смотрите:
c = a/b;
c = a*b;
printf("%x\n",c);
Все три рассматриваемых компилятора с лихвой справляются с удалением лишних выражений.
Удаление лишних вызовов функций
Удаление лишних выражений ни в коем случае нельзя распространять на удаление функций! (Во всяком случае, без дополнительных ухищрений, разговор о которых выход за рамки этой статьи).
Рассмотрим следующий пример:
c=func_1(0x666,0x777);
c=func_2(0);
printf("%x\n", c);
На первый взгляд, от вызова функции func_1 можно безболезненно избавиться – возращенное ею значение никак не используется, и переменной 'c' тут же присваивается результат работы func_2, который и выводится на экран. Но задумайтесь: что произойдет, если функция func_1
помимо возращения значения делает и другую работу? Ну, скажем, записывает переданные ей аргументы в дисковый файл. Правильно, - удаление этой функции нарушит нормальную работу программы!
Таким образом, оптимизирующий компилятор не должен сокращать вызовы функций, однако, он может (и должен) не присваивать возращенное значение переменной, если оно действительно нигде не используются (см. "Удаление лишних присвоений").
Ни один из трех рассматриваемых компилятором не удаляет "лишние" вызовы функций.
Удаление неиспользуемых переменных
Довольно часто программист объявляет переменную, но никак не использует ее в программе. Особенно актуальна эта проблема для языка Си, не поддерживающего (в отличие от его старшего собрата Си++) объявления переменных по месту использования. Чтобы не метаться между разными частями программы, опытные разработчики объявляют переменные загодя, с "запасом". А когда же выясняется, что можно обойтись и меньшим количеством переменных, удалить "излишки" как всегда забывают.
Оптимизирующие компиляторы, стремясь сэкономить память, автоматически удаляют такие переменные, зачастую сопровождая эту процедуру "ворчанием" – выдачей предупреждающих сообщений на экран. Действительно, не использование переменной может являться следствием ошибки или описки. Никакой опасности эти предупреждения не представляют, но все же лучше от них избавиться, соответствующим образом скорректировав код. Причем, инициализация переменной или присвоение ей некоторого значения (результата арифметических вычислений или результата работы функции) не "трудоустраивают" ее! Присвоенное переменной значение хотя бы раз должно использоваться в программе!
Рассмотрим следующий пример:
int a=0;
int b;
b=a;
Несмотря на то, что значение, присвоенное переменной 'a', передается переменной 'b', переменная 'a' все равно считается неиспользуемой, т.к. результат ее присвоения 'b' никак не используется в программе!
Компиляторы Microsoft Visual C++ и WATCOM – прекрасно справляются с удалением неиспользуемых переменных, выбрасывая в данном примере и переменную 'a', и переменную 'b'. Компилятор Borland C++ не умеет отслеживать генетические связи между переменными, поэтому, неявно неиспользуемые переменные удалять неспособен. В данном примере он удалит переменную 'b', т.к. присваиваемое ей значение никак не используется, но сохранит 'a', т.к. ее значение копируется в 'b'.
